
Tailings Settlement Velocity Identification Based on Unsupervised Learning

Abstract
:1. Introduction
2. Identification Model of Tailings Settlement Velocity Based on Unsupervised Learning
2.1. Unsupervised Learning
- Select k initialized samples as initial clustering centers.
- For each sample, in the dataset, calculate its distance to the k-many cluster centers and classify it into the class corresponding to the cluster center with the smallest distance.
- For each category, , recalculate its cluster center.
- Repeat the second and third steps above until a certain suspension condition (iteration times, minimum error change, etc.) is reached. Finally, the samples are divided into K classes, and the centroid is determined to ensure the minimum distance between each class of samples and the corresponding centroid.
2.2. Identification Model of Settling Velocity of Tailings
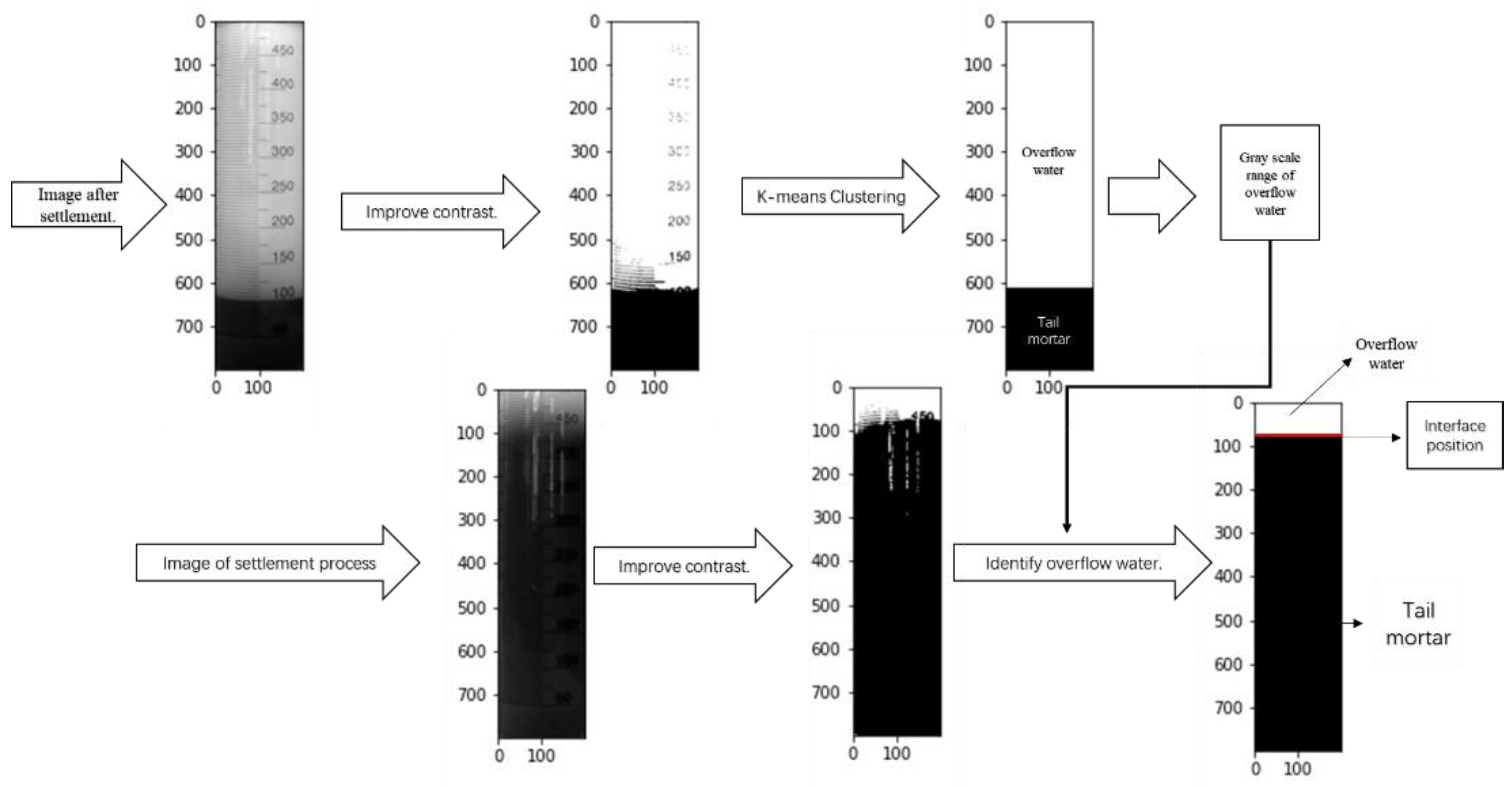
- Import high-definition video of the tailing sedimentation process, and take a final stable image as the classification basis. The upper liquid is generally regarded as the overflow water, which contains tailing particles that cannot settle.
