On Solving Large-Size Generalized Cell Formation Problems via a Hard Computing Approach Using the PMP


Abstract
:1. Introduction
- First, with regard to SCF, the 35 standard incidences available in the literature have been widely used for benchmark testing for the last 20 years, and a recent study adopting a hybrid algorithm [50] has reported the best optimal solutions with huge time-savings. However, there are few open large GCF data sets available in the literature regarding the standard instances for benchmark testing and the performance comparison of the solution algorithms used. As far as the present author knows, the largest example of an open GCF available in the literature has at most 55 machines, 60 part types, and a total of 124 process plans [51].
- Second, execution strategies for CF and complicated aspects inherent in the GCF problem itself make the solution quality of CF methods very sensitive to subsequent part assignment or improvement procedures that are necessary to follow after machine cells are obtained. Three different strategies have been used to execute the CF algorithm [52]: the part family identification (PGI) strategy forms part families first and then groups machines, the machine group identification (MGI) strategy creates machine cells first and then allocate parts to cells, and the part family/machine grouping (PF/MG) strategy forms machine cells and part families simultaneously. Most soft and hard computing approaches for CF use the MGI strategy to execute CF algorithms since it usually takes enormous computation time to implement the PF/MG strategy even for intermediate-size incidences. The PMP-based approach for CF also uses the MGI strategy to create cells. Therefore, once machine cells are obtained from the PMP solution, part families need to be formed by allocating parts to the best cells. Danilovic and Ilic [50] and Li et al. [53] have established sufficient conditions for the optimal assignment of parts to machine cells given a partition of machines of a SCF problem. However, it should be noted that their sufficient conditions may not guarantee the optimal assignment of parts maximizing the GE in the GCF problem due to the existence of alternative process plans and/or replicate machines.
- Two new linear 0–1 mathematical models of GCF are formulated: an exact model that directly maximizes the GE and a PMP-type model that indirectly maximizes the GE. Because the exact model contains too many binary variables and constraints, the PMP-type model is used to solve large-sized GCF instances optimally. According to the computational experiments applied to large GCF instances with over 10,000 binary variables, our PMP-type model solves those large GCF instances optimally within one second using the LINGO MILP solver.
- Since the PMP-type approach uses MGI strategy to form machine cells first, a subsequent part allocating step is needed to form the corresponding part families. In this paper, a systematic heuristic part assignment procedure based on a new classification scheme of part types with alternative process plans is used to assign the best process plan of each part to its best cell. A subsequent refinement procedure is the used to further improve the block diagonal solution by reassigning improperly assigned exceptional machines (EMs) in such a way that the GE is maximized. The computational burden of implementing these extra procedures is negligibly small since they accomplish a high-quality CF within 0.2 s, even for the largest GCF instances tested in our computational experiments.
- Unlike many comparative studies of SCF using the standard data set provided in Goncalves and Resende [19], studies of GCF lack the standard data set. Our computational experiment has been conducted over the widest range of GCF incidences that have ever appeared in the CF-related literature. Our collection of the GCF incidences can be used as a standard data set for subsequent benchmark tests in the future.
2. Materials and Methods
2.1. Basic Input
| part index; |
| process plan index; |
| machine or cell index; |
| copy index of replicate machine; |
| machine cell/part family index. |
| number of part types; |
| set of process plans of part type ; |
| total number of process plans; |
| number of different machine types; |
| number of cells; |
| upper limit on the cell size; |
| set of replicate machine types; |
| set of copies of replicate machine type ; |
| total number of machines including copies of replicate machine types (the symbol denotes the cardinality of the set X); |
| generalized similarity coefficient between machine types and ; |
| similarity coefficient between machines and ; |
| set of machines in machine cell c; |
| set of parts in part family c; |
| total number of 1s in the block diagonal solution matrix; |
| number of exceptional elements(EEs) in the block diagonal solution matrix; |
| number of voids in the block diagonal solution matrix.; |
2.2. Performance Measure
2.3. Mathematical Models
2.3.1. Exact Model
2.3.2. PMP-Type Model
2.3.3. Part Assignment to Cells
- A type I strongly nonexceptional part (SNEP) for which a unique process plan has the most 1s in a unique machine cell without EEs;
- A type II SNEP for which multiple process plans have the most 1s in a unique machine cell without EEs;
- A type I neutrally nonexceptional part (NNEP) for which a unique process plan has the most 1s in more than one machine cell without EEs;
- A type II NNEP for which multiple process plans have the most 1s in more than one machine cell without EEs;
- A type I weakly exceptional part (WEP) for which a unique process plan has the most 1s in a unique machine cell with EEs;
- A type II WEP for which multiple process plans have the most 1s in a unique machine cell with EEs;
- A type I neutrally exceptional part (NEP) for which a unique process plan has the most 1s in more than one machine cell with EEs;
- A type II NEP for which multiple process plans have the most 1s in more than one machine cell with EEs.
