1. Introduction
The growing global demand for meat, driven by population growth, has led to the expansion of pig farming. In the process of pig breeding, pig behavior relates to health, welfare, and the growth status, thereby indirectly influencing yields and economic benefits in the industry [
1]. At the same time, the daily behavior of piglets is also an important indicator of their overall health and development [
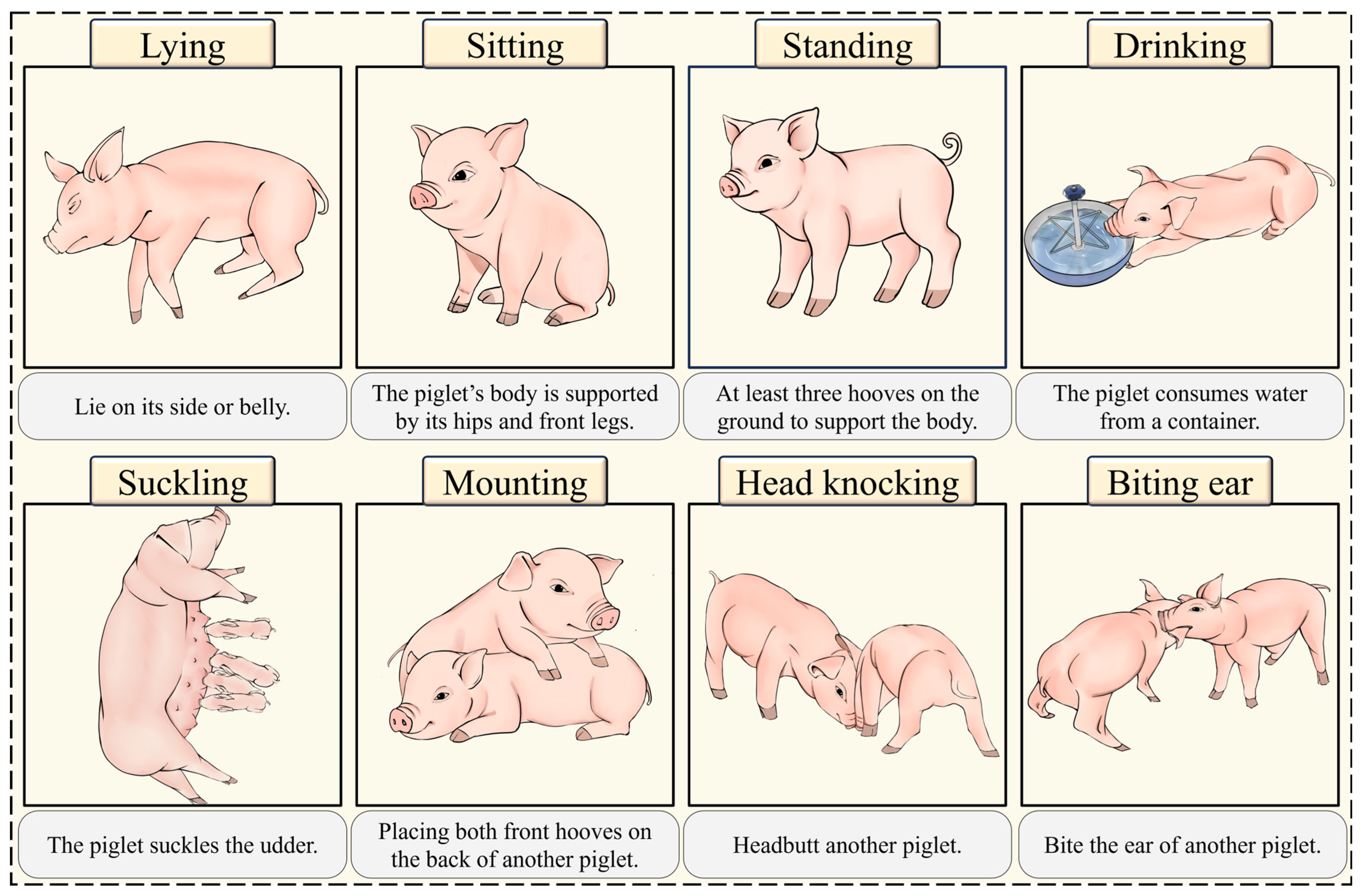
2]. Among these, lying provides necessary rest [
3], while sitting and standing promote muscle development and mobility [
4], collectively reflecting the overall health of piglets. Drinking and suckling are particularly critical, as subtle changes in these behaviors often serve as early warning signals of health issues [
5]. For instance, when piglets are sick, they commonly exhibit symptoms such as decreased food intake [
6]. Additionally, the social behavior of piglets also reflects their welfare [
7]. Mounting behavior can increase in new or overcrowded environments, serving as an indicator to assess whether the pigs are in a comfortable state [
8]. Head knocking and biting ears are aggressive behaviors in piglets that may result in stress, injuries, and economic losses [
9]. The automated monitoring and analysis of piglet behaviors help to improve their health, welfare, and productivity [
10], while also supporting sustainable pig farming [
11]. However, regarding the complexity of farming environments (such as obstruction by barriers and complex indoor lighting) and the complexity of piglet behaviors (such as occlusion between piglets and the intricacy of social behaviors), the actual recognition process presents significant challenges for the detection model [
12].
In early studies, traditional digital image processing and machine learning methods were widely used for pig behavior classification. Gronskyte et al. [
13] applied optical flow methods to analyze slaughterhouse unloading videos, allowing the real-time monitoring of pig behavior and the detection of events like tripping or stepping. Nasirahmadi et al. [
14] used binary images to calculate boundaries and convex hulls, followed by training a linear SVM classifier to detect lateral and sternal lying postures. However, traditional methods rely on manual feature extraction, which may affect their robustness and accuracy in dynamic and complex farming environments.
In recent years, the rapid development of deep learning has driven the advancement of precision agriculture. Deep learning methods can automatically extract features, providing substantial advantages across various tasks. Ji et al. [
15] used an improved YOLOX to recognize pig postures, such as standing, lying, and sitting, achieving an mAP of 95.7% in overall posture recognition. Wang et al. [
16] improved the YOLOv3 model by incorporating the Convolutional Block Attention Module (CBAM), enhancing the model’s ability to extract pig features. Li et al. [
17] proposed an enhanced YOLOX model incorporating a normalization attention mechanism to effectively detect pig attack behaviors, achieving a precision rate of 93.21%. Mao et al. [
18] developed the DM-GD-YOLO model, integrating multi-path coordinate attention and a gather-and-distribution mechanism to recognize both common and abnormal pig behaviors effectively, achieving an accuracy of 88.2%. However, the large parameter counts and computational complexity of these models present challenges for implementing piglet-behavior-recognition systems on devices with limited computing resources. To address these challenges, Wang et al. [
19] proposed deploying large models on cloud servers, utilizing cloud resources and infrastructure to perform agricultural detection tasks that require substantial computational power. However, this method has several limitations: network transmission leads to delays [
20], renting cloud servers incurs high costs [
21], and there is a potential risk of agricultural data leakage [
22]. Therefore, lightweight models designed for edge deployment provide a more secure and efficient alternative.
