5.3.1. Prediction Data Source and Influence Parameter Analysis
The improved quantification model was used to quantify the carbon emissions during the construction of a prefabricated public parking building, and a total of seven datasets were summarized, with floor as the variable. In order to expand the study samples, quantitative data on the carbon emissions during the construction of prefabricated buildings were collected from the existing research literature, and a total of 53 groups of data from quantitative studies were collected. The construction site of the prefabricated public parking building is shown in
Figure 10.
After obtaining these 60 sets of quantitative data, the carbon emission impact parameter correlation was analyzed using the method in
Section 3.2. The correlation heatmap is shown in
Figure 11, and the results of the Pearson correlation test are shown in
Figure 12.
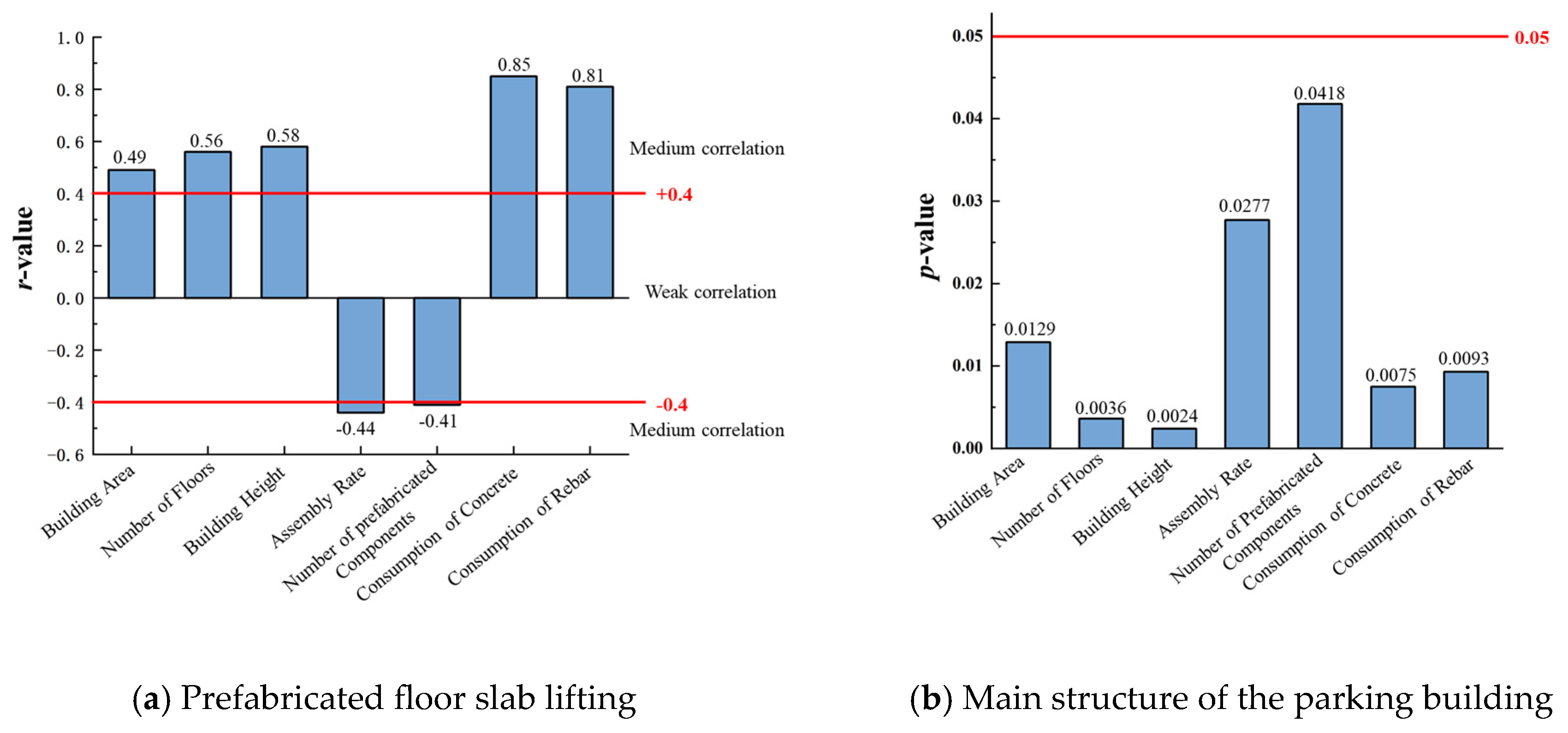
From the results of the Pearson correlation test in
Figure 11 and
Figure 12, it can be seen that the
r-value is greater than 0.4 and the
p-value is less than 0.05. According to the evaluation of
r-value presented in the previous section, it can be seen that all seven variables have a significant correlation with the carbon emissions per unit area, and the correlation is above the medium degree. The
r-value of the consumption of concrete and steel rebar is significantly higher than that of the other factors, in line with the dominant influencing factors of carbon emissions in building construction proposed by previous scholars [
14]. Therefore, these seven influence parameters are the significant influence parameters governing the carbon emissions in the construction stage of the prefabricated parking building.
