1. Introduction
In an era of marked concern over ideological and partisan polarization in the United States and other Western democracies, an increasing volume of research in political psychology investigates whether the differences between the political left and right reflect deep-seated predispositions, emotion-laden impulses, or might even have roots in innate characteristics. Probing below the level of issue opinions, political scientists and psychologists have argued that relatively intuitive or near-automatic responses often emerge in individuals as they react to various political contexts or stimuli. Further, these scholars maintain, there are clear and systematic differences in the ways that conservatives and liberals tend to respond to certain situations, reflecting a fundamental left/right distinction in political cognition (
Jost et al. 2003;
Amodio et al. 2007;
Graham et al. 2009;
Carraro et al. 2011;
Hibbing et al. 2014).
Thus far, the vast majority of research in this vein has examined left/right differences among mass publics, often using convenience samples of students or online questionnaire respondents. In applying this research to actual political systems, an important question is whether elite political actors—politicians themselves—exhibit left/right differences in intuitions and behaviors that are similar to those among the general public. Unfortunately, researchers are constrained in their ability to assess the political intuitions of elites, given the relatively scripted nature of politicians’ behavior and speech on the public stage, along with a lack of access to elites in their more private or unguarded moments (but for attempts, see
Neiman et al. 2016;
Lipsitz 2018;
Jones et al. 2018).
In order to take steps toward examining the political cognition of elites, one approach is to focus on their use of language in relatively unscripted occasions of political speech. In this paper, such an approach is followed in exploring whether there may be systematic partisan differences in the moral impulses that animate high-level political candidates. The study is motivated theoretically by two prominent frameworks from the field of political psychology, each of which highlights systematic differences in the ways that left-leaning and right-leaning individuals think and make judgments.
First, moral foundations theory (MFT) directs attention to left/right differences in the arousal of certain moral intuitions, also called moral foundations.
1 MFT studies of mass publics have found that the political views and judgments of left-leaning individuals (often called liberals or progressives) arise disproportionately from impulses regarding fairness and empathetic care. Right-leaning individuals (i.e., conservatives), meanwhile, are said to be considerably more motivated than are liberals by impulses relating to in-group loyalty, obedience to authorities seen as legitimate, and a concern with purity and avoidance of contamination (
Haidt 2007;
Haidt and Graham 2007;
Graham et al. 2009).
Second, the study draws upon the theory of conservatism as motivated social cognition (CMSC), which focuses on the underlying motivations that distinguish right- from left-leaning individuals’ thinking about politics. According to this framework, environmental stimuli evoking fear, threat, and uncertainty arouse certain existential and epistemic motivations, such as a concern with preventing losses or a desire for certainty. These motives, in turn, probabilistically influence individuals’ attraction to politically conservative beliefs, namely resistance to change and endorsement of status-quo hierarchies (
Jost et al. 2003). Specifically relevant for the current study, CMSC holds that there will be an association between an individual’s level of conservatism and their focus on elements in their environment that may be perceived as threatening, frightening, or unpleasant (
Janoff-Bulman 2009;
Jost et al. 2017).
While not necessarily “competing” theoretical accounts, MFT and CMSC place emphasis on different facets of political thinking (
Leeuwen and Park 2009). MFT focuses on left/right differences in the strength of specific moral intuitions. CMSC, on the other hand, highlights a broad negative/positive dimension, in which conservatives pay greater attention than liberals to negative stimuli. Both accounts are considered in the current study, exploring the manner in which political elites employ positive and negative moral concepts. Automated content analysis is applied to the U.S. presidential primary debates held in late 2015 and early 2016, as Democratic and Republican candidates jockeyed for advantage in appealing to their same-party voters during the nominating contest. Primary debates are appropriate for analysis of intuitive thinking (or fast thinking, see
Kahneman 2011) in that they represent a relatively unscripted occasion for political speech. They are also pressure-packed, suggesting that candidates operate under conditions of significant cognitive load. To examine verbal use of moral foundations, more than 800 segments of candidate speech are examined, each representing an extended response or statement during a debate. The data are drawn from five Democratic and five Republican debates that were closely matched in timing.
The study finds that some partisan differences are evident in the use of words associated with certain moral foundations, particularly after controlling for the issue domain under discussion. However, some of these differences are not in the direction anticipated by MFT. In addition, by distinguishing between words that describe positive and negative aspects of each moral foundation, the study finds clearer support for CMSC’s contention that conservatives tend to focus on negative elements. In the debates, the experienced Republican presidential candidates were more likely than their Democratic counterparts to use words describing the violation of moral concepts.
Not all of the Republican candidates were longtime politicians or establishment conservatives, however. A secondary research question in this paper asks whether the novice candidate Donald Trump, given his populist, anti-establishment posture, used a vocabulary with a distinctive moral palette. The results show differences between Trump and his fellow Republican candidates, with Trump most notable for his low overall use of words associated with moral foundations. This study, in combination with the relatively few others of its type (
Motyl 2012;
Clifford and Jerit 2013;
Sagi and Dehghani 2014;
Neiman et al. 2016;
Lipsitz 2018), should help scholars explore both the potential and the pitfalls of using automated text analysis to provide indications of left/right differences in cognition among political elites.
2. Moral Foundations, Motivated Cognition, and Ideological Differences
The notion that partisan or ideological differences among individuals rest in part on psychological affinities or identity-based motivations is an idea with a long history (see, among many others,
Converse 1964;
Pratto et al. 1994;
Green et al. 2004;
Mason 2018). While a rationalist approach to political behavior suggests that people first decide on their issue positions or ideological worldview and then choose a party affiliation that comports with those views, the intuitionist perspective suggests that partisan affiliations reflect
feeling as much as reasoning. Some scholars of biopolitics even argue that there are innate characteristics that tend to predispose individuals toward liberalism and conservatism (
Hibbing et al. 2014). Other social and political psychologists, meanwhile, point toward personality traits and deep-seated core values as individual differences that may underlie ideological or partisan differences (e.g.,
Block and Block 2006;
Carney et al. 2008;
Gerber et al. 2010).
