
Multi-Agent Distributed Deep Deterministic Policy Gradient for Partially Observable Tracking


Abstract
:1. Introduction
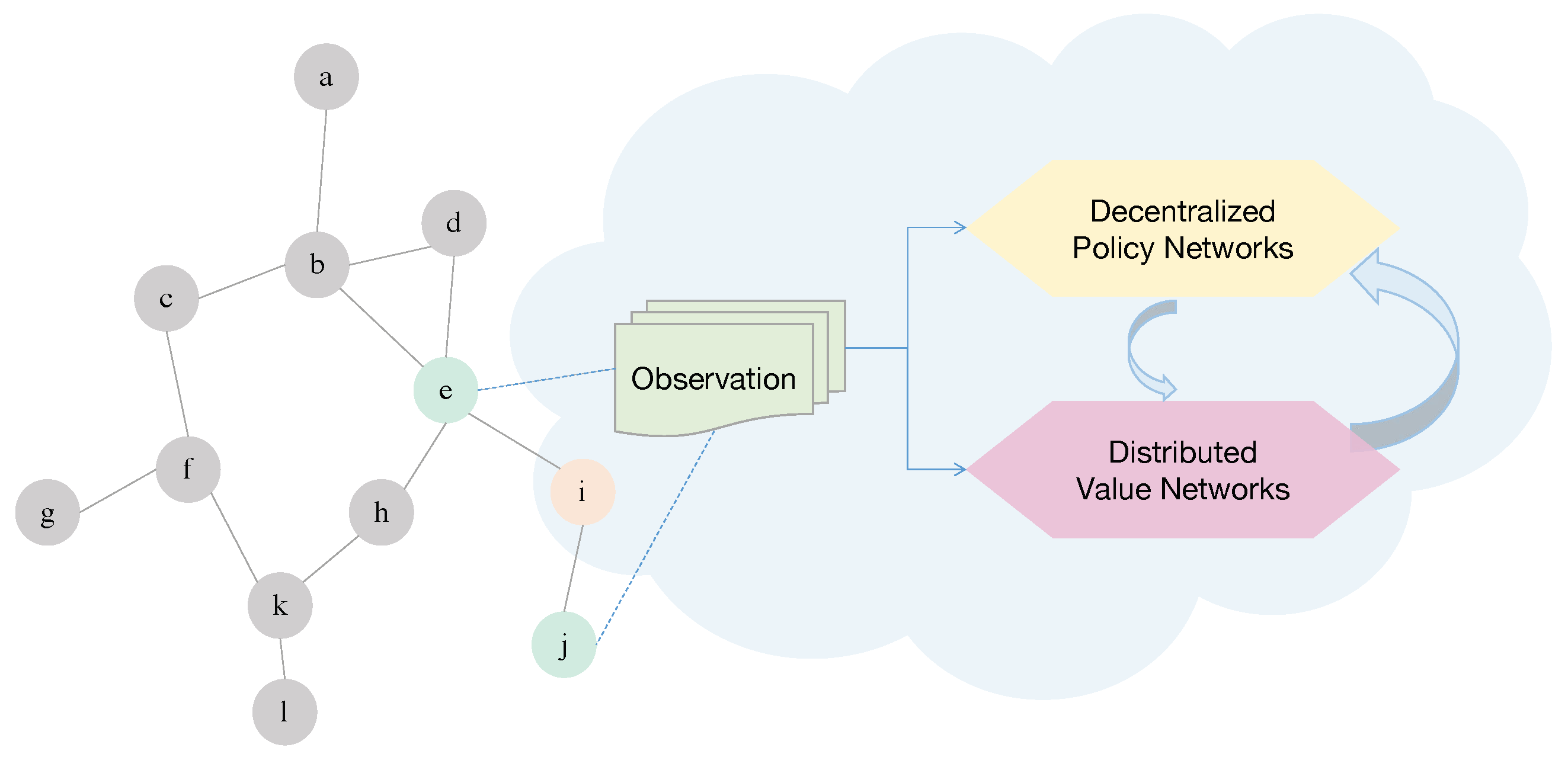
- A new multi-agent tracking environment based on the multi-agent particle environment (MPE) is built. Different from receiving observations of all agents, in our scenarios, each agent only obtains information from the neighbor agents, which is more practical under the condition of limited communication;
- In consideration of the distributed partially observable condition, this study establishes a framework of a private reward mechanism for the multi-agent tracking system, providing a kind of incentive method in distributed scenarios. This is the fundament of further research;
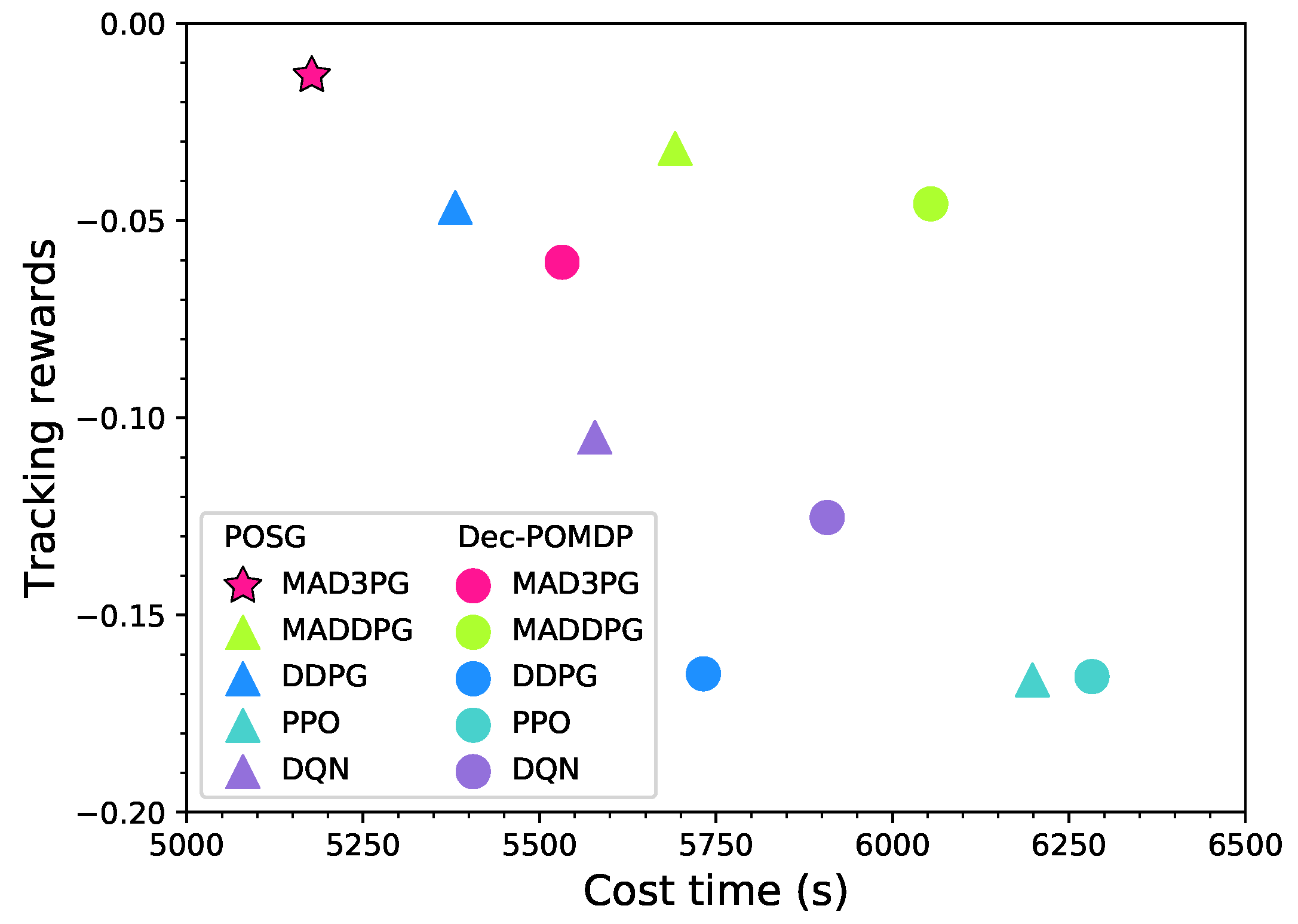
- A novel methodology named the multi-agent distributed deep deterministic policy gradient (MAD3PG) for the tracking system is proposed. In this method, a distributed critic and a decentralized actor are designed for the distributed scenario. The importance and originality of the MAD3PG is that it adopts distributed training with decentralized execution rather than centralized or decentralized training, which are widely used in current approaches. Compared with recent relevant algorithms, the MAD3PG has shorter time cost and better training performance.