5.3.3. Hyperparameter Optimization Results
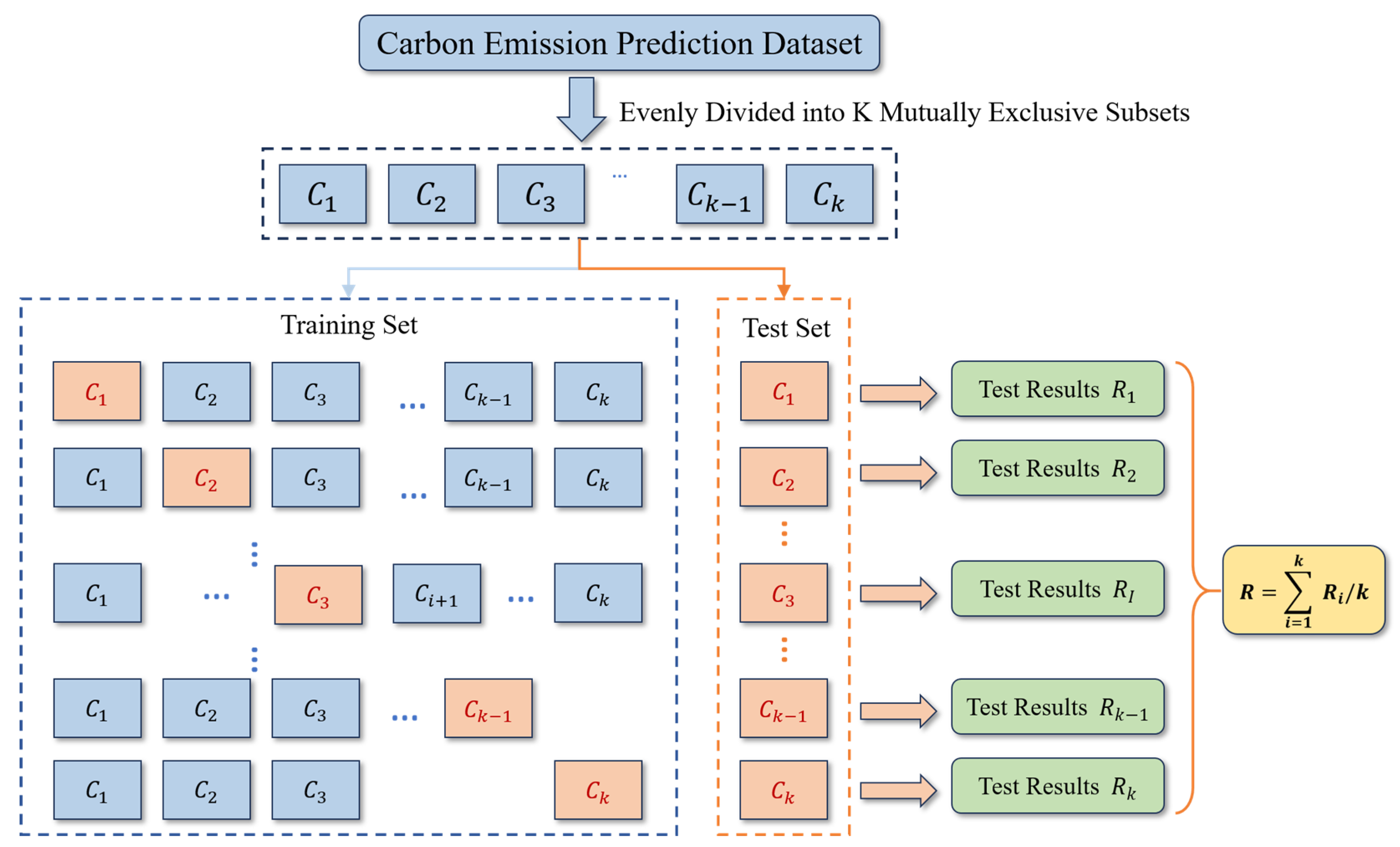
To predict the carbon emissions during the construction stage of prefabricated buildings, the optimal hyperparameters of four models, namely, SVR, BPNN, ELM, and RF, were determined using the lattice optimization and k-fold cross-validation methods. The number of cross-validation folds (k) was set to 3, 4, 5, and 6, respectively, and the Root Mean Square Error (RMSE) was used as the evaluation index. Theoretically, the closer the RMSE value is to 0, the smaller the model prediction error, and the more ideal the selected hyperparameter setting.
The key hyperparameters of the SVR include penalty factor
C and the kernel function scale parameter
γ. In order to determine the optimal combination of hyperparameters, the optimization range of the penalty factor
C was set to 0.1~10 with a step size of 0.1, and the optimization range of the kernel function scale parameter
γ was set to 0.01~1 with a step size of 0.01. The optimal parameter settings with different cross-validation folds were statistically analyzed using the grid optimization method. The results of the grid optimization and the optimal parameter settings are shown in
Figure 13 and
Table 3.
As can be seen from
Figure 13, in all four cases of cross-validation, the value of RMSE shows a tendency to first decrease and then increase with the increase in penalty factor
C and kernel function scale parameter
γ. As can be seen from
Table 3, the RMSE shows a tendency of decreasing and then increasing with the increase in the number of cross-validation folds. The optimal parameter search resulted in a value of 0.7 for the penalty factor
C and of 0.1 for the kernel function scale parameter
γ. At this time, the RMSE was the smallest, at 0.407, and the number of cross-validation folds,
k, was 4.
