1. Introduction
Lubricating oil plays a significant role in mechanical machines, reducing the contact surface friction and temperature, removing surface contamination, and extending the service life of lubricating oil to maintain good tribological performances [
1]. In recent years, oil monitoring technology has been continuously developing. It has been widely used in industry [
2], especially in the fields of condition monitoring and fault diagnosis [
3]. Lubricating oil contains a large amount of wear information on mechanical equipment, which, when analyzed, can directly or indirectly reflect the health status of mechanical equipment. Therefore, oil monitoring technology can provide a basis for early maintenance of mechanical equipment [
4]. Oil sampling is difficult due to the extreme working environment of mechanical equipment. As a result, the current oil monitoring data still have shortcomings such as scarce data samples, random errors, and unclear trends, making it difficult to achieve health status monitoring of mechanical equipment. Therefore, it is of great significance for early maintenance of mechanical equipment to increase the randomness and diversity of lubricating oil data and realize time series prediction of oil data.
The main methods for predicting oil include heuristic methods, computational economic models, machine learning, and other techniques. The heuristic methods for oil price prediction mainly rely on expert experience and professional knowledge. Computational economics models are the most widely used methods, such as autoregressive moving average (ARMA) models and vector autoregressive (VAR) models. However, most computational economics models are linear models that cannot capture the complexity and randomness of oil data [
5]. Therefore, machine learning technology is gradually being applied in oil prediction. Ali et al. [
6] proposed a prediction model based on soft computing methods, which combines an adaptive neural fuzzy inference system with an artificial network. The neural network model is trained using a least squares estimator (LSE) and gradient descent method to achieve price prediction of West Texas Intermediate (WTI) crude oil. Adnan et al. [
7] proposed an intelligent prediction system for crude oil prices based on support vector machines. The SVM model was trained using an RBF kernel and the cost parameter
C of the error term. The validation of the system used economic indicators that affect the weekly spot price of West Texas Intermediate (WTI) crude oil as inputs and crude oil prices as outputs. This method achieved an accuracy of 81% in predicting crude oil prices. Guliyev et al. [
8] used machine learning models such as Logistic Regression, Decision Tree, Random Forest, Adaptive Boosting, and Extreme Gradient Boosting to complete the dynamic prediction of West Texas Intermediate (WTI) oil prices. Empirical results show that the machine learning model can successfully and accurately predict the trend in WTI oil price changes. Yu et al. [
9] proposed a neural network ensemble learning paradigm for predicting world crude oil spot prices. This learning paradigm is based on empirical mode decomposition, which first decomposes the crude oil spot price sequence into finite and usually small intrinsic mode functions (IMF) using empirical mode decomposition. Then, a model using IMFs are established and the trend in IMFs is predicted. Finally, the predicted results are combined with an adaptive linear neural network (ALNN) to construct the price output of crude oil. The empirical results indicate that the proposed EMD-based neural network ensemble learning paradigm has successfully achieved the prediction of crude oil prices.
In summary, machine learning methods have drawbacks such as low prediction accuracy and inability to perceive the complex dynamic trends of oil prices. The emergence of long short-term memory networks has helped to address the drawbacks in oil prediction.
