Land-Use Change Detection with Convolutional Neural Network Methods




Abstract
1. Introduction
2. Overview of CNN Methods
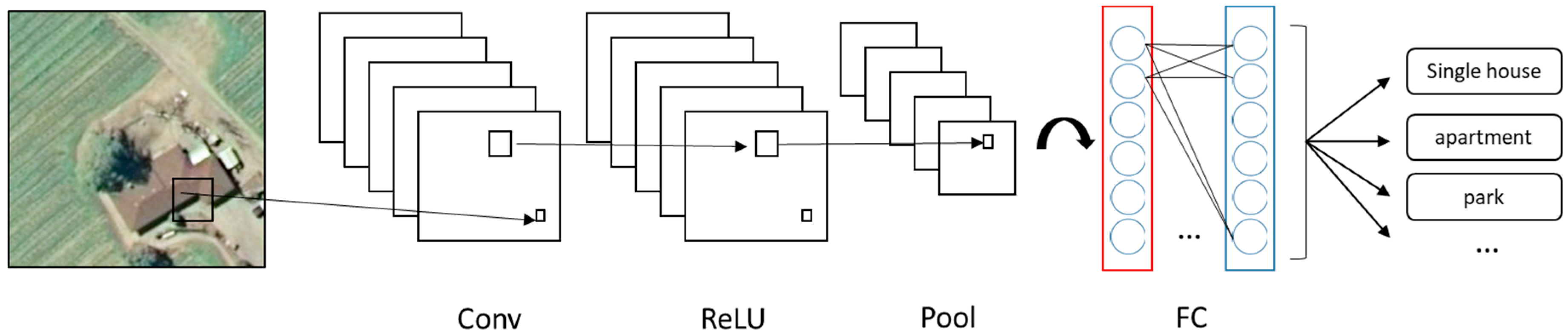
2.1. The Structure of CNN
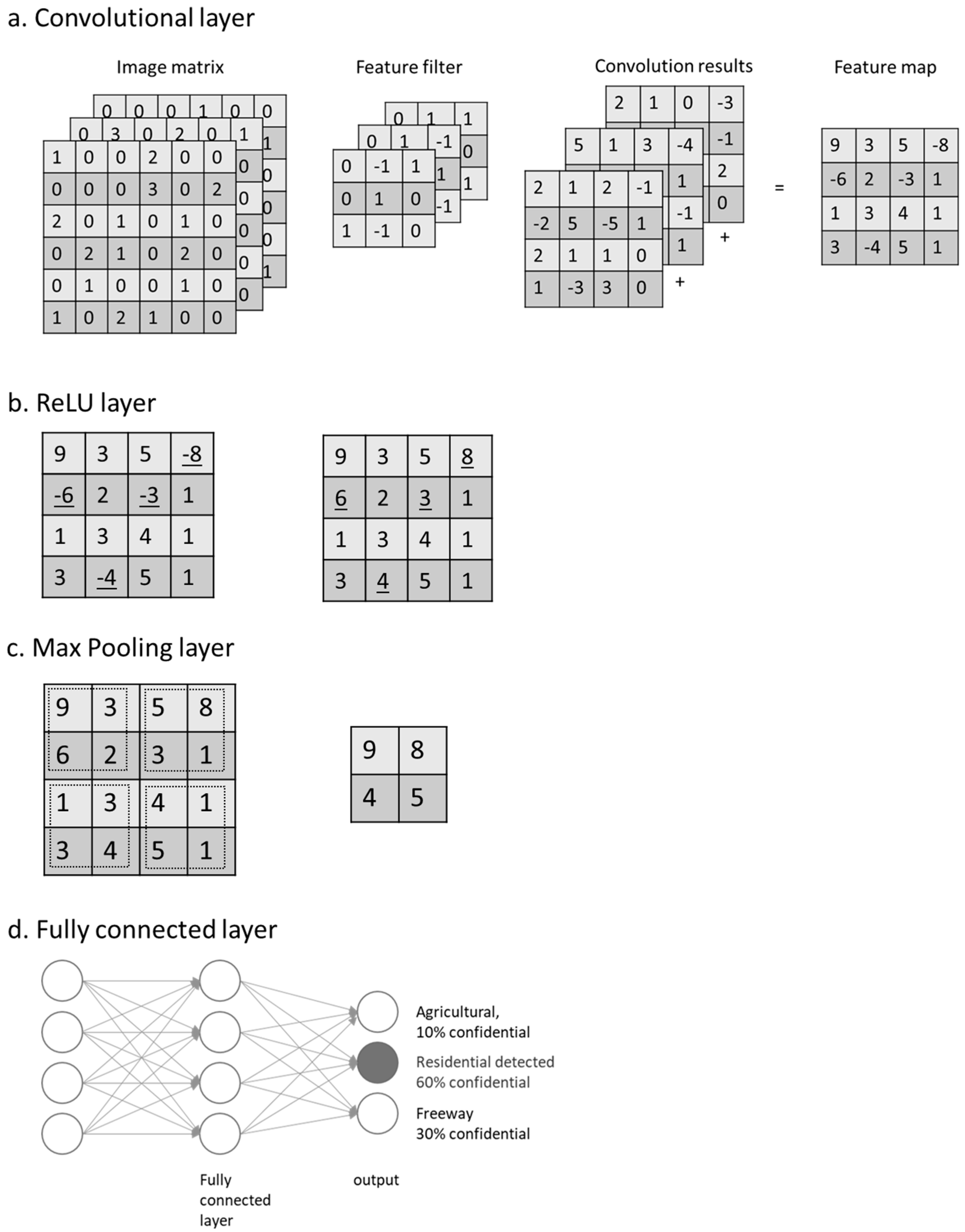
- Convolutional layer performs the linear operation by doing element-wise multiplications and summations on every sub-input, using a group of weight matrixes called feature filters (Figure 2a). Feature filters learn their weights from training data; then each filter can detect the existence of a specific feature. The outputs are called feature maps. A feature map records not only the operation values but also the relative spatial location of these values. On the feature map, a higher output value indicates the potential existence of the corresponding feature at its relative location.
