Abstract
Exhibition design in museum environments serves as a vital mechanism for enhancing cultural engagement, enriching visitor experience, and promoting heritage preservation. Despite the growing number of museums, improvements in exhibition quality remain limited. In this context, understanding exhibition visual content becomes fundamental to shaping visitor experiences in cultural heritage settings, as it directly influences how individuals perceive, interpret, and engage with displayed information. However, due to individual differences in cognitive processing, standardized visualization strategies may not effectively support all users, potentially resulting in unequal levels of knowledge acquisition and engagement. This study presents a quasi-experimental eye-tracking investigation examining how visualizer–verbalizer (V–V) cognitive styles influence content comprehension in a historical museum context. Participants were classified as visualizers or verbalizers via standardized questionnaires and explored six artifacts displayed through varying information modalities while their eye movements—including fixation durations and transition patterns—were recorded to assess visual processing behavior. The results revealed that participants’ comprehension performance was strongly associated with their visual attention patterns, which differed systematically between visualizers and verbalizers. These differences reflect distinct visual exploration strategies, with cognitive style influencing how individuals allocate attention and process multimodal exhibition content. Eye movement data indicated that visualizers engaged in broader cross-modal integration, whereas verbalizers exhibited more linear, text-oriented strategies. The findings provide empirical evidence for the role of cognitive style in shaping visual behavior and interpretive outcomes in museum environments, underscoring the need for cognitively adaptive exhibition design.
1. Introduction
Effective information presentation in museums requires consideration of both user-specific and context-specific factors [1], ensuring that cultural heritage content is communicated in ways that support meaningful and efficient interpretation. As cultural heritage experiences often rely on visual materials—such as artifacts and exhibition panels—individual cognitive differences in visual processing are particularly relevant to the design of personalized and cognitively adaptive exhibition environments.
Despite extensive research highlighting the influence of human cognition on content comprehension in domains like gaming [2,3] and e-learning [4,5], cognitive factors remain underutilized in museum exhibition design. One such factor is cognitive style, which refers to individuals’ characteristic ways of acquiring, organizing, and interpreting information [6,7]. Of relevance is the visualizer–verbalizer dimension: visualizers favor pictorial and spatial representations, while verbalizers prefer linguistic or textual formats [8]. This distinction significantly shapes how individuals engage with and interpret multimodal content, making it a critical variable in cultural heritage interface design. Yet, visual–verbal integration (V-V), though shown to impact comprehension, is rarely incorporated into museum design practices. Moreover, few studies have examined how cognitive style modulates gaze behavior and information navigation in realistic museum environments. Understanding how individuals with differing cognitive styles engage with complex cultural content in museum environments represents a critical yet underexplored area at the intersection of cognitive psychology and museum studies [9].
This study addresses this gap by investigating how cognitive styles influence visitor interaction with complex, multimodal exhibitions. Modern museum displays often combine diverse media formats—text, images, video, and physical objects—to cater to heterogeneous visitor needs. While enriching, such multimodality increases informational complexity, potentially imposing higher cognitive demands [10]. Drawing on Hick’s Law, which posits a logarithmic relationship between the number of available choices and decision time [11], exhibition elements can be conceptualized as parallel channels of input. Visitors must continuously prioritize and integrate information across modalities—processes that may be influenced by their cognitive style.
To explore these dynamics, this study employs mobile eye-tracking technology to capture real-time visual attention patterns as visitors engage with multimodal exhibitions. Eye-tracking offers precise data on fixation duration, gaze transitions, and attentional distribution, enabling a detailed analysis of how visualizers and verbalizers process complex cultural content [12]. By integrating cognitive theory, interface complexity, and empirical gaze data, this research advances understanding of how visitors cognitively engage with exhibitions. More broadly, it examines how visual attention patterns relate to learning performance, offering actionable insights for optimizing exhibition design and enhancing interpretive effectiveness in museum contexts.
2. Literature Review
2.1. Exhibition Information Display and Multimedia Learning
Museums serve as important platforms for facilitating diverse learning experiences among visitors from a wide range of cultural and educational backgrounds. Traditional multimedia exhibitions typically rely on a combination of visual artifacts and supporting textual information to convey content. Museum exhibitions increasingly rely on multimedia formats to present complex cultural and historical information. The integration of text, images, audio, video, and interactive elements reflects principles from multimedia learning theory, which emphasizes the importance of dual-channel information processing and the active integration of verbal and visual content. In this context, the evaluation of learning outcomes across different cognitive levels has emerged as a key strategy for improving exhibition effectiveness and optimizing educational impact [13]. Consequently, a growing body of research has focused on multimedia learning within both physical and digital museum settings, aiming to enhance the visitor experience through evidence-based exhibition design.
Recent studies on museum multimedia design have increasingly focused on manipulating fine-grained variables to optimize learning outcomes and visitor engagement—an approach to which the present study contributes. For example, in a series of laboratory-based painting exhibitions, Schwan et al. [14] examined the effects of text volume, presentation modality, and interactivity on the interpretation of paintings. Similarly, Li et al. [15], in a study simulating offline Chinese painting exhibitions, demonstrated that integrating video-based learning prior to interactive multimedia exhibits significantly enhanced visitors’ comprehension. Additional experimental work has primarily focused on the aesthetic experience of digital artworks, investigating factors such as color saturation [16], subject matter [17], and the presence of accompanying explanatory text [18]. Moreover, emerging research has begun to address how attentional allocation may vary across age groups in heritage environments [19]. However, these studies have largely centered on visual art contexts and digital prototypes, leaving artifact-based exhibitions underexplored.
To date, research on multimedia learning in museum contexts has largely focused on evaluating visitor engagement with well-integrated interactive systems or web-based applications. In contrast, comparatively little attention has been given to more fundamental aspects of exhibition design—specifically, the spatial and informational arrangement of basic elements such as text, images, and video. Moreover, previous experimental studies that have manipulated such fine-grained display configurations have primarily centered on art-based exhibits, particularly paintings. As far as we are aware, there is a notable lack of eye-tracking research examining how visitors engage with and cognitively process traditional offline combinations of text, image, and video in artifact-based exhibit displays. This gap highlights the need for more systematic investigations into the visual attention patterns and learning outcomes associated with core media elements in cultural heritage exhibitions.
2.2. Cognitive Style and Eye Movement
Visitors engage with exhibition content through a range of cognitive operations, including the identification, encoding, organization, reorganization, and interpretation of information, all mediated by processes of attention, perception, memory, and cognition. This complex interplay between cognitive processes and visual inputs has prompted researchers to explore how different design features influence user perception and comprehension. Recent research has increasingly focused on examining users’ responses to visual stimuli through the application of psychometric instruments [20,21]. These measures are employed to assess how variations in visual complexity influence users’ subjective evaluations, while also capturing individual differences in underlying cognitive characteristics. By integrating psychometric data with experimental observations, scholars aim to better understand the interplay between visual design elements and user cognition, particularly in contexts involving information-rich or multimodal environments.
Eye movements (EMs) constitute a fundamental component of visual perception and play a critical role in guiding visual exploration and information processing. Visual exploration is characterized by a sequence of saccadic movements, which are influenced by both bottom-up sensory input and top-down cognitive control mechanisms [22]. These mechanisms reflect an interplay between stimulus-driven saliency and goal-directed attentional strategies. Beyond their perceptual function, eye movements are closely linked to higher-order cognitive processes, including conceptualization, memory formation, and learning [23]. As such, the study of eye movement patterns provides valuable insights into the cognitive underpinnings of visual engagement, particularly in educational [24] and cultural-heritage contexts [25]. In essence, both learning and communication involve the ongoing restructuring of the cognitive maps that represent our understanding of the world, as they adapt to environmental inputs. Visualizer–verbalizer cognitive style seems to have an impact on the learning process. The visualizer–verbalizer (V–V) cognitive style represents a fundamental individual difference in information processing. According to V–V theory [8], cognitive processing occurs through two distinct representational modalities: visual and verbal. Accordingly, individuals are categorized based on their predominant mode of thinking—either as visualizers, who favor imagery-based representations, or as verbalizers, who rely primarily on linguistic forms of information [26]. Empirical studies have demonstrated that V–V style significantly influences learning outcomes and content comprehension [26,27] and is closely associated with patterns of visual attention and gaze behavior [4,28]. Therefore, the research question that this study discusses is whether there are specific visualization types, based on users’ V-V cognitive style, that can be used to help users towards a deeper understanding of the visual cultural heritage content.
