Identification of NLOS and Multi-Path Conditions in UWB Localization Using Machine Learning Methods

 , , , , and
, , , , and
Abstract
1. Introduction
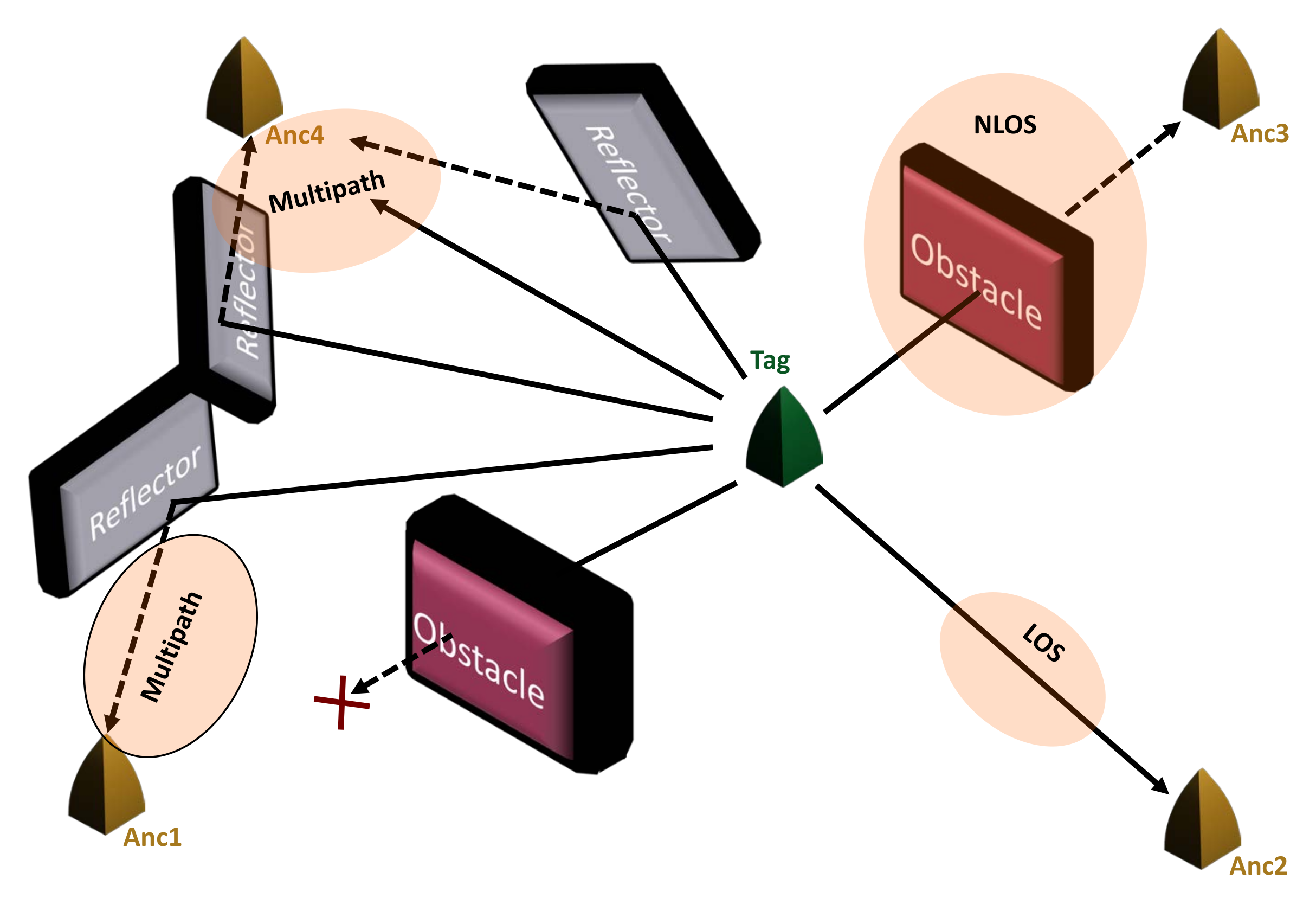
2. Problem Description
3. Related Works
3.1. Conventional NLOS Identification Techniques in UWB
3.2. Identification of the NLOS and MP Conditions in the Literature Based on Machine Learning Techniques
4. Measurement Scenarios and Data Preparation
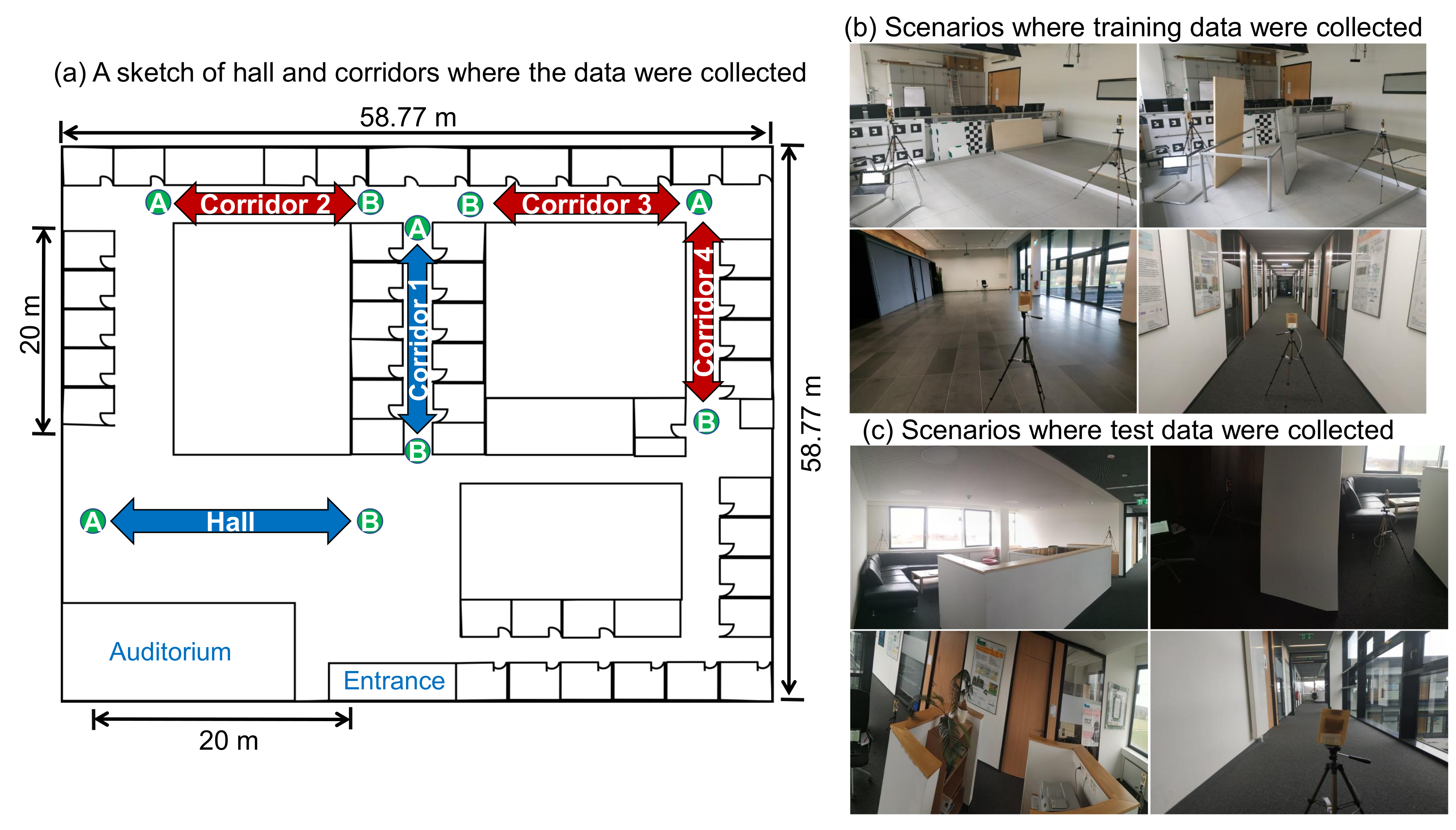
4.1. Experimental Setup
4.2. Data Collection Process
4.2.1. Labeling the Measured Data and Dealing with the Class Imbalance Case
4.2.2. Separation of the Training, Validation, and Test Dataset
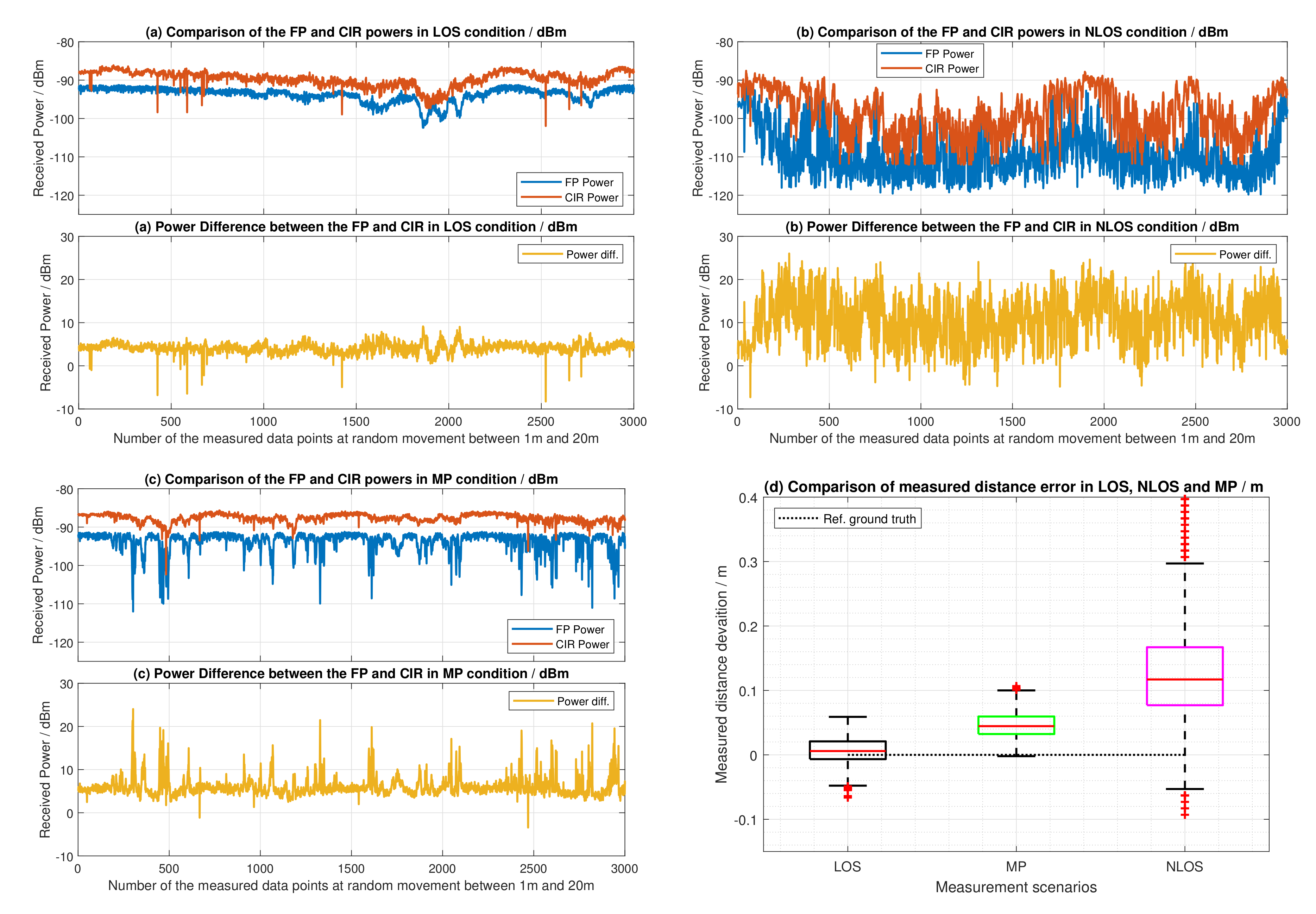
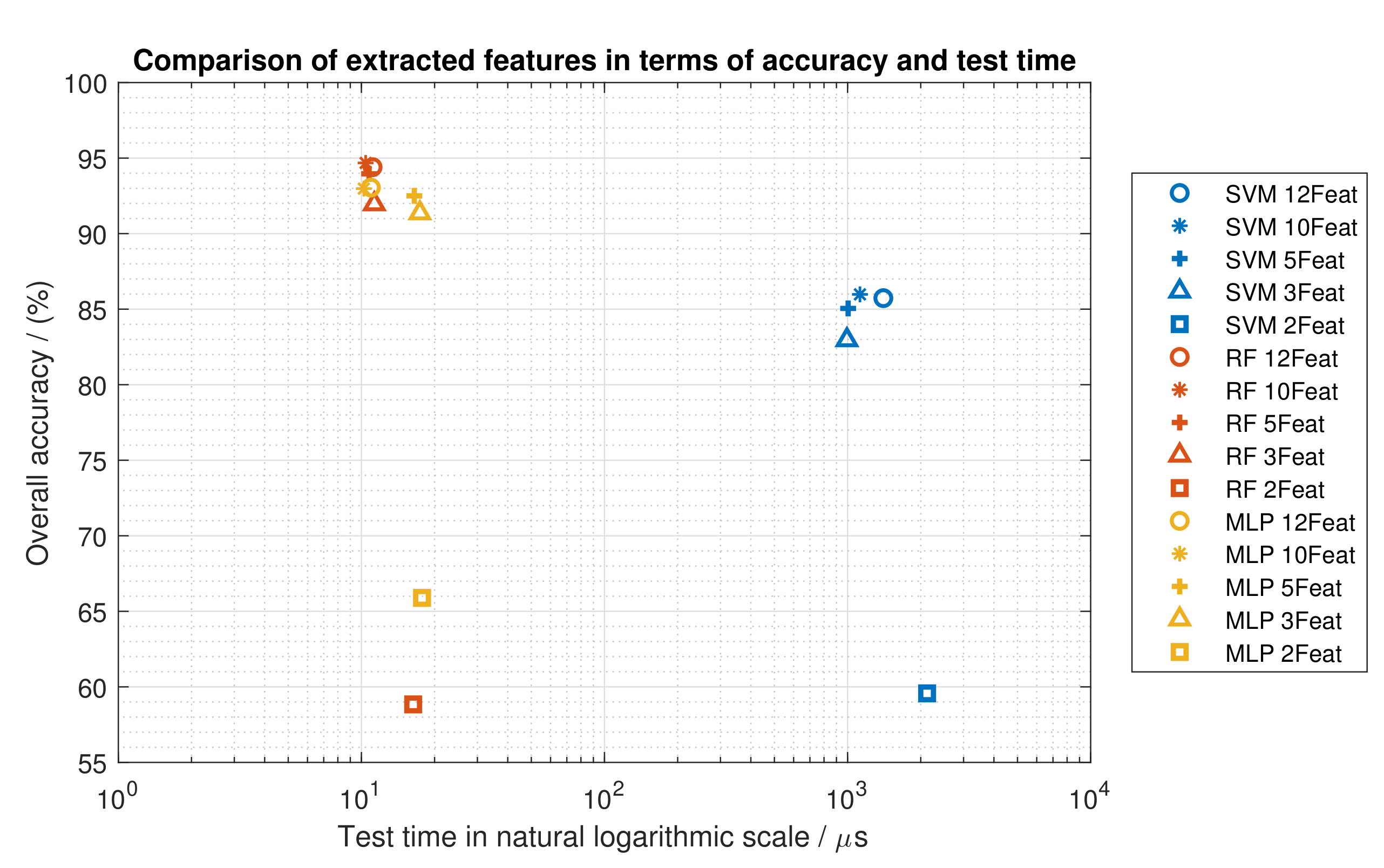
4.3. Feature Extraction
- the reported measured distance
- the compound amplitudes of multiple harmonics in the FP signal
- the amplitude of the first harmonic in the FP signal
- the amplitude of the second harmonic in the FP signal
- the amplitude of the third harmonic in the FP signal
- the amplitude of the channel impulse response (CIR)
- the preamble accumulation count reported in the DW1000 chip module
- the estimated FP power level using (1)
- the estimated RX power level using (2)
- the difference between the FP and RX power level using (3)
- the standard noise reported in the DW1000 chip module
- the maximum noise reported in the DW1000 chip module
5. Machine Learning Models for Identification of the LOS, NLOS, and MP Conditions
5.1. Support Vector Machine Classifier for the UWB Localization System
5.2. Random Forrest Classifier for the UWB Localization System