- Rectified linear units (ReLU) layer performs a nonlinear function (such as tanh and sigmoid) on the input (Figure 2b). Introducing nonlinearity to the system can improve computational efficiency without losing much accuracy. When performing a threshold operation: f(x) = max (0, x), where f is a nonlinear function applied to all values x in the matrixes, the negative values of input matrixes are rectified as 0 keeping the size of input volume unchanged.
- Pooling layer is a down-sampling layer (Figure 2c), aiming to decrease the size of the feature maps and to reduce the computational cost. A max pooling layer keeps only the maximal number of every sub-array (2 × 2) as the element of output array. Output omits unimportant features, while keeps the relative location of features.
- The fully connected layer multiplies the input by a weight matrix and then adds a bias vector to the output, an N-dimensional vector (Figure 2d). The output gives the probability of the input image belonging to each class, where N is the number of the category in a classification task.
2.2. Training and Testing of CNN
- Model initialization: all the parameters were randomly generated;
- Forward propagation: the input passed through the network layers and calculated the estimated output from the model;
- Loss function calculation: loss function was used to evaluate the prediction ability of the method. The most common loss function used the mean square error (E) between the model’s expected output and estimated output and can be formulated as follows:
- 4.
- Backpropagation: it is a process in which backward propagates the derivative of errors;
- 5.
- Parameters update: In general, the weights (parameters) update by the delta rules [45] was defined as follows:
- 6.
- Iterates the process until convergence. Based on the previous step, the weights get updated very slowly, thus requesting many iterations to get the desired weights and minimize loss function. In reality, the CNN does not process the images one-at-a-time in order to increase productivity. A batch of samples is propagated through the network at the same time.
3. The Land Use Classification Method
3.2. Datasets for Transfer Learning
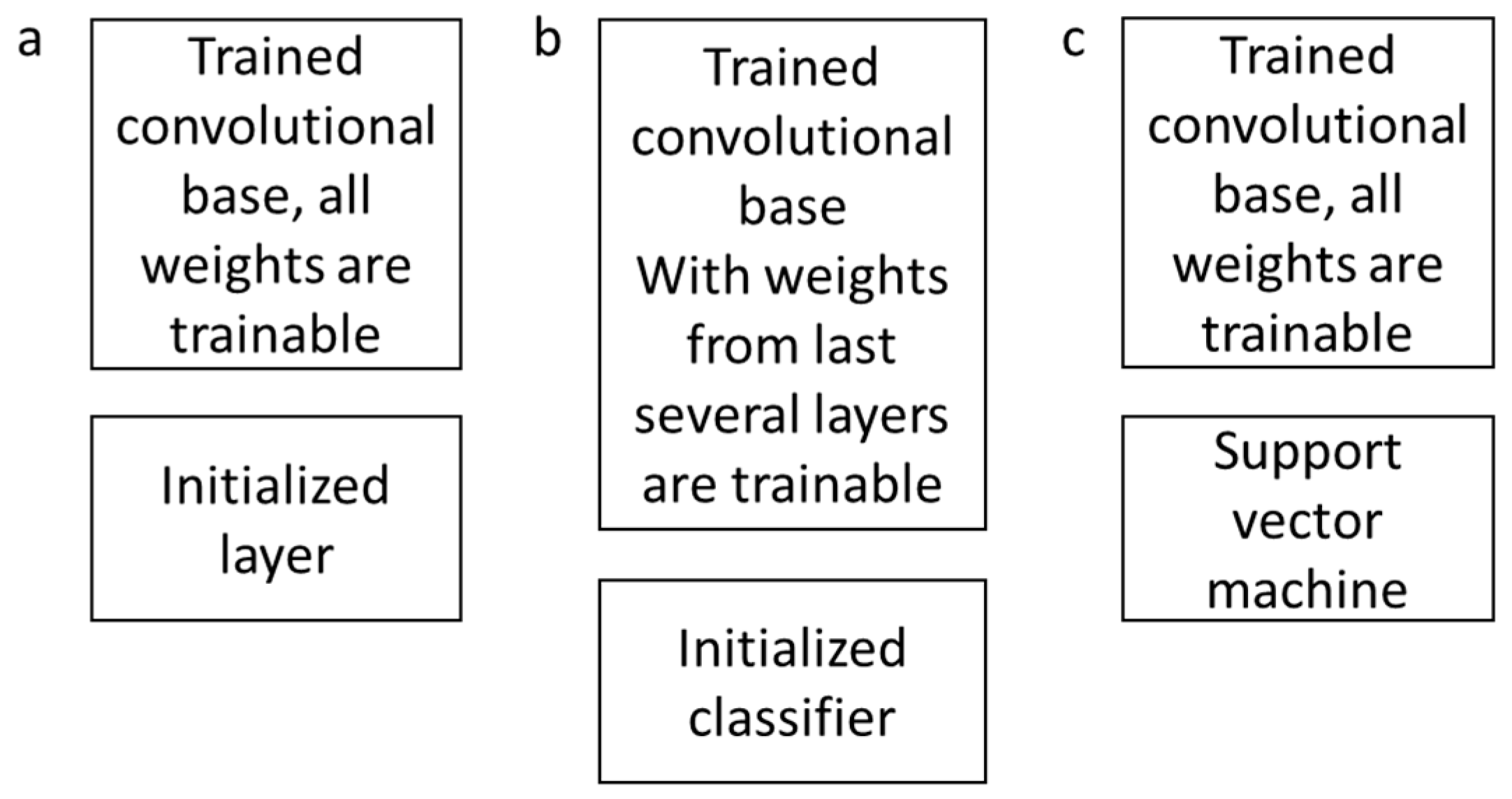
3.3. Transfer Learning Strategies
- Fine-tuning the whole network (Figure 4a): Loading the pre-trained network, replacing the fully connected layer of the network, retraining the network using new dataset, and fine-tuning the weights of all layers through backpropagation.