2.3. Eye-Tracking Technology and Exhibition Information Display
Effectively conveying novel concepts to a non-expert audience within quasi-educational environments such as museums presents a range of challenges. These include visitors’ uncertainty regarding navigation and focal points [29], limited prior knowledge of exhibition content [30], prevalent misconceptions, diverse cognitive and learning styles [27], as well as physical and cognitive fatigue [31], social and perceptual distractions, absence of clearly defined goals, and time constraints. To address these issues, eye-tracking research has emerged as a valuable method for investigating how visitors allocate visual attention, navigate multimodal displays, and process exhibit content in real time [32]. Eye-tracking technology is predominantly utilized to investigate the relationship between visual cognition and domain-specific expertise in real-world settings [33]. It is often employed to identify significant differences in gaze behavior, with the resulting data serving as a basis for informing future design and development strategies [34]. Studies have shown that fixation patterns, gaze duration, and transitions between elements can reveal underlying cognitive strategies and attentional bottlenecks [35].
In recent years, the application of eye-tracking technology in exhibition settings has gained increasing attention for its ability to reveal nuanced patterns of visual engagement. Garbutt highlighted the potential of eye-tracking to uncover novel modes of interaction with both artworks and their surrounding visual environments [36]. Their study further demonstrated that visitors employed varying label-reading strategies—ranging from thoroughly reading all content to focusing solely on the title—based on individual preferences. Notably, interpretive label reading was found to impose a higher cognitive load than viewing the artwork itself, as reflected in significantly longer fixation durations on text elements. Previous research has examined diverse aspects of visitor attention, including reading engagement with exhibition content [37], perceptual responses to different types of artworks [38], and the dynamics of visual attention flow within museum contexts [39]. More recently, an emerging body of work has concentrated specifically on label-reading behavior. For example, Bailey-Ross et al. explored how visitors responded to three distinct interpretive label formats, identifying substantial variation in visual engagement patterns [40]. These findings collectively underscore the importance of text-based elements in shaping visitor interpretation and attentional strategies in multimodal museum environments.
Consequently, exhibition information design must account for these multifaceted factors while remaining grounded in an understanding of the fundamental biological and cognitive mechanisms that govern perception, attention, and learning. By incorporating insights from eye-tracking data, designers can more effectively structure visual hierarchies, enhance cueing, and reduce extraneous cognitive load, thereby improving the clarity, accessibility, and educational impact of museum displays.
Prior eye-tracking research in museum contexts has predominantly focused on general patterns of visual attention (e.g., fixation durations on artifacts vs. labels) [37], without considering how individual cognitive preferences mediate these processes. Moreover, most studies adopt static metrics such as total fixation duration, failing to capture the dynamic nature of visual navigation—how visitors move across different information types and assemble meaning from the sequential flow of attention. Therefore, the research questions of this paper are as follows:
- (1)
- Do cognitive styles modulate attention allocation to visual versus verbal information elements, and if so, how?
- (2)
- How do visitors with distinct cognitive styles navigate multimodal exhibition environments under varying levels of interface complexity?
- (3)
- What sequential gaze patterns and information processing strategies are employed, particularly under cognitively demanding conditions?
3. Methodology and Design Objectives
To investigate the proposed research questions, a quasi-experimental design was employed (Figure 1). Participants completed a controlled viewing task under different exhibit display conditions during which both eye-tracking data and self-report questionnaires were collected. The analysis focused on examining the relationships among participants’ cognitive styles (visualizer vs. verbalizer), the complexity level of exhibit display formats, knowledge acquisition, cognitive load (as measured by recall performance and perceived task difficulty), and visual attention metrics (including total dwell time and fixation count). Furthermore, lag sequential analysis (LSA) was applied to compare the visual transition pattern of visualizer and verbalizer participants while viewing an exhibit.
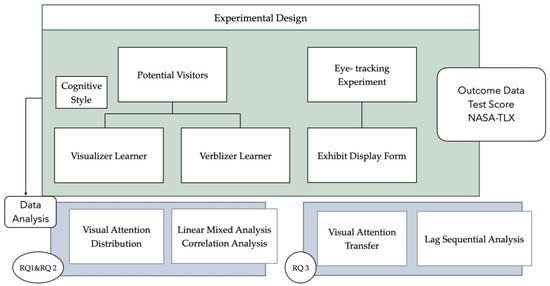
Figure 1.
Research framework.
3.1. Research Context and Stimuli
For the purposes of this study, six representative artifacts of Liangzhu culture were selected as experimental materials. These artifacts, excavated from the Liangzhu Ancient City Ruins and currently on display at the Liangzhu Museum, were chosen for their cultural relevance and symbolic value in representing key aspects of Liangzhu civilization. Each exhibition interface included the artifact’s title, a brief textual description of approximately 100 Chinese characters, as well as an image and a video introducing the artifact. The corresponding English translations are provided in Appendix A. All text content was derived from the museum websites and the exhibition. Based on varying levels of design complexity, each artifact was presented under three display conditions: Condition 1 (low-complexity), Condition 2 (moderate-complexity), and Condition 3 (high-complexity), shown in Figure 2.

Figure 2.
Example diagram for comparison of experimental samples.
Given the specificity of the Liangzhu artifacts used as stimulus materials, we acknowledge potential limitations regarding the methodological rigor and the generalizability of the findings. While the cultural and contextual characteristics of these artifacts may not be universally representative, this study is intended as an initial step toward expanding methodological frameworks in museum visitor research. It is hoped that the insights generated herein will contribute to broader discussions on the role of cognitive styles and interface complexity in shaping visitor engagement and interpretation within cultural heritage settings.
3.2. Participants
Gpower 3.1 [41] was used to determine the sample size required in a previous power analysis. F-test (ANOVA repeated measures, within–between interaction) was selected using effect size f = 0.25, α = 0.05, 1-β = 0.9, and correlation among repeated measures = 0.5. The total sample size was calculated as 44. We recruited 54 students from the university to participate (males: 15; females: 40; M = 23.04 years old). All participants were native Mandarin speakers who self-reported no academic background or professional expertise in cultural heritage, museum studies, or related fields. None of the participants exhibited color blindness or color weakness, and all had normal or corrected-to-normal vision. Prior to participation, all individuals were informed that their eye movement data would be recorded for research purposes, and they provided written informed consent in accordance with ethical research protocols. Furthermore, all participants confirmed that they had no prior exposure to the experimental materials and were viewing the stimulus content for the first time during the study. In terms of bioethics, the Chiba University Institutional Review Board approved all processes of this research.
3.3. Apparatus and Measurement
In our experiments, an EyeLink1000 eye tracker (SR Research Ltd., Oakville, ON, Canada) was used to record the eye movement data of the subjects. The sampling rate was 2000 Hz, the display screen was 24 inches, and the resolution was 1280 × 1024 pixels. The experiments were carried out in the laboratory of Chiba University to ensure that the external conditions were well controlled (Figure 3).

Figure 3.
Experimental equipment.
3.3.1. Measures of Eye Movement
Data were collected and analyzed after the test using Eye Link Data View software version 4.3. Three eye movement indicators were selected for this study: total duration of fixation (TFD), fixation count (FC), and pupil size (PS) [42]. Table 1 provides the specific meanings and definitions of these indicators. These metrics from the foundation for quantitative analysis reveal how participants distribute their overall visual attention. Total fixation duration (TFD) represents the cumulative duration of all fixations within a given area of interest (AOI) during the viewing period. It serves as an indicator of cognitive engagement and the extent of information processing, with higher TFD values reflecting more sustained and in-depth visual attention [43]. Fixation count (FC) refers to the number of times a participant’s gaze returns to a specific area of interest (AOI). A higher FC value suggests that the content within that AOI either demands more frequent cognitive reference or elicits greater visual engagement [44].

