
Compressive Strength Prediction of BFRC Based on a Novel Hybrid Machine Learning Model


Abstract
1. Introduction
- A large dataset on the basic mechanical properties of BFRC was constructed using experimental data on BFRC strength from published literature and made available to the public;
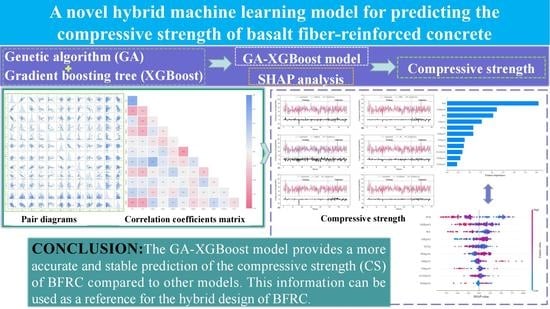
- GA-XGBoost was developed and applied to predict CS on BFRC, and the model was validated by SHAP analysis;
- Six independent regression models—XGBoost, gradient-boosted decision tree (GBDT) regressor, AdaBoost, RF, SVR, and GA-XGBoost—were adopted to predict the concrete CS, and the accuracy of these models’ predictions was compared.
2. Data Preprocessing
3. Methodology
3.1. Machine-Learning Algorithm
3.1.1. Brief Description of RF
3.1.2. Brief Description of AdaBoost
3.1.3. Brief Description of GBDT
3.1.4. Brief Description of SVR
3.1.5. Brief Description of XGBoost
3.1.6. Features, Advantages, and Disadvantages of the above Five Models
3.1.7. Combination of Genetic Algorithm and XGBoost
3.2. Model Performance Evaluation
3.3. Methodology Flowchart
3.3.1. Data Collection
3.3.2. Model Training
3.3.3. Model Verification
3.3.4. Sensitivity Analysis
4. Results and Discussion
4.1. Evaluation of Six Models
4.2. SHAP Analysis
5. Conclusions and Limitations
- (1)
- Compared to other regression models, the GA-XGBoost model shows the best accuracy and stability in predicting CS of BFRC. For the test dataset, the R2, MSE, RMSE, and MAE of GA-XGBoost were 0.9483, 7.6962 MPa, 2.7742 MPa, and 2.0564 MPa, and the errors were within the acceptable range.
- (2)
- By using GAs to tune the parameters in the ML algorithm, a lot of debugging work can be avoided and the best combination of parameters can be obtained. For engineering applications involving ML algorithms, this can greatly assist in developing practical solutions.
- (3)
- According to SHAP analysis, W/B of BFRC is the most important variable that dominates CS, followed by FA and W/C. The variable FC has some influence on CS, while other variables, such as CA and SF, have less influence on CS. This can provide some reference for the design of BFRC fits.
- (1)
- It can guide the calculation of BFRC compressive strength required for engineering;
- (2)
- It effectively reduces the difficulty of obtaining BFRC compressive strength, reduces the experimental workload, saves time and cost, and is more economical and environmentally friendly;
- (3)
- We developed a genetic algorithm for parameter optimization to determine the key parameters of the prediction model, which can provide an effective reference for the optimization of other machine models.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| BFRC | Basalt-fiber-reinforced concrete |
| XGBoost | Extreme gradient boosting tree |
| ML | Machine learning |
| GBDT | Gradient-boosted decision tree |
| AdaBoost | Adaptive gradient boosting |
| BF | Basalt fiber |
| MSE | Mean square error |
| W/C | Water–cement ratio |
| SF | Silica fume |
| S | High-efficiency water reducing agent |
| FL/FD | Ratio of length to diameter of fibers |
| F | Fly ash |
| CS | Compressive strength |
| GA | Genetic algorithm |
| RF | Random forest |
| SVR | Support vector regression |
| MAE | Mean absolute error |
| R2 | Coefficient of determination |
| RMSE | Root mean square error |
| CA | Coarse aggregate |
| W/B | Water–binder ratio |
| FA | Fine aggregate |
| FC | Fiber content |
References
- Jalasutram, S.; Sahoo, D.R.; Matsagar, V. Experimental investigation of the mechanical properties of basalt fiber-reinforced concrete. Struct. Concr. 2017, 18, 292–302. [Google Scholar] [CrossRef]
- Arslan, M.E. Effects of basalt and glass chopped fibers addition on fracture energy and mechanical properties of ordinary concrete: CMOD measurement. Constr. Build. Mater. 2016, 114, 383–391. [Google Scholar] [CrossRef]
