




A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems



Abstract
1. Introduction
2. Literature Review
3. Methodology
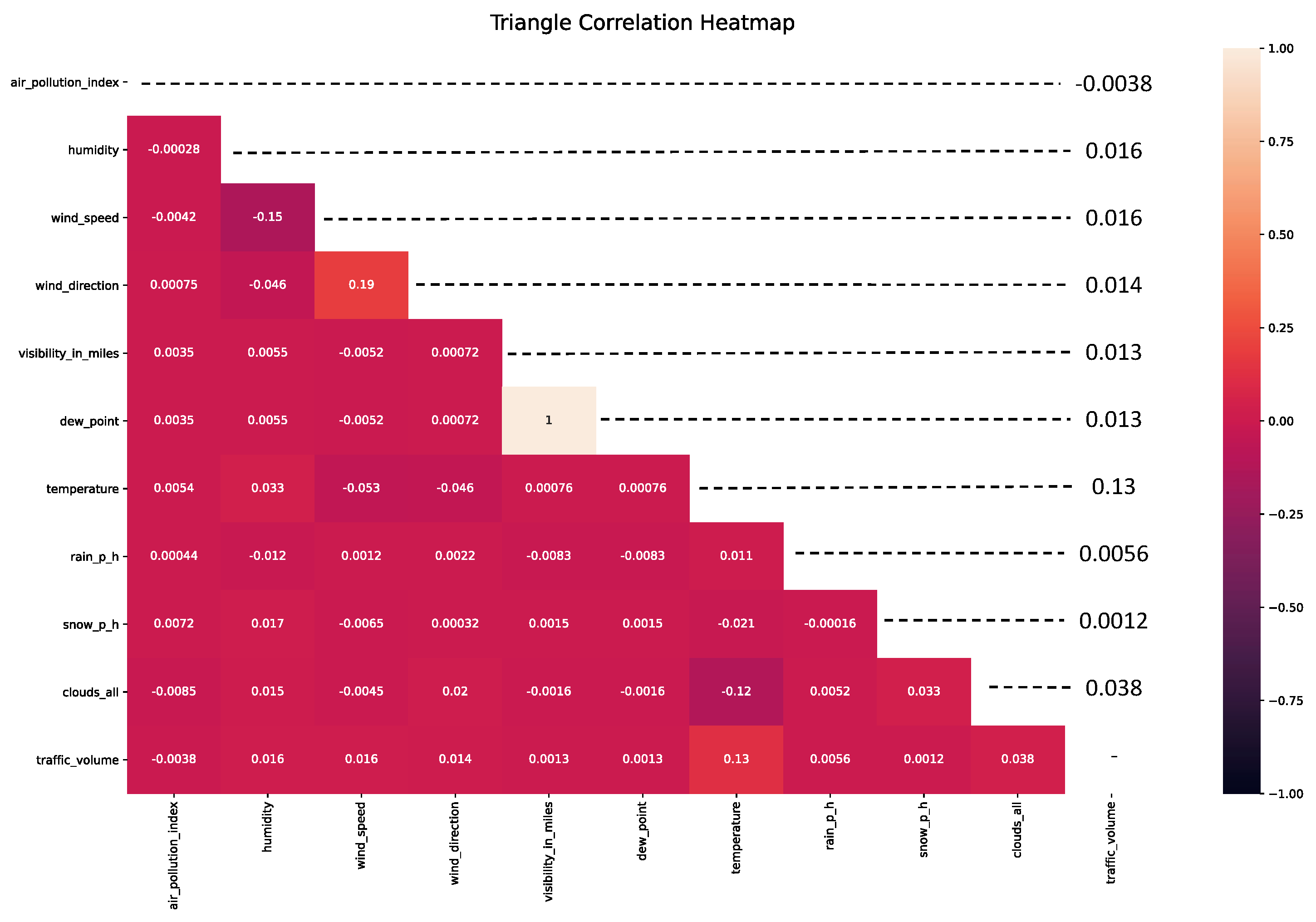
3.1. Data Collection, Processing, and Feature Selection
3.2. PCMCI Enabled Causal Discovery
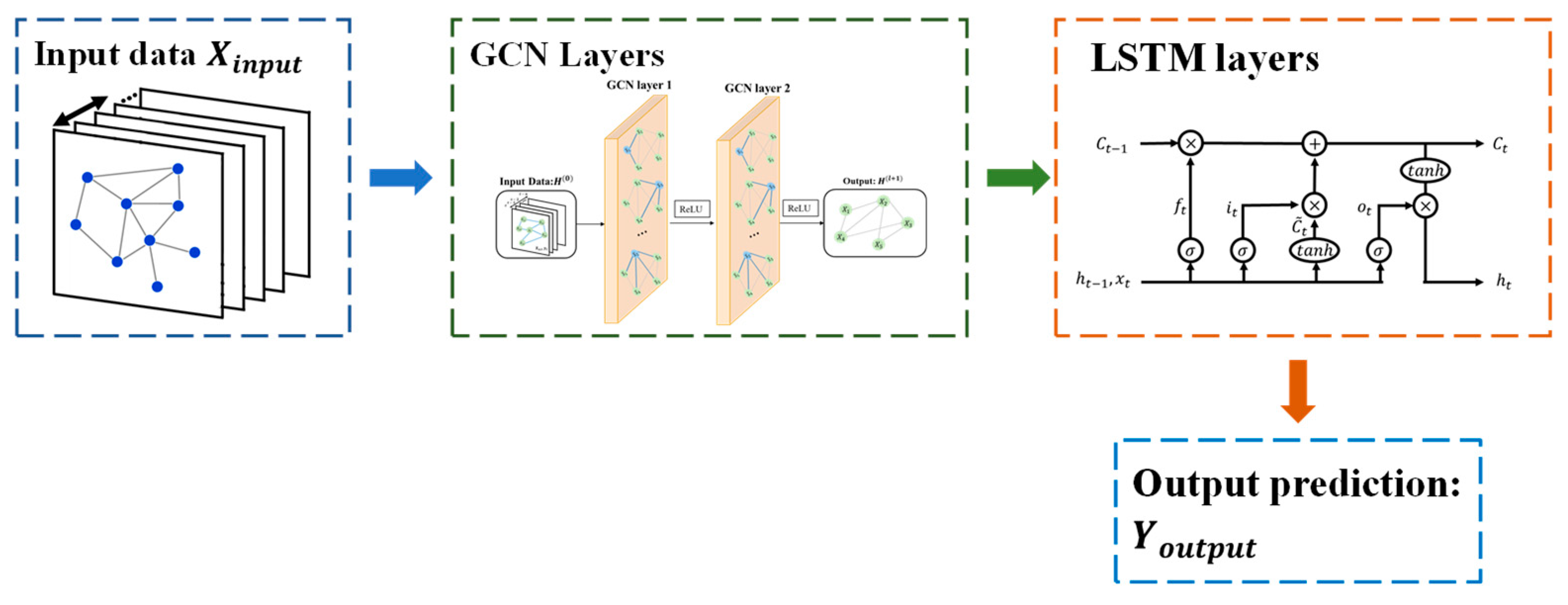
3.3. Model Development GCMN
3.3.1. Structure of LSTM Cells
3.3.2. Structure of GCN Cells
3.3.3. GCMN Model Training and Prediction
3.4. Model Evaluation
4. Case Study
4.1. Case Background and Data Collection
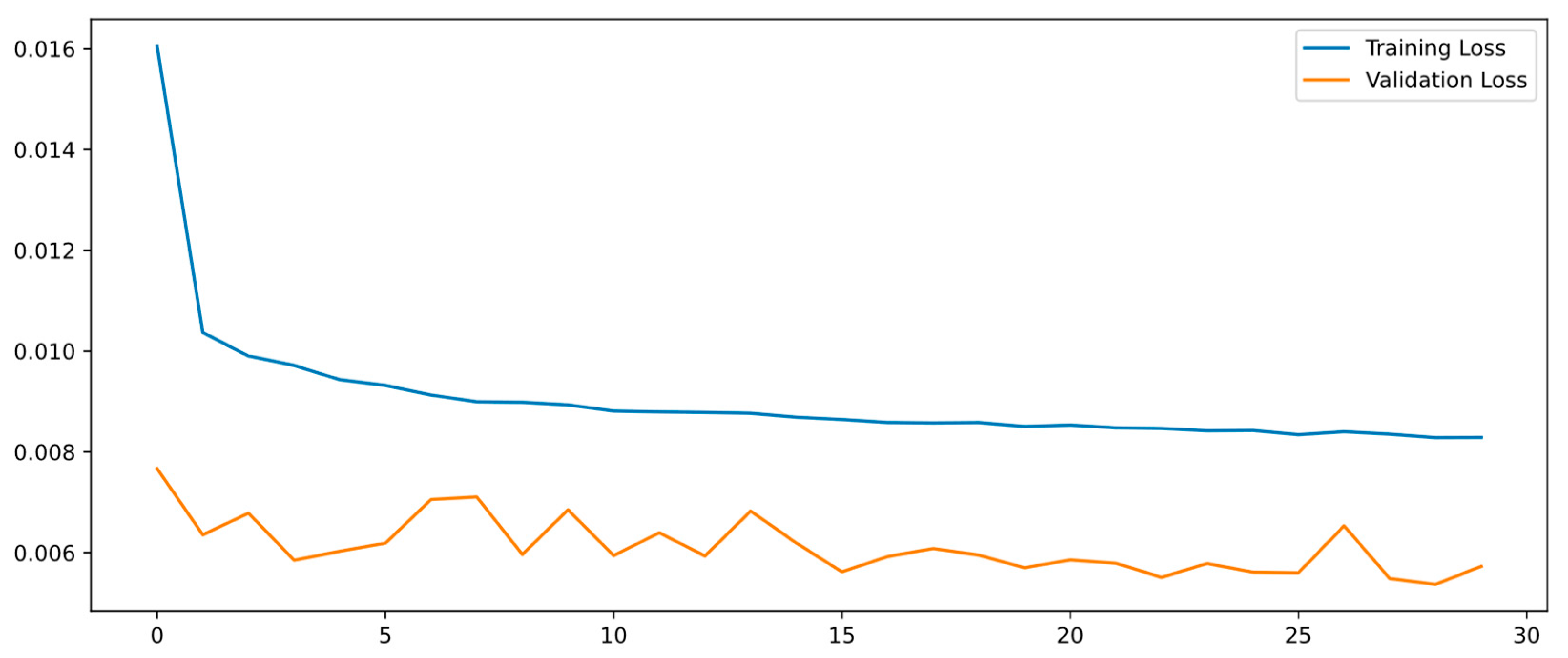
4.2. Training and Testing Details
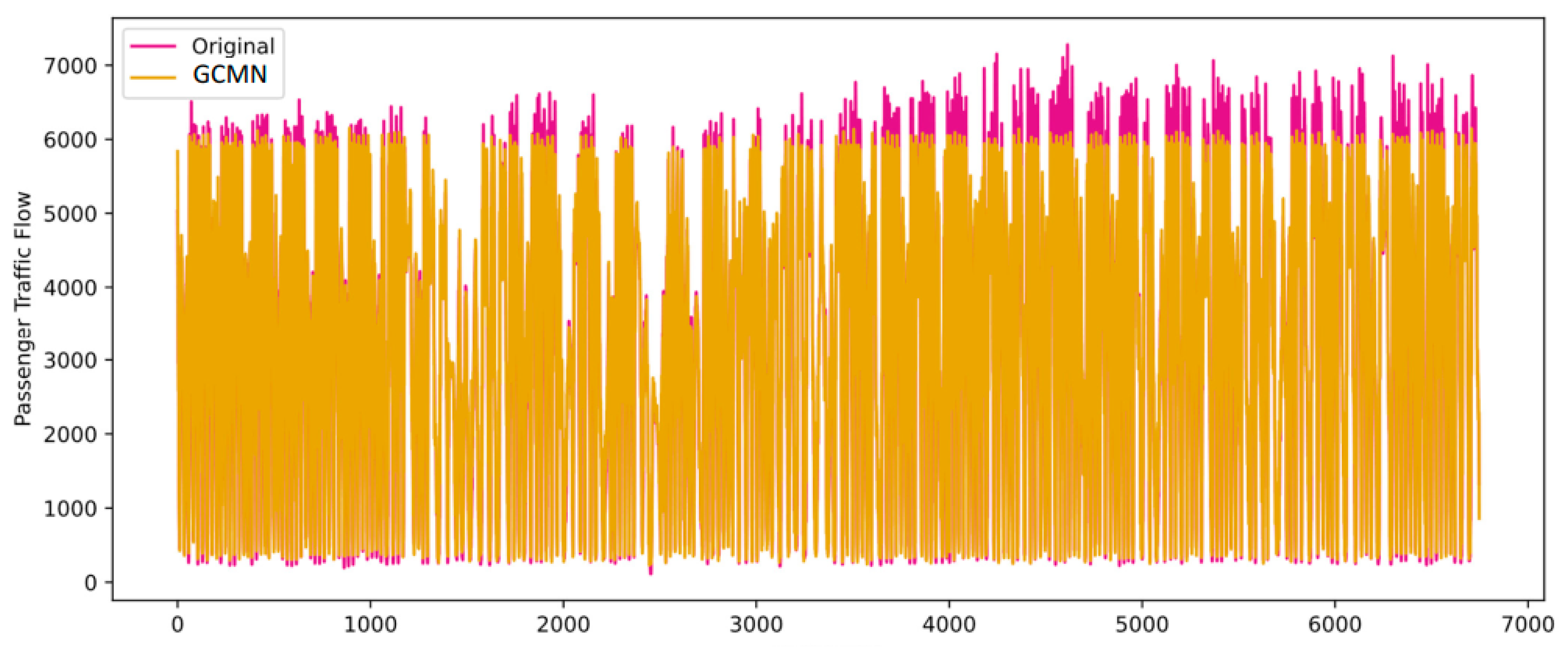
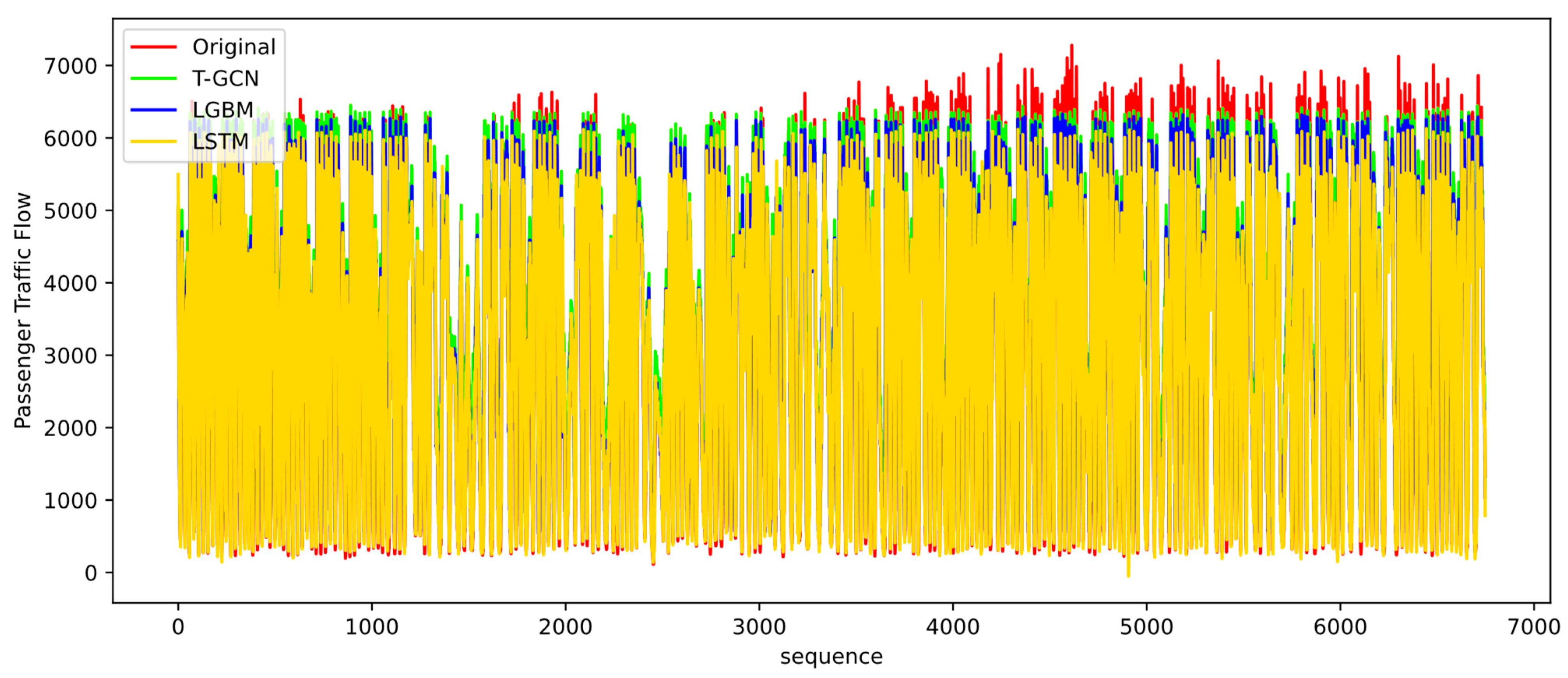
4.3. Analysis of Results
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lowe, M.D. Alternatives to the automobile: Transport for livable cities. Ekistics 1990, 269–282. [Google Scholar]
- Li, Q.Y.; Zhong, Z.D.; Liu, M.; Fang, W.W. Smart railway based on the Internet of Things. In Big Data Analytics for Sensor-Network Collected Intelligence; Academic Press: Amsterdam, The Netherlands, 2017; pp. 280–297. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.-Y. Traffic Flow Prediction with Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Sajanraj, T.D.; Mulerikkal, J.; Raghavendra, S.; Vinith, R.; Fábera, V. Passenger flow prediction from AFC data using station memorizing LSTM for metro rail systems. Neural Netw. World 2021, 31, 173–189. [Google Scholar] [CrossRef]
- Yoo, S.; Kim, H.; Kim, W.; Kim, N.; Lee, J. Controlling passenger flow to mitigate the effects of platform overcrowding on train dwell time. J. Intell. Transp. Syst. 2020, 26, 366–381. [Google Scholar] [CrossRef]
- Mulerikkal, J.; Thandassery, S.; Rejathalal, V.; Kunnamkody, D.M.D. Performance improvement for metro passenger flow forecast using spatio-temporal deep neural network. Neural Comput. Appl. 2021, 34, 983–994. [Google Scholar] [CrossRef]
- Garber, N.J.; Hoel, L.A. Traffic and Highway Engineering; Cengage Learning: Boston, MA, USA, 2019. [Google Scholar]
- Nihan, N.L.; Kjell, O.H. Use of the Box and Jenkins time series technique in traffic forecasting. Transportation 1980, 9, 125–143. [Google Scholar] [CrossRef]
- Sun, H.; Liu, H.; Xiao, H.; He, R.R.; Ran, B. Use of Local Linear Regression Model for Short-Term Traffic Forecasting. Transp. Res. Rec. J. Transp. Res. Board 2003, 1836, 143–150. [Google Scholar] [CrossRef]
- Boukerche, A.; Wang, J. Machine Learning-based traffic prediction models for Intelligent Transportation Systems. Comput. Networks 2020, 181, 107530. [Google Scholar] [CrossRef]
- Castillo, E.; Menéndez, J.M.; Sánchez-Cambronero, S. Predicting traffic flow using Bayesian networks. Transp. Res. Part B Methodol. 2008, 42, 482–509. [Google Scholar] [CrossRef]
- Hong, W.-C.; Ping-Feng, P.; Shun-Lin, Y.; Robert, T. Highway traffic forecasting by support vector regression model with tabu search algorithms. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006; pp. 1617–1621. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3848–3858. [Google Scholar] [CrossRef]
