

Moving Toward Automated Construction Management: An Automated Construction Worker Efficiency Evaluation System †


Abstract
1. Introduction
2. Related Work
2.1. Labor Efficiency Evaluation in Construction
2.2. Recognition of Construction Worker Activities by Computer Vision
2.3. Construction Scene Theory
2.4. Summary of Literature
3. Methodology
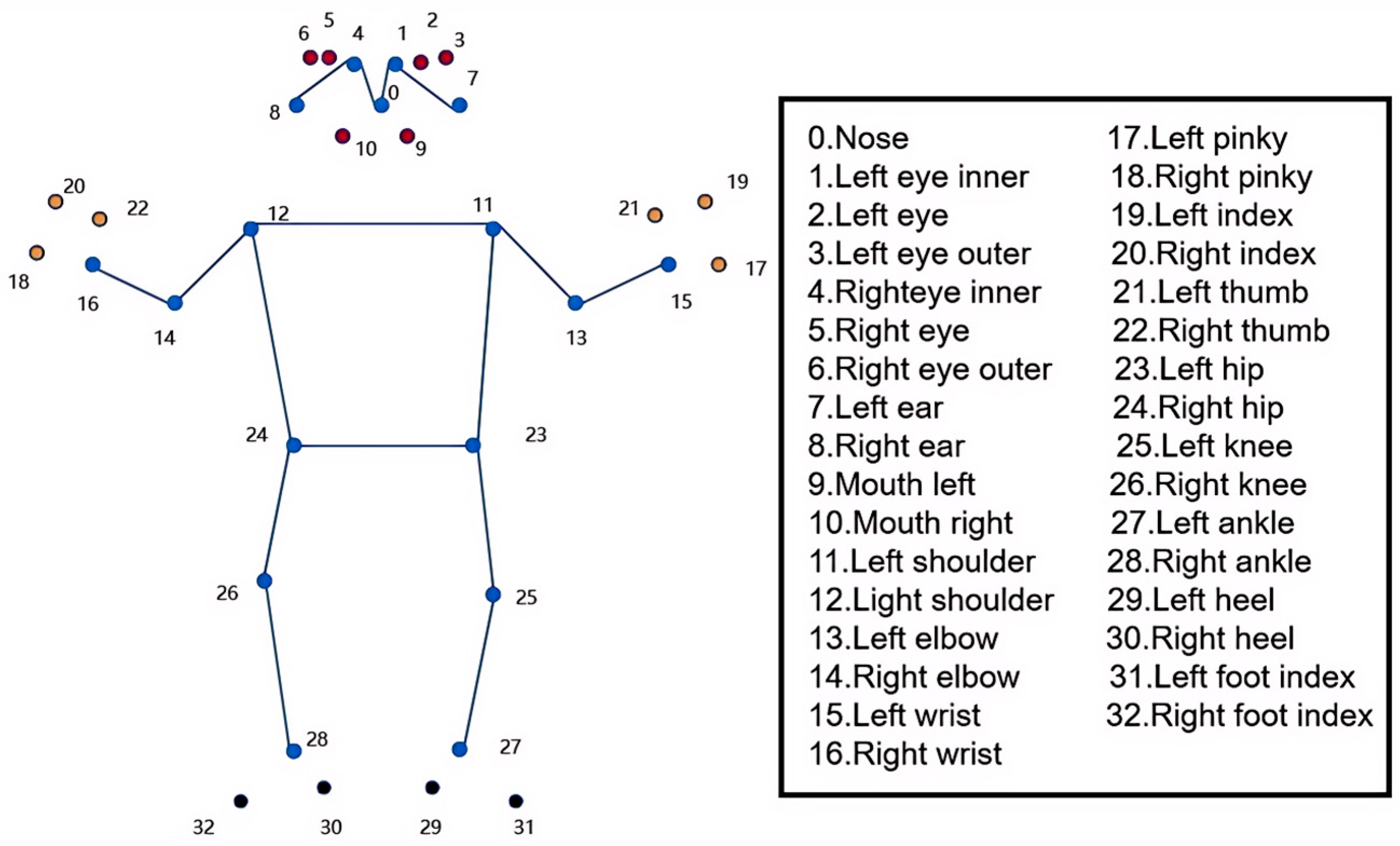
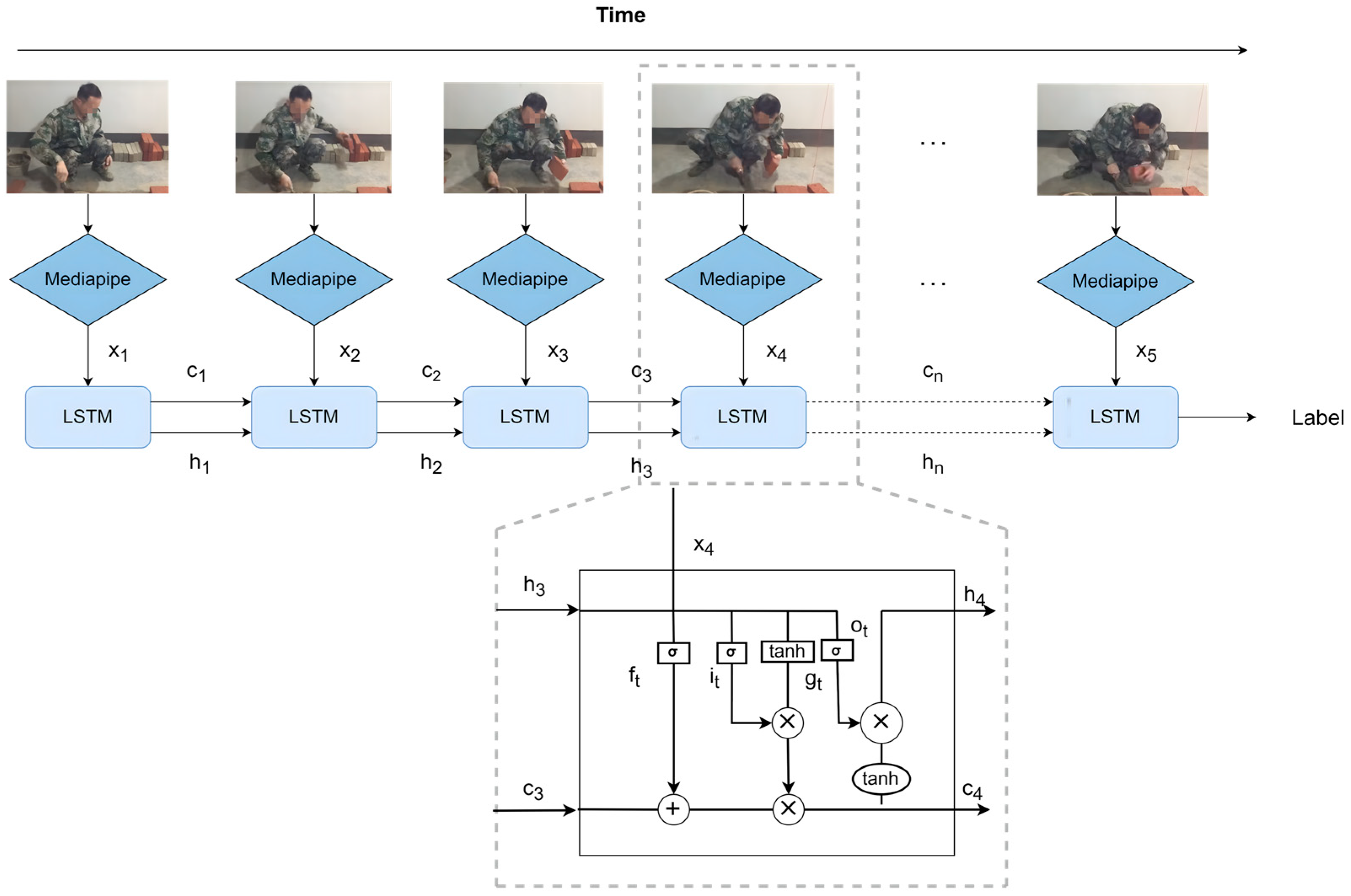
3.1. Extraction and Tracking of Worker Key Points
3.2. The Process of Deconstructing Construction Activity Scenes
3.3. Action Recognition of Time Series Data
3.4. Object Recognition in Scenes
3.5. Comprehensive Framework for Construction Productivity Evaluation
4. Result
4.1. Dataset Production and Preprocessing
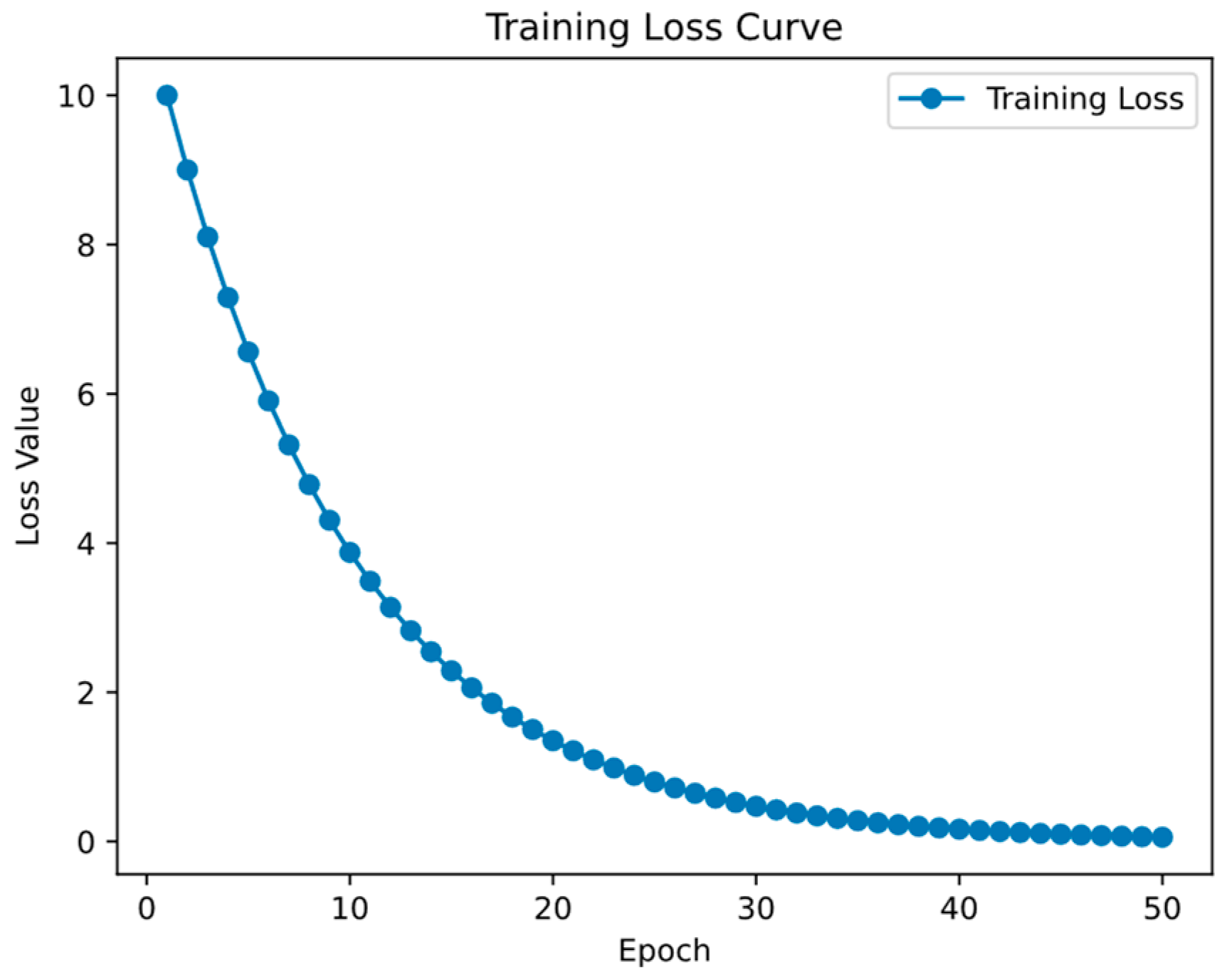
4.2. Action Recognition Model Training
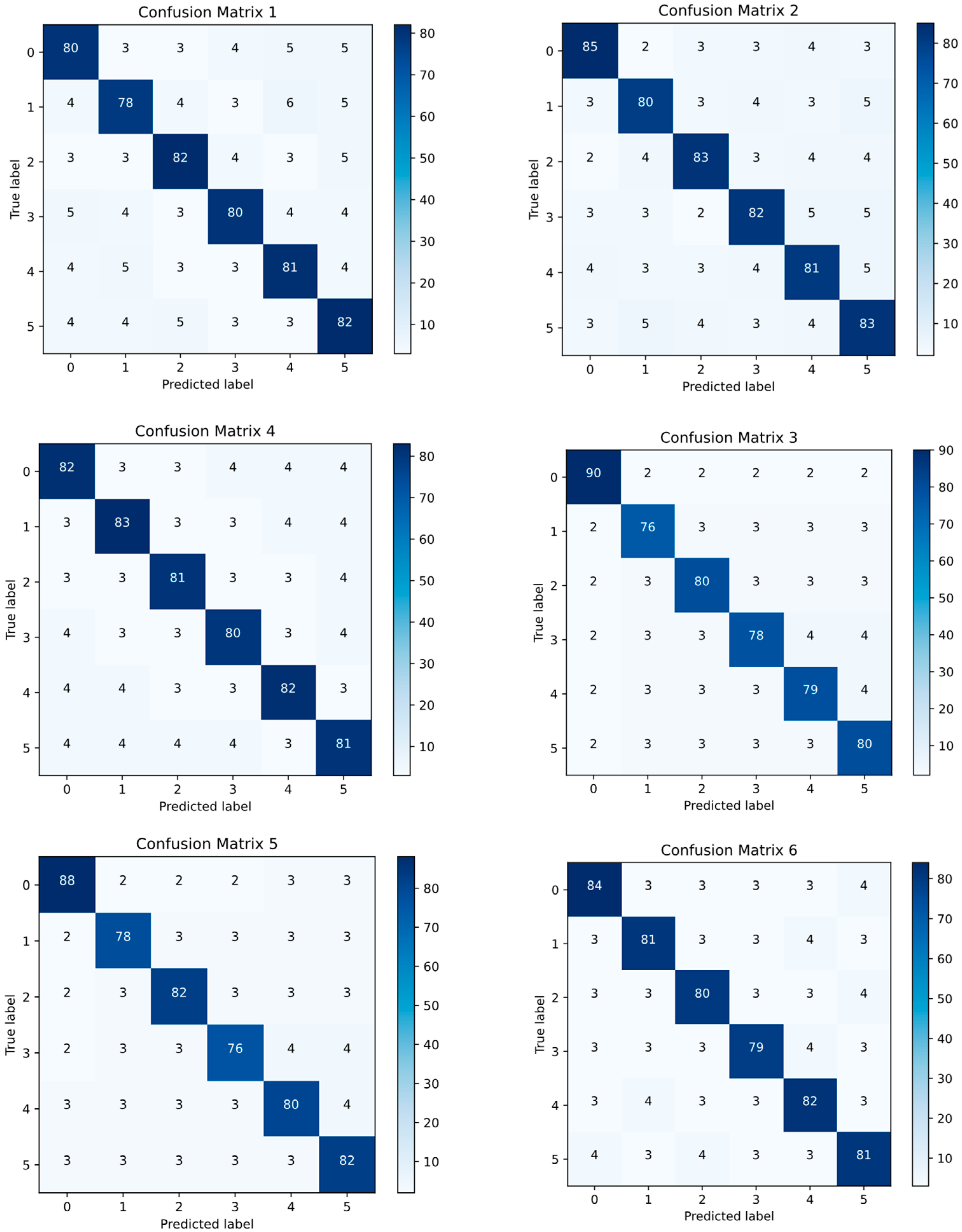
4.3. Model Test Results
4.4. Productivity Analysis
5. Discussion
5.1. Contributions
5.2. Practical Implications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akhavian, R.; Behzadan, A.H. Productivity Analysis of Construction Worker Activities Using Smartphone Sensors. In Proceedings of the 16th International Conference on Computing in Civil and Building Engineering (ICCCBE), Osaka, Japan, 6–8 July 2016; pp. 1067–1074. [Google Scholar]
- Alashhab, S.; Gallego, A.J.; Lozano, M.Á. Efficient Gesture Recognition for the Assistance of Visually Impaired People Using Multi-Head Neural Networks. Eng. Appl. Artif. Intell. 2022, 114, 105188. [Google Scholar] [CrossRef]
- Arshad, S.; Akinade, O.; Bello, S.; Bilal, M. Computer Vision and IoT Research Landscape for Health and Safety Management on Construction Sites. J. Build. Eng. 2023, 76, 107049. [Google Scholar] [CrossRef]
- Bassier, M.; Vergauwen, M. Unsupervised Reconstruction of Building Information Modeling Wall Objects from Point Cloud Data. Autom. Constr. 2020, 120, 103338. [Google Scholar] [CrossRef]
- Chan, A.P.C.; Yi, W.; Wong, D.P.; Yam, M.C.H.; Chan, D.W.M. Determining an Optimal Recovery Time for Construction Rebar Workers after Working to Exhaustion in a Hot and Humid Environment. Build. Environ. 2012, 58, 163–171. [Google Scholar] [CrossRef]
