
Validation of Machine Learning-Based Individualized Treatment for Depressive Disorder Using Target Trial Emulation

 , , and
, , and
Abstract
:1. Introduction
Aims of the Study
2. Methods
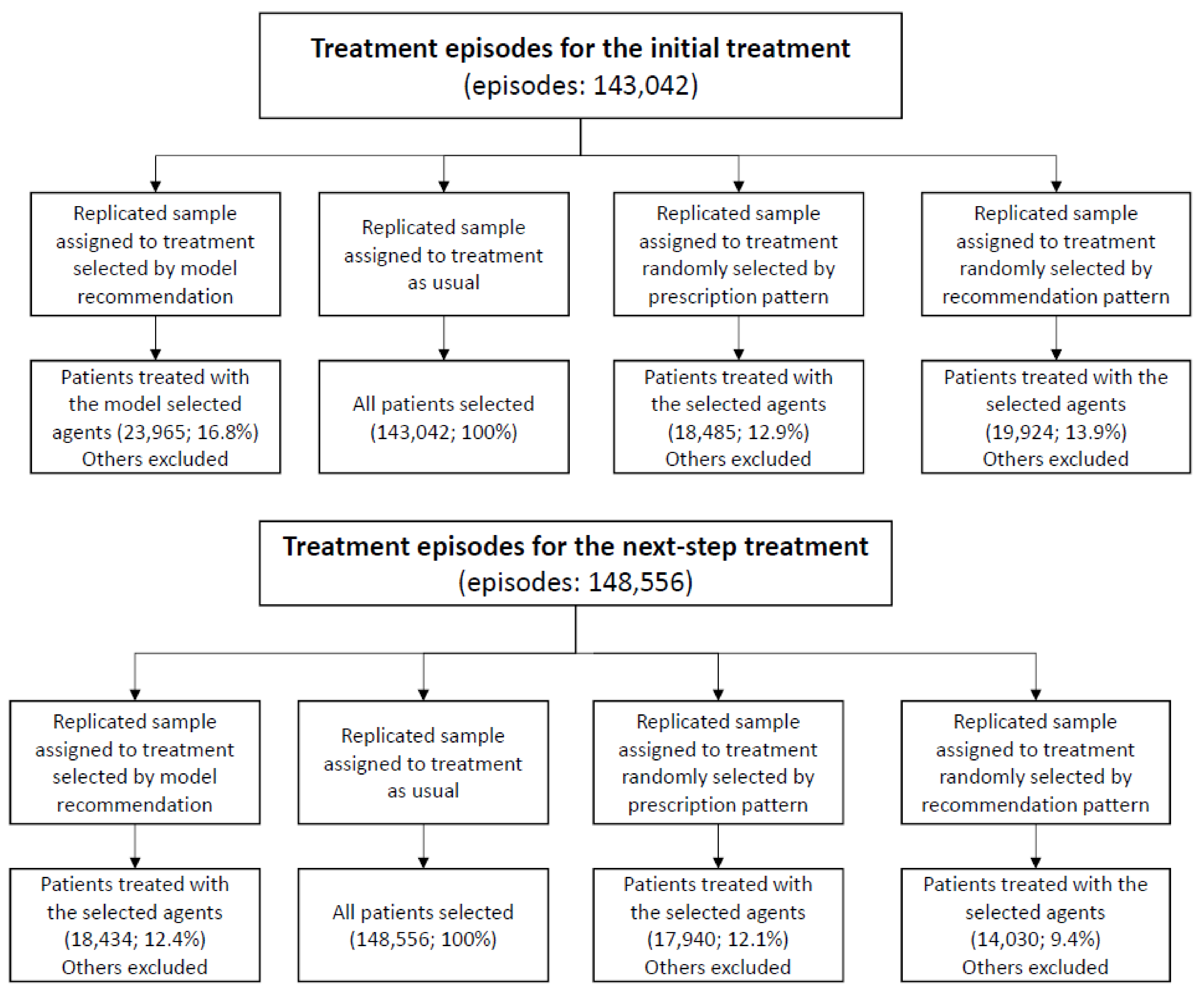
2.1. Data Source
2.2. Study Sample
2.3. The Development of the Prediction Model
2.3.1. Data Training and Testing
2.3.2. Study Outcome
2.4. Predictors
2.5. Model Development
2.6. Statistical Analysis for Evaluating the Prediction Models
Prediction Performance
2.7. Evaluating the Effectiveness of the Machine-Selected Agents in the Test Set
3. Results
Prediction Performance
Evaluating the Effectiveness of the Machine-Selected Agents in the Test Set
4. Discussion
4.1. Principal Results
4.2. Limitations
4.3. Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kessler, R.C.; Berglund, P.; Demler, O.; Jin, R.; Koretz, D.; Merikangas, K.R.; Rush, A.J.; Walters, E.E.; Wang, P.S. The epidemiology of major depressive disorder: Results from the National Comorbidity Survey Replication (NCS-R). JAMA 2003, 289, 3095–3105. [Google Scholar] [CrossRef]
- Ferrari, A.; Somerville, A.; Baxter, A.; Norman, R.; Patten, S.; Vos, T.; Whiteford, H. Global variation in the prevalence and incidence of major depressive disorder: A systematic review of the epidemiological literature. Psychol. Med. 2013, 43, 471–481. [Google Scholar] [CrossRef]
- Bauer, M.; Severus, E.; Möller, H.-J.; Young, A.H.; Disorders, W.T.F.o.U.D. Pharmacological treatment of unipolar depressive disorders: Summary of WFSBP guidelines. Int. J. Psychiatry Clin. Pract. 2017, 21, 166–176. [Google Scholar] [CrossRef] [PubMed]
- Trivedi, M.H.; Rush, A.J.; Wisniewski, S.R.; Nierenberg, A.A.; Warden, D.; Ritz, L.; Norquist, G.; Howland, R.H.; Lebowitz, B.; McGrath, P.J. Evaluation of outcomes with citalopram for depression using measurement-based care in STAR* D: Implications for clinical practice. Am. J. Psychiatry 2006, 163, 28–40. [Google Scholar] [CrossRef]
- Fava, M. Diagnosis and definition of treatment-resistant depression. Biol. Psychiatry 2003, 53, 649–659. [Google Scholar] [CrossRef]
- Cipriani, A.; Furukawa, T.A.; Salanti, G.; Chaimani, A.; Atkinson, L.Z.; Ogawa, Y.; Leucht, S.; Ruhe, H.G.; Turner, E.H.; Higgins, J.P. Comparative efficacy and acceptability of 21 antidepressant drugs for the acute treatment of adults with major depressive disorder: A systematic review and network meta-analysis. Lancet 2018, 391, 1357–1366. [Google Scholar] [CrossRef] [Green Version]
- Papakostas, G.I.; Fava, M. Predictors, moderators, and mediators (correlates) of treatment outcome in major depressive disorder. Dialogues Clin. Neurosci. 2008, 10, 439. [Google Scholar]
- Bradley, P.; Shiekh, M.; Mehra, V.; Vrbicky, K.; Layle, S.; Olson, M.C.; Maciel, A.; Cullors, A.; Garces, J.A.; Lukowiak, A.A. Improved efficacy with targeted pharmacogenetic-guided treatment of patients with depression and anxiety: A randomized clinical trial demonstrating clinical utility. J. Psychiatr. Res. 2018, 96, 100–107. [Google Scholar] [CrossRef]
