
Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning

 ,
,  ,
, 
 and
and
Abstract
:1. Introduction and Background
2. Materials and Methods
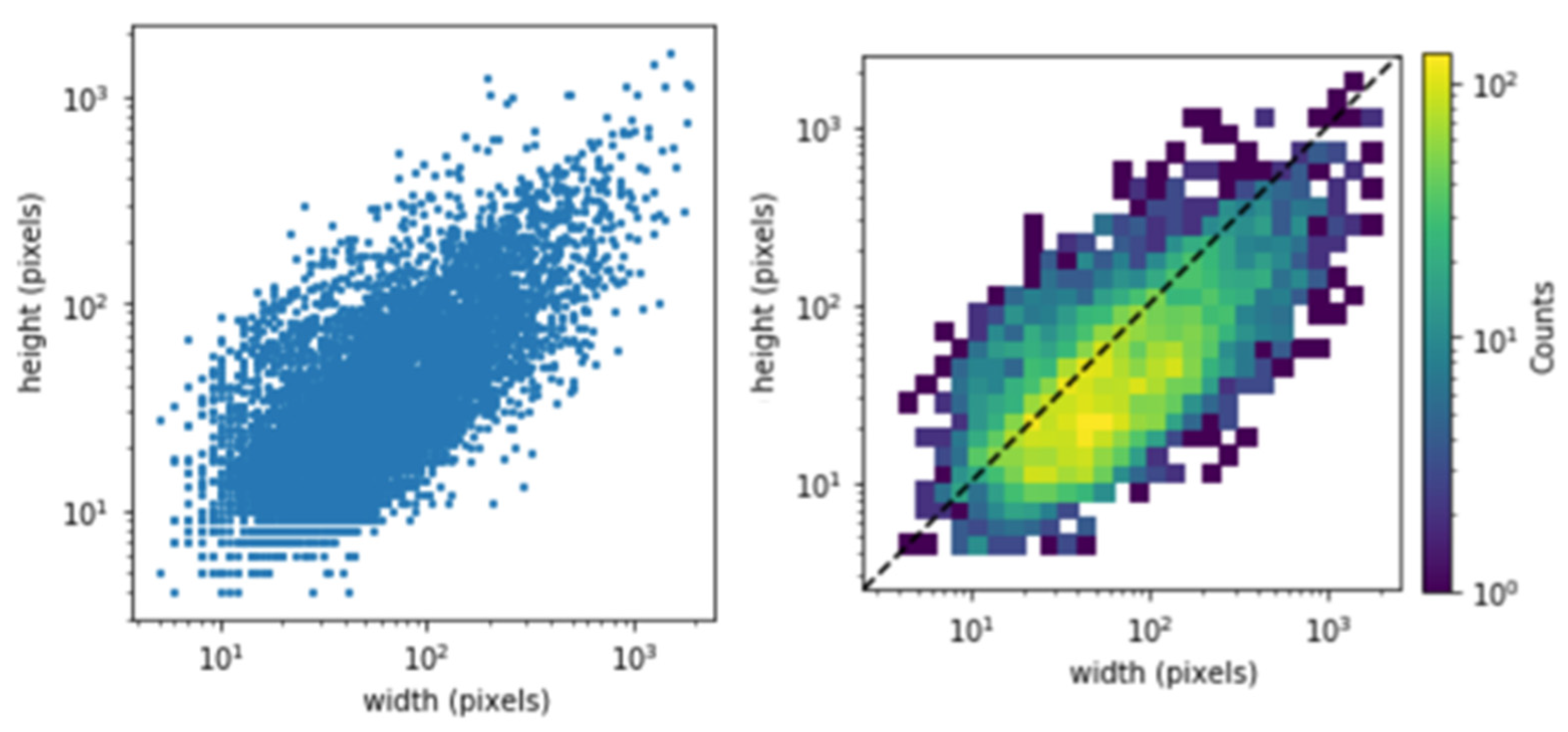
2.1. Data Collection
- No corrosion: All images without corrosion (negative class).
- Low-level corrosion: Images having less than 5% of corroded pixels.
- Medium-level corrosion: Images having less than 15% of corroded pixels.
