
Development of a Slow Loris Computer Vision Detection Model

Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Acquisition
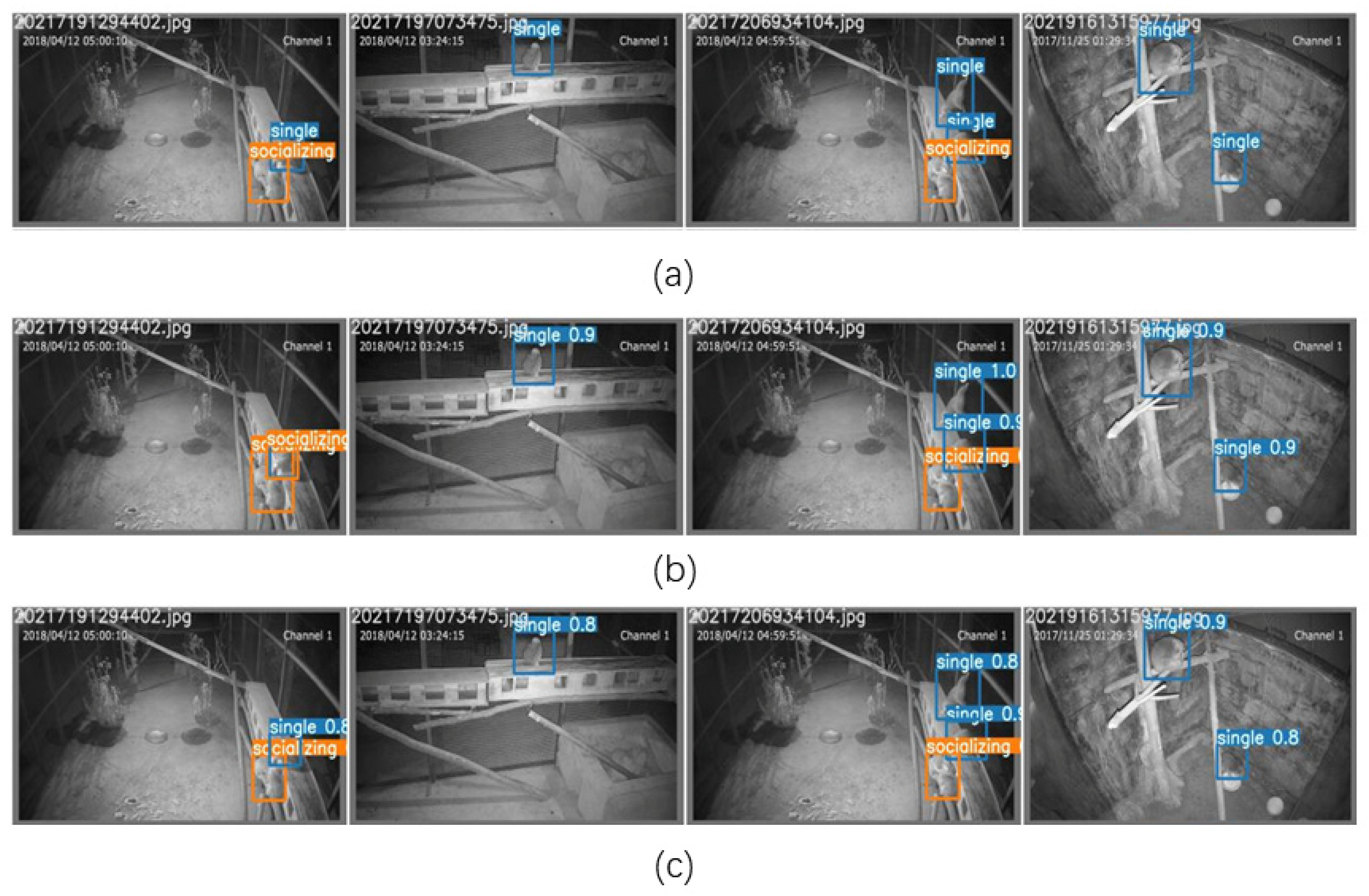
2.2. Definition of the Slow Loris States
2.3. Experimental Environment and Hardware Configuration
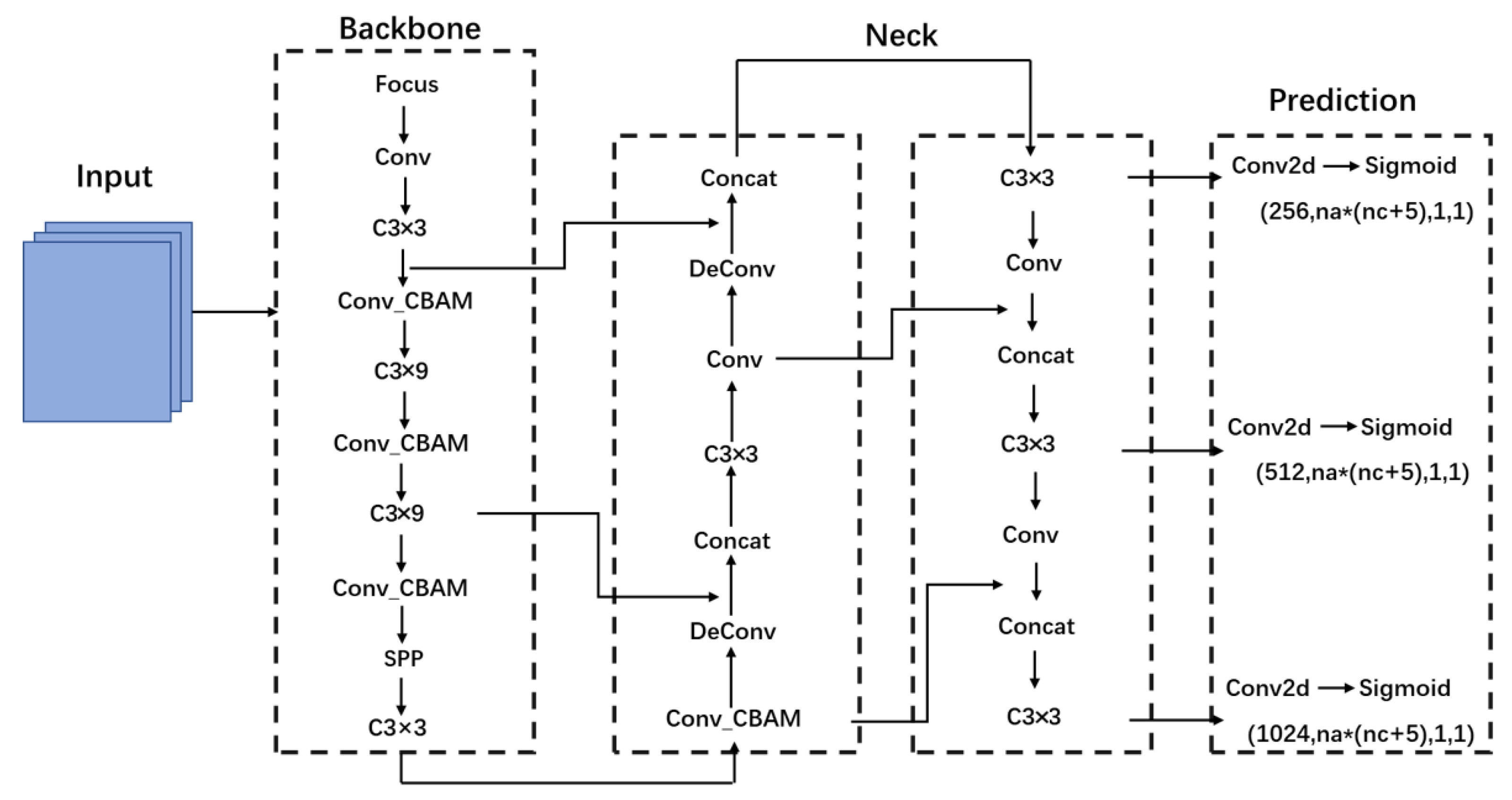
2.4. A YOLOv5 Network Introducing Attention Mechanism and Deconvolution
2.4.1. YOLO Series Models
2.4.2. Attention Mechanisms
2.4.3. Deconvolution
- Padding: Before the convolution operation, the boundaries of the original matrix are filled with padding. Specifically, some values are padded on the boundary of the matrix to increase the size of the matrix. 0 is commonly chosen.
- Stride: When sliding the convolution kernel, start with the top left corner of the input, and step over one column to the left or one row down at a time. The number of rows and columns in each slide is called Stride. During the convolution process, padding is used to avoid information loss and the step size (Stride) is also set to compress part of the information or make the output size smaller than the input one.