Long short-term memory (LSTM) network models have been widely used in oil prediction. Manowska et al. [
10] analyzed crude oil consumption data in Poland from 1965 to 2020. An artificial neural network structure based on an LSTM model was established, and the proposed LSTM model was verified to effectively predict nonlinear time series by constructing relevant indicators, such as mean absolute error (MAE) and root mean square error (RMSE). Wu et al. [
11] proposed a new method that combined the ensemble empirical mode decomposition (EEMD) method with the LSTM network structure model to achieve trend prediction. The proposed model can overcome the problem that EEMD re-decomposes differently after obtaining new data, which results in unsatisfactory prediction results. Vo et al. [
12] constructed an efficient oil price prediction model based on bidirectional long short-term memory (Bi-LSTM). The model consists of a three-layer Bi-LSTM network to extract time series features in the forward and backward directions and a fully connected layer to achieve the price prediction by using the features, so that the defect that the LSTM model only considers forward prediction can be solved. Abdullayeva et al. [
13] proposed a hybrid model based on a convolutional neural network (CNN) and LSTM network to realize production prediction of lubricating oil. The architecture of the CNN-LSTM model was hierarchical, where the CNN model was applied for the current time window, and the LSTM model was used to predict the relationship between the time windows. It not only retains the advantages of CNN models in feature extraction but also utilizes the high sensitivity of LSTM models for long sequence time prediction. Cui et al. [
14] proposed a LSTM-based sequence-to-sequence (Seq2Seq-LSTM) model to overcome the issue that oil production was difficult to predict using traditional methods. The model normalized multiple information, performed feature selection to determine the input features, and trained multiple samples with similar time series in a lumped model to achieve multi-target prediction. Aziz et al. [
15] proposed the prediction model based on a recurrent neural network (RNN) and LSTM to improve the prediction accuracy of nonlinear and unstable data sets, where RNN was applied to learn the features between data and LSTM was employed to learn the long-term dependencies of data. In order to optimize the accuracy of energy futures price prediction, Wang et al. [
16] combined the wavelet decomposition (WPD) of the LSTM model with the random time effective weight (SW) function method to establish a new hybrid model (WPD-SW-LSTM). This method first decomposes the original signal into different sub frequencies and then integrates the SW function into the LSTM model to construct a new prediction model that uses different sub frequencies as inputs to predict crude oil futures prices. This model can assign different weights to different data based on the time of mutation. Finally, the predictive ability of the model was successfully improved. Fan et al. [
17] proposed a new strategy that combines computational economics methods with deep learning methods to provide theoretical basis for predicting actual oil well production time series. Among them, the computational economics part uses the autoregressive ensemble moving average (ARIMA) model, and the deep learning part uses the LSTM model. The ARIMA model is mainly used to filter and model the linear part of time series, while the LSTM model is mainly responsible for predicting the nonlinear part. After experimental verification, the ARIMA-LSTM model was shown to be significantly superior to single ARIMA and LSTM methods.
In summary, the LSTM network model has shown significant advantages in oil prediction, which can effectively perform end-to-end modeling and capture changes in variables and has high automatic feature extraction and learning capabilities. Meanwhile, the prediction rate of the LSTM neural network model combined with other methods is higher than that of a single LSTM neural network model. However, artificial neural networks still have shortcomings, which are highly dependent on independent domains or the same distribution, and the significant performance degradation issue when testing external distribution scenarios. To address this issue, Li et al. [
18] proposed Domain Shifts with Uncertainty (DSU) as an adaptation strategy. The feature statistics of the intermediate feature statistics layer were considered as random values that followed a certain distribution, and the original feature statistics were replaced by the random values. The DSU model can effectively improve its generalization ability, reduce dependence on independent domain distribution, and increase the number of samples.
Therefore, a novel method combining DSU and LSTM is proposed in this paper to solve the problem that collecting historical oil data is limited by harsh conditions. By using the DSU model to preprocess the feature statistics (feature mean and variance) of the oil data, the uncertainty estimation of feature statistics can be obtained. Furthermore, oil data with uncertain features are calculated, increasing the sampling capacity and randomness of oil monitoring data. Then, the LSTM prediction model is applied to oil monitoring data with uncertain characteristics to achieve trend prediction of the monitoring data.
The rest of this paper is organized as follows. In
Section 2, the DSU-LSTM model is proposed, and the principles of the DSU model and the LSTM model are introduced, respectively. In
Section 3, an online oil monitoring system is established to obtain the oil data histories. The oil data are used to the DSU-LSTM model, and evaluation indicators, such as RMSE, MAE and MRE, are calculated to verify the effectiveness of the proposed model. Comparisons with the LSTM model, SVM model, and DSU-SVM model are conducted in
Section 4. Finally, conclusions are summarized in
Section 5.
