1. Introduction
As one of the components of the vehicle, the dynamic response of the suspension system plays an important role in the overall performance of the vehicle. Therefore, in order to improve the ride comfort of the vehicle, many suspension control methods have been proposed based on state measurement [
1,
2,
3]. However, the measurement results are subject to sensor uncertainty and unknown road conditions. As a result, the system state variables cannot be accurately measured. The Kalman filter is a recursive state space model based on optimal estimation that is widely used for dynamic system state estimation [
4,
5,
6]. such as localization, tracking and control. In the suspension state estimation process, filter performance mainly depends on the accuracy of the noise covariance, and an inaccurate noise covariance will lead to estimation errors or even filter divergence [
7]. The actual vehicle driving conditions tend to vary with time and are unknown to the road level, resulting in the process noise covariance matrix (PNCM) and the measurement noise covariance matrix (MNCM) having the same characteristics.
To estimate states with time-varying and unknown noise covariance, many adaptive Kalman filter (AKF) methods have been developed, mainly including the following categories: covariance matching, correlation, maximum likelihood and Bayesian [
8]. In addition to the adaptive Kalman filter, another well-known filter design for model uncertainty is the robust Kalman filter, which is equivalent to solving a minimax problem, i.e., selecting the worst model in a given uncertain fuzzy set and then designing the corresponding optimal filter [
9,
10,
11]. However, the idea of the robust strategy is to first find the worst case of the model at the current time, which is the boundary of the uncertain parameters that need to be known. This can of course be achieved statistically by repeated experiments in a single scenario but seems difficult to achieve for time-varying and unknown noise covariances. In addition, robust strategies may be too conservative in terms of the optimal solution obtained, given the convergence performance of the filter.
The covariance matching method uses a sliding window of the innovation sequence to approximate the true noise covariance. Due to its simplicity of implementation, it is widely used in many works [
12,
13,
14]. However, the estimation accuracy of this method is closely related to the window size and requires a priori knowledge of the innovation sequence. The basic idea of the correlation method is to correlate the system output or the autocorrelation function of the innovation sequence with the unknown system parameters [
15]. In the literature [
16], the correlation method is used to estimate the MNCM and to identify the PNCM based on the road classification method. However, the correlation method is mainly applicable to constant coefficient systems, which requires the assumption that the system performance is in steady state. The maximum likelihood estimation method defines a probability density function with the unknown parameters as independent variables, usually called the likelihood function, and solves for its extreme value points. Some improved maximum likelihood estimation methods can be found in [
17,
18,
19]. In [
19], the Maximum Likelihood Principle (MLP) is used to estimate the unknown noise of nonlinear dynamic systems, and a new expectation maximization technique is proposed to iteratively optimize the computational process of the MLP. However, this method is still not suitable for estimating unknown noise parameters with time-varying properties. The Bayesian method uses the Bayesian formula to iteratively solve the posterior PDF of the state and unknown parameters. For some complex probability distributions, variational inference can be combined to simplify the computational process [
20]. Recent studies have further reduced the estimation error by combining the Kalman smoother with variational Bayes [
21,
22,
23]. However, their output ignores the smoothed data series and approximates the prior of the covariance matrix with individual data values, which may result in the estimation of the noise covariance falling into a local optimum.
For the existing VBAKF methods, the noise covariance estimation process relies heavily on the parameter selection of the approximate distribution. The convergence of the iterative process is accelerated by selecting a suitable conjugate prior distribution and assuming that the nominal values of PNCM and MNCM are known. However, for unknown road conditions, the nominal values of the noise covariance corresponding to different road levels are obviously not fixed. To solve the above problem, this paper proposes a novel state estimation approach based on VBAKF and road classification to estimate the suspension state with time-varying and unknown noise covariance. In the proposed approach, the suspension state estimation process is still basically completed by VBAKF by assuming that the conjugate prior distribution of the matrix is approximately the inverse-Wishart (IW) distribution. However, in order to make full use of the valid data in the iterative process and to improve the accuracy of the state estimation, a heuristic propagation method is used to finitely sample the posterior noise variance, and the propagated estimated samples are folded. Then, to overcome the disadvantage that the traditional VBAKF cannot cope well with the unknown road gradient, a road classification method combining multi-objective optimization and the suspension dynamic response linear classifier is proposed.
In summary, the following contributions are made in this thesis:
For the estimation of the suspension state with time-varying and unknown noise covariance, a novel state estimation approach based on a variational Bayesian adaptive Kalman filter and road classification is proposed.
Using the variational Bayesian approach, the time-varying noise covariance can be inferred from the inverse Wishart distribution; then, state estimation is optimized by finite sampling the posterior probability distribution function of the noise covariance and backward Kalman smoothing.
To identify the unknown noise covariance, a new road classification algorithm based on multi-objective optimization and the linear classifier is proposed.
The rest of the paper is structured as follows. In the next section, the plant equations of the quarter-car vehicle model are presented, as well as the standard Kalman filter.
Section 3 mainly introduces the novel state estimation approach for a suspension system with time-varying and unknown noise covariance. In
Section 3.1, we introduce the variational Bayesian approach to approximate the time-varying noise covariance.
Section 3.2 presents the proposed road classification algorithm. Then, in
Section 4, some numerical experiments are provided. Finally,
Section 5 concludes this article.
2. Problem Formulation
In order to simulate the complex dynamic characteristics of the suspension system, various complex suspension models have been proposed [
24]. In this paper, the two-degree-of-freedom (2-DOF) linear suspension model is used to analyze the suspension dynamic response. The structure of the suspension model is shown in
Figure 1.
According to Newton’s second law, the dynamic equations of the suspension system are given by (
1) and (
2):
where
and
are the sprung mass and unsprung masses,
and
are the suspension spring stiffness and tyre stiffness,
is the suspension damping.
When the system state, measurement output and disturbance vectors are respectively defined as follows:
The equation of the continuous-time state space model can be written as
where
x is the system state vector with the dimension of
,
y is the system measurement vector with the dimension of
, and
,
,
are the state space parameter matrix, which can be written as follows:
Using the zero-order hold with sampling period
T, the discrete state space model can be obtained:
where
k is the sampling discrete-time instant, while the process disturbance vector
w and measurement noise vector
v are defined as
,
, respectively.
The basic idea of the standard Kalman filter is to solve for the optimal system state in the least squares sense and to estimate the state of the suspension system by state prediction (
8) and state correction (
9) iterative models.
where
denotes the approximate estimate of
x.
For the suspension system, the inaccurate PNCM (Q) and MNCM (R) tend to have both time-varying and unknown characteristics. The time-varying characteristic is that the covariance varies slowly with time, and the unknown characteristic is that the covariance has an unknown magnitude for different road levels.
