1. Introduction
Driven by advances in manipulation controllers and navigation systems, mobile manipulation research for emergency rescue scenarios has made significant progress. Although existing research has shown that wheeled manipulators can handle household tasks [
1,
2], their application in outdoor environments with complex terrains remains challenging. Consider emergency rescue missions in rugged terrains: a robot capable of clearing rubble or delivering emergency supplies in disaster areas would greatly enhance rescue efforts.
In light of this, we are dedicated to researching legged mobile manipulation systems equipped with robotic arms. Our research focuses on enabling these robots to autonomously approach rubble or supplies using their visual perception capabilities in unpredictable outdoor environments. Through this research, we aim to develop a flexible and practical robotic solution for emergency rescue applications.
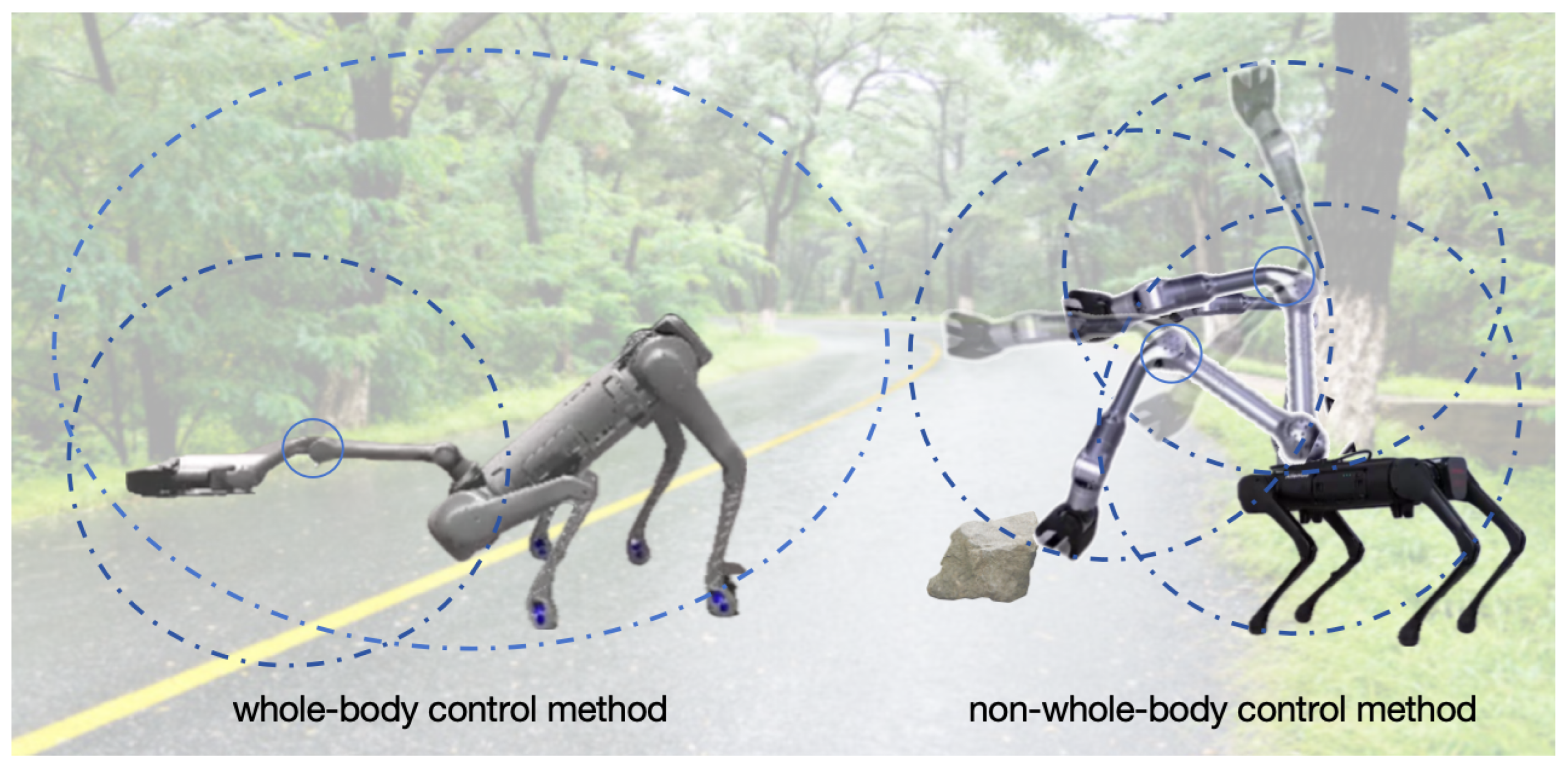
In the context of emergency rescue, position and orientation control offers a core advantage: it enables the full utilization of all degrees of freedom of the robot, facilitating coordinated control of its entire body. While the legs primarily handle locomotion, integrating all joints of both the legs and arms can significantly enhance the robot’s operational capabilities and flexibility in complex and dynamic environments, demonstrating substantial application potential. This concept aligns with human behavior patterns: we stand up and leverage the strength of our legs to reach high objects that are otherwise difficult to access; similarly, we may bend or squat to more easily accomplish tasks at lower heights (as shown in
Figure 1).
