
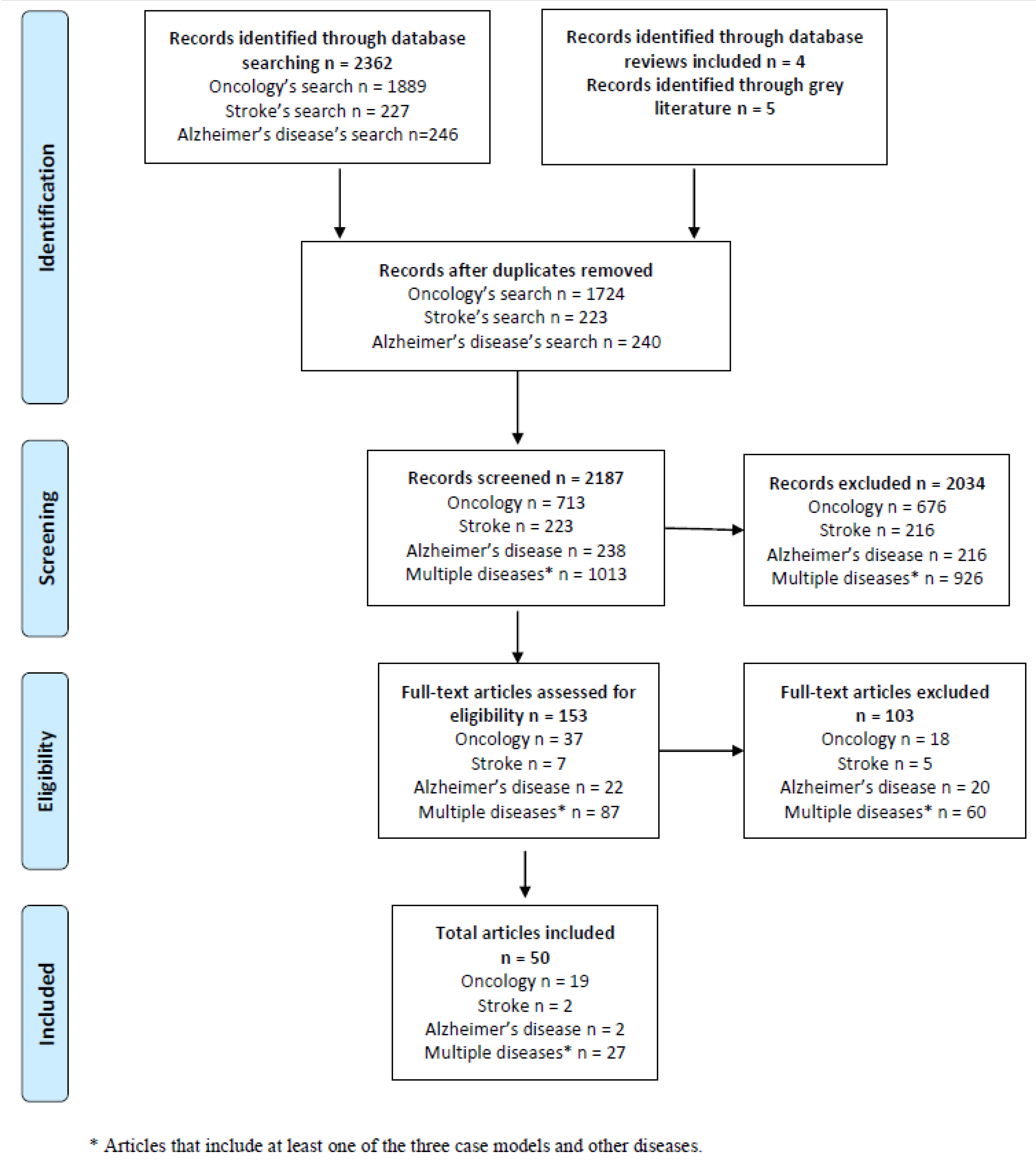
Methods for Stratification and Validation Cohorts: A Scoping Review

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Research Questions
- What are the differences, pros and cons of the prospective and retrospective design of stratification and validation cohorts?
- Which are the methods for defining the optimal size of stratification/validation cohorts? What are the prerequisites and methods used for the integration of multiple retrospective cohorts?
- What type of data (omics, imaging, exposome, lifestyle, etc.) are included and how are data generated?
- What are the tools used in personalized medicine for data management and multimodal data analysis?
- What quality of cohort data is needed to obtain a biomarker or multimodal data profiling? Are there requirements to monitor the collection of associated clinical data?
- Which current and reliable designs exist for the stratification (or clustering) in personalized medicine?
- Which methods and tools are used to build the cohorts for validation of patient strata?
- What are the methods for the evaluation of the risk of bias?