2. DSU-LSTM Method
Deep learning network models have achieved remarkable results in the fields of visual impact, semantic segmentation, condition monitoring and data prediction [
19,
20,
21]. However, deep learning network structure models are easily affected by data distribution. Therefore, in order to effectively solve the problems of scarcity of oil history and few oil data samples, this article proposes the DSU-LSTM model. The schematic diagram of the model is shown in
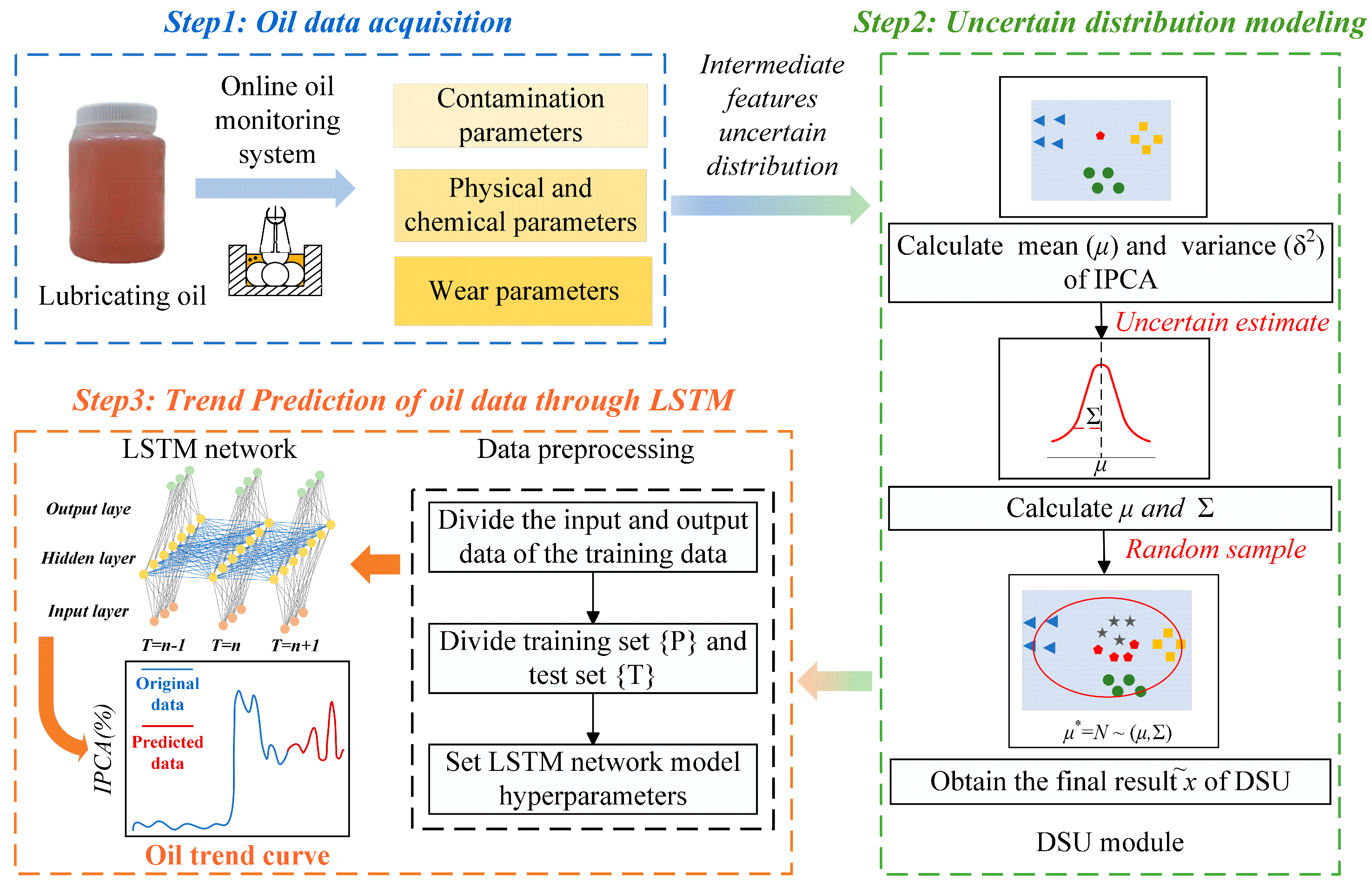
Figure 1.
