
Comparative Analysis of Machine Learning Models for Predicting Contaminant Concentration Distributions in Hospital Wards

Abstract
1. Introduction
2. Method
2.1. Correlation Analysis
2.2. Machine Learning
2.2.1. Multiple Linear Regression
2.2.2. Support Vector Regression
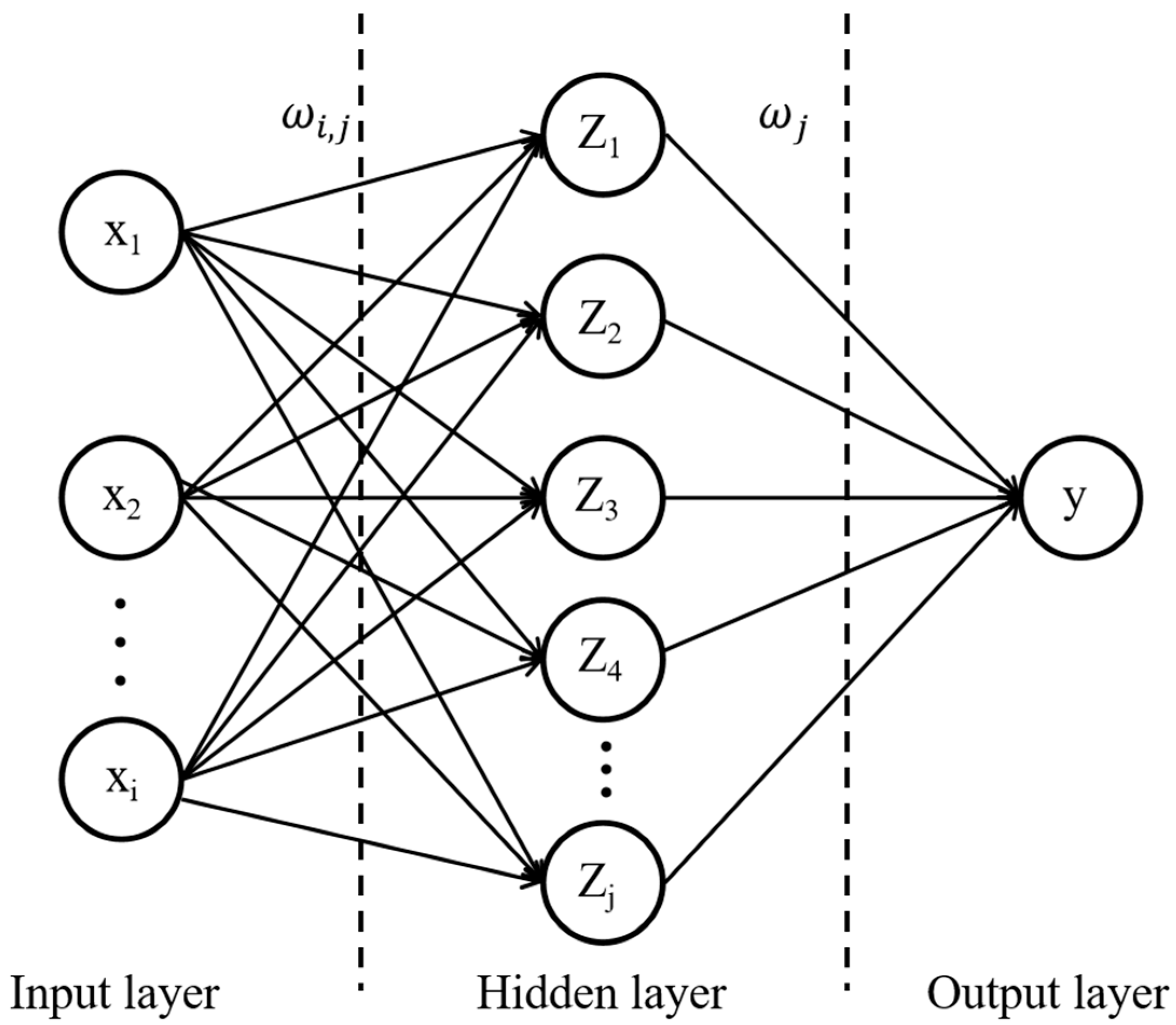
2.2.3. Backpropagation Neural Network
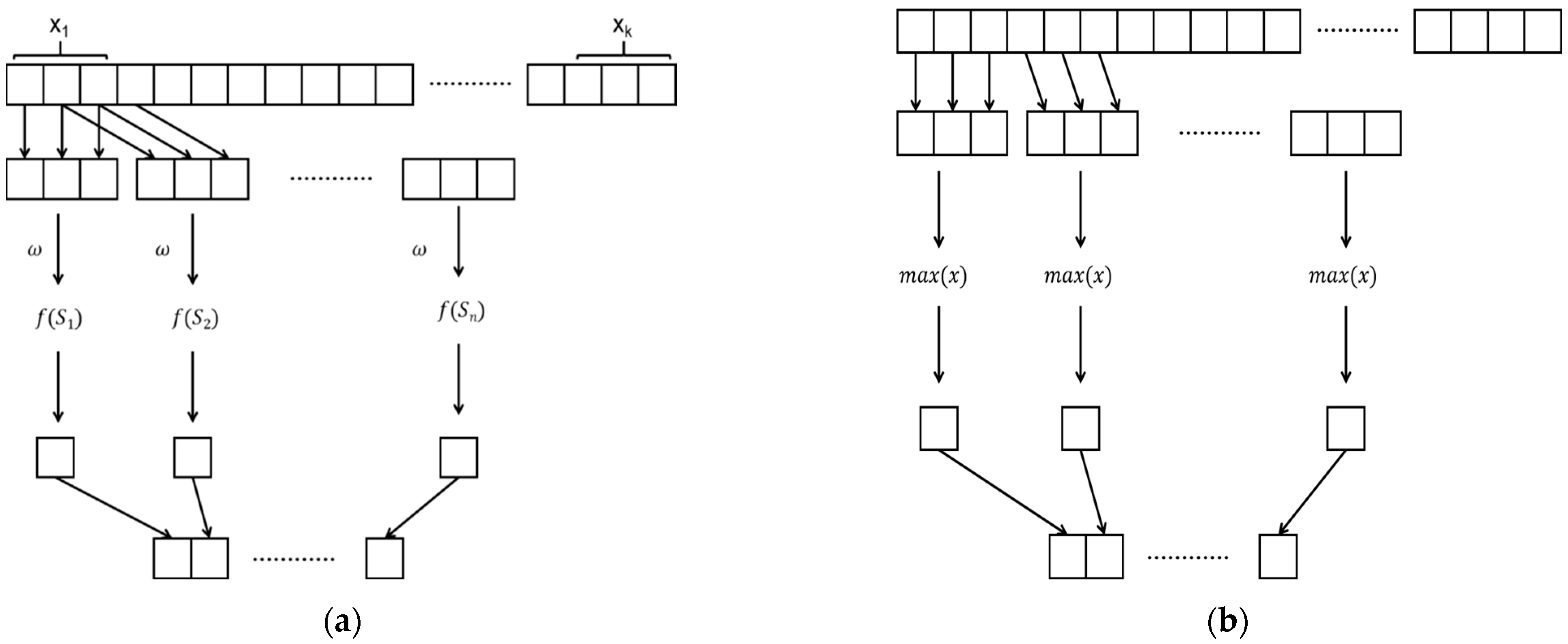
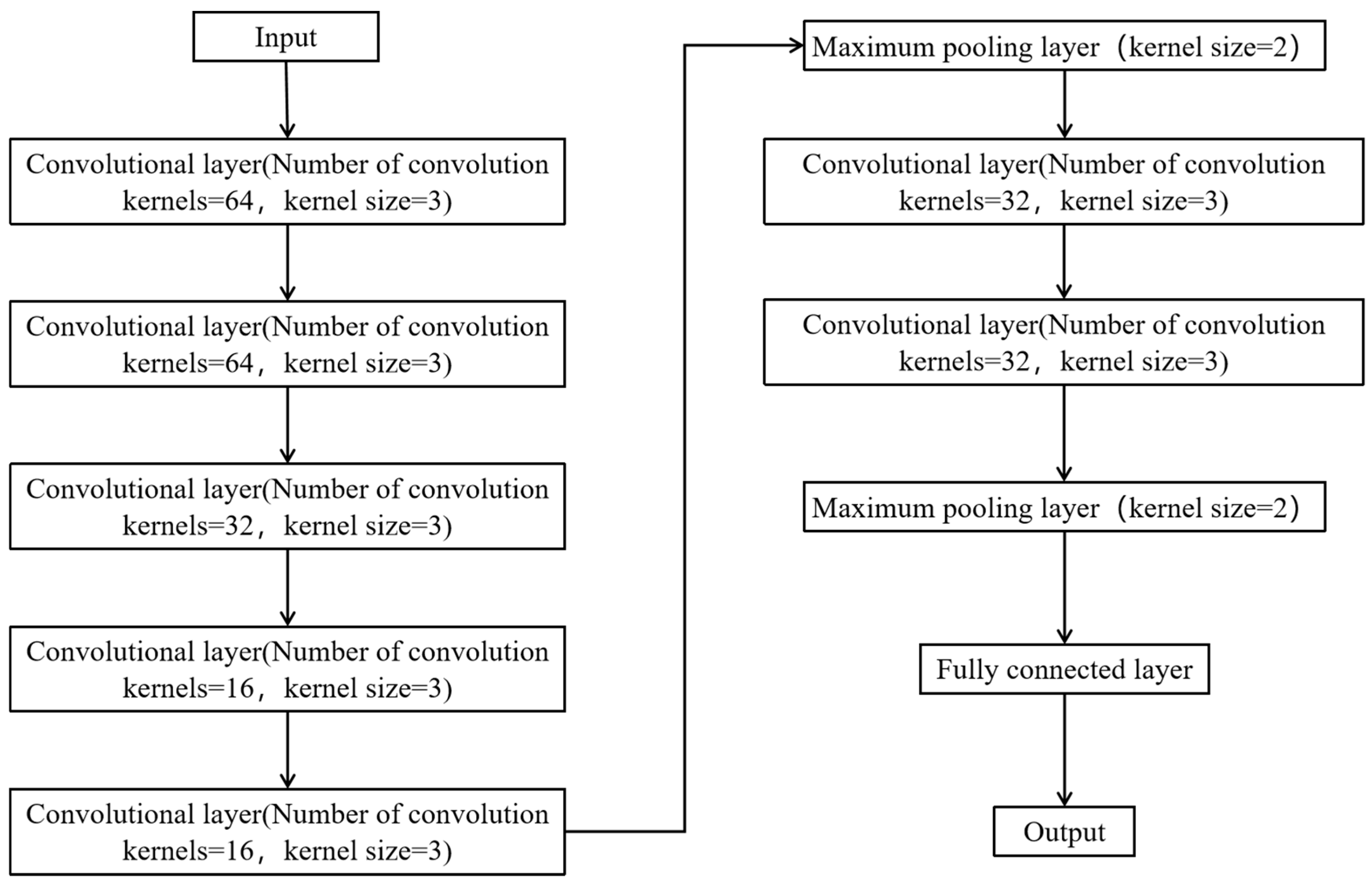
2.2.4. Convolutional Neural Network
2.3. Predictive Evaluation Indicators
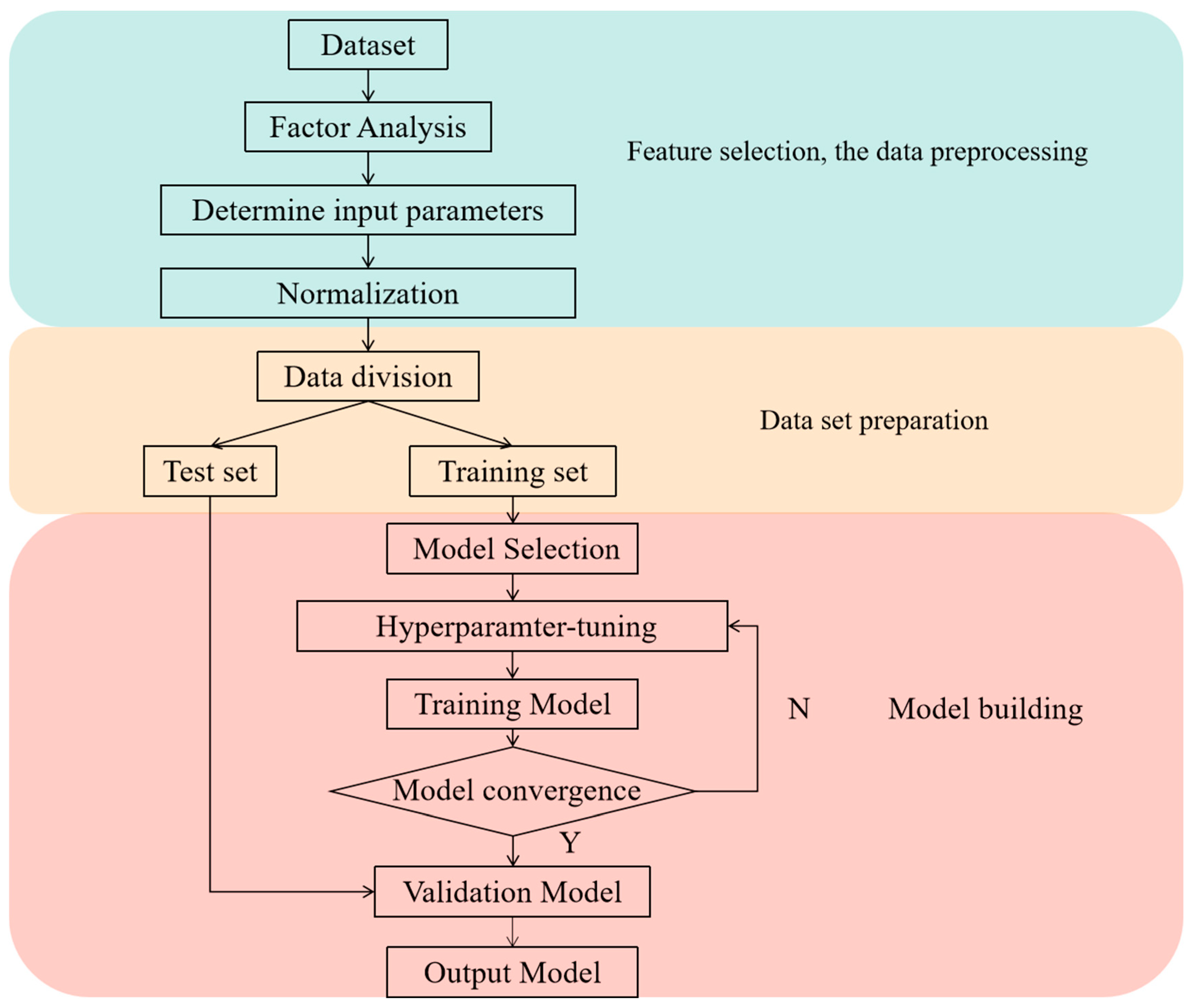
2.4. Machine Learning Model Construction Process
3. Dataset Acquisition
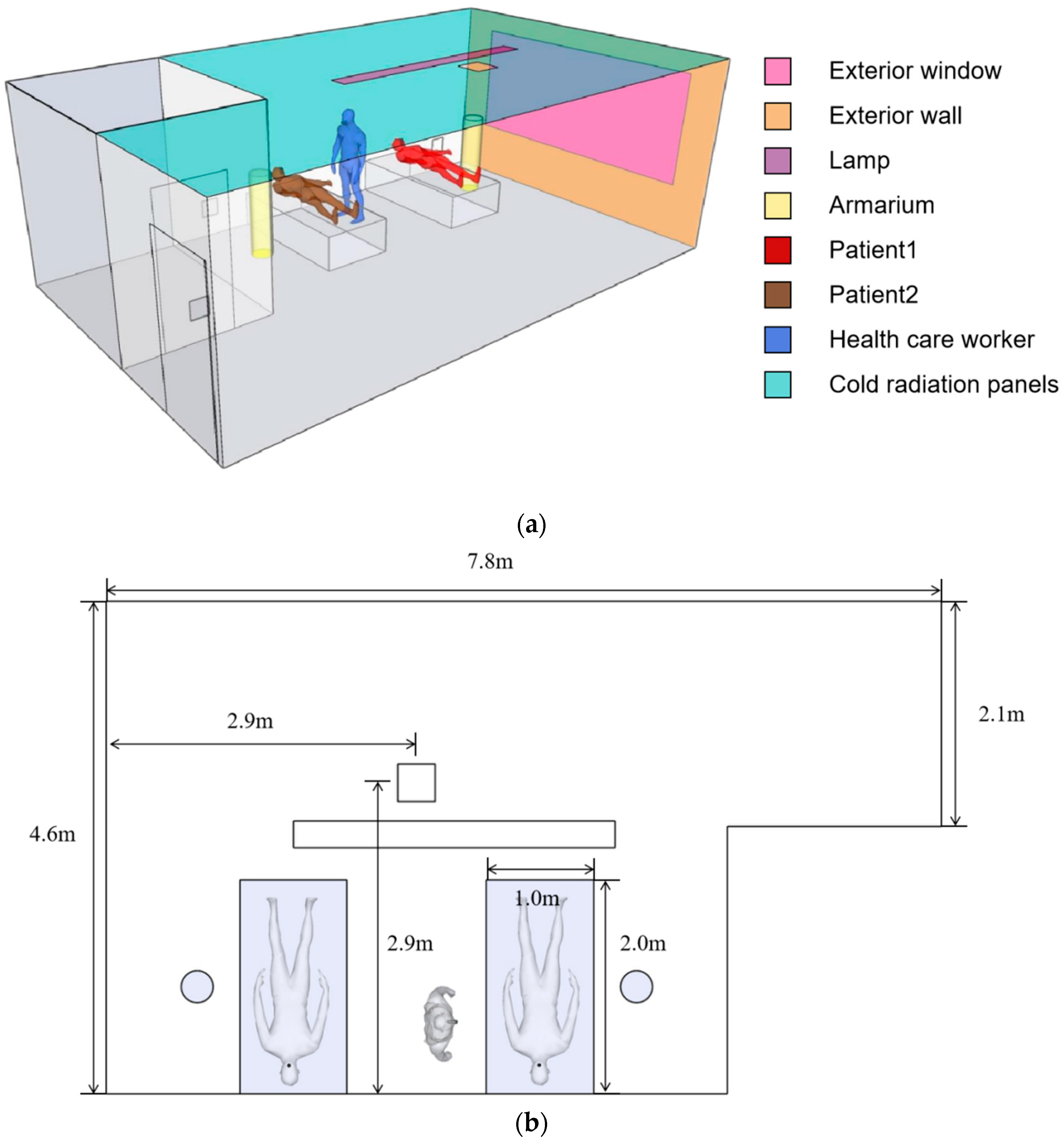
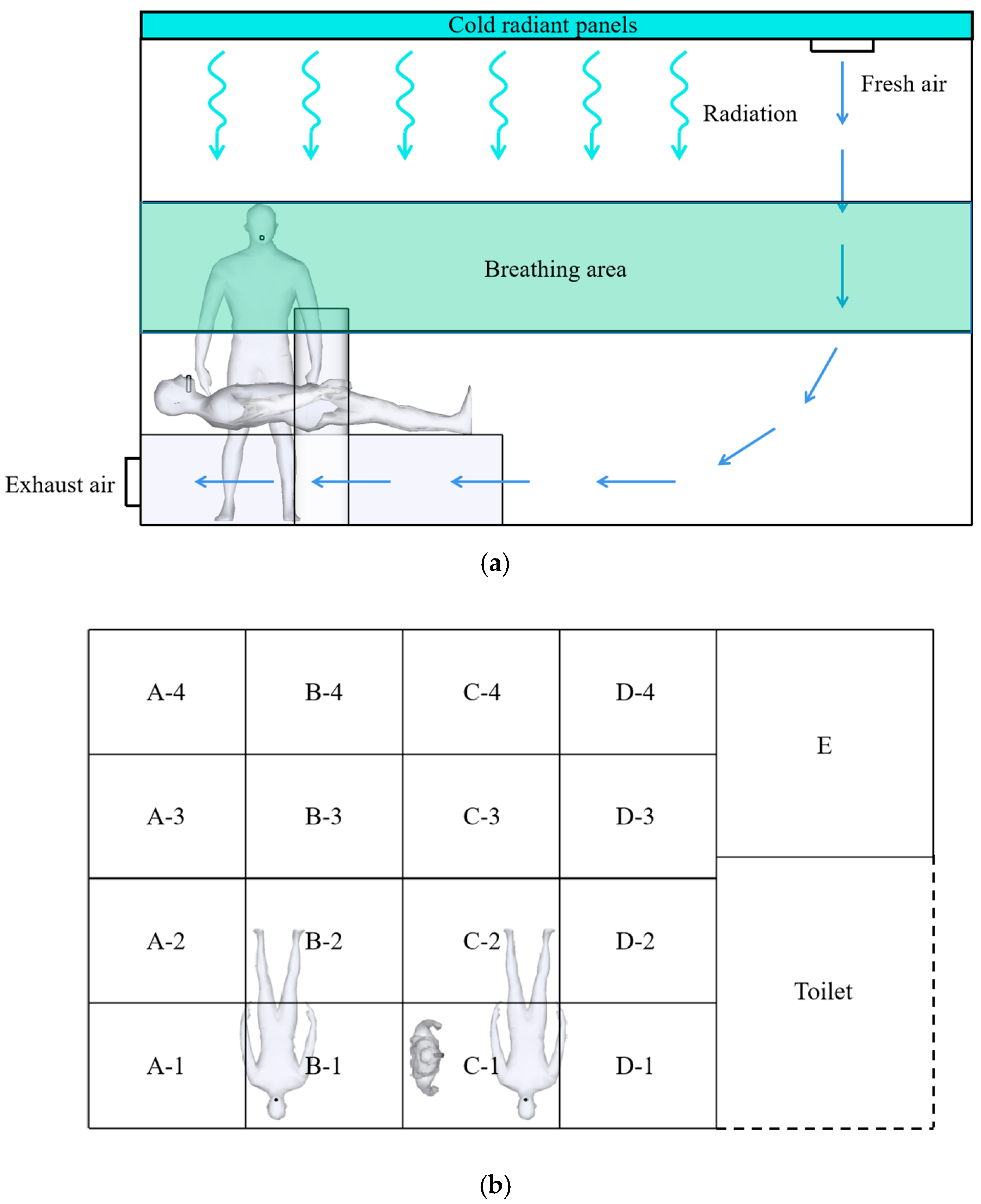
3.1. Indoor Environment Settings and Model Validation
3.2. Preparing the Dataset
4. Results and Discussion
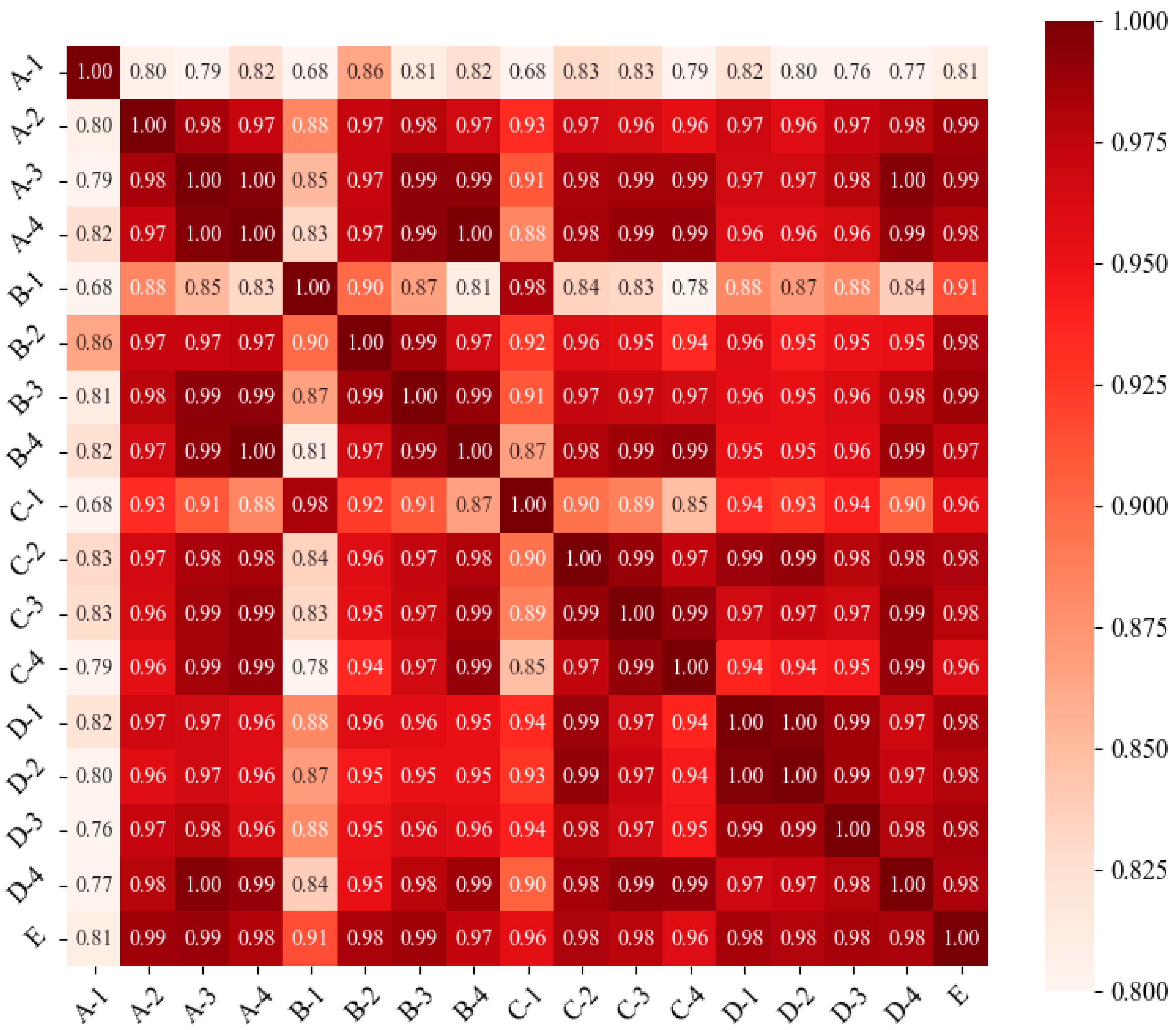
4.1. Regional Contamination Correlation Analysis
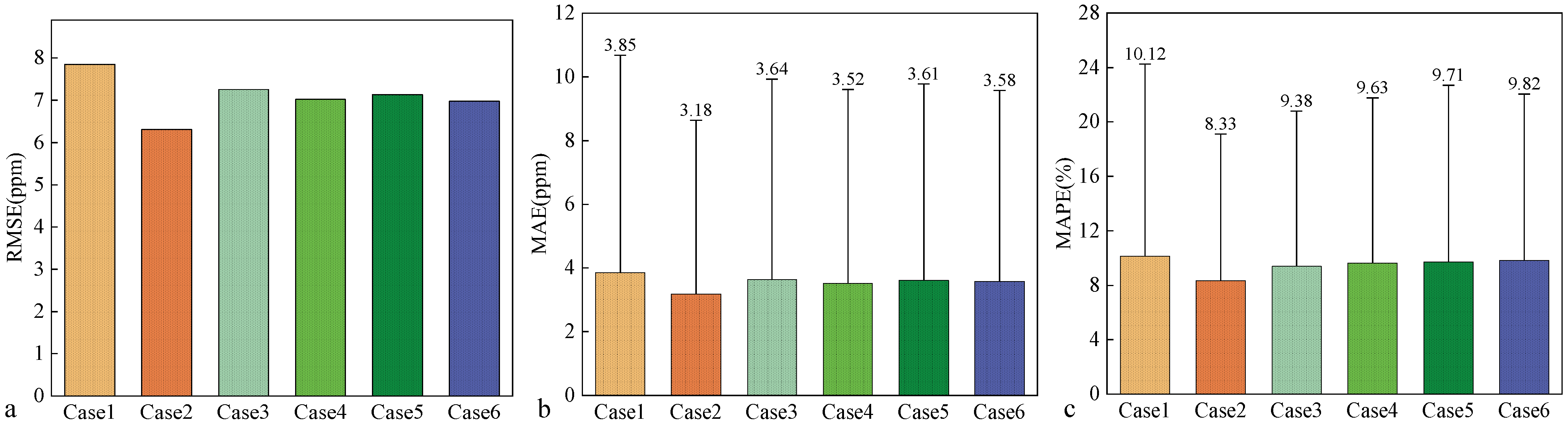
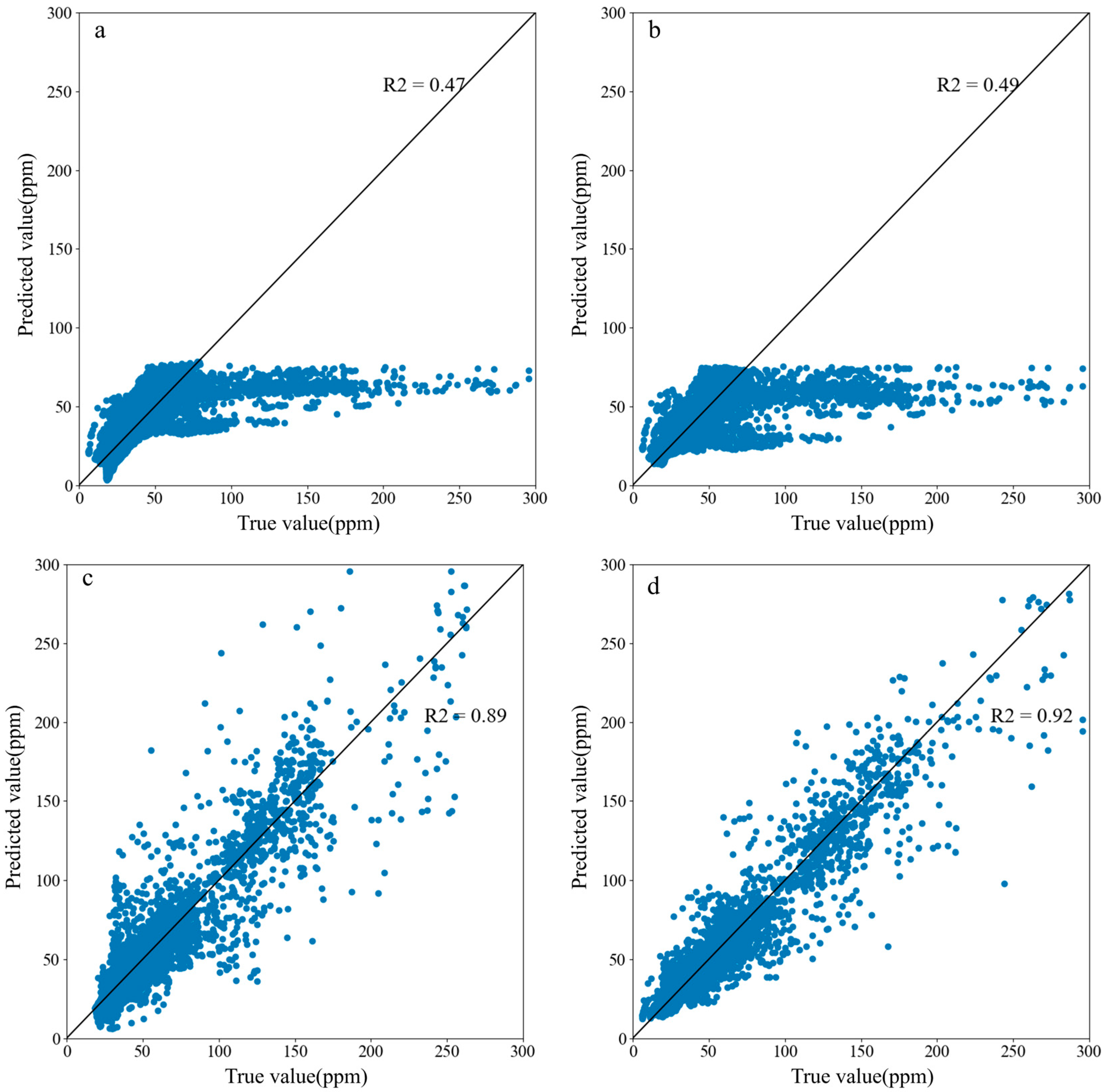
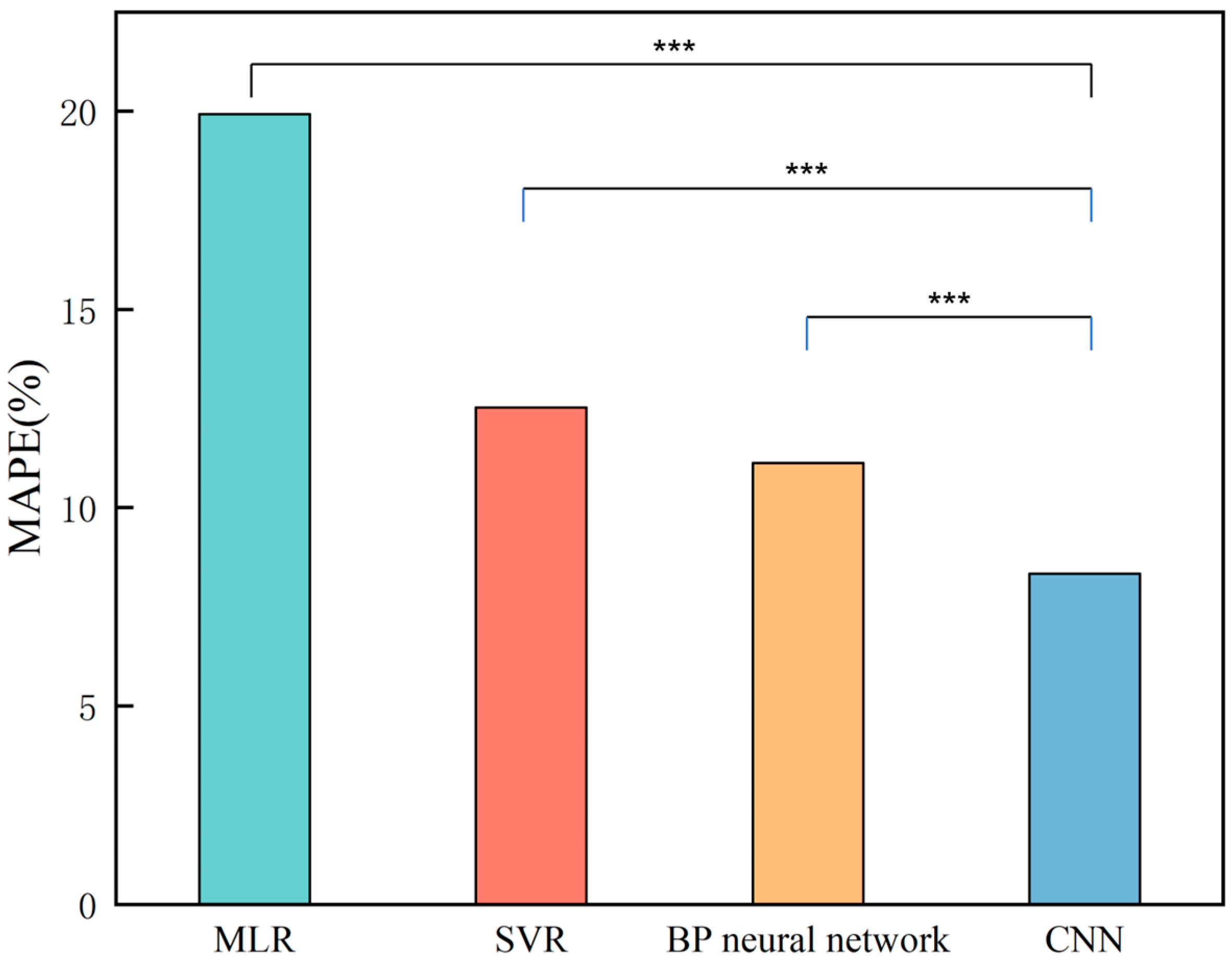
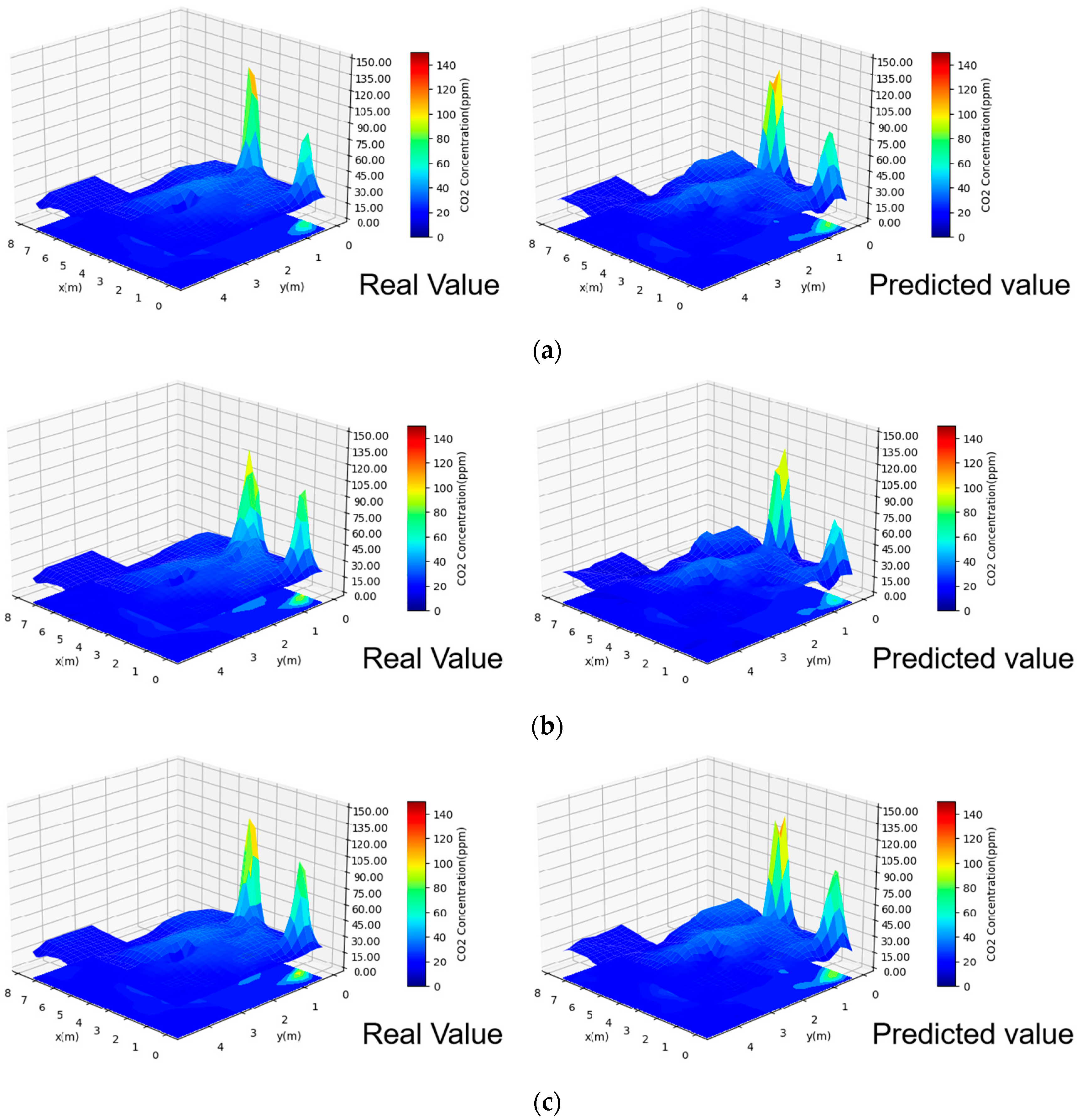
4.2. Indoor Contamination Concentration Prediction
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Riley, E.C.; Murphy, G.; Riley, R.L. Airborne spread of measles in a suburban elementary school. Am. J. Epidemiol. 1978, 107, 421–432. [Google Scholar] [CrossRef] [PubMed]
- Han, K.-T.; Kim, S. Impact of COVID-19 on nurse staffing levels and healthcare-associated infections in medical institutions: A retrospective cohort study. Sci. Rep. 2025, 15, 13351. [Google Scholar] [CrossRef] [PubMed]
