1. Introduction
The formation and propagation of cracks significantly impact the safety and service life of structures, potentially leading to severe accidents. Therefore, timely and accurate crack detection is critical to ensuring the operational safety of infrastructure. Traditional crack detection methods have relied on manual inspection, which is not only time-consuming but also prone to subjective biases, leading to potential errors in judgment. With the rapid development of the economy and the continuous expansion of infrastructure, the demand for crack detection has increased substantially. To improve detection efficiency and accuracy, a variety of automated crack detection methods have been explored, such as acoustic emission [
1,
2] and ultrasonic testing [
3]. While these methods offer certain levels of accuracy, their high equipment costs and operational complexity have limited their widespread application [
4,
5]. In contrast, crack detection techniques based on digital imaging have gained increasing attention for their significant advantages in cost, safety, and objectivity. These methods are now extensively applied to crack detection in concrete, pavements, and steel structures [
6,
7]. However, they still face numerous challenges, including complex backgrounds, variations in lighting conditions, and interference from extraneous objects in real-world engineering scenarios, which make achieving high-precision crack detection particularly difficult [
8,
9,
10].
In recent years, with the rapid advancement of deep learning technologies [
11], crack detection methods based on digital image processing have garnered widespread attention from both academia and the industry, achieving remarkable research progress [
12,
13,
14]. These studies can generally be categorized into two approaches: methods based on object detection models [
15,
16] and those based on image segmentation models [
17,
18]. The first category primarily relies on object detection models, such as YOLO [
19], SSD [
20], and Faster R-CNN [
21], to localize cracks. For example, Zhao et al. [
22] proposed an improved Faster R-CNN model to achieve high-precision crack detection on steel surfaces. Similarly, Yan et al. [
23] utilized the SSD model, incorporating deformable convolutions into the feature extraction network to successfully predict the locations and types of asphalt pavement cracks under complex conditions. Moreover, Raushan et al. [
24] and Chen et al. [
25] optimized the YOLO model to accurately detect cracks in concrete pavements and wall surfaces, respectively. Although these methods perform well in detecting simple and well-defined cracks, they tend to struggle with more complex or fine cracks, primarily due to the large area covered by rectangular detection boxes, which can lead to a decrease in detection accuracy.
In contrast, the second category of methods employs semantic segmentation models, such as U-Net [
26], HRNet [
27], and DeepLabv3+ [
28], enabling a more precise crack detection through pixel-wise predictions, thus drawing increased attention from researchers in the automated detection of cracks in steel structures, concrete, and pavements. For instance, Li et al. [
29] enhanced the PspNet [
30] algorithm to effectively separate crack regions from non-crack regions in steel bridges, mitigating background interference. However, the complexity of the network structure and the slow inference speed limit its practical application. Yang et al. [
31] proposed a multi-scale triple attention-based pixel-level concrete crack segmentation network, reducing the likelihood of missed detections. Nevertheless, its performance remains suboptimal when addressing complex backgrounds and low-contrast images. In addition, Liu et al. [
32] utilized HRNet and incorporated a parallel edge-enhancement branch to address the loss of fine-grained features in elongated concrete cracks. However, this approach may amplify local noise, potentially affecting detection accuracy.
In summary, although existing research on crack detection has made significant progress in various crack segmentation tasks and positively impacted infrastructure maintenance, current models still encounter several challenges. These challenges include the excessive number of parameters, which lead to high computational complexity and slow inference speeds; insufficient feature processing, particularly in capturing fine-grained details of cracks; information loss during feature extraction and fusion, which reduces the model’s ability to accurately segment cracks; and class imbalances, where the model tends to focus more on background information due to the significantly fewer crack pixels compared to non-crack regions. These limitations hinder the practical application of existing models in real-world engineering scenarios. To address these issues, this paper introduces a novel crack detection model based on multiple selective fusion (MSF), which is named as MSF-CrackNet. Unlike previous approaches, MSF-CrackNet integrates three innovative modules: the star-shaped feature enhancement (SFE) module, the multi-scale adaptive fusion (MAF) module, and the multi-scale monitoring and selective output (MMASO) module. These modules collectively address the limitations of existing methods by enhancing local feature processing, mitigating information loss, and tackling class imbalance. The SFE module reduces model complexity while improving local feature representation, the MAF module ensures effective multi-scale feature fusion, and the MMASO module dynamically adjusts the model’s focus on crack features, significantly improving detection accuracy. The effectiveness and superiority of MSF-CrackNet are demonstrated through extensive experiments conducted on three publicly available crack damage datasets: SCD, CFD, and DeepCrack. The experimental results show that MSF-CrackNet achieves state-of-the-art performance in terms of the Dice coefficient (Dice) score and the mean Intersection over Union (mIoU) value, outperforming existing models such as U-Net, DeepLabv3+, and Attention UNet. Specifically, MSF-CrackNet demonstrates superior robustness in handling complex backgrounds, fine cracks, and low-contrast images, making it a highly effective solution for practical crack detection tasks. The key contributions of this work are as follows.
MSF-CrackNet, a novel crack detection model based on multiple selective fusion mechanisms, is proposed. This network enables pixel-level crack localization in an automated and accurate manner, addressing the limitations of existing methods in handling complex backgrounds and fine cracks.
A SFE module that integrates GhostConv and Hadamard product operations is proposed as a solution to the problem of insufficient local feature processing. This module reduces the number of model parameters while enhancing the expressiveness of local features, making the model more efficient and effective in capturing fine crack details.
