
Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest



Abstract
1. Introduction
2. Study Area
Municipality of San Ignacio De Velasco
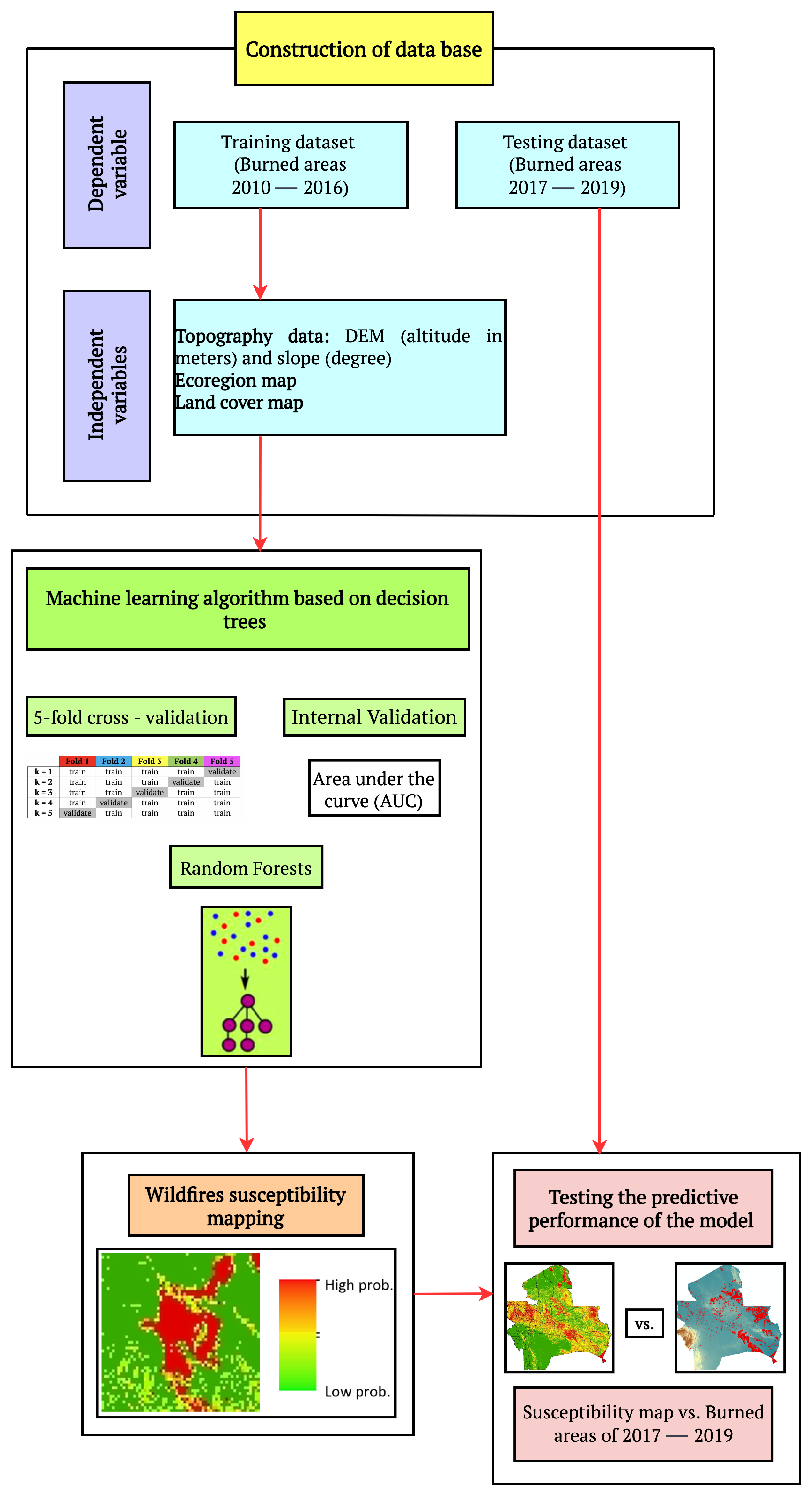
3. Materials and Methods
- Implementation of the database, including: (i) the dependent variable (i.e., the burned areas derived by MODIS product); (ii) the independent variables (based on the topographical, ecological, and land cover/vegetation).
- Implementation of an ML approach, using RF and five equal-size folds for the validation procedure, allowing to maximize the spatial generalization of the predictions.
- Elaboration of the wildfire susceptibility maps, based of the probabilistic outputs resulting from RF, and assessment of the variable importance ranking.