5.3. Multi-Layer Perceptron Classifier for the UWB Localization System
5.4. Section Summary
6. Data Preprocessing and Feature Selection
6.1. The Impact of Feature Extraction in the Evaluated Machine Learning Models
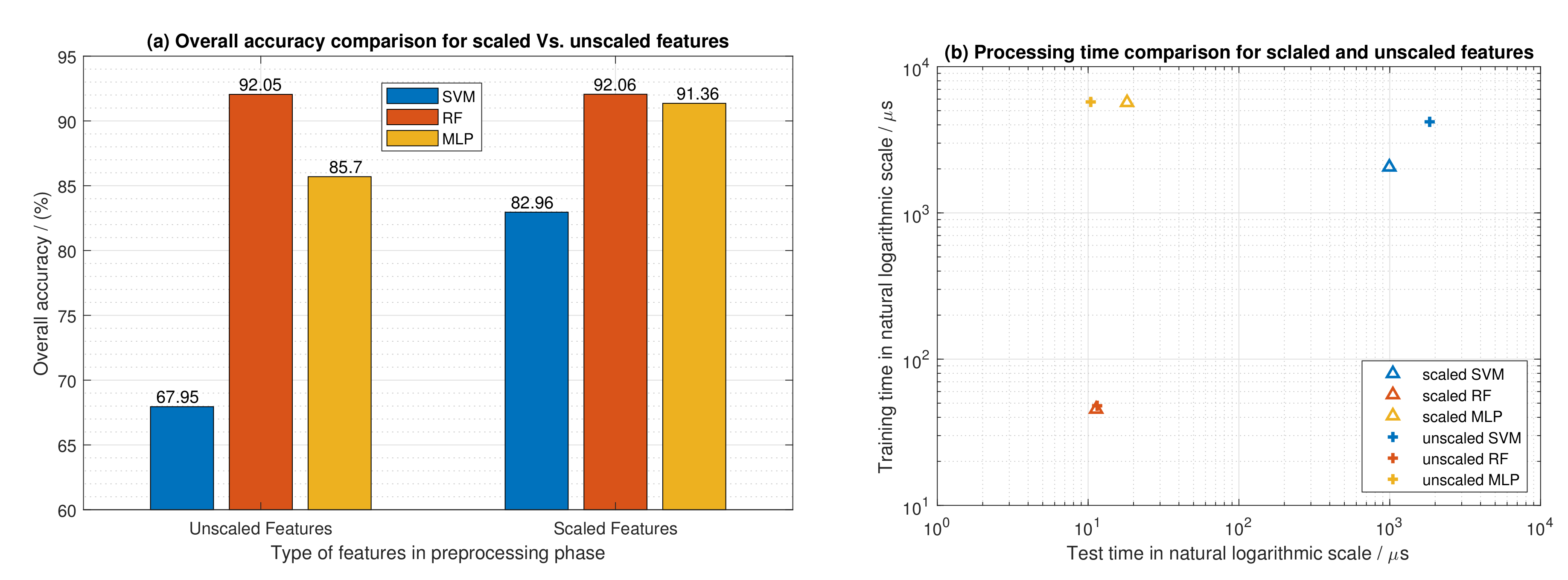
6.2. The Impact of Feature Scaling in the Evaluated Machine Learning Models
7. Evaluation Results
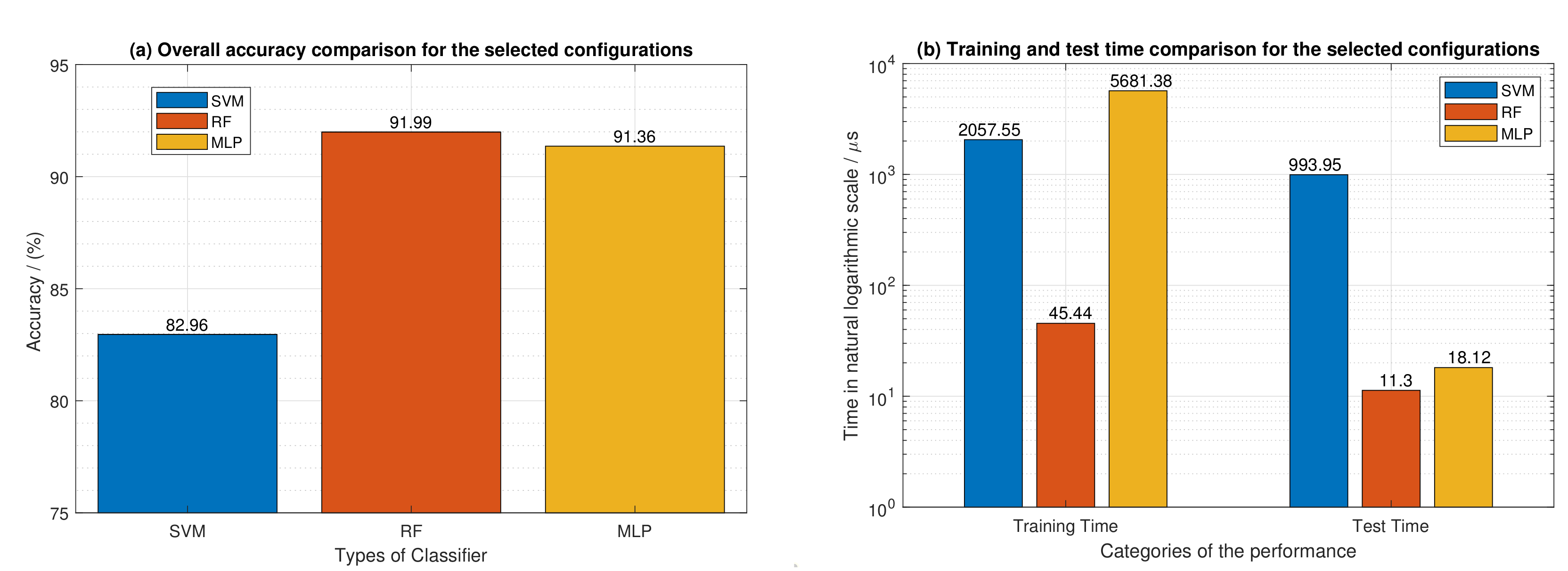
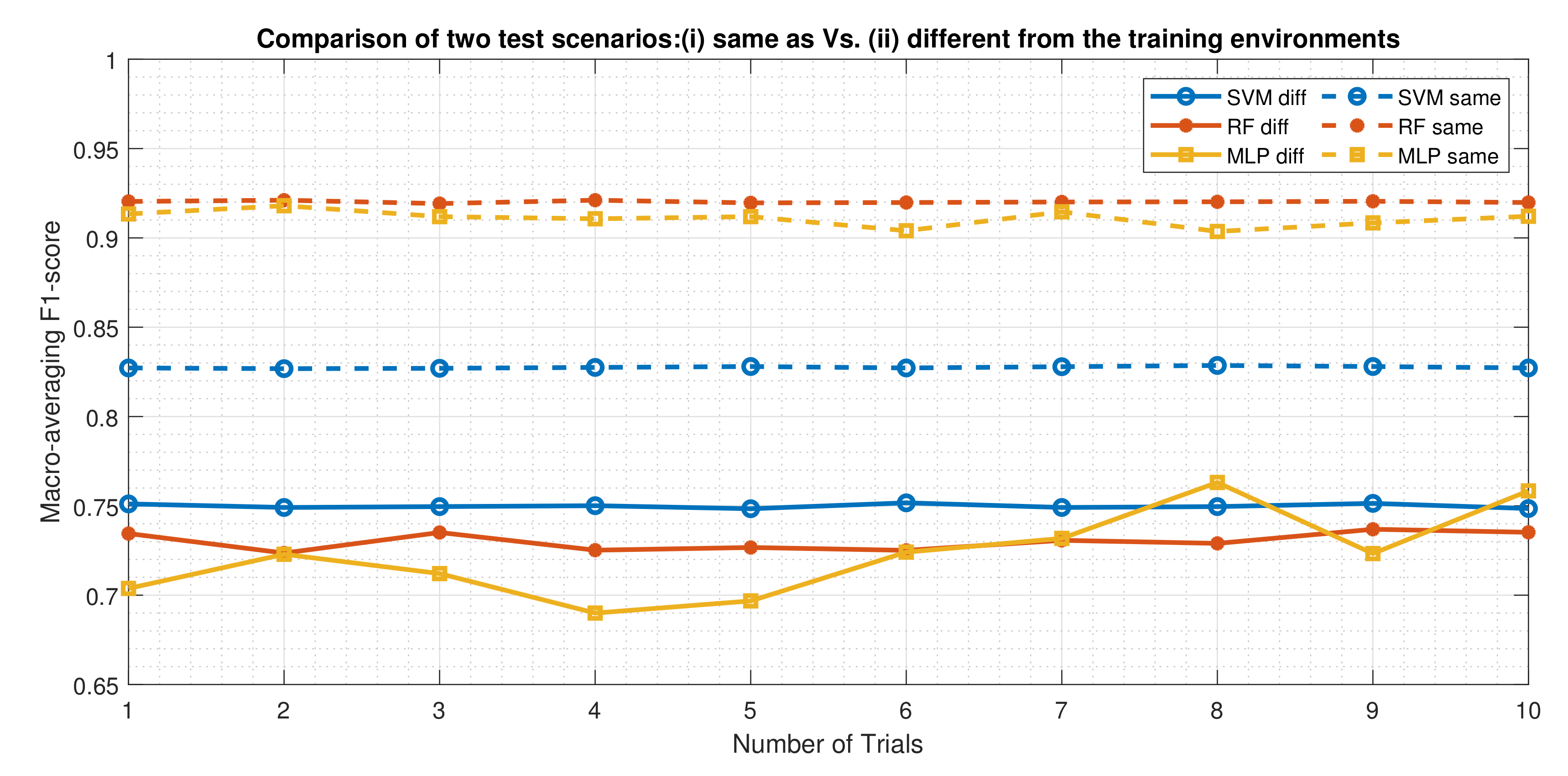
7.1. Performance Comparison of the Three Classifiers Using the Macro-Averaging F1-Score as a Metric
7.2. Result Representation of the Three Evaluated Classifiers Using the Confusion Matrix
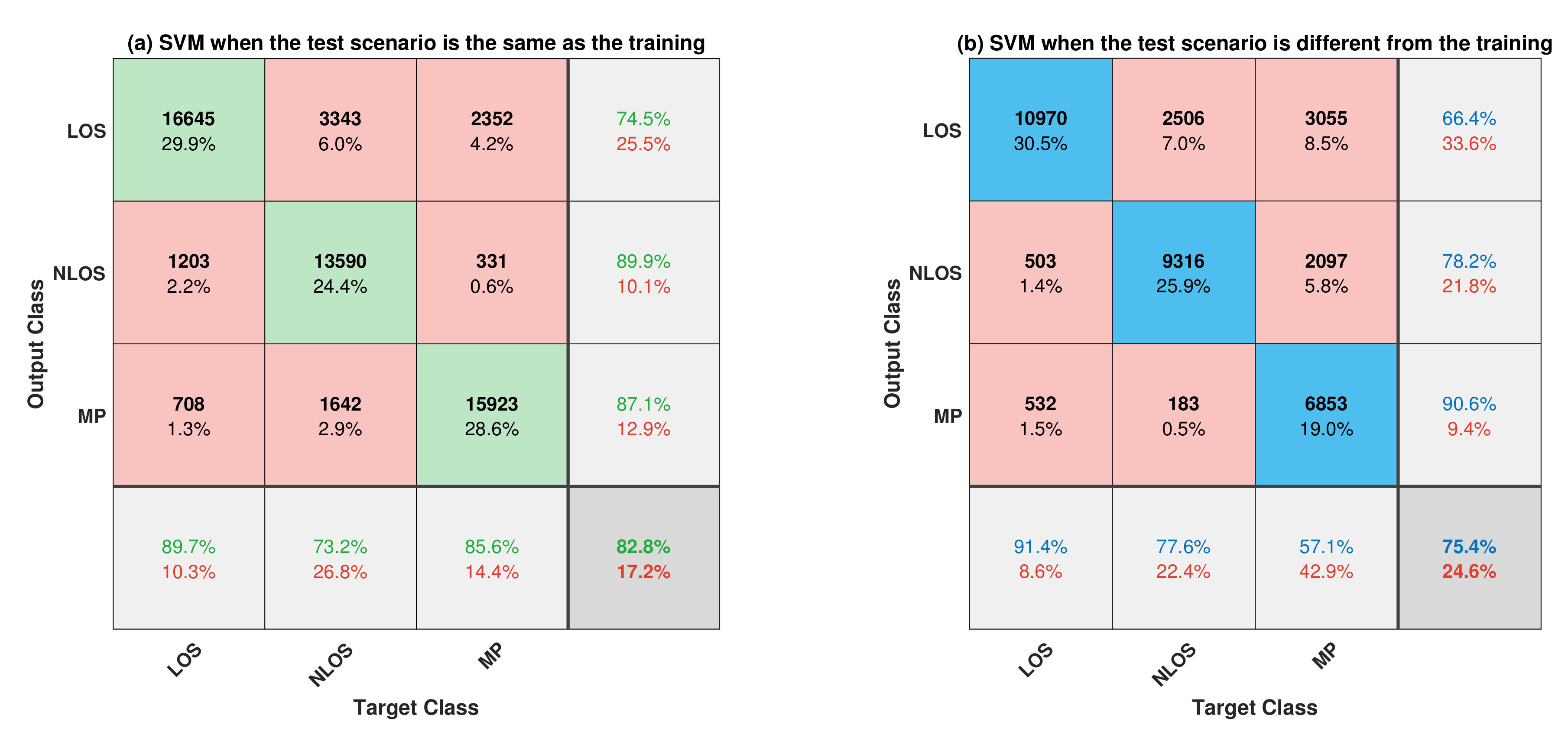
7.2.1. Comparative Analysis of the Two Test Scenarios for SVM Classifier
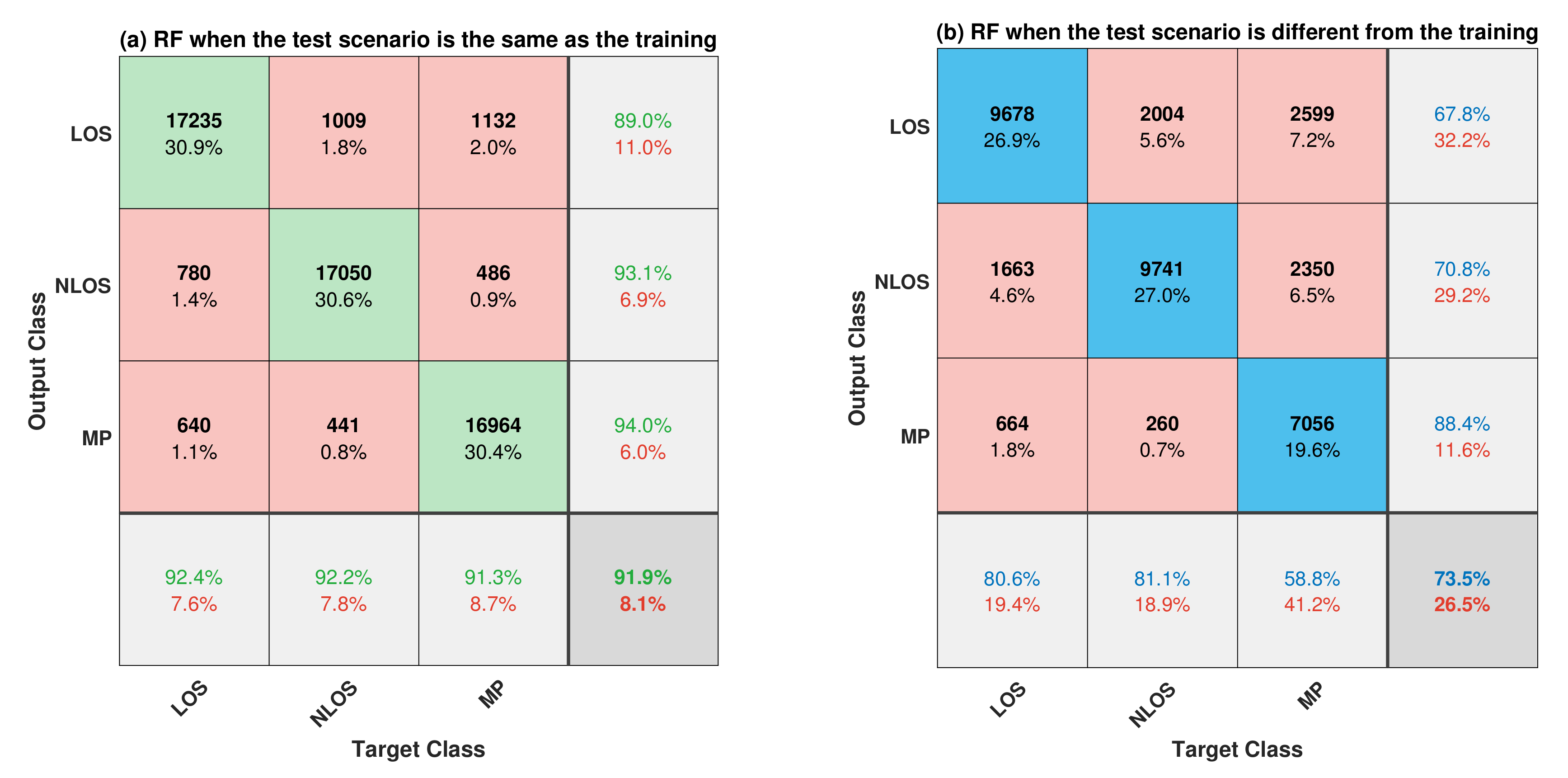
7.2.2. Comparative Analysis of the Two Test Scenarios for the RF Classifier
7.2.3. Comparative Analysis of the Two Test Scenarios for the MLP Classifier
7.3. Summary of the Experimental Evaluation Results
8. Discussions
9. Conclusions
Supplementary Materials
Supplementary File 1Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AltDS-TWR | Alternative double-sided two-way ranging |
| BDT | Boosted decision tree |
| CIR | Channel impulse response |
| CNN | Convolutional neural network |
| FP | First-path |
| GP | Gaussian process |
| HSI | High speed internal (clock) |
| IoT | Internet of Things |
| KNN | K-nearest neighbor |
| LOS | Line-of-sight |
| MCU | Microcontroller unit |
| ML | Machine learning |
| MLP | Multi-layer perceptron |
| MP | Multi-path |
| NLOS | Non-line-of-sight |
| PATD | Preamble accumulation time delay |
