
A Real-Time Lightweight Behavior Recognition Model for Multiple Dairy Goats


Simple Summary
Abstract
1. Introduction
2. Materials and Methods
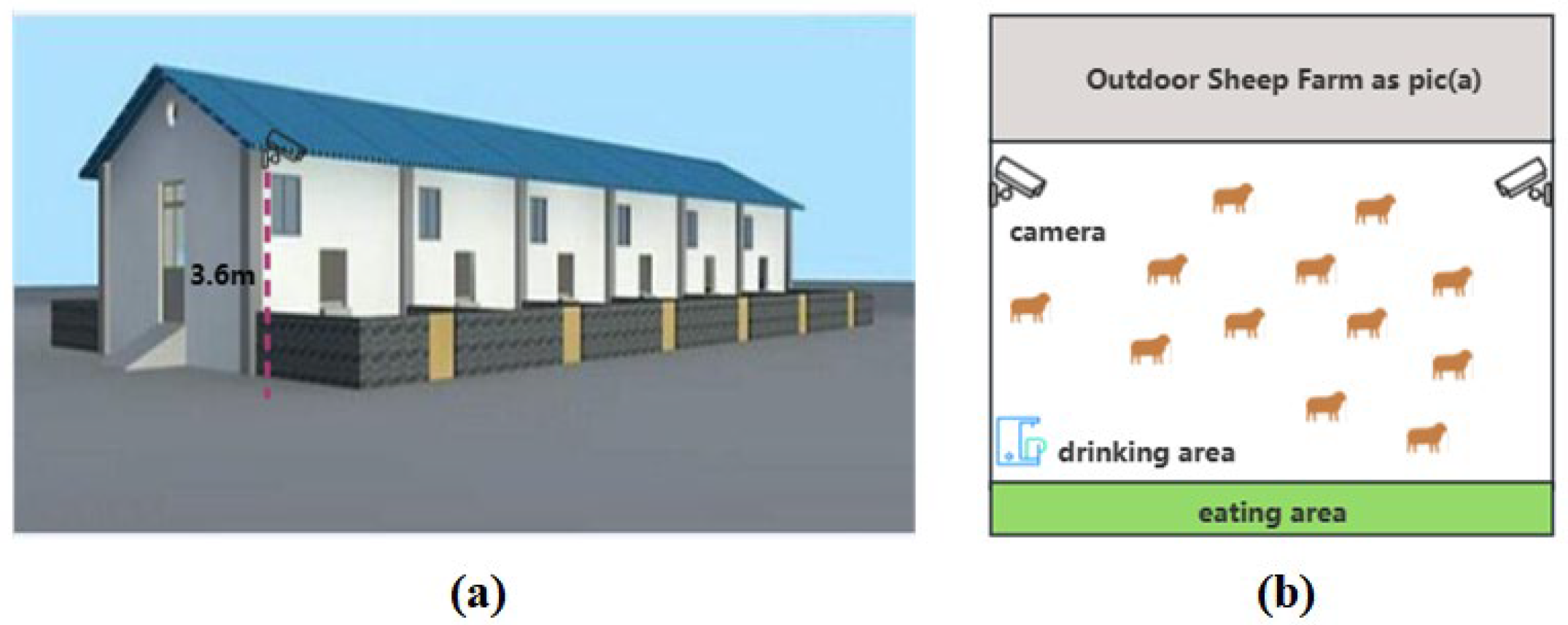
2.1. Dataset Construction
Data Source
2.2. Data Preprocessing
2.3. GSCW-YOLO Behavior Recognition Model
2.3.1. Lightweight Upsampling Operator CARAFE
2.3.2. Gaussian Context Transformer (GCT)
2.3.3. Small Object Detection (SOD) Layer
2.3.4. Optimization of Loss Function
3. Results
3.1. Experimental Platform
3.2. Evaluation Metrics
3.3. Ablation Study on the Model’s Performance
3.4. Comparative Experiments Between Different Models
3.5. Comparison of the Results of All Different Classes in the GoatABRD Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ducrot, C.; Barrio, M.; Boissy, A.; Charrier, F.; Even, S.; Mormède, P.; Petit, S.; Schelcher, F.; Casabianca, F.; Ducos, A. Animal Board Invited Review: Improving animal health and welfare in the transition of livestock farming systems: Towards social acceptability and sustainability. Animal 2024, 18, 101100. [Google Scholar] [CrossRef]
- Veerasamy Sejian, V.S.; Lakritz, J.; Ezeji, T.; Lal, R. Assessment methods and indicators of animal welfare. Asian J. Anim. Vet. Adv. 2011, 6, 301–315. [Google Scholar] [CrossRef]
- Fraser, D.; Weary, D.M. Applied animal behavior and animal welfare. In The Behavior of Animals, 2nd Edition: Mechanisms, Function Evolution; Wiley Online Library: Hoboken, NJ, USA, 2021; pp. 251–280. [Google Scholar]
- Marchant-Forde, J.N. The science of animal behavior and welfare: Challenges, opportunities, and global perspective. Front. Vet. Sci. 2015, 2, 16. [Google Scholar] [CrossRef]
- Matthews, S.G.; Miller, A.L.; Clapp, J.; Plötz, T.; Kyriazakis, I. Early detection of health and welfare compromises through automated detection of behavioural changes in pigs. Vet. J. 2016, 217, 43–51. [Google Scholar] [CrossRef]
- Cornish, A.R.; Briley, D.; Wilson, B.J.; Raubenheimer, D.; Schlosberg, D.; McGreevy, P.D. The price of good welfare: Does informing consumers about what on-package labels mean for animal welfare influence their purchase intentions? Appetite 2020, 148, 104577. [Google Scholar] [CrossRef] [PubMed]
- Alonso, M.E.; González-Montaña, J.R.; Lomillos, J.M. Consumers’ concerns and perceptions of farm animal welfare. Animals 2020, 10, 385. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.; Sturm, B. A new approach for categorizing pig lying behaviour based on a Delaunay triangulation method. Animal 2017, 11, 131–139. [Google Scholar] [CrossRef]