- Validation of the performances of the model performed by estimating the Area under the Receiver Operating Characteristic (ROC) curve (AUC), and computed considering the temporal splitting of the original dataset into training (2010–2016) and testing (2017–2019).
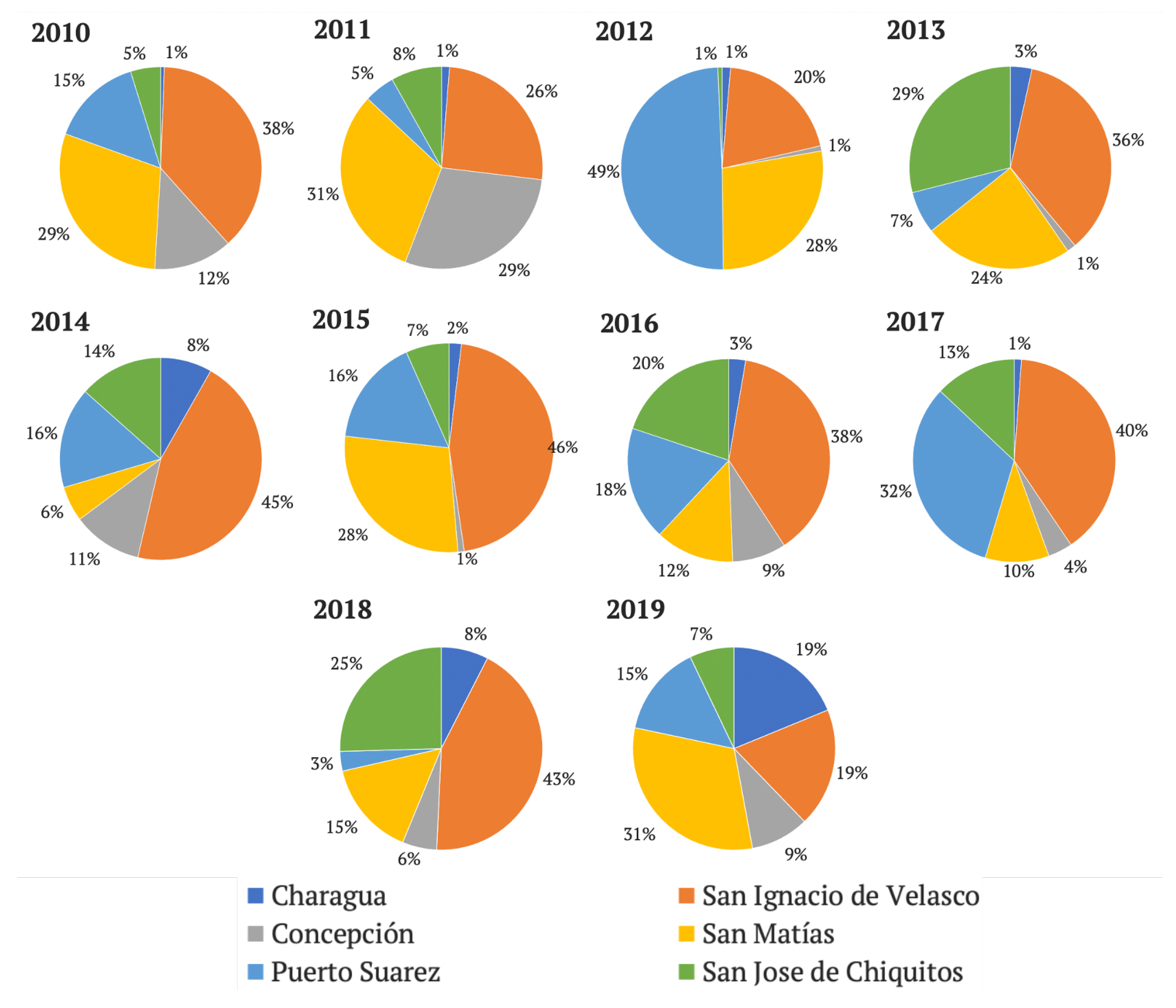
3.1. Dependent Variable: Burned Areas
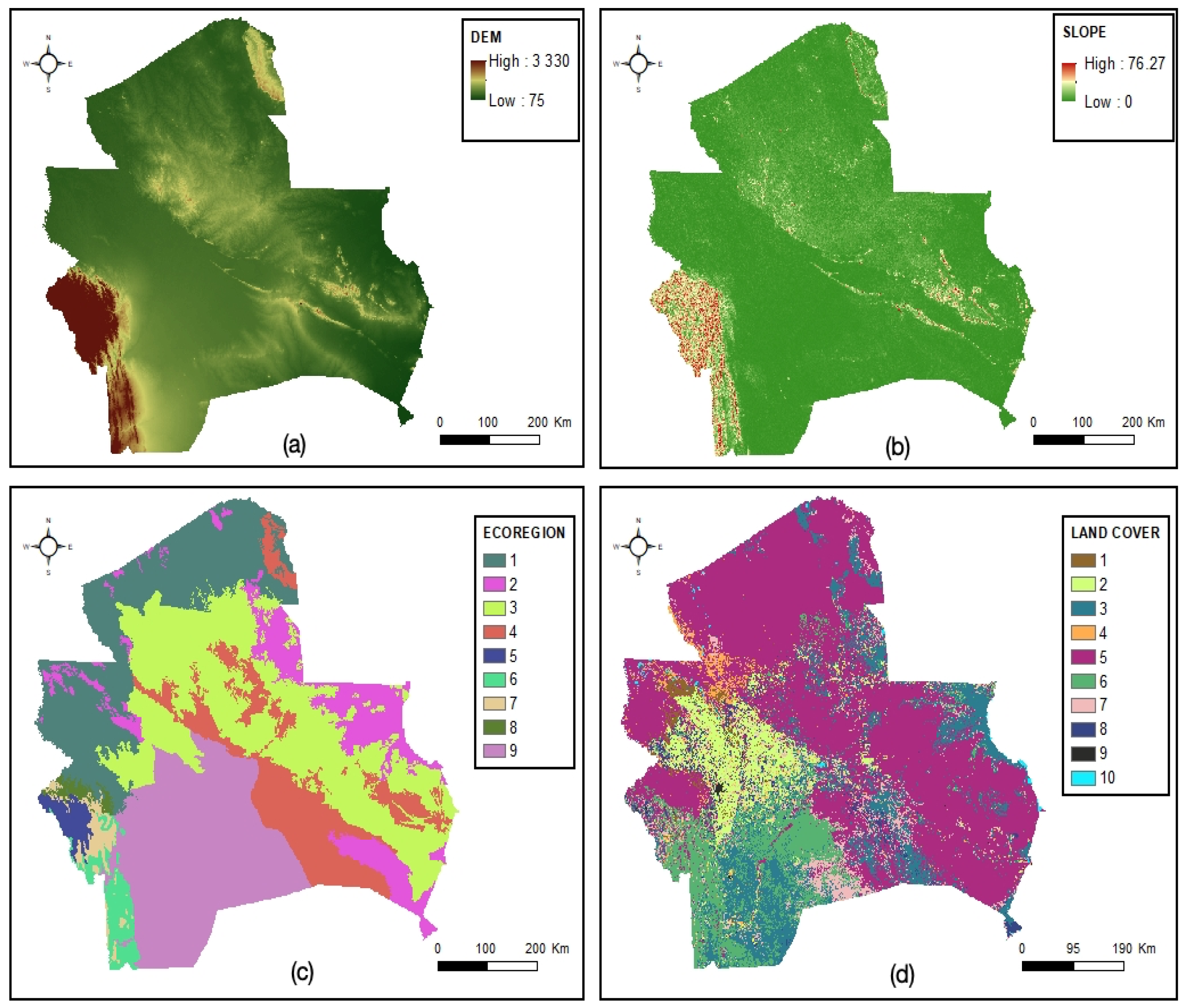
3.2. Independent Variables: Predisposing Factors
3.2.1. Topographic Conditions: Altitude and Slope
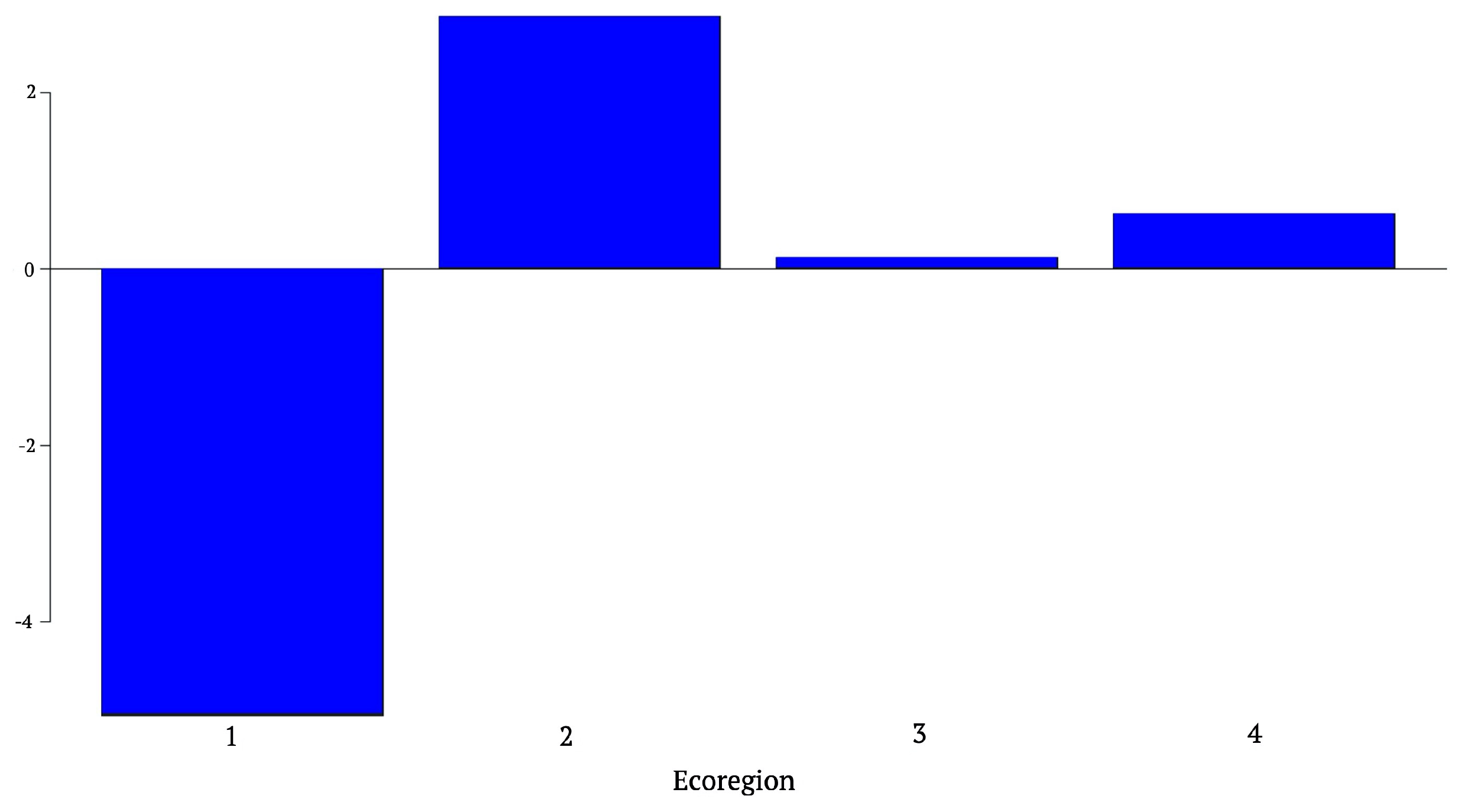
3.2.2. Ecological Conditions: Ecoregions
- Yungas (also called humid forest): a cloud forest located between 1000 and 3300 m.a.s.l., where permanent moisture is supplied by cloud drizzle and rainfall brought from the Amazon basin by the easterlies. The beta diversity of this ecosystem is the highest in Bolivia.
