

Deep Learning-Based Classification of Canine Cataracts from Ocular B-Mode Ultrasound Images
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
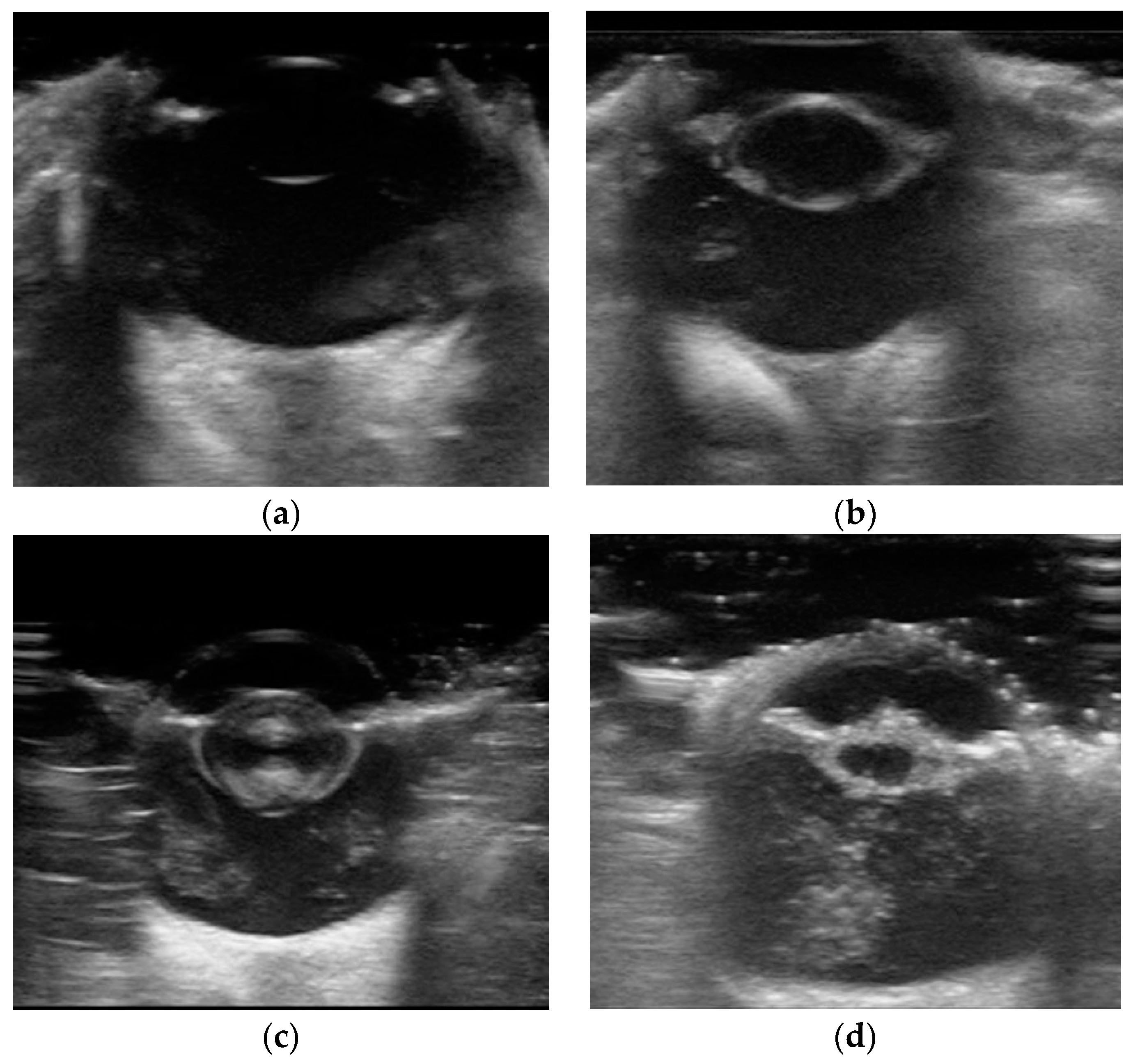
2.1. Datasets
2.2. Data Augmentation and Model Development
2.3. Computational Environment
2.4. Evaluation Metrics
3. Results
3.1. Classification Performance on the Combined Internal and External Test Dataset
3.2. External Validation Performance
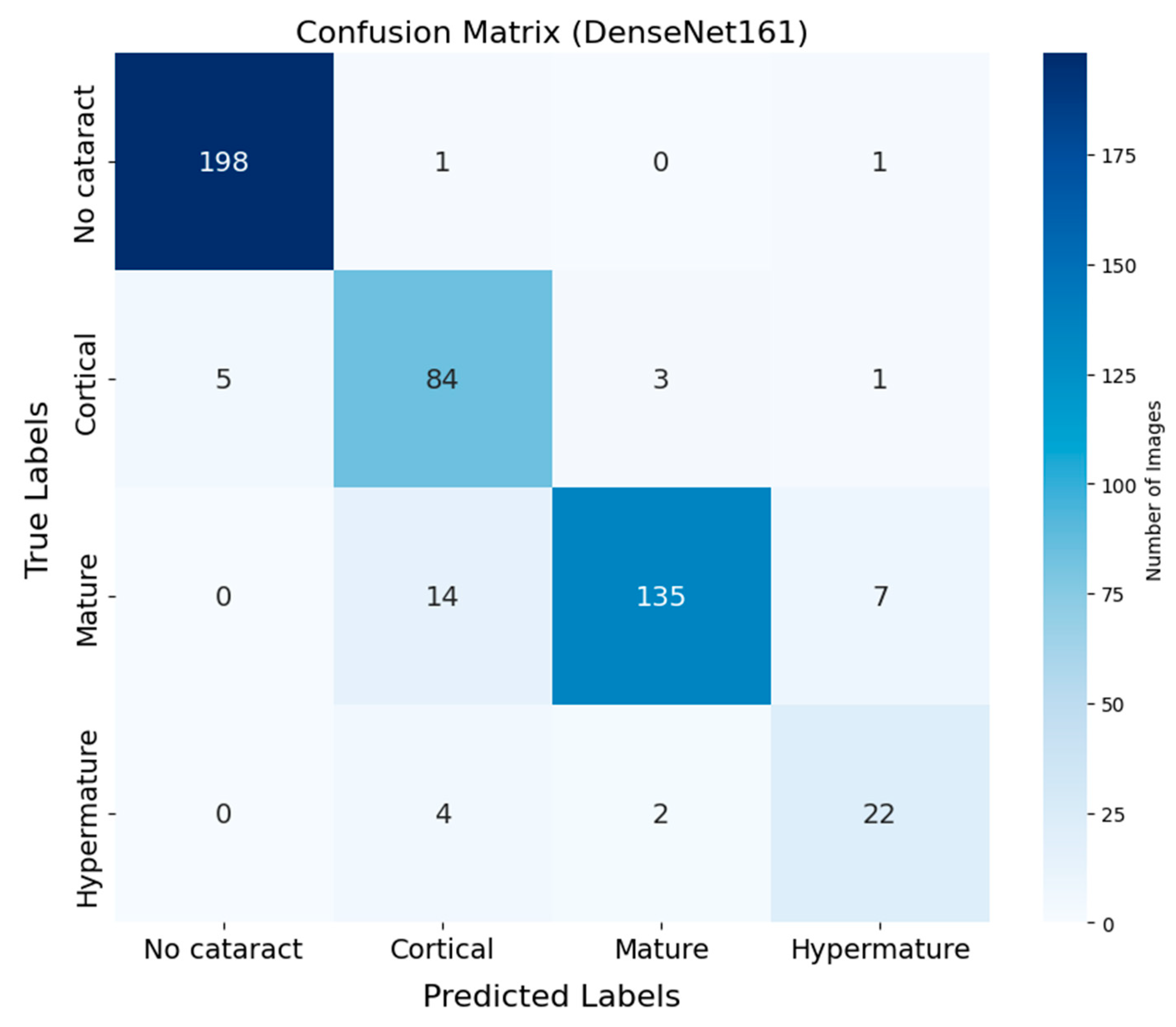
3.3. Confusion Matrix Analysis
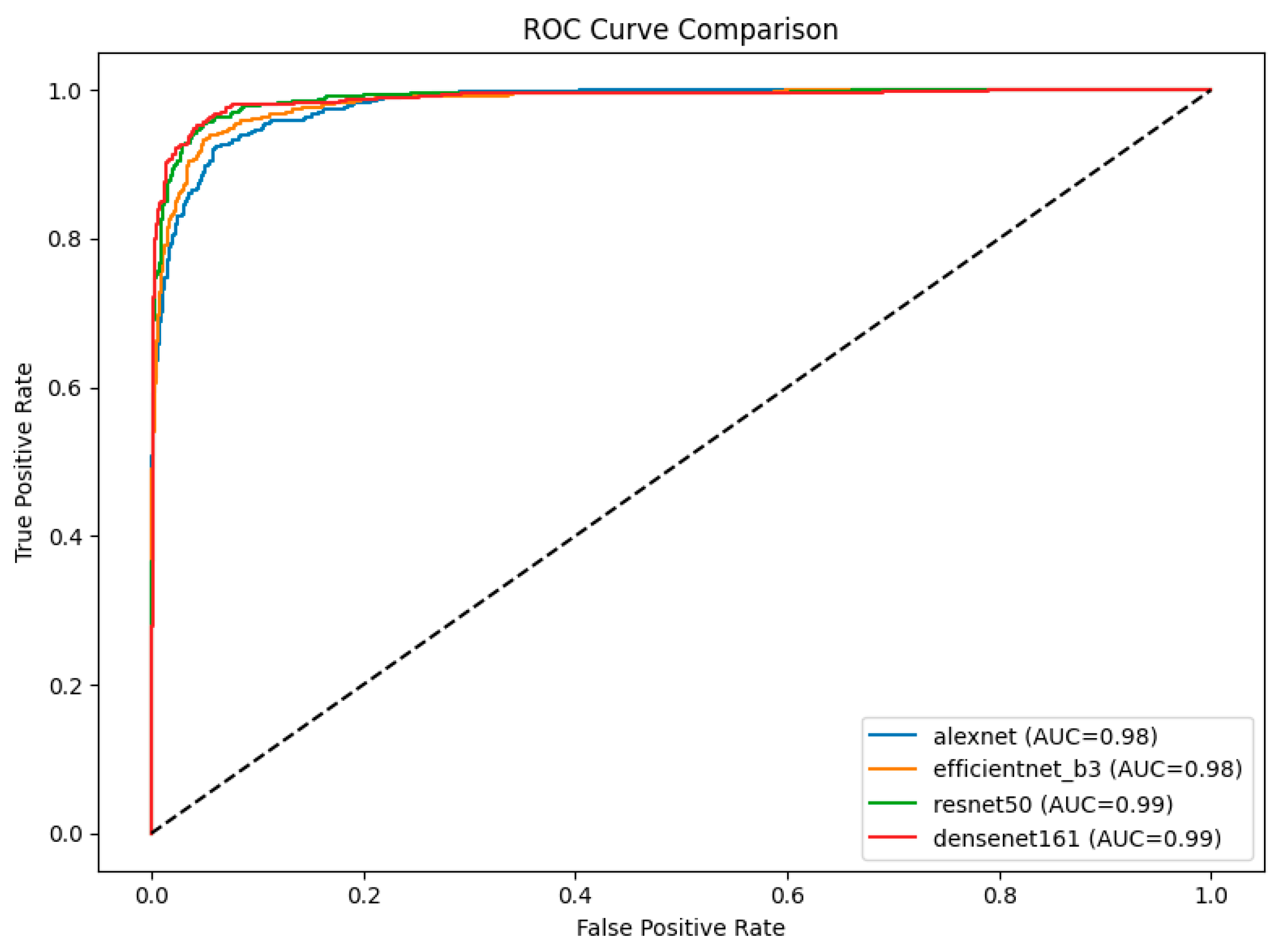
3.4. ROC Curve and AUC Analysis
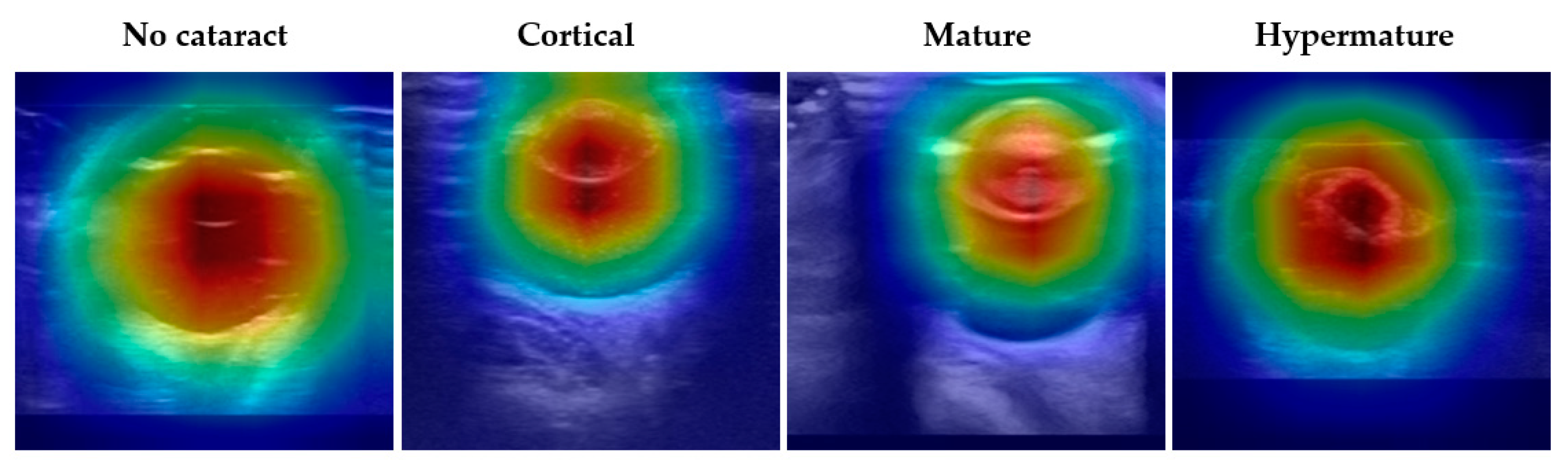
3.5. Model Interpretation Using Grad-CAM
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| ViTs | Vision Transformers |
| YOLO | You Only Look Once |
| GANs | Generative Adversarial Networks |
References
- Wang, Y.; Tang, C.; Wang, J.; Sang, Y.; Lv, J. Cataract detection based on ocular B-ultrasound images by collaborative monitoring deep learning. Knowl. Based Syst. 2021, 231, 107442. [Google Scholar] [CrossRef]
- Lavanya, B.; Venugopal, S.K.; Martin, K.J.; Ramankutty, S.; Sreeranjini, A.R. B-mode ultrasonographic biometry of cataractous eyes in dogs. J. Vet. Anim. Sci. 2021, 52, 377–382. [Google Scholar] [CrossRef]
- Gelatt, K.N.; MacKay, E.O. Prevalence of primary breed-related cataracts in the dog in North America. Vet. Ophthalmol. 2005, 8, 101–111. [Google Scholar] [CrossRef]
- Maggs, D.J.; Miller, P.E.; Ofri, R. Slatter’s Fundamentals of Veterinary Ophthalmology, 5th ed.; Elsevier Health Sciences: St. Louis, MO, USA, 2017. [Google Scholar]
