Walk, Look, Remember: The Influence of the Gallery’s Spatial Layout on Human Memory for an Art Exhibition

Abstract
:1. Introduction
2. Method
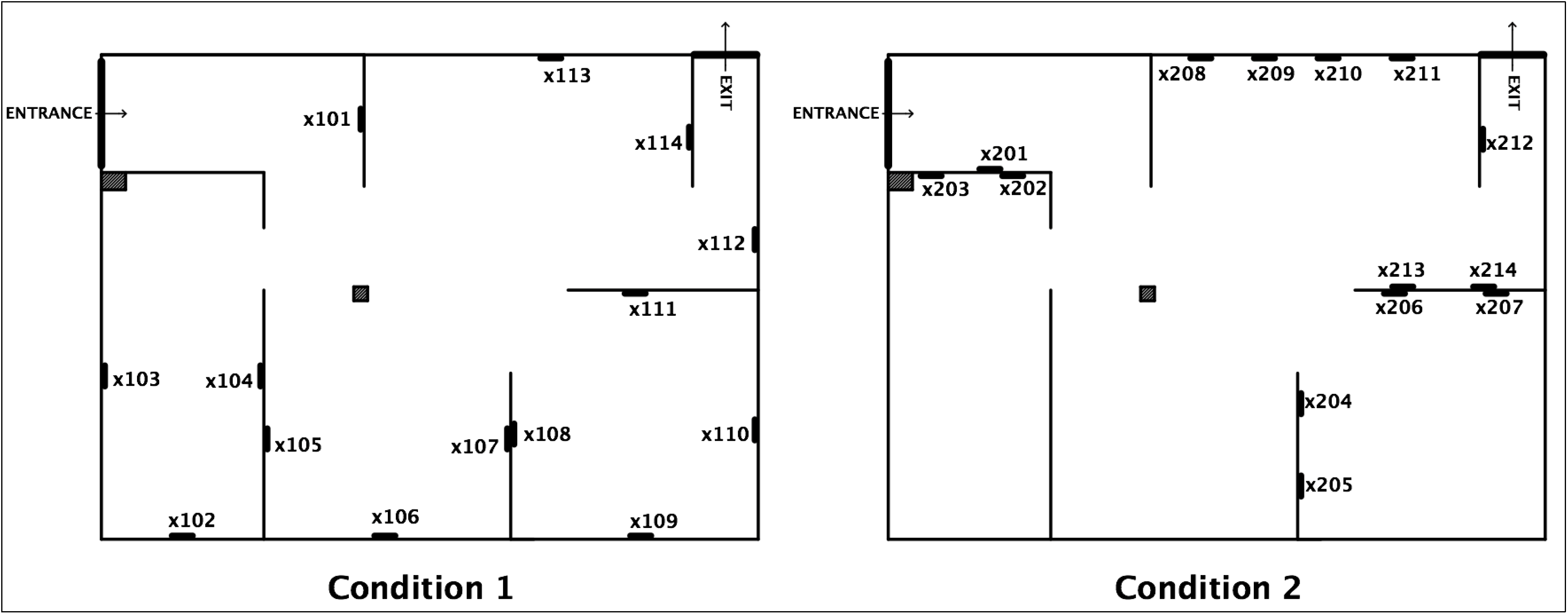
2.1. Space and Materials

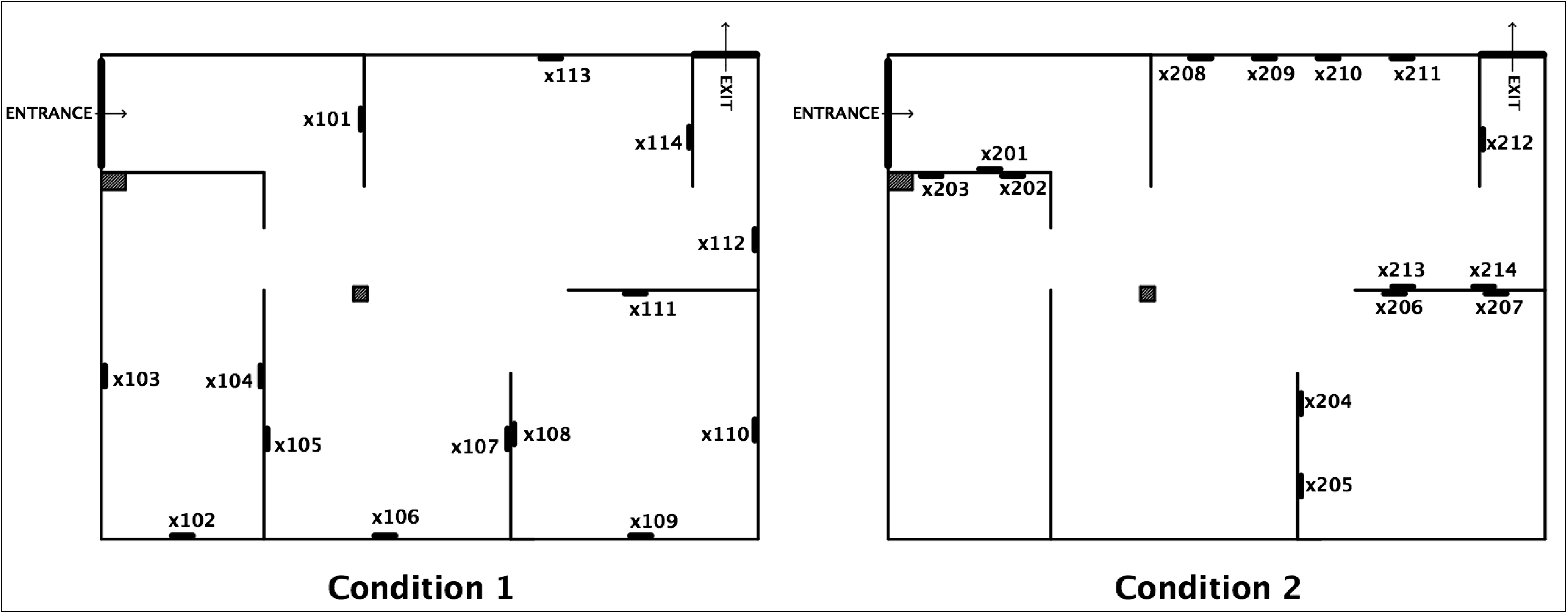
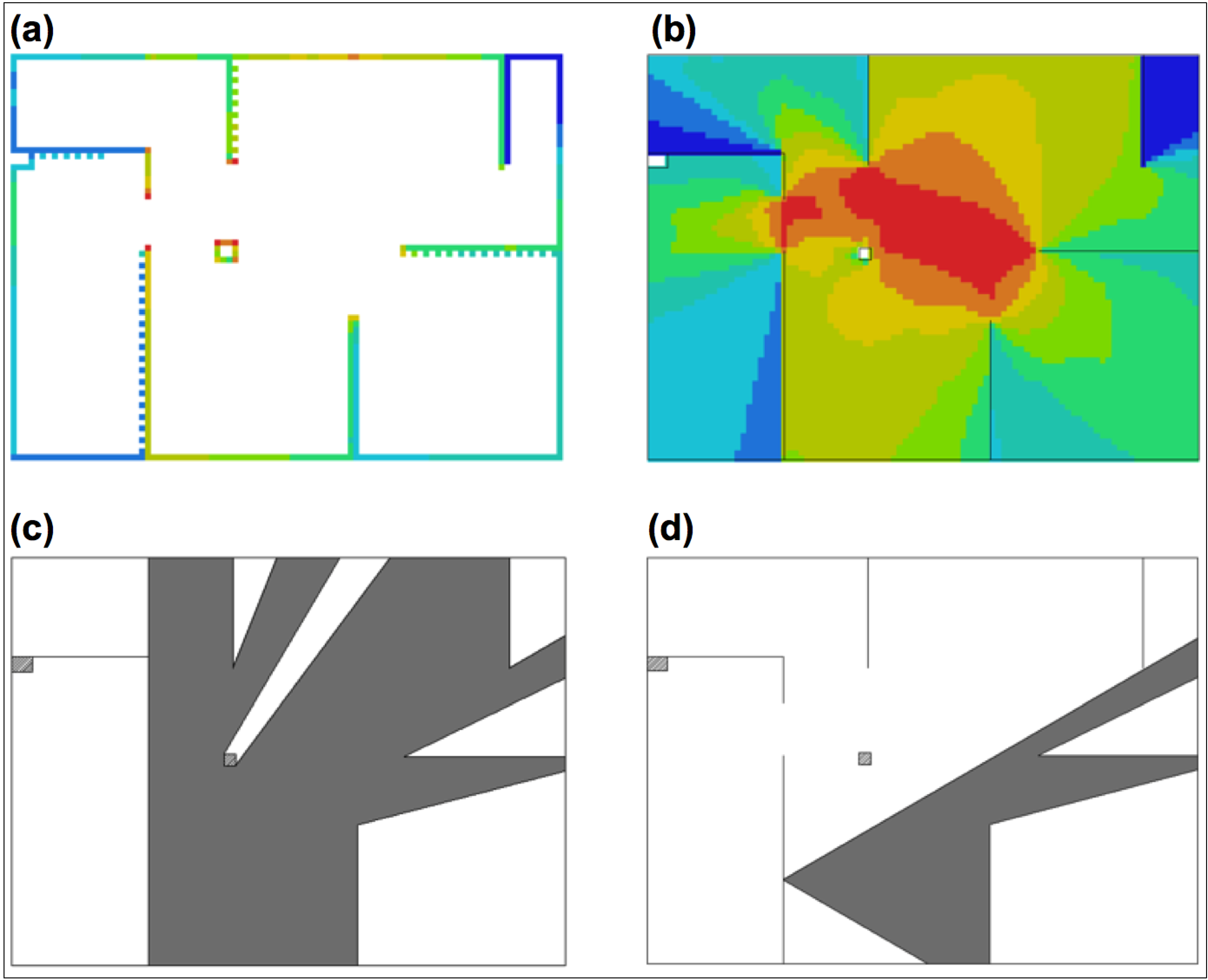
2.2. Space Syntax Measures
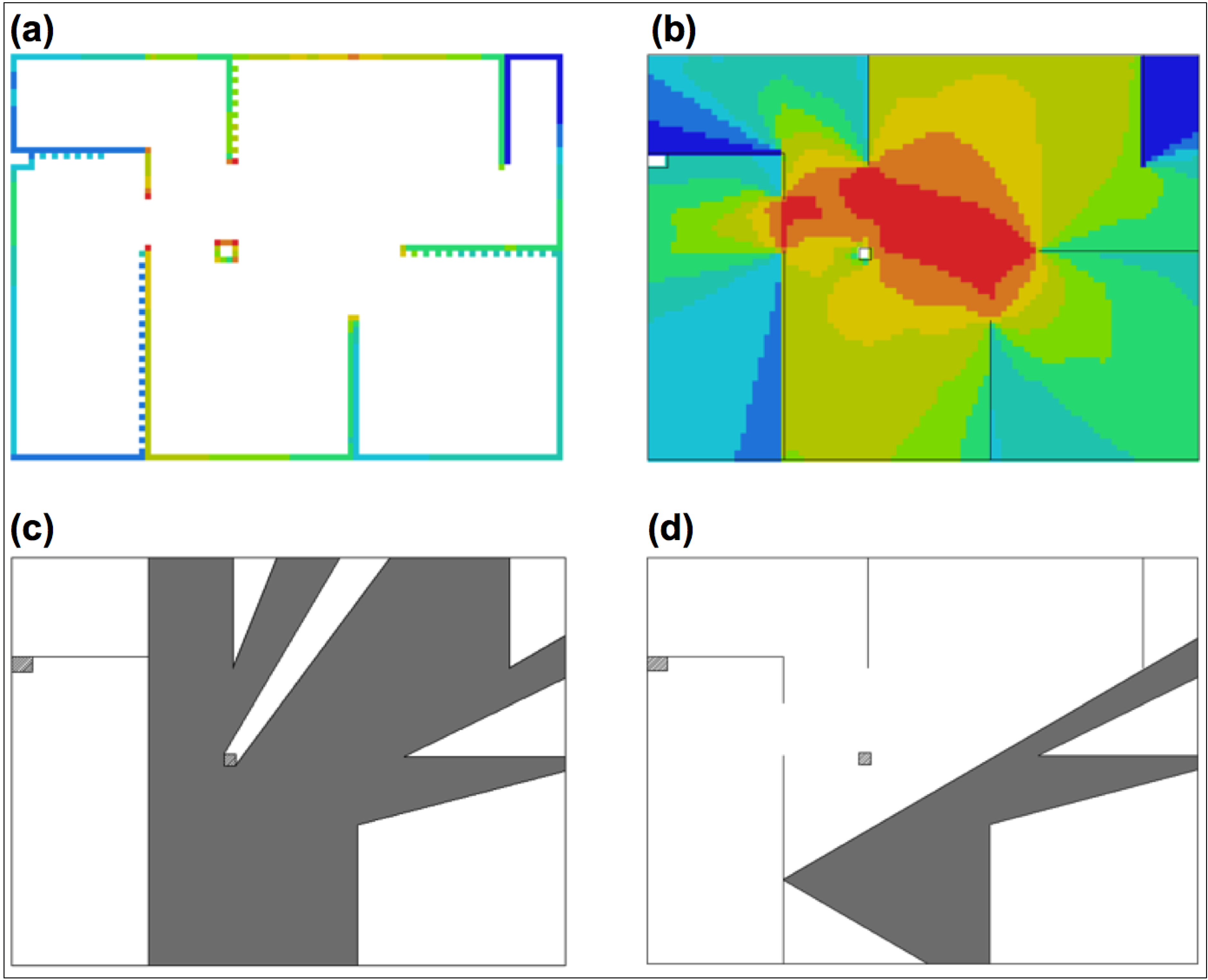
2.3. Participants
2.4. Procedure

2.5. Recognition Test
2.6. Miniature Task (Back-to-the-Wall Measure)

2.7. Salience Study on an Independent Group of Participants
3. Results
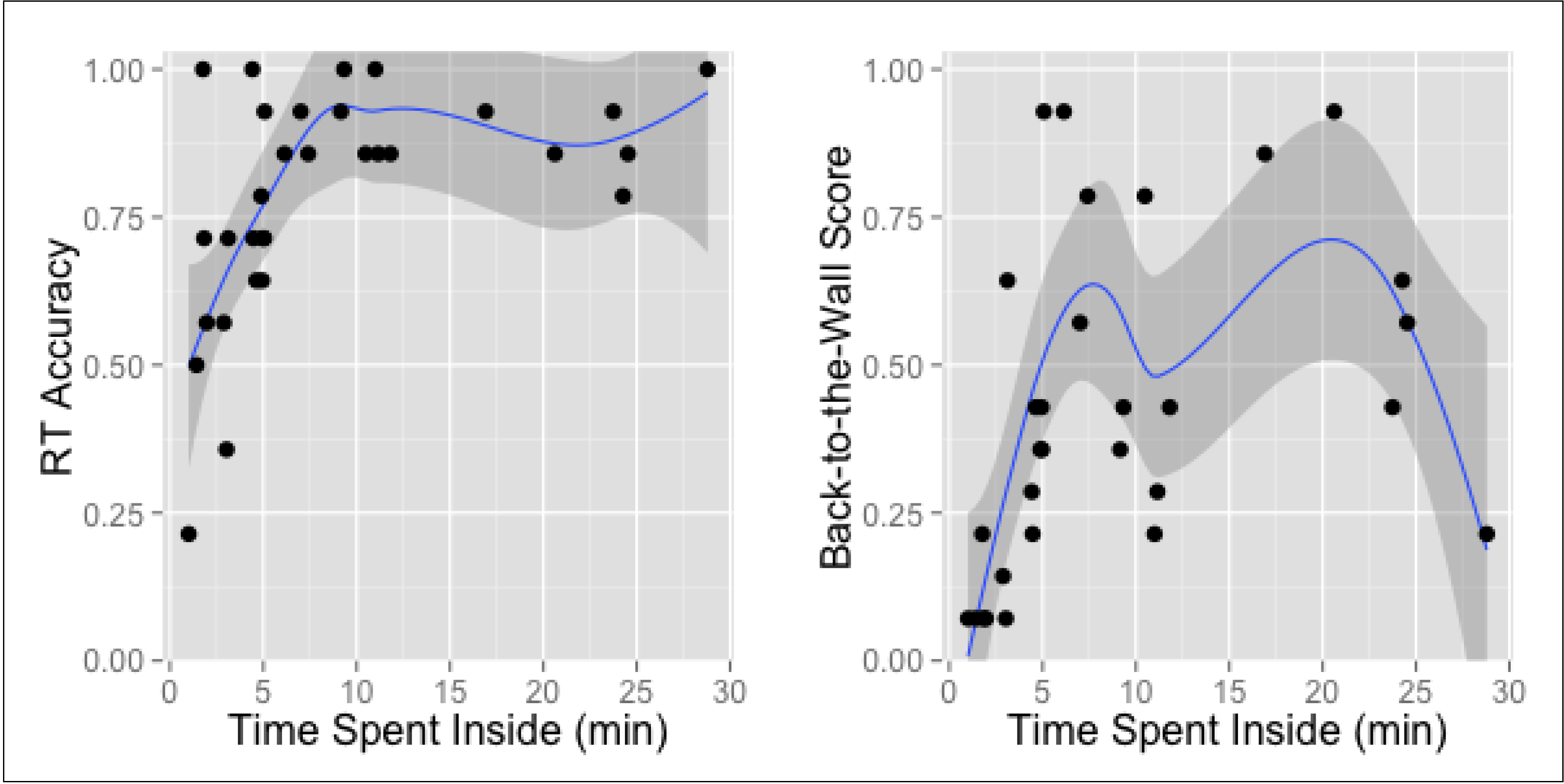
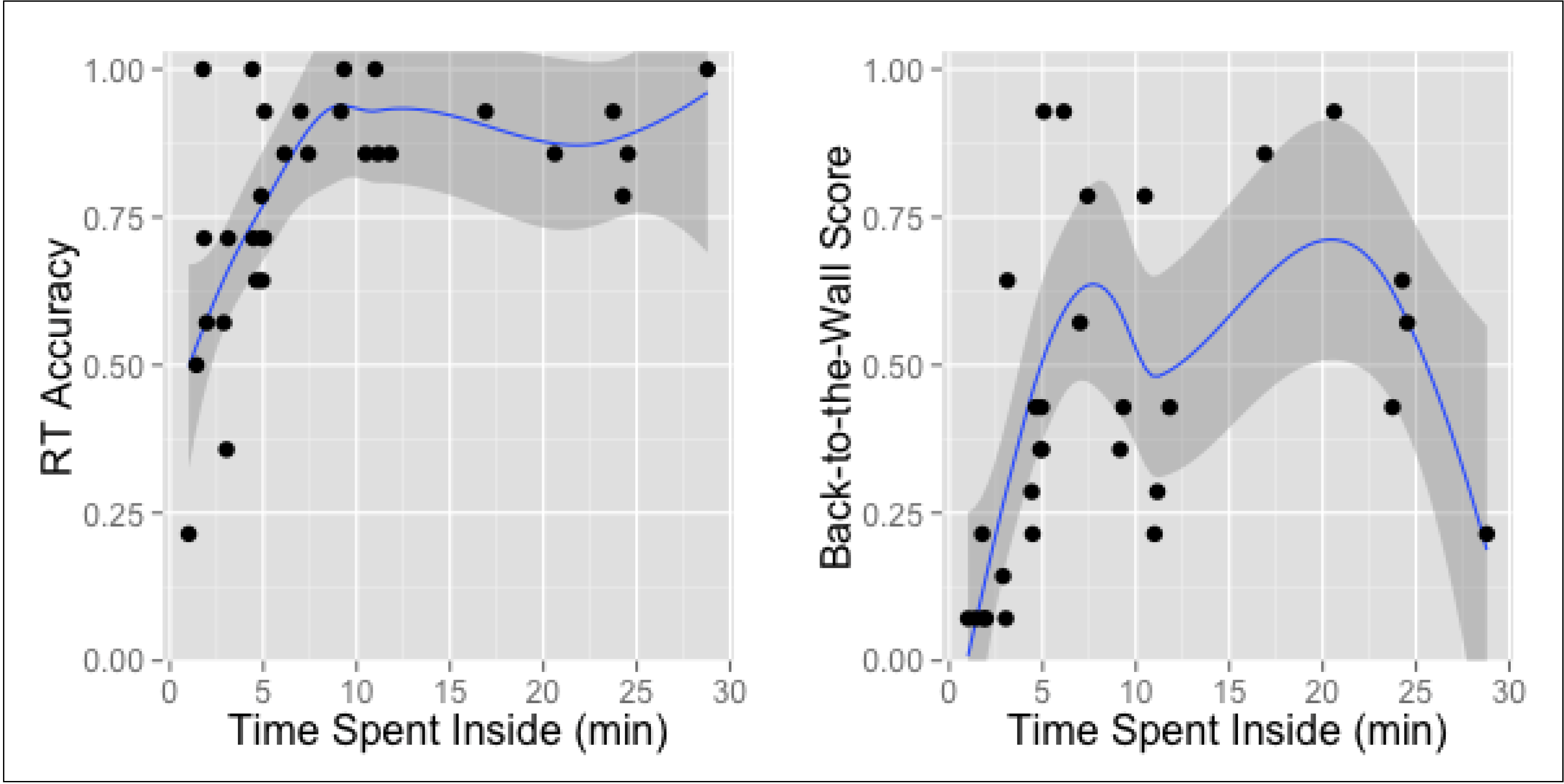
3.1. Time Spent Inside
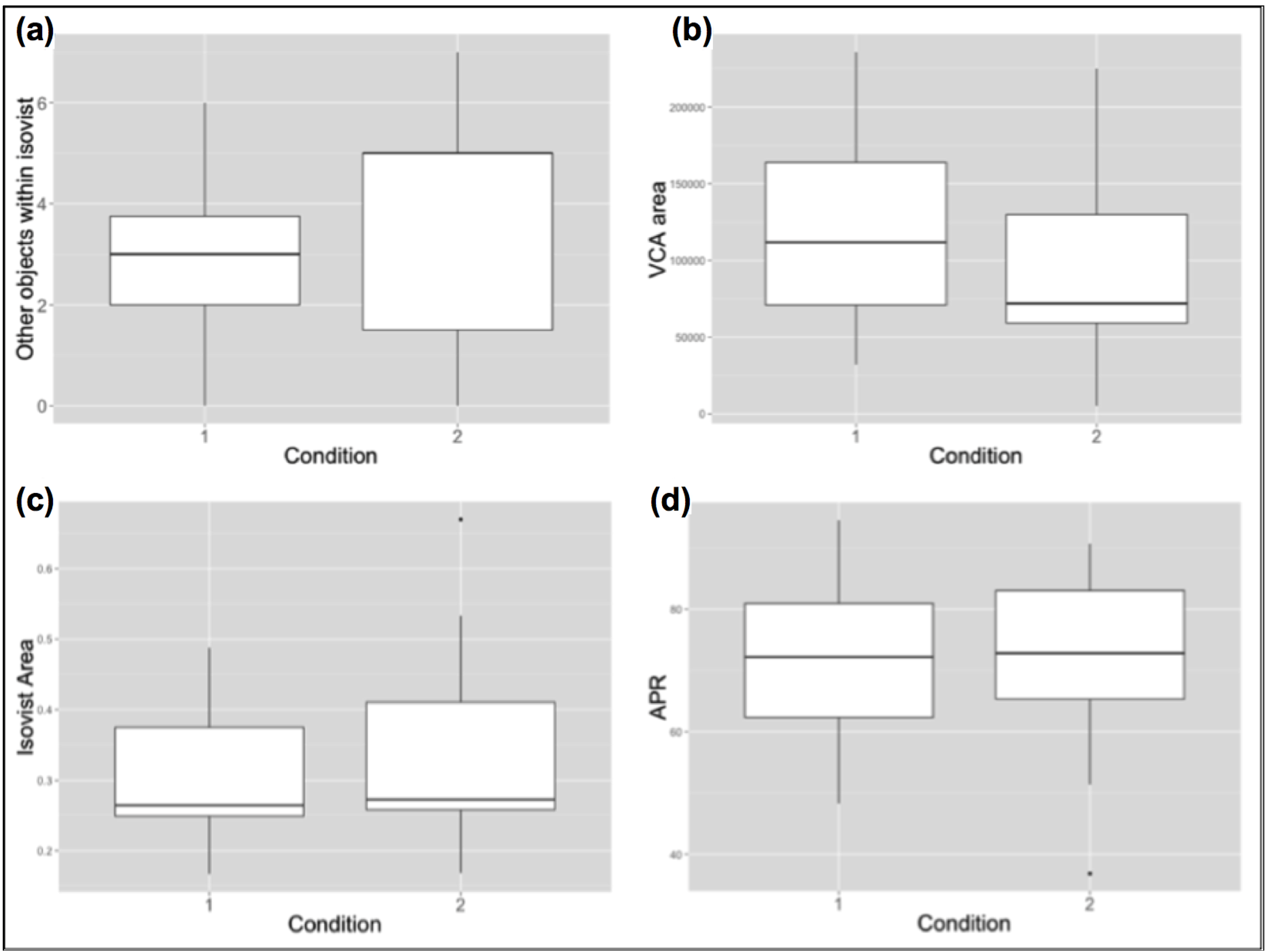
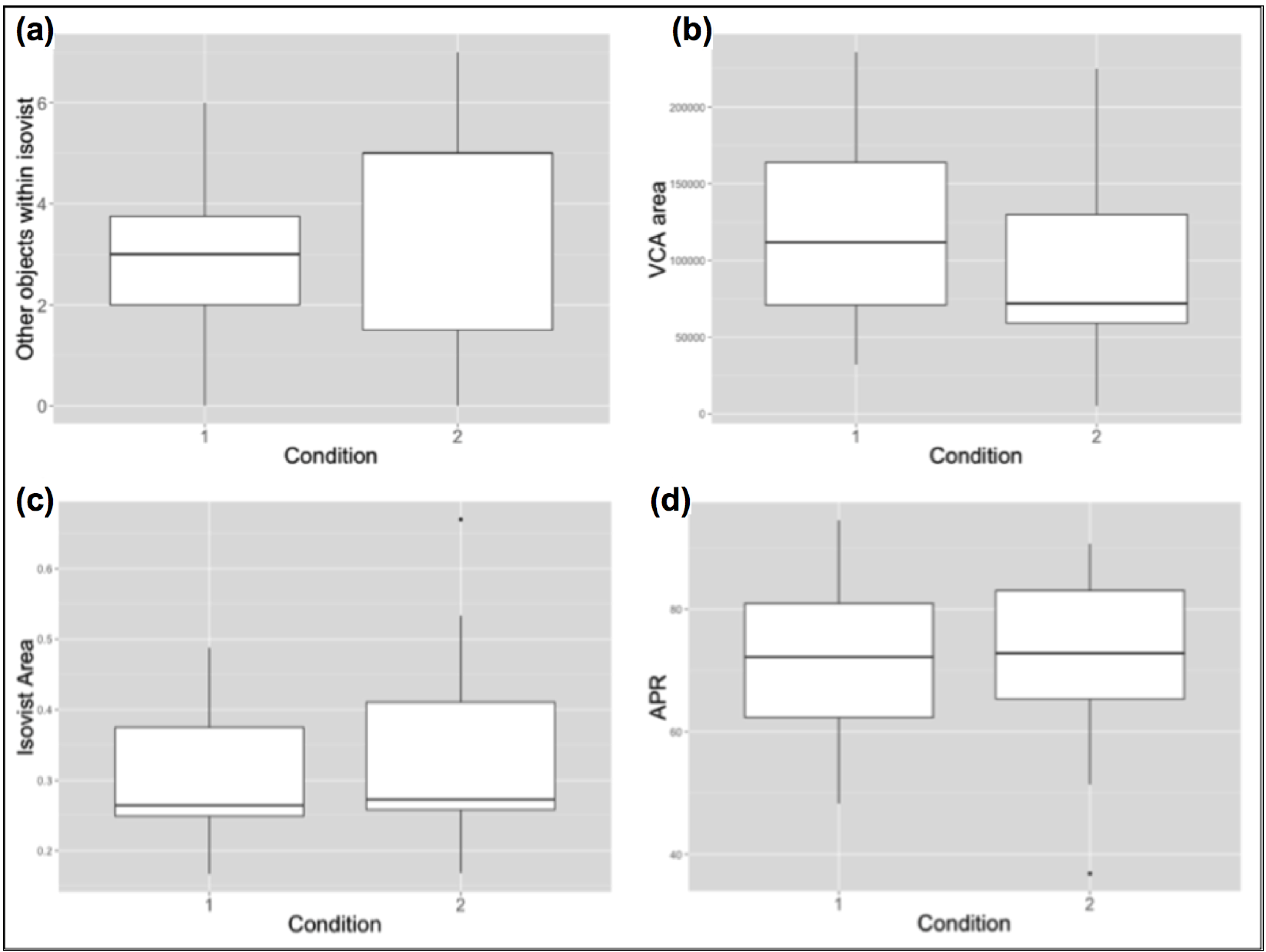
3.2. Cross-Condition Comparison of Personal Means
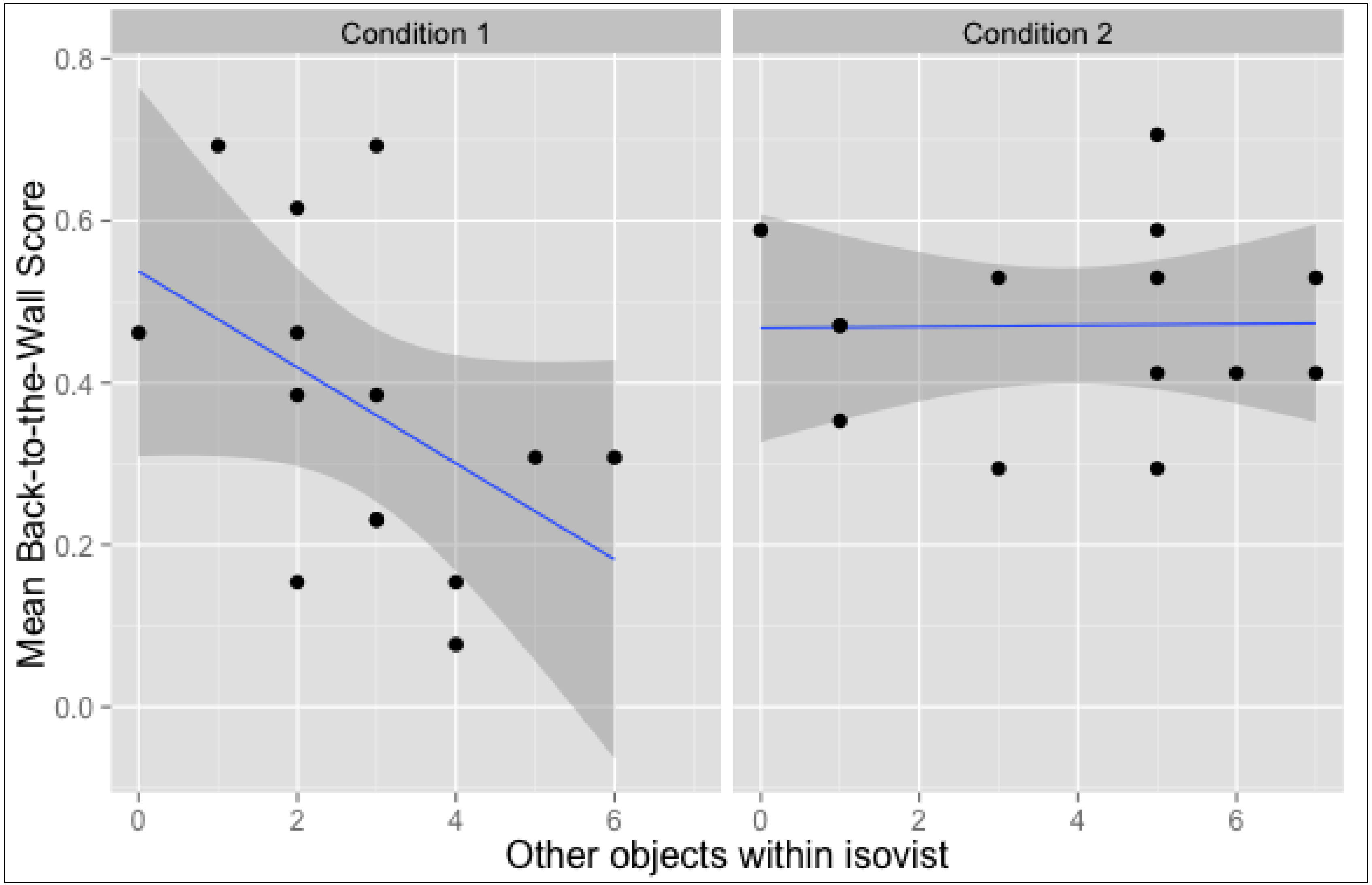
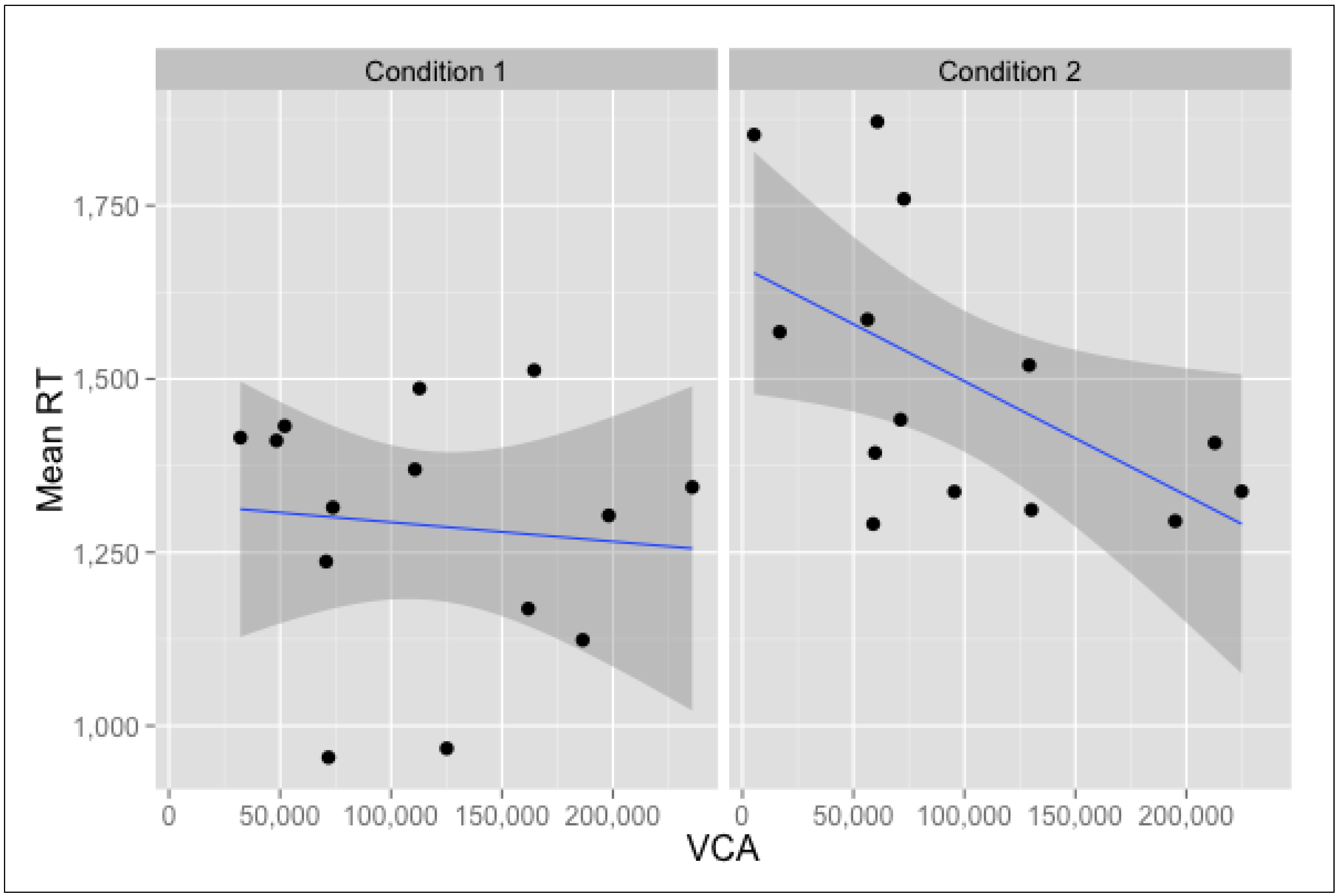
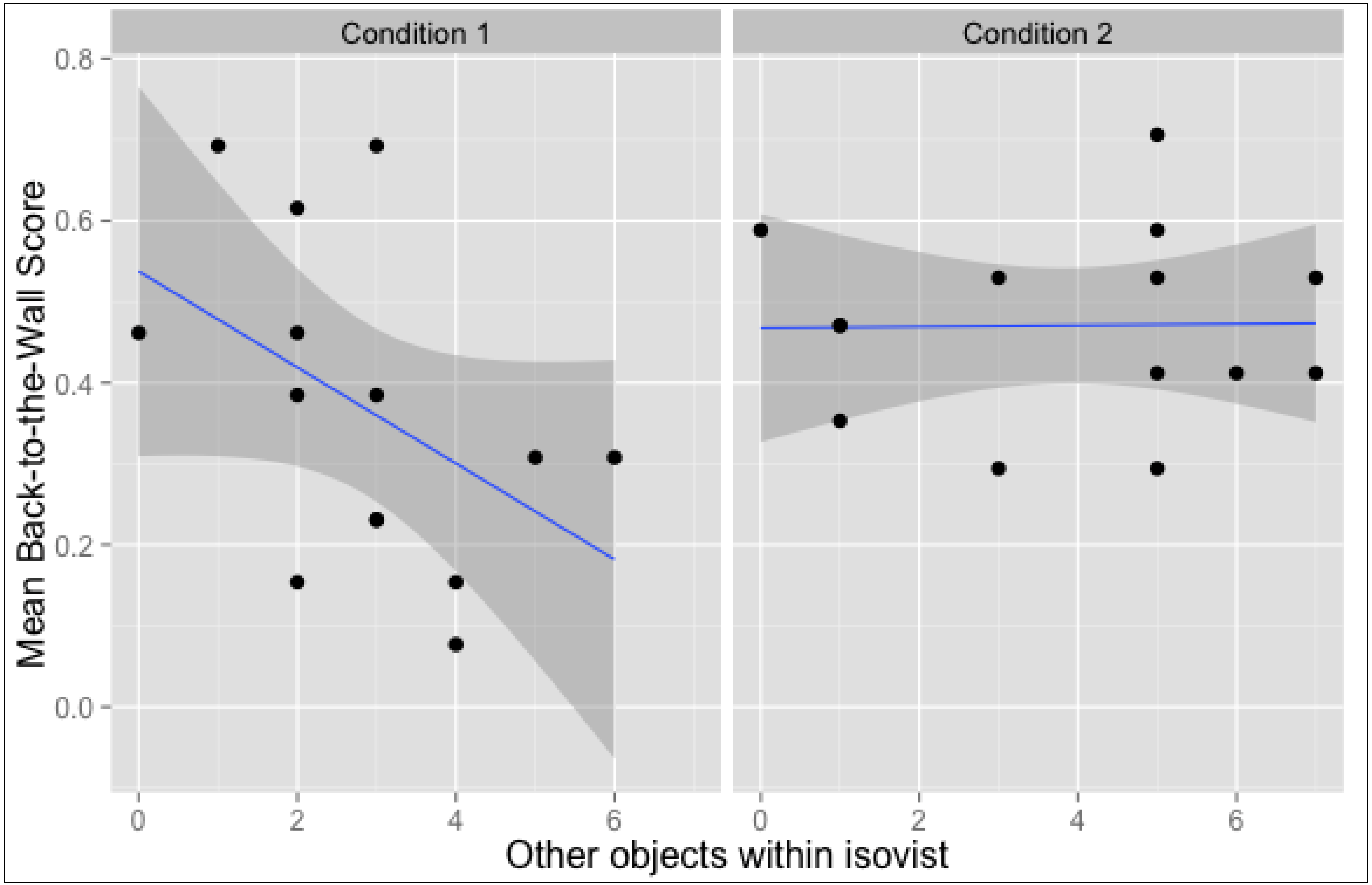
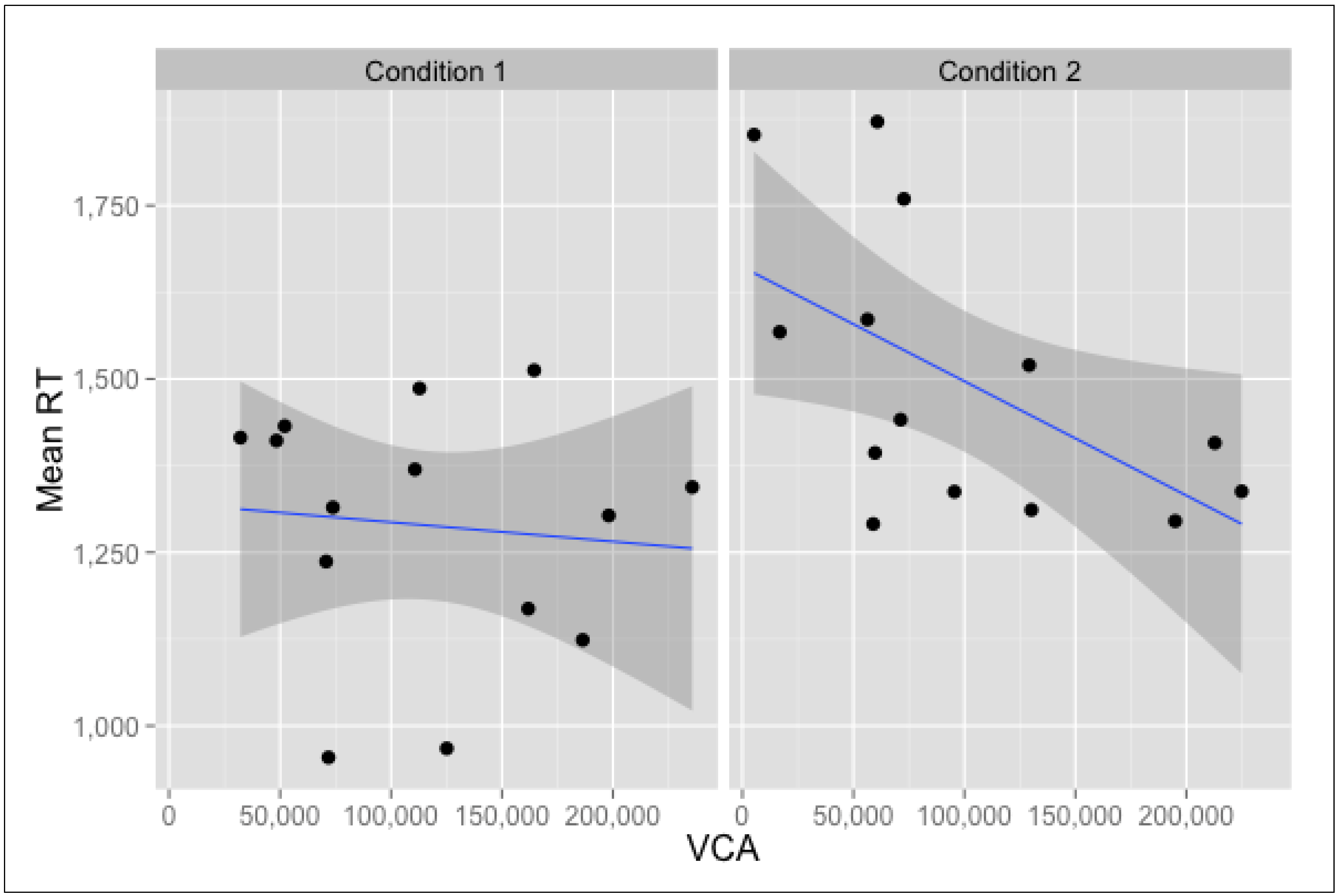
3.3. Location-Oriented Correlations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Both Conditions jointly (locations x101-x214) | Condition 1 (locations x1.) | Condition 2 (locations x2.) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RT | RT accuracy | Back-to-the-Wall | RT | RT accuracy | Back-to-the-Wall | RT | RT accuracy | Back-to-the-Wall | |
| RT accuracy | −0.01 | 0.35 | −0.17 | ||||||
| Back-to-the-Wall | 0.27 | −0.01 | 0.39 | 0.06 | −0.22 | −0.04 | |||
| Visibility Catchment Area (VCA) | −0.38 * | −0.12 | 0.04 | −0.1 | 0.19 | −0.12 | −0.56* | −0.35 | 0.41 |
| Other Objects Within Isovist | 0.15 | −0.11 | −0.12 | 0.11 | 0.14 | −0.47 | −0.02 | −0.22 | 0.02 |