- Fine-tuning the higher layers of the network (Figure 4b): Loading the pre-trained network, and freezing the parameters in the earlier layers of the network, so when retraining with new dataset, only the weights of last several layers will be updated.
- Convolutional base as a feature extractor and link a support vector machine (SVM) to form a CNN–SVM based model (Figure 4c): Loading the pre-trained network and feeding the data through the convolutional base; the output as the feature representations were then classified by SVM. This solution also required less computational effort.
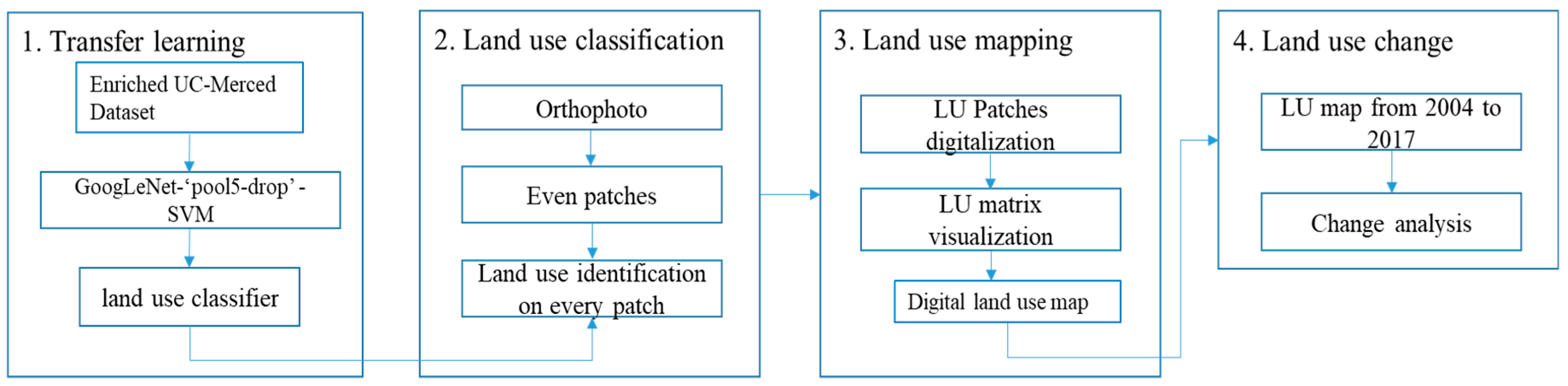
4. Methodology
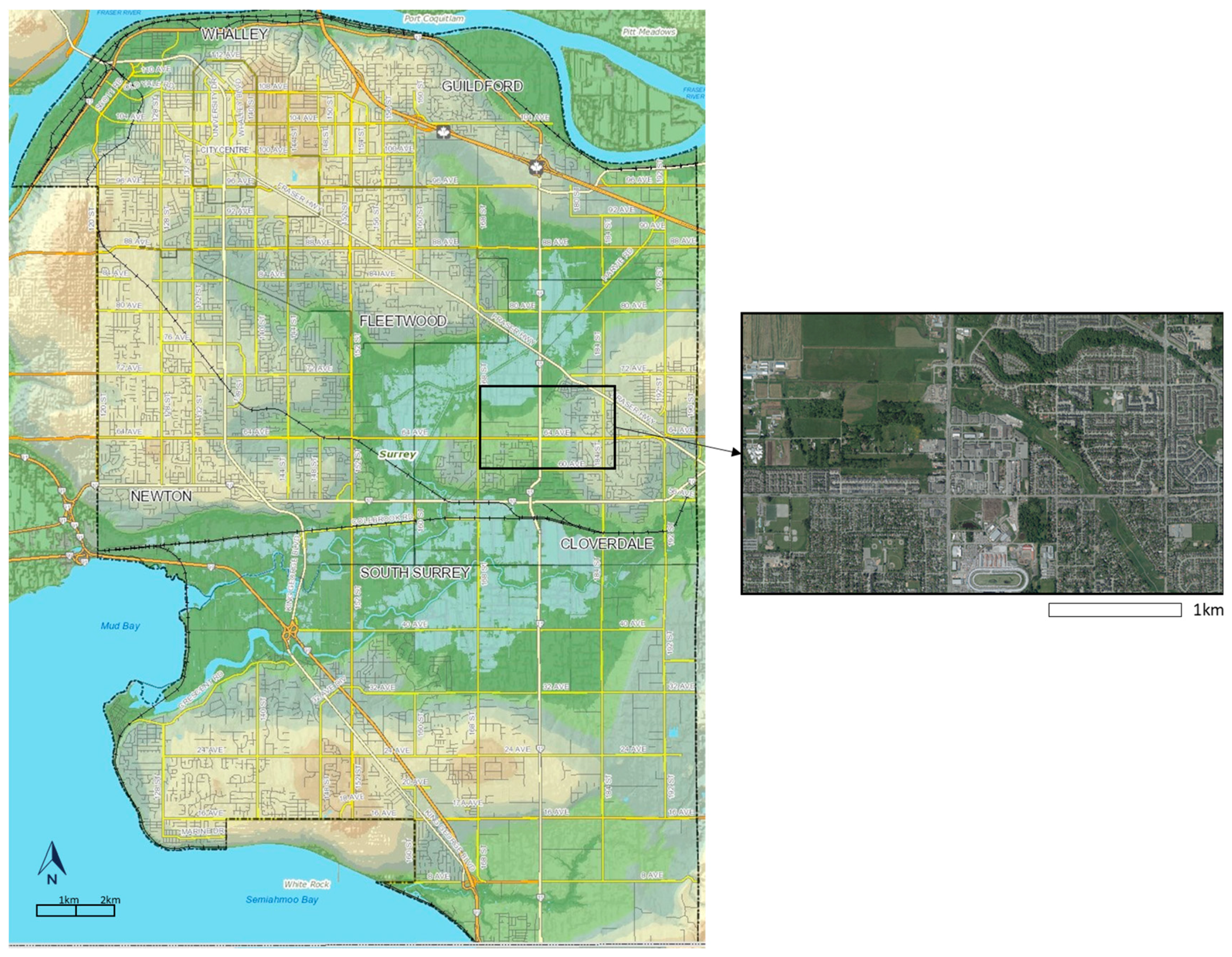
4.1. Study Area and Primary Data
4.2. Land Use Change Analysis
