1. Introduction
Anthropocentric bias can arise when interpreting the meaning of what is depicted in drawings. Most studies on figurative drawings; nevertheless, non-figurative drawings can also have meanings, as found in young children’s drawings [
1]. Moreover, drawings contain a large amount of information, and using a predefined set of handcrafted features limits the amount of information that can be extracted. This is particularly true when studying drawings made by non-human primates, as there may be an anthropocentric bias in choosing those features that are expected to be meaningful to us, even though they may be totally irrelevant to other species. Thus, predefined handcrafted features do not fully exploit the information content of drawings. In humans, a possible way to mitigate this issue is to ask the drawer what he or she intends to represent [
2]. However, the drawer may not be directly aware of the deep meaning of the produced drawing. For example, the method cannot be applied to scribbles drawn by very young children who are not able to communicate verbally or to children who cannot communicate because of pathologies. Obviously, verbal communication about intentions is also not applicable to non-human animals that can draw, such as other primate species [
3].
In the present study, we used artificial intelligence to analyze the drawings of a female orangutan named Molly († in 2011), who produced 1299 drawings in her last five years as part of a behavioral enrichment program [
4] at the Tama Zoo in Japan. Previous investigations of Molly’s drawings have already demonstrated that her drawings were influenced by her keeper’s identity and daily external events, such as the birth of conspecifics [
4]. The authors of [
3] investigated the differences among Molly’s drawings using traditional ethological methodologies (i.e., by selecting features and manually extracting them). These authors demonstrated the evolution of Molly’s drawings over time and the influence of seasons. For instance, Molly used green color mostly during the summer and winter seasons and pink color in spring and autumn. How she drew lines also differed according to the season. However, because of the time required to extract features manually, these analyses were conducted on only 749 of the 1299 available drawings. Moreover, the authors focused on features typically used to study children’s drawings [
5], such as loops, circles, and fan patterns, which may have a different meaning for orangutans and humans or may even be totally irrelevant.
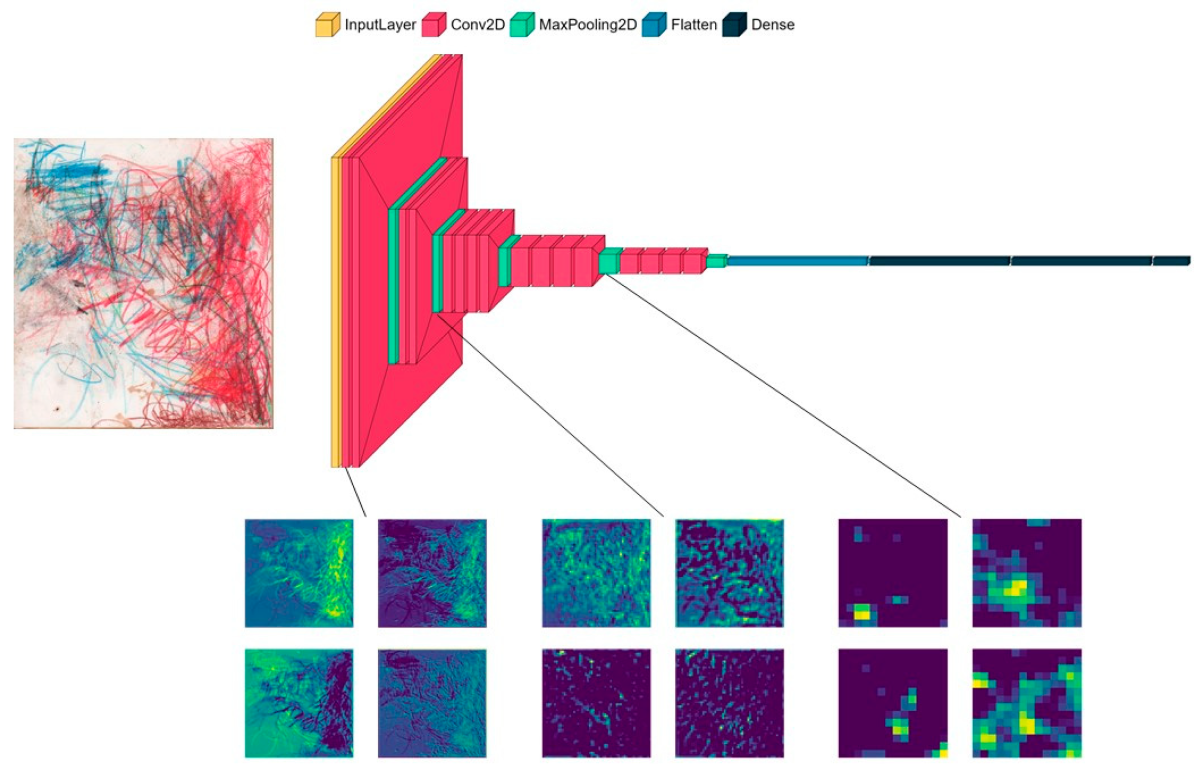
Deep learning can overcome these limitations. Deep learning is a set of artificial intelligence methods based on artificial neural networks [
6,
7] and is now widely used in computer vision. Deep learning is an efficient way to replace or complement human expertise in images analyzed in complex tasks, such as classifying microscopy images [
8] and diagnosing pathologies [
9]. Deep learning does not require handcrafted features; it only requires labeled images. Convolutional neural networks (CNNs), the most common class of deep learning algorithms in image analysis, automatically learn and extract features that are most relevant for a given task (e.g., classification of images based on their labels). CNNs are composed of multiple layers, each containing filters, which are matrices that learn feature representations. The filters are initially randomly initialized and then optimized during the training. The complexity of the features increases with the depth of the layers, from low-level features (e.g., edges, circles) in shallow layers (i.e., close to the input) to high-level