Table 1.
Eye movement indicators and explanations.
3.3.2. Measures of Learning Outcomes
After subjects viewed the relic materials, we used picture recognition, retention, and transfer tests to measure their information acquisition results. All test items were reviewed and validated by subject matter experts in the museum domain to ensure content relevance and appropriateness. The knowledge assessment comprised two components. The first component was a retention test, designed to evaluate participants’ recall of information explicitly presented in the exhibit display. It consisted of nine questions: six single-answer multiple-choice items (3 points each), one multiple-answer multiple-choice item (3 points per correct response), and two fill-in-the-blank items (3 points each). A student with all the correct answers would score 36 points. All nine questions were closely related to the exhibit content; therefore, the retention tests reflected the impact of the exhibit display form on the cognitive processes of information selection [45]. The second component was a transfer test, aimed at assessing participants’ ability to apply the acquired information to novel situations not directly addressed in the task. This section reflects higher-order cognitive processes, such as organization and integration of knowledge [45], and includes four open-ended questions requiring the application of learned concepts to new contexts. According to [13,46], retention test scores and fixation duration are markers of selecting information, whereas the number of transitions between text and picture areas and transfer test scores indicate organizing and integrating information. Since the retention tests in this study also involve the correct association of picture and text information, we also considered it as a measurement of the latter to some extent.
3.4. Procedure
The experimental procedure consisted of four sequential phases (Figure 4) and lasted approximately 20 min per participant. In the first phase, participants were provided with a brief overview of the study and signed an informed consent form. In the second phase, they completed a set of questionnaires comprising demographic information and assessments related to cognitive style. To classify the participants as either visualizers or verbalizers, we used a version of the Verbal Visual Learning Style Rating questionnaire (VVLSR) [26] and the Verbalizer-Visualizer Questionnaire (VVQ) [47]. In the third phase, participants proceeded to the experimental area, where the eye-tracking task was conducted. In the final phase, immediately following the eye-tracking session, participants completed a knowledge assessment and the NASA Task Load Index (NASA-TLX) to evaluate perceived cognitive load.
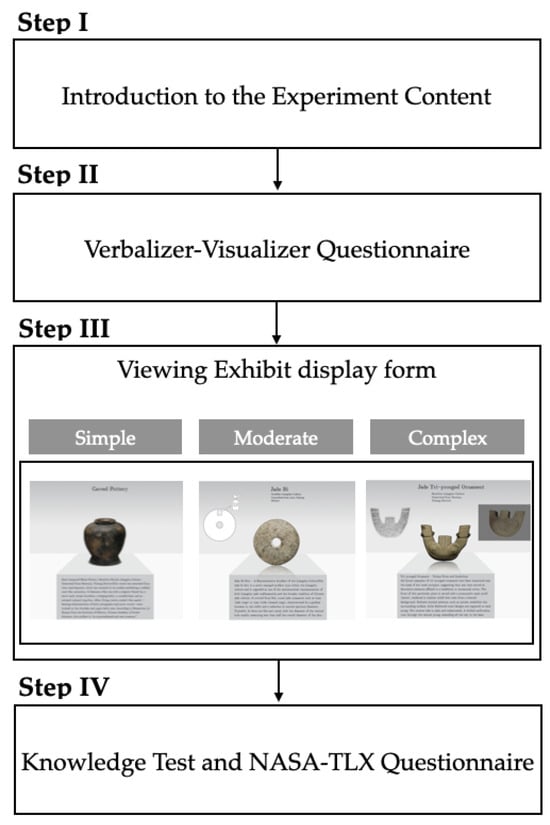
Figure 4.
Flow chart of the experiment.
In preparation for the eye-tracking experiment, participants were instructed to remove their glasses to ensure accurate calibration. Following calibration, each participant independently viewed a randomized sequence of stimulus images presented in full-screen mode. The experiment was conducted in silence to minimize auditory distractions. To control for extraneous variables, participants were seated at a fixed distance of 75 cm from the display screen, and no time constraints were imposed on image viewing. Throughout the session, participants were required to maintain a high level of concentration on the visual stimuli, thereby minimizing the influence of memory effects, emotional responses, or other potential confounding factors related to attention allocation and cognitive processing. The entire procedure lasted approximately 20 min (Figure 5).
Figure 5.
Experiment Process.
3.5. Data Analysis
Data analysis was performed on 54 subjects with valid data, where eye movement data were analysed and data processed using Eyelink Data View. Statistical analysis was conducted using Jamovi (Version 2.6) software. To examine how cognitive style interacts with display complexity in shaping visual attention patterns, we conducted a 2 × 3 repeated-measures ANOVA. The between-subjects factor was cognitive style (visualizer vs. verbalizer), and the within-subjects factor was display condition, which included three levels of multimodal interface complexity: Condition 1 (simple), Condition 2 (moderate), and Condition 3 (complex), as shown in Figure 6. The primary dependent variables were total fixation duration (TFD) and fixation count (FC), representing the intensity and frequency of visual attention. It was hypothesized that visualizers would exhibit a significant increase in TFD and FC as visual complexity increased, reflecting greater engagement with multimodal content. In contrast, verbalizers were expected to show relatively stable fixation patterns across the three conditions. To assess participants’ performance on the reading task, their written responses to post-reading knowledge questions were evaluated and converted into quantitative scores. To address Research Question 3, lag sequential analysis (LSA) was conducted using GSEQ 5.1 (Mangold International GmbH, Arnstorf, Germany). Participants’ scan path data were transformed into sequences of fixation transitions between predefined areas of interest (AOIs). These transitions were subsequently analyzed to compute z-scores and transition probabilities across the five AOIs. The resulting metrics enabled a comparative examination of visual transition patterns between the visualizer and verbalizer groups. In accordance with conventional thresholds, a z-value exceeding 1.96 was considered statistically significant, indicating a non-random, systematic transition between AOIs.

Figure 6.
Definition of areas of interest (AOIs) for exhibit display form.
4. Results
4.1. Descriptive Results
Table 2 presents the demographic distribution of participants across the two cognitive style groups. In terms of gender, women constituted the majority in both groups, accounting for 70.6% of visualizers and 85.7% of verbalizers. The age distribution was heavily skewed toward the 18–25 range (88.2% for visualizers; 95.2% for verbalizers), with only a small proportion of participants in the 26–30 range. Regarding educational attainment, most participants were undergraduates (82.4% and 85.7% for visualizers and verbalizers, respectively), while graduate-level participants were relatively few. Psychology was the most frequently reported major in both groups (55.9% and 52.4%), followed by education (26.5% and 33.3%). Other majors, including archeology, history, and unrelated fields, were represented by a small minority of participants.
Table 2.
Demographic characteristics.
4.2. Effects of Cognitive Style and Display Form Complexity on Visual Attention
To investigate how individuals with different cognitive styles (visualizer vs. verbalizer) allocate visual attention under varying levels of exhibition complexity, an RM-ANOVA was performed on TFD, with cognitive style as the between-subjects factor and exhibition condition (C1: low-complexity, C2: moderate-complexity, C3: high-complexity) as the within-subjects factor. The analysis shown in Table 3 revealed a significant main effect of cognitive style, F(1, 51) = 5.48, p = 0.023, indicating that visualizers exhibited significantly longer TFD times than verbalizers across all conditions, suggesting a generally greater engagement with visual information. A significant main effect of exhibition condition was also observed, F(2, 102) = 3.38, p = 0.038, demonstrating that increases in display complexity were associated with enhanced visual attention. However, the interaction between cognitive style and condition was not significant, F(2, 102) = 0.81, p = 0.448, suggesting that while both cognitive style and interface complexity independently influenced visual engagement, cognitive style did not significantly moderate the effect of condition on dwell time. These results collectively indicate that visualizers and verbalizers differ in overall attentional allocation and that richer visual environments promote increased attention regardless of cognitive preference.
