1. Introduction
Since the detection of ‘
51 Peg b’, the first exoplanet around a main sequence star [
1], many more planets around other stars have been discovered. Currently, more than 3500 exoplanets have been detected in our galaxy. The diversity of these exoplanets in terms of orbital and physical properties is overwhelming. This diversity challenges planet formation and evolution theories, which were tuned originally to explain the planets in our Solar System [
2,
3].
Several groups took it upon themselves to label and classify the known exoplanets, and compile catalogs to provide the scientific community with a comprehensive working tool to access the data and perform statistical studies of the exoplanet sample (hereafter, exostatistics). These databases include information about the physical properties of the planets, as well as their host stars. Analysis of this information is constantly improving our understanding of planet formation mechanisms [
4], protoplanetary disks [
5], and planetary composition and internal structure [
6,
7]. At the moment, several exoplanet catalogs are available and are used by the community (see [
8]).
The most widely-used exoplanet catalogs are:
These catalogs include data from ground-based observations as well as space missions such as CoRoT, Kepler, and K2. The available data in these catalogs are comprehensive and include the physical properties of the host star, available information on the planetary physical properties, and the referenced confirmation paper or other mentioned source.
The different teams of each catalog use different criteria to include a planet, which are usually based on the physical properties of the planet or statistical thresholds (see
Table 1). Furthermore, each catalog has a different approach to displaying the database. For example, ARCHIVE designates a set of default parameters for each planet. This set is extracted from a single published reference to ensure internal consistency. Additional values published in other papers can only be found by viewing the pages dedicated to individual planets, where multiple sets of parameters are displayed. As a result, the ARCHIVE table provides a self-consistent set of parameters for any system, with missing values when the information is unavailable. On the other hand, EU uses a table displaying information on specific planet extracted from different sources, thus making for a more complete parameter set, though not necessarily self-consistent.
Many exostatistics papers use one of these catalogs as their source of observational data. Nevertheless, so far, the different catalogs have not been compared in terms of their possible differences and potential biases and selection effects that might affect inferred results and conclusions.
In this work, we present a simple statistical comparison between the different exoplanet catalogs. We mainly focus on the EU, ARCHIVE and OPEN catalogs. The database of the ORG catalog contains a single and reliable set of parameters for each planet. However, since it has not been updated for a couple of years now (see website and discussion in Reference [
8]), we perform only a coarse comparison. As discussed in Reference [
8], there are plans to restart regular updates in the near future.
2. Methods
We have downloaded lists of confirmed planets from the following four catalogs: EU, ARCHIVE, OPEN and ORG on 3 April 2018. As discussed previously, because of the different planetary mass criteria of each catalog (see
Table 1), we set
as an upper bound for the planetary mass, to strictly exclude any potential brown dwarfs. Thus, we avoided any biases that might emerge from the different mass cutoffs the catalogs use.
The parameters we use in order to compare the catalogs are the stellar mass (
), surface temperature (
) and metallicity (
), and planetary mass (
), radius (
) and orbital period (
Period). We chose this set of six parameters because they are the fundamental parameters that are most easily available from current photometric and spectroscopic detection methods [
12]. Physically, these parameters provide basic, broad information about the planetary system [
6]. The process of deriving the stellar properties involves a collection of literature values for atmospheric properties (temperature, surface gravity, and metallicity) derived from different observational techniques (photometry, spectroscopy, asteroseismology, and exoplanet transits), and then fitting them to stellar isochrones (e.g., References [
13,
14]). The stellar properties are then used in the derivation of almost all planet properties from radial velocities (RV), transits or transit timing variation (TTV) data. Thus, a reliable estimate of these parameters is crucial for the quality of the planet properties estimate (e.g., Reference [
15]).
In the framework of this analysis, we compared separately (and in combination) the planetary properties of the confirmed planets from the listed catalogs. In addition, we performed a comparison between planetary systems by examining the distributions of stellar and planetary properties of the main star and each system’s first detected planet. By doing so, we were able to find the biases of the planet properties emerging from the stellar properties. There was no sense in comparing the stellar parameters of all the confirmed planets since it is possible to unintentionally give more weight to multi-planetary systems when performing the analysis.
Table 2 lists the total number of confirmed planets and systems of each catalog as a function of the different stellar and planet properties. The significant variability of those numbers raised the following questions: Does the catalog with the largest number of planets include all the listed objects of the other catalogs? How different is the distribution of planets from two different catalogs?
Most of the statistical work in this analysis is based on comparing the different sets using a two-sample Kolmogorov–Smirnov test (hereafter, KS test, [
16]). Broadly speaking, the
p-value of the KS test indicates to what extent two samples can be considered to be drawn from the same distribution—a high
p-value indicates a good agreement. It is sensitive to differences in both shape and location of the empirical distribution functions of the two samples. A KS test comparison between two catalogs would compare the distributions of all available estimates of one of the planetary properties mentioned above. If a specific object’s quantity is unavailable, we excluded the object from the comparison pertaining to this property. In cases where only lower/upper bounds were available, we set it to the listed value instead of excluding it. Thus, there were some cases in which two catalogs agreed on the planetary nature of a specific object, yet, since one of the catalogs had a missing value for some property, we excluded this planet from the test.
For each pair of catalogs, ‘
A’ and ‘
B’
, we compiled three subsets: (1) The
overlap subset, including all objects listed in both catalogs; (2) the
unique ‘
A’ subset, including only the planets that are unique to catalog ‘
A’ and not listed in catalog ‘
B’; and (3) the
unique ‘B’ subset, including only the planets that are unique to catalog ‘
B’ and not listed in catalog ‘
A’. We then applied the KS test to compare the three subsets. We performed this analysis for each one of the six parameters separately, as well as a comparison of subsets that include information about the planetary mass, radius and orbital period.
Figure 1 describes the methodology applied to compare the different catalogs.