- Zhao, Y.-R.; Wang, L.; Lei, Z.-K.; Han, X.-F.; Shi, J.-N. Study on bending damage and failure of basalt fiber reinforced concrete under freeze-thaw cycles. Constr. Build. Mater. 2018, 163, 460–470. [Google Scholar] [CrossRef]
- Li, M.; Gong, F.; Wu, Z. Study on mechanical properties of alkali-resistant basalt fiber reinforced concrete. Constr. Build. Mater. 2020, 245, 118424. [Google Scholar] [CrossRef]
- Wang, D.; Ju, Y.; Shen, H.; Xu, L. Mechanical properties of high performance concrete reinforced with basalt fiber and polypropylene fiber. Constr. Build. Mater. 2019, 197, 464–473. [Google Scholar] [CrossRef]
- Wang, X.; He, J.; Mosallam, A.S.; Li, C.; Xin, H. The Effects of Fiber Length and Volume on Material Properties and Crack Resistance of Basalt Fiber Reinforced Concrete (BFRC). Adv. Mater. Sci. Eng. 2019, 2019, 7520549. [Google Scholar] [CrossRef]
- Chen, W.; Zhu, Z.C.; Wang, J.; Chen, J.; Mo, Y. Numerical Analysis of Mechanical Properties of Chopped Basalt Fiber Reinforced Concrete. Key Eng. Mater. 2019, 815, 175–181. [Google Scholar] [CrossRef]
- Jiang, C.; Fan, K.; Wu, F.; Chen, D. Experimental study on the mechanical properties and microstructure of chopped basalt fibre reinforced concrete. Mater. Des. 2014, 58, 187–193. [Google Scholar] [CrossRef]
- Kizilkanat, A.B.; Kabay, N.; Akyüncü, V.; Chowdhury, S.; Akça, A.H. Mechanical properties and fracture behavior of basalt and glass fiber reinforced concrete: An experimental study. Constr. Build. Mater. 2015, 100, 218–224. [Google Scholar] [CrossRef]
- Pehlivanli, Z.O.; Uzun, I.; Demir, I. Mechanical and microstructural features of autoclaved aerated concrete reinforced with autoclaved polypropylene, carbon, basalt and glass fiber. Constr. Build. Mater. 2015, 96, 428–433. [Google Scholar] [CrossRef]
- Katkhuda, H.; Shatarat, N. Improving the mechanical properties of recycled concrete aggregate using chopped basalt fibers and acid treatment. Constr. Build. Mater. 2017, 140, 328–335. [Google Scholar] [CrossRef]
- Ahmad, M.R.; Chen, B. Effect of silica fume and basalt fiber on the mechanical properties and microstructure of magnesium phosphate cement (MPC) mortar. Constr. Build. Mater. 2018, 190, 466–478. [Google Scholar] [CrossRef]
- Sun, X.; Gao, Z.; Cao, P.; Zhou, C. Mechanical properties tests and multiscale numerical simulations for basalt fiber reinforced concrete. Constr. Build. Mater. 2019, 202, 58–72. [Google Scholar] [CrossRef]
- Naser, M.Z. Machine Learning Assessment of FRP-Strengthened and Reinforced Concrete Members. ACI Struct. J. 2020, 117, 237–251. [Google Scholar] [CrossRef]
- Aravind, N.; Nagajothi, S.; Elavenil, S. Machine learning model for predicting the crack detection and pattern recognition of geopolymer concrete beams. Constr. Build. Mater. 2021, 297, 123785. [Google Scholar] [CrossRef]
- Basaran, B.; Kalkan, I.; Bergil, E.; Erdal, E. Estimation of the FRP-concrete bond strength with code formulations and machine learning algorithms. Compos. Struct. 2021, 268, 113972. [Google Scholar] [CrossRef]
- Li, H.; Lin, J.; Lei, X.; Wei, T. Compressive strength prediction of basalt fiber reinforced concrete via random forest algorithm. Mater. Today Commun. 2022, 30, 103117. [Google Scholar] [CrossRef]
- Severcan, M.H. Prediction of splitting tensile strength from the compressive strength of concrete using GEP. Neural Comput. Appl. 2011, 21, 1937–1945. [Google Scholar] [CrossRef]
- Nguyen, M.H.; Mai, H.-V.T.; Trinh, S.H.; Ly, H.-B. A comparative assessment of tree-based predictive models to estimate geopolymer concrete compressive strength. Neural Comput. Appl. 2022, 35, 6569–6588. [Google Scholar] [CrossRef]
- Gupta, S.; Sihag, P. Prediction of the compressive strength of concrete using various predictive modeling techniques. Neural Comput. Appl. 2022, 34, 6535–6545. [Google Scholar] [CrossRef]
- Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Kotsonis, E.A.; Lourenço, P.B. Prediction of cement-based mortars compressive strength using machine learning techniques. Neural Comput. Appl. 2021, 33, 13089–13121. [Google Scholar] [CrossRef]
