
Prediction of Compaction and Strength Properties of Amended Soil Using Machine Learning



Abstract
:1. Introduction
2. Materials and Methods
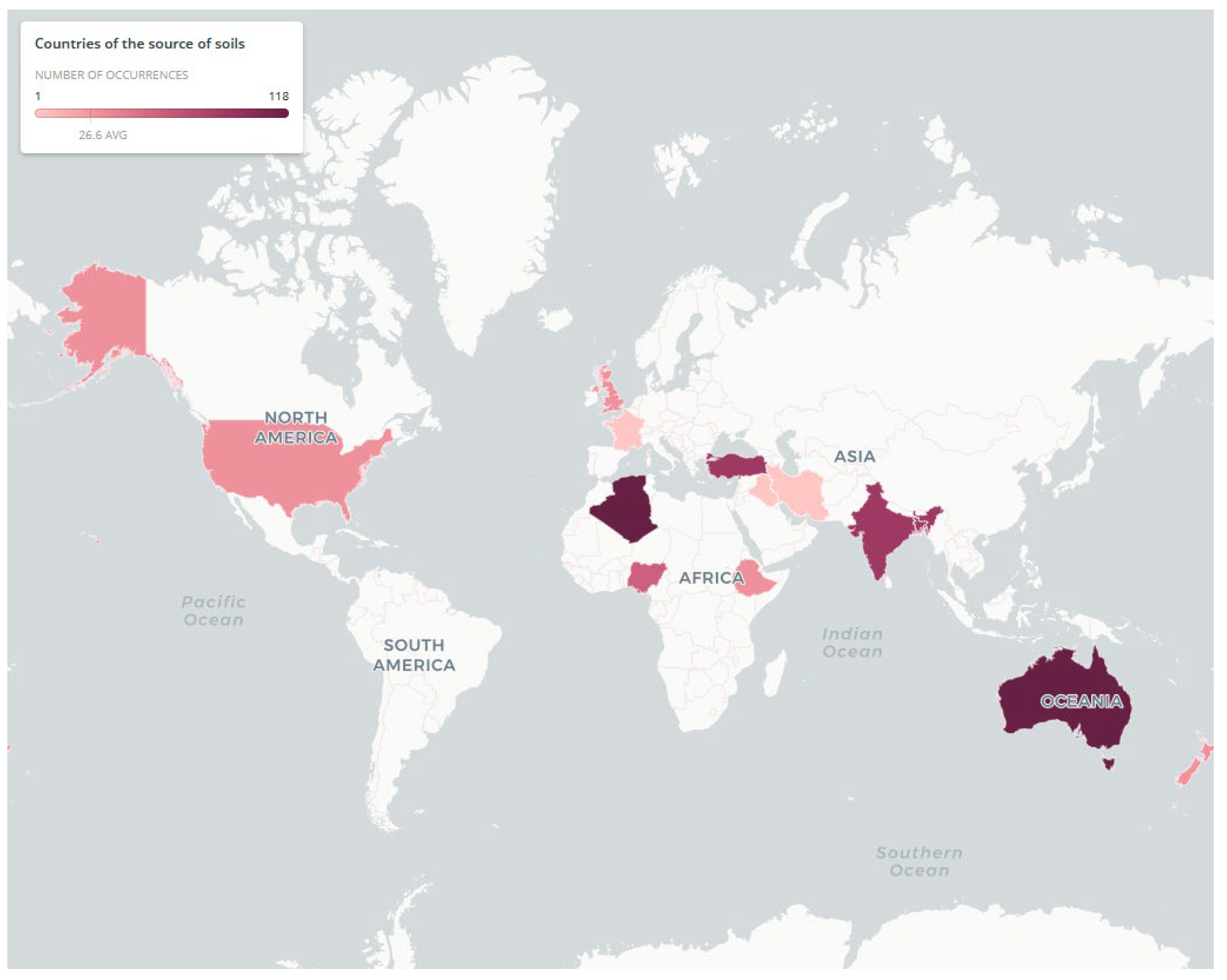
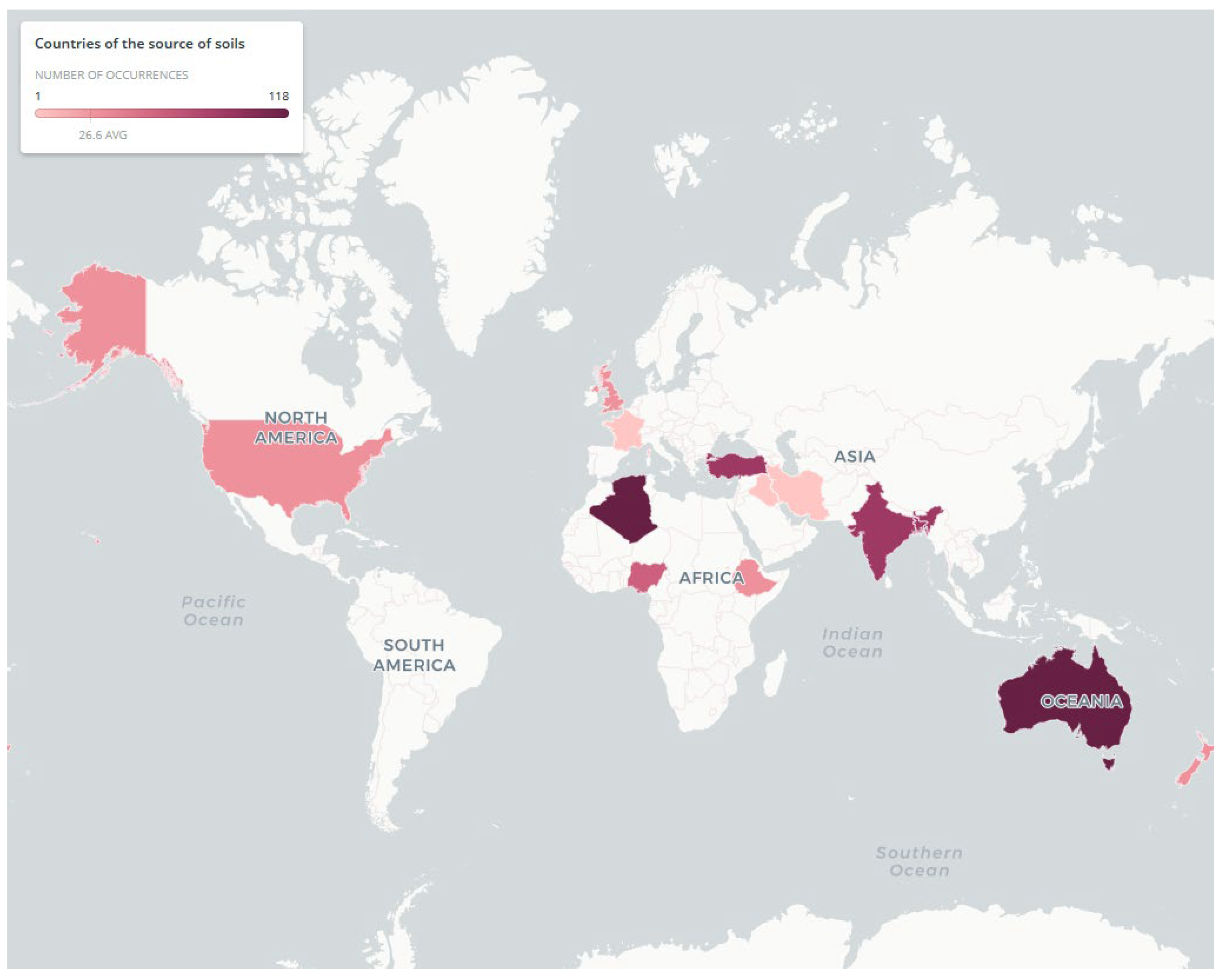
2.1. Experimental Data
2.2. Machine Learning
2.2.1. Optimizable Ensemble Method
Bagging Regression Tree
Boosting Regression Tree
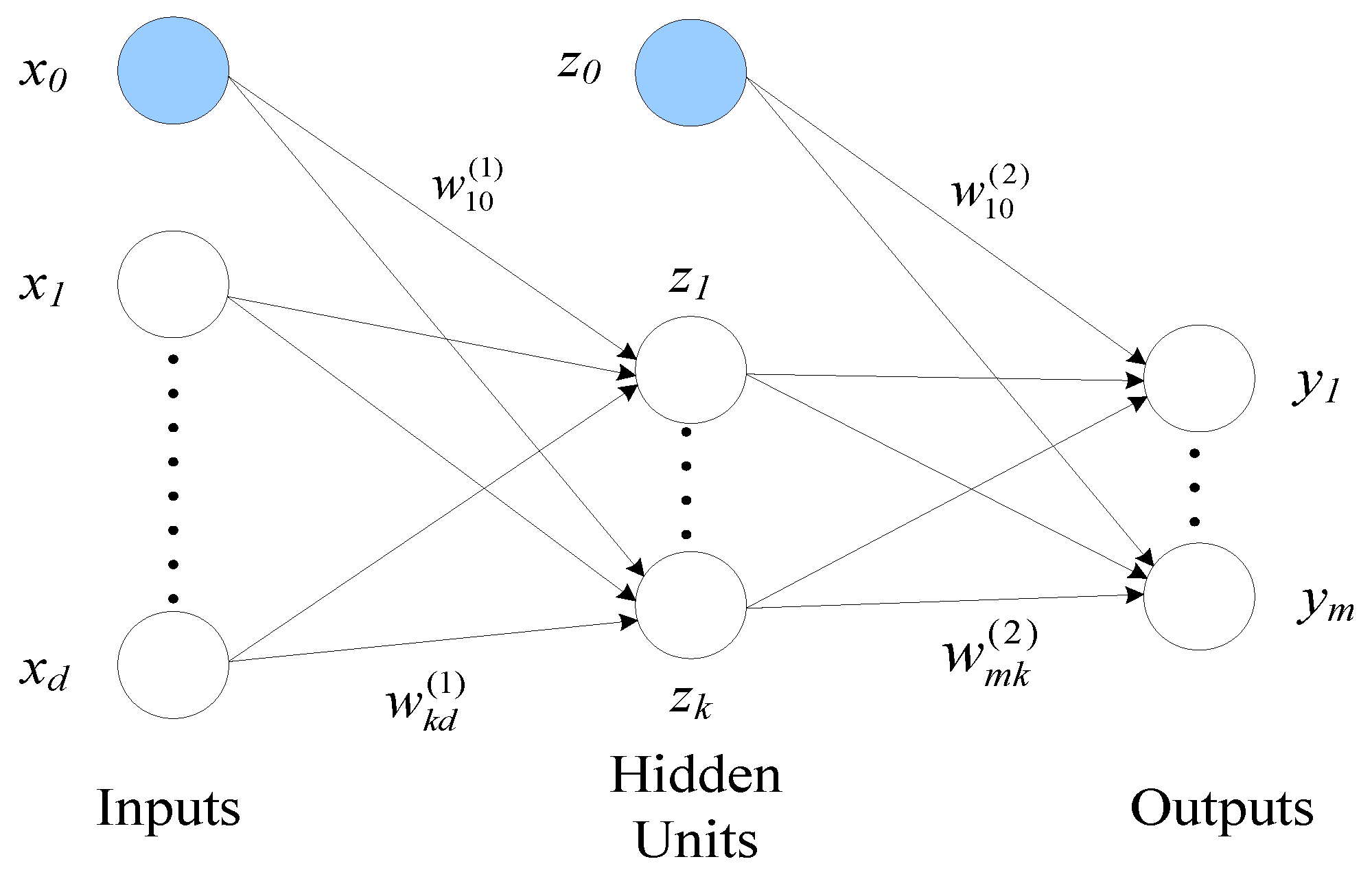
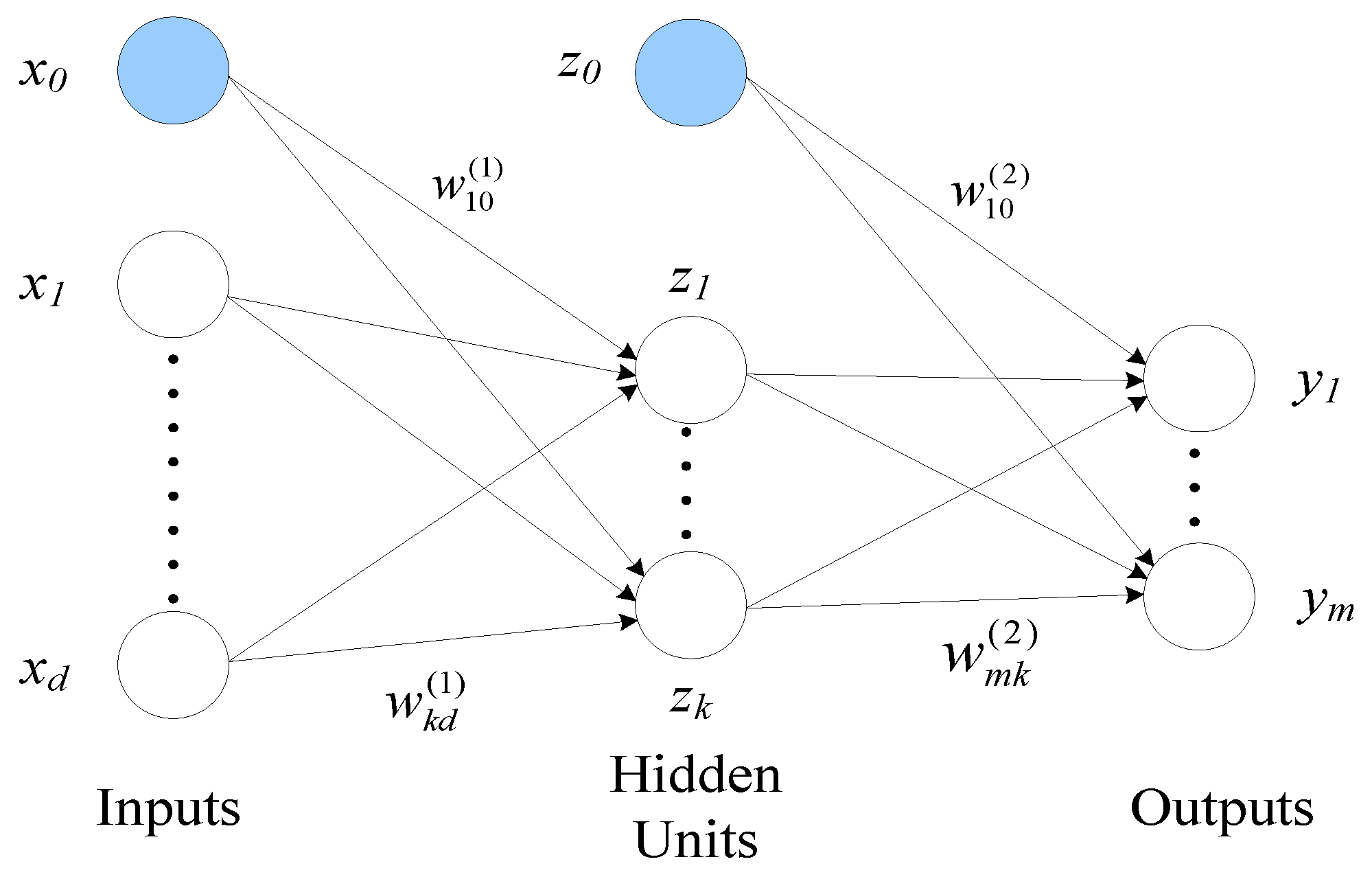
2.2.2. Artificial Neural Networks
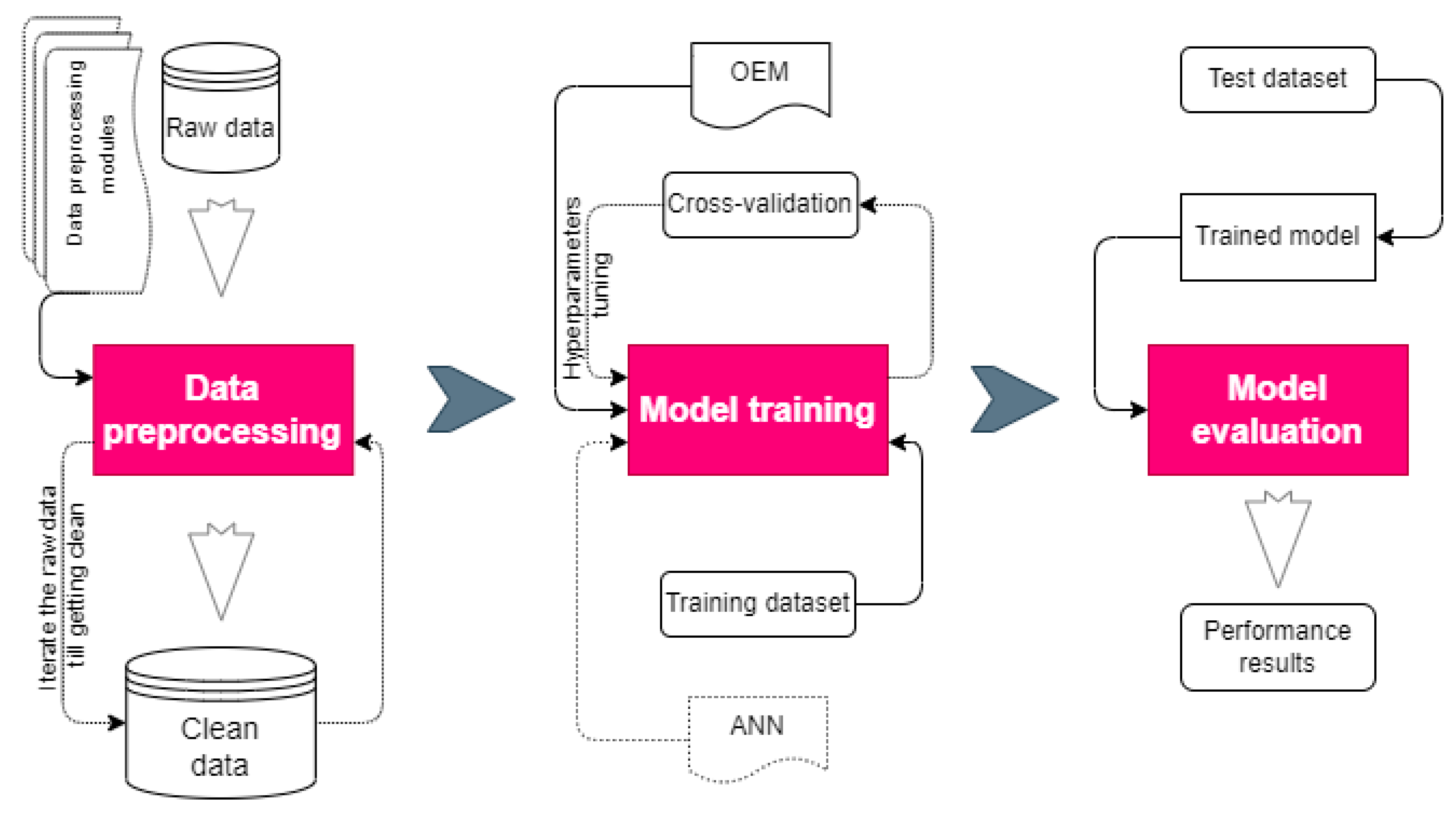
2.3. Model Development
2.3.1. Data Preprocessing
2.3.2. Detecting and Treating Outliers
2.3.3. Data Encoding
2.3.4. Data Normalization
2.3.5. Feature Engineering
2.3.6. Data Partitioning
2.4. Model Training
2.4.1. Optimizable Ensemble Methods
2.4.2. Artificial Neural Networks
2.5. Model Evaluation
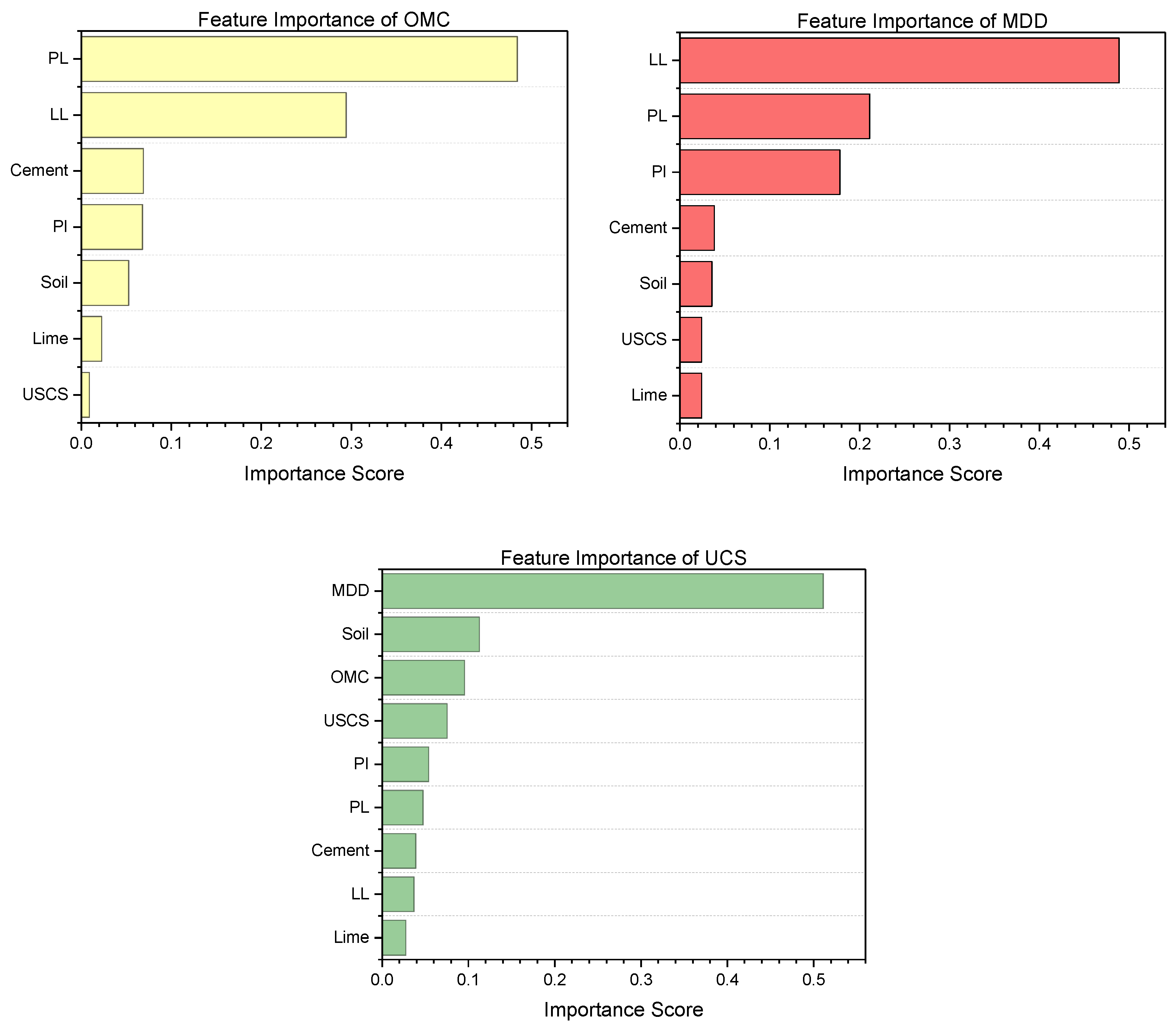
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Admassu, K. Hydration and carbonation reaction competition and the effect on the strength of under shed air dried amended compressed earth blocks (ACEBs). Zede J. 2021, 39, 19–29. [Google Scholar]
- Bahmed, I.T.; Harichane, K.; Ghrici, M.; Boukhatem, B.; Rebouh, R.; Gadouri, H. Prediction of geotechnical properties of clayey soils stabilised with lime using artificial neural networks (ANNs). Int. J. Geotech. Eng. 2019, 13, 191–203. [Google Scholar] [CrossRef]