- The numbers of EEs due to the assignment of each process plan to each cell;
- The number of voids due to the assignment of each process plan to each cell;
- The number of cells which have the most 1s for completing the required operations due to the assignment of each process plan to each cell;
- The total number of operations (1s) contained in each cell with all the parts assigned until the current stage;
- The number of parts assigned to each cell until the current stage; and
- The number of operations processed by the machines in each cell.
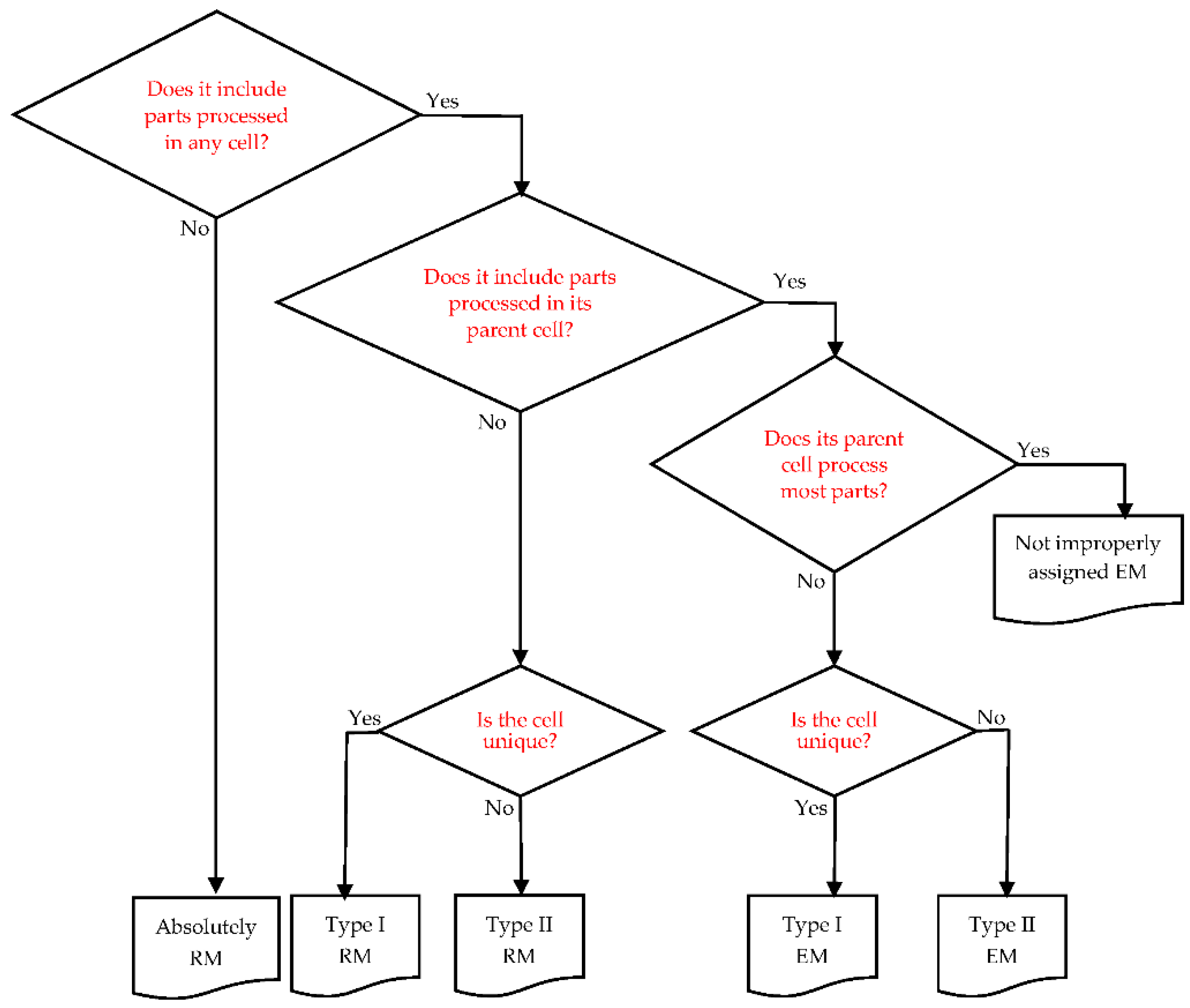
2.3.4. Reassigning Improperly Assigned Exceptional Machines (EMs) and Redundant Machines (RMs)
- An absolute RM which processes no parts in any cell;
- A type I RM which processes most parts in other unique cells except for its parent cell;
- A type II RM which processes most parts in two or more other cells except for its parent cell;
- A type I EM which processes some parts in its parent cell but processes most parts in other unique cells except for its parent cell;
- A type II EM which processes most parts in two or more cells including its parent cell.
- Its parent cell;
- Cells processing most parts;
- The total number of parts processed; and
- The number of parts processed in its parent cell.
- Reassign a type I RM or type I EM to another unique candidate cell;
- Reassign an absolute RM, type II RM or type II EM to the cell with the fewest 1s. If ties occur, reassign them to the cell with the lowest number of machines.
- Remove an absolute RM from the current cell since it does not process any parts under the incumbent cell configuration.
