
Introducing Twitter Daily Estimates of Residents and Non-Residents at the County Level




Abstract
1. Introduction
2. Related Work
2.1. Measuring Population Movements through Traditional Sources: Censuses, Registries, and Surveys
2.2. Digital Geospatial Shadow: An Opportunity
3. Materials and Methods
3.1. Case Study
3.2. Classification of Daily Residents and Non-Residents
- (1)
- For each day, for each county of the contiguous US, obtain a list of distinct (unique) users active in that county.
- (2)
- Retrieve all tweets available in our repository from each of the active users from the year of the study period. We used an entire year to eliminate the effect of seasonal variations had we chose a shorter timeframe.
- (3)
- Assign a distinctive code of the US county, or country if outside the US, from where each of the tweets was sent.
- (4)
- Compute the most repeated tweeting location for each user during the year of the study period.
- (5)
- Classify those whose most repeated tweeting location falls within the analyzed county as residents. If a user’s most repeated tweeting location is outside of the county, the program classifies this user as a non-resident. A third category, unknown, is reserved for those users whose most repeated tweeting location cannot be calculated (when having less than two tweets in the whole year, or more than one county as the most repeated tweeting location).
3.3. Validation
3.3.1. Internal Validation: Residency Assumption
3.3.2. External Validation of Final Estimates
4. Results