- Channel (number of filters): The number of output channel layers is only related to the number of channels in the current filter.
2.4.4. Network Structure
2.5. Evaluation Indicators for the Experiment
3. Results
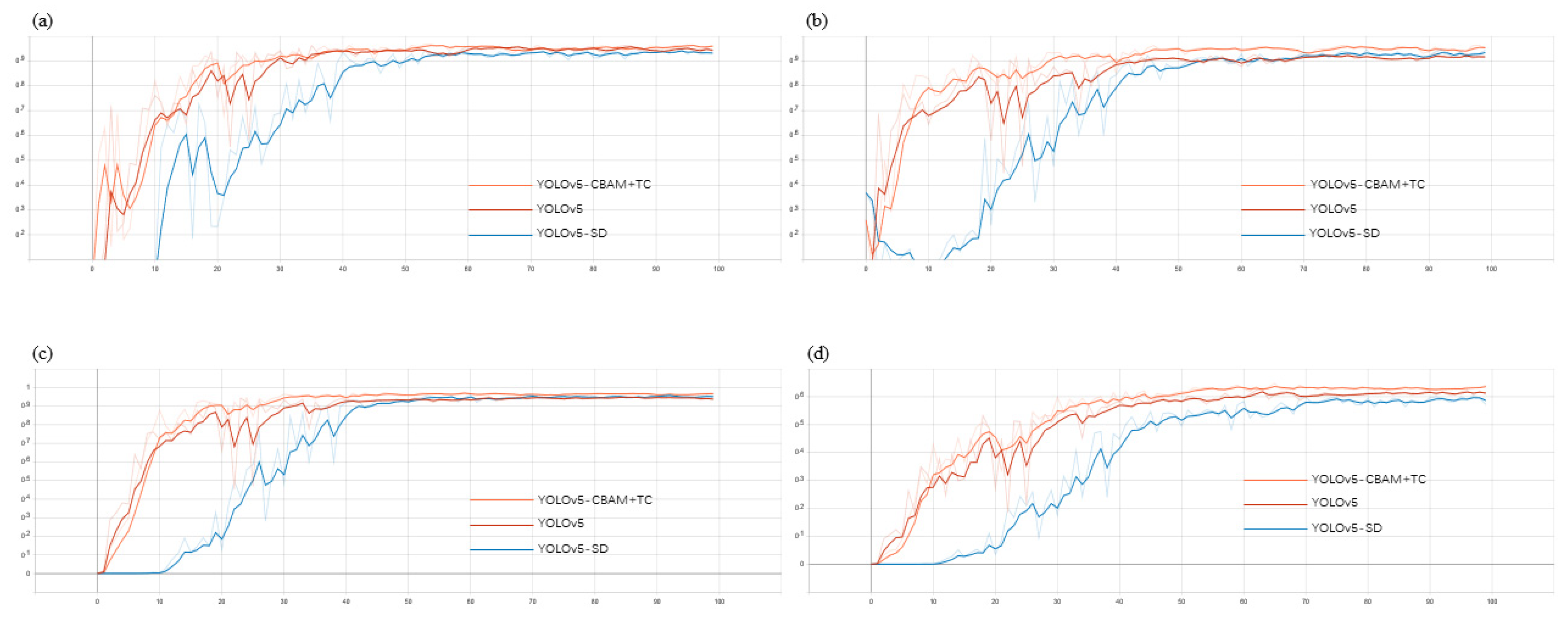
3.1. Model Comparison
3.2. Analysis
4. Discussion
- (1)
- Because the dataset in this study is collected by a limited number of cameras located on top of the interior of the cage, the observation angle will be limited, and misplacement may occur, leading to incorrect detection results. Therefore, in the subsequent study, the camera positions will be adjusted and the number of cameras will be increased to avoid this problem as much as possible.
- (2)
- In terms of processing speed, YOLOv5 has a high processing speed for the reasons explained in Section 2.4.1. Although the improved YOLOv5-CBAM + TC model has 0.6 MB more than YOLOv5, it only takes 0.1 s to process a single image, which can meet the needs of practical applications.
- (3)
- The datasets used in this study were all human-collected and the collection locations were fixed with relatively simple and single backgrounds. Thus, the accuracy of the model may be reduced in complex environments, such as in the wild. Considering that the scenario currently applied is a case of slow lorises, the scenario in actual application is relatively simple. The authors will continue their research on YOLOv5-CBAM+TS and extend its application scenarios.