- Gong, J.; Caldas, C.H. Computer Vision-Based Video Interpretation Model for Automated Productivity Analysis of Construction Operations. J. Comput. Civ. Eng. 2010, 24, 252–263. [Google Scholar] [CrossRef]
- Gouett, M.C.; Haas, C.T.; Goodrum, P.M.; Caldas, C.H. Activity Analysis for Direct-Work Rate Improvement in Construction. J. Constr. Eng. Manag. 2011, 137, 1117–1124. [Google Scholar] [CrossRef]
- Zhang, H.; Yan, X.; Li, H. Ergonomic Posture Recognition Using 3D View-Invariant Features from Single Ordinary Camera. Autom. Constr. 2018, 94, 1–10. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, N.; Lu, S. Productivity Model in Hot and Humid Environment Based on Heat Tolerance Time Analysis. Build. Environ. 2009, 44, 2202–2207. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, J.; Kim, J.I.; Kim, J. Lightweight Deep Learning Framework for Recognizing Construction Workers’ Activities Based on Simplified Node Combinations. Autom. Constr. 2024, 158, 105236. [Google Scholar] [CrossRef]
- Sherafat, B.; Ahn, C.R.; Akhavian, R.; Behzadan, A.H.; Golparvar-Fard, M.; Kim, H.; Lee, Y.-C.; Rashidi, A.; Azar, E.R. Automated Methods for Activity Recognition of Construction Workers and Equipment: State-of-the-Art Review. J. Constr. Eng. Manag. 2020, 146, 03120002. [Google Scholar] [CrossRef]
- Dixit, S.; Mandal, S.N.; Thanikal, J.V.; Saurabh, K. Evolution of Studies in Construction Productivity: A Systematic Literature Review (2006–2017). Ain Shams Eng. J. 2019, 10, 555–564. [Google Scholar] [CrossRef]
- Ghodrati, N.; Yiu, T.W.; Wilkinson, S. Unintended Consequences of Management Strategies for Improving Labor Productivity in Construction Industry. J. Saf. Res. 2018, 67, 107–116. [Google Scholar] [CrossRef]
- Alwasel, A.; Sabet, A.; Nahangi, M.; Haas, C.T.; Abdel-Rahman, E. Identifying Poses of Safe and Productive Masons Using Machine Learning. Autom. Constr. 2017, 84, 345–355. [Google Scholar] [CrossRef]
- Luo, X.; Li, H.; Cao, D.; Yu, Y.; Yang, X.; Huang, T. Towards Efficient and Objective Work Sampling: Recognizing Workers’ Activities in Site Surveillance Videos with Two-Stream Convolutional Networks. Autom. Constr. 2018, 94, 360–370. [Google Scholar] [CrossRef]
- Luo, X.; Li, H.; Cao, D.; Dai, F.; Seo, J.; Lee, S. Recognizing Diverse Construction Activities in Site Images via Relevance Networks of Construction-Related Objects Detected by Convolutional Neural Networks. J. Comput. Civ. Eng. 2018, 32, 04018006. [Google Scholar] [CrossRef]