A MAF module with selective context information fusion is designed to address the issue of information loss. This module progressively fuses features from different scales, enriching the representation of feature information and improving the model’s ability to capture both global and local contextual details.
To overcome class imbalance, an MMASO module is developed. This module dynamically weights multi-scale features, enhancing the model’s focus on crack features and suppressing background interference, thereby improving recognition accuracy.
2. Proposed Methodology
2.1. Network Overview
The original U-Net [
33] architecture consists of three essential components: the encoder, skip connections, and decoder. Convolutional and pooling layers in the encoder enable features to be extracted from the input image. The decoder comprises deconvolutional and convolutional layers that decode the features from the encoder pathway, progressively restoring the image size layer by layer. Skip connections allow the transfer of extra semantic information between the encoding and decoding processes by concatenating the features extracted by the encoder with those restored by the decoder.
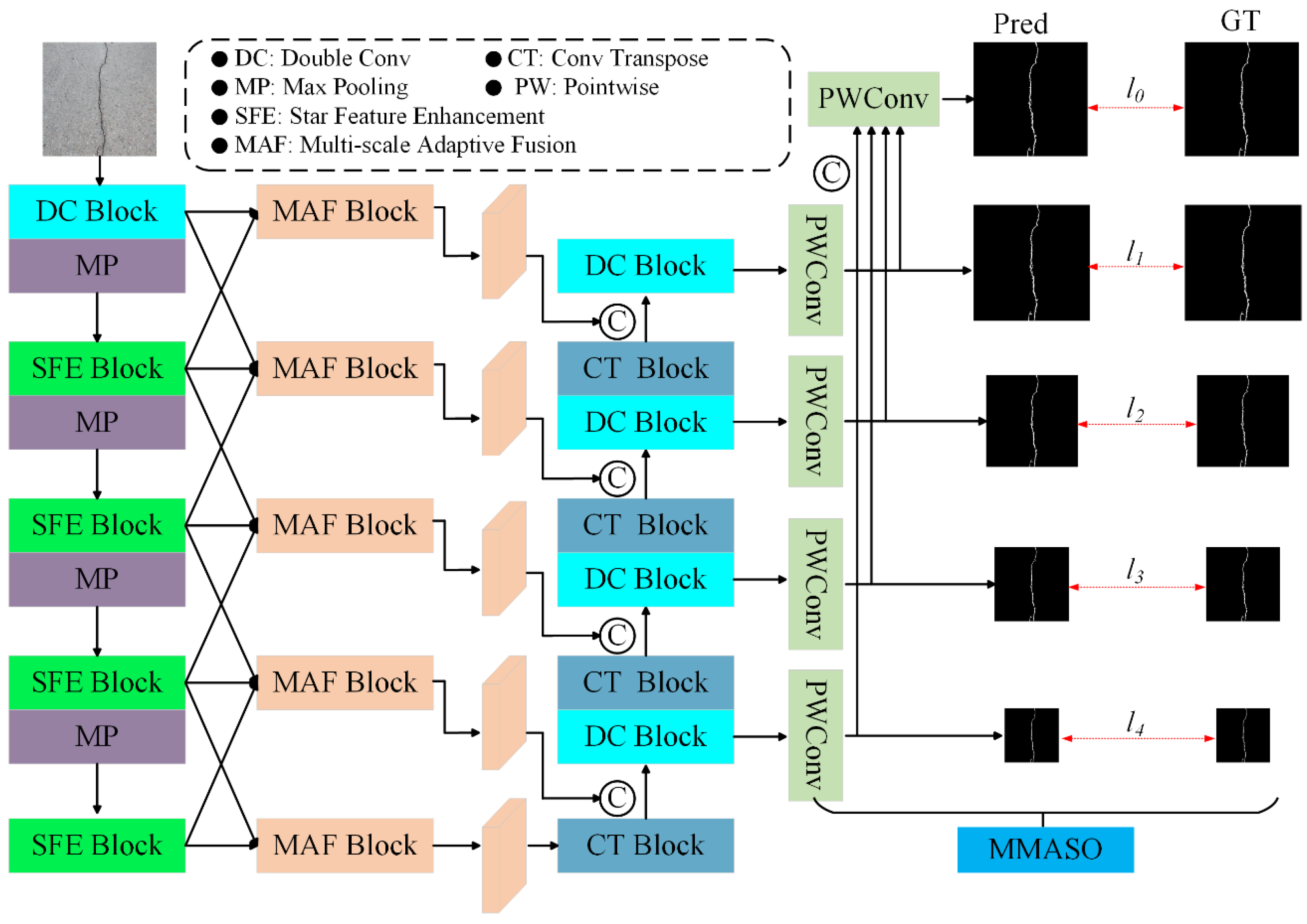
Based on this type of framework, this paper proposes a novel encoder–decoder crack segmentation network based on multiple selective fusion, to achieve faster and more accurate crack identification. The overall architecture is shown in
Figure 1. The SFE module is proposed to replace the convolutional part of the encoder. Moreover, a MAF module is integrated into skip connections. The decoder incorporates a MMASO module.
2.2. Star-Shaped Feature Enhancement Module
A common strategy to overcome the limitations of local feature processing is to expand the width of neural networks. While this method is effective, its side effects cannot be ignored: the increase in network width often leads to redundancy in feature representation, thereby intensifying the complexity of the model. Specifically, expanding the width of the network implies a significant growth in the number of parameters, which not only increases the consumption of computational resources and time, but also poses higher requirements for the deployment and maintenance of the model. To better address the aforementioned issues, based on the research findings of Ma et al. [
34], we propose a SFE module that leverages GhostConv and Hadamard operations. The aim is to significantly reduce the computational complexity of the model while enhancing its local feature processing capabilities by streamlining the number of channels and optimizing the computational process.