features (e.g., a nose, eyes) and entire objects (e.g., a face) in deeper layers (i.e., close to the output). Convoluting a filter with an image results in a new matrix, called a feature map. A feature map, also known as an activation map, represents the activation of the filter in different parts of the image. A high activation indicates the occurrence of a feature encoded by the filter in this part of the image. CNNs allow for high accuracy but have notoriously low interpretability. Nevertheless, multiple methods have recently been developed to better understand deep learning models, such as visualizing which parts of an image are important for its classification [
10].
Despite the power of artificial intelligence to analyze images, this method has rarely been applied to understand drawing behavior [
11]. Thus far, most applications have exploited the high performance of deep learning in classification, for example, to recognize stroke representations [
12] or to classify entire drawings according to the depicted object category [
13]. However, the use of deep learning to investigate ontogeny or phylogeny has received little attention.
Here, we investigate multiple methods of using deep learning to decipher Molly’s drawings. We first tested whether season could explain the variation among Molly’s drawings by training a deep learning model to classify each drawing into one of the four seasons during which it was created. The results confirm the seasonal effect revealed in a previous study using handcrafted features [
3]. To further understand this effect, we analyze how the information spreads within the network from shallow to deep layers. More precisely, we investigated the impact of feature complexity on classification accuracy. Finally, we leverage a particular type of artificial intelligence technique named ‘style transfer’ to dissociate features associated with drawing style from those describing the representational content, and to analyze the relative importance of these two types of features in explaining seasonal variation in the predictions of the model.
4. Discussion
The analysis of drawings is usually based on a limited number of features, which may fail to capture all the relevant information conveyed by this rich and generally meaningful communication and artistic medium. Moreover, the study of drawings is also limited by our subjective, human-based interpretation and understanding of what is represented, particularly for non-representative drawings, such as those produced by non-human primates. In this study, we proposed the use of deep learning models to overcome the limitations of traditional drawing analyses, as feature selection and extraction are not performed manually. Here, we focused on the classification of drawings of one female orangutan according to the season in which they were drawn. Previous analyses have shown differences based on the main color, where the main color is green in summer and winter, and pink in spring and autumn [
3]. Thus, this study aimed to use deep learning to analyze these drawings and interpret the differences found in seasons and compare our results with previous findings. To do so, we focused on convolutional neural networks (CNNs), the most common class of deep-learning models. By comparing the model accuracy with random predictions, we showed that the trained model was able to correctly classify drawings according to the season of production. Then, by exploring the information encoded by different levels of deep learning models, we could reveal how color, representational content, drawing style, and feature complexity contribute to seasonal variation in drawings.