- High-level corrosion: Images having more than 15% of corroded pixels.
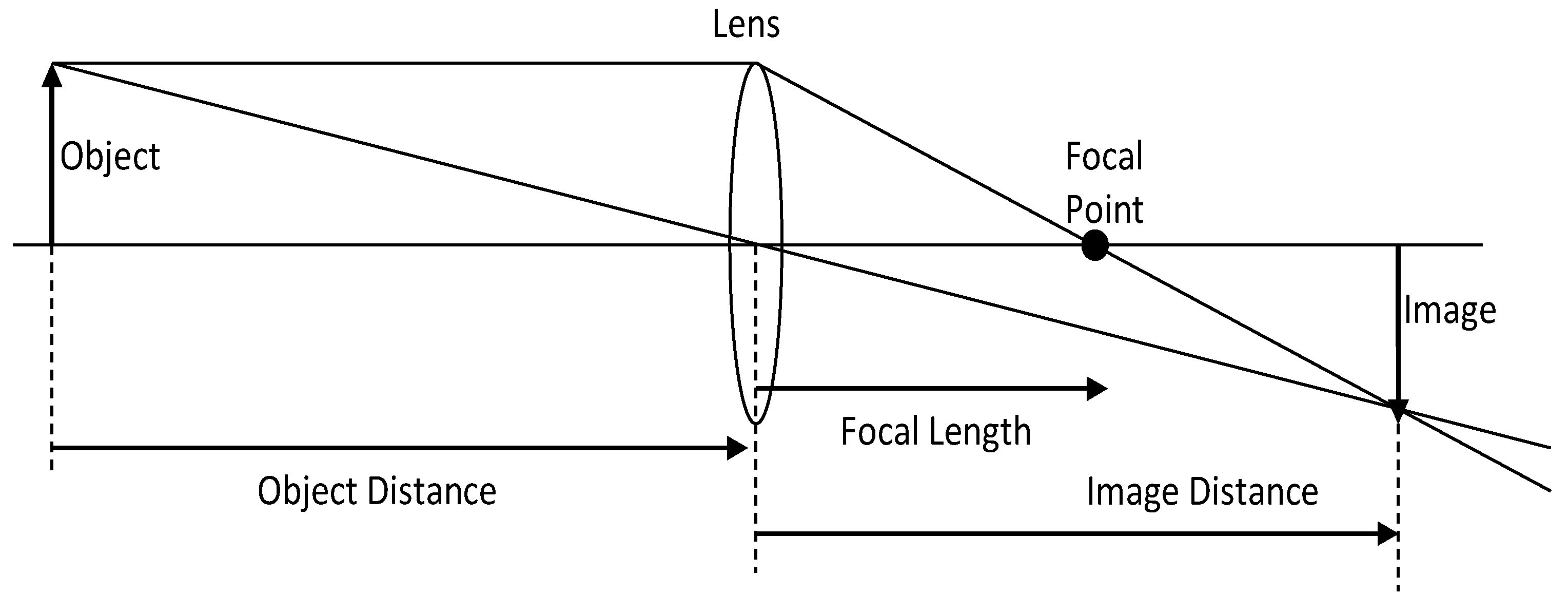
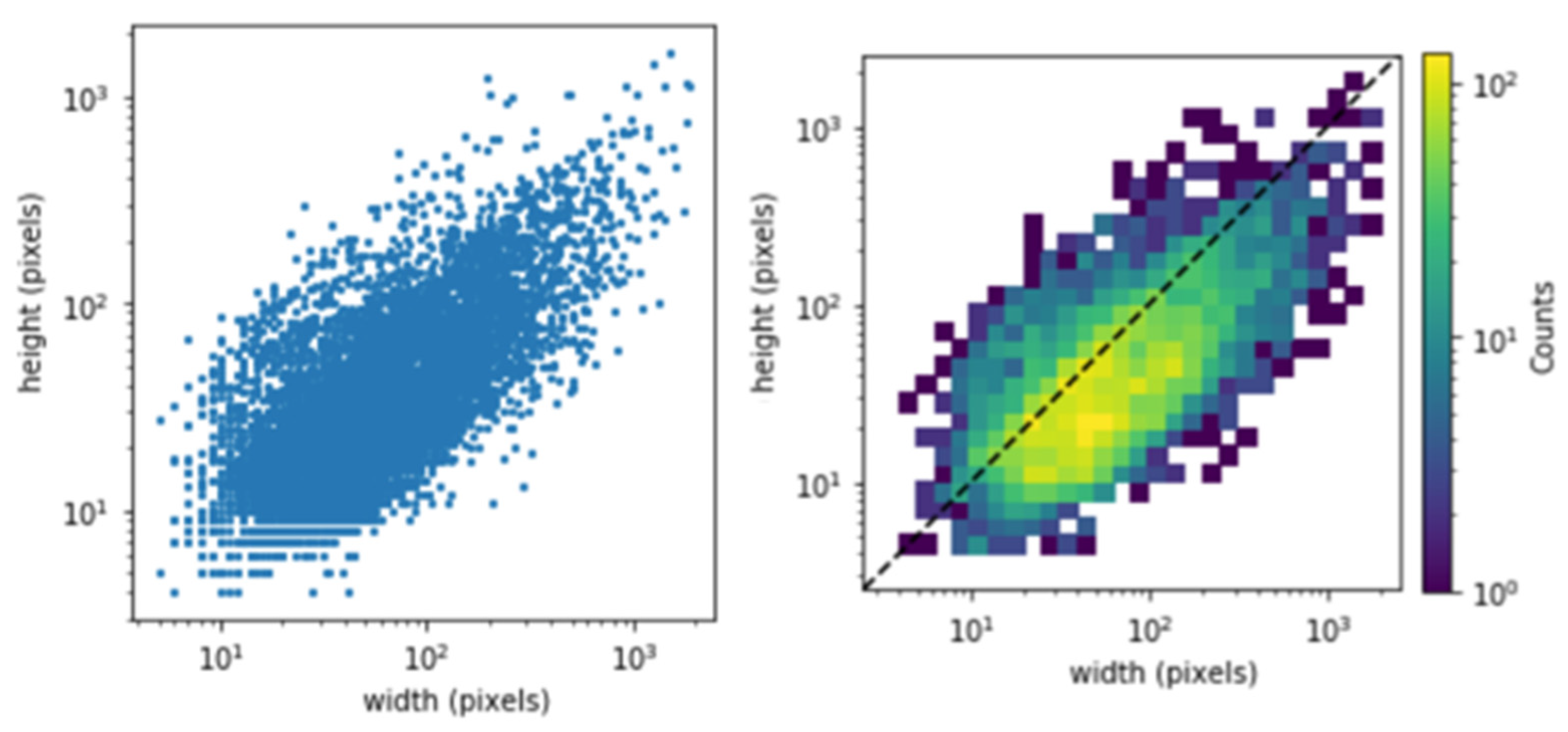
Image Pre-Processing and Data Augmentation
- The rotation of images to 8 different angles every 45° in [0°, 360°];
- Cropping the rotated image in terms of the largest rectangle without any blank regions;
- Flipping images horizontally at each angle.