The core design of the SFE module includes key operations such as channel pruning, GhostConv operations, Hadamard operations, and skip connections.
Figure 2 provides an illustration of the SFE module’s structure. Specifically, the overall number of channels in the model is firstly streamlined through experiments to reduce redundant features. Subsequently, the GhostConv operation is employed to double the number of input feature channels, where generating some feature maps through linear transformations, thereby significantly reducing computational complexity. Then, two pointwise (PW) convolution layers expand the feature channels to six times the original input count, incorporating activation functions that transform the transformation function W1 into a nonlinear form, thereby enhancing the model’s expressive power. Based on this, the Hadamard operation is applied to broaden the implicit dimensions of the features, capturing richer information. Next, to overcome the limitations of the Hadamard product operation in fine-tuning distributions, the module deploys another GhostConv operation after the pointwise convolution layers and employs skip connections to smooth the coefficient distributions, thereby improving the model’s generalization ability. Additionally, to effectively curb potential overfitting tendencies, DropPath operations are integrated into each SFE module.
The core advantage of the SFE module lies in its ability to maintain excellent feature representation while significantly enhancing computational efficiency. To better illustrate its computational efficiency, we compared the computational complexity of traditional convolutions with that of GhostConv. The computational complexity of traditional convolutional layers can be expressed as:
where
K represents the kernel size;
Cin and
Cout denote the input and output channels, respectively; and
H and
W represent the height and width of the feature map.
In contrast, the GhostConv operation generates a portion of the feature maps through linear transformations, greatly reducing the computational complexity. The computational complexity can be expressed as:
where
s represents the ratio of the number of feature maps generated by linear transformations to those generated by traditional convolutions. Obviously, the computational complexity of the GhostConv operation is much lower than that of traditional convolution.
Additionally, the Hadamard operation further reduces computational complexity, with its element-wise multiplication operation having a complexity of only O(n), significantly lower than the O(n2) complexity of traditional convolutions. By combining GhostConv and the Hadamard product, the SFE module achieves a balance between computational efficiency and feature representation, providing strong support for the efficient application of the model.
2.3. Multi-Scale Adaptive Fusion Module
Multi-scale feature fusion is a powerful technique for enhancing model performance. High-dimensional and low-dimensional features play distinct roles in segmentation outcomes. Although high-dimensional features process a larger receptive field and are better at capturing global semantic information, they may overlook details related to small objects. Conversely, low-dimensional features offer higher spatial resolution and enhanced ability in capturing fine details; however, they may not provide sufficient background information. Therefore, selective fusions of high- and low-dimensional features are beneficial in generating feature maps with richer and more complete information, which addresses the problems of information loss and semantic gaps.
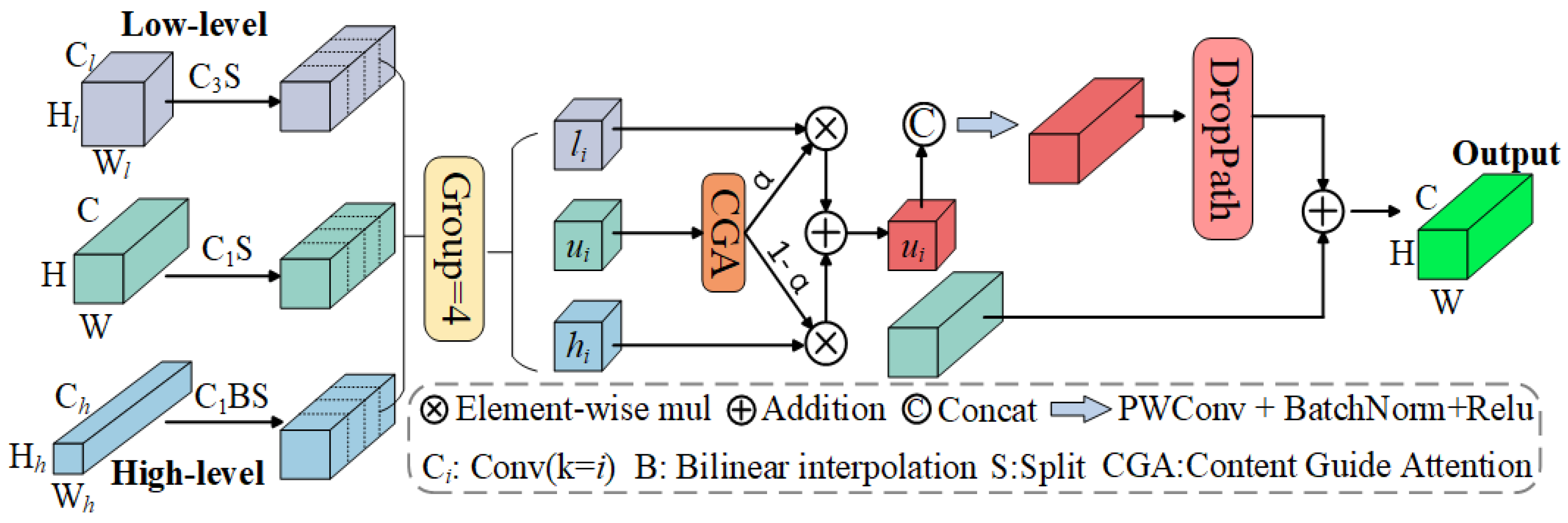
In this paper, a MAF module is proposed to progressively fuse the features of three different levels across adjacent network layers. The network structure of the MAF module is illustrated in
Figure 3. Through convolution and interpolation operations, the MAF module adjusts the size and channels of the adjacent low-dimensional feature
Flow and high-dimensional feature
Fhigh to align them with the current layer feature
Fcurrent. Subsequently, these features are split into four parts along the channel dimension, resulting in
,
, and
, where
i = 1, 2, 3, 4; and
,
,
represent the partition of the low-dimensional, high-dimensional, and current layer features, respectively. The partitioned features then undergo further processing.
