Understanding Dephosphorization in Basic Oxygen Furnaces (BOFs) Using Data Driven Modeling Techniques


Abstract
:1. Introduction
2. Materials and Methods
2.1. Nature of the Data
2.2. Theoretical Model
2.3. Model Adequacy
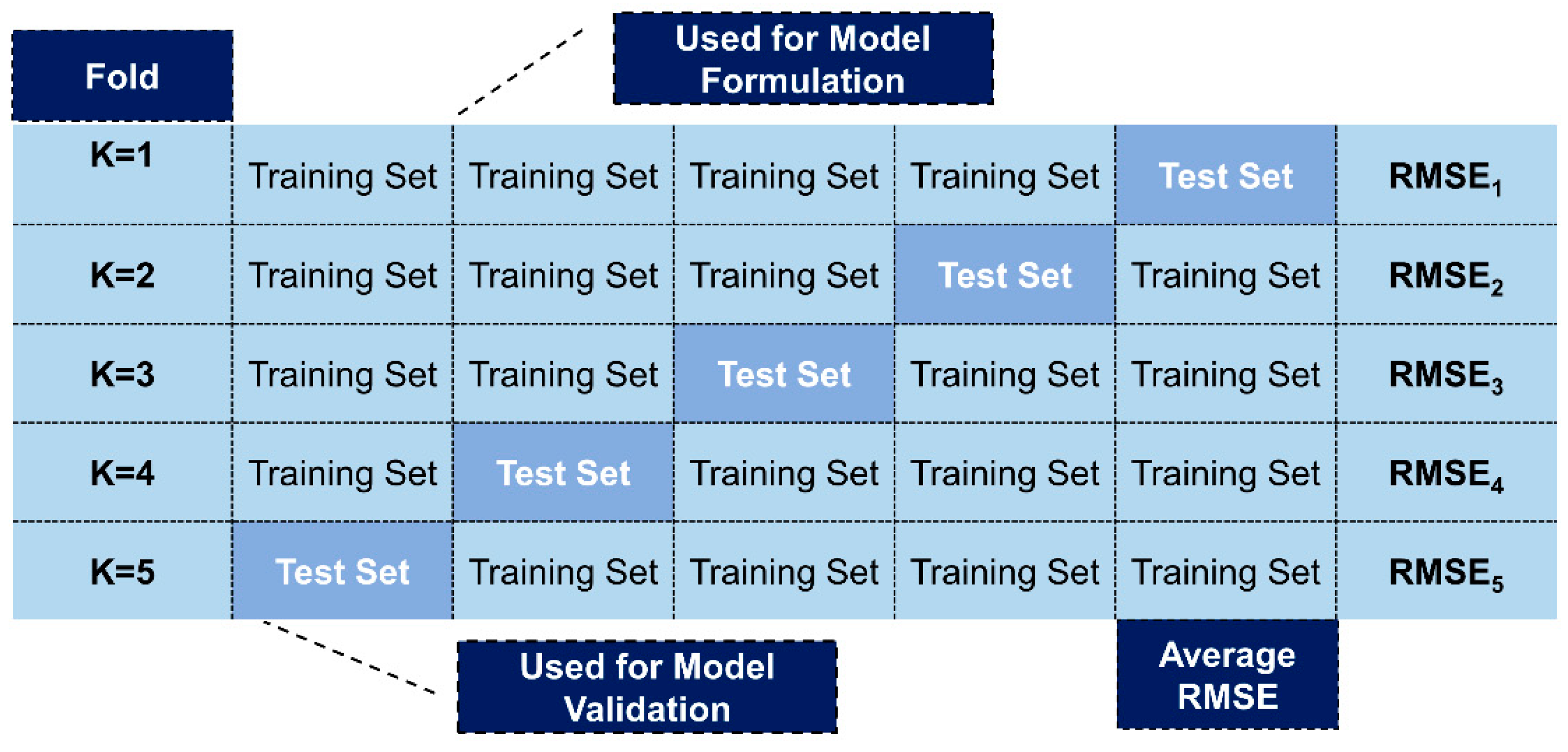
2.4. Model Validation
3. Results
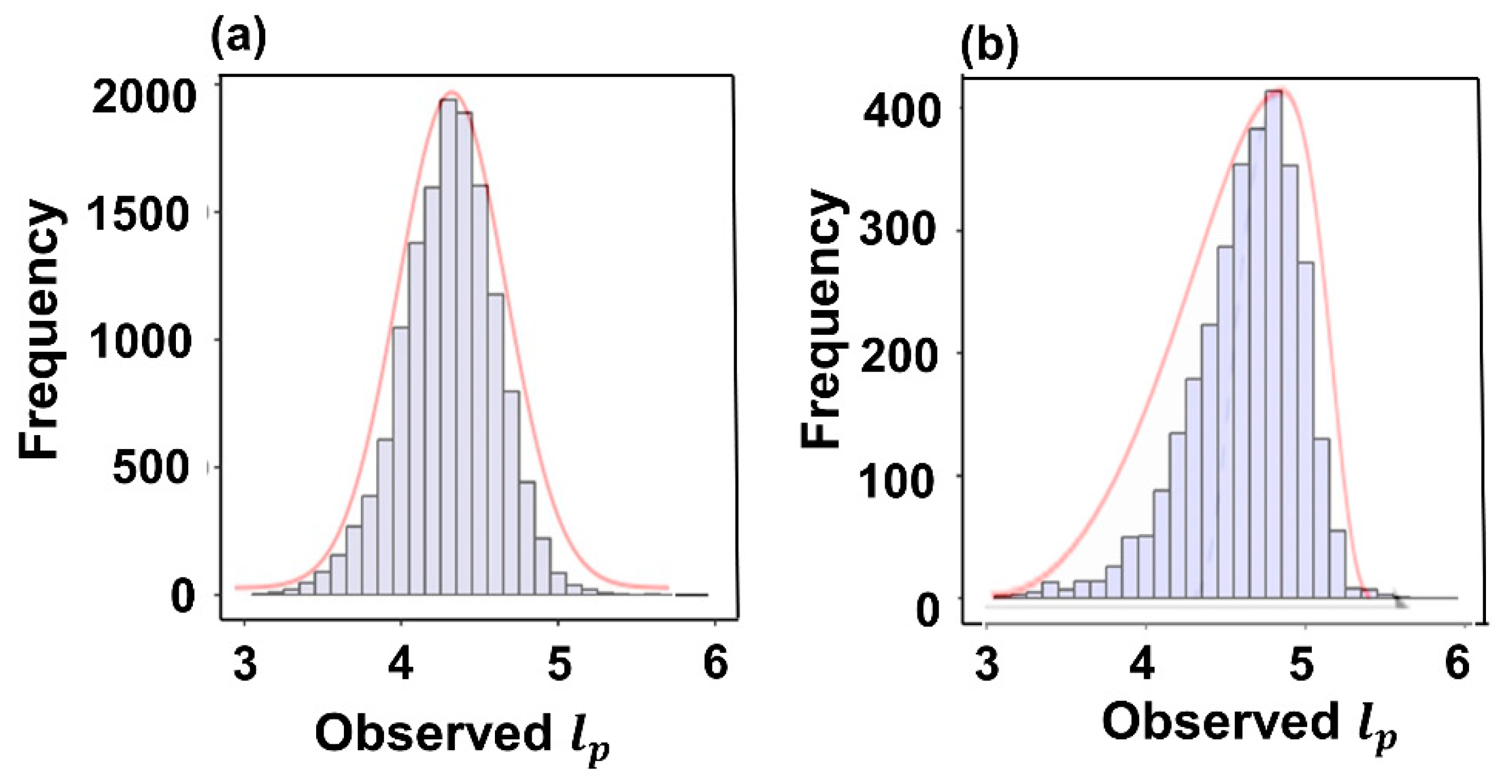
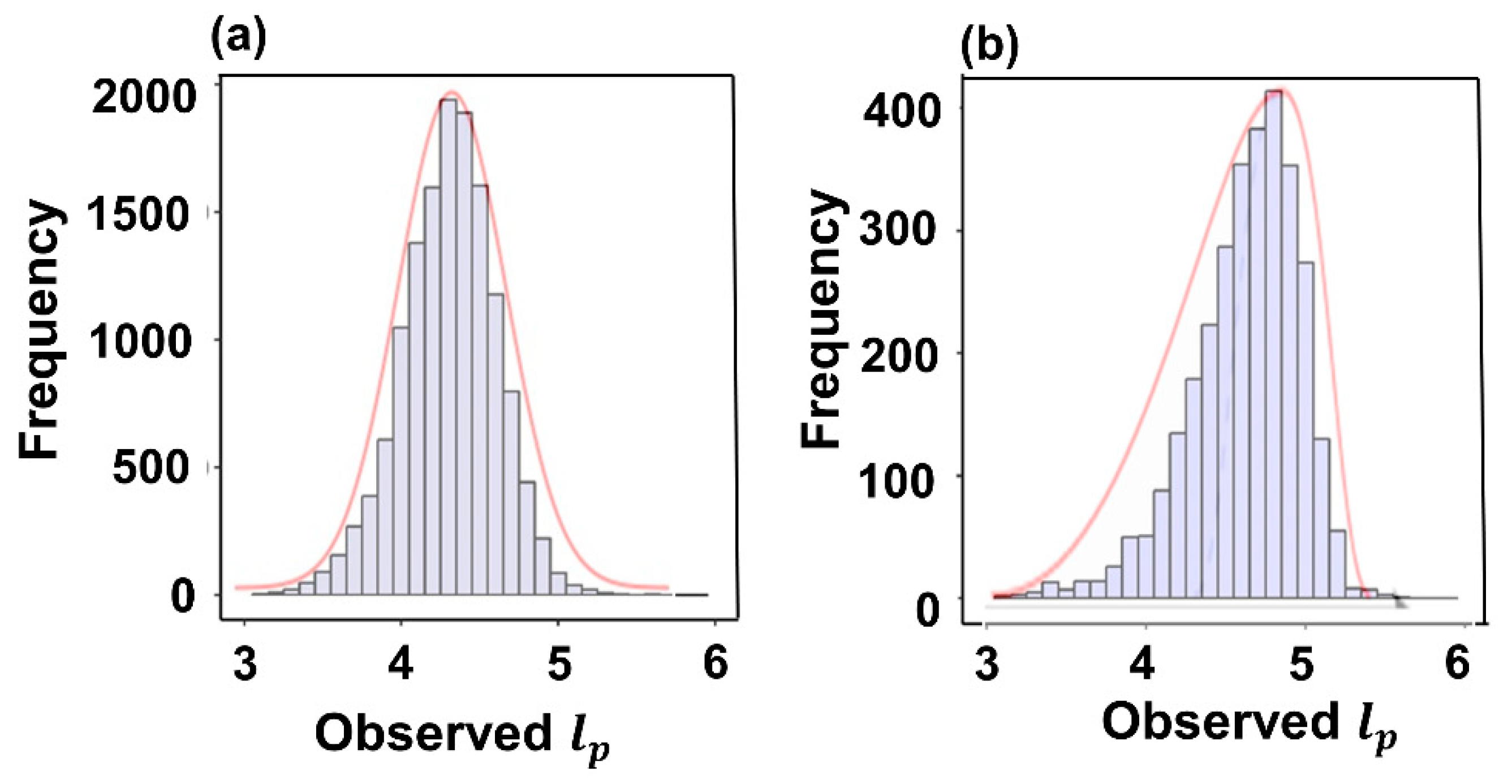