2.2. Manual Supervision
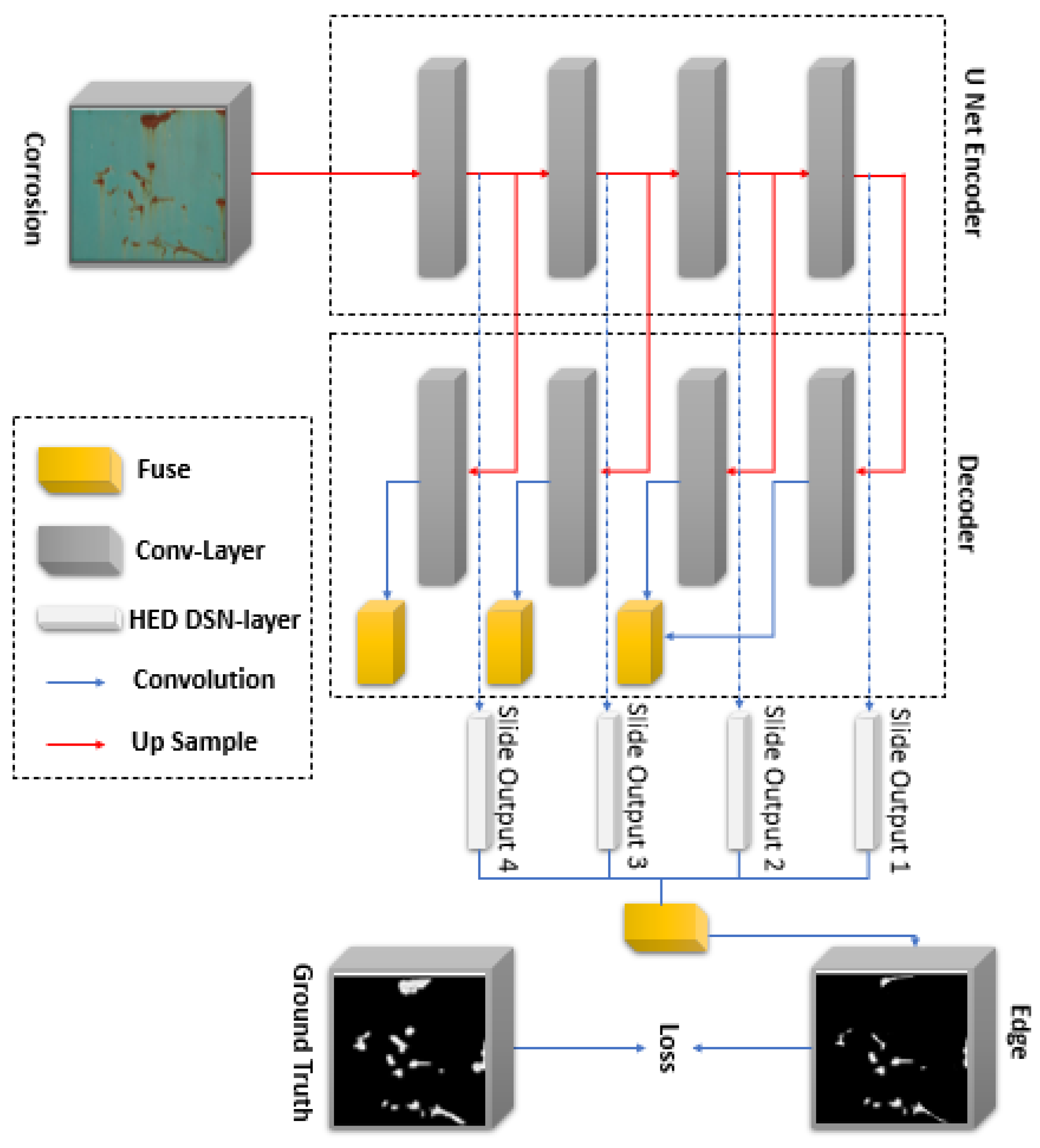
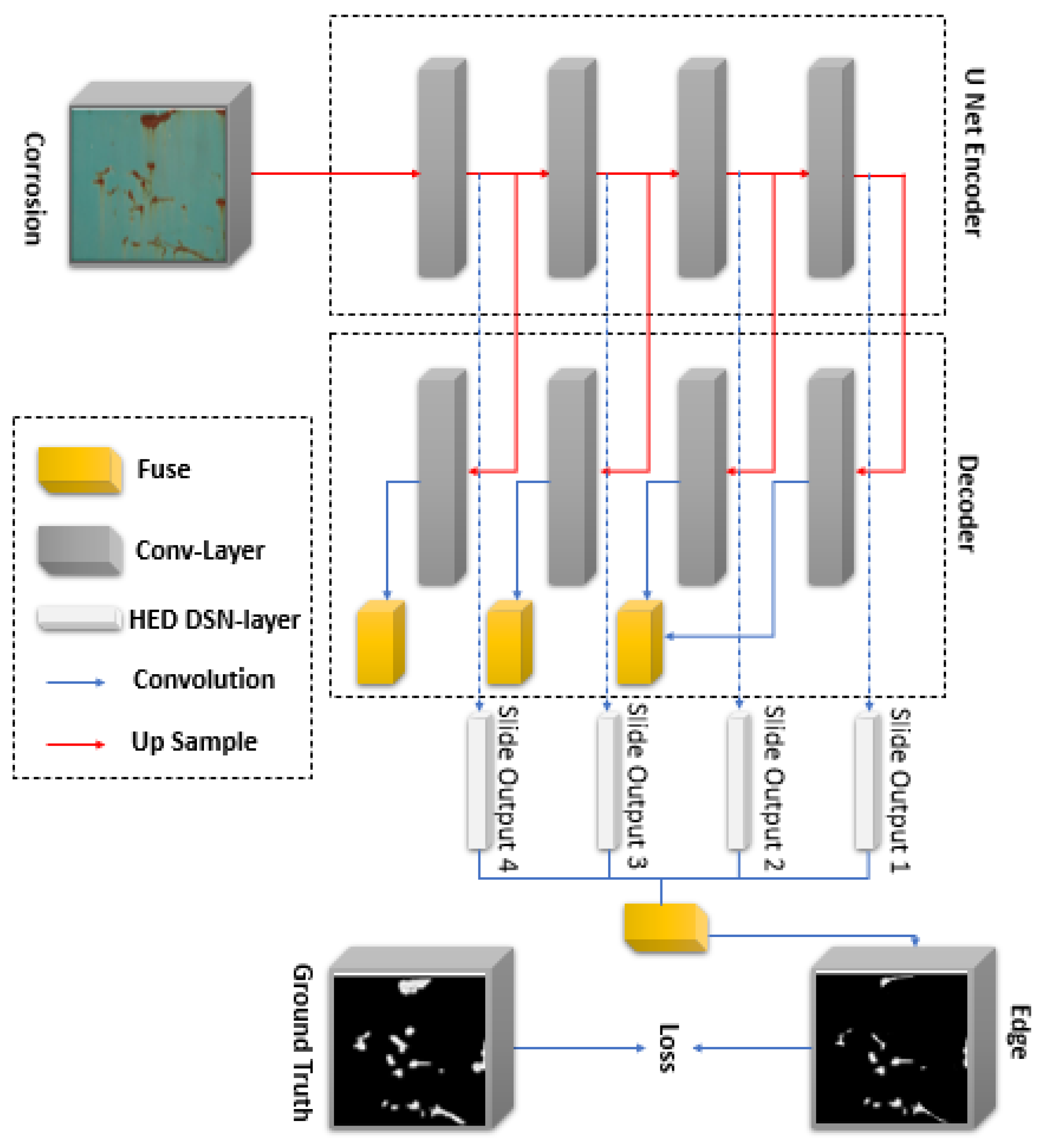
2.3. Image Classification and Processing
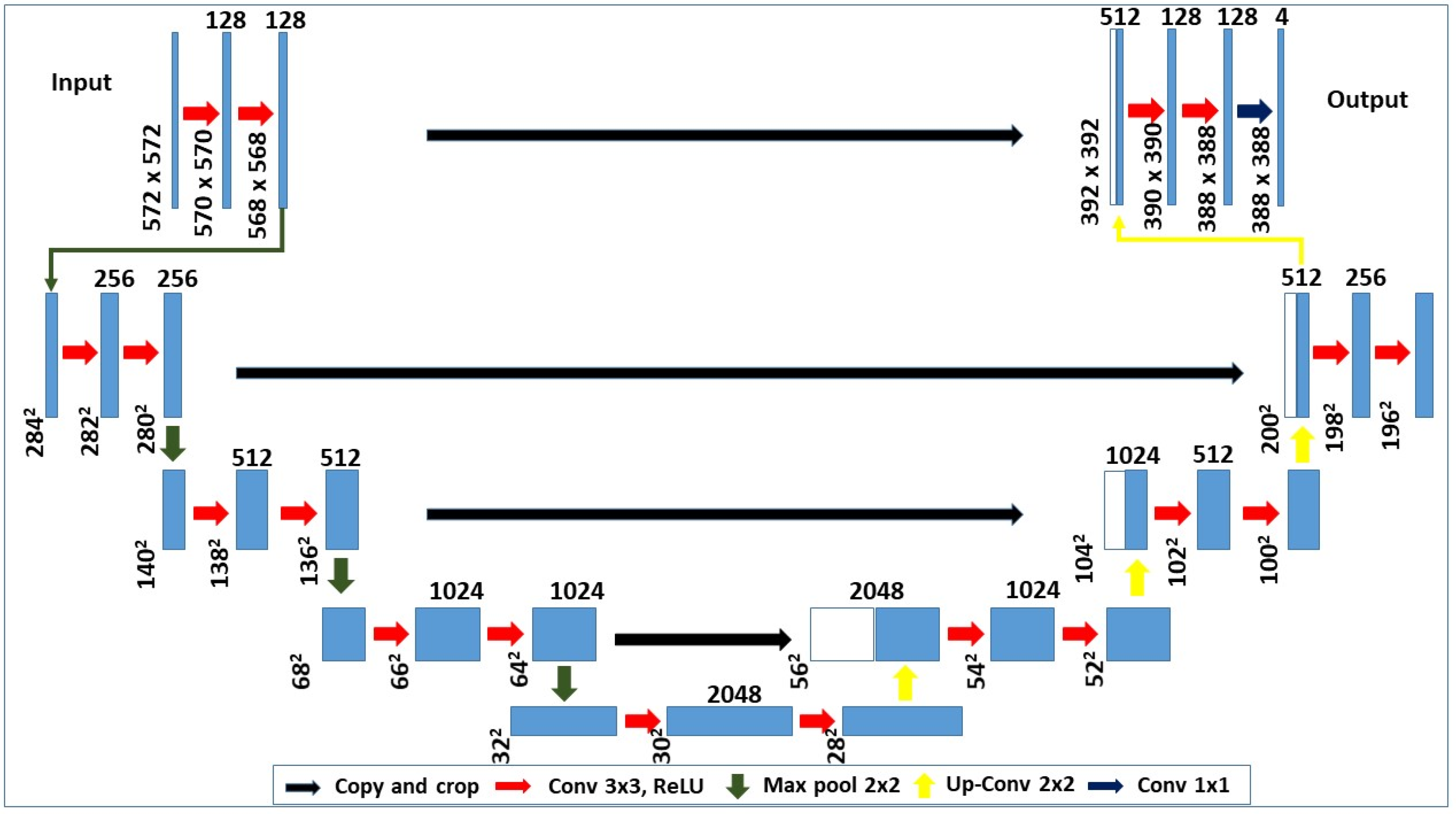
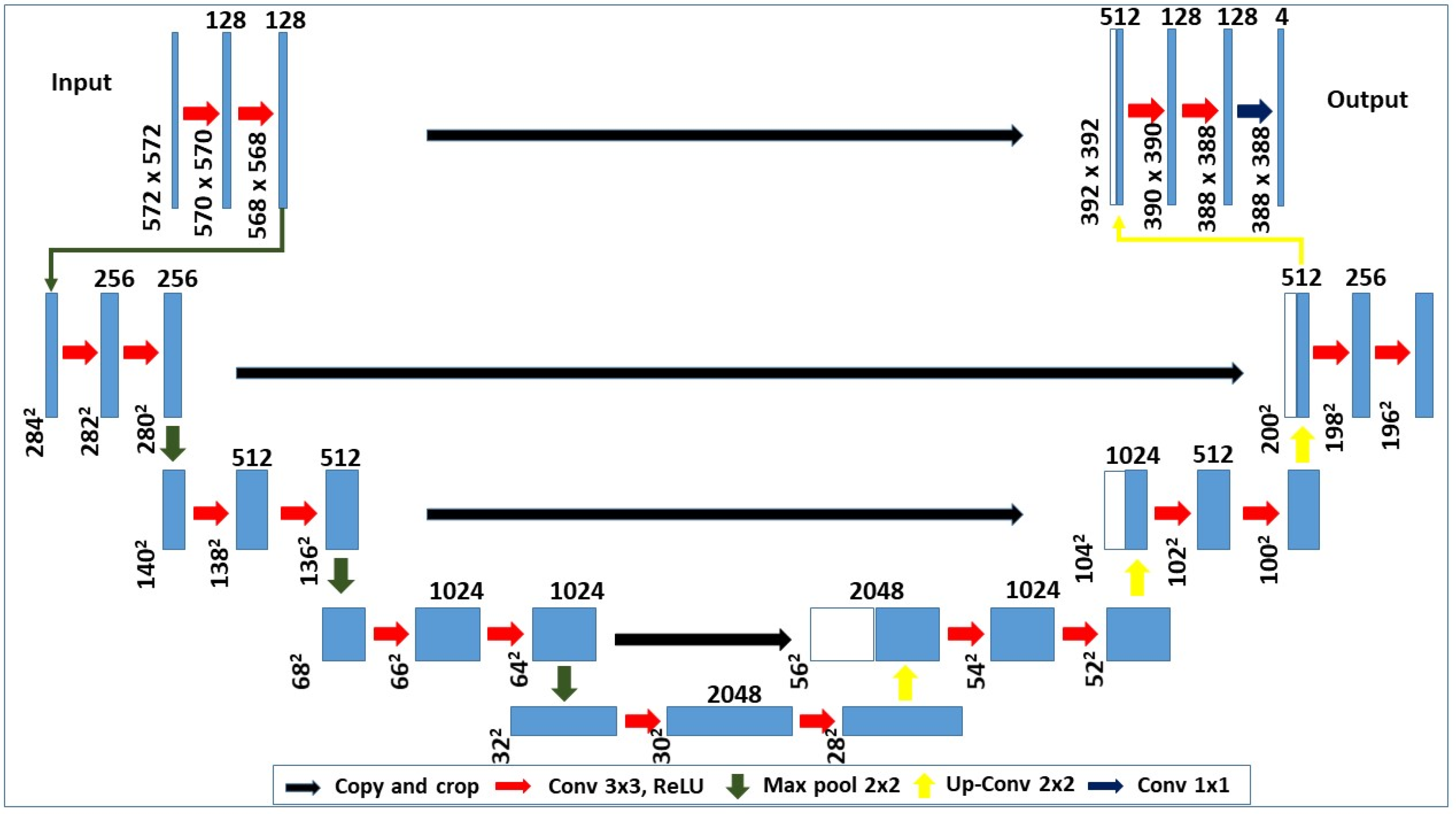
2.3.1. U-Net Model Architecture
- A conventional stack of layers and functions is used for the encoder architecture to capture features at different image scales.
