1. Introduction
Managing logistics and operating costs is the most important issue for managers to think about. Operating a logistics system includes managing transportation and inventory. Transportation in the real world not only has traveling costs, which include fuel costs, but in some areas special issues need to be considered. For example, in three southern provinces of Thailand, bombings often occur due to conflict among different groups. These three provinces are Narathiwat, Pattanee, and Yala. Their main business is selling palm. There are many palm fields that need to have palm collected at collecting points and then transported to factories, which will transform palm into the final product. All along this route there is a risk of bombing, which can generate sabotage risk and costs besides the transportation costs. Decision-makers face the problem that if they consider only costs, this will affect the safety of people who are involved in logistical activities. Therefore, the management of the logistical system in this special area needs to be reconsidered.
Palm is one of many sources of renewable energy. Energy is an important factor for the development of businesses, industries, and logistics. Most energy that we use comes from fossil fuels and is not renewable. This is one of the main causes of global warming. Therefore, renewable energy from plants is a good option that many countries are interested in. Sugar cane, cassava, and oil palms are renewable energy plants that can be grown in certain geographic locations in some countries. For example, Brazil was one of the leading countries that grew sugarcane to produce ethanol fuel in 2012 and 2013 (
Bargos et al. 2016). In addition, a case study investigating growing energy plants was performed by
Bojić et al. (
2013), and the optimal siting and size of bioenergy facilities using geographically dependent renewable resources was studied by
Sultana and Kumar (
2012).
Thailand is the only country in the world that can grow all three renewable energy plants all year round, especially oil palms. Oil palms play an important role in the transportation industry and are supported by the government to be grown in many areas according to the oil palm industry development plan. Starting from 2012 until 2021 in the three southern border provinces, the plan is to establish stability, to reduce social inequality, and to create peace. Information from 2004 to 2012 shows that 14,074 violent incidents occurred in the provinces, including 2478 bomb explosions in civilian areas and transportation routes. Narathiwat, one of the three southern border provinces, had the most violent incidents, 5021. These facts threaten palm producers when palms are being delivered to both palm-collecting centers and palm oil extraction factories. A study by
Krahomwong (
2016) shows that the most important problem for the industry is transporting oil palms in the three southern border provinces. Narathiwat has the largest area of oil palm cultivation and the biggest logistics problem as well. The high transportation cost in this province is due to improper palm-collecting center locations, causing higher costs for oil palm manufacturers and palm-collecting centers themselves. Because of the unpeaceful incidents in the three southern border provinces, the authors would like to present a solution that can decrease operating costs and risks. We will focus on Narathiwat Province and explore three important aspects in order to set mathematic conditions. The aspects are as follows:
- (1)
The lowest total operating cost.
- (2)
The lowest emission from transportation.
- (3)
The lowest risk of sabotage that might happen along transportation routes and at palm-collecting centers.
Managing transportation logistics for peaceful conditions needs to be reconsidered. Generally, the only things decision-makers need to consider when making decisions about transportation logistics are the total operating or transportation costs. Aside from making decisions on transportation logistics under sabotage risk for the area or the road that is normally used to transport the goods, under these conditions decision-makers face the difficulty of making decisions regarding the risk while keeping the cost as low as possible.
This case study is very complicated, and several factors need to be carefully considered in order to reach a break-even point for the investment. Metaheuristic algorithms are applied and used in a lot of research, and the differential evolution algorithm (DE), another method, has gained a lot of attention and can effectively solve problems, such as truck sequencing problems in cross-docking operations in a study by
Liao et al. (
2012) and the dynamic berth allocation problem in a study by
Şahin and Kuvvetli (
2016).
Many researchers have been successful at using DE to solve transportation problems such as Vehicle Routing Problem (VRP) (
Boon et al. 2015;
Huan and Jeichang 2012;
Akkararungruangkul and Kaewman 2018) and VRP with pickup and delivery system (
Mingyong and Erbia 2010). The location routing problem (LRP) is also a problem that some researchers are interested in, such as
Su et al. (
2016) and
Drexl and Schneider (
2015).