- Alavi, A.H.; Gandomi, A.H.; Gandomi, M.; Sadat Hosseini, S.S. Prediction of maximum dry density and optimum moisture content of stabilised soil using RBF neural networks. IES J. Part A Civ. Struct. Eng. 2009, 2, 98–106. [Google Scholar] [CrossRef]
- Admassu, K. Engineered soil and the need for lime-natural pozzolan mixture percentage approximation. SINET Ethiop. J. Sci. 2018, 41, 70–79. [Google Scholar]
- Admassu, K. Method of amended soils for compressed block and mortar in earthen construction. Zede J. 2019, 37, 69–84. [Google Scholar]
- Alavi, A.H.; Gandomi, A.H.; Mollahassani, A.; Heshmati, A.A.; Rashed, A. Modeling of maximum dry density and optimum moisture content of stabilized soil using artificial neural networks. J. Plant Nutr. Soil Sci. 2010, 173, 368–379. [Google Scholar] [CrossRef]
- Das, S.K.; Samui, P.; Sabat, A.K. Application of Artificial Intelligence to Maximum Dry Density and Unconfined Compressive Strength of Cement Stabilized Soil. Geotech. Geol. Eng. 2011, 29, 329–342. [Google Scholar] [CrossRef]
- Saadat, M.; Bayat, M. Prediction of the unconfined compressive strength of stabilised soil by Adaptive Neuro Fuzzy Inference System (ANFIS) and Non-Linear Regression (NLR). Geomech. Geoengin. 2022, 17, 80–91. [Google Scholar] [CrossRef]