Drawing upon social psychology, cultural anthropology, and evolutionary theories, moral foundations theory (MFT) is one leading attempt to provide a systematic account of the deep-seated basis of ideological differences (
Haidt 2007;
Haidt 2012). MFT maintains that individuals worldwide draw upon five clusters of moral intuitions, which are akin to emotional responses. Its theorists suggest that each of these moral impulses is present in all societies, to varying degrees, and perhaps in all humans. Each moral foundation, MFT posits, became imprinted as a cognitive tendency through a process of evolutionary selection. Behaviors consistent with the moral foundations likely were adaptive for individuals who lived in the foraging tribes that were the relevant social groups for the vast majority of human history. Accordingly, moral foundations are seen as being nearly instinctual and automatic, rather than a product of rational reasoning (
Haidt 2001;
Haidt 2012).
Care/Harm: A concern with nurturance and empathy, and a strong aversion for (or outrage regarding) situations evoking harm or cruelty;
Fairness/Cheating: A concern with just treatment and proportionality of rewards under a system of social rules
2;
Ingroup/Betrayal: Sometimes called Loyalty, a concern with primordial allegiance to one’s own family, clan, tribe, nation, or another relevant social group;
Authority/Subversion: A concern with adherence to traditional or legitimate authorities, whether they be sociopolitical hierarchies or doctrinal authorities (e.g., prescribed religious practices);
Purity/Degradation: Sometimes called Sanctity, a concern with avoiding contamination and elevating oneself above base, animalistic behaviors.
Although MFT posits that some adherence to these five foundations is near-universal in human societies, empirical MFT studies find that contemporary left/right distinctions in political ideology are associated with
differential arousal of these five foundations (
Haidt and Graham 2007;
Graham et al. 2009;
Graham et al. 2011). Liberals primarily are animated by impulses surrounding Care and Fairness, whereas conservatives tend to accord considerably more importance than liberals do to Ingroup, Authority, and Purity. These latter three, according to MFT, are
binding moral foundations that are inclined toward maintaining social order, traditional mores, and well-defined social roles and structures. By contrast, Care and Fairness are
individuating values that tend to prioritize the claims and nurturance needs of individuals (or social subgroups), sometimes against the claims of the more powerful (
Haidt 2012).
3In this view, then, differential emphases on the five moral foundations underlie many ideological differences between the left and right. In various survey- and lab-based studies deploying MFT, study participants who self-identify as liberal or left-leaning, regardless of their world region of origin, tend to indicate that Care and Fairness are by far the most relevant of the five foundations in determining whether a situation or behavior is morally wrong. Conservatives, by contrast, typically demonstrate a five-channel morality. That is, they are motivated by all five foundations, but give significantly more weight to Ingroup, Authority, and Purity than liberals do (
Haidt and Graham 2007;
Graham et al. 2009). The left/right differences regarding moral intuitions have been most apparent on social and cultural issues, rather than economic ones.
Nearly all published empirical work on judgments and behaviors relevant to moral foundations has focused on the mass public. However, to move beyond lab experiments, convenience samples, and public-opinion surveys to the realm of the political system itself necessitates establishing whether elite political actors demonstrate left/right differences in moral intuitions that are similar to lay respondents. This remains an open question. On one hand, politicians are political sophisticates, with more political and policy information available to them and more well-developed ideological worldviews than is typical among average citizens. This sophistication, as well as the strategic nature of much elite political action, might suggest that politicians are more likely to engage in effortful thinking about politics and policy, and are thus less likely to make gut-level political and policy judgments. On the other hand, politicians are no less human than other members of the public. They should not be immune to the habitual, emotion-laden cognition that appears to be common in political thinking (
Marcus et al. 2000;
Westen 2007;
Hetherington and Weiler 2009). Indeed, it is possible that the political convictions that induce people to seek elective office emerge from particularly strong, deep-seated motivations that are not always apparent at the level of conscious awareness.
One unobtrusive means of examining the moral intuitions of politicians is to analyze their use of words. To assist in analyzing moral rhetoric,
Graham et al. (
2009) developed the Moral Foundations Dictionary, a systematically derived list of words and word stems that pertain to the evocation of each of the five foundations. They initially applied this dictionary to examining sermons spoken in liberal and conservative religious denominations (
Graham et al. 2009). In subsequent work using the Moral Foundations Dictionary and focusing on political elites,
Neiman et al. (
2016) concluded that the rhetoric of politicians generally fails to follow the script anticipated by MFT.
Lipsitz (
2018), however, found, with some nuances, support for MFT in her analysis of the differences between Democratic and Republican campaign advertisements. Elsewhere,
Fulgoni et al. (
2016) found some relevant distinctions in moral word usage between liberal and conservative media outlets, while
Motyl (
2012) used the Moral Foundations Dictionary to describe the differences between Democratic and Republican party platforms across time.
When comparing political speech or text among liberals and conservatives, other theoretical perspectives emerging from political psychology might be operationalized, considering them alongside or in combination with MFT. One of the most influential frameworks regarding the fundamental left/right differences is the theory of conservatism as motivated social cognition (CMSC). CMSC views conservatives as highly attuned to situations or stimuli evoking threat (
Jost et al. 2003;
Jost et al. 2017). An oft-cited meta-analysis concludes that conservative beliefs are “adopted in part because they satisfy various psychological needs” and that “political conservatism [is] an ideological belief system that is significantly (but not completely) related to motivational concerns having to do with the psychological management of uncertainty and fear” (
Jost et al. 2003, p. 369). Similarly,
Janoff-Bulman (
2009, p. 120) holds that left/right ideological differences “reflect the fundamental psychological distinction between approach and avoidance motivation. Conservatism is avoidance based; it is focused on preventing negative outcomes (e.g., societal losses) …”
Consistent with CMSC, experimental evidence indicates that “negative information [in the form of unpleasant words or pictures] exerts a stronger automatic attention-grabbing power in the case of political conservatives, as compared to liberals” (
Carraro et al. 2011, p. 5).
Fessler et al. (
2017) found that conservatives were more likely than liberals to rate false statements about potential hazards as credible in comparison to false statements about potential benefits. Other research shows conservatives to be more sensitive to disgust than liberals, a difference that translates into more severe moral judgments among conservatives on a range of sociocultural issues (
Inbar et al. 2009;
Inbar et al. 2012;
Eskine et al. 2011;
Smith et al. 2011). This type of ideological difference, where aversive stimuli arouse conservatives more than liberals, has even been detected in individuals’ physiological processes. For example, skin conductance measures of electrodermal activity after subjects viewed unpleasant images led
Dodd et al. (
2012) to conclude that “the political left rolls with the good and the political right confronts the bad.”