- Import the stable grayscale image. The image is processed into an m × n two-dimensional matrix, where each element in the matrix represents the meeting value of the corresponding pixel, and the gray value varies from 0 (black) to 255 (white).
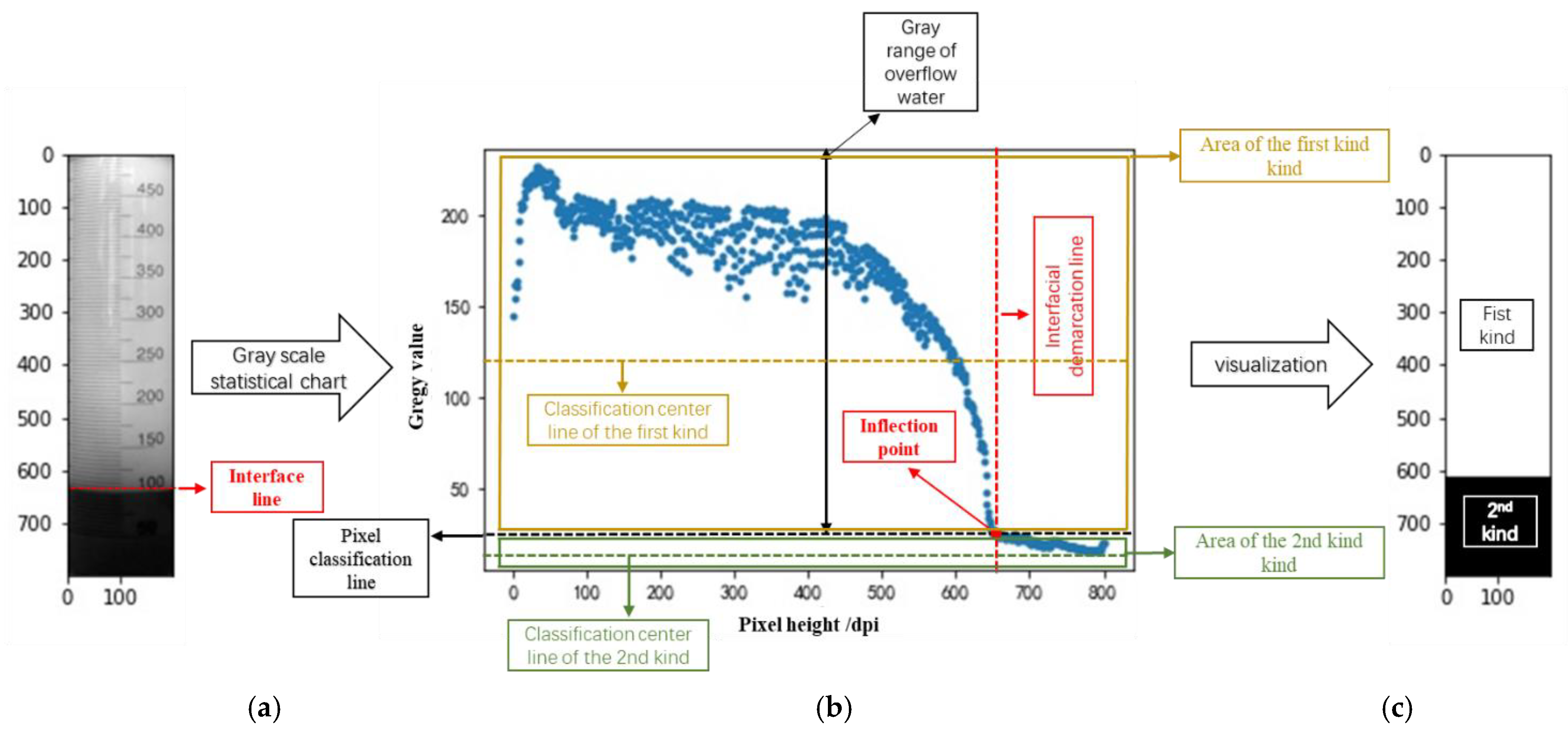
- Using the histogram equalization method, the contrast is improved, and the image is enhanced, so that the objects and shapes in the image are more prominent. Each row of pixels in the image is regarded as an object for K-means clustering analysis, and all objects are divided into two groups, namely the overflow water group and the tailings group. At the same time, center point A of the classification, that is, the basis point of the classification, can be obtained. In the gray image, the smaller the gray value, the darker the image; the more solid particles contained in the tail mortar, the darker the image will be, so the range of the gray value from 255 to “a” indicates the gray range of the tail mortar that cannot settle, that is, the gray range of the overflow water group.
