Tendency to Use Big Data in Education Based on Its Opportunities According to Andalusian Education Students




Abstract
1. Introduction
2. Material and Methods
2.1. Participants
2.2. Material
2.3. Process
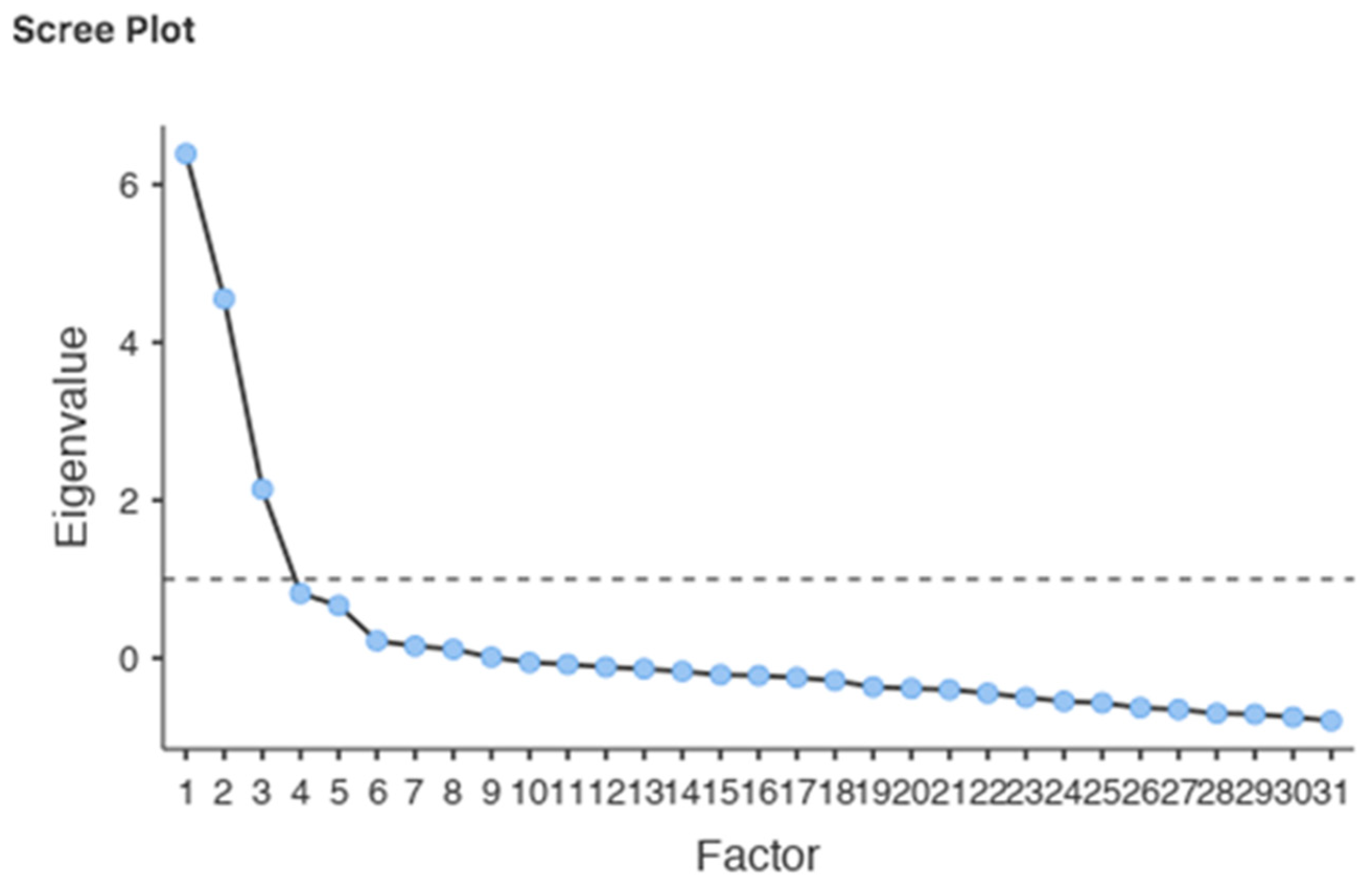