4.1. Internal Validation of Residency Assumption
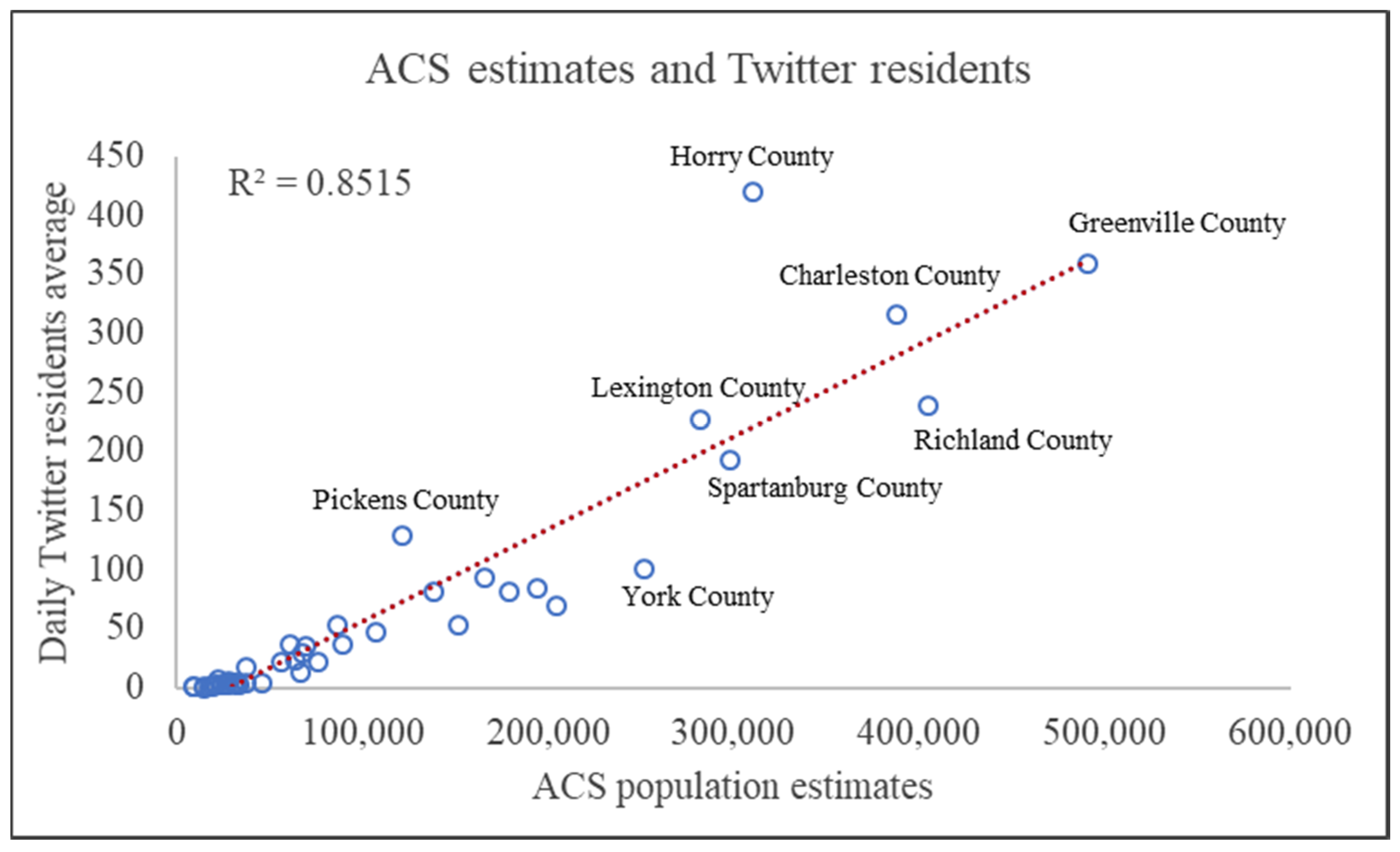
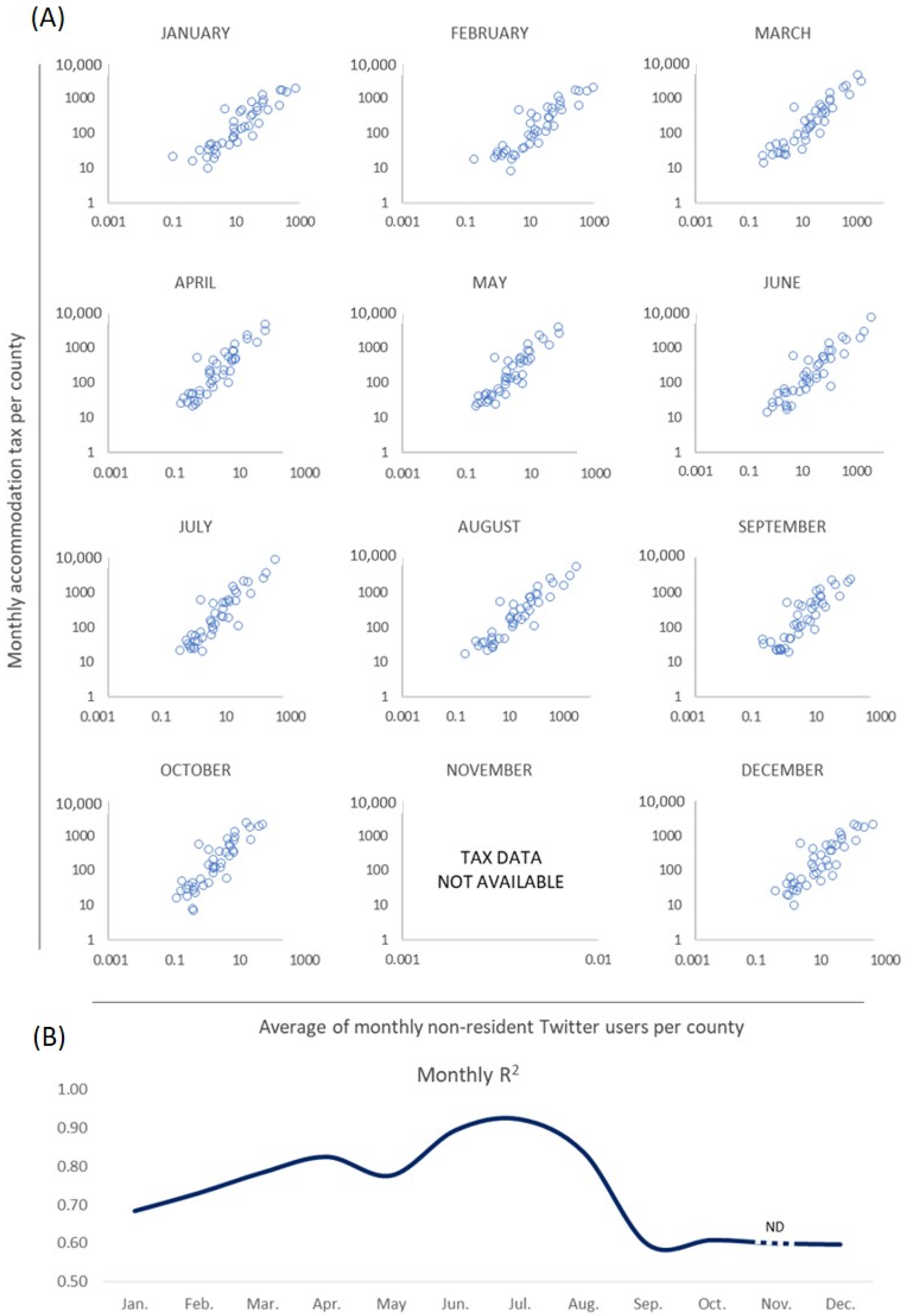
4.2. External Validation of Final Estimates
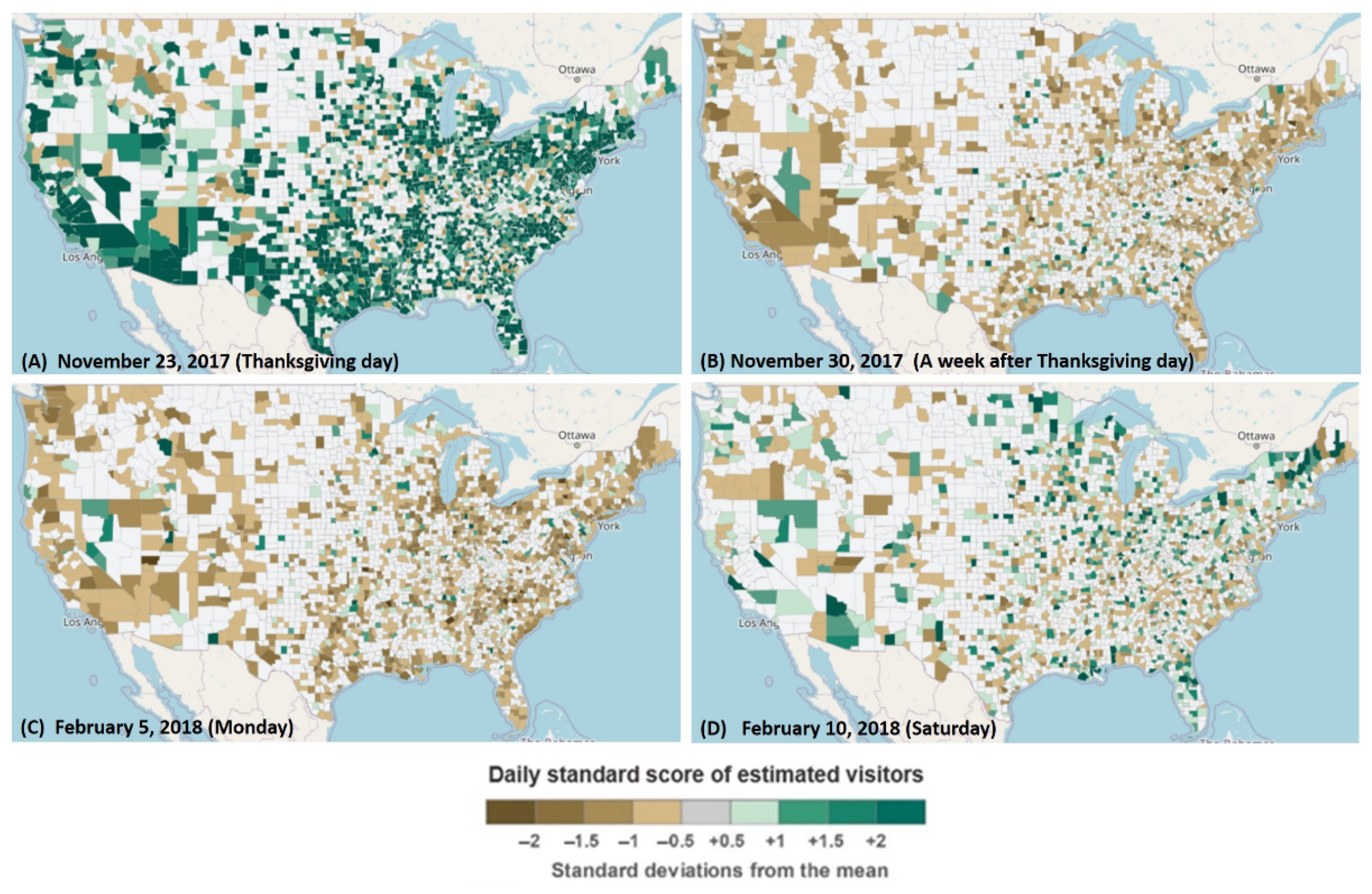
4.3. Case Study: Visitor Dynamics during the 2017 US Solar Eclipse
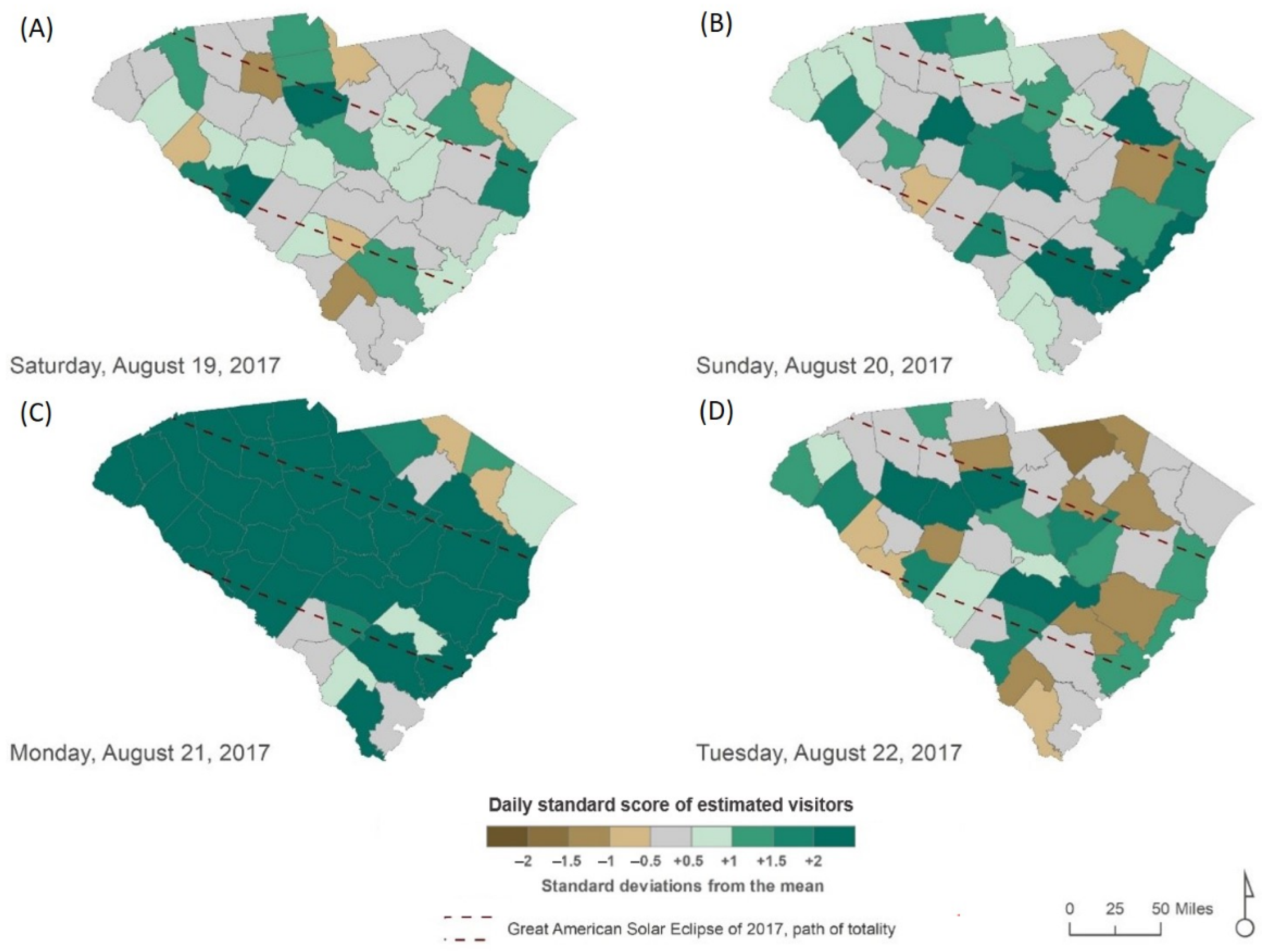
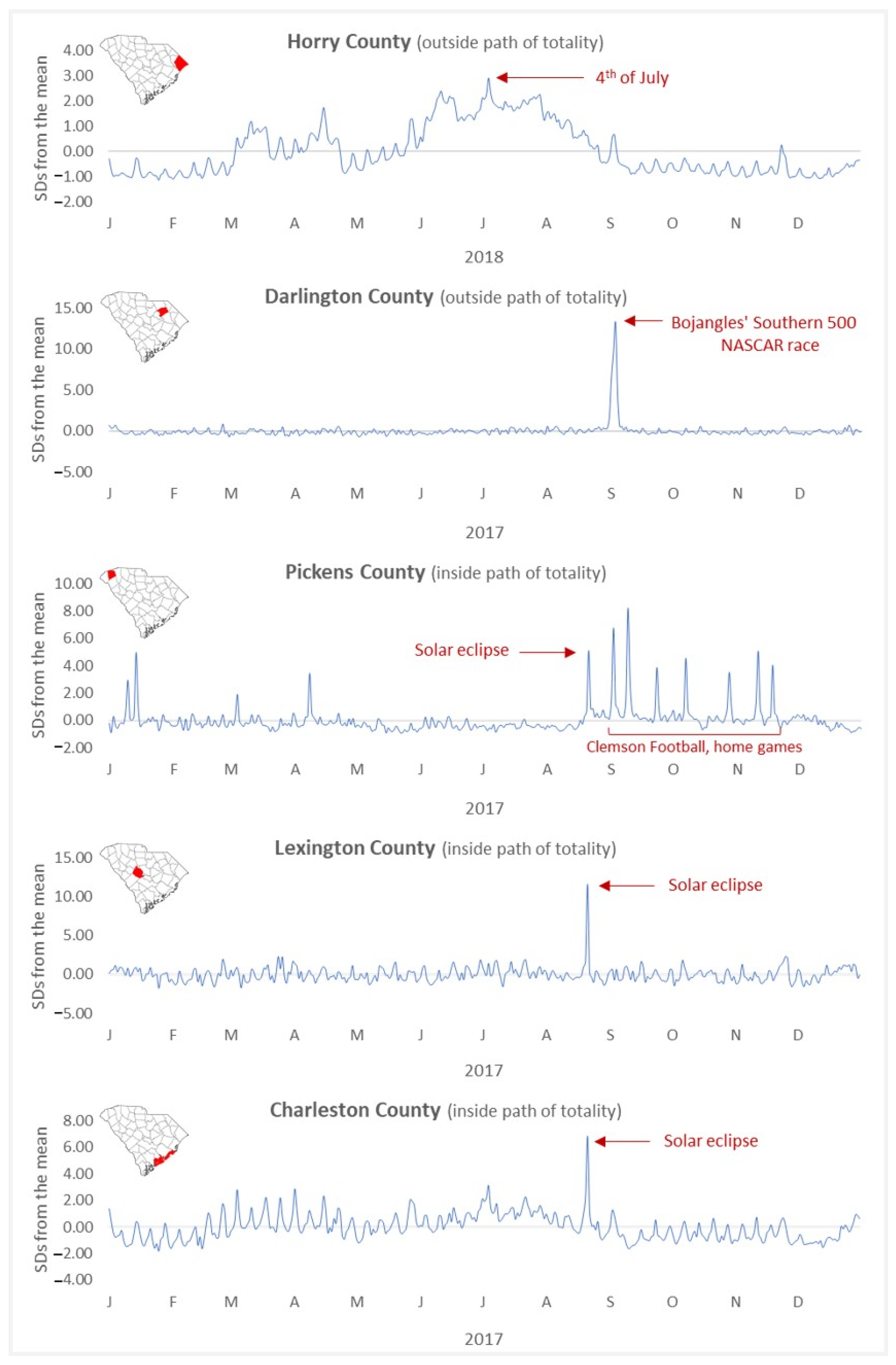
4.3.1. Visitor Dynamics in South Carolina
4.3.2. National Scale Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | http://gis.cas.sc.edu/GeoAnalytics/twittercensus.html, accessed on 13 June 2021. |
| 2 | https://www.youtube.com/watch?v=I7FEUpJ3KRw, accessed on 13 June 2021. |
References
- Alexander, Monica, Emilio Zagheni, and Kivan Polimis. 2019. The impact of Hurricane Maria on out-migration from Puerto Rico: Evidence from Facebook data. SocArXiv. [Google Scholar] [CrossRef]
- Alexander, Monica, Kivan Polimis, and Emilio Zagheni. 2020. Combining social media and survey data to nowcast migrant stocks in the United States. Population Research and Policy Review. [Google Scholar] [CrossRef]
- Amini, Alexander, Kevin Kung, Chaogui Kang, Stanislav Sobolevsky, and Carlo Ratti. 2014. The impact of social segregation on human mobility in developing and industrialized regions. EPJ Data Science 3: 1–20. [Google Scholar] [CrossRef]
- Barslund, Mikkel, and Matthias Busse. 2016. How Mobile Is Tech Talent? A Case Study of IT Professionals Based on Data from LinkedIn (CEPS Special Report, No. 140). Available online: https://ssrn.com/abstract=2859399 (accessed on 13 June 2021).
