1. Introduction
The day-age of a chicken is a concept similar to age calculated in years, while the day-age of a chicken is counted in days. The day-age of chickens is an extremely important indicator in chicken breeding and production. Chickens of different days have large differences in their physiological state. Chickens of different physiological states require different feeding management conditions. Divide the stages according to the physiological development of chickens to facilitate targeted feeding management, which is conducive to the healthy growth of chickens and improves their production performance. The general growth and development stages of chickens [
1] are divided according to their day age:
Chicks: from newborn to 60 days old;
Child chickens: from 61 to 150 day-ages for the egg type and up to 180 day-age for the part-time type;
Reserve chickens: new chickens that have not yet started laying eggs or breeding roosters that have not been bred.
Raising reserve chickens well is a stage that cannot be ignored to improve the production and breeding value of the chicken population. In terms of different classification standards, including production status, type of production, and development stages, the detailed category information of chickens is displayed in
Table 1.
By calculating the age of chickens and classifying chickens into stages, the following production arrangements can be effectively carried out. These measures contain:
Predicting and improving the new breeding environment.
Determining whether chickens have reached the appropriate breeding, fertility, or food standards for breeding scale expansion.
Predicting the susceptibility of chickens to diseases such as abdominal fat deposition [
2] and bone quality problems [
3] at different times and applying appropriate control measures, etc.
To determine the day-age of chickens, the following methods are usually used: First, look at the beak nail. Young chickens have sharp and thin beak nails, narrow and thin beak corners on both sides, and no crusts. Chickens over a year old have slight crusts. In contrast, adult chickens have thick and short beak nails with hard and slippery ends, broad and rough corners on both sides of the beak, and large crusts. The second way is to look at the nasal tumor. The nasal tumor of mammary chickens is red, the nasal tumor of child chickens is light red and shiny, the nasal tumor of chickens over two years old has a light pink color, and the nasal tumor is larger and soft, moist and shiny. The nasal tumors of chickens over four or five years old are pink and rougher. The third way is to look at the toes. Young chicken feet are fine and soft. They have soft, flat, tiny scales on their feet and inconspicuous scale patterns. Their feet are bright red, with soft and pointed toenails and a soft texture. Adult chicken feet are stout, with thick and hard scales, clear scales, dark red, and hard and curved toenails. The fourth method is to look at the feathers. The main wings of the chicken can be used to identify the month-age of child chickens [
4]. These commonly used ways, however, can only roughly classify chickens and cannot be pinpointed to their specific day-age. If we want to record the day-age of chickens, we need to be pinpointed from the day they are born, marked by physical methods of establishment, and then recorded by manual methods. Alternatively, physical division of chickens of the same day-age and keeping chickens of different day-ages in different locations for differentiation would be labor-intensive. It is highly costly in terms of labor and requires a large space to create a physical barrier for the chickens. At the same time, accuracy can not be guaranteed, and there are always some human errors that cannot be quantified.
Therefore, it is essential to use artificial intelligence to determine the chickens’ day-ages. Improving the accuracy and precision of chicken day-age recognition has many positive implications for chicken growth and reproduction. Firstly, the susceptibility of chickens to diseases can be predicted by day-age, and effective treatment or prevention can be carried out in advance, including but not limited to isolation and the use of drugs to effectively prevent the spread and deterioration of the disease [
5]. Secondly, during different periods of egg growth, it is necessary to use scientific methods to carry out reasonable egg breeding and to separate pens for malnourished hens to ensure their daily energy intake. During the brooding and breeding period, it is important to ensure sufficient vitamin and amino acid [
6] intake for the chickens’ development and maturity. During the high laying period, it is crucial to provide sufficient protein and calcium to prolong the duration of peak egg production and thus increase egg production [
7]. The organic acid is also an important indicator [
8]. By judging it, nutrition can be increased for chickens in time to improve egg-laying efficiency. Thirdly, through day-age judgment, chickens with the best export taste and different meat quality can be precisely selected for sale. It can improve the quality of chicken meat in catering and provide different chicken meat for different dishes and customer needs, improving meat quality in general [
9]. Fourth, the day-age can be used to determine the preferences and interests of chickens, and then the living environment conditions can be changed and updated, which is conducive to improving animal welfare, which is judged by animal behavior [
10].
Taxonomists have been searching for more efficient methods to meet species identification requirements, such as developing digital image processing and pattern recognition techniques [
11], using camera traps for objection detection, which would identify species accurately and concisely. Object recognition in images is a relatively new field and the first (deep) convolutional neural network architecture and early achievement in text document recognition was described by LeCun in 1998 [
12]. In 2007, Szabolcs Sergyán implemented an image classification based on color content, where the colors are stored in the intensity vector of image pixels, and the information can be easily retrieved. Colors can be represented in different color spaces or features and can be stored in several ways. RGB is a color space widely used for image display [
13].
Face recognition has already been a widely used technology, and it has been applied in many areas. Graham, E.H. et al. proposed a new GoogLeNet-M network with regularization and migration learning. It is demonstrated that the regularized GoogLeNet-M network with migration learning has the best performance, with a recall of 0.97 and an accuracy of 0.98. [
14]. Fang, Cheng et al. used a deep neural network technique to estimate the chicken pose. The standard deviation of the accuracy of the method proposed in this paper is 0.0128, and the confidence level (95%) is 0.9218 ± 0.0048. The other case is the standard deviation of recall is 0.0266, and the confidence level (95%) is 0.899 6 ± 0.0099 [
15].
After achieving significant results in face recognition, developments also started in pig face recognition. The adaptive pig face recognition method based on the convolutional neural network developed by Marsot achieved 83% accuracy, promoting the application of artificial intelligence for animal recognition in pig production [
16]. Li, G. et al. designed a noninvasive pig face recognition method based on the improved YOLOv3 recognition method. This method allows multiple pigs to be recognized simultaneously. The results show that the YOLOv3_DB_SPP model improves the feature extraction ability of the primary feature extractor and the accuracy of the detector [
17]. Li, S. et al. further proposed a method for individual pig recognition based on the improved YOLOv4 convolutional neural network. The results showed that the test set’s average accuracy (mAP) reached 98.12% when the threshold value was 0.5. The recall rate reached 95%, the F1 score was 96%, the average recognition time Mean FPS was 34.3ms, and the average crossover ratio (IoU) was 83.91%. Compared with the improved model of Fast R-CNN, YOLOv3 improves the recognition accuracy and speed of individual pigs; meanwhile, the recognition accuracy of the pig body dataset is significantly improved compared with the traditional pig face dataset [
18].