- Ren, C.; Wang, J.; Feng, Z.; Kim, M.K.; Haghighat, F.; Cao, S.-J. Refined design of ventilation systems to mitigate infection risk in hospital wards: Perspective from ventilation openings setting. Environ. Pollut. 2023, 333, 122025. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Wang, L.L.; Birnkrant, M.J.; Zhai, J.; Miller, S.L. Evaluating SARS-CoV-2 airborne quanta transmission and exposure risk in a mechanically ventilated multizone office building. Build. Environ. 2022, 219, 109184. [Google Scholar] [CrossRef]
- Mei, D.; Duan, W.; Li, Y.; Li, J.; Chen, W. Evaluating risk of SARS-CoV-2 infection of the elderly in the public bus under personalized air supply. Sustain. Cities Soc. 2022, 84, 104011. [Google Scholar] [CrossRef]
- Liu, Z.; Yao, G.; Li, Y.; Huang, Z.; Jiang, C.; He, J.; Wu, M.; Liu, J.; Liu, H. Bioaerosol distribution characteristics and potential SARS-CoV-2 infection risk in a multi-compartment dental clinic. Build. Environ. 2022, 225, 109624. [Google Scholar] [CrossRef]
- Fennelly, K.P.; Nardell, E.A. The relative efficacy of respirators and room ventilation in preventing occupational tuberculosis. Infect. Control Hosp. Epidemiol. 1998, 19, 754–759. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, Z. Dilution-based evaluation of airborne infection risk—Thorough expansion of Wells-Riley model. Build. Environ. 2021, 194, 107674. [Google Scholar] [CrossRef]
- Aganovic, A.; Cao, G.; Kurnitski, J.; Melikov, A.; Wargocki, P. Zonal modeling of air distribution impact on the long-range airborne transmission risk of SARS-CoV-2. Appl. Math. Model. 2022, 112, 800–821. [Google Scholar] [CrossRef]