A problem we often encountered in our analysis is the possibility of different planet names and aliases listed in each of the catalogs. The differences are typically caused by spaces, uppercase/lowercase mix-up, and numbers or unique symbols that are used in spelling the stellar and planet names. Yet, in most cases, we found a given object to have two different names in two different catalogs. To overcome this difficulty, we first cross-matched the different objects according to their stellar names using the SIMBAD database, and then identified the different planetary names that populate each system. This practice imparted us with the following unfortunate conclusion: Currently, there is no consensus on an unambiguous method to mark a specific planet and to find its aliases in a convenient way. Therefore, there is no reliable way to cross-match two planetary tables.
3. Results
In general, we found the distributions of planets and systems from the different catalogs to be quite similar. An exception was the ORG catalog, where its missing planetary mass values were derived from some theoretical mass–radius (M–R) relation. See
Appendix A for the detailed and complete analysis with the quantitative results (
Table A1 and
Table A8;
Figure A1 and
Figure A7). To infer the differences between the catalogs, we compared the derived populations of the
overlap and unique subsets for two catalogs at a time, as discussed above. We found the distributions of the
overlapping planets between the different catalogs to be similar. However, there were significant differences between the
overlap and unique subsets. In
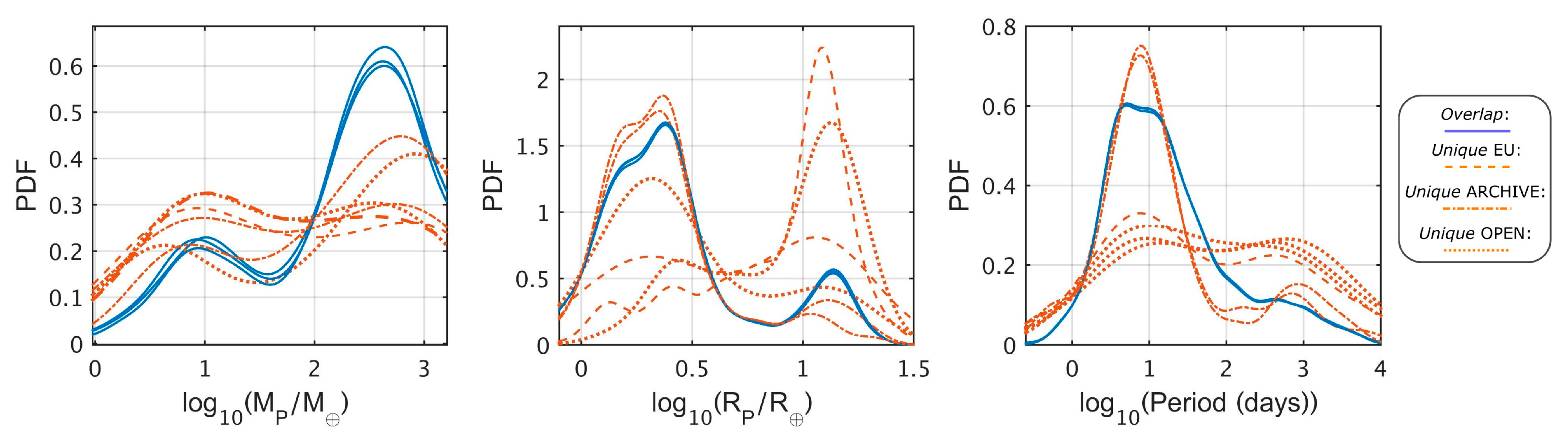
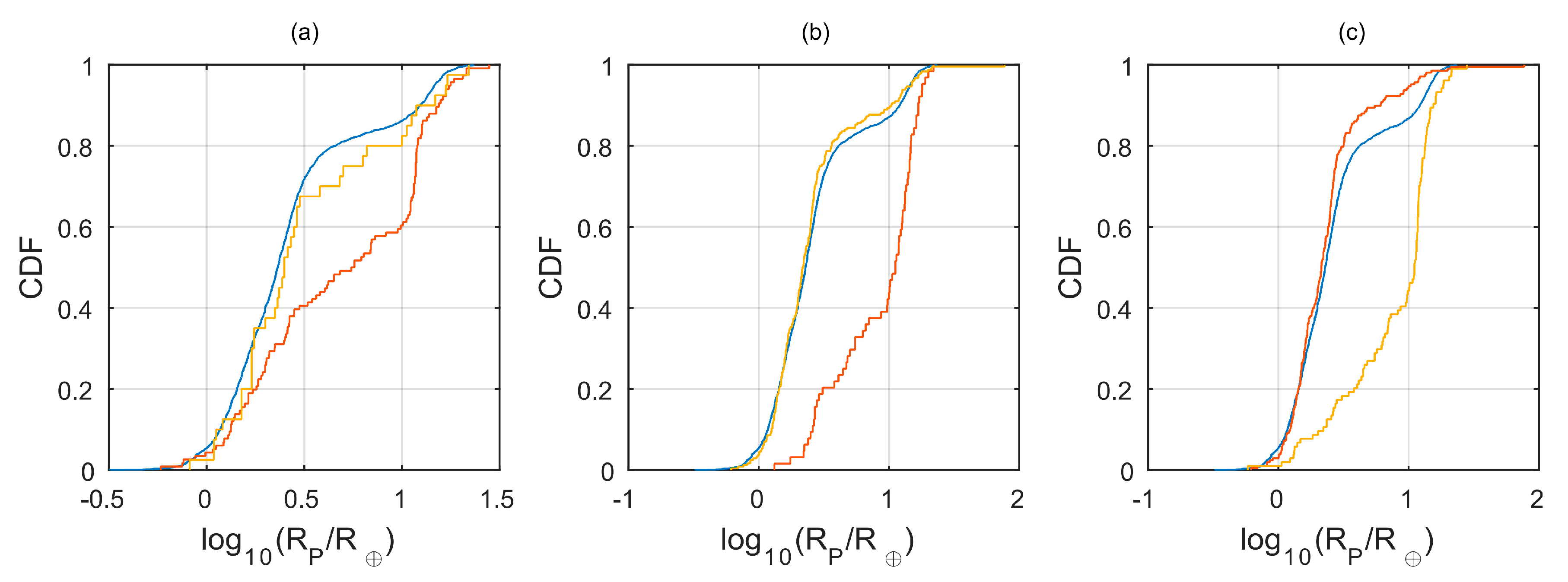
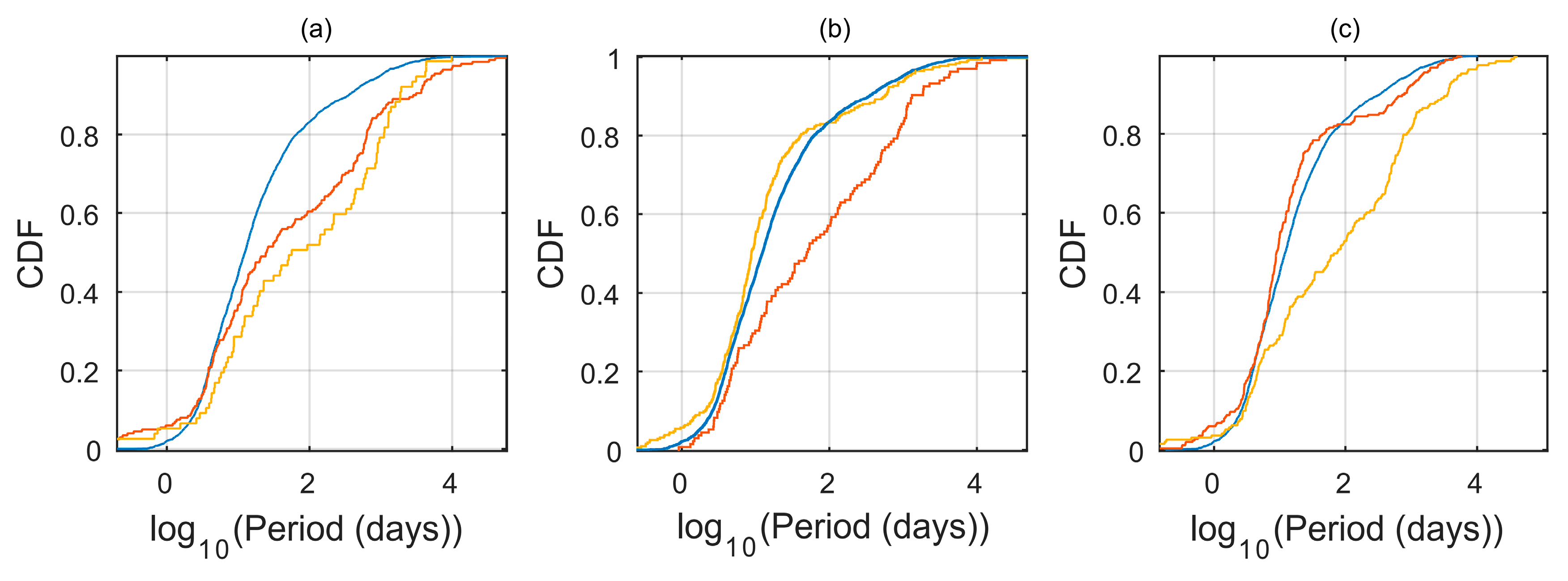
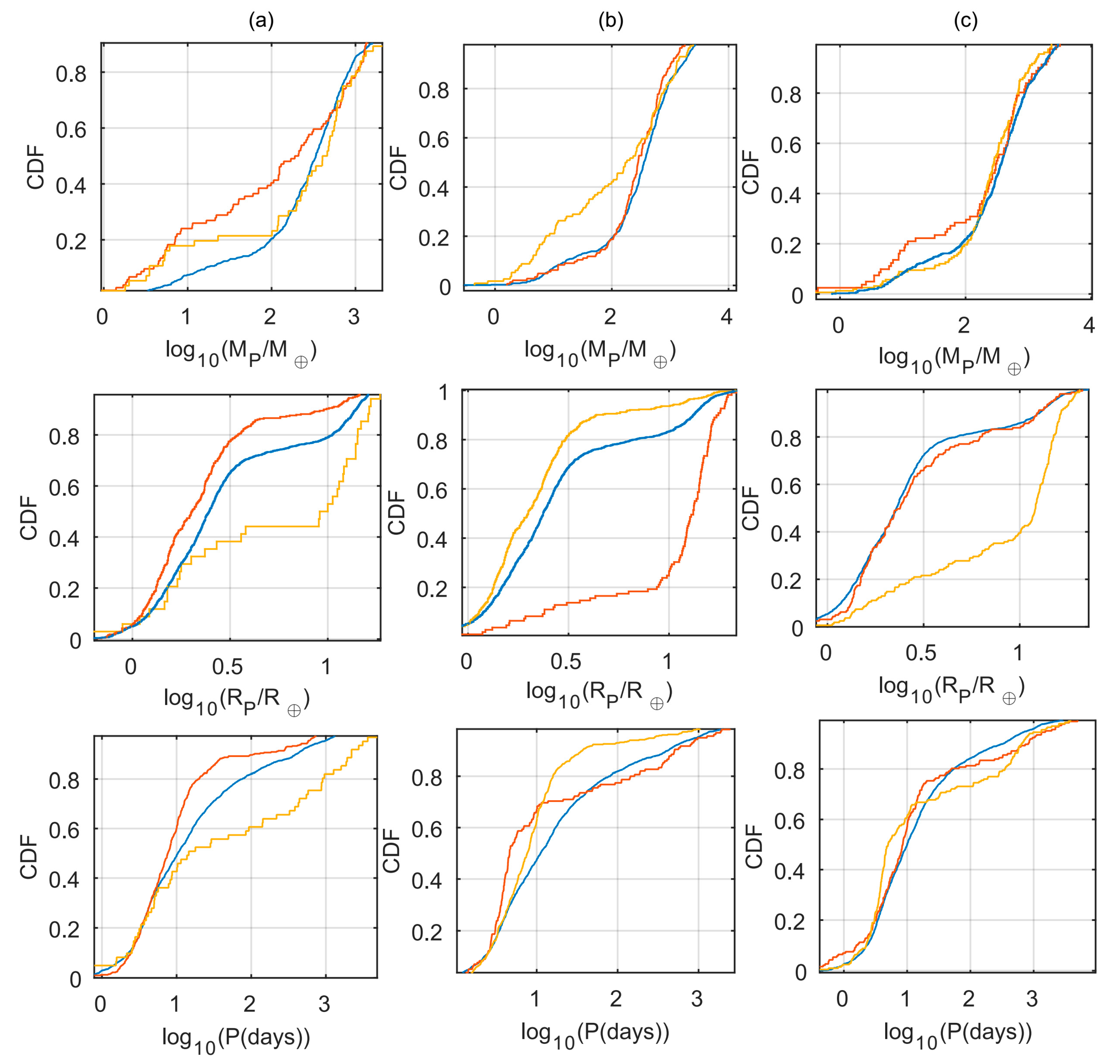
Figure 2, a kernel density estimation (KDE) [
17] for the probability density functions (PDF) of the mass, radius and orbital period for the different subsets is given. The solid blue curves represent the three
overlap subsets when comparing each pair of the EU-ARCHIVE-OPEN catalogs. The brown curves represent the unique subsets, where the dashed, dashed-dotted and dotted curves correspond to the unique EU, ARCHIVE and OPEN subsets, respectively. Evidently, the
overlap and unique subsets seem to have very different distributions for the three planet properties.