The results achieved in the study of pig faces have gradually turned people’s attention to other animal face recognition, and other animal face recognition has begun to attract people’s attention. Yao, L. et al. proposed a cattle face recognition framework using a dataset containing about 50,000 annotated cattle face detection data and 18,000 cow recognition data. They proposed a hybrid detection and recognition model to improve the recognition performance of the method with 98.3% accuracy for detection, and 94.1% accuracy for cow face recognition [
19]. Andersen, Pia Haubro et al. used two methods for horse face recognition. Preliminary results indicate that dynamics are essential for pain recognition and show that recurrent neural networks can classify experimental pain in horses better than human raters [
20]. Zang, X.L. et al. introduced an algorithm for oblique image correction of cow faces. The algorithm used color image preprocessing and image binarization to separate the cow’s facial image from the background. It improved the computational speed by improving the integral projection function and reducing the image resolution. Finally, it improved the accuracy of the angle according to the symmetry of the cow’s face and corrected the cow’s facial image according to the angle. Experiments show that the algorithm has good computational speed and correction effect [
21].
After studying biometric facial recognition comparison methods, research attention has also been extended to intelligent poultry farming systems and the study of chicken disease recognition. All these studies used deep learning [
22,
23,
24,
25,
26,
27,
28]. Chicken counting and gesture research methods are also gradually being carried out. These studies provide the basis for the research on chicken face recognition and indicate the development direction.
Encouraged by the above research, this paper has the following main contributions:
A module of attention encoder was proposed to improve the accuracy of CNN models using the attention mechanism.
Improved the quality of the training set using various dataset enhancement methods.
Applied the attention encoder module to various mainstream CNN models for validation.
Several ablation experiments were implemented to discuss the factors affecting the performance of attention encoders.
An iOS-based chick day-age recognition application was developed.
The rest of this paper is organized as follows: (1)
Section 2 describes basic information about CNNs and mainstream models. (2)
Section 3 provides the details and preprocessing methods of the dataset. It also explains the structure of the attention model. (3)
Section 4 gives the experimental environment and results. (4)
Section 5 summarizes the whole article.
2. Related Works
In the 1980s, computers showed excellent processing ability in digital recognition because the multilayer perceptron model [
29] was proposed. But due to the limitations of computing power, especially the processing power of CPU and storage resources, the size of the data that could be processed was small, the model expression ability was poor, and it usually could not handle complex picture problems. In 2006, Hinton et al. [
30] proposed a layer-by-layer pre-training algorithm for network models, which enabled artificial neural networks with multiple hidden layers to have powerful feature learning capability by increasing the number of layers of artificial neural networks. They trained multilayer neural networks with small central layers to reconstruct high-dimensional input vectors, and effectively reduced the deep training difficulty of neural networks by encoding dimensionality reduction. In addition, other researchers have used support vector machines to overcome some of the difficulties encountered in training deep CNNs [
31]. Afterward, the concept of deep learning and the rapid development of CNNs received much attention from researchers. In the early 21st century, many Internet technology companies such as Google and Microsoft invested a lot of human and material resources in developing and commercializing large-scale deep learning systems.
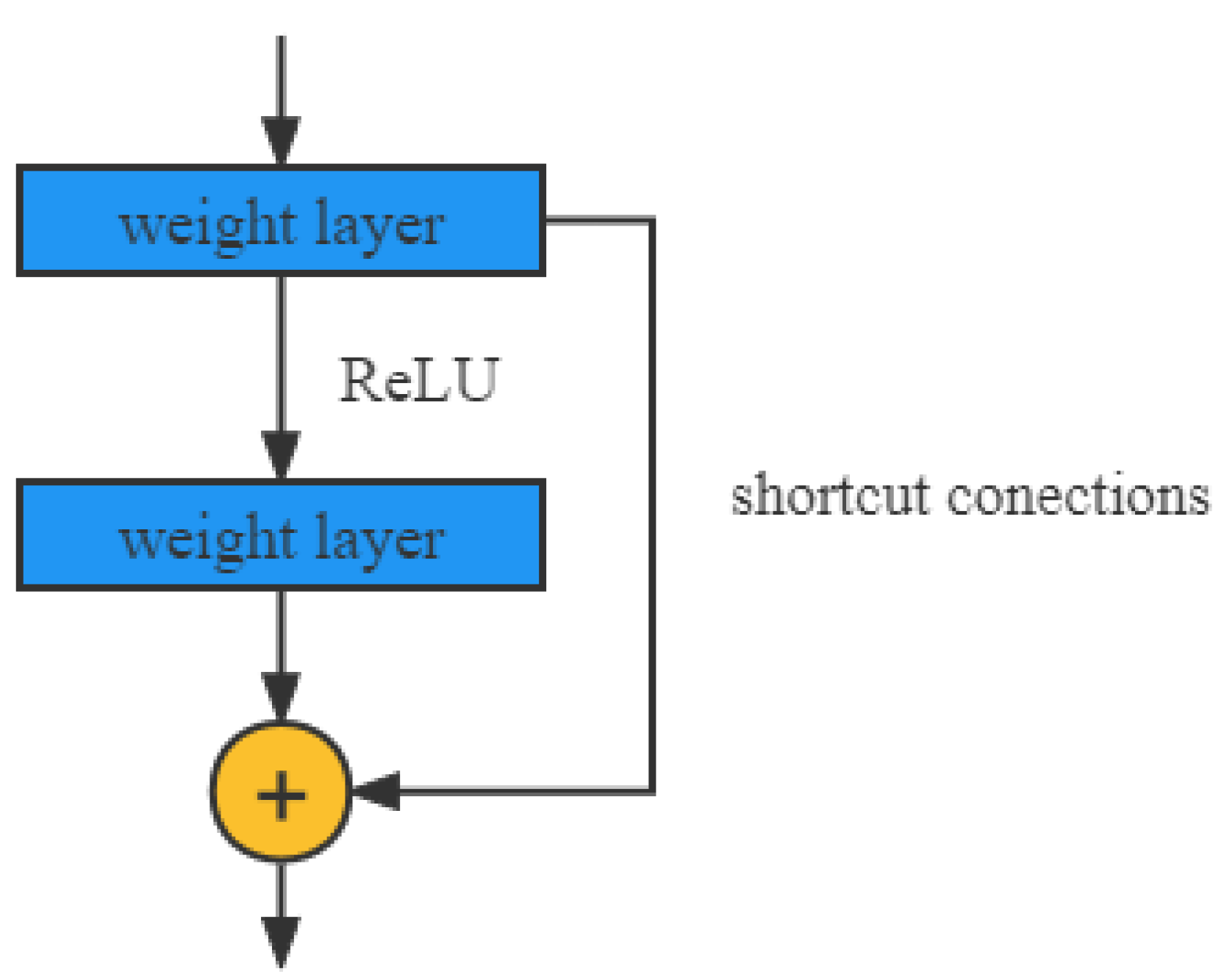
The convolutional model-a multilayer feedforward neural network model - its network structure is characterized by the use of a separate set of convolutional kernels in each layer. This structure helps to extract useful features from locally relevant data points. During the training process, CNNs learn through a backpropagation algorithm [
32]. This backpropagation algorithm optimizes the objective function using a response-based human brain-like learning mechanism. The continued success of backpropagation algorithms and CNNs has led to a new phase of development in the field of artificial intelligence.
