
Feature-Based Deep Learning Classification for Pipeline Component Extraction from 3D Point Clouds




Abstract
1. Introduction
2. Literature Review
2.1. Information Extraction and 3D Reconstruction of Pipeline Components
2.2. Deep Learning in Point Cloud
2.3. Deep Learning in Construction Industry
3. Methodology
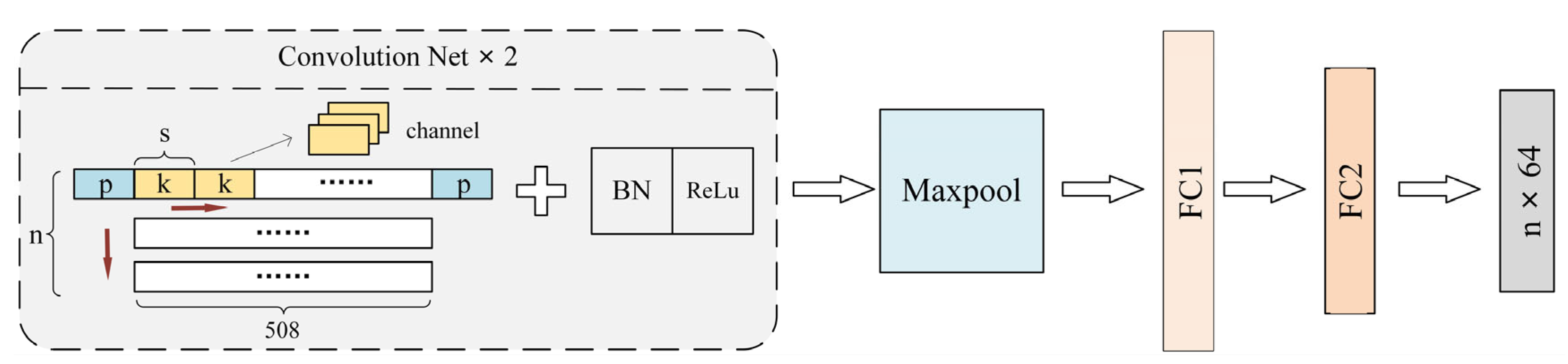
4. Network Architecture
4.1. Preprocessing Networks
4.1.1. Global Feature Extraction
4.1.2. Local Feature Extraction
4.2. FinalNet
5. Experiment
5.1. Architecture Design Validation
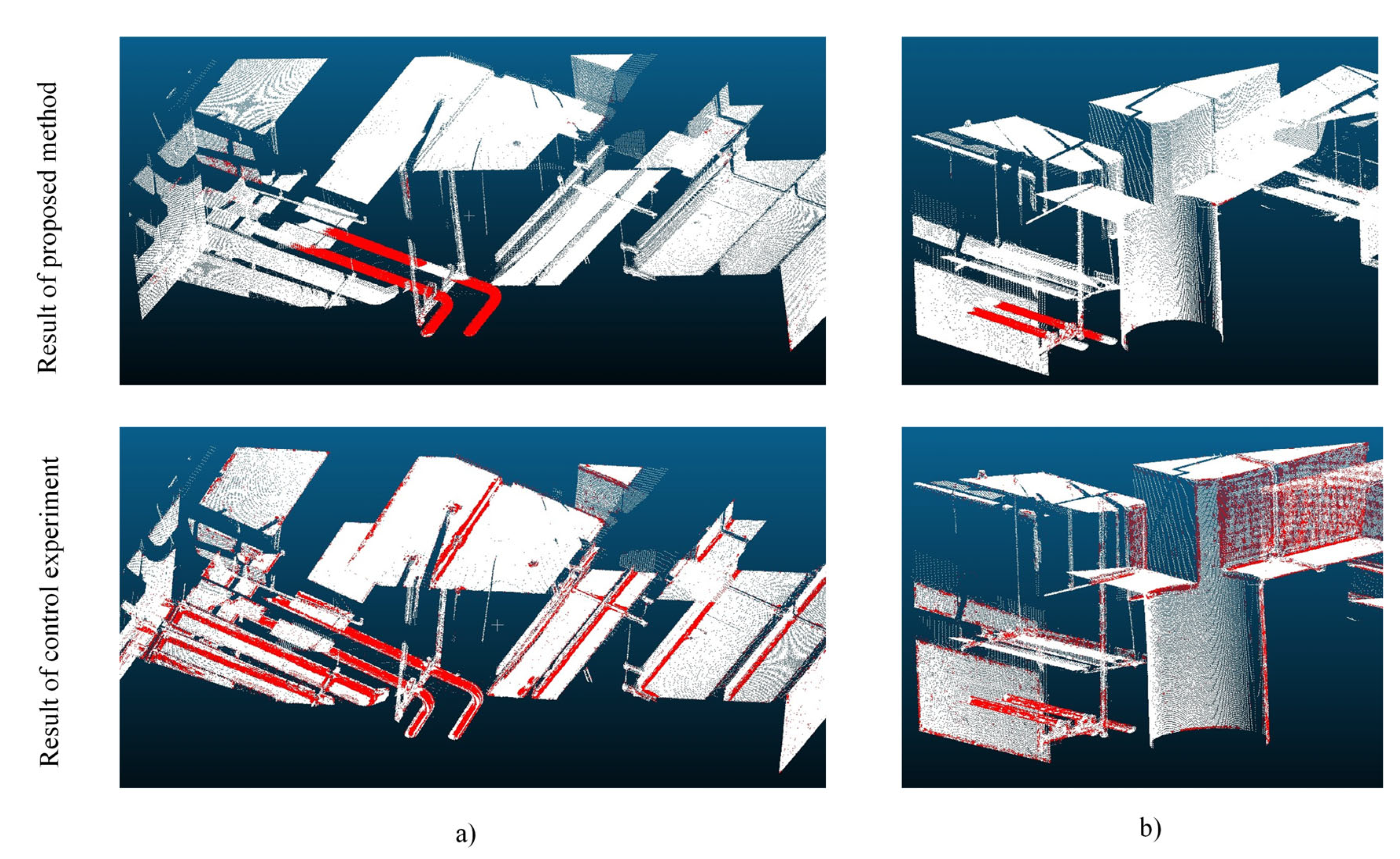
5.2. Results of the Dataset and Comparison
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, Z.; Liu, S. A review of 3D reconstruction techniques in civil engineering and their applications. Adv. Eng. Inform. 2018, 37, 163–174. [Google Scholar] [CrossRef]
- Wang, C.; Cho, Y.K.; Kim, C. Automatic BIM component extraction from point clouds of existing buildings for sustainability applications. Autom. Constr. 2015, 56, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, Z.; Wu, X. A Deep Learning Approach to the Classification of 3D Models under BIM Environment. Int. J. Control Autom. 2016, 9, 179–188. [Google Scholar] [CrossRef]
- Wang, Q.; Kim, M.-K. Applications of 3D point cloud data in the construction industry: A fifteen-year review from 2004 to 2018. Adv. Eng. Inform. 2019, 39, 306–319. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, G.; Wu, Z.; Han, S. Sphere-spin-image: A viewpoint-invariant surface representation for 3D face recognition. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 6–9 June 2004. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Barazzetti, L. Parametric as-built model generation of complex shapes from point clouds. Adv. Eng. Inform. 2016, 30, 298–311. [Google Scholar] [CrossRef]
- Xue, F.; Lu, W.; Chen, K.; Webster, C.J. BIM reconstruction from 3D point clouds: A semantic registration approach based on multimodal optimization and architectural design knowledge. Adv. Eng. Inform. 2019, 42, 100965. [Google Scholar] [CrossRef]
- Gao, T.; Akinci, B.; Ergan, S.; Garrett, J. An approach to combine progressively captured point clouds for BIM update. Adv. Eng. Inform. 2015, 29, 1001–1012. [Google Scholar] [CrossRef]
- Rodríguez-Gonzálvez, P.; Rodríguez-Martín, M.; Ramos, L.F.; González-Aguilera, D. 3D reconstruction methods and quality assessment for visual inspection of welds. Autom. Constr. 2017, 79, 49–58. [Google Scholar] [CrossRef]
- Rodríguez-Moreno, C.; Reinoso-Gordo, J.F.; Rivas-López, E.; Gómez-Blanco, A.; Ariza-López, F.J.; Ariza-López, I. From point cloud to BIM: An integrated workflow for documentation, research and modelling of architectural heritage. Surv. Rev. 2018, 50, 212–231. [Google Scholar] [CrossRef]