| Isovist Area | −0.23 | −0.12 | −0.1 | 0.05 | 0.3 | −0.32 | −0.42 | −0.35 | 0.18 |
| Connectivity (BVG) | −0.18 | −0.03 | 0.03 | 0.11 | 0.46 | −0.12 | −0.4 | −0.31 | 0.23 |
| Point 2nd Moment | −0.21 | −0.09 | −0.03 | 0.1 | 0.31 | −0.14 | −0.42 | −0.38 | 0.23 |
3.4. Salience Study
3.5. Picture-Oriented Analysis
| Both Conditions jointly | Condition 1 | Condition 2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RT | RT accuracy | Back-to-the-Wall | RT | RT accuracy | Back-to-the-Wall | RT | RT accuracy | Back-to-the-Wall | |
| RT accuracy | −0.57 * | −0.17 | −0.52 | ||||||
| Back-to-the-Wall | −0.64 * | 0.78 *** | −0.25 | 0.73 ** | −0.39 | 0.32 | |||
| Salience Rating | −0.26 | 0.2 | 0.32 | −0.17 | 0.24 | 0.01 | −0.21 | 0.14 | 0.56 * |
4. Discussion
5. Conclusions
Acknowledgments
Conflicts of Interest
References
- Serrell, B. Paying attention: The duration and allocation of visitors’ time in museum exhibitions. Curator Mus. J. 1997, 40, 108–125. [Google Scholar] [CrossRef]
- Bitgood, S. An Attention-Value Model of Museum Visitors; Center for Advancement of Informal Science Education: Washington, DC, USA, 2010. [Google Scholar]
- Vergo, P. The Reticent Object. In The New Museology; Vergo, P., Ed.; Reaktion Books: London, UK, 1989; pp. 41–59. [Google Scholar]
- Baxandall, M. Exhibiting Intention: Some Preconditions of the Visual Display of Culturally Purposeful Objects. In Exhibiting Cultures: The Poetics and Politics of Museum Display; Karp, I., Lavine, S.D., Eds.; Smithsonian Institution Press: Washington, DC, USA and London, UK, 1991; pp. 33–41. [Google Scholar]
- Newhouse, V. Art and the Power of Placement; The Monacelli Press: New York, NY, USA, 2005. [Google Scholar]