- The enriched UC-Merced dataset was used to fine-tune “GoogLeNet-‘pool5-drop’-SVM” models.
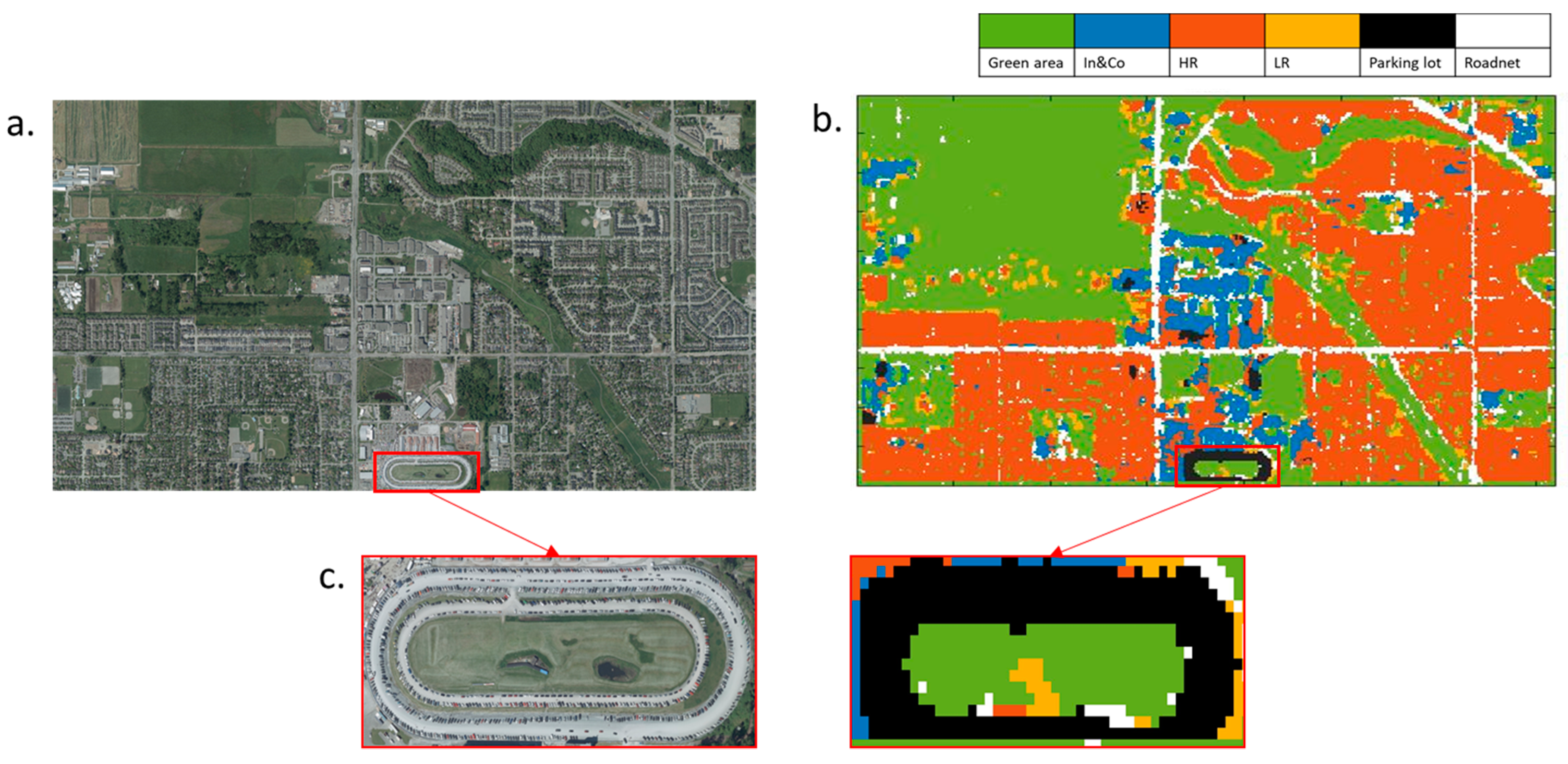
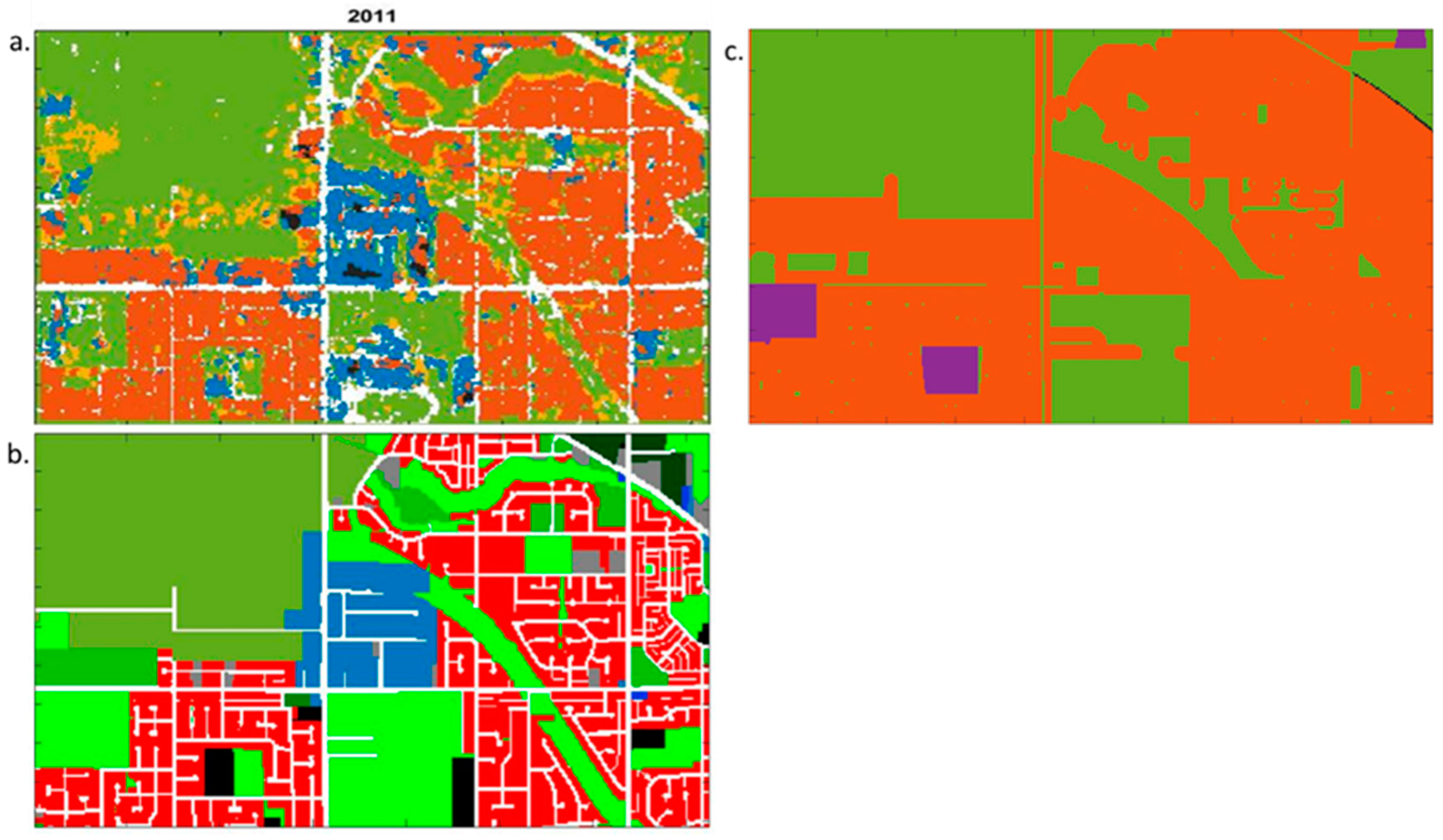
- The image of the study area was covering 20,000 × 36,000 pixels at a spatial resolution of 10 cm. The window with a pixel size of 700 × 700 shifted over and cropped the image in a specific order (from top to bottom and from left to right), with a stride of 100 pixels; therefore, there were {(20,000 − 700)/100 + 1} × {(36,000 − 700)/100 + 1} sub-patches, i.e., 194 × 354. The moving window covered all the image after 194 × 354 iterations with the same number of sequentially generated patches. These patches were sent to the classifier and land-use labels were returned. The numbers from 1 to 6 represent the six land-use labels. To extract the road network and green area land-use classes, the second process was repeated, while the size of moving window was set to 300 × 300 pixels, the matrix was only updated when the return label was 1 or 6. This process was done because green area and road network can exit in a small ground area independently. They can also become background of another feature if the moving window size was larger. For example, in a 700 × 700 pixels image, a small house can exist as agriculture land simultaneously, but the model will still think the image to be sparse residential. Therefore, the smaller window size, i.e. 300 × 300 pixels, was used again to separate out individual features from potentially misclassified 700 × 700 pixels images.