- Phillips, C. Cattle Behaviour and Welfare; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Yang, Q.; Xiao, D. A review of video-based pig behavior recognition. Appl. Anim. Behav. Sci. 2020, 233, 105146. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- Guo, Y.; He, D.; Chai, L. A machine vision-based method for monitoring scene-interactive behaviors of dairy calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef]
- Cheng, M.; Yuan, H.; Wang, Q.; Cai, Z.; Liu, Y.; Zhang, Y. Application of deep learning in sheep behaviors recognition and influence analysis of training data characteristics on the recognition effect. Comput. Electron. Agric. 2022, 198, 107010. [Google Scholar] [CrossRef]
- Yin, M.; Ma, R.; Luo, H.; Li, J.; Zhao, Q.; Zhang, M. Non-contact sensing technology enables precision livestock farming in smart farms. Comput. Electron. Agric. 2023, 212, 108171. [Google Scholar] [CrossRef]
- Shen, W.; Cheng, F.; Zhang, Y.; Wei, X.; Fu, Q.; Zhang, Y. Automatic recognition of ingestive-related behaviors of dairy cows based on triaxial acceleration. Inf. Process. Agric. 2020, 7, 427–443. [Google Scholar] [CrossRef]
- Kleanthous, N.; Hussain, A.; Khan, W.; Sneddon, J.; Liatsis, P. Deep transfer learning in sheep activity recognition using accelerometer data. Expert Syst. Appl. 2022, 207, 117925. [Google Scholar] [CrossRef]
- Neethirajan, S. The role of sensors, big data and machine learning in modern animal farming. Sens. Bio-Sens. Res. 2020, 29, 100367. [Google Scholar] [CrossRef]
- Watters, J.V.; Krebs, B.L.; Eschmann, C.L. Assessing animal welfare with behavior: Onward with caution. J. Zool. Bot. Gard. 2021, 2, 75–87. [Google Scholar] [CrossRef]
- Fuentes, S.; Viejo, C.G.; Tongson, E.; Dunshea, F.R. The livestock farming digital transformation: Implementation of new and emerging technologies using artificial intelligence. Anim. Health Res. Rev. 2022, 23, 59–71. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the recognition of single Cow’s motion behaviours in a complicated environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Ji, H.; Teng, G.; Yu, J.; Wen, Y.; Deng, H.; Zhuang, Y. Efficient aggressive behavior recognition of pigs based on temporal shift module. Animals 2023, 13, 2078. [Google Scholar] [CrossRef] [PubMed]
- Rohan, A.; Rafaq, M.S.; Hasan, M.J.; Asghar, F.; Bashir, A.K.; Dottorini, T. Application of deep learning for livestock behaviour recognition: A systematic literature review. Comput. Electron. Agric. 2024, 224, 109115. [Google Scholar] [CrossRef]
- Scott, P.; Sargison, N. Diagnosis and treatment of joint infections in 39 adult sheep. Small Rumin. Res. 2012, 106, 16–20. [Google Scholar] [CrossRef]
- Cruz-Paredes, C.; Tájmel, D.; Rousk, J. Can moisture affect temperature dependences of microbial growth and respiration? Soil Biol. Biochem. 2021, 156, 108223. [Google Scholar] [CrossRef]