- Fisk, W.J.; Seppänen, O.; Faulkner, D.; Huang, J. Economic benefits of an economizer system: Energy savings and reduced sick leave. ASHRAE Trans. 2005, 111, 673–679. [Google Scholar]
- Lu, Y.; Oladokun, M.; Lin, J.Z. Reducing the exposure risk in hospital wards by applying stratum ventilation system. Build. Environ. 2020, 183, 107204. [Google Scholar] [CrossRef]
- Cho, J. Investigation on the contaminant distribution with improved ventilation system in hospital isolation rooms: Effect of supply and exhaust air diffuser configurations. Appl. Therm. Eng. 2018, 148, 208–218. [Google Scholar] [CrossRef]
- Wei, S.; Wu, W.; Jeon, G.; Ahmad, A.; Yang, X. Improving resolution of medical images with deep dense convolutional neural network. Concurr. Comput. Pract. Exp. 2020, 32, e5084. [Google Scholar] [CrossRef]
- Mishra, J.; Goyal, S. An effective automatic traffic sign classification and recognition deep convolutional networks. Multimed. Tools Appl. 2022, 81, 18915–18934. [Google Scholar] [CrossRef]
- Luo, Q.; Ou, C.; Hang, J.; Luo, Z.; Yang, H.; Yang, X.; Zhang, X.; Li, Y.; Fan, X. Role of pathogen-laden expiratory droplet dispersion and natural ventilation explaining a COVID-19 outbreak in a coach bus. Build. Environ. 2022, 220, 109160. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Niu, D.; Lu, Y.; Lin, Z. Contaminant removal and contaminant dispersion of air distribution for overall and local airborne infection risk controls. Sci. Total Environ. 2022, 833, 155173. [Google Scholar] [CrossRef] [PubMed]