As depicted in
Figure 1, the oil trend prediction method comprises three core components: the acquisition of oil data, uncertain distribution modeling, and trend prediction of oil data through LSTM. Initially, an online oil monitoring system was initially implemented to track contamination indicators, wear indicators, and physical and chemical indicators of lubricating oil for collecting monitoring data. The statistical properties of the monitoring data were then primarily processed using the DSU module to enhance the randomness and diversity of the data. Finally, the optimized oil data, including the wear index IPCA (index of particle coverage area, representing the coverage area ratio of abrasive particles, which can reflect the concentration of wear particles per unit area and the wear state of the machine), was split into training and testing sets and inputted into the developed LSTM model for predicting oil trends.
2.1. Uncertain Distribution Modeling with DSU Module
As to the oil data, the changes in wear conditions, the entry of pollutants, and the degradation of oil performance can all lead to changes in the distribution of collected oil data to a certain extent, thereby increasing the error in predicting subsequent oil trends. Consequently, accurately modeling the uncertainty distribution of oil data is crucial for improving the robustness of subsequent oil trend prediction.
Considering the uncertainty and randomness of the oil data distribution, the statistics (mean, variance) of the sampled data can be regarded as following an approximate multivariate Gaussian distribution. As shown in the
Figure 1, the feature statistics (mean, variance) learned from the oil data are no longer considered as a fixed value, and the potential uncertain offset generated by the feature statistics is taken into account in the training process of the subsequent prediction models. For the sampled data
, the mean value of the original oil data is expressed as
. The variance is expressed as
, which can be expressed as:
where
h represents the number of groups for oil data and
w represents the number of sampling points for a set of oil data.
Oil data statistics are considered as abstract intermediate features and can well represent the distribution information of sampled data. The potential domain shifts under different collection conditions are also different, because the data statistics corresponding to different domains are different. Therefore, in order to describe the uncertainty range of the oil data statistics, the mean and standard deviation of oil data are assumed to follow
and
, respectively. The standard deviation of Gaussian distribution describes the uncertainty scope for different possible variations of oil data, as described in Equations (3) and (4) [
18].
Uncertain estimates represent the potential for a feature statistic to shift in different directions or strengths. The smaller the calculated uncertainty estimate, the less information the data contains and the less likely a potential domain shift is to occur. After obtaining the uncertainty estimate of the oil data statistics, the uncertainty estimate is used to construct a probability distribution model of the data statistics. The original data mean and feature variance are replaced by randomly selected probability points as new data statistics. The expression is as follows:
Based on the above strategy, the DSU module for modeling uncertainty in oil data has been completed, which can be expressed as:
2.2. Trend Prediction of Oil Data through LSTM
As typical temporal evolution data, oil data cannot be effectively captured by general machine learning models to acquire the relationships between adjacent data, resulting in significant errors in trend prediction. However, the LSTM is a type of recurrent network model (RNN) that can effectively solve the problems of RNN gradient disappearance, new information coverage, and inability to process long time series [
22,
23,
24]. The schematic diagram of LSTM is shown in
Figure 2. In the LSTM neural network model, conventional neurons are replaced by storage units, and new concepts such as long-term memory cells
C and short-term memory cells
h are proposed. At the same time, new threshold concepts such as forget gate, input gate, and output gate are added to manage the removal or addition of structures to the unit.