2.3.5. Illustrative Example
3. Results
4. Discussion
5. Conclusions
- Two new linear 0–1 mathematical models have been formulated to solve the GCF problem: an exact model to directly maximize the GE and a PMP-type model to indirectly maximize the GE;
- It seems still to be very difficult to use a hard computing approach to optimally solve large-sized GCF incidences of an exact mathematical model optimizing the objective function directly.
- The PMP-type model, as an alternative to optimizing the objective function of GCF indirectly, can use hard computing techniques to solve large-sized GCF incidences optimally in a very short computation time. Even a large GCF incidence containing 12,100 binary variables can be solved within only one second to the global optimum, and the machine cells can be identified.
- The computation time for subsequent part assignment procedures finding the associated part families and refinement steps and reassigning improperly assigned EMs/RMs is also negligibly small, even if some soft computing heuristics can work faster, as shown by Goldengorin et al. [34].
- The solution quality based on the proposed hard computing approach compares favorably to existing GCF solution approaches.
- The GCF incidences collected in our computation experiment can be used as a standard data set for subsequent benchmark tests in the future.
Funding
Acknowledgments
Conflicts of Interest
References
- Burbidge, J.L. The new approach to production. Prod. Eng. 1961, 40, 769–794. [Google Scholar] [CrossRef]
- Wemmerlöv, U.; Johnson, D.J. Empirical findings on manufacturing cell design. Int. J. Prod. Res. 2000, 38, 481–507. [Google Scholar] [CrossRef]
- Ballakur, A.; Steudel, H.J. A within–cell utilization based heuristic for designing cellular manufacturing systems. Int. J. Prod. Res. 1987, 25, 639–655. [Google Scholar] [CrossRef]
- Batsyn, M.V.; Batsyna, E.K.; Bychkov, I.S. On NP-completeness of the cell formation problem. Int. J. Prod. Res. 2019, in press. [Google Scholar] [CrossRef]
- Papaioannou, G.; Wilson, J.M. The evolution of cell formation problem methodologies based on recent studies (1997–2008): Review and directions for future research. Eur. J. Oper. Res. 2010, 206, 509–521. [Google Scholar] [CrossRef] [Green Version]
- Lozano, S.; Guerrero, F.; Eguia, I.; Onieva, L. Cell design and loading in the presence of alternative routing. Int. J. Prod. Res. 1999, 37, 3289–3304. [Google Scholar] [CrossRef]
- Islam, K.M.S.; Sarker, B.R. A similarity coefficient measure and machine-parts grouping in cellular manufacturing systems. Int. J. Prod. Res. 2000, 38, 699–720. [Google Scholar] [CrossRef]
- Heragu, S.S.; Chen, J.S. Optimal solution of cellular manufacturing system design: Benders’ decomposition approach. Eur. J. Oper. Res. 1998, 107, 175–192. [Google Scholar] [CrossRef]
- Borrero, J.S.; Gillen, C.; Prokopyev, O.A. Fractional 0–1 programming: Applications and algorithms. J. Glob. Optim. 2017, 69, 255–282. [Google Scholar] [CrossRef]
- Kumar, C.S.; Chandrasekharan, M.P. Grouping efficacy: A quantitative criterion for goodness of block diagonal forms of binary matrices in group technology. Int. J. Prod. Res. 1990, 28, 233–243. [Google Scholar] [CrossRef]
- Elbenani, B.; Ferland, J.A. Cell formation problem solved exactly with the Dinkelbach algorithm. CIRRET 2012, 7, 1–14. [Google Scholar]
- Elbenani, B.; Ferland, J.A. An exact method for solving the manufacturing cell formation problem. Int. J. Prod. Res. 2012, 50, 4038–4045. [Google Scholar] [CrossRef]
- Bychkov, I.; Batsyn, M.; Pardalos, P.M. Exact model for the cell formation problem. Optim. Lett. 2014, 8, 2203–2210. [Google Scholar] [CrossRef]