- Repeated use of layers is utilized in each block of the encoder. The non-linearity layer and a max-pooling layer are arranged after each convolution block.
- The decoder architecture is based on the symmetric expanding counterpart of the transposed convolution layers. These layers consider the up-sampling method and a set of trainable parameters to function as the reverse of pooling layers such as the max pool.
- Each convolution block is connected to an up-convolutional layer for the decoder architecture that receives the outputs (appended by the feature maps). This is generated by the corresponding encoder blocks.
- The feature maps for the encoder layer are cropped if the dimensions of any decoder layer are exceeded. Largely, the output is required to pass another convolution layer that displays an equal number of feature maps and defined labels.
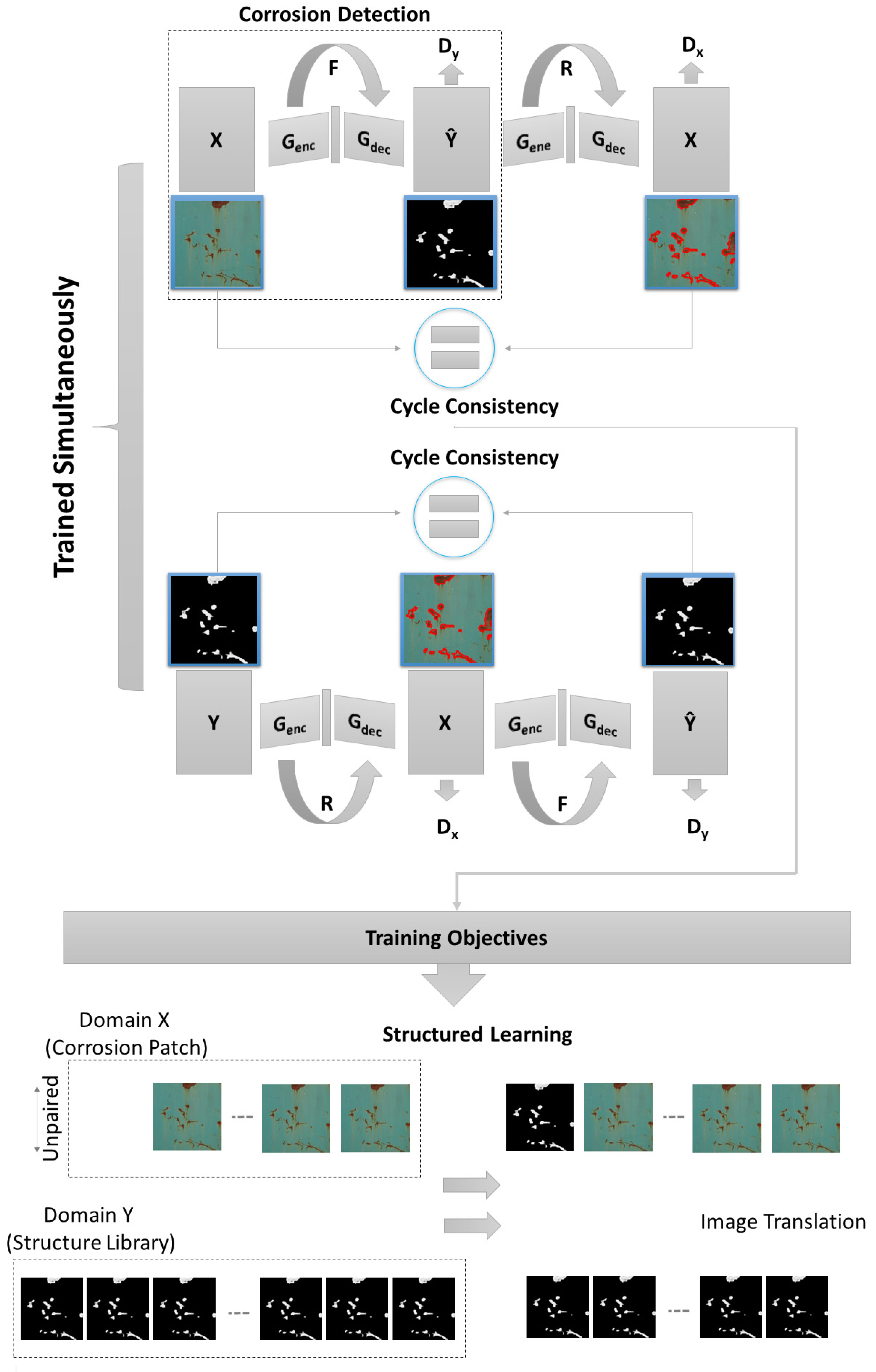
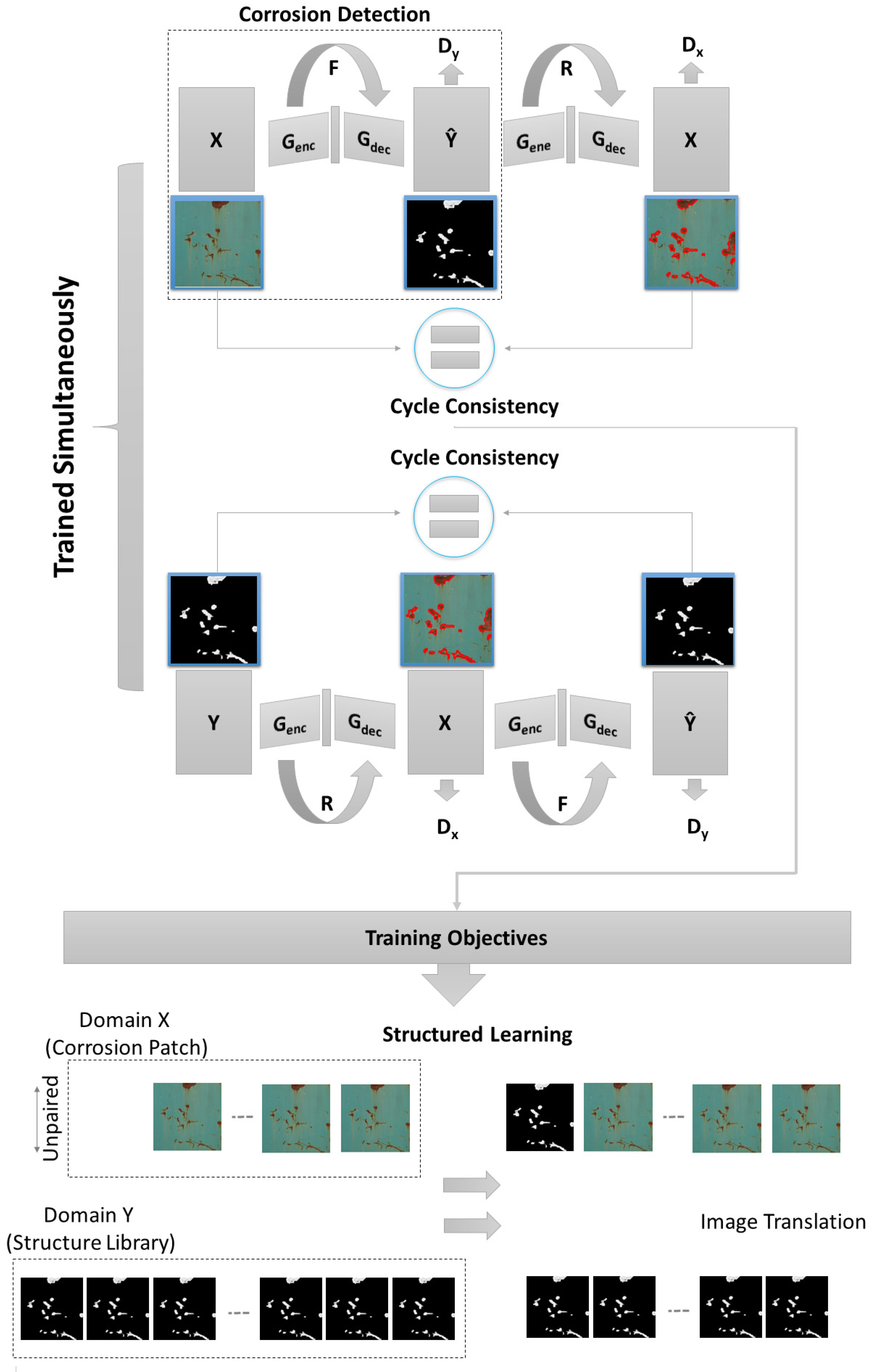
2.3.2. CycleGAN
- At first, the input image (x) is taken and converted to a reconstructed image based on the generator (G).