In practical emergency rescue applications, we envision robots, empowered by whole-body joint-coordinated control technology, to successfully perform a series of complex tasks. For example, during search and rescue missions in post-earthquake ruins, robots can use visual information to navigate to the roadside and, by bending their front legs and extending their arms, effortlessly pick up rubble or transport rescue supplies from grasslands or road surfaces. Without this whole-body coordination capability, robots might struggle to reach items on the ground using only the length of their arms, particularly in confined spaces. This limitation would significantly reduce their practicality and efficiency in emergency rescue operations.
Despite the practicality of whole-body coordination in actual rescue scenarios, simultaneously coordinating all high-degree-of-freedom joints is an extremely complex and challenging problem. A key challenge is ensuring that robots fully utilize visual feedback and maintain robustness against external disturbances.
Moreover, precise manipulation requires a stable robotic platform, which is more challenging for legged robots. Wheeled robots provide a stable base, while legged robots sacrifice stability for greater workspace flexibility.
Due to the tendency of relying solely on vision, which often produces low-frequency artifacts, jitter, and ghosts [
3,
4], adversely affecting perception outcomes, autonomously achieving all the aforementioned functionalities in diverse environments using only egocentric camera observations is significantly more challenging.
Recently, learning-based methods have shown promising results in enabling legged robots to navigate obstacles, climb stairs, and jump over steps robustly using visual input [
5,
6]. However, these studies focus solely on mobility and lack delicate manipulation, which demands higher precision. Given the complexity of scenarios and the precision required for manipulation, relying on a single network alone is insufficient to meet current demands.
In this paper, we achieve mobility and control functions by introducing a teacher–student training network framework. The main task of the teacher phase is to train the end effector’s posture and the robot body’s velocity commands based on visual information. Considering the difficulty of training the student network, full supervised learning is introduced to assist in training the student network. Additionally, a synchronous teacher–student network training strategy is introduced, which involves jointly comparing and optimizing the outputs of the teacher and student networks to simplify the training process. Therefore, the core of our method consists of three main points: supervised learning, synchronous teacher–student network, and visual information guidance.
Overall, we adopt the teacher–student framework primarily to provide high-quality prior knowledge and control strategies through a network of teachers. Specifically, the teacher network uses supervised learning to train encoders and policy networks to generate preliminary control commands, and optimizes the learning process of the student network through an information feedback mechanism. On this basis, the student network further generates more flexible and adaptable movement commands. Compared with a single network, the teacher–student framework not only accelerates the training process but also improves the robustness and diversity of control commands, especially in the task of adapting to grasping objects of different height positions.
Our simulation environment is configured in Isaac Gym, and the hardware platform is based on the Unitree B1 quadruped robot, which mainly consists of two parts: a mobile robotic dog and a robotic arm. The simulation results demonstrate that our proposed method can achieve mobility and manipulation in the simulation environment, and the strategies presented in this paper can be effectively transferred to real-world scenarios.
We summarize the contribution of this paper as:
We have developed a vision-based locomotion and manipulation method, which leverages supervised reinforcement learning and a synchronized teacher–student network strategy to reduce the learning discrepancy between the teacher and student networks, thereby more effectively generating whole-body control commands.
Our proposed method effectively integrates the mutual feedback strategies between the policy network and reinforcement learning, combined with teacher–student networks and supervised learning, enhancing the system’s adaptability in complex environments while optimizing the collaborative performance between quadruped robots and robotic arms.
Our proposed method has been thoroughly validated through simulations, demonstrating its capability to perform object manipulation tasks across varying height positions, distances, and diverse terrains.
The remainder of this paper is organized as follows: In
Section 2, we review typical methods for legged robot locomotion and manipulation, as well as recent advancements in robots integrating mobility with precision manipulation. In
Section 3, we detail the fusion of visual information with reinforcement learning and the control command generation method.
Section 4 describes the simulation setup and presents the results. Finally, in
Section 6, we summarize the robot’s capabilities and discuss future research directions.
