Intelligent Tool Wear Monitoring Method Using a Convolutional Neural Network and an Informer



Abstract
:1. Introduction
- (1)
- This study presents a new TWM approach that combines the advantages of the CNN, the Informer encoder, and BiLSTM. This is the first time these three DL techniques have been combined to monitor tool wear conditions.
- (2)
- This method can extract spatial features from the raw sensor data, capture long-term dependence and time patterns, and learn the feature representation of tool wear state comprehensively to enhance the TWM’s precision and reliability.
- (3)
- The presented approach has excellent efficiency and good interpretability, which can help to understand the key factors of tool wear and prepare a valuable reference to prevent and manage tool wear.
2. Methods
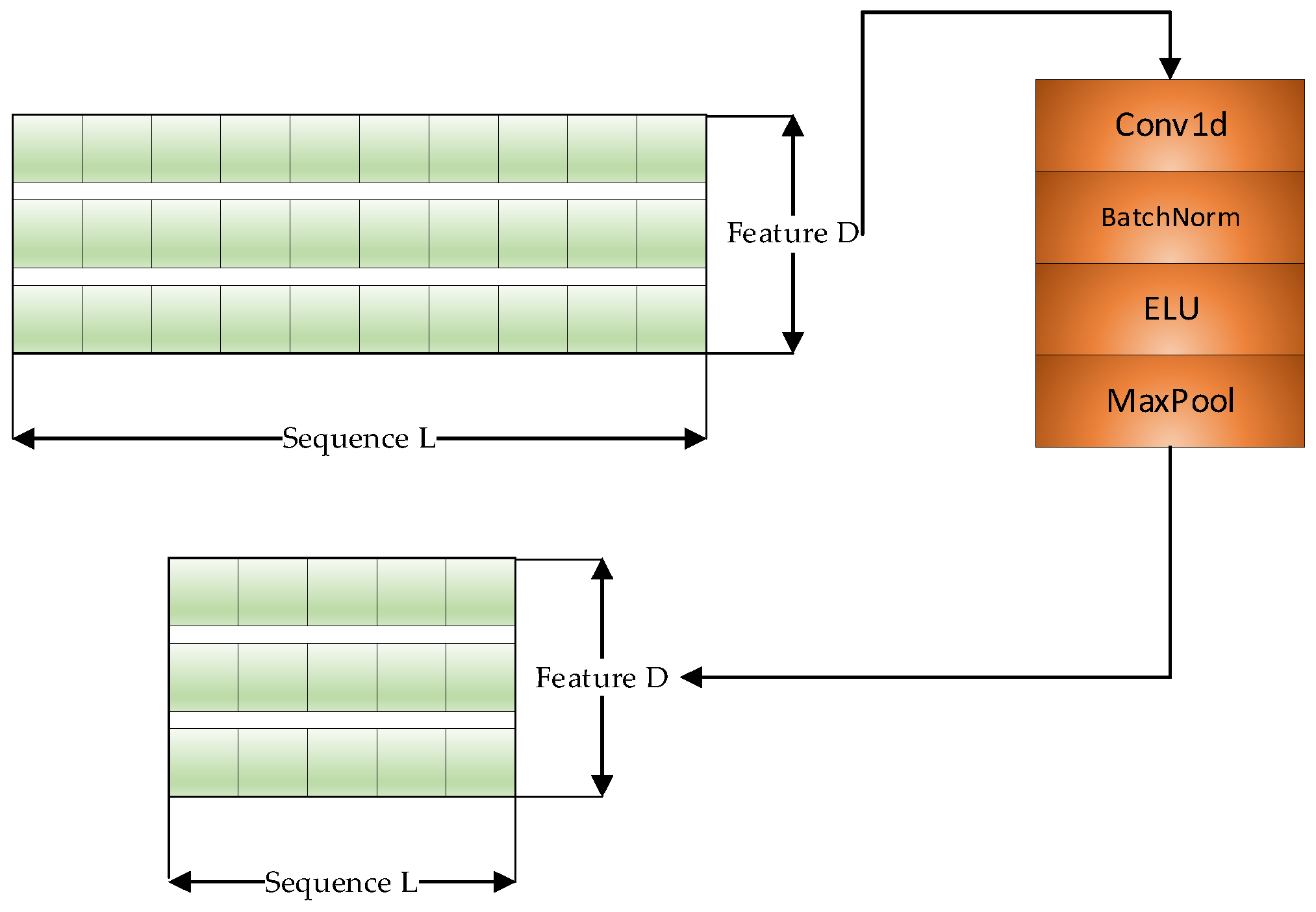
2.1. D-CNN
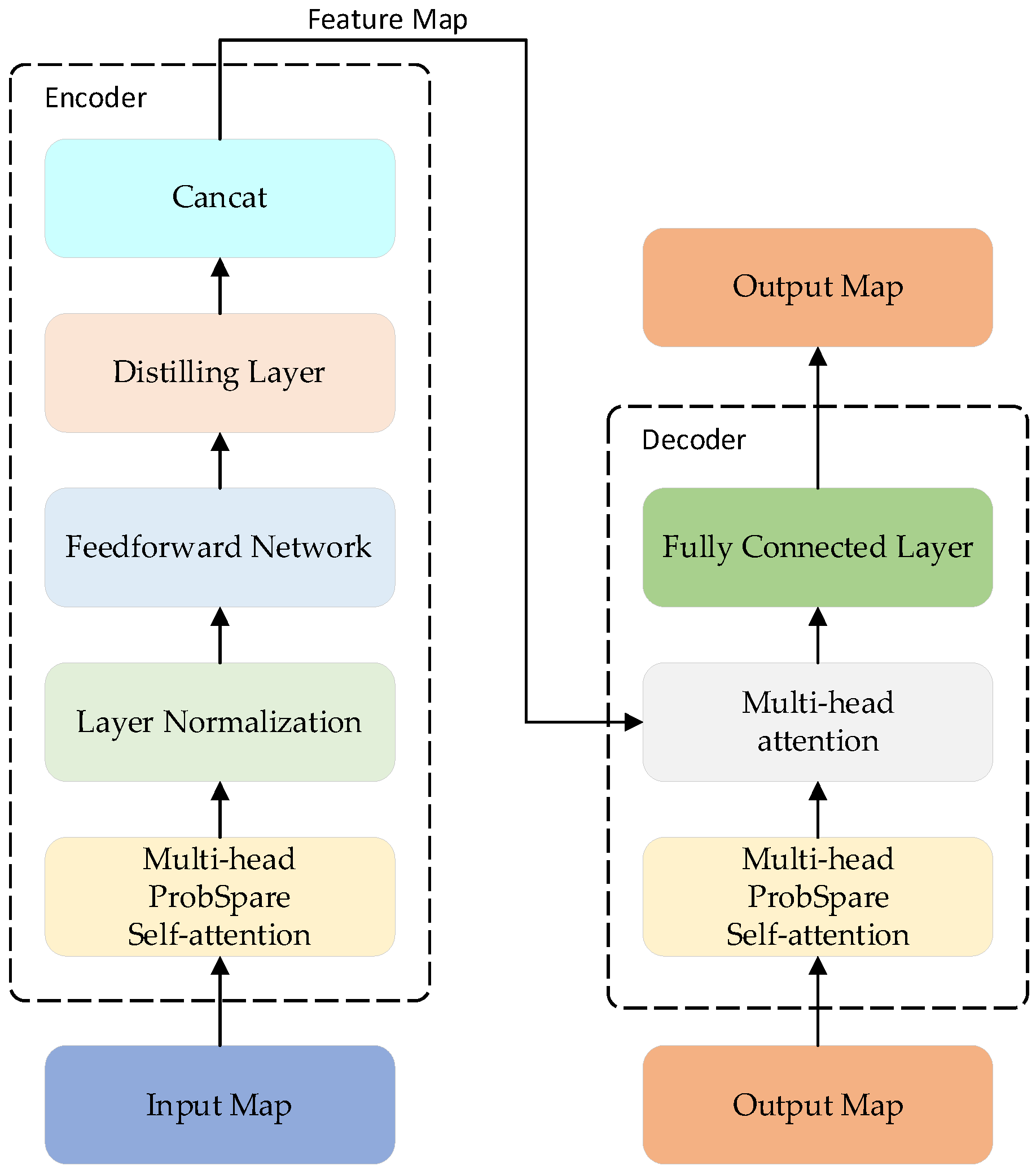
2.2. Informer Encoder
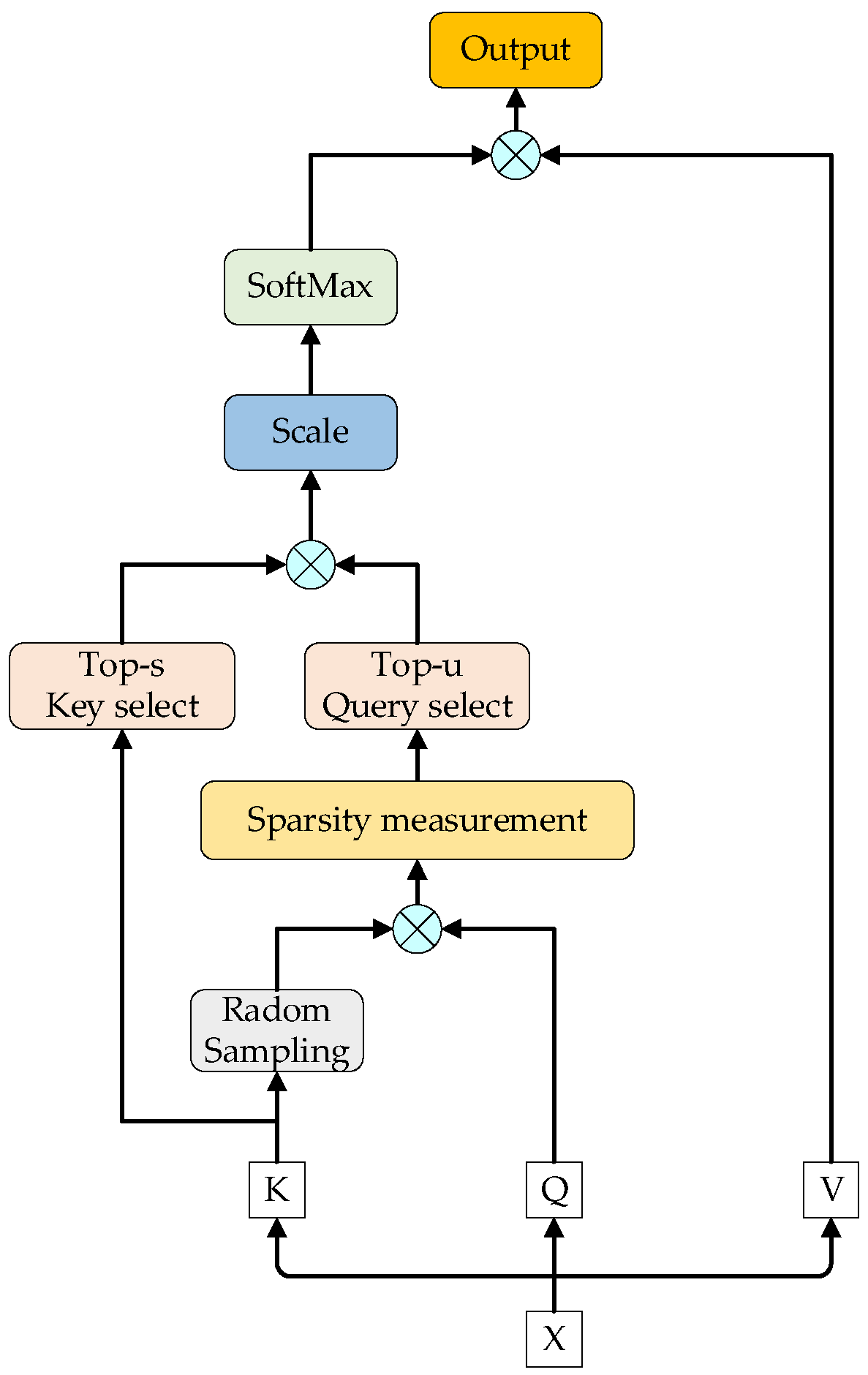
2.2.1. ProbSparse Self-Attention
2.2.2. Distilling Layer
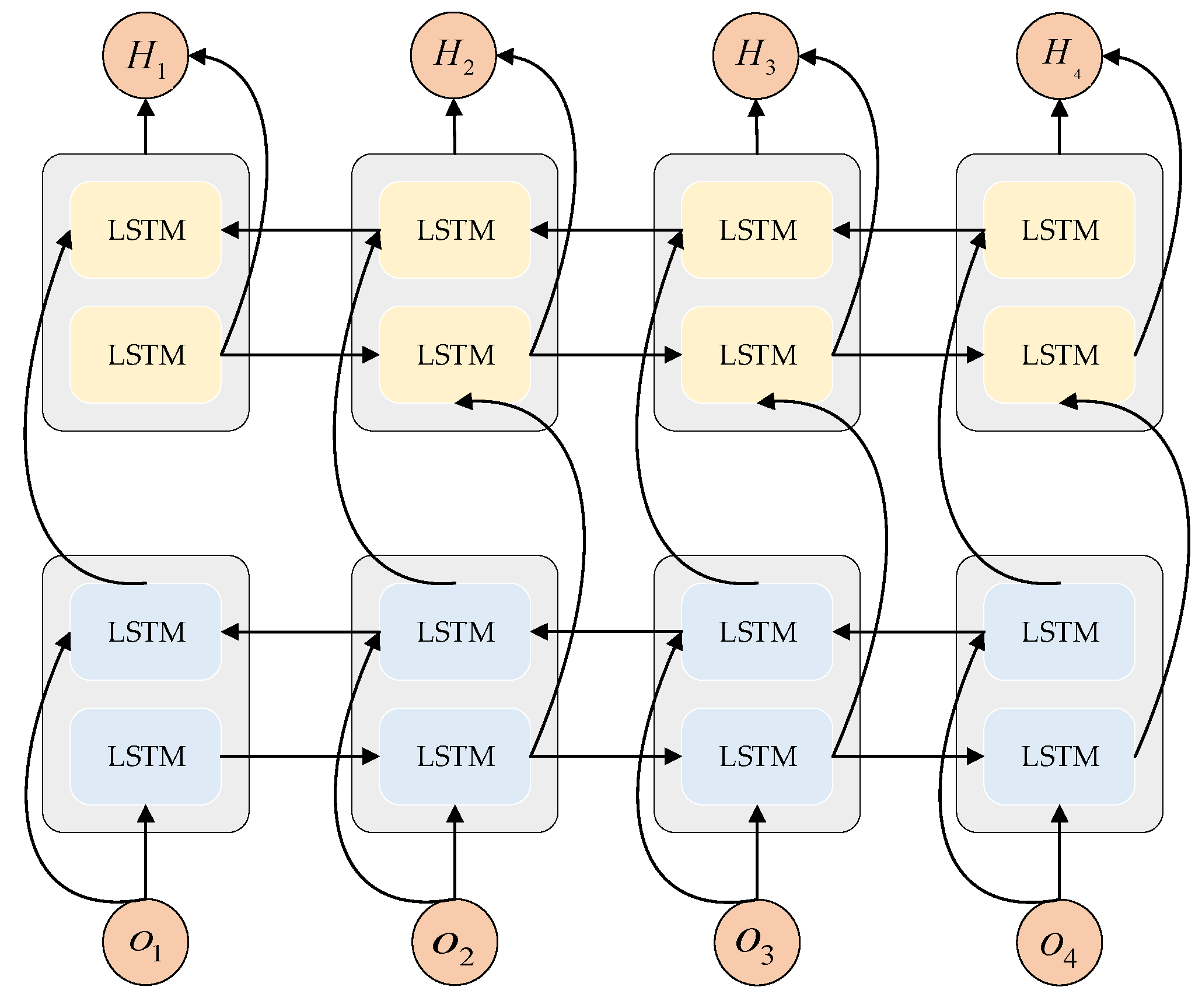
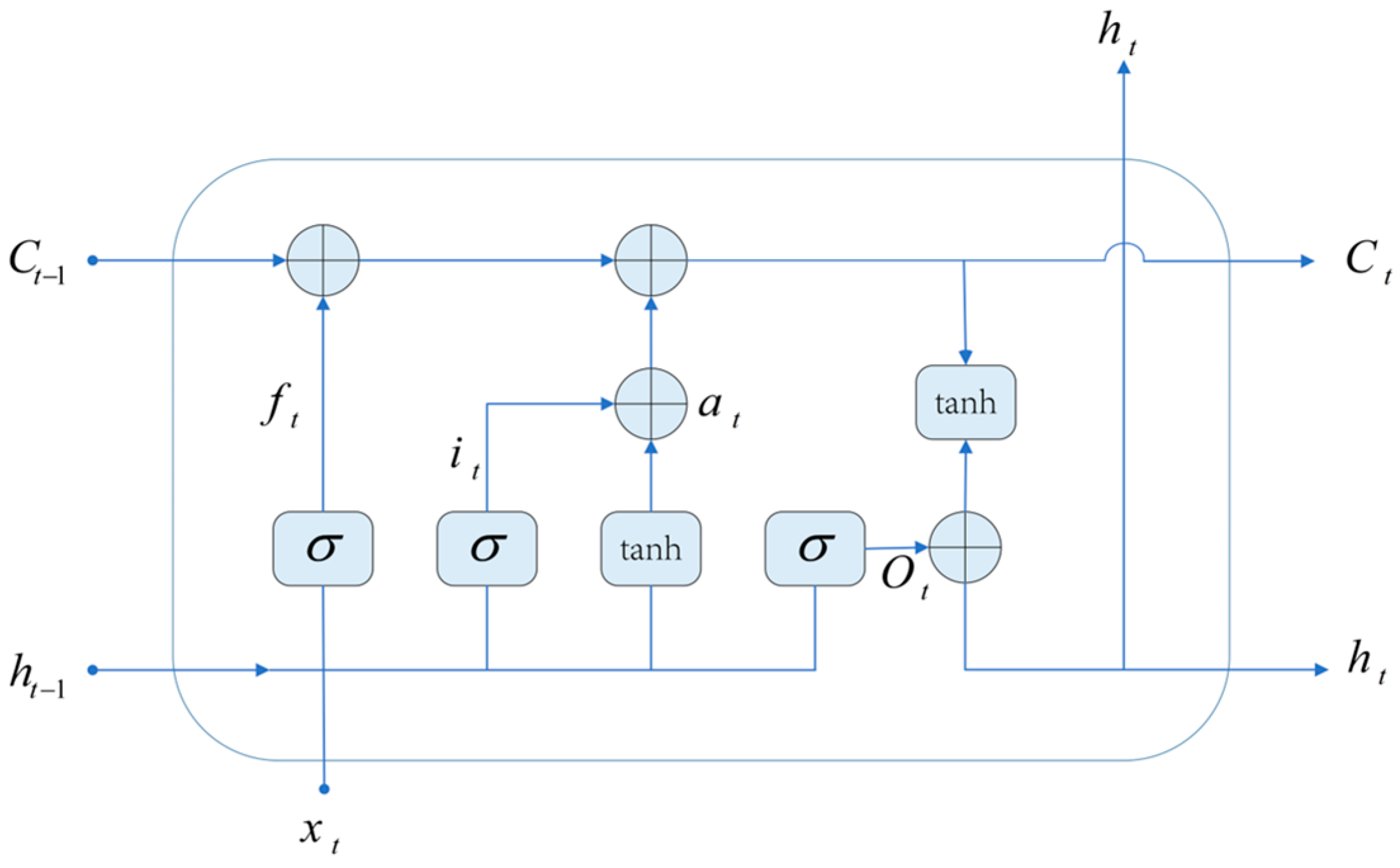
2.3. BiLSTM Network
3. Proposed Methods
3.1. Frame
3.2. Parameter Settings
4. Experiments