In
Figure 2,
t represents the current moment;
t − 1 represents the previous moment;
represents the data of the current time series;
is the state of the long-term memory cell at the previous time step;
represents the state of long-term memory cells at the current moment;
is indicates the state of the hidden value at the previous moment;
represents the state of the hidden value at the current moment; σ represents the sigmoid function;
,
,
, and
represent the weight parameters of the forget gate, input gate, calculation of current state and output gate, respectively;
and
represent the ratio of the input selected by the output gate to the output selected by the output gate; and
is the temporary cell state at the current time step.
Long-term memory cell
C is mainly used to update the state of the cell and store historical time series information. Short-term memory
h is mainly used to store the hidden state of the current time step information. Which elements of the control state vector
will be forgotten by the forget gate can be controlled based on the information of the previous time step, which is expressed as [
27]:
The network structure weight parameter is represented as ; the ratio calculated by the forget gate is expressed as and the value range is between [0, 1]. The higher the calculated ratio, the less information is chosen to be forgotten. For example, if is calculated as 0.7, 30% of the information will be forgotten, and 70% of the information will be retained to participate in the next update of the cell state.
The proportion of information absorbed into the long-term memory
C is determined by the input gate. Its mathematical essence is that all the information incoming at the current time step is multiplied by a certain proportion to filter the information. The expression is [
28]:
After calculating the information to be forgotten by the forgetting gate and the information absorbed by the input gate, the cell
C state needs to be further updated. The expression is as follows [
29]:
The output gate is an important threshold unit in the long short-term memory network. It is used to filter out the most effective information for time series and achieve time series prediction. The expression is as follows [
30]:
Based on the constructed LSTM model, the data processed by the DSU module is input into the LSTM as a time series data unit with a length of L, in order to predict the oil data for the next time node. Through continuous traversal and iteration, trend prediction of the oil data is achieved.
3. Case Study
In order to verify the effectiveness of the proposed model, an online lubricant monitoring system was established to simulate the lubricant performance decay process and obtain oil monitoring data (CM data). The flow chart is shown in
Figure 3.
As shown in
Figure 3, an online lubricating oil monitoring system is established to acquire the IPCA information of oil monitoring data. Subsequently, the IPCA data processed by the DSU module is input into the LSTM module to predict the trend in oil data.
3.1. Experiment Setup
To monitor the lubricating oil condition in reality, the desktop four-ball friction and wear tester (four-ball tester) is used to simulate the tribological system. The aging process of lubricating oil is accelerated in order to obtain the full lifetime data, which can be used to obtain the performance degradation of lubricating oil and the wear condition of the tribo-pairs. The system includes an online lubricating oil monitoring sensor, tribo-pairs, an oil circulation system, and an information transmission system. The system obtains IPCA information in lubricating oil via the OLVF (on-line visual Ferrograph) sensor [
31], which represents the wear particle coverage area ratio. The observations can indirectly reflect the wear condition of tribo-pairs. The design principle of the system is shown in
Figure 4.
The system uses a pump to circulate the oil circuit and extract lubricating oil from the bottom of the lubricating oil box containing the tribo-pairs. Firstly, the IPCA information in the lubricating oil is obtained by the OLVF sensor. Secondly, the lubricating oil is filtered through a filter and flows back to the lubricating oil box. The purpose of filtering lubricating oil is to ensure that the wear information collected at the next sampling time represents the current wear status from the tribo-pairs. The physical diagram of the system is shown in
Figure 5.
3.2. Experimental Results
In order to accelerate the decay process of the simulated lubricant, the experiment was carried out under different working conditions. The total duration of the experiment was 45.5 h, and the monitoring temperature was 50 °C. When the working conditions were changed, the experiment was shut down until room temperature was restored and restarted to ensure that each experiment started from room temperature. Since the four balls generated severe heat during the experiment, the experiment was divided into five stages in order to ensure the safety. The load, speed, and running time of the first stage were the same as those of the second stage, which were 1500 N, 1000 rpm, and 360 min, respectively. The load and speed of the third and fourth stage were the same, which were 2000 N and 1000 rpm, respectively. The experiment time in the third stage was 210 min, and that in the fourth stage was 240 min. In the last stage, the load was 1500 N, which was the same as the first and second stages, and the speed was 1500 rpm, which was higher than the former stages. The experiment time in the last stage was 60 min.
