1. Introduction
Copper production involves multiple stages, including mining, grinding, ore enrichment, smelting, refining, and waste management. As with any large and complex production facility, every stage of copper production generates waste that requires proper disposal. Unfortunately, before this waste is managed, it often leaves a significant impact on the planet’s ecology. Ashes, slags, and dusts, which are by-products of mining and metal processing, serve as sources of toxic metals like Cd, Pb, and As causing air, water, and soil pollution [
1,
2]. Addressing climate change has brought renewed focus on evaluating the environmental impact of metal production technologies [
3]. With copper’s environmental impact expected to grow significantly from 2010 to 2050 due to its large supply, this issue needs to be taken seriously [
4]. Some ways to address this issue include optimizing factory operations [
5,
6,
7,
8] or working directly with wastes. As an example, in Chile, where about 50 million tons of copper slag has been dumped throughout history, the government began to think about how to reduce the amount of slag [
9]. Slags are a by-product of pyrometallurgical processing, an important waste product of metallurgy as they are produced in large volumes and contain significant concentrations of metallic elements. Because the slags contain a large amount of useful metals, it is important to look for ways to take the most useful metals out of them and thus reduce the amount of the slag [
10,
11,
12].
Most of the methods used to extract metals include the following [
13]:
Pyrometallurgical [
9,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25];
Physical Separation [
19,
29];
Previous studies have explored both individual approaches and combinations of approaches to improve efficiency and minimize environmental impact. For example, the method with CaS [
15] recovered up to 98.51% copper at less than 5% iron in the matte, with a temperature of 1450 °C and carbon addition. Also, one of the pyrometallurgical methods, sulfidation–reduction using pyrite, recovered 97.58% copper, 98.20% lead, and 89.91% zinc, reducing Fe
3O
4 in the slag from 19.50% to 2.97% [
24].
On the other hand, hydrometallurgical methods such as sulfide roasting and leaching showed good efficiency in the extraction of valuable metals. Optimal conditions of the experiment made it possible to achieve recovery of copper up to 74.2%; nickel, 71.1%; and cobalt, 69.6%, while minimizing the recovery of iron (4.9%) and aluminum (17.6%) [
27].
Previous works also mentioned using secondary slag after recovery as a method to reduce the amount of slag. Carbothermal reduction at high temperatures (approximately 1440 °C) enabled the recovery of most of the valuable metals, such as Fe, Cu, and Mo, into an iron-rich alloy suitable for use as feedstock in steel production. Meanwhile, the non-metallic residue, referred to as secondary slag, found potential applications in glass and ceramics [
20]. In addition to recovering valuable metals through various extractive metallurgical methods, the by-products can be repurposed for producing materials such as cement, fillers, ballast, abrasives, aggregates, roofing granules, glass, and tiles [
34]. Beyond traditional chemical and metallurgical methods, machine learning (ML) has emerged as a powerful tool for optimizing and predicting outcomes in copper recovery processes.
Recently, the advent of Artificial Intelligence (AI) has allowed the usage of earlier data to make predictions about the future. Therefore, many industries stand to benefit from this technology, and the copper mining industry is one of them. With the availability of digital data, machine learning methods, which are a subset of AI, have been proven to predict various process parameters reliably. Flores et al. have shown the effectiveness of Random Forest in predicting copper recovery [
35]. In another study, they carried out a comparative analysis of three ML algorithms for copper recovery quality prediction in a leaching process. These models were Support Vector Machines, Random Forest, and Artificial Neural Networks (ANNs), and the study found that ANNs as the best-performing model, with class precision scores of more than 99.0 on the four datasets applied [
36]. In addition to these methods, fuzzy logic and Model Predictive Control (MPC) have shown promise in optimizing mining processes and waste management [
37]. However, challenges persist, including data scarcity, difficult sensor environments, and interoperability issues [
38]. Hybrid geometallurgical approaches, combining historical data and deep learning, can accurately predict metallurgical responses, reducing costs and improving planning [
39]. These approaches establish a comprehensive relationship between geological and mining characteristics and metallurgical parameters in a mineral processing plant. ML methods also accelerate alloy development, enabling rapid optimization of mechanical and electrical properties [
40]. ANN-based models assist in forecasting production while managing energy consumption effectively [
41]. Furthermore, ML-driven optimization of hydrodesulfurization processes helps reduce sulfur compounds, emissions, and costs, promoting environmental sustainability [
42]. There is more challenging work to be completed, like using metallurgical optimization employing the Genetic Algorithm–Back Propagation (GA-BP) method to predict matte grade [
43]. This approach combines the global search capability of Genetic Algorithms with the strong generalization ability of Back Propagation neural networks, improving the accuracy and reliability of matte grade predictions.