2. Background
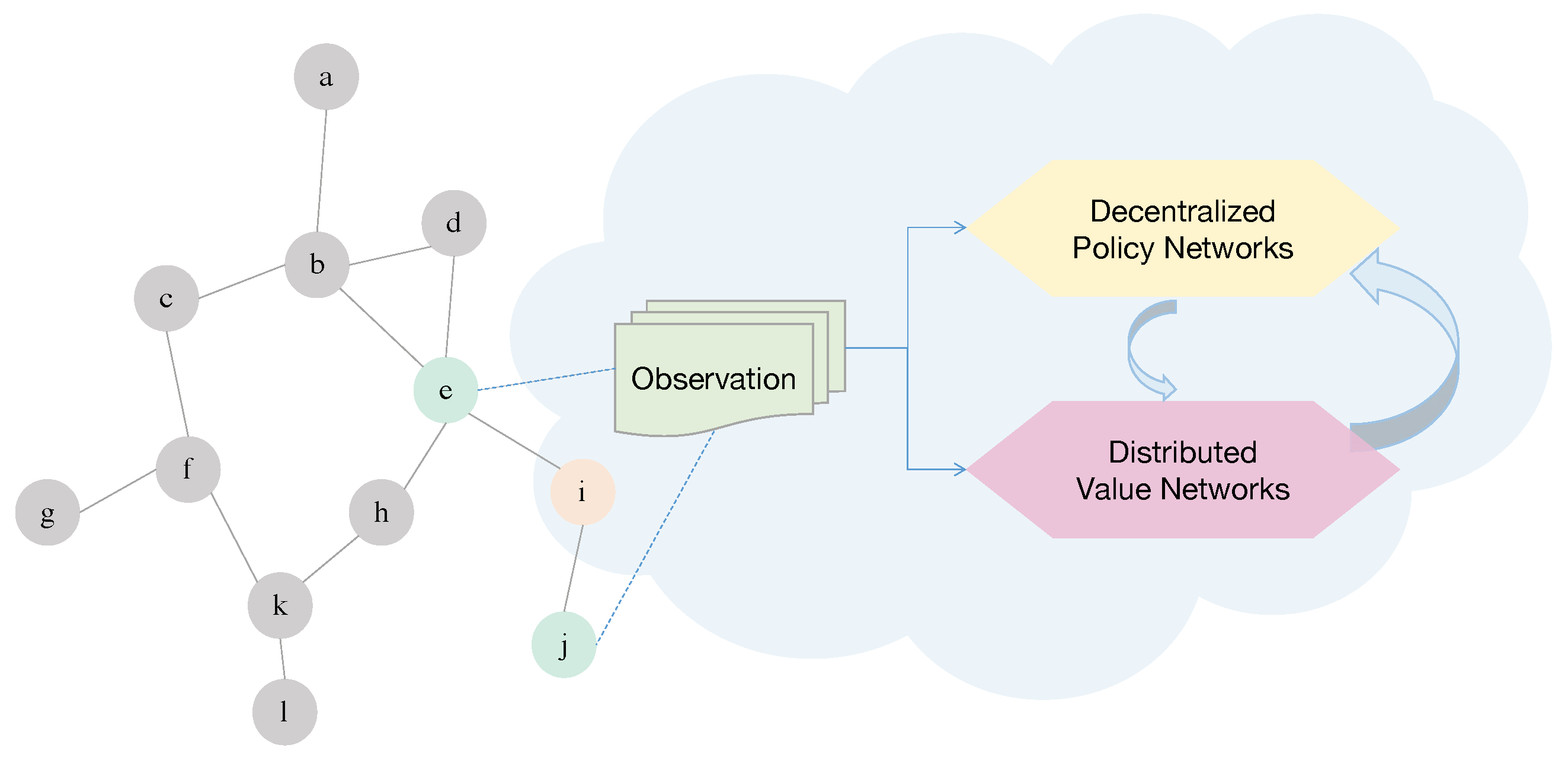
2.1. Graph Theory
2.2. Multi-Agent Decision Process
2.3. Policy Gradient
2.4. Value Function Methods
2.5. Deep Deterministic Policy Gradient
2.6. Multi-Agent Deep Deterministic Policy Gradient
3. Proposed Method
3.1. Distributed Observation
3.2. Reward Function
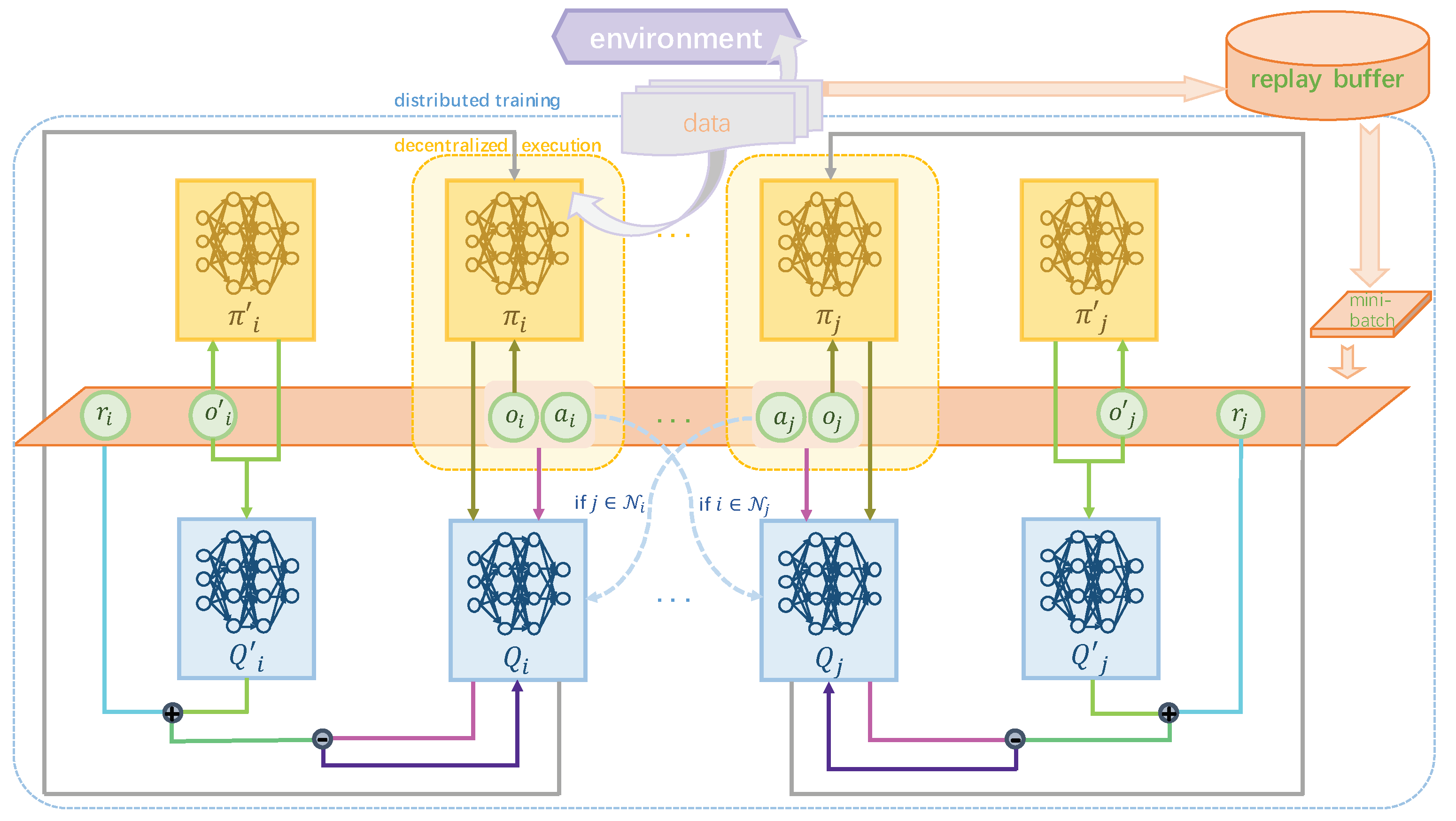
3.3. Multi-Agent Distributed Deep Deterministic Policy Gradient
| Algorithm 1 MAD3PG. |
|
1: Initialize the environment with N tracking agents and a target agent 2: Initialize an experience replay buffer 3: for episode=1 to E, where E denotes the number of training episodes do 4: Reset the environment, and obtain initial state ; each agent i obtains the initial observation 5: for to T, where T refers to the maximum number of steps in an episode do 6: for agent to N do 7: Select action based on the actor, as well as exploration 8: Execute action , then obtain reward and new observation 9: Store in 10: end for 11: State is