One study relevant to both MFT and CMSC examined a corpus of political news coverage in partisan-leaning American media sources, and concluded that researchers studying moral foundations also should give attention to negativity bias among conservatives. Drawing upon the distinction between positive- and negative-valenced words in the Moral Foundations Dictionary,
Fulgoni et al. (
2016, p. 3735) found that “intriguingly, while liberals were concerned with both the vice and virtue aspects in their moral foundations, conservatives seemed to focus only on the vice aspect, denouncing the lack of loyalty and respect for authority.” Similarly, the empirical analysis below distinguishes between positively and negatively valenced moral-foundations rhetoric while examining liberal/conservative differences.
3. Candidates’ Primary-Debate Responses as a Data Source
Existing research using the Moral Foundations Dictionary focuses on political texts or speech that most likely were carefully crafted, for example, party platforms, political advertisements, or politicians’ official Twitter feeds. This scripted text may be unsuited for assessing a speaker’s intuitive or deep-seated psychological orientation toward particular moral foundations. Instead, the author makes a case for analyzing the candidates’ speech in primary debates. Presidential primary debates are used as occasions to analyze a politicians’ use of moral vocabulary for three main reasons. First, televised debates are consequential in the United States: They are prominent, highly visible political spectacles, often seen as important in helping the media and voters make sense of candidates’ views and character (
Fridkin et al. 2007). This is particularly the case for debates in the lower-information context of the primary, as opposed to the general-election, season (
McKinney and Warner 2013).
Second, primary debates are held separately for each party, with an anticipated audience consisting disproportionately of active and involved supporters of that party (the so-called party base). Thus, it is anticipated that primary debates represent an occasion when Democratic and Republican candidates are particularly distinguishable from one another and concerned with demonstrating their ideological bona fides. In general-election debates, by contrast, only one candidate represents each party, and each may strategically aim to court the median voter in the upcoming general election, potentially toning down their more ideological appeals and emotional rhetoric. Indeed,
Lipsitz (
2018) showed that television advertising by candidates in 2008 tended to be more moderate or restrained in its moral vocabulary in the general-election stage than during the primary phase.
Graham et al. (
2009), in the debut application of their Moral Foundations Dictionary, decided not to analyze the convention acceptance speeches of presidential candidates as they initially intended, finding those speeches to be “so full of policy proposals, and of moral appeals to the political center of the country, that extracting distinctive moral content was unfeasible …” (2009, p. 1038).
Third, in contrast to party platforms or political TV advertising, which by their nature tend to be highly polished and developed by groups of people, speech during the debates tends to be at least partially unscripted and of the candidates’ own making. The unplanned nature of such speech is advantageous, since both MFT and CMSC hold that psychological predispositions manifest themselves as quick, gut-level responses to situations. Intuitive responses are particularly likely when individuals are operating under significant stress, or cognitive load (
Kahneman 2011;
Bargh and Chartrand 1999). By contrast, effortful (reflective) cognition, such as that involved in crafting campaign advertising, is much more likely to invoke rationalist considerations. Thus, the fact that primary debates are somewhat freewheeling, unpredictable, pressure-filled, and fast-paced events may be expected to accentuate authentic emotional or intuitive speech patterns, eliciting the candidates’ “natural inclination” (
Jordan et al. 2019, p. 3)
Granted, it is well known that candidates rehearse for debates, probably practicing canned responses to likely questions. In addition, if politicians can predict the emotional responses their word choices are likely to evoke among the public, they might try to use moral vocabulary strategically. That being said, the relatively loose and informal format of many primary debates—including unanticipated questions, moderator interruptions seeking clarification, inter-candidate crosstalk, attacks, and counter-claims, and in some cases audience involvement in questioning—means that even very experienced candidates cannot be entirely sure where the conversation will go. In such a setting, the candidates seem more likely to speak from their heart (or their gut). By contrast, in the case of paid advertising or social media campaigns, messages are likely to have been strategically formulated for anticipated audiences, often by paid consultants. Even Twitter messages, where there is textual evidence that members of Congress display significant left/right value differences in language use (
Jones et al. 2018), often are produced by professional communications staff.
Primary debate responses therefore seem a reasonable venue for investigating partisan differences in the relatively unscripted use of words relating to the five moral foundations. The theoretical discussion and literature review in the prior section suggests two hypotheses:
Hypothesis 1. Based on MFT’s description of differences in the deep-seated moral intuitions of liberals and conservatives, Democratic candidates are expected to make heavier use than Republicans of wording associated with the Care/Harm and Fairness/Cheating foundations. Republican candidates, on the other hand, are expected to emphasize Ingroup/Betrayal, Authority/Subversion, and Purity/Degradation concepts to a greater degree than Democrats.
Hypothesis 2. Given CMSC’s evidence on the tendency of conservatives to focus on aversive stimuli and potentially harmful outcomes, Republican candidates are expected to emphasize the negative aspects of moral foundations in their rhetoric, focusing more than Democrats on violations of particular moral commitments.
4. Data
The focus in this paper is on the Democratic and Republican candidates during the 2015–2016 primary campaign, as primary debates across numerous U.S. states helped each party’s electorate evaluate candidates and winnow the field in advance of the 2016 national election. The Democratic Party had clear frontrunners from the early going, Hillary Clinton and Bernie Sanders. The other Democrats suspended their campaigns by the end of 2015, with the exception of Martin O’Malley, who withdrew on 1 February, 2016. By contrast, the Republican field, at one point including 17 announced candidates, was slower to shrink, ultimately being reduced in March 2016 to Ted Cruz, John Kasich, and Donald Trump.
Ten debates were selected—five for each party—with several goals in mind: To match relatively closely in time across the two parties, thereby controlling as best as possible for political context; to capture both early and later dynamics of the front-loaded nominating season; to feature all of the candidates who wound up being the most competitive within their party’s field; and to include a variety of formats and media sponsors (see
Table 1).
4 With the exception of the first debates for each party, which were a month apart in September and October 2015, each of the remaining debates are separated by no more than four days from a companion debate in the other party.
