
Building Surface Defect Detection Based on Improved YOLOv8

 , and
, and
Abstract
1. Introduction
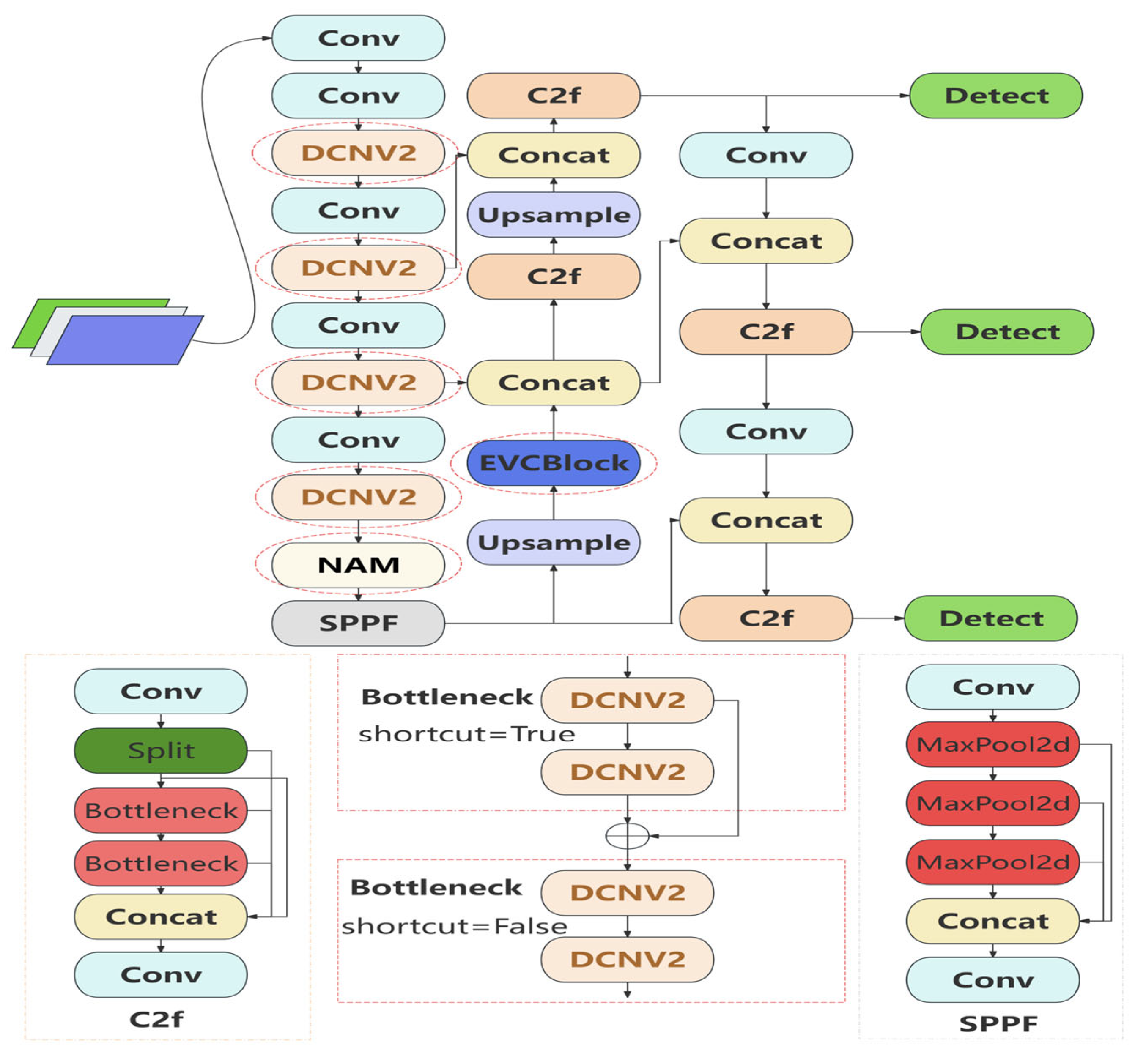
- The NAM is incorporated into the base model to prioritize prominent defects on the building surface while diminishing less important details. This optimization significantly enhances the algorithm’s precision and ensures that the model fully leverages crucial feature data.