For BPNNs, the number of hidden layers, the number of hidden layer nodes, and the learning rate are key parameters that determine their complexity and performance. The selection of these parameters directly affects the prediction ability and convergence speed of BPNNs. Due to the limited number of learning samples, the hidden layer configurations of BPNNs are only considered for single-layer and double-layer cases. The number of nodes in a single hidden layer and the number of nodes in two hidden layers, as well as the learning rate of the BPNN, are optimized using grid optimization and the
k-fold cross validation method. The optimization range of the number of hidden layer nodes was set to 1~50 with a step size of 1. The optimization range of the learning rate was set to 0.0002~0.01 with a step size of 0.0002. The number of network training times was set to 1000. The optimal parameter settings under different cross-validation methods were categorized and counted; the optimization results are shown in
Figure 14 and
Figure 15, and the optimal parameters for optimization are shown in
Table 4 and
Table 5.
As can be seen from
Figure 14, there is no obvious linear relationship between the prediction accuracy of the BPNN, the number of hidden layer nodes, and the learning rate. In the optimization search range, the RMSE is small when the learning rate and the number of hidden layer nodes are small, and large when the learning rate and the number of hidden layer nodes are large. As can be seen from
Table 4, with the increase in the number of cross-validation folds, the RMSE shows a trend of decreasing and then increasing. The optimal parameter search results for the single hidden layer were as follows: the number of hidden layer nodes is three and the learning rate is 0.0020. The RMSE was minimized to 0.415 and the number of cross-validation folds,
k, was 4.