- Dar, M.; Tiwari, D.K.; Patil, D.B.; Parikh, P.V. B-scan ultrasonography of ocular abnormalities: A review of 182 dogs. Iran. J. Vet. Res. 2014, 15, 102–106. [Google Scholar] [CrossRef]
- Tenajas, R.; Miraut, D.; Illana, C.I.; Alonso-Gonzalez, R.; Arias-Valcayo, F.; Herraiz, J.L. Recent advances in artificial intelligence-assisted ultrasound scanning. Appl. Sci. 2023, 13, 3693. [Google Scholar] [CrossRef]
- Ye, X.; He, S.; Dan, R.; Yang, S.; Xv, J.; Lu, Y.; Wu, B.; Zhou, C.; Xu, H.; Yu, J.; et al. Ocular disease detection with deep learning (fine-grained image categorization) applied to ocular B-scan ultrasound images. Ophthalmol. Ther. 2024, 13, 2645–2659. [Google Scholar] [CrossRef] [PubMed]
- Jung, J.-W. Deep Learning Estimation of Age in Geriatric Dogs Using Thoracic Radiographs. Ph.D. Thesis, Seoul National University, Seoul, Republic of Korea, 2023. [Google Scholar]
- Shim, H.; Lee, J.; Choi, S.; Kim, J.; Jeong, J.; Cho, C.; Kim, H.; Kim, J.I.; Kim, J.; Eom, K. Deep learning-based diagnosis of stifle joint diseases in dogs. Vet. Radiol. Ultrasound 2023, 64, 113–122. [Google Scholar] [CrossRef]
- Hauback, M.N.; Huynh, B.N.; Steiro, S.E.D.; Groendahl, A.R.; Bredal, W.; Tomic, O.; Futsaether, C.M.; Skogmo, H.K. Deep learning can detect elbow disease in dogs screened for elbow dysplasia. Vet. Radiol. Ultrasound 2025, 66, e13465. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Patil, A.; Rane, M. Convolutional neural networks: An overview and its applications in pattern recognition. In Information and Communication Technology for Intelligent Systems. Smart Innovation, Systems and Technologies; Senjyu, T., Mahalle, P.N., Perumal, T., Joshi, A., Eds.; Springer: Singapore, 2021; Volume 195, pp. 21–30. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D.; Grad, C.A.M. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 618–626. [Google Scholar] [CrossRef]
- SenGupta, S.; Singh, A.; Leopold, H.A.; Gulati, T.; Lakshminarayanan, V. Ophthalmic diagnosis using deep learning with fundus images–A critical review. Artif. Intell. Med. 2020, 102, 101758. [Google Scholar] [CrossRef]
- Gomes, D.A.; Alves-Pimenta, M.S.; Ginja, M.; Filipe, V. Predicting canine hip dysplasia in X-ray images using deep learning. In International Conference on Optimization, Learning Algorithms and Applications; Springer International Publishing: Cham, Switherlands, 2021; pp. 393–400. [Google Scholar]
- Arsomngern, P.; Numcharoenpinij, N.; Piriyataravet, J.; Teerapan, W.; Hinthong, W.; Phunchongharn, P. Computer-aided diagnosis for lung lesion in companion animals from X-ray images using deep learning techniques. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Dai, X.; Zhao, X.; Cen, F.; Zhu, F. Data augmentation using mixup and random erasing. In Proceedings of the 2022 IEEE International Conference on Networking, Sensing and Control (ICNSC), Shanghai, China, 15–18 December 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13001–13008. [Google Scholar] [CrossRef]