2.4. Analysis
3. Results
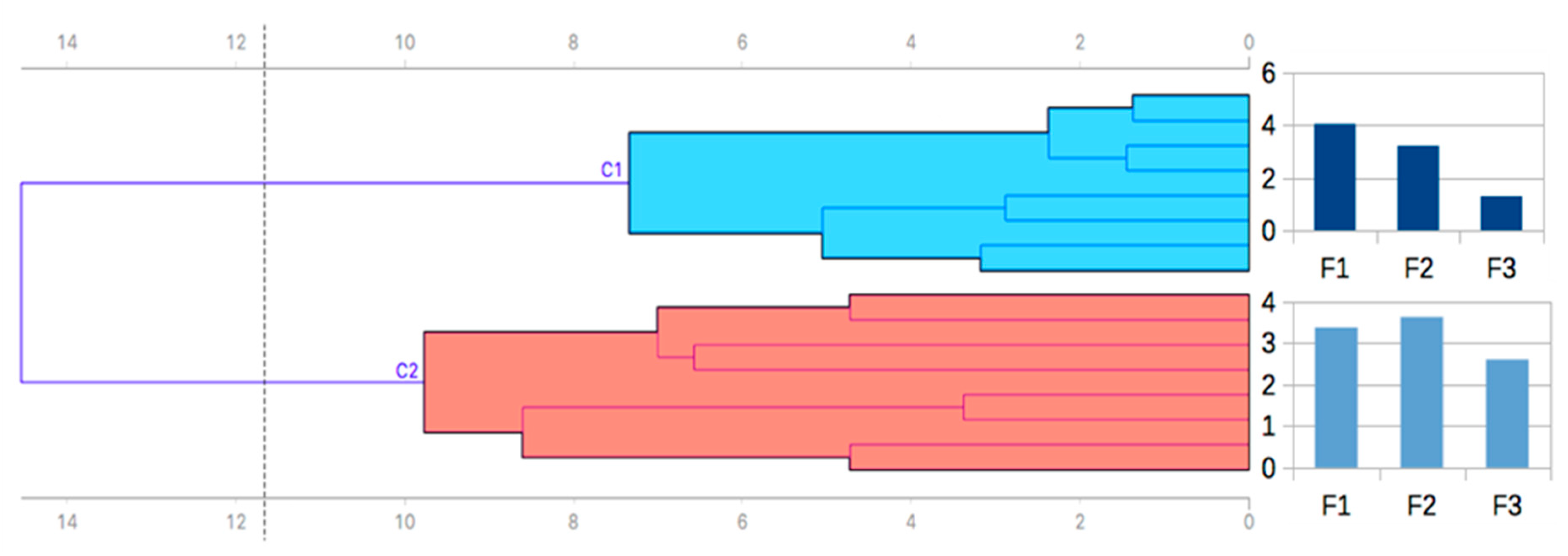
3.1. Study 1
- Know to what degree they are willing to incorporate it into their work.
- Explore different profiles among the participants regarding the dimensions of VABIDAE.