- Kalkan, E.; Akbulut, S.; Tortum, A.; Celik, S. Prediction of the unconfined compressive strength of compacted granular soils by using inference systems. Environ. Geol. 2009, 58, 1429–1440. [Google Scholar] [CrossRef]
- Suman, S.; Mahamaya, M.; Das, S.K. Prediction of Maximum Dry Density and Unconfined Compressive Strength of Cement Stabilised Soil Using Artificial Intelligence Techniques. Int. J. Geosynth. Gr. Eng. 2016, 2, 11. [Google Scholar] [CrossRef] [Green Version]
- Chore, H.S.; Magar, R.B. Prediction of unconfined compressive and brazilian tensile strength of fiber reinforced cement stabilized fly ash mixes using multiple linear regression and artificial neural network. Adv. Comput. Des. 2017, 2, 225–240. [Google Scholar] [CrossRef]
- Le, H.A.; Nguyen, T.A.; Nguyen, D.D.; Prakash, I. Prediction of soil unconfined compressive strength using artificial neural network model. Vietnam J. Earth Sci. 2020, 42, 255–264. [Google Scholar] [CrossRef]
- Fu, B.; Feng, D.-C. A machine learning-based time-dependent shear strength model for corroded reinforced concrete beams. J. Build. Eng. 2021, 36, 102118. [Google Scholar] [CrossRef]
- Fu, B.; Chen, S.-Z.; Liu, X.-R.; Feng, D.-C. A probabilistic bond strength model for corroded reinforced concrete based on weighted averaging of non-fine-tuned machine learning models. Constr. Build. Mater. 2022, 318, 125767. [Google Scholar] [CrossRef]