- Alaloul, W.S.; Alzubi, K.M.; Malkawi, A.B.; Al Salaheen, M.; Musarat, M.A. Productivity Monitoring in Building Construction Projects: A Systematic Review. Eng. Constr. Archit. Manag. 2022, 29, 2760–2785. [Google Scholar] [CrossRef]
- Baek, J.; Kim, D.; Choi, B. Deep Learning-Based Automated Productivity Monitoring for on-Site Module Installation in off-Site Construction. Dev. Built Environ. 2024, 18, 100382. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, Z.; Hammad, A. Automated Excavators Activity Recognition and Productivity Analysis from Construction Site Surveillance Videos. Autom. Constr. 2020, 110, 103045. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Y.; Wang, J.; Bouferguene, A.; Al-Hussein, M. Vision-Based Real-Time Process Monitoring and Problem Feedback for Productivity-Oriented Analysis in off-Site Construction. Autom. Constr. 2024, 162, 105389. [Google Scholar] [CrossRef]
- Jacobsen, E.L.; Teizer, J.; Wandahl, S. Work Estimation of Construction Workers for Productivity Monitoring Using Kinematic Data and Deep Learning. Autom. Constr. 2023, 152, 104932. [Google Scholar] [CrossRef]
- Teizer, J.; Cheng, T.; Fang, Y. Location Tracking and Data Visualization Technology to Advance Construction Ironworkers’ Education and Training in Safety and Productivity. Autom. Constr. 2013, 35, 53–68. [Google Scholar] [CrossRef]
- Small, E.P.; Baqer, M. Examination of Job-Site Layout Approaches and Their Impact on Construction Job-Site Productivity. Procedia Eng. 2016, 164, 383–388. [Google Scholar] [CrossRef]
- Qi, K.; Owusu, E.K.; Francis Siu, M.-F.; Albert Chan, P.-C. A Systematic Review of Construction Labor Productivity Studies: Clustering and Analysis through Hierarchical Latent Dirichlet Allocation. Ain Shams Eng. J. 2024, 15, 102896. [Google Scholar] [CrossRef]
- Oral, M.; Oral, E.L.; Aydın, A. Supervised vs. Unsupervised Learning for Construction Crew Productivity Prediction. Autom. Constr. 2012, 22, 271–276. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Khitam, A.F.K.; Tanto, H.H. Construction Worker Productivity Evaluation Using Action Recognition for Foreign Labor Training and Education: A Case Study of Taiwan. Autom. Constr. 2023, 150, 104809. [Google Scholar] [CrossRef]