- Fu, X.; Wu, M.; Ponnarasu, S.; Zhang, L. A hybrid deep learning approach for dynamic attitude and position prediction in tunnel construction considering spatio-temporal patterns. Expert Syst. Appl. 2023, 212, 118721. [Google Scholar] [CrossRef]
- Chen, C.-F.; Chang, Y.-H. Seasonal ARIMA forecasting of inbound air travel arrivals to Taiwan. Transportmetrica 2009, 5, 125–140. [Google Scholar] [CrossRef]
- Hamed, M.M.; Al-Masaeid, H.R.; Said, Z.M.B. Short-Term Prediction of Traffic Volume in Urban Arterials. J. Transp. Eng. 1995, 121, 249–254. [Google Scholar] [CrossRef]
- Crawford, F.; Watling, D.; Connors, R. A statistical method for estimating predictable differences between daily traffic flow profiles. Transp. Res. Part B Methodol. 2017, 95, 196–213. [Google Scholar] [CrossRef]
- Polson, N.G.; Vadim, O.S. Deep learning for short-term traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef]
- Nie, L.; Jiang, D.; Guo, L.; Yu, S. Traffic matrix prediction and estimation based on deep learning in large-scale IP backbone networks. J. Netw. Comput. Appl. 2016, 76, 16–22. [Google Scholar] [CrossRef]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Chen, H.; Grant-Muller, S. Use of sequential learning for short-term traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2001, 9, 319–336. [Google Scholar] [CrossRef]
- Chiang, W.-C.; Russell, R.A.; Urban, T.L. Forecasting ridership for a metropolitan transit authority. Transp. Res. Part A Policy Pr. 2011, 45, 696–705. [Google Scholar] [CrossRef]
- Tan, M.-C.; Wong, S.C.; Xu, J.-M.; Guan, Z.-R.; Zhang, P. An Aggregation Approach to Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2009, 10, 60–69. [Google Scholar]
- Tsai, T.-H.; Lee, C.-K.; Wei, C.-H. Neural network based temporal feature models for short-term railway passenger demand forecasting. Expert Syst. Appl. 2009, 36, 3728–3736. [Google Scholar] [CrossRef]
- Sedgwick, P. Pearson’s correlation coefficient. BMJ 2012, 345, e4483. [Google Scholar] [CrossRef]
- Obilor, I.E.; Amadi, C.E. Test for significance of Pearson’s correlation coefficient. Int. J. Innov. Math. Stat. Energy Policies 2018, 6, 11–23. [Google Scholar]
- Runge, J. Discovering contemporaneous and lagged causal relations in autocorrelated nonlinear time series datasets. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Online, 4–6 August 2020; pp. 1388–1397. [Google Scholar]
- Runge, J. Causal Inference and Complex Network Methods for the Geosciences. Available online: https://jakobrunge.github.io/tigramite/ (accessed on 28 September 2017).
- Krupenevich, R.L.; Funk, C.J.; Franz, J.R. Automated analysis of medial gastrocnemius muscle-tendon junction displacements in heathy young adults during isolated contractions and walking using deep neural networks. Comput. Methods Programs Biomed. 2021, 206, 106120. [Google Scholar] [CrossRef]
- “Delhi Metro Route Map, Timings, Lines, Facts—Fabhotels.” FabHotels Travel Blog. Available online: https://www.fabhotels.com/blog/indian-metro-rail-networks/delhi-metro/ (accessed on 3 March 2022).