- Import the gray image in the process of settlement, and use histogram equalization to improve the contrast and enhance the image. Use the gray scale range of the overflow water group, obtained in Step 3, to identify the overflow water group in the image. Finally, the position of the solid–liquid interface is obtained, from which the settling velocity can be calculated.
3. Application Example
3.1. Physical and Mechanical Properties of Tailings
3.2. Experimental Study
3.3. Experimental Results and Analysis
4. Conclusions
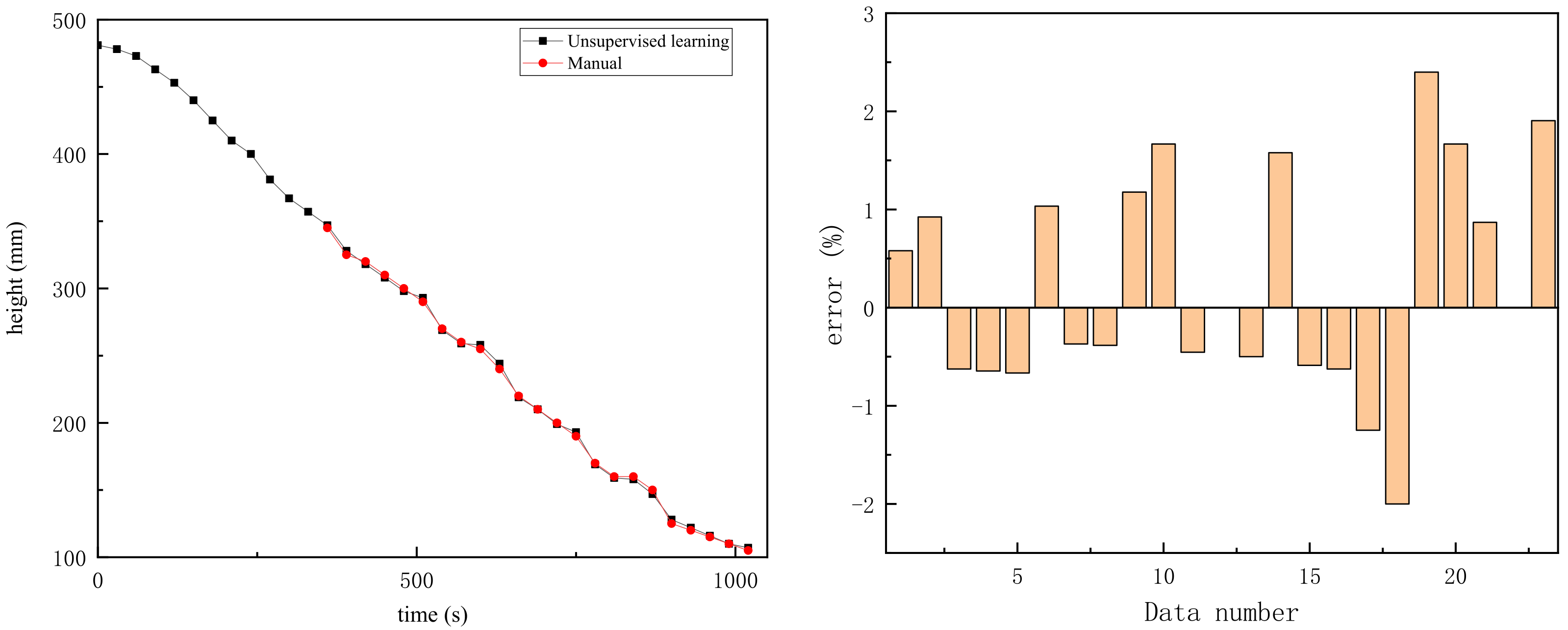
- The identification model of the tailing settlement speed adopts the K-means unsupervised classification method to identify the stabilized settlement image and judge the gray value interval of the overflow water. By identifying the overflow water, the interface in the settlement process can be judged, and the settlement speed can be calculated. The model has the characteristics of a high recognition accuracy and high speed. Because of the unsupervised learning method, the recognition accuracy of the model is independent of the amount of learning data, and only stable images are needed for recognition and analysis. Moreover, the model has a wide range of applications and has a high recognition accuracy for the settlement interface of tailing mortar with different particle size distributions, physical and mechanical properties, and flocculant addition or not.