Table 3 presents the KS tests p-values for the different comparisons between KS tests. We found a low p-value for most comparison tests.
As for the property of planetary mass, we noted that a higher density of small mass planets (
) populate the unique subsets. We found most of these planets to be TTV planets, detected in multi-planetary systems. Usually, the mass of a planet detected through TTV is not resolved directly, and in practice, is degenerate with the planet
’s eccentric orbit [
18]. As a result, we have many small TTV planets with an upper mass limit, rather than a nominal value. However, there is no uniform approach to displaying this mass limit. At times, the catalogs choose to omit the value altogether, while at other times it is displayed as an upper limit. However, in many cases, especially with the EU catalog, the mass limit is reported as a valid nominal estimate. Due to this difference in the mass property criteria, we found many small mass planets biasing the unique subset towards smaller masses.
For the planet radii and orbital period distributions, we found the EU and OPEN unique subsets to have a relative higher density of planets in radii values of , and periods of . Examining the planets that comprise these subsets suggests the reason for this difference is probably related to the different inclusion criteria the catalogs use. Some examples are: Listed planets where the confirmation paper has used some theoretical M–R relations to infer the planetary radius (or mass), some unusual large radii planets suffering strong tidal forces due to their proximity to the parent stars (in short periods), planets with ‘strange’ transiting light curves that make the planetary detection more controversial, etc. As for the higher consistency, in terms of the overlap and unique parts of the ARCHIVE catalog, we found it to be somewhat artificial. By examining the ARCHIVE unique planets, we found over 75% of them to be K2 planets, suggesting the reason for the good agreement with the overlap subsets related to the simple fact: Most of the overlap planets are transiting planets (Kepler and K2), with similar properties as the K2 planets.
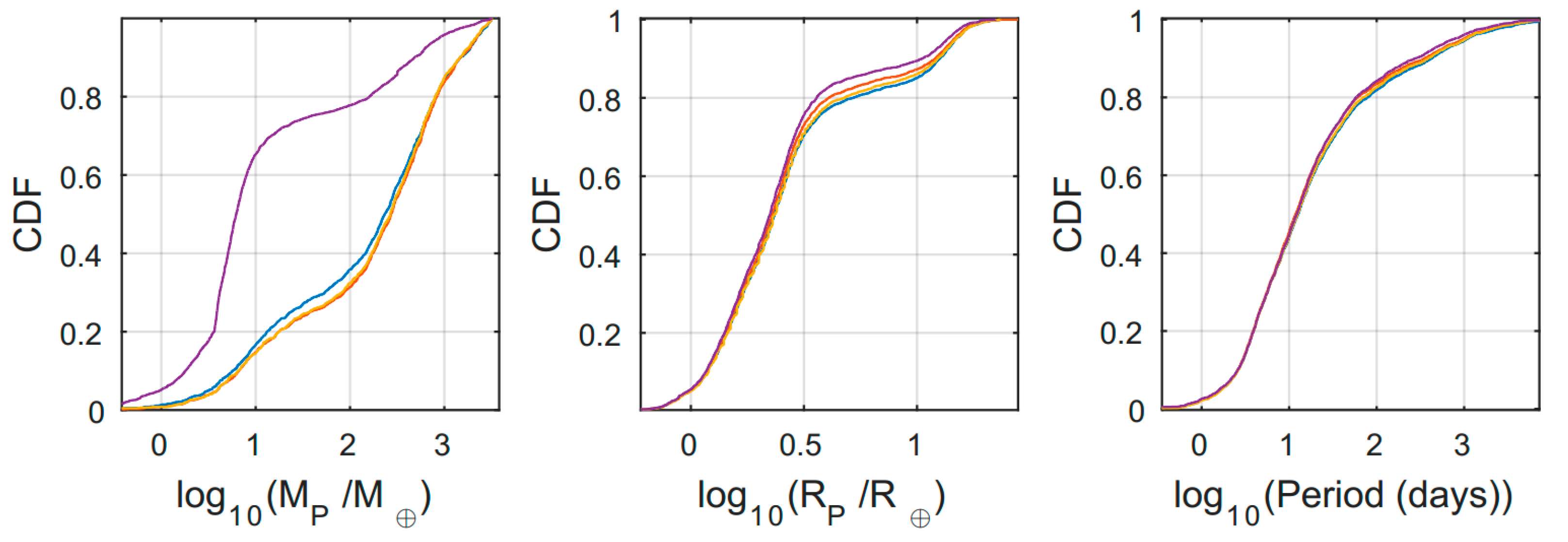
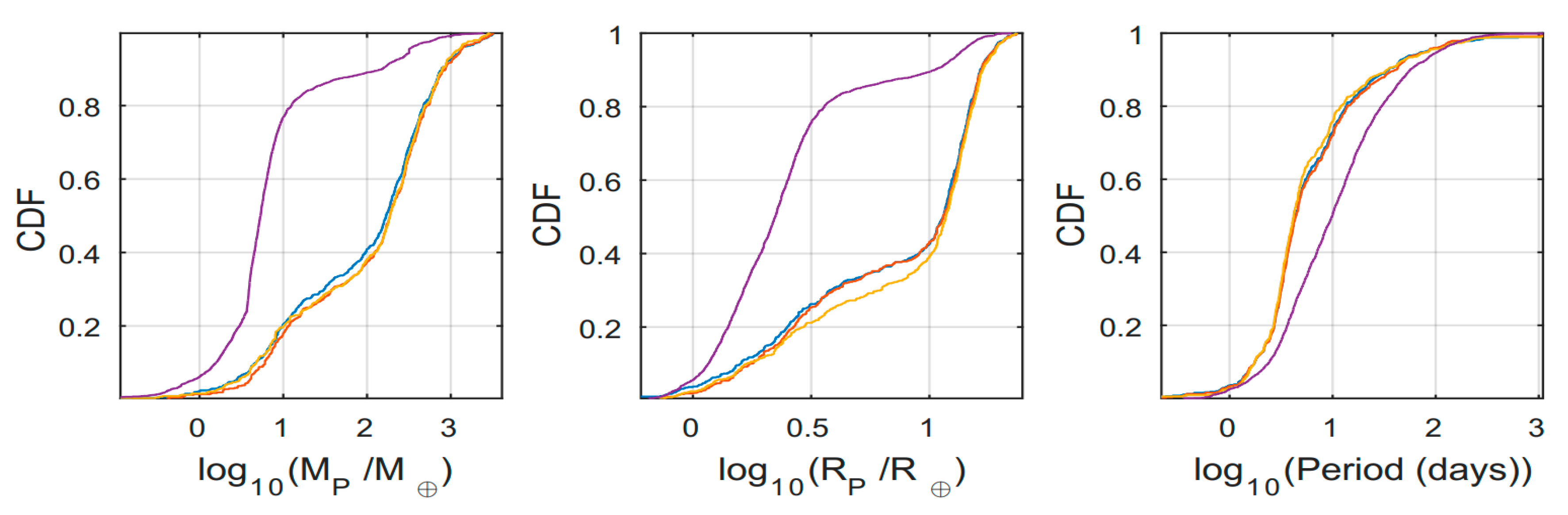
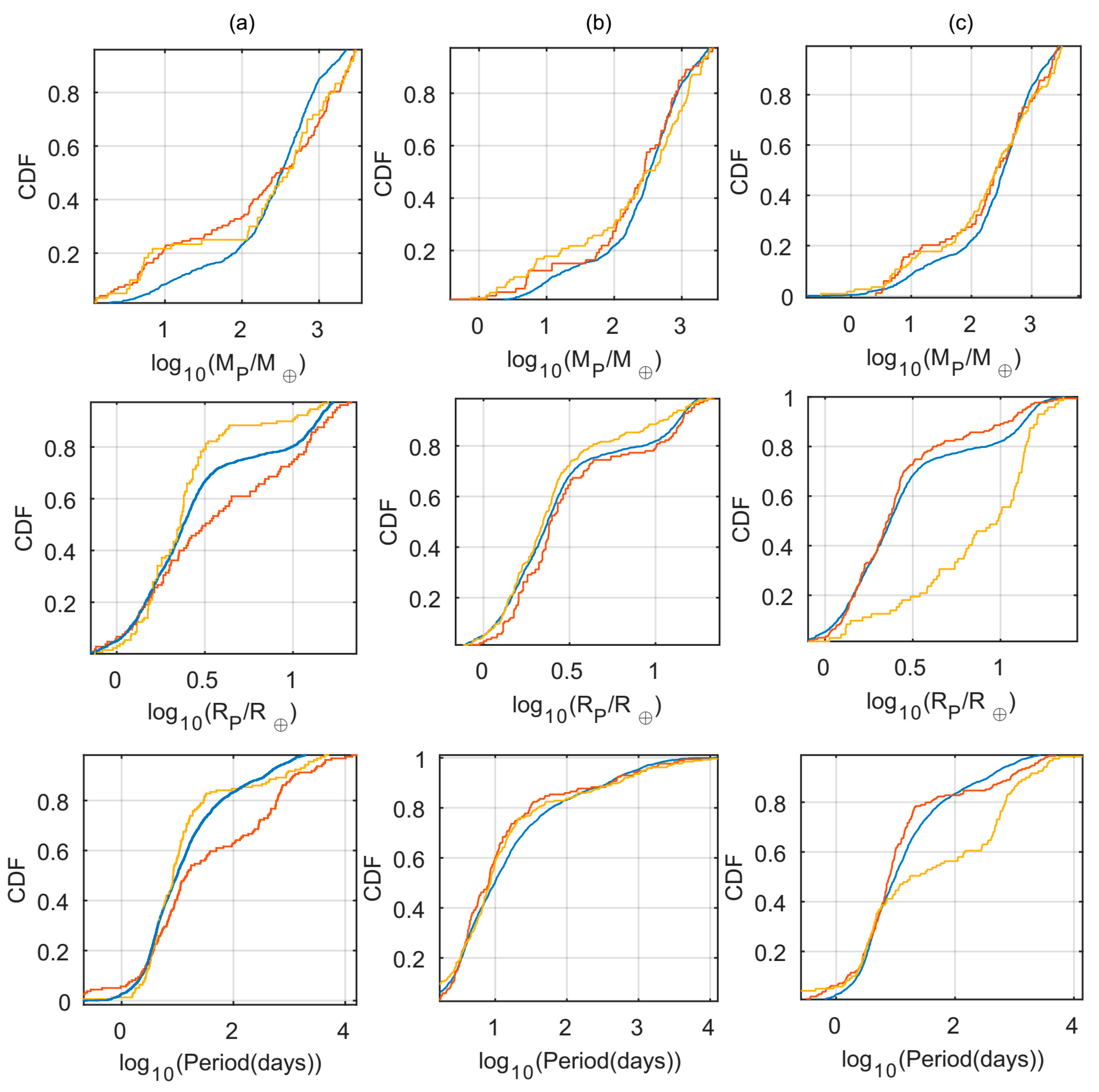
Performing a similar analysis for the subset of planets in which all three properties of planetary mass, radius and orbital period were available, we found the unique and overlap subsets were different again (
Figure 3), although having slightly higher p-values (
Table 4) than the individual property comparisons presented above.