- Laifa, H.; Ghezalaa, B.H.H. Train delay prediction in Tunisian railway through LightGBM model. Procedia Comput. Sci. 2021, 192, 981–990. [Google Scholar] [CrossRef]
- Jiang, F.; Ma, J.; Li, Z. Pedestrian volume prediction with high spatiotemporal granularity in urban areas by the enhanced learning model. Sustain. Cities Soc. 2021, 79, 103653. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Description |
|---|---|---|
| Air Pollution Index | Air quality index that ranges from 10 to 300 | |
| Humidity | General humidity measured in Celsius | |
| Wind Speed | Wind speed is measured in miles per hour | |
| Wind Direction | Cardinal wind direction (0 to 360 degrees) | |
| Visibility in Miles | Visibility of distance in miles | |
| Dew Point | Dew point measured in Celsius | |
| Temperature | Average national temperature measured in Kelvin | |
| Rain Per Hour | Amount of rainfall measured in millimeters in an hour | |
| Snow Per Hour | Amount of snowfall measured in millimeters in an hour | |
| Clouds All | Percentage of cloud cover in the sky | |
| Passenger Traffic Flow | Numeric hourly traffic volume bound in a specific direction at the urban railway system |
| Factor | Count | Mean | Std | Min | Max |
|---|---|---|---|---|---|
| 33,750 | 154.84 | 83.73 | 10.0 | 299.0 | |
| 33,750 | 71.21 | 16.85 | 13.0 | 100.0 | |
| 33,750 | 3.38 | 2.06 | 0 | 16.0 | |
| 33,750 | 199.47 | 99.84 | 0 | 360.0 | |
| 33,750 | 4.99 | 2.57 | 1.0 | 9.0 | |
| 33,750 | 4.99 | 2.57 | 1.0 | 9.0 | |
| 33,750 | 280.07 | 13.42 | 0 | 308.24 | |
| 33,750 | 0.449 | 53.53 | 0 | 9831.30 | |
| 33,750 | 0.00032 | 0.0098 | 0 | 0.510 | |
| 33,750 | 50.46 | 38.87 | 0 | 100.0 | |
| 33,750 | 3240.12 | 1991.46 | 0 | 7280.0 |
| Parameter Type | Setting |
|---|---|
| GCN Activation | ReLU |
| LSTM Activation | ELU |
| Epochs | 30 |
| Batch Size | 10 |
| Loss Function | MAE |
| Optimizers | Adam |
| Metrics | MSE |
| Layer | Type | Output Shape | Parameter |
|---|---|---|---|
| 1 | GCN | (None, 32, 16) | 2986 |
| 2 | GCN | (None, 32, 10) | 3130 |
| 3 | LSTM | (None, 10, 256) | 318,464 |
| 4 | LSTM | (None, 256) | 525,312 |
| 5 | Dense | (None, 32) | 13,878 |
| Metric | Average | |||||||
|---|---|---|---|---|---|---|---|---|
| R2 | 0.880 | 0.930 | 0.919 | 0.929 | 0.930 | 0.928 | 0.927 | 0.920 |
| MAE | 489.922 | 339.889 | 364.451 | 342.571 | 340.784 | 349.806 | 351.126 | 368.364 |
| RMSE | 672.406 | 510.627 | 554.765 | 523.717 | 512.702 | 533.192 | 539.283 | 549.527 |
| Average Time |
| Parameter Type | Setting |
|---|---|
| LSTM Activation | ELU |
| Epochs | 30 |
| Batch Size | 15 |
| Loss Function | MSE |
| Optimizers | Adam |
| Parameter Type | Candidate Values | |
|---|---|---|
| Maximum Depth | ||
| Number of Leaves | 10 | |
| Learning Rate () | ||
| Number of Estimators () |
| LSTM | LGBM | GCMN | |
|---|---|---|---|
| 0.851 | 0.872 | 0.880 | |
| MAE | 527.608 | 502.974 | 489.922 |
| RMSE | 754.067 | 698.095 | 672.406 |
| LSTM | LGBM | GCMN | |
|---|---|---|---|
| 0.915 | 0.925 | 0.930 | |
| MAE | 383.446 | 358.477 | 339.889 |
| RMSE | 570.601 | 535.749 | 510.627 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, X.; Wu, M.; Ponnarasu, S.; Zhang, L. A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems. Buildings 2023, 13, 1514. https://doi.org/10.3390/buildings13061514
Fu X, Wu M, Ponnarasu S, Zhang L. A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems. Buildings. 2023; 13(6):1514. https://doi.org/10.3390/buildings13061514
Chicago/Turabian StyleFu, Xianlei, Maozhi Wu, Sasthikapreeya Ponnarasu, and Limao Zhang. 2023. "A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems" Buildings 13, no. 6: 1514. https://doi.org/10.3390/buildings13061514
APA StyleFu, X., Wu, M., Ponnarasu, S., & Zhang, L. (2023). A Hybrid Deep Learning Approach for Real-Time Estimation of Passenger Traffic Flow in Urban Railway Systems. Buildings, 13(6), 1514. https://doi.org/10.3390/buildings13061514