Comparative Study of Movie Shot Classification Based on Semantic Segmentation


Abstract
1. Introduction
2. Related Works
2.1. Shot Type Classification
2.2. CNN Technology Used for Shot Type Classification
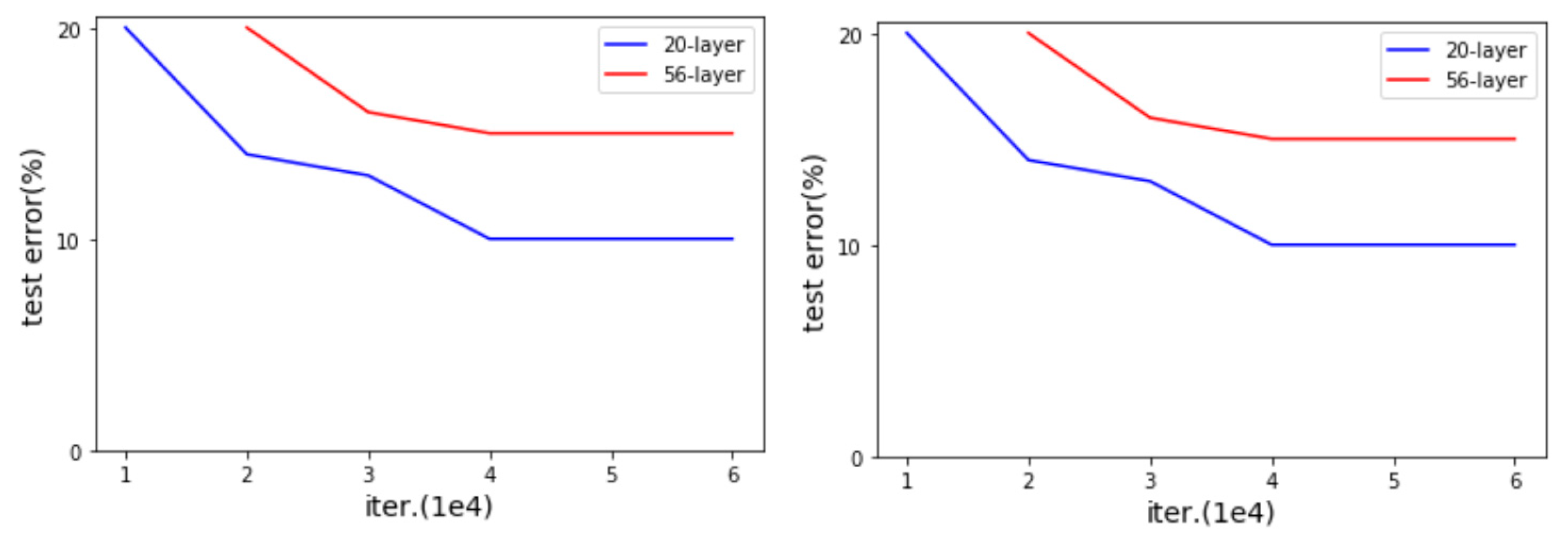
2.2.1. VGGNet
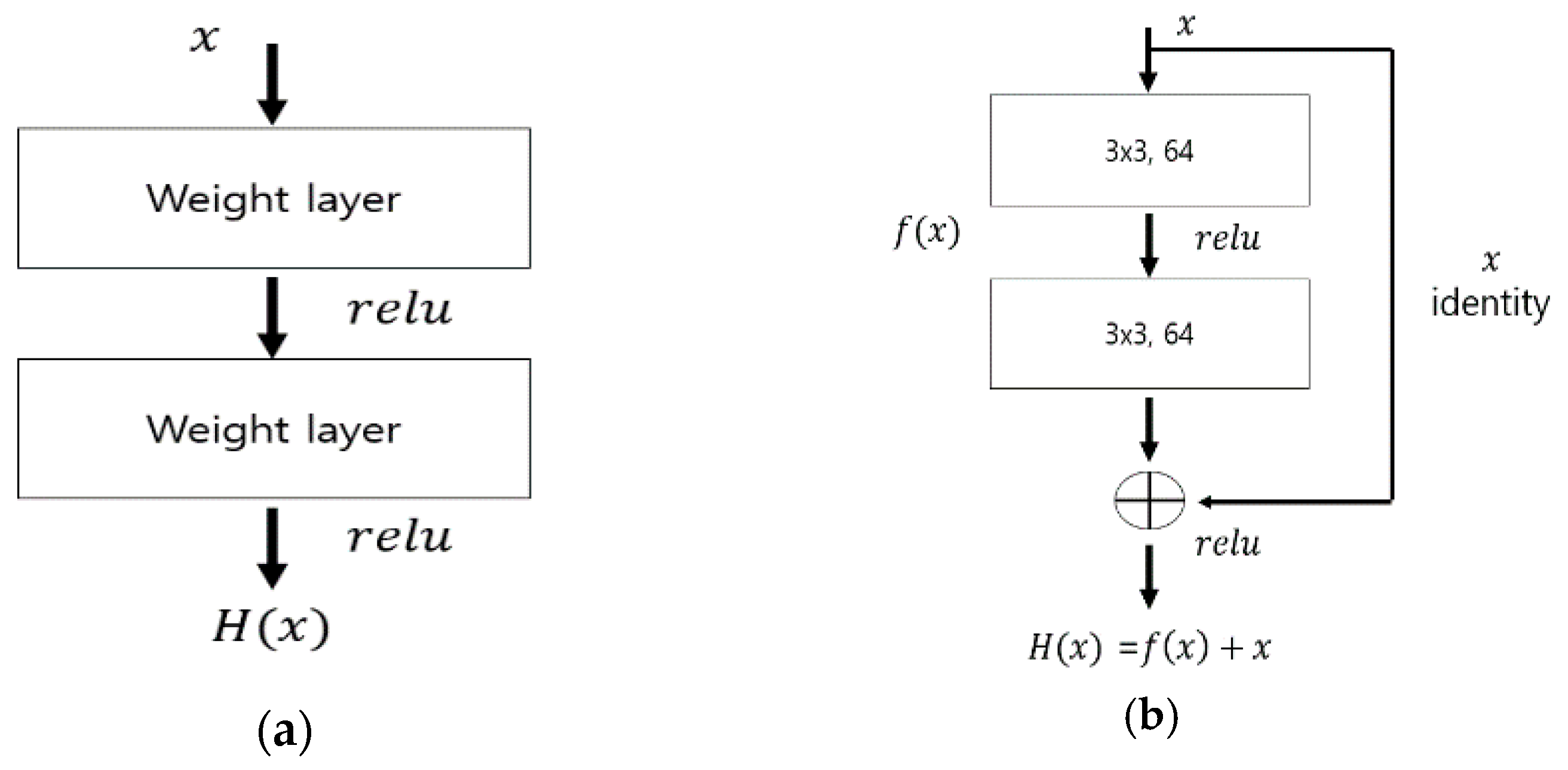
2.2.2. ResNet
2.2.3. Semantic Segmentation
3. Comparison of Shot Type Classification Methods Based on Semantic Segmentation
3.1. Shot Type Based on Semantic Segmentation
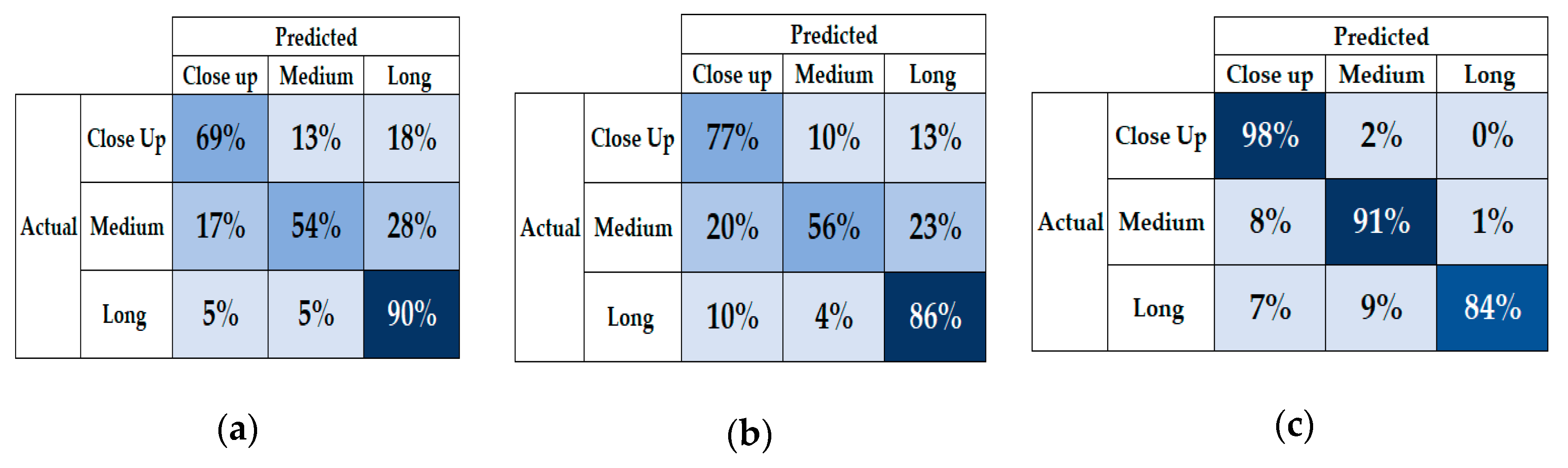
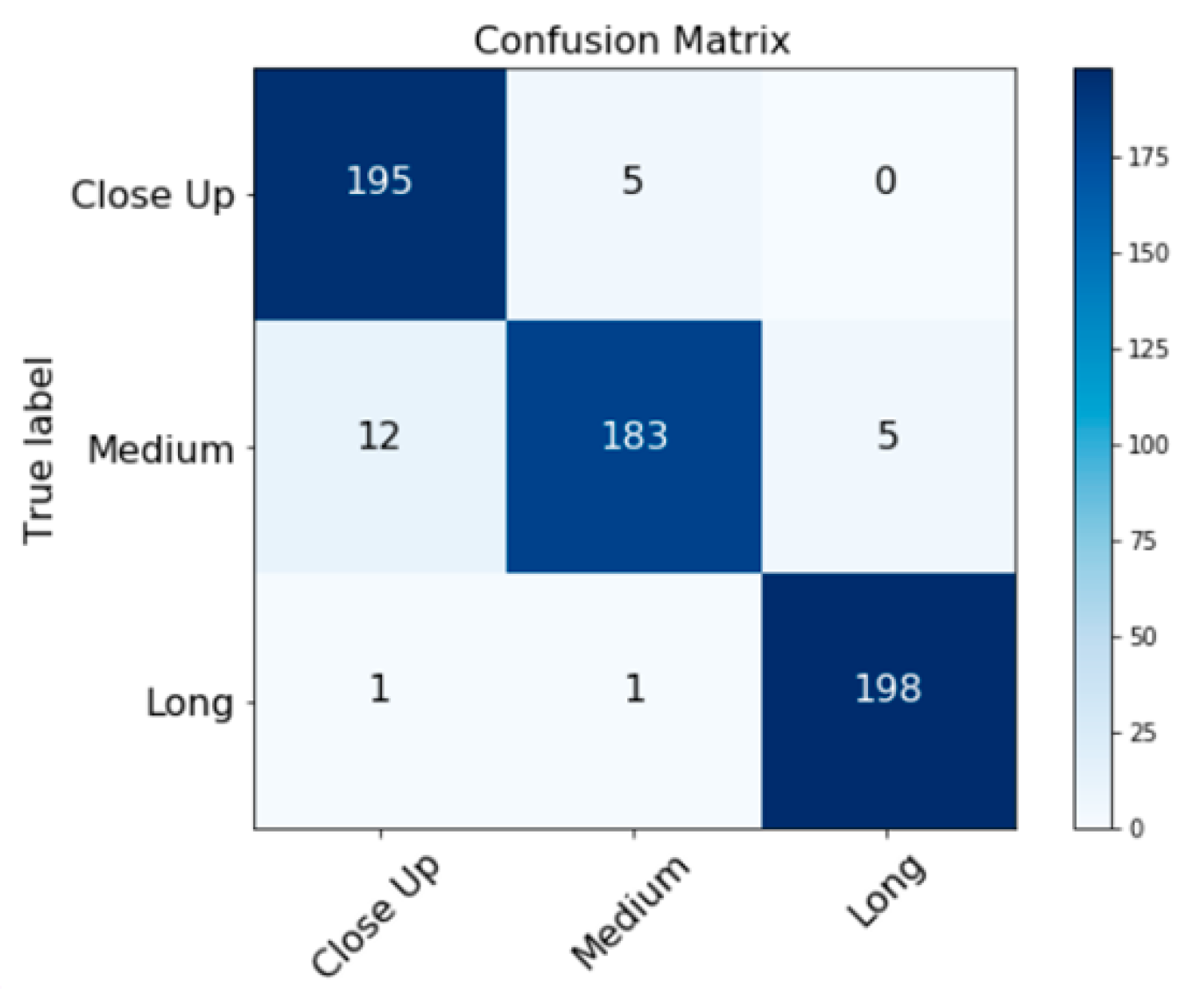
3.2. Experimental Results
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Savardi, M.; Signoroni, A.; Migliorati, P.; Benini, S. Shot scale analysis in movies by convolutional neural networks. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2620–2624. [Google Scholar]
- Katz, S.D.; Katz, S. Film Directing: Shot by Shot; Michael Wiese Productions: Studio City, CA, USA, 1991. [Google Scholar]
- Thompson, R. Grammar of the Edit, 2nd ed.; Focal Press: Waltham, MA, USA, 2009. [Google Scholar]
- Canini, L.; Benini, S.; Leonardi, R. Affective analysis on patterns of shot types in movies. In Proceedings of the 7th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 4–6 September 2011; pp. 253–258. [Google Scholar]
- Cherif, I.; Solachidis, V.; Pitas, I. Shot type identification of movie content. In Proceedings of the 9th International Symposium on Signal Processing and Its Applications, Sharjah, UAE, 12–15 February 2007; pp. 1–4. [Google Scholar]