3. Main Results
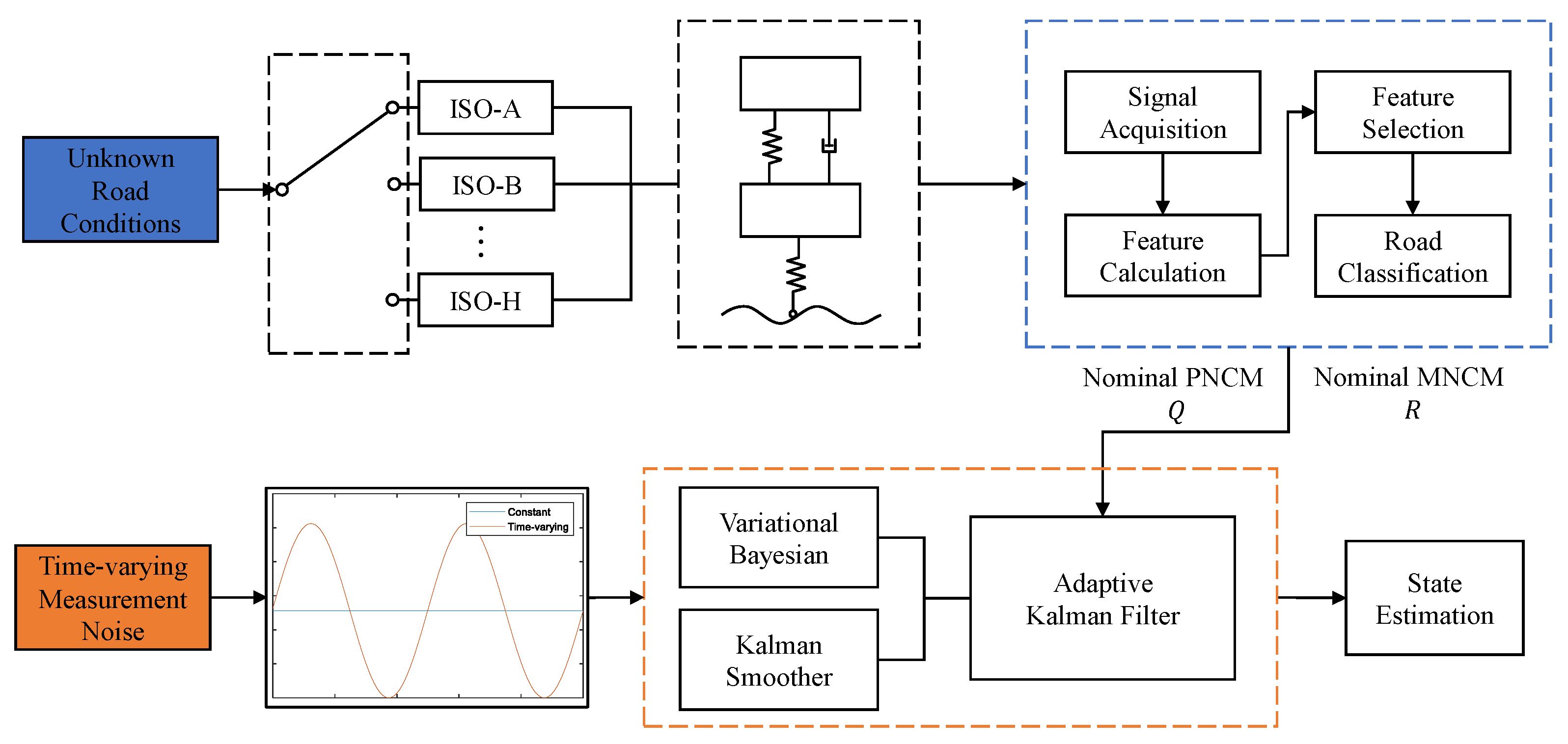
The overall flowchart of the proposed variable fractional Bayesian adaptive Kalman filter combined with road classification recognition for the suspension state estimator is shown in
Figure 2. The sensor-induced time-varying observational noise differs from the conventional sense of a fixed constant value, and therefore a forward adaptive Kalman filter must be designed via a variational Bayesian to obtain estimates of the time-varying noise covariance matrices PNCM (
Q) and MNCM (
R). In addition, a backward propagating Kalman smoother can be combined with this to further improve the accuracy of the time-varying noise estimation. However, the application of a variational Bayesian filter requires a combination of a priori knowledge of the noise covariance matrices
Q and
R, i.e., nominal values. Therefore, based on the fact that the dynamic response of the suspension varies significantly on different road classes, a linear classifier can be used to identify the currently unknown road condition and finally obtain an accurate estimate of the suspension state. The specific process of applying VBAKF under time-varying noise covariance and unknown road level is further described in the following section.
3.1. Variational Bayes
According to Bayesian optimal filter theory, to obtain the state estimate
, the joint posterior PDF of
must first be solved. Formally, there are only approximate solutions to this PDF, and a well-known method for solving it is the VB approximation. Using the VB method, this posterior PDF can be expanded as follows:
where the optimal approximation
can be solved by minimizing the Kullback–Leibler (KL) divergence between the approximation distribution and the true joint posterior [
25], that is,
Using the same variational Bayes calculation methods as in [
26,
27], the solution of (
11) can be simplified to the following form:
where
denotes the elements in
that are complementary to
, and
denotes taking expectation over
and
. Next, only the joint PDF
needs to be computed to approximate the posterior PDF
,
and
.
In the recursive model of KF (
8) and (
9), the filtering posterior PDF
and
are approximated as Gaussian distributions.
In the theoretical framework of VB, the conjugate prior distribution of
,
can be assumed to be the inverse Wishart distribution, because its prior distribution has the same functional form as the multivariate normal distribution [
28], that is,
where
is a parameter representing the degrees of freedom of the IW distribution and
denotes the scale parameter of the IW distribution, which must be positive definite. In addition,
and
have the same parametric meaning.
Considering that there are many constant terms in the inverse Wishart distribution and Gaussian distributions that do not affect the shape of the PDF that can be safely removed, the simplified density function can be written as
where
denotes the noise covariance with the matrix dimension of
, and
denotes the IW distribution with the DOF parameter
and the inverse scale matrix
. The mean value of
is
The system state
and the process error covariance matrix (PECM)
refer only to the data at time
, and the measurement noises
are independent random vectors. Thus, using the concept of conditional probabilities, the joint PDF
can be decomposed as follows:
Using (
17) and (
19),
can be formulated as
Using (
20), (
12) can be referenced as follows:
where
From Equations (
21) and (
22), it can be seen that the posterior PDF at time
k follows the functional form of the IW distribution. Furthermore, according to the Equations (
15) and (
16), the posterior PDF of
,
has the following densities:
By adjusting the elements of (
21)–(
26), the posterior PDF parameters in (
25) and (
26) can be updated as follows:
Since the one-step approximation method cannot accurately estimate the distribution parameters of (
27) PECM (
) and MNCN (
), the fixed-point iteration method must be used to find the optimal estimate. In addition, a heuristic parameter propagation method similar to [
29] is used to iteratively update the approximate posterior PDF
,
, that is,
where
is a forgetting factor value that reflects the time-varying fluctuation of the noise covariance, and
indicates that the noise covariance is stable.