- Locher, P. Contemporary experimental aesthetics: State of the art technology. I-Perception 2011, 2, 697–707. [Google Scholar] [CrossRef]
- Kirchberg, V.; Tröndle, M. Experiencing exhibitions: A review of studies on visitor experiences in museums. Curator Mus. J. 2012, 55, 435–452. [Google Scholar] [CrossRef]
- Tröndle, M.; Greenwood, S.; Kirchberg, V.; Tschacher, W. An Integrative and Comprehensive Methodology for Studying Aesthetic Experience in the Field Merging Movement Tracking, Physiology and Psychological Data. Environ. Behav. 2014, 46, 102–135. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vision. Res. 2000, 40, 1489–1506. [Google Scholar] [CrossRef]
- Land, M.F.; Tatler, B.W. Looking and Acting: Vision and Eye Movements in Natural Behaviour; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Buchner, A.; Jansen-Osmann, P. Is Route Learning More Than Serial Learning? Spat. Cogn. Comput. 2008, 8, 289–305. [Google Scholar] [CrossRef]
- O’Doherty, B. Inside the White Cube: The Ideology of the Gallery Space; The Lapis Press: San Francisco, CA, USA, 1986. [Google Scholar]
- Chan, E.; Baumann, O.; Bellgrove, M.A.; Mattingley, J.B. From objects to landmarks: The function of visual location information in spatial navigation. Front. Psychol. 2012, 3, 304. [Google Scholar] [CrossRef]
- Janzen, G.; van Turennout, M. Selective neural representation of objects relevant for navigation. Nat. Neurosci. 2004, 7, 673–677. [Google Scholar] [CrossRef]
- Caduff, D.; Timpf, S. On the assessment of landmark salience for human navigation. Cogn. Process. 2008, 9, 249–267. [Google Scholar] [CrossRef]