In the experiment, 10 sets of monitoring data were obtained. In order to improve data processing efficiency and reduce storage costs, the data from the four-ball running-in stage was removed, reducing the number of data points in each data sample from 312 to 242. One of the typical experimental results is shown in
Figure 6.
The wear condition of mechanical equipment will go through three stages: running-in period, stable period, and severe wear period. The wear curve conforms to the “Bathtub Curve” [
32]. The IPCA results monitored in
Figure 6 show that the wear condition of the four-ball tribo-pairs goes through the stages of stable period to severe wear, which conforms to the “Bathtub Curve”. Due to the severe heating of the four grinding balls in the friction and wear experiment, in order to ensure the safety of the experiment, the experiment was divided into 5 stages in total. The numbers 1–5 in the figure represent 1–5 experimental stages respectively. The peaks that appeared in each stage are caused by the secondary running-in due to each start up and shutdown. It can be seen that IPCA is sensitive to the wear condition of mechanical equipment and can reflect the wear status online.
3.3. Evaluation Indicators
The evaluation indicators of time series models typically include root mean square error (RMSE), mean absolute error (MAE), mean relative error (MRE) [
33]. RMSE assesses the model’s performance, with smaller values indicating better predictive ability. MAE is a commonly used metric that calculates the average absolute difference between predicted and actual values. MRE evaluates models by computing the average relative error between predicted and actual values. Due to the complexity and specificity of LSTM models, RMSE, MAE, and MRE are chosen as the evaluation indicators, which are widely used to evaluate time series prediction models. The specific calculation formula of each indicator is detailed in
Table 1, and the smaller the indicators, the better the prediction performance of the model.
3.4. DSU-LSTM Model Verification