- Brusco, M.J. An exact algorithm for maximizing grouping efficacy in part-machine clustering. IIE Trans. 2015, 47, 653–671. [Google Scholar] [CrossRef]
- Pinheiro, R.G.S.; Martins, I.C.; Protti, F.; Ochi, L.S.; Simonetti, L.G.; Subramanian, A. On solving manufacturing cell formation via bicluster editing. Eur. J. Oper. Res. 2016, 254, 769–779. [Google Scholar] [CrossRef] [Green Version]
- Utkina, I.; Batsyn, M.V.; Batsyna, E.K. A branch and bound algorithm for a fractional 0-1 programming problem. In Discrete Optimization and Operations Research; Kochetov, Y., Khachay, M., Beresnev, V., Nurminski, E., Pardalos, P., Eds.; Lecture Notes in Computer Science; Springer: New York, NY, USA, 2016; Volume 9869, pp. 244–255. [Google Scholar]
- Bychkov, I.; Batsyn, M. An efficient exact model for the cell formation problem with a variable number of production cells. Comput. Oper. Res. 2018, 91, 112–120. [Google Scholar] [CrossRef] [Green Version]
- Utkina, I.; Batsyn, M.V.; Batsyna, E.K. A branch-and-bound algorithm for the cell formation problem. Int. J. Prod. Res. 2018, 56, 3262–3273. [Google Scholar] [CrossRef]
- Goncalves, J.F.; Resende, M.G.C. An evolutionary algorithm for manufacturing cell formation. Comput. Ind. Eng. 2004, 47, 247–273. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum location of switching centers and the absolute centers and medians of a graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum distribution of switching centers and some graph related theoretic problems. Oper. Res. 1965, 13, 462–475. [Google Scholar] [CrossRef]
- Shi, J.; Zheng, X.; Jiao, B.; Wang, R. Multi-scenario cooperative evolutionary algorithm for the β-Robust p-median problem with demand uncertainty. Appl. Sci. 2019, 9, 4174. [Google Scholar] [CrossRef] [Green Version]
- ReVelle, C.S.; Swain, R.W. Central Facilities location. Geogr. Anal. 1970, 2, 30–42. [Google Scholar] [CrossRef]
- Balinski, M. Integer programming: Methods, uses, computations. Manag. Sci. 1965, 12, 253–313. [Google Scholar] [CrossRef]
- Efroymson, M.A.; Ray, T.L. A branch-bound algorithm for plant location. Oper. Res. 1966, 14, 361–368. [Google Scholar] [CrossRef]
- Church, R.L. COBRA: A new formulation of the classic p-median location problem. Ann. Oper. Res. 2003, 122, 103–120. [Google Scholar] [CrossRef]
- Goldengorin, B.; Ghosh, D.; Sierksma, G. Branch and peg algorithms for the simple plant location problem. Comput. Oper. Res. 2003, 30, 967–981. [Google Scholar] [CrossRef] [Green Version]
- Goldengorin, B.; Tijssen, G.A.; Ghosh, D.; Sierksma, G. Solving the simple plant location problems using a data correcting approach. J. Global Optim. 2003, 25, 377–406. [Google Scholar] [CrossRef]
- Church, R.L. BEAMR: An exact and approximate model for the p-median problem. Comput. Oper. Res. 2008, 35, 417–426. [Google Scholar] [CrossRef]
- Elloumi, S. A tighter formulation of the p-median problem. J. Glob. Optim. 2010, 19, 69–83. [Google Scholar] [CrossRef]
- García, S.; Labbé, M.; Marín, A. Solving large p-median problems with a radius formulation. INFORMS J. Comput. 2011, 23, 546–556. [Google Scholar] [CrossRef]
- Kusiak, A. The part families problem in flexible manufacturing systems. Ann. Oper. Res. 1985, 3, 279–300. [Google Scholar] [CrossRef]
- Kusiak, A. The Generalized group technology concept. Int. J. Prod. Res. 1987, 25, 561–569. [Google Scholar] [CrossRef]
- Goldengorin, B.; Krushinsky, D.; Slomp, J. Flexible PMP approach for large-size cell formation. Oper. Res. 2012, 60, 1157–1166. [Google Scholar] [CrossRef]
- Sankran, S.; Kasilingam, R.G. An integrated approach to cell formation and part routing in group technology. Eng. Optim. 1990, 16, 235–245. [Google Scholar] [CrossRef]