- Montello, D.R. A New Framework for Understanding the Acquisition of Spatial Knowledge in Large-Scale Environments. In Spatial and Temporal Reasoning in Geographic Information Systems; Egenhofer, M.J., Ed.; Oxford University Press: New York, NY, USA, 1998; pp. 143–154. [Google Scholar]
- Janzen, G. Memory for object location and route direction in virtual large-scale space. Q. J. Exp. Psychol. 2006, 59, 493–508. [Google Scholar] [CrossRef]
- Miller, J.; Carlson, L. Selecting landmarks in novel environments. Psychon. Bull. Rev. 2011, 18, 184–191. [Google Scholar] [CrossRef]
- Steck, S.; Mallot, H. The role of global and local landmarks in virtual environment navigation. Presence Teleoperator. Virtual Env. 2000, 9, 69–83. [Google Scholar] [CrossRef]
- Psarra, S. Architecture and Narrative: the Formation of Space and Cultural Meaning; Routledge: London, UK, 2009. [Google Scholar]
- Peponis, J.; Hedin, J. The layout of theories in the Natural History Museum. 9H 1982, 3, 21–25. [Google Scholar]
- Hillier, B.; Major, M.; Desyllas, J.; Karimi, K.; Campos, B.; Stonor, T. Tate Gallery, Millbank: A Study of the Existing Layout and New Masterplan Proposal; UCL (University College London): London, UK, 1996. [Google Scholar]
- Choi, Y.K. The morphology of exploration and encounter in museum layouts. Environ. Plan. B 1999, 26, 241–250. [Google Scholar]
- Kaynar, I. Visibility, Movement Paths And Preferences in Open Plan Museums: An Observational and Descriptive Study of the Ann Arbor Hands-on Museum. In Proceedings of the 5th International Space Syntax Symposium, Delft, The Netherlands, 13–17 June 2005; van Nes, A., Ed.; Techne Press: Delft, The Netherlands, 2005; pp. 189–203. [Google Scholar]