The full-text transcript of each debate (gathered from
Woolley and Peters 2018) was read and converted to a plain-text file, while correcting the small number of typographical errors and misspellings. These files were then separated into chunks, or segments of text. Each segment comprises a particular candidate’s response to a specific debate question or discussion topic. Any interruptions or extraneous text (e.g., follow-up questions from moderators, brief interjections from competing candidates, indications of audience applause, etc.) were deleted, such that the remaining words represent a candidate’s entire response on a particular topic, up to the point at which the debate moved on to a new issue or to a different candidate. In debates where candidates made opening and closing statements, these were included as individual segments, although such statements often referred to multiple topics or issues. The opening and closing statements, representing 10% of all segments, present a potentially interesting contrast to the remainder of the corpus, as candidates are probably more likely to script them in advance.
The 832 text segments resulting from this approach constitute the units of analysis for the study. Segments had a median length of 176 words, with a range from 19 to 864 words. Each segment was coded for the candidate speaking, the date of the debate, the media organization moderating the debate, and, importantly for considerations of which moral concerns might be evoked, the issue domain or policy topic under discussion.
For the substantive issue coding, each segment was assigned exclusively to one topic that was its predominant focus. In addition to opening/closing statements, there are several categories:
Security includes national security, terrorism, war and peace, military budget, intelligence, surveillance, foreign aid, sovereignty, and events in specific foreign countries, as well as domestic security topics relating to crime, policing, prisons, illegal drugs, and homeland security.
Economy/Budget refers to subjects such as economic management and trends, monetary policy, economic regulation (including environmental regulation), discussions of specific industries, international trade, and all topics relating primarily to fiscal policy, taxes and budgeting (except military spending).
Immigration includes topics related to legal or unauthorized immigration and refugees.
Social welfare includes discussions of poverty, inequality, education, and healthcare, as well as specific social insurance or entitlement programs, including veteran benefits.
Culture/Identity comprises issues concerning race relations, ethnicity, gender, and religion, as well as social regulations such as gun control, abortion, and same-sex marriage.
Campaign Dynamics/General Politics includes campaign strategy, views of and events pertaining to competing candidates and their records, campaign funding, polls, media coverage, interest-group politics, civic engagement, discussions of Congress, the Supreme Court, then-President Obama, and other U.S. political actors.
Self refers to segments focused on the candidate’s own experience, character, record, values, governing style, priorities, or temperament. Finally, a residual
Other (miscellaneous) category accounts for the balance of the segments.
5Table 2 provides some summary statistics (with the social welfare and culture/identity topics combined for display purposes), showing how often each candidate addressed the various topics. Overall, just over half of the segments (54%) were spoken by Republicans. Given the more rapid winnowing of the Democratic field, the dataset captures considerably more segments for Clinton and Sanders, reflecting the lack of other competitors dividing the time with them, than for any individual Republican speaker. The major candidates within each party dealt with most of the substantive topics to a comparable degree. However, the novelty of the Trump candidacy is apparent in that he was asked about himself (or in some cases, turned the topic of conversation to himself) approximately three times as often as the other candidates spoke about themselves (15% compared to 5%,
p < 0.001). In comparing the two parties as a whole, the only substantive categories addressed to a significantly different degree were social welfare and culture/identity issues, which received more attention in Democratic debates. The Republicans had significantly more opening and closing statements due to that party’s greater number of candidates.
The automated text-analysis program Recursive Inspection of Text Scanner (RIOT Scan) is designed to identify the frequency of words or word stems from pre-specified dictionaries in a particular segment of text (
Boyd 2016). In this case, the Moral Foundations Dictionary developed by
Graham et al. (
2009) is used, and the program identifies the percentage of words reflecting the five categories of Care, Fairness, Authority, Ingroup, and Purity.
Importantly, it also decomposes each of the five categories into words carrying a positive valence—identified in the Moral Foundations Dictionary as virtue words—and those carrying a negative valence—vice words.
Graham et al. (
2009, p. 1039) conceived of vice words as those expressing a violation of the foundation in question. For example, for the Care/Harm foundation, word stems such as
compassion* and
secur* are among the virtue words (representing Care), whereas
violen* and
abandon* are among the vice (i.e., Harm) words. The disaggregation of positive and negative words within each foundation is useful for judging the potential negativity bias of the Republican candidates (Hypothesis 2). A tendency of Republicans to focus more on vice words would be broadly consistent with the attention of conservatives to threat, highlighted by the CMSC perspective (
Jost et al. 2003).
In addition to tabulating words representing each moral foundation, the software provides a variety of additional statistics for each segment, including its length in words and the percentage of its words dealing with general morality. This latter category refers to words indicative of normative judgments (e.g., good, immoral*), but which do not invoke a specific moral foundation.