replaced by the next state 12: for agent to N do 13: Randomly sample a mini-batch B of from 14: Set the ground truth of the critic networks to be 15: Update the distributed critic by minimizing the loss: where and 16: Update the decentralized actor: 17: end for 18: if episode , where n denotes the target update interval then 19: Update the parameters of the target actor networks and target critic networks for each agent i: 20: end if 21: end for 22: end for |
4. Experimental Setup and Validation
4.1. Task Description
4.2. Implementation Specifications
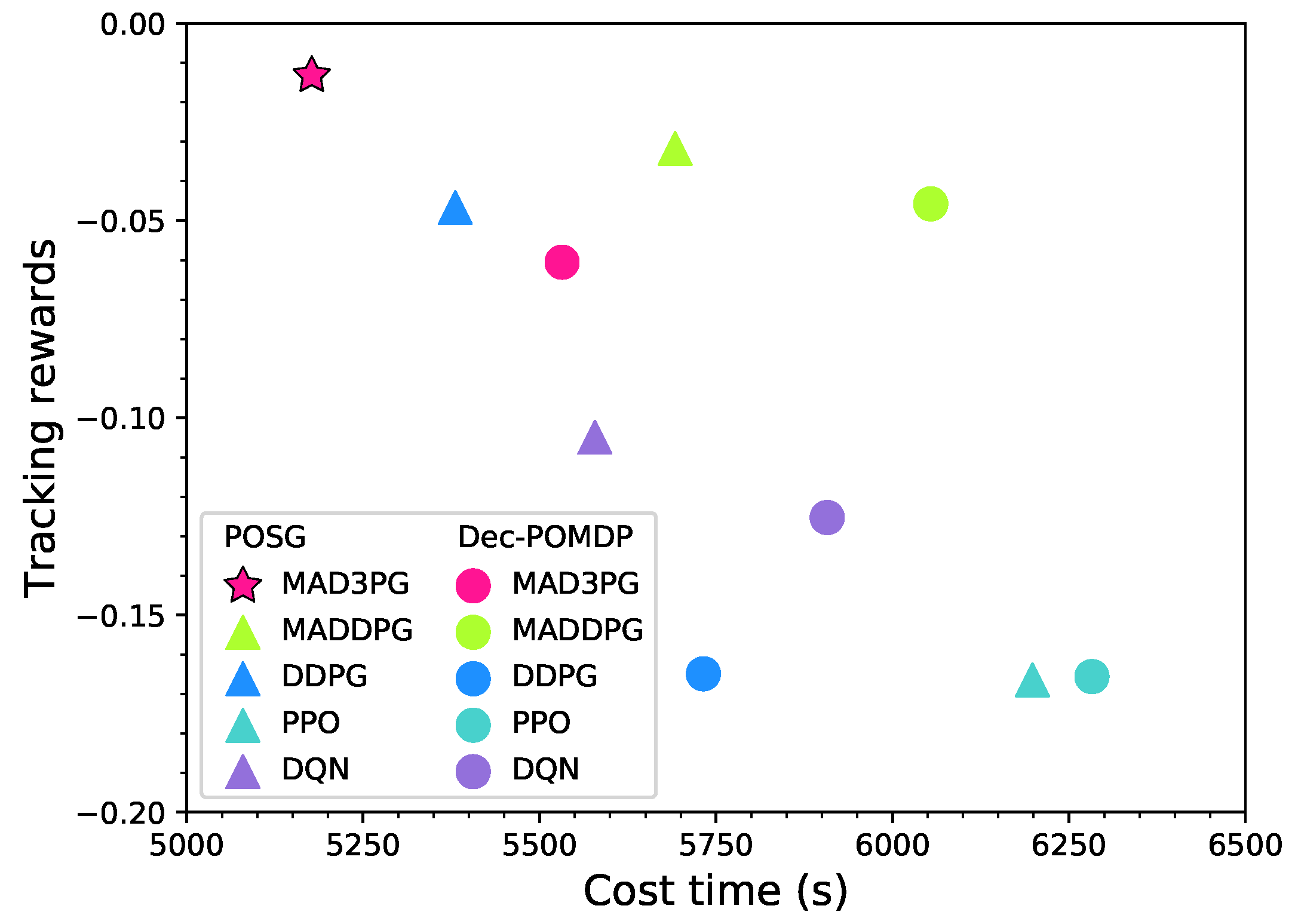
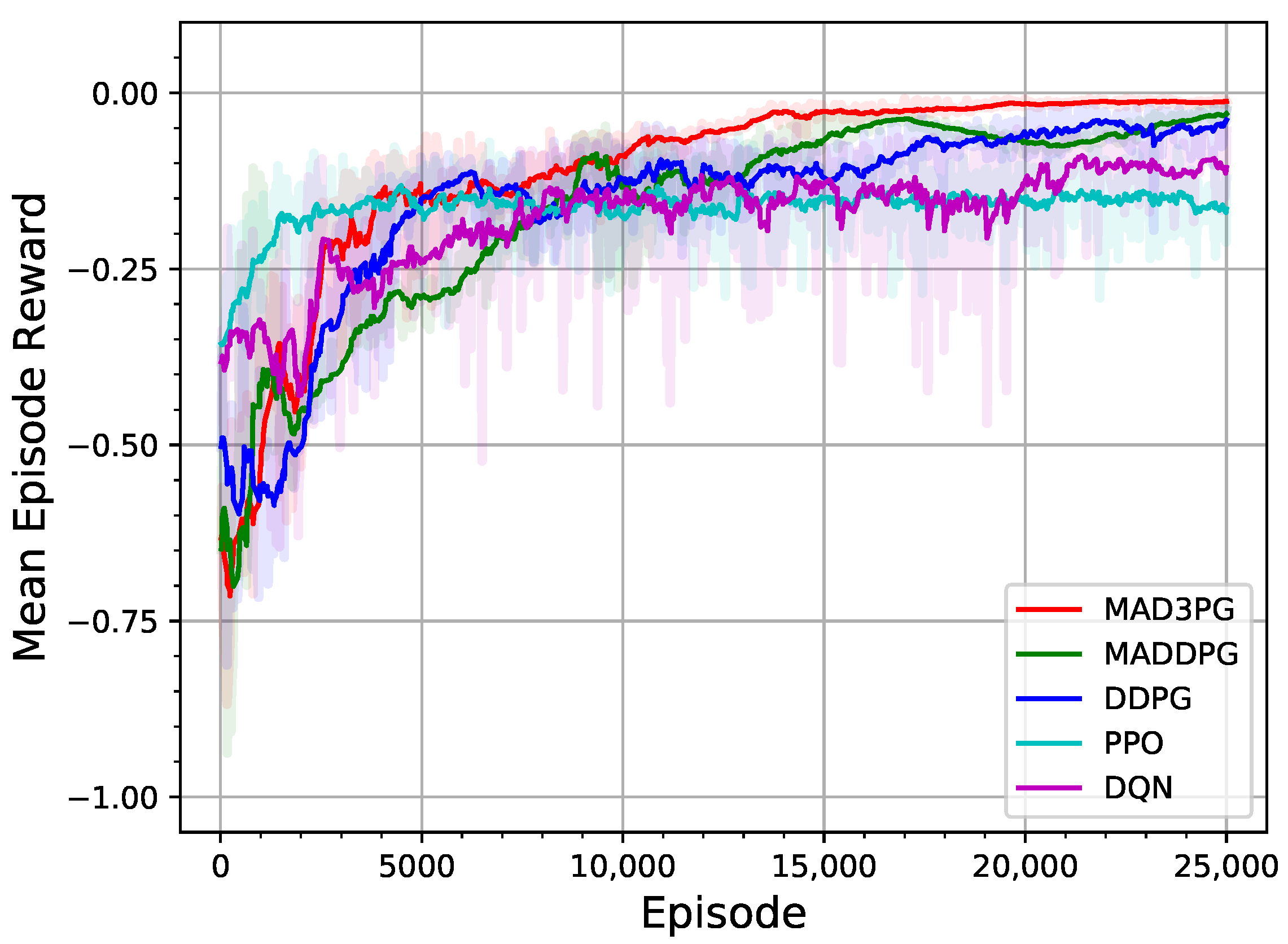
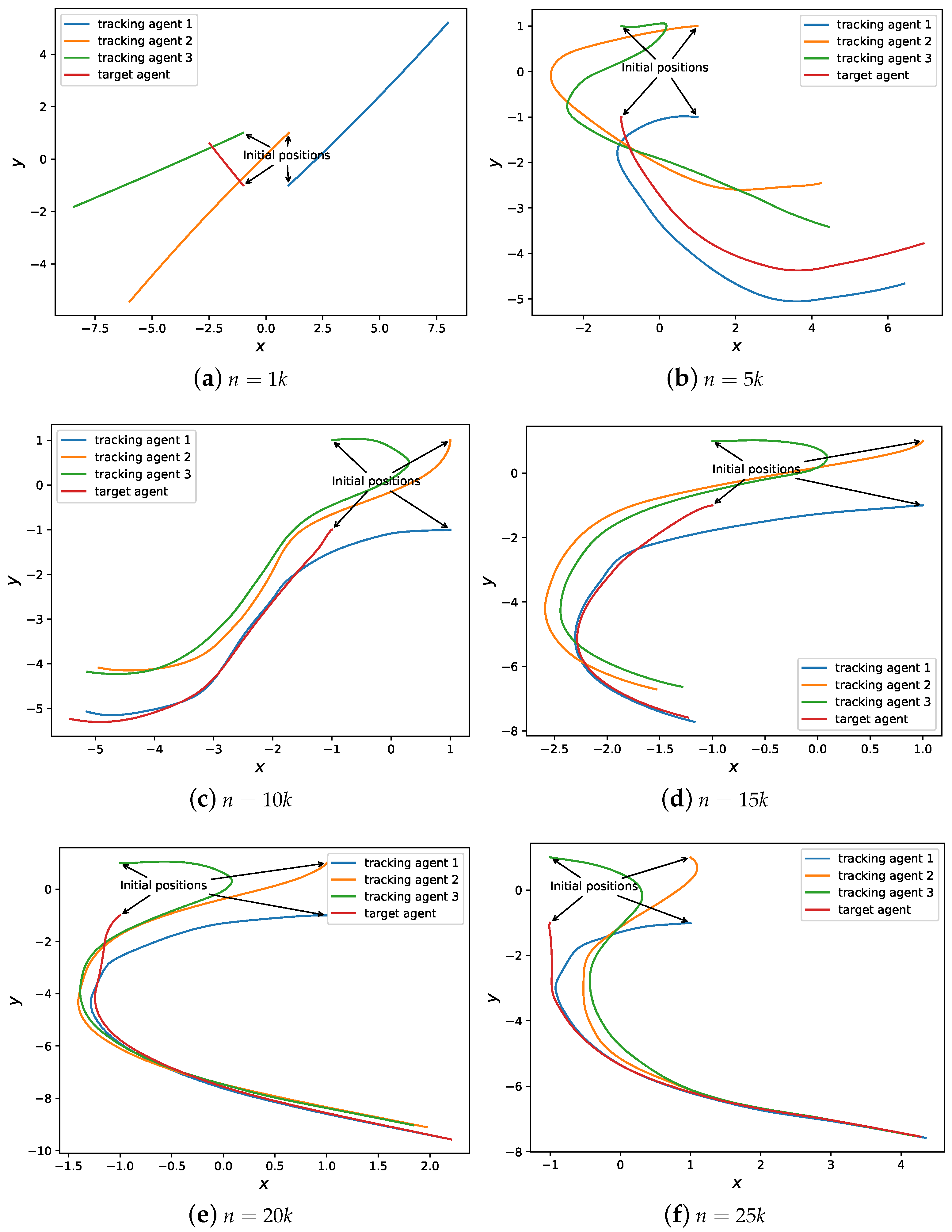
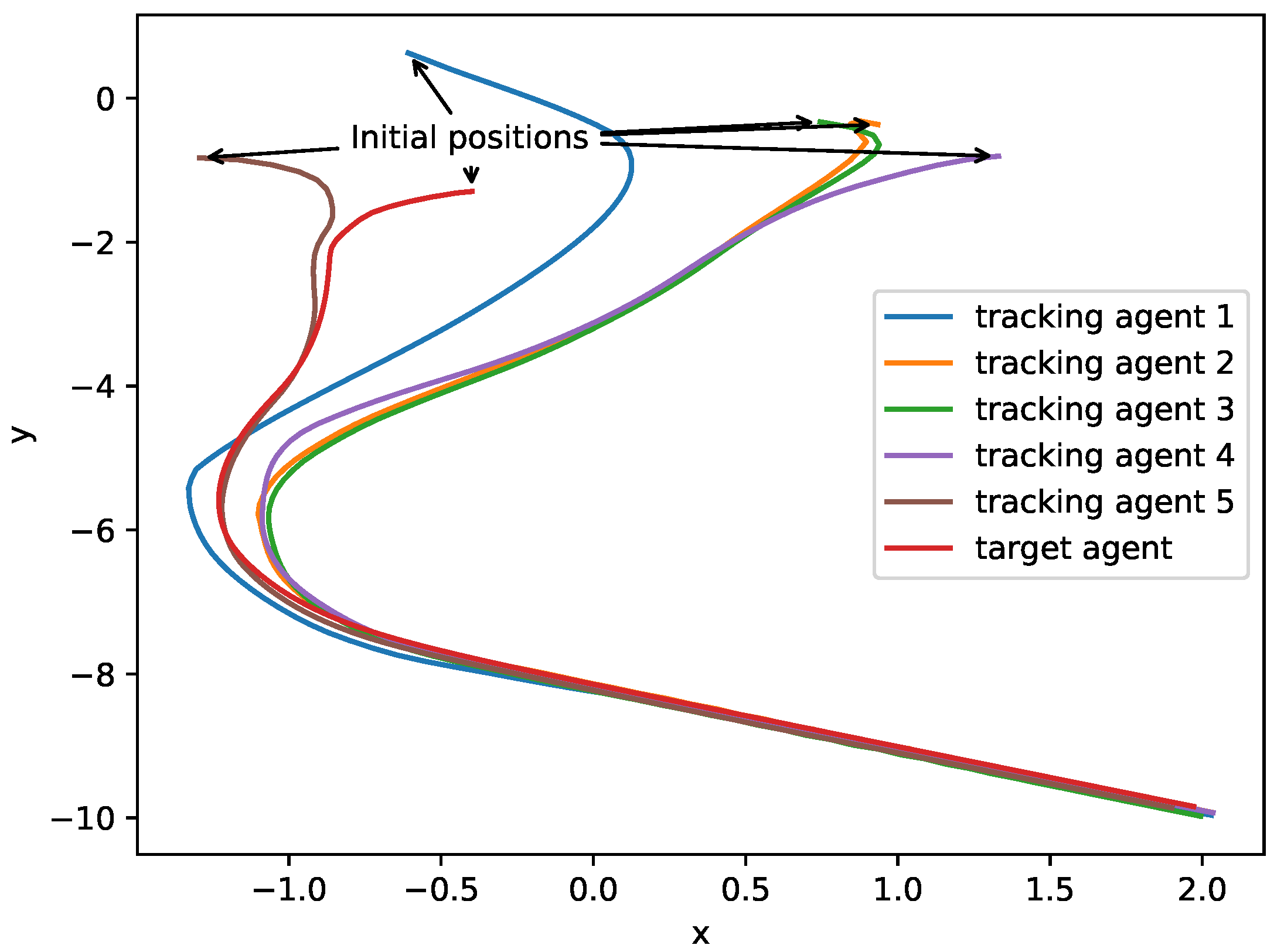
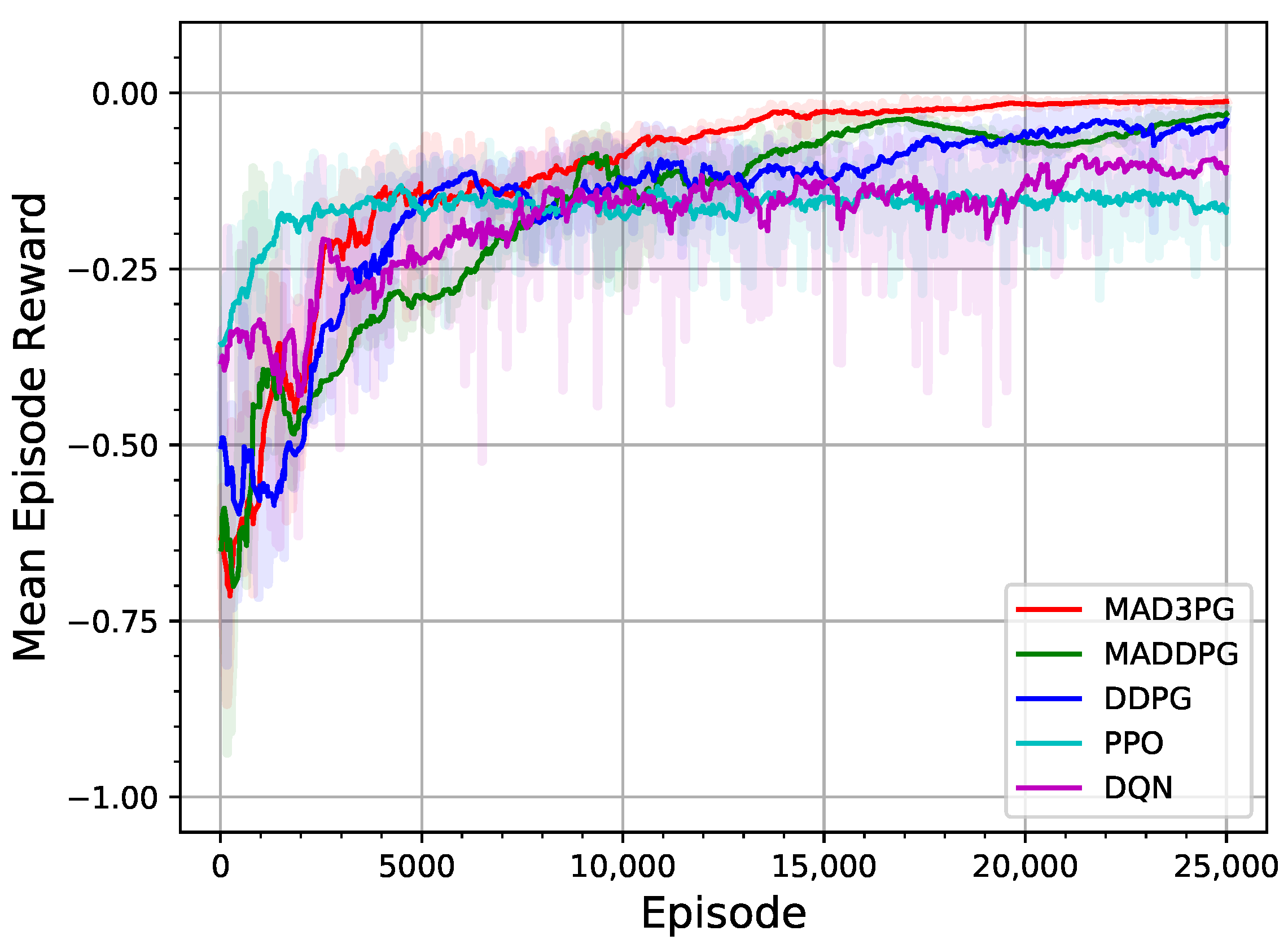
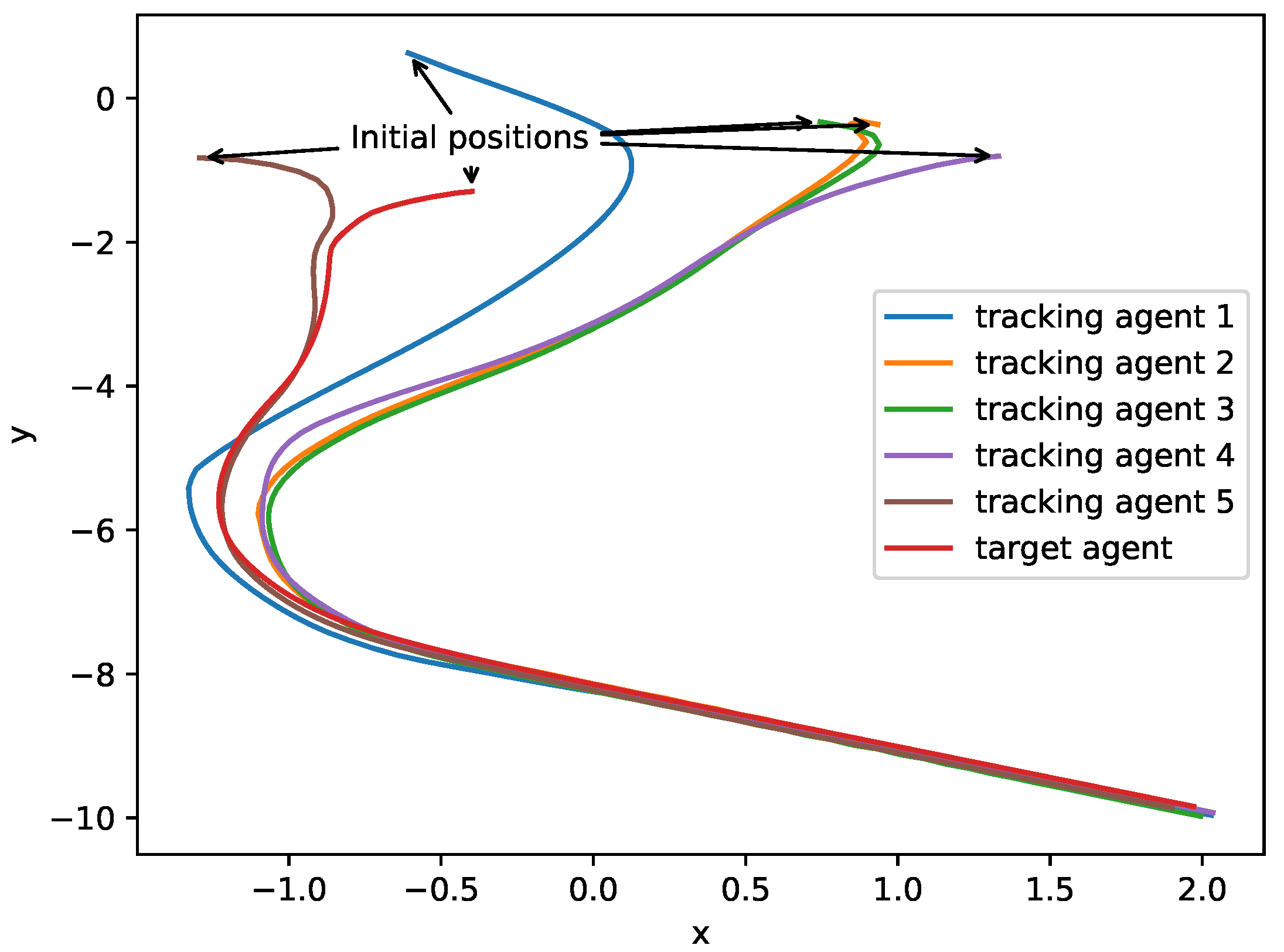
4.3. Experimental Evaluation Results of a System with Three Tracking Agents
4.4. Experimental Evaluation Results of System with Five Tracking Agents