Table 3.
RM-ANOVA results of eye movement data for different exhibit display formats.
Given the theoretical relevance of individual differences in multimedia learning, we further examined the estimated marginal means (Table 4) to explore potential trends underlying the non-significant interaction. Visual inspection of the estimated marginal means plot revealed consistent trends across conditions: visualizers demonstrated progressively longer dwell times as display complexity increased from C1 to C3 (M = 25.2, 26.9, and 29.1, respectively), whereas verbalizers showed only marginal increases across the same conditions (M = 18.5, 20.1, and 20.8). Although this trend did not reach statistical significance as an interaction, it suggests that visualizers may benefit more from visually enriched interfaces compared to verbalizers, whose attentional engagement appears less sensitive to interface complexity.
Table 4.
Estimated marginal means for cognitive style and condition.
A linear mixed model was conducted to examine the effects of cognitive style (visualizer vs. verbalizer) and AOI type (title, text, pic, object, video) on pupil size, with subject specified as a random effect (Table 5). The results revealed a significant main effect of AOI Type, F(4, 13466.6) = 44.99, p < 0.001, indicating that pupil size differed across types of visual–verbal display elements. No significant main effect of cognitive style was found, F(1, 42.1) = 0.06, p = 0.811. Importantly, the interaction between AOI type and cognitive style was significant, F(4, 13466.6) = 16.12, p < 0.001, suggesting that visualizers and verbalizers exhibited distinct pupil responses depending on the specific type of AOI.
Table 5.
Fixed-effects omnibus test results for cognitive style and AOI type on pupil size.
4.3. Lag Sequential Analysis Results
To investigate whether individuals with different cognitive styles exhibit systematic differences in gaze behavior under Condition 3—the condition characterized by the highest level of visual information complexity—lag sequential analysis (LSA) was conducted. In this analysis, each fixation location was treated as a discrete event, and each transition between fixations was regarded as an action. LSA was employed to quantify the temporal structure of fixation sequences for both the visualizer and verbalizer groups. Table 6 presents the z-values derived from the LSA, indicating the statistical significance of transitions between areas of interest (AOIs). A z-value greater than 1.96 denotes a significant fixation transition from the AOI in the corresponding row to the AOI in the column, suggesting non-random, systematic shifts in visual attention.
Table 6.
Z-values from LSA results for fixation transitions of the two groups.
4.3.1. The Influence of Cognition Style on Fixations and Pupil Size
To facilitate a comparative analysis of fixation transition patterns across groups, Figure 7 visualizes the gaze behavior of visualizers and verbalizers, enabling clearer interpretation of group-specific viewing strategies under high-complexity visual conditions. AOIs were used in this study. The arrows indicate the directions of significant aggregate transitions. The line on the arrow represents the cognitive style group (visualizer/verbalizer). Under each area label, the mean, standard deviation, and bootstrapped 95% confidence interval of total fixation duration and average pupil size are shown. For total fixation duration, the mean proportion, in percentage, of fixation durations out of the grand total fixation durations covering the entire workstation, is also presented.
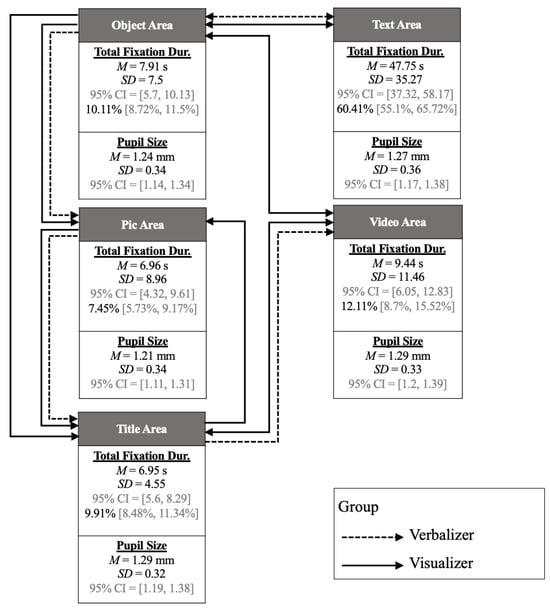
Figure 7.
Fixation duration and pupil-size metrics across AOIs for visualizer and verbalizer groups.
Across both groups, the text area commanded the longest TFD (M = 47.75 s, SD = 35.27; 95% CI [37.32, 58.17]) and the largest pupil diameters (M = 1.27 mm, SD = 0.36; 95% CI [1.17, 1.38]), indicating that verbal descriptions elicited the greatest cognitive effort. In contrast, the title area showed the shortest fixations (M = 6.55 s, SD = 4.55; 95% CI [5.06, 8.29]) and smallest pupil sizes (M = 1.29 mm, SD = 0.32; 95% CI [1.19, 1.38]). The object, picture, and video areas yielded intermediate durations (object: M = 7.91 s, SD = 7.5; picture: M = 6.96 s, SD = 8.96; video: M = 9.44 s, SD = 11.46) and moderate pupil responses (1.21–1.29 mm), reflecting balanced visual and textual processing demands. A fixation transformation diagram is shown based on the adjusted residual results of the two groups’ fixation. The fixation transition diagram revealed distinct patterns of visual exploration between cognitive style groups. Visualizers demonstrated a distributed scanning strategy with transitions among all AOIs, particularly favoring routes from object and title areas to text and video zones. In contrast, verbalizers exhibited a more focused pattern, primarily cycling between text and video AOIs, suggesting a linguistically driven attention allocation. Furthermore, the longest fixation durations and largest pupil sizes were observed in the text area, indicating it served as the central locus of semantic processing across both groups. These findings underscore the interplay between cognitive style and information modality in shaping visitor engagement with multimodal museum displays.
4.3.2. Lag-Sequential Gaze Transition Networks
The visualizer group exhibited significantly higher visual attention toward the object AOI, which served as the central node in their visual exploration network (Figure 8). Notably, fixation transitions between object and text were the most frequent (13.02 and 7.99), suggesting that visualizers actively engaged in cross-modal information integration by referencing textual information to complement the understanding of object features. The object AOI demonstrated the strongest visual saliency, showing consistently high transition frequencies with all other AOIs (label, picture, video, text), indicating its role as a visual anchor for systemic information integration. Additionally, moderate transition frequencies were observed between label and video (7.31 and 4.24), further illustrating the group’s tendency to connect dynamic audiovisual content with static referential cues. The verbalizer group demonstrated a more streamlined visual transition pattern. Their gaze behavior was primarily concentrated on object–text (6.94 and 2.62) and object–picture (5.61) transitions, indicating a preference for efficient and direct information processing. This suggests a cognitive style focused on quickly extracting meaning through clear, unambiguous content channels. Video interacted with the object in a unidirectional manner (4.22), implying that video content was used as a supplementary rather than integrative resource. Additionally, label transitions were minimal (2.18), highlighting the limited role of labels in the verbalizer group’s visual strategy.
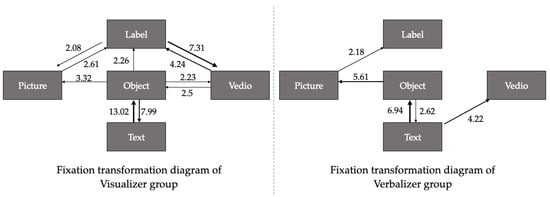
Figure 8.
Fixation transformation of the visualizer and verbalizer groups.