- Zamani, P. Architecture as Curatorial Device. In Proceedings of the 7th International Space Syntax Symposium, Stockholm, Sweden, 8–11 June 2009; Koch, D., Marcus, L., Steen, J., Eds.; KTH Royal Institute of Technology: Stockholm, Sweden, 2009; pp. 134:1–134:12. [Google Scholar]
- Hillier, B.; Tzortzi, K. Space Syntax: The Language of Museum Space. In A Companion to Museum Studies; Macdonald, S., Ed.; Blackwell Publishing Ltd.: Oxford, UK, 2007; pp. 282–301. [Google Scholar]
- Tzortzi, K. An approach of the microstructure of the gallery space: The case of the Sainsbury Wing. In Proceedings of the 4th International Space Syntax Symposium, London, UK, 17–19 June 2003; UCL: London, UK, 2003; pp. 67:1–67:16. [Google Scholar]
- Tzortzi, K. Museum building design and exhibition layout. In Proceedings of the 6th International Space Syntax Symposium, Istanbul, Turkey, 12–15 June 2007; Istanbul Technichal University: Istanbul, Turkey, 2007; pp. 072:01–072:16. [Google Scholar]
- Stavroulaki, G.; Peponis, J. The spatial construction of seeing at Castelvecchio. In Proceedings of the 4th International Space Syntax, London, UK, 17–19 June 2003; UCL: London, UK, 2003; pp. 66:1–66:13. [Google Scholar]
- Wineman, J.; Peponis, J.; Dalton, R.C. Exploring, Engaging, Understanding in Museums. In Space Syntax and Spatial Cognition Workshop: Spatial Cognition ’06; Hoelscher, C., Dalton, R.C., Turner, P., Eds.; Universität Bremen: Bremen, Germany, 2006; pp. 33–51. [Google Scholar]
- Wiener, J.M.; Franz, G.; Rossmanith, N.; Reichelt, A.; Mallot, H.A.; Bülthoff, H.H. Isovist analysis captures properties of space relevant for locomotion and experience. Perception 2007, 36, 1066–1083. [Google Scholar] [CrossRef]