| PUB | Publications at Bielefeld University |
| RBF | Radial basis function |
| RF | Random forest |
| RSS | Received signal strength |
| RX | Received or receiver |
| SNR | Signal-to-noise ratio |
| SVM | Support vector machine |
| TOF | Time-of-flight |
| UWB | Ultra-wideband |
References
- Win, M.Z.; Dardari, D.; Molisch, A.F.; Wiesbeck, W.; Zhang, J. History and Applications of UWB [Scanning the Issue]. Proc. IEEE 2009, 97, 198–204. [Google Scholar] [CrossRef]
- Sang, C.L.; Adams, M.; Korthals, T.; Hörmann, T.; Hesse, M.; Rückert, U. A Bidirectional Object Tracking and Navigation System using a True-Range Multilateration Method. In Proceedings of the 2019 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Pisa, Italy, 30 September–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Dardari, D.; Conti, A.; Ferner, U.; Giorgetti, A.; Win, M.Z. Ranging With Ultrawide Bandwidth Signals in Multipath Environments. Proc. IEEE 2009, 97, 404–426. [Google Scholar] [CrossRef]
- Win, M.Z.; Scholtz, R.A. Impulse radio: How it works. IEEE Commun. Lett. 1998, 2, 36–38. [Google Scholar] [CrossRef]
- Win, M.Z.; Scholtz, R.A. Ultra-wide bandwidth time-hopping spread-spectrum impulse radio for wireless multiple-access communications. IEEE Trans. Commun. 2000, 48, 679–689. [Google Scholar] [CrossRef]
- Sang, C.L.; Adams, M.; Hesse, M.; Hörmann, T.; Korthals, T.; Rückert, U. A Comparative Study of UWB-based True-Range Positioning Algorithms using Experimental Data. In Proceedings of the 2019 16th Workshop on Positioning, Navigation and Communications (WPNC), Bremen, Germany, 23–24 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Sang, C.L.; Adams, M.; Hörmann, T.; Hesse, M.; Porrmann, M.; Rückert, U. An Analytical Study of Time of Flight Error Estimation in Two-Way Ranging Methods. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Lian Sang, C.; Adams, M.; Hörmann, T.; Hesse, M.; Porrmann, M.; Rückert, U. Numerical and Experimental Evaluation of Error Estimation for Two-Way Ranging Methods. Sensors 2019, 19, 616. [Google Scholar] [CrossRef]
- Maranò, S.; Gifford, W.M.; Wymeersch, H.; Win, M.Z. NLOS identification and mitigation for localization based on UWB experimental data. IEEE J. Sel. Areas Commun. 2010, 28, 1026–1035. [Google Scholar] [CrossRef]
- Li, W.; Zhang, T.; Zhang, Q. Experimental researches on an UWB NLOS identification method based on machine learning. In Proceedings of the 2013 15th IEEE International Conference on Communication Technology, Guilin, China, 17–19 November 2013; pp. 473–477. [Google Scholar] [CrossRef]
- Barral, V.; Escudero, C.J.; García-Naya, J.A.; Maneiro-Catoira, R. NLOS Identification and Mitigation Using Low-Cost UWB Devices. Sensors 2019, 19, 3464. [Google Scholar] [CrossRef]
- Lian Sang, C.; Adams, M.; Hörmann, T.; Hesse, M.; Porrmann, M.; Rückert, U. Supplementary Experimental Data for the Paper entitled Numerical and Experimental Evaluation of Error Estimation for Two-Way Ranging Methods. Sensors 2019, 19, 616. [Google Scholar] [CrossRef]