- A 194 × 354 void matrix was created; the cells in the matrix with index i corresponded to the ith image patches. The ith cell values were updated as the label number of the ith patch. Each cell represented a land-use category of a 10m spatial resolution for ground truth.
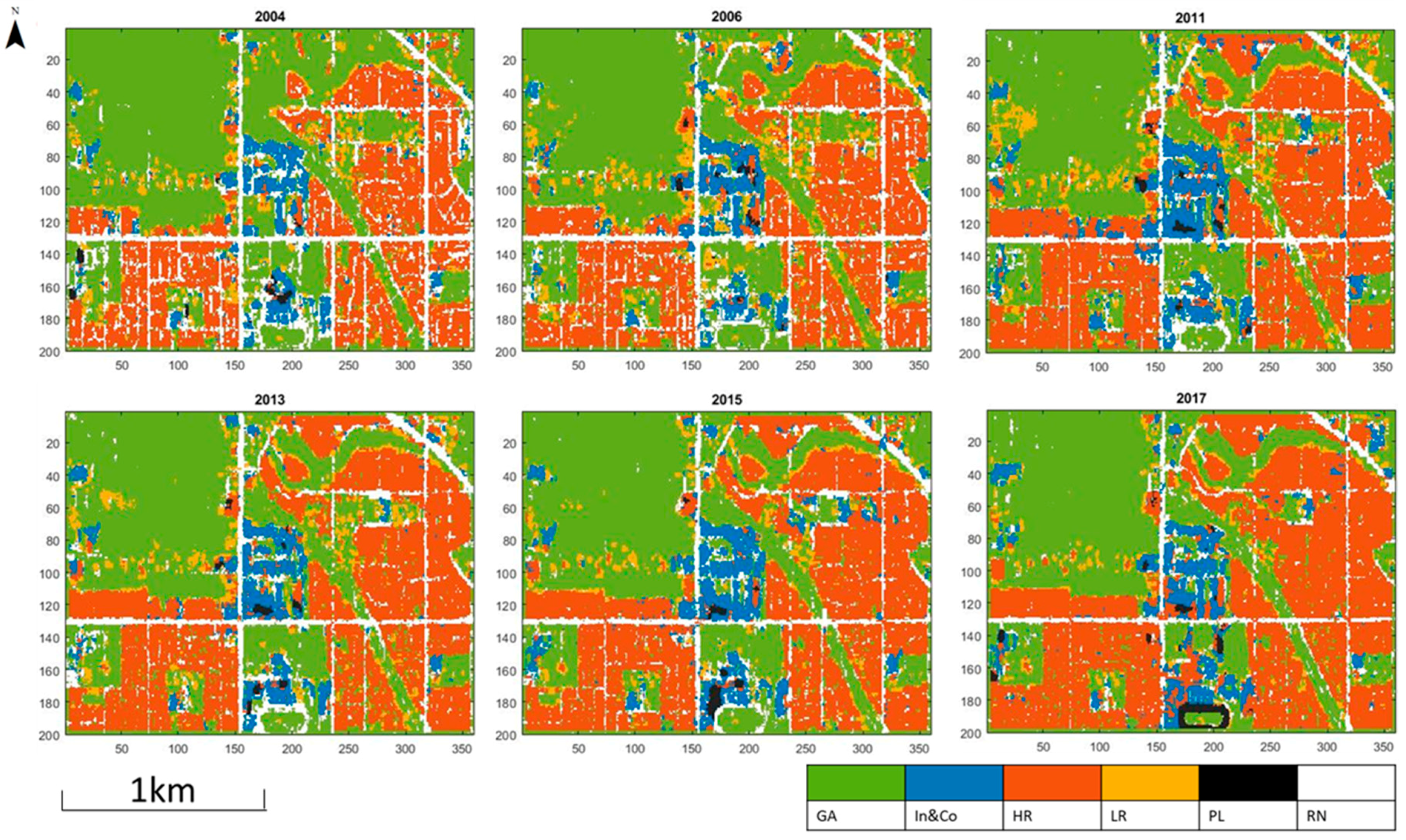
- The same classification method was applied to orthophotos for different years 2004, 2006, 2011, 2013, 2015 and 2017. Through the comparisons and statistical analyses of the obtained LU maps, the land-use change was quantified and analyzed.