- (4)
- In terms of model generalization capability, YOLOv5 adopts a mosaic data enhancement strategy to improve the generalization capability and robustness of the model [27].
- (5)
- Compared with the application of computer vision in the detection of other mammals (such as elephant (Elephantidae) [28] and golden monkey (Rhinopithecus roxellana) [29]), the performance of the proposed YOLOv5 CBAM + TC model in the detection of slow loris exceeds the average level and meets the needs of practical applications.
- (6)
- The YOLOv5 CBAM + TC model was operated on a professional server in this study, but it can also be run smoothly on a common laptop, indicating that the model would be economical and practical in a real-world application.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Munds, R.A.; Nekaris, K.A.I.; Ford, S.M. Taxonomy of the Bornean Slow loris, With New Species Nycticebus kayan (Primates, Lorisidae). Am. J. Primatol. 2013, 75, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Nekaris, K.A.I.; Starr, C.R. Conservation and ecology of the neglected slow loris: Priorities and prospects. Endanger. Species Res. 2015, 28, 87–95. [Google Scholar] [CrossRef] [Green Version]
- Broom, D.M. Animal welfare: Concepts and measurement. J. Anim. Sci. 1991, 69, 4167–4175. [Google Scholar] [CrossRef]
- Broom, D.M. The scientific assessment of animal welfare. Appl. Anim. Behav. Sci. 1988, 20, 5–19. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, J. A review of object detection based on convolutional neural network. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 11104–11109. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef]
- Tolba, A.S.; El-Baz, A.H.; El-Harby, A.A. Face recognition: A literature review. Int. J. Signal Process. 2006, 2, 88–103. [Google Scholar]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When face recognition meets with deep learning: An evaluation of convolutional neural networks for face recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 142–150. [Google Scholar]
- Ye, Q.; Doermann, D. Text detection and recognition in imagery: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1480–1500. [Google Scholar] [CrossRef]
- Huang, X.; Hu, Z.; Wang, X.; Yang, X.; Zhang, J.; Shi, D. An improved single shot multibox detector method applied in body condition score for dairy cows. Animals 2019, 9, 470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hou, J.; He, Y.; Yang, H.; Connor, T.; Gao, J.; Wang, Y.; Zeng, Y.; Zhang, J.; Huang, J.; Zheng, B. Identification of animal individuals using deep learning: A case study of giant panda. Biol. Conserv. 2020, 242, 108414. [Google Scholar] [CrossRef]
- Schütz, A.K.; Schöler, V.; Krause, E.T.; Fischer, M.; Müller, T.; Freuling, C.; Conraths, F.; Stanke, M.; Homeier-Bachmann, T.; Lentz, H. Application of YOLOv4 for Detection and Motion Monitoring of Red Foxes. Animals 2021, 11, 1723. [Google Scholar] [CrossRef] [PubMed]
- Kalhagen, E.S.; Olsen, Ø.L. Hierarchical Fish Species Detection in Real-Time Video Using YOLO. Master’s Thesis, University of Agder, Kristiansand, Norway, 2020. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Caballero, J.; Theis, L.; Huszar, F.; Aitken, A.; Ledig, C.; Wang, Z. Is the deconvolution layer the same as a convolutional layer? arXiv 2016, arXiv:1609.07009. [Google Scholar]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuiness, K.; O’Connor, N. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 598–606. [Google Scholar]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Premarathna, K.S.P.; Rathnayaka, R.M.K.T.; Charles, J. An Elephant Detection System to Prevent Human-Elephant Conflict and Tracking of Elephant Using Deep Learning. In Proceedings of the 5th International Conference on Information Technology Research (ICITR), Moratuwa, Sri Lanka, 2–4 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Rui, S.; Xu, Z.; Ying, G.; Xinwen, Y.; Yan, C.; Yanan, H. Optimized Detection Method for Snub-Nosed Monkeys Based on Faster R-CNN. Laser Optoelectron. Prog. 2020, 57, 121022. [Google Scholar]