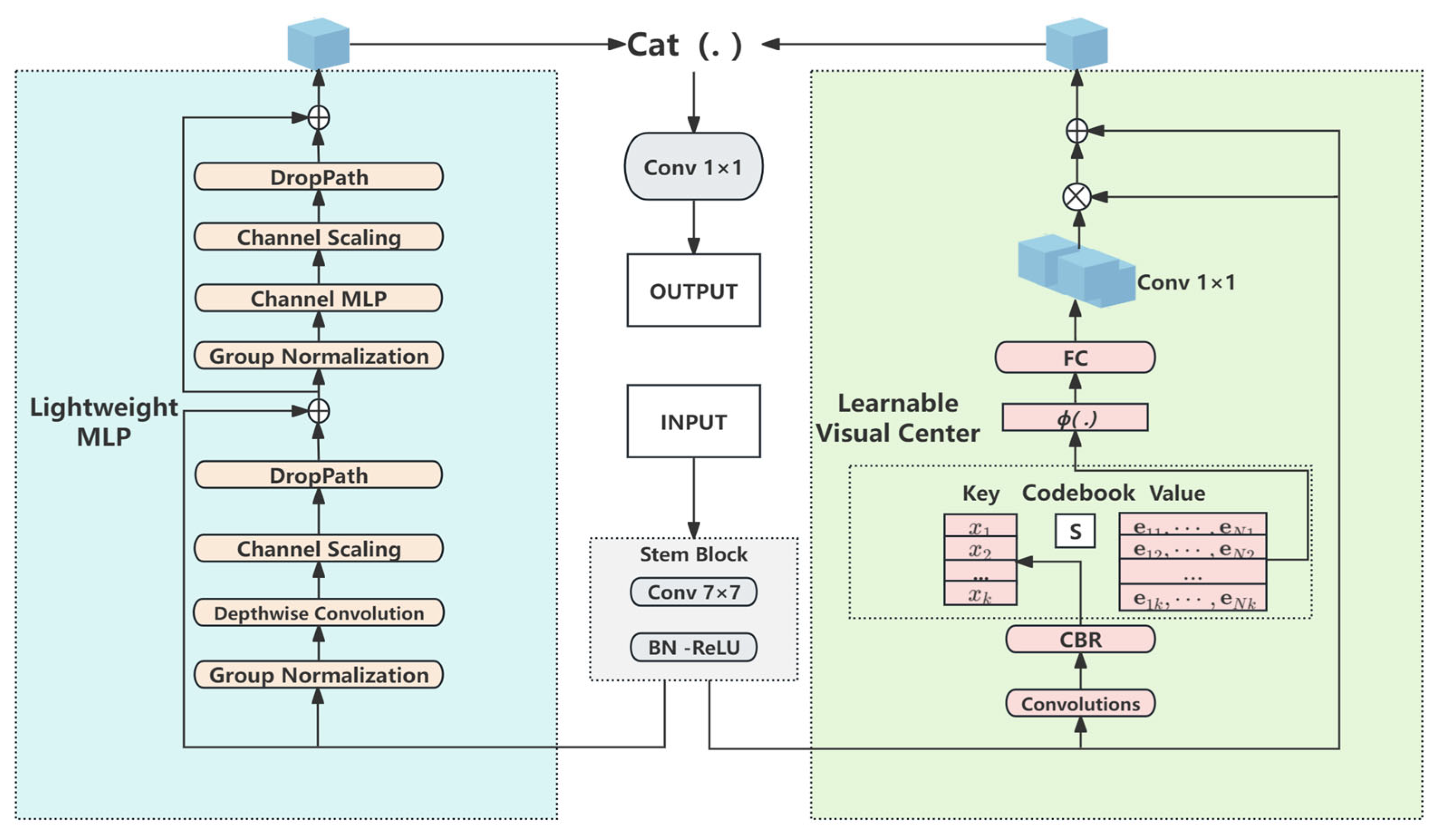
- The use of an EVC feature fusion strategy in the backbone part of the network, which aims to deeply explore local and global features, provides comprehensive and accurate feature recognition and greatly improves our ability to detect subtle targets and small objects, making our model more sensitive in capturing building defects.
- DCNV2 is implemented to substitute C2f; this modification greatly enhances feature extraction capabilities and strengthens the model’s robustness against anomalies. This advancement makes our model more adept and adaptable at identifying irregularly shaped defects.
