
Using Domain Knowledge and Data-Driven Insights for Patient Similarity Analytics

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
- Euclidean distance on normalized input data.
- Locally supervised metric learning (LSML) [15]. LSML is a metric learning method to find an optimal weight vector that maximizes local class discriminability. Here, we train LSML on normalized input data with macrovascular complication as the label.
3. Results
3.1. Models Performance
3.2. Kappa Statistics
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Diabetes. 2020. Available online: https://www.who.int/news-room/fact-sheets/detail/diabetes (accessed on 19 March 2021).
- World Health Organization. Hypertension. 2019. Available online: https://www.who.int/news-room/fact-sheets/detail/hypertension (accessed on 19 March 2021).
- World Health Organization. Global Health Observatory (GHO) Data. 2008. Available online: https://www.who.int/gho/ncd/risk_factors/cholesterol_text/en/ (accessed on 19 March 2021).
- Williams, R.; Karuranga, S.; Malanda, B.; Saeedi, P.; Basit, A.; Besançon, S.; Bommer, C.; Esteghamati, A.; Ogurtsova, K.; Zhang, P.; et al. Global and regional estimates and projections of diabetes-related health expenditure: Results from the International Diabetes Federation Diabetes Atlas. Diabetes Res. Clin. Pract. 2020, 162, 108072. [Google Scholar] [CrossRef] [Green Version]
- Papatheodorou, K.; Banach, M.; Bekiari, E.; Rizzo, M.; Edmonds, M. Complications of diabetes 2017. Hindawi 2018, 2018, 3086167. [Google Scholar] [CrossRef] [PubMed]
- Sharafoddini, A.; Dubin, J.A.; Lee, J. Patient similarity in prediction models based on health data: A scoping review. JMIR Med. Inform. 2017, 5, e7. [Google Scholar] [CrossRef] [Green Version]
- Seligson, N.D.; Warner, J.L.; Dalton, W.S.; Martin, D.; Miller, R.S.; Patt, D.; Kehl, K.L.; Palchuk, M.B.; Alterovitz, G.; Wiley, L.K.; et al. Recommendations for patient similarity classes: Results of the AMIA 2019 workshop on defining patient similarity. J. Am. Med. Inform. Assoc. 2020, 27, 1808–1812. [Google Scholar] [CrossRef]
- Lean, M.E.; Leslie, W.S.; Barnes, A.C.; Brosnahan, N.; Thom, G.; McCombie, L.; Peters, C.; Zhyzhneuskaya, S.; Al-Mrabeh, A.; Hollingsworth, K.G.; et al. Primary care-led weight management for remission of type 2 diabetes (DiRECT): An open-label, cluster-randomised trial. Lancet 2018, 391, 541–551. [Google Scholar] [CrossRef] [Green Version]
- Chow, C.K.; Thakkar, J.; Bennett, A.; Hillis, G.; Burke, M.; Usherwood, T.; Vo, K.; Rogers, K.; Atkins, E.; Webster, R.; et al. Quarter-dose quadruple combination therapy for initial treatment of hypertension: Placebo-controlled, crossover, randomised trial and systematic review. Lancet 2017, 389, 1035–1042. [Google Scholar] [CrossRef]
- Bove, M.; Cicero, A.F.G.; Borghi, C. Emerging drugs for the treatment of hypercholesterolemia. Expert Opin. Emerg. Drugs 2019, 24, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Vitali, F.; Marini, S.; Pala, D.; de Martini, A.; Montoli, S.; Zambelli, A.; Bellazzi, R. Patient similarity by joint matrix trifactorization to identify subgroups in acute myeloid leukemia. JAMIA Open 2018, 1, 75–86. [Google Scholar] [CrossRef] [Green Version]
- Batal, I.; Valizadegan, H.; Cooper, G.F.; Hauskrecht, M. A temporal pattern mining approach for classifying electronic health record data. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 4, 1–22. [Google Scholar] [CrossRef]