- Jones, B.A.; Muhammed, A.; Ali, E.T.; Homewood, K.M.; Pfeiffer, D.U. Pastoralist knowledge of sheep and goat disease and implications for peste des petits ruminants virus control in the Afar Region of Ethiopia. Prev. Vet. Med. 2020, 174, 104808. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Oczak, M.; Maschat, K.; Baumgartner, J.; Pletzer, B.; He, D.; Norton, T. A computer vision-based method for spatial-temporal action recognition of tail-biting behaviour in group-housed pigs. Biosyst. Eng. 2020, 195, 27–41. [Google Scholar] [CrossRef]
- Gu, Z.; Zhang, H.; He, Z.; Niu, K. A two-stage recognition method based on deep learning for sheep behavior. Comput. Electron. Agric. 2023, 212, 108143. [Google Scholar] [CrossRef]
- Jiang, M.; Rao, Y.; Zhang, J.; Shen, Y. Automatic behavior recognition of group-housed goats using deep learning. Comput. Electron. Agric. 2020, 177, 105706. [Google Scholar] [CrossRef]
- Bao, J.; Xie, Q. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 2022, 331, 129956. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-Aware Reassembly of Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Ruan, D.; Wang, D.; Zheng, Y.; Zheng, N.; Zheng, M. Gaussian Context Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15129–15138. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies SETS new State-of-the-Art for REAL-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D. ultralytics/yolov5: v7. 0-yolov5 sota realtime instance segmentation. Zenodo, 2022. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Alvarenga, F.; Borges, I.; Palkovič, L.; Rodina, J.; Oddy, V.; Dobos, R. Using a three-axis accelerometer to identify and classify sheep behaviour at pasture. Appl. Anim. Behav. Sci. 2016, 181, 91–99. [Google Scholar] [CrossRef]
- Decandia, M.; Giovanetti, V.; Molle, G.; Acciaro, M.; Mameli, M.; Cabiddu, A.; Dimauro, C. The effect of different time epoch settings on the classification of sheep behaviour using tri-axial accelerometry. Comput. Electron. Agric. 2018, 154, 112–119. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.C.; Jeppsson, K.H.; Müller, S.; Edwards, S.; Hensel, O. Automatic scoring of lateral and sternal lying posture in grouped pigs using image processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Yang, Q.; Xiao, D.; Cai, J. Pig mounting behaviour recognition based on video spatial–temporal features. Biosyst. Eng. 2021, 206, 55–66. [Google Scholar] [CrossRef]
- Lodkaew, T.; Pasupa, K.; Loo, C.K. CowXNet: An automated cow estrus detection system. Expert Syst. Appl. 2023, 211, 118550. [Google Scholar] [CrossRef]
- Wang, Z.; Hua, Z.; Wen, Y.; Zhang, S.; Xu, X.; Song, H. E-YOLO: Recognition of estrus cow based on improved YOLOv8n model. Expert Syst. Appl. 2024, 238, 122212. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typical Behaviors | Description | Instance |
