1. Introduction
With the development of aerospace technology, space exploration activities become increasingly frequent, and the on-orbit operations, such as spacecraft assembly, maintenance, debris removal, etc., become urgent demands. The space environment has the features of no gravity, no air and high radiation, which makes astronauts face great safety risks when performing on-orbit operations. As a type of typical aerospace equipment, space robots have high autonomy and flexibility, so they are widely used in various on-orbit tasks instead of astronauts [
1,
2]. Moving or carrying loads safely to the target position is the basic operation in on-orbit operations and also should be the most basic function for space robots. In general, a space robot is composed of a base with control system and solar arrays, as well as a manipulator with several links and an end-effector which carries the load. Therefore, safely moving contains two meanings: Firstly, a smooth, collision-free trajectory for the load should be provided so that it can reach the target position along this trajectory. Secondly, the body of the space robot, especially the links of the manipulator, needs to avoid obstacles in the environment as the load moves along this trajectory. These two conditions should be met simultaneously, which derives the obstacle-avoidance motion planning for the space robot [
3].
Obstacle-avoidance motion planning is a long-term direction in robotic research. Some methods, such as visibility graph [
4], Voronoi diagram [
5], probabilistic roadmap method (PRM) [
6], rapidly exploring random tree (RRT) [
7], A* algorithm [
8], etc., are widely used in robotic community. Most of the above methods are aimed at stationary obstacles or the situations, where environmental information is known. However, the working environment of space robot is unstructured and dynamic. There are not only stationary obstacles, but also moving obstacles that cannot be predicted to their moving trajectories (e.g., floating debris, and unfixed tools), requiring the obstacle-avoidance motion planning method to be real-time. Similar to the biological stimulus–feedback mechanism, Khatib [
9] proposed a reactive obstacle-avoidance method based on artificial potential field (APF), which enables real-time response to unstructured dynamic scenes. However, it only constrains the end-effector’s target position while not the whole trajectory. As a result, the end-effector’s predetermined trajectory for the task cannot be guaranteed if the obstacle approaches, which means this method cannot be applied to the tasks that have requirements on the end-effector’s trajectory. For this problem, researchers noticed that the redundant degrees of freedom (DOF) of the manipulator can be used to track the end-effector’s predetermined trajectory while avoiding obstacles. It uses the null-space motion characteristic of the redundant robot. According to this, many solutions have been proposed, such as null-space vector assignment [
10], redundant manipulator-based APF [
11,
12], gradient projection method (GPM) [
13,
14], objective function optimization [
15,
16], etc. Among them, redundant manipulator-based APF and GPM are the common used methods with high efficiency in practice.
In fact, for on-orbit operation tasks, there are strict requirements for the end-effector’s trajectory, such as maintenance, grasping, and docking, etc., which requires the space robots to avoid unpredicted moving obstacles as much as possible on the premise of ensuring the tracking of the end-effector’s predetermined trajectory. Even partial contact or slight collision is allowed in extreme cases, such as emergency repair on critical fault. Fortunately, most space robots have redundant DOFs, it means that we can tap the potential of obstacle avoidance as much as possible without changing the end-effector’s trajectory. However, unlike the ground robot, there is a motion coupling between the free-floating base and the manipulator of the space robot. Once the manipulator’s joints are actuated, the end-effector and the base will move at the same time so that the identical method to the ground robot cannot achieve the desired effect of obstacle avoidance. At present, the most active research in this field is GPM and the objective function optimization method. Mu et al. [
17] constructed a unified framework to model the obstacles for a redundant space robot, and combined GPM to obtain the collision-free trajectories. Hu et al. [
18] proposed the gradient projection weighted Jacobian matrix (GPWJM) method, which takes the end-effector’s trajectory tracking as the main task, as well as meeting the motion constraints of the base and links. Wang et al. [
19] described the target position arrival and obstacle avoidance as linear inequality constraints, then integrated them into a quadratic programming (QP) optimization to calculate the trajectory with the help of non-linear model predictive control (NMPC). Ni et al. [
20] transformed the motion planning problem into a multi-objective optimization that achieves the target configuration while avoiding obstacles, which is solved by the particle swarm optimization (PSO) method. Rybus et al. [
21] introduced joint splines into motion planning, then constructed a constrained nonlinear optimization problem to solve the collision-free and task-required trajectory, which used the active set method to generate the solution. However, the above methods introduce complex solution strategies and operation rules, including differentiation, integration and nonlinear functions, which reduces the computational efficiency. For the space robots with limited computing resources, low computing efficiency will seriously affect the task performance.
Recently, with the development of reinforcement learning (RL) theory, new solutions have been provided to solve the problem of reactive obstacle-avoidance motion planning for unpredicted moving obstacles. RL builds an agent that continuously interacts with the environment, which optimizes its own action generation policy according to the feedback states and rewards from the environment during each interaction process so as to maximize the sum of rewards. It has good environmental adaptability and computational real-time performance, such as DDPG [
22,
23], TD3 [
24], PPO [
25], SAC [
26], etc., showing great potential in robotics applications. These methods can generate safe and collision-free trajectories from the specified start point to target point based on the feedback states from the unstructured dynamic environment, but most of them are aimed at mobile robots that can be regarded as moving particles. For the robots with a chained manipulator, such as service robots and industrial robots, the research focus is on the completion of manipulation tasks, which means that the designed RL structures lack native obstacle-avoidance mechanisms. Their state space and rewards lack the representation of obstacle information [
27], or only aim at some specific obstacles [
28] such that these methods are difficult to be applied to unstructured dynamic environments, where the number and motion state of the obstacles are not specified. When there are unexpected obstacles which do not exist during the training process, they are difficult to achieve effective obstacle avoidance, unless a large number of randomly moving obstacles are introduced during training, or retraining a new policy for the changed environment. However, adopting these methods will also greatly reduce the training efficiency of RL. In terms of space applications, the research on RL-based spacecraft control to improve its autonomous decision-making performance has made a lot of progress, including spacecraft landing on celestial bodies, maneuver planning, attitude controlling, rover path planning, etc. [
29]. Most of these methods also regard the spacecraft as a mobile robot with special motion response in space, rather than a ground industrial or service robot with a chain manipulator, so they cannot achieve on-orbit operation tasks. However, unlike the ground chain manipulator, using RL to achieve obstacle avoidance is more difficult for space robots due to the free-floating characteristic of the base. Yan et al. [
30], Du et al. [
31], and Wu et al. [
32] explored the application of RL in space robots, preliminarily proving that RL methods, such as soft Q-learning and DDPG can achieve effective motion planning and control for the space robot with free-floating base, but obstacle avoidance was not discussed. Wang et al. [
33] developed a model-free hierarchical decoupling optimization (HDO) algorithm for space robots. The upper layer uses RRT to sample collision-free path points, while the lower layer uses DDPG to connect each sampling point, so the collision-free motion trajectories can be generated. Li et al. [
34] combined DDPG and APF, then introduced the self-collision avoidance constraints of the end-effector to realize the motion planning. Although these methods can be applied to redundant space robots, they do not have the ability to maintain the end-effector’s predetermined trajectory during the obstacle-avoidance process. As mentioned above, this ability is very important for the space robot.