- Krijnen, T.; Beetz, J. An IFC schema extension and binary serialization format to efficiently integrate point cloud data into building models. Adv. Eng. Inform. 2017, 33, 473–490. [Google Scholar] [CrossRef]
- Agapaki, E.; Brilakis, I. CLOI-NET: Class segmentation of industrial facilities’ point cloud datasets. Adv. Eng. Inform. 2020, 45, 101121. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cao, M.-T.; Tran, Q.-V.; Nguyen, N.-M.; Chang, K.-T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inform. 2020, 46, 101182. [Google Scholar] [CrossRef]
- Czerniawski, T.; Leite, F. Automated segmentation of RGB-D images into a comprehensive set of building components using deep learning. Adv. Eng. Inform. 2020, 45, 101131. [Google Scholar] [CrossRef]
- Koo, B.; Jung, R.; Yu, Y. Automatic classification of wall and door BIM element subtypes using 3D geometric deep neural networks. Adv. Eng. Inform. 2021, 47, 101200. [Google Scholar] [CrossRef]
- Saovana, N.; Yabuki, N.; Fukuda, T. Development of an unwanted-feature removal system for Structure from Motion of repetitive infrastructure piers using deep learning. Adv. Eng. Inform. 2020, 46, 101169. [Google Scholar] [CrossRef]
- Hichri, N.; Stefani, C.; De Luca, L.; Veron, P.; Hamon, G. From point cloud to bim: A survey of existing approaches. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci 2013, XL-5/W2, 343–348. [Google Scholar] [CrossRef]
- Golovinskiy, A.; Funkhouser, T. Randomized cuts for 3D mesh analysis. In Proceedings of the ACM SIGGRAPH Asia 2008, Singapore, 10–13 December 2008. [Google Scholar]
- Kalogerakis, E.; Hertzmann, A.; Singh, K. Learning 3D mesh segmentation and labeling. In Proceedings of the ACM SIGGRAPH 2010, Los Angeles, CA, USA, 26–30 July 2010. [Google Scholar]
- Woo, H.; Kang, E.; Wang, S.; Lee, K.H. A new segmentation method for point cloud data. Int. J. Mach. Tools Manuf. 2002, 42, 167–178. [Google Scholar] [CrossRef]
- Guo, K.; Zou, D.; Chen, X. 3D Mesh Labeling via Deep Convolutional Neural Networks. ACM Trans. Graph. 2015, 35, 1–12. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Lin, Y.; Jiang, M.; Yao, Y.; Zhang, L.; Lin, J. Use of UAV oblique imaging for the detection of individual trees in residential environments. Urban For. Urban Green. 2015, 14, 404–412. [Google Scholar] [CrossRef]
- Liu, J.; Xu, G.; Ren, L.; Qian, Z.; Ren, L. Defect intelligent identification in resistance spot welding ultrasonic detection based on wavelet packet and neural network. Int. J. Adv. Manuf. Technol. 2017, 90, 2581–2588. [Google Scholar] [CrossRef]