- Luo, H.; Xiong, C.; Fang, W.; Love, P.E.D.; Zhang, B.; Ouyang, X. Convolutional Neural Networks: Computer Vision-Based Workforce Activity Assessment in Construction. Autom. Constr. 2018, 94, 282–289. [Google Scholar] [CrossRef]
- Xing, X.; Zhong, B.; Luo, H.; Rose, T.; Li, J.; Antwi-Afari, M.F. Effects of Physical Fatigue on the Induction of Mental Fatigue of Construction Workers: A Pilot Study Based on a Neurophysiological Approach. Autom. Constr. 2020, 120, 103381. [Google Scholar] [CrossRef]
- Bassino-Riglos, F.; Mosqueira-Chacon, C.; Ugarte, W. AutoPose: Pose Estimation for Prevention of Musculoskeletal Disorders Using LSTM. In Innovative Intelligent Industrial Production and Logistics; Terzi, S., Madani, K., Gusikhin, O., Panetto, H., Eds.; Communications in Computer and Information Science; Springer Nature: Cham, Switzerland, 2023; Volume 1886, pp. 223–238. ISBN 978-3-031-49338-6. [Google Scholar]
- Han, S.; Lee, S. A Vision-Based Motion Capture and Recognition Framework for Behavior-Based Safety Management. Autom. Constr. 2013, 35, 131–141. [Google Scholar] [CrossRef]
- Jarkas, A.M.; Bitar, C.G. Factors Affecting Construction Labor Productivity in Kuwait. J. Constr. Eng. Manag. 2012, 138, 811–820. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Smartphone-Based Construction Workers’ Activity Recognition and Classification. Autom. Constr. 2016, 71, 198–209. [Google Scholar] [CrossRef]
- Nath, N.D.; Akhavian, R.; Behzadan, A.H. Ergonomic Analysis of Construction Worker’s Body Postures Using Wearable Mobile Sensors. Appl. Ergon. 2017, 62, 107–117. [Google Scholar] [CrossRef] [PubMed]
- Baduge, S.K.; Thilakarathna, S.; Perera, J.S.; Arashpour, M.; Sharafi, P.; Teodosio, B.; Shringi, A.; Mendis, P. Artificial Intelligence and Smart Vision for Building and Construction 4.0: Machine and Deep Learning Methods and Applications. Autom. Constr. 2022, 141, 104440. [Google Scholar] [CrossRef]
- Escorcia, V.; Dávila, M.A.; Golparvar-Fard, M.; Niebles, J.C. Automated Vision-Based Recognition of Construction Worker Actions for Building Interior Construction Operations Using RGBD Cameras. In Proceedings of the Construction Research Congress 2012, West Lafayette, IN, USA, 21–23 May 2012; American Society of Civil Engineers: Reston, VA, USA, 2012; pp. 879–888. [Google Scholar]