- Taffese, W.Z. Case-based reasoning and neural networks for real estate valuation. In Proceedings of the IASTED International Conference on Artificial Intelligence and Applications, AIA, Innsbruck, Austria, 12–14 February 2007; Devedzic, V., Ed.; ACTA Press: Innsbruck, Austria, 2007; pp. 84–89. [Google Scholar]
- Taffese, W.Z.; Sistonen, E.; Puttonen, J. Prediction of concrete carbonation depth using decision trees. In Proceedings of the 23rd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–23 April 2015; i6doc.com Publisher: Louvain-la-Neuve, Belgium, 2015. [Google Scholar]
- Kardani, N.; Zhou, A.; Nazem, M.; Shen, S.L. Improved prediction of slope stability using a hybrid stacking ensemble method based on finite element analysis and field data. J. Rock Mech. Geotech. Eng. 2021, 13, 188–201. [Google Scholar] [CrossRef]
- Ren, Q.; Ding, L.; Dai, X.; Jiang, Z.; De Schutter, G. Prediction of Compressive Strength of Concrete with Manufactured Sand by Ensemble Classification and Regression Tree Method. J. Mater. Civ. Eng. 2021, 33, 04021135. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Sistonen, E. Significance of chloride penetration controlling parameters in concrete: Ensemble methods. Constr. Build. Mater. 2017, 139, 9–23. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Nigussie, E.; Isoaho, J. Internet of things based durability monitoring and assessment of reinforced concrete structures. Procedia Comput. Sci. 2019, 155, 672–679. [Google Scholar] [CrossRef]