- Schmid, L.; Salido-Monzú, D.; Wieser, A. Accuracy Assessment and Learned Error Mitigation of UWB ToF Ranging. In Proceedings of the 2019 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Pisa, Italy, 30 September–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Shen, G.; Zetik, R.; Thoma, R.S. Performance comparison of TOA and TDOA based location estimation algorithms in LOS environment. In Proceedings of the 2008 5th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 27 March 2008; pp. 71–78. [Google Scholar] [CrossRef]
- Khodjaev, J.; Park, Y.; Saeed Malik, A. Survey of NLOS identification and error mitigation problems in UWB-based positioning algorithms for dense environments. Ann. Telecommun. Ann. Des Télécommun. 2010, 65, 301–311. [Google Scholar] [CrossRef]
- Guvenc, I.; Chong, C.; Watanabe, F. NLOS Identification and Mitigation for UWB Localization Systems. In Proceedings of the 2007 IEEE Wireless Communications and Networking Conference, Kowloon, China, 11–15 March 2007; pp. 1571–1576. [Google Scholar] [CrossRef]
- Huang, C.; Molisch, A.F.; He, R.; Wang, R.; Tang, P.; Ai, B.; Zhong, Z. Machine Learning-Enabled LOS/NLOS Identification for MIMO System in Dynamic Environment. IEEE Trans. Wirel. Commun. 2020, 1. [Google Scholar] [CrossRef]
- Wymeersch, H.; Marano, S.; Gifford, W.M.; Win, M.Z. A Machine Learning Approach to Ranging Error Mitigation for UWB Localization. IEEE Trans. Commun. 2012, 60, 1719–1728. [Google Scholar] [CrossRef]
- Savic, V.; Larsson, E.G.; Ferrer-Coll, J.; Stenumgaard, P. Kernel Methods for Accurate UWB-Based Ranging With Reduced Complexity. IEEE Trans. Wirel. Commun. 2016, 15, 1783–1793. [Google Scholar] [CrossRef]