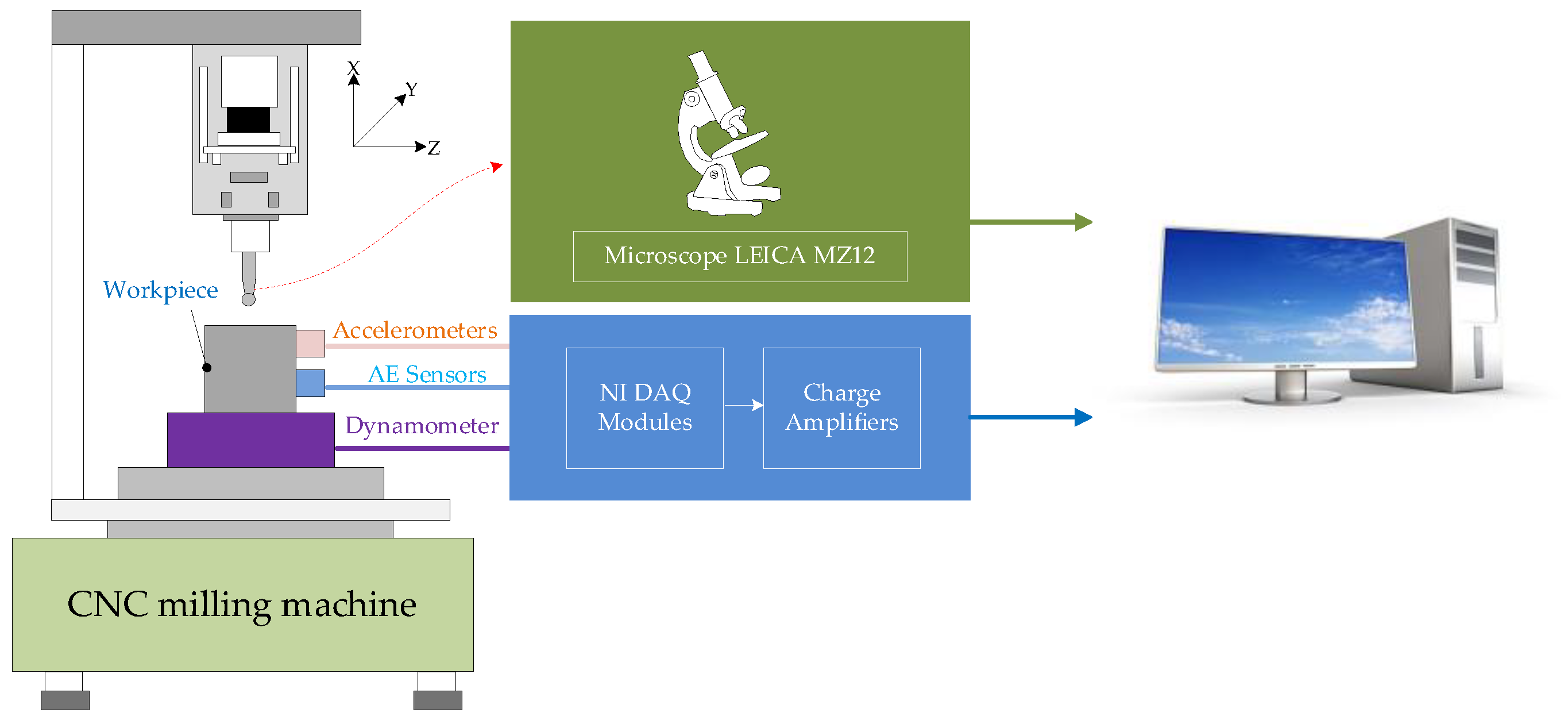
4.1. Experimental Sets
4.2. Data Pre-Processing
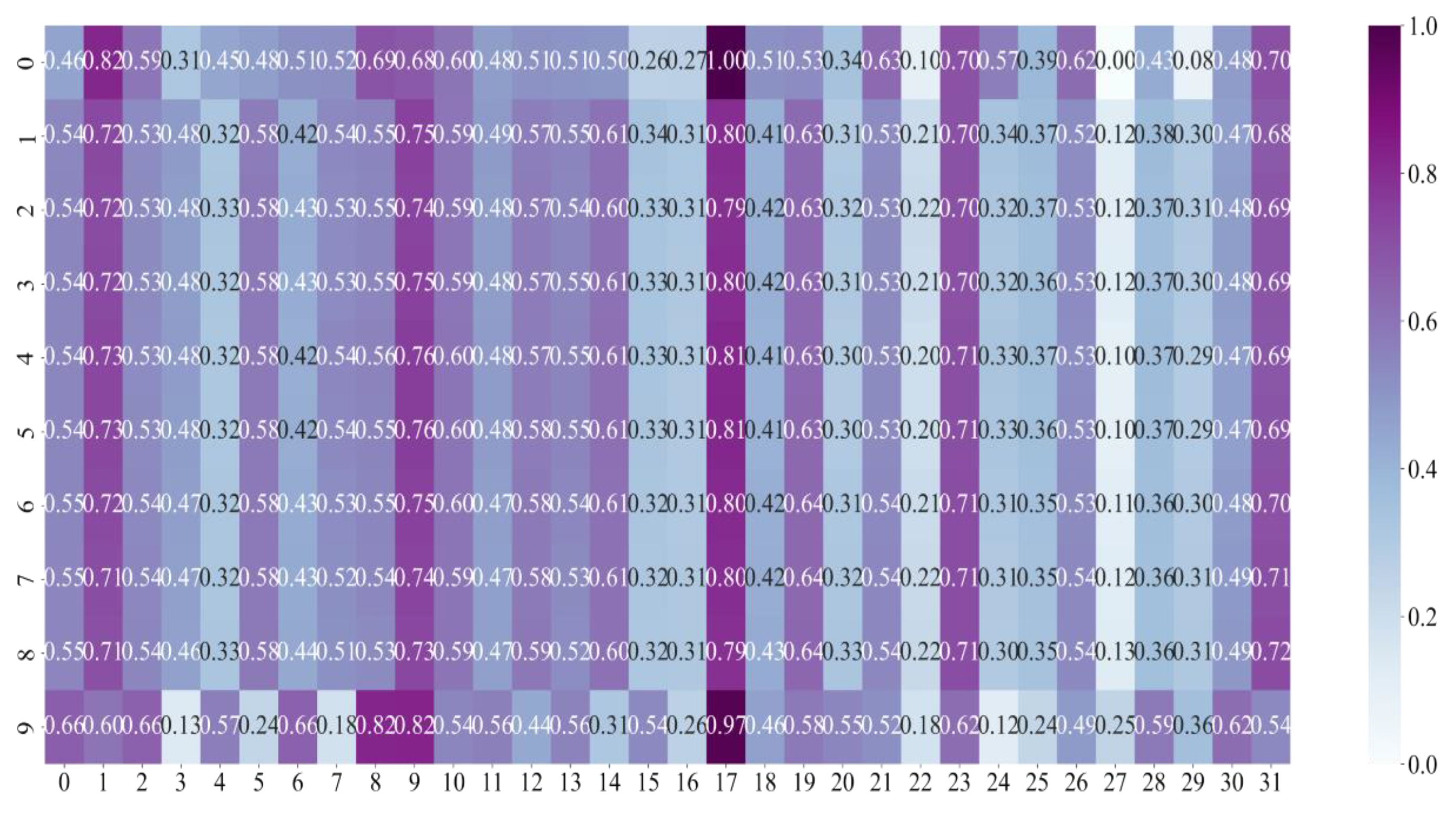
4.3. Hyperparameter Setting
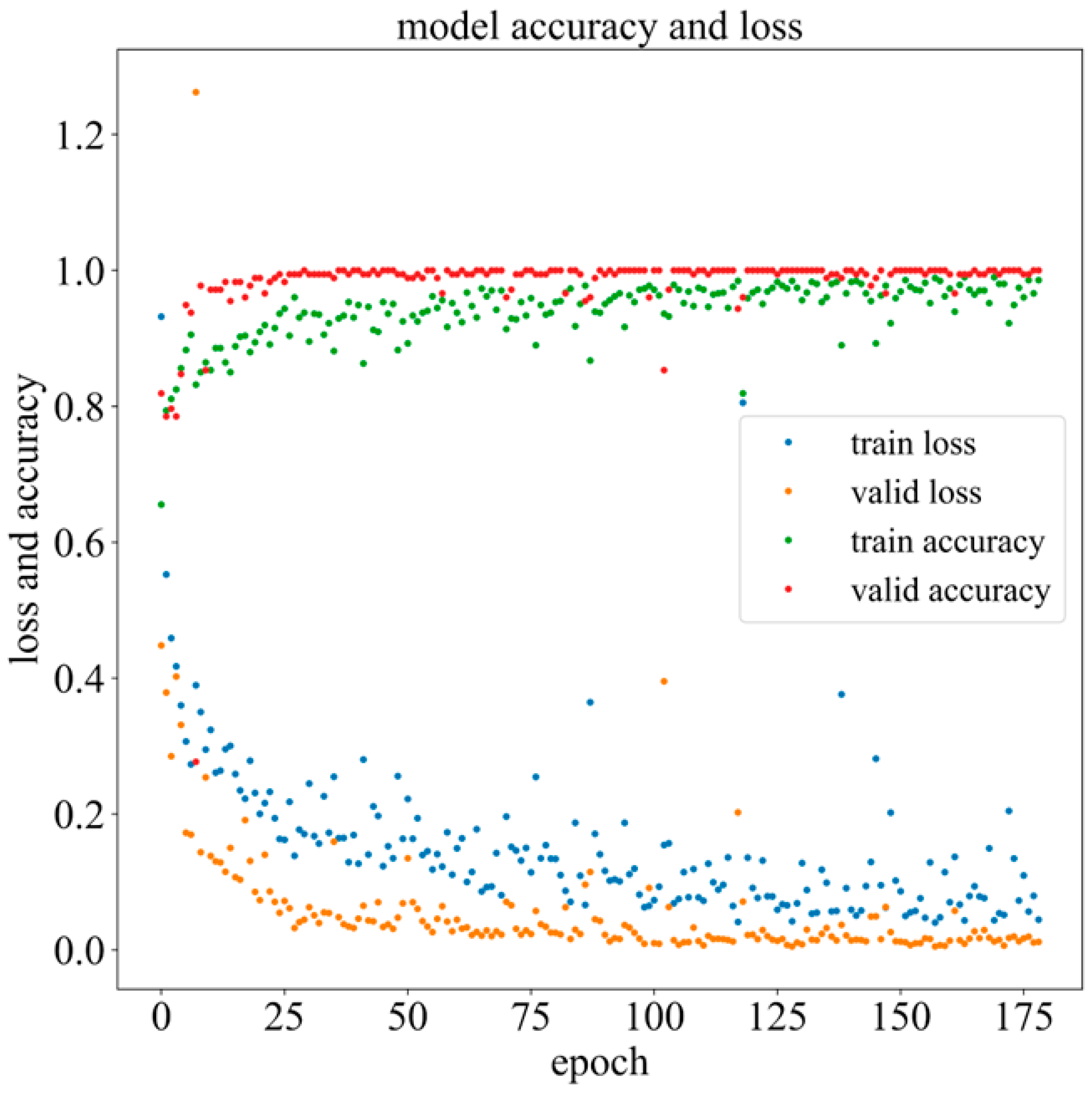
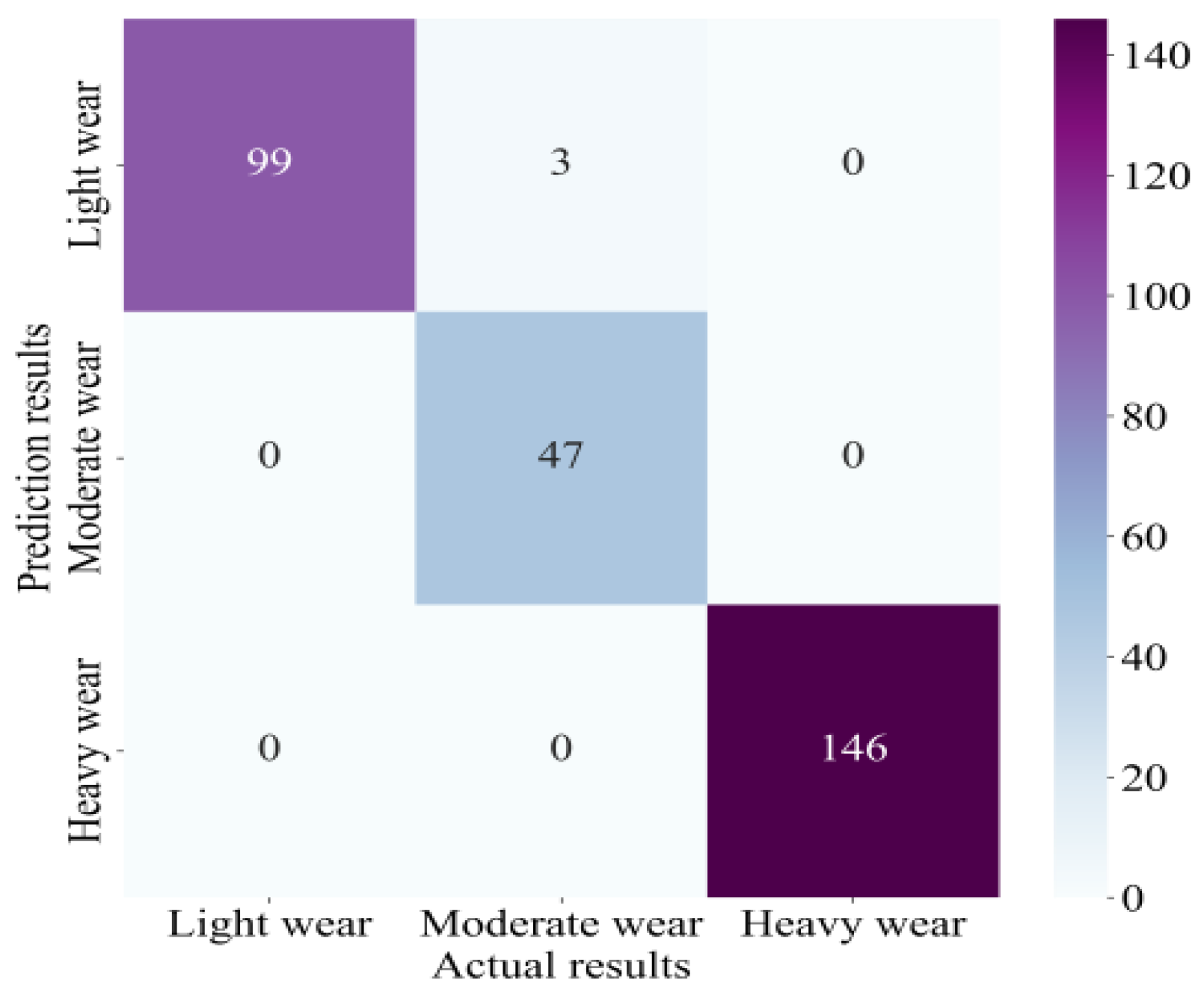
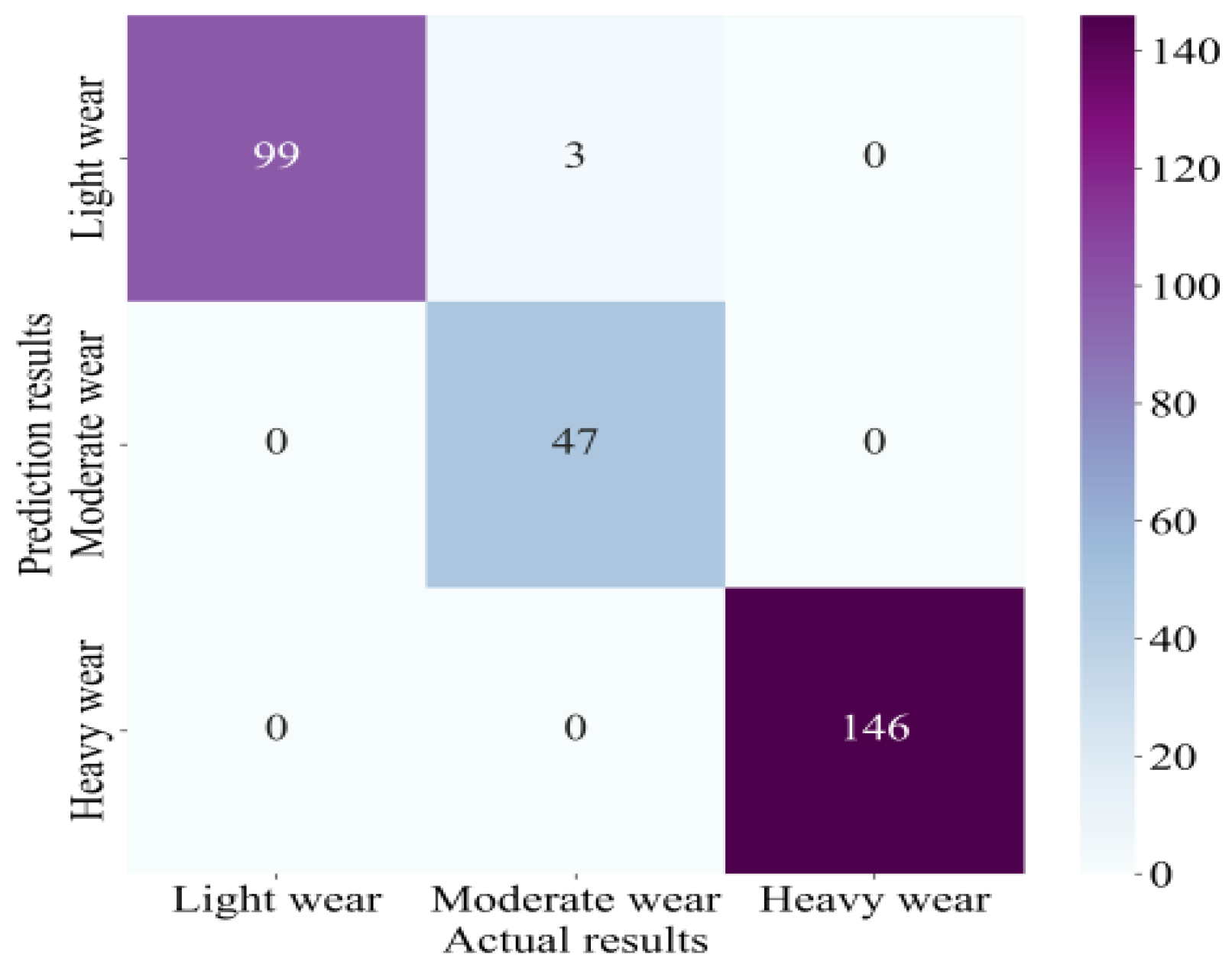
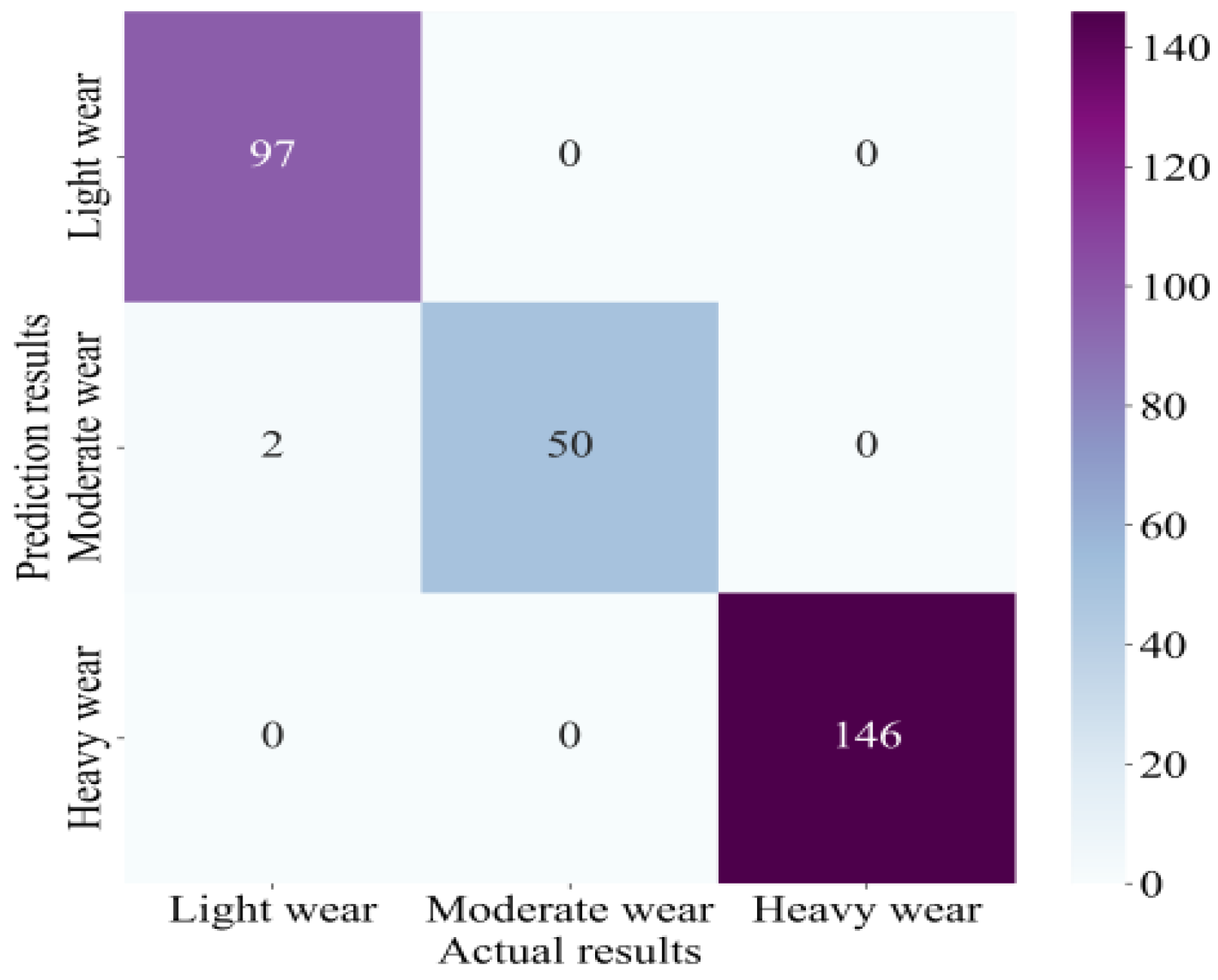
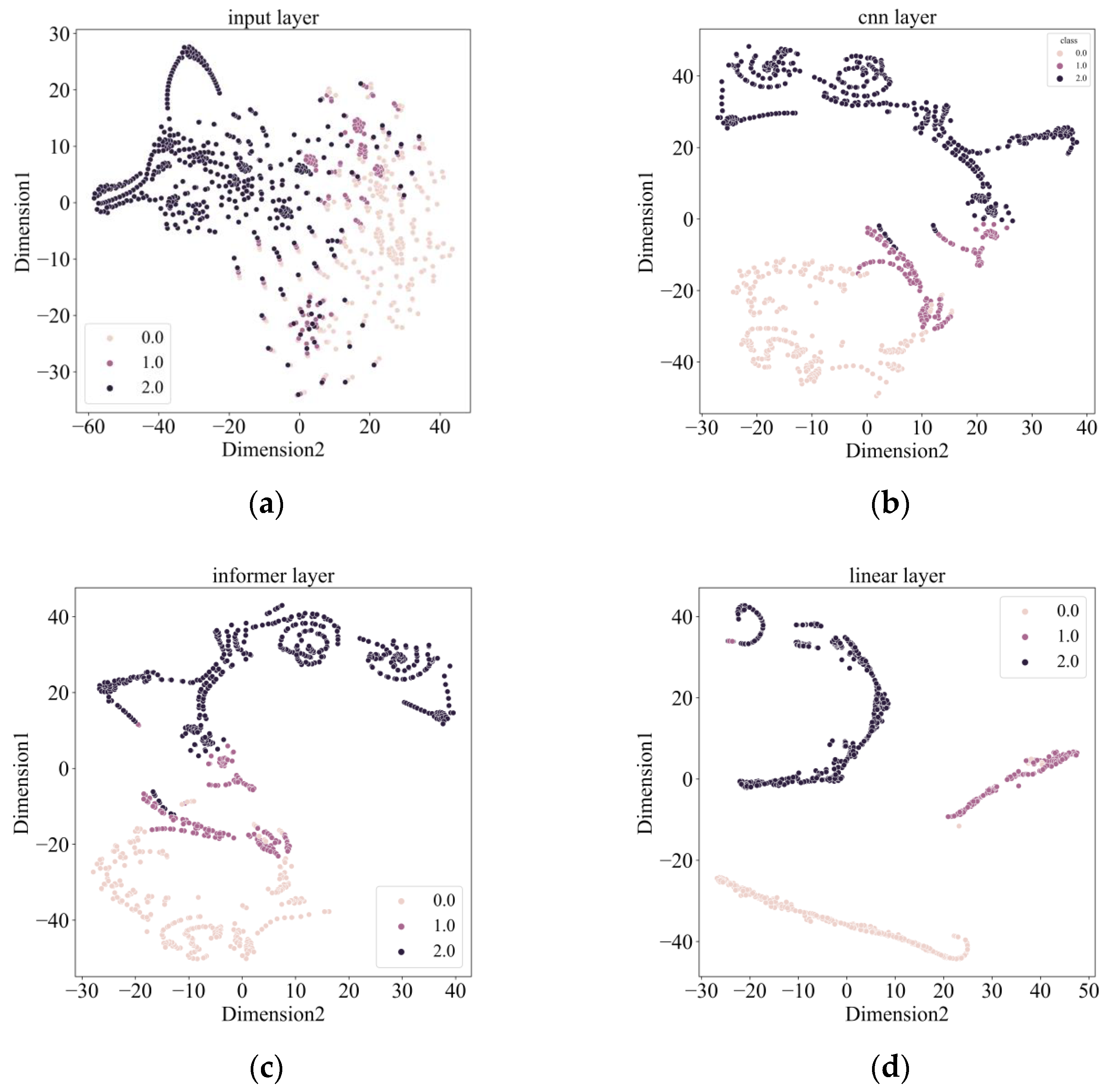
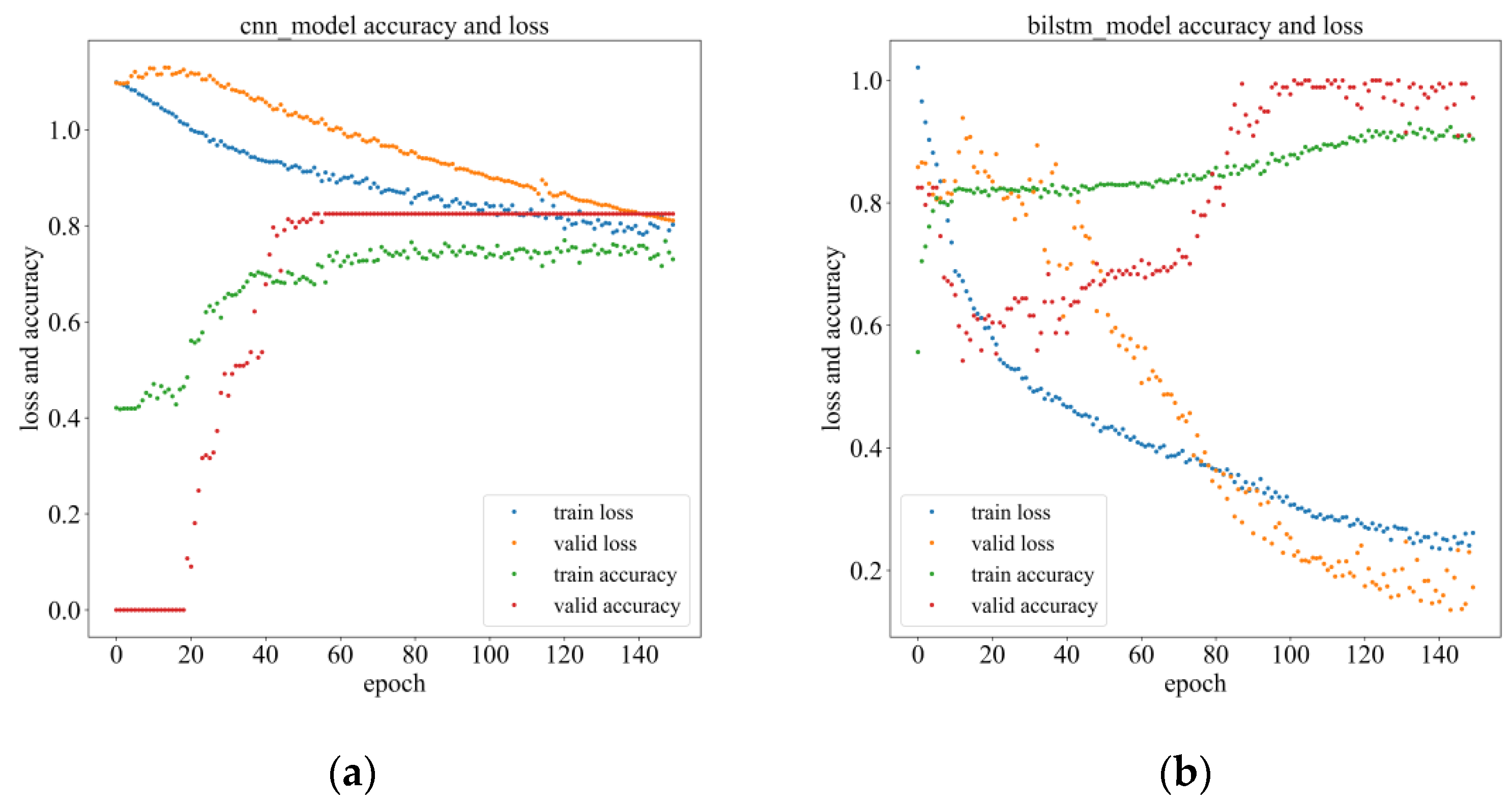