- Tsingalis, I.; Vretos, N.; Nikolaidis, N.; Pitas, I. Svm-based shot type classification of movie content. In Proceedings of the 9th Mediterranean Electro Technical Conference, Istanbul, Turkey, 16–18 October 2012; pp. 104–107. [Google Scholar]
- Marín-Reyes, P.A.; Lorenzo-Navarro, J.; Castrillón-Santana, M.; Sánchez-Nielsen, E. Shot classification and keyframe detection for vision based speakers diarization in parliamentary debates. In Conference of the Spanish Association for Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2016; pp. 48–57. [Google Scholar]
- Baek, Y.T.; Park, S.-B. Shot Type Detecting System using Face Detection. J. Korea Soc. Comput. Inf. 2012, 17, 49–56. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems: Nevada, MA, USA, 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale ImageRecognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, J.C.; Wei, W.L.; Liu, T.L.; Yang, Y.H.; Wang, H.M.; Tyan, H.R.; Liao, H.Y.M. Coherent Deep-Net Fusion to Classify Shots In Concert Videos. IEEE Trans. Multimed. 2018, 20, 3123–3136. [Google Scholar] [CrossRef]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. ‘Shot classification of field sports videos using alexnet convolutional neural network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef]
- Jun, H.; Shuai, L.; Jinming, S.; Yue, L.; Jingwei, W.; Peng, J. Facial Expression Recognition Based on VGGNet Convolutional Neural Network. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 4146–4151. [Google Scholar]
- Muhammad, U.; Wang, W.; Chattha, S.P.; Ali, S. Pre-trained VGGNet Architecture for Remote-Sensing Image Scene Classification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1622–1627. [Google Scholar]
- Li, B.; He, Y. An Improved ResNet Based on the Adjustable Shortcut Connections. IEEE Access 2018, 6, 18967–18974. [Google Scholar] [CrossRef]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 646–661. [Google Scholar]
- Romera-Paredes, B.; Torr, P.H. Recurrent instance segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 312–329. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Almutairi, A.; Almashan, M. Instance Segmentation of Newspaper Elements Using Mask R-CNN. In Proceedings of the 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1371–1375. [Google Scholar]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object Detection and Instance Segmentation in Remote Sensing Imagery Based on Precise Mask R-CNN. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Ying, H.; Huang, Z.; Liu, S.; Shao, T.; Zhou, K. Embedmask: Embedding coupling for one-stage instance segmentation. arXiv 2019, arXiv:1912.01954. [Google Scholar]