In order to verify the effectiveness of the proposed DSU-LSTM model, 10 groups of experimental data histories are used in this section. Firstly, the feature means and feature variances of the sample points at the same sample time in different data histories are calculated, which is the center of the uncertain distribution. Secondly, the variance of the feature means and feature variances calculated at different sample times is calculated, which are 0.0036 and 0.0018, respectively. The results represent the range of uncertain distribution. Thirdly, the offset factor
and scaling factor
are calculated, which represent the uncertainty. Finally, the feature
considering the uncertain distribution is calculated.
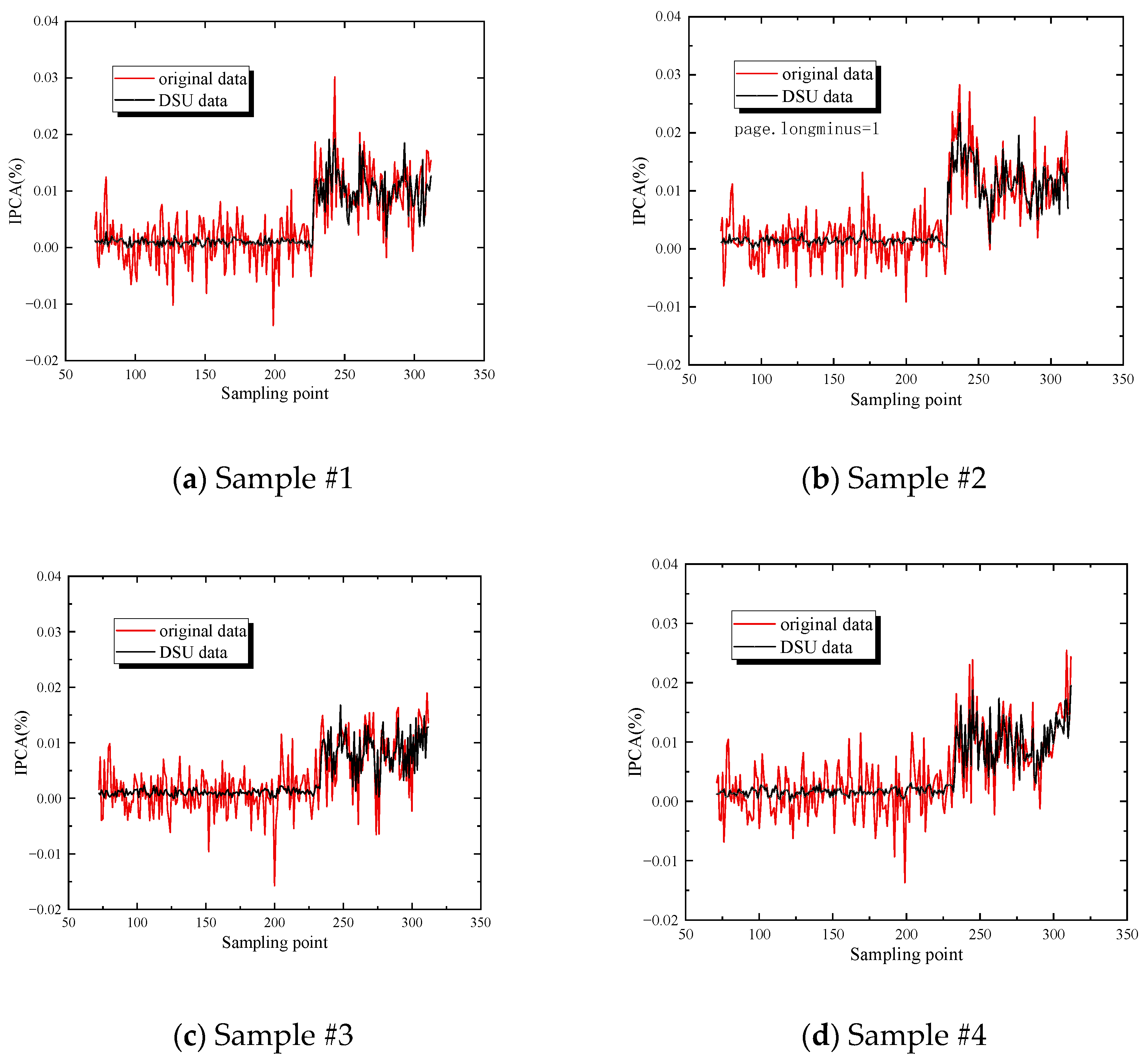
Figure 7 illustrates four samples calculated by the DSU model.
In the results shown above, the original data monitored by the online oil monitoring system are represented by red, and the data with uncertain characteristics are represented by blue. It can be clearly seen that the data fluctuate irregularly around the original data . It has been proven that the DSU method can effectively increase the diversity and randomness of oil monitoring data.
Before validating the model, DSU data need to be preprocessed. Firstly, it is necessary to determine the size of the time window. Since the data length is limited, a smaller window is selected in the LSTM network structure. And after experimental verification, the prediction result is the best when the window size is set to 5; that is, the true value of the next time series is outputted by the input of every five time series. Secondly, the training data and the test data can be determined. Pan et al. [
36] selected 40%, 60%, and 80% of the full-cycle monitoring data to construct small sample data for sample expansion. As the number of samples increases, the prediction accuracy becomes higher. Therefore, 80% of the oil data is used to predict the remaining 20% of the oil data. Finally, a training set containing 15 data samples and a test set containing 2 data samples are constructed.
The LSTM neural network structure is comprised of numerous hyperparameters, and the configuration of these hyperparameters plays a crucial role in predicting the status of lubricating oil. By thorough debugging, the specific parameters are summarized in
Table 2.