- What is the outlook of data generation seen as (CE-labelled) in vitro diagnostics?
2.2. Information Sources and Search of Studies
2.3. Selection of Sources of Evidence
2.4. Data Charting Process
2.5. Consultation Exercise
3. Results
3.1. What Are the Differences, Pros and Cons of the Prospective and Retrospective Design of Stratification and Validation Cohorts?
3.2. Which Are the Methods for Defining the Optimal Size of Stratification/Validation Cohorts? What Are the Prerequisites and Methods Used for the Integration of Multiple Retrospective Cohorts?
3.3. What Type of Data (Omics, Imaging, Exposome, Lifestyle, Etc.) Is Included and How Are Data Generated?
- Genetic variation data. This type of data is an unbiased source of the genetic basis of disease and allows the direct inference of causality.
- Epigenetics data. It is useful to know the functional impact and makes the inference of causality easy, but it does not apply to all phenotypes.
- Gene expression data. It shows the picture of an intermediate step towards the phenotype.
- Proteomics and metabolomics data. This type of data is the closest to the phenotype, but both data are expensive, especially proteomics.
- Microbiome data. It is very close to the phenotype and measures a combination of genetic and environmental influences. The combination of genetic and environmental influences makes it difficult to infer the direction of causality.
- Image and environmental data on different biological layers. These two types of data are hard to measure quantitatively [34].
3.4. What Are the Tools Used in Personalized Medicine for Data Management and Multimodal Data Analysis?
3.4.1. Methods and Tools for Data Management and Multi-Omics Data Analysis
3.4.2. Methods for Data Integration
3.5. What Quality of Cohort Data Is Needed to Obtain a Biomarker or Multimodal Data Profiling? Are There Requirements to Monitor the Collection of Associated Clinical Data?
3.6. Which Current and Reliable Designs Exist for the Stratification (or Clustering) in Personalized Medicine?
3.6.1. Oncology
3.6.2. Alzheimer’s Disease
3.6.3. Multiple Disease Reviews
3.7. Which Methods and Tools Are Used to Build the Cohorts for the Validation of Patient Strata?
3.7.1. Oncology
3.7.2. Multiple Disease Reviews
3.7.3. Stroke
3.8. What Are the Methods for the Evaluation of the Risk of Bias?
3.9. What Is the Outlook of Data Generation Seen as (CE-Labelled) In Vitro Diagnostics?
4. Discussion
4.1. Summary of Evidence
4.2. Gaps Detected in Stratification and Validation Cohorts in Personalized Medicine
4.3. Future Research and Guidelines Proposals
4.4. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Outline of Methods and Tools for Data Analysis and for Data Integration
Appendix A.1. Methods and Tools for Data Analysis
Appendix A.1.1. Oncology
- (A)
- Statistical method approaches.
- -
- Dimension reductionPrincipal Component Analysis (PCA) and Factor Analysis and variations. These variations include Multiple Factor Analysis (MFA), consensus PCA (CPCA), multiple-block PCA (MBPCA) and non-negative matrix factorization (NMF).
- -
- Data integration or data fusion.Multivariate, concatenation-based and transformation-based methods.Tools: R/Bioconductor packages MultiDataSet and MulltiAssay experiment (between others), and some tools more specific: Caleydo StratomeX, CAS-viewer, cBio Cancer Genomic Portal, Genboree Workbench, MARIO, mixOmics, ModulOmics, Omics Integrator and XENA UCSC browser.
- -
- Causal inferenceParallel regression, Bayesian networks, sparse generalized canonical correlation analysis (sGCCA), Multi-omics factor analysis (MOFA), Mendelian randomization, and Joint and Individual Variation Explained (JIVE), Inverse probability weighting and component-based method.
- -
- Criterion for predictor selection:Method of predictor selection used within multivariable analysisBackward selection, forward selection, added value of a specific predictor to existing predictors or model, all predictors included regardless of statistical significance and similar predictors combinedCriterion for selection of predictors in multivariable analysesp-Value cut-off at, 0.05 or lower, p-Value cut-off higher than 0.05, Akaike’s information criterion, Bayesian information criterion, explained variance (R2) and change in C-statistic.
- -
- Multiple imputation
- (B)
- Machine learning approach
- Support vector machine (SVM)
- Random forest (RF)
- Convolutional neural network (CNN)
- Deep learning
- (C)
- Network modelling approachTypes of networks: Protein–protein interaction (PPI) network, miRNAmRNA regulatory network and gene co-expression network.Analysis methods for networks:
- Network analysesTools: Cytoscape, ARACNe, WGCNA, IPA, Bibliosphere
- Enrichment analysis (Gene Set Enrichment Analysis)Tools: DAVID, g:Profiler, AmiGO, Onto-Tools, ClueGO Golorize, FatiGO, GoStat
- Analysis of protein interactionsTools: HPRDR, Bioconductor, Matlab, GenePattern, BIND, DIP, BioGRID, STRING, Annotator, Pfam, PROSITE, InterPro, ProDom, SMART, BLOCKS, UniProt
- Pathway analysisTools: Reactome, Cancer Cell Map, PathwayExplorer, GenMAPP, INOHGEO, ArrayExpress, SMD, Oncomine, PANTHER, Science signaling map
- Multistage or meta-dimensional fashion (as an example, for drawing inferences from these data, involves pairwise analyses of data sets).