4.4. Correlation Analysis Results
To examine the relationships among gaze behavior and cultural knowledge acquisition (KA) and cognition load, Pearson correlation coefficients were computed for fixation counts (FC) and total fixation durations (TFD) across verbal and visual AOIs (Table 7). Pearson correlation analysis was conducted to explore the relationships among subjective cognitive load (NASA-TLX), eye-tracking metrics, and knowledge acquisition (KA). The results indicated no significant correlation between NASA-TLX and any of the eye-tracking indices (all p > 0.19), suggesting that self-reported workload was not associated with participants’ fixation duration or count on either visual or verbal AOIs. Knowledge acquisition (KA) was also not significantly correlated with any eye-tracking metric, including TFD_Verbal (r = 0.023, p = 0.871), TFD_Visual (r = 0.079, p = 0.579), FC_Verbal (r = 0.095, p = 0.504), or FC_Visual (r = 0.074, p = 0.602). Similarly, no significant association was observed between KA and NASA-TLX (r = 0.193, p = 0.163), indicating that cognitive load did not directly impact factual recall performance in this context.
Table 7.
Correlation results between viewing performance and visual attention.
5. Discussion
5.1. Effects of Cognitive Style and Display Form Complexity on Visual Attention
This study examined how cognitive style influences visual attention across exhibition interfaces of varying complexity. The significant main effect of display condition indicates that increasing interface complexity—via the integration of diagrams, multimedia, and layered content—enhanced overall visual attention. This supports the Cognitive Theory of Multimedia Learning [26], which suggests that learning is facilitated when verbal and visual inputs are meaningfully combined. Although excessive complexity can induce cognitive overload [48], the results suggest that within the tested range, added complexity increased rather than impeded engagement.
A significant main effect of cognitive style was also observed: Visualizers consistently demonstrated longer dwell times than verbalizers, regardless of interface type. This aligns with prior findings [26,49] and reinforces the idea that visualizers are more attuned to processing spatial and graphical information. These results highlight cognitive style as a stable individual difference shaping attention allocation in visually mediated learning environments, such as museum exhibitions. While the interaction between cognitive style and display complexity was not statistically significant, descriptive trends suggest potential differentiation in attentional patterns. Visualizers showed increased fixation durations on visually rich displays, whereas verbalizers maintained relatively consistent attention across all complexity levels. Though not conclusive, these trends are in line with prior evidence that the impact of cognitive style is often modality- and task-specific [26].
The results revealed a significant main effect of AOI type on pupil size, indicating that different types of exhibition content evoked varying levels of visual–cognitive load. Specifically, text- and video-based elements elicited larger pupil dilations, which are commonly interpreted as physiological indicators of increased mental effort and cognitive processing [50]. This supports the notion that content modality plays a critical role in shaping attentional and cognitive engagement in multimedia environments [51]. In contrast, the main effect of cognitive style was not statistically significant, suggesting that visualizers and verbalizers, on average, did not differ in their overall cognitive load. However, the significant interaction between AOI type and cognitive style suggests that individual differences in cognitive style influenced the way participants processed specific types of content. For instance, verbalizers showed stronger pupil dilation in text-based AOIs compared to visualizers, indicating a heightened processing demand aligned with their linguistic preference. Conversely, visualizers maintained relatively stable or lower cognitive load across visual content types. This interaction highlights the importance of cognitive style in mediating not only perceptual strategies but also physiological responses to information processing, particularly in environments rich in multimodal stimuli [48].
Taken together, these findings highlight the imperative for cognitively adaptive exhibition design that accounts for individual differences in users’ cognitive preferences and processing styles. Instead of relying on standardized interfaces, museums and cultural institutions may benefit from personalized presentation modes—such as “visual-first” or “text-first” layouts—that align with visitors’ cognitive styles. Such adaptive strategies could reduce cognitive mismatches, optimize attentional allocation, and enhance interpretive engagement. Ultimately, tailoring content to user-specific cognitive characteristics may foster deeper learning, more meaningful cultural experiences, and broader accessibility in heritage environments.
5.2. Patterns Differential Gaze Patterns and Integration Strategies Across Cognitive Styles
This study employed lag sequential analysis to examine fixation transition patterns between cognitive style groups during engagement with multimodal exhibition displays. The results revealed distinct attentional and processing strategies between visualizers and verbalizers.
Visualizers demonstrated a complex and interconnected gaze pattern, frequently shifting attention across object, text, label, and video AOIs. This exploratory behavior suggests a strong tendency toward cross-modal integration, aligning with prior studies that highlight visualizers’ proficiency in navigating and synthesizing complex visual–spatial information [27,52]. In contrast, verbalizers exhibited a more linear and selective gaze pattern, focusing primarily on direct transitions between object and text AOIs. Their reduced transition frequency and minimal engagement with supplementary media suggest a linguistically oriented processing style, consistent with existing findings that verbalizers prefer structured, text-driven interfaces and show limited use of non-verbal elements [53,54].
These findings reaffirm the influence of cognitive style on visual behavior in cultural heritage learning contexts and support a growing body of research on individual differences in multimedia learning [55]. From a design perspective, the results emphasize the value of adaptive exhibition strategies. For visualizers, interfaces should support dynamic interactivity and explicit visual–verbal linkages to promote deeper content integration. For verbalizers, designs incorporating clear textual explanations and salient object–label pairings may enhance information clarity and reduce cognitive load. Aligning exhibition design with cognitive processing preferences can foster more inclusive, personalized, and effective museum experiences, improving both visitor engagement and learning outcomes in complex multimodal environments.
5.3. Correlation Between Viewing Performance and Visual Attention
This study explored the association between viewing task performance and visual attention and found no significant correlation between knowledge acquisition scores and standard eye-tracking metrics. These findings suggest that memory retention in prospective museum visitors may not be directly determined by the quantity or distribution of visual attention. Rather, the ability to recall information may be more closely influenced by prior knowledge or individual encoding strategies employed during the learning process. This interpretation aligns with Cognitive Load Theory, which emphasizes that the effectiveness of information retention is contingent upon the allocation of cognitive resources and the strategic organization of information, rather than the mere intensity or frequency of fixations [48,56]. One possible explanation is that participants adopted compensatory strategies such as selective reading or prior knowledge activation, which may have mitigated the need for extensive visual engagement. Furthermore, the absence of a relationship between NASA-TLX and eye-tracking metrics reinforces the notion that self-reported load does not necessarily align with externally observable attentional behaviors, especially in low-stakes environments like museum contexts.
6. Conclusions
6.1. Findings of the Study
This study examined the influence of cognitive style on visual attention and information navigation within multimodal museum exhibition environments. While contemporary exhibitions increasingly integrate text, imagery, artifacts, and video, limited empirical research has addressed how individual differences—particularly the distinction between visualizers and verbalizers—affect attentional allocation and interpretive strategies. Utilizing eye-tracking methodology, a controlled experiment was conducted in which participants viewed six artifacts presented under three display conditions of varying informational complexity. Participants’ performance was closely associated with their visual behavior, which exhibited distinct patterns between visualizers and verbalizers. This study thus provides empirical evidence that individuals with differing visualizer–verbalizer cognitive styles adopt divergent strategies when engaging in visually exploratory cultural heritage tasks. These strategic variations are manifested in their gaze behavior and contribute to disparities in content comprehension.
The results revealed that visualizers exhibited increased fixation durations and more complex gaze transitions as visual complexity rose, whereas verbalizers maintained relatively stable and text-centered strategies across conditions. Cognitive style significantly influenced both the spatial distribution and temporal flow of visual attention, suggesting divergent meaning-making pathways in response to multimodal content. This study emphasizes that clearly identifying and discussing the museum’s target audience in terms of cognitive styles (e.g., visualizer–verbalizer) enables the design of personalized cultural heritage experiences. Such targeted approaches can effectively enhance content comprehension and address potential learning disparities among diverse visitor groups, thereby optimizing visitor engagement tailored specifically to their cognitive characteristics.
6.2. Design Strategy for Cognition-Based Exhibit Display
Drawing on the analysis of visual preferences and cognitive styles, this study proposes a set of strategies aimed at enhancing the visual and experiential quality of exhibition formats. These recommendations are intended to support the development of more cognitively aligned display environments, thereby improving visitor engagement and overall interpretive experience.