- Next, the process is reversed to convert a restructured image to an original image through the generator (F)
- Later, the mean squared error loss between real and reconstructed images is calculated.
2.4. Loss Formulation
2.4.1. Adversarial Loss
2.4.2. Cycle-Consistency Loss
2.4.3. Model Parameters
3. Model Development and Training
3.1. Model Training
3.2. Evaluation Metrics
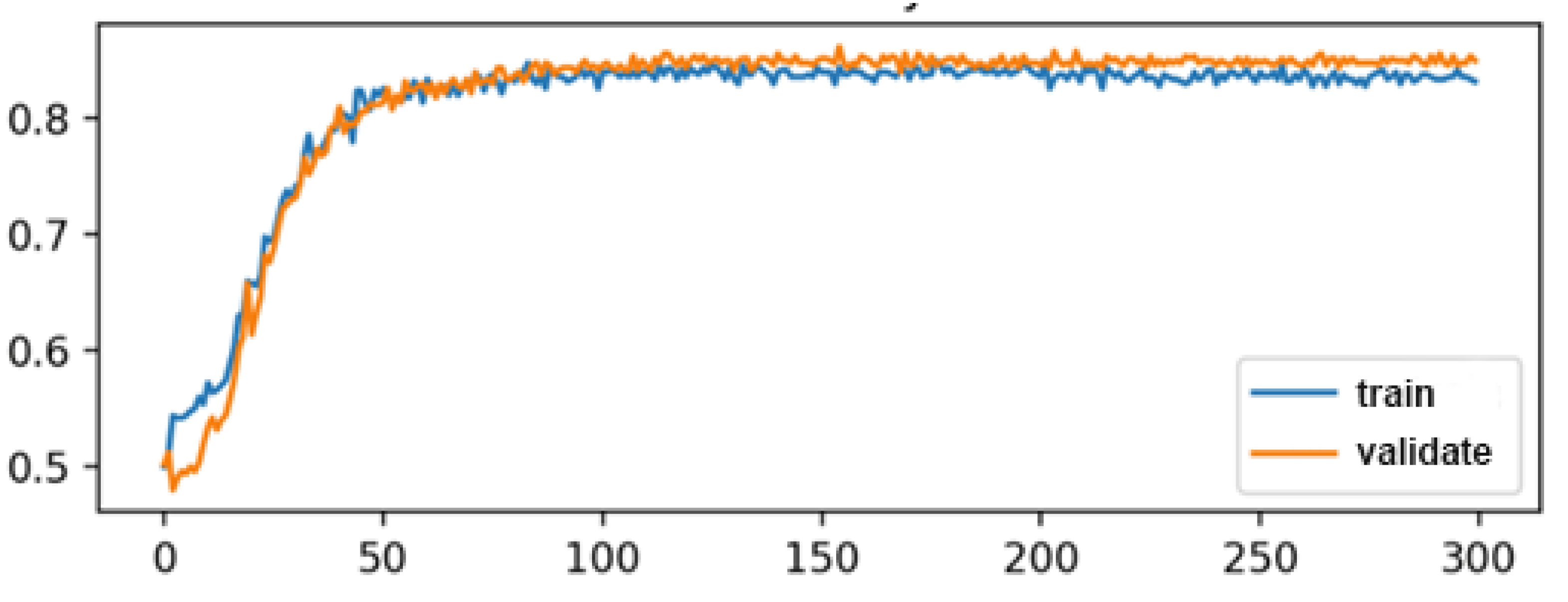
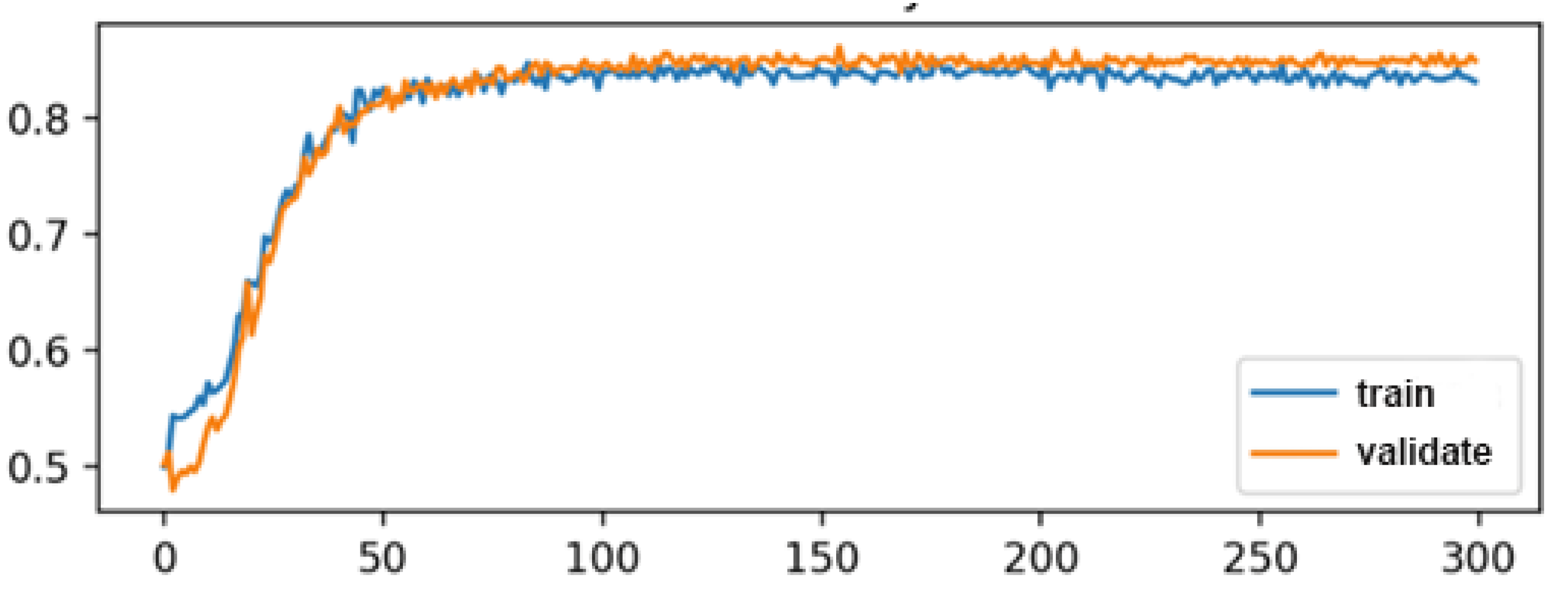
3.3. Training and Test Accuracy
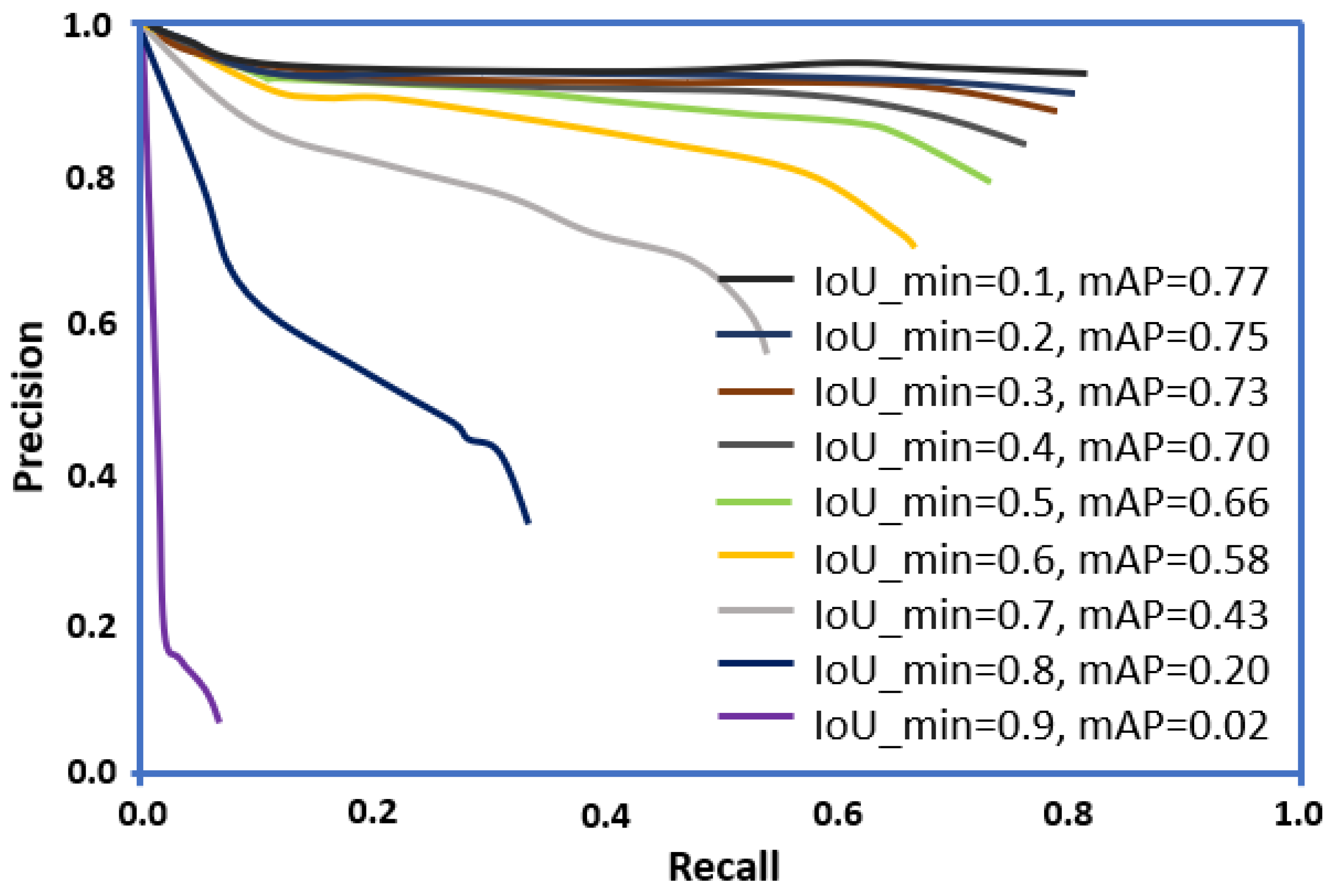
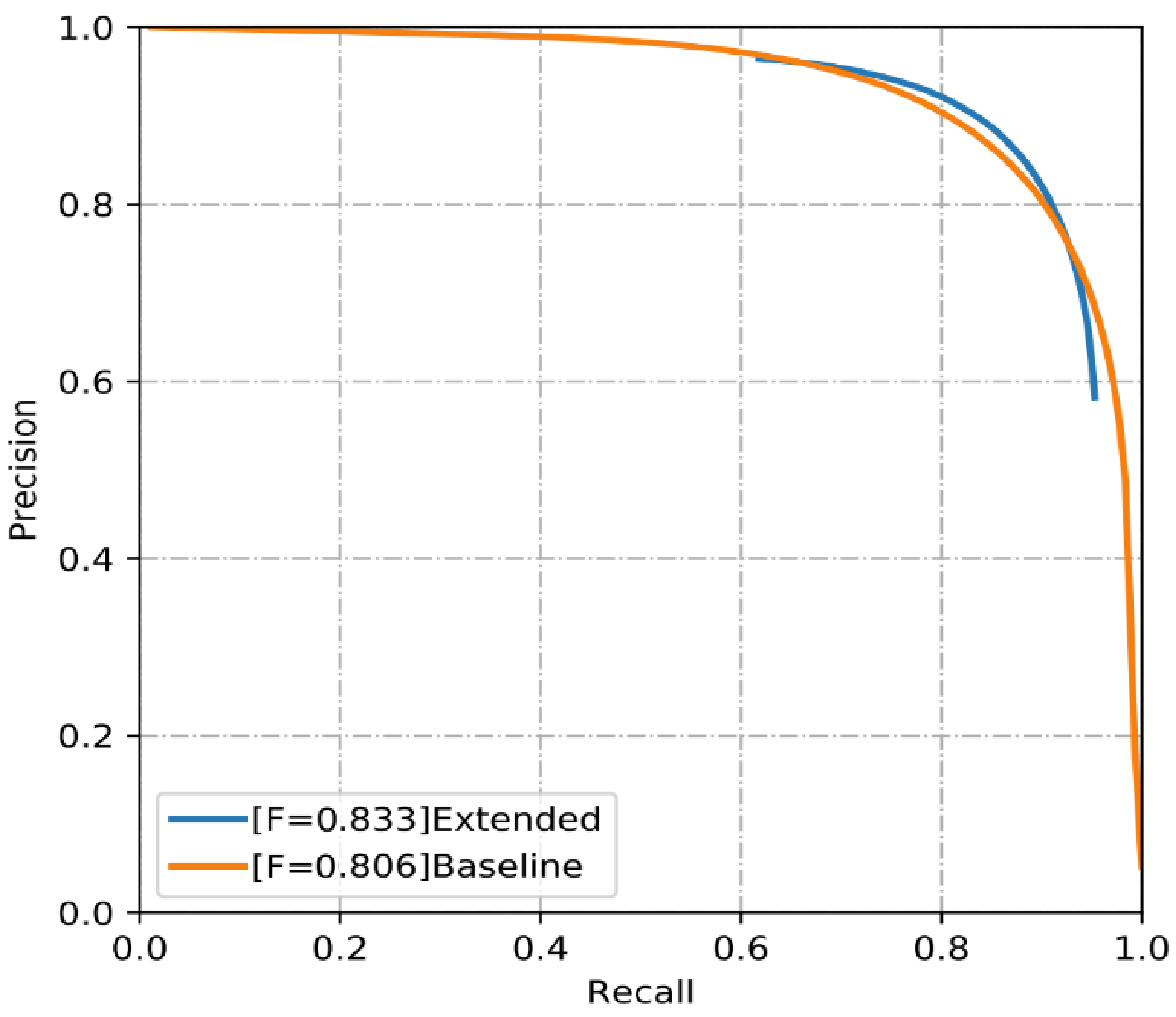
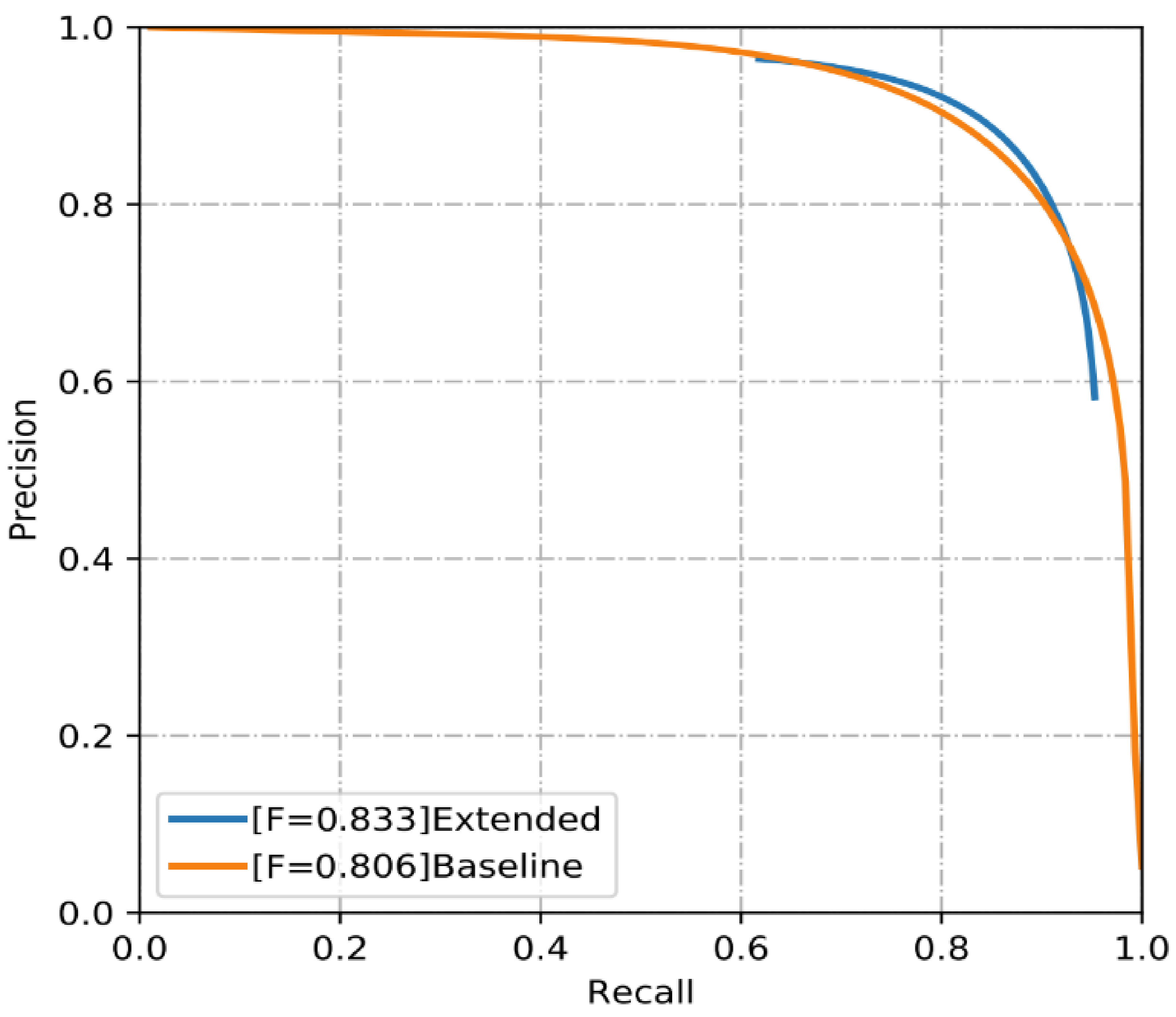
3.4. Evaluation of Network Performance
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANNs | Artificial Neural Networks |
| CNNs | Convolutional Neural Networks |
| CycleGAN | cycle generative adversarial network |
| CRFs | Conditional Random Fields |
| CAC | Class Average Accuracy |
| FoV | Field of View |
| FCN | Fully Convolutional Network |
| FPR | False Positive Rate |
| GC | Global Accuracy |
| GNSS | Global Navigation Satellite System |
| HSV | Hue Saturation, Value |
| HED | Holistically-Nested Edge Detection |
| KL | Kullback–Leibler |
| MMS | Mobile Measurement System |
| MB | megabytes |
| ROC | Receiver Operating Characteristic |
| SGD | Stochastic Gradient Descent |
| TPR | True Positive Rate |
| UAV | Unmanned Aerial Vehicle |
| VGG | Visual Geometry Group |
| VTOL | vertical take-off and landing |
References
- Hembara, O.; Andreikiv, O. Effect of hydrogenation of the walls of oil-and-gas pipelines on their soil corrosion and service life. Mater. Sci. 2012, 47, 598–607. [Google Scholar] [CrossRef]
- Ahuja, S.K.; Shukla, M.K. A Survey of Computer Vision Based Corrosion Detection Approaches. In Information and Communication Technology for Intelligent Systems (ICTIS 2017); Satapathy, S., Joshi, A., Eds.; Springer: Cham, Switzerland, 2017; Volume 2, pp. 55–63. [Google Scholar]