- Dalton, S.; Marshall, P.; Dalton, R.C. Measuring Environments for Public Displays: A Space Syntax Approach. In CHI ’10 Extended Abstracts on Human Factors in Computing Systems; Association for Computing Machinery (ACM): New York, NY, USA, 2010; pp. 3841–3846. [Google Scholar]
- Lu, Y.; Peponis, J. Exhibition visitors are sensitive to patterns of display covisibility. Environ. Plan. B 2013, 41, 53–68. [Google Scholar]
- Bellamy, S.; Northumbria University. Strike a Pose (digital images from a collage). Personal communication, unpublished work. 2012.
- Hillier, B.; Hanson, J. The Social Logic of Space; Cambridge University Press: Cambridge, UK, 1984. [Google Scholar]
- Peponis, J.; Wineman, J.; Bafna, S. (Eds.) Syntax Symposium; University of Michigan: Atlanta, GA, USA, 2001; pp. 31:1–31:9.
- Turner, A.; Doxa, M.; O’Sullivan, D.; Penn, A. From isovists to visibility graphs: A methodology for the analysis of architectural space. Environ. Plan. B Plan. Des. 2001, 28, 103–121. [Google Scholar] [CrossRef]
- Benedikt, M.L. To take hold of space: Isovists and isovist fields. Environ. Plan. B Plan. Des. 1979, 6, 47–65. [Google Scholar]
- Xie, H.; Filippidis, L.; Gwynne, S.; Galea, E.R.; Blackshields, D.; Lawrence, P.J. Signage Legibility Distances as a Function of Observation Angle. J. Fire Prot. Eng. 2007, 17, 41–64. [Google Scholar] [CrossRef]
- Schmidt, C.; Müller, J.; Bailly, G. Screenfinity: Extending the Perception Area of Content on Very Large Public Displays. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; Association for Computing Machinery (ACM): Paris, France, 2013; pp. 1719–1728. [Google Scholar]