Feature attention calculation [
35] is applied to the partitioned features of the current layer
, as outlined below:
where max (0,
x) represents the ReLU activation function;
Convk×k (•) denotes a convolutional layer with a kernel size of
k ×
k; [•] means the channel-wise concatenation operation;
,
, and
are global average pooling across the spatial dimension, global average pooling across the channel dimension, and global max pooling across the channel dimension, respectively. σ indicates Sigmoid activation;
CS (•) is the channel shuffle operation; and
GConvk×k (•) stands for the group convolution operation.
For the adjacent low-dimensional partitioned feature
and high-dimensional partitioned feature
, selective information fusion is described below:
where
i = 1, 2, 3, 4;
w denotes the attention weight calculated from the current layer’s partitioned feature;
is the fused feature of the
i-th partition; and [•] represents the channel-wise concatenation operation.
In order to derive the final features to be transmitted, the following operations are conducted:
where α indicates the DropPath operation;
Convk×k (•) stands for a convolutional layer with a kernel size of
k × k;
Fcurrent means the current layer feature; and
Ffused is the fused feature.
It should be noted that, in the absence of low-dimensional or high-dimensional features, a channel-wise concatenation operation is carried out directly on the partitioned features without selective processing.
The MAF module’s design ensures that the model can effectively capture both global and local contextual information, leading to more accurate and robust crack segmentation. By progressively fusing features from different scales, the MAF module mitigates information loss and semantic gaps, resulting in feature maps that are rich in both detail and context. This multi-scale fusion approach is particularly beneficial for crack detection tasks, where the ability to capture fine details while maintaining an understanding of the overall context is crucial for accurate segmentation.
2.4. Multi-Scale Monitoring and Selective Output Module
While the features enriched by the MAF module contain significant information, the pixels of cracks are substantially lower than the background information. The model may place more emphasis on learning background information if loss calculation is conducted only at the final output. This could deviate from the desired training direction and result in ineffective learning.
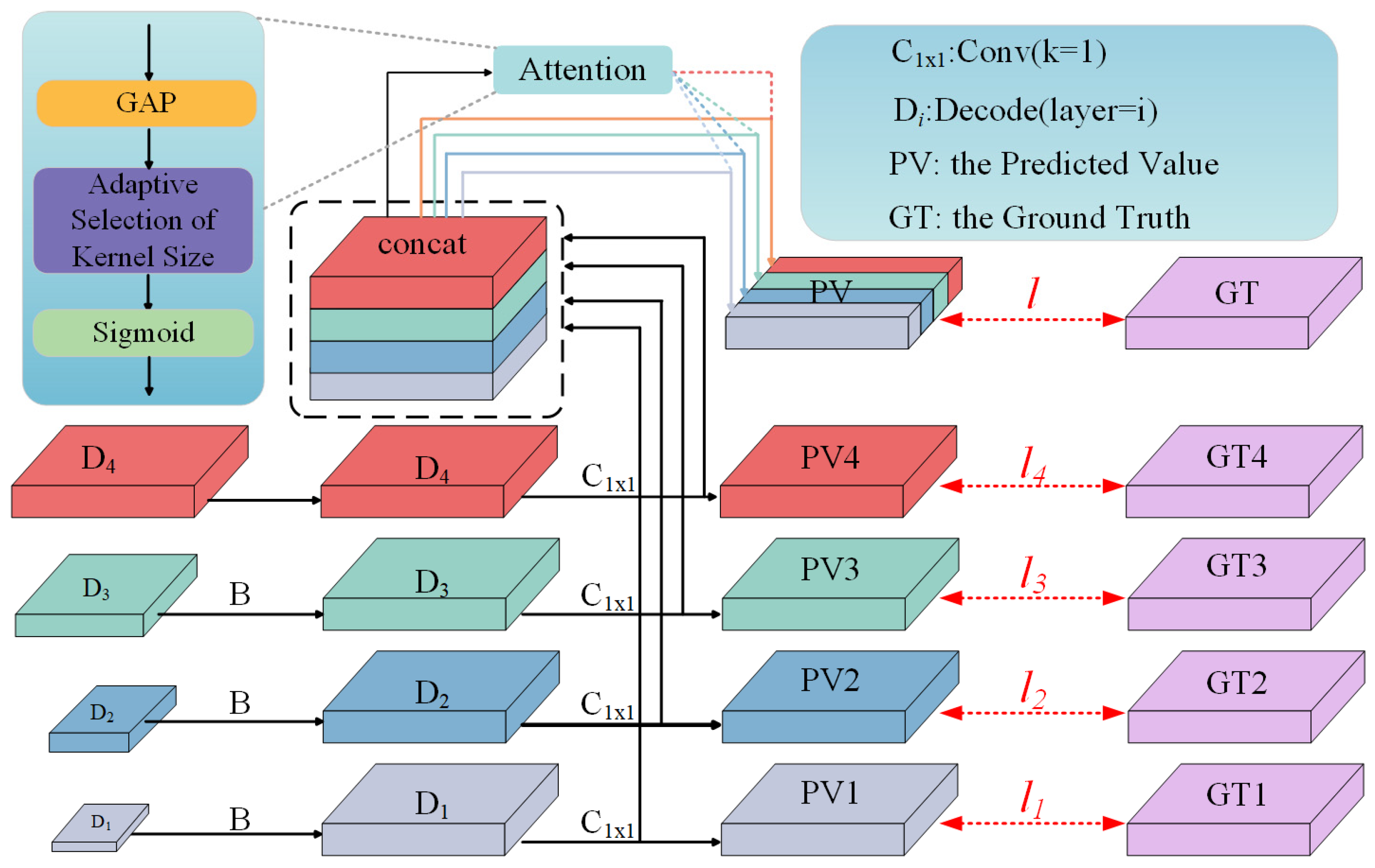
Based on previous research [
36], this paper proposes an MMASO module to successfully address the above challenge. This module is designed to force the model to concentrate on crack information in the features and use dynamic weighting to aggregate multi-scale features in order to guarantee the validity of the output. As illustrated in