- Portal-Porras, K.; Fernandez-Gamiz, U.; Zulueta, E.; Irigaray, O.; Garcia-Fernandez, R. Hybrid LSTM+CNN architecture for unsteady flow prediction. Mater. Today Commun. 2023, 35, 106281. [Google Scholar] [CrossRef]
- Portal-Porras, K.; Fernandez-Gamiz, U.; Zulueta, E.; Ballesteros-Coll, A.; Zulueta, A. CNN-based flow control device modelling on aerodynamic airfoils. Sci. Rep. 2022, 12, 8205. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Afshar, Y.; Pan, S.; Duraisamy, K.; Kaushik, S. Prediction of aerodynamic flow fields using convolutional neural networks. Comput. Mech. 2019, 64, 525–545. [Google Scholar] [CrossRef]
- Tian, X.; Cheng, Y.; Lin, Z. Modelling indoor environment indicators using artificial neural network in the stratified environments. Build. Environ. 2022, 208, 108581. [Google Scholar] [CrossRef]
- Liu, G.; Ren, L.; Qu, G.; Zhang, Y.; Zang, X. Fast prediction model of three-dimensional temperature field of commercial complex for entrance-atrium temperature regulation. Energy Build. 2022, 273, 112380. [Google Scholar] [CrossRef]
- Warey, A.; Kaushik, S.; Khalighi, B.; Cruse, M.; Venkatesan, G. Data-driven prediction of vehicle cabin thermal comfort: Using machine learning and high-fidelity simulation results. Int. J. Heat Mass Transf. 2020, 148, 119083. [Google Scholar] [CrossRef]
- Pang, S.; Song, L.; Kasabov, N. Correlation-aided support vector regression for forex time series prediction. Neural Comput. Appl. 2011, 20, 1193–1203. [Google Scholar] [CrossRef]
