
Real-Time Data-Driven Method for Bolt Defect Detection and Size Measurement in Industrial Production


Abstract
1. Introduction
2. Research Foundation
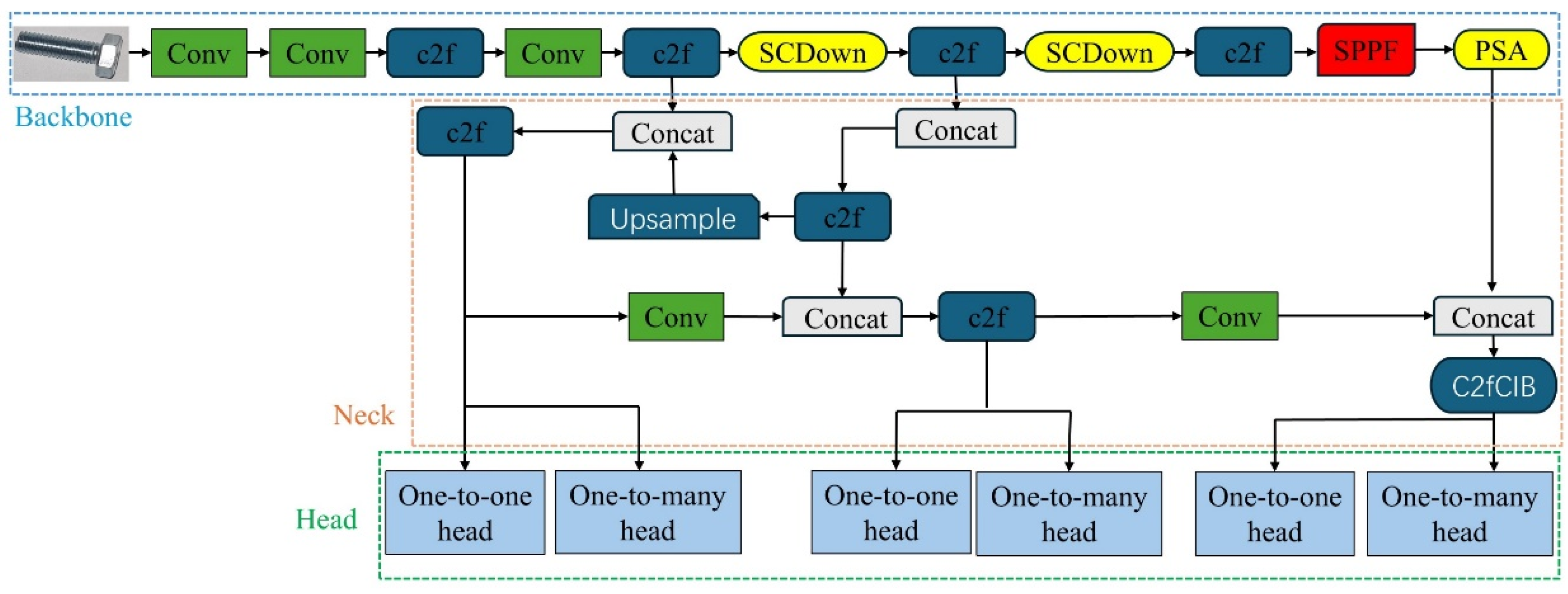
2.1. YOLO
- YOLOv10 utilizes an NMS training strategy and a consistent dual allocation strategy. The consistent dual allocation strategy refers to a method for optimizing feature allocation within the target detection framework. This approach ensures that both small and large targets can be effectively detected by maintaining consistency in target allocation across feature layers of varying scales and by employing a dual allocation mechanism. During the training process, multiple prediction boxes (Positive Predictions) are assigned to each ground truth (GT), implementing a one-to-many matching method (one-to-many head). This approach generates additional supervision signals during training, thereby enhancing both classification and localization capabilities. The one-to-one matching (one-to-one head) eliminates the necessity for NMS during the inference stage, resulting in the output of a singular prediction box. This significantly enhances inference efficiency and minimizes errors that may arise from redundant predictions and NMS. By employing consistent matching measurement formulas and hyperparameter adjustments, these two mechanisms can achieve synchronized optimization during the training phase.
- Depthwise separable convolutions are utilized instead of traditional full convolution layers, along with lightweight classification heads, to alleviate computational and parameter burdens. Depthwise convolution facilitates spatial sampling from different regions, while pointwise convolution enables linear combinations within the channel dimension. This approach enhances feature representation capabilities, decouples downsampling operation, improves computational efficiency, and preserves more feature information.
- Considering the high redundancy observed in the shallow stage, the CIB module is introduced. The CIB module enhances feature expression and discrimination capabilities through information compression and enhancement mechanisms, combining channel attention, depthwise separable convolution, and lightweight feature fusion. For the deeper stages, this module maintains sufficient expressive power while preventing excessive compression, thereby ensuring comprehensive feature extraction. Consequently, the overall performance of the model is enhanced while maintaining the integrity of feature extraction.