Thongdee and Pitakaso (
2015) successfully employed the original DE to solve the multilevel location–allocation problem (MLLAP). They used DE to find a good location to establish an ethanol plant using bagasse and tapioca waste as the raw material, and these two materials are delivered from the sugar factory and tapioca starch. The objective function is to minimize total distance to reduce environmental impact. In our study, we solve a problem in the same class as MLLAP, but besides being interested in environmental impact, sabotage risk is our main interest, because the case study is in an area where the risk of a deliberate act is quite high. Therefore, the decision-making of MLLAP will shift the interest so that not only the distance between point to point is interesting but also the risk of bombs.
DE has been successfully applied to many combinatorial optimizations. This because it is simple to apply to solve problems and uses only a few parameters. Many researchers have tried to improve the efficiency of DE by adding a few behaviors to the original DE and calling it modified DE (MDE).
Pitakaso and Sethanan (
2016) suggested using a good combination of different mutations and recombination formula.
Yong et al. (
2018) presented a new strategy to select a solution for the mutation process.
Wang et al. (
2016) introduced the use of cumulative population distribution with the DE mechanism.
Sethanan and Pitakaso (
2016a) added more steps to the original DE to introduce a local search strategy by using reborn vectors. The computational results show that adding new attributes can improve the efficiency of DE, because MDE outperforms the original DE in finding good solutions.
From the review we can see that introducing new behaviors to DE can increase the solution quality. Among the studies mentioned above, some add more intensification behavior to search more intensively in some interested areas (
Sethanan and Pitakaso 2016a,
2016b), and some use more diversification with the original DE to enhance its capability to explore more searching space (
Wang et al. 2016;
Yong et al. 2018); both ways are successful. In this paper, the original DE has both diversification and intensification behavior. The proposed heuristics will first be searched for intensively, and when a better solution cannot be found within the predefined condition, the process that can enhance the capability of the diversification behavior of DE will be used. Therefore, this paper has two main contributions: (1) a new class of MLLAP is introduced, MLLAP-SB, and (2) new attributes of DE are introduced so that the original DE has more diversified behavior.
The paper is organized as follows:
Section 2 presents the problem definition and mathematics in which the authors can see the whole body of the proposed problem;
Section 3 presents the proposed heuristics in which the differential evolution (DE) algorithm is explained; and
Section 4 and
Section 5 are the computational results and conclusion.
3. Proposed Heuristics
Generally, the differential evolution (DE) algorithm comprises four steps: (1) generating the initial solution, (2) performing the mutation process, (3) performing the recombination process, and (4) performing the selection process. In our modified DE (MDE), one step is added to these general steps. When the best solution is not updated for the predefined iterations (in our pretest, the best value of the unchanged solution is 25 iterations), the best solution will produce the offspring vectors. The offspring vectors will be increased and reduced using our designed mechanism, which will be explained later. This step is called the best vector reproduction process; thus, in total, the MDE is composed of five steps: (1) generating the initial solution, (2) performing the mutation process, (3) performing the recombination process, (4) performing the selection process, and (5) performing the best vector reproduction process.
DE was first developed to solve continuous optimization. To let DE be applicable to combinatorial optimization, it is necessary to design a decoding method well.