- Benbarka, N.; Zell, A. FourierNet: Compact mask representation for instance segmentation using differentiable shape decoders. arXiv 2020, arXiv:2002.02709. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shot Type | Training | Validation | Testing |
|---|---|---|---|
| Close-up | 3586 | 782 | 200 |
| Medium | 2392 | 413 | 200 |
| Long | 2701 | 592 | 200 |
| Total | 8679 | 1787 | 600 |
| Without Semantic Segmentation | Semantic Segmentation–Based Classification Method |
|---|---|
| 93% | 94.9% |
| Classification Type | Without Semantic Segmentation | With Semantic Segmentation | |
|---|---|---|---|
| Mask R-CNN Added | Yolact Added | ||
| VGG-16 | 92.5% | 94.8% | 93.8% |
| ResNet-50 | 93.5% | 95.3% | 96% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bak, H.-Y.; Park, S.-B. Comparative Study of Movie Shot Classification Based on Semantic Segmentation. Appl. Sci. 2020, 10, 3390. https://doi.org/10.3390/app10103390
Bak H-Y, Park S-B. Comparative Study of Movie Shot Classification Based on Semantic Segmentation. Applied Sciences. 2020; 10(10):3390. https://doi.org/10.3390/app10103390
Chicago/Turabian StyleBak, Hui-Yong, and Seung-Bo Park. 2020. "Comparative Study of Movie Shot Classification Based on Semantic Segmentation" Applied Sciences 10, no. 10: 3390. https://doi.org/10.3390/app10103390
APA StyleBak, H.-Y., & Park, S.-B. (2020). Comparative Study of Movie Shot Classification Based on Semantic Segmentation. Applied Sciences, 10(10), 3390. https://doi.org/10.3390/app10103390