Appendix A.1.2. Multiple Diseases
- (A)
- Statistical method approaches
- Dimension reduction
Principal Component Analysis (PCA) and Factor Analysis and variations. These variations include Multiple Factor Analysis (MFA), non-negative matrix factorization (NMF) of different kinds: iNMF, Joint NMF and regularized NMF.- Data integration or data fusion.
Multivariate analysis:Multiple co-inertia analysis (MCIA), Joint and Individual Variation Explained (JIVE), Joint NMF, Single vector decomposition (t-SVD), Sparse multi-block partial least squares (smBPLS), Penalized multivariate analysis (PMA), Feature selection multiple kernel learning (FSMKL), Non-negative matrix factorization (NMF), Graph-regularized non-negative matrix tri-factorization (GNMTF), Multiple factor analysis (MFA), Mocluster and Regularized multiple kernel learning- locality preserving projection (rMKL-LPP), Joint kernel matrices, Multiple similarities collaborative matrix factorization (MSCMF), CNAmetMultivariate, concatenation-based and transformation-based methods:Tools: R/Bioconductor packages mixOmics, Integromics, iPAC, Camelot- Causal inference
- Bayesian inference
Joint and Individual Variation Explained (JIVE), multi-omics factor analysis (MOFA)Bayesian consensus clustering (BCC), patient-specific data fusion (PSDF), Pathway Recognition Algorithm using Data Integration on Genomic Models (PARADIGM), iCluster, iClusterPlus, LRAcluster, Joint Bayesian factor, multi-omics factor analysis (MOFA), Multiple dataset integration (MDI), Molecular Regularized Consensus Patient Stratification (MRCPS), factor analysis-linear discriminant analysis (FALDA) - (B)
- Machine learning approachClassification considering five specific computational challenges associated with integrative analysis:
- Curse of dimensionality
Feature extraction (FE) or feature selection (FS)- Data heterogeneity
Tree-based learning, penalized linear models, Multiple Kernel Learning, Graphs and Networks, Latent Sub-space Clustering and Deep Learning)- Missing data
Single Imputation, Maximum likelihood, Multiple imputation, Matrix Factorization, Deep Learning/Autoencoder, Integrative imputation- Class imbalance
Data Sampling, Cost-Sensitive Learning and Evaluation Measure-based- Scalability issues
Efficient Algorithms for Big Data, Online Machine Learning, Distributed ML implementations and Cloud computing solutions- Specific methods of deep learning
Autoencoder, convolutional neural network, recurrent neural network, DNN-MDA (DNN, deep neural network; MDA, mean decrease accuracy) and DeepNovo. - (C)
- Network modelling approachPathway Recognition Algorithm using Data Integration on Genomic Models (PARADIGM), similarity network fusion (SNF), network-based (NBS), Coupled network propagation, Network completion, and NetICS.
Appendix A.1.3. Stroke
- (A)
- Statistical method approaches
- -
- Causal inference
Appendix A.2. Methods for Different Kinds of Data Integration
Appendix A.2.1. Multiple Disease
- Genetic risk scores, regression methods and Bayesian networks.
- Constraint-based modelling
- Methods that allow to overcome multicollinearity problem while modelling huge number of variables:
Appendix A.2.2. Oncology
References
- Di Paolo, A.; Sarkozy, F.; Ryll, B.; Siebert, U. Personalized medicine in Europe: Not yet personal enough? BMC Health Serv. Res. 2017, 17, 289. [Google Scholar] [CrossRef] [PubMed]
- Fröhlich, H.; Balling, R.; Beerenwinkel, N.; Kohlbacher, O.; Kumar, S.; Lengauer, T.; Maathuis, M.T.; Moreau, Y.; Murphy, S.A.; Przytycka, T.M.; et al. From hype to reality: Data science enabling personalized medicine. BMC Med. 2018, 16, 150. [Google Scholar] [CrossRef] [PubMed]
- Personalized Medicine Coalition. Available online: http://www.personalizedmedicinecoalition.org (accessed on 25 July 2021).