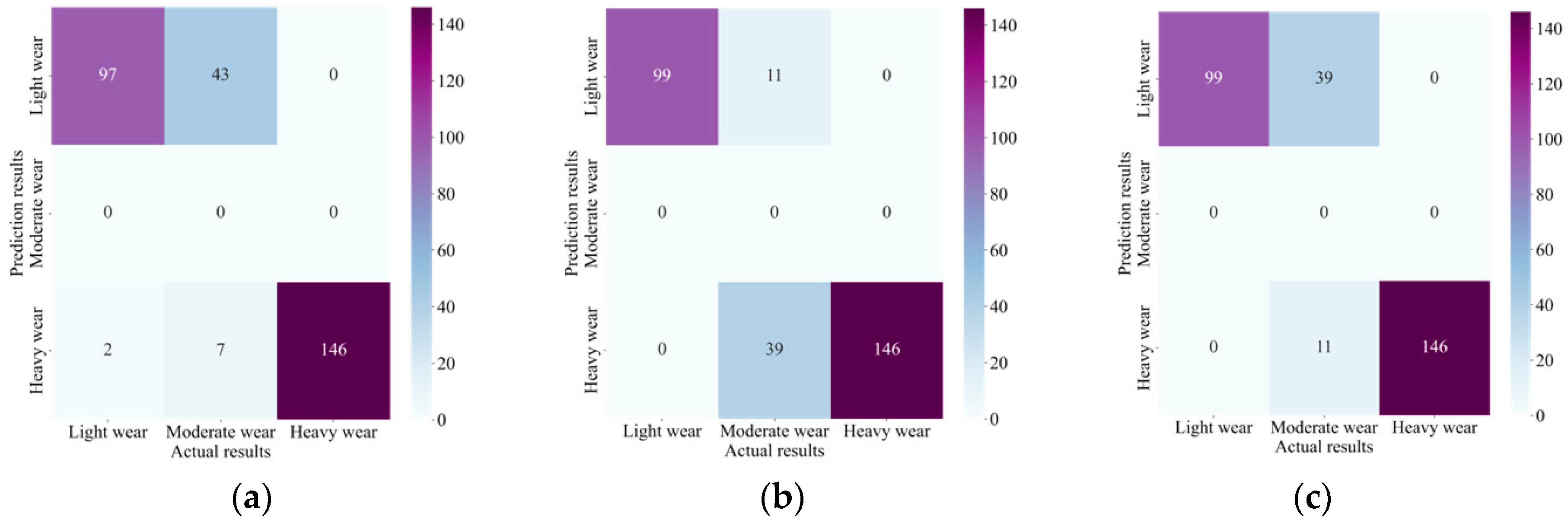
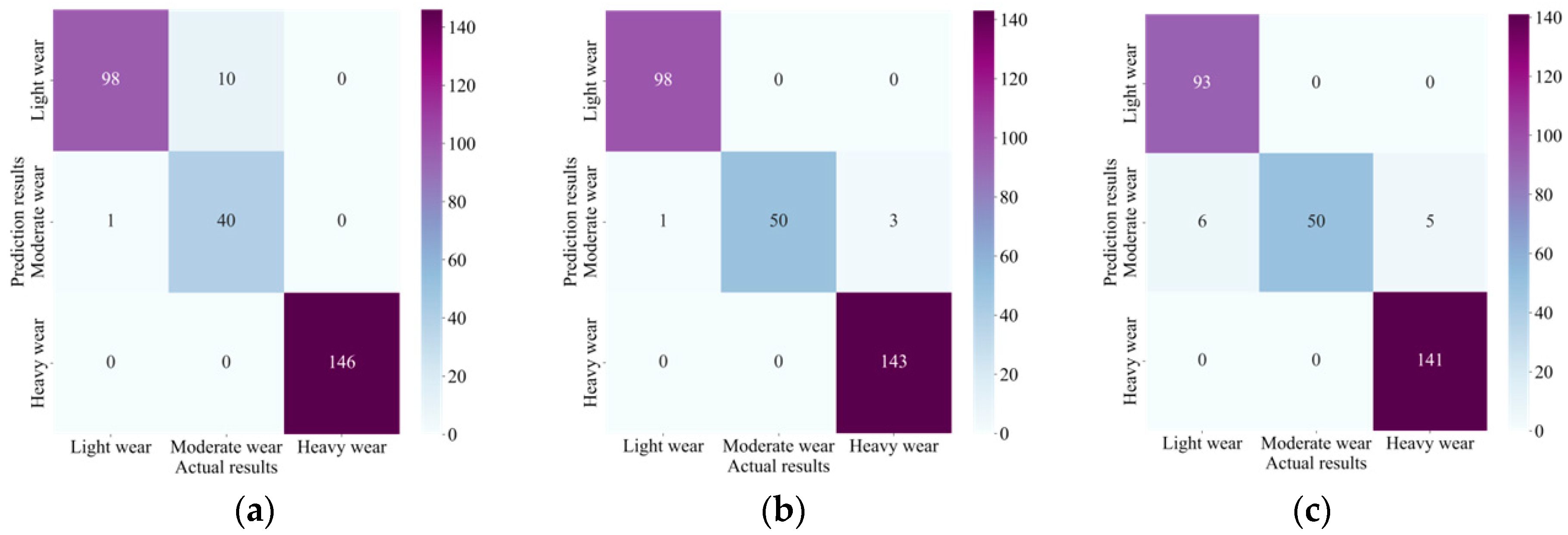
4.4. Results
4.5. Comparative Analysis
5. Conclusions
- (1)
- Experimental results reveal that the presented TWM approach based on CNN, Informer encoder, and BiLSTM has high accuracy in TWM. All of them reached over 95% in the relevant evaluation indexes, reflecting the excellent performance of the CIEBM model, which can efficiently classify and forecast the tool wear state.
- (2)
- In tool wear monitoring, CNN can extract spatial features from sensor data. Informer encoders can model long-term dependencies and capture global context information with ProbSparse Self-Attention and a feedforward neural network layer. BiLSTM captures temporal patterns and context information to further improve monitoring accuracy.
- (3)
- Our model is the first to use CNN, an Informer encoder, and BiLSTM together for tool wear condition monitoring, and it is also the first to target global feature modeling based on the non-linearity of the tool wear process to enable the model to better learn the relationship between the features of different wear stages. This is of great importance for further research.