- Bell, Martin, Elin Charles-Edwards, Dorota Kupiszewska, Marek Kupiszewski, John Stillwell, and Yu Zhu. 2015. Internal migration data around the world: Assessing contemporary practice. Population, Space and Place 21: 1–17. [Google Scholar] [CrossRef]
- Bengtsson, Linus, Xin Lu, Anna Thorson, Richard Garfield, and Johan von Schreeb. 2011. Improved response to disasters and outbreaks by tracking population movements with mobile phone network data: A post-earthquake geospatial study in Haiti. PLoS Medicine 8: e1001083. [Google Scholar] [CrossRef]
- Billari, Francesco C., and Emilio Zagheni. 2017. Big Data and Population Processes: A Revolution? SocArXiv. [Google Scholar] [CrossRef]
- Bisanzio, Donal, Moritz U. Kraemer, Isaac I. Bogoch, Thomas Brewer, John S. Brownstein, and Richard Reithinger. 2020. Use of Twitter social media activity as a proxy for human mobility to predict the spatiotemporal spread of COVID-19 at global scale. Geospatial Health 15. [Google Scholar] [CrossRef]
- Bittermann, André, Veronika Batzdorfer, Sarah Marie Müller, and Holger Steinmetz. 2021. Mining Twitter to Detect Hotspots in Psychology. Zeitschrift für Psychologie 229: 3–14. [Google Scholar] [CrossRef]
- Blumenstock, Joshua. E. 2012. Inferring patterns of internal migration from mobile phone call records: Evidence from Rwanda. Information Technology for Development 18: 107–25. [Google Scholar] [CrossRef]
- Boyle, Rebecca. 2017. The Largest Mass Migration to See a Natural Event Is Coming. The Atlantic. Available online: https://www.theatlantic.com/science/archive/2017/08/the-greatest-mass-migration-in-american-history/535734/ (accessed on 13 June 2021).
- Burton, Scott H., Kesler W. Tanner, Christophe G. Giraud-Carrier, Joshua H. West, and Michael D. Barnes. 2012. “Right time, right place” health communication on Twitter: Value and accuracy of location information. Journal of Medical Internet Research 14. [Google Scholar] [CrossRef]
- Cesare, Nina, Hedwig Lee, Tyler McCormick, Emma Spiro, and Emilio Zagheni. 2018. Promises and pitfalls of using digital traces for demographic research. Demography 55: 1979–99. [Google Scholar] [CrossRef]
- Coleman, David. 2013. The twillight of the census. Population and Development Review 38: 334–51. [Google Scholar] [CrossRef]
- Colleoni, Matteo. 2016. A social science approach to the study of mobility: An introduction. In Understanding Mobilities for Designing Contemporary Cities. Edited by Paola Pucci and Matteo Colleoni. Cham: Springer, pp. 23–33. [Google Scholar] [CrossRef]
- Cresswell, Tim. 2011. Mobilities I: Catching up. Progress in Human Geography 35: 550–58. [Google Scholar] [CrossRef]
- Ćurlin, Tamara, Božidar Jaković, and Ivan Miloloža. 2019. Twitter usage in tourism: Literature review. Business Systems Research: International Journal of the Society for Advancing Innovation and Research in Economy 10: 102–19. [Google Scholar] [CrossRef]
- Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A density-based algorithm for discovering clusters in large spatial databases with noise. Kdd 96: 226–31. [Google Scholar]
- Faggian, Alessandra, and Philip McCann. 2008. Human capital, graduate migration and innovation in British regions. Cambridge Journal of Economics 33: 317–33. [Google Scholar] [CrossRef]
- Franklin, Rachel S., and David A. Plane. 2006. Pandora’s box: The potential and peril of migration data from the American Community Survey. International Regional Science Review 29: 231–46. [Google Scholar] [CrossRef]
- Fussell, Elizabeth, Lori M. Hunter, and Clark L. Gray. 2014. Measuring the environmental dimensions of human migration: The demographer’s toolkit. Global Environmental Change 28: 182–91. [Google Scholar] [CrossRef]
- Fussell, Elizabeth, Sara R. Curran, Matthew D. Dunbar, Michael A. Babb, Luanne Thompson, and Jacqueline Meijer-Irons. 2017. Weather-related hazards and population change: A study of hurricanes and tropical storms in the United States, 1980–2012. The Annals of the American Academy of Political and Social Science 669: 146–67. [Google Scholar] [CrossRef] [PubMed]
- Harvey, David. 1989. The Condition of Postmodernity. An Enquiry into the Origins of Cultural Change. Oxford: Blackwell. [Google Scholar]
- Hawelka, Bartosz, Isabela Sitko, Euro Beinat, Stanislav Sobolevsky, Pavlos Kazakopoulos, and Carlo Ratti. 2014. Geo-located Twitter as proxy for global mobility patterns. Cartography and Geographic Information Science 41: 260–71. [Google Scholar] [CrossRef]