- Jauregibeitia, I.; Portune, K.; Rica, I.; Tueros, I.; Velasco, O.; Grau, G.; Castaño, L.; di Nolfo, F.; Ferreri, C.; Arranz, S. Potential of Erythrocyte Membrane Lipid Profile as a Novel Inflammatory Biomarker to Distinguish Metabolically Healthy Obesity in Children. J. Pers. Med. 2021, 11, 337. [Google Scholar] [CrossRef] [PubMed]
- Jia, Z.; Zeng, X.; Duan, H.; Lu, X.; Li, H. A patient-similarity-based model for diagnostic prediction. Int. J. Med. Inform. 2020, 135, 104073. [Google Scholar] [CrossRef] [PubMed]
- Ebadollahi, S.; Sun, J.; Gotz, D.; Hu, J.; Sow, D.; Neti, C. Predicting Patient’s Trajectory of Physiological Data using Temporal Trends in Similar Patients: A System for Near-Term Prognostics. AMIA Annu. Symp. Proc. 2010, 2010, 192–196. [Google Scholar] [PubMed]
- Lee, J.; Maslove, D.M.; Dubin, J.A. Personalized mortality prediction driven by electronic medical data and a patient similarity metric. PLoS ONE 2015, 10, e0127428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leutner, M.; Haug, N.; Bellach, L.; Dervic, E.; Kautzky, A.; Klimek, P.; Kautzky-Willer, A. Risk of Typical Diabetes-Associated Complications in Different Clusters of Diabetic Patients: Analysis of Nine Risk Factors. J. Pers. Med. 2021, 11, 328. [Google Scholar] [CrossRef]
- Haas, K.; Morton, S.; Gupta, S.; Mahoui, M. Using similarity metrics on real world data and patient treatment pathways to recommend the next treatment. In Proceedings of the AMIA Summits on Translational Science Proceedings, San Francisco, CA, USA, 25–28 March 2019; Volume 2019, p. 398. [Google Scholar]
- Wang, Y.; Tian, Y.; Tian, L.-L.; Qian, Y.-M.; Li, J.-S. An electronic medical record system with treatment recommendations based on patient similarity. J. Med. Syst. 2015, 39, 55. [Google Scholar] [CrossRef]
- Tang, P.C.; Miller, S.; Stavropoulos, H.; Kartoun, U.; Zambrano, J.; Ng, K. Precision population analytics: Population management at the point-of-care. J. Am. Med. Inform. Assoc. 2020, 28, 588–595. [Google Scholar] [CrossRef]
- Ng, K.; Sun, J.; Hu, J.; Wang, F. (Eds.) Personalized predictive modeling and risk factor identification using patient similarity. AMIA Summits Transl. Sci. Proc. 2015, 2015, 132–136. [Google Scholar]
- Panahiazar, M.; Taslimitehrani, V.; Pereira, N.L.; Pathak, J. Using EHRs for heart failure therapy recommendation using multidimensional patient similarity analytics. Stud. Health Technol. Inform. 2015, 210, 369. [Google Scholar] [PubMed]
- Gower, J.C. A general coefficient of similarity and some of its properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Conroy, B.; Xu-Wilson, M.; Rahman, A. (Eds.) Patient similarity using population statistics and multiple kernel learning. In Proceedings of the Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017. [Google Scholar]
- Pokharel, S.; Zuccon, G.; Li, X.; Utomo, C.P.; Li, Y. Temporal Tree Representation for Similarity Computation between Medical Patients. Artif. Intell. Med. 2020, 108, 101900. [Google Scholar] [CrossRef] [PubMed]
- Pokharel, S.; Li, X.; Zhao, X.; Adhikari, A.; Li, Y. (Eds.) Similarity Computing on Electronic Health Records; PACIS: Yokohama, Japan, 2018. [Google Scholar]
- Ministry of Health Singapore. MOH Clinical Practice Guidelines on Diabetes Mellitus. 2014. Available online: https://www.moh.gov.sg/hpp/doctors/guidelines/GuidelineDetails/cpgmed_diabetes_mellitus (accessed on 19 March 2021).
- Ministry of Health Singapore. MOH Clinical Practice Guidelines on Hypertension. 2017. Available online: https://www.moh.gov.sg/hpp/doctors/guidelines/GuidelineDetails/cpgmed_hypertension (accessed on 19 March 2021).