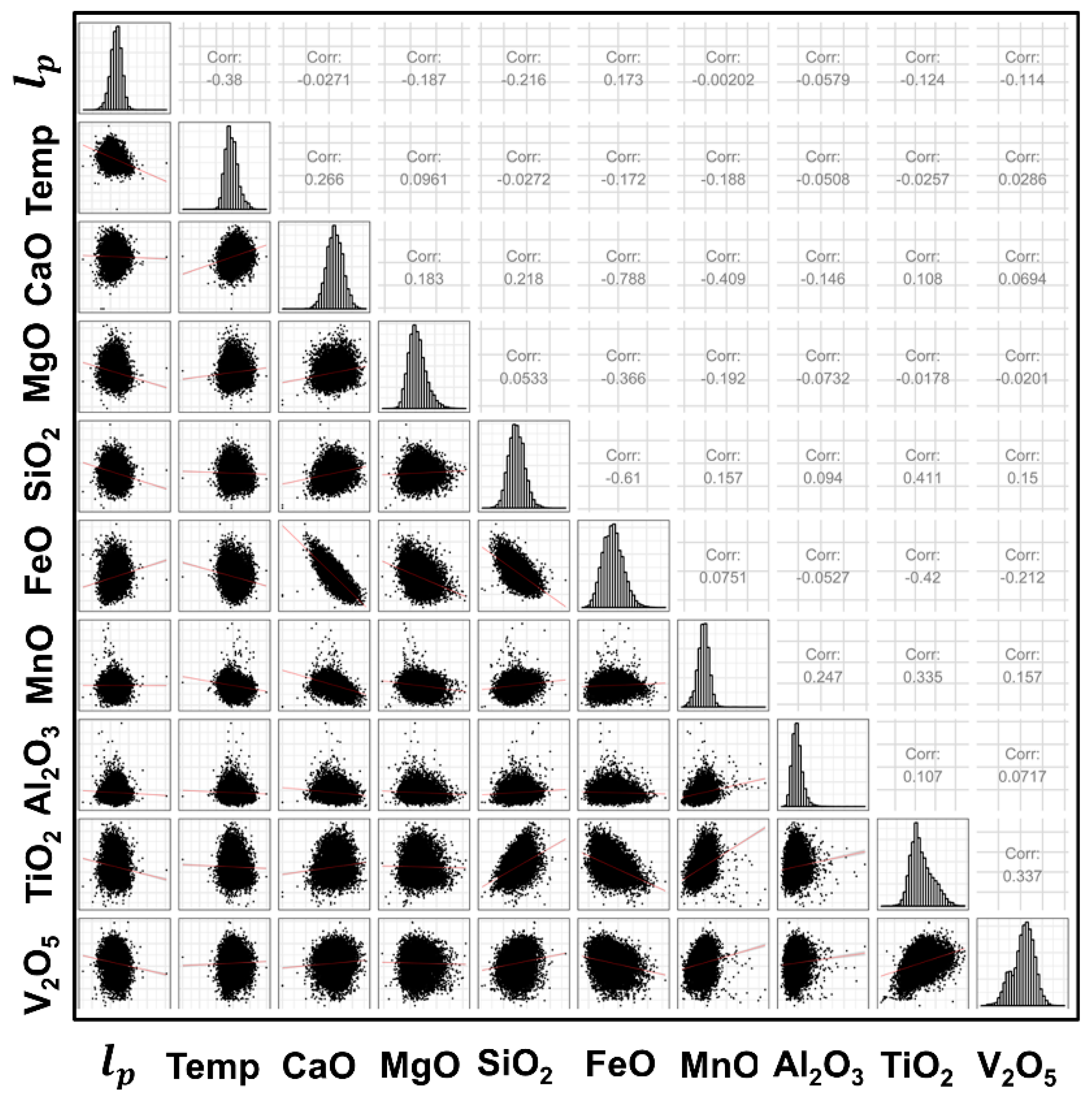
3.1. Descriptive Statistics
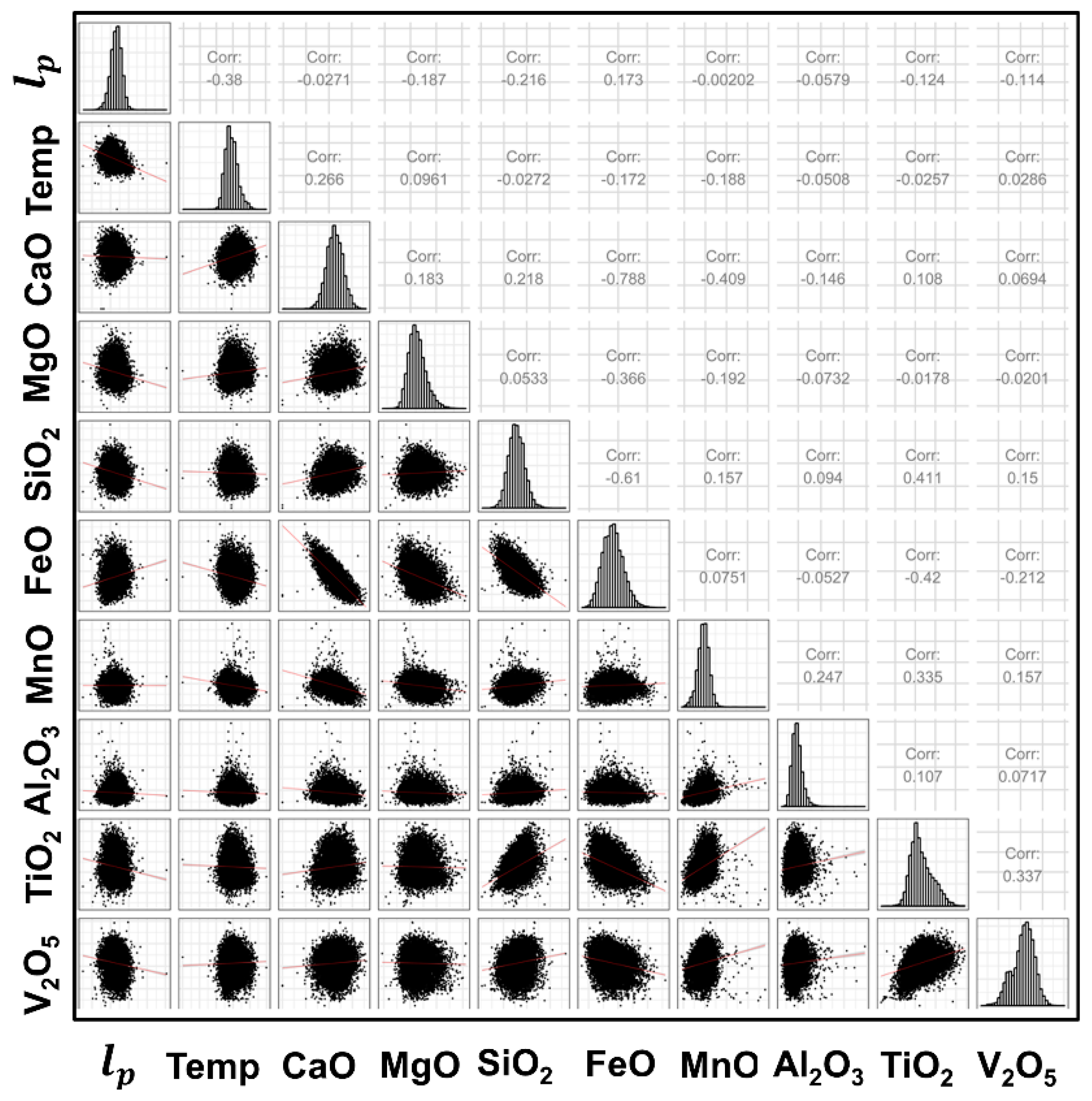
3.2. Individual Predictor Analysis
3.3. Multiple Linear Regression Model Fit