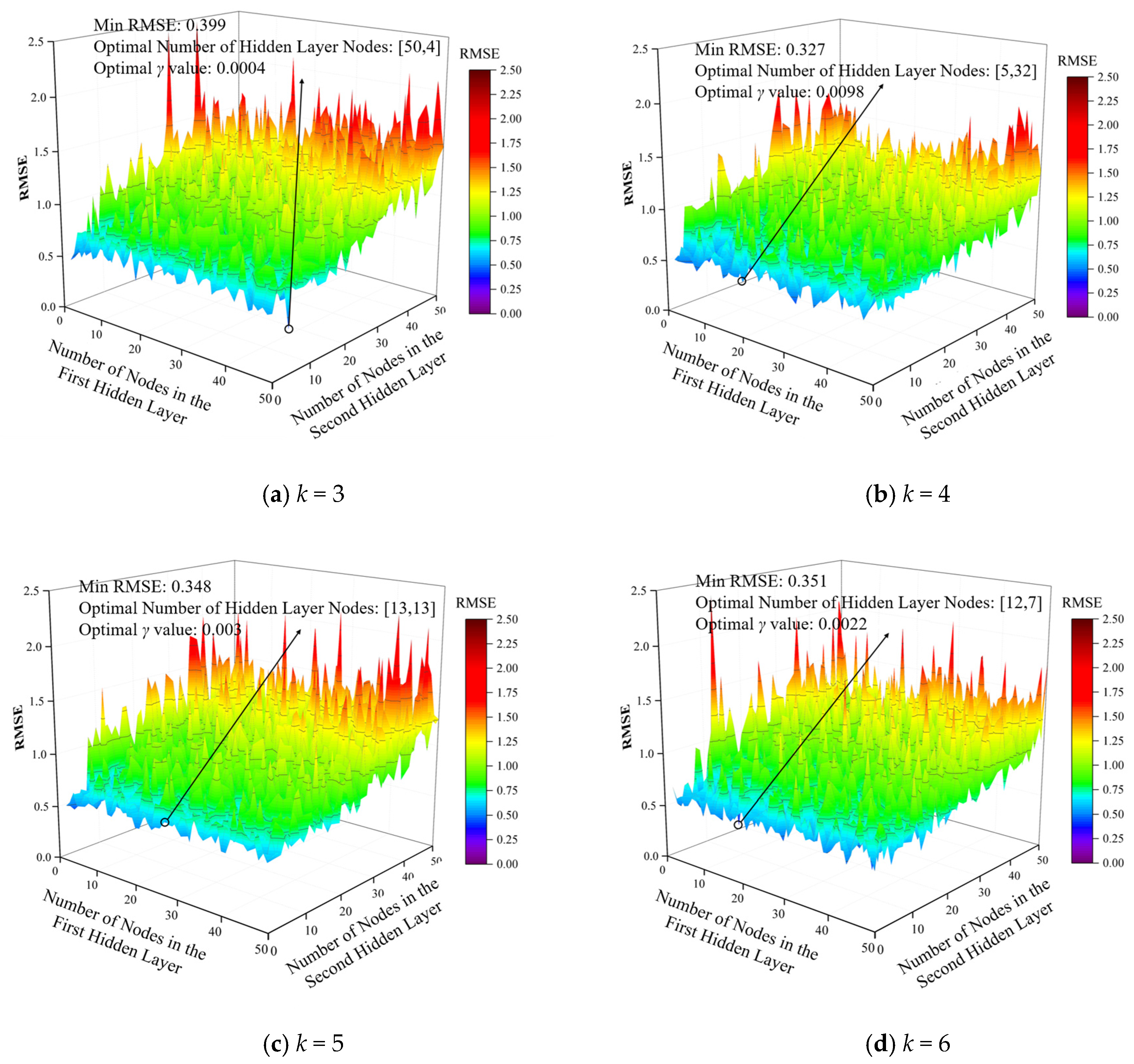
Comparing
Figure 14 and
Figure 15, it can be seen that there is a great deal of randomness in the influence of the number of nodes in the hidden layer and the learning rate of the BPNN on its prediction accuracy, but with the increase in the number of cross-validation folds, the range of the distribution of the RMSE gradually decreases and then increases in the range of the number of nodes searched. The overall prediction effect of the BPNN with two hidden layers is better than that of the one with a single hidden layer. The final selected BPNN parameters were as follows: two hidden layers, 5 and 32 nodes in the hidden layers, and a learning rate of 0.0098, with four cross-validation folds and an RMSE of 0.327.