- Zandian, R.; Witkowski, U. NLOS Detection and Mitigation in Differential Localization Topologies Based on UWB Devices. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Kolakowski, M.; Modelski, J. Detection of direct path component absence in NLOS UWB channel. In Proceedings of the 2018 22nd International Microwave and Radar Conference (MIKON), Poznan, Poland, 14–17 May 2018; pp. 247–250. [Google Scholar] [CrossRef]
- Niitsoo, A.; Edelhäusser, T.; Mutschler, C. Convolutional Neural Networks for Position Estimation in TDoA-Based Locating Systems. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Cwalina, K.K.; Rajchowski, P.; Blaszkiewicz, O.; Olejniczak, A.; Sadowski, J. Deep Learning-Based LOS and NLOS Identification in Wireless Body Area Networks. Sensors 2019, 19, 4229. [Google Scholar] [CrossRef] [PubMed]
- Leech, C.; Raykov, Y.P.; Ozer, E.; Merrett, G.V. Real-time room occupancy estimation with Bayesian machine learning using a single PIR sensor and microcontroller. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Lian Sang, C.; Steinhagen, B.; Homburg, J.D.; Adams, M.; Hesse, M.; Rückert, U. Supplementary Research Data for the Paper entitled Identification of NLOS and Multi-path Conditions in UWB Localization using Machine Learning Methods. Appl. Sci. 2020. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Borras, J.; Hatrack, P.; Mandayam, N.B. Decision theoretic framework for NLOS identification. In Proceedings of the VTC ’98. 48th IEEE Vehicular Technology Conference. Pathway to Global Wireless Revolution (Cat. No.98CH36151), Ottawa, ON, Canada, 21 May 1998; Volume 2, pp. 1583–1587. [Google Scholar] [CrossRef]