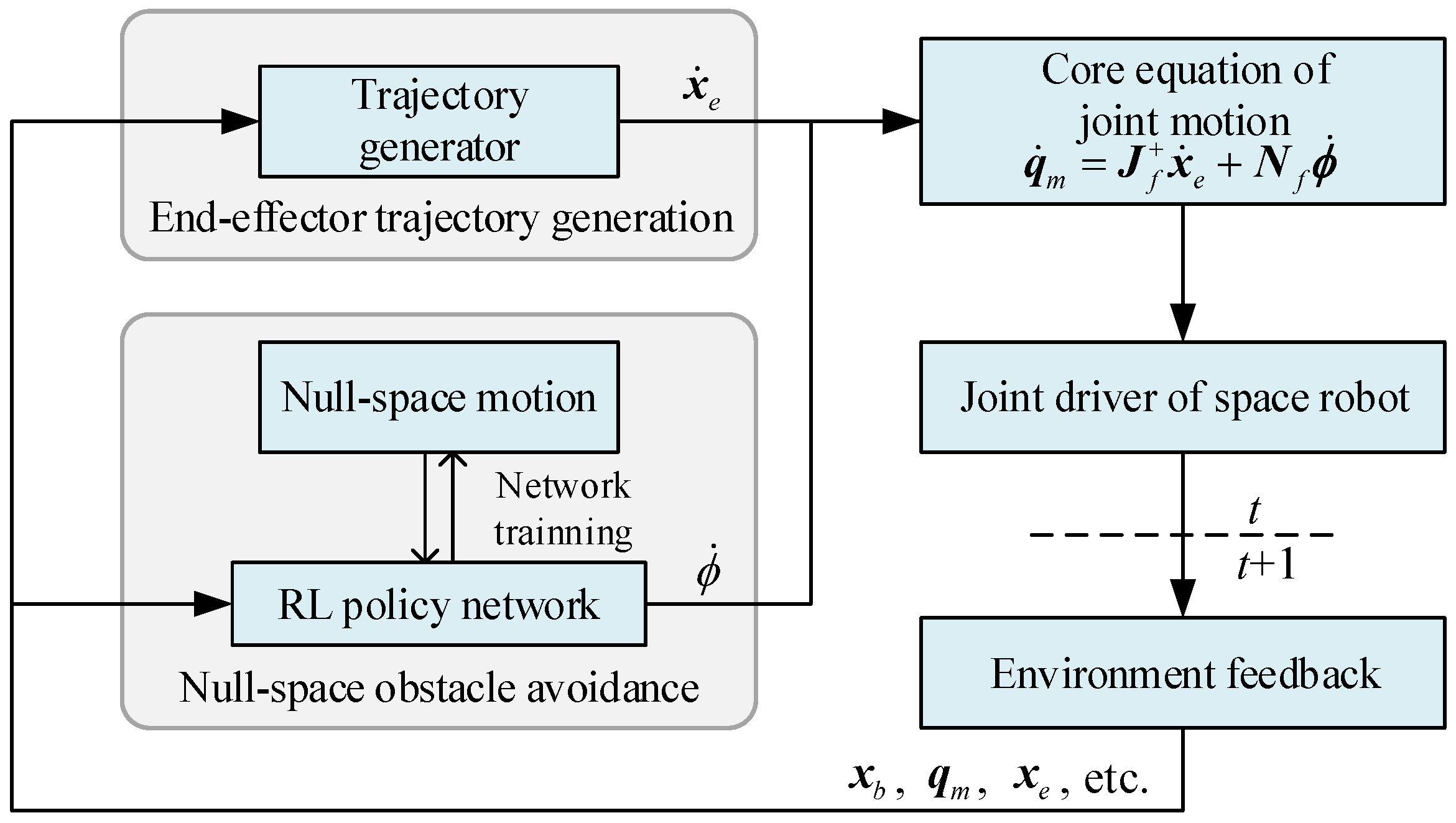
In summary, considering the on-orbit operation constraint of obstacle-avoidance motion and inspired by GPM, we propose a new obstacle-avoidance motion planning method for redundant space robots by combining the null-space motion with reinforcement learning. Unlike PRM, RRT and other obstacle-avoidance methods which cannot constrain the end-effector’s movement, our method can realize reactive obstacle avoidance while maintaining the end-effector’s predetermined trajectory with good adaptability to the unstructured dynamic environment, which can cope with the changes of obstacles in the environment without retraining. The major contributions of this paper are as follows:
The motion planning framework combining RL with null-space motion for space robots is proposed to realize reactive obstacle avoidance without changing the end-effector’s predetermined trajectory.
The RL agent’s state space and reward function independent of the specific information of obstacles are defined from the aspect of the robot itself, so that the RL agents can be applied to unstructured dynamic environments, avoiding retraining for obstacle changes.
A curriculum learning-based training strategy for RL agent is designed to further improve the sample efficiency, training stability and performance of the obstacle avoidance.
The rest of this paper is organized as follows: In
Section 2, the proposed motion planning framework is introduced, which contains the end-effector trajectory generation module and the RL-based null-space obstacle-avoidance module. In
Section 3, the RL paradigm for null-space obstacle avoidance module, as well as state space, action space, reward function, and the curriculum learning-based training strategy, are described in detail. In
Section 4, the simulation results are presented and discussed. Finally, the conclusions of this paper are given in
Section 5.
3. Null-Space Obstacle Avoidance Based on RL
Reinforcement learning has excellent environmental adaptability. After training is accomplished, RL can generate instant actions for environmental changes, which is suitable for the applications in dynamic scene. Considering the dynamic and unstructured characteristics of the working environment of space robots, we design the details about the RL-based null-space obstacle-avoidance strategy, which prevents the collision between the links and the obstacles, simultaneously maintaining the current pose of the end-effector.