- Gao, K.; Mei, G.; Piccialli, F.; Cuomo, S.; Tu, J.; Huo, Z. Julia language in machine learning: Algorithms, applications, and open issues. Comput. Sci. Rev. 2020, 37, 100254. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems, 9; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Malik, A.; Tikhamarine, Y.; Souag-Gamane, D.; Kisi, O.; Pham, Q.B. Support vector regression optimized by meta-heuristic algorithms for daily streamflow prediction. Stoch. Environ. Res. Risk Assess. 2020, 34, 1755–1773. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y. A Hybrid Model of EMD and PSO-SVR for Short-Term Load Forecasting in Residential Quarters. Math. Probl. Eng. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E.; PDP Research Group. Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1986; Volume 2, pp. 20–21. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ren, J.; Cao, S.J. Incorporating online monitoring data into fast prediction models towards the development of artificial intelligent ventilation systems. Sustain. Cities Soc. 2019, 47, 101498. [Google Scholar] [CrossRef]
- Richardson, E.T.; Morrow, C.D.; Kalil, D.B.; Bekker, L.G.; Wood, R. Shared air: A renewed focus on ventilation for the prevention of tuberculosis transmission. PLoS ONE 2014, 9, e96334. [Google Scholar] [CrossRef]
- Qian, H.; Li, Y.; Nielsen, P.V.; Hyldgaard, C.E.; Wong, T.W.; Chwang, A.T. Dispersion of exhaled droplet nuclei in a two-bed hospital ward with three different ventilation systems. Indoor Air 2006, 16, 111–128. [Google Scholar] [CrossRef]