2.2. Intel RealSense D435
3. Methods
3.1. Dataset
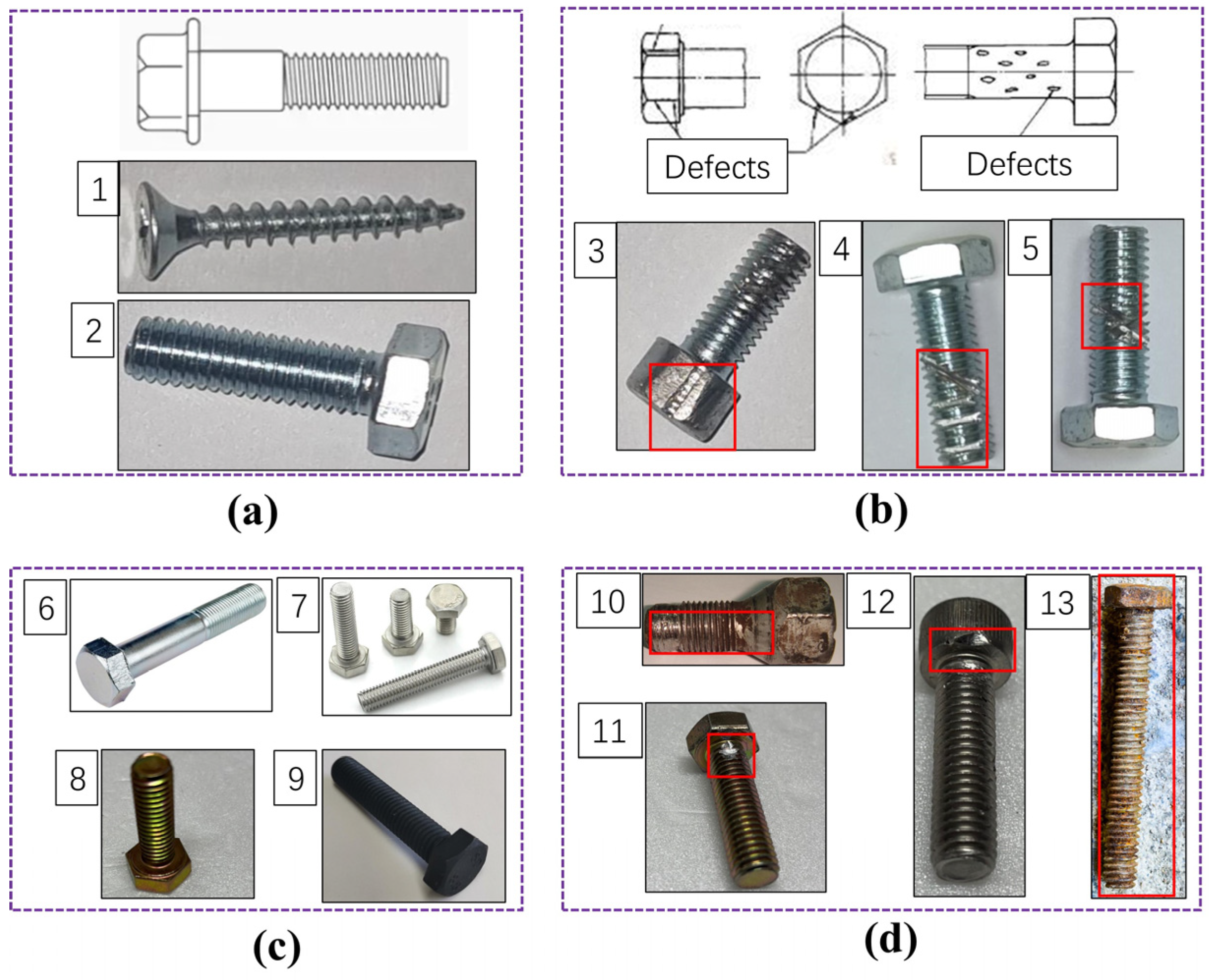
- To address the impact of variations in bolt types, images of bolts with different colors and shapes were collected. The sizes of the bolts range from M4 to M45, thereby enhancing the diversity of the dataset.
- Significant differences exist in the shapes of various bolt defect types. To monitor as many defective bolts as possible, it is essential to include a variety of defect types to enrich the database. In addition to the dents and scratches present in the original database, we added cracks, fractures, corrosion, and notches. The specific defect types and forms are detailed in Table 2.
- Multiple variants were generated by altering the camera’s shooting angle (e.g., 45°, 90°, and 135°) to simulate the differences in image angles caused by positional variations during real-time detection. This approach aims to enhance the accuracy of model detection.
- A fill light device was utilized to adjust light intensity and illumination direction, simulating the effects of light variations encountered in actual factory production processes. In the experiment, images with varying light intensities were collected, spanning a grayscale value range of 20 to 255, with increments of 20. The overall grayscale level range is from 0 to 255, where 255 indicates maximum intensity. This process aims to gather bolt image information under diverse lighting conditions, thereby improving the model’s stability and generalization ability across different lighting environments.
- Given the significant variability in the surrounding environment during industrial production, it is essential to adapt to detection needs across various backgrounds. To achieve this, images were obtained against different backgrounds, including industrial production settings, engineering applications, and variations in background color. This strategy is intended to enhance the model’s adaptability in diverse production environments and bolster its robustness.
- To improve the model’s adaptability to images captured by various camera devices, including standard RGB cameras, depth cameras, and mobile phone cameras with differing focal lengths and exposures, a comprehensive approach to bolt image collection was employed. These measures are designed to enhance data diversity and improve the model’s generalization ability.
3.2. Training Platform
3.3. Performance Evaluation
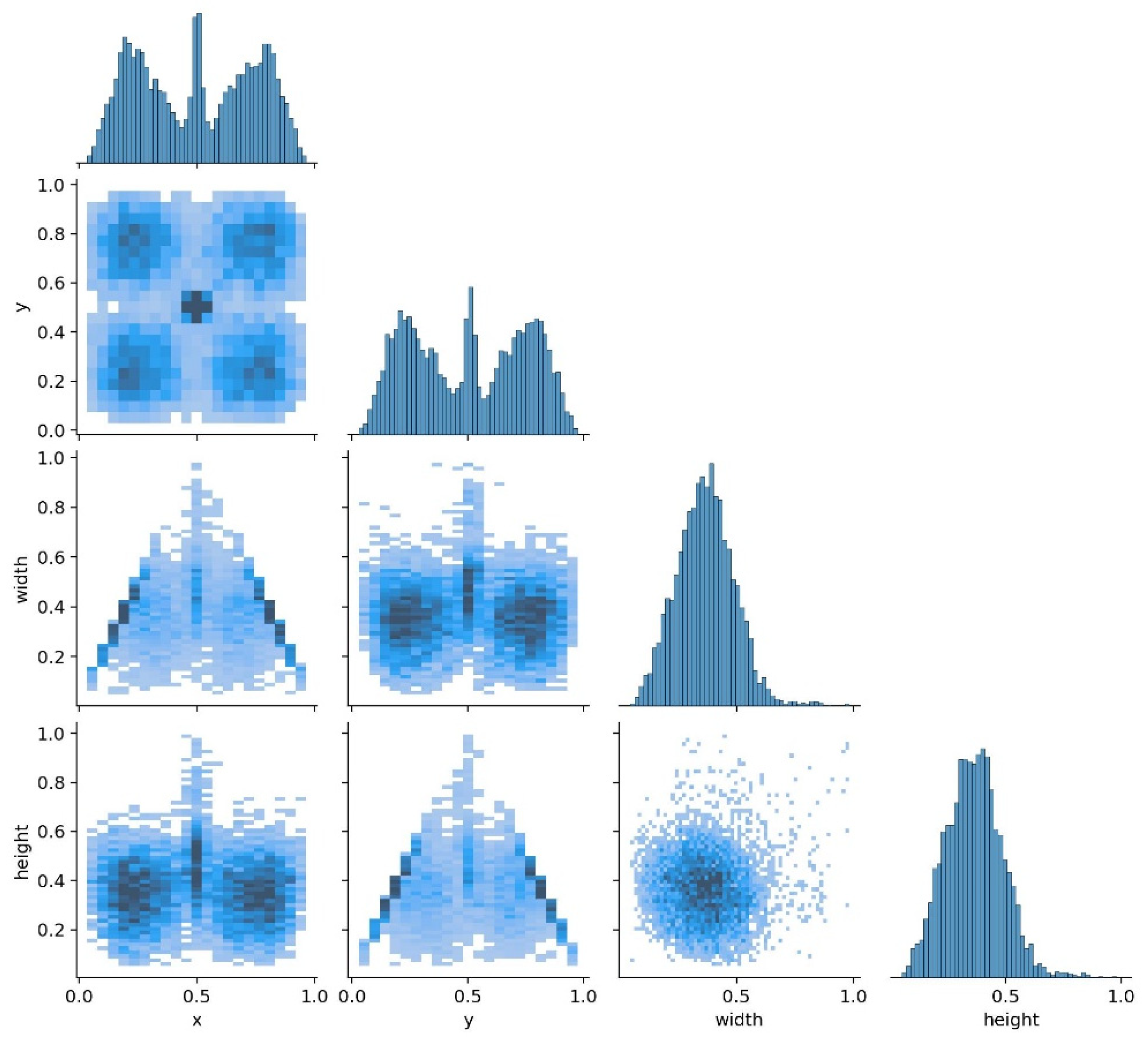
- The histogram reveals that the x and y coordinates are evenly distributed across the image, indicating that the target locations cover the entire image area without bias toward any specific region. Conversely, the width and height histograms demonstrate that the sizes of most target boxes are concentrated in the medium-size range, with a slight concentration near the smaller sizes, as evidenced by the peak near the low end of the histogram.