- Bolivian Tucuman forest: located between 300 and 3300 m.a.s.l. In this ecoregion, the minimum annual temperature range is lower than in Yungas because of the influence of cold southerly winds, called "surazos". The vegetation cover is dense, including trees more than 15 m tall.
- Southwestern Amazon forest: located between 150 and 500 m.a.s.l., it is composed of all the Amazon forest types. The species richness is the same as that of the moist Yungas forest. Trees are more than 45 m tall. This region has suffered from strong human pressure.
- Flooded savanna: located between 100 and 200 m.a.s.l., it is in fact a seasonally flooded savanna due to the numerous rivers from the Andes that flow through the Amazon lowlands.
- Gran Chaco (also called dry forest): located between 200 and 600 m.a.s.l. It has the lowest mean annual precipitation (795 mm), a mean annual temperature of 21.7 °C, and a maximum of 48 °C. It is among the largest and best preserved dry forests in the world.
- Chiquitano Dry forest: located in a transition zone between the moist Amazon rain forest and the Gran Chaco dry forest, at an altitude between 100 and 1400 m.a.s.l. It is endemic to Bolivia, highly biodiverse, and it has been extremely affected by wildfires in recent years.
- Dry Inter-Andean forest: located between 500 and 3300 m.a.s.l., and includes patches of dry forest alternated with Yungas forest and deep inaccessible valleys. Due to its topographical specificity, this ecosystem is characterized by a variety of endemic species.
- Chaco Serrano: is dominated by the horco-quebracho (Schinopsis hanckeana) along with the drinking molle (Lithrea molleoides), especially in the south, and by a large number of cacti and spiny legumes in the north. At higher altitudes, the forest is replaced by grasslands or gramineous steppes with a predominance of species of the genus Stipa and Festuca.
- Cerrado: a wide range of climatic conditions exists across the Cerrado ecoregion. Precipitations are between 1000 and 2000 mm per year, with a pronounced dry season from April to September, and mean annual temperatures ranging from 16 °C to 25 °C. This ecoregion is characterized by an enormous biodiversity of plants and animals that is progressively threatened by the expansion of agriculture and the burning of vegetation to make charcoal.
3.2.3. Landscape Features: Land Cover
3.3. Machine Learning Approach: Random Forest
3.4. Model Validation
4. Results and Discussions
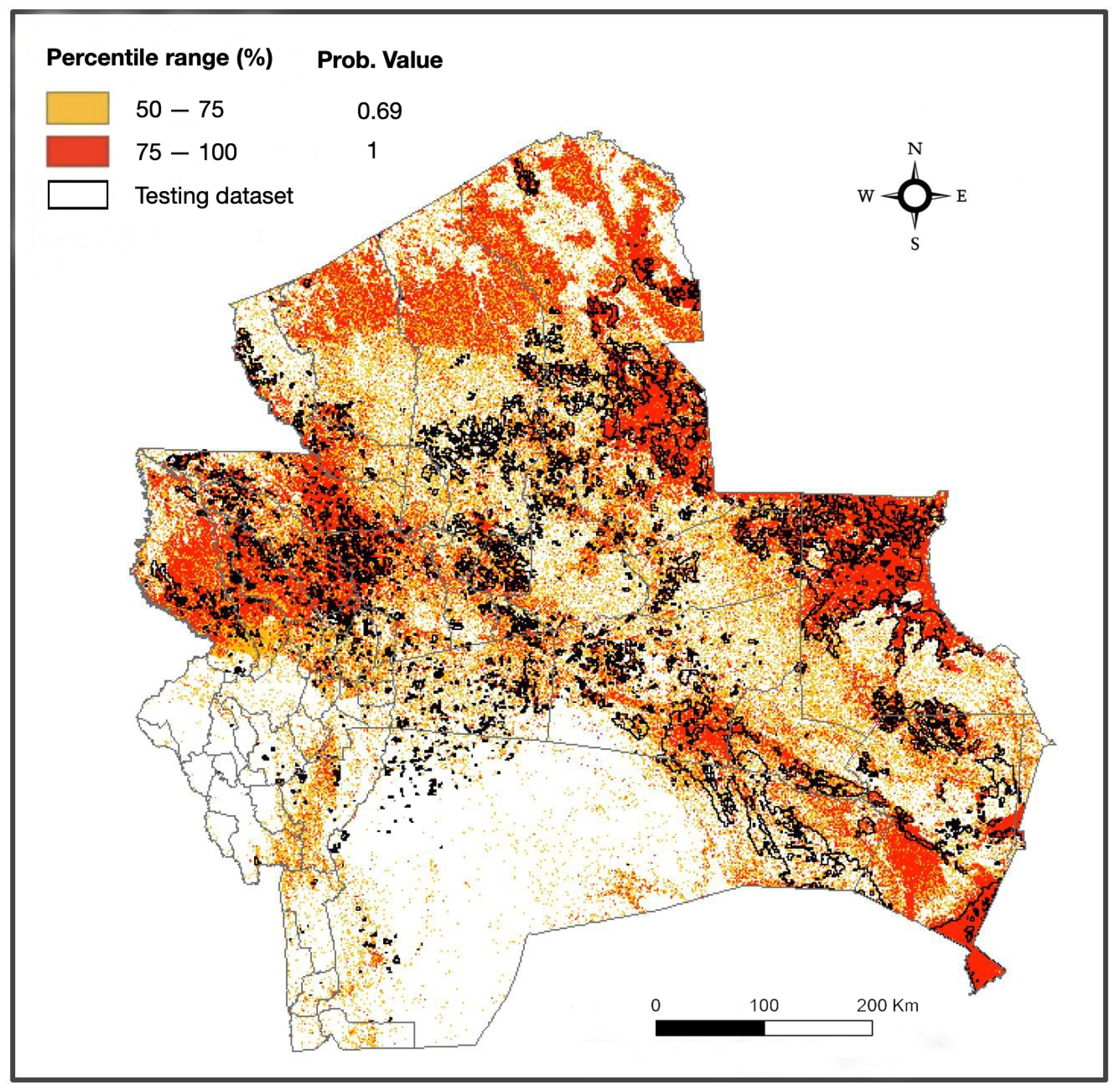
4.1. Wildfires Susceptibility Mapping in Santa Cruz
- The high rates of deforestation that occur in the different municipalities. Four out of ten municipalities with the largest deforested areas in Bolivia until 2013 are located in the Obispo Santistevan province [62]. Similarly, according with more recent data [63], the municipality of San Ignacio de Velasco in the province of José Miguel de Velasco headed the list of the 25 Bolivian municipalities with the highest levels of deforestation between 2016 and 2018.
- The presence of large livestock properties known for burning large areas to enlarge pastures and agricultural lands. For instance, in the municipality of San Matías, located in the province Ángel Sandoval and corresponding to the second area most affected by the extreme fires of 2019, 75% of the burned areas can be imputed to the farming industry [50].
- High rates of wildfires initiated in neighboring countries, close to the border. For example, the Germán Busch province, located in the Bolivian Pantanal, has large areas with very high wildfire incidence due to the spreading of fires that start in Brazil. It was indeed verified that many of the fires that affected the National Park and the Integrated Management Area Otuquis originated in Brazil and then spread up to this area [64].
- Activities linked to the urban areas. For instance, in the Sara province, one of the main causes of wildfires is uncontrolled waste burning [62].