- Fang, W.; Ding, L.; Love, P.E.D.; Luo, H.; Li, H.; Peña-Mora, F.; Zhong, B.; Zhou, C. Computer Vision Applications in Construction Safety Assurance. Autom. Constr. 2020, 110, 103013. [Google Scholar] [CrossRef]
- Kim, J.; Chi, S. A Few-Shot Learning Approach for Database-Free Vision-Based Monitoring on Construction Sites. Autom. Constr. 2021, 124, 103566. [Google Scholar] [CrossRef]
- Luo, H.; Wang, M.; Wong, P.K.-Y.; Cheng, J.C.P. Full Body Pose Estimation of Construction Equipment Using Computer Vision and Deep Learning Techniques. Autom. Constr. 2020, 110, 103016. [Google Scholar] [CrossRef]
- Mansouri, S.; Castronovo, F.; Akhavian, R. Analysis of the Synergistic Effect of Data Analytics and Technology Trends in the AEC/FM Industry. J. Constr. Eng. Manag. 2020, 146, 04019113. [Google Scholar] [CrossRef]
- Balci, R.; Aghazadeh, F. The Effect of Work-Rest Schedules and Type of Task on the Discomfort and Performance of VDT Users. Ergonomics 2003, 46, 455–465. [Google Scholar] [CrossRef]
- Kim, H.; Ham, Y.; Kim, W.; Park, S.; Kim, H. Vision-Based Nonintrusive Context Documentation for Earthmoving Productivity Simulation. Autom. Constr. 2019, 102, 135–147. [Google Scholar] [CrossRef]
- Kim, J.; Golabchi, A.; Han, S.; Lee, D.-E. Manual Operation Simulation Using Motion-Time Analysis toward Labor Productivity Estimation: A Case Study of Concrete Pouring Operations. Autom. Constr. 2021, 126, 103669. [Google Scholar] [CrossRef]
- Mirahadi, F.; Zayed, T. Simulation-Based Construction Productivity Forecast Using Neural-Network-Driven Fuzzy Reasoning. Autom. Constr. 2016, 65, 102–115. [Google Scholar] [CrossRef]
- Rao, A.S.; Radanovic, M.; Liu, Y.; Hu, S.; Fang, Y.; Khoshelham, K.; Palaniswami, M.; Ngo, T. Real-Time Monitoring of Construction Sites: Sensors, Methods, and Applications. Autom. Constr. 2022, 136, 104099. [Google Scholar] [CrossRef]
- Joshua, D.; Varghese, K. Accelerometer-Based Activity Recognition in Construction. Autom. Constr. 2010, 19, 837–848. [Google Scholar] [CrossRef]