- Ministry of Health Singapore. 2016. Available online: https://www.moh.gov.sg/docs/librariesprovider4/guidelines/moh-lipids-cpg---booklet.pdf (accessed on 19 March 2021).
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef] [PubMed]
- Suo, Q.; Ma, F.; Yuan, Y.; Huai, M.; Zhong, W.; Gao, J.; Zhang, A. Deep patient similarity learning for personalized healthcare. IEEE Trans. Nanobiosci. 2018, 17, 219–227. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
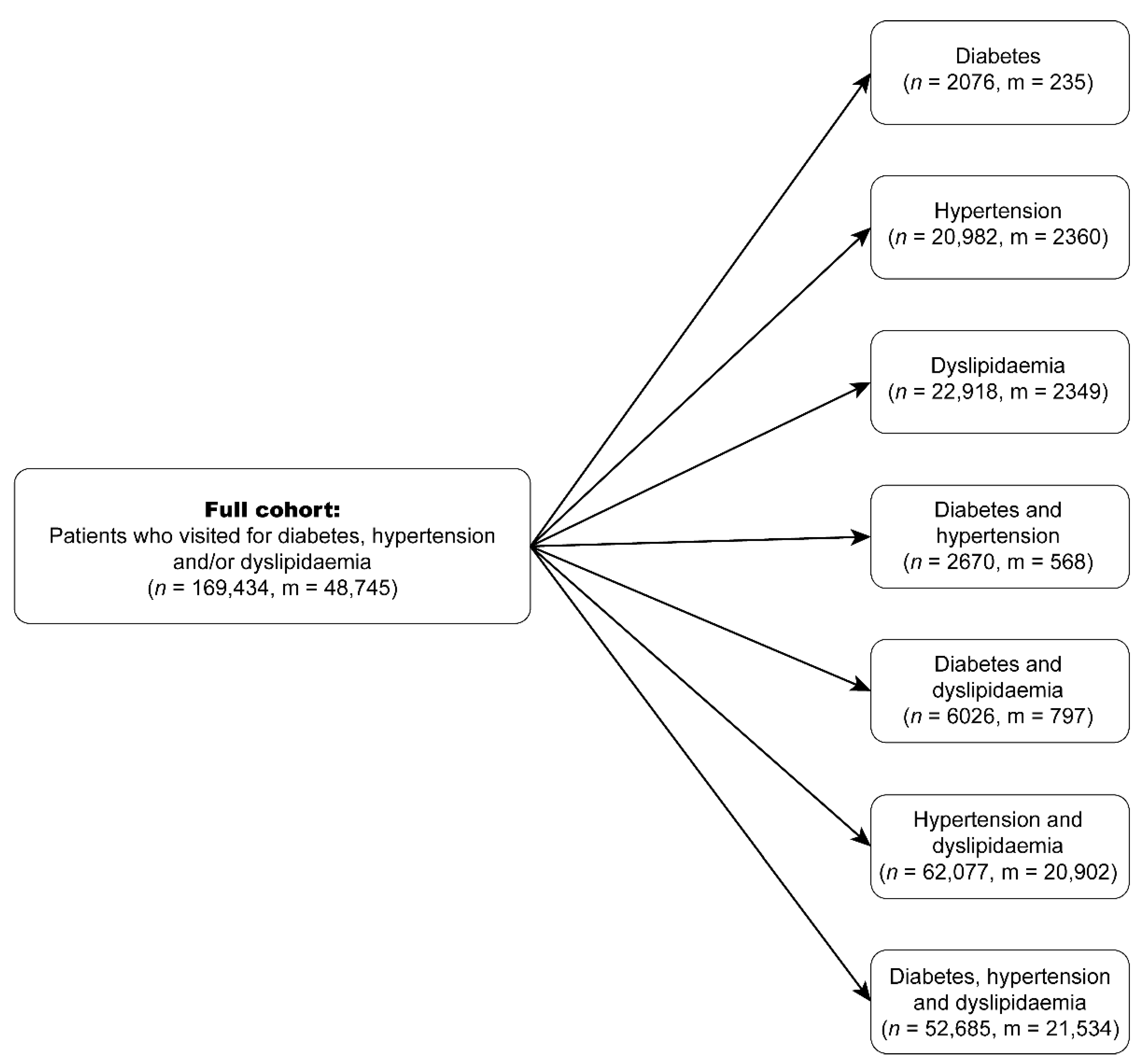
| Cohort | Description | Number of Patients | Age | Gender | |
|---|---|---|---|---|---|
| Male | Female | ||||
| CD | Diabetes only | 2076 | 52.70 (±13.89) | 1141 | 935 |
| CH | Hypertension only | 20,982 | 60.84 (±13.29) | 11,001 | 9981 |
| CL | Dyslipidaemia only | 22,918 | 50.81 (±10.55) | 14,333 | 8585 |
| CDH | Diabetes and hypertension only | 2670 | 63.28 (±12.69) | 1436 | 1234 |
| CDL | Diabetes and dyslipidaemia only | 6026 | 57.23 (±11.01) | 2959 | 3067 |
| CHL | Hypertension and dyslipidaemia only | 62,077 | 67.14 (±11.23) | 29,261 | 32,816 |
| CDHL | Diabetes, hypertension, and dyslipidaemia | 52,685 | 67.11 (±11.07) | 25,319 | 27,366 |
| Category | Class | Medication |
|---|---|---|
| Anti-diabetic | Biguanides | Metformin |
| Alpha-glucosidase inhibitors | Acarbose | |
| Dipeptidyl peptidase 4 inhibitors | Linagliptin | |
| Sulfonylureas | Gliclazide, glipizide, tolbutamide | |
| Sodium-glucose co-transporter 2 inhibitors | Dapagliflozin, empagliflozin | |