4.1.1. Model Validation and Performance Evaluation
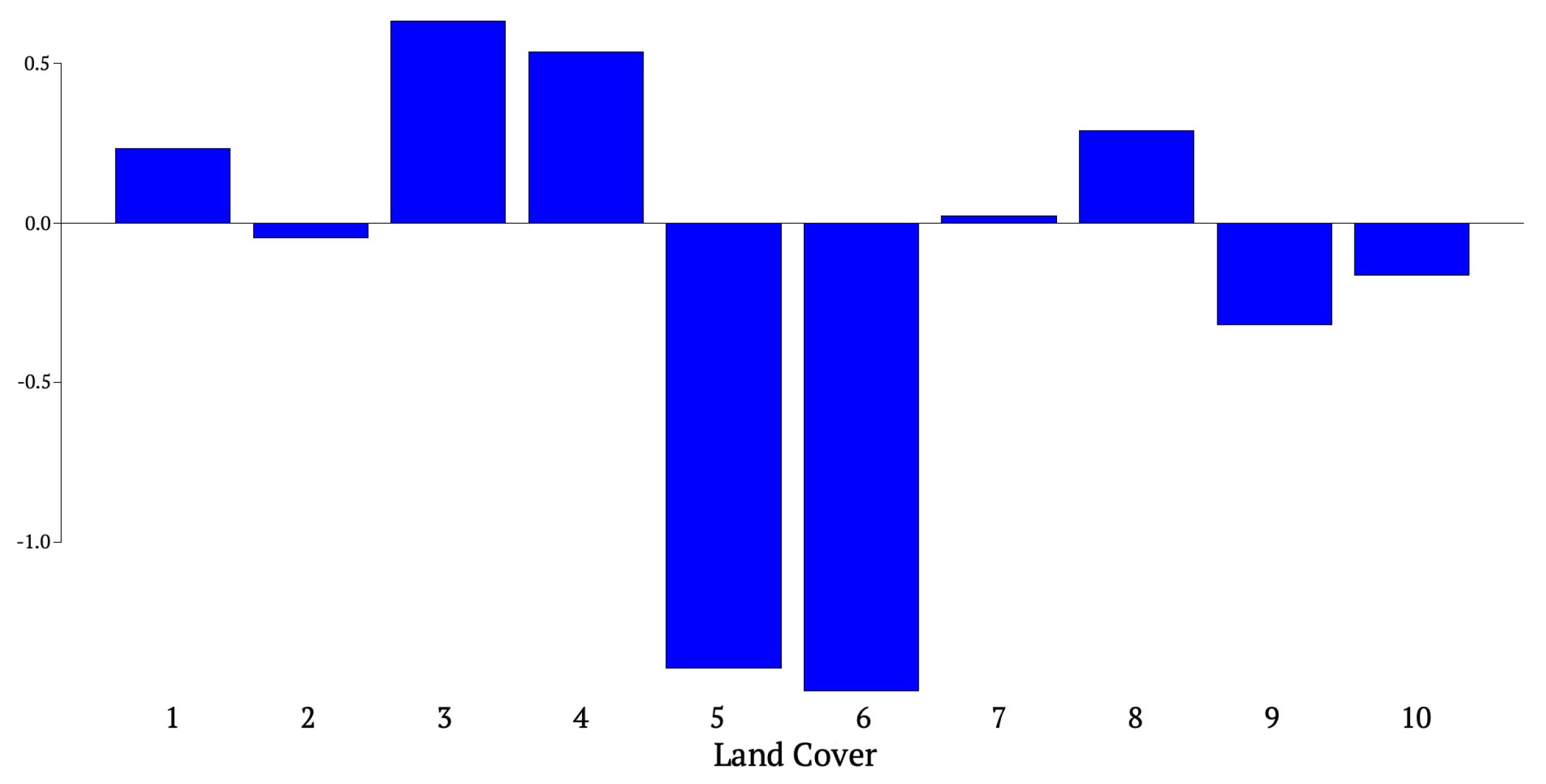
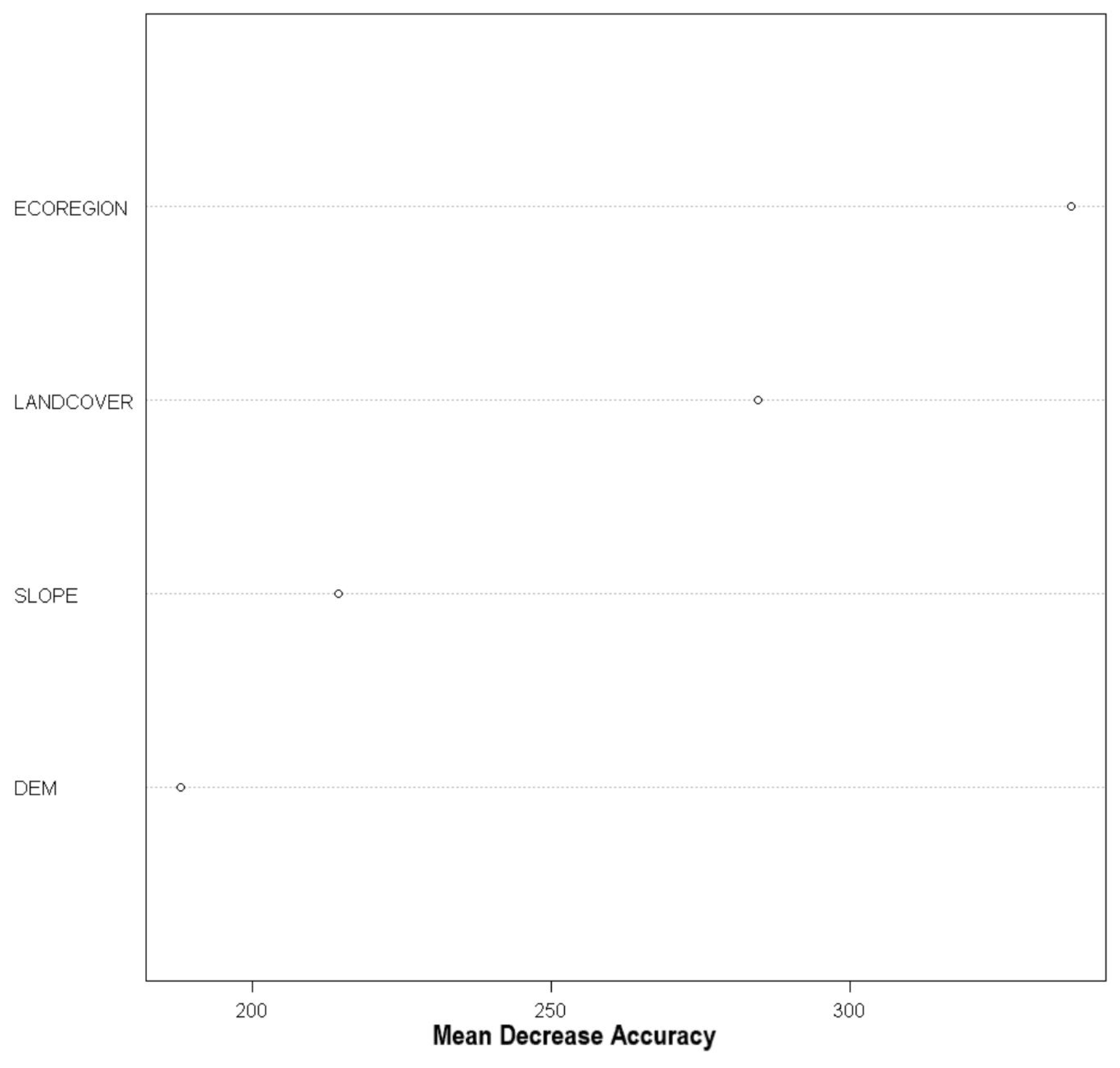
4.1.2. Variable Importance Ranking
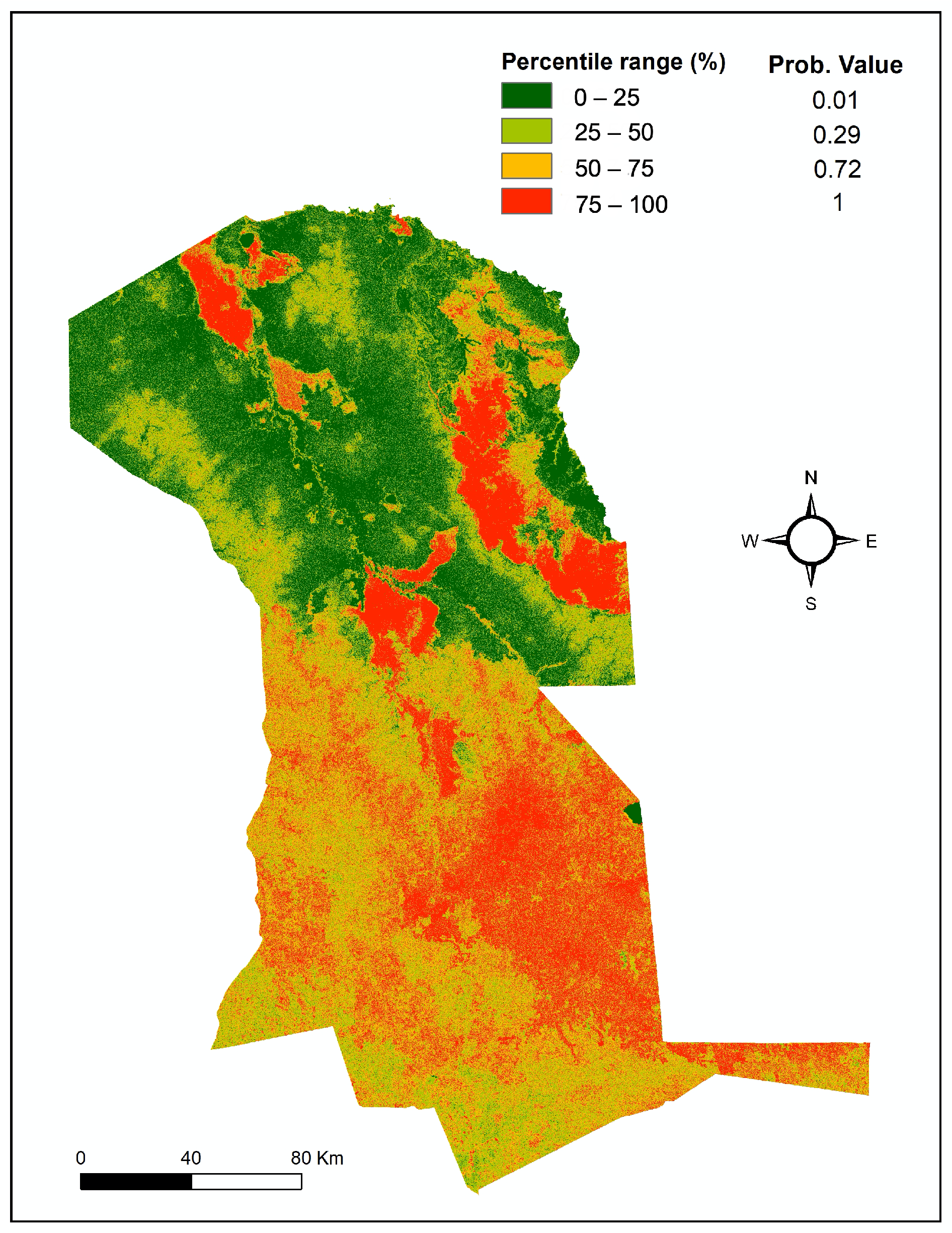
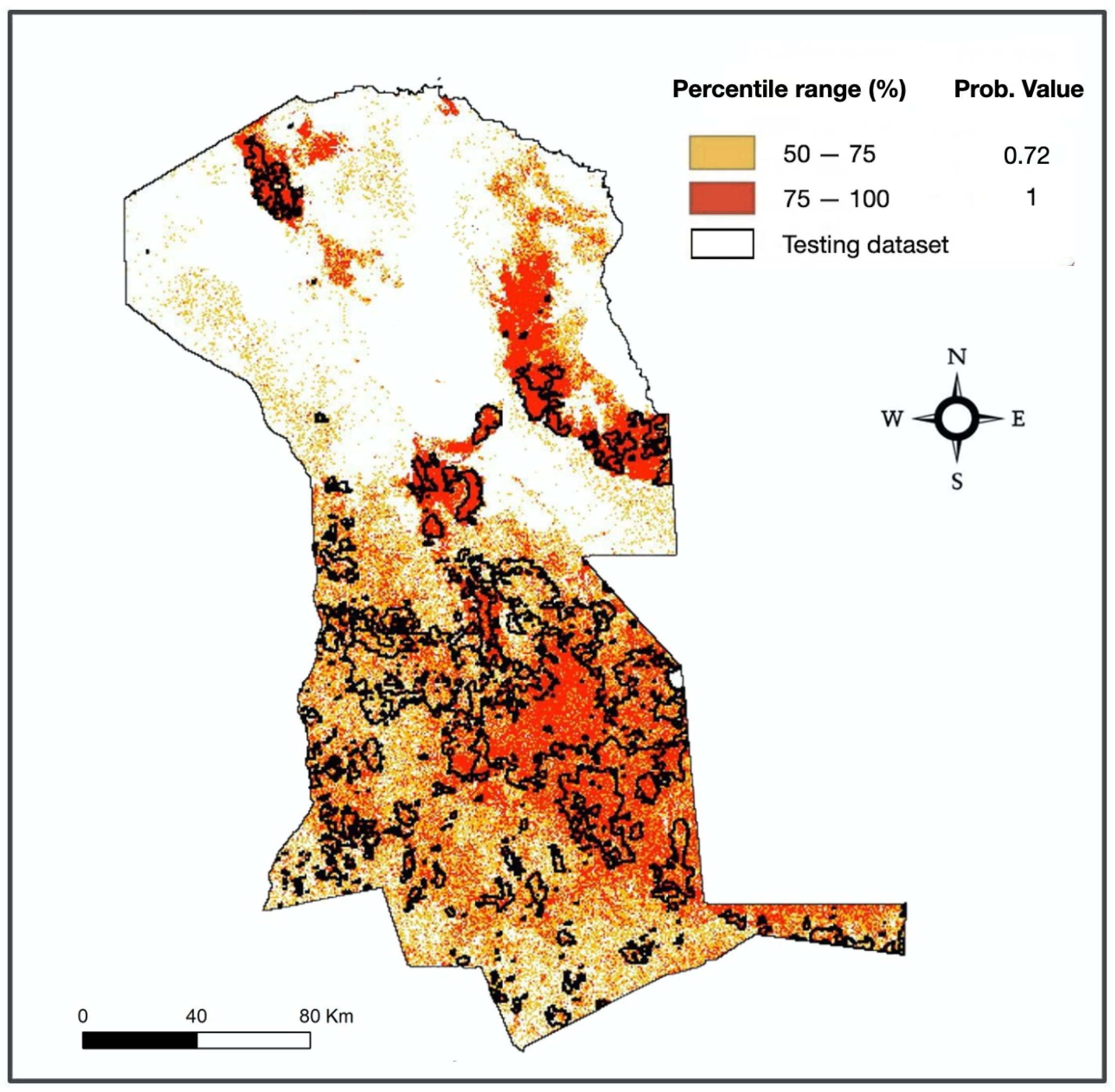
4.2. Results of the Model in San Ignacio De Velasco Municipality
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gill, A.M.; Stephens, S.L.; Cary, G.J. The worldwide “wildfire” problem. Ecol. Appl. 2013, 23, 438–454. [Google Scholar] [CrossRef]
- Thomas, D.; Butry, D.; Gilbert, S.; Webb, D.; Fung, J. The costs and losses of wildfires. NIST Spec. Publ. 2017, 1215. [Google Scholar] [CrossRef]
- Dittrich, R.; McCallum, S. How to measure the economic health cost of wildfires—A systematic review of the literature for northern America. Int. J. Wildland Fire 2020, 29, 961–973. [Google Scholar] [CrossRef]
- Flannigan, M.; Stocks, B.; Wotton, M. Climate change and forest fires. Sci. Total Environ. 2000, 262, 221–230. [Google Scholar] [CrossRef]
- Parente, J.; Pereira, M.G.; Amraoui, M.; Fischer, E.M. Heat waves in Portugal: Current regime, changes in future climate and impacts on extreme wildfires. Sci. Total Environ. 2018, 631–632, 534–549. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Kolden, C.A.; Abatzoglou, J.T.; Johnston, F.H.; van der Werf, G.R.; Flannigan, M. Vegetation fires in the Anthropocene. Nat. Rev. Earth Environ. 2020, 1, 500–515. [Google Scholar] [CrossRef]
- Viedma, O.; Moity, N.; Moreno, J.M. Changes in landscape fire-hazard during the second half of the 20th century: Agriculture abandonment and the changing role of driving factors. Agric. Ecosyst. Environ. 2015, 207, 126–140. [Google Scholar] [CrossRef]
- Tonini, M.; Parente, J.; Pereira, M.J. Global assessment of rural–urban interface in Portugal related to land cover changes. Nat. Hazards Earth Syst. Sci. 2018, 18, 1647–1664. [Google Scholar] [CrossRef]
- Carlucci, M.; Zambon, I.; Colantoni, A.; Salvati, L. Socioeconomic Development, Demographic Dynamics and Forest Fires in Italy, 1961–2017: A Time-Series Analysis. Sustainability 2019, 11, 1305. [Google Scholar] [CrossRef]
- Halofsky, J.E.; Peterson, D.L.; Harvey, B.J. Changing wildfire, changing forests: The effects of climate change on fire regimes and vegetation in the Pacific Northwest, USA. Fire Ecol. 2020, 16. [Google Scholar] [CrossRef]
- Kanga, S.; Singh, S.K. Forest Fire Simulation Modeling using Remote Sensing & GIS. Int. J. Adv. Res. Comput. Sci. 2017, 8, 326–332. [Google Scholar]
- Prieto-Herráez, D.; Asensio Sevilla, M.I.; Ferragut Canals, L.; Cascón Barbero, M.J.; Morillo Rodríguez, A. A GIS-based fire spread simulator integrating a simplified physical wildland fire model and a wind field model. Int. J. Geogr. Inf. Sci. 2017, 31, 2142–2163. [Google Scholar] [CrossRef]
- Petrasova, A.; Harmon, B.; Petras, V.; Tabrizian, P.; Mitasova, H. Wildfire Spread Simulation. In Tangible Modeling with Open Source GIS; Springer International Publishing: Cham, The Netherlands, 2018; pp. 155–163. [Google Scholar] [CrossRef]
- Trucchia, A.; D’Andrea, M.; Baghino, F.; Fiorucci, P.; Ferraris, L.; Negro, D.; Gollini, A.; Severino, M. PROPAGATOR: An Operational Cellular-Automata Based Wildfire Simulator. Fire 2020, 3, 26. [Google Scholar] [CrossRef]
- Mangiameli, M.; Mussumeci, G.; Cappello, A. Forest Fire Spreading Using Free and Open-Source GIS Technologies. Geomatics 2021, 1, 5. [Google Scholar] [CrossRef]
- Oliveira, S.; Pereira, J.; San-Miguel-Ayanz, J.; Lourenço, L. Exploring the spatial patterns of fire density in Southern Europe using Geographically Weighted Regression. Appl. Geogr. 2014, 51, 143–157. [Google Scholar] [CrossRef]