Recently, the trend of model lightweighting in smart agriculture has gained popularity. Liu et al. [
23] introduced a lightweight RTMDet model for pig behavior detection, incorporating the MobileNetV3 backbone to significantly reduce model parameters. Gong et al. [
24] proposed the GAB-YOLO model, integrating GhostNet and the Self-Attention Mixed Module as the backbone, reducing parameters by 14.5%. Luo et al. [
25] proposed a piglet multi-behavior recognition model, PBR-YOLO, by integrating GhostNet as the backbone and an efficient multi-scale attention (EMA), achieving a 9.1 ms reduction in inference latency and a 59.1% decrease in the parameter count. Wang et al. [
26] proposed a lightweight pig face detection method based on YOLOv8, utilizing a shared parameter detection head (SPHead), achieving a 17.0% reduction in parameters and a 38.2% decrease in computation. Although the above manually designed architectures have shown promising results in reducing computational and memory costs, they still face limitations in certain aspects. On one hand, manual design heavily depends on expert knowledge to balance accuracy, efficiency, and computing cost, which often leads to sub-optimal solutions [
27]. On the other hand, designing and optimizing compact modules requires extensive experimentation and fine-tuning, increasing the development complexity and cost [
28].
Moreover, the computational cost of the above lightweight networks is still relatively high, indicating potential for further compression and optimization [
29]. Model compression reduces the network size by removing redundant parameters and structures. Model compression is divided into pruning, knowledge distillation, quantization, and low-rank decomposition [
30]. Collaborative design and optimization is a promising direction that enables various compression methods to work together effectively [
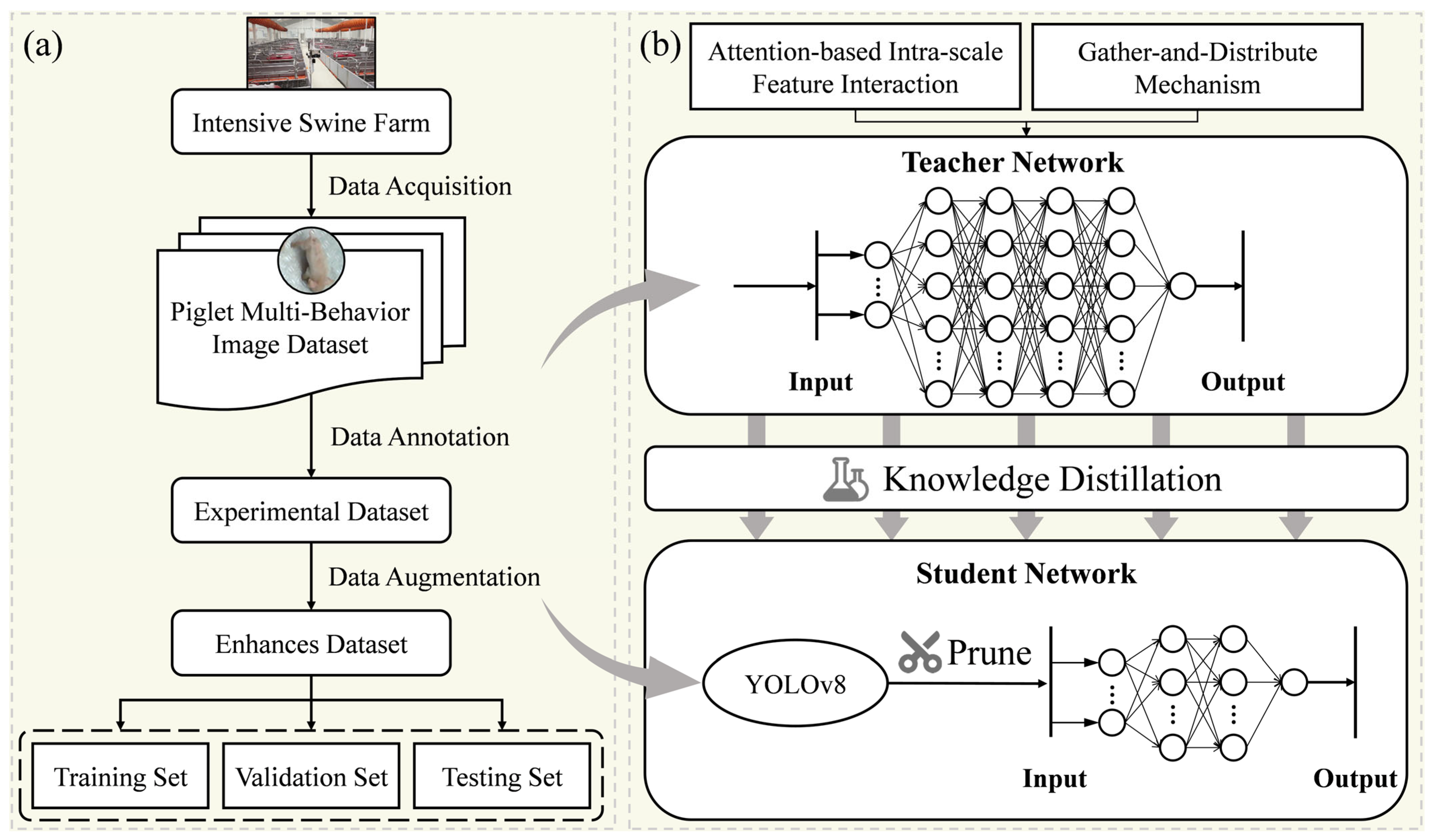
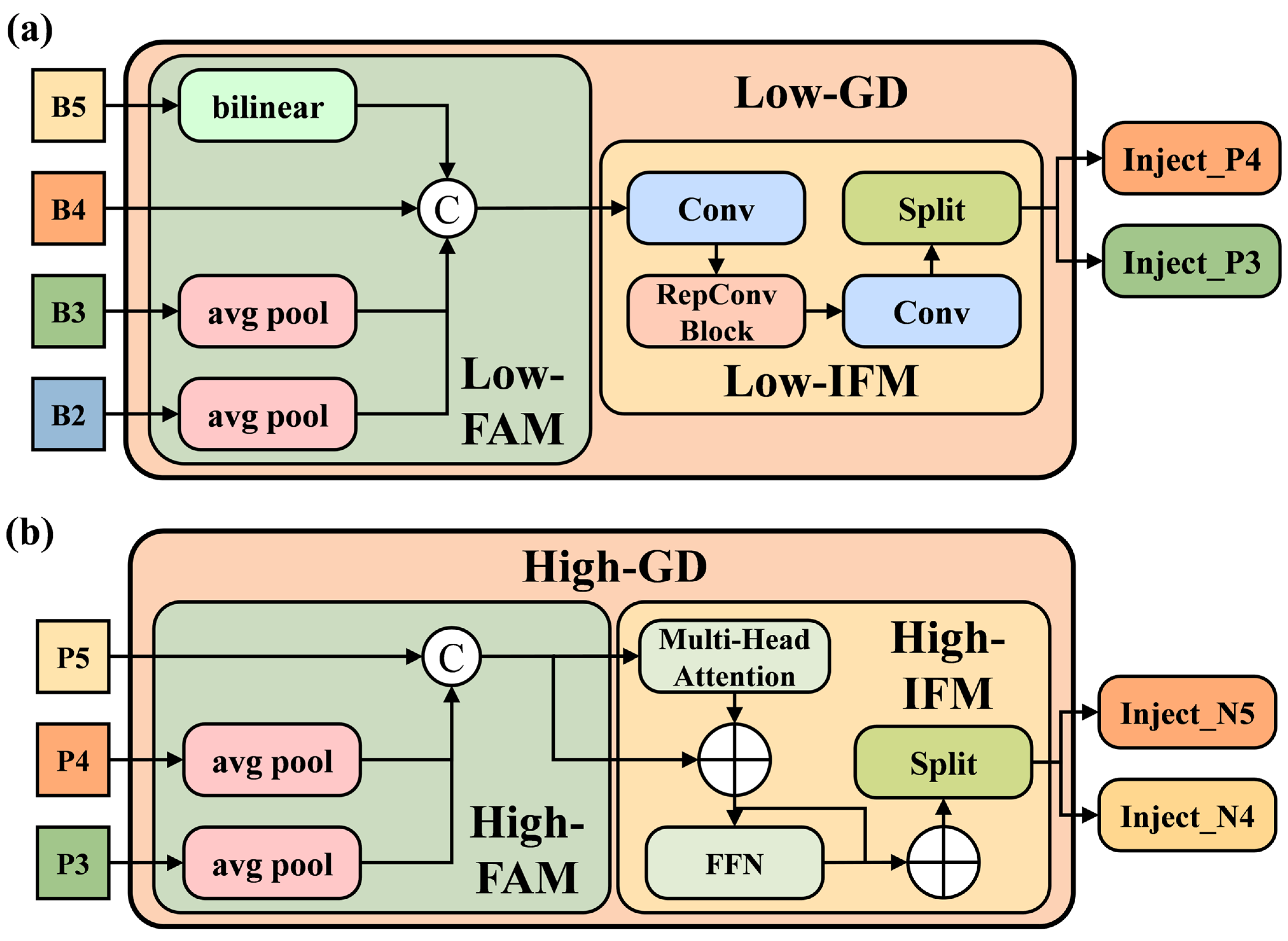
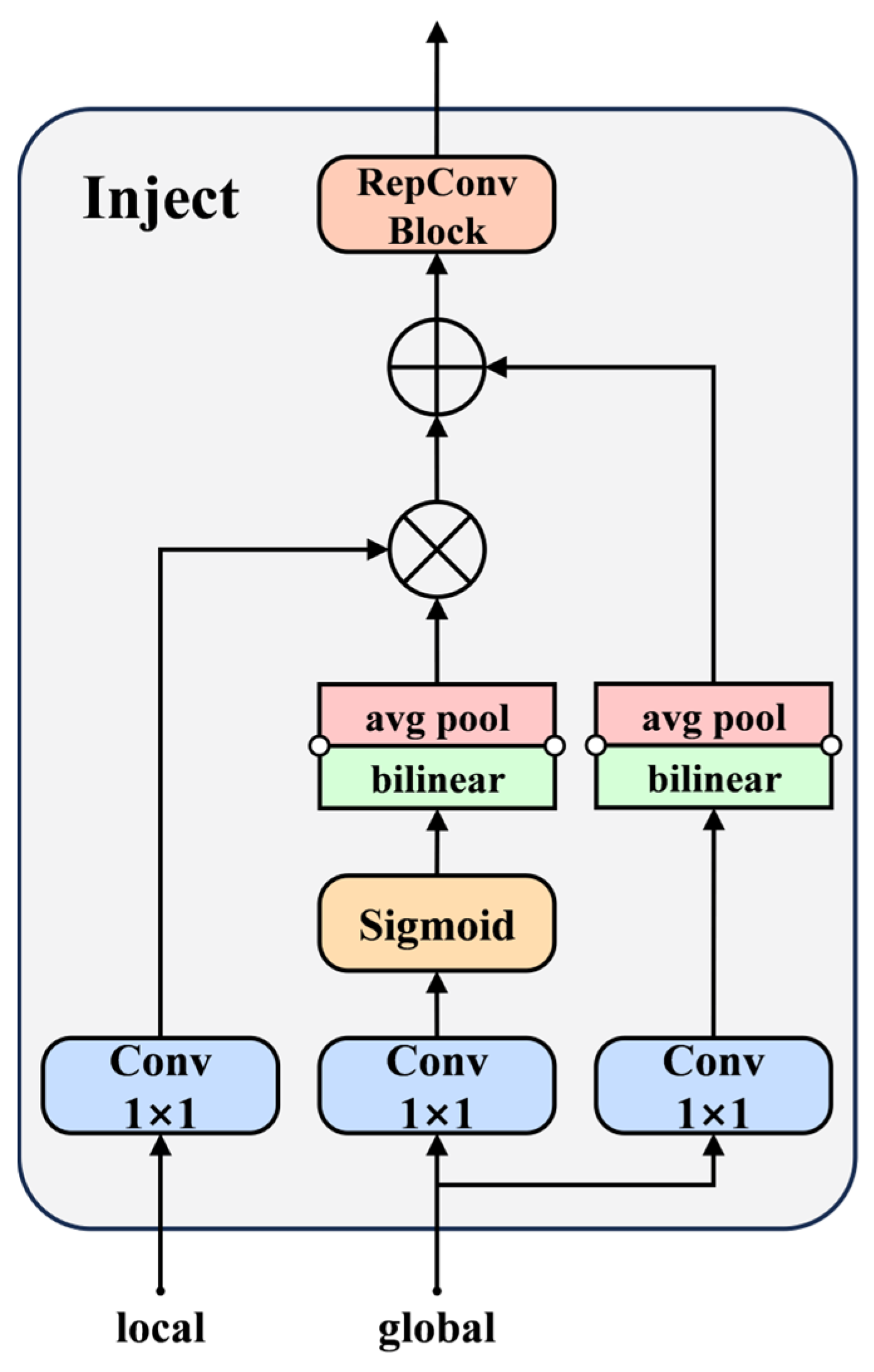
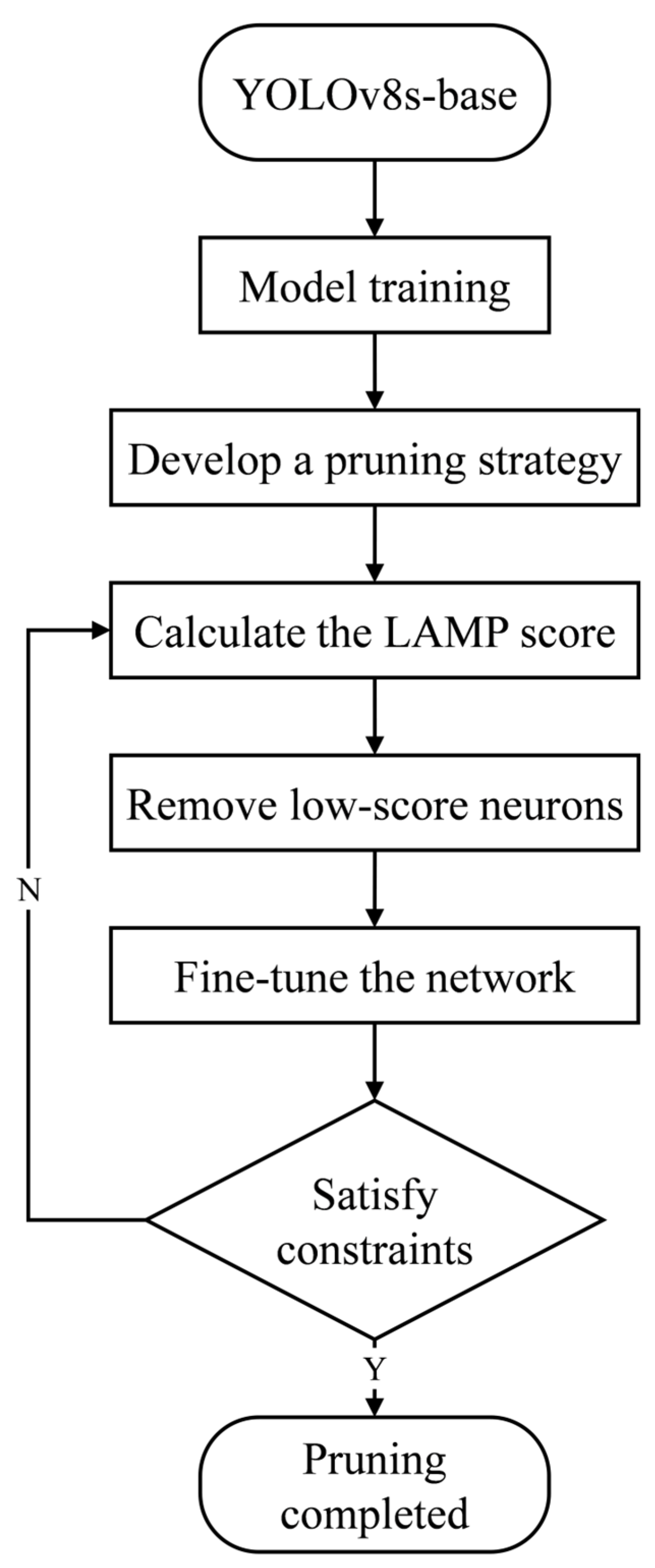
31]. To deploy the piglet multi-behavior recognition model on edge devices with limited computational resources in farming environments while maintaining a balance between detection performance and model lightweighting, this study proposes a three-stage collaborative optimization scheme. In the first stage, the LAMP pruning algorithm is used to eliminate non-essential redundancies, resulting in a lightweight YOLOv8-Prune model. In the second stage, the AIFI module and the Gather–Distribute mechanism are introduced based on YOLOv8, leading to the YOLOv8-GDA model. In the third stage, knowledge distillation is applied, with YOLOv8-GDA as the teacher model and YOLOv8-Prune as the student model, to further enhance the detection accuracy, resulting in the YOLOv8-Piglet model, which strikes a balance between detection accuracy and speed.