| Insulin | Rapid-acting insulin, isophane insulin, insulin glargine, insulin detemir, pre-mixed insulin | |
| Anti-hypertensive | Diuretics | Hydrochlorothiazide, co-amilozide, indapamide, spironolactone |
| Beta blockers | Atenolol, bisoprolol, nifetex 1, propranolol | |
| Alpha antagonists | Prazosin | |
| Sympatholytics | Methyldopa | |
| Angiotensin-converting enzyme inhibitors | Captopril, enalapril, lisinopril, perindopril | |
| Angiotensin II receptor blockers | Candesartan, losartan, telmisartan, valsartan | |
| Calcium channel blockers | Amlodipine, nifedipine (long-acting) | |
| Direct vasodilators | Hydralazine | |
| Lipid-lowering | Hydroxymethylglutaryl-CoA (HMG-CoA) reductase inhibitors | Atorvastatin, lovastatin, pravastatin, rosuvastatin, simvastatin |
| Cholesterol absorption inhibitors | Ezetimibe | |
| Bile acid sequestrants | Cholestyramine | |
| Fibric acid derivatives | Fenofibrate, gemfibrozil |
| Variable | Type | Description |
|---|---|---|
| Age (years) | Discrete | Age at base visit |
| Gender | Categorical | Female, Male |
| Disease duration | Discrete | Number of years since diagnosis of disease |
| Systolic BP (mmHg) | Continuous | Systolic blood pressure |
| Diastolic BP (mmHg) | Continuous | Diastolic blood pressure |
| HbA1c level (%) | Continuous | Haemoglobin A1c level |
| LDL level (mmol/L) | Continuous | Low-density lipoprotein level |
| HDL level (mmol/L) | Continuous | High-density lipoprotein level |
| TG level (mmol/L) | Continuous | Triglyceride level |