- Schroeder, J.; Galler, S.; Kyamakya, K.; Jobmann, K. NLOS detection algorithms for Ultra-Wideband localization. In Proceedings of the 2007 4th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 22 March 2007; pp. 159–166. [Google Scholar] [CrossRef]
- Denis, B.; Daniele, N. NLOS ranging error mitigation in a distributed positioning algorithm for indoor UWB ad-hoc networks. In Proceedings of the International Workshop on Wireless Ad-Hoc Networks, Oulu, Finland, 31 May–3 June 2004; pp. 356–360. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, S.; Xu, K.; Huang, D. Neural Network Localization With TOA Measurements Based on Error Learning and Matching. IEEE Access 2019, 7, 19089–19099. [Google Scholar] [CrossRef]
- Maali, A.; Mimoun, H.; Baudoin, G.; Ouldali, A. A new low complexity NLOS identification approach based on UWB energy detection. In Proceedings of the 2009 IEEE Radio and Wireless Symposium, San Diego, CA, USA, 18–22 January 2009; pp. 675–678. [Google Scholar] [CrossRef]
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N.; Blunsom, P.; Frolik, J. Non-Line-of-Sight Identification and Mitigation Using Received Signal Strength. IEEE Trans. Wirel. Commun. 2015, 14, 1689–1702. [Google Scholar] [CrossRef]
- Gururaj, K.; Rajendra, A.K.; Song, Y.; Law, C.L.; Cai, G. Real-time identification of NLOS range measurements for enhanced UWB localization. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sapporo, Japan, 18–21 September 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Decawave. DW1000 User Manual: How to Use, Configure and Program the DW1000 UWB Transceiver. 2017. Available online: https://www.decawave.com/sites/default/files/resources/dw1000_user_manual_2.11.pdf (accessed on 5 June 2020).