The main contributions of this study are as follows:
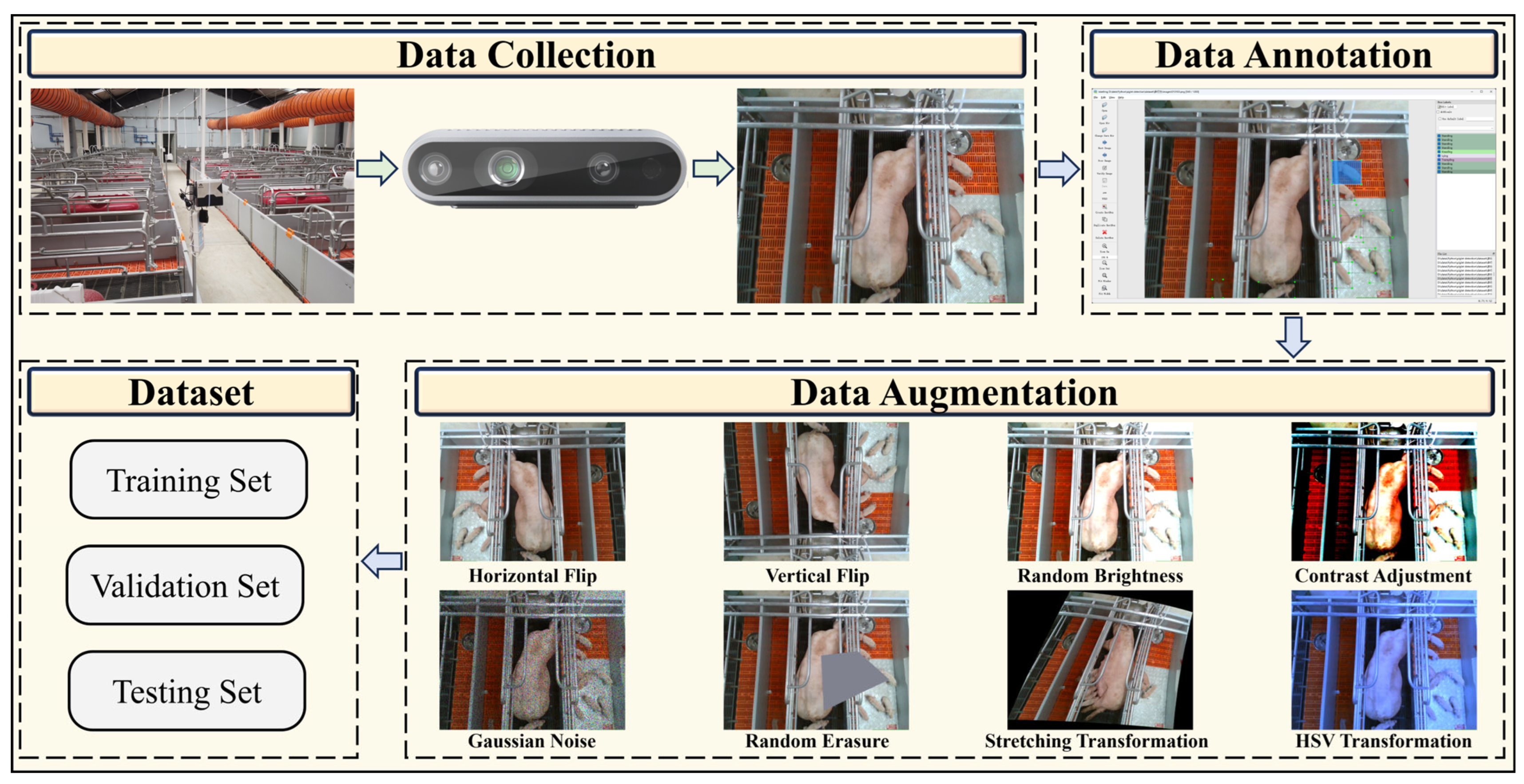
A comprehensive dataset was established, encompassing various piglet behaviors in an intensive farming environment, including complex environments and occlusion scenarios.
A collaborative optimization model, YOLO-Piglet, was proposed for piglet multi-behavior recognition, integrating pruning and distillation to achieve a balance between accuracy and model lightweighting.
TensorRT technology was employed to optimize and accelerate the model, allowing for efficient deployment and inference on the NVIDIA Jetson Orin NX edge device (Nvidia, Santa Clara, CA, USA).
The rest of the paper is organized as follows:
Section 2 describes the dataset construction, model architecture, and the proposed improvements.
Section 3 presents the experimental setup, evaluation metrics, and results.
Section 4 discusses the findings in depth. Finally,
Section 5 concludes the study with a summary and future directions.
3. Results and Analysis
3.1. Experiment Environment
The computational infrastructure for this study comprised an NVIDIA GeForce RTX 3080 Ti GPU (Nvidia, Santa Clara, CA, USA) with 12 GB VRAM, coupled with an Intel Core i7-10700 processor (2.9 GHz base clock, 16-core architecture (Intel, Santa Clara, CA, USA)) and 32 GB DDR4 RAM. To ensure reproducibility, all experiments were conducted on a dedicated computation platform running Ubuntu 22.04.4, with Python package management carried out through Anaconda 23.1.0.
The deep learning framework was implemented in Python 3.8 using PyTorch 1.11.0, with CUDA 11.3 and cuDNN 8.2.0 acceleration libraries for GPU-accelerated computations. All experiments in this study maintained identical initialization seeds and parallel processing configurations, with the critical hyperparameter settings detailed in
Table 1.