Building on such insights, this study suggests a unique approach. Instead of searching for ways to increase recovery from slag, which requires additional energy inputs and is accompanied by environmental risks, we aim to determine the optimal masses of different ores to ensure a given stable chemical composition of both matte and slag [
44]. In other words, we work backward: starting from the desired result, we determine the most efficient feed strategy. This approach ensures homogeneity, quality, and waste reduction, which ultimately improves the efficiency of metallurgical production.
We will employ advanced machine learning [
45] and AI models capable of handling the non-linear, interconnected factors in copper smelting. By seamlessly integrating predictions with evolutionary algorithms, our work moves beyond traditional optimization, driving more sustainable, consistent metallurgical processes, and helps to reduce ecological damage.
2. Materials and Methods
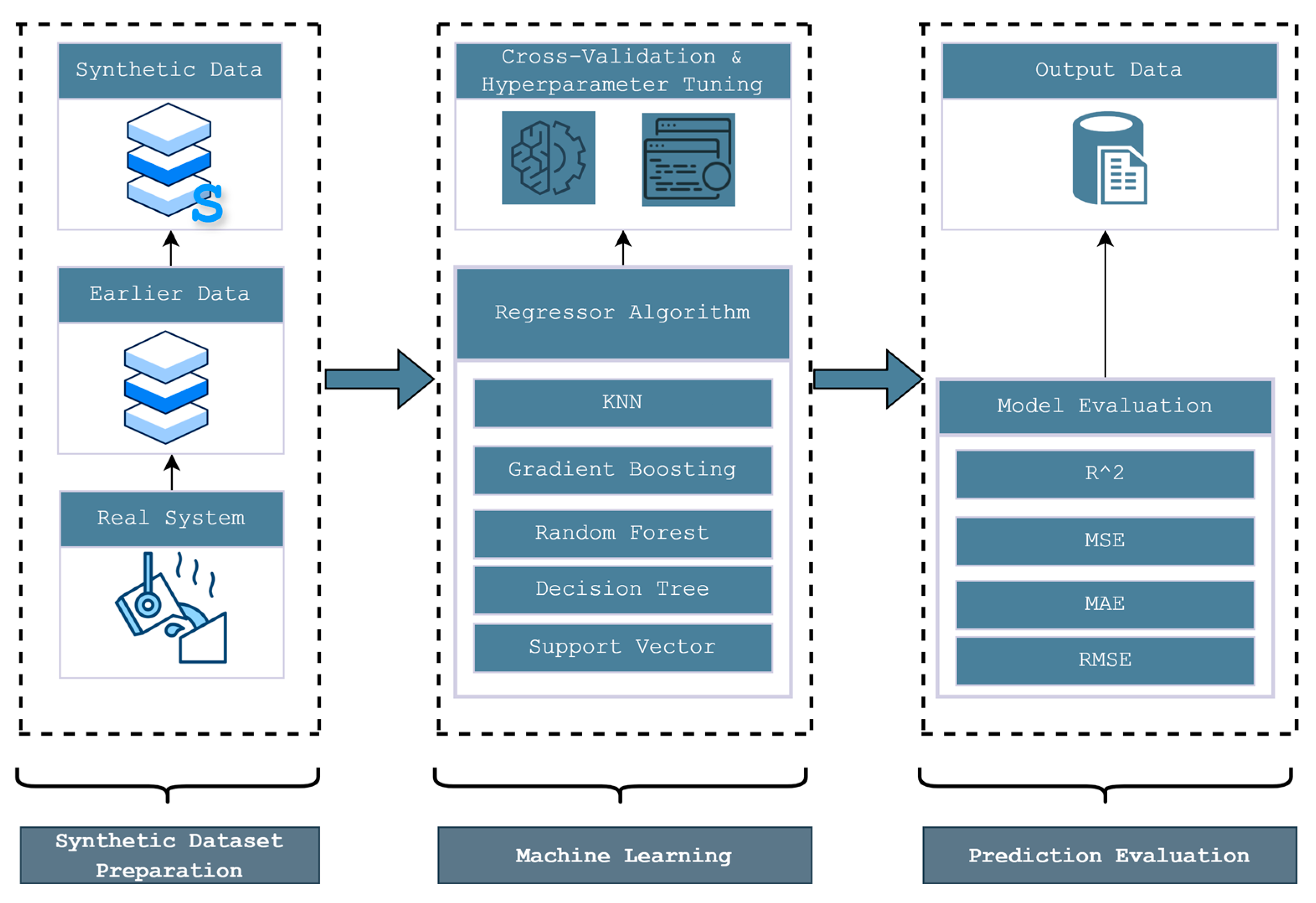
At the core of this study is an intelligent system designed to optimize metallurgical processes by leveraging machine learning techniques. The system follows a structured workflow comprising three main stages: synthetic dataset preparation, machine learning modeling, and prediction evaluation.