2. Materials and Methods
2.1. Data
2.2. Related Works
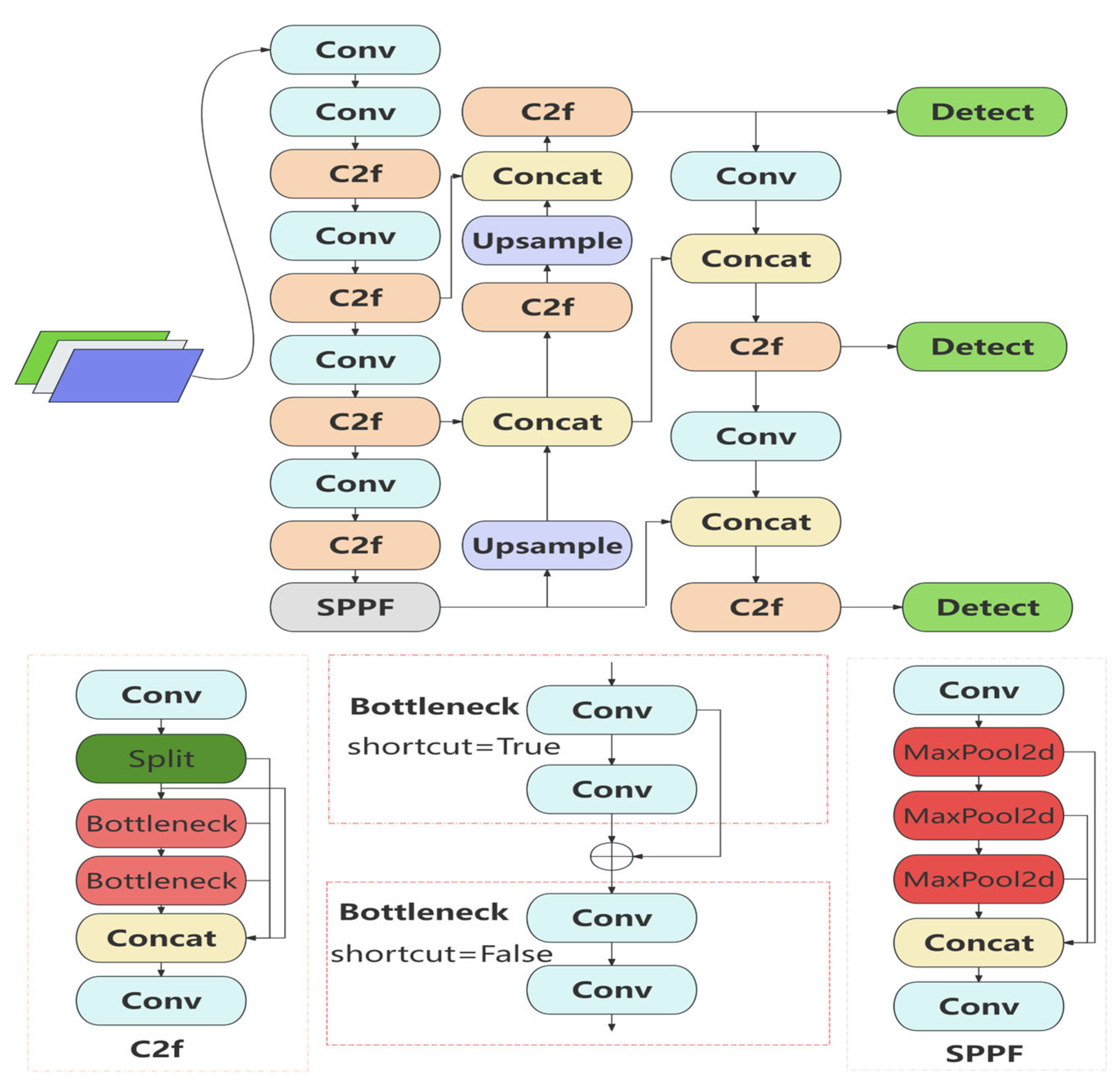
2.3. YOLOv8 Algorithm
3. Improvements to YOLOv8
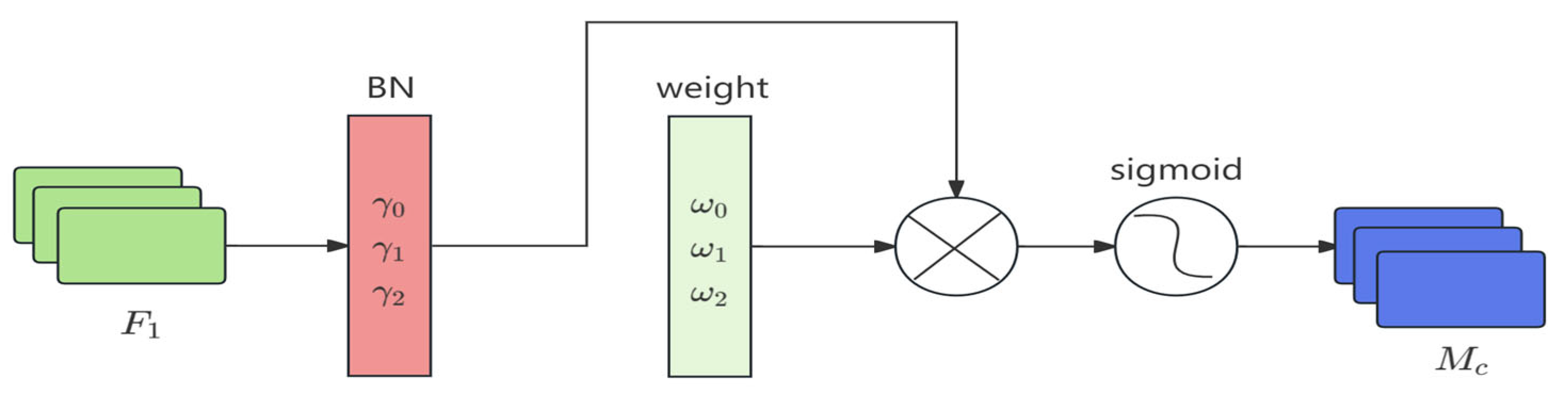
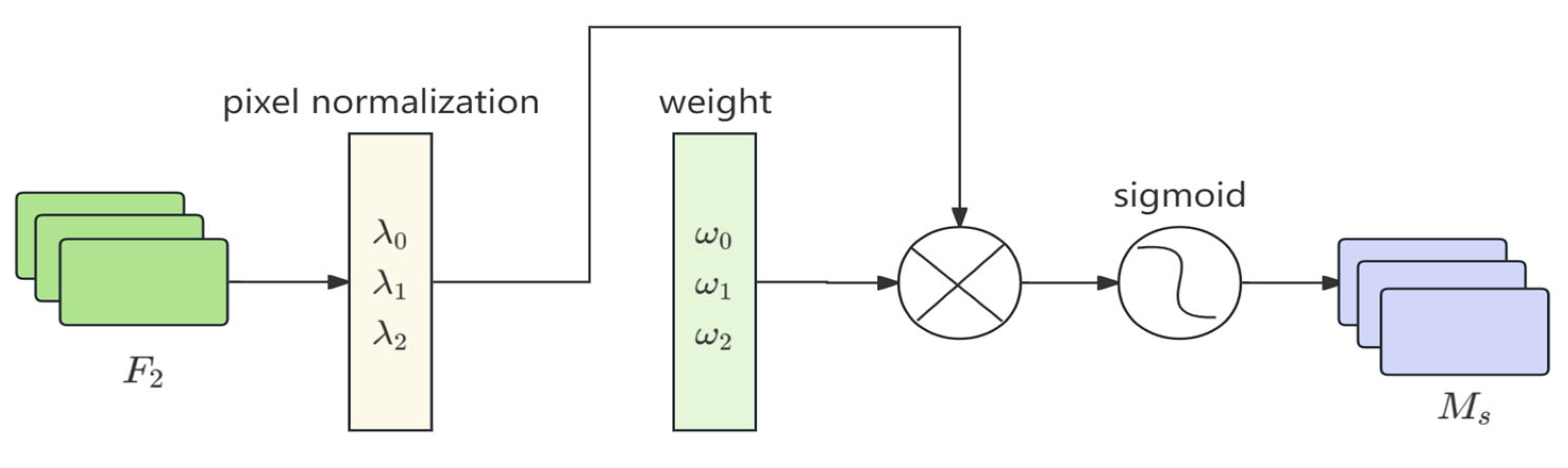
3.1. The NAM
3.2. The EVC Module
3.3. The DCNV2 Module
4. Experiments
4.1. Environment and Configuration of Experiments