- Liu, P.; Li, Y.; Hu, W.; Ding, X.B. Segmentation and reconstruction of buildings with aerial oblique photography point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 109. [Google Scholar] [CrossRef]
- Ibrahim, M.; Smith, R.; Wang, C.H. Ultrasonic detection and sizing of compressed cracks in glass-and carbon-fibre reinforced plastic composites. Ndt E Int. 2017, 92, 111–121. [Google Scholar] [CrossRef]
- Kim, M.-K.; Wang, Q.; Park, J.-W.; Cheng, J.C.; Sohn, H.; Chang, C.-C. Automated dimensional quality assurance of full-scale precast concrete elements using laser scanning and BIM. Autom. Constr. 2016, 72, 102–114. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pu, S.; Vosselman, G. Knowledge based reconstruction of building models from terrestrial laser scanning data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 575–584. [Google Scholar] [CrossRef]
- Xu, Y.; Tuttas, S.; Hoegner, L.; Stilla, U. Geometric Primitive Extraction From Point Clouds of Construction Sites Using VGS. IEEE Geosci. Remote Sens. Lett. 2017, 14, 424–428. [Google Scholar] [CrossRef]
- Rebolj, D.; Pučko, Z.; Babič, N.Č.; Bizjak, M.; Mongus, D. Point cloud quality requirements for Scan-vs-BIM based automated construction progress monitoring. Autom. Constr. 2017, 84, 323–334. [Google Scholar] [CrossRef]
- Tsai, Y.-H.; Wang, J.; Chien, W.-T.; Wei, C.-Y.; Wang, X.; Hsieh, S.-H. A BIM-based approach for predicting corrosion under insulation. Autom. Constr. 2019, 107, 102923. [Google Scholar] [CrossRef]
- Arulogun, O.; Falohun, A.; Akande, N. Radio frequency identification and internet of things: A fruitful synergy. Br. J. Appl. Sci. Technol. 2016, 18, 1–16. [Google Scholar] [CrossRef][Green Version]
- Domdouzis, K.; Kumar, B.; Anumba, C. Radio-Frequency Identification (RFID) applications: A brief introduction. Adv. Eng. Inform. 2007, 21, 350–355. [Google Scholar] [CrossRef]
- Patil, A.K.; Holi, P.; Lee, S.K.; Chai, Y.H. An adaptive approach for the reconstruction and modeling of as-built 3D pipelines from point clouds. Autom. Constr. 2017, 75, 65–78. [Google Scholar] [CrossRef]
- Tran, T.-T.; Cao, V.-T.; Laurendeau, D. Extraction of cylinders and estimation of their parameters from point clouds. Comput. Graph. 2015, 46, 345–357. [Google Scholar] [CrossRef]
- Johnson, A.E.; Hebert, M. Using spin images for efficient object recognition in cluttered 3D scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2017, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1/W1, 91–98. [Google Scholar] [CrossRef]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Huang, J.; You, S. Point cloud labeling using 3d convolutional neural network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Klokov, R.; Lempitsky, V. Escape from cells: Deep kd-networks for the recognition of 3d point cloud models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Rose, T.M.; An, W. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Rose, T.M.; An, W.; Yu, Y. A deep learning-based method for detecting non-certified work on construction sites. Adv. Eng. Inform. 2018, 35, 56–68. [Google Scholar] [CrossRef]