- Ryu, J.; McFarland, T.; Banting, B.; Haas, C.T.; Abdel-Rahman, E. Health and Productivity Impact of Semi-Automated Work Systems in Construction. Autom. Constr. 2020, 120, 103396. [Google Scholar] [CrossRef]
- Xiao, B.; Yin, X.; Kang, S.-C. Vision-Based Method of Automatically Detecting Construction Video Highlights by Integrating Machine Tracking and CNN Feature Extraction. Autom. Constr. 2021, 129, 103817, Erratum in Autom. Constr. 2021, 132, 103924. [Google Scholar] [CrossRef]
- Sheng, D.; Ding, L.; Zhong, B.; Love, P.E.D.; Luo, H.; Chen, J. Construction Quality Information Management with Blockchains. Autom. Constr. 2020, 120, 103373. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, Y.; Xu, X.; Ren, Z.; Zhang, Y.; Liu, S.; Luo, W. Multi-View Emotional Expressions Dataset Using 2D Pose Estimation. Sci. Data 2023, 10, 649. [Google Scholar] [CrossRef]
- Bora, J.; Dehingia, S.; Boruah, A.; Chetia, A.A.; Gogoi, D. Real-Time Assamese Sign Language Recognition Using MediaPipe and Deep Learning. Procedia Comput. Sci. 2023, 218, 1384–1393. [Google Scholar] [CrossRef]
- Sundar, B.; Bagyammal, T. American Sign Language Recognition for Alphabets Using MediaPipe and LSTM. Procedia Comput. Sci. 2022, 215, 642–651. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. BlazePose: On-Device Real-Time Body Pose Tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Konstantinou, E. Vision-Based Construction Worker Task Productivity Monitoring. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2018. [Google Scholar]
- Teizer, J. Status Quo and Open Challenges in Vision-Based Sensing and Tracking of Temporary Resources on Infrastructure Construction Sites. Adv. Eng. Inform. 2015, 29, 225–238. [Google Scholar] [CrossRef]
- Xiao, B.; Xiao, H.; Wang, J.; Chen, Y. Vision-Based Method for Tracking Workers by Integrating Deep Learning Instance Segmentation in off-Site Construction. Autom. Constr. 2022, 136, 104148. [Google Scholar] [CrossRef]
- Xiao, B.; Zhang, Y.; Chen, Y.; Yin, X. A Semi-Supervised Learning Detection Method for Vision-Based Monitoring of Construction Sites by Integrating Teacher-Student Networks and Data Augmentation. Adv. Eng. Inform. 2021, 50, 101372. [Google Scholar] [CrossRef]