- The scatter plots of coordinates x and y are evenly distributed, further confirming that the objects are well distributed in both the horizontal and vertical directions of the image. The scatter plots of width against x and y coordinates exhibit a triangular distribution, while the scatter plots of height against x and y coordinates show a similar triangular pattern. This indicates a scarcity of objects with larger heights, with smaller heights being more prevalent. Additionally, the scatter plots of width and height reveal that smaller objects are concentrated, whereas larger objects are sparse. This suggests that the target size range in the training dataset is broad, but small and medium sizes are dominant.
- The coordinates x and y are evenly distributed across the image, covering all areas and ensuring that the model can learn to detect targets at various locations. The distribution of width and height indicates that small- and medium-sized targets are predominant in the training set, while the number of large targets is limited.
3.4. Test
- Each image in the test set is processed individually, with the total processing time recorded for each image, encompassing preprocessing, inference, and postprocessing phases;
- The inference results are generated as visual images and subsequently stored in the designated output directory;
- The categories and locations of the targets are extracted from the actual labels, which are then compared with the model’s detection results. This comparison allows for the quantification of errors in both classification and positioning, including instances of missed detections and false detections. The results are shown in Table 3.
4. Real-Time Detection System Design and Testing
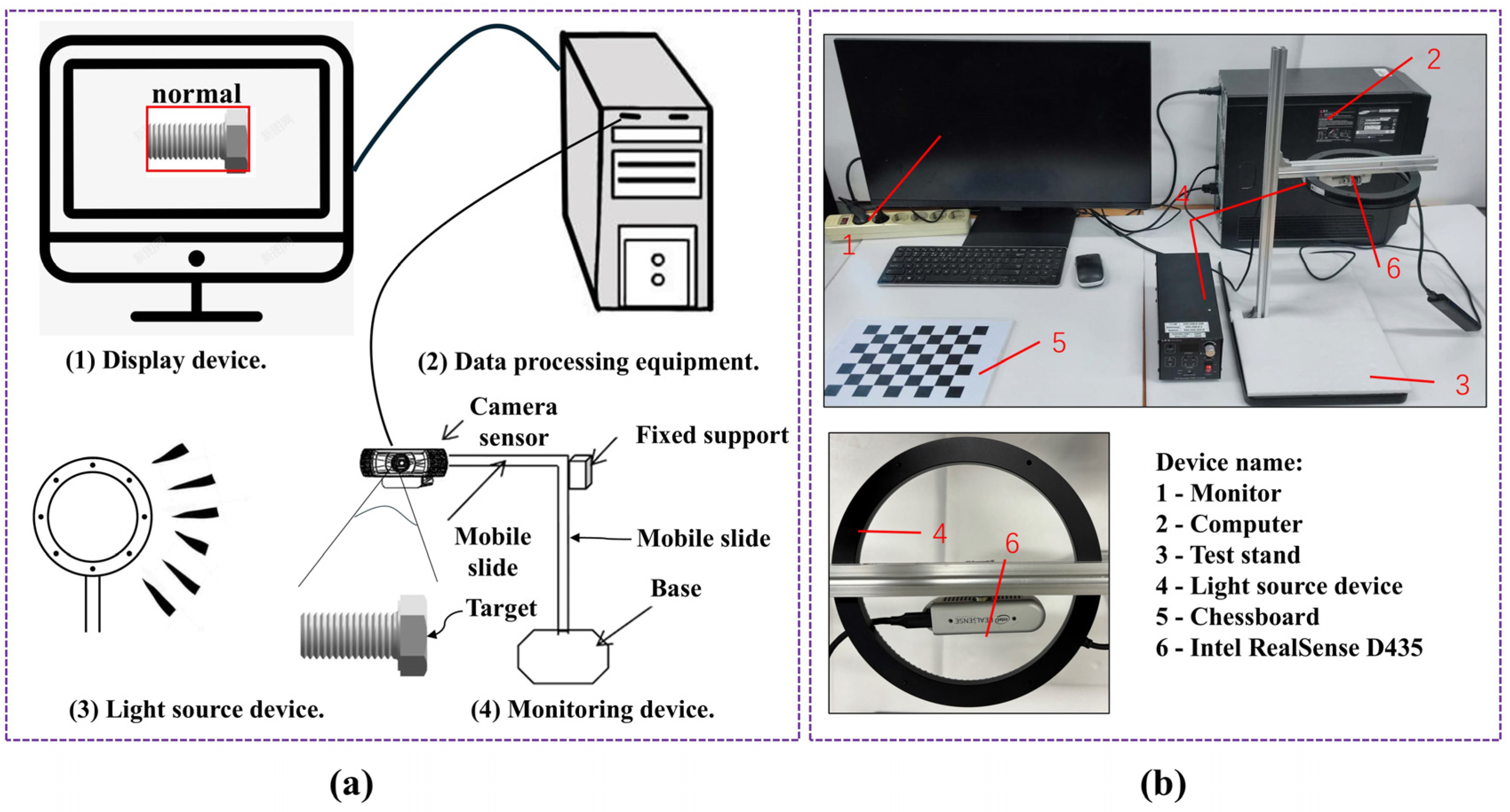
4.1. System Design
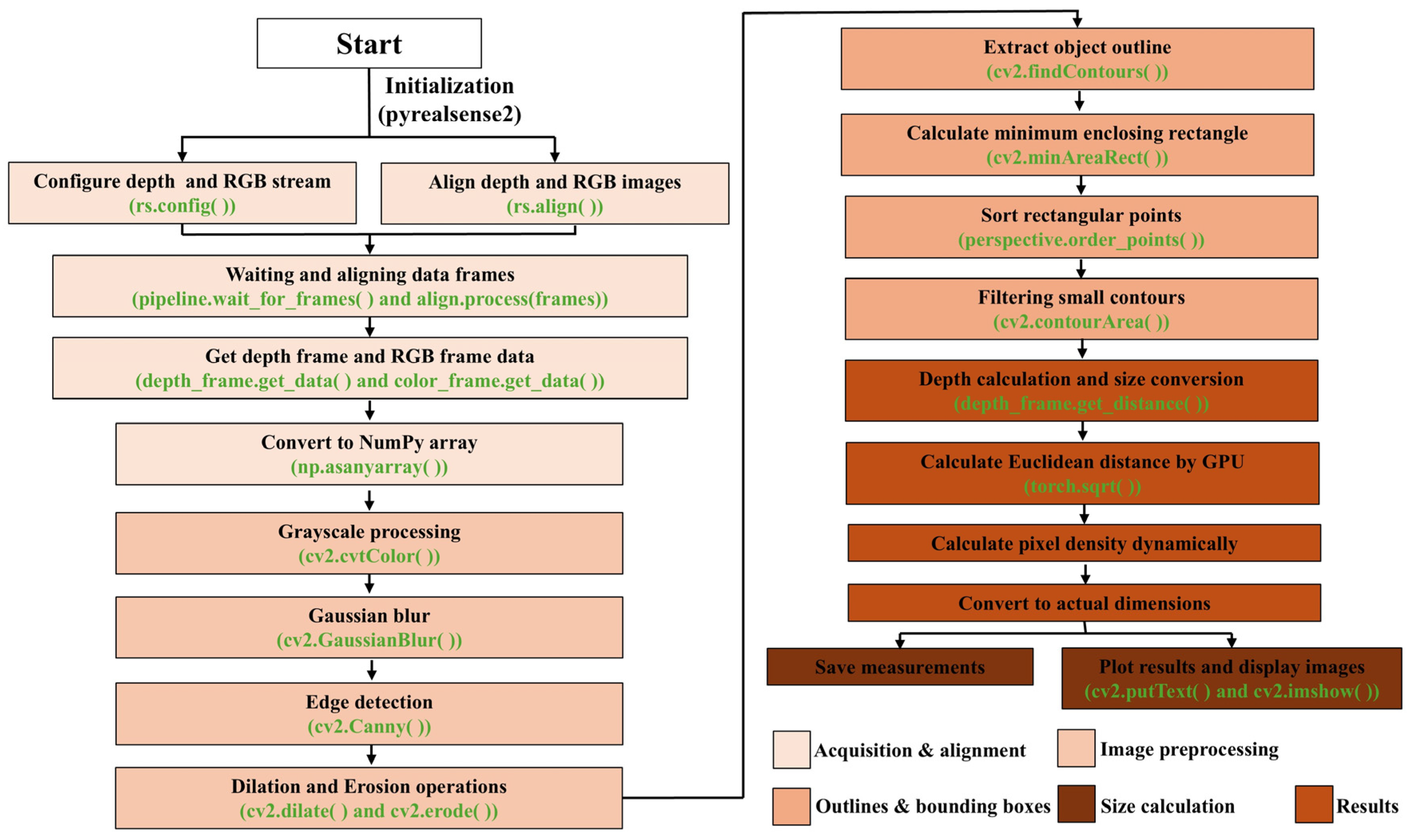
4.2. Size Measurement
4.2.1. Camera Calibration
4.2.2. Measurement Method
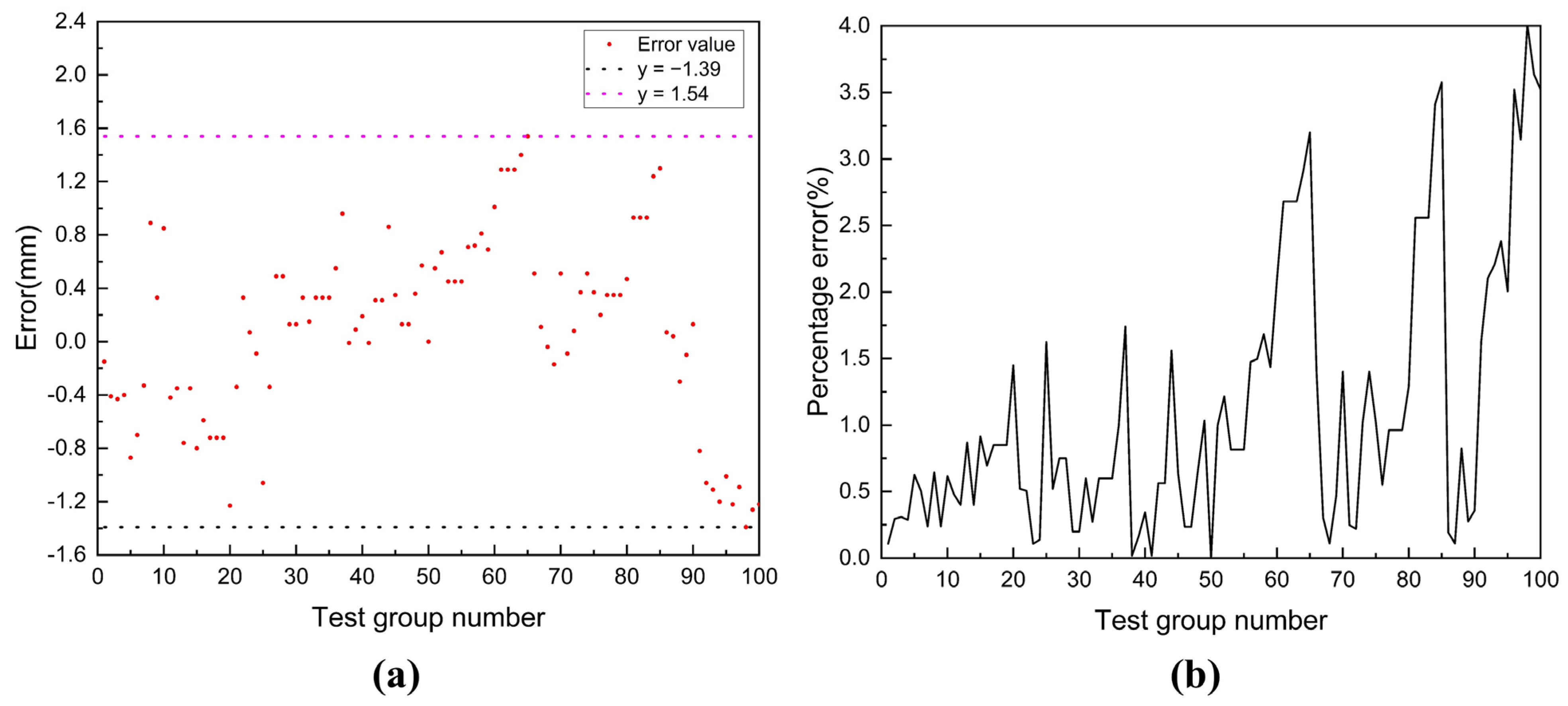
4.2.3. Evaluation and Result Analysis
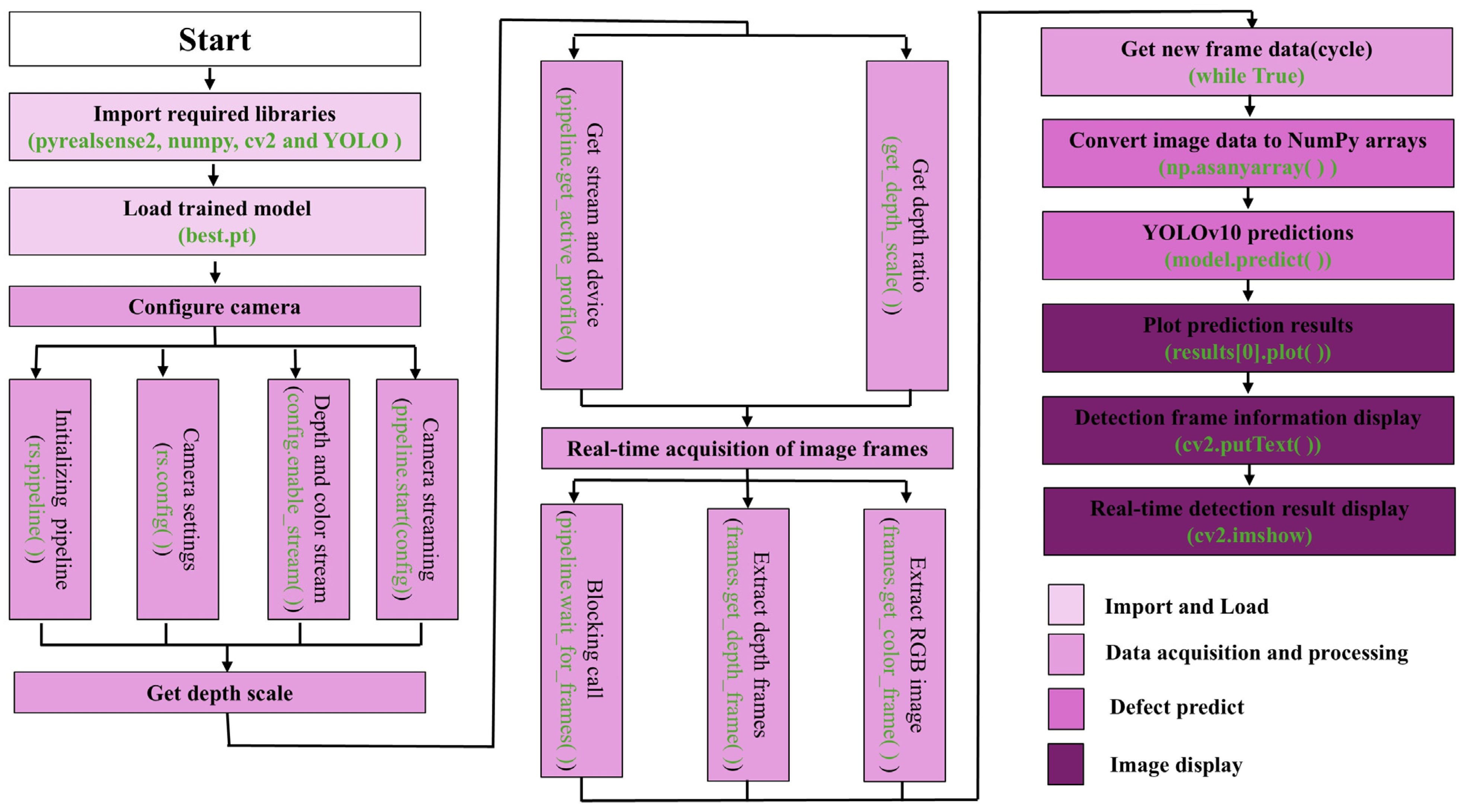
4.3. Defect Detection
4.3.1. Defect Detection Test and Analysis
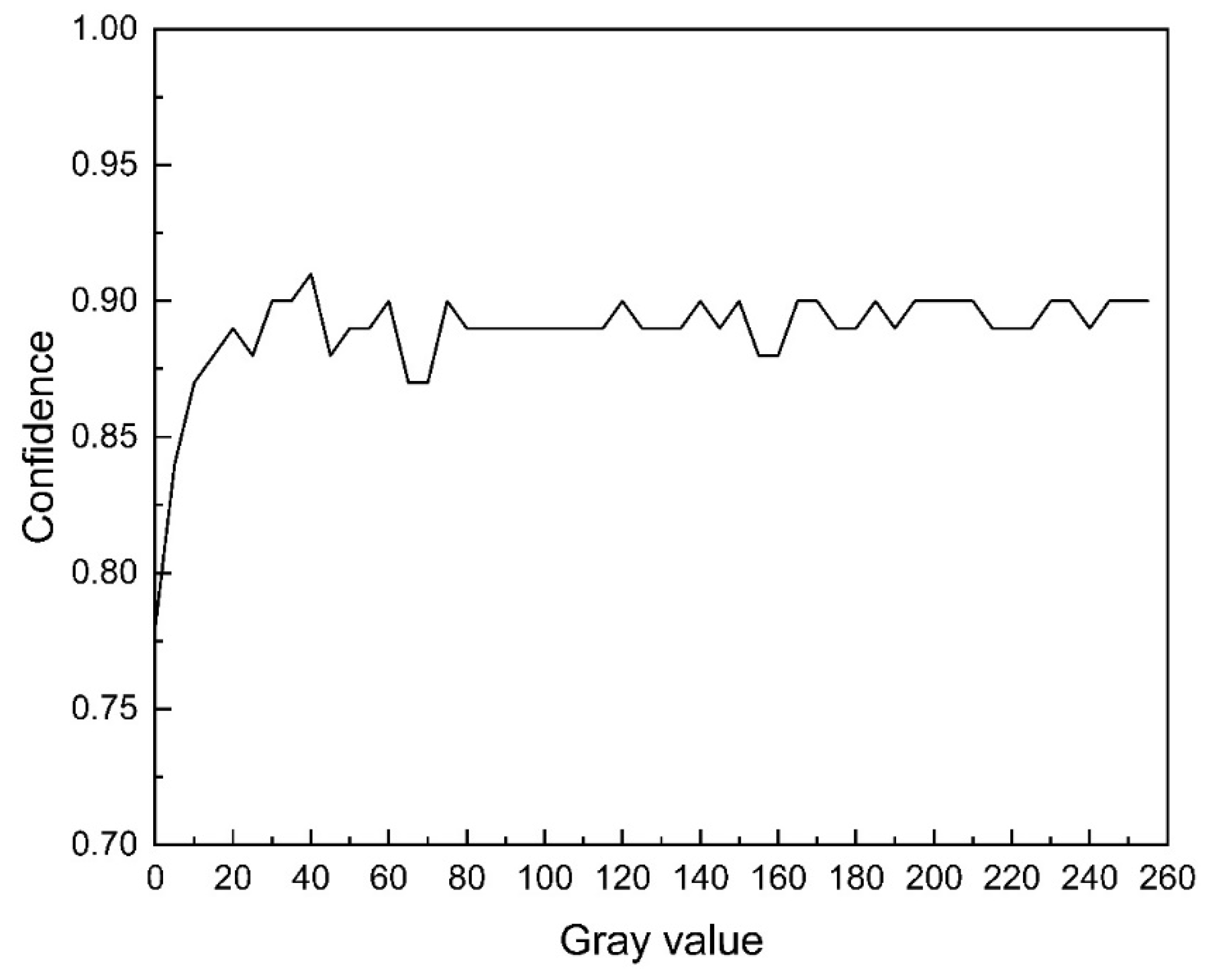
4.3.2. Influence of Lighting Changes on Model Performance
5. Conclusions
- To enhance data quality, addressing the issue of data uniformity within the original dataset, as well as incorporating a greater variety of bolt types and defect categories, can facilitate the model’s ability to learn more nuanced features. This, in turn, enhances its recognition capabilities for various bolt types and defect manifestations, thereby