3.2. Evaluation Indicators
This study establishes a multi-dimensional evaluation framework to comprehensively assess algorithm performance through two principal dimensions: model accuracy and computational efficiency. The model accuracy is characterized by the precision (
P), recall (
R), and mean average precision (
mAP), while computational efficiency is evaluated through the parameter count (Params), weights (Model Size), floating-point operations per second (FLOPs), and single-frame inference time. The mathematical formulations of these metrics are defined as follows:
Among them, true positives (TP) represent the number of piglet behaviors correctly detected by the model; false positives (FP) denote the number of behaviors wrongly detected by the model as other behaviors; false negatives (FN) indicate the number of piglet behaviors that the model fails to detect. Precision is the ratio of TP to the sum of TP and FP, which is used to measure the correctness of the model’s detection results for the recognized behaviors. Recall is the ratio of TP to the sum of TP and FN, evaluating the model’s ability to capture positive samples. The average precision (AP) is the area under the precision—recall (P—R) curve, and it is the average AP of k (k = 8) categories of group-living piglet behaviors. The number of parameters refers to the quantity of parameters within the model, which indicates the size of the model. Smaller models are easier to deploy in various application scenarios. On the other hand, FLOPs quantify the computational complexity of the algorithm. Models with lower FLOPs are considered to have lower requirements in terms of hardware conditions. The single-frame inference time is the time required for a single input sample to undergo forward propagation and obtain the output results, reflecting the model’s performance in terms of resource consumption and the response time.
3.3. Experiments on Model Pruning
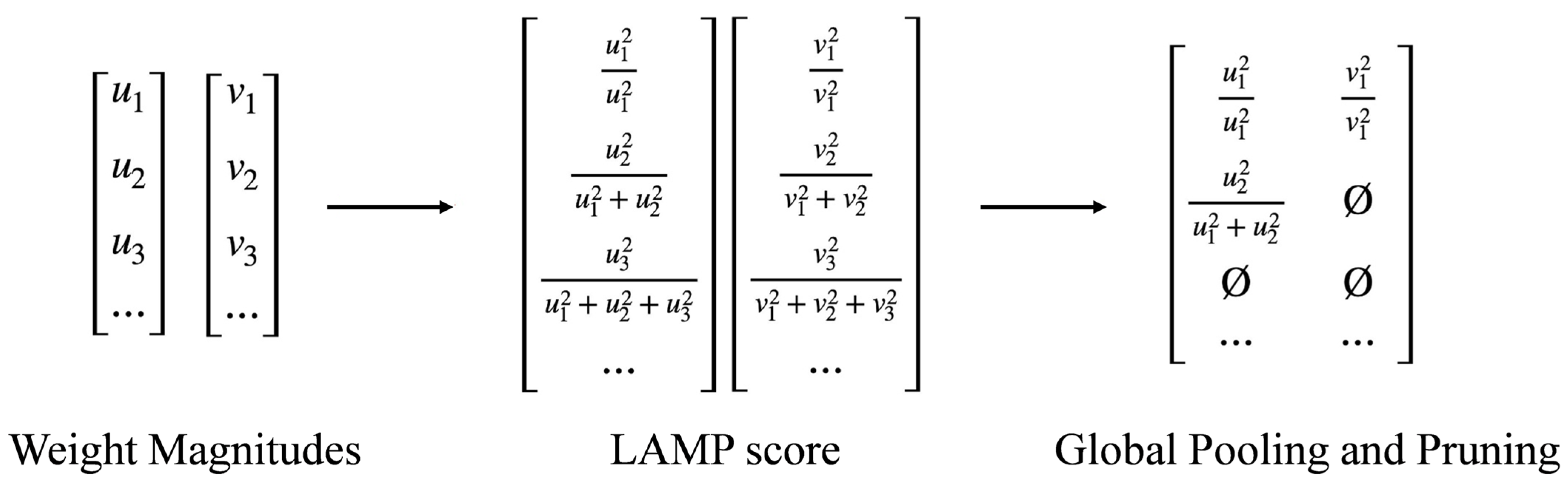
Different pruning methods and pruning rates significantly affect the accuracy of the pruned model for the same model, where the pruning rate represents the compression ratio of computational costs. To investigate the impact of various pruning methods and pruning rates on model performance, this section conducts pruning experiments on the piglet multi-behavior dataset. By comparing the performance metrics of the YOLOv8s model under different pruning methods and rates, this section aims to assess the impact of pruning on the model and provide a basis for selecting the optimal student model.
3.3.1. Comparison of Different Pruning Methods
To evaluate the effectiveness of different pruning methods, this study conducted experiments on five commonly used pruning techniques: LAMP, Slim [
45], Group_slim [
46], Group_hessian [
47], and Group_taylor [
48]. In this experiment, a pruning rate of 1.5 was applied, and global channel pruning was employed, ensuring that the number of pruned channels in each layer was approximately consistent. YOLOv8s was used as the baseline model, and a comparison was made with the five pruning methods. The experimental results are shown in
Table 2.
The experimental results show that among the five pruning methods, the LAMP method achieves the best overall performance. Compared to the baseline model, the LAMP method improved accuracy by 0.3% and recall by 3.4%. At the same time, FLOPs were reduced by approximately 33.7%, and both the number of parameters and model weights decreased by about 58%. These results demonstrate that the LAMP method effectively enhances model performance while significantly reducing the computational complexity and storage requirements.
3.3.2. Comparison of Different Pruning Rates
To investigate the impact of the pruning rate on model performance, this experiment selected LAMP as the pruning method and set four different pruning rate gradients: 1.5, 2.0, 2.5, and 3.0. A pruning rate of 2.0 means that the floating-point operations (FLOPs) of the pruned model are half of the original model, with 50% of the channel connections in the original network being removed. After pruning, the network requires fine-tuning to compensate for the lost connections, restore accuracy, and improve the overall network performance. Detailed information for each group is provided in
Table 3.
The experimental results indicate that as the pruning rate increases, the number of model parameters and computational complexity significantly decrease. When the pruning rate is set to 2.0, the model achieves its best performance, with an accuracy of 86.8%, a recall of 84.1%, and an mAP of 87.8%. This result suggests that a pruning rate of 2.0 strikes the optimal balance between performance and computational efficiency. Although further increases in the pruning rate (e.g., 2.5 and 3.0) reduce the computational complexity and parameter count even more, the model performance drops significantly. Particularly, when the pruning rate is 3.0, accuracy and recall decrease to 53.7% and 52.1%, respectively, demonstrating that excessive pruning negatively impacts the model performance.
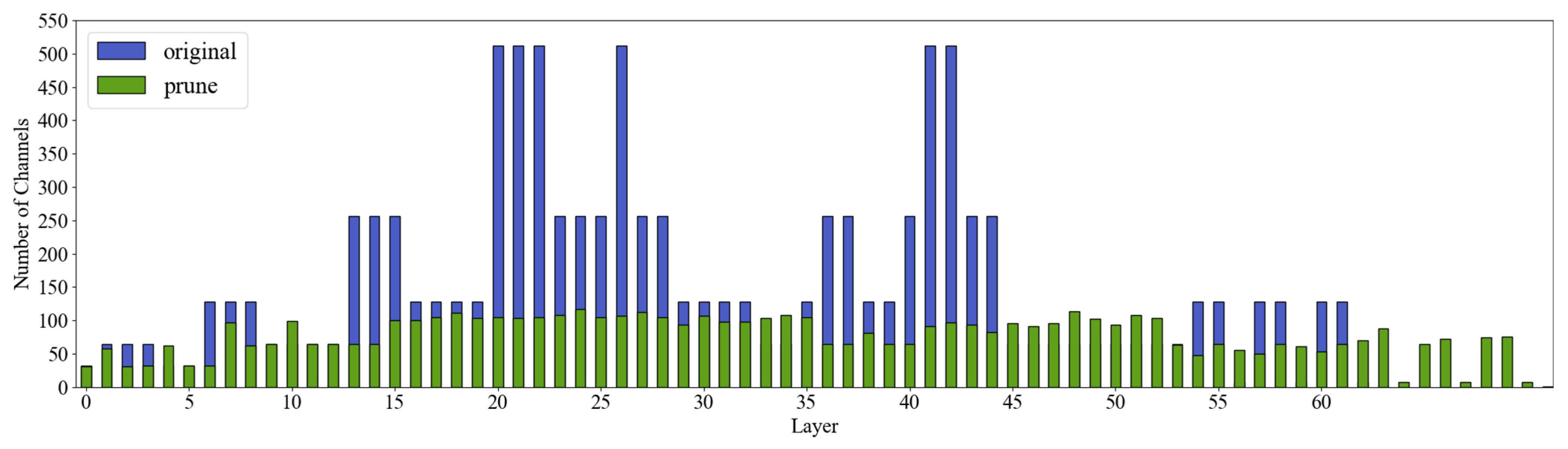
Ultimately, we selected the LAMP pruning method and set the pruning rate to 2.0 to retain more important connections in the shallow feature extraction layers, while applying more aggressive pruning to the redundant layers. This approach significantly reduces the computational complexity and the number of parameters in the model while maintaining its performance. To further understand the changes in the channels during the pruning process, we present the channel diagram of the pruned model.