3.4. Final Predictive Models
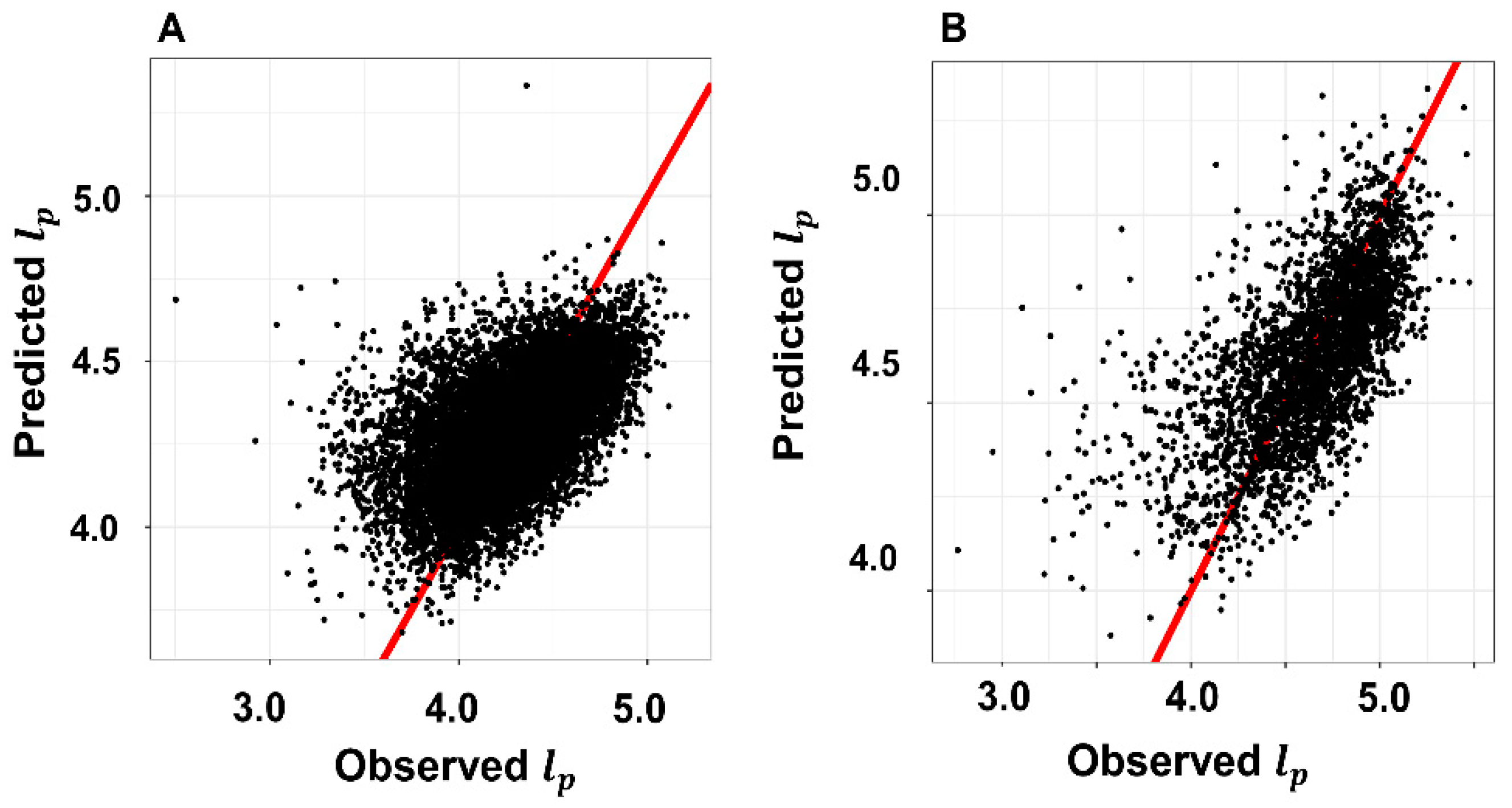
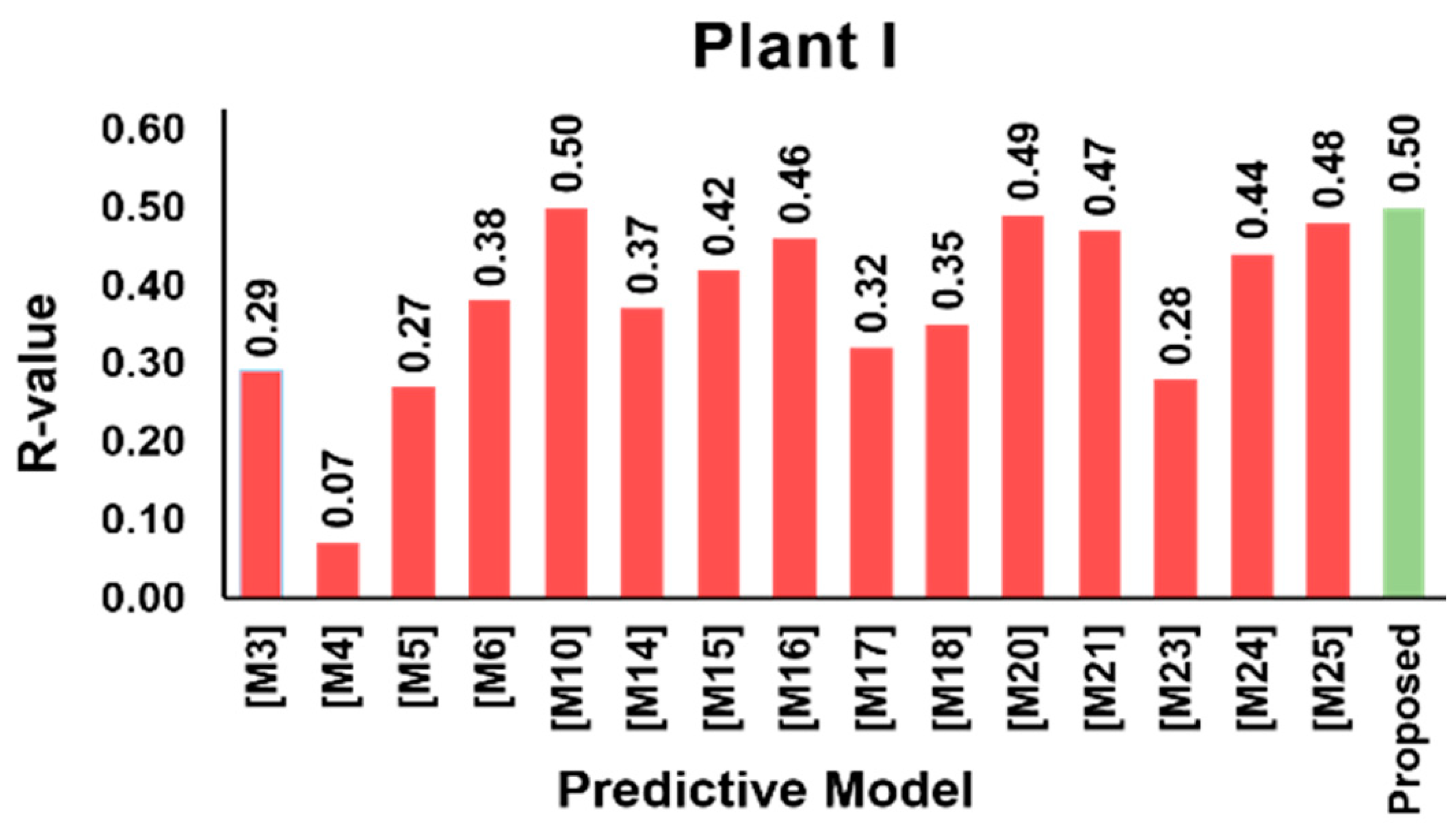
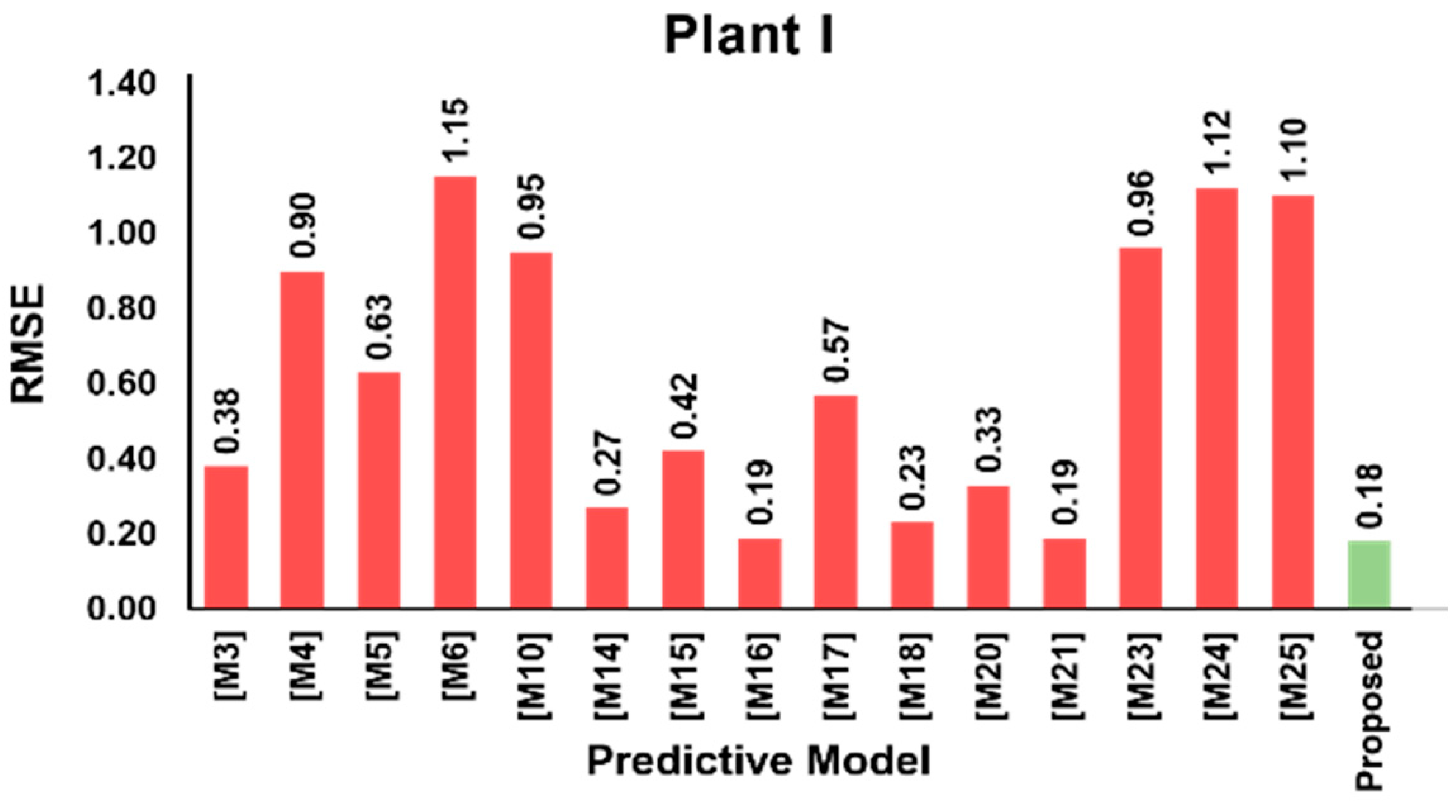