Figure 1 provides an overview of this workflow. Initially, real-world data from the metallurgical process are used to generate synthetic data to create a comprehensive dataset. This dataset is then used to train regression models, with cross-validation and hyperparameter tuning applied to enhance performance. The software used in this study are Python (3.10.2) for scripting, NumPy (2.1.3) and Pandas (2.2.3) for synthetic data computation, and scikit-learn (1.4.2) for machine learning modelling.
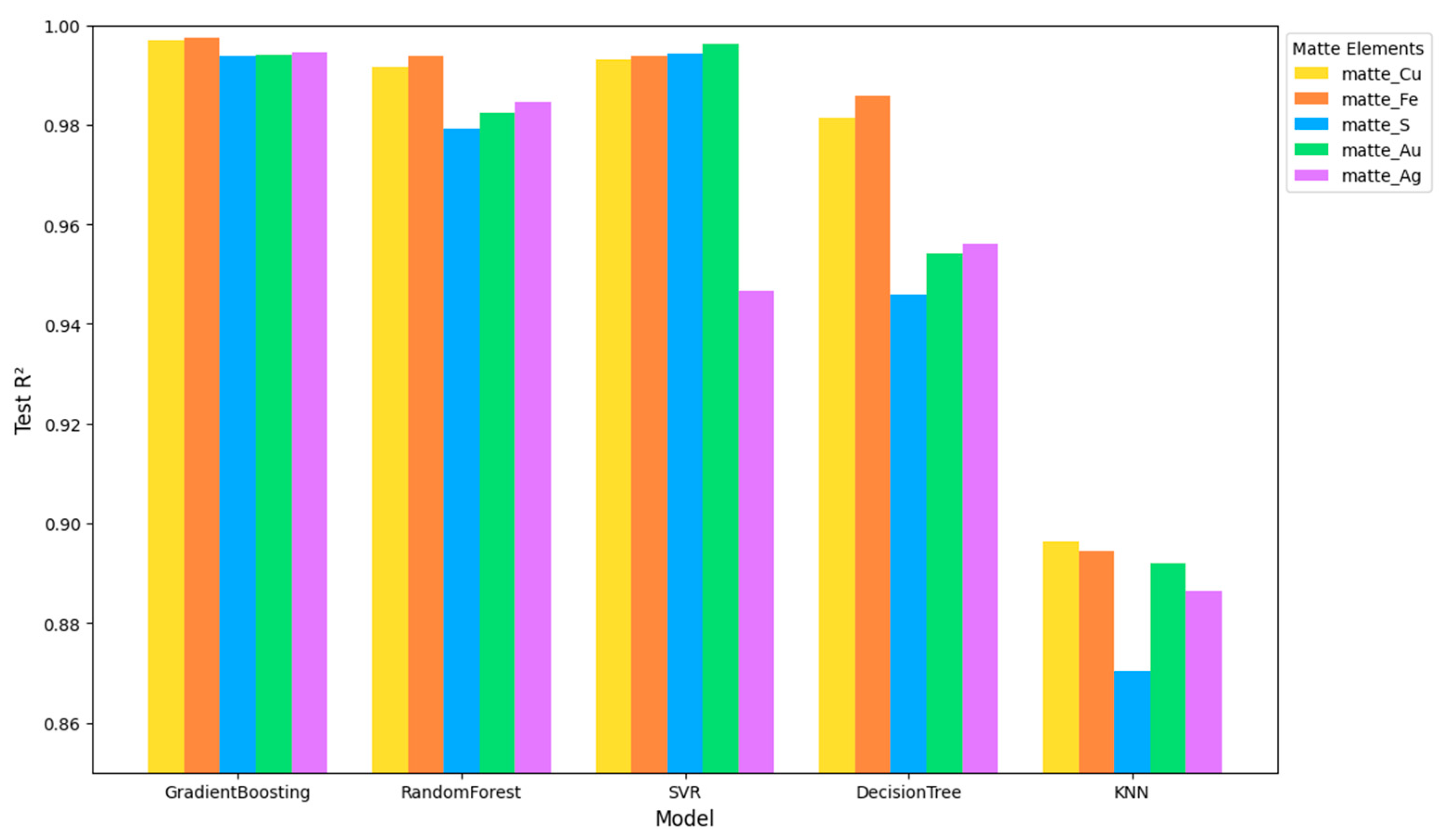
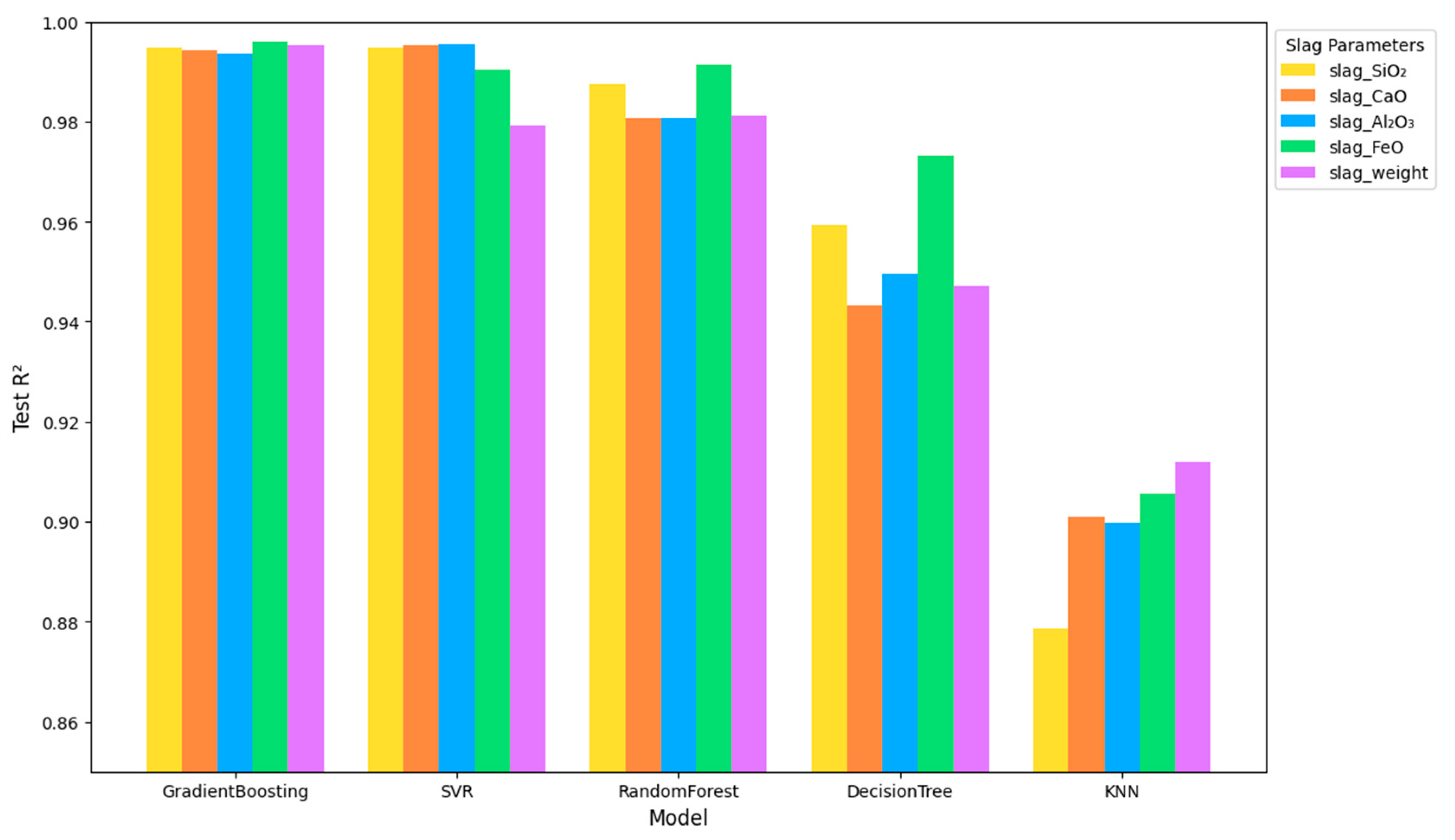
The objective is to train models to first predict the resulting matte and slag compositions based on the ore composition, and secondly, to predict the ore composition from the resulting matte and slag compositions (reverse modeling). The trained models are then evaluated based on the test set using key performance metrics, including coefficient of determination, mean squared error, mean absolute error, and root mean squared error, to ensure accurate predictions of metallurgical outputs. This structured approach enables precise modeling of metallurgical processes, facilitating data-driven decision-making to improve efficiency and reduce waste.