Our general finding that deep learning methods can successfully encode visual information and detect variations among drawings is consistent with that of previous studies on abstract paintings. For example, [
24] used a neural network to detect the correct orientation in such paintings, and [
25] used deep learning to recognize art styles in paintings, notably, abstract art. Our results extend these reports by showing that deep learning can discover structured variations that have often been considered scribbles with unpredictable variations in the literature [
26].
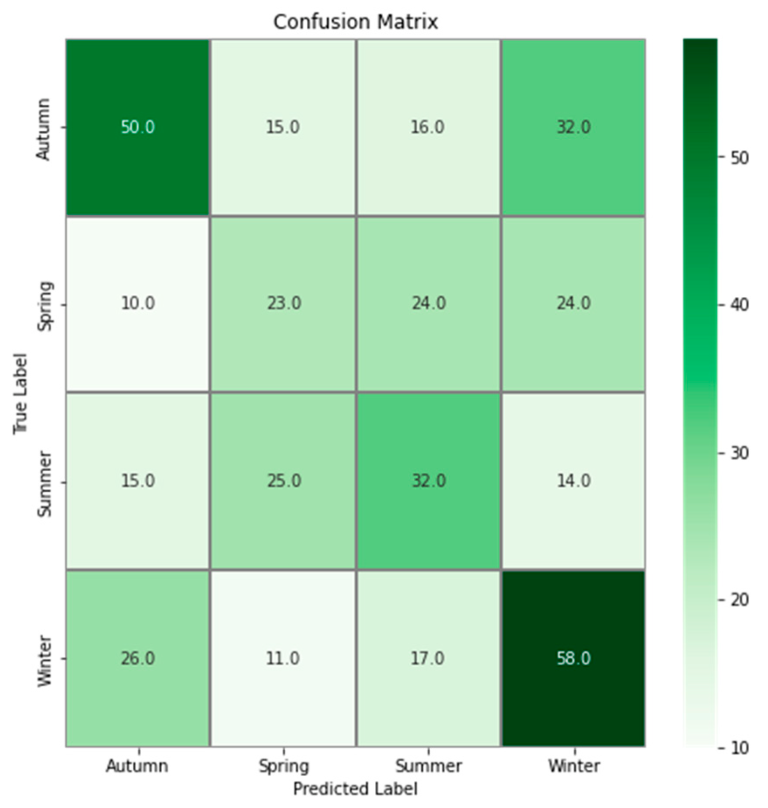
Although the CNN model classification was better than random classification, the achieved accuracy remained relatively low (41.6%). This result could be explained by multiple reasons. The first interpretation comes from the confusion matrix, which shows that drawings produced in autumn are mostly misclassified as winter; conversely, drawings produced in winter are mostly misclassified as autumn. The same pattern was observed in spring and summer. These results are inconsistent with those of [
3], in which the suggested subgroups were summer and winter in autumn and spring. This may be because the CNN analyzes more complex features that were not considered in [
3]. The relatively low accuracy of 41.6% may also be explained by the lack of a protocol when the drawings were realized, but also by external events that occurred at Tama Zoological Park. For example, [
4] observed that the drawing produced by Molly on the day another orangutan gave birth was particularly red. They also observed that when elementary school students visited the zoo, the drawings were particularly rich in color and lines. It has also been demonstrated that the behavior of captive orangutans is directly linked to their familiarity with the keeper [
27]. The sex of the keeper and the people Molly has met could also influence her behavior, as was found for a female Japanese monkey [
28], whose arterial blood pressure was different in the presence of men and women, and of strangers and caretakers. All these environmental factors likely added heterogeneity to Molly’s drawings, which contributed to blurring the seasonal variation.