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zin, T.T.; Lin, J.C.-W. Big Data Analysis and Deep Learning Applications. In Proceedings of the First International Conference on Big Data Analysis and Deep Learning; Springer: Berlin, Germany, 2018. [Google Scholar]
- Progress towards the Sustainable Development Goals; N1713409; HLPF: New York, NY, USA, 2017.
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global Consequences of Land Use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Etingoff, K. Urban Land Use: Community-Based Planning; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land Cover Classification via Multitemporal Spatial Data by Deep Recurrent Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1685–1689. [Google Scholar] [CrossRef]
- Joseph, G. Fundamentals of Remote Sensing; Universities Press: Hyderabad, India, 2005. [Google Scholar]
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep Machine Learning—A New Frontier in Artificial Intelligence Research. IEEE Comput. Intell. Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A Survey of Deep Neural Network Architectures and Their Applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face Recognition: A Convolutional Neural-Network Approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Lu, Y.; Yi, S.; Zeng, N.; Liu, Y.; Zhang, Y. Identification of Rice Diseases Using Deep Convolutional Neural Networks. Neurocomputing 2017, 267, 378–384. [Google Scholar] [CrossRef]
- Nia, K.R.; Mori, G. Building Damage Assessment Using Deep Learning and Ground-Level Image Data. In Proceedings of the 2017 14th Conference on Computer and Robot Vision (CRV), Edmonton, AB, Canada, 16–19 May 2017; pp. 95–102. [Google Scholar] [CrossRef]
- Xu, G.; Zhu, X.; Fu, D.; Dong, J.; Xiao, X. Automatic Land Cover Classification of Geo-Tagged Field Photos by Deep Learning. Environ. Model. Softw. 2017, 91, 127–134. [Google Scholar] [CrossRef]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Luus, F.P.S.; Salmon, B.P.; van den Bergh, F.; Maharaj, B.T.J. Multiview Deep Learning for Land-Use Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land-Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, GIS ’10, San Jose, FL, USA, 2–5 November 2010; ACM: New York, NY, USA, 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L.P. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and Efficient Midlevel Visual Elements-Oriented Land-Use Classification Using VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhu, Q.; Qin, Q.; Liu, Y.; Zhong, Y.; Fei, F.; Zhu, Q.; Qin, Q. Scene Classification Based on a Deep Random-Scale Stretched Convolutional Neural Network. Remote Sens. 2018, 10, 444. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards Better Exploiting Convolutional Neural Networks for Remote Sensing Scene Classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1, NIPS’12, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition; ICLR: San Diego, CA, USA, 2015. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying Corresponding Patches in SAR and Optical Images with a Pseudo-Siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhang, L. Scene Semantic Classification Based on Random-Scale Stretched Convolutional Neural Network for High-Spatial Resolution Remote Sensing Imagery. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 763–766. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing Spatial Distribution of Urban Land Use by Integrating Points-of-Interest and Google Word2Vec Model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L. AID: A Benchmark Dataset for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and Transferring Mid-Level Image Representations Using Convolutional Neural Networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- King, J.; Kishore, V.; Ranalli, F. Scene Classification with Convolutional Neural Networks; Course Project Reports 102; Stanford University: Stanford, CA, USA, 2017; p. 7. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Weng, Q.; Mao, Z.; Lin, J.; Guo, W. Land-Use Classification via Extreme Learning Classifier Based on Deep Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 704–708. [Google Scholar] [CrossRef]
- Cloverdale. Available online: http://www.surrey.ca/community/6799.aspx (accessed on 20 January 2019).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Russell, I. The Delta Rule. Available online: http://uhaweb.hartford.edu/compsci/neural-networks-delta-rule.html (accessed on 21 December 2018).
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Karpathy, A. CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/transfer-learning/ (accessed on 29 July 2018).
- City of Surrey. Available online: https://www.surrey.ca (accessed on 29 July 2018).
- City of Surrey’s Open Data. Available online: http://data.surrey.ca/ (accessed on 21 December 2018).
- Open Data Catalogue. Available online: http://www.metrovancouver.org/data (accessed on 21 December 2018).
- CanMap® GIS Data for GIS Mapping Software—DMTI Spatial. Available online: https://www.dmtispatial.com/canmap/ (accessed on 21 December 2018).
- City of Surrey Mapping Online System (COSMOS). Available online: http://cosmos.surrey.ca/external/ (accessed on 6 February 2019).