3. Our Control Method
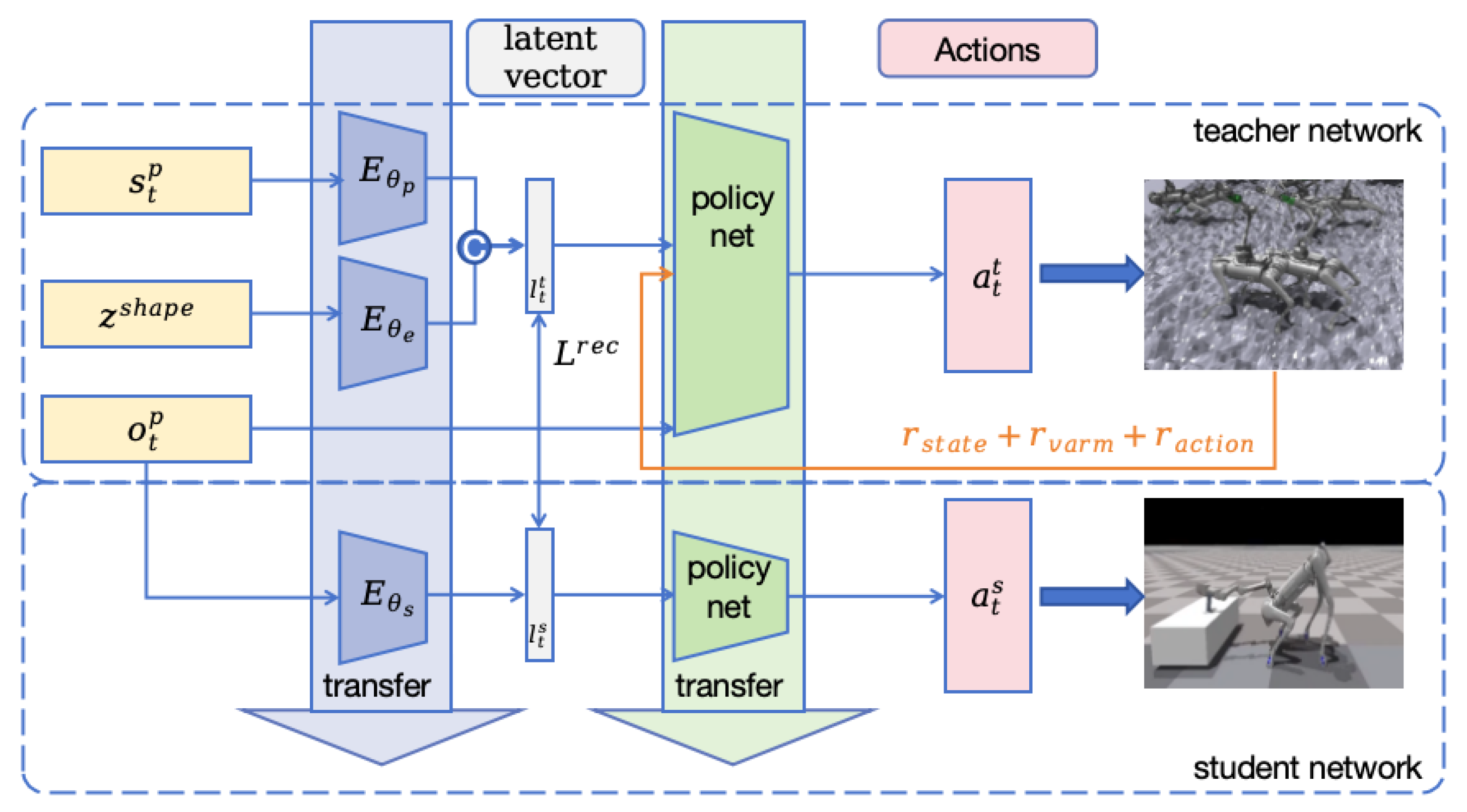
In this section, the main content is to introduce our visual consistency whole-body control framework (as described in
Figure 2). Our structure is shown in the figure, where privileged information and environmental information are used as inputs to the encoding network in the teacher network, and the proprioceptive observation state is used as input to the policy network in the teacher network and the encoding network in the student network. The main goal of our method is to allow the robot to approach and manipulate objects, while autonomously moving to the vicinity of the target object and executing manipulation commands relying only on proprioceptive states. In this section, we mainly elaborate on the core concepts involved in the network, such as the teacher–student network, observation information, reward function and objective function settings, and the policy network.
3.1. Teacher-Student Network
Firstly, initialize the policy network of the teacher network into the student network, which means that the initial policy network parameters of the student network are the same as those of the teacher network. Secondly, train the encoder and policy network of the teacher network through supervised learning, using labeled data (e.g., predefined actions and cor responding environmental states) to adjust network parameters so that the output is closer to the expected control commands. Meanwhile, information feedback learning is conducted between the teacher network and the student network, where the policy network of the teacher network and the encoder of the student network learn and improve by sharing information and feedback. The encoder network is optimized by comparing the output vectors of the encoder and calculating the loss, with the loss function mainly based on the consistency of encoded information.
Finally, the trained encoder and policy network can generate more flexible motion commands, which are used to control the quadruped robot and robotic arm, enabling them to autonomously move and manipulate objects.
3.2. Observations
In terms of environmental observation, we use visual sensors to acquire environmental information and process the visual information through a pre-trained visual information processing network. This extracts environmental features crucial for the motion planning of the quadruped robot, including but not limited to obstacle positions and terrain features. Based on the processed environmental information, we adjust the state of the quadruped robot’s base, including its position, posture, and movement speed, to ensure the robot can traverse complex environments stably and efficiently. Finally, we focus on the state of the end effector, achieving precise interaction with the environment by accurately controlling its position and posture to accomplish tasks such as grasping and placing. The entire process can be summarized as: .
For the teacher policy, the state
is composed of proprioceptive observations
, privileged state
, and environmental point cloud information
. The proprioceptive observations
encompass joint positions, joint velocities (excluding the gripper joint velocity), end-effector position and orientation, base velocities, and the previous action
selected by the current policy. Given the presence of target objects in the task, the local state of the target object, including position and orientation, is incorporated as part of the privileged state
to guide the end-effector and robot body towards executing actions. The environmental variable
represents a latent shape feature vector encoded from the object point cloud, obtained through a pre-trained PointNet++. For the student policy, it can only access and utilize proprioceptive observations
. This implies that the student policy must make decisions solely based on these limited internal state information. This can be mathematically expressed as:
3.3. Policy Network Architecture
After processing the observation data, we pass these high-dimensional observation vectors as inputs to the policy network. The policy network performs dimensional transformation and feature extraction through its internal structure and algorithms, ultimately outputting actions to control the quadruped robot and the robotic arm.