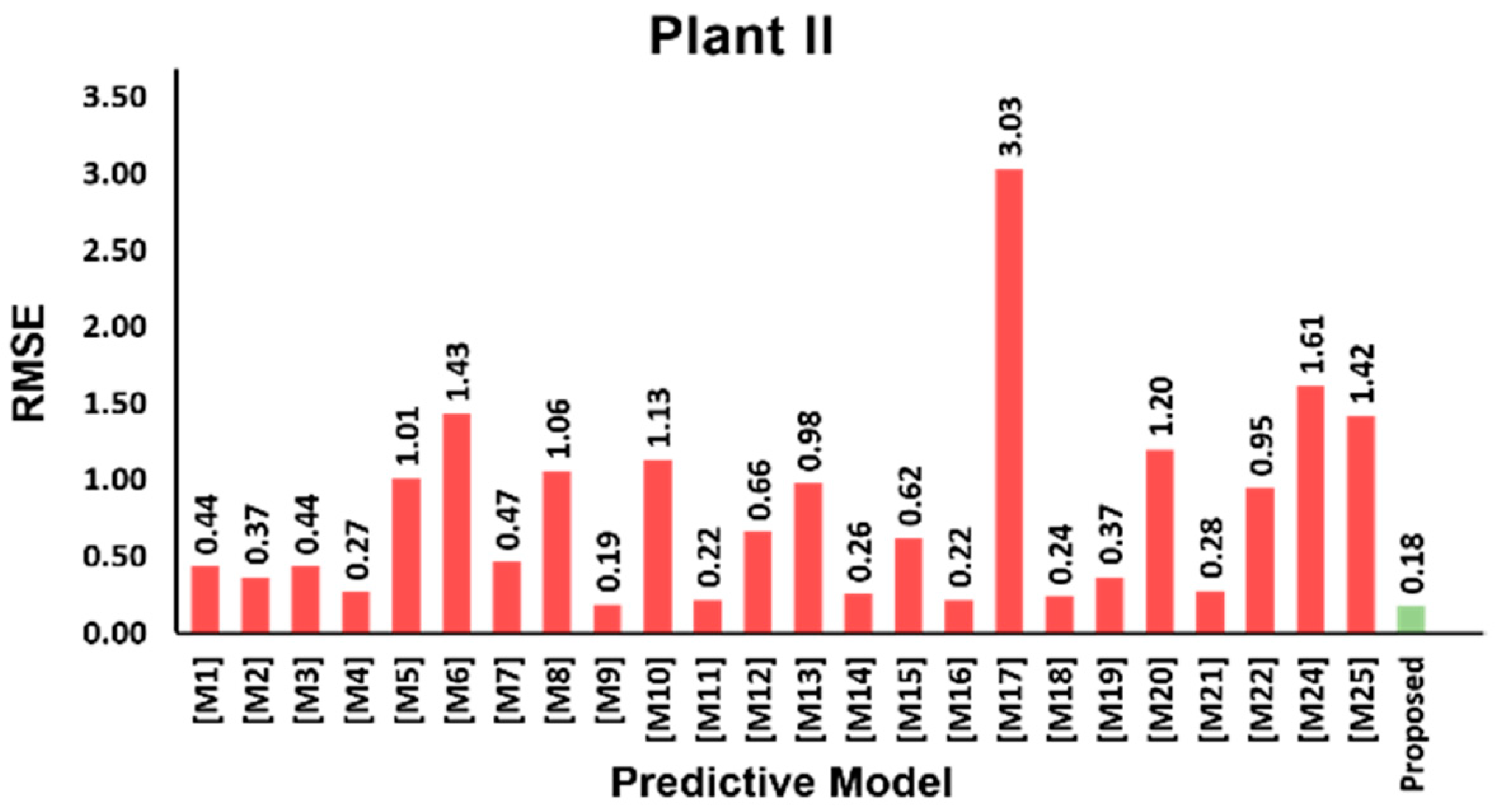
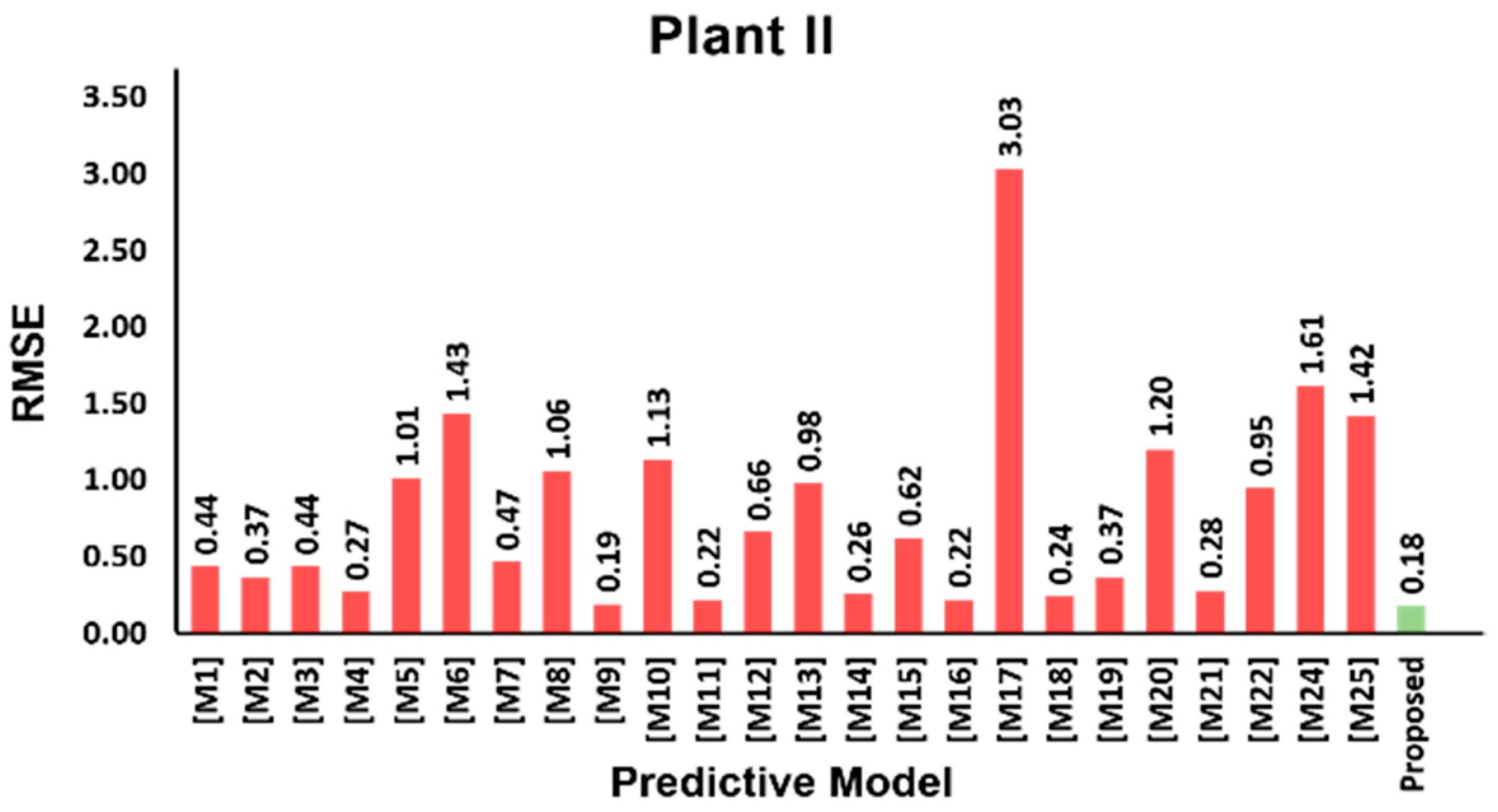
3.5. Model Validation Results
3.6. Exploratory Analysis
4. Discussion
5. Conclusion and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Iron Ore Monthly Price-US Dollars per Dry Metric Ton. Available online: https://www.indexmundi.com/commodities/?commodity=iron-ore (accessed on 10 July 2019).