- Ishihara, S. Test for Coiour-Blindness; Hongo Harukicho: Tokyo, Japan, 1917. [Google Scholar]
- O’Neill, M.J. Effects of familiarity and plan complexity on wayfinding in simulated buildings. J. Environ. Psychol. 1992, 12, 319–327. [Google Scholar] [CrossRef]
- Von Stülpnagel, R.; Steffens, M.C. Can Active Navigation Be as Good as Driving? A Comparison of Spatial Memory in Drivers and Backseat Drivers. J. Exp. Psychol. 2012, 18, 162–177. [Google Scholar]
- Krukar, J.; Dalton, R.C. Spatial Predictors of Eye Movement in a Gallery Setting. In Eye Tracking for Spatial Research, Proceedings of the 1st International Workshop (In Conjunction with COSIT 2013), Scarborough, UK, 2–6 September 2013; Kiefer, P., Giannopoulos, I., Raubal, M., Hegarty, M., Eds.; Ergoneers: Scarborough, UK, 2013; pp. 14–19. [Google Scholar]
- Mathôt, S.; Schreij, D.; Theeuwes, J. OpenSesame: An open-source, graphical experiment builder for the social sciences. Behav. Res. Methods 2012, 44, 314–324. [Google Scholar] [CrossRef]
- Ratcliff, R. Methods for dealing with reaction time outliers. Psychol. Bull. 1993, 114, 510–532. [Google Scholar] [CrossRef]
- Whelan, R. Effective analysis of reaction time data. Psychol. Rec. 2008, 58, 475–482. [Google Scholar]
- Münzer, S.; Zimmer, H.D.; Schwalm, M.; Baus, J.; Aslan, I. Computer-assisted navigation and the acquisition of route and survey knowledge. J. Environ. Psychol. 2006, 26, 300–308. [Google Scholar] [CrossRef]
- R Core Team. R:A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Hollingworth, A. Visual Memory for Natural Scenes. In Visual Memory; Luck, S.J., Hollingworth, A., Eds.; Oxford University Press: Oxford, 2008; pp. 123–162. [Google Scholar]