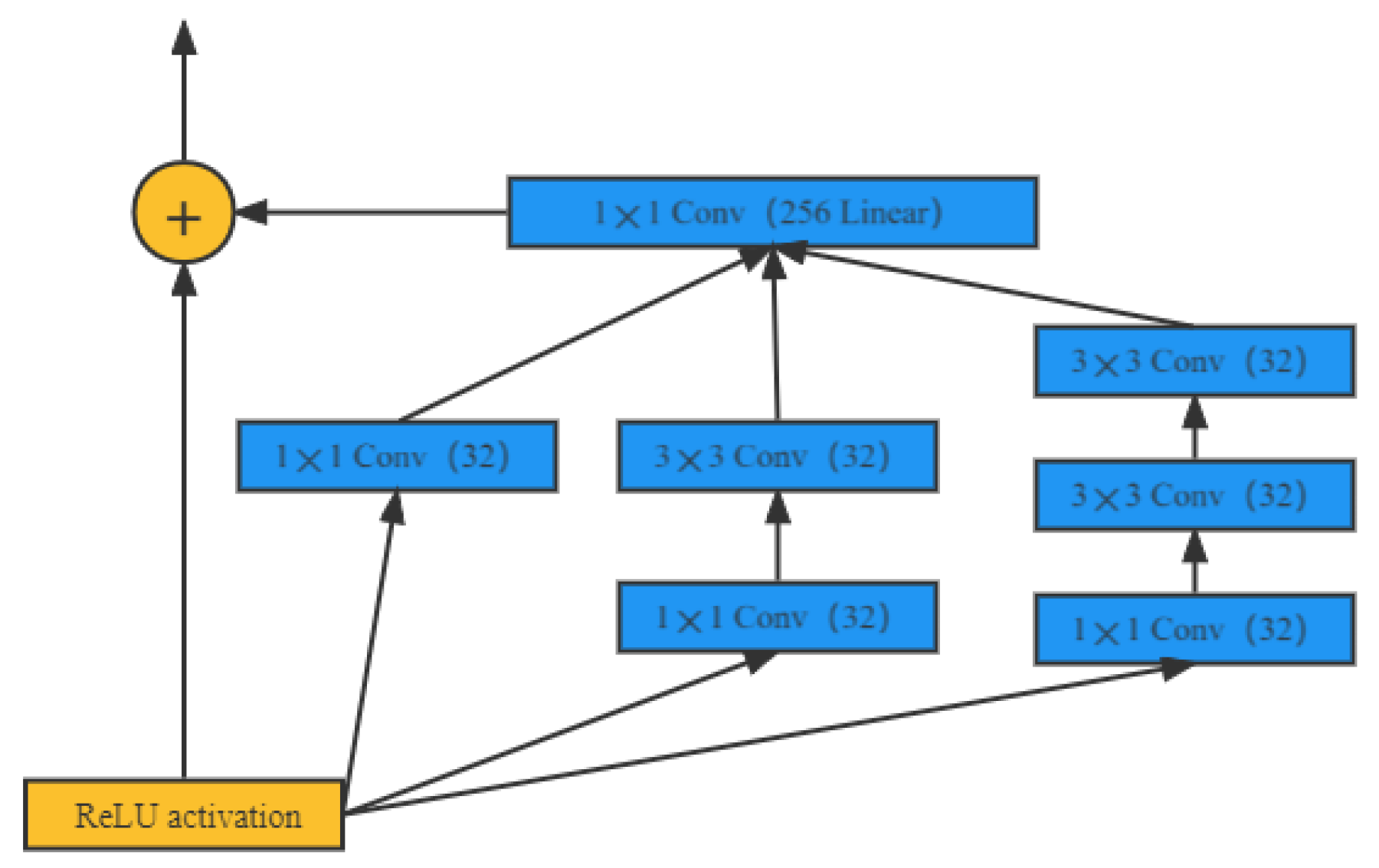
Deep architectures often perform better than shallow architectures when dealing with complex learning problems, especially after the LeNet convolutional neural network model [
33] on the Minst dataset, related network models such as AlexNet [
11], VGG [
34], GoogLeNet [
35], ResNet [
36], and MobileNet [
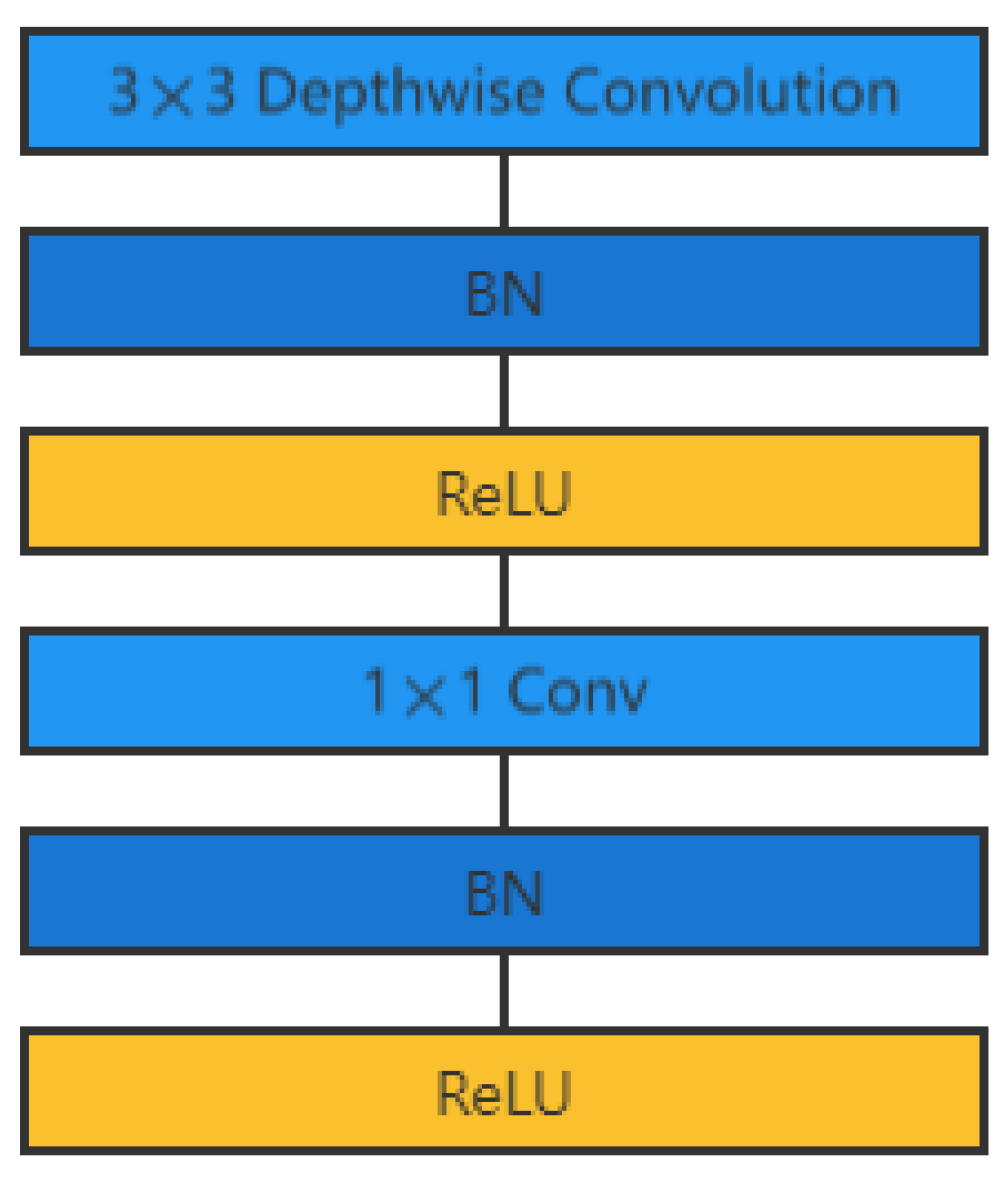
37] have emerged successively. They have been widely used in the fields of medical image processing and case segmentation.
2.1. Basic Structure of CNN
Modeled after biological neural networks, CNN uses a core weight-sharing network structure that allows them to scale the network model by varying the depth and width of the network. This chapter summarizes some representative components of popular deep neural network models.
2.1.1. Convolutional Layer
CNN models have strong assumptions about natural images, namely statistical smoothness and local correlation. The convolution operation can effectively reduce the learning complexity of the network model with fewer connection and weight parameters, which makes it easier to train than a fully connected network of the same size. There are four common convolution operations: normal convolution [
38], transposed convolution [
39], dilated convolution [
40], and deeply separable convolution [
37].
Ordinary convolution is the process of sliding the convolution kernel over the image and finally completing the computation of gray values of all image pixels through a series of matrix operations. Transposed convolution implements the sampling operation in the reverse direction of ordinary convolution and is widely used in semantic segmentation [
41], image recognition [
42], etc. Dilated convolution, also known as hole convolution, injects holes into the convolution kernel to increase the perceptual field [
43] of the model for better feature extraction. Dilated convolution has achieved better performance in tasks such as image recognition [
44]; deeply separable convolution has also been extended for the lightweight network model MobileNet. Compared with the typical convolutional approach, it significantly reduces the number of parameters required for the network model operation. Most importantly, the depth-separable convolution separates channels and regions in the regular convolutional operation. The convolution method’s improvement alleviates the feature extraction problem to some extent.