- Taking the tailing settlement of a copper mine as an example, the unsupervised learning model is applied to the tailing settlement process. Based on images of tailings at different concentrations in a final stable state, the interface position in the process of tailing settlement is identified, and the settlement speed of the tailings is obtained. The experimental results show that the model can identify the interface position, which cannot be distinguished manually, and gives the settlement velocity of the initial settlement. In addition, when the position of the interface can be determined, the accuracy of the model recognition is high, and the error rate is small.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, A.; Yang, Y.; Cheng, H.; Chen, S.; Han, Y. Development status and trend of paste technology in China. J. Eng. Sci. 2018, 40, 517–525. [Google Scholar]
- Wu, A.; Wang, Y.; Wang, H. Present situation and trend of paste filling technology. Metal. Mine 2016, 7, 1–9. [Google Scholar]
- Qiao, D.; Cheng, W.; Zhang, L.; Yao, W.; Wang, X.; Wang, H. Modern mining concept and filling mining. Sci. Eng. Nonferr. Met. 2011, 2, 7–14. [Google Scholar]
- Rulyov, N.; Laskowski, J.S.; Concha, F. The use of ultra-flocculation in optimization of the experimental flocculation procedures. Physicochem. Probl. Miner. Proc. 2011, 1, 5–16. [Google Scholar]
- Jiao, H.; Wu, A.; Wang, H.; Liu, X.; Yang, S.; Xiao, Y. Experiment study on the flocculation settlement characteristic of unclassified tailings. J. Beijing Univ. Sci. Technol. 2011, 33, 1437–1441. [Google Scholar] [CrossRef]
- Zhang, Q.; Xie, S.; Zheng, J.; Wang, X. Study on settlement law of filling slurry and feasibility analysis of transportation. J. Chongqing Univ. 2011, 34, 105–107. [Google Scholar]
- Shi, X.; Hu, H.; Du, X.; Li, M.; Wang, H. Experimental study on flocculation settlement of mortar liquid at the tail of vertical sand silo. Min. Metall. Eng. 2010, 30, 1–11. [Google Scholar]
- Caifu, U.; Cuiping, L.; Bingheng, Y.; Gezhong, C. Effect of water reducer on rheological properties of fine tailings paste. Trans. Nonferr. Met. Soc. China 2021, 10–13, 1–17. [Google Scholar]
- Wen, Z.; Yang, X.; Li, L.; Gao, Q.; Wang, Z. Selection and optimization of flocculation settlement parameters of whole mortar based on RSM-BBD. Trans. Nonferr. Met. Soc. China 2020, 30, 1437–1445. [Google Scholar]
- Xi, W.; Chao, Y.; Qu, W.; Kun, G. Research on speech emotion recognition based on PCA-RF classification. Sci. Technol. Innov. 2021, 29, 91–93. [Google Scholar]
- Wu, X.; Yan, D. Analysis and research on data dimension reduction methods. Res. Comput. Appl. 2009, 26, 2832–2835. [Google Scholar]
- Elkin, M.; Niyogi, P. Laplacian Eigenmaps and Spectral Techniques for Embedding and Clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Yuting, K.; Fuxiang, T.; Xin, Z.; Zhenghang, Z.; Lu, B.; Yurong, Q. Review of K-means Algorithm Optimization Based on Differential Privacy. Comput. Sci. 2021, 1–21. [Google Scholar] [CrossRef]
- Lu, X.; Xu, L.; Zhang, M. Security hierarchical virtual network mapping method based on clustering. Telecommun. Sci. 2021, 37, 112–117. [Google Scholar]