- Fang, Y.; Xie, J.; Dai, G.; Wang, M.; Zhu, F.; Xu, T.; Wong, E. 3d deep shape descriptor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Akinosho, T.D.; Oyedele, L.O.; Bilal, M.; Ajayi, A.O.; Delgado, M.D.; Akinade, O.O.; Ahmed, A.A. Deep learning in the construction industry: A review of present status and future innovations. J. Build. Eng. 2020, 32, 101827. [Google Scholar] [CrossRef]
- Sun, S.; Wang, S.; Wei, Y. A new ensemble deep learning approach for exchange rates forecasting and trading. Adv. Eng. Inform. 2020, 46, 101160. [Google Scholar] [CrossRef]
- Ziari, H.; Sobhani, J.; Ayoubinejad, J.; Hartmann, T. Prediction of IRI in short and long terms for flexible pavements: ANN and GMDH methods. Int. J. Pavement Eng. 2016, 17, 776–788. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Deng, F.; He, Y.; Zhou, S.; Yu, Y.; Cheng, H.; Wu, X. Compressive strength prediction of recycled concrete based on deep learning. Constr. Build. Mater. 2018, 175, 562–569. [Google Scholar] [CrossRef]
- Nguyen, T.; Kashani, A.; Ngo, T.; Bordas, S. Deep neural network with high-order neuron for the prediction of foamed concrete strength. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 316–332. [Google Scholar] [CrossRef]
- Rahman, A.; Srikumar, V.; Smith, A.D. Predicting electricity consumption for commercial and residential buildings using deep recurrent neural networks. Appl. Energy 2018, 212, 372–385. [Google Scholar] [CrossRef]
- Rafiei, M.H.; Adeli, H. Novel machine-learning model for estimating construction costs considering economic variables and indexes. J. Constr. Eng. Manag. 2018, 144, 04018106. [Google Scholar] [CrossRef]
- Kolar, Z.; Chen, H.; Luo, X. Transfer learning and deep convolutional neural networks for safety guardrail detection in 2D images. Autom. Constr. 2018, 89, 58–70. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Pathirage, C.S.N.; Li, J.; Li, L.; Hao, H.; Liu, W.; Ni, P. Structural damage identification based on autoencoder neural networks and deep learning. Eng. Struct. 2018, 172, 13–28. [Google Scholar] [CrossRef]