3.1. RL Model for Null-Space Obstacle Avoidance
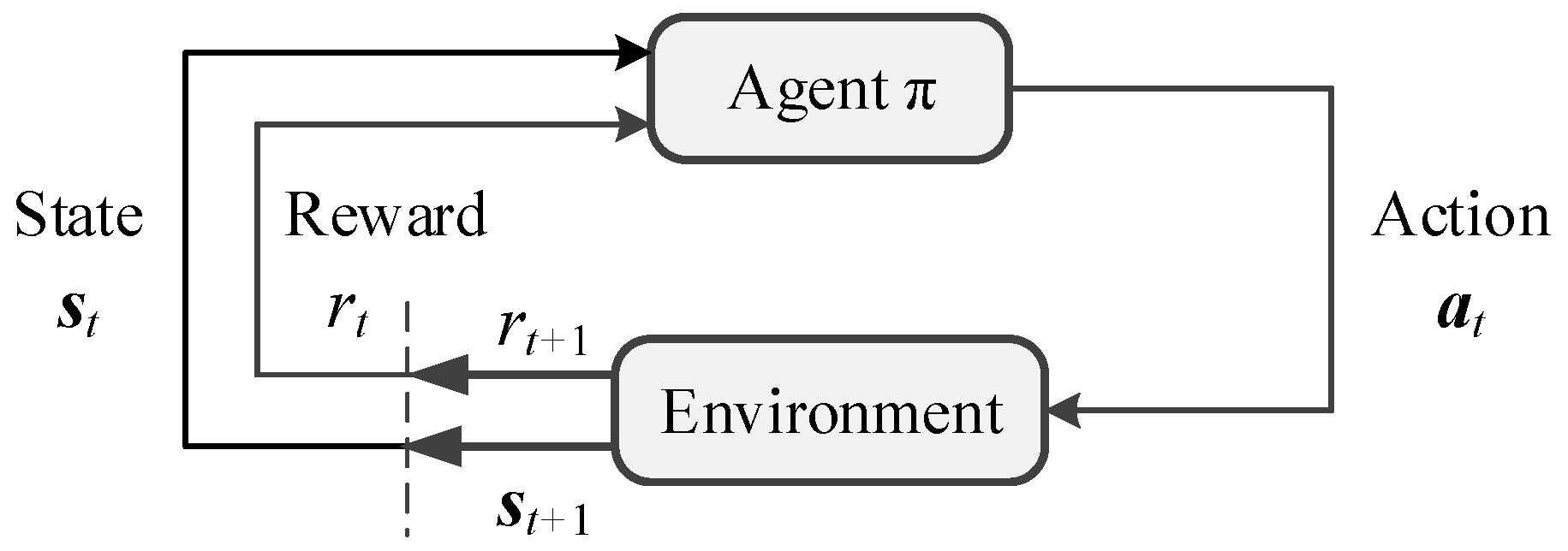
In order to introduce RL to realize null-space obstacle avoidance, we should transform this task into a mathematical paradigm for RL problems. The main idea of RL is that the agent continuously interacts with the environment to adjust and optimize its action policy according to the feedback states and rewards from the environment during each interaction so as to maximize the sum of rewards after the task is completed. The process of RL is shown in
Figure 3.
As shown in
Figure 3, the agent is constantly maintaining an action generation policy
. For each timestep
t, the agent obtains the current state vector
and the feedback reward
from the environment, where
represents the state space composed of all possible states in the environment, and
is the set of real numbers. If the policy
has been trained and deployed, it generates the action
according to
, where
represents the action space composed of all executable actions of the agent. Otherwise, the agent will make decisions based on its interaction experience, knowledge base or other manual methods to generate action
. Subsequently, the action
acts on the environment to obtain the state
and reward
at the next timestep. The above process is repeated over time. In this process, the agent will train or optimize its own action generation policy
according to the obtained reward. The ultimate goal of the agent is to train an optimal policy
to maximize the cumulative reward
. It can be expressed as
where
is the discount factor of the reward.
For the null-space obstacle-avoidance of space robots, the agent is a certain policy that generates the null-space angular velocity of the joints. The goal of this policy is to generate the null-space solution vector at the current timestep according to the feedback information—the states of the space robot and the positions of the obstacles in the environment—so that the manipulator can avoid the obstacles in an optimal way under a certain evaluation criterion.
Therefore, the action of the agent
is the null-space solution vector, namely,
The state of the agent
consists of the information about the space robot and obstacles. In previous works [
28], it is usually defined similar to
where
t is the timestep,
is the joint angle of the manipulator,
is the pose of the end-effector, and
is the position of the obstacle. The reward from the interaction between the agent and the environment
is a feedback function, which is denoted as
It determines whether the space robot collides with obstacles, and evaluates whether the current configuration is reasonable so as to guide the policy’s training process. The specific forms of
and
in our method are defined in
Section 3.2.
Unlike the traditional tabular RL methods, the action vector
and state vector
we defined are high-dimensional continuous and differentiable variables so that the RL agent must support continuous action/state space, and has the ability to prevent from “dimensional disaster” (i.e., inefficient or invalid learning in high-dimensional state space). Soft actor–critic (SAC) is the current state-of-the-art RL method, which is robust to the learning of continuous high-dimensional variables, such as robotics. Thus, we adopt SAC to optimize policy
for better training performance. It should be pointed out that, except for the requirement of continuous action/state space, our method does not specify the RL network structure and parameter optimization strategy. In fact, as mentioned in the introduction, there are many applications of robot planning or controlling with DDPG, PPO and the other RL methods. Here, we choose SAC, as it has higher data efficiency to avoid long-time training [
26,
36]. That is to say, if a better RL method is developed in the future, we can also use it instead of SAC. The policy
is described as a neural network with input
and output
, which is expressed as
where
represents the neural network that constitutes the policy
, and
is the parameters of the neural network. The idea of SAC is to add an entropy function into Equation (
6) to enhance the randomness of policy exploration so as to accelerate the policy convergence during the training process. Thus, Equation (
6) becomes
where
is the entropy function, which generates a random distribution that affects the direction of policy exploration according to the action of the neural network
;
is the temperature of the entropy, which adjusts the ratio of the cumulative reward to the entropy value.