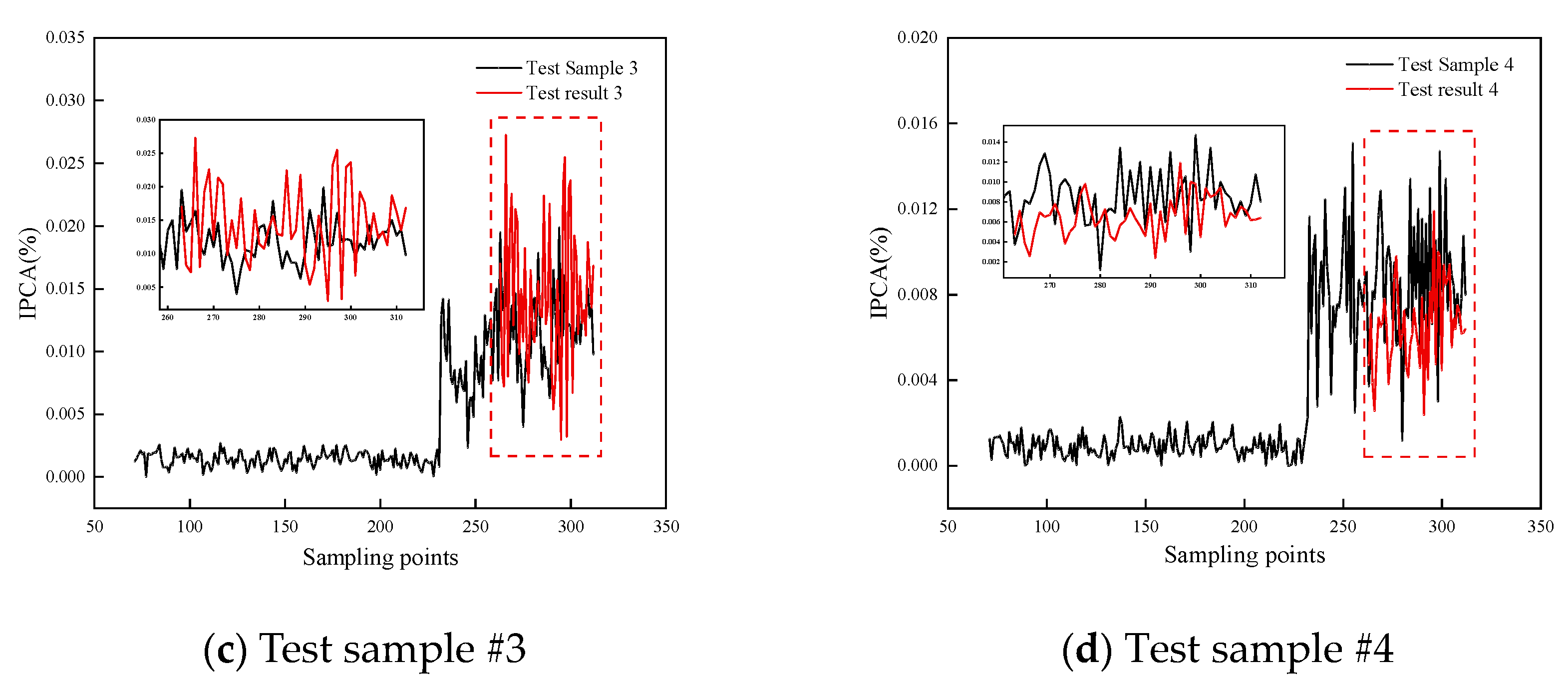
The prediction results are illustrated in
Figure 8, and the evaluation indicators are shown in
Table 3.
The RMSE, MAE, and MRE values calculated for the four test samples from the curves and charts are relatively small. The RMSE values for the four test samples are 0.010568, 0.0081624, 0.0078452, and 0.0039831, respectively. Similarly, the MAE values are 0.3857, 0.27913, 0.2553, and 0.12123, and the MRE values are 0.91575, 0.49649, 0.29079, and 0.0011908, respectively. The prediction results of the data post the DSU model operation in the LSTM model exhibit relatively good performance with small errors.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}