- (4)
- Further analysis shows that our method has an excellent classification impact on normal and different degrees of wear, and the confusion between normal and heavy wear is slight, indicating that the method can effectively distinguish tool states with different degrees of wear.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Calculated output | |
| b | Shift factor |
| Weighting coefficient | |
| Sequence input value | |
| Activation function output | |
| Weight matrix | |
| Model input | |
| Q/q | Query vector |
| K/k | Key vector |
| V/v | Value vector |
| Number of vectors | |
| d | Length of vector |
| Attention score | |
| Forget gate output | |
| Previous cell state | |
| Input gate output | |
| Candidate | |
| New cell state | |
| Output gate output | |
| Hidden state | |
| TP | True positive |
| FN | False negative |
| FP | False positive |
| TN | True negative |
References
- Zhang, C.; Wang, W.; Li, H. Tool wear prediction method based on symmetrized dot pattern and multi-covariance Gaussian process regression. Measurement 2022, 189, 110466. [Google Scholar] [CrossRef]
- Shi, D.; Gindy, N.N. Tool wear predictive model based on least squares support vector machines. Mech. Syst. Signal Process 2007, 21, 1799–1814. [Google Scholar] [CrossRef]
- Gomes, M.C.; Brito, L.C.; da Silva, M.B.; Duarte, M.A.V. Tool wear monitoring in micromilling using Support Vector Machine with vibration and sound sensors. Precis. Eng. 2021, 67, 137–151. [Google Scholar] [CrossRef]
- Cheng, Y.; Gai, X.; Jin, Y.; Guan, R.; Lu, M.; Ding, Y. A new method based on a WOA-optimized support vector machine to predict the tool wear. Int. J. Adv. Manuf. Technol. 2022, 121, 6439–6452. [Google Scholar] [CrossRef]
- Gai, X.; Cheng, Y.; Guan, R.; Jin, Y.; Lu, M. Tool wear state recognition based on WOA-SVM with statistical feature fusion of multi-signal singularity. Int. J. Adv. Manuf. Technol. 2022, 123, 2209–2225. [Google Scholar] [CrossRef]
- Xu, D.; Qiu, H.; Gao, L.; Yang, Z.; Wang, D. A novel dual-stream self-attention neural network for remaining useful life estimation of mechanical systems. Reliab. Eng. Syst. Safe 2022, 222, 108444. [Google Scholar] [CrossRef]
- Liu, B.; Li, H.; Ou, J.; Wang, Z.; Sun, W. Intelligent recognition of milling tool wear status based on variational auto-encoder and extreme learning machine. Int. J. Adv. Manuf. Technol. 2022, 119, 4109–4123. [Google Scholar] [CrossRef]
- Liu, Z.; Hao, K.; Geng, X.; Zou, Z.; Shi, Z. Dual-Branched Spatio-Temporal Fusion Network for Multihorizon Tropical Cyclone Track Forecast. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3842–3852. [Google Scholar] [CrossRef]
- Dai, W.; Liang, K.; Wang, B. State Monitoring Method for Tool Wear in Aerospace Manufacturing Processes Based on a Convolutional Neural Network (CNN). Aerospace 2021, 8, 335. [Google Scholar] [CrossRef]
- García-Pérez, A.; Ziegenbein, A.; Schmidt, E.; Shamsafar, F.; Fernández-Valdivielso, A.; Llorente-Rodríguez, R.; Weigold, M. CNN-based in situ tool wear detection: A study on model training and data augmentation in turning inserts. J. Manuf. Syst. 2023, 68, 85–98. [Google Scholar] [CrossRef]
- Kothuru, A.; Nooka, S.P.; Liu, R. Application of deep visualization in CNN-based tool condition monitoring for end milling. Procedia Manuf. 2019, 34, 995–1004. [Google Scholar] [CrossRef]
- Wu, X.; Liu, Y.; Zhou, X.; Mou, A. Automatic Identification of Tool Wear Based on Convolutional Neural Network in Face Milling Process. Sensors 2019, 19, 3817. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Zhang, W.; Gao, S.; He, X.; Lu, J. Sensor Fault Diagnosis of Autonomous Underwater Vehicle Based on LSTM. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 6067–6072. [Google Scholar] [CrossRef]
- Xu, W.; Miao, H.; Zhao, Z.; Liu, J.; Sun, C.; Yan, R. Multi-Scale Convolutional Gated Recurrent Unit Networks for Tool Wear Prediction in Smart Manufacturing. Chin. J. Mech. Eng. 2021, 34, 53. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, B.; Li, X.; Liu, S.; Yue, C.; Liang, S.Y. An approach for tool wear prediction using customized DenseNet and GRU integrated model based on multi-sensor feature fusion. J. Intell. Manuf. 2023, 34, 885–902. [Google Scholar] [CrossRef]
- Cheng, M.; Jiao, L.; Yan, P.; Jiang, H.; Wang, R.; Qiu, T.; Wang, X. Intelligent tool wear monitoring and multi-step prediction based on deep learning model. J. Manuf. Syst. 2022, 62, 286–300. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.; Jia, W.; Zhang, D.; Wang, Q.; Tan, J. Tool wear estimation using a CNN-transformer model with semi-supervised learning. Meas. Sci. Technol. 2021, 32, 125010. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.; Jia, W.; Lin, X.; Zhang, S. A novel transformer-based neural network model for tool wear estimation. Meas. Sci. Technol. 2020, 31, 065106. [Google Scholar] [CrossRef]
- Lin, H.; Sun, Q. Financial Volatility Forecasting: A Sparse Multi-Head Attention Neural Network. Information 2021, 12, 419. [Google Scholar] [CrossRef]
- Zou, R.; Duan, Y.; Wang, Y.; Pang, J.; Liu, F.; Sheikh, S.R. A novel convolutional informer network for deterministic and probabilistic state-of-charge estimation of lithium-ion batteries. J. Energy Storage 2023, 57, 106298. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems 30 (NIPS 2017). In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Zhang, W. In Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar] [CrossRef]
- Li, R.; Ye, X.; Yang, F.; Du, K.L. ConvLSTM-Att: An Attention-Based Composite Deep Neural Network for Tool Wear Prediction. Machines 2023, 11, 297. [Google Scholar] [CrossRef]
- Xie, X.; Huang, M.; Liu, Y.; An, Q. Intelligent Tool-Wear Prediction Based on Informer Encoder and Bi-Directional Long Short-Term Memory. Machines 2023, 11, 94. [Google Scholar] [CrossRef]
- Li, W.; Liang, Y.; Wang, S. Data Driven Smart Manufacturing Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar] [CrossRef]
- Sun, M.; Liu, Z.; Zhang, M.; Liu, Y. Chinese computational linguistics and natural language processing based on naturally annotated big data. In Proceedings of the S14th China National Conference, CCL 2015 and Third International Symposium, NLP-NABD 2015, Guangzhou, China, 13–14 November 2015. [Google Scholar] [CrossRef]
- Cheng, Y.; Gai, X.; Guan, R.; Jin, Y.; Lu, M.; Ding, Y. Tool wear intelligent monitoring techniques in cutting: A review. J. Mech. Sci. Technol. 2023, 37, 289–303. [Google Scholar] [CrossRef]
- 2010 phm Society Conference Data Challenge 2010. Available online: https://phmsociety.org/competition/phm/10 (accessed on 6 September 2023).
- Huang, Q.; Wu, D.; Huang, H.; Zhang, Y.; Han, Y. Tool Wear Prediction Based on a Multi-Scale Convolutional Neural Network with Attention Fusion. Information 2022, 13, 504. [Google Scholar] [CrossRef]
- Du, M.; Wang, P.; Wang, J.; Cheng, Z.; Wang, S. Intelligent Turning Tool Monitoring with Neural Network Adaptive Learning. Complexity 2019, 2019, 8431784. [Google Scholar] [CrossRef]
- Bergs, T.; Holst, C.; Gupta, P.; Augspurger, T. Digital image processing with deep learning for automated cutting tool wear detection. Procedia Manuf. 2020, 48, 947–958. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape |
|---|---|
| Conv1D | (20, 16) |
| MaxPooling | (10, 16) |
| Informer Encoder | (10, 32) |
| LayerNormalization | (10, 32) |
| Attention | (10, 32) |
| Dropout | (10, 32) |
| Lstm | (10, 30) |
| Dropout | (10, 30) |
| Lstm | (10, 15) |
| Dropout | (10, 15) |
| Lstm | (1, 15) |
| Dropout | (1, 15) |
| Output | (1, 3) |
| Parameter | Value |
|---|---|
| Spindle | 10,400 (r/min) |
| Feed rate | 1555 (mm/min) |
| Depth of cut (y direction, radial) | 0.125 (mm) |
| Depth of cut (z direction, axial) | 0.2 (mm) |
| Sampling rate | 50 (kHz) |
| Workpiece material | Stainless steel (HRC52) |
| Degree of Wear | Light Wear | Moderate Wear | Heavy Wear |
|---|---|---|---|
| Wear loss (mm) | 0–0.12 | 0.12–0.17 | 0.17–0.30 |
| One-hot coding | 0 | 1 | 2 |
| Tool Number | Category | ||
|---|---|---|---|
| Light Wear | Moderate Wear | Heavy Wear | |
| C1 | 99 | 50 | 146 |
| C4 | 99 | 50 | 146 |
| C6 | 99 | 50 | 146 |
| Project | Value |
|---|---|
| Epoch | 150 |
| Batch size | 32 |
| Learning rate | 0.0001 |
| Dropout | 0.2 |
| Objective function | CrossEntropy Loss |
| Objective function | RMSprop |
| Activation function | ReLU |
| Bilstm Stack number | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Huang, M.; Sun, W.; Li, Y.; Liu, Y. Intelligent Tool Wear Monitoring Method Using a Convolutional Neural Network and an Informer. Lubricants 2023, 11, 389. https://doi.org/10.3390/lubricants11090389
Xie X, Huang M, Sun W, Li Y, Liu Y. Intelligent Tool Wear Monitoring Method Using a Convolutional Neural Network and an Informer. Lubricants. 2023; 11(9):389. https://doi.org/10.3390/lubricants11090389
Chicago/Turabian StyleXie, Xingang, Min Huang, Weiwei Sun, Yiming Li, and Yue Liu. 2023. "Intelligent Tool Wear Monitoring Method Using a Convolutional Neural Network and an Informer" Lubricants 11, no. 9: 389. https://doi.org/10.3390/lubricants11090389
APA StyleXie, X., Huang, M., Sun, W., Li, Y., & Liu, Y. (2023). Intelligent Tool Wear Monitoring Method Using a Convolutional Neural Network and an Informer. Lubricants, 11(9), 389. https://doi.org/10.3390/lubricants11090389