According to (
18), the
ith iteration estimates of PECM and MNCM can be expressed as the expected value of the IW distribution:
Using the
-function, the posterior PDF of MNCM can be assumed to be obtained by averaging over finite approximate solutions
[
30]. Thus, the posterior PDF
can be represented in the following form:
Using the Bayes rule, the calculation of
can be performed as follows:
where the samples of
are independent and uniformly distributed, so
.
The random conditional PDF of
has a mean value of
and a covariance
To minimize the mean squared error of
, the state estimate must be equal to the conditional mean
, which can be computed as follows:
If the PDF
is updated by
N steps of fixed-point iterations, a finite set of approximate estimates can be obtained; then, replacing the integral operation in (
36) with the summation of this finite set, the state estimate can be written as follows:
Furthermore, the state estimation error covariance can be refactored by a finite set of MNCM
as a weighted sum of different
, as follows:
Solving the optimal estimation problem of
through
N steps of time series measurement, the output time series
is called fixed interval smoothing. Using the theory of maximum likelihood estimation [
31], the solution to the smoothing problem is described as follows:
The above procedure of the proposed adaptive Kalman filter scheme is summarized in Algorithm 1.
| Algorithm 1 Variational Bayesian Adaptive Kalman Filter (VBAKF) algorithm. |
| |
|
Input:
|
|
Output: |
| Forward Process: |
|
|
|
|
|
|
|
(28) |
| |
| Initialization: |
|
|
|
(32) |
|
|
|
|
|
|
| Update:
|
|
|
|
|
| Update:
|
|
|
|
|
|
(29) and (30) |
| end for |
|
|
|
|
|
|
| end for |
| |
|
Backward Process: |
| Initialization: |
|
|
|
|
|
|
|
|
|
|
| end for |
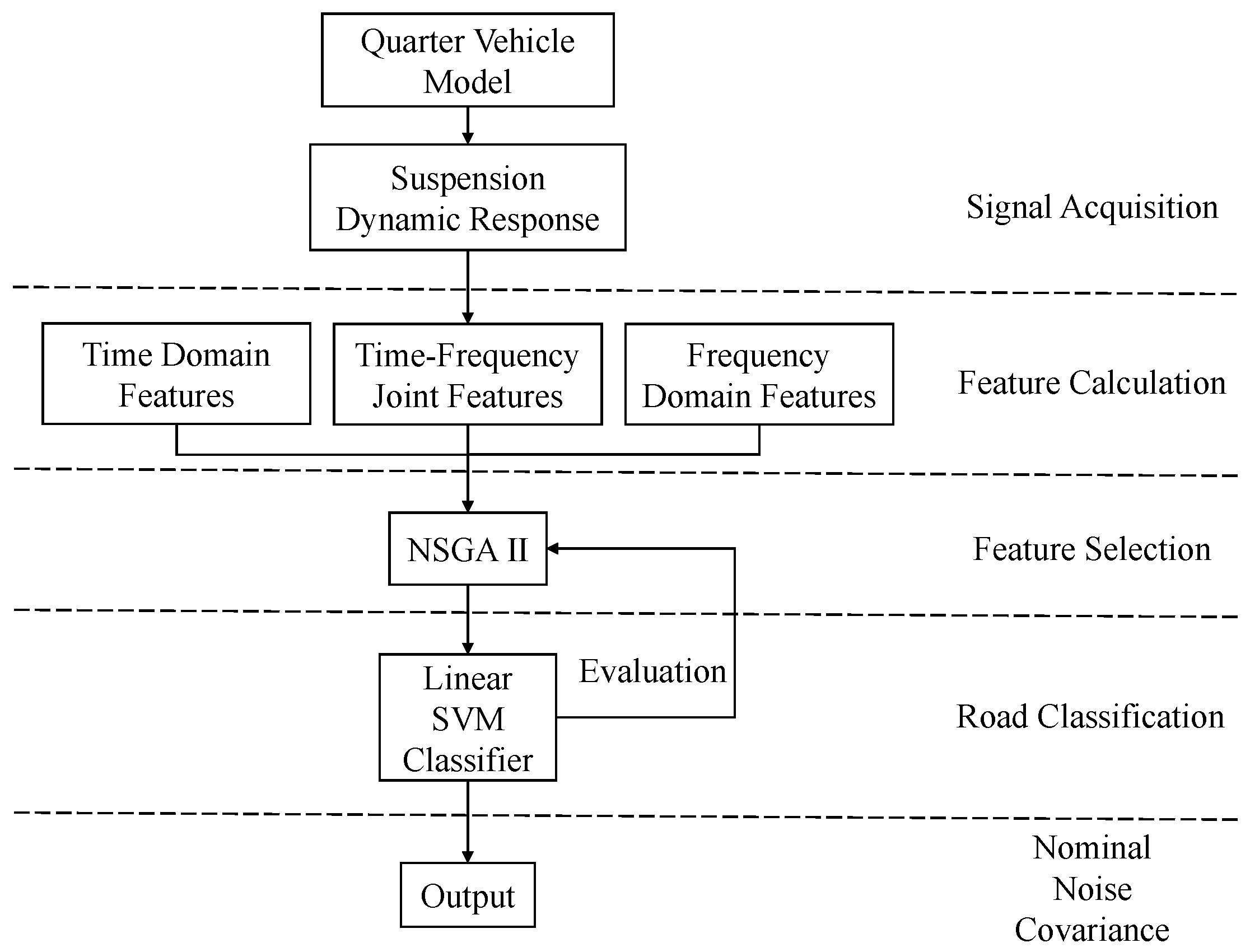
3.2. Road Classification Algorithm
When the suspension system is on an unknown road condition, the dynamic response of the suspension system is used to estimate the current road level; then, the nominal PNCM () and MNCN () can be selected for Algorithm 1 and can be selected simply by matching the nominal values corresponding to different road levels.
To improve the accuracy of road level estimation, a new road level classification method based on multi-objective optimization and the linear classifier is proposed as follows:
Suspension dynamic response signals include sprung mass acceleration, rattle space and tyre deflection. Considering that the road frequency spectrum corresponding to the speed of 10–40 km/h is only 0.44–28.3 Hz, the acquisition frequency of the suspension system response can be set to 100 Hz, which can include not only the natural frequency of the body mass 1–2 Hz but also the natural frequency of the unsprung mass 10–16 Hz.
- 2.
Feature sets selection:
Commonly used feature extraction methods include time domain feature extraction, frequency domain feature extraction and joint time–frequency domain feature extraction [
32].