2.1.2. Activation Function Layer
The application of activation functions increases the nonlinearity of neural network models. The commonly used activation functions are Rectified Linear Unit (ReLU) [
11], Randomized ReLU [
45], Exponential Linear Unit (ELU) [
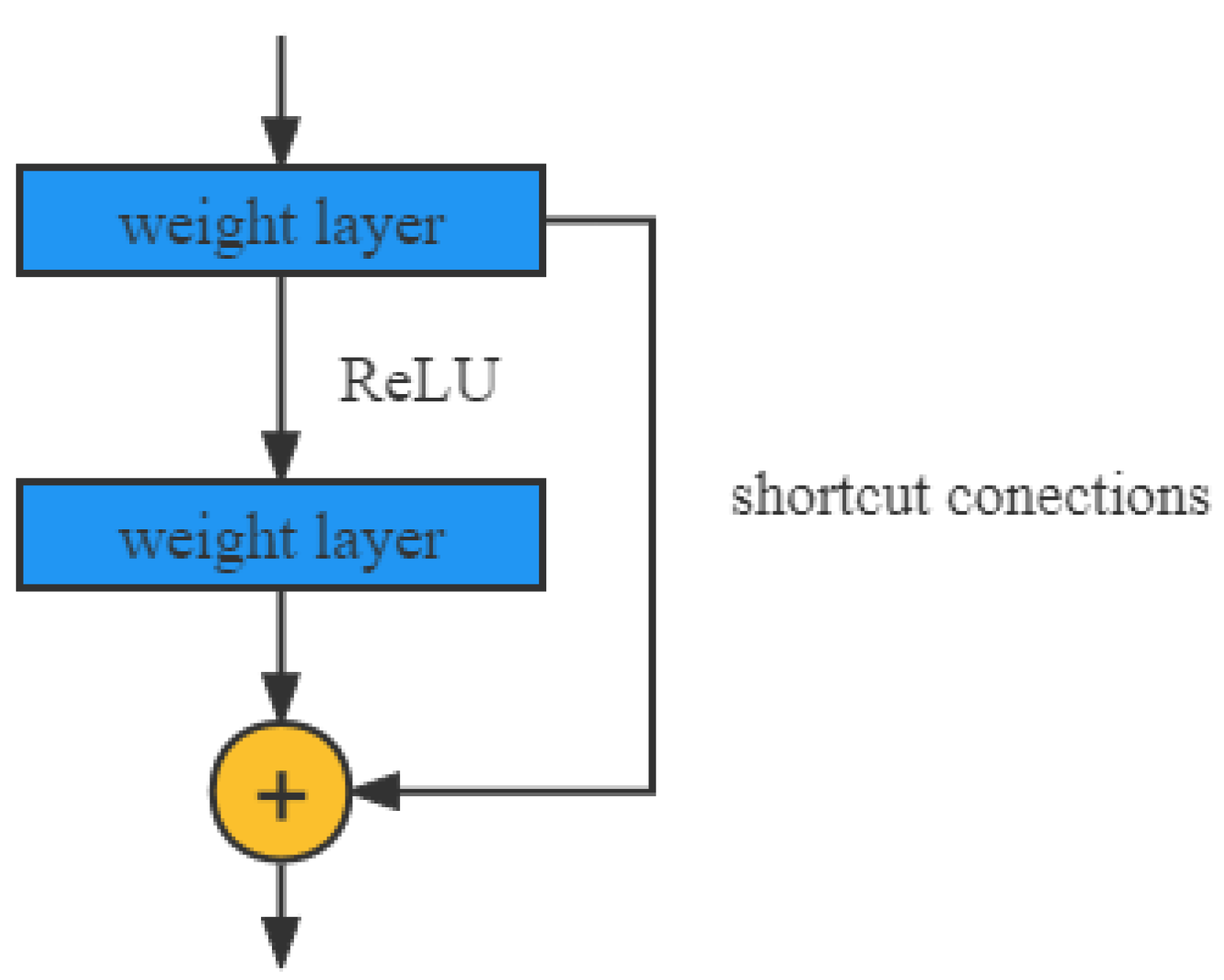
46], and so on. ReLU is one of the most remarkable non-saturation activation functions, as shown in
Figure 1, and its mathematical expression is as follows:
Although the discontinuity when ReLU is 0 may impair the backpropagation performance, it has been shown that ReLU is more effective than Sigmoid and tanh activation functions [
47].
2.1.3. Batch Normalization Layer
Gradient descent is a simple method used to train neural networks, but it requires artificial parameter selection, resulting in much of the researchers’ time consumption in uncertain tuning efforts. In 2015 the Google team proposed the idea of Batch Normalization (BN) [
48]. This method allows researchers to choose a more significant learning rate, allowing the model to multiply in training while also giving the model fast convergence.
The BN layer avoids the problem of gradient dispersion and gradient explosion in addition to the data death of the ReLU activation function. It also reduces the difficulty of initializing the weights. Usually, for the data to be trained, the mean
and variance of the current batch
of data should be calculated first. The output of BN is calculated according to the following equation:
The parameter
avoids division by zero and increases numerical stability; the learnable parameters
and
are used to adjust the data to a reasonable distribution range. The statistics of the global training data
and
are also updated iteratively according to Equations (
2) and (
3).
Among them, momentum is a hyperparameter to be set to balance the update magnitude of
and
. The BN layer calculates the output
in the test phase according to Equation (
4).
Among them, are obtained from the statistical or optimization results of the training phase and are used directly in the testing phase without updating these parameters.
2.1.4. Pooling
The pooling layer is one of the standard components in current CNNs and has been named pooling since the AlexNet [
11]. Pooling layers represent images by mimicking the human visual system to reduce the dimensionality of the data and use higher-level features.
In practice, the most commonly used pooling methods are max pooling, average pooling, spatial pyramid pooling, etc. In addition to reducing the model computation and information redundancy, the pooling operation also improves the model’s scale and rotation invariance to different degrees, effectively preventing overfitting. The improvements in various pooling methods also better achieve feature compression and extraction, significantly reducing the time required for model training.
2.2. Mainstream Models
Deep learning-based CNN can be used for image recognition and classification. This method automatically learns features from a large amount of data used to improve the performance of pattern recognition systems. Most of the current approaches of conventional image classification networks directly use common deep convolutional networks for direct image classification, such as AlexNet [
11], VGG [
34], GoogleNet [
35], ResNet [
36], MobileNet [
37], and so on, which have been used in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
49] to prove their application value.
4. Results and Discussion
4.1. Platform and Parameters
The test device is a desktop computer with a Core i9-10900k CPU and Nvidia RTX3080 GPU. In the training process, the experiments were run on Ubuntu 20.14, using the Python programming language, and the model implementation was based on the PyTorch framework. The number of learning rounds was set to 150, and the network was optimized using the stochastic gradient descent algorithm, where the initial learning rate is .
4.2. Experiment Results
The results of the experiment are shown in
Table 3.
The model using ResNet-50 as the backbone achieves 95.2% accuracy, outperforming a range of automatic augmented search methods. Also, this paper compared the GPU hours of pre-training and pre-search. Moreover, once pre-trained, the model in this paper can be applied to multiple classification tasks without additional fine-tuning. CutMix and its variants can be used to obtain better results by introducing inter-sample regularization. This model can also be combined with CutMix to improve performance further.
To further investigate the accuracy of ResNet-50 on different day-age, we conducted experiments and obtained
Table 4.
From the experimental results, it can be seen that the model is most accurate in identifying the day-age of the three periods-1–10, 10–15 and 15–20, and its accuracy rate is over 97%. The accuracy of the model for the three periods 21–24, 25–28 and 29–32 decreased, probably because the time steps of the last three periods were shorter and the changes of the facial features of chickens in this period were smaller.