- Arriba-Rodriguez, L.-D.; Villanueva-Balsera, J.; Ortega-Fernandez, F.; Rodriguez-Perez, F. Methods to evaluate corrosion in buried steel structures: A review. Metals 2018, 8, 334. [Google Scholar] [CrossRef] [Green Version]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of deep learning approaches based on convolutional neural networks for corrosion detection. Struct. Health Monit. 2018, 17, 1110–1128. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khalid, U.; Maqsood, A. Modern day detection of mines; using the vehicle based detection robot. In Proceedings of the 2nd International Conference on Culture Technology (ICCT), Tokyo, Japan, 8–10 December 2017; Available online: http://www.iacst.org/iacst/Conferences/The2ndICCT/The%202nd%20ICCT_%20Proceeding(final).pdf (accessed on 1 December 2021).
- Qayyum, S.; Ullah, F.; Al-Turjman, F.; Mojtahedi, M. Managing smart cities through six sigma DMADICV method: A review-based conceptual framework. Sustain. Cities Soc. 2021, 72, 103022. [Google Scholar] [CrossRef]
- Ullah, F.; Qayyum, S.; Thaheem, M.J.; Al-Turjman, F.; Sepasgozar, S.M. Risk management in sustainable smart cities governance: A TOE framework. Technol. Forecast. Soc. Change 2021, 167, 120743. [Google Scholar] [CrossRef]
- Qadir, Z.; Ullah, F.; Munawar, H.S.; Al-Turjman, F. Addressing disasters in smart cities through UAVs path planning and 5G communications: A systematic review. Comput. Commun. 2021, 168, 114–135. [Google Scholar] [CrossRef]
- Khayatazad, M.; De Pue, L.; De Waele, W. Detection of corrosion on steel structures using automated image processing. Dev. Built Environ. 2020, 3, 100022. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.; Waller, S.T. A review on flood management technologies related to image processing and machine learning. Autom. Constr. 2021, 132, 103916. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.; Thaheem, M.J.; Al-Turjman, F. Barriers to the digitalisation and innovation of Australian Smart Real Estate: A managerial perspective on the technology non-adoption. Environ. Technol. Innov. 2021, 22, 101527. [Google Scholar] [CrossRef]
- Ullah, F.; Sepasgozar, S.M.; Thaheem, M.J.; Wang, C.C.; Imran, M. It’s all about perceptions: A DEMATEL approach to exploring user perceptions of real estate online platforms. Ain Shams Eng. J. 2021, 12, 4297–4317. [Google Scholar] [CrossRef]