- Schleidgen, S.; Klingler, C.; Rogowski, W.H.; Marckmann, G. What is personalised medicine? Sharpening a vague term based on a systematic literature review. BMC Med. Ethics 2013, 14, 55. [Google Scholar] [CrossRef] [PubMed]
- De Grandis, G.; Halgunset, V. Conceptual and terminological confusion around personalised medicine: A coping strategy. BMC Med. Ethics 2016, 17, 43. [Google Scholar] [CrossRef] [PubMed]
- Crosby, D.; Bossuyt, P.; Brocklehurst, P.; Chamberlain, C.; Dive, C.; Holmes, C.; Isaacs, J.; Kennedy, R.; Matthews, F.; Parmar, M.; et al. The MRC Framework for the Development, Design and Analysis of Stratified Medicine Research. UK Medical Research Council. 2018. Available online: https://eprints.ncl.ac.uk/245866 (accessed on 25 July 2021).
- Pham, M.T.; Rajić, A.; Greig, J.D.; Sargeant, J.M.; Papadopoulos, A.; McEwen, S.A. A scoping review of scoping reviews: Advancing the approach and enhancing the consistency. Res. Synth. Methods 2014, 5, 371–385. [Google Scholar] [CrossRef]
- Munn, Z.; Peters, M.D.J.; Stern, C.; Tufanaru, C.; McArthur, A.; Aromataris, E. Systematic review or scoping review? Guidance for authors when choosing between a systematic or scoping review approach. BMC Med. Res. Methodol. 2018, 18, 143. [Google Scholar] [CrossRef]
- Council, E. Council conclusions on personalised medicine for patients. Off. J. Eur. Union 2015, 431, 1–4. [Google Scholar]
- Banzi, R.; Gerardi, C.; Fratelli, M.; Garcia, P.; Torres, T.; Haro, J.M.; Sanchez Niubo, A.; Glaab, E.; Oldoni, E.; Bietrix, F.; et al. Methodological approaches for personalised medicine: A series of scoping reviews Protocol V.2. Zenodo 2020, 1–20. [Google Scholar] [CrossRef]
- Peters, M.; Godfrey, C.; McInerney, P.; Soares, C.; Khalil, H.; Parker, D. The Joanna Briggs Institute Reviewers’ Manual 2015: Methodology for JBI Scoping Reviews; Adelaide Joanna Briggs Institute: Adelaide, Australia, 2015. [Google Scholar]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Blucher, A.S.; Mills, G.B.; Tsang, Y.H. Precision oncology for breast cancer through clinical trials. Clin. Exp. Metastasis 2021, 39, 71–78. [Google Scholar] [CrossRef]
- Crimini, E.; Repetto, M.; Aftimos, P.; Botticelli, A.; Marchetti, P.; Curigliano, G. Precision medicine in breast cancer: From clinical trials to clinical practice. Cancer Treat. Rev. 2021, 98, 102223. [Google Scholar] [CrossRef]
- Forloni, G. Alzheimer’s disease: From basic science to precision medicine approach. BMJ Neurol. Open 2020, 2, e000079. [Google Scholar] [CrossRef]
- Herrgårdh, T.; Madai, V.I.; Kelleher, J.D.; Magnusson, R.; Gustafsson, M.; Milani, L.; Gennemark, P.; Cedersund, G. Hybrid modelling for stroke care: Review and suggestions of new approaches for risk assessment and simulation of scenarios. NeuroImage Clin. 2021, 31, 102694. [Google Scholar] [CrossRef] [PubMed]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan-a web and mobile app for systematic reviews. Syst. Rev. 2016, 5, 1–10. [Google Scholar] [CrossRef]
- Sung, J.Y.; Wang, Y.L.; Chandrasekaran, S.; Witten, D.M.; Price, N.D. Molecular signatures from omics data: From chaos to consensus. Biotechnol. J. 2012, 7, 946–957. [Google Scholar] [CrossRef] [PubMed]
- Ensor, J.E. Biomarker validation: Common data analysis concerns. Oncologist 2014, 19, 886–891. [Google Scholar] [CrossRef] [PubMed]
- Flynn, A.A. Pharmacogenetics: Practices and opportunities for study design and data analysis. Drug Discov. Today 2011, 16, 862–866. [Google Scholar] [CrossRef]
- Moons, K.G.M.; Royston, P.; Vergouwe, Y.; Grobbee, D.E.; Altman, D.G. Prognosis and prognostic research: What, why, and how? BMJ 2009, 338, 1317–1320. [Google Scholar] [CrossRef]