We also tested the generalization performance of our model on several fine-grained classification datasets. For all experiments, 90 rounds of fine-tuning were performed on ResNet-50 from the official pre-training checkpoint provided by PyTorch. To ensure a fair comparison, we keep the hyperparameters identical during the experiments running the baseline and present models. The experimental results are shown in
Table 5.
From the results in the above table, it can be seen that the model in this paper can effectively improve the performance of fine-grained classification.
4.3. Ablation Study
In order to investigate how the masking rate affects the model performance, this paper experimented with masking rates ranging from 20% to 80%. The experimental results are shown in
Table 6.
The experimental results show that the pre-trained mini-Model achieves the best performance at a rate of 40%. This suggests that smaller models may not converge well at higher masking rates. However, a minimal masking rate can also make the pre-training task too easy, which may affect the generalization ability of the pre-trained mini-Model.
Therefore, in this paper, we conduct experiments for different model sizes, and the results are shown in
Table 7.
The experimental results show that using a larger model as an enhancer brings higher classification accuracy for the same masking rate. This is because the larger model captures more accurate attention information and provides more robust regularization. However, the memory and speed costs of the large-Model are unaffordable. By tuning the masking rate, the mini-Model achieves better performance with a 6x speedup and 95% parameter reduction compared to the large model.
The Pretraining epoch is an important hyperparameter for self-supervised learning. For example, MoCo-v2 requires 800 epochs, and MAE requires 1600 epochs to converge with large models. Therefore, this paper investigated the model’s accuracy with different pretraining epochs. The result is shown in
Table 8.
The experimental results show no significant difference in model performance when extending the pre-training epochs from 200 to 800, indicating that the 200 pre-training epochs are sufficient for the mini-Model.
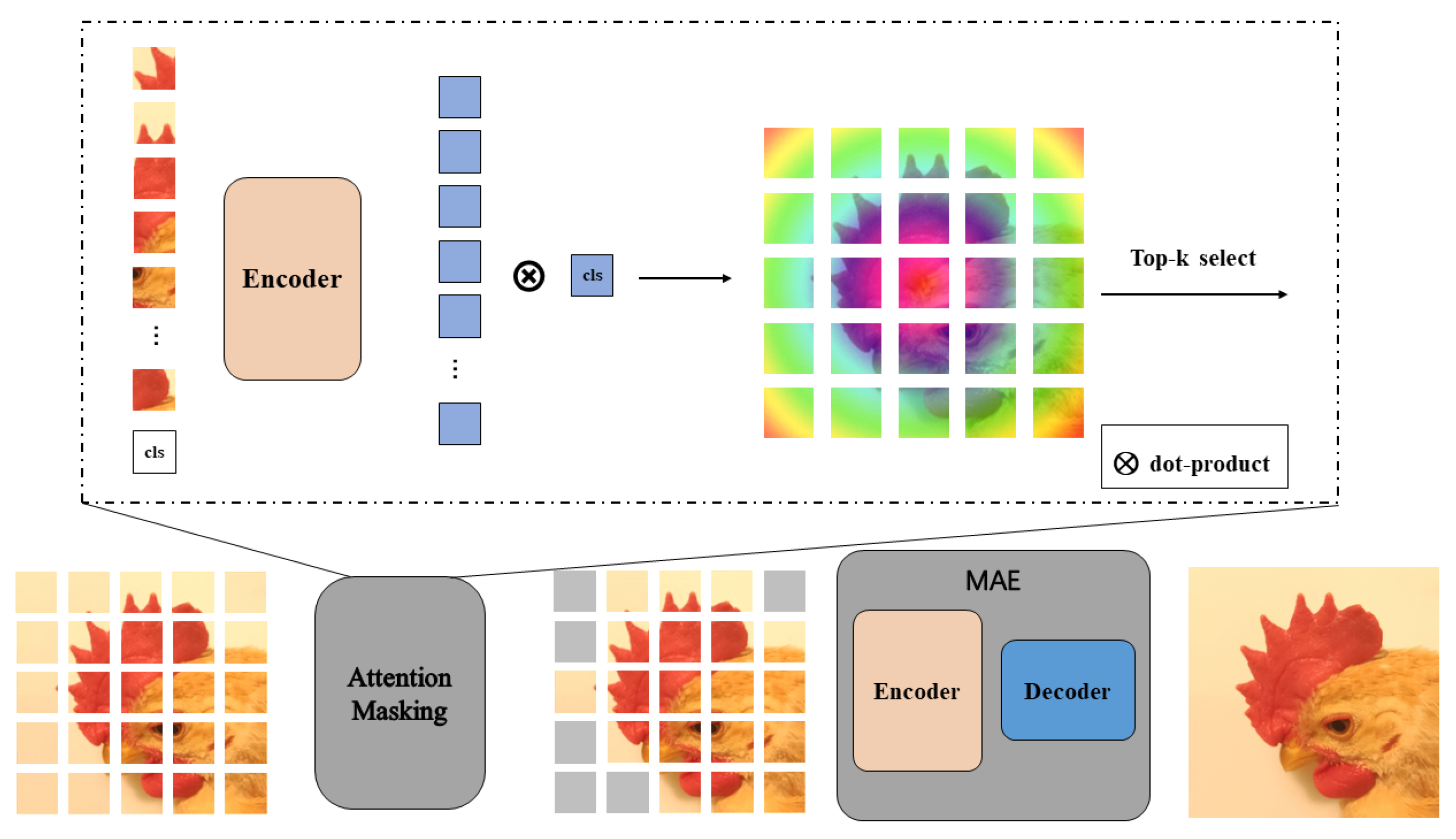
4.4. Intelligent Chick Recognition System
4.4.1. Wireless Collection System for Chicken Farms
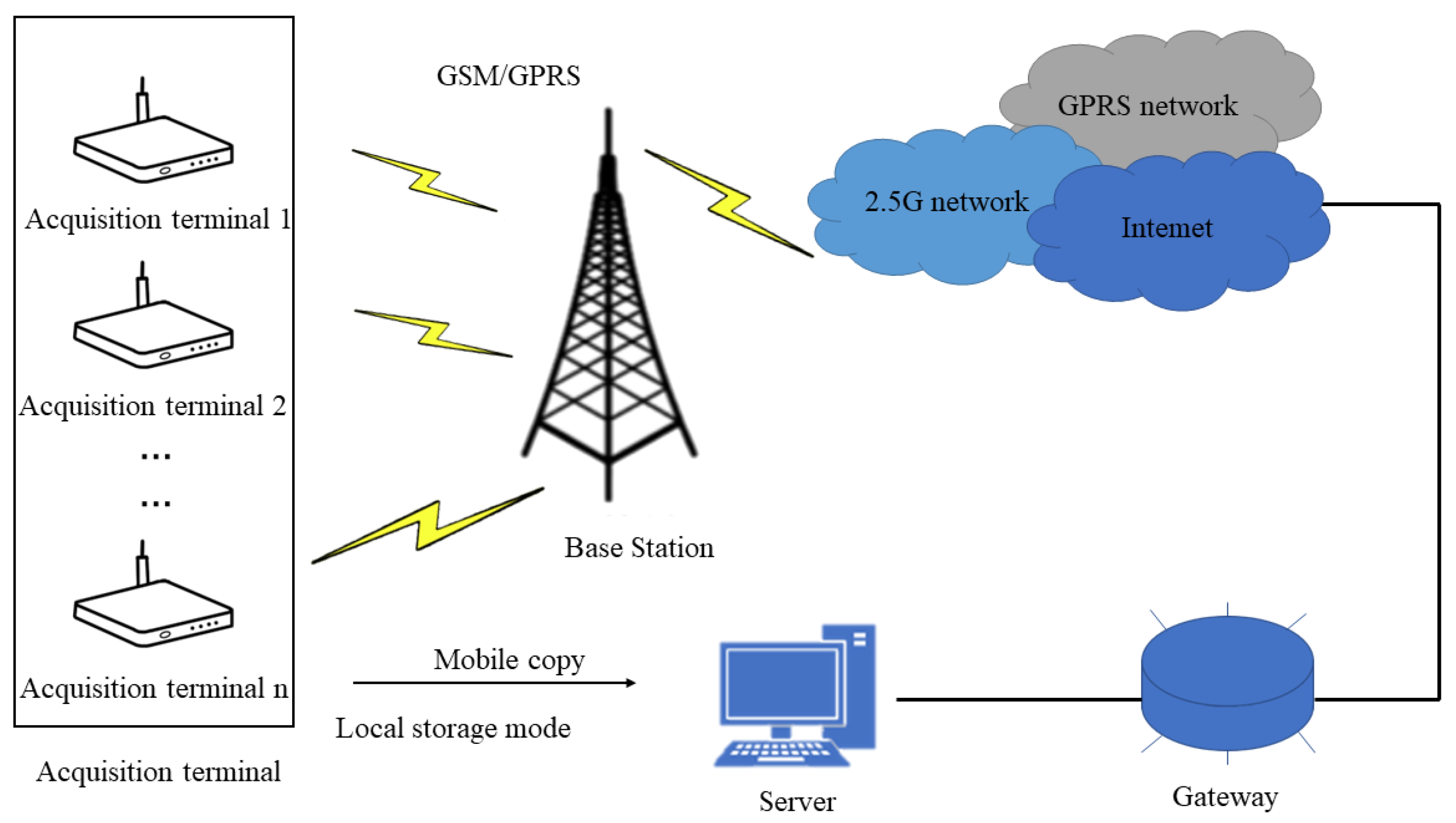
Based on the existing system, this paper designed a broiler farm acquisition system based on wireless transmission technology, which includes three parts: the acquisition terminal, the wireless communication module, and the remote server, as shown in