To further explore this seasonal variation, we considered that an image can be seen as an association of the following two components: content and style, and that these two components can be analyzed separately. Feature maps are commonly associated with the content of the image, where the content is ‘the things represented or suggested in something written or created as art, or the ideas it communicates’, according to the Cambridge Dictionary [
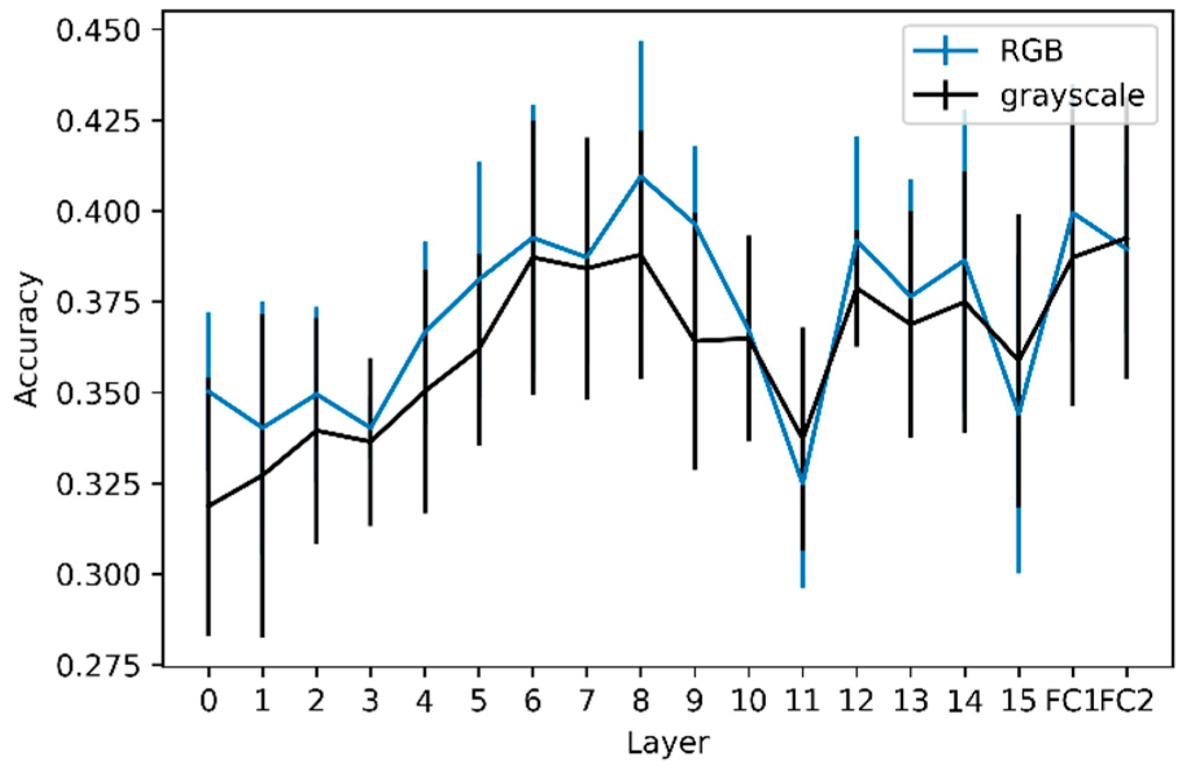
29]. For a given image, the content will be encoded through all the layers and can be analyzed by extracting activations. The complexity of the content grasped in the activations increases with layer depth. The classification of the extracted activations at each layer was significantly better than random classification, showing the latent complexity of Molly’s drawings, in which activations (i.e., content features) from low to high levels can be discriminated to a certain extent. The accuracy of activation extractions tends to increase from shallow layers to mid-layers, demonstrating the need for more complex and global content features than simple edges. However, the slope of the accuracy as a function of layer depth was not significantly positive, demonstrating that high-level features linked to the content, describing the drawing as a whole, do not contain more relevant information for prediction than mid-level content features. However, this was not the case for grayscale images, where the slope was significantly different from zero. This difference between the analyses of color and grayscale versions of the drawings demonstrates that color information on seasonal variation in Molly’s drawings is encoded more in the early layers than in the deeper layers. This is not surprising, considering that traditional analyses provide evidence for a difference in main colors depending on the season [
3]. Indeed, the main color is a low-level feature, which should be captured in the early layers, which could partly explain the importance of colors in the early layers. It is important to note that, even if not significant, the accuracy of the RGB models seems higher than that of the grayscale models. This slight difference may be explained by the features linked to colors that contain information to predict the season of the drawings. Moreover, [
30] demonstrated that shallow layers in VGG models encode information on the average hue and other low-level features, saturation, and other variables, whereas high-level features (i.e., deeper layers) can be linked to the concreteness and dynamics of the drawing. It is a complex task to disentangle high-level features that could have played a role in the predictions, but the average hue could be a proxy for the main color that was already analyzed in Molly’s drawings [
3]. The accuracies of the RGB and grayscale models were significantly different only for layer FC2. With our analyses, it is not possible to determine whether the relevant features for the RGB and grayscale models are the same. Moreover, differences between seasons are not only related to colors, as grayscale models are better than random models. As RGB models are not significantly better than grayscale models (except for FC2), adding colors only slightly refines these differences, showing that the seasonal variation lies more in the shape of the strokes than their colors.