5. Exploring Differences in Moral Rhetoric
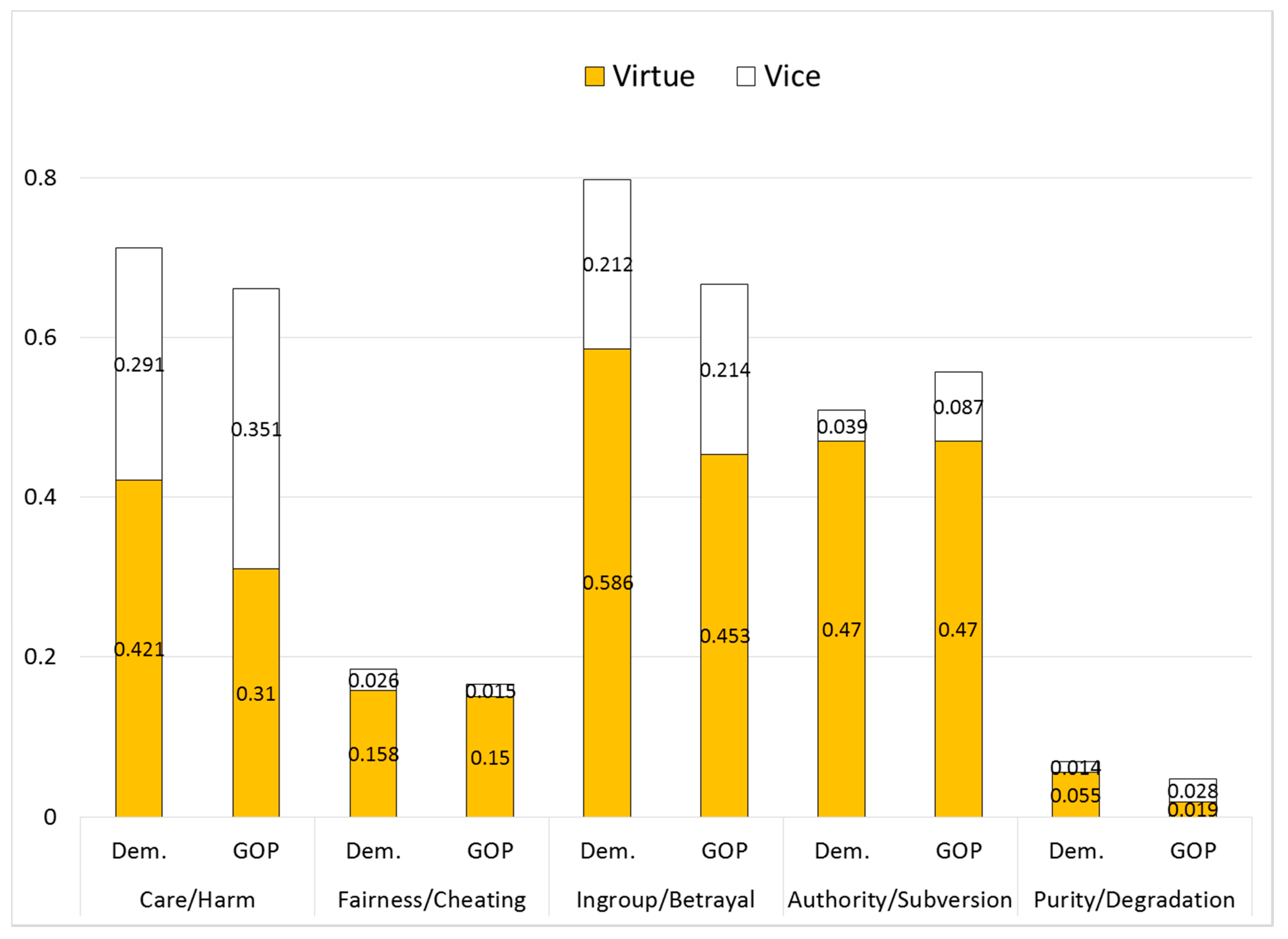
Several initial impressions are apparent from an exploration of descriptive statistics regarding the occurrence of words representing the five moral foundations (see
Figure 1). First, the vast majority of words used in a typical spoken response do not fall within any of the five foundations. None of the foundations represent even 1 percent of the average segment. However, these low averages obscure that fact that while many segments have zero words representing any particular foundation, some candidate statements use certain foundations in a much more pronounced way. As
Lipsitz (
2018, pp. 64–65) noted in her study of political ads, the Moral Foundations Dictionary contains only the tiniest fraction of words in the English language, so it is unrealistic to expect high numbers of morality words to appear in any given chunk of speech. Considering all candidates, 2.2% of the words in the mean segment represented any of the five foundations (similar to the percentage found in
Graham et al. 2009 and
Lipsitz 2018). This average percentage of moral-foundations words is slightly but not significantly higher among Democrats than Republicans (2.27% vs. 2.10%,
p = 0.11; all significance tests two-tailed).
Second, the five foundations appear with quite unequal frequency. The words relating to Ingroup, Care, and Authority are used much more than Fairness or Purity words. As in other studies of political text or speech (
Kraft 2018;
Lipsitz 2018;
Clifford and Jerit 2013), Purity/Degradation words appear very infrequently, constituting something of a rare event. Since mentions of Purity words are minimal, this paper refrains from drawing any conclusions about that moral foundation, as explained in greater detail below. Theoretically speaking, this is unfortunate, since it was the Purity-related emotion of disgust and its opposite awe (elevation) that initially inspired much of Haidt’s research leading to MFT (
Haidt 2012). Realistically, however (and despite Donald Trump’s seemingly frequent labeling of unwelcome things and behaviors as “disgusting”), there seems to be relatively little use of Purity words in contemporary political talk.
6Third, examining the relative height of the bars in
Figure 1, the partisan differences in the usage of the five foundations do not comport very strongly with MFT’s expectations. Although, as Hypothesis 1 anticipates, Democratic candidates used a higher percentage of Care and Fairness terminology in their statements, and Republicans used more Authority words, these differences are slight and none is statistically significant, according to t-tests for differences in the means. The one set of partisan differences that is significant—for Ingroup—is in the unanticipated direction, with Democrats, on average, using more Ingroup words than Republicans (
p = 0.04). Purity words, as noted, occur very infrequently among either party.
Fourth, however, additional partisan differences appear if positive-valence (virtue) words are distinguished from negative-valence (vice) words within each foundation. As the top part of each bar in
Figure 1 shows, the Republicans used the vice dimension of four of the five foundations more frequently than Democrats. Moreover, in four of five cases Democrats used more virtue words (with a tie in the fifth, Authority). If the total usage of virtue words and of vice words is summed across all five moral foundations, the partisan differences are significant for the combined total for virtue (Democrats 1.69%, Republicans 1.40%,
p = 0.001), while differences appear but do not reach standard levels of statistical significance for vice (Democrats 0.58%, Republicans 0.69%,
p = 0.11).