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MASs | Multi-agent systems |
| RL | Reinforcement learning |
| DRL | Deep reinforcement learning |
| MADRL | Multi-agent deep reinforcement learning |
| CLEAN | Coordinated learning without exploratory action noise |
| IQL | Independent Q-learning |
| VDN | Value decomposition networks |
| QMIX | Monotonic value function factorization |
| QTRAN | Learning to factorize with transformation |
| MADDPG | Multi-agent deep deterministic policy gradient |
| DDPG | Deep deterministic policy gradient |
| Dec-POMDP | Decentralized partially observable Markov decision process |
| POSG | Partially observable stochastic game |
| MPE | Multi-agent particle environment |
| MAD3PG | Multi-agent distributed deep deterministic policy gradient |
| MDP | Markov decision process |
| POMDP | Partially observable Markov decision process |
| Dec-POMDP | Decentralized POMDP |
| PPO | Proximal policy optimization |
| CTDE | Centralized training and decentralized execution |
| ReLU | Rectified linear unit |
| MLP | Multilayer perception |
| FIFO | First in, first out |
| DQN | Deep Q-learning |
References
- Shoham, Y.; Leyton-Brown, K. Multiagent Systems—Algorithmic, Game-Theoretic, and Logical Foundations; Cambridge University Press: New York, NY, USA, 2009. [Google Scholar]
- Mahmoud, M.S. Multiagent Systems: Introduction and Coordination Control; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Hasan, Y.A.; Garg, A.; Sugaya, S.; Tapia, L. Defensive Escort Teams for Navigation in Crowds via Multi-Agent Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2020, 5, 5645–5652. [Google Scholar] [CrossRef]
- Kappel, K.S.; Cabreira, T.M.; Marins, J.L.; de Brisolara, L.B.; Ferreira, P.R. Strategies for Patrolling Missions with Multiple UAVs. J. Intell. Robot. Syst. 2020, 99, 499–515. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Y.; Shen, Y. Cooperative Tracking by Multi-Agent Systems Using Signals of Opportunity. IEEE Trans. Commun. 2020, 68, 93–105. [Google Scholar] [CrossRef]
- Yu, X.; Andersson, S.B.; Zhou, N.; Cassandras, C.G. Scheduling Multiple Agents in a Persistent Monitoring Task Using Reachability Analysis. IEEE Trans. Autom. Control 2020, 65, 1499–1513. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; Schutter, B.D. A Comprehensive Survey of Multiagent Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Buşoniu, L.; Babuška, R.; De Schutter, B. Multi-agent Reinforcement Learning: An Overview. In Innovations in Multi-Agent Systems and Applications—1; Srinivasan, D., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 183–221. [Google Scholar]
- Schwartz, H.M. Multi-Agent Machine Learning: A Reinforcement Approach; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: London, UK, 2018. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.; Guez, A.; Sifre, L.; Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2018. Available online: https://arxiv.org/pdf/1707.06347v2 (accessed on 13 August 2018).