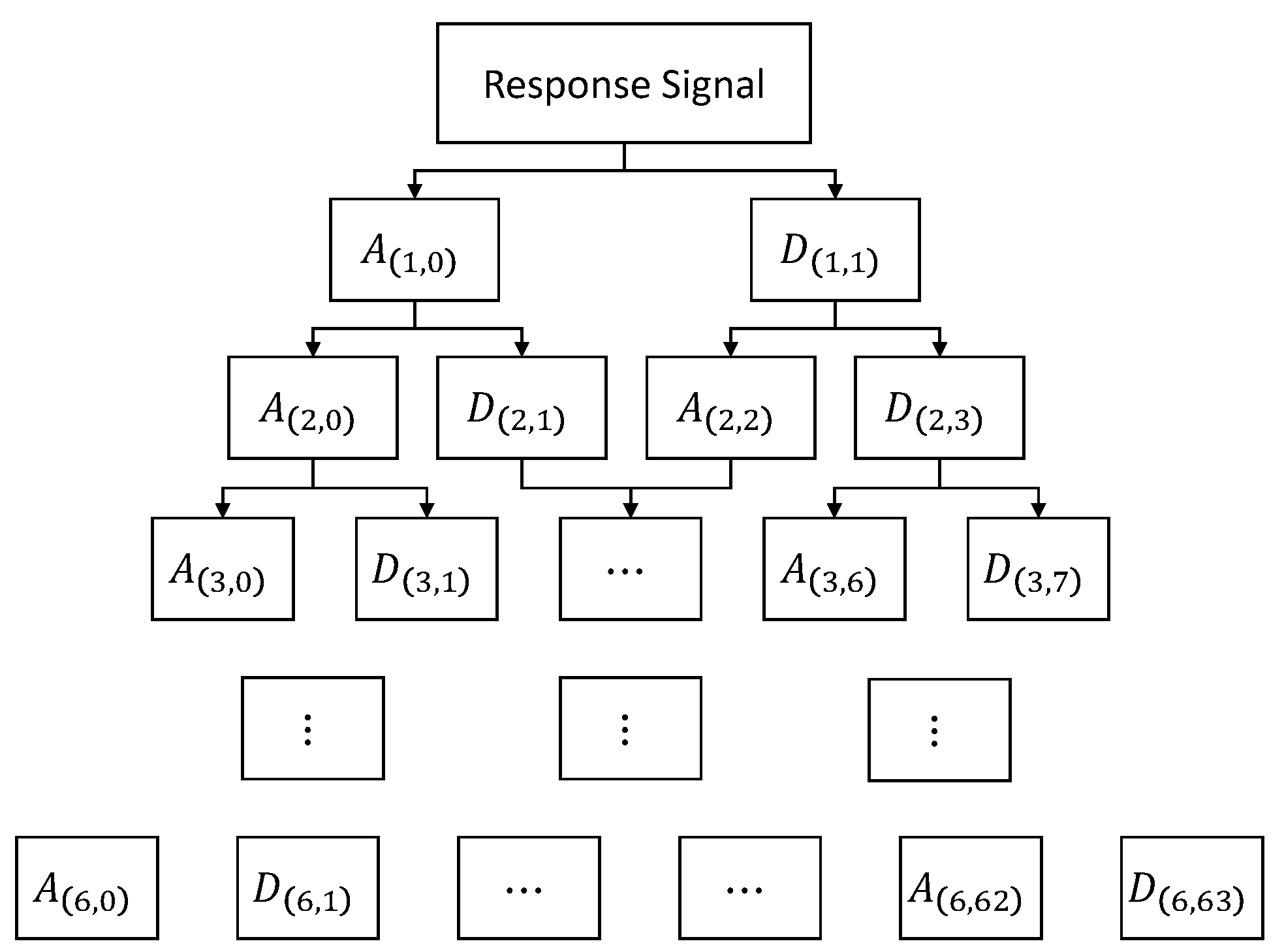
Time-domain features include common signal statistics: root mean square, variance, peak-to-peak, etc. Frequency domain features include root mean square of frequency, standard deviation of frequency and amplitude power spectrum, etc. The time–frequency joint feature is the statistical energy of different frequency bands obtained after six-layer wavelet packet decomposition, and its structure is shown in
Figure 3.
Finally, each suspension system response signal has 75 statistical characteristic parameters, which can be found in the
Appendix A.
- 3.
Feature reduction
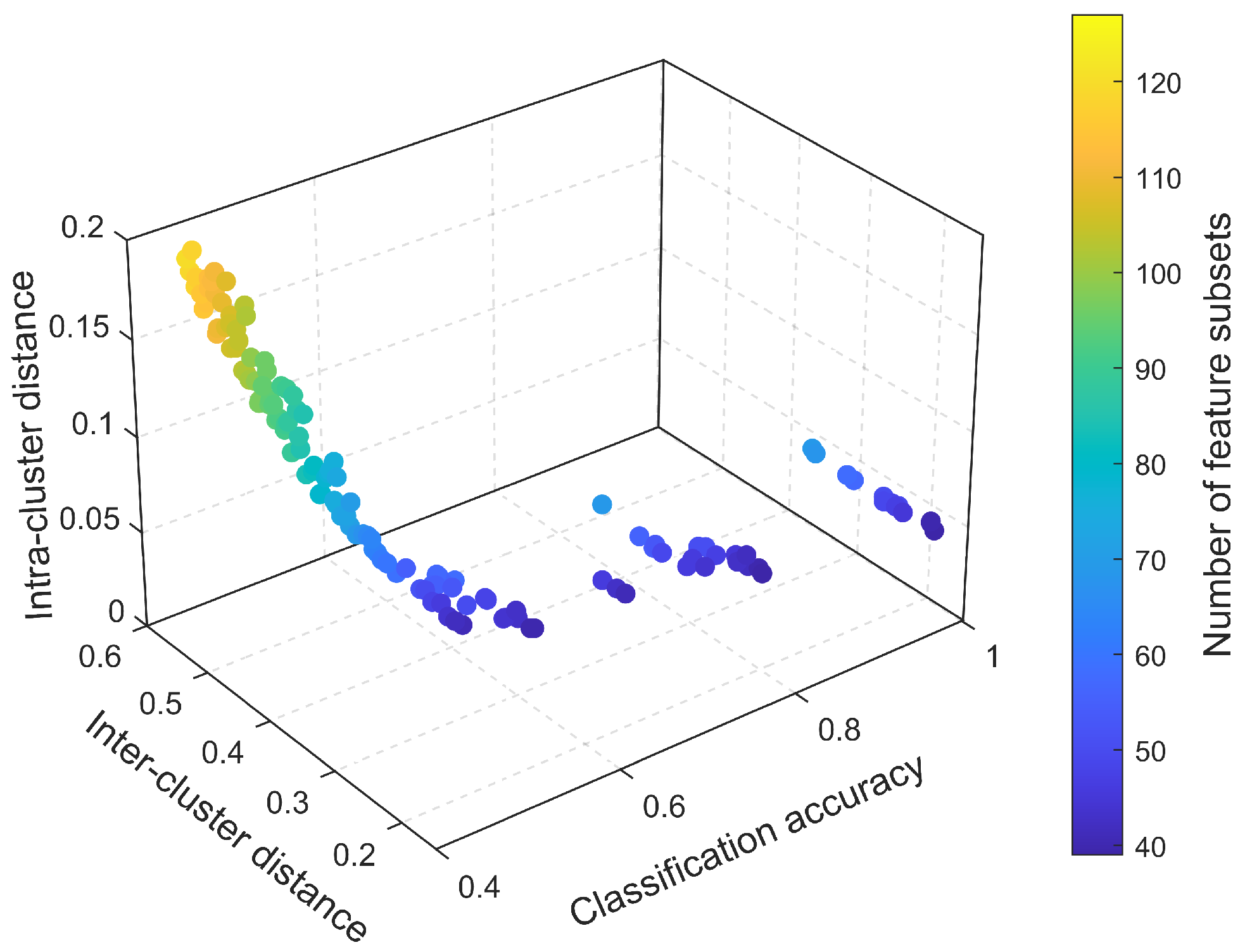
The feature set generated in step 2 has a large amount of irrelevant and redundant information, which will degrade the performance of road classification models. In order to obtain the optimal feature combination quickly and accurately, this paper transforms the feature dimension reduction problem into a multi-objective optimization and selects the optimal features by the NSGA-II algorithm with the following parameters: a population size of 150, a number of generations of 200, and the probabilities of crossover and mutation are 0.9 and 0.1, respectively.