- Eastman, C.M.; Eastman, C.; Teicholz, P.; Sacks, R.; Liston, K. BIM Handbook: A Guide to Building Information Modeling for Owners, Managers, Designers, Engineers and Contractors; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Franz, S.; Irmler, R.; Rüppel, U. Real-time collaborative reconstruction of digital building models with mobile devices. Adv. Eng. Inform. 2018, 38, 569–580. [Google Scholar] [CrossRef]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.-C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Shen, Z.; Ma, X.; Li, Y. A hybrid 3D descriptor with global structural frames and local signatures of histograms. IEEE Access 2018, 6, 39261–39272. [Google Scholar] [CrossRef]
- Salti, S.; Tombari, F.; Di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Assfalg, J.; Bertini, M.; Del Bimbo, A.; Pala, P. Content-based retrieval of 3-D objects using Spin Image Signatures. IEEE Trans. Multimed. 2007, 9, 589–599. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, L.; Tong, X.; Du, B.; Wang, Y.; Zhang, L.; Zhang, Z.; Liu, H.; Mei, J.; Xing, X.; et al. A three-step approach for TLS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5412–5424. [Google Scholar] [CrossRef]
- He, Y.Q.; Mei, Y.G. An efficient registration algorithm based on spin image for LiDAR 3D point cloud models. Neurocomputing 2015, 151, 354–363. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Loss | Train Accuracy | Test Accuracy | |
|---|---|---|---|
| Control Experiment | 0.0036 | 99.87% | 82.37% |
| Proposed method | 0.0054 | 99.75% | 94.62% |
| Dataset | Mean | Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | Set 6 | Set 7 | Set 8 | Set 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Points number | 191,404 | 696,406 | 1,419,606 | 718,361 | 411,160 | 296,335 | 521,597 | 1,203,240 | 732,260 | |
| Control Experiment | 84.06% | 80.29% | 88.07% | 91.55% | 92.73% | 82.98% | 86.10% | 92.78% | 78.59% | 63.45% |
| Proposed method | 98.03% | 97.24% | 97.50% | 94.93% | 98.91% | 97.80% | 98.17% | 99.59% | 98.54% | 99.63% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Kang, R.; Li, H. Feature-Based Deep Learning Classification for Pipeline Component Extraction from 3D Point Clouds. Buildings 2022, 12, 968. https://doi.org/10.3390/buildings12070968
Xu Z, Kang R, Li H. Feature-Based Deep Learning Classification for Pipeline Component Extraction from 3D Point Clouds. Buildings. 2022; 12(7):968. https://doi.org/10.3390/buildings12070968
Chicago/Turabian StyleXu, Zhao, Rui Kang, and Heng Li. 2022. "Feature-Based Deep Learning Classification for Pipeline Component Extraction from 3D Point Clouds" Buildings 12, no. 7: 968. https://doi.org/10.3390/buildings12070968
APA StyleXu, Z., Kang, R., & Li, H. (2022). Feature-Based Deep Learning Classification for Pipeline Component Extraction from 3D Point Clouds. Buildings, 12(7), 968. https://doi.org/10.3390/buildings12070968