Figure 12 compares the pruning channels before and after pruning for each layer, where the horizontal axis represents the names of the layers in the network and the vertical axis represents the number of parameters for each layer. This comparison allows us to visually observe the impact of pruning on the network structure at different levels and how pruning effectively optimizes the parameter configuration of the network.
3.4. Experiments on the Improved Model
3.4.1. Comparison of Different Neck Networks
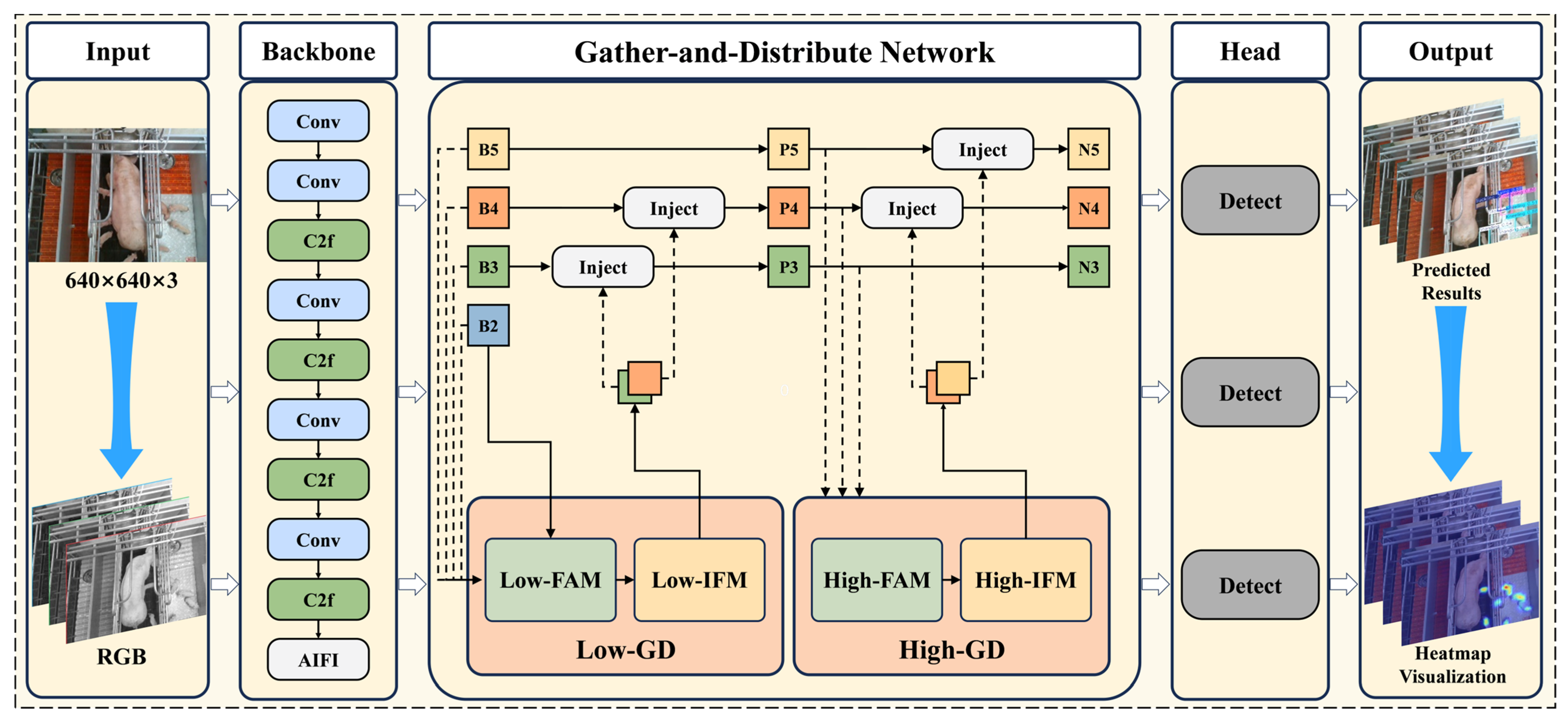
In order to evaluate the effectiveness and advantages of the Gather-and-Distribute (GD) mechanism for piglet multi-behavior recognition in the complex environment of pig farms, we conducted systematic experiments under consistent training conditions. This section compares the GD mechanism with several mainstream Neck Networks, including Bidirectional Feature Pyramid Network (BiFPN) [
49], Hybrid-Scale Feature Pyramid Network (HS_FPN) [
50], and Global Feature Pyramid Network (GFPN) [
51]. In the experiments, we replaced the original FPN-PAN network of YOLOv8 with the aforementioned Neck Networks to assess the performance differences among these methods in practical applications. The detailed experimental results are presented in
Table 4.
The experimental results show that, compared to other Neck Networks, the GD mechanism achieved the highest performance in piglet multi-behavior recognition. Its precision, recall, and mAP all surpassed those of other Neck Networks. Specifically, the precision of the GD mechanism reached 87.9%, the recall was 85.2%, and the mAP was 87.8%. Compared to FPN-PAN, BiFPN, HS_FPN, and GFPN, the precision of the GD mechanism was improved by 1.6%, 4.6%, 2.3%, and 4.2%, respectively.
In the task of piglet multi-behavior recognition, the GD mechanism significantly improved model accuracy compared to other Neck Networks. However, this improvement came with an increase in the computational complexity, parameter count, and model storage requirements. To address these challenges, we applied knowledge distillation to the improved model, allowing the student model to learn the rich feature representations and logical reasoning capabilities of the improved model. This approach enables the student model to reduce the parameter size and computational complexity while maintaining or even surpassing the performance of the teacher model.
3.4.2. Ablation Experiments on the Improved Model
In this section, we use YOLOv8s as the baseline model and optimize it by incorporating the Gather-and-Distribute (GD) mechanism and the AIFI module. To assess the effectiveness of the improvements made to the teacher model, we conducted an ablation study using the controlled variable method. Multiple groups were tested, with the precision (P), recall (R), mean average precision (mAP@0.5), parameter count, floating point operations, and model size as evaluation metrics.
Experiment A involves replacing the neck network of YOLOv8s with a feature fusion network based on the “Gather-and-Distribute” mechanism for multi-scale feature fusion. Experiment B replaces the SPPF module in the backbone of the original YOLOv8s with the AIFI module. Experiment A + B builds upon Experiment A by additionally replacing the SPPF module in the backbone with the AIFI module. All ablation experiments were conducted under the same dataset and training parameters, with the results shown in
Table 5.