- Hernandez, C.; Keribin, C.; Drobinski, P.; Turquety, S. Statistical modelling of wildfire size and intensity: A step toward meteorological forecasting of summer extreme fire risk. Ann. Geophys. 2015, 33, 1495–1506. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Rossi, M. Forest fire susceptibility mapping in the Minudasht forests, Golestan province, Iran. Environ. Earth Sci. 2015, 73. [Google Scholar] [CrossRef]
- Parente, J.; Pereira, M. Structural fire risk: The case of Portugal. Sci. Total Environ. 2016, 573, 883–893. [Google Scholar] [CrossRef]
- Nami, M.; Jaafari, A.; Fallah, M.; Nabiuni, S. Spatial prediction of wildfire probability in the Hyrcanian ecoregion using evidential belief function model and GIS. Int. J. Environ. Sci. Technol. 2017, 15. [Google Scholar] [CrossRef]
- Eugenio, F.C.; dos Santos, A.R.; Fiedler, N.C.; Ribeiro, G.A.; da Silva, A.G.; dos Santos, Á.B.; Paneto, G.G.; Schettino, V.R. Applying GIS to develop a model for forest fire risk: A case study in Espírito Santo, Brazil. J. Environ. Manag. 2016, 173, 65–71. [Google Scholar] [CrossRef]
- Jaafari, A.; Mafi-Gholami, D.; Thai Pham, B.; Tien Bui, D. Wildfire Probability Mapping: Bivariate vs. Multivariate Statistics. Remote Sens. 2019, 11, 618. [Google Scholar] [CrossRef]
- Hong, H.; Jaafari, A.; Zenner, E. Predicting spatial patterns of wildfire susceptibility in the Huichang County, China: An integrated model to analysis of landscape indicators. Ecol. Indic. 2019, 101, 878–891. [Google Scholar] [CrossRef]
- Price, O.F.; Bedward, M. Using a statistical model of past wildfire spread to quantify and map the likelihood of fire reaching assets and prioritise fuel treatments. Int. J. Wildland Fire 2020, 29, 401–413. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117. [Google Scholar] [CrossRef]
- Rodrigues, M.; Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Bui, D.; Le, K.T.; Nguyen, V.; Le, H.; Revhaug, I. Tropical Forest Fire Susceptibility Mapping at the Cat Ba National Park Area, Hai Phong City, Vietnam, Using GIS-Based Kernel Logistic Regression. Remote Sens. 2016, 8, 347. [Google Scholar] [CrossRef]
- Goldarag, Y.; Mohammadzadeh, A.; Ardakani, A. Fire Risk Assessment Using Neural Network and Logistic Regression. J. Indian Soc. Remote Sens. 2016, 44, 1–10. [Google Scholar] [CrossRef]
- Guo, F.T.; Zhang, L.; Jin, S.; Tigabu, M.; Su, Z.; Wang, W. Modeling Anthropogenic Fire Occurrence in the Boreal Forest of China Using Logistic Regression and Random Forests. Forests 2016, 7, 250. [Google Scholar] [CrossRef]
- Pourghasemi, H.R. GIS-based forest fire susceptibility mapping in Iran: A comparison between evidential belief function and binary logistic regression models. Scand. J. For. Res. 2015, 31. [Google Scholar] [CrossRef]
- Tien Bui, D.; Bui, Q.T.; Phi, Q.; Pradhan, B.; Nampak, H.; Trinh, P. A Hybrid Artificial Intelligence Approach Using GIS-Based Neural-Fuzzy Inference System and Particle Swarm Optimization for Forest Fire Susceptibility Modeling at A Tropical Area. Agric. For. Meteorol. 2017, 233. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.X.; Xu, C. Applying genetic algorithms to set the optimal combination of forest fire related variables and model forest fire susceptibility based on data mining models. The case of Dayu County, China. Sci. Total Environ. 2018, 630, 1044–1056. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.; Pham, B. Wildfire spatial pattern analysis in the Zagros Mountains, Iran: A comparative study of decision tree based classifiers. Ecol. Inform. 2017, 43. [Google Scholar] [CrossRef]