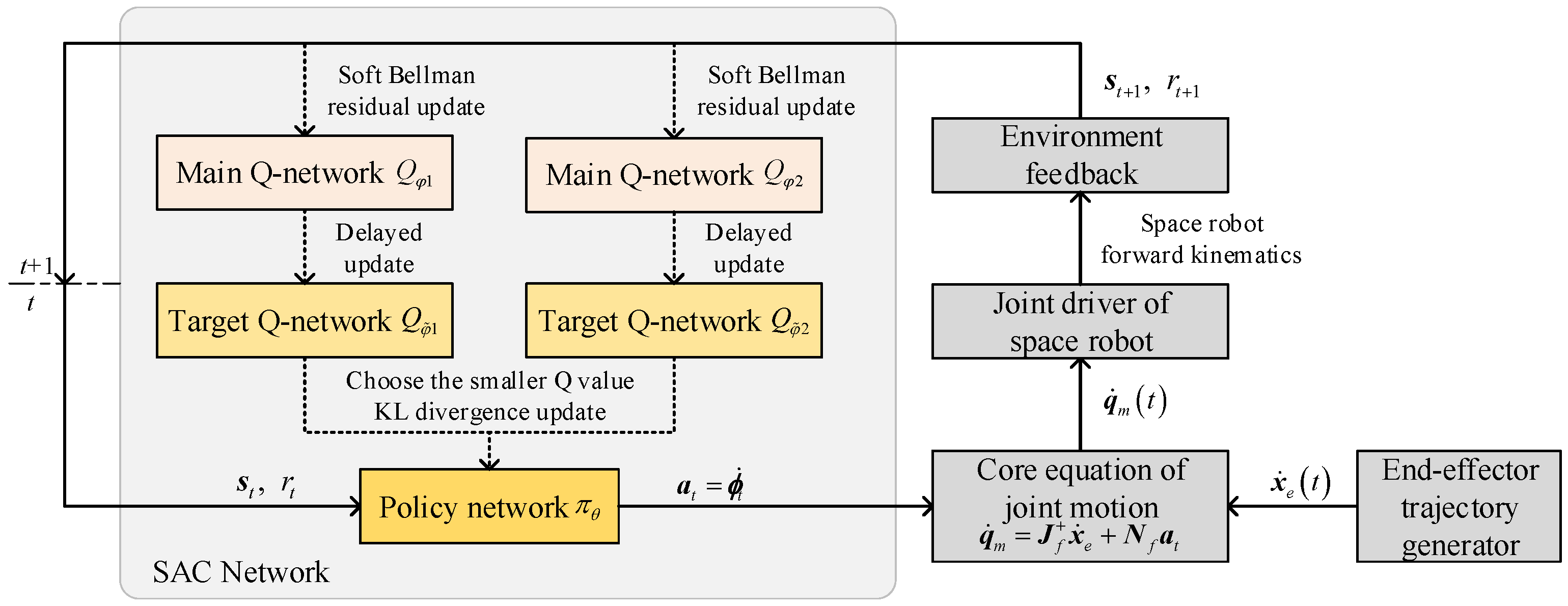
Specifically, SAC contains a policy network
that generates actual actions (i.e., the null-space solution vector
for space robot), as well as two main Q-networks
,
and two target Q-networks
,
that evaluate the quality of the current policy, where
,
,
,
, and
represent the parameter vectors of their corresponding networks, respectively. The network structure is shown in
Figure 4. The detailed training process of SAC network is described in [
26], and we do not explore it in this paper.
3.2. State and Reward Function Definition
It is important to choose appropriate states and reward function for solving the RL task of space robot obstacle avoidance. As mentioned above, in the previous RL-based robot planning methods, the state vector is mostly defined similar to Equation (
8). However, this definition is only suitable for a fixed number of obstacles in the working environment. In the unstructured dynamic environment, the number of obstacles is usually unknown and even may change during task execution such that the defined state vector cannot match the actual working environment. It can only be solved by modifying the state definition and retraining for every change of the scene configuration, which is not practical to be deployed in reality.
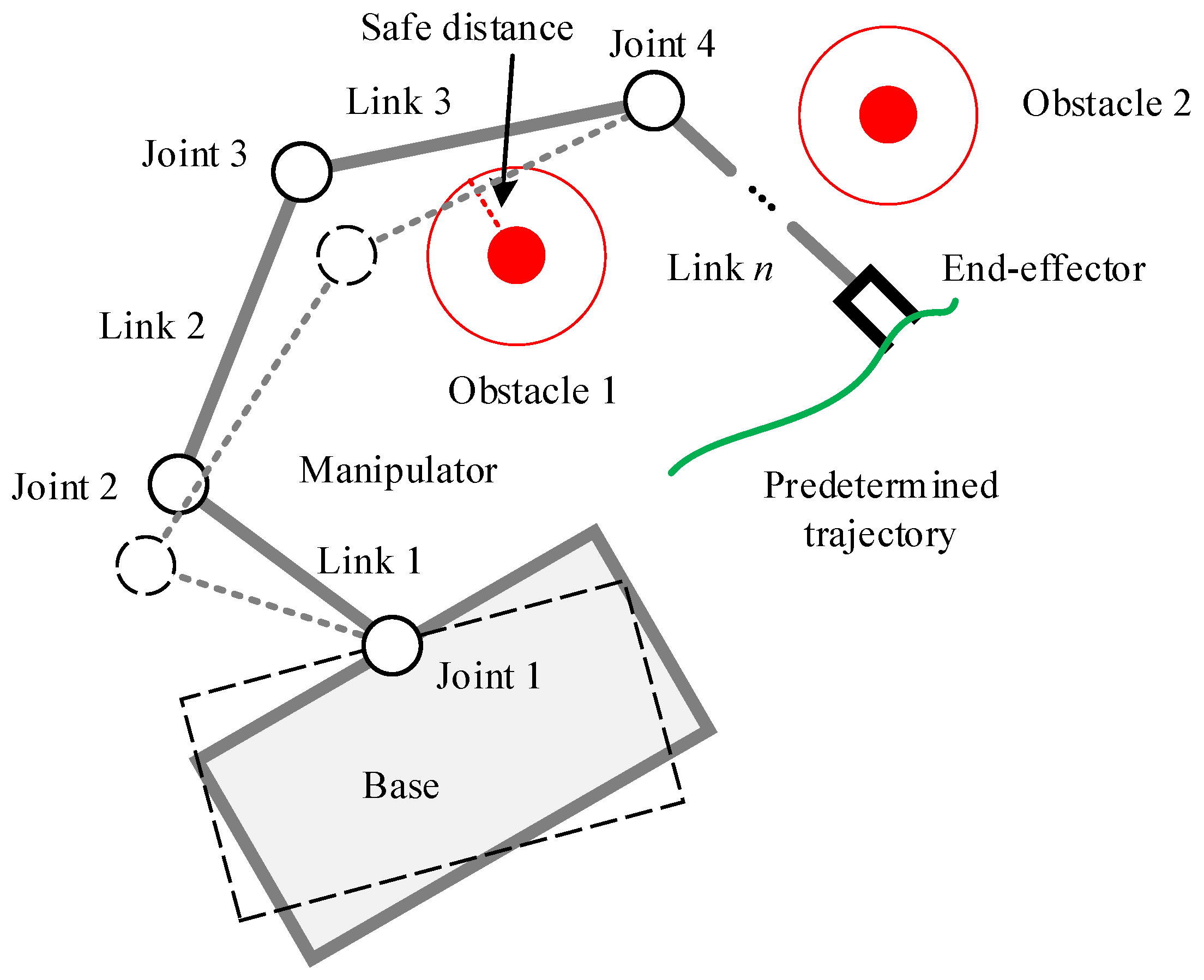
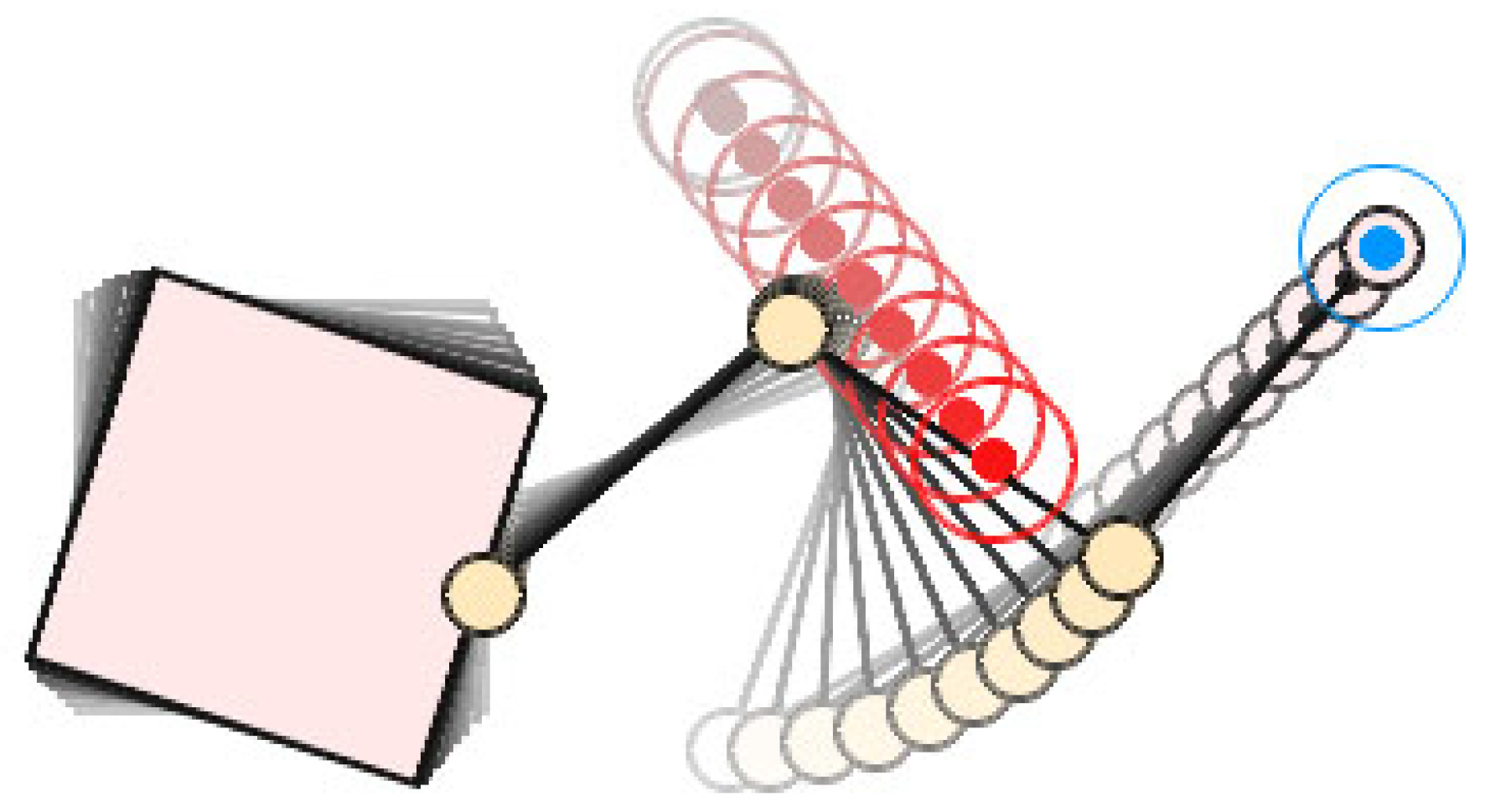
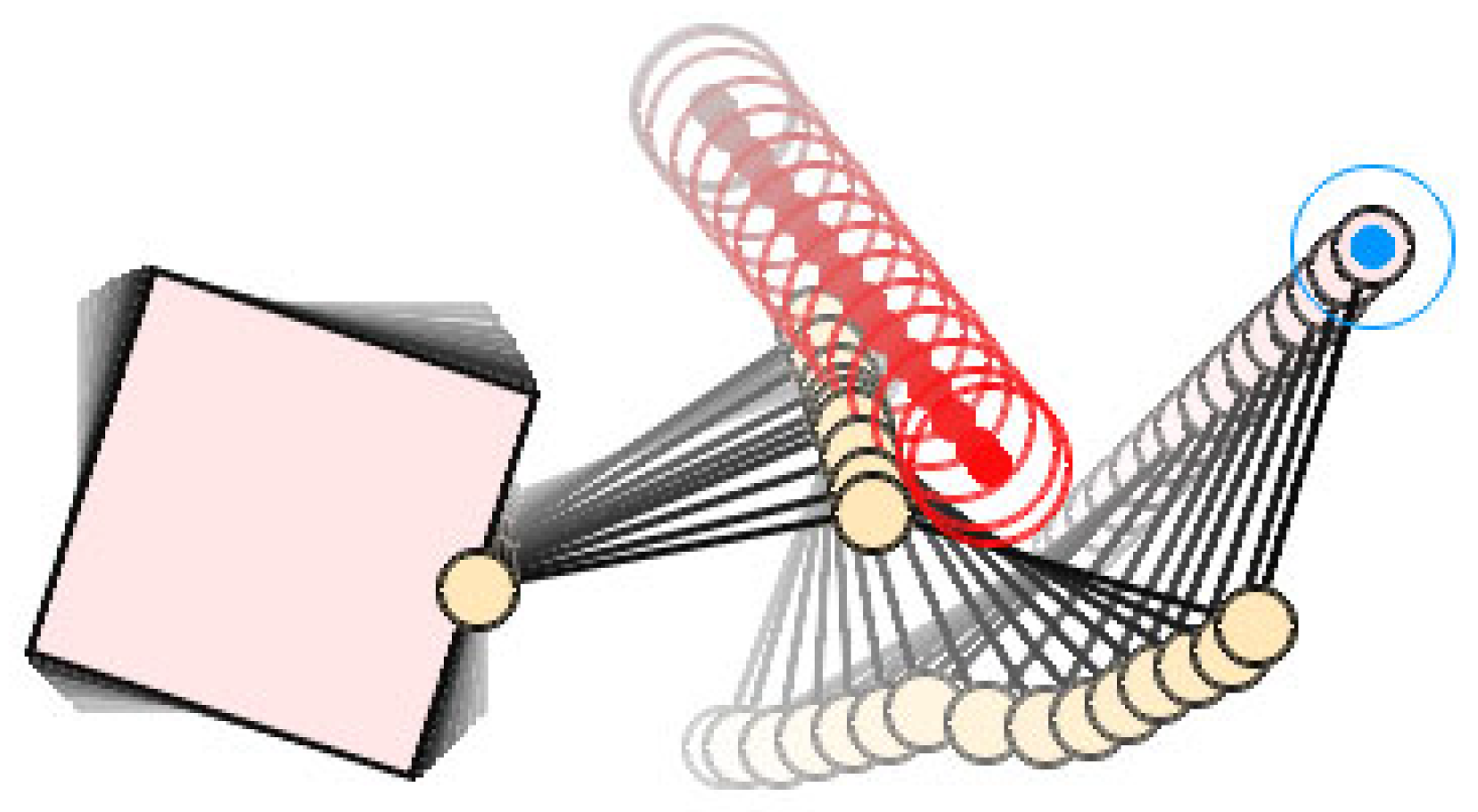
In our method, we treat the obstacles’ state from the perspective of the space robot itself to solve this problem, i.e., we use the vector
, which represents the distance of each link and its nearest obstacle to replace the obstacle position
in Equation (
8), as shown in
Figure 5. Specifically, we number the space robot components with
to represent the base as well as Link 1~Link
n, respectively. Let
be the set that contains all the surface points’ position vectors of Component
i, then let
be a certain point’s position vector of Component
i. Suppose there are
k obstacles in the environment. Let