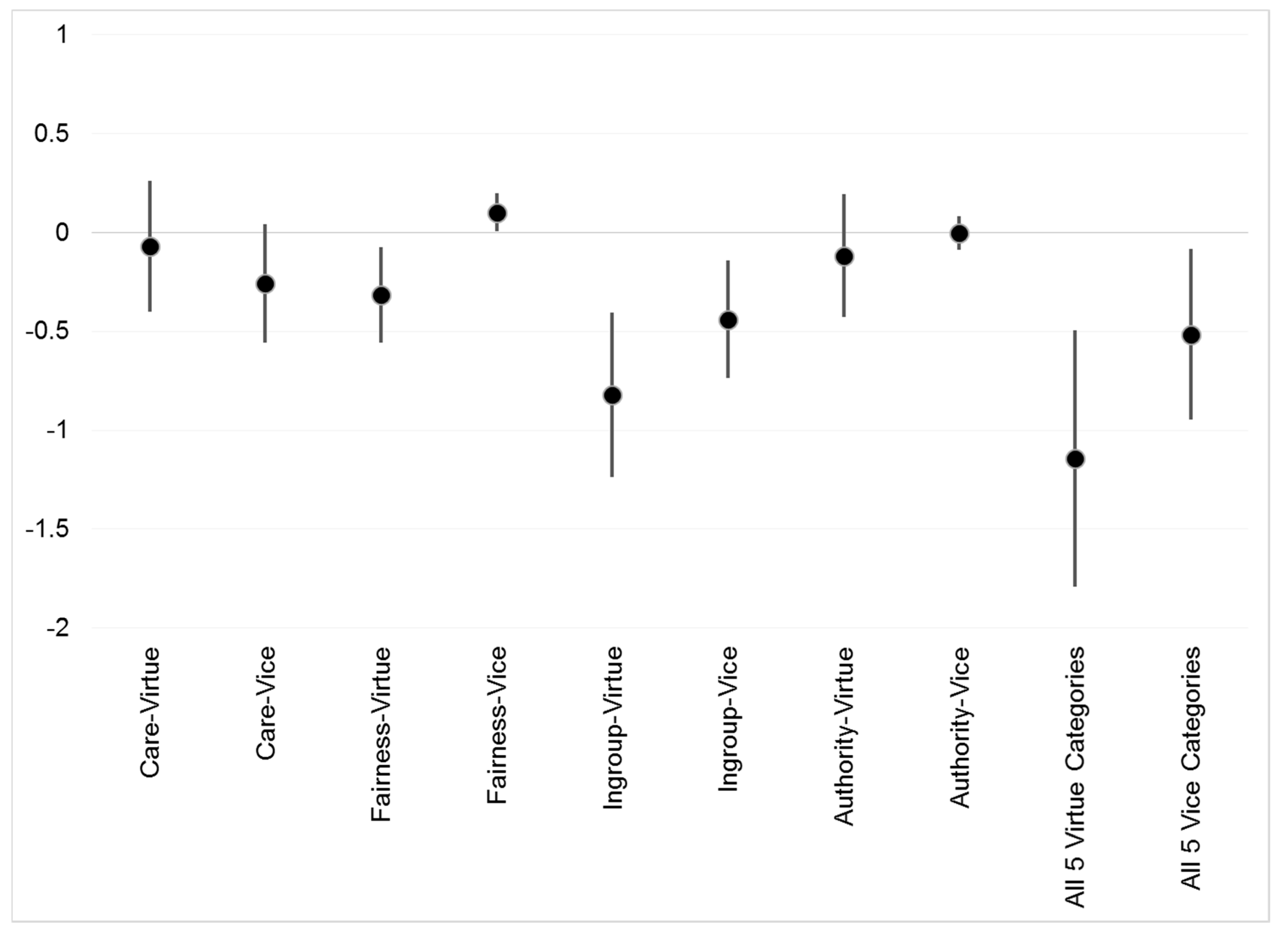
With the five foundations disaggregated between virtue and vice, the partisan differences are statistically significant for four types of words: Care-Virtue (Democrats higher, p = 0.02); Ingroup-Virtue (Democrats higher, p = 0.01), Purity-Virtue (Democrats higher, p = 0.003); and Authority-Vice (Republicans higher, p = 0.04). This pattern provides some initial support for Hypothesis 2 (conservatives’ negativity bias), but appears unsupportive of Hypothesis 1 concerning differential party appeal to moral foundations. Of the four significant differences, only two (Care-Virtue and Authority-Vice) follow the expectation that the liberal party will emphasize the individuating moral foundations and the conservative party will embrace the binding foundations.
The significant Democratic advantage in the use of Ingroup-Virtue words, surprising given the expectations of MFT, merits closer examination. To investigate how candidates of each party used these loyalty-oriented words, the text of every segment containing at least two such words was gathered, yielding a similar number of segments for each party (106 Republican, 100 Democratic).
Figure 2 shows the most frequently used Ingroup-Virtue words in these segments by party. The Republican candidates, consistent with a nationalistic orientation, were more inclined to mention the United States (
united is an Ingroup word) as well as the word
nation. Democrats, on the other hand, were more likely to talk about
community or
communities and to use the adverb
together. In general, many Ingroup-Virtue words in the Moral Foundation Dictionary seem quite consistent with a social and political philosophy that stresses communitarian or mutualistic obligations (e.g.,
collective and
solidarity, although those words were not much used in the debates). These sentiments are reflected in the proverb, “It takes a village to raise a child,” which formed the basis for the title of a book by then-First Lady
Hillary Clinton (
1996), and in her 2016 campaign slogan “Stronger Together.”
Graham et al. (
2009) found a similarly unexpected difference with respect to Ingroup words in their analysis of the sermons of liberal and conservative churches. In that case, the liberal denomination (Unitarian Universalists) made more Ingroup references than the conservative denomination (Southern Baptists). By examining the sermons’ Ingroup words in context, the authors provided an explanation, concluding “liberals were much more likely than conservatives to use these words in order to
reject the foundational concerns of ingroup loyalty and group solidarity” (
Graham et al. 2009, p. 1039, emph. added). The interpretation in the current study is different, however, namely, that the Democratic candidates spoke
affirmatively about certain positive-valence Ingroup concepts (such as community) more than the Republicans did.
Whereas an examination of how candidates used Ingroup-Virtue words in context helps illuminate the Democrats’ heavier use, the same cannot be said for the use of Purity-Virtue words, in which Democrats also were higher, despite MFT’s expectations. Although the Purity-Virtue list includes words that bring to mind precepts of religious and social conservatism (
holy,
sacred*,
virtuous), it also includes words with more secular applications that may resonate with left-leaning environmentalists, social-justice advocates, and reformers (e.g.,
innocent,
pure*,
integrity). The truth of the matter, however, is that Purity-Virtue words saw such scant use by either party that there is too little information to draw conclusions. Even less in evidence are Purity-Vice words. Given the rareness of these occurrences, the multivariate analysis below omits any separate examination of Purity words.
7If the segments in the dataset are sorted by issue domain, it is apparent that the topic of discussion has some relationship to the amount of moral foundations rhetoric (see
Table 3, top panel). For instance, immigration emerges as a topic provoking a somewhat more moralistic vocabulary, not only in the case of the Ingroup foundation (for which one of the vice word stems is
immigra*), but also for the Authority foundation and for general morality words. Social welfare topics tended to evoke Care rhetoric while making sparse use of Ingroup, Authority, and (surprisingly) Fairness words. Finally, compared to other substantive topics, segments on economy/budget topics tended to feature fewer Care, Ingroup, and Authority words.