The Pareto optimal front, corresponding to the combination of optimal solutions that minimizes the classification model accuracy, the number of feature subsets, the feature inter-cluster distance and the intra-cluster distance, respectively, is shown in
Figure 4.
Combining the importance of several evaluation metrics, the optimal subset of suspension characteristics includes the following 39 variables, which can be found in
Appendix A.
- 4.
Classification:
The recognition accuracy of the road classification model needs to be used as an evaluation function for the NSGA-II algorithm; thus, in order to fully learn the suspension dynamic response feature, the receiver operating characteristic (ROC) curves are plotted in
Figure 5 and the area under the ROC curve (AUC) values are calculated by testing the recognition results of different classification models. The classification models used for testing include Naive Bayes (NB), Narrow Bandwidth Neural Network (N-NN), K-Nearest Neighbor (KNN), Linear Support Vector Machine (L-SVM) and Decision Tree (DT), all of which are computed by the MATLAB Classification Learner toolbox. By selecting the L-SVM classification model with the highest AUC value, the unknown road level can be well determined.
Finally, when the unknown road level is determined by the classification algorithm, we can refer to the empirical nominal values corresponding to different roads given in
Table 1 [
33].
The above procedure of the proposed road classification scheme is summarized in
Figure 6.
4. Simulations
The simulations in this paper focus on verifying the performance improvement effect of the proposed hybrid system based on VBAKF and road classification for 2-DOF suspension model state estimation with time-varying and unknown PNCM and MNCM. The source code is available at
www.github.com/33lqq/Klaman. As mentioned in [
34], the convergence principle of the Kalman filter is that the system parameters are in a time-invariant, detectable and stable state. Therefore, the suspension system considered in this paper only considers the linear time-varying system, and the 2-DOF suspension parameters are listed in
Table 2. The constant values of the system modeling parameters are chosen to ensure the convergence of the filter.
According to the random road surface modeling method described in [
35,
36], the time domain signal of a random road profile according to the ISO (International Organization for Standardization)-8608 standard can be expressed as
where
n is the number of intervals obtained by uniformly dividing the frequency range of interest, center frequency
and
represents a random phase over
.
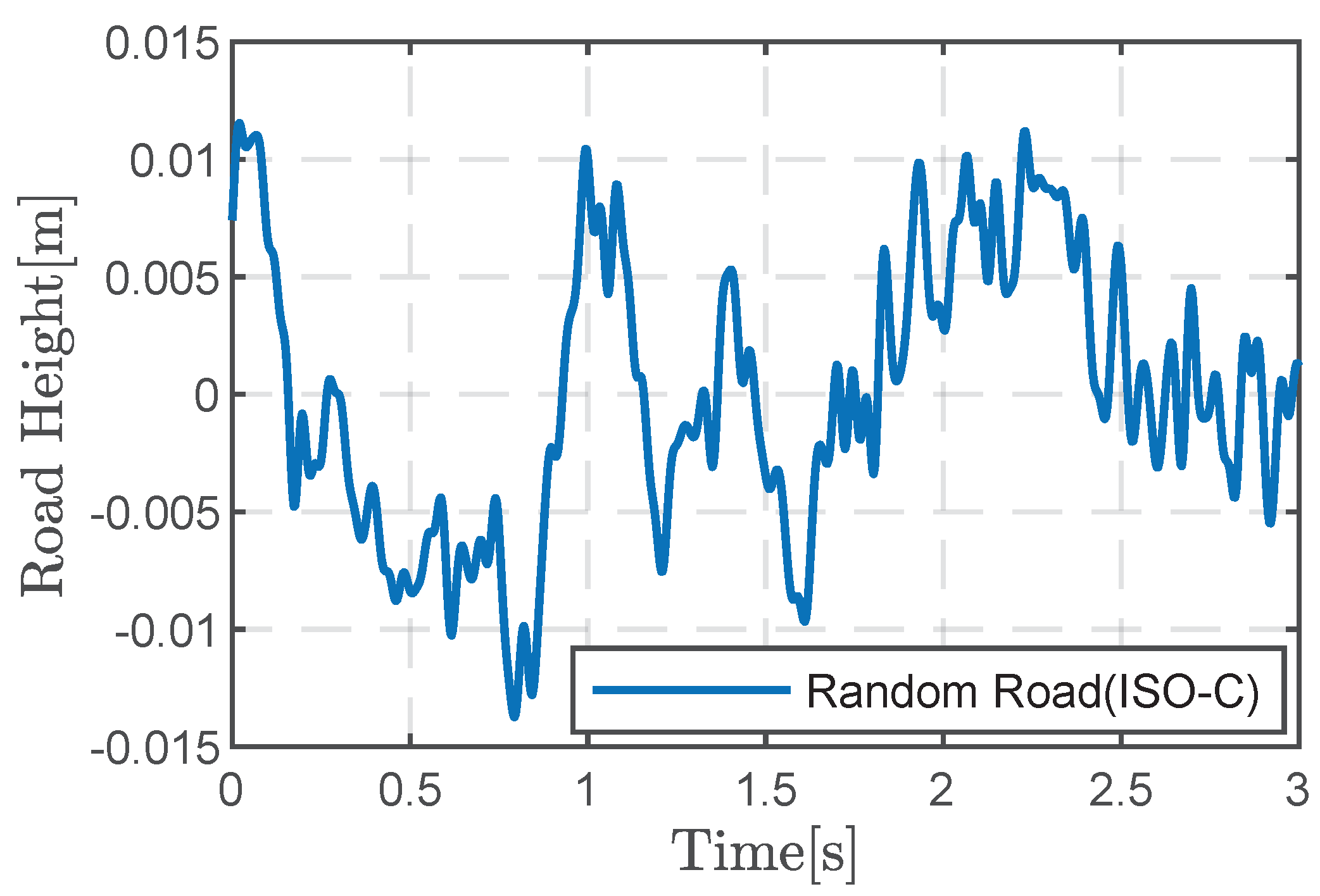
Figure 7 shows the time domain spectrum of the ISO-C random road via Equation (
40).