Figure 4, the MMASO module operates in three main stages: feature map adjustment, dynamic weighting, and selective output. In the feature map adjustment stage, the module employs bilinear interpolation to resize the feature maps from different decoder layers to match the size of the ground truth labels. This ensures that the feature maps are aligned with the labels for accurate loss calculation. The resized feature maps are then passed through a pointwise convolution layer to generate the corresponding output for each scale. In the dynamic weighting stage, an attention mechanism is applied to the outputs from different scales. The attention mechanism calculates the importance of each scale based on the feature content and assigns appropriate weights. This process involves computing attention scores using a combination of global average pooling and Conv with an adaptive selection of kernel size, followed by a sigmoid function to normalize the scores. The weighted outputs are then aggregated to produce the final output. In the selective output stage, the module ensures that the final output focuses more on the crack features by dynamically adjusting the weights based on the crack content in the feature maps. This is achieved by increasing the perception of the model to crack pixels. This design ascribes crack pixels a higher weight in the loss calculation, thus guiding the model to pay more attention to crack features.
4. Experimental Results and Discussion
4.1. Implementation Details
The experiments in this study were conducted in an environment of PyTorch 1.12.1 and Python 3.8. The hardware setup included a GeForce RTX 3050 graphics card with 4GB of VRAM, purchased from Changsha, China and featuring CUDA 11.8 as the GPU computing environment. Training was conducted for 100 epochs and a batch size of 2, and the initial learning rate was set to 0.0005. To guarantee a smooth and efficient training process, the Adam optimizer was selected and a cosine annealing learning rate decay strategy was employed. Additionally, to minimize training time and make comparisons easier, all crack images input to the network for training were resized to 256 × 256 pixels.
4.2. Ablation Experiments
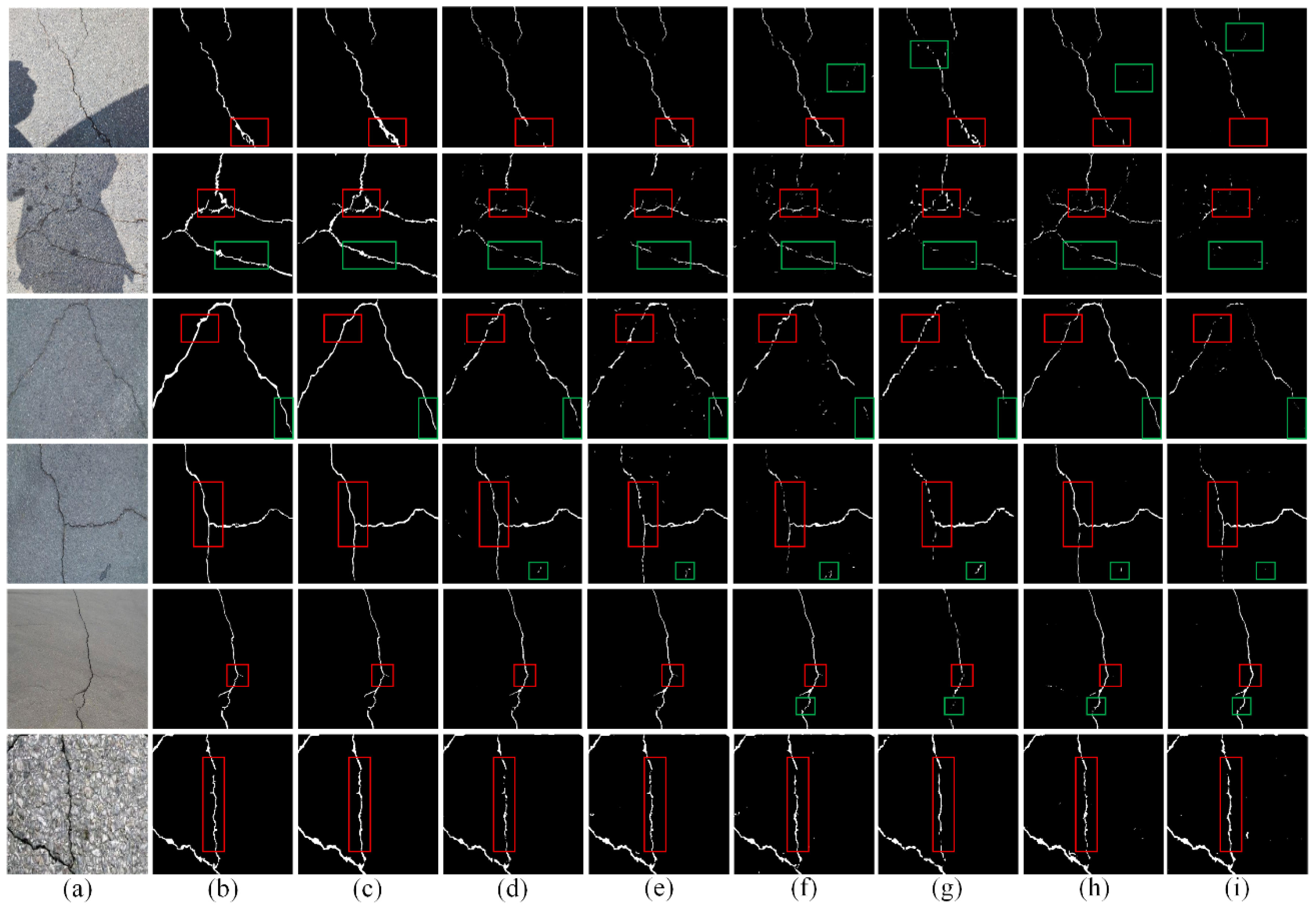
To investigate the effectiveness of the SFE, MAF, and MMASO modules on crack segmentation, this study conducted ablation experiments based on the SCD, CFD, and DeepCrack datasets. U-Net serves as the baseline model, and other network configurations were constructed by combining the baseline model with the proposed modules. The experimental results are shown in
Table 1 and
Figure 5.