|---|---|---|
| Standing | Goats maintain a stable quadrupedal posture, with their limbs either crossed or perpendicular to the ground. |  |
| Lying | Goats lie flat on the ground with their legs folded under them or slightly extended. |  |
| Eating | Goats chew food with their mouths in contact with the food, and their heads intersect with the feeding area. |  |
| Drinking | Goats approach the water surface with their mouths, and their heads intersect with the water surface. |  |
| Scratching | Goats use their necks or bodies to rub against the walls, or they scratch their heads with their hooves. |  |
| Grooming | Goats groom themselves by licking their abdominal region or other parts of their bodies with their tongues. |  |
| Limping | Goats exhibit an unsteady gait and often display symptoms of lameness or difficulty walking. |  |
| Attacking | Goats engage in head-butting by swiftly pushing their heads against the neck, head, or ears of another goat. |  |
| Gnawing | Dairy goats bite their hoof joints with their mouths. |  |
| Death | Goats lie down on the ground horizontally, remaining still and unresponsive. |  |
| Behavior | Train_set | Val_set | Test_set | Total |
|---|---|---|---|---|
| Standing | 8274 | 1931 | 1113 | 11,318 |
| Lying | 9033 | 2319 | 1291 | 12,643 |
| Eating | 8161 | 1995 | 1058 | 11,214 |
| Drinking | 897 | 223 | 126 | 1246 |
| Scratching | 866 | 220 | 125 | 1211 |
| Grooming | 704 | 188 | 112 | 1004 |
| Limping | 548 | 144 | 73 | 765 |
| Attacking | 411 | 103 | 55 | 569 |
| Gnawing | 353 | 88 | 63 | 504 |
| Death | 457 | 103 | 54 | 614 |
| Configuration Item | Value |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00 GHz |
| GPU | NVIDIA GeForce RTX 3090 |
| Operating system | Ubuntu 18.04.6 LTS |
| Learning rate | 0.01 |
| Training epochs | 150 |
| Batch size | 32 |
| Image size | 224 × 224 |
| Optimizer | SGD |
| Model | Precision (%) | Recall (%) | mAP (%) | MB |
|---|---|---|---|---|
| YOLOv8n | 90.5 | 91.0 | 95.5 | 6.2 |
| YOLOv8n+CARAFE | 91.7 | 93.0 | 96.9 | 6.3 |
| YOLOv8n+GCT | 93.7 | 91.8 | 96.8 | 5.9 |
| YOLOv8n+SOD | 91.4 | 94.9 | 96.7 | 6.1 |
| YOLOv8n+Wise-IOU | 92.8 | 91.8 | 96.4 | 6.2 |
| YOLOv8n+GCT+CARAFE | 92.9 | 93.0 | 96.9 | 5.9 |
| YOLOv8n+GCT+CARAFE+SOD | 92.5 | 94.1 | 97.3 | 5.9 |
| GSCW-YOLO | 93.5 | 94.1 | 97.5 | 5.9 |
| Model | Percentage (%) | MB | FPS | ||
|---|---|---|---|---|---|
| Precision | Recall | mAP | |||
| YOLOv10n | 89.8 | 87.9 | 93.5 | 5.7 | 142 |
| YOLOv8n | 90.5 | 91.0 | 95.5 | 6.2 | 126 |
| YOLOv7 | 83.3 | 85.7 | 89.6 | 74.8 | 169 |
| YOLOv6n | 91.7 | 86.3 | 93.8 | 32.7 | 161 |
| YOLOv5n | 91.0 | 88.9 | 94.5 | 19.6 | 125 |