improving the model’s generalization ability, accuracy, and robustness. These improvements were crucial for overcoming the variability associated with different bolt types and defects, ensuring the model’s effectiveness across diverse industrial production environments.
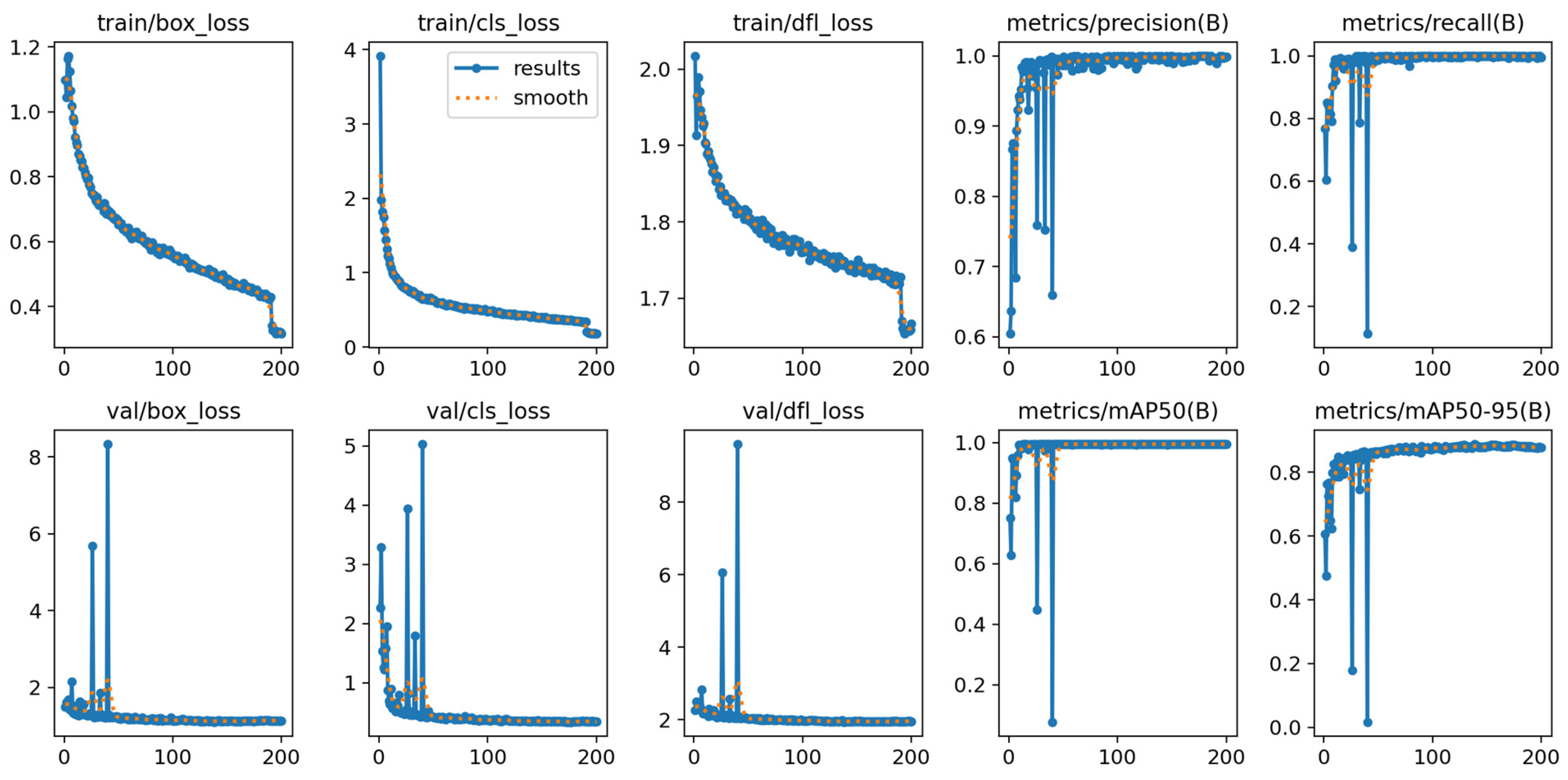
- For the training and testing of the defect detection model, the data distribution was appropriate, and the model demonstrated a strong balance between precision and recall, as indicated by an F1 score that approaches 1. The optimal F1 value was reached at a confidence level of 0.308, where both precision and recall remain stable. The average inference time was 0.049 s, with a missed detection rate of 1.25%. The detection confidence exhibited a high range (0.84 to 0.98), allowing for the accurate capture of details related to bolt defects.