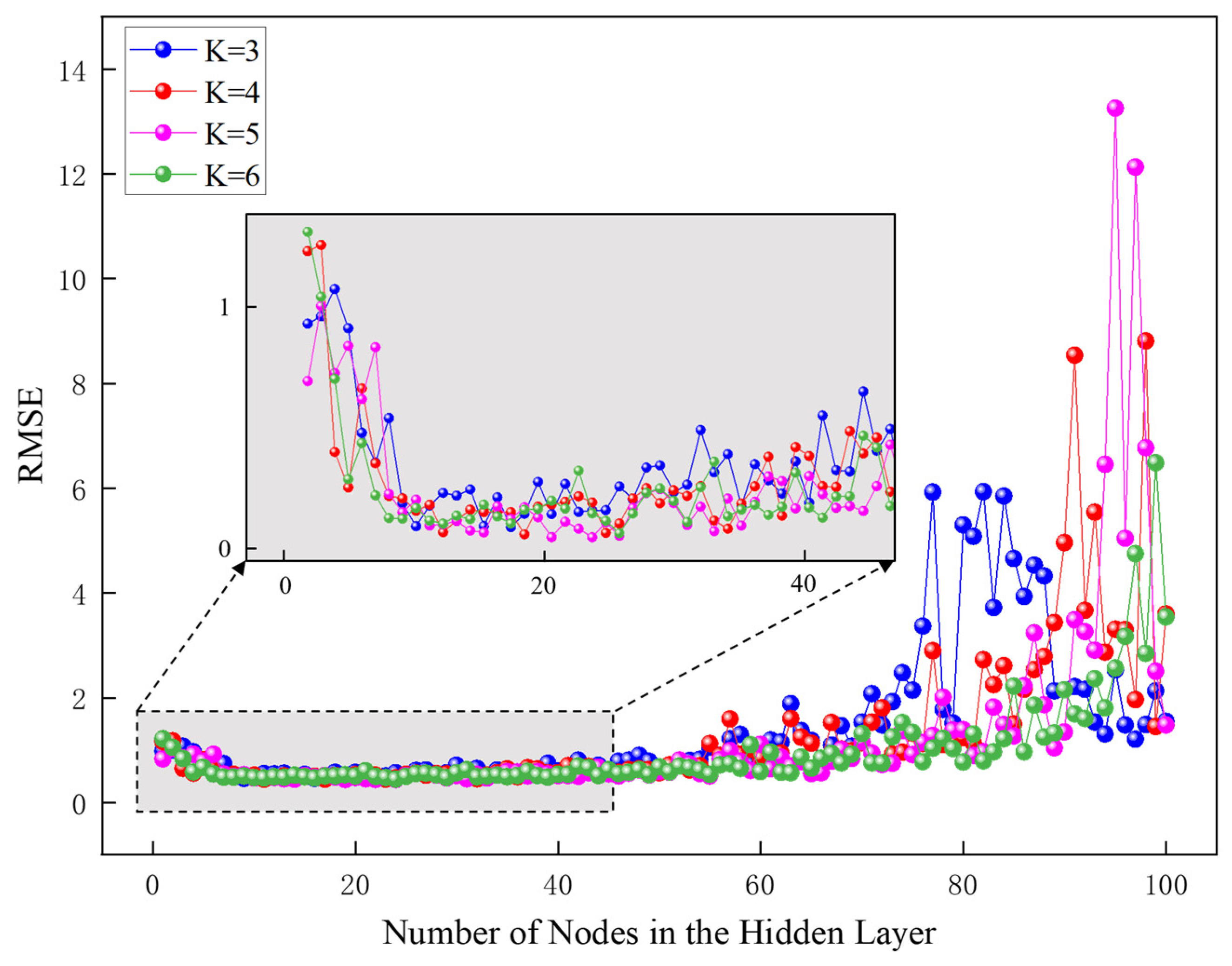
The main parameter to be adjusted for the ELM model is the number of implied nodes. In order to find the optimal parameter settings, the number of implied layer nodes n was set to 1~100, and the step size was 1. The optimal parameter settings under different cross-validation techniques were categorized and counted. The results of the search for optimality are shown in
Figure 16, and the results of the search for the optimal parameters are shown in
Table 6.