- Gong, J.; Caldas, C.H. An Intelligent Video Computing Method for Automated Productivity Analysis of Cyclic Construction Operations. In Proceedings of the Computing in Civil Engineering (2009), Austin, TX, USA, 24–27 June 2009; American Society of Civil Engineers: Washington, DC, USA, 2009; pp. 64–73. [Google Scholar]
- Ishioka, H.; Weng, X.; Man, Y.; Kitani, K. Single Camera Worker Detection, Tracking and Action Recognition in Construction Site. In Proceedings of the 37th International Symposium on Automation and Robotics in Construction (ISARC), Kitakyushu, Japan, 14–18 June 2020; IAARC Publications: Oulu, Finland, 2020; Volume 37, pp. 653–660. [Google Scholar]
- Kikuta, T.; Chun, P. Development of an Action Classification Method for Construction Sites Combining Pose Assessment and Object Proximity Evaluation. J. Ambient Intell. Humaniz. Comput. 2024, 15, 2255–2267. [Google Scholar] [CrossRef]
- Li, C.; Lee, S. Computer Vision Techniques for Worker Motion Analysis to Reduce Musculoskeletal Disorders in Construction. In Proceedings of the Computing in Civil Engineering (2011), Miami, FL, USA, 19–22 June 2011; American Society of Civil Engineers: Washington, DC, USA, 2011; pp. 380–387. [Google Scholar]
- Panahi, R.; Louis, J.; Aziere, N.; Podder, A.; Swanson, C. Identifying Modular Construction Worker Tasks Using Computer Vision. In Proceedings of the Computing in Civil Engineering 2021, Orlando, FL, USA, 12–14 September 2022; American Society of Civil Engineers: Washington, DC, USA, 2022; pp. 959–966. [Google Scholar]
- Jang, Y.; Jeong, I.; Younesi Heravi, M.; Sarkar, S.; Shin, H.; Ahn, Y. Multi-Camera-Based Human Activity Recognition for Human–Robot Collaboration in Construction. Sensors 2023, 23, 6997. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. arXiv 2016, arXiv:1604.06573v2. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. arXiv 2014, arXiv:1411.4389v4. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Liu, H.; Wang, G.; Huang, T.; He, P.; Skitmore, M.; Luo, X. Manifesting Construction Activity Scenes via Image Captioning. Autom. Constr. 2020, 119, 103334. [Google Scholar] [CrossRef]