The metrics
Dice score and
mIoU value in the CFD and DeepCrack datasets, as shown in
Table 1, indicate little difference between the Baseline model and the model that includes the SFE module. However, on the SCD dataset, which features complex scenes with significant noise interference, such as shadows and road signs, the model with the SFE module demonstrates a modest improvement. Specifically, there is an increase in the
Dice score from 0.615 to 0.634 and an elevation in the
mIoU value from 0.718 to 0.728. This improvement can be attributed to the SFE module’s ability to enhance local feature representation, which is crucial for handling noisy backgrounds. Moreover, by introducing the SFE module, the parameter count is dramatically reduced, with only 1/14 of the parameters compared to the Baseline model. This indicates that the SFE module not only reduces the model’s parameter count but also enhances its capacity to process local information. Additionally, integrating the MAF and MMASO modules into the model further enhances performance across all datasets, including CFD, DeepCrack, and SCD.
In the SCD dataset, the addition of the MAF module further boosts the Dice score to 0.650 and the mIoU value to 0.737, indicating that multi-scale feature fusion helps in capturing both global and local contextual information. Finally, the incorporation of the MMASO module, which dynamically adjusts the model’s focus on crack features, achieves the best performance with a Dice score of 0.662 and an mIoU value of 0.744. This demonstrates the effectiveness of the MMASO module in enhancing the model’s ability to prioritize crack features in complex environments.
Turning to the CFD dataset, which contains small cracks with uneven lighting, the SFE module alone provides only a slight improvement in performance, with the Dice score increasing from 0.468 to 0.472 and the mIoU value from 0.641 to 0.643. However, the addition of the MAF module significantly improves the Dice score to 0.524 and the mIoU value to 0.666, demonstrating its effectiveness in handling small cracks. The integration of the MMASO module further enhances the model’s ability to focus on crack features, resulting in a Dice score of 0.542 and an mIoU value of 0.675. This highlights the importance of multi-scale feature fusion and dynamic weighting in scenarios with small cracks and uneven lighting.
In contrast, the DeepCrack dataset features relatively large crack sizes set against simple backgrounds. Here, the SFE module does not significantly improve performance, the Dice score remains almost unchanged (from 0.832 to 0.831), and the mIoU slightly decreases (from 0.855 to 0.849). However, the addition of the MAF module improves the Dice score to 0.848 and the mIoU to 0.863, indicating that multi-scale feature fusion is beneficial even in simpler backgrounds. Furthermore, the integration of the MMASO module achieves the best performance with a Dice score of 0.868 and an mIoU of 0.879, demonstrating its effectiveness in enhancing the model’s focus on crack features, even when the background is less complex.
Figure 5 provides several visualization results from the ablation experiments. As can be seen, the crack segmentation results for the three images gradually converge towards the ground truth. Specifically, the crack segmentation outcomes for the images in the fourth column highlight the model’s enhanced proficiency in handling complex backgrounds, particularly demonstrating increased robustness in the presence of shadows. According to the fifth and sixth columns, the model’s capacity to capture crack details shows a progressive improvement. Compared to the baseline model, the models incorporated with the MAF and MMASO modules demonstrate superior precision in detecting fine cracks, indicating advancements in multi-scale feature extraction and detail processing capabilities. Thus, it can be concluded that, as the model was optimized and improved, crack segmentation accuracy and detail capture increased. As a result, the segmentation outcomes are more closely consistent with the ground truth, further confirming the effectiveness and superiority of the proposed method.
4.3. Comparative Experiments
To better demonstrate the superiority of the proposed model, the following models were selected as references for comparative studies, including PspNet [
30], SegNet [
39], DeepLabv3+ [
40], U-Net [
33], ResUNet [
41], and Attention UNet [
42]. In this section, the proposed MSF-CrackNet was evaluated on three datasets models with the comparative models.