3.1.1. Analysis
3.1.2. Results Study 1
3.2. Study 2
3.2.1. Analysis
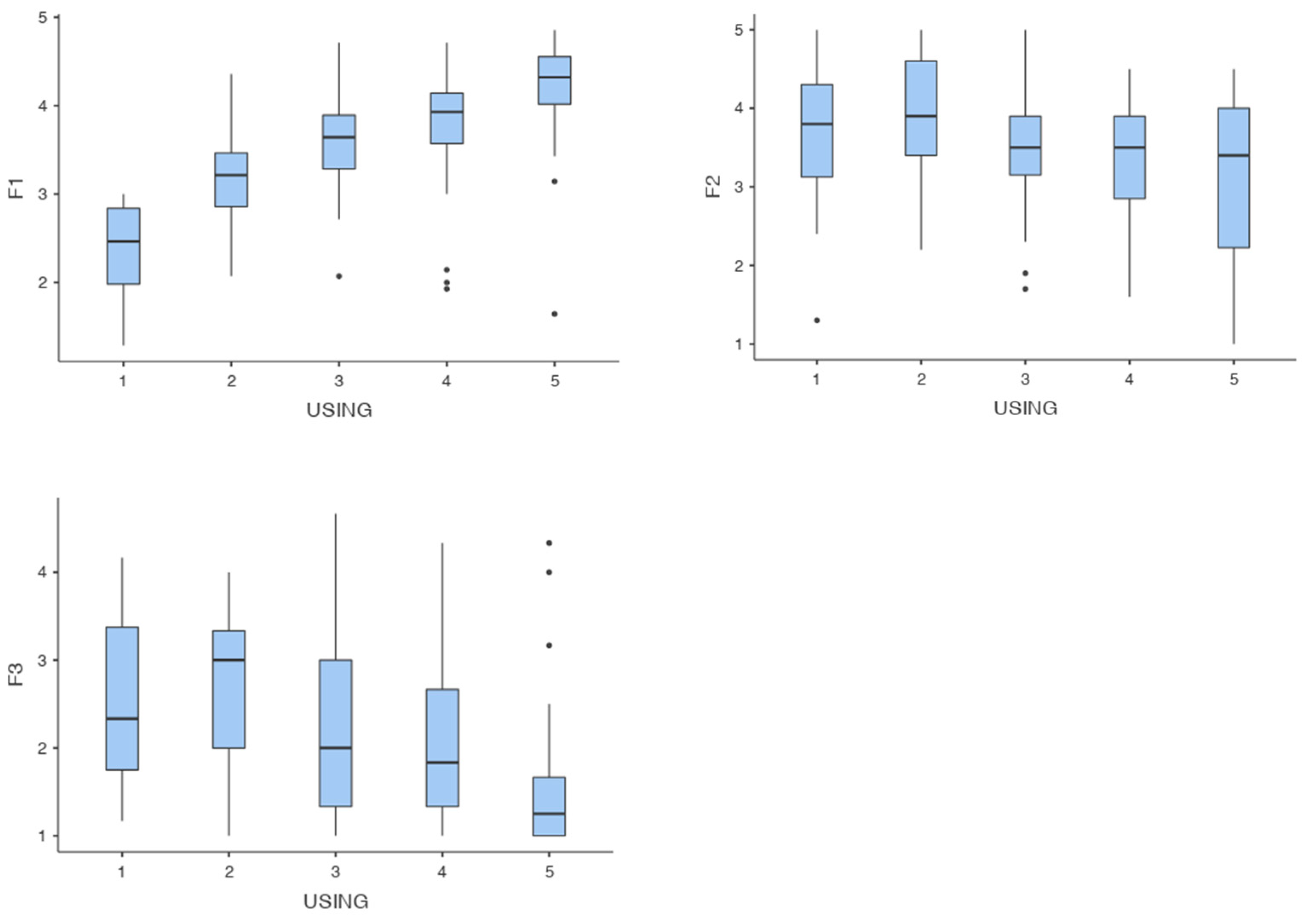
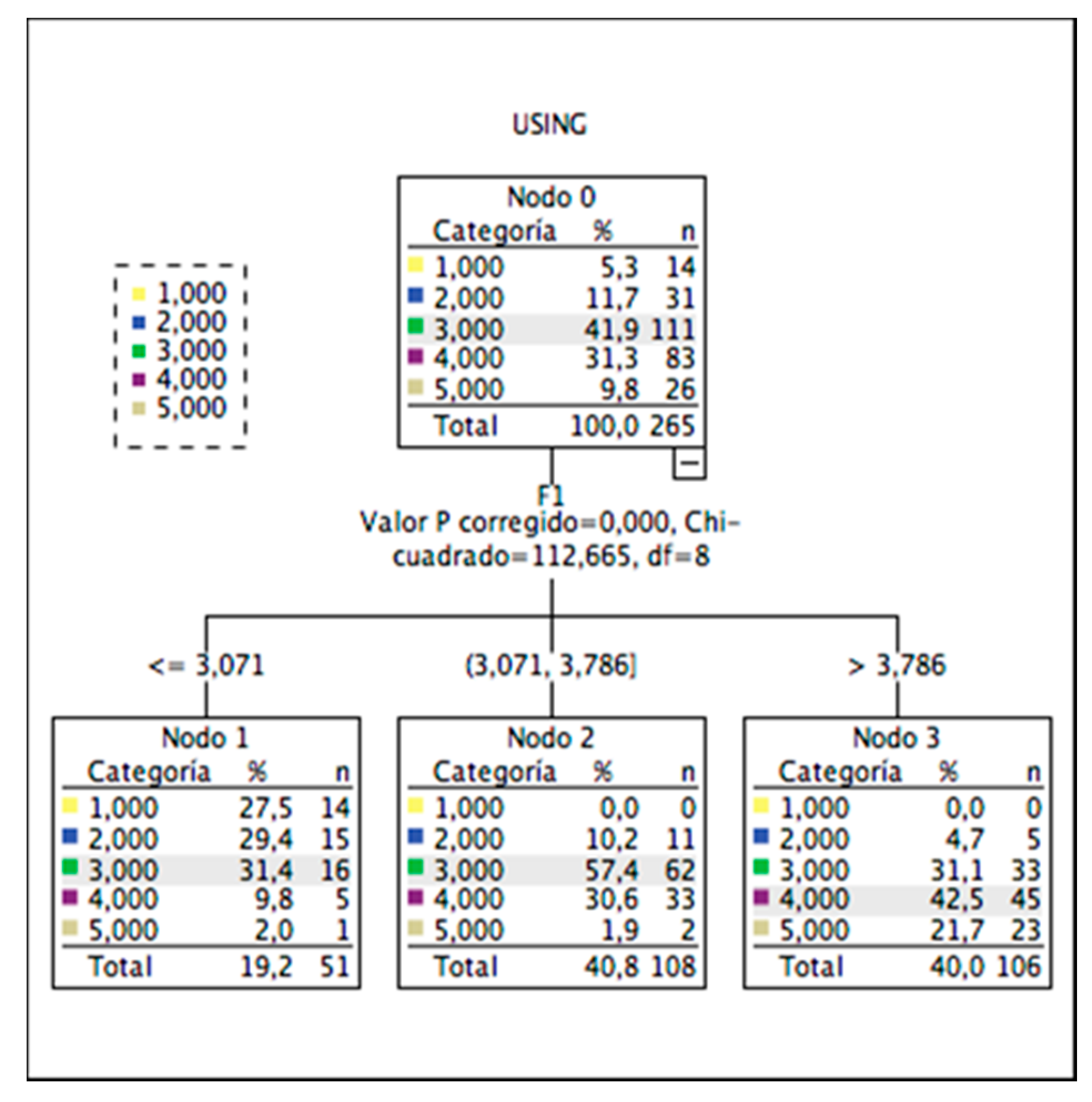
3.2.2. Results Study 2
4. Discussion
5. Conclusions
- -
- There are two stances taken by participants in relation to BD. One of them focused on opportunities, the second on negative issues.
- -
- The “opportunities” subscale (factor 1) is the variable or dimension of the scale that best predicts the tendency to use BD in professional practice.
Author Contributions
Funding
Conflicts of Interest
References
- Aghaei, Sina, Andres Gomez, and Phebe Vayanos. 2020. Learning optimal classification trees: Strong max-flow formulations. Available online: https://arxiv.org/abs/2002.09142 (accessed on 21 September 2020).