- Based on the Intel RealSense D435 binocular camera, a high-precision camera calibration method was employed, and image processing was accelerated through GPU parallel computing to ensure efficient and real-time target size measurement. The test results indicated that the average measurement time was merely 0.021616 s, with an overall error range of −1.39 mm to +1.54 mm, and an error fluctuation of 4%. To evaluate the model more comprehensively, we calculated the average relative error rate, which decreased from 1.1% to 0.41%, and the maximum relative error rate, which dropped from 4% to 1%, under varying light intensities. Increasing the light intensity enhances signal quality, reduces noise interference, and improves image quality, thereby increasing measurement accuracy and decreasing relative measurement errors.
- The combination of the Intel RealSense D435 depth camera and the YOLOv10 model enables efficient real-time target detection and defect recognition. Among the 100 test bolt samples, the model achieved an accuracy of 99%, a recall of 90%, and an F1 score of 94.7%. It demonstrated strong performance in detecting most defective bolts while effectively balancing precision and recall. With the use of GPU parallel computing, the average prediction time was 0.009241 s, showcasing excellent real-time processing capabilities. Furthermore, the model exhibits high stability under varying lighting conditions; as the lighting intensity increases, the confidence level gradually rises and stabilizes above 0.9. Given these results, the model is well suited for rapid defect detection tasks in industrial environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANNs | Artificial Neural Networks |
| CNNs | Convolutional Neural Networks |
| RNNs | Recurrent Neural Networks |
| CV | Computer Vision |
| YOLO | You Only Look Once |
| R-CNN | Region-Based Convolutional Neural Network |
| PPYOLOE | Paddle Paddle You Only Look Once—Efficient |
| RTMDET | Real-Time Multi-Scale Detector |
| YOLO-MS | You Only Look Once—Multi-Scale |
| Gold-YOLO | Gradient Optimization Learning-Based Dynamic YOLO |
| NMS | Non-Maximum Suppression |
| SPFF | Spatial Pyramid Pooling Fusion |
| FPS | Frames Per Second |
| PGI | Progressive Gradient Integration |
| GELAN | Global Enhancement Local Attention Network |
| GT | Ground Truth |
| CIB | Compact Information Block |
| SGD | Stochastic Gradient Descent |
| IoU | Intersection over Union |
| TP | True Positives |
| TN | True Negatives |
| FP | False Positives |
| FN | False Negatives |
| mAP | Mean Average Precision |
| ROS | Robot Operating System |
References
- Kriegeskorte, N. Deep neural networks: A new framework for modeling biological vision and brain information processing. Annu. Rev. Vis. Sci. 2015, 1, 417–446. [Google Scholar] [CrossRef] [PubMed]
- Korteling, J.E.H.; van de Boer-Visschedijk, G.C.; Blankendaal, R.A.M.; Boonekamp, R.C.; Eikelboom, A.R. Human-versus artificial intelligence. Front. Artif. Intell. 2021, 4, 622364. [Google Scholar] [CrossRef]
- Zupan, J. Introduction to artificial neural network (ANN) methods: What they are and how to use them. Acta Chim. Slov. 1994, 41, 327. [Google Scholar]
- Han, S.H.; Kim, K.W.; Kim, S.; Youn, Y.C. Artificial neural network: Understanding the basic concepts without mathematics. Dement. Neurocogn. Disord. 2018, 17, 83–89. [Google Scholar] [CrossRef]
- Deng, L.; Wu, Y.; Hu, X.; Liang, L.; Ding, Y.; Li, G.; Xie, Y. Rethinking the performance comparison between SNNS and ANNS. Neural Netw. 2020, 121, 294–307. [Google Scholar] [CrossRef]
- Song, J.; Gao, S.; Zhu, Y.; Ma, C. A survey of remote sensing image classification based on CNNs. Big Earth Data 2019, 3, 232–254. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Xu, W.; Fu, Y.L.; Zhu, D. ResNet and its application to medical image processing: Research progress and challenges. Comput. Methods Programs Biomed. 2023, 240, 107660. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Bharati, P.; Pramanik, A. Deep learning techniques—R-CNN to mask R-CNN: A survey. Comput. Intell. Pattern Recognit. Proc. CIPR 2019, 2020, 657–668. [Google Scholar]
- Ahmad, T.; Zhang, D.; Huang, C.; Zhang, H.; Dai, N.; Song, Y.; Chen, H. Artificial intelligence in sustainable energy industry: Status Quo, challenges and opportunities. J. Clean. Prod. 2021, 289, 125834. [Google Scholar] [CrossRef]
- Radulov, N. Artificial intelligence and security. Security 4.0. Secur. Future 2019, 3, 3–5. [Google Scholar]
- Park, C.W.; Seo, S.W.; Kang, N.; Ko, B.; Choi, B.W.; Park, C.M.; Yoon, H.J. Artificial intelligence in health care: Current applications and issues. J. Korean Med. Sci. 2020, 35, e379. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial intelligence in education: A review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Vergara-Villegas, O.O.; Cruz-Sánchez, V.G.; de Jesús Ochoa-Domínguez, H.; de Jesús Nandayapa-Alfaro, M.; Flores-Abad, Á. Automatic product quality inspection using computer vision systems. In Lean Manufacturing in the Developing World: Methodology, Case Studies and Trends from Latin America; Springer: Cham, Switzerland, 2014; pp. 135–156. [Google Scholar]
- Golnabi, H.; Asadpour, A. Design and application of industrial machine vision systems. Robot. Comput. -Integr. Manuf. 2007, 23, 630–637. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q. Machine vision inspection of electrical connectors based on improved Yolo v3. IEEE Access 2020, 8, 166184–166196. [Google Scholar] [CrossRef]
- Yu, L.; Zhu, J.; Zhao, Q.; Wang, Z. An efficient yolo algorithm with an attention mechanism for vision-based defect inspection deployed on FPGA. Micromachines 2022, 13, 1058. [Google Scholar] [CrossRef]
- Jung, H.; Rhee, J. Application of YOLO and ResNet in heat staking process inspection. Sustainability 2022, 14, 15892. [Google Scholar] [CrossRef]
- Li, G.; Zhao, S.; Zhou, M.; Li, M.; Shao, R.; Zhang, Z.; Han, D. YOLO-RFF: An industrial defect detection method based on expanded field of feeling and feature fusion. Electronics 2022, 11, 4211. [Google Scholar] [CrossRef]
- Qi, Z.; Ding, L.; Li, X.; Hu, J.; Lyu, B.; Xiang, A. Detecting and Classifying Defective Products in Images Using YOLO. arXiv 2024, arXiv:2412.16935. [Google Scholar]
- Zuo, Y.; Wang, J.; Song, J. Application of YOLO object detection network in weld surface defect detection. In Proceedings of the 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Jiaxing, China, 27–31 July 2021; pp. 704–710. [Google Scholar]
- Pulli, K.; Baksheev, A.; Kornyakov, K.; Eruhimov, V. Real-time computer vision with OpenCV. Commun. ACM 2012, 55, 61–69. [Google Scholar] [CrossRef]
- Xie, G.; Lu, W. Image edge detection based on opencv. Int. J. Electron. Electr. Eng. 2013, 1, 104–106. [Google Scholar] [CrossRef]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NY, USA, 27–30 June 2016. [Google Scholar]
- Gupta, S.; Devi, D.T.U. YOLOv2 based real time object detection. Int. J. Comput. Sci. Trends Technol. IJCST 2020, 8, 26–30. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Thuan, D. Evolution of Yolo Algorithm and Yolov5: The State-of-the-Art Object Detention Algorithm. 2021. Available online: https://www.theseus.fi/handle/10024/452552 (accessed on 3 November 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canda, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Yaseen, M. What is YOLOv9: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector. arXiv 2024, arXiv:2409.07813. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Beliuzhenko, D. Screw Detection Test (v21). Roboflow. 2024. Available online: https://universe.roboflow.com (accessed on 3 November 2024).