- Montello, D. Scale and multiple psychologies of space. In Spatial information theory: A theoretical basis for GIS; Frank, A.U., Campari, I., Eds.; Springer: Berlin, Germany, 1993; pp. 312–321. [Google Scholar]
- Dorsett, C. Making Meaning Beyond Display. In Museum Materialities: Objects, Engagements, Interpretations; Dudley, S.H., Ed.; Routledge: London, UK and New York, USA, 2010; pp. 241–259. [Google Scholar]
- Krukar, J.; Dalton, R.C. Walk, Look, Remember: Art galleries as spaces facilitating memory. In Proceedings of Ninth International Space Syntax Symposium, Seoul, Korea, 31 October–3 November 2013; Kim, Y.O., Park, H.T., Seo, K.W., Eds.; Sejong University Press: Seoul, Korea, 2013; pp. 074:1–074:19. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Krukar, J. Walk, Look, Remember: The Influence of the Gallery’s Spatial Layout on Human Memory for an Art Exhibition. Behav. Sci. 2014, 4, 181-201. https://doi.org/10.3390/bs4030181
Krukar J. Walk, Look, Remember: The Influence of the Gallery’s Spatial Layout on Human Memory for an Art Exhibition. Behavioral Sciences. 2014; 4(3):181-201. https://doi.org/10.3390/bs4030181
Chicago/Turabian StyleKrukar, Jakub. 2014. "Walk, Look, Remember: The Influence of the Gallery’s Spatial Layout on Human Memory for an Art Exhibition" Behavioral Sciences 4, no. 3: 181-201. https://doi.org/10.3390/bs4030181
APA StyleKrukar, J. (2014). Walk, Look, Remember: The Influence of the Gallery’s Spatial Layout on Human Memory for an Art Exhibition. Behavioral Sciences, 4(3), 181-201. https://doi.org/10.3390/bs4030181