- Taffese, W.Z.; Abegaz, K.A. Artificial intelligence for prediction of physical and mechanical properties of stabilized soil for affordable housing. Appl. Sci. 2021, 11, 7503. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; MIT press: Cambridge, MA, USA, 2020; ISBN 978-0-262-01243-0. [Google Scholar]
- Cichosz, P. Data Mining Algorithms: Explained Using R; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2015; ISBN 978-1-118-33258-0. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2011; ISBN 978-0-12-374856-0. [Google Scholar]
- Berthold, M.R.; Borgelt, C.; Höppner, F.; Klawonn, F. Guide to Intelligent Data Analysis: How to Intelligently Make Sense of Real Data; Springer: London, UK, 2010; ISBN 978-1-84882-260-3. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2009; ISBN 978-0-13-129376-2. [Google Scholar]
- Vinaykumar, K.; Ravi, V.; Mahil, C. Software cost estimation using soft computing approaches. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; Olivas, E.S., Guerrero, J.D.M., Sober, M.M., Benedito, J.R.M., López, A.J.S., Eds.; IGI Global: Hershey, PA, USA, 2010; pp. 499–518. ISBN 978-160566-766-9. [Google Scholar]
- Wu, J.; Coggeshall, S. Foundations of Predictive Analytics; CRC Press: Boca Raton, FL, USA, 2012; ISBN 978-1-4398-6946-8. [Google Scholar]
- Taffese, W.Z. Data-Driven Method for Enhanced Corrosion Assessment of Reinforced Concrete Structures; University of Turku: Turku, Finland, 2020. [Google Scholar]
- Nguyen, G.H.; Bouzerdoum, A.; Phung, S.L. Efficient supervised learning with reduced training exemplars. In Proceedings of the IEEE International Joint Conference on Neural Networks, IJCNN 2008, Hong Kong, China, 1–8 June 2008; pp. 2981–2987. [Google Scholar]
- Al Bataineh, A.; Kaur, D. A Comparative Study of Different Curve Fitting Algorithms in Artificial Neural Network using Housing Dataset. In Proceedings of the IEEE National Aerospace Electronics Conference, NAECON, Dayton, OH, USA, 23–26 July 2018; pp. 174–178. [Google Scholar]
- Babani, L.; Jadhav, S.; Chaudhari, B. Scaled conjugate gradient based adaptive ANN control for SVM-DTC induction motor drive. In IFIP Advances in Information and Communication Technology; Iliadis, L., Maglogiannis, I., Eds.; Springer: Cham, Switzerland, 2016; pp. 384–395. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Category | No. | Feature Subcategory | |
|---|---|---|---|
| Soil and stabilizers | 1 | Soil | |
| 2 | Cement | ||
| 3 | Lime | ||
| Soil classification | 4 | USCS | CH |
| CL | |||