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Weiss, G. Multiagent Systems, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Lanctot, M.; Zambaldi, V.F.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4190–4203. [Google Scholar]
- Hernandez-Leal, P.; Kartal, B.; Taylor, M.E. A Survey and Critique of Multiagent Deep Reinforcement Learning. Auton. Agents-Multi-Agent Syst. 2019, 33, 750–797. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Yang, Z.; Başar, T. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. In Handbook of Reinforcement Learning and Control; Vamvoudakis, K.G., Wan, Y., Lewis, F.L., Cansever, D., Eds.; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar]
- Gronauer, S.; Diepold, K. Multi-agent Deep Reinforcement Learning: A Survey. Artif. Intell. Rev. 2021, 1–49. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shoham, Y.; Powers, R.; Grenager, T. If multi-agent learning is the answer, what is the question? Artif. Intell. 2007, 171, 365–377. [Google Scholar] [CrossRef] [Green Version]
- Albrecht, S.V.; Stone, P. Autonomous Agents Modelling Other Agents: A Comprehensive Survey and Open Problems. Artif. Intell. 2018, 258, 66–95. [Google Scholar] [CrossRef] [Green Version]
- Hung, S.M.; Givigi, S. A Q-Learning Approach to Flocking with UAVs in a Stochastic Environment. IEEE Trans. Cybern. 2016, 47, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Leibo, J.Z.; Zambaldi, V.F.; Lanctot, M.; Marecki, J.; Graepel, T. Multi-agent Reinforcement Learning in Sequential Social Dilemmas. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems (AAMAS 2017), São Paulo, Brazil, 8–12 May 2017; pp. 464–473. [Google Scholar]
- Hong, Z.; Su, S.; Shann, T.; Chang, Y.; Lee, C. A Deep Policy Inference Q-Network for Multi-Agent Systems. In Proceedings of the 17th International Conference on Autonomous Agents and Multi Agent Systems (AAMAS 2018), Richland, SC, USA, 10–15 July 2018; pp. 1388–1396. [Google Scholar]
- Prasad, A.; Dusparic, I. Multi-agent Deep Reinforcement Learning for Zero Energy Communities. In 2019 IEEE PES Innovative Smart Grid Technologies Europe, ISGT-Europe; IEEE: Bucharest, Romania, 2019; pp. 1–5. [Google Scholar]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef] [Green Version]
- Jaderberg, M.; Czarnecki, W.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.; Beattie, C.; Rabinowitz, N.; Morcos, A.; Ruderman, A.; et al. Human-level Performance in 3D Multiplayer Games with Population-based Reinforcement Learning. Science 2019, 364, 859–865. [Google Scholar] [CrossRef] [Green Version]
- Menda, K.; Chen, Y.; Grana, J.; Bono, J.W.; Tracey, B.D.; Kochenderfer, M.J.; Wolpert, D. Deep Reinforcement Learning for Event-Driven Multi-Agent Decision Processes. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1259–1268. [Google Scholar] [CrossRef]
- Wu, F.; Zhang, H.; Wu, J.; Song, L. Cellular UAV-to-Device Communications: Trajectory Design and Mode Selection by Multi-Agent Deep Reinforcement Learning. IEEE Trans. Commun. 2020, 68, 4175–4189. [Google Scholar] [CrossRef] [Green Version]
- Agogino, A.; Turner, K. Multi-Agent Reward Analysis for Learning in Noisy Domains. In Proceedings of the 4th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS 2005), Utrecht, The Netherlands, 25–29 July 2005; pp. 81–88. [Google Scholar]
- HolmesParker, C.; Taylor, M.E.; Agogino, A.K.; Tumer, K. CLEANing the Reward: Counterfactual Actions to Remove Exploratory Action Noise in Multiagent Learning. In Proceedings of the 13th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2014), Paris, France, 5–9 May 2014; pp. 1353–1354. [Google Scholar]
- Foerster, J.N.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence/30th Innovative Applications of Artificial Intelligence Conference/8th AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI 2018), New Orleans, LA, USA, 2–7 February 2018; pp. 2974–2982. [Google Scholar]
- Tan, M. Multi-Agent Reinforcement Learning: Independent vs. Cooperative Agents. In Proceedings of the 10th International Conference of Machine Learning (ICML 1993), Amherst, MA, USA, 27–29 June 1993; pp. 330–337. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.F.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-Decomposition Networks for Cooperative Multi-Agent Learning Based on Team Reward. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS 2018), Stockholm, Sweden, 10–15 July 2018; pp. 2085–2087. [Google Scholar]