- Verma, G.K.; Gupta, P. Wild animal detection using deep convolutional neural network. In Proceedings of the 2nd International Conference on Computer Vision & Image Processing, Hong Kong, China, 29–31 December 2018; Springer: Singapore, 2018; pp. 327–338. [Google Scholar]
- Eikelboom, J.A.J.; Wind, J.; van de Ven, E.; Kenana, L.M.; Schroder, B.; de Knegt, H.J.; van Langevelde, F.; Prins, H.H.T. Improving the precision and accuracy of animal population estimates with aerial image object detection. Methods Ecol. Evol. 2019, 10, 1875–1887. [Google Scholar] [CrossRef] [Green Version]
- Khan, R.H.; Kang, K.W.; Lim, S.J.; Youn, S.D.; Kwon, O.J.; Lee, S.H.; Kwon, K.R. Animal Face Classification using Dual Deep Convolutional Neural Network. J. Korea Multimed. Soc. 2020, 23, 525–538. [Google Scholar]
- Zuerl, M.; Stoll, P.; Brehm, I.; Raab, R.; Zanca, D.; Kabri, S.; Happold, J.; Nille, H.; Prechtel, K.; Wuensch, S.; et al. Automated Video-Based Analysis Framework for Behavior Monitoring of Individual Animals in Zoos Using Deep Learning-A Study on Polar Bears. Animals 2022, 12, 692. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Captive Site | Xishuangbanna | Puer |
|---|---|---|
| Coordinate | 22.39276° N, 100.89636° E | 22.62198° N, 101.08916° E |
| Altitude (m) | 1060 | 1600 |
| Annual mean temperature (°C) | 17.5 | 17.5 |
| No. of individuals | 9 | 9 |
| No. of enclosures | 1 | 1 |
| Enclosure size (L × W × H) (m) | 5.7 × 4.2 × 3.5 | 3.5 × 2.1 × 2.0 |
| No. of cameras | 3 | 2 |
| Confusion Matrix | Predicted Results | ||
|---|---|---|---|
| Positive | Negative | ||
| Expected Results | positive | TP 1 | FN 2 |
| negative | FP 3 | TN 4 | |
| Model | Category | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | Model Size |
|---|---|---|---|---|---|---|
| YOLOv5 | All | 0.936 | 0.916 | 0.934 | 0.609 | 14.4 MB |
| Single | 0.955 | 0.926 | 0.956 | 0.554 | ||
| Socializing | 0.923 | 0.906 | 0.913 | 0.665 | ||
| YOLOv5-SD | All | 0.931 | 0.943 | 0.95 | 0.572 | 16.4 MB |
| Single | 0.912 | 0.924 | 0.955 | 0.523 | ||
| Socializing | 0.951 | 0.963 | 0.944 | 0.622 | ||
| YOLOv5-CBAM + TC | All | 0.965 | 0.953 | 0.969 | 0.642 | 15.0 MB |
| Single | 0.956 | 0.943 | 0.964 | 0.568 | ||
| Socializing | 0.974 | 0.963 | 0.973 | 0.716 |
| Category | YOLOv5-CBAM + TC | SSD | CenterNet | Faster-RCNN |
|---|---|---|---|---|
| mAP | 0.969 | 0.911 | 0.889 | 0.939 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Y.; Xiang, Y.; Zhu, Y.; Guan, Y.; Zhang, Y.; Yang, X.; Yao, X.; Li, T.; Xie, M.; Mu, J.; et al. Development of a Slow Loris Computer Vision Detection Model. Animals 2022, 12, 1553. https://doi.org/10.3390/ani12121553
Lei Y, Xiang Y, Zhu Y, Guan Y, Zhang Y, Yang X, Yao X, Li T, Xie M, Mu J, et al. Development of a Slow Loris Computer Vision Detection Model. Animals. 2022; 12(12):1553. https://doi.org/10.3390/ani12121553
Chicago/Turabian StyleLei, Yujie, Ying Xiang, Yuhui Zhu, Yan Guan, Yu Zhang, Xiao Yang, Xiaoli Yao, Tingxuan Li, Meng Xie, Jiong Mu, and et al. 2022. "Development of a Slow Loris Computer Vision Detection Model" Animals 12, no. 12: 1553. https://doi.org/10.3390/ani12121553
APA StyleLei, Y., Xiang, Y., Zhu, Y., Guan, Y., Zhang, Y., Yang, X., Yao, X., Li, T., Xie, M., Mu, J., & Ni, Q. (2022). Development of a Slow Loris Computer Vision Detection Model. Animals, 12(12), 1553. https://doi.org/10.3390/ani12121553