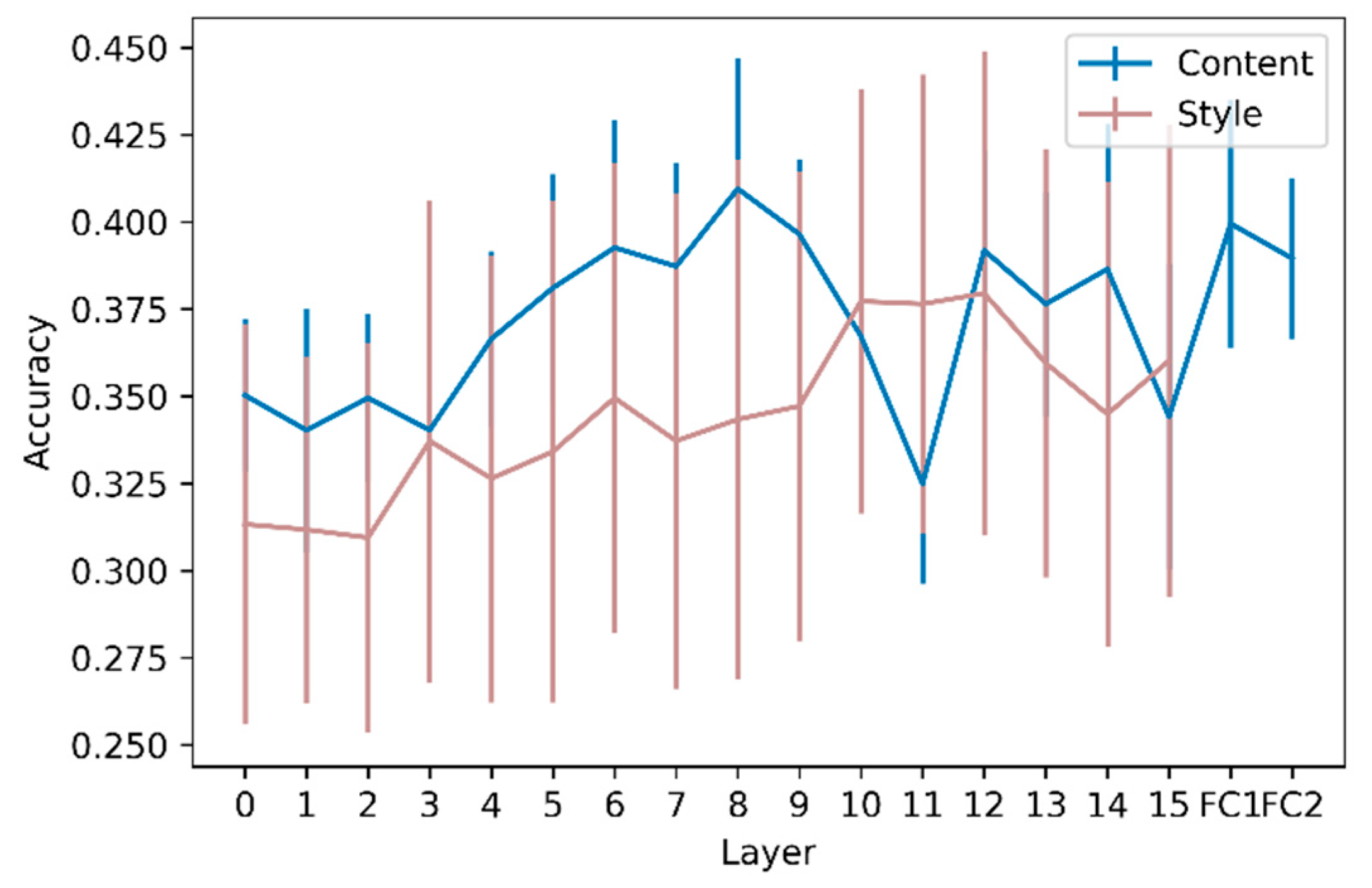
To complement the study of Molly’s drawings, which describes what is depicted, we further investigated Molly’s drawing style. To do so, we extracted Gram matrices that have been widely used in deep learning. However, how Gram matrices and styles are linked is not self-explanatory. Gram matrices in neural networks were first proposed to analyze the texture of images [
23]. Here, the word ’style also refers to the ‘texture’. No consensus has been established on the meaning of these two words; however, according to [
31], the region in an image has a constant texture if a set of local statistics or other local properties of the picture function are constant, slowly varying, or approximately periodic. The introduction of Gram matrices can be applied to analyze the style of an image dating back to [
32]. In their study, the authors proposed decomposing artistic images into content and style, with the goal of transferring the style of an image onto another image whose content is kept unchanged. Our results suggest that the content represented by neuronal activation is not sufficient to extract all the latent information conveyed by Molly’s drawings. First, the accuracy based on Gram matrices was higher than random for every layer, showing that Molly’s drawing style varied across seasons. More importantly, style-based classification became more accurate when information from deeper layers was considered. This demonstrates that the layout of the drawings, that is, their global stylistic aspect, prevails over the local stylistic features. While the peak accuracy is reached in the intermediate layers in content analyses, it is reached in the deepest layers for style, which highlights the importance of considering aspects, content, and style in drawing analysis.
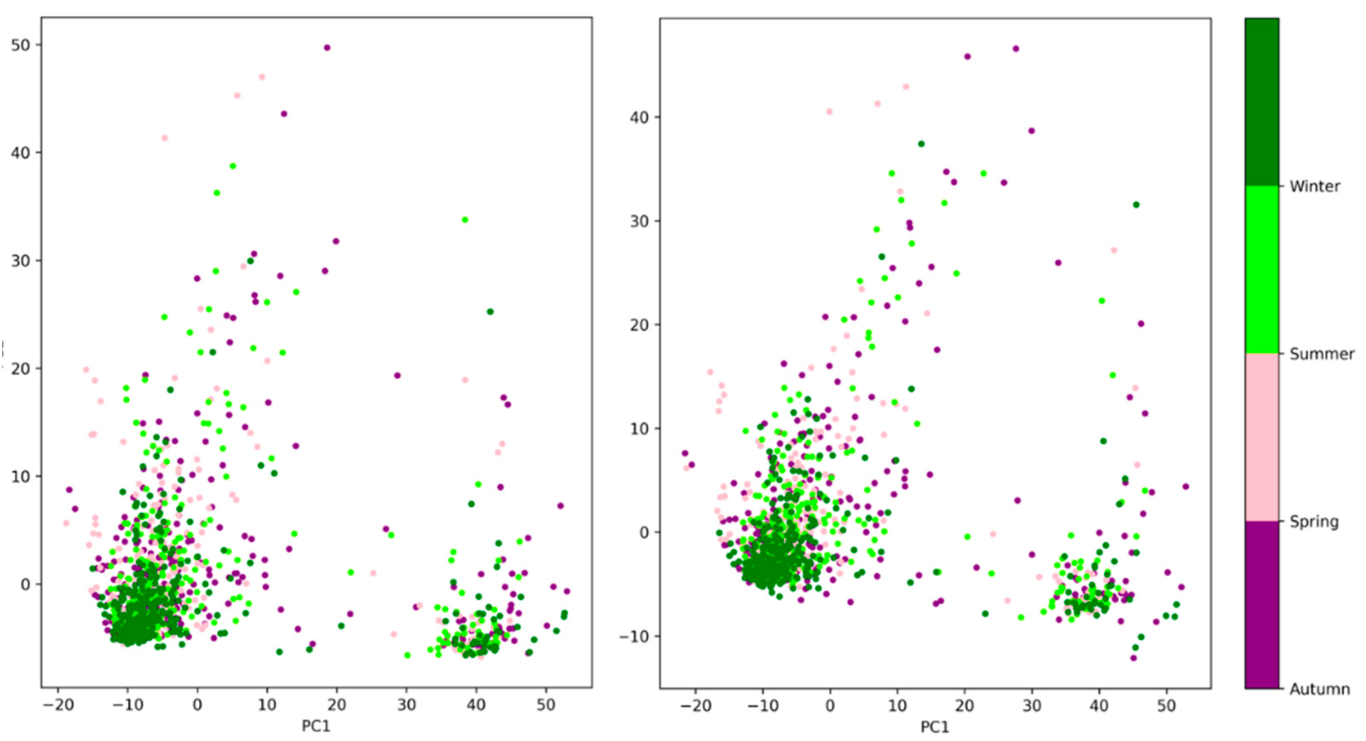
The PCA applied to the Gram matrices showed that 80% of the variation could be retained with only two principal components for the first two convolutional layers. The corresponding scatter plots of PC1 versus PC2 revealed two possible clusters that did not appear to be season-dependent (