- Hecht, Brent J., and Monica Stephens. 2014. A tale of cities: Urban biases in volunteered geographic information. ICWSM 14: 197–205. [Google Scholar]
- Hu, Fei, Zhenlong Li, Chaowei Yang, and Yongyao Jiang. 2019. A graph-based approach to detecting tourist movement patterns using social media data. Cartography and Geographic Information Science 46: 368–82. [Google Scholar] [CrossRef]
- Huang, Qunying, and Yu Xiao. 2015. Geographic situational awareness: Mining tweets for disaster preparedness, emergency response, impact, and recovery. ISPRS International Journal of Geo-Information 4: 1549–68. [Google Scholar] [CrossRef]
- Huang, Xiao, Cuizhen Wang, and Zhenlong Li. 2018. Reconstructing flood inundation probability by enhancing near real-time imagery with real-time gauges and tweets. IEEE Transactions on Geoscience and Remote Sensing 56: 4691–701. [Google Scholar] [CrossRef]
- Huang, Xiao, Zhenlong Li, Cuizhen Wang, and Huan Ning. 2019. Identifying disaster related social media for rapid response: A visual-textual fused CNN architecture. International Journal of Digital Earth 13: 1017–39. [Google Scholar] [CrossRef]
- Huang, Xiao, Zhenlong Li, Yuqin Jiang, Xiaoming Li, and Dwayne Porter. 2020. Twitter reveals human mobility dynamics during the COVID-19 pandemic. PLoS ONE 15: e0241957. [Google Scholar] [CrossRef] [PubMed]
- Isaacson, Michal, and Noam Shoval. 2006. Application of tracking technologies to the study of pedestrian spatial behavior. The Professional Geographer 58: 172–83. [Google Scholar] [CrossRef]
- Jiang, Yuqin, Zhenlong Li, and Susan L. Cutter. 2019. Social Network, Activity Space, Sentiment, and Evacuation: What Can Social Media Tell Us? Annals of the American Association of Geographers 109: 1795–810. [Google Scholar] [CrossRef]
- Jiang, Yuqin, Zhenlong Li, and Xinyue Ye. 2018. Understanding demographic and socioeconomic biases of geotagged Twitter users at the county level. Cartography and Geographic Information Science 46: 228–42. [Google Scholar] [CrossRef]
- Jurdak, Raja, Kun Zhao, Jiajun Liu, Maurice AbouJaoude, Mark Cameron, and David Newth. 2015. Understanding human mobility from Twitter. PLoS ONE 10: e0131469. [Google Scholar] [CrossRef] [PubMed]
- Kikas, Riivo, Marlon Dumas, and Ando Saabas. 2015. Explaining international migration in the skype network: The role of social network features. Paper presented at 1st ACM Workshop on Social Media World Sensors, Guzelyurt, Cyprus, September 17–22; pp. 17–22. [Google Scholar] [CrossRef]
- Koylu, Caglar. 2018. Discovering multi-scale community structures from the interpersonal communication network on Twitter. In Agent-Based Models and Complexity Science in the Age of Geospatial Big Data. Cham: Springer, pp. 87–102. [Google Scholar]
- Laczko, Frank. 2015. Factoring migration into the development data revolution. Journal of International Affairs 68: 1. [Google Scholar]
- Li, Zhenlong, Cuizhen Wang, Christopher T. Emrich, and Diansheng Guo. 2018. A novel approach to leveraging social media for rapid flood mapping: A case study of the 2015 South Carolina floods. Cartography and Geographic Information Science 45: 97–110. [Google Scholar] [CrossRef]
- Li, Zhenlong, Shan Qiao, Yuqin Jiang, and Xiaoming Li. 2021a. Building a Social media-based HIV Risk Behavior Index to Inform the Prediction of HIV New Diagnosis: A Feasibility Study. AIDS 35: S91–S99. [Google Scholar] [CrossRef]
- Li, Zhenlong, Xiao Huang, Xinyue Ye, Yuqin Jiang, Martín Yago, Huan Ning, Michael E. Hodgson, and Xiaoming Li. 2021b. Measuring Global Multi-Scale Place Connectivity using Geotagged Social Media Data. arXiv arXiv:2102.03991. [Google Scholar]
- Li, Zhenlong, Xiao Huang, Tao Hu, Huan Ning, Xinyue Ye, and Xiaoming Li. 2021C. ODT FLOW: A Scalable Platform for Extracting, Analyzing, and Sharing Multi-source Multi-scale Human Mobility. arXiv arXiv:2104.05040. [Google Scholar]
- Lin, Jie, and Robert G. Cromley. 2018. Inferring the home locations of Twitter users based on the spatiotemporal clustering of Twitter data. Transactions in GIS 22: 82–97. [Google Scholar] [CrossRef]
- Mallick, Bishawjit, and Joachim Vogt. 2014. Population displacement after cyclone and its consequences: Empirical evidence from coastal Bangladesh. Natural Hazards 73: 191–212. [Google Scholar] [CrossRef]
- Martín, Yago, Susan L. Cutter, and Zhenlong Li. 2020a. Bridging twitter and survey data for evacuation assessment of Hurricane Matthew and Hurricane Irma. Natural Hazards Review 21: 04020003. [Google Scholar] [CrossRef]