- Munawar, H.S. Image and video processing for defect detection in key infrastructure. Mach. Vis. Insp. Syst. Image Processing Concepts Methodol. Appl. 2020, 1, 159–177. [Google Scholar]
- Ullah, F.; Thaheem, M.J.; Sepasgozar, S.M.; Forcada, N. System dynamics model to determine concession period of PPP infrastructure projects: Overarching effects of critical success factors. J. Leg. Aff. Disput. Resolut. Eng. Constr. 2018, 10, 04518022. [Google Scholar] [CrossRef]
- Bisby, L.; Eng, P.; Banthia, N.; Bisby, L.; Britton, R.; Cheng, R.; Mufti, A.; Neale, K.; Newhook, J.; Soudki, K. An Introduction to Structural Health Monitoring. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2005, 365, 303–315. [Google Scholar]
- Ullah, F.; Sepasgozar, S.M.; Wang, C. A systematic review of smart real estate technology: Drivers of, and barriers to, the use of digital disruptive technologies and online platforms. Sustainability 2018, 10, 3142. [Google Scholar] [CrossRef] [Green Version]
- Brownjohn, J.M. Structural health monitoring of civil infrastructure. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 589–622. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.-J.; You, K.; Choi, W. Vision-based detection of loosened bolts using the Hough transform and support vector machines. Autom. Constr. 2016, 71, 181–188. [Google Scholar] [CrossRef]
- Tian, H.; Li, W.; Wang, L.; Ogunbona, P. A novel video-based smoke detection method using image separation. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 532–537. [Google Scholar]
- Hoang, N.-D. Image processing-based pitting corrosion detection using metaheuristic optimized multilevel image thresholding and machine-learning approaches. Math. Probl. Eng. 2020, 2020, 6765274. [Google Scholar] [CrossRef]
- Munawar, H.S.; Khalid, U.; Maqsood, A. Fire detection through Image Processing; A brief overview. In Proceedings of the 2nd International Conference on Culture Technology (ICCT), Tokyo, Japan, 8–10 December 2017; Available online: http://www.iacst.org/iacst/Conferences/The2ndICCT/The%202nd%20ICCT_%20Proceeding(final).pdf (accessed on 1 December 2021).