- Kang, M.-C.; Yoo, D.-Y.; Gupta, R. Machine learning-based prediction for compressive and flexural strengths of steel fiber-reinforced concrete. Constr. Build. Mater. 2020, 266, 121117. [Google Scholar] [CrossRef]
- Altayeb, M.; Wang, X.; Musa, T.H. An ensemble method for predicting the mechanical properties of strain hardening cementitious composites. Constr. Build. Mater. 2021, 286, 122807. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2021, 33, 4501–4532. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Mostafa, R.R.; Mohammed, A.; Sihag, P.; Qadir, A. Support vector regression (SVR) and grey wolf optimization (GWO) to predict the compressive strength of GGBFS-based geopolymer concrete. Neural Comput. Appl. 2023, 35, 2909–2926. [Google Scholar] [CrossRef]
- Nazar, S.; Yang, J.; Ahmad, W.; Javed, M.F.; Alabduljabbar, H.; Deifalla, A.F. Development of the New Prediction Models for the Compressive Strength of Nanomodified Concrete Using Novel Machine Learning Techniques. Buildings 2022, 12, 2160. [Google Scholar] [CrossRef]
- Esmaeili-Falak, M.; Benemaran, R.S. Ensemble deep learning-based models to predict the resilient modulus of modified base materials subjected to wet-dry cycles. Geomech. Eng. 2023, 32, 583–600. [Google Scholar]
- Benemaran, R.S.; Esmaeili-Falak, M.; Javadi, A. Predicting resilient modulus of flexible pavement foundation using extreme gradient boosting based optimised models. Int. J. Pavement Eng. 2022, 24, 1–20. [Google Scholar] [CrossRef]
- Li, D.; Zhang, X.; Kang, Q.; Tavakkol, E. Estimation of unconfined compressive strength of marine clay modified with recycled tiles using hybridized extreme gradient boosting method. Constr. Build. Mater. 2023, 393, 131992. [Google Scholar] [CrossRef]
- Malami, S.I.; Anwar, F.H.; Abdulrahman, S.; Haruna, S.; Ali, S.I.A.; Abba, S. Implementation of hybrid neuro-fuzzy and self-turning predictive model for the prediction of concrete carbonation depth: A soft computing technique. Results Eng. 2021, 10, 100228. [Google Scholar] [CrossRef]
- Iqbal, M.; Zhang, D.; Jalal, F.E.; Javed, M.F. Computational AI prediction models for residual tensile strength of GFRP bars aged in the alkaline concrete environment. Ocean Eng. 2021, 232, 109134. [Google Scholar] [CrossRef]
- Liu, Q.-F.; Iqbal, M.F.; Yang, J.; Lu, X.-Y.; Zhang, P.; Rauf, M. Prediction of chloride diffusivity in concrete using artificial neural network: Modelling and performance evaluation. Constr. Build. Mater. 2021, 268, 121082. [Google Scholar] [CrossRef]
- Salami, B.A.; Olayiwola, T.; Oyehan, T.A.; Raji, I.A. Data-driven model for ternary-blend concrete compressive strength prediction using machine learning approach. Constr. Build. Mater. 2021, 301, 124152. [Google Scholar] [CrossRef]
- Zhang, Y.; Aslani, F. Compressive strength prediction models of lightweight aggregate concretes using ultrasonic pulse velocity. Constr. Build. Mater. 2021, 292, 123419. [Google Scholar] [CrossRef]
- Oey, T.; Jones, S.; Bullard, J.W.; Sant, G. Machine learning can predict setting behavior and strength evolution of hydrating cement systems. J. Am. Ceram. Soc. 2019, 103, 480–490. [Google Scholar] [CrossRef]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. Open Access J. 2014, 2, 602–609. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Yuvaraj, P.; Murthy, A.R.; Iyer, N.R.; Sekar, S.; Samui, P. Support vector regression based models to predict fracture characteristics of high strength and ultra high strength concrete beams. Eng. Fract. Mech. 2013, 98, 29–43. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, J.; Gu, Y.; Huang, Y.; Sun, Y.; Ma, G. Prediction of permeability and unconfined compressive strength of pervious concrete using evolved support vector regression. Constr. Build. Mater. 2019, 207, 440–449. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, W.; Zhang, R.; Wu, C.; Goh, A.T.C.; Lacasse, S.; Liu, Z.; Liu, H. State-of-the-art review of soft computing applications in underground excavations. Geosci. Front. 2020, 11, 1095–1106. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Mohammadimanesh, F.; Homayouni, S. Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation. Remote Sens. 2021, 13, 4405. [Google Scholar] [CrossRef]