(1) To support cognition-centered exhibition design, it is essential to implement regular collection of visitor evaluation data to quantitatively assess the effectiveness of display formats. In particular, eye-gaze metrics can serve as key components of a cognitive profiling framework, facilitating both the implicit inference of users’ cognitive characteristics and the delivery of personalized visualizations tailored to individual processing preferences. Such data-driven strategies contribute to the iterative optimization of exhibition interfaces, ensuring enhanced interpretive effectiveness and user engagement.
(2) In exhibition design, optimizing visual engagement requires aligning the presentation format with the intrinsic characteristics of the artifacts and the perceptual needs of the target audience. To mitigate cognitive overload, information should be structured in a hierarchically organized and perceptually accessible manner, balancing richness of content with clarity of layout. Strategic modulation of informational complexity can enhance attentional focus, facilitate knowledge acquisition, and support a more efficient interpretive experience.
Museums should adopt cognition-centered applications to enhance visitor experiences by offering personalized cultural-heritage interpretation aligned with individual cognitive styles and preferences. Such an approach enables interdisciplinary stakeholders, including curators, educators, guides, and exhibition designers, to develop targeted activities that effectively address visitors’ specific cognitive needs. Consequently, visitors can experience reduced cognitive load and improved comprehension of exhibition content, thereby facilitating more meaningful and engaging interactions with cultural heritage resources.
7. Limitations and Further Study
As a result of exploring psychological experimental methods in visitor studies, this study has some relevant deficiencies. First, the present study exclusively recruited Chinese college students, thereby limiting the diversity of visitor profiles represented in the sample. Prior knowledge is recognized as a critical determinant of learning outcomes [57], and its influence cannot be fully controlled by selecting participants solely based on their academic major. Given the widespread role of museums in public education, it is challenging to eliminate the confounding effects of prior knowledge in experimental studies employing museum-related materials. Consequently, future research should incorporate more rigorous and context-sensitive measures of prior knowledge to better account for its impact on learning performance. Second, this study employed exhibition content based on Liang Zhu artifacts, which presents limitations in terms of the diversity and generalizability of display categories. The findings may not fully extend to other types of cultural heritage exhibits with different thematic or representational characteristics. Additionally, while this study examined variations in exhibition formats, the design complexity and combinatorial possibilities of display elements remain extensive. Future research should adopt a more comprehensive approach by incorporating a broader range of exhibition components and representational styles across different cultural contexts.
Although technological advancements allow for increasingly complex combinations of exhibition modalities, this research focused primarily on visually based display formats under controlled laboratory conditions. However, cultural heritage exhibitions in real-world settings often involve multimodal interactions, including auditory elements and spatially embedded experiences such as digital storytelling applications [58] and location-based games [59]. While the laboratory condition eye-tracking experiment ensured experimental precision, it may not fully capture the complexity of real-world museum experiences, where physical movement, social presence, and contextual engagement play important roles [60]. To enhance ecological validity, future studies could integrate eye-tracking with scenario-based tasks in actual museum settings, enabling a more nuanced and realistic evaluation of visitor attention and behavior in situ.
Moreover, recent scholarship in the cultural heritage domain has emphasized the significance of visitors’ emotional engagement [61], an aspect that warrants further investigation in conjunction with cognitive style differences. Additionally, integrating eye-tracking data with other physiological measures (e.g., galvanic skin response, heart rate) or scenario-based interactive tasks may offer a more comprehensive and nuanced understanding of visitor engagement and cognitive processing. Expanding both the range of display formats and visitor characteristics considered will enhance the depth and precision of experiential evaluations in future exhibition design research.
Future exhibition design should consider cognition-based visualizations to support visitors with diverse cognitive styles in effectively interpreting the visual information presented in cultural heritage environments. By aligning visual presentation strategies with individual cognitive processing preferences, such designs can enhance comprehension and engagement across heterogeneous audiences.
Author Contributions
Conceptualization, W.S. and K.O.; methodology, W.S.; software, W.S.; validation, W.S. and M.Z.; formal analysis, W.S.; investigation, W.S.; resources, W.S. and M.Z.; data curation, W.S. and M.Z.; writing—original draft preparation, W.S.; writing—review and editing, W.S.; visualization, W.S.; supervision, K.O.; project administration, W.S. and K.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| TFD | Total fixation duration |
| FC | Fixation Count |
| PS | Pupil Size |
Appendix A
Table A1.
Translation of stimuli.
Table A1.
Translation of stimuli.
| Artifacts | Information |
| Incised Symbol Pottery Jar | Neolithic Liang Zhu culture ceramic vessel, excavated from Nanhu in Yuhang. This sand-tempered, black-fired pottery was buried in riverine sands, imparting a rust-red patina to its surface. The vessel has a flat rim with a slightly everted mouth, a short neck, broad shoulders, a globular body, a rounded base, and an outward-splaying ring foot. After firing, twelve pictographic-ideographic symbols were incised around its shoulder and upper abdomen. Professor Li Xueqin of the Institute of History, Chinese Academy of Social Sciences, has hailed it as “an unprecedented treasure.” |
| Jade Bird Pendant | Neolithic Liang Zhu culture jade artifact, recovered from Fanshan in Yuhang. The pendant takes the form of a flat-spread bird in mid-flight, with a pointed beak, short tail, and outstretched wings. Its eyes are rendered as concentric circles, and the ridge between them is accentuated by lateral flaking. The back slopes obliquely toward each wing via precise cutting, and several transverse cut lines run between the head and back. Two transverse boreholes pierce the back, indicating suspension. In Liangzhu contexts, small, finely wrought pendants—shaped as crescents, plaques, triangles, hemispheres, birds, or turtles—were often strung with jade tubes or beads to form necklaces, bracelets, or anklets. |
| Jade Bi Disc | Neolithic Liang Zhu culture ritual disc, unearthed at Anxi in Yuhang. The bi disc is a hallmark of Liang Zhu—and indeed early Chinese—jade craftsmanship, evolving from flat, circular rings (yuanyuan) into discs with widening rims and reduced bore diameters. Typically, the disc is flat and circular, with a central aperture less than half the overall diameter. Most examples are unadorned, though a few bear bird-pillar or bird-symbol carvings. As one of the most prevalent imperial jades of Liang Zhu, bi discs are typically interred on or below the chest of the tomb owner through to the feet. They are conventionally interpreted as ritual implements for sky worship; other scholars view them as emblems of material wealth. |