The policy networks in the teacher–student network are composed of a three-layer Multi-Layer Perceptron (MLP), with each layer having 128 neurons and using ELU as the activation function. This network receives latent variables output by the encoder. Additionally, in the teacher–student network, the policy network of the teacher network is initialized into the student network. Through supervised learning and information feedback learning, the encoder and policy network of the teacher network are trained to provide a basis for generating control commands. Our method aims to generate more flexible motion commands.
3.4. Reward Functions
The reward settings in the simulation are divided into three parts: state reward, speed limit reward, and action smoothness reward. The total reward settings in the simulation are as follows:
State rewards
, which include success reward, failure reward, and operation reward. The success reward, denoted as
, is given when the robot successfully moves the object. The failure reward, also known as the approach reward
, is given when the robot fails to move the object. The operation reward
is given for the robot’s effort in executing the commands. In the task, the robot needs to move the target object to a specified location, and the task is considered complete when the displacement of the target object exceeds a preset threshold.
The first stage is the approach phase, where the reward
encourages the robotic arm and quadruped robot to get close to the target object:
where
represents the current minimum distance between the gripper and the target object. The second stage is the task execution phase, where the reward
guides the robotic arm and robot to achieve their goals, such as touching or moving the object:
where
is the current maximum distance of the object. The third stage is the task completion phase, where a reward
is given when the quadruped robot and robotic arm complete the task:
In tasks involving lifting a target object, the condition for successful completion is met when the object’s displacement exceeds a predefined threshold. The design of auxiliary rewards is intended to enhance the smoothness of robot behavior, mitigating deviations and the accumulation of non-informative data. This involves ensuring that the robot’s body and gripper maintain alignment with the object, thereby preventing the camera from losing track of the target. Furthermore, action-related rewards have been defined to expedite the convergence of the algorithm. The primary goals encompass adhering to instructions, providing opportunities for the robot to re-explore, and ultimately achieving consistent command execution. This is mathematically represented as follows:
In these equations, serves to limit the rate of change in the arm joint velocity, while facilitates smoother command execution by preventing excessively rapid transitions.
3.5. Actions
In our policy architecture, the teacher network and the student network exhibit significant differences in the definition and execution of action commands. Specifically, the core function of the teacher network is to generate complex and highly adaptive action commands, which have a decisive influence on the execution layer of the student network.
The commands generated by the teacher network and the student network,
, are defined as a vector comprising three components: the incremental gripper posture
(six dimensions), the linear and yaw velocity commands of the quadruped robot
(two dimensions), and the gripper state
(one dimension, representing open or closed). These commands together form a nine-dimensional vector, expressed as:
When executing these commands, the linear velocity is uniformly sampled from the range , and the yaw velocity is sampled from .
In summary, the teacher network is mainly used to learn action commands in complex environments, while the student network is responsible for learning and generating simpler commands and executing them. The two networks are structurally identical but have slight functional differences.
3.6. Objective Function
Due to the structural change of the overall architecture and the way we exploit the information from the teacher and student groups, the conventional training process does not apply directly and hence needs to be adjusted. Since agents are divided into two groups, the Monte-Carlo approximation of PPO-Clip objective functions of each group
is defined as:
where
and
are sets of teacher group and student group trajectories by interacting with environment using
and
, respectively.
T is the length of corresponding trajectory.
In the Proximal Policy Optimization (PPO) algorithm, the clip function is utilized to constrain the magnitude of policy updates. It is formally defined as:
where
are ratio functions of two groups:
In order to enhance the learning of the student network from the teacher network, while taking into account the consistency of encoded information, the latent information reconstruction loss is introduced. This loss is used to further update the student network by minimizing the output discrepancy between the teacher network and the student network. Its approximate definition is as follows:
3.7. Randomization
To develop a robust gripper, we sample and track multiple gripper orientations. To ensure smooth trajectories, we define a coordinate system with the robot’s base as the origin and sample trajectories at fixed time intervals. This approach reduces the impact of the quadruped robot on sampled targets and improves the system’s adaptability to diverse environments and objects. During training, we implemented a comprehensive randomization strategy to enhance system robustness. We randomized terrain types (flat and rugged), friction coefficients, robot mass, and center of mass position. These measures enhance the robot’s adaptability to diverse environments. For picking tasks, we randomized table height, robot initial position and orientation, and object position and orientation. This ensures robust system performance across diverse and complex environments.
To enhance the method’s robustness and generalization, we introduced randomization during training. Specifically, the initial position is randomized within ±0.5 m of the target object, and the initial orientation is randomized within ±30 degrees. This randomization simulates real-world uncertainties, enabling the method to adapt to varying initial conditions.