- Population Estimates & Projections. Available online: http://www.surrey.ca/business-economic-development/1418.aspx (accessed on 21 January 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Total Accuracy |
|---|---|
| a. AlexNet, full-trained | 95.80% |
| b. GoogLeNet, full-trained | 95.06% |
| c. AlexNet-‘fc7’-SVM | 95.68% |
| d. AlexNet-‘fc6’-SVM | 97.11% |
| e. GoogLeNet-‘loss classifier’-SVM | 97.47% |
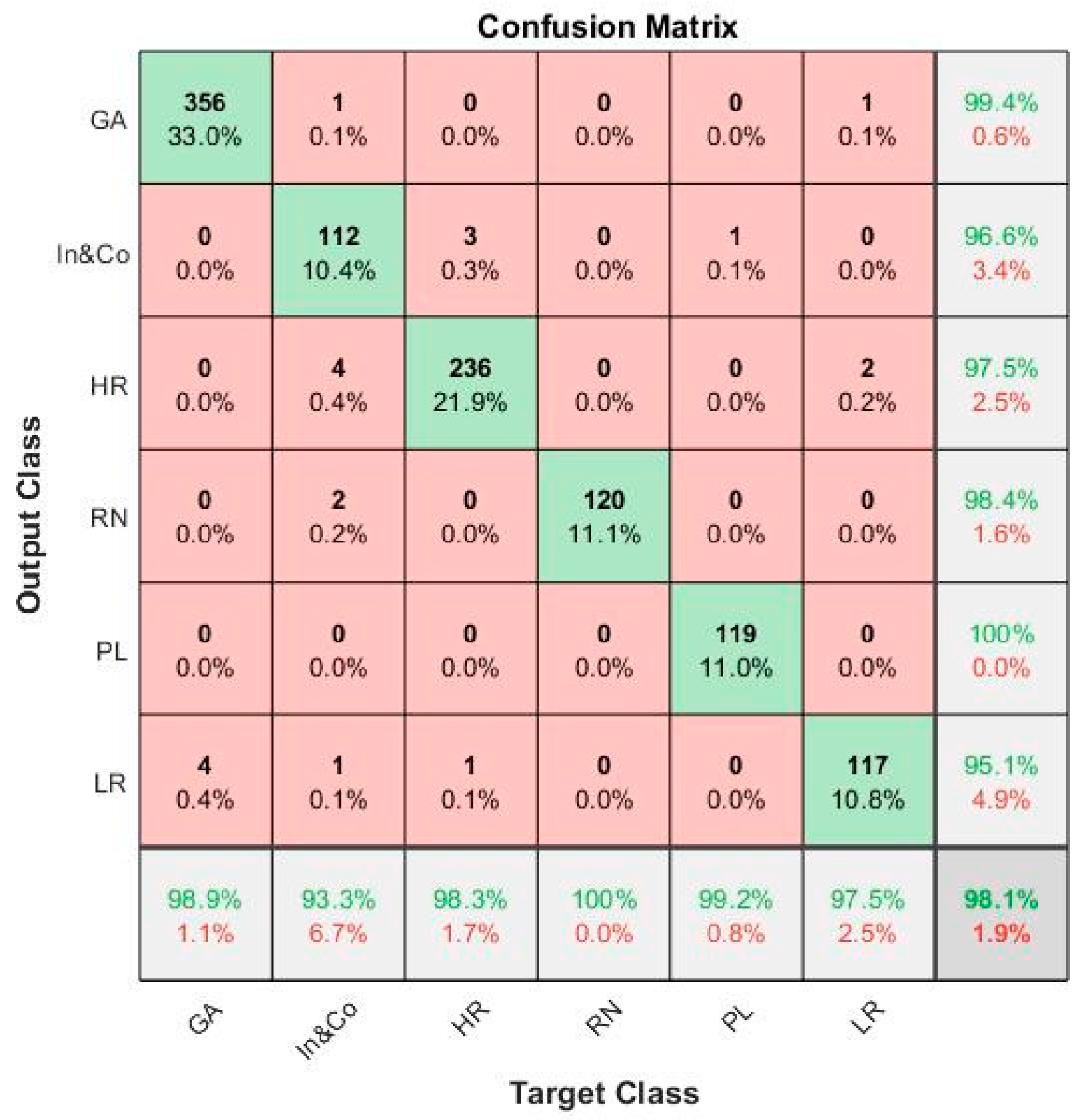
| f. GoogLeNet-‘pool5-drop’-SVM | 98.14% |
| g. VGGNet-‘fc6’-SVM | 95.93% |
| h. VGGNet-‘fc7’-SVM | 96.99% |
| GA | In&Co | HR | LR | PL | RN | |
|---|---|---|---|---|---|---|
| 2004 | 44.13% | 5.45% | 26.61% | 5.52% | 0.37% | 15.25% |
| 2006 | 40.77% | 5.69% | 30.39% | 7.51% | 0.37% | 12.35% |
| 2011 | 36.79% | 8.44% | 35.46% | 6.37% | 0.45% | 9.19% |
| 2013 | 39.30% | 5.85% | 34.77% | 6.43% | 0.44% | 10.00% |
| 2015 | 38.91% | 7.55% | 35.93% | 4.91% | 0.52% | 8.87% |
| 2017 | 37.61% | 6.60% | 40.89% | 3.83% | 1.01% | 6.62% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, C.; Dragićević, S.; Li, S. Land-Use Change Detection with Convolutional Neural Network Methods. Environments 2019, 6, 25. https://doi.org/10.3390/environments6020025
Cao C, Dragićević S, Li S. Land-Use Change Detection with Convolutional Neural Network Methods. Environments. 2019; 6(2):25. https://doi.org/10.3390/environments6020025
Chicago/Turabian StyleCao, Cong, Suzana Dragićević, and Songnian Li. 2019. "Land-Use Change Detection with Convolutional Neural Network Methods" Environments 6, no. 2: 25. https://doi.org/10.3390/environments6020025
APA StyleCao, C., Dragićević, S., & Li, S. (2019). Land-Use Change Detection with Convolutional Neural Network Methods. Environments, 6(2), 25. https://doi.org/10.3390/environments6020025