| CL-ML | |||
| MH | |||
| ML | |||
| Atterberg limits | 5 | Liquid limit | |
| 6 | Plastic limit | ||
| 7 | Plasticity index | ||
| Physical and mechanical properties | 8 | Optimum moisture content | |
| 9 | Maximum dry density | ||
| 10 | Unconfined comprehensive strength | ||
| Soil | Cement | Lime | LL | PL | PI | OMC | MDD | UCS | |
|---|---|---|---|---|---|---|---|---|---|
| count | 162 | 162 | 162 | 162 | 162 | 162 | 162 | 162 | 162 |
| mean | 93.89 | 3.72 | 2.40 | 34.37 | 20.20 | 14.18 | 11.83 | 1835.88 | 2466.12 |
| std | 3.44 | 3.28 | 3.54 | 10.15 | 5.97 | 8.84 | 4.60 | 182.94 | 1070.11 |
| min | 70.00 | 0.00 | 0.00 | 18.00 | 12.00 | 0.00 | 5.40 | 1440.00 | 55.31 |
| 25% | 94.00 | 0.00 | 0.00 | 27.00 | 16.00 | 6.10 | 8.55 | 1700.00 | 1860.00 |
| 50% | 94.00 | 4.00 | 2.00 | 32.00 | 19.00 | 15.00 | 10.50 | 1835.00 | 2300.00 |
| 75% | 95.00 | 6.00 | 4.00 | 40.00 | 23.00 | 20.00 | 13.38 | 1970.00 | 3075.00 |
| max | 100.00 | 30.00 | 30.00 | 66.00 | 39.00 | 42.00 | 28.00 | 2210.00 | 4900.00 |
| Algorithm | Learning Method | Training Error | Test Error | ||
|---|---|---|---|---|---|
| MSE | MSE | ||||
| OEM | OMC | 9.69 | 0.48 | 12.77 | 0.56 |
| MDD | 22,054 | 0.27 | 34,410 | 0.21 | |
| UCS | 295,900 | 0.75 | 370,860 | 0.61 | |
| ANN | OMC | 5.70 | 0.73 | 8.84 | 0.55 |
| MDD | 25,670 | 0.19 | 33,958 | 0.25 | |