- Arranz, Olga, and Vidal Alonso. 2013. Big Data & Learning Analytics: A Potential Way to Optimize eLearning Technological Tools. Available online: https://bit.ly/2VweSsw7 (accessed on 21 September 2019).
- Bednall, Timothy C., Sanders Karin, and Piety Runhaar. 2014. Stimulating informal learning activities through perceptions of performance appraisal quality and human resource management system strength: A two-wave study. Academy of Management Learning & Education 13: 45–61. [Google Scholar] [CrossRef]
- Belleflamme, Paul, and Julien Jacqmin. 2016. An economic appraisal of MOOC platforms: business models and impacts on higher education. CESifo Economic Studies 62: 148–69. [Google Scholar] [CrossRef]
- Borrego, Mariano, Guadeño Cristina, Jiménez Cristina, Montero Raquel, Negro Cristina, and Antonio Matas-Terron. 2019. VABIDAE 2019. Available online: https://vabidae.gitlab.io/vabidae/ (accessed on 2 January 2020).
- Conway, Mike, and Daniel O’Connor. 2016. Social media, big data, and mental health: current advances and ethical implications. Current Opinion in Psychology 9: 77–82. [Google Scholar] [CrossRef] [PubMed]
- Costello, Anna B., and Jason Osborne. 2005. Best practices in exploratory factor analysis: Four recommendations for getting the most from your analysis. Practical Assessment, Research, and Evaluation 10: 1–9. [Google Scholar]
- Daniel, Ben Kei. 2019. Big Data and data science: A critical review of issues for educational research. British Journal of Educational Technology 50: 101–13. [Google Scholar] [CrossRef]
- Gámez, David, and María Dolores Guerra. 2016. Aprendizaje inverso en formación profesional: opiniones de los estudiantes. Innoeduca International Journal of Technology and Educational Innovation 2: 29–37. [Google Scholar] [CrossRef]
- Hair, Joseph F., William C. Black, Barry J. Babin, Rolph E. Anderson, and Ronald L. Tatham. 1998. Multivariate Data Analysis, 5th ed. Upper Saddle River: Prentice Hall. [Google Scholar]
- Larson, Erik. 1989. What Sort of Car-rt-sort am I? Harper’s Magazine. Available online: https://harpers.org/archive/1989/07/what-sort-of-car-rt-sort-am-i-junk-mail-and-the-search-for-self/ (accessed on 4 March 2019).
- Li, Kuan-Ching, Hai Jiang, Laurence T. Yang, and Alfredo Cuzzocrea. 2015. Big Data: Algorithms, Analytics, and Applications. Boca Raton: CRC Press. ISBN 9781482240559. [Google Scholar]
- Matas-Terrón, Antonio, Juan José Leiva Olivencia, and Pablo D. Franco Caballer. 2020. Big Data irruption in education. Pixel-Bit: Revista de Medios y Educación 57: 59–90. [Google Scholar] [CrossRef]
- Matas-Terrón, Antonio, Juan José Leiva Olivencia, Pablo D. Franco-Caballero, and Francisco J. García-Aguilera. 2020. Validity of the “Big Data Tendency in Education” Scale as a Tool Helping to Reach Inclusive Social Development. Sustainability 12: 5470. [Google Scholar] [CrossRef]
- Mayer-Schönberger, Viktor, and Kenneth Cukier. 2018. Aprender con Big Data [Learn with Big Data]. Madrid: Turner. ISBN 9788417141516. [Google Scholar]
- Molinari, Andrea, Vincenzo Maltese, Lorenzino Vaccari, Andrea Almi, and Eleonora Bassi. 2014. Big data and open data for a smart city. IEEE-TN Smart Cities White Papers Trento, Italy 10–11: 1–8. [Google Scholar]
- Pallant, Julie. 2010. SPSS Survival Manual: A Step By Step Guide to Data Analysis Using SPSS. Maidenhead: Open University Press/McGraw-Hill. ISBN 9780335242399. [Google Scholar]
- R Core Team. 2019. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 3 January 2019).