| Jade Cong | Neolithic Liang Zhu culture cylindrical jade, discovered at Fanshan in Yuhang. The cong is a tube-shaped jade vessel featuring a circular interior and a square exterior; its function has been variously ascribed to connecting heaven and earth or venerating deities. This particular cong is exceptionally large and broad, weighing approximately 6500 g, and is richly decorated—earning it the sobriquet “Cong King.” The outer square faces taper from a larger top to a smaller base, with a pair of oppositely drilled round holes at mid-height. Each of the four faces bears a recessed vertical groove within which, in both upper and lower registers, a detailed anthropomorphic-zoomorphic mask is carved in shallow relief and line engraving; the deity wears a feathered headdress and astride a mythical beast. |
| Trident-Shaped Jade Ornament | Neolithic Liang Zhu culture jade object, excavated from Yaoshan in Yuhang. All known trident-shaped pieces have been recovered from tombs positioned above the head of the interred, suggesting use as headdress ornaments. This specimen’s obverse bears a beast-mask motif rendered in low relief, with surrounding fine spiral and linear carvings; each tine is incised with feather-crown patterns. The reverse is plain, and the central tine is drilled through to its base, indicating attachment to another element. |
| Jade Scepter Cap | Neolithic Liang Zhu culture jade fitting, from Tomb 12 at Fanshan in Yuhang. The scepter handle was likely of organic material (e.g., wood), now decayed, leaving only the two jade fittings—the “mao” (cap) at the head and the “dui” (terminal) at the base—positioned roughly 55 cm apart, implying an original scepter length of about 60 cm. The cap (“mao”) has flat top and bottom surfaces, the latter pierced by a mortise hole. One lateral section is square in cross section, the opposite side pointed and rounded, producing a curved longitudinal profile—a form of exceptional rarity. |
References
- Ardissono, L.; Kuflik, T.; Petrelli, D. Personalization in Cultural Heritage: The Road Travelled and the One Ahead. User Model. User-Adapt. Interact. 2012, 22, 73–99. [Google Scholar] [CrossRef]
- Raptis, G.E.; Katsini, C. Analyzing Scanpaths From A Field Dependence-Independence Perspective When Playing A Visual Search Game. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, Stuttgart, Germany, 25–29 May 2021; ACM: Berlin, Germany, 2021; pp. 1–7. [Google Scholar]
- Alharthi, S.A.; Raptis, G.E.; Katsini, C.; Dolgov, I.; Nacke, L.E.; Toups Dugas, P.O. Investigating the Effects of Individual Cognitive Styles on Collaborative Gameplay. ACM Trans. Comput.-Hum. Interact. 2021, 28, 1–49. [Google Scholar] [CrossRef]
- Tsianos, N.; Germanakos, P.; Lekkas, Z.; Mourlas, C.; Samaras, G. Eye-Tracking Users’ Behavior in Relation to Cognitive Style within an E-Learning Environment. In Proceedings of the 2009 Ninth IEEE International Conference on Advanced Learning Technologies, Riga, Latvia, 15–17 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 329–333. [Google Scholar]
- Pradnya Sidhawara, A.G.; Wibirama, S.; Adji, T.B.; Kusrohmaniah, S. Classification of Visual-Verbal Cognitive Style in Multimedia Learning Using Eye-Tracking and Machine Learning. In Proceedings of the 2020 6th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 7–8 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Miron, E.; Erez, M.; Naveh, E. Do Personal Characteristics and Cultural Values That Promote Innovation, Quality, and Efficiency Compete or Complement Each Other? J. Organ. Behavior. 2004, 25, 175–199. [Google Scholar] [CrossRef]
- Dillon, A.; Watson, C. User Analysis in HCI—The Historical Lessons from Individual Differences Research. Int. J. Hum.-Comput. Stud. 1996, 45, 619–637. [Google Scholar] [CrossRef]
- Paivio, A. Mental Representations: A Dual Coding Approach; Oxford Psychology Series; Clarendon Press: Oxford, UK, 1990; ISBN 978-0-19-503936-8. [Google Scholar]
- Raptis, G.E.; Fidas, C.; Katsini, C.; Avouris, N. A Cognition-Centered Personalization Framework for Cultural-Heritage Content. User Model. User-Adapt. Interact. 2019, 29, 9–65. [Google Scholar] [CrossRef]
- Falk, J.H.; Dierking, L.D. The Museum Experience Revisited; Routledge: London, UK; Taylor & Francis Group: New York, NY, USA, 2016; ISBN 978-1-61132-044-2. [Google Scholar]
- Hick, W.E. On the Rate of Gain of Information. Q. J. Exp. Psychol. 1952, 4, 11–26. [Google Scholar] [CrossRef]
- Raptis, G.E.; Katsini, C.; Fidas, C.; Avouris, N. Visualization of Cultural-Heritage Content Based on Individual Cognitive Differences. 2018. Available online: https://ceur-ws.org/Vol-2091/paper9.pdf (accessed on 19 August 2025).
- Zheng, X.; Jiang, Y.; Cheng, H.; Nie, A. How to Arrange Texts and Pictures for Online Visitors—Comparing Basic Ceramic Display Forms with Eye Tracking. J. Comput. Cult. Herit. 2024, 17, 1–23. [Google Scholar] [CrossRef]
- Schwan, S.; Dutz, S.; Dreger, F. Multimedia in the Wild: Testing the Validity of Multimedia Learning Principles in an Art Exhibition. Learn. Instr. 2018, 55, 148–157. [Google Scholar] [CrossRef]
- Li, Q.; Luo, T.; Wang, J. The Role of Digital Interactive Technology in Cultural Heritage Learning: Evaluating a Mid-air Gesture-based Interactive Media of Ruihetu. Comput. Animat. Virtual Worlds 2022, 33, e2085. [Google Scholar] [CrossRef]
- Reymond, C.; Pelowski, M.; Opwis, K.; Takala, T.; Mekler, E.D. Aesthetic Evaluation of Digitally Reproduced Art Images. Front. Psychol. 2020, 11, 615575. [Google Scholar] [CrossRef]
- Villani, D.; Morganti, F.; Cipresso, P.; Ruggi, S.; Riva, G.; Gilli, G. Visual Exploration Patterns of Human Figures in Action: An Eye Tracker Study with Art Paintings. Front. Psychol. 2015, 6, 1636. [Google Scholar] [CrossRef]
- Lin, F.; Yao, M. The Impact of Accompanying Text on Visual Processing and Hedonic Evaluation of Art. Empir. Stud. Arts 2018, 36, 180–198. [Google Scholar] [CrossRef]
- Yuan, L.; Cao, Z.; Mao, Y.; Mohd Isa, M.H.; Abdul Nasir, M.H. Age-Related Differences in Visual Attention to Heritage Tourism: An Eye-Tracking Study. J. Eye Mov. Res. 2025, 18, 16. [Google Scholar] [CrossRef]
- Goldberg, J.H. Measuring Software Screen Complexity: Relating Eye Tracking, Emotional Valence, and Subjective Ratings. Int. J. Hum.-Comput. Interact. 2014, 30, 518–532. [Google Scholar] [CrossRef]
- Nisiforou, E.A.; Michailidou, E.; Laghos, A. Using Eye Tracking to Understand the Impact of Cognitive Abilities on Search Tasks. In Universal Access in Human-Computer Interaction: Design for All and Accessibility Practice, Proceedings of the 8th International Conference, UAHCI 2014, Held as Part of HCI International 2014, Heraklion, Greece, 22–27 June 2014; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 46–57. ISBN 978-3-319-07508-2. [Google Scholar]
- Liman, T.G.; Zangemeister, W.H. Scanpath Eye Movements during Visual Mental Imagery in a Simulated Hemianopia Paradigm. J. Eye Mov. Res. 2012, 5. [Google Scholar] [CrossRef]
- Workman, M. Performance and Perceived Effectiveness in Computer-Based and Computer-Aided Education: Do Cognitive Styles Make a Difference? Comput. Hum. Behav. 2004, 20, 517–534. [Google Scholar] [CrossRef]
- Ye, L.; Su, H.; Zhao, J.; Hang, Y. The Impact of Multimedia Effect on Art Learning: Eye Movement Evidence from Traditional Chinese Pattern Learning. Int. J. Art Des. Educ. 2021, 40, 342–358. [Google Scholar] [CrossRef]