- Bouwmeester, W.; Zuithoff, N.P.A.; Mallett, S.; Geerlings, M.I.; Vergouwe, Y.; Steyerberg, E.W.; Altman, D.G.; Moons, K.G. Reporting and methods in clinical prediction research: A systematic review. PLoS Med. 2012, 9, e1001221-12. [Google Scholar] [CrossRef]
- Baker, S.G.; Kramer, B.S.; McIntosh, M.; Patterson, B.H.; Shyr, Y.; Skates, S. Evaluating markers for the early detection of cancer: Overview of study designs and methods. Clin. Trials 2006, 3, 43–56. [Google Scholar] [CrossRef]
- Hamada, T.; Nowak, J.A.; Milner, D.A., Jr.; Song, M.; Ogino, S. Integration of microbiology, molecular pathology, and epidemiology: A new paradigm to explore the pathogenesis of microbiome-driven neoplasms. J. Pathol. 2019, 247, 615–628. [Google Scholar] [CrossRef]
- Zalcman, G.; Bergot, E.; Creveuil, C.; Levallet, G.; Lechapt, E. Integrating biomarkers into clinical trials: Methodological issues for a new paradigm in nonsmall cell lung cancer. Curr. Opin. Oncol. 2011, 23, 106–111. [Google Scholar] [CrossRef]
- Shahinas, J.; Hysi, D. Methods and risk of bias in molecular marker prognosis studies in oral squamous cell carcinoma. Oral. Dis. 2018, 24, 115–119. [Google Scholar] [CrossRef]
- Bradley, A.; van der Meer, R.; McKay, C. Personalized pancreatic cancer management: A systematic review of how machine learning is supporting decision-making. Pancreas 2019, 48, 598–604. [Google Scholar] [CrossRef] [PubMed]
- Borad, M.J.; LoRusso, P.M. Twenty-first century precision medicine in oncology: Genomic profiling in patients with cancer. Mayo Clin. Proc. 2017, 92, 1583–1591. [Google Scholar] [CrossRef] [PubMed]
- Pesch, B.; Brüning, T.; Johnen, G.; Casjens, S.; Bonberg, N.; Taeger, D.; Müller, A.; Weber, D.G.; Behrens, T. Biomarker research with prospective study designs for the early detection of cancer. Biochim. Biophys. Acta 2014, 1844, 874–883. [Google Scholar] [CrossRef] [PubMed]
- Hayes, D.F. From genome to bedside: Are we lost in translation? Breast 2013, 22 (Suppl. 2), S22–S26. [Google Scholar] [CrossRef] [PubMed]
- Parikh, R.B.; Gdowski, A.; Patt, D.A.; Hertler, A.; Mermel, C.; Bekelman, J.E. Using big data and predictive analytics to determine patient risk in oncology. Am. Soc. Clin. Oncol. Educ. Book 2019, 39, e53–e58. [Google Scholar] [CrossRef]
- Ard, M.C.; Edland, S.D. Power calculations for clinical trials in Alzheimer’s disease. J. Alzheimer’s Dis. 2011, 2, 653–661. [Google Scholar] [CrossRef] [PubMed]
- Hackl, H.; Stocker, G.; Charoentong, P.; Mlecnik, B.; Bindea, G.; Galon, J.; Trajanoski, Z. Information technology solutions for integration of biomolecular and clinical data in the identification of new cancer biomarkers and targets for therapy. Pharmacol. Ther. 2010, 128, 488–498. [Google Scholar] [CrossRef]
- Lin, Y.; Zhao, X.; Miao, Z.; Ling, Z.; Wei, X.; Pu, J.; Hou, J.; Shen, B. Data-driven translational prostate cancer research: From biomarker discovery to clinical decision. J. Transl. Med. 2020, 18, 119. [Google Scholar] [CrossRef] [PubMed]
- Abraham, J.A.; Golubnitschaja, O. Time for paradigm change in management of hepatocellular carcinoma: Is a personalized approach on the horizon? Pers. Med. 2016, 13, 455–467. [Google Scholar] [CrossRef] [PubMed]
- Verma, M. Mechanistic and Technical Challenges in Studying the Human Microbiome and Cancer Epidemiology. Technol. Cancer Res. Treat. 2017, 16, 150–158. [Google Scholar] [CrossRef] [PubMed]
- Zanfardino, M.; Franzese, M.; Pane, K.; Cavaliere, C.; Monti, S.; Esposito, G.; Salvatore, M.; Aiello, M. Bringing radiomics into a multi-omics framework for a comprehensive genotype-phenotype characterization of oncological diseases. J. Transl. Med. 2019, 17, 337. [Google Scholar] [CrossRef]
- Karczewski, K.J.; Snyder, M.P. Integrative omics for health and disease. Nat. Rev. Genet. 2018, 19, 299–310. [Google Scholar] [CrossRef] [PubMed]