Considering that the state estimation error of the suspension system increases exponentially under different road levels, in this paper, in order to verify the robustness of the proposed state estimation algorithm, three different road sections are selected for simulation experiments, namely ISO-A, ISO-C and ISO-E.
The true values of the time-varying PNCM and MNCM can be assumed as follows:
where
T = 1500 is the total number of discrete system simulations.
In addition, the initial parameters of the VBAKF algorithm in this paper are set as follows:
The initial state and the error covariance matrix are assumed to be Gaussian distribution with for each component.
Taking the nominal PNCM
and MNCM
as the prior information of the IW distribution, the distribution parameter can be chosen as follows:
Finally, the forgetting factor is , and the number of iterations is .
Due to the different dimensions of the suspension state
x, the root mean square error (RMSE) of the suspension state estimation cannot be calculated directly, so the simulation results are divided into two parts, namely the position component
and the velocity component
. In addition, in order to eliminate the random errors caused by random numbers in the simulation process, we performed Monte Carlo (MC) operation, and used the average root mean square error (ARMSE) to quantitatively compare the performance of each filter on different road sections.
where
= 2000 represents the total number of the Monte Carlo runs, while
and
denote the estimated and true state of the
ith component in the
jth MC run.
The proposed hybrid systems are compared with the standard KF with true covariance matrices and (KFTCM), the KF with nominal covariance and (KFNCM), the AKF estimating based on the residual sequences (denoted by RSAKF) and the existing VBAKF estimating only (denoted by VBAKF-R).
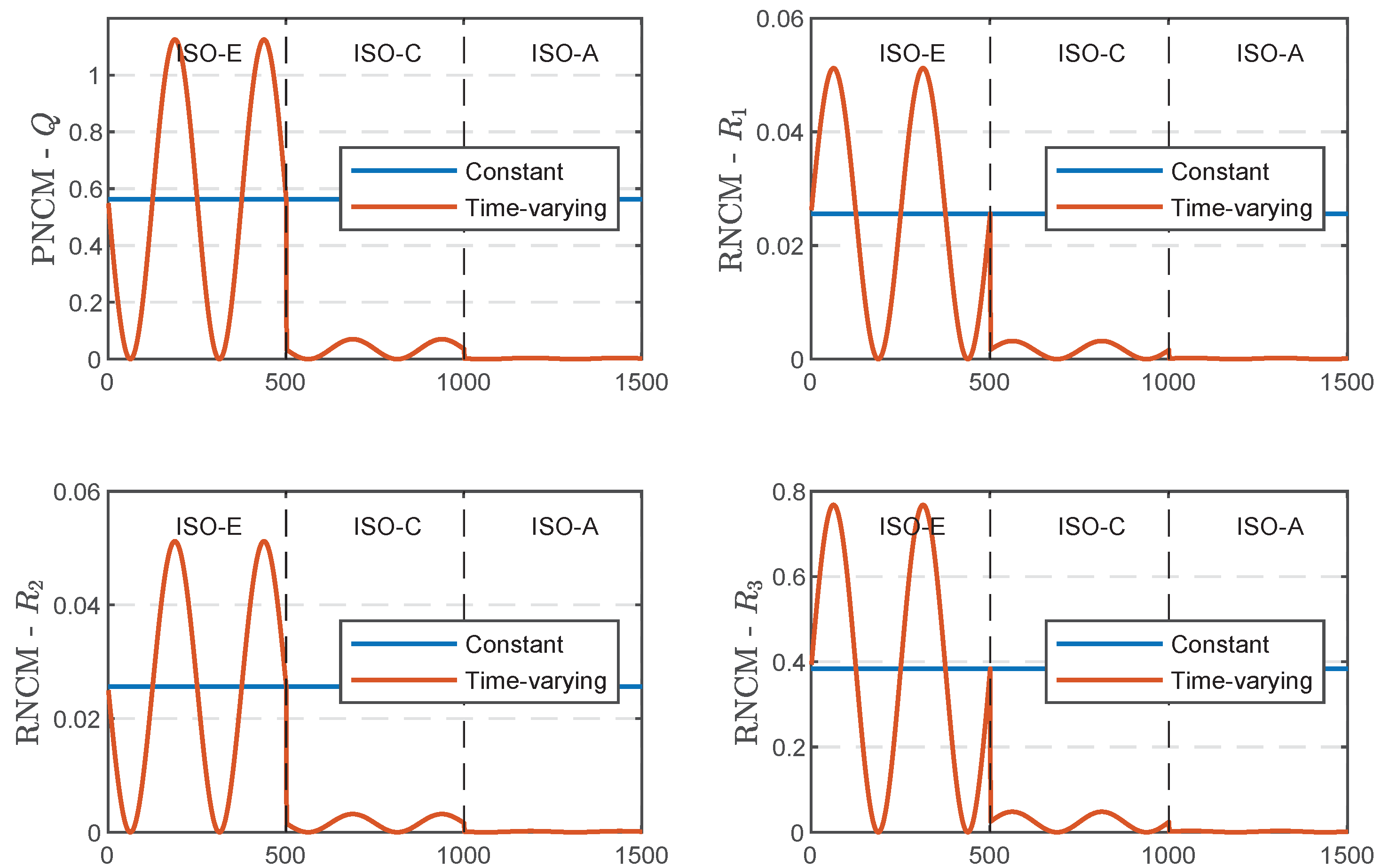
(1) First, we compare the performance results of different AKFs without road classification methods. Due to the lack of the guidance from the road classification model in the state estimation process, the suspension system cannot accurately identify the changes in the road profile level. Therefore, the nominal values of PNCM and MNCM throughout the entire simulation process only depend on the initial values of the road profile, as shown in
Figure 8, where the nominal values on Stretch 2 (ISO-C) and Stretch 3 (ISO-A) have the same values as on Stretch 1 (ISO-E), i.e., the constant curve.