- Bloom, T. The Influence of Phosphorus on the Properties of Sheet Steel Products and Methods Used to Control Steel Phosphorus Level in Steel Product Manufacturing. Iron Steelmak. 1990, 17, 35–41. [Google Scholar]
- Chukwulebe, B.O.; Klimushkin, A.N.; Kuznetsov, G.V. The utilization of high-phosphorous hot metal in BOF steelmaking. Iron Steel Technol. 2006, 3, 45–53. [Google Scholar]
- Urban, D.I.W.; Weinberg, I.M.; Cappel, I.J. De-Phosphorization Strategies and Modelling in Oxygen Steelmaking. Iron Steel Technol. 2014, 134, 27–39. [Google Scholar]
- He, F.; Zhang, L. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. J. Process Control 2018, 66, 51–58. [Google Scholar] [CrossRef]
- Wang, H.B.; Xu, A.J.; Ai, L.X.; Tian, N.Y. Prediction of endpoint phosphorus content of molten steel in BOF using weighted K-means and GMDH neural network. J. Iron Steel Res. Int. 2012, 19, 11–16. [Google Scholar] [CrossRef]
- Wang, Z.; Xie, F.; Wang, B.; Liu, Q.; Lu, X.; Hu, L.; Cai, F. The Control and Prediction of End-Point Phosphorus Content during BOF Steelmaking Process. Steel Res. Int. 2014, 85, 599–606. [Google Scholar] [CrossRef]
- Balajiva, K.; Quarrell, A.; Vajragupta, P. A laboratory investigation of the phosphorus reaction in the basic steelmaking process. J. Iron Steel Inst. 1946, 153, 115. [Google Scholar]
- Turkdogan, E.; Pearson, J. Activities of constituents of iron and steelmaking slags. JISI 1953, 175, 398–401. [Google Scholar]
- Turkdogan, T.; Pearson, J. Part III Phosphorus Pentoxide. J. Iron Steel Inst. Lond. 1953, 175, 398–401. [Google Scholar]
- Healy, G. New look at phosphorus distribution. J. Iron Steel Inst. 1970, 208, 664–668. [Google Scholar]
- Suito, H.; Inoue, R. Thermodynamic assessment of hot metal and steel dephosphorization with MnO-containing BOF slags. ISIJ Int. 1995, 35, 258–265. [Google Scholar] [CrossRef]
- Turkdogan, E. Slag composition variations causing variations in steel dephosphorisation and desulphurisation in oxygen steelmaking. ISIJ Int. 2000, 40, 827–832. [Google Scholar] [CrossRef]
- Drain, P.B.; Monaghan, B.J.; Zhang, G.; Longbottom, R.J.; Chapman, M.W.; Chew, S.J. A review of phosphorus partition relations for use in basic oxygen steelmaking. Ironmak. Steelmak. 2017, 44, 721–731. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: New York, NY, USA, 2012; Volume 821. [Google Scholar]
- Chattopadhyay, K.; Kumar, S. Application of thermodynamic analysis for developing strategies to improve BOF steelmaking process capability. In Proceedings of the AISTech 2013 Iron and Steel Technology Conference, Pittsburgh, PA, USA, 6 May 2013; pp. 809–819. [Google Scholar]
- Chatterjee, S.; Hadi, A.S. Regression Analysis by Example; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Shapiro, S.S.; Francia, R. An approximate analysis of variance test for normality. J. Am. Stat. Assoc. 1972, 67, 215–216. [Google Scholar] [CrossRef]
- Cook, R.D. Detection of influential observation in linear regression. Technometrics 1977, 19, 15–18. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1974; pp. 215–222. [Google Scholar]
- Nelder, J.A.; Wedderburn, R.W. Generalized linear models. J. R. Stat. Soc. Ser. A (Gen.) 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Chen, G.; He, S. Effect of MgO content in slag on dephosphorisation in converter steelmaking. Ironmak. Steelmak. 2015, 42, 433–438. [Google Scholar] [CrossRef]
- Assis, A.; Fruehan, R.; Sridhar, S. In Phosphorus Equilibrium between Liquid Iron and CaOSiO2-MgO-FeO Slags. In Proceedings of the AISTech 2012 Iron and Steel Technology Conference and Exposition, Georgia, Ga, USA, 7 May 2012; pp. 861–870. [Google Scholar]
- Assis, A.N.; Fruehan, R. In Phosphorus Removal in Oxygen Steelmaking: A Comparison between Plant and Laboratory Data. In Proceedings of the AISTech 2013 Iron and Steel Technology Conference, Pittsburgh, PA, USA, 6 May 2013; pp. 889–895. [Google Scholar]
- Ide, K.; Fruehan, R. Evaluation of phosphorus reaction equilibrium in steelmaking. Iron Steelmak. 2000, 27, 65–70. [Google Scholar]
- IKEDA, T.; MATSUO, T. The dephosphorization of hot metal outside the steelmaking furnace. Trans. Iron Steel Inst. Jpn. 1982, 22, 495–503. [Google Scholar] [CrossRef]
- Ito, Y.; Sato, S.; Kawachi, Y.; Tezuka, H. Dephosphorization in LD converter with low Si hot metal-develop of minimum slag practice. Tetsu-Hagane 1979, 65, S737. [Google Scholar]
- Kawai, Y.; Takahashi, I.; Miyashita, Y.; Tachibana, K. For dephosphorization equilibrium between slag and molten steel in the converter furnace. Tetsu-Hagane 1977, 63, S156. [Google Scholar]
- Turkdogan, E.; Pearson, J. Reaction equilibria between metal and slag in acid and basic open-hearth steelmaking. J. Iron Steel Inst. 1954, 176, 59–63. [Google Scholar]
- Balajiva, K.; Vajragupta, P. The effect of temperature on the phosphorus reaction in the basic steelmaking process. J. Iron Steel Inst. 1947, 155, 563–567. [Google Scholar]
- Vajragupta, P. Note on further work on the phosphorus reaction in basic steelmaking. J. Iron Steel Inst. 1948, 158, 494–496. [Google Scholar]
- Sipos, K.; Alvez, E. Dephosphorization in BOF Steelmaking. In Proceedings of the Molten 2009: VIII International Conference on Molten Slags, Fluxes and Salts, Santiago, Chile, 18–21 January 2009; GECAMIN: Santiago, Chile, 2009; pp. 1023–1030. [Google Scholar]
- Lee, C.; Fruehan, R. Phosphorus equilibrium between hot metal and slag. Ironmak. Steelmak. 2005, 32, 503–508. [Google Scholar] [CrossRef]