- Ji, Q.; Sun, Y.; Hu, Y.; Yin, B. A survey of deep clustering algorithms. J. Beijing Univ. Technol. 2021, 47, 912–924. [Google Scholar]
- Deng, X.; Yu, L. Summary of Deep Clustering Algorithms. Commun. Technol. 2021, 54, 1807–1814. [Google Scholar]
- Yin, F.; Cao, X.; Qi, X. Summary of recommendation algorithms based on clustering. J. Southwest Minzu Univ. 2021, 47, 303–309. [Google Scholar]
- Zhou, Y.; Ren, Q.; Niu, H. A summary of research on training sample data selection methods. Comput. Sci. 2020, 47, 402–408. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Particle size | Liuju Copper Mine | Dayao Copper Mine | Jiangfeng Iron Mine | Lala Copper Mine | Dahongshan Copper Mine |
|---|---|---|---|---|---|
| 500.00 μm | 0.00% | 0.00% | 4.27% | 0.00% | 0.00% |
| 250.00 μm | 1.79% | 6.98% | 24.22% | 7.98% | 15.25% |
| 185.00 μm | 19.27% | 36.95% | 22.33% | 21.50% | 32.25% |
| 97.50 μm | 21.37% | 21.37% | 11.84% | 32.45% | 27.03% |
| 61.50 μm | 23.90% | 18.97% | 10.33% | 24.18% | 15.77% |
| 43.00 μm | 7.70% | 5.38% | 4.35% | 4.72% | 2.77% |
| 34.50 μm | 6.37% | 3.29% | 4.40% | 3.12% | 1.97% |
| 30.00 μm | 13.40% | 6.01% | 10.22% | 4.84% | 4.97% |
| 20.00 μm | 6.21% | 1.05% | 8.05% | 1.21% | 0.00% |
| Average particle size (μm) | 86.43 μm | 123.77 μm | 138.50 μm | 111.04 μm | 137.20 μm |
| Number of Tests | Mass (g) | Volume (mm3) | Apparent Density (t/m3) | Loose Density (t/m3) | Packing Compactness | Void Ratio |
|---|---|---|---|---|---|---|
| Test 1 | 53.76 | 20.40 | 2.64 | 1.39 | - | - |
| Test 2 | 53.75 | 20.40 | 2.64 | 1.37 | - | - |
| Test 3 | 56.61 | 21.39 | 2.65 | 1.38 | - | - |
| Average | - | - | 2.68 | 1.38 | 51.50% | 48.50% |
| Particle Size (μm) | Distribution (%) |
|---|---|
| 250 | 1.79 |
| 185 | 19.27 |
| 97.5 | 21.37 |
| 61.5 | 23.90 |
| 43 | 7.70 |
| 34.5 | 6.37 |
| 30 | 19.61 |
| Mineral Name | Mineral Content (%) |
|---|---|
| Calcite | 40–50 |
| Mica | 25–35 |
| Fluorite | 5–10 |
| Dolomite | 5–10 |
| Amphibole | 1–5 |
| Mass Concentration | PH |
|---|---|
| 15% | 7.15 |
| 20% | 7.15 |
| 25% | 7.15 |
| 30% | 7.15 |
| 35% | 7.16 |
| 40% | 7.16 |
| Mass Concentration (%) | Volume Concentration (%) | Sedimentation Rate (m/s) |
|---|---|---|
| 15 | 5.68 | 8.333 × 10−4 |
| 20 | 7.86 | 7.658 × 10−4 |
| 25 | 10.21 | 6.982 × 10−4 |
| 30 | 12.76 | 6.270 × 10−4 |
| 35 | 15.52 | 6.091 × 10−4 |
| 40 | 18.54 | 5.466 × 10−4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, J.; Qiao, D.; Han, R.; Wang, J. Tailings Settlement Velocity Identification Based on Unsupervised Learning. Metals 2021, 11, 1903. https://doi.org/10.3390/met11121903
Xie J, Qiao D, Han R, Wang J. Tailings Settlement Velocity Identification Based on Unsupervised Learning. Metals. 2021; 11(12):1903. https://doi.org/10.3390/met11121903
Chicago/Turabian StyleXie, Jincheng, Dengpan Qiao, Runsheng Han, and Jun Wang. 2021. "Tailings Settlement Velocity Identification Based on Unsupervised Learning" Metals 11, no. 12: 1903. https://doi.org/10.3390/met11121903
APA StyleXie, J., Qiao, D., Han, R., & Wang, J. (2021). Tailings Settlement Velocity Identification Based on Unsupervised Learning. Metals, 11(12), 1903. https://doi.org/10.3390/met11121903