- Aurelio, Y.S.; Ribeiro, M.H.D.M.; Mariani, V.C.; dos Santos Coelho, L. Learning from imbalanced data sets with weighted cross-entropy function. Neural Process. Lett. 2019, 50, 1937–1949. [Google Scholar] [CrossRef]
- Tang, W.; Sun, J.; Wang, S.; Zhang, Y. Review of AlexNet for medical image classification. arXiv 2023, arXiv:2311.08655. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Shanghai, China, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Vrindavanam, J.; Kumar, P.; Kamath, G.; Bharadwaj, A.S. Transfer learning in endoscopic imaging: A machine vision approach to GIT disease identification. In Proceedings of the 2024 1st International Conference on Communications and Computer Science (InCCCS), Bangalore, India, 22–24 May 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.A. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Li, T.; Bo, W.; Hu, C.; Kang, H.; Liu, H.; Wang, K.; Fu, H. Applications of deep learning in fundus images: A review. Med. Image Anal. 2021, 69, 101971. [Google Scholar] [CrossRef]
- Boroffka, S.A.E.B.; Voorhout, G.; Verbruggen, A.-M.; Teske, E. Intraobserver and interobserver repeatability of ocular biometric measurements obtained by means of B-mode ultrasonography in dogs. Am. J. Vet. Res. 2006, 67, 1743–1749. [Google Scholar] [CrossRef]
- Deininger, L.; Stimpel, B.; Yuce, A.; Abbasi-Sureshjani, S.; Schönenberger, S.; Ocampo, P.; Korski, K.; Gaire, F. A comparative study between vision transformers and CNNs in digital pathology. arXiv 2022, arXiv:2206.00389. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Caxinha, M.; Velte, E.; Santos, M.; Perdigão, F.; Amaro, J.; Gomes, M.; Santos, J. Automatic cataract classification based on ultrasound technique using machine learning: A comparative study. Phys. Procedia 2015, 70, 1221–1224. [Google Scholar] [CrossRef]
- Wen, J.; Liu, D.; Wu, Q.; Zhao, L.; Iao, W.C.; Lin, H. Retinal image-based artificial intelligence in detecting and predicting kidney diseases: Current advances and future perspectives. VIEW 2024, 5, 20220070. [Google Scholar] [CrossRef]
- Lustgarten, J.L.; Zehnder, A.; Shipman, W.; Gancher, E.; Webb, T.L. Veterinary informatics: Forging the future between veterinary medicine, human medicine, and one health initiatives-a joint paper by the Association for Veterinary Informatics (AVI) and the CTSA One Health Alliance (COHA). JAMIA Open 2020, 3, 306–317. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Bria, A.; Marrocco, C.; Tortorella, F. Addressing class imbalance in deep learning for small lesion detection on medical images. Comput. Biol. Med. 2020, 120, 103735. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Thompson, A.C.; Jammal, A.A.; Medeiros, F.A. A review of deep learning for screening, diagnosis, and detection of glaucoma progression. Transl. Vis. Sci. Technol. 2020, 9, 42. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Tang, W.; Zhu, J.; Cui, J.; Chen, Y.; Gu, M.; Xu, H.; Zhan, M.; Chen, Q.; Xu, B. Predicting the pathological subdiagnosis of benign prostatic hyperplasia with MRI Radiomics: A noninvasive approach. VIEW 2025, 6, 20240092. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training Count | Validation Count | Test Count | Total Count |