- Kaparthi, S.; Suresh, N.C. Performance of selected part-machine grouping techniques for data sets of wide ranging sizes and imperfection. Decis. Sci. 1994, 25, 515–539. [Google Scholar] [CrossRef]
- Lee, H.; Garcia-Diaz, A. Network flow procedures for the analysis of cellular manufacturing systems. IIE Trans. 1996, 28, 333–345. [Google Scholar] [CrossRef]
- Viswanathan, S. A new approach for solving the p-median problem in group technology. Int. J. Prod. Res. 1996, 34, 2691–2700. [Google Scholar] [CrossRef]
- Deutsch, S.J.; Freeman, S.F.; Helander, M. Manufacturing cell formation using an improved p-median model. Comput. Ind. Eng. 1998, 34, 135–146. [Google Scholar] [CrossRef]
- Won, Y. New p-median approach to cell formation with alternative process plans. Int. J. Prod. Res. 2000, 38, 229–240. [Google Scholar] [CrossRef]
- Won, Y. Two-phase approach to GT cell formation using efficient p-median formulations. Int. J. Prod. Res. 2000, 38, 1601–1613. [Google Scholar] [CrossRef]
- Won, Y.; Lee, K.C. Modified p-median approach for efficient GT cell formation. Comput. Ind. Eng. 2004, 46, 495–510. [Google Scholar] [CrossRef]
- Ashayeri, J.; Heuts, R.; Tammel, B. A modified simple heuristic for the p-median problem, with facilities design applications. Robot. CIM Int. Manuf. 2005, 21, 451–464. [Google Scholar] [CrossRef]
- Won, Y.; Currie, K.R. An effective p-median model considering production factors in machine cell/part family formation. J. Manuf. Syst. 2006, 25, 58–64. [Google Scholar] [CrossRef]
- Süer, G.A.; Huang, J.H.; Maddisetty, S. Design of dedicated, shared and remainder cells in a probabilistic demand environment. Int. J. Prod. Res. 2010, 48, 5613–5646. [Google Scholar] [CrossRef]
- Egilmez, G.; Süer, G.A.; Huang, J. Stochastic cellular manufacturing system design subject to maximum acceptable risk level. Comput. Ind. Eng. 2012, 63, 842–854. [Google Scholar] [CrossRef]
- Egilmez, G.; Süer, G.A. The impact of risk on the integrated cellular design and control. Int. J. Prod. Res. 2014, 52, 1455–1478. [Google Scholar] [CrossRef]
- Won, Y.; Logendran, R. Effective two-phase p-median approach for the balanced cell formation in the design of cellular manufacturing system. Int. J. Prod. Res. 2015, 53, 2730–2750. [Google Scholar] [CrossRef]
- Alhawari, O.; Süer, G. Modified p-median model with minimum threshold for average family similarity. Procedia Manuf. 2019, 39, 1048–1056. [Google Scholar] [CrossRef]
- Danilovic, M.; Ilic, O. A novel hybrid algorithm for manufacturing cell formation problem. Expert Syst. Appl. 2019, 135, 327–350. [Google Scholar] [CrossRef]
- Kao, Y.; Chen, C.C. Automatic clustering for generalised cell formation using a hybrid particle swarm optimisation. Int. J. Prod. Res. 2014, 52, 3466–3484. [Google Scholar] [CrossRef]
- Riccardo, M.; Riccardo, A.; Marco, B. Similarity-based cluster analysis for the cell formation problem. In Operations Management Research and Cellular Manufacturing Systems: Innovative Methods and Approaches; Modrák, V., Pandian, R.S., Eds.; IGI Global: Hershey, PA, USA, 2012; pp. 140–163. [Google Scholar]
- Li, X.; Baki, M.; Aneja, Y. An ant colony optimization metaheuristic for machine-part cell formation problems. Comput. Oper. Res. 2010, 37, 2071–2081. [Google Scholar] [CrossRef]
- Vin, E.; Delchambre, A. Generalized cell formation: Iterative versus simultaneous resolution with grouping genetic algorithm. J. Intell. Manuf. 2014, 25, 1113–1124. [Google Scholar] [CrossRef]
- Sarker, B.R. Measures of grouping efficiency in cellular manufacturing systems. Eur. J. Oper. Res. 2001, 130, 588–611. [Google Scholar] [CrossRef]
- Sarker, B.R.; Khan, M. A comparison of existing grouping efficiency measures and a new weighted grouping efficiency measure. IIE Trans. 2001, 33, 11–27. [Google Scholar] [CrossRef]