4. Simulation
We conducted a series of simulations for mobile object tasks, demonstrating the method’s adaptability to varying heights and distances, as well as its stability across different terrains.
The core advantage of our method is the successful decoupling of base movement and robotic arm control through a state reward constraint mechanism, significantly enhancing task adaptability and execution efficiency. Specifically, the state reward mechanism comprises three stages: (1) the quadruped robot approaches objects on the table plane, (2) the robotic arm fine-tunes its distance to the object, and (3) the state reward is completed. This staged reward mechanism enables a full-body control decoupling strategy. Unlike traditional methods that rely on fixed collaboration strategies, our method dynamically adjusts base and robotic arm control instructions based on task requirements.
Additionally, it utilizes consistent environmental information and the state-of-the-art PointNet++ network to analyze object shape features in depth. This foundation enables the execution of complex tasks, such as drawer opening.
4.1. Overview of the Simulation Platform
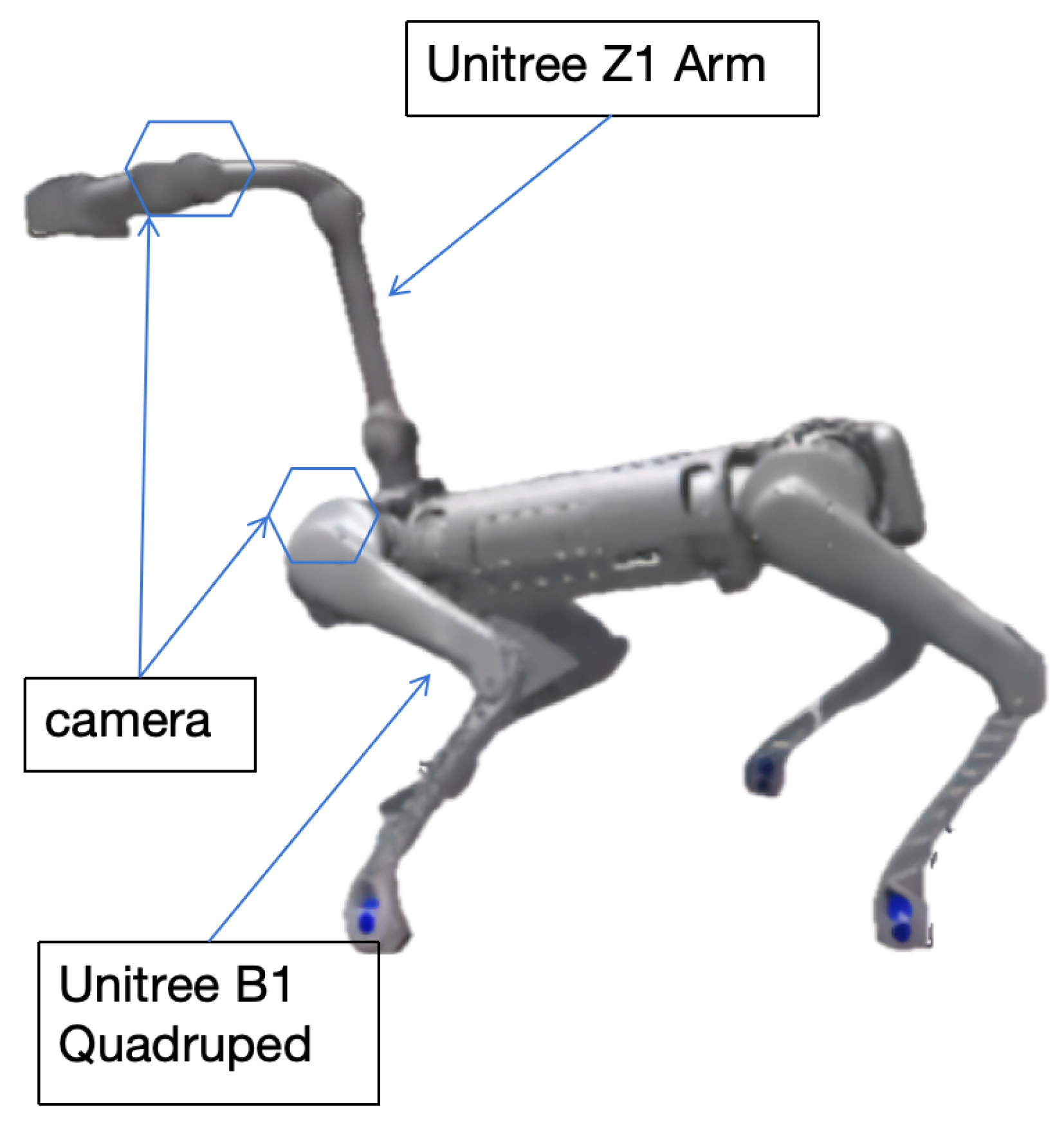
In this study, we simulate a robotic system based on the Unitree B1 quadruped robot, integrated with a Unitree Z1 robotic arm and a gripper. Two RealSense D435 cameras are simulated: one mounted on the quadruped body and the other near the gripper. The simulated system has 19 degrees of freedom (DoFs): 12 for the quadruped, 6 for the robotic arm, and 1 for the gripper. The system is visualized in
Figure 3. For object detection, we employed a virtual depth camera in the simulation. The camera features a resolution of 640 × 480 pixels, a 30 fps frame rate, and ±2 mm accuracy.