be the set that contains all the surface points’ position vectors of Obstacle
j, where
, then let
be a certain point’s position vector of Obstacle
j. Thus, the distance vector between each component of the space robot and the obstacle can be defined as
So represents the position vector of the two closest points between the base and the nearest obstacle, and ~ represent the position vector of the two closest points between Link 1~n and their nearest obstacle, respectively.
Therefore, the state vector of the RL model for null-space obstacle avoidance is defined as
where
and
represent the configuration and joint angular velocity of the manipulator at timestep
t;
describes the influence of all the possible obstacles in the environment on the base and the links. It can be seen that the definition is independent of the environment-specific information, such as the number or the shape of obstacles, which ensures the generality of the strategy in various unstructured dynamic scenes. In addition, the action
, which is generated by the policy network
, will not change the pose of the end-effector, so there is no need to add the related state variables (e.g., end-effector position
, and velocity
) to the vector.
Then, we design the reward function of the environment feedback for the null-space motion of the space robot. Since the space robot needs to complete other operation tasks, such as expected trajectory tracking, it is necessary to make the null-space motion have higher stability and operability to prevent the space robot from generating an oscillating path or falling into the local optimum in the process of obstacle avoidance. For this purpose, we propose the following reward function:
In Equation (
14),
is the obstacle-avoidance feedback term, which is defined as
where
is the specified safe distance between the space robot and the obstacle, and
a and
b are the scoping values. In particular, when the distance between the space robot components (the base or the links) and the single obstacle is less than