- Mahdavi, I.; Javadi, B.; Fallah-Alipour, K.; Slomp, J. Designing a new mathematical model for cellular manufacturing system based on cell utilization. Appl. Math. Comput. 2007, 190, 662–670. [Google Scholar] [CrossRef]
- Paydar, M.M.; Saidi-Mehrabad, M. A hybrid genetic-variable neighborhood search algorithm for the cell formation problem based on grouping efficacy. Comput. Oper. Res. 2013, 40, 980–990. [Google Scholar] [CrossRef]
- Won, Y.; Kim, S. Multiple criteria clustering algorithm for solving the group technology problem with multiple process routings. Comput. Ind. Eng. 1997, 32, 207–220. [Google Scholar] [CrossRef]
- Mukattash, A.M.; Adil, M.B.; Tahboub, K.K. Heuristic approaches for part assignment in cell formation. Comput. Ind. Eng. 2002, 42, 327–341. [Google Scholar] [CrossRef]
- Wu, T.H.; Chung, S.H.; Chang, C.C. Hybrid simulated annealing algorithm with mutation operator to the cell formation problem with alternative process routings. Expert Syst. Appl. 2009, 36, 3652–3661. [Google Scholar] [CrossRef]
- Shiyasa, C.R.; Pillaia, V.M. Cellular manufacturing system design using grouping efficacy-based genetic algorithm. Int. J. Prod. Res. 2014, 52, 3504–3517. [Google Scholar] [CrossRef]
- Won, Y. P-median approach for the large-size multi-objective generalized cell formation. Korean Manag. Sci. Rev. 2018, 35, 35–55. [Google Scholar] [CrossRef]
- Al-Zawahreha, A.; Dahmanib, N.; Alethem, K.A.; Mukattash, A. Sensitivity analysis of the impact of part assignment in cellular manufacturing systems. Decis. Sci. Lett. 2019, 8, 109–120. [Google Scholar] [CrossRef]
- Nagi, R.; Harhalakis, G.; Proth, J. Multiple routings and capacity consideration in group technology applications. Int. J. Prod. Res. 1990, 28, 2243–2257. [Google Scholar] [CrossRef]
- Moon, Y.B.; Chi, S.C. Generalized part family formation using neural network techniques. J. Manuf. Syst. 1992, 11, 149–159. [Google Scholar] [CrossRef]
- Kasilingam, R.G.; Lashkari, R.S. Cell formation in the presence of alternate process plans in flexible manufacturing systems. Prod. Plan. Control. 1991, 2, 135–141. [Google Scholar] [CrossRef]
- Logendran, R.; Ramakrishna, P.; Sriskandarajah, C. Tabu search-based heuristics for cellular manufacturing systems in the presence of alternative process plans. Int. J. Prod. Res. 1994, 32, 273–297. [Google Scholar] [CrossRef]
- Adil, G.K.; Rajamani, D.; Strong, D. Cell formation considering alternate routeings. Int. J. Prod. Res. 1996, 34, 1361–1380. [Google Scholar] [CrossRef]
- Lee, M.K.; Luong, H.S.; Abhary, K. A genetic algorithm based cell design considering alternative routing. Comput. Integr. Manuf. 1997, 10, 93–107. [Google Scholar] [CrossRef]
- Han, J. Formation of Part and Machine Cells with Consideration of Alternative Machines. Master’s Thesis, Ohio University, Athens, OH, USA, 1998. [Google Scholar]
- Sofianopoulou, S. Manufacturing cells design with alternative process plans and/or replicate machines. Int. J. Prod. Res. 1999, 37, 707–720. [Google Scholar] [CrossRef]
- Gen, M.; Cheng, R. Manufacturing cell design. In Genetic Algorithms and Engineering Optimization; John Wiley & Sons: New York, NY, USA, 2000; pp. 390–450. [Google Scholar]
- Aktürk, M.S.; Turkcan, A. Cellular manufacturing system design using a holonistic approach. Int. J. Prod. Res. 2000, 38, 2327–2347. [Google Scholar] [CrossRef]
- Yin, Y.; Yasuda, K. Manufacturing cells’ design in consideration of various production factors. Int. J. Prod. Res. 2002, 40, 885–906. [Google Scholar] [CrossRef]
- Solimanpur, M.; Vrat, P.; Shankar, R. A multi-objective genetic algorithm approach to the design of cellular manufacturing systems. Int. J. Prod. Res. 2004, 42, 1419–1441. [Google Scholar] [CrossRef]