4.2. Simulation Setting
In the simulation setup, given our focus on applications in disaster scenarios, we have categorized objects into six types based on their shape characteristics: spherical, cuboidal, cylindrical, concave, convex, and others (encompassing shapes that cannot be unequivocally classified into the aforementioned five categories).
During the simulation process, when the robot initiates the execution of a command, both its initial position and orientation, as well as the initial position and orientation of the object, are randomly assigned. There are two metrics to measure the proposed method. Success rate is defined as the successful movement of the object, whereas failure encompasses situations where the object is incorrectly initialized underneath the table, drops to the ground, or remains unmoved after 100 attempts. The failure rate refers to the proportion of tasks that result in failure relative to the total number of tasks. While the success rate indicates positive performance, the failure rate, by contrast, indicates negative performance.
4.3. Algorithm
The algorithm “Enconder-consistency Training” as shown in Algorithm 1 initializes the environment and networks. For each iteration
, it collects sets of trajectories
and
using the latest policy and computes
and
using the encoder. In the policy optimization loop, for each epoch
, it uses
to represent
and
for notational brevity, updates
by adding
times the gradient of the combined PPO loss
. Where
is a hyperparameter used to control the magnitude of gradient updates in policy optimization. In this paper, the value of
adopted is 0.0005. In the reconstruction loss optimization loop, for each epoch
, it updates
by subtracting
times the gradient of the reconstruction loss
. This process iteratively trains the networks to improve visual consistency and policy performance.
| Algorithm 1 Enconder-consistency Training |
- 1:
Initialize environment and networks - 2:
for
do - 3:
Collect sets of trajectories and with latest policy - 4:
Compute and using Enconder - 5:
for epoch do - 6:
Use represent for notational brevity - 7:
- 8:
end for - 9:
for epoch do - 10:
- 11:
end for - 12:
end for
|
4.4. Quantitative Simulation
During the simulation process, we compared our method with networks designed for the following three scenarios and evaluated their performance across six shape datasets.
Without Visual Consistency Strategy : This is a scenario where the variability of sensory information is not taken into account.
Non-Full-Body Control Strategy: This strategy possesses superior navigation capabilities, but lacks full-body coordination control. The robot can achieve good results within a height range of 0.4 to 0.55 m, but the workspace is limited, with 0.4 m serving as the lower bound. Here, the advantage of the larger workspace provided by the full-body control strategy becomes apparent.
Non-Phased Control Strategy: This strategy jointly trains the first and second stages in an end-to-end manner without differentiation. It combines observations from both stages and outputs the target positions for 12 robot joint angles and the target posture for the gripper. However, using this method did not yield satisfactory results, further validating the effectiveness and necessity of our proposed method.
In our quantitative simulation, we evaluated the success rate of manipulating six objects under four control strategies and tested them in a simulated environment. We collected test results for each object, and during the testing process, the initial heights of each object’s location were randomly set within the range of 0 to 0.5 m. As shown in
Table 1, our method performs best on cuboid objects. It is worth noting that the strategy of not considering visual consistency, that is, not using visual information, performs best on spherical objects, that is, objects with regular shapes. The key reason for this phenomenon is that the consideration of visual consistency contains richer information, which has a more significant impact on objects with more complex shapes.
In addition, we tested the success rate of tasks at different heights in the simulator, as shown in
Figure 4. Wherein, the height refers to the height of the object’s position. It can be observed that the success rate of the same object model processed by different methods varies with height, but our method performs equally at different heights, which also proves the superiority of our method in adapting to objects of different heights. Moreover, to validate the decoupling strategy of the model, we tested the success rate of different distance tasks in the simulator, as shown in
Table 2. Our method outperforms methods lacking visual consistency and demonstrates superiority in handling object manipulation tasks at different distances. (The distance refers to the space between the object and the robot.).
At the same time, relying on the advantage of a larger inclination angle in the whole-body control strategy, our method can adapt more stably and maintain balance when tackling tasks on different terrains. Therefore, we use the failure rate as a measure of stability and test the mission failure rate for different terrains (plane, heightfield, trimesh) in the simulator, as shown in
Table 3. It can be observed that our method is superior to the method lacking visual consistency in different terrain tasks, indicating that it can adapt to different terrain tasks.