The results of the ablation experiments demonstrate that the performance of the model significantly improved with the gradual integration of each modification module. As shown in the table, the baseline model achieved precision, recall, and mAP values of 86.3%, 80.0%, and 87.5%, respectively. When the GD mechanism was introduced (Experiment A), the precision, recall, and mAP increased by 1.6%, 5.2%, and 0.3%, respectively. With the addition of the AIFI module (Experiment B), the precision and recall increased by 1.8% and 6.9%, and the mAP improved by 0.8%. Finally, the combination of both the GD mechanism and AIFI module (Experiment A + B) further enhanced model performance, with precision reaching 88.5%, recall at 87.6%, and mAP at 89.6%. Compared to the baseline model, the precision increased by 2.2%, recall by 7.6%, and mAP by 2.1%, indicating that the design and construction of the network are rational and that the modules are well-compatible.
Furthermore, the results of the ablation experiment also reveal that the GD mechanism in the neck optimization enhances feature fusion, enabling the model to more comprehensively recognize target behaviors. The Attention-based Intra-scale Feature Interaction (AIFI) module better captures the relationships between different conceptual entities within the image, reducing the impact of the occlusions caused by obstacles or other piglets’ bodies. The experimental results validate the optimization and enhancement provided by these two modules in the YOLOv8 backbone and neck, significantly boosting the model’s recognition capabilities.
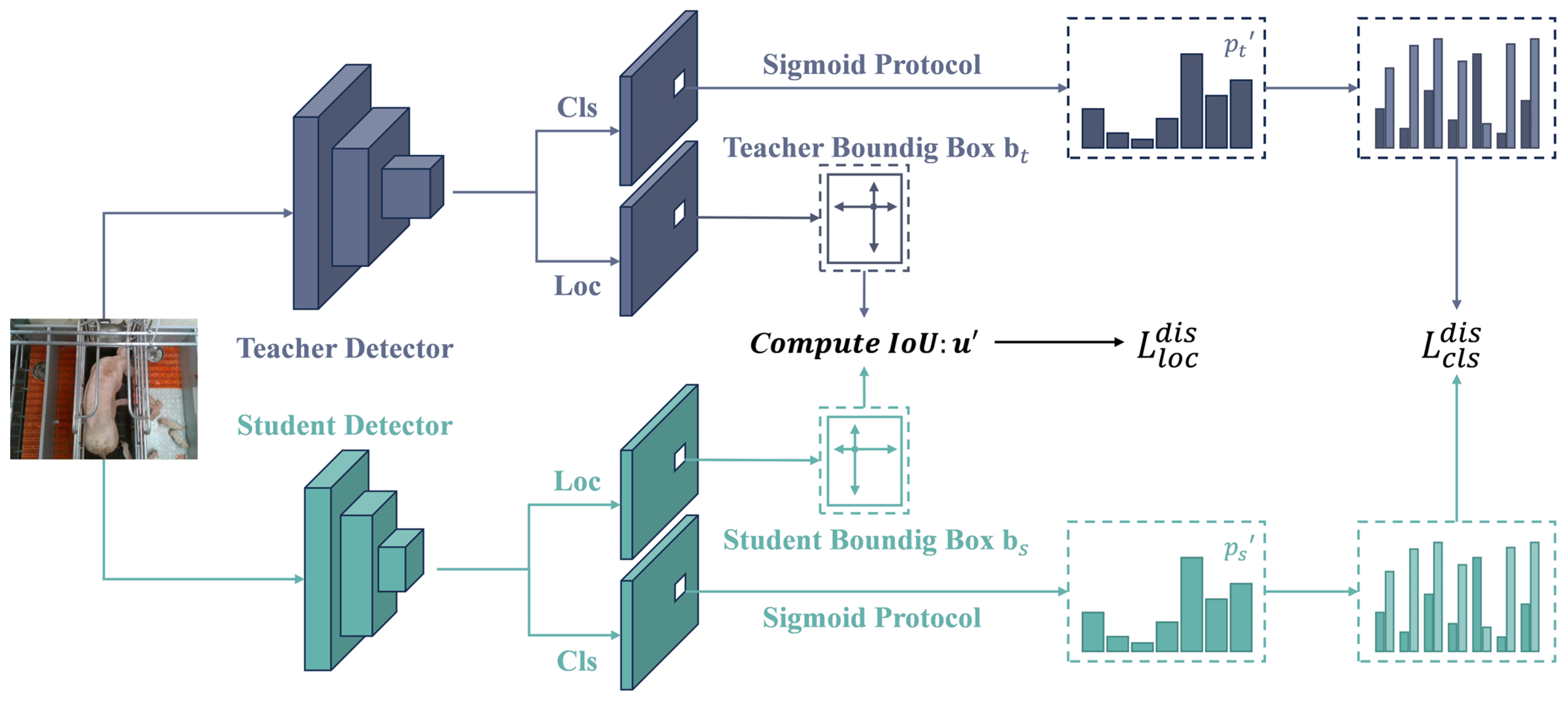
3.5. Experiments on Knowledge Distillation
3.5.1. Comparison of Different Distillation Methods
In this section, we optimize the pruned student model (YOLOv8-prune) using knowledge distillation, with the teacher model being the improved YOLOv8s model (YOLOv8-GDA). The core idea of knowledge distillation is to transfer the knowledge embedded in the complex teacher model to the relatively simpler student model, thereby enhancing the performance of the student model. Knowledge distillation is typically divided into feature distillation and logical distillation, with different distillation methods having a significant impact on the final performance. To investigate the effects of different distillation methods on model performance, this study employs several distillation techniques, including Mean Gradient Distillation (MGD) [
52], Correlation Weight Distillation (CWD) [
53], L1 [
54], L2 [
55], and BCKD. We conducted experiments using these distillation methods to evaluate their impact on improving the accuracy and computational efficiency of the student model and selected the most suitable distillation method through a comparative analysis. The detailed results of the experiment are shown in
Table 6.
The experimental results indicate that the overall performance of feature distillation methods is suboptimal, with MGD showing the poorest performance, achieving only 88.4% accuracy. In contrast, among the logical distillation methods, BCKD achieved the best results, with an accuracy of 92.6%, recall of 91.2%, and mAP of 91.8%. This suggests that BCKD effectively preserves the generalization ability of the teacher model, significantly enhancing the performance of the student model and demonstrating outstanding results.
3.5.2. Ablation Experiments
We conducted a systematic ablation study on the proposed YOLOv8-Piglet model to evaluate the impact of two optimization techniques, pruning and knowledge distillation, on its performance. The experimental results are summarized in
Table 7. The experiment confirms the effectiveness of pruning and distillation in striking a balance between efficiency and accuracy. After undergoing LAMP pruning, the YOLOv8-Piglet model maintained nearly lossless accuracy while significantly reducing the computational demands: parameters were reduced by 74.7%, FLOPs decreased by 50.5%, inference time shortened by 66.5%, and model size shrank by 73.8%. Subsequently, knowledge distillation preserved the same level of model complexity but substantially enhanced the detection performance, increasing the precision by 5.8%, recall by 7.1%, and raising the mAP@0.5 to 91.8%. These results show that pruning improves model efficiency, while knowledge distillation compensates for the loss in representation by transferring semantic priors from the teacher model. Consequently, the student network’s ability to accurately recognize multiple piglet behaviors (suckling, mounting, head knocking, and biting ear) in dynamic and complex scenarios is significantly improved. This approach mitigates the performance degradation of lightweight models under occlusion and lighting changes, while providing a reliable solution for intelligent monitoring in intensive pig farming.