- Martín, Yago, Susan L. Cutter, Zhenlong Li, Christopher T. Emrich, and Jerry T. Mitchell. 2020b. Using geotagged tweets to track population movements to and from Puerto Rico after Hurricane Maria. Population and Environment 42: 4–27. [Google Scholar] [CrossRef]
- Martín, Yago, Zhenlong Li, and Susan L. Cutter. 2017. Leveraging Twitter to gauge evacuation compliance: Spatiotemporal analysis of Hurricane Matthew. PLoS ONE 12: e0181701. [Google Scholar] [CrossRef] [PubMed]
- McNeill, Graham, Jonathan Bright, and Scott A. Hale. 2017. Estimating local commuting patterns from geolocated Twitter data. EPJ Data Science 6: 24. [Google Scholar] [CrossRef]
- Messias, Johnnatan, Fabrício Benevenuto, Ingmar Weber, and Emilio Zagheni. 2016. From migration corridors to clusters: The value of Google+ data for migration studies. Paper presented at 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, San Francisco, CA, USA, August 18–21; pp. 421–28. [Google Scholar] [CrossRef]
- Mislove, Alan, Sune Lehmann, Yong-Yeol Ahn, Jukka-Pekka Onnela, and James N. Rosenquist. 2011. Understanding the demographics of Twitter users. Paper presented at Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, July 17–21; Available online: http://www.aaai.org/ocs/index.php/ICWSM/ICWSM11/paper/viewFile/2816/3234 (accessed on 13 June 2021).
- Pershad, Yash, Patrick T. Hangge, Hassan Albadawi, and Rahmi Oklu. 2018. Social medicine: Twitter in healthcare. Journal of Clinical Medicine 7: 121. [Google Scholar] [CrossRef]
- Rango, Marzia, and Michele Vespe. 2017. Big Data and Alternative Data Sources on Migration: From Case-Studies to Policy Support (Summary report European Commission—Joint Research Centre). Available online: https://gmdac.iom.int/big-data-and-alternative-data-sources-on-migration-from-case-studies-to-policy-support (accessed on 13 June 2021).
- Roberts, Helen, Jon Sadler, and Lee Chapman. 2019. The value of Twitter data for determining the emotional responses of people to urban green spaces: A case study and critical evaluation. Urban Studies 56: 818–35. [Google Scholar] [CrossRef]
- SCPRT—South Carolina Department of Parks, Recreation and Tourism. 2019. Research and Statistics. Available online: https://www.scprt.com/research (accessed on 13 June 2021).
- Sheffer, Mary L., and Brad Schultz. 2010. Paradigm shift or passing fad? Twitter and sports journalism. International Journal of Sport Communication 3: 472–84. [Google Scholar] [CrossRef]
- Skeldon, Ronald. 2012. Migration and its measurement: Towards a more robust map of bilateral flows. In Handbook of Research Methods in Migration. Edited by Carlos Vargas-Silva. Cheltenham: Edward Elgar Publishing Ltd., pp. 229–48. [Google Scholar]
- Spyratos, Spyridon, Michele Vespe, Fabrizio Natale, Ingmar Weber, Emilio Zagheni, and M. Rango. 2018. Migration Data Using Social Media: A EUROPEAN Perspective (EUR 29273 EN). Luxembourg: Publications Office of the European Union. [Google Scholar] [CrossRef]
- Squire, Vicki, ed. 2010. The Contested Politics of Mobility: Borderzones and Irregularity. New York: Routledge. [Google Scholar]
- Stock, Kristin. 2018. Mining location from social media: A systematic review. Computers, Environment and Urban Systems 71: 209–40. [Google Scholar] [CrossRef]
- Takhteyev, Yuri, Anatoliy Gruzd, and Barry Wellman. 2012. Geography of Twitter networks. Social Networks 34: 73–81. [Google Scholar] [CrossRef]
- Tamgno, James. K., Roger M. Faye, and Claude Lishou. 2013. Verbal autopsies, mobile data collection for monitoring and warning causes of deaths. Paper presented at 2013 15th International Conference on Advanced Communications Technology (ICACT), PyeongChang, Korea, January 27–30; pp. 495–501. [Google Scholar]
- Taylor, Linnet. 2016. No place to hide? The ethics and analytics of tracking mobility using mobile phone data. Environment and Planning D: Society and Space 34: 319–36. [Google Scholar] [CrossRef]
- Tinati, Ramine, Susan Halford, Leslie Carr, and Catherine Pope. 2014. Big data: Methodological challenges and approaches for sociological analysis. Sociology 48: 663–81. [Google Scholar] [CrossRef]
- Traunmueller, Martin W., Nicholas Johnson, Awais Malik, and Constantine E. Kontokosta. 2018. Digital footprints: Using WiFi probe and locational data to analyze human mobility trajectories in cities. Computers, Environment and Urban Systems 72: 4–12. [Google Scholar] [CrossRef]
- Turner, Ash. 2020. How Many Smartphones Are in the World? Available online: https://www.bankmycell.com/blog/how-many-phones-are-in-the-world (accessed on 13 June 2021).