4.2. Evaluation Indicators
5. Analysis and Results of YOLO-NED
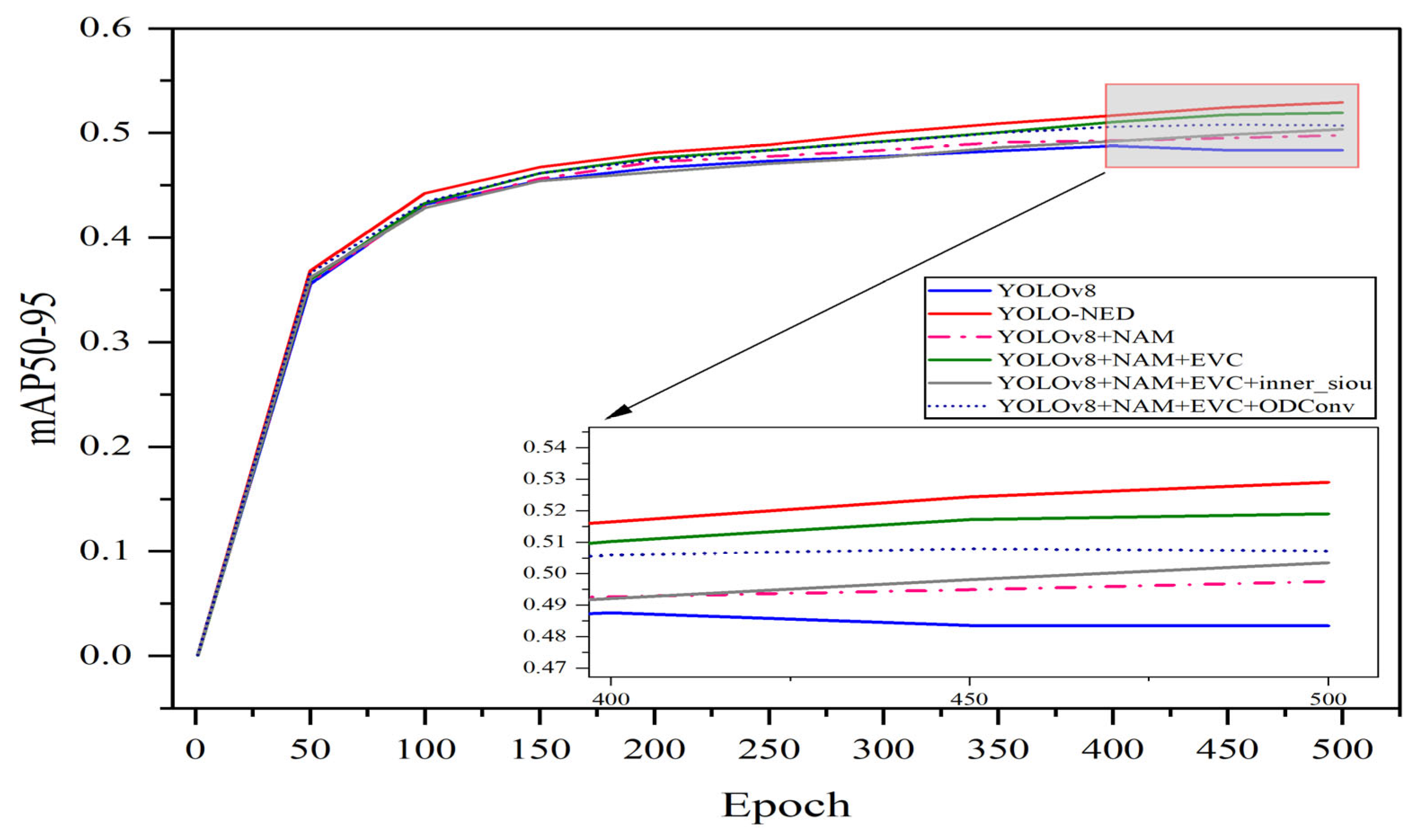
5.1. Experimental Results of Ablation
5.2. Comparative Experiments
6. Discussion
7. Conclusions
- The addition of the attention mechanism to the model captures information related to building surface defects, making the model more effective in recognizing them against complex backgrounds. The model then incorporates a feature fusion module, which enhances its ability to recognize small targets. Finally, Deformable Convolutional Network v2 is introduced at the backbone network level to enhance the model’s feature extraction capability.