- Bhide, P.; Bhandwale, A.; Kesavadas, T. Cell formation using multiple process plans. J. Intell. Manuf. 2005, 16, 53–65. [Google Scholar] [CrossRef]
- Hu, L.; Yasuda, K. Minimising material handling cost in cell formation with alternative processing routes by grouping genetic algorithm. Int. J. Prod. Res. 2006, 44, 2133–2167. [Google Scholar] [CrossRef]
- Hwang, H.; Ree, P. Routes selection for the cell formation problem with alternative part process plans. Comput. Ind. Eng. 1996, 30, 423–431. [Google Scholar] [CrossRef]
- Adil, G.K.; Rajamani, D.; Strong, D. Assignment allocation and simulated annealing algorithms for cell formation. IIE Trans. 1997, 29, 53–67. [Google Scholar] [CrossRef]
- Wu, T.H.; Chen, J.F.; Yeh, J.Y. A decomposition approach to the cell formation problem with alternative process plans. Int. J. Adv. Manuf. Technol. 2004, 24, 834–840. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part No. | Process Plan | Machines | Part No. | Process Plan | Machines |
|---|---|---|---|---|---|
| 1 | a | 1, 5 | 9 | a | 5, 7 |
| b | 1, 3, 4, 6 | b | 2, 4 | ||
| 2 | a | 3, 5, 7 | 10 | a | 1, 3, 4 |
| b | 2, 3 | b | 1, 2, 5 | ||
| 3 | a | 2, 3, 4 | 11 | a | 2, 3, 4, 6 |
| 4 | a | 2, 3, 4, 5 | b | 1, 2, 5 | |
| b | 1, 2, 4, 5 | c | 5, 6, 7 | ||
| c | 2, 5, 6 | d | 2, 3, 4, 5, 7 | ||
| d | 2, 3, 4, 7 | 12 | a | 3, 5 | |
| 5 | a | 3, 4, 5, 6 | b | 2, 6 | |
| b | 2, 7 | c | 2, 3, 4 | ||
| c | 1, 3, 4, 5, 7 | 13 | a | 1, 2, 3, 6 | |
| 6 | a | 2, 4 | 14 | a | 2, 3, 4, 6 |
| b | 1, 3, 6 | b | 1, 2, 3, 4 | ||
| 7 | a | 3, 5 | 15 | a | 2, 7 |
| b | 4, 5, 7 | b | 3, 4 | ||
| 8 | a | 2, 3, 5 | |||
| b | 4, 6, 7 | ||||
| c | 1, 2, 3, 6 |
| Part No. | Process Plan | Cells Assigned | Criteria | Part Type | Criteria | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 5 | 6 | ||||
| 1 | a * | 1 * | 1 * | 2 | Type II NEP | |||
| 2 | 2 | 3 | ||||||
| 3 * | 1 * | 3 | ||||||
| b ** | 1 ** | 1 * | 0 * | |||||
| 2 | 2 | 1 | ||||||
| 3 | 2 | 2 | ||||||
| 2 | a ** | 1 | 2 | 2 | Type II NNEP | |||
| 2 | 2 | 2 | ||||||
| 3 ** | 0 * | 1 * | 0 * | 0 * | 3 ** | |||
| b * | 1 | 1 | 2 | |||||
| 2 * | 0 * | 1 * | 0 * | 0 * | 2 | |||
| 3 | 1 | 3 | ||||||
| 3 | a ** | 1 | 2 | 2 | Type I SNEP | |||
| 2 ** | 0 * | 0 * | ||||||
| 3 | 1 | 2 | ||||||
| Problem | Problem Size | Reference Algorithm | Proposed Approach | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Source | n(q) | m | t | p | U | e | EEs | Voids | GE (%) | e | EEs | Voids | GE (%) | CPU (s) |
| 1. [33] | 4 | 5 | 11 | 2 | 2 | 9 | 0 | 1 | 90.00 | 9 | 0 | 1 | 90.00 | 0.05 a + 0.044 b |
| 2. [35] | 6 | 10 | 20 | 2 | 4 | 28 | 2 | 8 | 72.22 | 28 | 2 | 8 | 72.22 | 0.05 + 0.047 |
| 6(7) | 10 | 20 | 2 | 4 | 27 | 0 | 10 | 72.97 | 31 | 0 | 8 | 79.49 | 0.09 + 0.054 | |
| 3. [65] | 20 | 20 | 51 | 5 | 5 | 66 | 1 | 17 | 78.31 | 67 | 6 | 16 | 73.49 | 0.09 + 0.189 |
| 4. [66] | 6 | 6 | 13 | 2 | 3 | 15 | 0 | 3 | 83.33 | 15 | 0 | 3 | 83.33 | 0.05 + 0.044 |
| 5. [67] | 10 | 10 | 27 | 3 | 5 | 47 | 10 | 17 | 57.81 | 49 | 12 | 12 | 60.66 | 0.08 + 0.062 |
| 10(13) | 15 | 27 | 3 | 5 | 49 | 5 | 20 | 63.77 c | 49 | 4 | 21 | 64.29 | 0.08 + 0.050 | |
| 6. [68] | 7 | 14 | 32 | 3 | 3 | 31 | 5 | 6 | 70.27d | 29 | 5 | 6 | 68.57 | 0.06 + 0.048 |
| 7. [69] | 10 | 10 | 24 | 3 | 5 | 31 | 1 | 3 | 88.24 | 31 | 1 | 3 | 88.24 | 0.08 + 0.050 |
| 10(11) | 10 | 24 | 3 | 5 | 33 | 3 | 10 | 69.77 | 33 | 1 | 3 | 88.89 | 0.06 + 0.049 | |
| 8. [70] | 8 | 13 | 26 | 3 | 3 | 33 | 2 | 5 | 81.58 | 33 | 3 | 4 | 81.08 | 0.09 + 0.049 |
| 9. [70] | 30 | 30 | 89 | 6 | 7 | 151 | 1 | 48 | 75.38 | 150 | 1 | 46 | 76.02 | 0.11 + 0.065 |
| 10. [59] | 4 | 4 | 8 | 2 | 2 | 8 | 0 | 0 | 100.00 | 8 | 0 | 0 | 100.00 | 0.05 + 0.040 |
| 7 | 10 | 23 | 3 | 3 | 25 | 3 | 2 | 81.48 | 23 | 4 | 5 | 67.86 | 0.06 + 0.045 | |