- Olmedo, I.; Nielsen, P.V.; Ruiz de Adana, M.; Jensen, R.L.; Grzelecki, P. Distribution of exhaled contaminants and personal exposure in a room using three different air distribution strategies. Indoor Air 2012, 22, 64–76. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, C.; Qian, H.; Zheng, X.; Nielsen, P.V. Direct or indirect exposure of exhaled contaminants in stratified environments using an integral model of an expiratory jet. Indoor Air 2019, 29, 591–603. [Google Scholar] [CrossRef] [PubMed]
- Ministry of Housing and Urban-Rural Development of the People’s Republic of China. Code for Design of General Hospital; China Planning Press: Beijing, China, 2015. [Google Scholar]
- Zhou, C.G.; Ding, Y.F.; Ye, L.F. Study on infection risk in a negative pressure ward under different fresh airflow patterns based on a radiation air conditioning system. Environ. Sci. Pollut. Res. 2024, 31, 14135–14155. [Google Scholar] [CrossRef] [PubMed]
- Du, B.; Lund, P.D.; Wang, J.; Kolhe, M.; Hu, E. Comparative study of modelling the thermal efficiency of a novel straight through evacuated tube collector with MLR, SVR, BP and RBF methods. Sustain. Energy Technol. Assess. 2021, 44, 101029. [Google Scholar] [CrossRef]
- Hang, J.; Li, Y.; Ching, W.; Wei, J.; Jin, R.; Liu, L.; Xie, X. Potential airborne transmission between two isolation cubicles through a shared anteroom. Build. Environ. 2015, 89, 264–278. [Google Scholar] [CrossRef]