, a negative log reward
will be obtained, guiding the space robot to perform obstacle-avoidance operations. We set
and
empirically for normalization.
is the motion stabilization term, which is defined as
where
is the angular velocity component of the joint null-space motion. A lower null-space angular velocity can prevent the manipulator from oscillating during the obstacle-avoidance process.
and
are the weights of
and
, respectively, which are used to adjust the relative size to keep the reward value
r within a suitable range.
is the collision penalty term with a large negative value, and
is the indicator function that judges whether the collision has occurred, which is defined as
Thus, once any component of the space robot collides with any obstacle, the RL agent will obtain a large negative reward value, then the current training episode will be terminated.
3.3. Training Strategy
Usually, during the training of RL agent, the training environment is required to be as random as possible so as to ensure that the policy has sufficient generalization to deal with various environmental states. However, the obstacles only occupy a small part of the area compared to the workspace of the space robot so that in most randomly generated scenarios, the moving space robot does not collide with obstacles. As a result, in the training process of obstacle avoidance, it is difficult to generate enough obstacle collision negative rewards to guide the neural network to search in the direction of the optimal policy. Thus, it results in low training efficiency, unstable convergence and poor performance of obstacle avoidance. In order to avoid this problem, we propose the corresponding training strategy for null-space obstacle avoidance, which gradually improves the RL policy’s adaptability to various scenarios and states by curriculum learning so as to achieve a trade-off between the convergence of the training process and generalization to different scenarios.