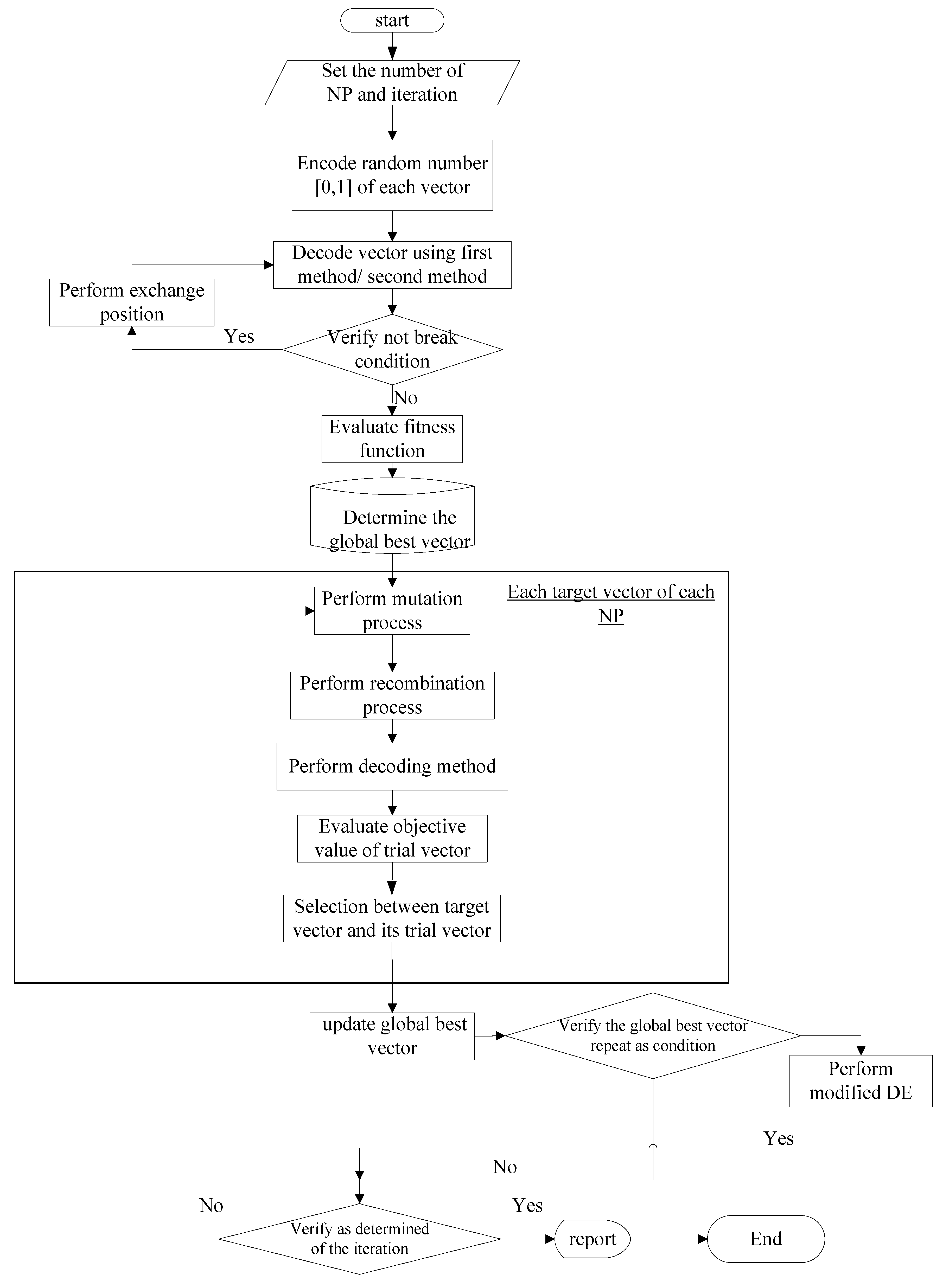
The flowchart of the proposed heuristics is shown in
Figure 2.