- Hu, L.; Shan, Q.; Chen, L.; Liao, S.; Li, J.; Ren, G. Survey on the Impact of Historical Museum Exhibition Forms on Visitors’ Perceptions Based on Eye-Tracking. Buildings 2024, 14, 3538. [Google Scholar] [CrossRef]
- Mayer, R.E.; Massa, L.J. Three Facets of Visual and Verbal Learners: Cognitive Ability, Cognitive Style, and Learning Preference. J. Educ. Psychol. 2003, 95, 833–846. [Google Scholar] [CrossRef]
- Koć-Januchta, M.; Höffler, T.; Thoma, G.-B.; Prechtl, H.; Leutner, D. Visualizers versus Verbalizers: Effects of Cognitive Style on Learning with Texts and Pictures—An Eye-Tracking Study. Comput. Hum. Behav. 2017, 68, 170–179. [Google Scholar] [CrossRef]
- Mehigan, T.J.; Barry, M.; Kehoe, A.; Pitt, I. Using Eye Tracking Technology to Identify Visual and Verbal Learners. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Bitgood, S. An Analysis of Visitor Circulation: Movement Patterns and the General Value Principle. Curator Mus. J. 2006, 49, 463–475. [Google Scholar] [CrossRef]
- Falk, J.H.; Dierking, L.D. Learning from Museums: Visitor Experiences and the Making of Meaning; American Association for State and Local History Book Series; AltaMira Press: Walnut Creek, CA, USA, 2000; ISBN 978-0-7425-0294-9. [Google Scholar]
- Bitgood, S. Museum Fatigue: A Critical Review. Visit. Stud. 2009, 12, 93–111. [Google Scholar] [CrossRef]
- Shi, W.; Ono, K.; Li, L. Cognitive Insights into Museum Engagement: A Mobile Eye-Tracking Study on Visual Attention Distribution and Learning Experience. Electronics 2025, 14, 2208. [Google Scholar] [CrossRef]
- Stein, I.; Jossberger, H.; Gruber, H. Investigating Visual Expertise in Sculpture: A Methodological Approach Using Eye Tracking. J. Eye Mov. Res. 2022, 15, 15. [Google Scholar] [CrossRef]
- Hsieh, Y.-L.; Lee, M.-F.; Chen, G.-S.; Wang, W.-J. Application of Visitor Eye Movement Information to Museum Exhibit Analysis. Sustainability 2022, 14, 6932. [Google Scholar] [CrossRef]
- Jarodzka, H.; Holmqvist, K.; Nyström, M. A Vector-Based, Multidimensional Scanpath Similarity Measure. In Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications—ETRA ’10, Austin, TX, USA, 22–24 March 2010; ACM Press: New York, NY, USA, 2010; p. 211. [Google Scholar]
- Garbutt, M.; East, S.; Spehar, B.; Estrada-Gonzalez, V.; Carson-Ewart, B.; Touma, J. The Embodied Gaze: Exploring Applications for Mobile Eye Tracking in the Art Museum. Visit. Stud. 2020, 23, 82–100. [Google Scholar] [CrossRef]
- Thébault, M.; Dubuis, M.; Raymond, F.; Girveau, B.; Schmitt, D. Short but Meaningful: Visitors’ Experiences Underlying Time Spent Looking at Artworks and Labels. Mus. Manag. Curatorship 2024, 1–32. [Google Scholar] [CrossRef]
- Yi, T.; Chang, M.; Hong, S.; Lee, J.-H. Use of Eye-Tracking in Artworks to Understand Information Needs of Visitors. Int. J. Hum.–Comput. Interact. 2021, 37, 220–233. [Google Scholar] [CrossRef]
- Kiefer, P.; Giannopoulos, I.; Raubal, M. Using Eye Movements to Recognize Activities on Cartographic Maps. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; ACM: New York, NY, USA, 2013; pp. 488–491. [Google Scholar]
- Bailey-Ross, C.; Beresford, A.M.; Smith, D.T.; Warwick, C. Aesthetic Appreciation and Spanish Art: Insights from Eye-Tracking. Digit. Scholarsh. Humanit. 2019, 34, i17–i35. [Google Scholar] [CrossRef]
- Faul, F.; Erdfelder, E.; Lang, A.-G.; Buchner, A. G*Power 3: A Flexible Statistical Power Analysis Program for the Social, Behavioral, and Biomedical Sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef]
- Meghanathan, R.N.; Van Leeuwen, C.; Nikolaev, A.R. Fixation Duration Surpasses Pupil Size as a Measure of Memory Load in Free Viewing. Front. Hum. Neurosci. 2015, 8, 1063. [Google Scholar] [CrossRef] [PubMed]
- Duchowski, A.T. Eye Tracking Methodology: Theory and Practice, 2nd ed.; Springer: London, UK, 2007; ISBN 978-1-84628-608-7. [Google Scholar]
- Bojko, A. Eye Tracking the User Experience: A Practical Guide to Research; Rosenfeld Media: Brooklyn, NY, USA, 2013; ISBN 978-1-933820-10-1. [Google Scholar]
- Ponce, H.R.; Mayer, R.E. An Eye Movement Analysis of Highlighting and Graphic Organizer Study Aids for Learning from Expository Text. Comput. Hum. Behav. 2014, 41, 21–32. [Google Scholar] [CrossRef]
- Wang, X.; Lin, L.; Han, M.; Spector, J.M. Impacts of Cues on Learning: Using Eye-Tracking Technologies to Examine the Functions and Designs of Added Cues in Short Instructional Videos. Comput. Hum. Behav. 2020, 107, 106279. [Google Scholar] [CrossRef]
- Antonietti, A.; Giorgetti, M. The Verbalizer-Visualizer Questionnaire: A Review. Percept. Mot. Ski. 1998, 86, 227–239. [Google Scholar] [CrossRef] [PubMed]
- Sweller, J. Cognitive Load Theory. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 2011; pp. 37–76. [Google Scholar]
- Kozhevnikov, M.; Kosslyn, S.; Shephard, J. Spatial versus Object Visualizers: A New Characterization of Visual Cognitive Style. Mem. Cogn. 2005, 33, 710–726. [Google Scholar] [CrossRef]
- Van Der Wel, P.; Van Steenbergen, H. Pupil Dilation as an Index of Effort in Cognitive Control Tasks: A Review. Psychon. Bull. Rev. 2018, 25, 2005–2015. [Google Scholar] [CrossRef]
- Mayer, R.E.; Fiorella, L. (Eds.) The Cambridge Handbook of Multimedia Learning, 3rd ed.; Cambridge University Press: Cambridge, UK, 2021; ISBN 978-1-108-89433-3. [Google Scholar]
- Ulcej, D.; Podlesek, A. Evaluation of Information Visualization in Digital Intelligence Product. J. Strateg. Secur. 2024, 17, 89–112. [Google Scholar] [CrossRef]
- Trofanenko, B.M. The Educational Promise of Public History Museum Exhibits. Theory Res. Soc. Educ. 2010, 38, 270–288. [Google Scholar] [CrossRef]
- Florax, M.; Ploetzner, R. What Contributes to the Split-Attention Effect? The Role of Text Segmentation, Picture Labelling, and Spatial Proximity. Learn. Instr. 2010, 20, 216–224. [Google Scholar] [CrossRef]
- Austin, K.A. Multimedia Learning: Cognitive Individual Differences and Display Design Techniques Predict Transfer Learning with Multimedia Learning Modules. Comput. Educ. 2009, 53, 1339–1354. [Google Scholar] [CrossRef]
- Papathanassiou-Zuhrt, D. Cognitive Load Management of Cultural Heritage Information: An Application Multi-Mix for Recreational Learners. Procedia—Soc. Behav. Sci. 2015, 188, 57–73. [Google Scholar] [CrossRef]
- Shapiro, A.M. How Including Prior Knowledge As a Subject Variable May Change Outcomes of Learning Research. Am. Educ. Res. J. 2004, 41, 159–189. [Google Scholar] [CrossRef]
- Not, E.; Petrelli, D. Empowering Cultural Heritage Professionals with Tools for Authoring and Deploying Personalised Visitor Experiences. User Model. User-Adapt. Interact. 2019, 29, 67–120. [Google Scholar] [CrossRef]
- Vassilakis, K.; Charalampakos, O.; Glykokokalos, G.; Kontokalou, P.; Kalogiannakis, M.; Vidakis, N. Learning History Through Location-Based Games: The Fortification Gates of the Venetian Walls of the City of Heraklion. In Interactivity, Game Creation, Design, Learning, and Innovation, Proceedings of the 6th International Conference, ArtsIT 2017, and Second International Conference, DLI 2017, Heraklion, Greece, 30–31 October 2017; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer International Publishing: Cham, Switzerland, 2018; pp. 510–519. ISBN 978-3-319-76907-3. [Google Scholar]
- Eghbal-Azar, K.; Widlok, T. Potentials and Limitations of Mobile Eye Tracking in Visitor Studies: Evidence From Field Research at Two Museum Exhibitions in Germany. Soc. Sci. Comput. Rev. 2013, 31, 103–118. [Google Scholar] [CrossRef]
- Perry, S.; Roussou, M.; Economou, M.; Young, H.; Pujol, L. Moving beyond the Virtual Museum: Engaging Visitors Emotionally. In Proceedings of the 2017 23rd International Conference on Virtual System & Multimedia (VSMM), Dublin, Ireland, 31 October–2 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).