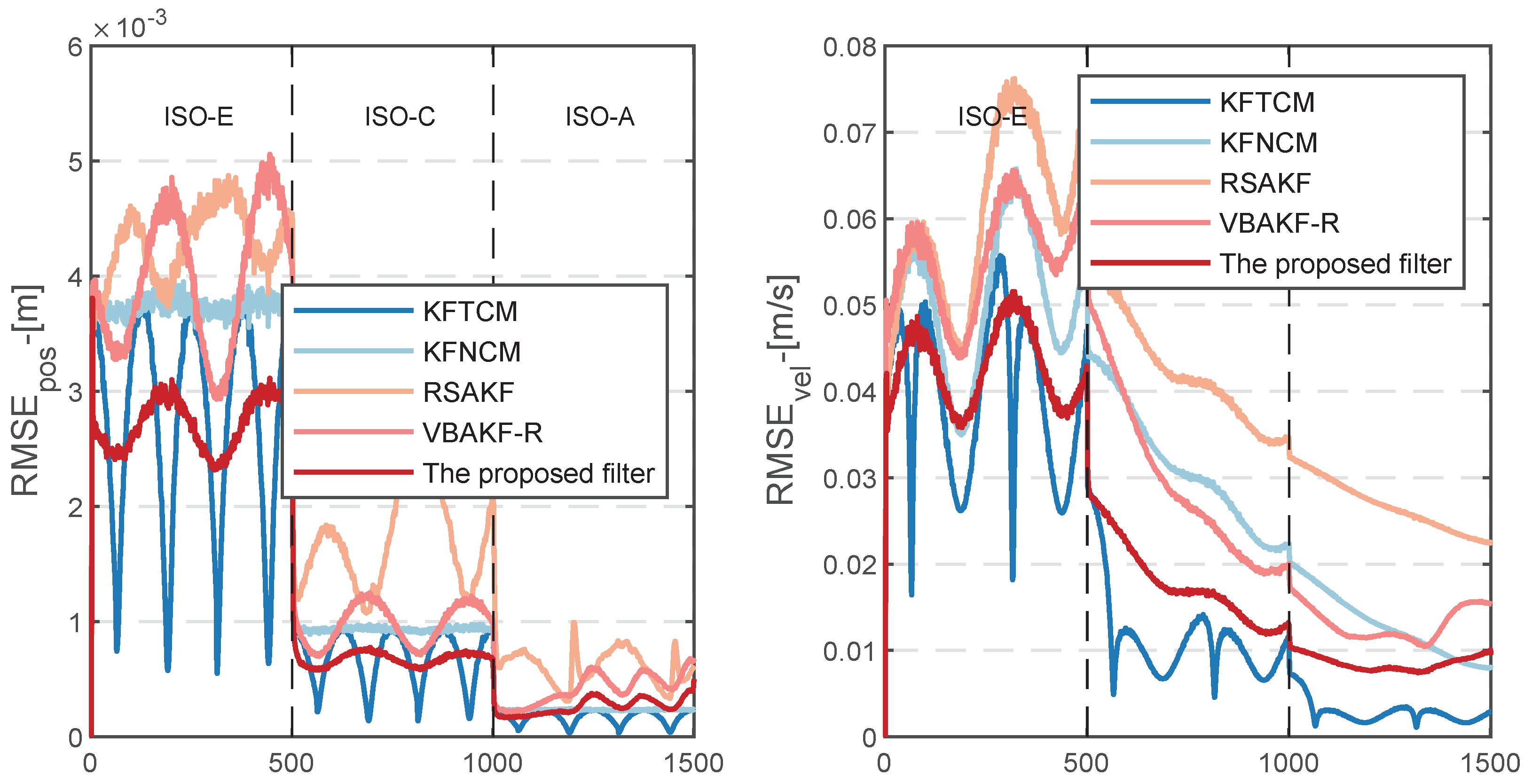
In
Figure 9, from Stretch 1, it can be clearly seen that the proposed VBAKF filter algorithm is better than KFNCM, RSAKF and VBAKF-R. In
Table 3, the ARMSEs of position and velocity from the proposed filter are respectively reduced by 27.03% and 15.85% compared to the existing KFNCM. In this section, the state estimation error of the proposed VBAKF filter algorithm is smoother than that of the KFTCM, and the maximum peak value is smaller than the latter. This is mainly due to the use of the Kalman smoother, which reduces the effect of time-varying fluctuations of the variance matrix on the state estimation process.
In Stretch 2 and Stretch 3, the state estimation errors of KFTCM, VBAKF-R and the VBAKF filter proposed in this paper are close to each other. This is because these two stretches use the incorrect PNCM and MNCM nominal values for state estimation, so these filters have difficulty converging to the true state in the limited iterative optimization.
Since RSAKF relies on the innovative sequence information of the historical sliding window, it is only applicable to the dynamic system for which the process noise matrix PNCM is known, so the continuous use of the incorrect PNCM nominal value leads to the continuous high level of state estimation error.
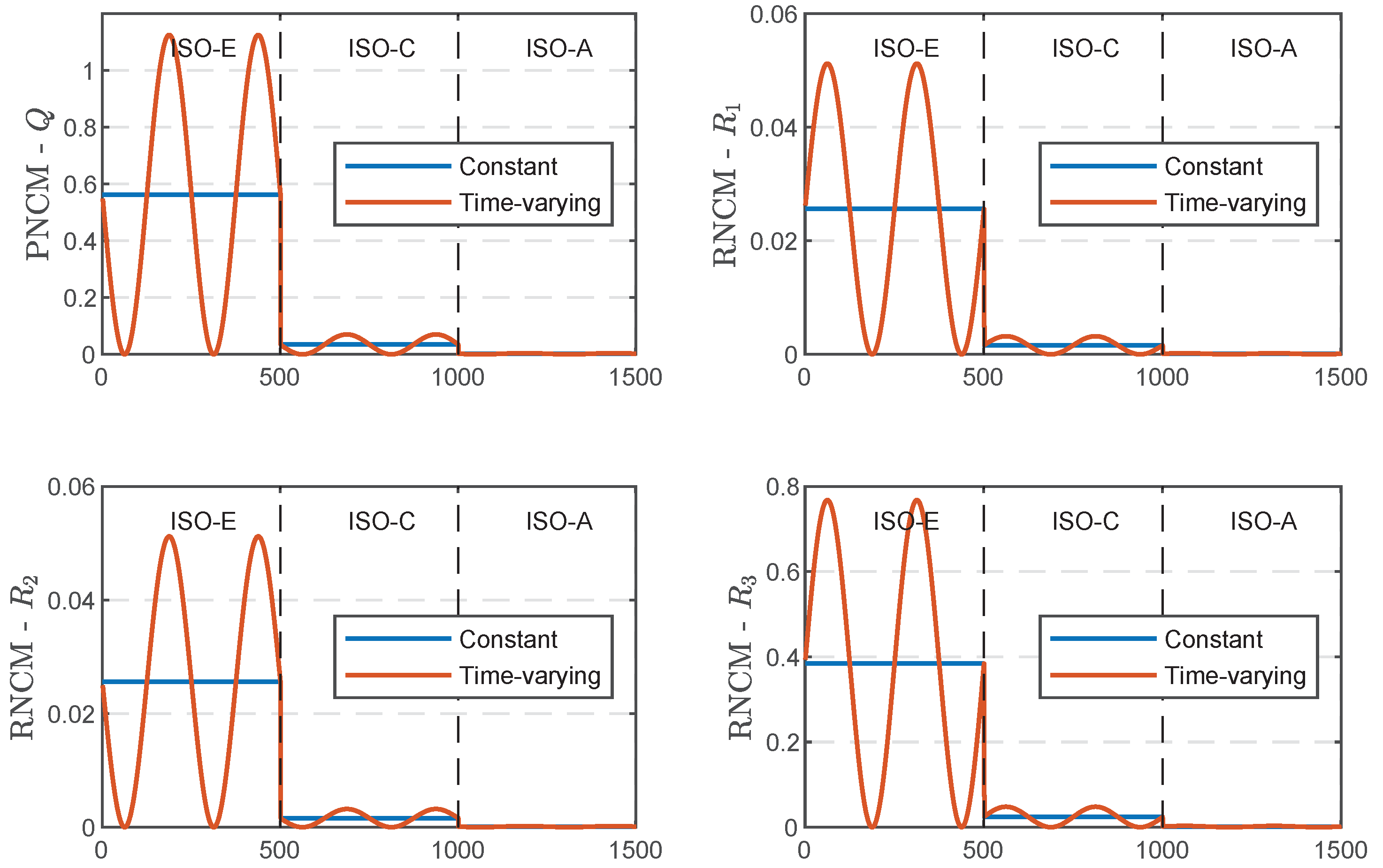
(2) Secondly, in order to verify the effectiveness of the road level classification algorithm for different adaptive filters, we still use three different random road profiles, as shown in
Figure 10.