| Total daily dose per medication | Discrete | Total daily dose for each prescribed medication |
| Medication count per class | Discrete | Count of medication prescribed for each class |
| Medication count | Discrete | Total number of medications prescribed |
| Macrovascular complication | Discrete | Yes if patient developed macrovascular complication within five years after base visit, otherwise no |
| Cohort | Number of Patient Pairs Sampled | Number of Patient Pairs Deem Similar by Both Physicians | Number of Patient Pairs Deem Dissimilar by Both Physicians | Number of Patient Pairs Discarded Due to Disagreement |
|---|---|---|---|---|
| CD | 120 | 53 | 59 | 8 |
| CH | 300 | 125 | 122 | 53 |
| CL | 440 | 164 | 165 | 111 |
| CDH | 100 | 48 | 48 | 4 |
| CDL | 140 | 65 | 67 | 8 |
| CHL | 820 | 341 | 352 | 127 |
| CDHL | 320 | 104 | 132 | 84 |
| Bin | Systolic BP (mmHg) | Diastolic BP (mmHg) | LDL Level (mmol/L) | HDL Level (mmol/L) | TG Level (mmol/L) | HbA1c Level (%) |
|---|---|---|---|---|---|---|
| 1 | Normal (<130) | Normal (<85) | Optimal (<2.6) | Optimal (≥1.6) | Optimal (<1.7) | Good control (<7) |
| 2 | High-normal (130–139) | High-normal (85–89) | Desirable (2.6–3.3) | Desirable (1.3–1.5) | Desirable (1.7–2.2) | Adequate control (7.1–8.9) |
| 3 | Grade 1 hypertension (140–159) | Grade 1 hypertension (90–99) | Borderline high (3.4–4.0) | Low (1.0–1.3) | Borderline high (2.3–3.3) | Inadequate control (9.0–11.9) |