- Cheng, P.; Chen, D.; Wang, J. Research on prediction model of thermal and moisture comfort of underwear based on principal component analysis and Genetic Algorithm–Back Propagation neural network. Int. J. Nonlinear Sci. Numer. Simul. 2021, 22, 607–619. [Google Scholar] [CrossRef]
- Kwon, S.; Park, G.; Jang, Y.; Cho, J.; Chu, M.-G.; Min, B. Determination of oil well placement using convolutional neural network coupled with robust optimization under geological uncertainty. J. Pet. Sci. Eng. 2021, 201, 108118. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surface | Boundary Conditions |
|---|---|
| Interior walls, floors | Wall; Adiabatic |
| Exterior walls | Wall; Heat flux: 35.89 W/m2 |
| Exterior windows | Wall; Heat flux: 389 W/m2 |
| Lamp | Wall; Heat flux: 133 W/m2 |
| Patients and health care workers | Wall; Heat flux: 45 W/m2 [11] |
| Armarium | Wall; Heat flux: 389.71 W/m2 |
| Mouth | Velocity-inlet: 0.88 m/s [32,33]; Temperature: 34 °C [34] |
| New air vent | Velocity-inlet: 1.13 m/s; Temperature: 18.64 °C |
| Ceiling | Wall; Temperature: 19 °C |
| Exhaust air vent | EA1, EA2, Velocity-inlet: −0.96 m/s; EA3 Velocity-inlet: −0.95 m/s [35] |
| Scenario | Air Changes Under a Steady State | Air Changes After State Changes | Scenario | Air Changes Under a Steady State | Air Changes After State Changes |
|---|---|---|---|---|---|
| Scenario 1 | 3 | 3 | Scenario 12 | 12 | 6 |
| Scenario 2 | 4 | 4 | Scenario 13 | 12 | 9 |
| Scenario 3 | 5 | 5 | Scenario 14 | 9 | 3 |
| Scenario 4 | 6 | 6 | Scenario 15 | 9 | 6 |
| Scenario 5 | 7 | 7 | Scenario 16 | 9 | 12 |