From
Figure 2, we can explain the process step-by-step as follows:
- (1)
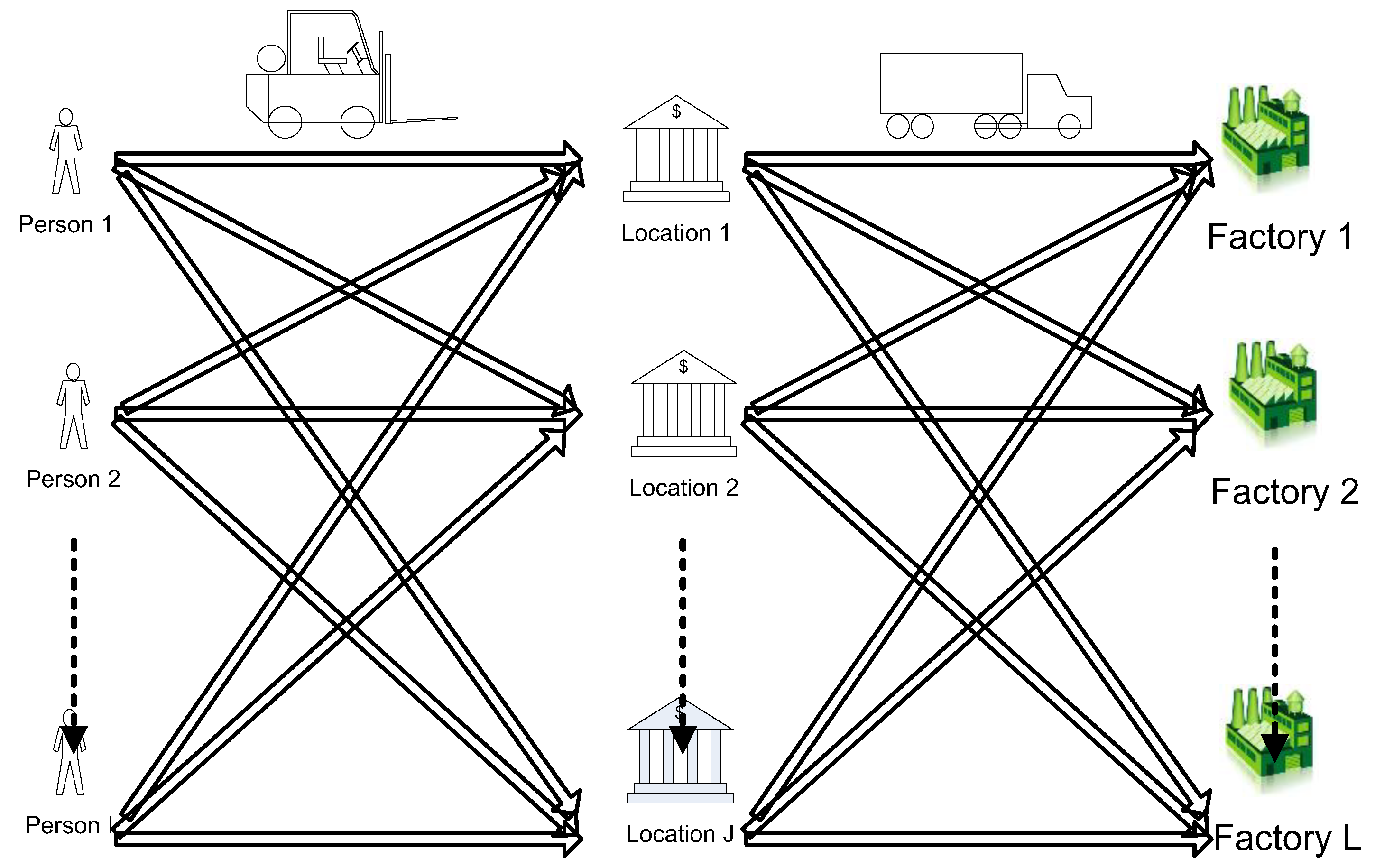
Generate the initial population (NP) according to the size of D-dimensional vectors that are set by the number of producers, the number of palm-collecting centers in the candidate process, and the number of oil palm factories. This step can be executed by generating random numbers [0, 1] in an array in each vector, as shown in
Table 1.
The vector generated in
Table 1 has D-dimensions that have to be divided into three groups. The first group is the vector for the farmer:
Table 1 has five farmers (the name of the farmer is shown in the first row, while the second row shows the demand of each farmer, and the third row is the randomly generated number). The second group is the information of the collecting center: in rows 1, 2, and 3, this is the name of the collecting center, its capacity, and the randomly generated number, respectively. The last group is the factory details, which are its name, its capacity, and the randomly generated number. The vector in
Table 1 can be decoded by using decoding methods. The decoding method is composed of five steps, as follows:
- (a)
Arrange the values of random numbers in each group in ascending order. From
Table 2, the order of the field is 1, 5, 2, 4, and 3, which have 14, 4, 11, 4, and 13 tons of palm available in the field, respectively. The order of the collection center is 5, 4, 3, 2, and 1. All the collecting centers in the example have a capacity of 20 tons. Finally, the factory order is 1 and 2, each of which has a capacity of 35 tons.