| 11 | 10 | 22 | 4 | 3 | 28 | 3 | 3 | 80.65 | 27 | 3 | 4 | 77.42 | 0.08 + 0.041 | |
| 26 | 28 | 71 | 6 | 7 | 124 | 16 | 25 | 72.48 | 121 | 15 | 27 | 71.62 | 0.10 + 0.059 | |
| 11. [71] | 8 | 15 | 46 | 2 | 4 | 30 | 1 | 31 | 47.54 | 35 | 1 | 26 | 55.74 | 0.08 + 0.049 |
| 8 | 15 | 46 | 2 | 5 | NA | NA | NA | NA | 33 | 0 | 22 | 60.00 | 0.07 + 0.048 | |
| 8 | 15 | 46 | 3 | 3 | 32 | 1 | 12 | 70.45 | 33 | 1 | 9 | 76.19 | 0.09 + 0.047 | |
| 12. [72] | 12 | 20 | 26 | 3 | 5 | NA | 29 | NA | 47.06 e | 85 | 31 | 26 | 48.65 | 0.08 + 0.047 |
| 13. [72] | 14 | 20 | 45 | 3 | 5 | 85 | 24 | 35 | 50.83e | 85 | 31 | 27 | 48.21 | 0.09 + 0.051 |
| 14. [72] | 18 | 18 | 59 | 3 | 6 | 116 | 26 | 108 | 40.18 e | 116 | 32 | 84 | 42.00 | 0.09 + 0.054 |
| 15. [73] | 10(13) | 7 | 13 | 3 | 5 | 22 | 0 | 9 | 70.97 | 23 | 1 | 11 | 64.71 | 0.08 + 0.053 |
| 16. [74] | 6(15) | 20 | 34 | 3 | 5 | 49 | 0 | 52 | 48.51 e | 49 | 0 | 51 | 49.00 | 0.08 + 0.048 |
| 17. [75] | 6 | 8 | 14 | 2 | 3 | 21 | 1 | 4 | 80.00 | 22 | 1 | 3 | 84.00 | 0.05 + 0.046 |
| 18. [75] | 5 | 7 | 11 | 2 | 3 | 15 | 0 | 3 | 83.33 | 17 | 1 | 1 | 88.89 | 0.05 + 0.047 |
| 19. [75] | 10(14) | 16 | 31 | 2 | 7 | 68 | 8 | 52 | 50.00 | 68 | 1 | 45 | 59.29 | 0.08 + 0.050 |
| 20. [76] | 10(16) | 20 | 35 | 2 | 10 | 77 | 0 | 87 | 46.95 | 77 | 4 | 79 | 46.79 | 0.09 + 0.049 |
| 21. [77] | 9 | 8 | 20 | 2 | 6 | 28 | 2 | 13 | 63.41 | 28 | 2 | 10 | 68.42 | 0.08 + 0.046 |
| 22. [78] | 30 | 70 | 149 | 2 | 15 | NA | NA | NA | NA | 477 | 132 | 717 | 28.89 | 0.15 + 0.079 |
| 30 | 70 | 149 | 3 | 10 | NA | NA | NA | NA | 478 | 193 | 415 | 31.91 | 0.28 + 0.082 | |
| 30 | 70 | 149 | 4 | 8 | NA | NA | NA | NA | 477 | 219 | 290 | 33.64 | 0.17 + 0.081 | |
| 30 | 70 | 149 | 5 | 6 | NA | NA | NA | NA | 478 | 249 | 192 | 34.18 | 0.16 + 0.081 | |
| 23. [51] | 30 | 35 | 82 | 4 | 8 | 224 | 52 | 92 | 54.43 | 229 | 52 | 86 | 56.19 | 0.18 + 0.067 |
| 30 | 35 | 100 | 5 | 7 | NA | NA | NA | NA | 233 | 58 | 38 | 64.58 | 0.13 + 0.066 | |
| 24. [51] | 40 | 45 | 100 | 6 | 8 | 263 | 39 | 86 | 64.18 | 263 | 37 | 85 | 64.94 | 0.19 + 0.076 |
| 40 | 45 | 100 | 7 | 7 | NA | NA | NA | NA | 266 | 42 | 36 | 74.17 | 0.26 + 0.069 | |
| 25. [51] | 55 | 60 | 124 | 8 | 9 | 402 | 50 | 62 | 75.86 | 411 | 50 | 53 | 77.80 | 0.27 + 0.076 |
| 26. [62] | 8 | 20 | 27 | 3 | 4 | 60 | 10 | 2 | 80.65 | 60 | 10 | 2 | 80.65 | 0.07 + 0.051 |
| Original Problem | Expanded Problem Size | Proposed Approach | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n(q) | m | t | p | U | e | EEs | Voids | GE (%) | CPU (s) | |
| 1. [70] | 60 | 60 | 178 | 12 | 7 | 302 | 2 | 90 | 76.53 | 0.28 + 0.085 |
| 2. [78] | 60 | 140 | 298 | 10 | 6 | 956 | 502 | 386 | 33.83 | 0.89 + 0.129 |
| 3. [51] | 60 | 70 | 164 | 10 | 7 | 466 | 116 | 76 | 64.58 | 0.58 + 0.095 |
| 4. [51] | 80 | 90 | 200 | 14 | 7 | 533 | 81 | 70 | 74.96 | 0.77 + 0.101 |
| 5. [51] | 110 | 120 | 248 | 16 | 9 | 822 | 100 | 106 | 77.80 | 0.63 + 0.121 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Won, Y. On Solving Large-Size Generalized Cell Formation Problems via a Hard Computing Approach Using the PMP. Appl. Sci. 2020, 10, 3478. https://doi.org/10.3390/app10103478
Won Y. On Solving Large-Size Generalized Cell Formation Problems via a Hard Computing Approach Using the PMP. Applied Sciences. 2020; 10(10):3478. https://doi.org/10.3390/app10103478
Chicago/Turabian StyleWon, Youkyung. 2020. "On Solving Large-Size Generalized Cell Formation Problems via a Hard Computing Approach Using the PMP" Applied Sciences 10, no. 10: 3478. https://doi.org/10.3390/app10103478
APA StyleWon, Y. (2020). On Solving Large-Size Generalized Cell Formation Problems via a Hard Computing Approach Using the PMP. Applied Sciences, 10(10), 3478. https://doi.org/10.3390/app10103478