- Mao, C.; Zhang, C.; Liao, Y.; Zhou, J.; Liu, H. An Automated Vision-Based Construction Efficiency Evaluation System with Recognizing Worker’s Activities and Counting Effective Working Hours. In Advances in Information Technology in Civil and Building Engineering, Proceedings of the ICCCBE 2024, Montreal, Canada, 25–28 August 2024; Francis, A., Miresco, E., Melhado, S., Eds.; Lecture Notes in Civil Engineering; Springer: Cham, Switzerland, 2025. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| fps | X0 | X1 | X2 | X3 | … | X32 |
|---|---|---|---|---|---|---|
| 1 | 0.618238 | 0.232524 | 0.555385 | 0.78614 | 0.760563 | |
| 2 | 0.651198 | 1.01199 | 0.407865 | 0.57514 | 0.499335 | |
| 3 | 0.760563 | 0 | 1.32282 | 0.407865 | 0.760563 | |
| 4 | 0.534423 | 0.555385 | 0.73582 | 0.794876 | 0.925179 | |
| 5 | 0.509691 | 0.679963 | 1.01199 | 0.464099 | 0.543936 | |
| … | … | … | … | … | … | … |
| 40 | 0.525569 | 0.599635 | 0.564189 | 0 | 0.760563 |
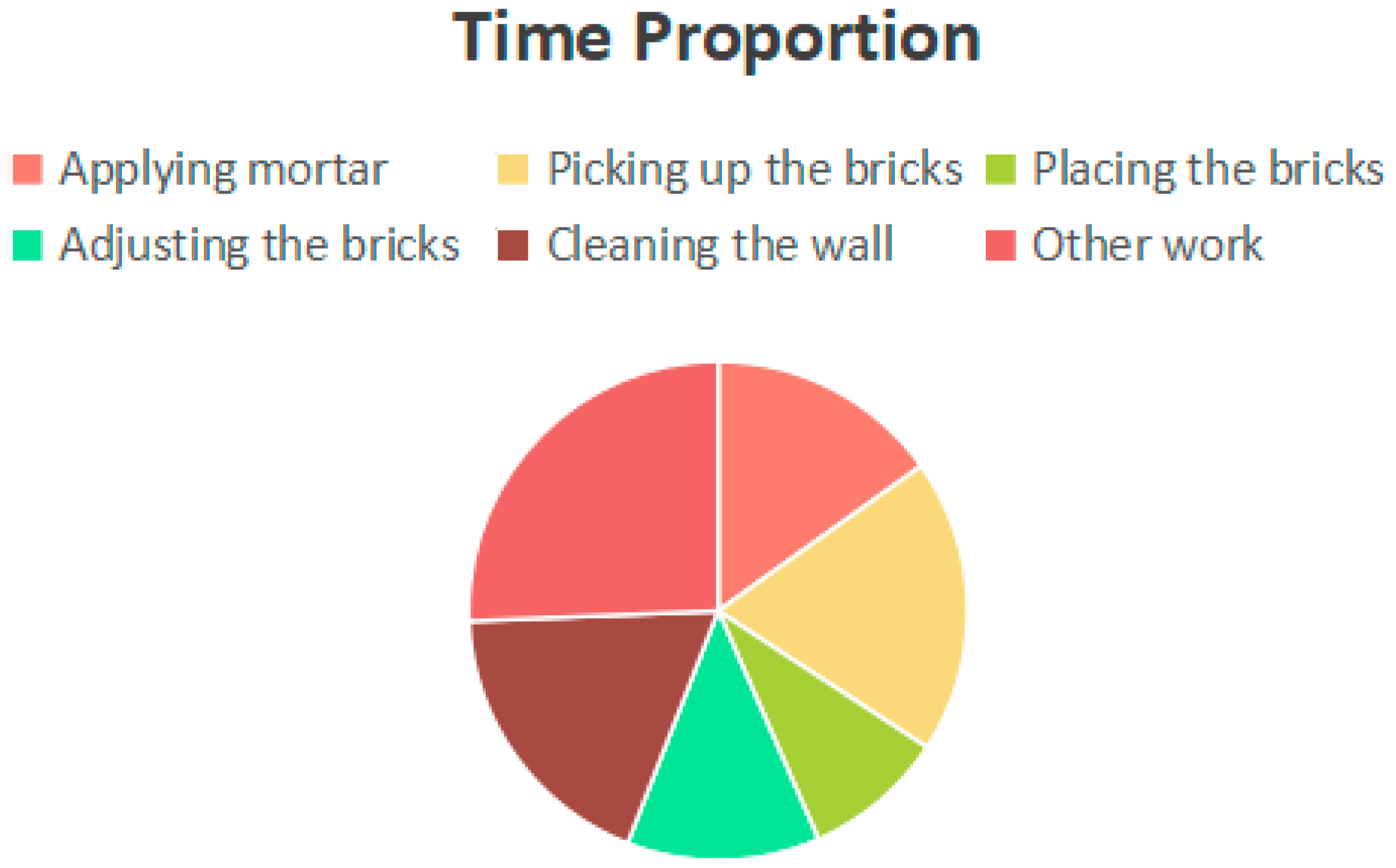
| Name | The Total Time of Manual Segmentation (s) | Proportion of Total Time Spent on Manual Segmentation (%) | The Total Time of Model Recognition (s) | Proportion of Total Model Recognition Time (%) |
|---|---|---|---|---|
| Applying mortar | 6 | 15.78 | 5.75 | 15.13 |
| Picking up the bricks | 7 | 18.42 | 7.25 | 19.07 |
| Placing the bricks | 4 | 10.52 | 3.5 | 9.21 |
| Adjusting the bricks | 4 | 10.52 | 4.75 | 12.5 |
| Cleaning the wall | 7 | 18.42 | 7 | 18.42 |
| Other work | 10 | 26.31 | 9.75 | 25.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Mao, C.; Liu, H.; Liao, Y.; Zhou, J. Moving Toward Automated Construction Management: An Automated Construction Worker Efficiency Evaluation System. Buildings 2025, 15, 2479. https://doi.org/10.3390/buildings15142479
Zhang C, Mao C, Liu H, Liao Y, Zhou J. Moving Toward Automated Construction Management: An Automated Construction Worker Efficiency Evaluation System. Buildings. 2025; 15(14):2479. https://doi.org/10.3390/buildings15142479
Chicago/Turabian StyleZhang, Chaojun, Chao Mao, Huan Liu, Yunlong Liao, and Jiayi Zhou. 2025. "Moving Toward Automated Construction Management: An Automated Construction Worker Efficiency Evaluation System" Buildings 15, no. 14: 2479. https://doi.org/10.3390/buildings15142479
APA StyleZhang, C., Mao, C., Liu, H., Liao, Y., & Zhou, J. (2025). Moving Toward Automated Construction Management: An Automated Construction Worker Efficiency Evaluation System. Buildings, 15(14), 2479. https://doi.org/10.3390/buildings15142479