| 4 | Grade 2 hypertension (160–179) | Grade 2 hypertension (100–109) | High (4.1–4.8) | Very low (<1.0) | High (3.4–4.4) | Poor control (12.0–13.9) |
| 5 | Grade 3 hypertension (≥180) | Grade 3 hypertension (≥110) | Very high (≥4.9) | Very high (≥4.5) | Very poor control (≥14) |
| Bin | Age (Years) | Disease Duration (Years) | Medication Count per Class | Total Medication Count |
|---|---|---|---|---|
| 1 | ≤39 | 1 | 0 | 0 |
| 2 | 40–49 | 2 | 1 | 1 |
| 3 | 50–59 | 3 | 2 | 2 |
| 4 | 60–69 | 4 | 3 | 3 |
| 5 | ≥70 | ≥5 | ≥4 | ≥4 |
| Type of HMG-CoA Reductase Inhibitors | Low-Intensity | Moderate-Intensity | High-Intensity |
|---|---|---|---|
| Pravastatin | (0, 40) | >40 | - |
| Lovastatin | (0, 40) | >40 | - |
| Simvastatin | (0, 20) | (20, 80) | >80 |
| Atorvastatin | (0, 10) | (10, 40) | ≥40 |
| Rosuvastatin | (0, 5) | (5, 20) | ≥20 |
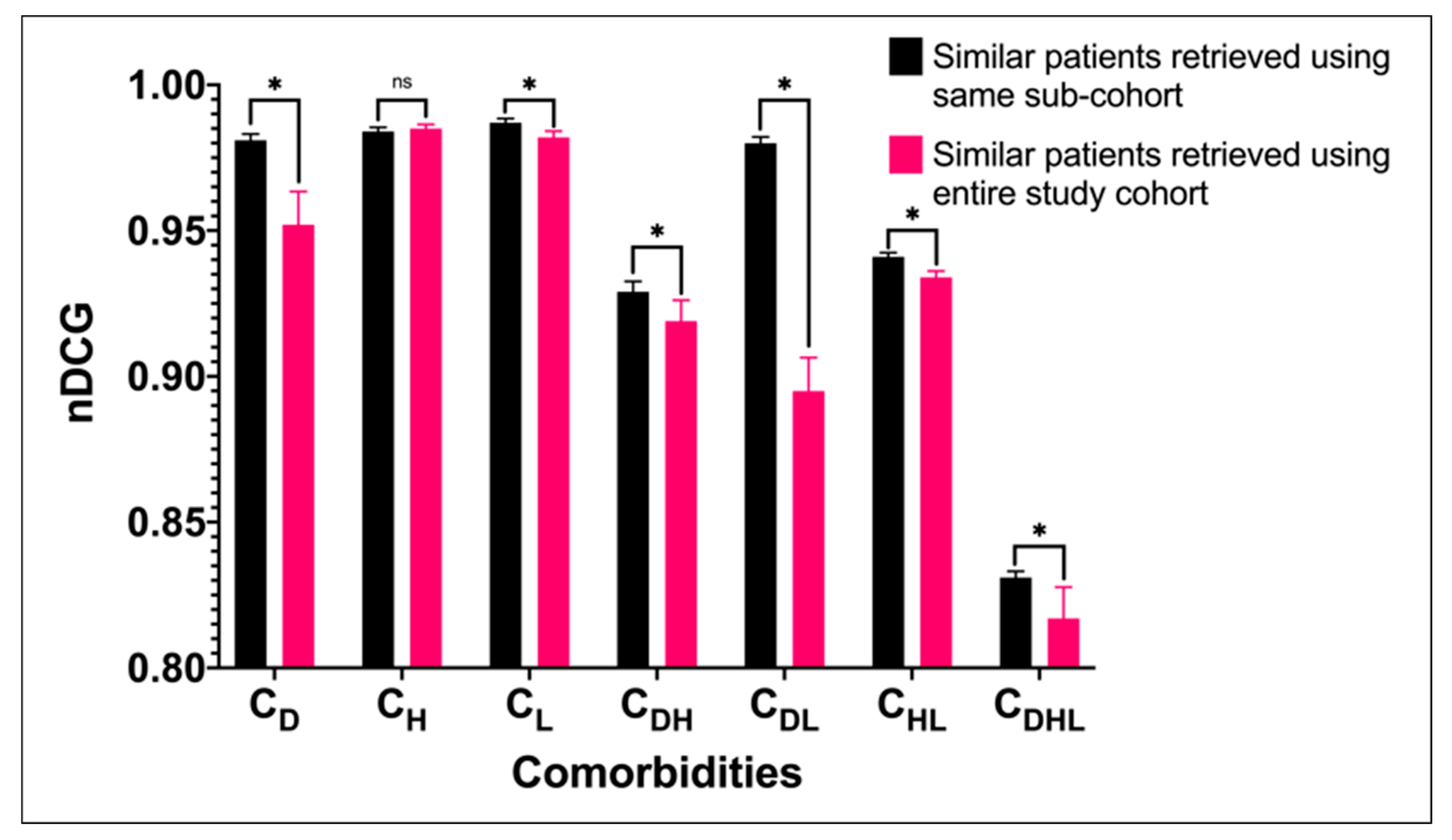
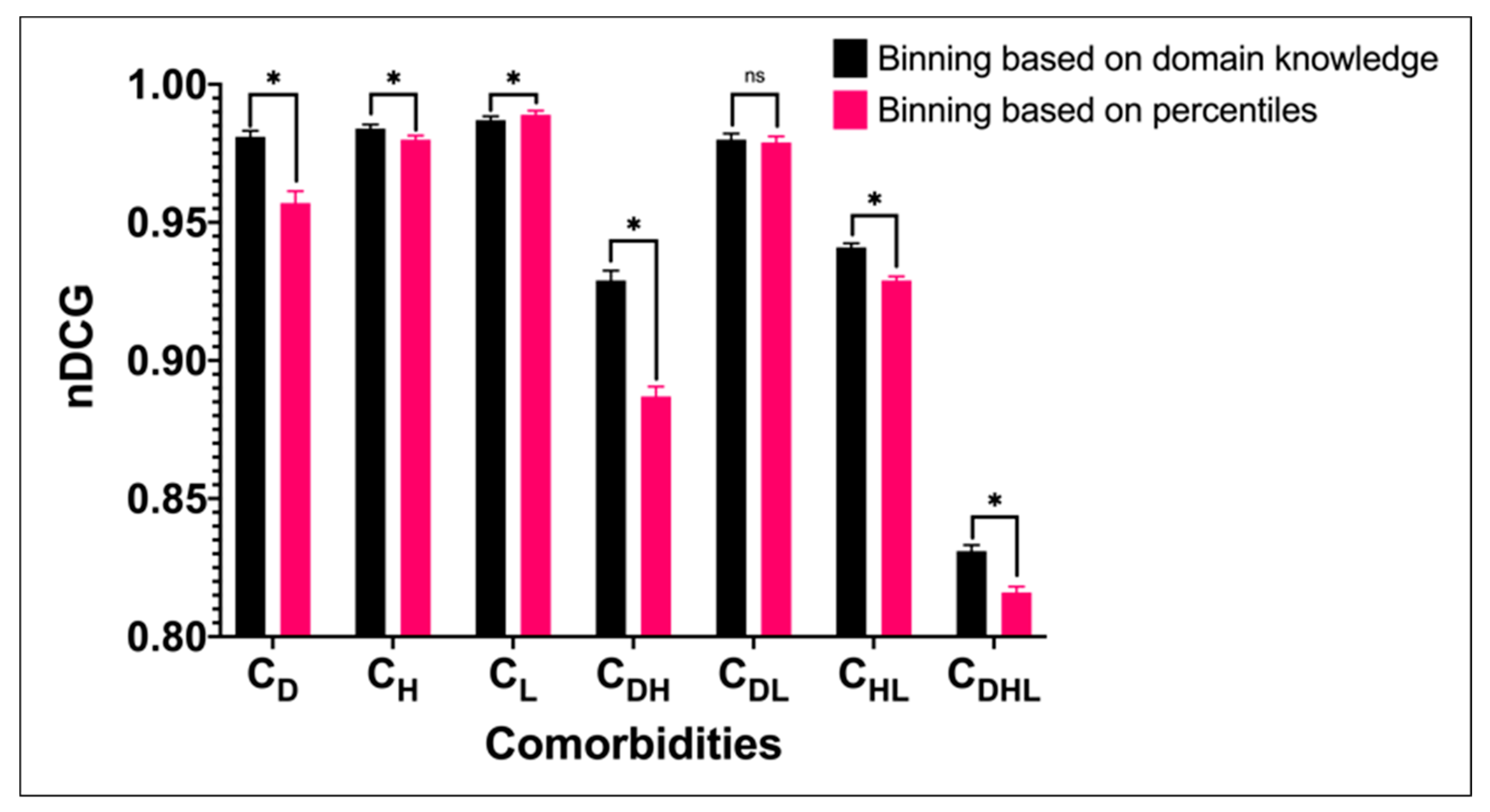
| Cohort | Size | Number of Patients with Macrovascular Complications | D3K | Euclidean Distance | LSML |
|---|---|---|---|---|---|
| CD | 2076 | 235 | 0.981 (0.979–0.983) * | 0.922 (0.918–0.926) | 0.905 (0.896–0.914) |
| CH | 20,982 | 2360 | 0.984 (0.983–0.985) * | 0.928 (0.926–0.930) | 0.923 (0.921–0.925) |
| CL | 22,918 | 2349 | 0.987 (0.986–0.988) * | 0.936 (0.934–0.938) | 0.929 (0.926–0.932) |
| CDH | 2670 | 568 | 0.929 (0.926–0.932) * | 0.864 (0.854–0.874) | 0.849 (0.844–0.854) |
| CDL | 6026 | 797 | 0.980 (0.978–0.982) * | 0.918 (0.914–0.922) | 0.957 (0.954–0.960) |