Other than the culture/identity segments, the candidates’ opening and closing statements, likely the least spontaneous responses in a typical debate, were the topic with the heaviest inclusion of Fairness words (0.31%), nearly double the percentage as in segments on other topics (0.16%;
p = 0.001). Given the opportunity afforded by opening and closing statements to choose one’s own topics, the candidates may have made special effort to address Fairness, a moral foundation that otherwise was evidently not very much invoked in these debates.
8Turning to the usage of moral rhetoric by individual candidates (bottom panel of
Table 3), perhaps most distinctive are the low levels of moral-foundations language used by Donald Trump. Among the candidates with at least three dozen segments in the dataset (who might be considered major candidates), Trump showed the absolute lowest use of three of the five moral foundations: Care, Fairness, and Ingroup. Using t-tests to compare Trump to all 15 of the non-Trump candidates, Trump was significantly lower than the rest for Care and Ingroup, and nearly so for Fairness (
p = 0.06). If all five sets of concepts are combined, Trump used moral-foundations language approximately one-third less often than the other candidates (Trump mean = 1.51%, mean of other candidates combined = 2.27%;
p < 0.001). Further investigation indicates that Trump’s uniqueness primarily stemmed from his low use of virtue words (1.00% Trump versus 1.61% others,
p < 0.001) rather than from differences in vice rhetoric (0.51% vs. 0.66%, n.s.).
9 Media coverage during the campaign sometimes portrayed Trump as being prone to drawing pessimistic or even dystopian conclusions about the contemporary United States, notably in his acceptance speech at the Republican National Convention (
Meyerson 2016). His tendency to use very few positive-valence words about the five moral foundations offers some tentative support for these anecdotal impressions.
Although Trump apparently eschewed rhetoric evoking the moral foundations, he was not averse to using words with more general moral connotations. Of the major candidates, Trump was the highest in percentage use of general morality terminology, words like
bad,
correct, or
offensive that do not directly derive from any of the five foundations. These words constituted 0.53% of the average Trump segment, compared to an average of 0.35% in all other candidates’ segments combined (
p = 0.01). This pattern may arise in part as a function of Trump’s tendency to use superlatives when speaking, but also from his predilection for casting judgment, whether in the form of bitter aspersions of his critics or high praise of his supporters. Other analyses of text corpora have similarly found Trump to be an outlier in his political speech. For example, examining a wide range of texts,
Jordan and Pennebaker (
2017) found that Trump displayed far lower use of analytic language than the norm among major-party presidential candidates in the most recent five election cycles.
Oliver and Rahn (
2016) argued that Trump’s style of speech stood out as more populist than other 2016 candidates in its brief sentences, simple vocabulary, anti-elitism, and appeals to common sense.
7. Concluding Discussion
7.1. Reconsidering Moral Foundations Theory in Conjunction with Motivated Social Cognition
Are there left/right differences in moral intuitions among politicians, as MFT reveals there to be among members of the mass public? Judging by how often candidates of the two major U.S. parties use morally tinged words in the heat of presidential primary debates, the answer appears to be a partial “yes.” However, not all of the partisan differences reflect the expectations of MFT. Instead, the results suggest that when comparing the moral vocabulary of left and right, researchers should give as much (if not more) attention to the question of negative versus positive valence as to the five moral foundations emphasized by MFT.
MFT suggests that the moral impulses motivating liberals primarily reflect the individuating Care and Fairness foundations. By contrast, the theory anticipates that the binding moral foundations (Ingroup, Authority, and Purity) mainly are the province of conservatives. The data analyzed here, however, suggest a more nuanced perspective is in order. First, the candidates’ usage of Purity terminology is minimal (consistent with the scant occurrence of Purity words in other studies using the Moral Foundations Dictionary). Thus, the multivariate analysis did not separately examine the use of Purity vocabulary. Fairness words, though more common than Purity language, also were surprisingly infrequent, as was the case in the political ads analyzed by
Lipsitz (
2018).
Second and more importantly, the results suggest important distinctions between positive- and negative-valence words representing the various moral impulses. Once controls are introduced for the topic under discussion, the Republican primary candidates (setting aside the idiosyncratic Trump) used more Authority-Vice words than Democrats, consistent with theoretical expectations. Further consistent with MFT, the Democrats were heavier users of Fairness-Vice concepts (i.e., a concern with cheating). Fairness-Vice words (e.g., unfair, injustice, discrimination, exclusion) fit quite well with liberal Democratic ideological orientations.
So far, so good for MFT. However, the non-Trump Republicans used more Care-Vice (i.e., Harm) words than Democrats did, while the Democrats exceeded the Republicans in use of Ingroup-Virtue words. These patterns contradict MFT’s expectation that the left focuses heavily on Care, and the right on Ingroup concepts. In short, reconsideration may be in order regarding the expected relationship of political ideology to the Care/Harm and Ingroup/Betrayal impulses, at least in the case of spoken communication by the 2016 U.S. presidential candidates. The Ingroup-Virtue terminology, in particular, seems quite consistent with solidarity-oriented or communitarian tenets of the political left.
13 It is possible that this tendency of Democratic candidates to emphasize Ingroup-Virtue is a characteristic specific to political elites, who tend to have a considerably more well-developed and coherently structured political ideology than lay citizens do (
Kinder and Kalmoe 2017). The Ingroup foundation merits further research regarding possible elite/mass differences, especially since MFT has drawn its evidence predominantly from the mass public.
With regard to Republican candidates’ greater emphasis than Democrats on the vocabulary of Harm, these findings suggest greater support for CMSC’s perspective (highlighting the tendency of conservatives to be attuned to threat and aversive stimuli) than for MFT (which anticipates liberals to focus disproportionately on violations of care and empathy). Consistent with the conservatives’ focus on the negative, when words from all five moral foundations were summed, there was a clear tendency for the experienced Republican candidates to use vice words more often than their Democratic counterparts. The current study hints that, at least among these political elites, the negativity bias of conservatives may override their tendency (if any) to focus on binding moral foundations.