3.6. Comparative Experiments of Different Models
To evaluate the effectiveness of the YOLOv8s-Piglet model proposed in this study, we compared it with YOLOv5s, YOLOv7-x, YOLOv8s, and YOLOv10s. Additionally, the performance of the single-stage model SSD, the two-stage model Faster R-CNN, and other object detection models RT-DETR, was also assessed. As shown in
Table 8, the experimental results indicate that the FLOPs and parameter counts of SSD, Faster R-CNN, and RT-DETR models are significantly higher than those of other models, resulting in larger model weights. In comparison, the model size of YOLOv8s-Piglet is only 5.9 MB, which is 7.5% of SSD, 6.3% of Faster R-CNN, and 6.9% of RT-DETR. These results suggest that SSD, Faster R-CNN, and RT-DETR do not meet the lightweight real-time detection requirements of piglet behavior, whereas YOLOv8s-Piglet provides an efficient performance with a smaller model size and faster inference speed.
YOLOv8s-Piglet exhibits exceptional accuracy in piglet behavior detection tasks, achieving an accuracy of 92.6%, a recall of 91.2%, and an mAP@0.5 of 91.8%. Compared with other YOLO models—including YOLOv5s, YOLOv7-x, YOLOv8s, and YOLOv10s—YOLOv8s-Piglet demonstrates significant advantages in detection accuracy, parameter efficiency, and model size. Specifically, in terms of the detection accuracy, it outperforms YOLOv5s, YOLOv7-x, YOLOv8s, and YOLOv10s by 19.4%, 20.8%, 6.3%, and 13.3%, respectively; its recall is improved by 13.2%, 16.0%, 11.2%, and 22.1%, respectively—a high recall rate indicates that the model minimizes missed detections, thereby detecting more targets; and for mAP, the advantages are 15.3%, 16.7%, 4.3%, and 17.4%, respectively. The high average precision not only reflects the model’s superior accuracy but also indicates its excellent performance in reducing false positives and adapting to various target behaviors, backgrounds, and environmental conditions.
Furthermore, the experimental results confirm that the YOLOv8s-Piglet model designed in this study exhibits outstanding performance. By employing knowledge distillation, the deep feature representations and contextual reasoning capabilities inherently contained within the teacher model (YOLOv8-GDA) are effectively transferred to the structurally pruned student model (YOLOv8-prune). In this process, the student model not only inherits the teacher model’s precise target-recognition abilities but also significantly reduces the network’s computational complexity and parameter scale, thereby achieving lower inference latency and a smaller model size while maintaining high detection accuracy. This strategy provides a feasible solution for deploying efficient and accurate object detection models in resource-constrained environments.
3.7. Deployment Experiments on Edge Computing Devices
In response to the real-time monitoring demands of large-scale farming scenarios, this study proposes a lightweight piglet multi-behavior recognition model architecture for widespread deployment across various farms. To evaluate the practical performance of the proposed YOLOv8-Piglet model on edge computing devices, we selected the NVIDIA Jetson Orin NX as the deployment platform and employed the TensorRT inference library for accelerated optimization. TensorRT is a high-performance inference optimization framework that utilizes techniques such as layer fusion, precision calibration, and automatic kernel tuning to maximize hardware utilization on NVIDIA GPU architectures, thereby significantly enhancing the model’s inference speed. The experimental results are presented in
Table 9.
As shown in
Table 9, YOLOv8-Piglet demonstrates a significant advantage in inference efficiency across heterogeneous computing environments (Desktop and Jetson Orin NX). On a standardized test set containing 120 images, YOLOv8-Piglet achieves an average single-frame inference time of just 6.6 ms on the desktop, a 66.5% reduction compared to the baseline model YOLOv8s (19.7 ms). On the Jetson Orin NX, YOLOv8-Piglet requires only 163.2 ms, representing a 53.8% decrease from YOLOv8s (353.9 ms). These findings indicate that, through pruning and distillation strategies, YOLOv8-Piglet not only achieves a lightweight model but also significantly enhances the edge-side computational efficiency. Consequently, it meets the stringent low-latency requirements of real-time monitoring systems and is well-suited for deployment on resource-constrained edge computing devices, making it highly promising for widespread adoption in farm environments. The diagram of the actual model deployment is shown in
Figure 13.
5. Conclusions
This study presents a lightweight behavior detection model based on the YOLOv8s architecture, capable of the real-time recognition of eight core piglet behaviors (lying, sitting, standing, drinking, suckling, mounting, head knocking, biting ear). The model accurately tracks individual development trajectories and evaluates group health metrics. By incorporating the Attention-based Intra-scale Feature Interaction (AIFI), the Gather-and-Distribute (GD) mechanism, the Layer-Adaptive Magnitude-Based Pruning (LAMP), and knowledge distillation techniques, the model achieves computational efficiency optimization while maintaining high detection accuracy.
To reduce the impact of occlusion caused by barriers or other piglets’ bodies, we introduced the AIFI module at the end of the backbone network, enhancing the model’s ability to extract features related to piglet behavior. This improvement allows the model to more accurately identify fine-grained behaviors. Additionally, the Gather-and-Distribute (GD) mechanism was incorporated into the neck network to enable lossless cross-layer transmission of feature information. Finally, the improved YOLOv8-GDA model, used as the teacher model, achieved a precision of 88.5%, recall of 87.6%, and mAP of 89.6%. To ensure that the model can adapt to most devices while maintaining detection performance in resource-constrained environments, this study conducted comparative experiments on five different pruning methods. The LAMP method was ultimately selected for pruning, with a pruning rate set to 2.0. Compared to the original model, the YOLOv8-prune model maintained nearly lossless accuracy while reducing the number of parameters by 74.7%, floating point operations (FLOPs) by 50.5%, inference time by 66.5%, and model size by 73.8%. As part of the overall optimization strategy, we applied the BCKD feature knowledge distillation technique, which significantly enhanced the performance of YOLOv8-Piglet without increasing the model complexity. As show in the experimental results, YOLOv8-Piglet outperforms the baseline model in all key metrics. Specifically, compared to the baseline model, YOLOv8-Piglet achieved a 6.3% increase in precision, a 11.2% increase in recall, and an mAP@0.5 of 91.8%, underscoring its superiority in piglet behavior recognition. When deployed on the NVIDIA Jetson Orin NX edge computing platform, the model demonstrates efficient inference speed and exceptional real-time performance. Furthermore, the model is highly scalable and can be applied to other domains, such as individual behavior detection in cattle or behavioral monitoring of small livestock like poultry.
However, there are some limitations to this study. The complex deformations occurring during pig movement—such as limb extension, torso twisting, and skin folding—induce nonlinear rigid-body transformations in the target’s appearance, which significantly increases the ambiguity in feature representation. Existing convolutional neural networks (CNNs) exhibit insufficient feature space representation when modeling such complex deformations. Future work will focus on addressing these challenges, such as by exploring deformation compensation algorithms based on biomechanical models, and incorporating 3D point cloud data augmentation to enhance the model’s ability to generalize across nonlinear deformations.
Furthermore, our research will be extended to explore the extraction of piglet behavior features in more complex environments, with the goal of enhancing the model’s robustness. This approach will enable a more comprehensive understanding of piglet growth patterns and behavioral characteristics, thereby more effectively ensuring their health and welfare, improving farm operational efficiency, and ultimately providing the livestock industry with more reliable, practical, and efficient solutions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}