- Cao, J.; Kwong, S.; Wang, R. A noise-detection based AdaBoost algorithm for mislabeled data. Pattern Recognit. 2012, 45, 4451–4465. [Google Scholar] [CrossRef]
- Sun, Y.; Ding, S.; Zhang, Z.; Jia, W. An improved grid search algorithm to optimize SVR for prediction. Soft Comput. 2021, 25, 5633–5644. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Units | Mean | Std | Min | Max | Count |
|---|---|---|---|---|---|---|
| W/C | - | 0.450 | 0.0722 | 0.280 | 0.717 | 346 |
| W/B | - | 0.400 | 0.0753 | 0.241 | 0.573 | 346 |
| C | 395.3 | 69.25 | 217 | 613.3 | 346 | |
| F | 40.92 | 53.98 | 0 | 168 | 346 | |
| SF | 13.14 | 28.28 | 0 | 126 | 346 | |
| CA | 1093 | 170.6 | 512 | 1540 | 346 | |
| FA | 697.9 | 110.7 | 507 | 1194 | 346 | |
| W | 175.2 | 29.15 | 112 | 301 | 346 | |
| S | 3.088 | 2.292 | 0 | 8.360 | 346 | |
| FL/FD | 1.037 | 0.377 | 0.345 | 2 | 346 | |
| FC | % | 0.141 | 0.131 | 0 | 0.730 | 346 |
| CS | MPa | 50.15 | 11.80 | 15.52 | 96.25 | 346 |
| Model | Main Features | Advantages | Disadvantages |
|---|---|---|---|
| RF | RF is an integrated model consisting of multiple decision trees, which can reduce the variance of individual decision trees. |
|
|
| AdaBoost | AdaBoost is an integrated model consisting of several weak classifiers for binary and multivariate classification problems. |
|
|
| GBDT | GBDT Regressor is an integrated decision-tree-based learning algorithm that improves the accuracy and generalization performance through gradient boosting method. |
|
|
| SVR | SVR is a support vector machine (SVM)-based regression algorithm that can be used to handle nonlinear regression problems. |
|
|
| XGBoost | XGBoost is a decision-tree-based gradient boosting algorithm that also uses regularization to enhance the accuracy and generalization performance. |
|
|
| Type of Set | Metrics | XGBoost | GBDT | AdaBoost | RF | SVR | GA-XGBoost |
|---|---|---|---|---|---|---|---|
| Train | R2 | 0.9307 | 0.987 | 0.7822 | 0.96 | 0.9527 | 0.9834 |
| Rank | 5 | 1 | 6 | 3 | 4 | 2 | |
| MSE | 9.4145 | 1.7631 | 29.6077 | 5.4331 | 6.4333 | 2.2596 | |
| Rank | 5 | 1 | 6 | 3 | 4 | 2 | |
| RMSE | 3.0683 | 1.3278 | 5.4413 | 2.3309 | 2.5364 | 1.5032 | |
| Rank | 5 | 1 | 6 | 3 | 4 | 2 | |
| MAE | 1.9637 | 0.8235 | 4.4515 | 1.6056 | 0.758 | 1.0116 | |
| Rank | 5 | 2 | 6 | 4 | 1 | 3 | |
| Test | R2 | 0.9133 | 0.914 | 0.826 | 0.9322 | 0.9123 | 0.9483 |
| Rank | 4 | 3 | 6 | 2 | 5 | 1 | |
| MSE | 12.6259 | 12.5174 | 25.321 | 9.8671 | 12.7635 | 7.6962 | |
| Rank | 4 | 3 | 6 | 2 | 5 | 1 | |
| RMSE | 3.5533 | 3.538 | 5.032 | 3.1412 | 3.5726 | 2.7742 | |
| Rank | 4 | 3 | 6 | 2 | 5 | 1 | |
| MAE | 2.5726 | 2.473 | 4.0276 | 2.2175 | 2.5728 | 2.0564 | |
| Rank | 4 | 3 | 6 | 2 | 5 | 1 | |
| Total rank score | 36 | 17 | 48 | 21 | 33 | 13 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Yao, T.; Yue, J.; Wang, M.; Xia, S. Compressive Strength Prediction of BFRC Based on a Novel Hybrid Machine Learning Model. Buildings 2023, 13, 1934. https://doi.org/10.3390/buildings13081934
Zheng J, Yao T, Yue J, Wang M, Xia S. Compressive Strength Prediction of BFRC Based on a Novel Hybrid Machine Learning Model. Buildings. 2023; 13(8):1934. https://doi.org/10.3390/buildings13081934
Chicago/Turabian StyleZheng, Jiayan, Tianchen Yao, Jianhong Yue, Minghui Wang, and Shuangchen Xia. 2023. "Compressive Strength Prediction of BFRC Based on a Novel Hybrid Machine Learning Model" Buildings 13, no. 8: 1934. https://doi.org/10.3390/buildings13081934
APA StyleZheng, J., Yao, T., Yue, J., Wang, M., & Xia, S. (2023). Compressive Strength Prediction of BFRC Based on a Novel Hybrid Machine Learning Model. Buildings, 13(8), 1934. https://doi.org/10.3390/buildings13081934