- YOLO-NED attains mAP50 and mAP50-95 scores of 72.9% and 52.9% on our building surface defects dataset, which are 3.9% and 4.2% higher than the baseline algorithm, respectively. Its performance reaches 156 FPS, suitable for real-time inspection in smart construction scenarios.
- This approach fulfills the demand for precision in identifying structural surface flaws, while considering ease of use and adaptability in real-world settings, offering robust assistance for construction quality assessments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO. | Acronyms | Full Name |
|---|---|---|
| 1 | BN | Batch normalization |
| 2 | DETR | Detection Transformer |
| 3 | EVC | Explicit vision center |
| 4 | LVC | Learnable vision center |
| 5 | mAP | Mean average precision |
| 6 | MLP | Multilayer perceptron |
| 7 | NAM | Normalization-based attention module |
| 8 | P | Precision |
| 9 | R | Recall |
| 10 | ROI | Region of interest |
| 11 | R-CNN | Region-based CNN |
| 12 | SSD | Single-Shot Multibox Detector |
| 13 | SGD | Stochastic gradient descent |
| 14 | YOLO | You Only Look Once |
| 15 | CFPN | Centralized feature pyramid network |
| 16 | CBAM | Convolutional block attention module |
References
- Basu, S.; Orr, S.A.; Aktas, Y.D. A geological perspective on climate change and building stone deterioration in London: Implications for urban stone-built heritage research and management. Atmosphere 2020, 11, 788. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, X.; Jin, X.; Yu, H.; Rao, J.; Tian, S.; Luo, L.; Li, C. Road pavement condition mapping and assessment using remote sensing data based on MESMA. In Proceedings of the 9th Symposium of the International Society for Digital Earth, Halifax, NS, Canada, 5–9 October 2015. [Google Scholar]
- Amin, D.; Akhter, S. Deep learning-based defect detection system in steel sheet surfaces. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 444–448. [Google Scholar]
- Vivekananthan, V.; Vignesh, R.; Vasanthaseelan, S.; Joel, E.; Kumar, K.S. Concrete bridge crack detection by image processing technique by using the improved OTSU method. Mater. Today 2023, 74, 1002–1007. [Google Scholar] [CrossRef]
- Meng, X.B.; Lu, M.Y.; Yin, W.L.; Bennecer, A.; Kirk, K.J. Evaluation of Coating Thickness Using Lift-Off Insensitivity of Eddy Current Sensor. Sensors 2021, 21, 419. [Google Scholar] [CrossRef]
- Wang, G.; Xiao, Q.; Gao, Z.H.; Li, W.; Jia, L.; Liang, C.; Yu, X. Multifrequency AC Magnetic Flux Leakage Testing for the Detection of Surface and Backside Defects in Thick Steel Plates. IEEE Magn. Lett. 2022, 13, 8102105. [Google Scholar] [CrossRef]
- Jing, X.; Yang, X.-Y.; Xu, C.-H.; Chen, G.; Ge, S. Infrared thermal images detecting surface defect of steel specimen based on morphological algorithm. J. China Univ. Pet. 2012, 36, 146–150. [Google Scholar]
- Andi, M.; Yohanes, G.R. Experimental study of crack depth measurement of concrete with ultrasonic pulse velocity (UPV). In Proceedings of the IOP Conference Series: Materials Science and Engineering, Bali, Indonesia, 7–8 August 2019; Volume 673, p. 012047. [Google Scholar]
- Zhu, Z.; Al-Qadi, I.L. Crack Detection of Asphalt Concrete Using Combined Fracture Mechanics and Digital Image Correlation. J. Transp. Eng. Part B Pavements 2023, 149, 04023012. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Choutri, K.; Lagha, M.; Meshoul, S.; Batouche, M.; Bouzidi, F.; Charef, W. Fire Detection and Geo-Localization Using UAV’s Aerial Images and Yolo-Based Models. Appl. Sci. 2023, 13, 11548. [Google Scholar] [CrossRef]
- Singla, R.; Sharma, S.; Sharma, S.K. Infrared imaging for detection of defects in concrete structures. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Stavanger, Norway, 30 November–1 December 2023; Volume 1289, p. 012064. [Google Scholar]
- Liu, Y.; Zhou, T.; Xu, J.; Hong, Y.; Pu, Q.; Wen, X. Rotating Target Detection Method of Concrete Bridge Crack Based on YOLOv5. Appl. Sci. 2023, 13, 11118. [Google Scholar] [CrossRef]
- Ye, G.; Qu, J.; Tao, J.; Dai, W.; Mao, Y.; Jin, Q. Autonomous surface crack identification of concrete structures based on the YOLOv7 algorithm. J. Build. Eng. 2023, 73, 106688. [Google Scholar] [CrossRef]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/abs/1804.02767 (accessed on 22 May 2024).