- Cazaly, E.; Saad, J.; Wang, W.Y.; Heckman, C.; Ollikainen, M.; Tang, J. Making Sense of the Epigenome Using Data Integration Approaches. Front. Pharmacol. 2019, 10, 126. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P.A. A roadmap for successful applications of clinical proteomics. Proteom. Clin. Appl. 2011, 5, 241–247. [Google Scholar] [CrossRef]
- Ritchie, M.D.; Holzinger, E.R.; Li, R.W.; Pendergrass, S.A.; Kim, D. Methods of integrating data to uncover genotype-phenotype interactions. Nat. Rev. Genet. 2015, 16, 85–97. [Google Scholar] [CrossRef]
- Ransohoff, D.F. Proteomics research to discover markers: What can we learn from Netflix? Clin. Chem. 2010, 56, 172–176. [Google Scholar] [CrossRef] [PubMed]
- Angione, C. Human Systems Biology and Metabolic Modelling: A ReviewFrom Disease Metabolism to Precision Medicine. Biomed. Res. Int. 2019, 2019, 8304260. [Google Scholar] [CrossRef]
- Grapov, D.; Fahrmann, J.; Wanichthanarak, K.; Khoomrung, S. Rise of Deep Learning for Genomic, Proteomic, and Metabolomic Data Integration in Precision Medicine. Omics A J. Integr. Biol. 2018, 22, 630–636. [Google Scholar] [CrossRef] [PubMed]
- Casamassimi, A.; Federico, A.; Rienzo, M.; Esposito, S.; Ciccodicola, A. Transcriptome profiling in human diseases: New advances and perspectives. Int. J. Mol. Sci. 2017, 18, 1652. [Google Scholar] [CrossRef] [PubMed]
- Schrodi, S.J.; Yingshan, S.; Shan, Y.; Tromp, G.; Sninsky, J.J.; Callear, A.P.; Carter, T.C.; Ye, Z.; Haines, J.L.; Brilliant, M.H.; et al. Genetic-based prediction of disease traits: Prediction is very difficult, especially about the future. Front. Genet. 2014, 5, 162. [Google Scholar] [CrossRef] [PubMed]
- Habes, M.; Grothe, M.J.; Tunc, B.; McMillan, C.; Wolk, D.A.; Davatzikos, C. Disentangling Heterogeneity in Alzheimer’s Disease and Related Dementias Using Data-Driven Methods. Biol. Psychiatry 2020, 88, 70–82. [Google Scholar] [CrossRef]
- Swerdlow, D.I.; Hingorani, A.D.; Humphries, S.E. Genetic Risk Factors and Mendelian Randomization in Cardiovascular Disease. Curr. Cardiol. Rep. 2015, 17, 33. [Google Scholar] [CrossRef] [PubMed]
- Edwardson, M.A.; Fernandez, S.J. Recruiting Control Participants into Stroke Biomarker Studies. Transl. Stroke Res. 2020, 11, 861–870. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, I.; Verma, S.; Kumar, S.; Jere, A.; Anamika, K. Multi-omics Data Integration, Interpretation, and Its Application. Bioinform. Biol. Insights 2020, 14, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Gligorijevic, V.; Malod-Dognin, N.; Przulj, N. Integrative methods for analyzing big data in precision medicine. Proteomics 2016, 16, 741–758. [Google Scholar] [CrossRef]
- Mirza, B.; Wang, W.; Wang, J.; Choi, H.; Chung, N.C.; Ping, P. Machine Learning and Integrative Analysis of Biomedical Big Data. Genes 2019, 10, 87. [Google Scholar] [CrossRef]
- De Maturana, E.L.; Pineda, S.; Brand, A.; Van Steen, K.; Malats, N. Toward the integration of Omics data in epidemiological studies: Still a “long and winding road”. Genet. Epidemiol. 2016, 40, 558–569. [Google Scholar] [CrossRef] [PubMed]
- Desai, M.; Kubo, J.; Esserman, D.; Terry, M.B. The handling of missing data in molecular epidemiology studies. Cancer Epidemiol. Biomark. Prev. 2011, 20, 1571–1579. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Parimbelli, E.; Marini, S.; Sacchi, L.; Bellazzi, R. Patient similarity for precision medicine: A systematic review. J. Biomed. Inf. 2018, 83, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Bersanelli, M.; Mosca, E.; Remondini, D.; Giampieri, E.; Sala, C.; Castellani, G.; Milanesi, L. Methods for the integration of multi-omics data: Mathematical aspects. BMC Bioinform. 2016, 17, 167–177. [Google Scholar] [CrossRef] [PubMed]