- Musa, A.; Nugraha, G.D.; Han, H.; Choi, D.; Seo, S.; Kim, J. A decision tree-based NLOS detection method for the UWB indoor location tracking accuracy improvement. Int. J. Commun. Syst. 2019, 32, e3997. [Google Scholar] [CrossRef]
- Smith, D.R.; Pendry, J.B.; Wiltshire, M.C.K. Metamaterials and Negative Refractive Index. Science 2004, 305, 788–792. [Google Scholar] [CrossRef]
- Bregar, K.; Hrovat, A.; Mohorcic, M. NLOS Channel Detection with Multilayer Perceptron in Low-Rate Personal Area Networks for Indoor Localization Accuracy Improvement. In Proceedings of the 8th Jožef Stefan International Postgraduate School Students’ Conference, Ljubljana, Slovenia, 31 May–1 June 2016; Volume 31. [Google Scholar]
- Krishnan, S.; Xenia Mendoza Santos, R.; Ranier Yap, E.; Thu Zin, M. Improving UWB Based Indoor Positioning in Industrial Environments Through Machine Learning. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1484–1488. [Google Scholar] [CrossRef]
- Fan, J.; Awan, A.S. Non-Line-of-Sight Identification Based on Unsupervised Machine Learning in Ultra Wideband Systems. IEEE Access 2019, 7, 32464–32471. [Google Scholar] [CrossRef]
- STMicroelectronics. UM1724 User Manual: STM32 Nucleo-64 Boards (MB1136). 2019. Available online: https://www.st.com/resource/en/user_manual/dm00105823-stm32-nucleo-64-boards-mb1136-stmicroelectronics.pdf (accessed on 5 June 2020).
- STMicroelectronics. STM32L476xx Datasheet—Ultra-low-power Arm Cortex-M4 32-bit MCU+FPU, 100DMIPS, up to 1MB Flash, 128 KB SRAM, USB OTG FS, LCD, ext. SMPS. 2019. Available online: https://www.st.com/resource/en/datasheet/stm32l476je.pdf (accessed on 5 June 2020).
- Charte, F.; Rivera, A.J.; del Jesus, M.J.; Herrera, F. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing 2015, 163, 3–16. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York Inc.: New York, NY, USA, 2001. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Choi, J.; Lee, W.; Lee, J.; Lee, J.; Kim, S. Deep Learning Based NLOS Identification With Commodity WLAN Devices. IEEE Trans. Veh. Technol. 2018, 67, 3295–3303. [Google Scholar] [CrossRef]
Sample Availability: The experimental research data and the corresponding source code used in this paper are
publicly available in PUB—Publication at Bielefeld University [25]. |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Hardware | Properties | Values |
|---|---|---|
| UWB module | Module name | DWM1000 |
| Data rate | bps | |
| Center frequency | ||
| Bandwidth | ||
| Channel | 2 | |
| Pulse-repetition frequency (PRF) | 16 | |
| Reported precision | 10 cm | |
| manufacturer | Decawave | |
| Microcontroller (MCU) | Module type | STM32L476RG |
| Development board | NUCLEO-L476RG | |
| Manufacturer | STMicroelectronics |
| Kernel Types | Mean Accuracy with std (%) | Mean Training Time per Sample (ms) | Mean Test Time per Sample (ms) |
|---|---|---|---|
| Radial basis function (RBF) | |||
| Linear function | |||
| 3rd order polynomial function | |||
| Sigmoid function |
| No. of Decision Trees in the Forest | Mean Accuracy with std (%) | Mean Training Time per Sample (s) | Mean Test Time per Sample (s) |
|---|---|---|---|
| 5 decision trees | |||
| 10 decision trees | |||
| 20 decision trees | |||
| 30 decision trees | |||
| 50 decision trees | |||
| 100 decision trees | |||
| 200 decision trees | |||
| 500 decision trees |
| No. of Neurons in each Hidden Layers | No. of Hidden Layers | Mean Accuracy with std (%) | Mean Training Time per Sample (ms) | Mean Test Time per Sample (s) |
|---|---|---|---|---|
| 50 | 1 | |||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 100 | 1 | |||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 |
| Scenarios | Classifiers | Individual F1-Scores | Macro-Averaging F1-Scores | Overall Accuracy (%) | ||
|---|---|---|---|---|---|---|
| LOS | NLOS | MP | ||||
| Training and test environments are different | SVM | 0.77 | 0.78 | 0.70 | 0.75 | 75.35 |
| RF | 0.74 | 0.76 | 0.71 | 0.73 | 73.52 | |
| MLP | 0.72 | 0.75 | 0.71 | 0.73 | 72.86 | |
| Training and test environments are the same | SVM | 0.81 | 0.81 | 0.86 | 0.83 | 82.80 |
| RF | 0.91 | 0.93 | 0.93 | 0.92 | 91.90 | |
| MLP | 0.90 | 0.92 | 0.92 | 0.91 | 91.20 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sang, C.L.; Steinhagen, B.; Homburg, J.D.; Adams, M.; Hesse, M.; Rückert, U. Identification of NLOS and Multi-Path Conditions in UWB Localization Using Machine Learning Methods. Appl. Sci. 2020, 10, 3980. https://doi.org/10.3390/app10113980
Sang CL, Steinhagen B, Homburg JD, Adams M, Hesse M, Rückert U. Identification of NLOS and Multi-Path Conditions in UWB Localization Using Machine Learning Methods. Applied Sciences. 2020; 10(11):3980. https://doi.org/10.3390/app10113980
Chicago/Turabian StyleSang, Cung Lian, Bastian Steinhagen, Jonas Dominik Homburg, Michael Adams, Marc Hesse, and Ulrich Rückert. 2020. "Identification of NLOS and Multi-Path Conditions in UWB Localization Using Machine Learning Methods" Applied Sciences 10, no. 11: 3980. https://doi.org/10.3390/app10113980
APA StyleSang, C. L., Steinhagen, B., Homburg, J. D., Adams, M., Hesse, M., & Rückert, U. (2020). Identification of NLOS and Multi-Path Conditions in UWB Localization Using Machine Learning Methods. Applied Sciences, 10(11), 3980. https://doi.org/10.3390/app10113980