| CenterNet | 93.2 | 74.7 | 94.6 | 124.9 | 34 |
| EfficientDet | 88.8 | 89.4 | 92.5 | 15.1 | 113 |
| GSCW-YOLO | 93.5 | 94.1 | 97.5 | 5.9 | 175 |
| Model | Standing | Lying | Eating | Drinking | Scratching | Grooming | Limping | Attacking | Death | Gnawing |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv10n | 91.7 | 98.5 | 96.0 | 93.6 | 97.8 | 98.0 | 98.9 | 92.3 | 74.4 | 94.1 |
| YOLOv8n | 91.9 | 98.0 | 94.6 | 95.0 | 97.2 | 98.4 | 99.0 | 93.8 | 96.3 | 95.8 |
| YOLOv7 | 87.8 | 95.9 | 91.6 | 92.1 | 95.8 | 90.9 | 96.9 | 89.6 | 62.4 | 93.1 |
| YOLOv6n | 90.3 | 96.9 | 92.0 | 93.2 | 96.8 | 97.2 | 97.8 | 92.7 | 86.5 | 95.0 |
| YOLOv5n | 91.0 | 97.7 | 93.7 | 93.1 | 97.5 | 97.5 | 98.7 | 96.7 | 82.7 | 96.2 |
| CenterNet | 94.4 | 98.7 | 95.6 | 91.8 | 95.2 | 94.2 | 99.4 | 91.1 | 92.2 | 93.1 |
| EfficientDet | 92.3 | 98.3 | 96.3 | 90.3 | 93.9 | 95.1 | 98.9 | 89.7 | 77.7 | 92.2 |
| GSCW-YOLO | 94.5 | 99.2 | 97.2 | 95.9 | 98.1 | 98.7 | 98.8 | 97.3 | 98.3 | 97.5 |
| Livestock | Methods | Behavior Categories | Performance (%) | ||
|---|---|---|---|---|---|
| mAP | Accuracy | F1 | |||
| Sheep (Alvarenga et al., 2016) [40] | Decision Tree Algorithm | grazing, lying, running, standing, walking | 92.5 | ||
| Sheep (Decandia et al., 2018) [41] | canonical discriminant analysis (CDA), and discriminant analysis (DA) | Grazing, ruminating | 89.7 | ||
| Pig (Nasirahmadi et al., 2019) [42] | Support Vector Machine (SVM) | different pig lying postures | 94.4 | ||
| Single Cow (Yin et al., 2020) [20] | EfficientNet-LSTM | lying, standing, walking, drinking, feeding | 97.8 | ||
| Pig (Yang et al., 2021) [43] | Faster R-CNN | mounting | 95.2 | ||
| Sheep (Cheng et al., 2022) [13] | YOLOv5 | standing, lying, feeding, drinking | 97.4 | ||
| Cows (Lodkaew et al., 2023) [44] | CowXNet | estrus | 89.0 | ||
| Cows (Wang et al., 2024) [45] | Improved YOLOv8n | estrus, mounting | 93.7 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Hu, Y.; Wang, M.; Li, M.; Zhao, W.; Mao, R. A Real-Time Lightweight Behavior Recognition Model for Multiple Dairy Goats. Animals 2024, 14, 3667. https://doi.org/10.3390/ani14243667
Wang X, Hu Y, Wang M, Li M, Zhao W, Mao R. A Real-Time Lightweight Behavior Recognition Model for Multiple Dairy Goats. Animals. 2024; 14(24):3667. https://doi.org/10.3390/ani14243667
Chicago/Turabian StyleWang, Xiaobo, Yufan Hu, Meili Wang, Mei Li, Wenxiao Zhao, and Rui Mao. 2024. "A Real-Time Lightweight Behavior Recognition Model for Multiple Dairy Goats" Animals 14, no. 24: 3667. https://doi.org/10.3390/ani14243667
APA StyleWang, X., Hu, Y., Wang, M., Li, M., Zhao, W., & Mao, R. (2024). A Real-Time Lightweight Behavior Recognition Model for Multiple Dairy Goats. Animals, 14(24), 3667. https://doi.org/10.3390/ani14243667