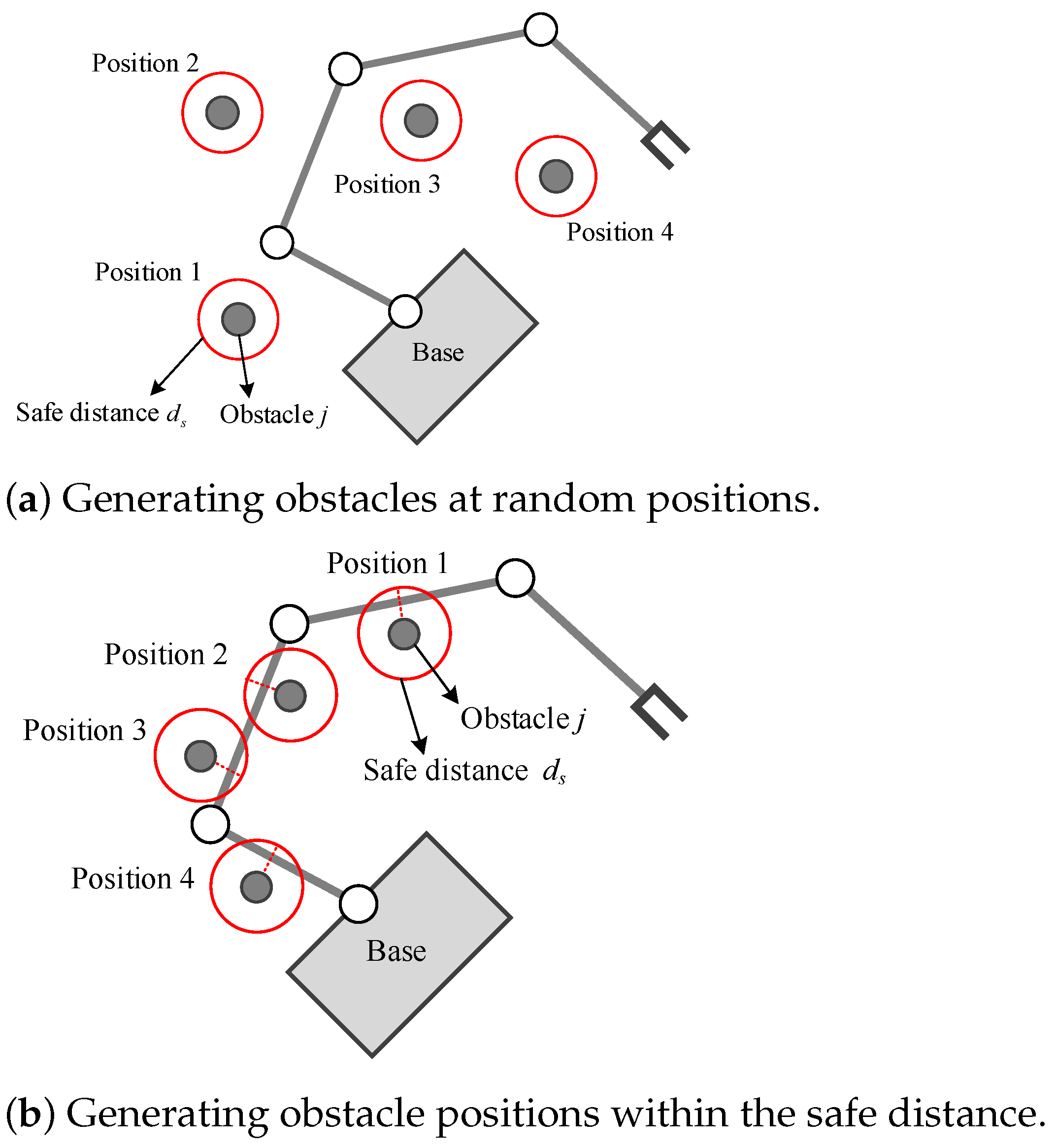
Firstly, if the position of obstacle in the scenario is randomly generated, in most cases, the motion of the space robot is always outside the obstacle’s safe area, as shown in
Figure 6a. This will generate a large number of invalid samples and seriously reduce the training efficiency. In order to avoid this problem, in each training episode, the initial state is set as the space robot has entered the obstacle’s safe area, as shown in
Figure 6b. In this way, the RL agent can receive a negative reward at the beginning of the episode according to the designed reward function, making the trajectory of this episode an effective sample that can guide the direction of the agent’s policy searching. The detailed process is described as follows:
- (a)
Specify the maximum number of training episode , the obstacle safe distance and the manipulator’s initial configuration of the space robot ;
- (b)
Randomly select the obstacle position which subjects to the condition , where j is the serial number of the obstacles;
- (c)
Start the current episode to sample the trajectory which is generated from the SAC policy network, then update the network parameters by the SAC training pipeline;
- (d)
Turn to (b) for the next episode, until reaching .