- Anderson, D.C.; Kodukula, K. Biomarkers in pharmacology and drug discovery. Biochem. Pharmacol. 2014, 87, 172–188. [Google Scholar] [CrossRef]
- Hurgobin, B.; de Jong, E.; Bosco, A. Insights into respiratory disease through bioinformatics. Respirology 2018, 23, 1117–1126. [Google Scholar] [CrossRef] [PubMed]
- De Maturana, E.L.; Alonso, L.; Alarcón, P.; Martín-Antoniano, I.A.; Pineda, S.; Piorno, L. Challenges in the integration of omics and non-omics data. Genes 2019, 10, 238. [Google Scholar] [CrossRef] [PubMed]
- Roden, D.M.; Denny, J.C. Integrating electronic health record genotype and phenotype datasets to transform patient care. Clin. Pharmacol. Ther. 2016, 99, 298–305. [Google Scholar] [CrossRef] [PubMed]
- Eyassu, F.; Angione, C. Modelling pyruvate dehydrogenase under hypoxia and its role in cancer metabolism. R. Soc. Open Sci. 2017, 4, 170360. [Google Scholar] [CrossRef] [PubMed]
- Yaneske, E.; Angione, C. The poly-omics of ageing through individual-based metabolic modelling. BMC Bioinform. 2018, 19, 415–496. [Google Scholar] [CrossRef]
- Austin, P.C. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivar. Behav. Res. 2011, 46, 399–424. [Google Scholar] [CrossRef] [PubMed]
- Rundle, A.; Ahsan, H.; Vineis, P. Better cancer biomarker discovery through better study design. Eur. J. Clin. Investig. 2012, 42, 1350–1359. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A.; Bossuyt, P.M.M. Waste, Leaks, and Failures in the Biomarker Pipeline. Clin. Chem. 2017, 63, 963–972. [Google Scholar] [CrossRef] [PubMed]
- Food and Drug Administration. Diagnostics In Vitro. 2019. Available online: https://www.fda.gov/medical-devices/products-and-medical-procedures/in-vitro-diagnostics#:~:text=In%20vitro%20diagnostics%20are%20tests,%202C%20treat%2C%20or%20prevent%20diseases (accessed on 27 July 2021).
- Food and Drug Administration. Principles for Codevelopment of an In Vitro Companion Diagnostic Device with a Therapeutic Product; FDA: Silver Spring, MD, USA, 2016; pp. 1–48. Available online: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/principles-codevelopment-vitro-companion-diagnostic-device-therapeutic-product (accessed on 27 July 2021).
- Food and Drug Administration. Companion Diagnostics. Available online: https://www.fda.gov/medical-devices/vitro-diagnostics/companion-diagnostics (accessed on 26 July 2021).
- TUVSUD. In Vitro Diagnostic Medical Device Regulation (IVDR). Available online: https://www.tuvsud.com/en-ae/industries/healthcare-and-medical-devices/medical-devices-and-ivd/medical-device-market-approval-and-certification/eu-in-vitro-diagnostic-medical-device-regulation/faqs-in-vitro-diagnostic-medical-device-regulation-ivdr (accessed on 26 July 2021).
- European Comission. In Vitro Diagnostic Medical Devices. Directive 98/79/EC. Available online: https://ec.europa.eu/growth/single-market/european-standards/harmonised-standards/iv-diagnostic-medical-devices_en (accessed on 26 July 2021).
- Mordor Inteligence. 2019. Available online: https://www.mordorintelligence.com/industry-reports/in-vitro-diagnostics-market?gclid=EAIaIQobChMIm7KXq-Dt7AIVmO3tCh2dcwmLEAAYASAAEgIkhPD_BwE (accessed on 26 July 2021).
- Kalorama Information. 2020. Available online: https://kaloramainformation.com/the-in-vitro-diagnostics-market/ (accessed on 26 July 2021).
- Zion Market Research. 2019. Available online: https://www.zionmarketresearch.com/news/in-vitro-diagnostics-market (accessed on 26 July 2021).
- Graphical Research. Available online: https://www.graphicalresearch.com/industry-insights/1019/europe-in-vitro-diagnostics-market?gclid=EAIaIQobChMIm7KXq-Dt7AIVmO3tCh2dcwmLEAAYAiAAEgL8KPD_BwE (accessed on 26 July 2021).