This Methodology section further details the data collection process, synthetic data generation, model training procedures, evaluation metrics, and the overall approach used to develop and validate the predictive models.
2.1. Data Preparation
The data presented in this study were prepared by integrating real-world data with synthetic data generation techniques. The dataset is based on detailed records provided by the Institute of Metallurgy and Ore Beneficiation, a leading organization in Almaty, Kazakhstan, specializing in industrial pyrometallurgical processes. Due to confidentiality agreements, the data are available on request from the corresponding author. The original dataset includes critical information on the composition of various ores and the parameters associated with the pyrometallurgical smelting process.
Each ore sample in the dataset represents a complex mixture of metallic and non-metallic compounds. The primary parameters recorded for each ore included the weight and composition of specific elements. These elements were categorized into metals such as gold, silver, copper, and iron, and non-metallic compounds including silicon dioxide (SiO2), calcium oxide (CaO), aluminum oxide (Al2O3), sulfur, and arsenic. The concentrations of gold and silver were provided in units of grams per ton, while the other elements were expressed as percentages of the total ore weight. Additionally, constants related to the pyrometallurgical process, such as the combined weight of the melt (comprising both matte and slag), were included.
Given the constraints of real-world data availability, synthetic data were generated to expand the dataset and simulate a broader range of pyrometallurgical scenarios. The generation process involved sampling ore compositions from the original dataset to create a base distribution that reflects realistic variability. To ensure diversity while maintaining the integrity of the data, random perturbations were introduced to the concentrations of each element. These perturbations were carefully bounded to prevent unrealistic values, ensuring that the total elemental composition remained consistent, with percentages summing to 100%.
The synthetic data generation process also ensured that the distributions of element concentrations closely mirrored those found in industrial settings. For each synthetic sample, the total weight of the ore and the proportions of individual elements were adjusted to reflect plausible conditions under which the pyrometallurgical process operates. This approach facilitated the creation of a dataset that balances authenticity with variability, allowing for more generalized modeling and analysis.
The final dataset consists of 10,000 rows and 20 columns. The columns are divided into ore compositions as seen in
Table 1, and pyrometallurgical process results, and described in
Table 2. A detailed statistical description of the dataset can be found in
Appendix A.1.
The data preparation process aligns closely with the principles of pyrometallurgical smelting, a method extensively used for extracting non-ferrous metals. In this process, ores are crushed and mixed to ensure uniform composition, followed by smelting in high-temperature furnaces with the addition of fluxes like lime and gases such as oxygen. The smelting process results in the formation of three distinct fractions: the matte, which contains the valuable metals and sulfur; the slag, which captures the oxides and impurities; and the sublimates, which are volatile compounds like sulfur and arsenic that can be captured or lost as waste.
In this research, we employ two prediction approaches using machine learning models: forward prediction and backward prediction. These approaches allow us to explore the relationships between ore composition and the resulting outputs of the pyrometallurgical process from different perspectives.
In forward prediction, we use the ore composition as the input features to predict the resulting matte and slag compositions. This approach models the traditional pyrometallurgical process, where the goal is to determine the output (composition of matte and slag) based on known input parameters (composition of the ores).
In backward prediction, we reverse the modeling process by using the matte and slag compositions as the input features to predict the ore composition. This approach is useful for scenarios where the characteristics of the resulting products are known, and we want to infer the properties of the original ore. Backward prediction can provide insights into the types of ores that may have produced specific outputs.
The dataset was divided into training and testing subsets. Specifically, 80% of the data were used for training the models, while 20% were reserved for testing. The data were randomly shuffled before splitting. This prevents any inherent order or patterns in the dataset from influencing the training or testing results. This ensures that the models are trained on one subset of the data and evaluated on a separate, unseen subset to assess their generalization performance. The same splitting strategy was applied to both forward and backward prediction tasks.
Since the features in the dataset vary widely in scale (e.g., ore weights in grams, element concentrations in percentages, or grams per ton), it was essential to standardize them. Standardization ensures that all features contribute equally to the model, preventing features with larger scales from dominating the learning process. The scaling was applied independently to the training and testing subsets to avoid data leakage, ensuring that the testing data remained unseen during training.

 ,
, 
{kind=link}
{kind=link}
{kind=link}