- (b)
Assign the farm in the first order of the farmer group to the first collecting center in this group, and this farm and collecting center will be assigned to the first list in the factory group. The second farmer in the farmer order is assigned to the first collecting center as long as it has enough capacity; if it does not have enough capacity, the second collecting center in the list will be used. This mechanism is also used with the factory level. From step 1, field 1 (14 tons) will be assigned to collecting center 5 (20 tons). Field 1 has 14 tons available; therefore, collecting center 5 has 6 tons of available space for the next field to be assigned in. Thus, field 5 can be assigned to collecting center 5. Resulting from that, collecting center 5 has 2 tons remaining, which means that if no field can be assigned to collecting center 5, then collecting center 5 is closed. After the collecting center is closed, we will decide to transport palm to another factory, and collecting center 5 will deliver the product to factory 1, which is first on the factory list.
- (c)
Repeat step 2 until all farms are assigned. At this step, all fields will be assigned to exactly one collecting center, and the assigned collecting center will deliver the product to one of the factories. The result is shown in
Table 3.
- (d)
Determine the number of rounds of trucks (30 tons) that will be used to deliver palms from the collecting center to the factory (delivery of palms from the farmer to the collecting center means the direct shipping form of the farmer to the collecting center and its parameters). For example, collecting center 5 has a total 18 tons of palm to deliver. Therefore, it needs 2 rounds, because the truck has 15-ton capacity. On the first round, the truck will deliver 15 tons, and the remaining 3 tons will be delivered in the second round. Results of calculating numbers of rounds are shown in
Table 3.
Table 3 shows that factory 1 will serve collecting centers 5 and 4, while factory 2 will serve collecting center 3. Collecting center 5 will get palm from fields 1 and 5. Fields 2 and 4 will deliver palm to collecting center 4, and field 3 will deliver product to collecting center 3. Finally, collecting centers 5, 4, and 3 have 2, 1, and 1 rounds of trucking, respectively, to transport their product to the assigned factory.
- (e)
Calculate the total cost of the solution constructed in steps 1–4. In this step, all important data will be collected and calculated, such as distance, investment to open the collecting center, and the sabotage cost. The distance from fields to collecting centers is shown in
Table 4. The distance from collecting centers to factories is shown in
Table 5. The average density of population living along the road from fields to collecting centers and from collecting centers to factories (within a radius of 0.1 km) is shown in
Table 6 and
Table 7, respectively. The possibility of having a bomb in each road connection is shown in
Table 8 and
Table 9. The investment cost of collecting centers 1, 2, 3, 4, and 5 is 1000, 1200, 1100, 1000, and 1300 baht, respectively.
The emission cost of transport is 4 baht per km (converting carbon dioxide emission to baht), and the fuel cost is 5 baht per km. The investment cost is 3400 baht when collecting centers 3, 4, and 5 are in operation. The total distance of the connection between all fields to collecting centers is 312 km (two ways), and the total distance between fields and factories is 334 km. Note that the distance from collecting center 5 to factory 1 is two-way transport, and each way has to go two rounds; thus, the total distance used in this plan is 646 km, which costs 3300 baht, and this generates a total emission cost of 2584 baht (4 baht per km). The total density of people who could possibly be affected in the transport is calculated from the number of people in the connection multiplied by the probability of having a bomb along that road. For example, the connection from field 1 to collecting center 5 has a population of 210, and the probability a bomb will occur is 0.06; thus, the probability that people will be affected by the bomb is 12.6, and each will need 1500 baht to recover when they are injured. Thus, the cost of this connection is 18,900 baht (this method can also be applied to the connection between collection centers and factories). The results show that the total sabotage cost is 292,080 baht. Thus, the total cost for this plan is 301,364 baht.
- (2)
Perform the mutation process.
The NP mutant vector
is the value adjustment within the same vector using function (13). In each target vector of NP, it will make a random selection
, and the
value equals 2.0 (
Qin et al. 2009;
Sethanan and Pitakaso 2016b):
- (3)
Perform the recombination process.