Figure 8.
Among them, the acquisition terminal is placed in the broiler farm to collect the broiler video signal regularly or in real-time and add a filtering algorithm to collect high-quality signals. The wireless communication module specifically contains GSM/GPRS communication module and WiFi communication module, which are used to establish the socket communication connection between the collection terminal and the remote server, and send the collected audio signals from the collection terminal to the remote server. After the remote server receives the signal, it stores it in the external memory so that the manager can further process the signal.
The system is currently deployed in Rizhao City, Shandong Province, China. This system helps chicken farm staff automatically detect the behavior of chickens.
4.4.2. Application of Chick Day-age Recognition
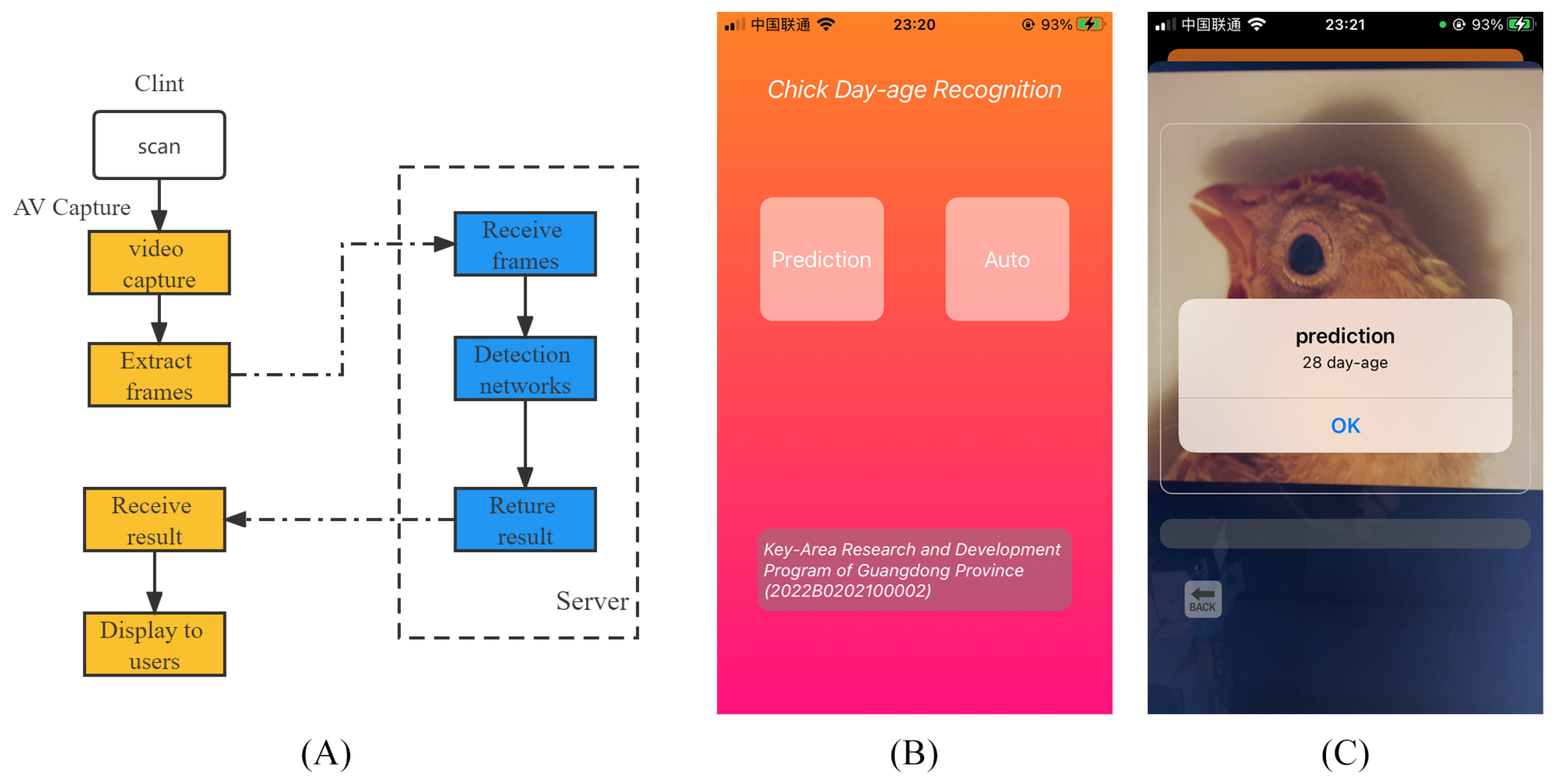
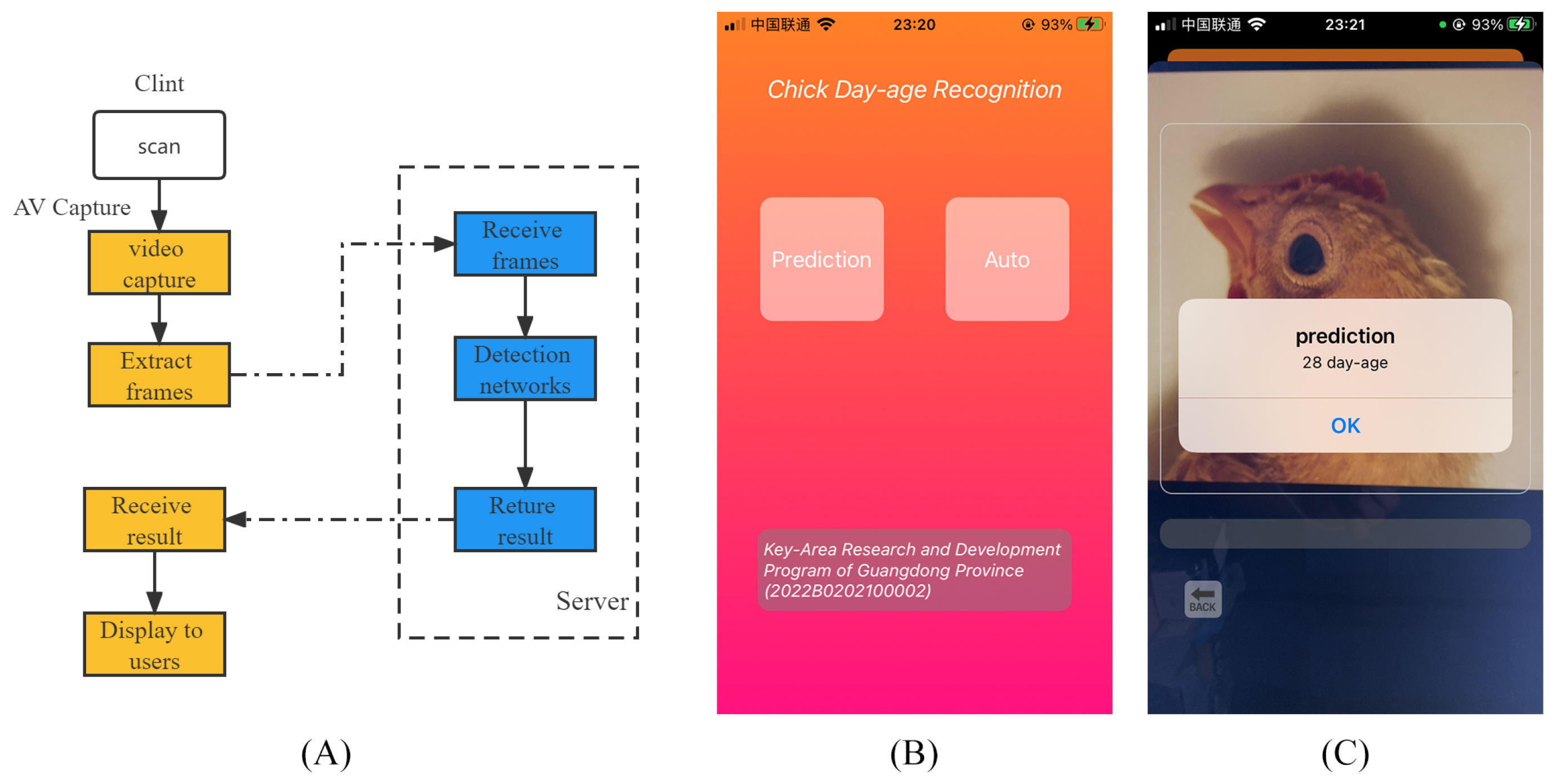
In addition, in order to apply the model in this paper to a practical scenario, we designed a chicken day-age recognition application based on iOS development techniques, as shown in
Figure 9.
Figure 9A shows the technical process of the application, and
Figure 9B is a screenshot of the application in use.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}