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 20 May 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. Available online: https://arxiv.org/abs/2209.02976 (accessed on 25 May 2024).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks. arXiv 2015, arXiv:1506.02626. Available online: https://arxiv.org/abs/1506.02626 (accessed on 15 May 2024).
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. Available online: https://arxiv.org/abs/1503.02531 (accessed on 15 May 2024).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. Available online: https://arxiv.org/abs/1704.04861 (accessed on 15 May 2024).
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083. Available online: https://arxiv.org/abs/1707.01083 (accessed on 16 May 2024).
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, Z.; Su, C.; Deng, Y. A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques. Appl. Sci. 2024, 14, 1892. [Google Scholar] [CrossRef]
- Wu, P.; Liu, A.; Fu, J.; Ye, X.; Zhao, Y. Autonomous Surface Crack Identification of Concrete Structures Based on an Improved One-Stage Object Detection Algorithm. Eng. Struct. 2022, 272, 114962. [Google Scholar] [CrossRef]
- Zhang, X.; Luo, Z.; Ji, J.; Sun, Y.; Tang, H.; Li, Y. Intelligent Surface Cracks Detection in Bridges Using Deep Neural Network. Int. J. Struct. Stab. Dyn. 2024, 24, 2450046. [Google Scholar] [CrossRef]
- Xing, Y.; Han, X.; Pan, X.; An, D.; Liu, W.; Bai, Y. EMG-YOLO: Road Crack Detection Algorithm for Edge Computing Devices. Front. Neurorobot. 2024, 18, 1423738. [Google Scholar] [CrossRef]
- Wang, J.; Wang, P.; Qu, L.; Pei, Z.; Ueda, T. Automatic Detection of Building Surface Cracks Using UAV and Deep Learning combined Approach. Struct. Concr. 2024, 25, 2302–2322. [Google Scholar] [CrossRef]
- Qi, Y.; Ding, Z.; Luo, Y.; Ma, Z. A Three-Step Computer Vision-Based Framework for Concrete Crack Detection and Dimensions Identification. Buildings 2024, 14, 2360. [Google Scholar] [CrossRef]
- Ni, Y.-H.; Wang, H.; Mao, J.-X.; Xi, Z.; Chen, Z.-Y. Quantitative Detection of Typical Bridge Surface Damages Based on Global Attention Mechanism and YOLOv7 Network. Struct. Health Monit. 2024, 24, 941–962. [Google Scholar] [CrossRef]
- Dong, X.; Liu, Y.; Dai, J. Concrete Surface Crack Detection Algorithm Based on Improved YOLOv8. Sensors 2024, 24, 5252. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv 2017, arXiv:1703.06211. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]





| Hyperparameters | Value |
|---|---|
| Input image size | 640 × 640 |
| Training epochs | 500 |
| Batch size | 8 |
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Number | NAM | EVC | DCNV2 | Inner-IoU | ODConv | Precision | Recall | mAP50 | F1 | mAP50-95 | GFLOPs | Parameters |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | × | 0.727 | 0.611 | 0.690 | 0.664 | 0.487 | 8.1 | 3.0 |