- Leuenberger, M.; Parente, J.; Tonini, M.; Pereira, M.; Kanevski, M. Wildfire susceptibility mapping: Deterministic vs. stochastic approaches. Environ. Model. Softw. 2018, 101, 194–203. [Google Scholar] [CrossRef]
- Ngoc-Thach, N.; Dang Ngo, T.; Pham, X.C.; Nguyen, H.T.; Bui, H.; Hoang, N.D.; Tien Bui, D. Spatial Pattern Assessment of Tropical Forest Fire Danger at Thuan Chau area (Vietnam) using GIS-Based Advanced Machine Learning Algorithms: A comparative study. Ecol. Inform. 2018, 46. [Google Scholar] [CrossRef]
- Valdez, M.; Chang, K.T.; Chen, C.F.; Chiang, S.H.; Santos, J. Modelling the spatial variability of wildfire susceptibility in Honduras using remote sensing and geographical information systems. Geomat. Nat. Hazards Risk 2017, 8, 1–17. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; valizadeh kamran, K.; Blaschke, T.; Aryal, J.; Naboureh, A.; Einali, J.; Bian, J. Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire 2019, 2, 43. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2018, 266–267, 198–207. [Google Scholar] [CrossRef]
- Gholamnia, K.; Gudiyangada, T.; Ghorbanzadeh, O.; Blaschke, T. Comparisons of Diverse Machine Learning Approaches for Wildfire Susceptibility Mapping. Symmetry 2020, 12, 20. [Google Scholar] [CrossRef]
- Tonini, M.; D’andrea, M.; Biondi, G.; Esposti, S.; Trucchia, A.; Fiorucci, P. A Machine Learning-Based Approach for Wildfire Susceptibility Mapping. The Case Study of the Liguria Region in Italy. Geosciences (Switzerland) 2020, 10, 105. [Google Scholar] [CrossRef]
- Marker, B.R. Hazard and Risk Mapping. In Encyclopedia of Natural Hazards; Bobrowsky, P.T., Ed.; Springer Netherlands: Dordrecht, The Netherlands, 2013; pp. 426–435. [Google Scholar] [CrossRef]
- Meng, Y.; Deng, Y.; Shi, P. Mapping Forest Wildfire Risk of the World. In World Atlas of Natural Disaster Risk; Shi, P., Kasperson, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 261–275. [Google Scholar] [CrossRef]
- Zhang, Z.; Long, T.; He, G.; Wei, M.; Tang, C.; Wang, W.; Wang, G.; She, W.; Zhang, X. Study on Global Burned Forest Areas Based on Landsat Data. Photogramm. Eng. Remote Sens. 2020, 86, 503–508. [Google Scholar] [CrossRef]
- Pacheco, P.; Mertens, B. Land use change and agriculture development in Santa Cruz, Bolivia. Bois Forêt Tropiques 2004, 280, 29–40. [Google Scholar]
- Aragão, L.; Malhi, Y.; Barbier, N.; Lima, A.; Shimabukuro, Y.; Anderson, L.; Saatchi, S. Interactions between rainfall, deforestation and fires during recent years in the Brazilian Amazonia. Philos. Trans. R. Soc. London. Ser. B Biol. Sci. 2008, 363, 1779–1785. [Google Scholar] [CrossRef]
- Devisscher, T.; Boyd, E.; Malhi, Y. Anticipating future risk in social-ecological systems using fuzzy cognitive mapping: The case of wildfire in the Chiquitania, Bolivia. Ecol. Soc. 2016, 21. [Google Scholar] [CrossRef]
- Carmenta, R.; Parry, L.; Blackburn, A.; Vermeylen, S.; Barlow, J. Understanding human-fire interactions in tropical forest regions: A case for interdisciplinary research across the natural and social sciences. Ecol. Soc. 2011, 16. Available online: http://www.ecologyandsociety.org/vol16/iss1/art53 (accessed on 18 May 2021). [CrossRef]
- Devisscher, T.; Malhi, Y.; Boyd, E. Deliberation for wildfire risk management: Addressing conflicting views in the Chiquitania, Bolivia. Geogr. J. 2019, 185, 38–54. [Google Scholar] [CrossRef]
- Anívarro, R.; Azurduy, H.; Maillard, O.; Markos, A. Diagnoóstico por Teledeteccioón de aóreas Quemadas en la Chiquitania; Fundacioón para la Conservacioón del Bosque Chiquitano: Santa Cruz, Bolivia, 2019; Available online: https://www.fcbc.org.bo/wp-content/uploads/2019/12/Resumen-de-diagnostico-de-areas-quemadas-en-la-chiquitania.pptx.pdf (accessed on 18 May 2021).