Figure 6). With current data, it is difficult to identify the factors that explain these two clusters. They may be linked to the identity of the keeper or to various events that occurred at the Tama Zoological Park [
4]. However, the corresponding scatter plots obtained from the activation vector (i.e., for content-based classification) also exhibited two clusters. These clusters become less distinct and less marked when looking at deeper layers and completely vanish in the deepest layers, suggesting that they are primarily rooted in low-level features such as edges (orientation and width).
The approach of this study is based on the fact that biases can arise in analyses that require manual feature selection and extraction. However, deep learning reproduces biases such as race biases [
33]. Because we used transfer learning through the VGG19 architecture pretrained on a global classification task (the ImageNet dataset), the features learned by the model are generic. The choice of architecture is not crucial, as it has been shown that features from ImageNet pretrained VGG19 are shared when using other architectures [
34].
Analyzing activations and Gram matrices does not require feature selection and extraction, thus being an objective methodology. Of course, the approach proposed here is still slightly anthropocentric when interpreting the results. Indeed, the concepts of content and style are human ones, and Molly may not perceive these concepts the same way as humans do. Deep learning and feature extraction partially allow for getting rid of anthropocentric biases as no feature selection or extraction involves humans. The authors of [
3] extracted 12 simple and objective features from orangutan drawings (e.g., coverage rate, distance to the center, number of loops, number of triangles), including Molly’s ones, before performing a PCA, and the features the most correlated with the first axis were also highly linked to the content of the drawings whilst variables in the second correspond more to the style, demonstrating that even objective features will be linked to subjective ones. Whatever the approach, some anthropocentric bias linked to the production of the drawings will always remain. For example, the perceived affordance of a white canvas will be different for a human and a chimpanzee, and there will also be variability between individuals [