| Scenario 6 | 8 | 8 | Scenario 17 | 6 | 3 |
| Scenario 7 | 9 | 9 | Scenario 18 | 6 | 9 |
| Scenario 8 | 10 | 10 | Scenario 19 | 6 | 12 |
| Scenario 9 | 11 | 11 | Scenario 20 | 3 | 6 |
| Scenario 10 | 12 | 12 | Scenario 21 | 3 | 9 |
| Scenario 11 | 12 | 3 | Scenario 22 | 3 | 12 |
| Case | Sensor Arrangement Area | Sensor Number |
|---|---|---|
| Case 1 | E | Sensor 1 |
| Case 2 | E,A-1 | Sensors 1–2 |
| Case 3 | E,A-1,B-1 | Sensors 1–3 |
| Case 4 | E,A-1,B-1,C-1 | Sensors 1–4 |
| Case 5 | E,A-1,B-1,C-1,C-4 | Sensors 1–5 |
| Case 6 | E,A-1,B-1,C-1,C-4,B-4 | Sensors 1–6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, C.; Ding, Y. Comparative Analysis of Machine Learning Models for Predicting Contaminant Concentration Distributions in Hospital Wards. Buildings 2025, 15, 1828. https://doi.org/10.3390/buildings15111828
Zhou C, Ding Y. Comparative Analysis of Machine Learning Models for Predicting Contaminant Concentration Distributions in Hospital Wards. Buildings. 2025; 15(11):1828. https://doi.org/10.3390/buildings15111828
Chicago/Turabian StyleZhou, Chonggang, and Yunfei Ding. 2025. "Comparative Analysis of Machine Learning Models for Predicting Contaminant Concentration Distributions in Hospital Wards" Buildings 15, no. 11: 1828. https://doi.org/10.3390/buildings15111828
APA StyleZhou, C., & Ding, Y. (2025). Comparative Analysis of Machine Learning Models for Predicting Contaminant Concentration Distributions in Hospital Wards. Buildings, 15(11), 1828. https://doi.org/10.3390/buildings15111828