- Fundación TIERRA. Fuego en Santa Cruz: Balance de los Incendios Forestales 2019 y su Relación con la Tenencia de la Tierra; TIERRA: La Paz, Bolivia, 2019. [Google Scholar]
- Devisscher, T.; Anderson, L.; Aragão, L.; Galván, L.; Malhi, Y. Increased Wildfire Risk Driven by Climate and Development Interactions in the Bolivian Chiquitania, Southern Amazonia. PLoS ONE 2016, 11, e0161323. [Google Scholar] [CrossRef]
- Van Marle, M.J.E.; Field, R.D.; van der Werf, G.R.; Estrada de Wagt, I.A.; Houghton, R.A.; Rizzo, L.V.; Artaxo, P.; Tsigaridis, K. Fire and deforestation dynamics in Amazonia (1973–2014). Glob. Biogeochem. Cycles 2017, 31, 24–38. [Google Scholar] [CrossRef]
- De la Vega-Leinert, A.C. Too small to count? Making Land Use Transformations in Chiquitano communities of San Ignacio de Velasco, East Bolivia, visible. J. Land Use Sci. 2020, 15, 172–202. [Google Scholar] [CrossRef]
- Giglio, L.; Boschetti, L.; Roy, D.; Humber, M.; Justice, C. The Collection 6 MODIS burned area mapping algorithm and product. Remote Sens. Environ. 2018, 217, 72–85. [Google Scholar] [CrossRef]
- Olson, D.; Dinerstein, E. The Global 200: A Representation Approach to Conserving the Earth’s Most Biologically Valuable Ecoregions. Conserv. Biol. 1998, 12, 502–515. [Google Scholar] [CrossRef]
- Olson, D.; Dinerstein, E.; Wikramanayake, E.; Burgess, N.; Powell, G.; Underwood, E.; D’amico, J.; Itoua, I.; Strand, H.; Morrison, J.; et al. Terrestrial Ecoregions of the World: A New Map of Life on Earth. BioScience 2001, 51, 933–938. [Google Scholar] [CrossRef]
- Ortuño, T.; Ledru, M.P.; Cheddadi, R.; Kuentz, A.; Favier, C.; Beck, S. Modern pollen rain, vegetation and climate in Bolivian ecoregions. Rev. Palaeobot. Palynol. 2011, 165, 61–74. [Google Scholar] [CrossRef]
- Torrella, S.; Adámoli, J. Situación ambiental de la ecorregión del Chaco Seco. La SituacióN Ambient. Argent. 2006, 2006, 73–100. [Google Scholar]
- Sano, E.; de Almeida Rodrigues, A.; Martins, E.; Bettiol, G.; Bustamante, M.; Bezerra, A.; Vasconcelos, V.; Schüler, J.; Bolfe, E.; Couto Junior, A. Cerrado ecoregions: A spatial framework to assess and prioritize Brazilian savanna environmental diversity for conservation. J. Environ. Manag. 2019, 232, 818–828. [Google Scholar] [CrossRef]
- European Space Agency (ESA); Climate Change Initiative (CCI). Land cover Classification Gridded Maps from 1992 to Present Derived from Satellite Observations; Technical Report; Copernicus, European Union’s Earth Observation Programme: Reading, UK, 2019; Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/satellite-land-cover?tab=doc (accessed on 18 May 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Larrea-Alcázar, D. Atlas Socioambiental de las Tierras Bajas y Yungas de Bolivia; Fundación Amigos de la Naturaleza: La Plaz, Bolivia, 2015. [Google Scholar]
- Andersen, L.E.; Ledezma, J.C. Deforestación e Incendios Forestales en Bolivia; Technical Report; Red de Soluciones para el Desarrollo Sostenible de Bolivia (SDSN): La Plaz, Bolivia, 2019; Available online: https://www.sdsnbolivia.org/en/deforestacion-eincendios-forestales-en-bolivia/ (accessed on 18 May 2021).
- Fundación Solón. Incendio en el Parque Nacional Otuquis y 673 Focos de Calor en el Resto del País; Technical Report; Fundación Solón: La Plaz, Bolivia, 2020; Available online: https://fundacionsolon.org/2020/03/16/incendio-en-el-parque-nacional-otuquis-y-673-focos-de-calor-en-el-resto-del-pais/ (accessed on 18 May 2021).