| 2 | ✓ | × | × | × | × | 0.716 | 0.651 | 0.707 | 0.682 | 0.497 | 8.1 | 3.0 |
| 3 | ✓ | ✓ | × | × | × | 0.750 | 0.653 | 0.724 | 0.698 | 0.517 | 21.4 | 7.3 |
| 4 | ✓ | ✓ | ✓ | × | × | 0.758 | 0.665 | 0.729 | 0.708 | 0.529 | 21.1 | 7.4 |
| 5 | ✓ | ✓ | × | ✓ | × | 0.735 | 0.652 | 0.714 | 0.695 | 0.503 | 21.6 | 7.3 |
| 6 | ✓ | ✓ | × | × | ✓ | 0.757 | 0.631 | 0.710 | 0.688 | 0.507 | 20.5 | 8.6 |
| NO. | NAM | EVC | DCNV2 | Exposed Reinforcement | Rust Stain | Crack | Spalling | Delamination | Efflorescence | mAP50 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | 0.815 | 0.635 | 0.693 | 0.688 | 0.727 | 0.584 | 0.690 |
| 2 | ✓ | × | × | 0.819 | 0.646 | 0.714 | 0.699 | 0.784 | 0.582 | 0.707 |
| 3 | ✓ | ✓ | × | 0.829 | 0.665 | 0.726 | 0.736 | 0.783 | 0.597 | 0.724 |
| 4 | ✓ | ✓ | ✓ | 0.830 | 0.662 | 0.748 | 0.726 | 0.796 | 0.611 | 0.729 |
| Model | Precision | Recall | mAP50 | mAP50-95 | Parameters (M) |
|---|---|---|---|---|---|
| YOLOv5n | 0.646 | 0.644 | 0.655 | 0.404 | 1.7 |
| YOLOv6 | 0.638 | 0.582 | 0.612 | 0.417 | 4.2 |
| YOLOv7 | 0.723 | 0.651 | 0.715 | 0.511 | 36.5 |
| YOLOv8n | 0.727 | 0.611 | 0.690 | 0.487 | 3.0 |
| YOLOv10n | 0.718 | 0.617 | 0.689 | 0.495 | 2.7 |
| YOLOv11n | 0.709 | 0.607 | 0.684 | 0.479 | 2.6 |
| YOLOv12n | 0.708 | 0.630 | 0.687 | 0.477 | 2.6 |
| SSD | 0.657 | 0.511 | 0.581 | 0.377 | 146.5 |
| RT-DETR | 0.792 | 0.659 | 0.728 | 0.527 | 32.8 |
| Faster R-CNN | 0.424 | 0.376 | 0.440 | 0.285 | 137.1 |
| YOLOv8-NED | 0.758 | 0.665 | 0.729 | 0.529 | 7.4 |
| Model | Exposed Reinforcement | Rust Stain | Crack | Spalling | Delamination | Efflorescence | mAP50 | Training Time (h) |
|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 0.815 | 0.635 | 0.693 | 0.688 | 0.727 | 0.584 | 0.690 | 7.88 |
| YOLOv10n | 0.799 | 0.595 | 0.695 | 0.684 | 0.788 | 0.571 | 0.689 | 12.78 |
| YOLOv11n | 0.811 | 0.623 | 0.685 | 0.681 | 0.739 | 0.562 | 0.684 | 11.25 |
| YOLOv12n | 0.812 | 0.649 | 0.691 | 0.663 | 0.723 | 0.582 | 0.687 | 14.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Meng, Y.; Sun, L.; Yang, X.; Leng, C.; Li, Y.; Niu, Z.; Gong, W.; Xiao, X. Building Surface Defect Detection Based on Improved YOLOv8. Buildings 2025, 15, 1865. https://doi.org/10.3390/buildings15111865
Lin X, Meng Y, Sun L, Yang X, Leng C, Li Y, Niu Z, Gong W, Xiao X. Building Surface Defect Detection Based on Improved YOLOv8. Buildings. 2025; 15(11):1865. https://doi.org/10.3390/buildings15111865
Chicago/Turabian StyleLin, Xiaoxia, Yingzhou Meng, Lin Sun, Xiaodong Yang, Chunwei Leng, Yan Li, Zhenyu Niu, Weihao Gong, and Xinyue Xiao. 2025. "Building Surface Defect Detection Based on Improved YOLOv8" Buildings 15, no. 11: 1865. https://doi.org/10.3390/buildings15111865
APA StyleLin, X., Meng, Y., Sun, L., Yang, X., Leng, C., Li, Y., Niu, Z., Gong, W., & Xiao, X. (2025). Building Surface Defect Detection Based on Improved YOLOv8. Buildings, 15(11), 1865. https://doi.org/10.3390/buildings15111865