In this case, most of the
overlap planets had large masses and radii, with short periods. This in itself is a bias, caused by the combined sensitivity of the RV and transit detection methods [
19]. As for the distributions of the
unique subsets, we found them to be compromised by a higher number of TTV-detected planets, causing the distributions to be almost uniform in the regime of both small and large planets. Another interesting aspect we observed about these
unique subsets was their relative similarity between each other, as displayed quantitative in
Table A10 displaying the unique subsets
p-values. In spite of this relative similarity, these subsets populate different planets, causing this resemblance to be a product of the TTV biases in the catalogs planet mass inclusion criteria.
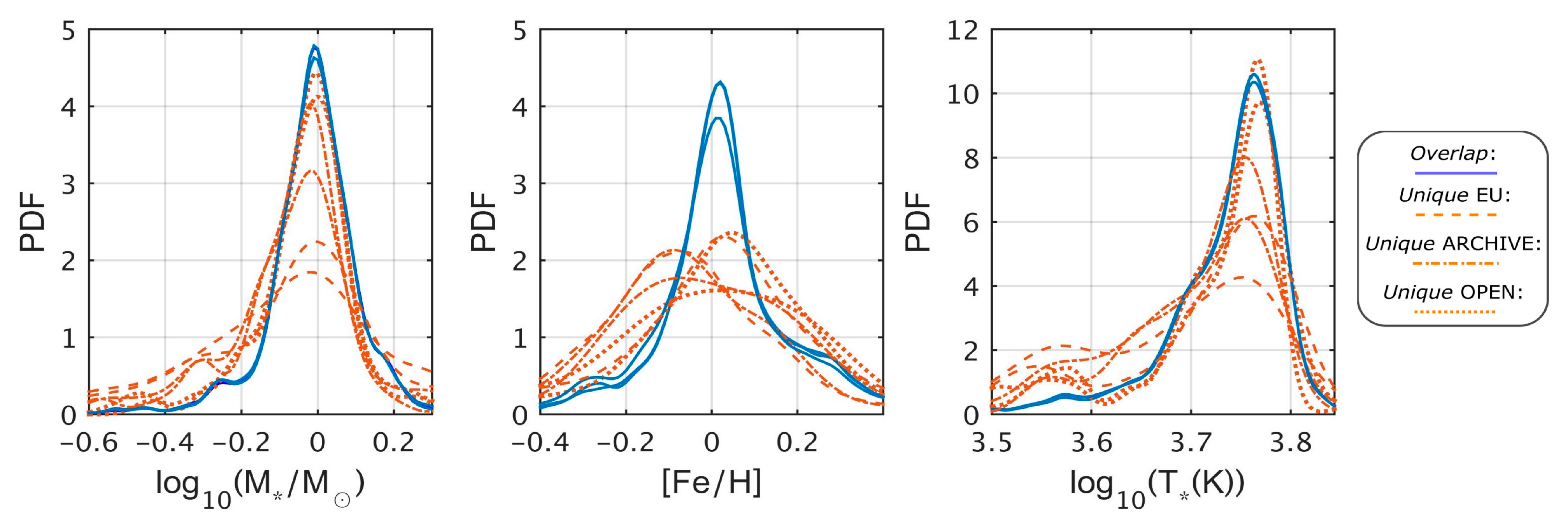
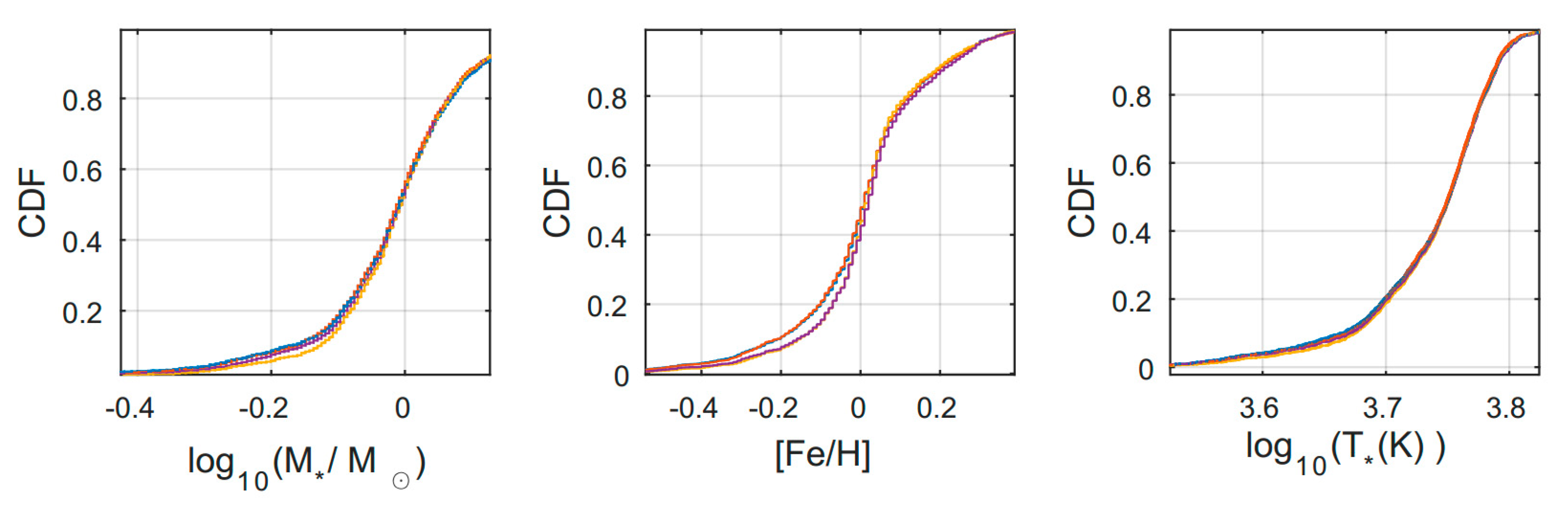
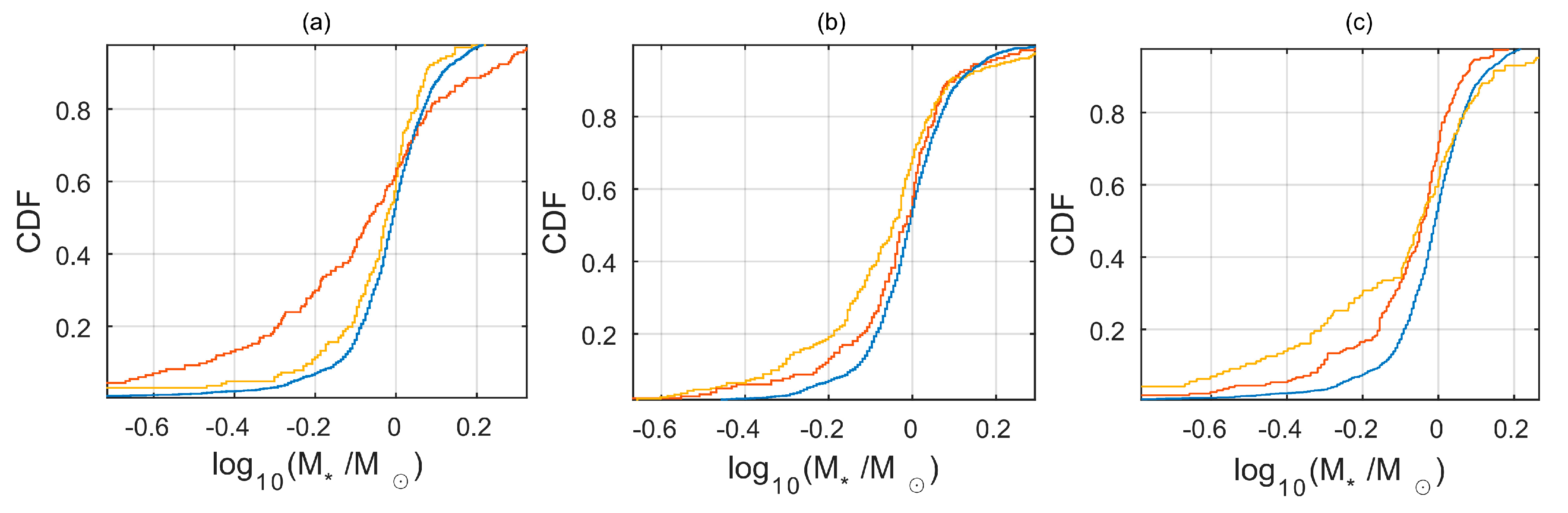
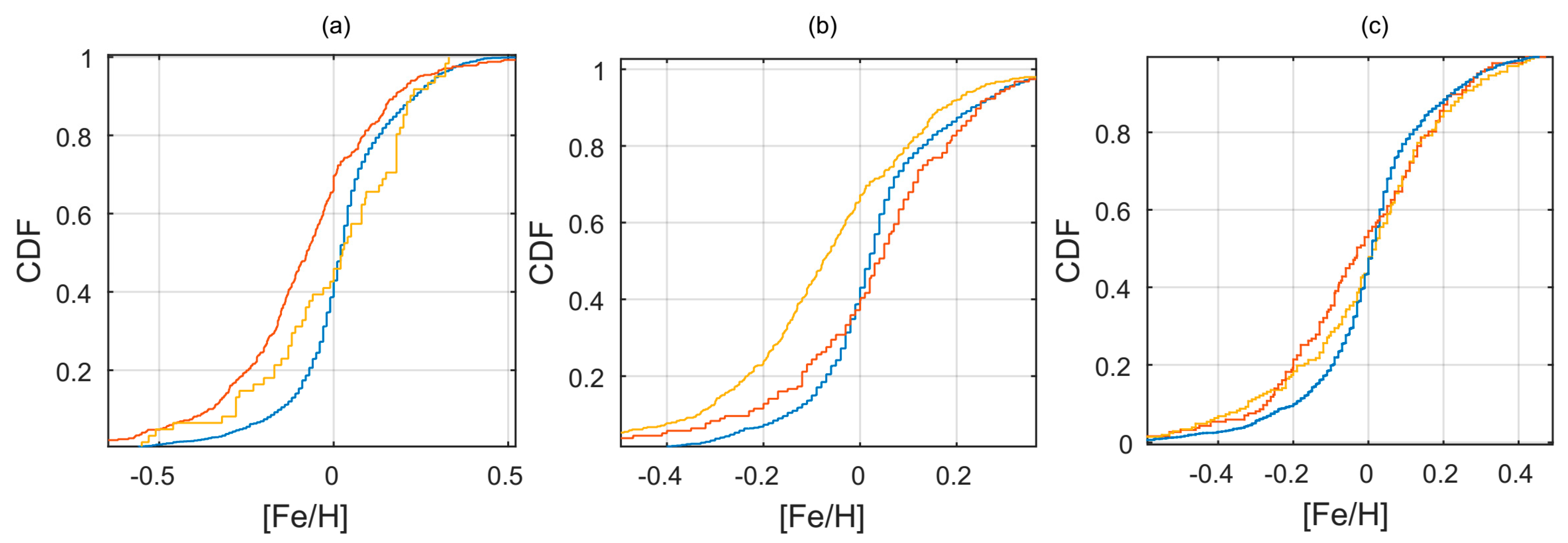
After examining the planetary systems according to the stellar properties, we again found similarity between the
overlap subsets and significant differences between the
unique to
overlap subsets (
Figure 4). We noted that the
unique distributions of stellar mass and surface temperature were biased towards smaller mass and lower temperature stars (K, M-stars). Spectroscopy of small stars (especially M-stars) is challenging because of their intrinsic faintness and high activity [
20]. As a result, detection of planets around these stars is purportedly more difficult and somewhat controversial, thus explaining why we found a higher relative number of these objects in the
unique subsets. As for the stellar metallicity, we found it to be an unreliable property when analyzing possible biases in the catalog comparison. Although the metallicity is an important property, providing an early record of the chemical composition of the initial protoplanetary disk [
21], the planetary detection methods do not rely on this property directly. The catalogs usually reported this property with high relative errors, probably linked to the imprecise derivation that is used to determine the metallicity value. Adding to this the fact that each catalog referred to different stellar survey sources, we found the highest inconsistency between catalogs to be in this parameter (when compared with the other stellar and planetary properties). Nevertheless, we still found the following trends: The
unique subsets that included larger planets, especially in terms of the OPEN catalog, was biased towards higher metallicity values, as expected from previous studies [
22,
23]. On the other hand, small planets, especially listed in the unique ARCHIVE catalog, had a wider distribution of metallicities [
24]. As before, the
p-values for the different KS tests of stellar properties in the
overlap vs.