7.2. The Trump Difference
Additionally, there is the matter of the ultimate Republican nominee, Donald Trump. Trump repeatedly presented himself during the nominating campaign as sui generis, a figure very different from the existing political establishment of either party. However, was he a different moral type of candidate? In the primary debates examined here, Trump was indeed distinctive: He deviated from his GOP competitors (and from the Democrats) in making the least use overall of moral-foundations vocabulary. The one exception, Trump’s high usage of words related to Fairness-Vice (i.e., cheating), rendered him more similar to the Democrats than to his fellow Republicans.
At the same time, however, Trump was the highest of any of the major candidates in his use of generalized morality (i.e., good/bad) words that lack moral-foundations content. Trump also was the most likely of the major candidates to make himself the subject of discussion, though some of that is likely a function of the type of debate questions asked of such a unique figure.
14 These results provide suggestive quantitative support for the notion that Trump is a very different type of politician. By the yardstick of the admittedly limited measures used here, Trump spoke in significantly different ways than the more traditional conservative Republicans who ran against him. Perhaps surprisingly, he deemphasized the vice aspects as well as virtue aspects of various moral foundations. Nor was he similar to the Democratic candidates (a party he had identified with in the past). Future research could examine additional text corpuses (e.g., Twitter posts) to see whether they, too, show Trump using distinctive moral vocabularies in comparison to other politicians (see also
Jordan and Pennebaker 2017;
Oliver and Rahn 2016).
7.3. Limitations of the Study and Considerations for Future Research
The current analysis is admittedly limited in scope. It draws upon 10 debates involving 16 candidates in a single representative democracy, arguably an usual one (
Taylor et al. 2014). Equally important to note, it covers only a six-month period during one recent election campaign involving two political parties. Compared to many other democracies, U.S. parties often are viewed as ideologically broad, thus possibly presenting a more difficult empirical test for finding significant left/right differences than in some systems. However, in recent decades American parties have grown significantly more polarized and their voters more well-sorted ideologically (
Schier and Eberly 2016). Rather than being the last word on the political intuitions of elites, this study’s intention was to lay groundwork and suggest a general approach to measuring left/right differences in unscripted political speech that might be applied to study candidates in other years, and perhaps in other nations. Admittedly, there are few if any other democracies with the sort of wide-open nominating competition seen in American primary elections, although other venues exist in these countries for contesting intra-party leadership battles and for engaging in unscripted political speech. While the author makes no broad claims about the universality of the patterns found, this case study of a single country in a single election year offers a level of detail and context that may be less easily attainable in studies aggregating data from many years or countries.
Nevertheless, to validate the current results regarding MFT and CMSC and make broader claims for generalizability, future studies could widen the lens to other time periods and other types of states and election systems. Within the United States, an examination of primary debates during other presidential election years in which no incumbent candidate was running (e.g., 1988, 2000, 2008) would prove useful. (Election years in which presidents run for reelection generally lack primary debates for the president’s party, since the incumbent is the presumptive nominee.) In particular, including variation in which party held the White House would help to establish whether Republicans’ greater negativity in 2016 might have been time-bound, due to an inclination to criticize conditions under then-President Obama. More generally, the different sets of issues and different perceived threats on the political agenda in other election years would provide additional variation in the electoral context.
The current study can make no claims about how partisan elites’ word choice ultimately influences public evaluations of the parties or candidates. Instead, the proximate goal was to assess the possibility of using debate speech to render some basic assessments of how politicians think about moral concepts and categories, since nearly all MFT and CMSC research to date has focused on mass publics. Ultimately, it may be possible to compare elites’ unscripted talk about political issues to citizens’ conceptions, with the latter perhaps measured through speech at public meetings, in deliberative polls, or in professionally facilitated focus groups. However, much more challenging, and beyond the scope of the types of evidence investigated here, would be the possibility of finding ways to make micro/macro linkages between the moral self-presentation of candidates, the changing opinions of various categories of the mass public, and ultimately, voting behavior and election outcomes. If moral foundations matter politically to the public, then the manner in which political elites and the mass media frame their rhetoric morally may strongly shape the public’s judgments of candidates or of policy issues (
Clifford and Jerit 2013;
Kraft 2018). Indeed,
Lipsitz’s (
2018) findings suggest that political elites use moral appeals strategically in order to provoke voters’ emotions, at least in the context she examines, which is scripted campaign advertising.
A key finding of the current study involves the differences between the virtue and vice subcategories when considering how often candidates of each party draw upon particular moral foundations. Future research applying MFT, not only among political elites but also among the mass public, likewise should consider ways to overlay the negative/positive valence dimension on measures of adherence to the moral foundations (see also
Kraft 2018, p. 1032;
Leeuwen and Park 2009). In other words, wherever possible, researchers should separately consider people’s evaluations of behaviors that uphold, and behaviors that violate, each foundation.
Finally, a methodological consideration for future studies in this vein involves the question of whether to continue to rely upon automated content analysis. Many social scientists seek to avoid the fallibility of human judgment by automating the measurement of political communication where possible. The current analysis suggests some of the positive potential, but also pitfalls, of the Moral Foundations Dictionary in particular. Comparing a speaker’s words to a pre-prepared dictionary gives the aura of a more objective scientific enterprise, in comparison to interpretive analyses in which researchers engage with political speech post-hoc and attempt to intuit the speaker’s meanings. However, there likely is no avoiding the need for some subjective interpretation, especially to take into account the political context of the rhetoric in question. Machine learning techniques for analyzing text ultimately may overcome some of these limitations, but present their own set of interpretive challenges (
Jones et al. 2018, p. 430;
Langer et al. 2019). In the present analysis, a first pass at the data, looking only at the frequency of words from each of the moral foundations, suggested one, somewhat murky, set of conclusions. Disaggregating between the virtue and vice aspects of the foundations suggested different sorts of partisan and candidate differences. The tendency of the Democratic candidates to emphasize Ingroup-Virtue words, initially puzzling from the MFT perspective, made considerably more sense when considering the actual list of such words in the Moral Foundations Dictionary (e.g.,
together,
collective,
commun*), especially in the context of a race in which Democratic candidates tried to appeal to the party’s progressive base.
In short, although the Moral Foundations Dictionary is potentially a very useful tool, it should be deployed with care. It ought to be viewed as a starting point, not as a definitive scorecard, in assessing the types of deep-seated intuitions that individuals—including high-level politicians—draw upon when making political judgments.



{kind=link}
{kind=link}
{kind=link}
{kind=link}