- Pragalath, H.; Seshathiri, S.; Rathod, H.; Esakki, B.; Gupta, R. Deterioration assessment of infrastructure using fuzzy logic and image processing algorithm. J. Perform. Constr. Facil. 2018, 32, 04018009. [Google Scholar] [CrossRef]
- Huang, M.; Zhao, W.; Gu, J.; Lei, Y. Damage Identification of a Steel Frame Based on Integration of Time Series and Neural Network under Varying Temperatures. Adv. Civ. Eng. 2020, 2020, 4284381. [Google Scholar] [CrossRef]
- Liu, L.; Tan, E.; Zhen, Y.; Yin, X.J.; Cai, Z.Q. AI-facilitated coating corrosion assessment system for productivity enhancement. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 606–610. [Google Scholar]
- Munawar, H.S.; Hammad, A.W.; Haddad, A.; Soares, C.A.P.; Waller, S.T. Image-Based Crack Detection Methods: A Review. Infrastructures 2021, 6, 115. [Google Scholar] [CrossRef]
- Suh, G.; Cha, Y.-J. Deep faster R-CNN-based automated detection and localization of multiple types of damage. In Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems 2018; International Society for Optics and Photonics: Denver, CO, USA, 2018; p. 105980T. [Google Scholar]
- Ullah, F.; Sepasgozar, S.M.; Shirowzhan, S.; Davis, S. Modelling users’ perception of the online real estate platforms in a digitally disruptive environment: An integrated KANO-SISQual approach. Telemat. Inform. 2021, 63, 101660. [Google Scholar] [CrossRef]
- Rakha, T.; Gorodetsky, A. Review of Unmanned Aerial System (UAS) applications in the built environment: Towards automated building inspection procedures using drones. Autom. Constr. 2018, 93, 252–264. [Google Scholar] [CrossRef]
- Forkan, A.R.M.; Kang, Y.-B.; Jayaraman, P.P.; Liao, K.; Kaul, R.; Morgan, G.; Ranjan, R.; Sinha, S. CorrDetector: A Framework for Structural Corrosion Detection from Drone Images using Ensemble Deep Learning. Expert Syst. Appl. 2021, 193, 116461. [Google Scholar] [CrossRef]
- Luo, C.; Yu, L.; Yan, J.; Li, Z.; Ren, P.; Bai, X.; Yang, E.; Liu, Y. Autonomous detection of damage to multiple steel surfaces from 360° panoramas using deep neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 1585–1599. [Google Scholar] [CrossRef]
- Ham, Y.; Kamari, M. Automated content-based filtering for enhanced vision-based documentation in construction toward exploiting big visual data from drones. Autom. Constr. 2019, 105, 102831. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Thomson, C.; Apostolopoulos, G.; Backes, D.; Boehm, J. Mobile laser scanning for indoor modelling. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2013, 5, 66. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Sledz, A.; Unger, J.; Heipke, C. UAV-based thermal anomaly detection for distributed heating networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 499–505. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Khan, S.I.; Qadir, Z.; Qayyum, S. UAV Assisted Spatiotemporal Analysis and Management of Bushfires: A Case Study of the 2020 Victorian Bushfires. Fire 2021, 4, 40. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. arXiv 2017, arXiv:1702.04595. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 3, pp. 770–778. [Google Scholar]
- Han, L.; Liang, H.; Chen, H.; Zhang, W.; Ge, Y. Convective Precipitation Nowcasting Using U-Net Model. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4103508. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H. Self-supervised structure learning for crack detection based on cycle-consistent generative adversarial networks. J. Comput. Civ. Eng. 2020, 34, 04020004. [Google Scholar] [CrossRef]
- Graybeal, B.A.; Phares, B.M.; Rolander, D.D.; Moore, M.; Washer, G. Visual inspection of highway bridges. J. Nondestruct. Eval. 2002, 21, 67–83. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Corrosion Pixels (%) Classes | Non-Corrosion Pixels (%) | Grand Total (All Corrosion + Non-Corossion Pixels) | ||
|---|---|---|---|---|---|
| Low | Medium | High | |||
| Training | 3.61 | 1.30 | 0.49 | 74.60 | 80 |
| Validation | 0.65 | 0.34 | 0.26 | 18.65 | 20 |
| Total | 4.26 | 1.64 | 0.75 | 93.25 | 100 |
| Parameter | Value Tuned | |
|---|---|---|
| (1) | Size of the input image size | 544 × 384 × 3 |
| (2) | Ground truth size | 544 × 384 × 1 |
| (3) | Size of mini-batch | 1 |
| (4) | Learning rate | 1 × 10−4 |
| (5) | Loss weight associated with each side-output layer | 1.0 |
| (6) | The loss weight associated with the final fused layer | 1.0 |
| (7) | Momentum | 0.9 |
| (8) | Weight decay | 2 × 10−4 |
| (9) | Training iterations | 2 × 105; reduce learning rate by 1/5 after 5 × 104 |
| Outputs | Global Accuracy | Class Average Accuracy | Mean IoU | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|
| Extended | 0.989 | 0.931 | 0.878 | 0.849 | 0.818 | 0.833 |
| Baseline | 0.983 | 0.899 | 0.892 | 0.83 | 0.784 | 0.806 |
| PSPNet | 0.962 | 0.873 | 0.822 | 0.785 | 0.724 | 0.753 |
| DeepLab | 0.932 | 0.82 | 0.76 | 0.725 | 0.654 | 0.687 |
| SegNet | 0.870 | 0.815 | 0.642 | 0.625 | 0.66 | 0.642 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Munawar, H.S.; Ullah, F.; Shahzad, D.; Heravi, A.; Qayyum, S.; Akram, J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings 2022, 12, 156. https://doi.org/10.3390/buildings12020156
Munawar HS, Ullah F, Shahzad D, Heravi A, Qayyum S, Akram J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings. 2022; 12(2):156. https://doi.org/10.3390/buildings12020156
Chicago/Turabian StyleMunawar, Hafiz Suliman, Fahim Ullah, Danish Shahzad, Amirhossein Heravi, Siddra Qayyum, and Junaid Akram. 2022. "Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning" Buildings 12, no. 2: 156. https://doi.org/10.3390/buildings12020156
APA StyleMunawar, H. S., Ullah, F., Shahzad, D., Heravi, A., Qayyum, S., & Akram, J. (2022). Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings, 12(2), 156. https://doi.org/10.3390/buildings12020156