Each NP trial vector
is the result of the recombination process using function (14) between target vectors of each present NP and mutant vectors with the possibility of crossing set
at 0.8 (
Qin et al. 2009;
Sethanan and Pitakaso 2016b) in order to change values in each vector:
Set as a random number that has a value between [0, 1], which is within a target vector. In each present NP and mutant vector, is a random selection of the position that changes value in both vectors. If the value of is less than or equal to that of in position of both of these vectors, the mutant value in this position will be in a trial vector. On the other hand, if the value of is more than that of in the position, the value in this position will be in a trial vector.
- (4)
Perform the selection process by using Equation (15) to determine the target vector of the next processing round
that can be selected from the better vector, a current target vector
or a trail vector
:
- (5)
If the best solution is not changed within the predefined iteration, then perform the best vector reproduction process. This process can be executed by generating a new vector (NV) of DE. The reproduction of the best vector is performed using Equation (1), but the first two vectors (
r1 and
r2) are selected from the current set of vectors (NP), and the last vector is newly randomly generated. If the new vector cannot find the new best solution, then the number of vectors that will be reproduced is increased one vector at a time. If the new vector is not able to find a new best solution when the number of the new vectors generated reaches the maximum limitation that can be calculated form Equation (16), it will reduce the number of NV until it is reduced to one. When NV is equal to 1, the reproduction process is terminated. The termination condition of the reproduction process can be both when NV reaches 1 and when it finds a new best solution. An example of increasing and reducing NV is shown in
Table 10.
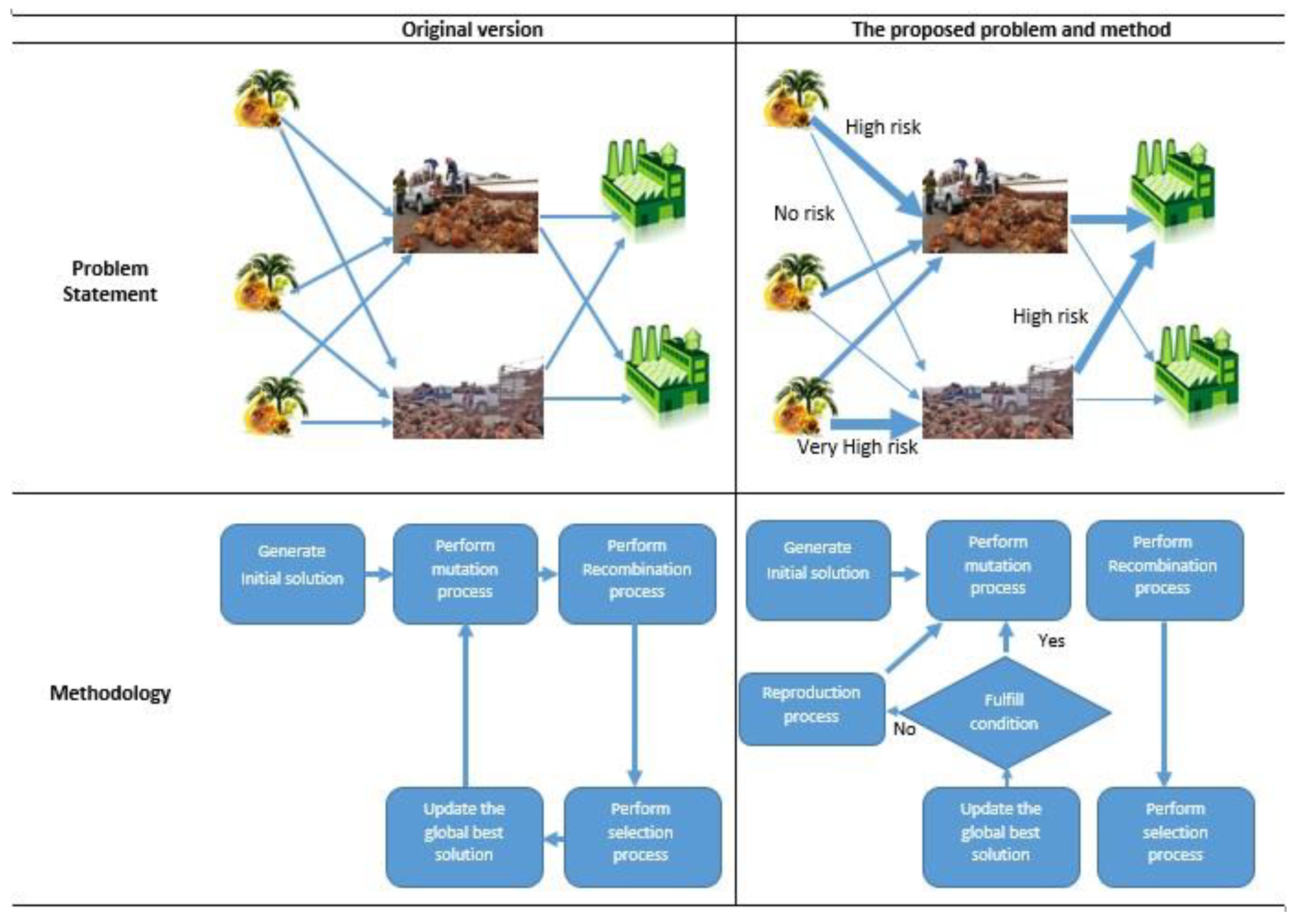
Figure 3 depicts the proposed problem and heuristics that we designed to solve the multilevel location–allocation problem. The original version of the problem does not take sabotage risk into account in the model solving, while the proposed problem integrates sabotage risk into the model so that the decision-maker can make better decisions. In the proposed methodology, a reproduction process has been added to introduce new generated vectors to the system, so the proposed algorithm has more diversification in searching the new solution to allow it to escape from the local optimal. The reproduction process will be applied only when the algorithm cannot fulfill the predefined search conditions, as the algorithm can find a better solution within the predefined iterations.
4. Computational Results