- United Nations. 2008. Principles and Recommendations for Population and Housing Censuses (Statistical Papers (Seri. M)). New York: United Nations. [Google Scholar] [CrossRef]
- Wesolowski, Amy, Caroline O. Buckee, Linus Bengtsson, Erik Wetter, Xin Lu, and Andrew J. Tatem. 2014. Commentary: Containing the Ebola outbreak-the potential and challenge of mobile network data. PLoS Currents, 6. [Google Scholar] [CrossRef] [PubMed]
- Wesolowski, Amy, Nathan Eagle, Andrew J. Tatem, David L. Smith, Abdisalan M. Noor, Robert W. Snow, and Caroline O. Buckee. 2012. Quantifying the impact of human mobility on malaria. Science 338: 267–70. [Google Scholar] [CrossRef] [PubMed]
- Willekens, Frans, Douglas Massey, James Raymer, and Cris Beauchemin. 2016. International migration under the microscope. Science 352: 897–99. [Google Scholar] [CrossRef]
- Zagheni, Emilio, and Ingmar Weber. 2012. You are where you e-mail: Using e-mail data to estimate international migration rates. Paper presented at 4th Annual ACM Web Science Conference, Evanston, IL, USA, June 22–24; pp. 348–51. [Google Scholar] [CrossRef]
- Zagheni, Emilio, Ingmar Weber, and Krishna Gummadi. 2017. Leveraging Facebook’s advertising platform to monitor stocks of migrants. Population and Development Review 43: 721–34. [Google Scholar] [CrossRef]
- Zagheni, Emilio, Kivan Polimis, Monica Alexander, Ingmar Weber, and Francesco C. Billari. 2018. Combining social media data and traditional surveys to nowcast migration stocks. Paper presented at Annual Meeting of the Population Association of America, Austin, TX, USA, April 10–13. [Google Scholar]
- Zagheni, Emilio, Venkata R. K. Garimella, and Ingmar Weber. 2014. Inferring international and internal migration patterns from twitter data. Paper presented at 23rd International Conference on World Wide Web, Seoul, Korea, April 7–11; pp. 439–44. [Google Scholar] [CrossRef]
- Zeiler, Michael. 2017. Predicting Eclipse Visitation with Population Statistics. Available online: https://www.greatamericaneclipse.com/statistics/ (accessed on 13 June 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users | % Total | % Successful | |
|---|---|---|---|
| Cannot compute mode | 28 | 4.24% | / |
| All users * | 633 | 100.0% | 77.3% |
| Users 3 tweets or more * | 631 | 99.7% | 77.3% |
| Users 5 tweets or more * | 616 | 97.3% | 77.6% |
| Users 10 tweets or more * | 582 | 91.9% | 77.8% |
| Users 15 tweets or more * | 547 | 86.4% | 77.1% |
| Users 20 tweets or more * | 515 | 81.4% | 77.7% |
| Users 25 tweets or more * | 483 | 76.3% | 78.1% |
| Users 30 tweets or more * | 466 | 73.6% | 78.1% |
| Users 50 tweets or more * | 387 | 61.1% | 78.3% |
| Users 100 tweets or more * | 274 | 43.3% | 78.5% |
| Users 200 tweets or more * | 166 | 26.2% | 82.5% |
| Users 500 tweets or more * | 58 | 9.2% | 82.8% |
| Users 1000 tweets or more * | 18 | 2.8% | 83.3% |
| Affected Counties | Users | % Total |
|---|---|---|
| Fulton (GA)/Gwinnett (GA) | 1 | 0.7% |
| Charleston/Dorchester/Berkeley | 11 | 7.6% |
| Richland/Lexington | 15 | 10.4% |
| Pickens/Greenville | 5 | 3.5% |
| York/Lancaster | 5 | 3.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martín, Y.; Li, Z.; Ge, Y.; Huang, X. Introducing Twitter Daily Estimates of Residents and Non-Residents at the County Level. Soc. Sci. 2021, 10, 227. https://doi.org/10.3390/socsci10060227
Martín Y, Li Z, Ge Y, Huang X. Introducing Twitter Daily Estimates of Residents and Non-Residents at the County Level. Social Sciences. 2021; 10(6):227. https://doi.org/10.3390/socsci10060227
Chicago/Turabian StyleMartín, Yago, Zhenlong Li, Yue Ge, and Xiao Huang. 2021. "Introducing Twitter Daily Estimates of Residents and Non-Residents at the County Level" Social Sciences 10, no. 6: 227. https://doi.org/10.3390/socsci10060227
APA StyleMartín, Y., Li, Z., Ge, Y., & Huang, X. (2021). Introducing Twitter Daily Estimates of Residents and Non-Residents at the County Level. Social Sciences, 10(6), 227. https://doi.org/10.3390/socsci10060227