As indicated in
Table 2,
Table 3 and
Table 4, the proposed MSF-CrackNet model achieved the best results in terms of both
Dice score and
mIoU value across the SCD, CFD, and DeepCrack datasets. Specifically, MSF-CrackNet model achieved a
Dice score of 66.2% and an
mIoU value of 74.4% on the SCD dataset, surpassing the second-best model by 4.7% and 2.6%, respectively. Moreover, the model outperformed the second-best model by 7.4% and 3.4%, respectively, with a
Dice score and
mIoU value of 54.2% and 67.5% on the CFD dataset. The
Dice score and
mIoU value for the DeepCrack dataset were 86.8% and 87.9%, exceeding the second-best model by 3.1% and 2.4%, respectively. According to the further analysis of the precision and recall metrics, although the MSF-CrackNet model did not achieve the highest recall, its performance was very close to the optimal situation. This indicates that the MSF-CrackNet model effectively identifies cracks while maintaining a high recall rate. Overall, the MSF-CrackNet model outperformed several existing models across various evaluation metrics, particularly achieving optimal detection results on multiple datasets. This further demonstrates the model’s generalization ability and robustness in different scenarios. These experimental results suggest that the MSF-CrackNet model possesses stronger recognition capabilities and higher robustness, making it broadly applicable in practical applications.
To further evaluate the performance of the proposed MSF-CrackNet model, the visualization results across various datasets are provided in
Figure 6. In particular, the results from the SCD dataset are shown in the first two rows, those from the CFD dataset in the third and fourth rows, and those from the DeepCrack dataset in the last two rows. These visualization results illustrate that the MSF-CrackNet model more effectively suppresses false positives than other models in complex backgrounds (like the first two rows), enabling a more accurate crack localization in noisy backgrounds. Moreover, the MSF-CrackNet model demonstrates its superior performance in handling boundary ambiguity by successfully identifying the shapes and locations of cracks in situations with fuzzy borders (like the third and fourth rows). Additionally, the MSF-CrackNet model outperforms other models in terms of micro-crack detection and detail capture (which includes the fifth and sixth rows). The remarkable performance of the MSF-CrackNet model in a variety of complicated scenarios is further supported by these visualization results, which are in line with the quantitative experimental data above and show its potential and benefits in practical applications.
4.4. Robustness Experiments
In this part, cross-validation experiments were carried out to further confirm the robustness of the proposed model. In particular, the MSF-CrackNet model was trained on the CFD dataset and then validated on the SCD dataset, which exhibits significantly different characteristics. The CFD dataset contains small cracks with uneven lighting, while the SCD dataset features complex scenes with substantial noise interference, such as shadows, road signs, and other challenging backgrounds. This cross-dataset validation allows us to assess the model’s robustness and adaptability to varying crack sizes, lighting conditions, and background complexities. To evaluate the model’s performance thoroughly, two models with exceptional performance were selected as comparison objects.
As illustrated in
Table 5, MSF-CrackNet achieves a
Dice score of 62.6% and an
mIoU value of 72.3% on the SCD dataset, significantly outperforming both U-Net and Attention UNet. This demonstrates that MSF-CrackNet maintains strong performance even when tested on a dataset with different characteristics from the training data. The model’s ability to generalize across datasets highlights its robustness and adaptability, which are critical for real-world applications where crack detection systems must operate in diverse environments.
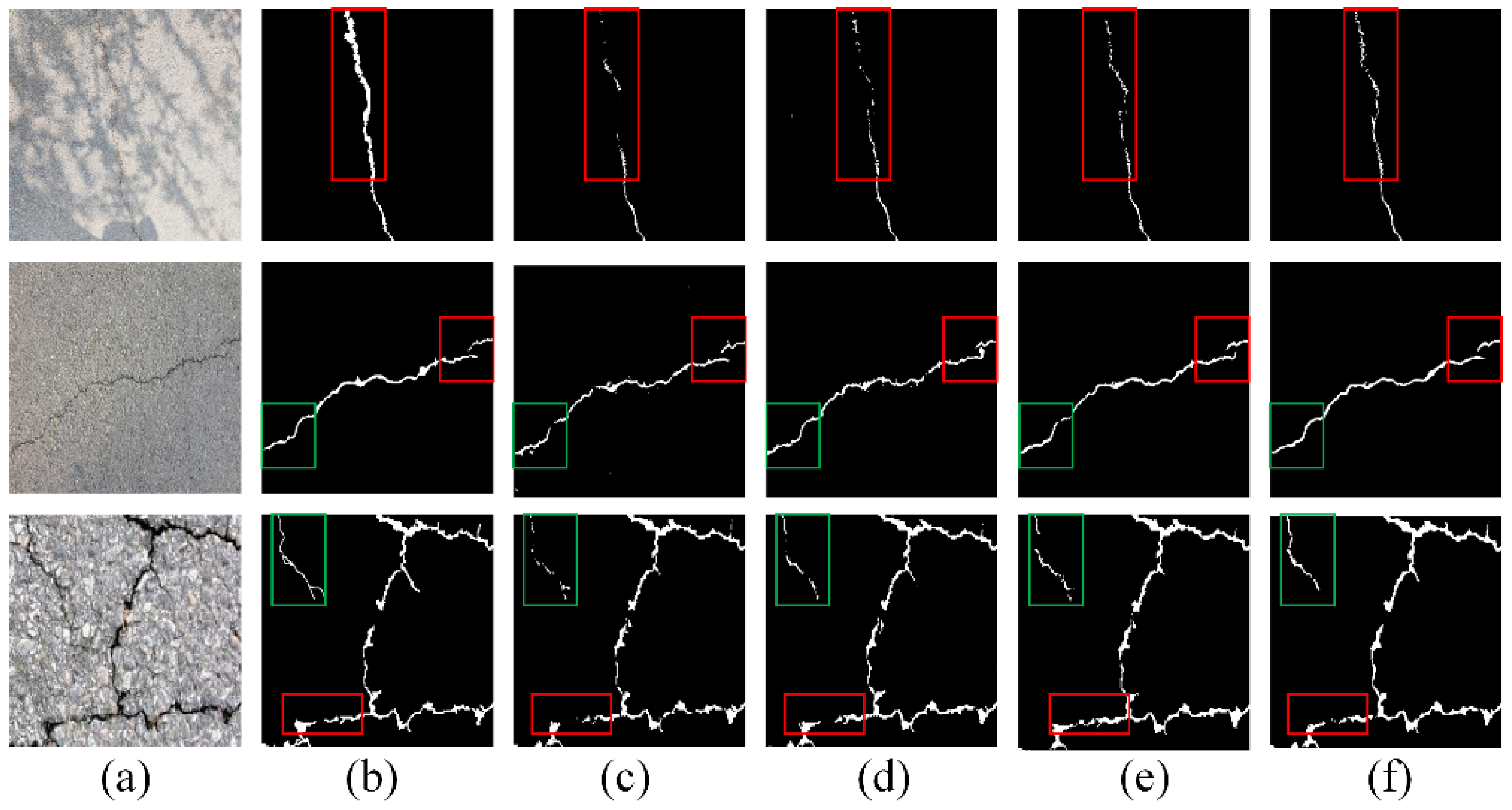
The visualization results in
Figure 7 further supports the quantitative findings. In complex scenes with shadows and noise, MSF-CrackNet demonstrates superior performance in crack localization compared to U-Net and Attention UNet. For instance, in the fourth column of
Figure 7, MSF-CrackNet accurately identifies cracks in the presence of strong shadows, while the other models produce false positives. Similarly, in the sixth column, MSF-CrackNet successfully detects fine cracks that are missed by the comparison objects. These results indicate that MSF-CrackNet’s ability to adapt to varying dataset characteristics is not only reflected in quantitative metrics but also in its practical performance in challenging environments.