35]. Regardless of these biases linked to the models or data collection procedures, the interpretation of the results will be performed by humans, making it impossible to completely erase these anthropocentric biases. As Nagel wrote [
36], a human could never be able to know what it is to be another animal, but we think that artificial intelligence can help to decrease the number of biases.
5. Conclusions
Deep learning has great potential for improving our understanding of drawing behavior, both ontogenetically and phylogenetically. Such models can grasp the latent features present in abstract drawings, which is a time-consuming, laborious, and complex task for traditional analyses. The present case study on Molly’s drawings demonstrates how the complexity of content and style, which is directly linked to Molly’s drawing behavior, can be studied through a CNN, from shallow to deep layers. The layers of a CNN can be seen as the layers of a painting as follows: each layer contains partial information about the art at different levels of detail (such as colors, shapes, and contrast), and to understand a painting, one needs to combine these layers.
This study brings new advances in the understanding of drawings in non-human primates and can give highlights both on fundamental and more applied research. As regards non-verbal drawers, applying the current deep learning methodology to several ape species may lead to discoveries in the domain of evolutionary anthropology and comparative psychology. Moreover, analyzing drawings thanks to deep learning may help to assess neurodegenerative diseases in apes and enhance animal welfare. In humans, problems with languages (forgetting words, persons, etc.) allow targeting such problems but this cannot be performed with apes. Changes identified by AI in drawings with the age of individuals may help to identify such diseases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