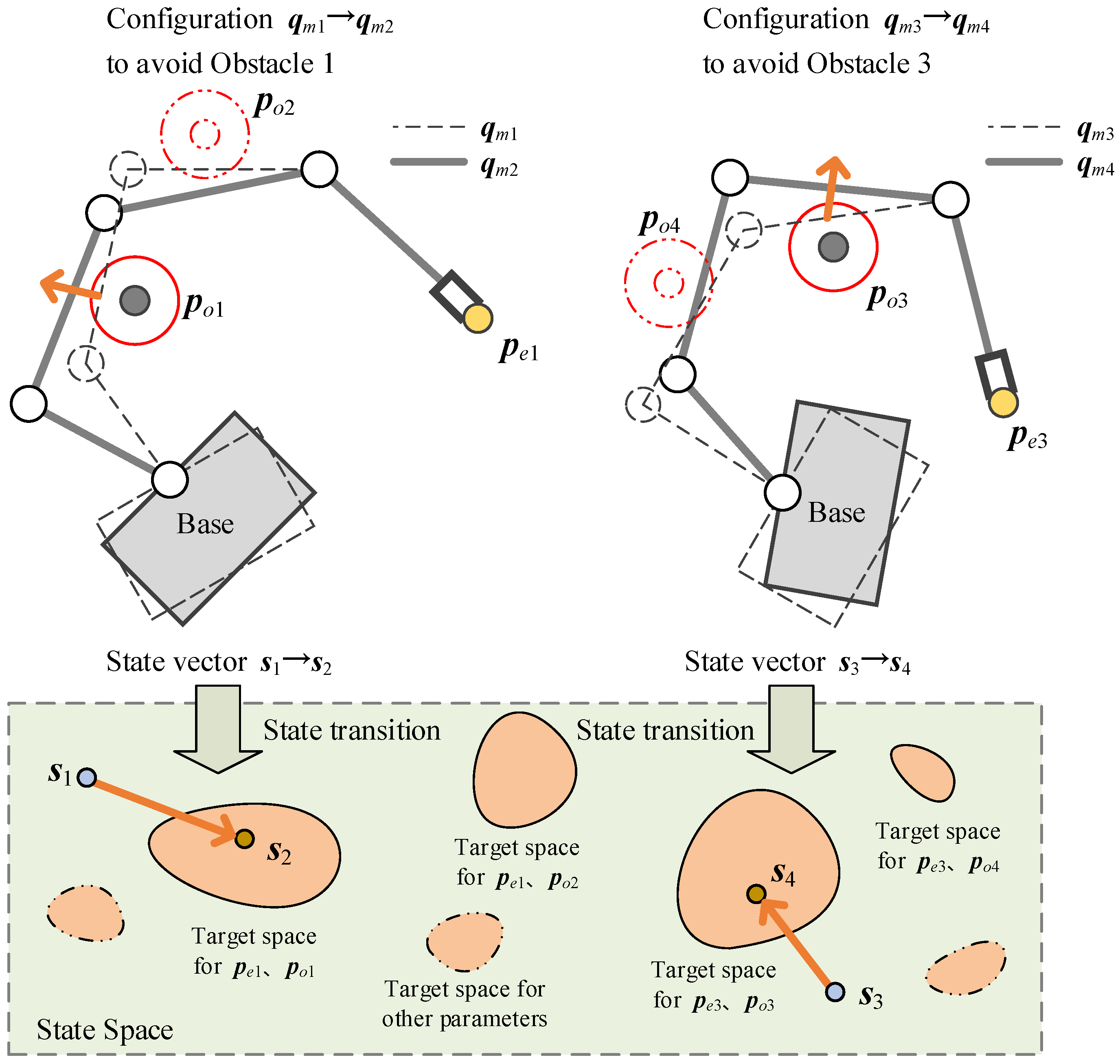
Secondly, the manipulator configurations and the end-effector positions are changeable for different scenarios or tasks. The RL agent needs to simultaneously learn a null-space policy for the changes of obstacle position, end-effector position and manipulator configuration. However, in practical applications, the possible obstacle positions are independent of the end-effector positions, which leads to the distribution discontinuity of the target state space in the whole state space, as shown in
Figure 7. If the number of training samples is insufficient, it is easy to fall into the local optimum, which greatly reduces the policy’s performance. To this end, we design the adjustment strategies for the end-effector positions and the manipulator configuration for different training stages:
- (a)
Specify the maximum number of training episode , the cumulative reward threshold , and an initial manipulator configuration ;
- (b)
Calculate the end-effector position by forward kinematics according to ;
- (c)
Start current episode under the condition of the unchanged to sample the trajectory of the space robot in null-space, and learn the obstacle-avoidance policy in null space by the SAC training pipeline;
- (d)
If the cumulative reward in this episode is , which means the space robot has learned an available policy under the condition of the end-effector position , then let , where is a random configuration-changing vector. Otherwise, skip this step.
- (e)
Turn to (b) for the next episode, until reaching .
In addition, we also use automating entropy adjustment strategy [
37] to update
automatically for Equation (
11):
where
is the objective function to update
,
is the specified target entropy value,
is the scale factor. As the training progresses,
will be gradually decreased to make
approach the target entropy value
. Therefore, the randomness of actions will be greater at the initial stage of training to expand the action exploration space and increase the possibility of searching for better policy. Then the randomness will be gradually reduced over the training process to ensure the convergence.
Combining all the above training strategies, the final training process is shown in the following Algorithm 1:
| Algorithm 1: The training strategy for null-space obstacle avoidance of space robot. |
![Actuators 12 00069 i001]() |
5. Conclusions
In this paper, a new obstacle-avoidance motion planning method for redundant space robots via reinforcement learning is proposed. Utilizing the redundant characteristics of the space robot, this method constructs an obstacle-avoidance motion planning framework, which introduces RL into null-space motion to realize reactive obstacle avoidance without changing the end-effector’s predetermined trajectory. Then, the proposed RL agent model as well as the training strategy for null-space obstacle avoidance is combined to the framework, which enables our method to have good adaptability to unstructured dynamic environments. The simulation results show that our method can avoid the stationary/moving obstacles steadily and effectively with sufficient computational efficiency, as well as having no need to retrain for the changes of obstacle number or motion states in the dynamic environment. Our method has good robustness to the space robot’s load mass, which is an important case to be considered in the practical application of space robot methods. We prove the advantages of our method in this aspect through a large number of tests. In addition, the simulation results also demonstrate the openness and extensibility of our method, which can be easily combined with the end-effector trajectory generation strategies, simultaneously realizing the complex motion tracking of the end-effector and the obstacle avoidance of the links for trajectory focused tasks.
In order to apply our method to real scenarios, the following steps need to be implemented: firstly, obtain the relatively accurate kinematics and dynamic parameters of the space robot so that the simulation environment can reliably simulate the real motion response in the space environment; secondly, train the RL agent according to the proposed strategy in the simulation environment built by the ground computer; thirdly, deploy the trained RL agent program to the control computer, which is launched into orbit with the space robot; finally, start this program when the space robot performs on-orbit operation tasks, where the joint angle and velocity come from the joint sensor embedded in the manipulator, and the obstacle information depends on the measurement results from the visual sensor so that the necessary state value is provided for the RL agent to realize null-space obstacle avoidance. Our method mainly consumes hardware resources in the ground training stage. After training, the RL agent can be executed without excessive hardware conditions, so it can be easily deployed to the control computer of the space robot.
It should be pointed out that null-space motion cannot guarantee the absolute obstacle-avoidance capability of the space robot in the full range of its workspace. Specifically, the links of the space robot may lose single directional motion capability by the null-space constraint such that it cannot avoid the obstacle in this direction unless the end-effector is no longer restricted to following the predetermined trajectory. Therefore, under the premise of the null-space constraint, the success rate of obstacle avoidance cannot reach 100% for random obstacles. For this situation, we need to allow the RL agent to relax the null-space constraint of tracking the end-effector’s predetermined trajectory when necessary so that once the obstacle’s motion exceeds the coping ability of null-space obstacle avoidance, the RL agent can still ensure the safety of the space robot. We will solve this problem in future research so as to further improve the performance of obstacle avoidance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}