As can be seen in
Figure 16, under the four cross-validation conditions, as the number of nodes in the hidden layer increases, the RMSE value shows a tendency to stabilize and then increase with oscillations. As can be seen from
Table 6, there is no obvious trend in RMSE as the number of cross-validation folds increases. The optimal parameter search obtained 22 nodes in the hidden layer, at which time the RMSE was 0.430 and the cross-validation discount was 5.
In the RF prediction model, the number of decision trees (
n) and the minimum number of leaves (
leaf) are two important parameters; a larger
n can improve the accuracy of the model but can also increase the computation time, and a larger
leaf prevents overfitting but may also lead to the underfitting of the model, so it is necessary to optimize parameters
n and
leaf of the RF carbon emissions prediction model. Since the number of learning samples was 120, the range of
n was set to 1~30 and the step size was set to 1, while the range of
leaf was set to 1~30 and the step size was set to 1 for optimization [
34]. The results are shown in
Figure 17, and the optimal parameter settings under cross-validation folds are shown in
Table 7.
As can be seen from
Figure 17, the RMSE decreases with an increase in leaf and increases with n. In
Table 7, it can be seen that the model’s prediction is best when leaf is set to 6 and n is set to 5, and the model’s minimum error RMSE is 0.463 when the number of cross-validation folds is four.
5.3.4. Analysis of Carbon Emission Prediction Results
According to the optimization search results in
Section 5.3.3, the four machine learning algorithms, namely, SVR, BPNN, ELM, and RF, have the smallest prediction model error for carbon emissions during the construction of prefabricated buildings when the cross-validation fold
k is 4. In order to compare the effects of the four models’ predictions of carbon emissions during the construction of prefabricated buildings under the same conditions, the learning samples were divided into a training set and test set and numbered from 3 to 1. The model training samples were divided into 120 groups, with 90 groups functioning as training sets and 30 groups as test sets. The parameters of the model were set according to the minimum RMSE when the cross-validation discount
k was 4. The evaluation indexes of the carbon emissions prediction model are the RMSE and the goodness-of-fit coefficient (R