- Miller, J.; Collins, B.; Lutz, J.; Stephens, S.; van Wagtendonk, J.; Yasuda, D. Differences in wildfires among ecoregions and land management agencies in the Sierra Nevada region, California, USA. Ecosphere 2012, 3. [Google Scholar] [CrossRef]
- Devisscher, T.; Malhi, Y.; Rojas Landívar, V.D.; Oliveras, I. Understanding ecological transitions under recurrent wildfire: A case study in the seasonally dry tropical forests of the Chiquitania, Bolivia. For. Ecol. Manag. 2016, 360, 273–286. [Google Scholar] [CrossRef]
- Power, M.; Whitney, B.; Mayle, F.; Neves, D.; de Boer, E.; Maclean, K. Fire, climate and vegetation linkages in the Bolivian Chiquitano Seasonally Dry Tropical Forest. Philos. Trans. R. Soc. Biol. Sci. 2016, 371. [Google Scholar] [CrossRef] [PubMed]
- Cardoso, M.; Nobre, C.; Sampaio, G.; Hirota, M.; Valeriano, D.; Câmara, G. Long-term potential for tropical-forest degradation due to deforestation and fires in the Brazilian Amazon. Biologia 2009, 64, 433–437. [Google Scholar] [CrossRef]
- Sun, Q.; Miao, C.; Hanel, M.; Borthwick, A.G.; Duan, Q.; Ji, D.; Li, H. Global heat stress on health, wildfires, and agricultural crops under different levels of climate warming. Environ. Int. 2019, 128, 125–136. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Yu, P.; Abramson, M.J.; Johnston, F.H.; Samet, J.M.; Bell, M.L.; Haines, A.; Ebi, K.L.; Li, S.; Guo, Y. Wildfires, Global Climate Change, and Human Health. N. Engl. J. Med. 2020, 383, 2173–2181. [Google Scholar] [CrossRef] [PubMed]
- Maillard, O.; Vides-Almonacid, R.; Flores-Valencia, M.; Coronado, R.; Vogt, P.; Vicente-Serrano, S.M.; Azurduy, H.; Anívarro, R.; Cuellar, R.L. Relationship of Forest Cover Fragmentation and Drought with the Occurrence of Forest Fires in the Department of Santa Cruz, Bolivia. Forests 2020, 11, 910. [Google Scholar] [CrossRef]
- Vargas-Cuentas, N.I.; Roman-Gonzalez, A. Satellite-Based Analysis of Forest Fires in the Bolivian Chiquitania and Amazon Region: Case 2019. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 38–54. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Williamson, G.J.; Abatzoglou, J.T.; Kolden, C.A.; Cochrane, M.A.; Smith, A.M.S. Human exposure and sensitivity to globally extreme wildfire events. Nat. Ecol. Evol. 2017, 1. [Google Scholar] [CrossRef] [PubMed]
- Tedim, F.; Leone, V.; Amraoui, M.; Bouillon, C.; Coughlan, M.R.; Delogu, G.M.; Fernandes, P.M.; Ferreira, C.; McCaffrey, S.; McGee, T.K.; et al. Defining Extreme Wildfire Events: Difficulties, Challenges, and Impacts. Fire 2018, 1, 9. [Google Scholar] [CrossRef]
- Pinto, J.A.R.R.; Mews, H.A.; Jancoski, H.S.; Marimon, B.S.; Bomfim, B.A.D.O. Woody vegetation dynamics in a floodplain campo de murundus in central Brazil. Acta Bot. Bras. 2014, 28, 519–526. [Google Scholar] [CrossRef]
- Da Silva, A.P.G.; Mews, H.A.; Marimon-Junior, B.H.; De Oliveira, E.A.; Morandi, P.S.; Oliveras, I.; Marimon, B.S. Recurrent wildfires drive rapid taxonomic homogenization of seasonally flooded Neotropical forests. Environ. Conserv. 2018, 45, 378–386. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pred. Factors | Variable Type | Range |
|---|---|---|
| DEM | Numerical (meters) | 75–3330 |
| Slope | Numerical (degrees) | 0–76.27 |
| Ecoregions | Categorical | 9 classes |
| Land cover | Categorical | 10 classes |
| Pred. Factors | #. Class | Area (ha) | Area (%) |
|---|---|---|---|
| Ecoregions | 1. Southwestern Amazon forest | 7,095,085 | 19.42 |
| 2. Flooded Savanna | 3,855,600 | 10.55 | |
| 3. Chiquitano Dry forest | 10,282,677 | 28.14 | |
| 4. Cerrado | 4,768,190 | 13.05 | |
| 5. Dry Inter-Andean forest | 504,133 | 1.38 | |
| 6. Chaco Serrano | 934,197 | 2.56 | |
| 7. Bolivian Tucuman forest | 535,884 | 1.47 | |
| 8. Yungas | 261,457 | 0.72 | |
| 9. Gran Chaco | 8,297,441 | 22.71 | |
| Land cover | 1. Cropland, rainfed | 499,512 | 1.37 |
| 2. Herbaceous cover | 2,476,316 | 6.77 | |
| 3. Shrub or herbaceous cover, flooded, fresh/saline/brakish water | 5,517,848 | 15.09 | |
| 4. Mosaic cropland (>50%) / Natural vegetation (tree, shrub, herbaceous cover) (<50%) | 919,420 | 2.51 | |
| 5. Tree cover, broadleaved, evergreen, closed to open (>15%) | 19,873,239 | 54.33 | |
| 6. Tree cover, broadleaved, deciduous, closed/open (15-40%) | 3,988,847 | 10.91 | |
| 7. Mosaic natural vegetation (tree, shrub, herbaceous cover) / cropland (<50%) | 2,245,102 | 6.14 | |
| 8. Grassland | 890,728 | 2.44 | |
| 9. Bare areas/Urban areas/Sparse vegetation (>15%) | 46,897 | 0.13 | |
| 10. Water bodies | 120,082 | 0.33 |
| Perc. | p-Value | Testing BA | BA 2017 | BA 2018 | BA 2019 | ||||
|---|---|---|---|---|---|---|---|---|---|
| [%] | [ha] | [%] | [ha] | [%] | [ha] | [%] | [ha] | ||
| <25% | 0-0.04 | 6.77 | 281,460 | 4.7 | 25,142 | 5.7 | 41,546 | 6.7 | 223,272 |
| 25–50% | 0.04–0.3 | 17.4 | 725,102 | 10.9 | 58,315 | 13.2 | 96,672 | 18 | 598,737 |
| 50–75% | 0.3–0.7 | 25.1 | 1,043,996 | 20.8 | 111,147 | 25 | 182,732 | 24.6 | 820,684 |
| >75% | >0.7 | 50.7 | 2,108,121 | 63.5 | 339,153 | 56.2 | 411,119 | 50.7 | 1,687,505 |
| >50% | >0.3 | 75.8 | 3,152,117 | 84.4 | 450,300 | 81.1 | 593,851 | 75.3 | 2,508,189 |
| Total | 100 | 4,158,679 | 100 | 533,757 | 100 | 732,089 | 100 | 3,330,198 | |
| Study Area | Perc. | Testing Dataset | Year 2017 | Year 2018 | Year 2019 | ||||
|---|---|---|---|---|---|---|---|---|---|
| [%] | [ha] | [%] | [ha] | [%] | [ha] | [%] | [ha] | ||
| S. Ignatio de Velasco | >50% | 87.59 | 667,850 | 92.36 | 134,816 | 92.15 | 207,346 | 86.29 | 448,879 |
| >75% | 56.51 | 430,868 | 66.52 | 97,095 | 69.14 | 155,577 | 52.48 | 272,994 | |
| Santa Cruz | >50% | 75.79 | 3,152,117 | 84.36 | 450,300 | 81.12 | 593,851 | 75.31 | 2,508,189 |
| >75% | 50.69 | 2,108,121 | 63.54 | 339,153 | 56.16 | 411,119 | 50.67 | 1,687,505 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bustillo Sánchez, M.; Tonini, M.; Mapelli, A.; Fiorucci, P. Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest. Geosciences 2021, 11, 224. https://doi.org/10.3390/geosciences11050224
Bustillo Sánchez M, Tonini M, Mapelli A, Fiorucci P. Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest. Geosciences. 2021; 11(5):224. https://doi.org/10.3390/geosciences11050224
Chicago/Turabian StyleBustillo Sánchez, Marcela, Marj Tonini, Anna Mapelli, and Paolo Fiorucci. 2021. "Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest" Geosciences 11, no. 5: 224. https://doi.org/10.3390/geosciences11050224
APA StyleBustillo Sánchez, M., Tonini, M., Mapelli, A., & Fiorucci, P. (2021). Spatial Assessment of Wildfires Susceptibility in Santa Cruz (Bolivia) Using Random Forest. Geosciences, 11(5), 224. https://doi.org/10.3390/geosciences11050224