unique subsets are provided in
Table 5. The seemingly improved mean
p-value results of the OPEN catalog are caused by its relative smaller number of listed stellar property objects.
Although it would be reasonable to detect most biases in the exoplanets catalogs in the extreme ends of the examined distributions, the analysis we have presented used a quantitative approach to study the biases the catalogs possess. We conclude that the biases in the catalogs are caused by: Some missing or obsolete information about a planets’ properties (e.g., the system of ‘
Kepler 53 b,c’ is labeled in the ARCHIVE catalog with main planetary masses of
<
and
<
, for planets ‘
b’, ‘
c’ respectively [
25], however a later paper [
26] finds the masses to be much smaller
,
, respectively, as listed in both EU and OPEN); model dependent planetary information based on some theoretical assumption and not a direct measurement (e.g., ‘
Kepler-446 b,c,d’: Both EU and OPEN display their mass property, however, according to the reference article [
27], the given value is only a coarse estimate for the planets’ masses and expected RV semi-amplitude signatures using recent empirically-measured data); roughly estimated measurements, which is especially relevant for stellar parameters; or approximated upper limits as the nominal value (e.g., ‘
Kepler-114 c’ is a TTV detected mass planet. The EU catalog displays its mass to be
[
26]. However, since this measurement is an upper limit, we find it to be inconsistent with the nominal measurement the ARCHIVE displays of
[
28], while the OPEN catalog does not include this planet).
4. Summary & Discussion
Our analysis suggests that, although the main exoplanet catalogs overlap significantly, which results in similar distributions for most astrophysical parameters, the small discrepancies between the subsets highlight some of the catalogs’ biases. These biases can best be seen in the extreme ends of the examined distributions of small mass, long orbital period planets or small stars (less than our sun). These biases do not only result from different numbers of confirmed planets in each catalog, but mainly from contributing factors, related to the data collection policy of each catalog, such as: The process each catalog uses to present and collect the properties of a specific planet, the decision whether to include a controversial object as a planet, or the routine maintenance each catalog team performs to its current listed planets.
Furthermore, in our analysis, we excluded planets with masses larger than . However the different catalogs use different mass boundaries, which also adds to their different biases. Unfortunately, most of the biases we found are due to the use of various subjective criteria in compiling and maintaining the database. Although all catalogs usually include in their database planets announced in peer-reviewed publications, this should not be the only criterion for a confirmed planet. We suggest that the explosive growth in the known planet population in recent years once again highlights the need for a more rigorous and objective mechanism to tag planets as confirmed. The differences among the catalogs demonstrate that there are conflicting views in the community regarding such criteria. The International Astronomical Union (IAU) is an objective and well-accepted authority by the community, and we therefore suggest that a central catalog could be maintained by Division F (Planetary Systems and Bio-astronomy) of the IAU, and specifically its Commission F2 (Exoplanets and the Solar Systems). Discussions within the commission should resolve the various differences and arrive at a system that can be agreed upon.
After performing this analysis and scrutinizing the different calculated biases, we can carefully make the following statements:
The ARCHIVE catalog is the most up-to-date catalog, with recent Kepler and K2 planet discoveries. It is also the least biased catalog in terms of the interpretation of the mass upper limit, being the true value or the adoption of a model-based value instead of a genuine measurement. Another interesting feature the catalog has is a list of “removed targets” displaying objects that had been listed in the catalog but were removed, suggesting a more rigorous process applied by the ARCHIVE team.
The EU catalog is less restrictive when listing the planetary properties, and therefore could include imprecise estimates. The EU catalog differs the most with the overlap subsets, probably due to its more permissive acceptance criteria and the use of mixed sources of information. However, it has the most wide and large coverage of planets.
The OPEN catalog is somewhere in the middle, between ARCHIVE and EU. In some cases, we find that it resembles the EU subsets, while in others the ARCHIVE. This might not be surprising, given that this catalog is an open-source catalog which is managed and updated by the astronomical community. Although its interface is elegant and user friendly, it has its drawbacks, especially the lack of detection reference and a smaller planet population.
Finally, while each catalog suffers biases, for an exostatistics work, there should not be too much difference among the databases, since the planet population (especially the one compared in this work) is large enough to wash out the small biases and discrepancies. Nevertheless, we find the fusion of catalogs (the
overlap subset) a powerful tool as a starting point for increasing the reliability of exostatistics research. A promising platform seems to be the Data & Analysis Center for Exoplanets (DACE) database (
https://dace.unige.ch), which includes a linked table to commonly-used exoplanet catalogs. DACE offers an accessible option to check the properties of a specific planet listed in different catalogs, and to compare its properties as they are displayed on the catalogs.
Besides a careful and detailed inspection of each exoplanet related paper confirmation, other useful techniques that can be used to increase the confidence of some exoplanet databases is to check other related parameters such as: Discovery date and update times, which can solve issues of “catch-up” times between catalogs and the rate by which they upload new exoplanets; a measure of the velocity semi-amplitude K parameter can suggest the mass measurement is truly deduced from a RV measurement and not derived from some theoretical model; a TTV flag with reported eccentricity parameter can suggest the reported mass measurement is probably not an upper limit, but some nominal value.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