In summary, the cross-validation experiments demonstrate that MSF-CrackNet exhibits strong generalization ability across datasets with different characteristics. The model’s robust performance on the SCD dataset, despite being trained on the CFD dataset, underscores its adaptability to varying crack sizes, lighting conditions, and background complexities. This adaptability is crucial for real-world applications, where crack detection systems must operate in diverse and unpredictable environments. The combination of quantitative results and visual analysis confirms that MSF-CrackNet is a highly effective solution for practical crack detection tasks.
4.5. Computational Complexity Analysis
For crack detection in practical engineering applications, low computational complexity and high inference speed are crucial. This section analyzed the performance of the proposed MSF-CrackNet model and compared it with other advanced models in terms of computational complexity and inference speed on the SCD dataset.
Table 6 presents the experimental outcomes.
The results in
Table 6 demonstrate that the proposed MSF-CrackNet model achieves a lower computational resource consumption while maintaining a high inference speed. Specifically, MSF-CrackNet has 72.6% fewer parameters than Attention UNet, the second-best model. In terms of computational complexity, MSF-CrackNet is 74.6% less than Attention UNet. Additionally, in terms of inference speed, MSF-CrackNet performs 19% faster than DeepLabv3+, the second-fastest model. According to these findings, it can be concluded that MSF-CrackNet has great potential to efficiently perform crack detection tasks in resource-constrained environments.
5. Conclusions
This paper proposes MSF-CrackNet, an efficient lightweight multiple selective fusion network, for crack segmentation. The model addresses several key challenges in crack detection, including inadequate local feature processing, information loss, and class imbalance, through the integration of three innovative modules: the SFE module, the MAF module, and the MMASO module.
The SFE module significantly reduces the number of model parameters while enhancing local feature representation, leading to a more efficient and effective model. The MAF module ensures effective multi-scale feature fusion, capturing both global and local contextual information, while the MMASO module dynamically adjusts the model’s focus on crack features, improving detection accuracy. Extensive experiments conducted on three publicly available crack datasets (SCD, CFD, and DeepCrack) demonstrate that MSF-CrackNet exhibits outstanding performance across multiple key performance metrics, with Dice scores of 66.2%, 54.2%, and 86.8% and mIoU values of 74.4%, 67.5%, and 87.9%, respectively. These results outperform those of existing models, such as U-Net, DeepLabv3+, and Attention UNet, particularly in handling complex backgrounds, fine cracks, and low-contrast images.
Moreover, MSF-CrackNet significantly reduces computational complexity, with only 2.39 million parameters and 8.58 GFLOPs, making it a practical and efficient solution for real-world crack detection tasks, especially in scenarios with limited computational resources. The model’s lightweight design and high inference speed further enhance its applicability in resource-constrained environments.
Finally, despite its promising performance, MSF-CrackNet has some limitations that warrant further investigation. Although the model demonstrates strong generalization ability across different datasets, its performance may still be affected by extreme variations in lighting conditions or highly complex backgrounds that were not extensively covered in the training data. Future work could explore the integration of more robust data augmentation techniques or domain adaptation methods to enhance the model’s ability to handle such scenarios. Additionally, even though MSF-CrackNet achieves a significant reduction in computational complexity, its inference speed on very high-resolution images could still be improved, especially for real-time applications. Optimizing the network architecture or leveraging hardware acceleration techniques could address this limitation. Lastly, the current model is primarily designed for crack segmentation in static images. Extending its capabilities to video-based crack detection remains an open challenge.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}