|---|---|---|---|---|
| No cataract | 930 | 199 | 200 | 1329 |
| Cortical | 429 | 92 | 93 | 614 |
| Mature | 723 | 154 | 156 | 1033 |
| Hypermature | 125 | 26 | 28 | 179 |
| Model | Test Accuracy (%) | F1 Score |
|---|---|---|
| AlexNet | 87.00 | 0.8086 |
| EfficientNet-B3 | 89.52 | 0.8264 |
| ResNet-50 | 91.82 | 0.8553 |
| DenseNet-161 | 92.03 | 0.8744 |
| Model | Test Accuracy (%) | F1 Score |
|---|---|---|
| AlexNet | 84.71 | 0.8532 |
| EfficientNet-B3 | 90.08 | 0.9064 |
| ResNet-50 | 91.74 | 0.9181 |
| DenseNet-161 | 92.15 | 0.9231 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Go, S.; Kim, S.; Shim, J. Deep Learning-Based Classification of Canine Cataracts from Ocular B-Mode Ultrasound Images. Animals 2025, 15, 1327. https://doi.org/10.3390/ani15091327
Park S, Go S, Kim S, Shim J. Deep Learning-Based Classification of Canine Cataracts from Ocular B-Mode Ultrasound Images. Animals. 2025; 15(9):1327. https://doi.org/10.3390/ani15091327
Chicago/Turabian StylePark, Sanghyeon, Seokmin Go, Seonhyo Kim, and Jaeho Shim. 2025. "Deep Learning-Based Classification of Canine Cataracts from Ocular B-Mode Ultrasound Images" Animals 15, no. 9: 1327. https://doi.org/10.3390/ani15091327
APA StylePark, S., Go, S., Kim, S., & Shim, J. (2025). Deep Learning-Based Classification of Canine Cataracts from Ocular B-Mode Ultrasound Images. Animals, 15(9), 1327. https://doi.org/10.3390/ani15091327