- Ogawa, Y.; Yano, M.; Kitamura, S.; Hirata, H. Development of the continuous dephosphorization and decarburization process using BOF. Tetsu-Hagané 2001, 87, 21–28. [Google Scholar] [CrossRef]
- Ogawa, Y.; Yano, M.; Kitamura, S.Y.; Hirata, H. Development of the continuous dephosphorization and decarburization process using BOF. Steel Res. Int. 2003, 74, 70–76. [Google Scholar] [CrossRef]
- Selin, R. Studies on MgO Solubility in Complex Steelmaking Slags in Equilibrium with Liquid Iron and Distribution of Phosphorus and Vanadium Between Slag and Metal at MgO Saturation. I. Reference System CaO–FeO–MgO sub sat–SiO sub 2. Scand. J. Metall. (Den.) 1991, 20, 279–299. [Google Scholar]
- Selin, R. The Role of Phosphorus, Vanadium and Slag Forming Oxides in Direct Reduction Based Steelmaking; Royal Institute of Technology: Stockholm, Sweden, 1990. [Google Scholar]
- Zhang, X.; Sommerville, I.; Toguri, J. An equation for the equilibrium distribution of phosphorus between basic slags and steel. J. Met. 1983, 35, 93. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Mean | SD | Min | Q1 | Median | Q3 | Max | |
|---|---|---|---|---|---|---|---|---|
| Plant I | ||||||||
| 13,853 | 4.31 | 0.30 | 2.50 | 4.12 | 4.32 | 4.51 | 7.06 | |
| Temp | 13,853 | 1648.82 | 19.14 | 1500.00 | 1635.00 | 1647.00 | 1660.00 | 1749.00 |
| CaO | 13,853 | 42.43 | 3.62 | 20.00 | 40.00 | 42.40 | 44.90 | 55.90 |
| MgO | 13,853 | 9.23 | 1.37 | 3.75 | 8.29 | 9.09 | 10.00 | 16.46 |
| SiO2 | 13,853 | 12.89 | 1.74 | 5.40 | 11.70 | 12.80 | 14.00 | 23.30 |
| FeO | 13,853 | 18.22 | 3.53 | 7.70 | 15.72 | 18.10 | 20.50 | 36.00 |
| MnO | 13,853 | 4.80 | 0.70 | 2.28 | 4.38 | 4.82 | 5.23 | 11.98 |
| Al2O3 | 13,853 | 1.80 | 0.48 | 0.59 | 1.49 | 1.74 | 2.04 | 7.79 |
| TiO2 | 13,853 | 1.13 | 0.28 | 0.17 | 0.93 | 1.08 | 1.30 | 2.21 |
| V2O5 | 13,853 | 2.13 | 0.49 | 0.25 | 1.84 | 2.19 | 2.48 | 3.95 |
| Plant II | ||||||||
| 3084 | 4.63 | 0.34 | 2.77 | 4.44 | 4.68 | 4.87 | 5.64 | |
| Temp | 3084 | 1679.10 | 27.11 | 1579.00 | 1661.00 | 1678.00 | 1698.00 | 1777.00 |
| CaO | 3084 | 53.45 | 2.30 | 42.33 | 52.00 | 53.49 | 55.02 | 64.06 |
| MgO | 3084 | 0.99 | 0.34 | 0.30 | 0.76 | 0.93 | 1.15 | 3.18 |
| SiO2 | 3084 | 13.52 | 1.44 | 8.16 | 12.54 | 13.54 | 14.50 | 18.74 |
| FeO | 3084 | 19.34 | 2.06 | 13.71 | 17.88 | 19.19 | 20.56 | 29.72 |
| MnO | 3084 | 0.62 | 0.18 | 0.24 | 0.50 | 0.59 | 0.71 | 2.50 |
| Al2O3 | 3084 | 0.94 | 0.25 | 0.46 | 0.78 | 0.93 | 1.08 | 4.09 |
| Plant I | Estimate | Standard Error | T | p |
| Intercept | 15.3238 | 0.2542 | 60.28 | <0.0001 |
| CaO | 0.0209 | 0.0018 | 11.64 | <0.0001 |
| MgO | −0.0363 | 0.0022 | −16.29 | <0.0001 |
| SiO2 | −0.0434 | 0.0022 | −19.96 | <0.0001 |
| FeO | 0.0049 | 0.0023 | 2.10 | 0.0360 |
| MnO | 0.0273 | 0.0042 | 6.52 | <0.0003 |
| Al2O3 | −0.0294 | 0.005 | −5.85 | <0.0002 |
| TiO2 | −0.0573 | 0.0102 | −5.62 | <0.0001 |
| V2O5 | −0.0299 | 0.0047 | −6.35 | <0.0000 |
| Temp | −0.0067 | 0.0001 | −56.71 | <0.0001 |
| Plant II | Estimate | Standard Error | T | p |
| Intercept | 19.0145 | 0.7214 | 26.40 | <0.0001 |
| CaO | 0.0019 | 0.0072 | 0.26 | 0.7920 |
| MgO | −0.0382 | 0.0181 | −2.10 | 0.0350 |
| SiO2 | −0.0399 | 0.0078 | −5.10 | <0.0001 |
| FeO | −0.0173 | 0.0097 | −1.77 | 0.0780 |
| MnO | −0.1654 | 0.0315 | −5.24 | <0.0001 |
| Temp | −0.0080 | 0.0001 | −44.50 | <0.0001 |
| Plant | Temperature | CaO | MgO | SiO2 | FeO | MnO | Al2O3 | TiO2 | V2O5 |
|---|---|---|---|---|---|---|---|---|---|
| Plant I | 1.09 | 8.91 | 1.97 | 3.03 | 14.4 | 1.83 | 1.2 | 1.73 | 1.16 |
| Plant II | 1.06 | 13.14 | 1.64 | 5.7 | 19.51 | 1.36 | 1.52 | - | - |
| Predictor | Residual Deviance | AIC |
|---|---|---|
| Full Model | 210.9133 | −8176.002 |
| Except CaO | 210.9137 | −8177.997 |
| Except Al2O3 | 211.0168 | −8178.501 |
| Data | Family of Distribution of Errors | Link Function | AIC |
|---|---|---|---|
| Plant I | Gaussian | “Identity” | 2228.1 |
| Gamma | “Inverse” | 2485.7 | |
| Inverse Gaussian | “” | 2693.5 | |
| Plant II | Gaussian | “Identity” | 608.6 |
| Gamma | “Inverse” | 893.8 | |
| Inverse Gaussian | “” | 1067.1 |
| Model | Equation |
|---|---|
| [M1] [24,25] | |
| [M2] [24,25] | |
| [M3] [16] | |
| [M4] [16] | |
| [M5] [16] | |
| [M6] [4] | |
| [M7] [26] | |
| [M8] [27] | |
| [M9] [28] | |
| [M10] [29] | |
| [M11] [9,30] | |
| [M12] [8,31,32] | |
| [M13] [8,31,32] | |
| [M14] [4] | |
| [M15] [33] | |
| [M16] [33] | |
| [M17] [34] | |
| [M18] [35,36] | |
| [M19] [4] | |
| [M20] [2] | |
| [M21] [37,38] | |
| [M22] [4] | |
| [M23] [39] | |
| [M24] [11] | |
| [M25] [11] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barui, S.; Mukherjee, S.; Srivastava, A.; Chattopadhyay, K. Understanding Dephosphorization in Basic Oxygen Furnaces (BOFs) Using Data Driven Modeling Techniques. Metals 2019, 9, 955. https://doi.org/10.3390/met9090955
Barui S, Mukherjee S, Srivastava A, Chattopadhyay K. Understanding Dephosphorization in Basic Oxygen Furnaces (BOFs) Using Data Driven Modeling Techniques. Metals. 2019; 9(9):955. https://doi.org/10.3390/met9090955
Chicago/Turabian StyleBarui, Sandip, Sankha Mukherjee, Amiy Srivastava, and Kinnor Chattopadhyay. 2019. "Understanding Dephosphorization in Basic Oxygen Furnaces (BOFs) Using Data Driven Modeling Techniques" Metals 9, no. 9: 955. https://doi.org/10.3390/met9090955
APA StyleBarui, S., Mukherjee, S., Srivastava, A., & Chattopadhyay, K. (2019). Understanding Dephosphorization in Basic Oxygen Furnaces (BOFs) Using Data Driven Modeling Techniques. Metals, 9(9), 955. https://doi.org/10.3390/met9090955