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholm, Sweden, 10–15 July 2018; pp. 4295–4304. [Google Scholar]
- Son, K.; Kim, D.; Kang, W.J.; Hostallero, D.; Yi, Y. QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; pp. 5887–5896. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6379–6390. [Google Scholar]
- Bernstein, D.S.; Givan, R.; Immerman, N.; Zilberstein, S. The Complexity of Decentralized Control of Markov Decision Processes. Math. Oper. Res. 2002, 27, 819–840. [Google Scholar] [CrossRef]
- Oliehoek, F.A.; Amato, C. A Concise Introduction to Decentralized POMDPs, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Hansen, E.A.; Bernstein, D.S.; Zilberstein, S. Dynamic Programming for Partially Observable Stochastic Games. In Proceedings of the 19th National Conference on Artificial Intelligence/16th Conference on Innovative Applications of Artificial Intelligence, San Jose, CA, USA, 25–29 July 2004; pp. 709–715. [Google Scholar]
- Dong, L.; Chai, S.; Zhang, B.; Nguang, S.K.; Savvaris, A. Stability of a Class of Multiagent Tracking Systems With Unstable Subsystems. IEEE Trans. Cybern. 2017, 47, 2193–2202. [Google Scholar] [CrossRef]
- Doshi, P.; Gmytrasiewicz, P. A Framework for Sequential Planning in Multi-Agent Settings. J. Artif. Intell. Res. 2005, 24, 49–79. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Foerster, J.N.; Nardelli, N.; Farquhar, G.; Afouras, T.; Torr, P.H.S.; Kohli, P.; Whiteson, S. Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, NSW, Australia; 6-11 August 2017; pp. 1146–1155. [Google Scholar]
- Omidshafiei, S.; Pazis, J.; Amato, C.; How, J.P.; Vian, J. Deep Decentralized Multi-task Multi-Agent Reinforcement Learning under Partial Observability. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, NSW, Australia, 6–11 August 2017; pp. 2681–2690. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M.A. Deterministic Policy Gradient Algorithms. In Proceedings of the 31th International Conference on Machine Learning (ICML 2014), Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning | Dec-POMDP | POSG |
|---|---|---|---|
| a finite set of agents indexed | ✓ | ✓ | |
| a finite set of states | ✓ | ✓ | |
| a finite set of actions available to agent i | ✓ | ✓ | |
| a Markovian transition function | ✓ | ✓ | |
| a finite set of observations available to agent i | ✓ | ✓ | |
| a reward function | ✓ | ||
| an individual reward function of the i-th agent | ✓ | ||
| h | a finite horizon | ✓ | ✓ |
| Parameters | Value |
|---|---|
| discount factor () | 0.95 |
| soft target update rate () | 0.01 |
| capacity of the replay buffer | |
| mini-batch size | 1024 |
| learning rate | 0.01 |
| number of total episodes | 25,000 |
| Method | Dec-POMDP | POSG | ||
|---|---|---|---|---|
| Reward | Time (s) | Reward | Time (s) | |
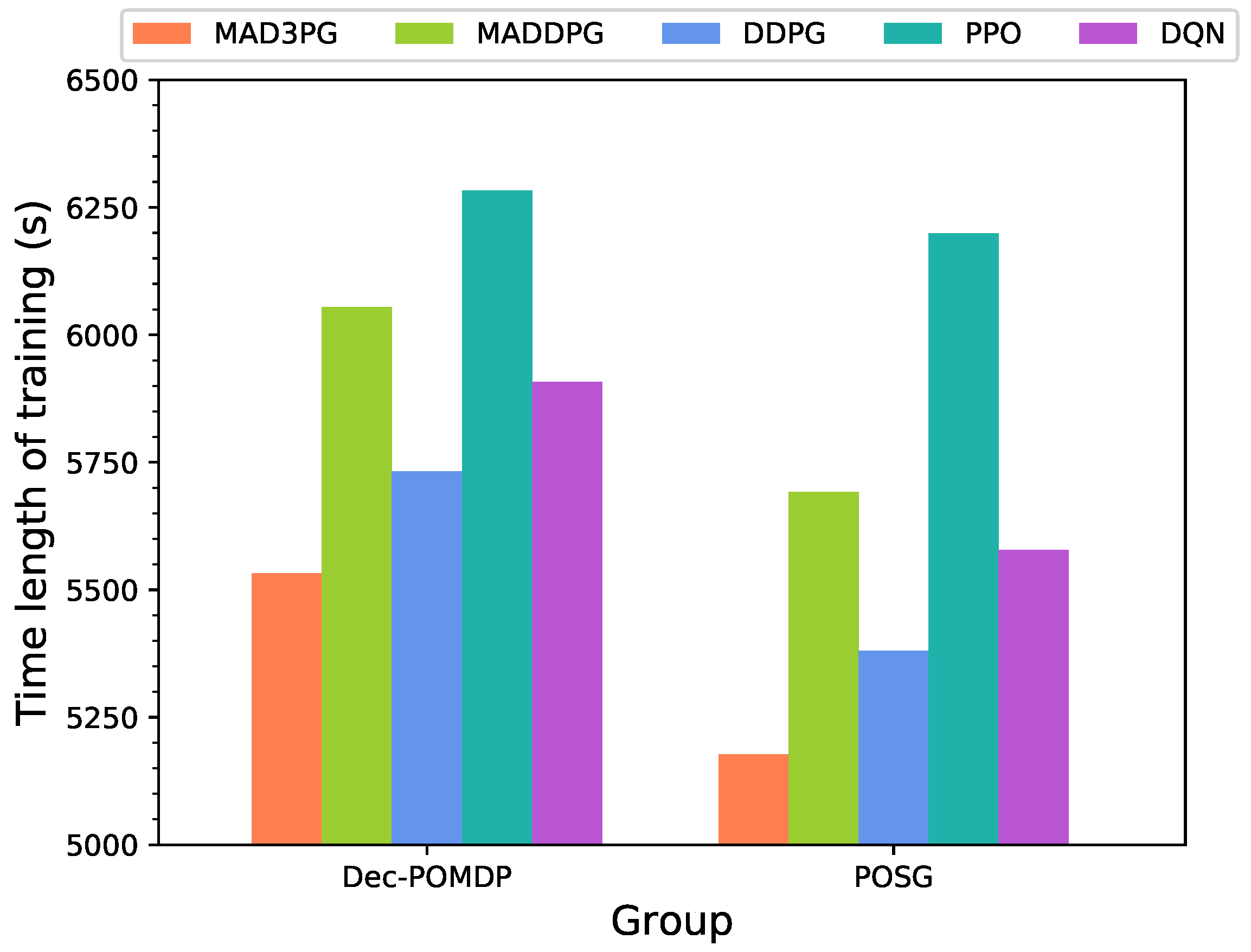
| MAD3PG | −0.061 | 5532 | −0.013 | 5177 |
| MADDPG | −0.046 | 6054 | −0.032 | 5692 |
| DDPG | −0.165 | 5732 | −0.047 | 5381 |
| PPO | −0.166 | 6283 | −0.166 | 6198 |
| DQN | −0.125 | 5907 | −0.105 | 5578 |
| Method | ||
|---|---|---|
| MAD3PG | ||
| MADDPG | ||
| DDPG | ||
| PPO | ||
| DQN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, D.; Shen, H.; Dong, L. Multi-Agent Distributed Deep Deterministic Policy Gradient for Partially Observable Tracking. Actuators 2021, 10, 268. https://doi.org/10.3390/act10100268
Fan D, Shen H, Dong L. Multi-Agent Distributed Deep Deterministic Policy Gradient for Partially Observable Tracking. Actuators. 2021; 10(10):268. https://doi.org/10.3390/act10100268
Chicago/Turabian StyleFan, Dongyu, Haikuo Shen, and Lijing Dong. 2021. "Multi-Agent Distributed Deep Deterministic Policy Gradient for Partially Observable Tracking" Actuators 10, no. 10: 268. https://doi.org/10.3390/act10100268
APA StyleFan, D., Shen, H., & Dong, L. (2021). Multi-Agent Distributed Deep Deterministic Policy Gradient for Partially Observable Tracking. Actuators, 10(10), 268. https://doi.org/10.3390/act10100268