In this research, we present an MDE that is efficient at solving a multilevel location–allocation problem. In the case study, we compare the efficiency of the optimal solution from Lingo v.11 to the traditional DE and our MDE. The proposed heuristics involve coding in Dev C++ using PC Intel Core i3 CPU 3.70 GHz Ram DDR4 8 GB.
In testing to find the most efficient results of these four algorithms, we compared the computation time for instance tests with 5, 10, 20, and 50 farms. Each size randomly generates three sets of parameters; thus, we have 12 random test instances and one real case study. The case study has 77 farms. The number of potential collecting centers is equal to the number of farms, and the number of factories varies from one to five. Each instance test was repeated five times. The best among all solutions was taken as representative of the proposed method. Thus, our first experiment was executed to compare the efficiency of the proposed heuristics with the results generated by Lingo v.11.
Table 11 shows the results comparing the proposed method (DE and MDE) with the optimal solution generated from Lingo v.11. Lingo is executed until it finds an optimal solution, while DE and MDE collect the time to find the optimal solution, which is equal to the result generated by Lingo as the stopping criterion.
From
Table 11, we can see that, on average, Lingo can find an optimal solution in 96,156.67 s, while DE and MDE can find an optimal solution within 104 s. The computational time of Lingo is dramatically increased when the number of farms is 10. This means that Lingo cannot find the solution in the remaining test instances. In the next simulation result, we compare the performance of the MDE and DE algorithms with a larger number of test instances. In this experiment, we execute DE and MDE in six test instances (20 and 50 farms) and one real case study (77 farms). The stopping criterion is 90 min computational time, and the results are shown in
Table 12.
From
Table 12, in this group of problems, DE has an average cost of 25,997,859 baht, while MDE has an average cost of 25,923,139 baht. When we calculate the percentage difference of DE and MDE, there is a 0.404% difference, but MDE requires 100% lower cost than DE, which means that the modified version of DE outperforms the original DE.
From
Table 13, the results show that when we run long enough, MDE outperforms DE. The next question is whether there is some sense that DE outperforms MDE. The experiment was executed with the second group of data. For the stopping criterion we used computational time, which is set to 10, 30, 40, 60, 80, and 100 min, and the results of the simulation are shown in
Table 13. The simulation was executed five times, and the best solution is representative of the simulation. Percentage difference between cost generated from DE and MDE is calculated from Equation (17):
From
Table 13, we can see that only in instances 20.2 and 20.3 did DE have a better solution than MDE when run for 10 min; in all other instances, MDE outperformed DE.