2); the smaller the RMSE, the smaller the model error, and the closer the R
2 is to 1, the higher the prediction accuracy of the model [
35,
36]. The carbon emissions in the figure are normalized carbon emissions. The carbon emission prediction results are shown in
Figure 18, a comparison between the predicted and actual values of carbon emissions is shown in
Figure 19, and a comparison of the carbon emissions prediction model performance indicators is shown in
Table 8.
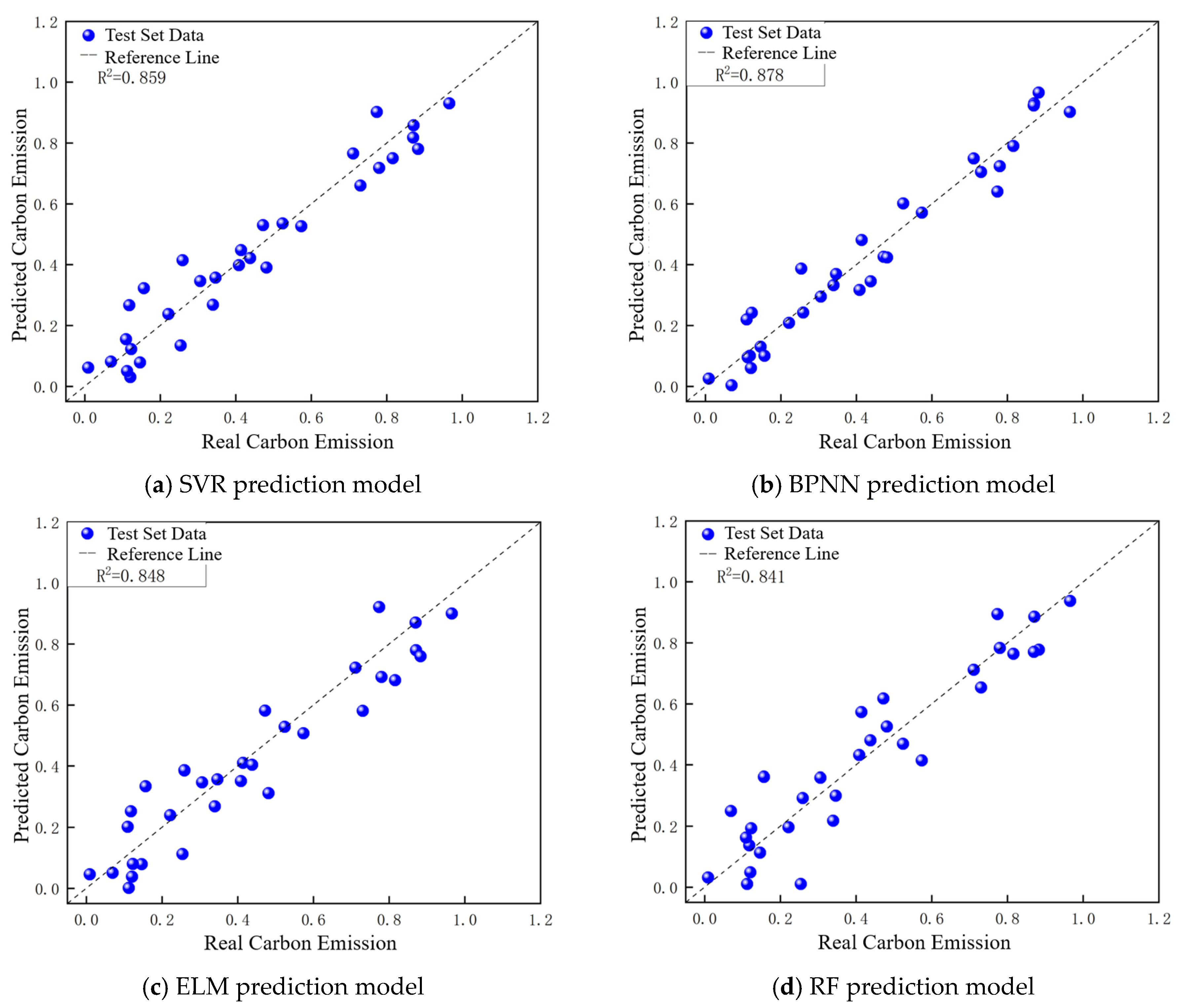
In
Figure 18, the RMSE of the SVR prediction model is 0.385, the RMSE of the BPNN prediction model is 0.364, the RMSE of the ELM prediction model is 0.404, and the RMSE of the RF prediction model is 0.413. Judging from the RMSE, the BPNN prediction model obtains the best results in the prediction of carbon emissions, with the smallest error. The RF prediction model obtained the worst carbon emission prediction results, which coincides with the optimal hyperparameter optimization search results in
Section 5.3.3.
In
Figure 19 and
Table 8, it can be seen that the R
2 of the SVR prediction model, the BPNN prediction model, the ELM prediction model, and the RF prediction model are 0.859, 0.878, 0.848, and 0.841, respectively. The points of comparison between the predicted carbon emissions value and the actual value obtained by the BPNN prediction model are more concentrated on the reference line, the coefficient of goodness-of-fit is lower, and the prediction of the carbon emissions effect is the best. These results further validate the significant advantage of BPNN in capturing higher-order nonlinear relationships. Its core mechanism enables it to dynamically and iteratively optimize the weights via a back-propagation algorithm to more accurately model the complex correlation between the input parameters and carbon emissions [
37,
38]. In
Figure 19b, it can be seen that the comparison points between the predicted and actual values of carbon emissions obtained by the BPNN prediction model are uniformly distributed on both sides of the reference line, which indicates that the amount of carbon emissions has no effect on the results of the prediction model, that the model’s predictions of carbon emissions show good stability, and that it has good applicability.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}