| UCS | 241,730 | 0.79 | 457,271 | 0.65 | |
| Optimizable Ensemble Methods | Artificial Neural Networks | ||||||
|---|---|---|---|---|---|---|---|
| Ensemble Method | Minimum Leaf Size | No. of Learners | Learning Rate | No. of Predictors to Sample | Algorithms | No. of Hidden Neurons | |
| OMC | Bag | 1 | 475 | - | 7 | Bayesian Regularization | 5 |
| MDD | Bag | 1 | 402 | - | 5 | Bayesian Regularization | 10 |
| UCS | LSBoost | 2 | 493 | 0.15708 | 6 | Bayesian Regularization | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taffese, W.Z.; Abegaz, K.A. Prediction of Compaction and Strength Properties of Amended Soil Using Machine Learning. Buildings 2022, 12, 613. https://doi.org/10.3390/buildings12050613
Taffese WZ, Abegaz KA. Prediction of Compaction and Strength Properties of Amended Soil Using Machine Learning. Buildings. 2022; 12(5):613. https://doi.org/10.3390/buildings12050613
Chicago/Turabian StyleTaffese, Woubishet Zewdu, and Kassahun Admassu Abegaz. 2022. "Prediction of Compaction and Strength Properties of Amended Soil Using Machine Learning" Buildings 12, no. 5: 613. https://doi.org/10.3390/buildings12050613
APA StyleTaffese, W. Z., & Abegaz, K. A. (2022). Prediction of Compaction and Strength Properties of Amended Soil Using Machine Learning. Buildings, 12(5), 613. https://doi.org/10.3390/buildings12050613