Figure 4 shows the plot of average percent difference between DE and MDE.
From
Figure 4, we can see that when using longer computational time, the gap between DE and MDE is greater, except with computational time of 40 and 60 min, in which the performance of DE and MDE differs the least. When the runtime from 60 min is increased, the performance of MDE is higher again. From this, we can conclude that when using longer computational time, DE will be stuck in the local optimal, while MDE can escape from the local optimal and generate a better solution.
The last experiment focuses on a strategy to deal with transportation logistics when sabotage risk is considered and the question of whether it is different when we do not take risk into account in the decision model. This experiment was executed using MDE to solve the second group of problems. MDE-1 is MDE that takes the last two terms from the objective function (Equation (1)), but after MDE-1 finishes the simulation (90 min run), the best solution is used to calculate the total cost, including sabotage cost, while MDE is the original version that uses Equation (1) as the objective function.
Table 14 shows the results of MDE and MDE-1 for total cost (including sabotage cost), sabotage cost, and the percent of sabotage cost generated from MDE and MDE-1. Percent of sabotage cost can be calculated with Equation (18):
5. Conclusions
This paper presents a modified DE (MDE) to solve the multistage location–allocation problem when considering sabotage risk as the constraint. The proposed algorithm adds one more step to the original version of DE, which is the best vector reproduction process, and this gives MDE better efficiency, which can be seen in
Table 12; it generates better solutions than the original DE in all test instances. This is because when MDE cannot find an improved solution, it will escape from the local optimal by introducing a new vector to the system, and this vector will lead the new search space. Searching for new solutions from the new search space will increase the chances of finding better solutions for the algorithm. At the same time, diversification of the original DE is improved by the reproduction process; therefore, MDE outperforms the original DE.
The difference between MDE and DE becomes larger (solution quality of MDE is greater than that of DE) when using longer computational time. The difference is 0.08% when using 10 min computational time and 0.54% when using 100 min computational time (see
Table 13 and
Figure 4). This means that when the computational time is longer, the performance of MDE is better.
Comparing DE and MDE with the optimal solution generated from Lingo v.11 (see
Table 11), we can see that both can find the optimal solution the same as Lingo, but using less computational time (
Table 11). Lingo uses an average of 96,156.67 s to explore the optimal solution for a small number of test instances, while DE and MDE use only 140 and 90 s, respectively. This shows that DE and MDE are indeed suitable for this kind of problem, even when the problem size is small, although sometimes the heuristics need more time to find a better solution than Lingo. However, in this case, even though the problem size is small, our proposed heuristics generated the same result as Lingo but used much less computational time. This was because the decoding method is effective at finding a good solution in a short computational time.
Managing transportation logistics in the multilevel location–allocation problem when there is sabotage cost, we need to take care of it in order to generate lower total cost (see
Table 14). MDE has been used to solve the integration model of transportation logistics when sabotage risk is considered. MDE-1 is the same method, but solves the transportation logistics model without considering the risk. MDE generates an average total cost of 30,652,360 baht, while MDE-1 generates an average total cost of 32,772,361 baht for large numbers of test instances. This means that when we consider sabotage risk in the model, we can reduce cost by 9.61%, even we use the same method to solve the problem. Therefore, when the special cost term occurs in the objective function, the decision-maker has to take care of it carefully to get the most effective methodology to get the best answer for the firm.
From the computational results, MDE can generate better solutions than the original version. This is because its ability to escape from the local optimal is better than that of DE, by introducing a new random vector. This is because we add the process of enhancing the diversification behavior of DE. Thus, a more effective process to increase diversification of the algorithm can be added. The algorithm’s designer can also add new DE processes to intensify the algorithm so that it will have more diversification and intensification behavior. Another point that can be further studied is to formulate the problem as a multi-objective model so that multiple cost terms in the problem can be easily traced.







{kind=link}
{kind=link}
{kind=link}
{kind=link}