- Reyes, Jacqueleen A. 2015. The skinny on big data in education: Learning analytics simplified. TechTrends 59: 75–80. [Google Scholar] [CrossRef]
- Ruiz-Palmero, Julio, Ernesto Colomo-Magaña, José Ríos-Ariza, and Melchor Gómez-García. 2020. Big Data in Education: Perception of Training Advisors on Its Use in the Educational System. Social Sciences 9: 53. [Google Scholar] [CrossRef]
- Sheng, Jie, Joseph Amankwah-Amoah, and Xiaojun Wang. 2017. A multidisciplinary perspective of big data in management research. International Journal of Production Economics 191: 97–112. [Google Scholar] [CrossRef]
- Soares, Sunil. 2013. Big Data Governance: An Emerging Imperative. Boise: MC Press. [Google Scholar]
- Stevens, James. 1996. Applied Multivariate Statistics for the Social Sciences, 3th ed. Mahwah: Lawrence Erlbaum Associates. ISBN 9780805837766. [Google Scholar]
- Strobl, Carolin, James Malley, and Gerhard Tutz. 2009. An introduction to recursive partitioning: rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychological Methods 14: 323–48. [Google Scholar] [CrossRef] [PubMed]
- Tourón, Javier, Emelina López González, Luis Lizasoain, Enrique Navarro-Asencio, and María José García-San Pedro. 2018. Alumnado español de alto y bajo rendimiento en ciencias en PISA 2015: análisis del impacto de algunas variables de contexto. Revista de Educacion 380: 156–84. [Google Scholar] [CrossRef]
- Villegas, William, Sergio Luján-Mora, Diego Buenaño-Fernandez, and Xavier Palacios-Pacheco. 2018. Big data, the next step in the evolution of educational data analysis. Advances in Intelligent Systems and Computing 721: 138–47. Available online: https://www.academia.edu/download/60552546/SPRINGERLIBRO_pag._1094_Ecuador_Miguel_Orosa-comprimido20190910-50947-3np0nk.pdf#page=160 (accessed on 29 November 2019).
- Wallet, Matthew A., and Stanley E. Fawcett. 2013. Data science, predictive analytics, and big data: A revolution that will transform supply chain design and management. Journal of Business Logistics 34: 77–84. [Google Scholar] [CrossRef]
- Williamson, Ben. 2016. Digital education governance: data visualization, predictive analytics, and ‘real-time’ policy instruments. Journal of Education Policy 31: 123–41. [Google Scholar] [CrossRef]
- Williamson, Ben. 2017. Big Data in Education: The Digital Future of Learning, Policy and Practice. London: Sage. ISBN 9781473948006. [Google Scholar]
- Zablith, Fouad. 2015. Interconnecting and enriching higher education programs using linked data. Paper presented at the 24th International Conference on World Wide Web, Florence, Italy, May 18; pp. 711–16. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | ||||
|---|---|---|---|---|
| F1 (A+) | F2 (C−) | F3 (E−) | Uniqueness | |
| Promote educational quality in general (FOR_10) | 0.823 | 0.306 | ||
| Helps prevent school failure (FOR_11) | 0.716 | 0.483 | ||
| Personalize Education (FOR_3) | 0.696 | 0.505 | ||
| Better meet the needs of students (FOR_1) | 0.696 | 0.458 | ||
| Improve the organization of schools (FOR_6) | 0.675 | 0.524 | ||
| Produce educational resources adapted to students (FOR_8) | 0.667 | 0.530 | ||
| Improve academic results (FOR_2) | 0.622 | 0.595 | ||