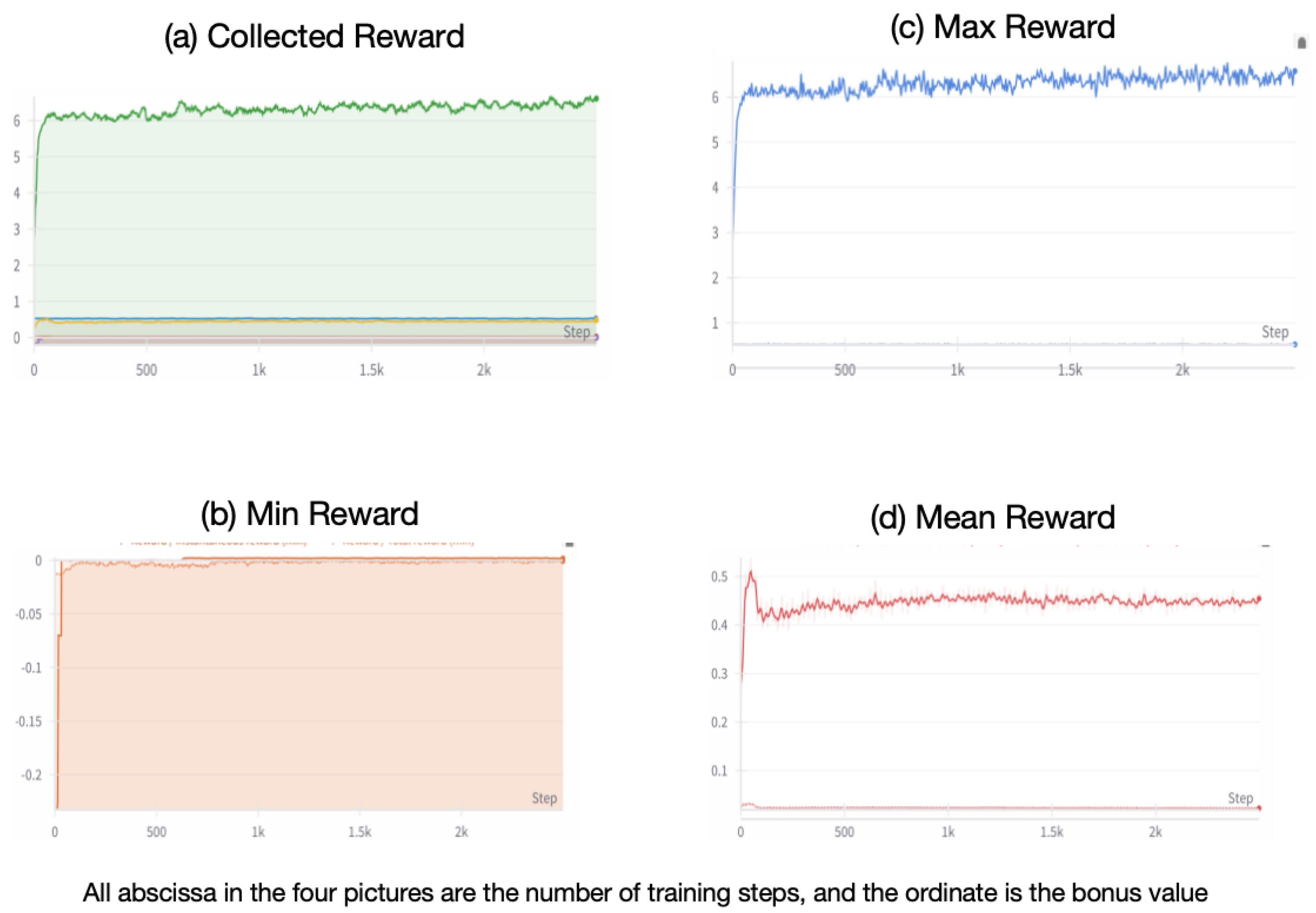
Finally, the rewards in the simulation setup include three types of rewards, which are uniformly weighted and summed: the reward for successfully moving the object. As shown in
Figure 5, we can see that as the training process continues, the reward values gradually increase, indicating that our method gradually converges during training and ultimately achieves good results. The top left corner shows the combined display of the maximum, minimum, and average rewards, where it can be seen that the rewards converge, demonstrating superior performance.
4.5. Qualitative Simulation
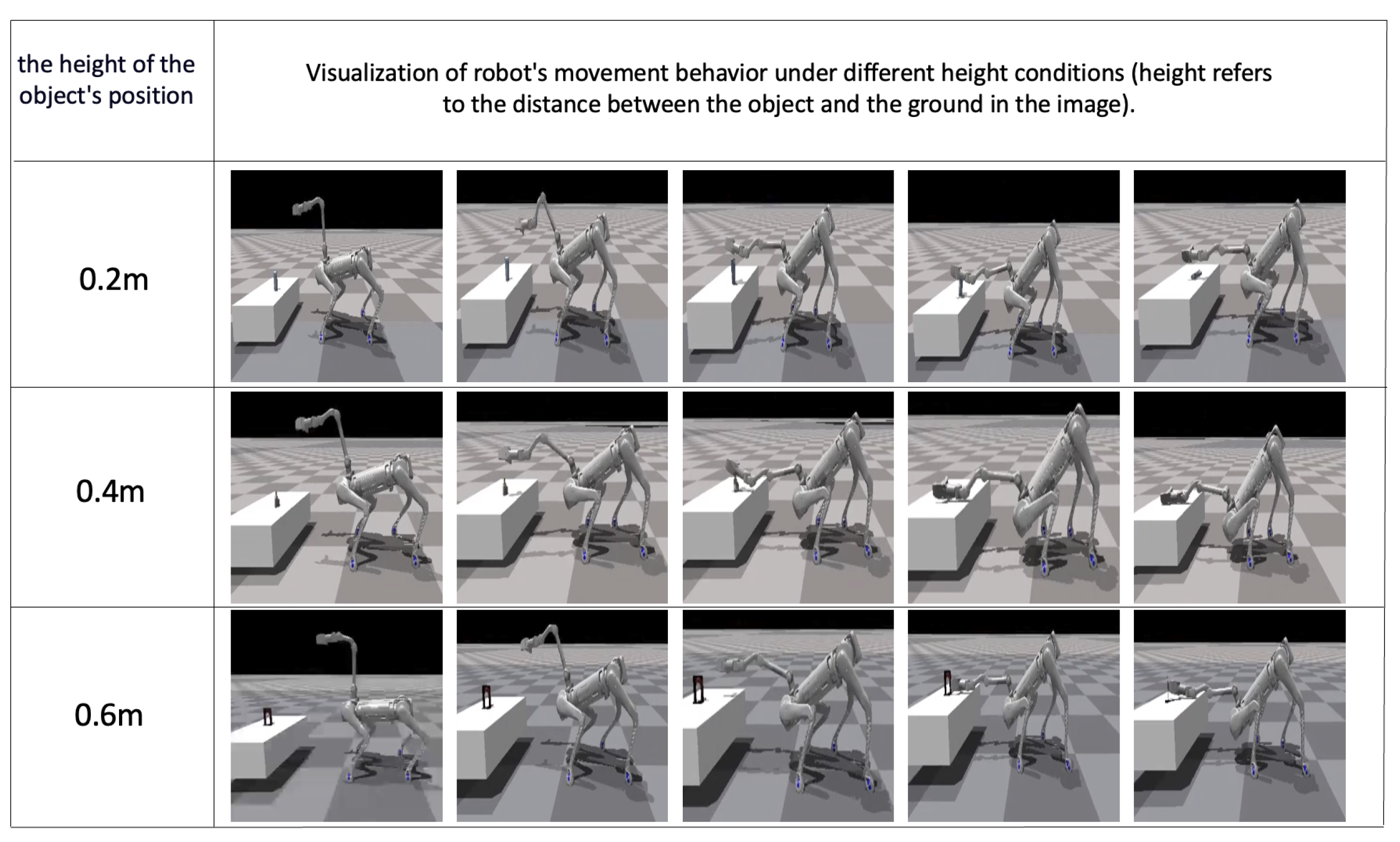
In qualitative simulation,
Figure 6 presents the visualization of a quadruped robot manipulating a robotic arm to move objects. It particularly demonstrates the adaptability of the robot dog and robotic arm, under the full-body control strategy, to objects of different heights and the achievement of object manipulation. In the figure, we observe the posture of the quadruped robot on flat ground, including squatting, leaning forward and other actions. Through simulation data analysis, we found that leaning forward behavior can effectively reduce the center of gravity and improve stability in specific tasks, such as when grabbing objects at a low height. However, this behavior also increases the use of control torque, so it needs to be further optimized in terms of task completion efficiency.
Furthermore, the information in the figure indicates that in a scene with a height of 0.6, the process of a quadruped robot transitioning from its initial pose to a pose that is not parallel to the ground is demonstrated. The figure shows that by combining full-body control with consistent visual information, the quadruped robot and robotic arm can collaborate more effectively. They can handle objects of different heights or shapes. Meanwhile, for the task of full-body control grasping, the proposed grasping structure can initially achieve full-body control moving. However, since this article focuses on the collaboration between quadruped robots and robotic arms, flexible grasping ends are not utilized. In summary, this figure vividly showcases the diversity and flexibility of robot behavior under the full-body control strategy, as well as its better performance in object manipulation tasks.