- Mintz, R.L.; Gao, M.A.; Lo, K.; Lao, Y.H.; Li, M.; Leong, K.W. CRISPR Technology for Breast Cancer: Diagnostics, Modeling, and Therapy. Adv. Biosyst. 2018, 2, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Palmirotta, R.; Lovero, D.; Cafforio, P.; Felici, C.; Mannavola, F.; Pellè, E.; Quaresmini, D.; Tucci, M.; Silvestris, F. Liquid biopsy of cancer: A multimodal diagnostic tool in clinical oncology. Ther. Adv. Vaccines 2018, 9, 259–261. [Google Scholar] [CrossRef] [PubMed]
- Beltrán-García, J.; Osca-Verdegal, R.; Mena-Mollá, S.; García-Giménez, J.L. Epigenetic IVD tests for personalized precision medicine in cancer. Front. Genet. 2019, 10, 621. [Google Scholar] [CrossRef]
- Cortés, J.; González, J.A.; Medina, M.N.; Vogler, M.; Vilaró, M.; Elmore, M.; Senn, S.J.; Campbell, M.; Cobo, E. Does evidence support the high expectations placed in precision medicine? A bibliographic review. F1000Research 2019, 7, 30. [Google Scholar] [CrossRef]
- Kourou, K.D.; Pezoulas, V.C.; Georga, E.I.; Exarchos, T.P.; Tsanakas, P.; Tsiknakis, M.; Varvarigou, T.; De Vita, S.; Tzioufas, A.; Fotiadis, D.I. Cohort Harmonization and Integrative Analysis from a Biomedical Engineering Perspective. IEEE Rev. Biomed. Eng. 2018, 12, 303–318. [Google Scholar] [CrossRef]
- Schmid, K.T.; Cruceanu, C.; Böttcher, A.; Lickert, H.; Binder, E.B.; Theis, F.J.; Heinig, M. Design and power analysis for multi-sample single cell genomics experiments. bioRxiv 2020, 1–30. [Google Scholar] [CrossRef]
- Hong, E.P.; Park, J.W. Sample Size and Statistical Power Calculation in Genetic Association Studies. Genom. Inform. 2012, 10, 117. [Google Scholar] [CrossRef] [PubMed]
- Broadhurst, D.I.; Kell, D.B. Statistical strategies for avoiding false discoveries in metabolomics and related experiments. Metabolomics 2006, 2, 171–196. [Google Scholar] [CrossRef]
- Tarazona, S.; Balzano-Nogueira, L.; Gómez-Cabrero, D.; Schmidt, A.; Imhof, A.; Hankemeier, T.; Tegnér, J.; Westerhuis, J.; Conesa, A. Harmonization of quality metrics and power calculation in multi-omic studies. Nat. Commun. 2020, 11, 3092. [Google Scholar] [CrossRef]
- Karp, N.A.; Lilley, K.S. Design and analysis issues in quantitative proteomics studies. Proteom.-Pract. Proteom. 2007, 2, 42–50. [Google Scholar] [CrossRef] [PubMed]
- Ching, T.; Huang, S.; Garmire, L.X. Power analysis and sample size estimation for RNA-Seq differential expression. RNA 2014, 20, 1684–1696. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Wu, H. Experimental Design and Power Calculation for RNA-seq Experiments. In Statistical Genomics; Humana Press: New York, NY, USA, 2017; pp. 141–148. [Google Scholar] [CrossRef]


{kind=link}
| Methods and Tools | Most Frequent Strategy Used | |
|---|---|---|
| Within-Subject Correlation |
|
|
| Multiplicity |
|
|
| Multiple Clinical Endpoints |
|
|
| Selection bias |
|
|
| Publication bias |
|
|
| Methods and Tools | Most Frequent Strategy Used | |
|---|---|---|
| Within-Subject Correlation |
|
|
| Multiplicity |
|
|
| Multiple Clinical Endpoints |
|
|
| Selection bias |
|
|
| Publication bias |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres Moral, T.; Sanchez-Niubo, A.; Monistrol-Mula, A.; Gerardi, C.; Banzi, R.; Garcia, P.; Demotes-Mainard, J.; Haro, J.M.; the PERMIT Group. Methods for Stratification and Validation Cohorts: A Scoping Review. J. Pers. Med. 2022, 12, 688. https://doi.org/10.3390/jpm12050688
Torres Moral T, Sanchez-Niubo A, Monistrol-Mula A, Gerardi C, Banzi R, Garcia P, Demotes-Mainard J, Haro JM, the PERMIT Group. Methods for Stratification and Validation Cohorts: A Scoping Review. Journal of Personalized Medicine. 2022; 12(5):688. https://doi.org/10.3390/jpm12050688
Chicago/Turabian StyleTorres Moral, Teresa, Albert Sanchez-Niubo, Anna Monistrol-Mula, Chiara Gerardi, Rita Banzi, Paula Garcia, Jacques Demotes-Mainard, Josep Maria Haro, and the PERMIT Group. 2022. "Methods for Stratification and Validation Cohorts: A Scoping Review" Journal of Personalized Medicine 12, no. 5: 688. https://doi.org/10.3390/jpm12050688
APA StyleTorres Moral, T., Sanchez-Niubo, A., Monistrol-Mula, A., Gerardi, C., Banzi, R., Garcia, P., Demotes-Mainard, J., Haro, J. M., & the PERMIT Group. (2022). Methods for Stratification and Validation Cohorts: A Scoping Review. Journal of Personalized Medicine, 12(5), 688. https://doi.org/10.3390/jpm12050688