| Improve teacher selection (FOR_7) | 0.605 | 0.625 | ||
| Improve employability (FOR_4) | 0.597 | 0.636 | ||
| It gives me hope (MOOD_2) | 0.592 | 0.542 | ||
| It makes me proud (MOOD_3) | 0.510 | 0.670 | ||
| The theme amuses me (MOOD_1) | 0.483 | 0.748 | ||
| Facilitate decision-making at the political level (FOR_9) | 0.463 | 0.772 | ||
| It brings me relief (MOOD_8) | 0.425 | 0.730 | ||
| Avoid plagiarism (FOR_5) | 0.843 | |||
| Control of the educational system by the company (NEGATIVE_10) | 0.812 | 0.334 | ||
| Control of the education system by governments (NEGATIVE_9) | 0.785 | 0.366 | ||
| Produce educational resources adapted to students (NEGATIVE_8) | 0.781 | 0.389 | ||
| Increase in power of politicians (NEGATIVE_7) | 0.713 | 0.472 | ||
| Loss of privacy of students (NEGATIVE_1) | 0.655 | 0.567 | ||
| Increased power of center managers (NEGATIVE_6) | 0.607 | 0.614 | ||
| Computer attacks (NEGATIVE_4) | 0.579 | 0.647 | ||
| Loss of the school’s own socialization (NEGATIVE_3) | 0.535 | 0.669 | ||
| Loss of teacher privacy (NEGATIVE_2) | 0.510 | 0.729 | ||
| Loss of teacher functions (NEGATIVE_5) | 0.503 | 0.717 | ||
| I feel ashamed (MOOD_6) | 0.903 | 0.174 | ||
| I feel guilty (MOOD_7) | 0.863 | 0.251 | ||
| I feel powerless (MOOD_9) | 0.722 | 0.451 | ||
| It makes me feel angry (MOOD_4) | 0.669 | 0.416 | ||
| It causes me anxiety (MOOD_5) | 0.660 | 0.488 | ||
| It bores me (MOOD_10) | 0.506 | 0.707 | ||
| Variance explained | 18.3% | 15.6% | 11.5% | 45.3% |
| F1 | F2 | F3 | USING | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | Spearman’s rho | - | |||||||
| p-value | - | ||||||||
| F2 | Spearman’s rho | −0.084 | - | ||||||
| p-value | 0.172 | - | |||||||
| F3 | Spearman’s rho | −0.239 | *** | 0.316 | *** | - | |||
| p-value | < 0.001 | <0.001 | - | ||||||
| USING | Spearman’s rho | 0.535 | *** | −0.190 | ** | −0.317 | *** | - | |
| p-value | < 0.001 | 0.002 | <0.001 | - | |||||
| Model Coefficients—USING | ||||
|---|---|---|---|---|
| Predictor | Estimate | SE | Wald | p |
| F1 | 2.074 | 0.222 | 87.043 | <0.001 |
| F2 | −0.398 | 0.165 | 5.832 | 0.016 |
| F3 | −0.465 | 0.143 | 10.588 | <0.001 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matas-Terrón, A.; Leiva-Olivencia, J.J.; Negro-Martínez, C. Tendency to Use Big Data in Education Based on Its Opportunities According to Andalusian Education Students. Soc. Sci. 2020, 9, 164. https://doi.org/10.3390/socsci9090164
Matas-Terrón A, Leiva-Olivencia JJ, Negro-Martínez C. Tendency to Use Big Data in Education Based on Its Opportunities According to Andalusian Education Students. Social Sciences. 2020; 9(9):164. https://doi.org/10.3390/socsci9090164
Chicago/Turabian StyleMatas-Terrón, Antonio, Juan José Leiva-Olivencia, and Cristina Negro-Martínez. 2020. "Tendency to Use Big Data in Education Based on Its Opportunities According to Andalusian Education Students" Social Sciences 9, no. 9: 164. https://doi.org/10.3390/socsci9090164
APA StyleMatas-Terrón, A., Leiva-Olivencia, J. J., & Negro-Martínez, C. (2020). Tendency to Use Big Data in Education Based on Its Opportunities According to Andalusian Education Students. Social Sciences, 9(9), 164. https://doi.org/10.3390/socsci9090164