It is equally noteworthy that during the training phase in a simulated environment, the robot exhibits retrying behavior when executing commands. Specifically, when the robot fails to successfully grasp an object, it automatically attempts to grasp again without any human intervention, showcasing the advantage of self-feedback learning in reinforcement learning. During our simulation process, we observed that randomly initialized poses and movements of the robot provided a safeguard for success rates.
6. Conclusions, Limitations, and Future Works
In this paper, we propose a fully autonomous mobile manipulation system based on quadruped robots and a teacher–student network. Our proposed method comprises a command generation module and a command execution module, which are trained through reinforcement learning and a teacher–student network. It also considers the consistency of visual information and employs a loss optimization method to enhance the training effect of the teacher–student network. Despite achieving remarkable results in moving and manipulating obstacles of various shapes, the system still has limitations due to system-level and real-world deployment constraints, which are outlined below: Hardware and Environmental Adaptation: Our phased approach to mobility and manipulation demands high-precision and coherent modules for seamless cooperation between the quadruped robot and the robotic arm. However, the depth estimates provided by current depth cameras are inaccurate in certain scenarios, particularly in dimly lit environments with indistinct features. Gripper Design Limitations: The currently used parallel gripper has a tendency to push objects away during operation, which makes precise manipulation challenging.
These two factors are the most common causes of failure in our real-world experiments. It is worth noting that, due to the incomplete exploitation of environmental perception information, we plan to incorporate visual SLAM into the system to fully leverage this information. Specifically, by integrating lidar, visual odometry, and a computing board onto the quadruped robot, it can identify objects to be manipulated within a 3D model, fully understand environmental information, and improve manipulation accuracy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}