| CHL | 62,077 | 20,902 | 0.941 (0.940–0.942) * | 0.851 (0.849–0.853) | 0.802 (0.801–0.803) |
| CDHL | 52,685 | 21,534 | 0.831 (0.829–0.833) * | 0.809 (0.807–0.811) | 0.781 (0.780–0.782) |
| Age (Years) | Gender | Disease History (Years) | Systolic BP (mmHg) | Diastolic BP (mmHg) | Medication Count | Macrovascular Complication | |
|---|---|---|---|---|---|---|---|
| Index patient | 76 | Male | 3 | 132 | 78 | 2 | 1 |
| D3K | 69 | Male | 3 | 135 | 72 | 2 | 1 |
| 87 | Female | 3 | 136 | 66 | 2 | 0 | |
| 84 | Male | 2 | 131 | 66 | 2 | 1 | |
| 73 | Male | 3 | 141 | 70 | 2 | 0 | |
| 74 | Female | 3 | 157 | 59 | 2 | 1 | |
| 82 | Female | 3 | 154 | 61 | 2 | 0 | |
| 68 | Male | 3 | 149 | 74 | 2 | 0 | |
| 69 | Male | 3 | 157 | 59 | 2 | 0 | |
| 91 | Female | 3 | 158 | 75 | 2 | 0 | |
| 77 | Male | 3 | 142 | 75 | 2 | 0 | |
| nDCG | 0.886 | ||||||
| Euclidean distance | 68 | Male | 3 | 149 | 74 | 2 | 0 |
| 77 | Male | 3 | 142 | 75 | 2 | 0 | |
| 78 | Male | 3 | 108 | 71 | 2 | 0 | |
| 69 | Male | 3 | 135 | 72 | 2 | 1 | |
| 69 | Male | 3 | 157 | 59 | 2 | 0 | |
| 67 | Male | 3 | 125 | 75 | 2 | 0 | |
| 63 | Male | 3 | 149 | 90 | 2 | 0 | |
| 63 | Male | 3 | 121 | 65 | 2 | 0 | |
| 65 | Male | 3 | 160 | 75 | 2 | 0 | |
| 64 | Male | 3 | 110 | 60 | 2 | 0 | |
| nDCG | 0.431 | ||||||
| LSML | 81 | Female | 3 | 171 | 89 | 1 | 0 |
| 76 | Female | 3 | 160 | 98 | 4 | 0 | |
| 88 | Female | 1 | 194 | 92 | 1 | 1 | |
| 72 | Male | 1 | 223 | 120 | 1 | 0 | |
| 64 | Female | 1 | 138 | 82 | 1 | 0 | |