- Nie, L.; Ren, Y.; Wu, R.; Tan, M. Sensor fault diagnosis, isolation, and accommodation for heating, ventilating, and air conditioning systems based on soft sensor. Actuators 2023, 12, 389. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Zeng, N.; Wang, N. Sensitivity, Specificity, Accuracy, Associated Confidence Interval and ROC Analysis with Practical SAS Implementations. In NESUG Proceedings: Health Care and Life Sciences; NESUG Publisher: Baltimore, MD, USA, 2010; Volume 19, p. 67. [Google Scholar]
- Yang, G.; Heo, J.; Kang, B.B. Adaptive Vision-Based Gait Environment Classification for Soft Ankle Exoskeleton. Actuators 2024, 13, 428. [Google Scholar] [CrossRef]
- Hua, J.; Zeng, L. Hand–eye calibration algorithm based on an optimized neural network. Actuators 2021, 10, 85. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | Main Improvement Areas | Main Problem Solved |
|---|---|---|
| YOLOv1 [27] | Target detection framework | Unified and efficient real-time object detection framework |
| YOLOv2 [28] | Anchor box mechanism, GPU acceleration and confidence | Small target detection and implementation detection |
| YOLOv3 [29] | Feature extraction network and multi-scale prediction | Multi-scale detection and multi-label classification |
| YOLOv4 [30] | Backbone network and feature fusion and aggregation (Neck) | Large-scale data training and increasing adaptation scenarios |
| YOLOv5 [31] | Automatic anchor box and code implementation by PyTorch (version 1.8) | Lightweight models, simplified processes, and improved real-time detection |
| YOLOv6 [32] | Network architecture optimization, loss function improvement, and industrial scenario optimization | Feature extraction efficiency, classification accuracy, and convergence performance |
| YOLOv7 [33] | Plan reparameterization, coarse-to-fine label assignment, and addition of auxiliary heads | Inference speed (5 FPS → 120 FPS) and enhanced model robustness |
| YOLOv8 [34] | C2f and SPPF module, lightweight, and attention mechanism | Optimized mAP, reduced computation and memory, sped-up convergence, and expanded multi-scale detection layer to five scales |
| YOLOv9 [35] | GELAN: combination of multiple modules; PGI: stabilization of gradient flow and combination of focal loss and IoU loss | Optimized resource efficiency, accelerated inference (GPU—23 ms), and training time reduced by 16% |
| YOLOv10 [36] | Consistent dual allocation strategy, adoption of lightweight classification head and space-channel decoupled downsampling, introduction of large kernel convolution in deep stage, partial self-attention module that enhances global modeling ability, and unified matching index | mAP increased by 0.3–1.4%, inference speed increased by 1.3 times, improved training efficiency, accelerated convergence speed, and increased suitability for large-scale data training |
| Defect Type | Definition | Image Information |
|---|---|---|
| Cracks | Cracks due to mechanical stress, fatigue, or external impact. |  |
| Breakage | Excessive stress or material defects resulting in complete breakage or partial loss. |  |
| Corrosion | Damage caused by chemical reactions such as rust. |  |
| Notches | Small dents or cuts caused by improper machines or external friction. |  |
| Dents | Small and deep dents on surface of bolt, typically circular or elliptical in shape. |  |
| Scratches | Long and shallow linear marks caused by external friction. |  |
| Parameters | Peak RAM | Size | Total Samples | Average Inference Time | True Positives | False Negative | False Negative Rate |
|---|---|---|---|---|---|---|---|
| 2.71 M | 10.33 MB | 5.5 MB | 80 | 0.049 s | 79 | 1 | 1.25% |
| Name | Camera Matrix | Distortion Coefficients | Rectification Matrix | Projection Matrix |
|---|---|---|---|---|
| Camera (left) | ||||
| Camera (right) |
| Group | Gray Value | Average Relative Error (%) | Maximum Relative Error (%) |
|---|---|---|---|
| 1 | 0 | 1.1 | 4 |
| 2 | 50 | 0.66 | 2.2 |
| 3 | 100 | 0.48 | 1.4 |
| 4 | 150 | 0.63 | 1.7 |
| 5 | 200 | 0.64 | 1.3 |
| 6 | 255 | 0.41 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Lee, C.-H. Real-Time Data-Driven Method for Bolt Defect Detection and Size Measurement in Industrial Production. Actuators 2025, 14, 185. https://doi.org/10.3390/act14040185
Yang J, Lee C-H. Real-Time Data-Driven Method for Bolt Defect Detection and Size Measurement in Industrial Production. Actuators. 2025; 14(4):185. https://doi.org/10.3390/act14040185
Chicago/Turabian StyleYang, Jinlong, and Chul-Hee Lee. 2025. "Real-Time Data-Driven Method for Bolt Defect Detection and Size Measurement in Industrial Production" Actuators 14, no. 4: 185. https://doi.org/10.3390/act14040185
APA StyleYang, J., & Lee, C.-H. (2025). Real-Time Data-Driven Method for Bolt Defect Detection and Size Measurement in Industrial Production. Actuators, 14(4), 185. https://doi.org/10.3390/act14040185