Unlike
Figure 9, the nominal values of PNCM and MNCM corresponding to the current road level can be obtained by the road classification model.
In
Figure 9, when the road profile level is unknown, the ARMSE of the position is only better than other filters only in segment 1. This segment is the initial road profile, and the nominal values of PNCM and MNCM have been given. In
Figure 11, after using the road level classification algorithm, the road level of different segments can be accurately identified. In
Table 4, for each road segment, the proposed filters are better than other filters. For Stretch 2, the ARMSEs of position and velocity from the proposed filter are respectively reduced by 28.29% and 44.82% compared to the existing KFNCM. For Stretch 3, the proposed filter reduces the ARMSEs of position and velocity by 28.25% and 28.30%, respectively, compared to the existing KFNCM.
In Experiments 1 and 2, the AEMSEs of position and velocity of KFTCM remain essentially unchanged because the method uses the true values of PNCM and MNCM, while the presence or absence of road classification methods only affects the algorithms that depend on nominal values, i.e., KFNCM, RSAKF and VBAKF. Therefore, the performance improvement of the road classification method on the VBAKF algorithm can be evaluated by comparing the ARMSEs of the KFTCM and the filter proposed in this paper on the suspension state estimation in two experiments. As shown in
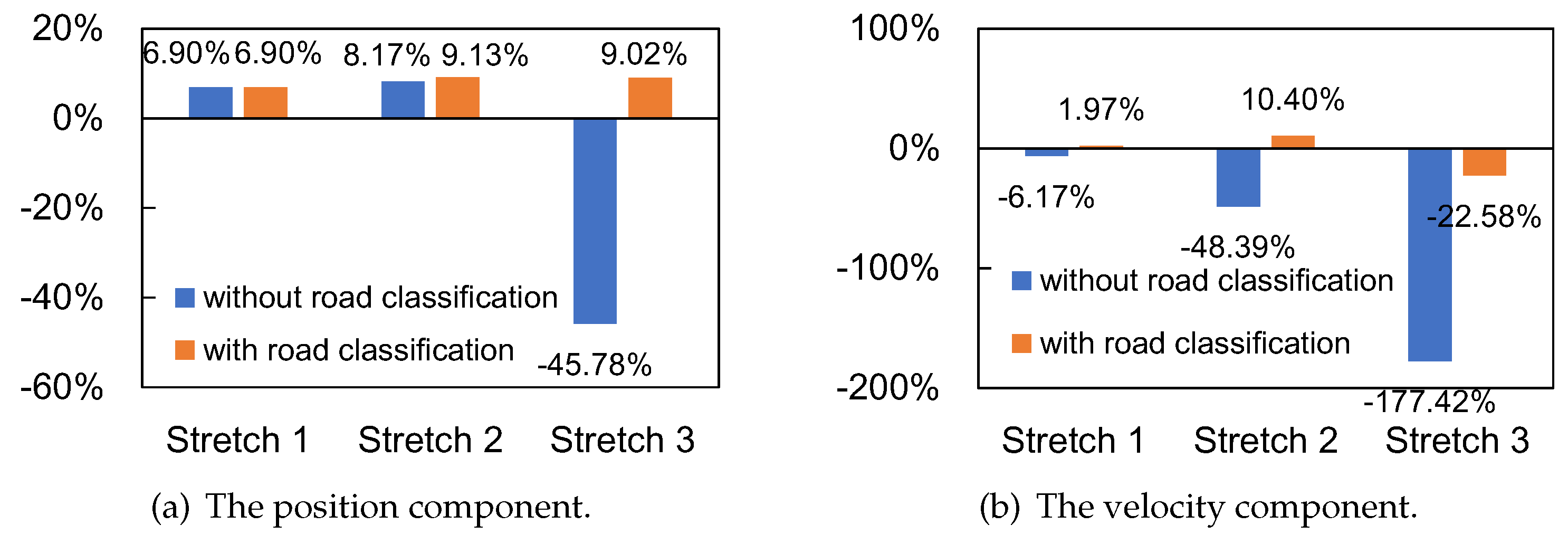
Figure 12, the coordinates of the Y-axis coordinate represent the improvement rate of the proposed filter compared to KFTCM, and its calculation formula is as follows:
Using the KFTCM as a benchmark for comparison, the use of the road category classification model significantly improved the state estimation accuracy of the VBAKF. In the second part, the performance of the location ARMS system was improved by 58.79% using the road surface identification method. In
Section 3, the method improved the velocity ARMS and position ARMS by 57.8% and 154.84%, respectively. It can be noted that in
Section 3, the accuracy improvement of the road classification algorithm for VBAKF estimation on ISO-A roads is exceptional. This improvement compared to ISO-C roads in
Section 1 is mainly due to the low road variability in this region and the high accuracy of road class identification, which allows more accurate nominal values of the noise covariance matrix to be used during the state estimation iterations. In fact, this is not a performance improvement in the strict sense of the word. This improvement rate is calculated by the VBAKF algorithm relative to the road classification algorithm because the road classification model provides the filter with accurate PNCM and MNCM nominal values to avoid unknown nominal values causing the filter to converge in the wrong direction, i.e., increased state estimation error without VBAKF road classification.
In this experiment, the unknown characteristics of the road surface are transformed once at an interval of 500 sampling points. It is unlikely that the road surface category remains constant over time during the actual driving process, and the road surface class ahead of the vehicle is constantly changing. Of course, this type of problem can be solved by using sensors such as radar or cameras to obtain information about the road surface profile ahead and to identify the road surface class in advance. In addition, some specific road surface types such as concave and convex excitation, matrix excitation and triangular excitation are not considered in this paper and will be the focus of future studies.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}