| 89 | Male | 3 | 169 | 72 | 1 | 0 | |
| 85 | Female | 1 | 172 | 81 | 2 | 0 | |
| 87 | Male | 3 | 140 | 57 | 3 | 0 | |
| 79 | Female | 3 | 140 | 66 | 3 | 0 | |
| 77 | Female | 1 | 156 | 60 | 3 | 0 | |
| nDCG | 0.500 | ||||||
| Cohen’s Kappa | 95% Confidence Interval | p-Value | |
|---|---|---|---|
| Physician A vs. D3K | 0.715 | 0.666–0.764 | <0.001 |
| Physician B vs. D3K | 0.863 | 0.814–0.911 | <0.001 |
| Physician A vs. Physician B | 0.660 | 0.611–0.709 | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oei, R.W.; Fang, H.S.A.; Tan, W.-Y.; Hsu, W.; Lee, M.-L.; Tan, N.-C. Using Domain Knowledge and Data-Driven Insights for Patient Similarity Analytics. J. Pers. Med. 2021, 11, 699. https://doi.org/10.3390/jpm11080699
Oei RW, Fang HSA, Tan W-Y, Hsu W, Lee M-L, Tan N-C. Using Domain Knowledge and Data-Driven Insights for Patient Similarity Analytics. Journal of Personalized Medicine. 2021; 11(8):699. https://doi.org/10.3390/jpm11080699
Chicago/Turabian StyleOei, Ronald Wihal, Hao Sen Andrew Fang, Wei-Ying Tan, Wynne Hsu, Mong-Li Lee, and Ngiap-Chuan Tan. 2021. "Using Domain Knowledge and Data-Driven Insights for Patient Similarity Analytics" Journal of Personalized Medicine 11, no. 8: 699. https://doi.org/10.3390/jpm11080699
APA StyleOei, R. W., Fang, H. S. A., Tan, W.-Y., Hsu, W., Lee, M.-L., & Tan, N.-C. (2021). Using Domain Knowledge and Data-Driven Insights for Patient Similarity Analytics. Journal of Personalized Medicine, 11(8), 699. https://doi.org/10.3390/jpm11080699