- Pérez, V.; Salavert, A.; Espadaler, J.; Tuson, M.; Saiz-Ruiz, J.; Sáez-Navarro, C.; Bobes, J.; Baca-García, E.; Vieta, E.; Olivares, J.M. Efficacy of prospective pharmacogenetic testing in the treatment of major depressive disorder: Results of a randomized, double-blind clinical trial. BMC Psychiatry 2017, 17, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Webb, C.A.; Trivedi, M.H.; Cohen, Z.D.; Dillon, D.G.; Fournier, J.C.; Goer, F.; Fava, M.; McGrath, P.J.; Weissman, M.; Parsey, R. Personalized prediction of antidepressant v. placebo response: Evidence from the EMBARC study. Psychol. Med. 2019, 49, 1118–1127. [Google Scholar] [CrossRef] [Green Version]
- Perlman, K.; Benrimoh, D.; Israel, S.; Rollins, C.; Brown, E.; Tunteng, J.F.; You, R.; You, E.; Tanguay-Sela, M.; Snook, E.; et al. A systematic meta-review of predictors of antidepressant treatment outcome in major depressive disorder. J. Affect. Disord. 2019, 243, 503–515. [Google Scholar] [CrossRef] [PubMed]
- VanderWeele, T.J.; Luedtke, A.R.; van der Laan, M.J.; Kessler, R.C. Selecting optimal subgroups for treatment using many covariates. Epidemiology 2019, 30, 334–341. [Google Scholar] [CrossRef] [Green Version]
- Kessler, R.C.; van Loo, H.M.; Wardenaar, K.J.; Bossarte, R.M.; Brenner, L.A.; Cai, T.; Ebert, D.D.; Hwang, I.; Li, J.; de Jonge, P. Testing a machine-learning algorithm to predict the persistence and severity of major depressive disorder from baseline self-reports. Mol. Psychiatry 2016, 21, 1366. [Google Scholar] [CrossRef]
- Wu, C.-S.; Luedtke, A.R.; Sadikova, E.; Tsai, H.-J.; Liao, S.-C.; Liu, C.-C.; Gau, S.S.-F.; VanderWeele, T.J.; Kessler, R.C. Development and validation of a machine learning individualized treatment rule in first-episode schizophrenia. JAMA Netw. Open 2020, 3, e1921660. [Google Scholar] [CrossRef] [PubMed]
- Bertsimas, D.; Kallus, N.; Weinstein, A.M.; Zhuo, Y.D. Personalized diabetes management using electronic medical records. Diabetes Care 2017, 40, 210–217. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.-S.; Kuo, C.-J.; Su, C.-H.; Wang, S.H.; Dai, H.-J. Using text mining to extract depressive symptoms and to validate the diagnosis of major depressive disorder from electronic health records. J. Affect. Disord. 2020, 260, 617–623. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. Available online: https://www.R-project.org/ (accessed on 1 December 2020).
- Demyttenaere, K.; Enzlin, P.; Dewe, W.; Boulanger, B.; De Bie, J.; De Troyer, W.; Mesters, P. Compliance with antidepressants in a primary care setting, 1: Beyond lack of efficacy and adverse events. J. Clin. Psychiatry 2001, 62, 30–33. [Google Scholar] [PubMed]
- Mitchell, A.J.; Selmes, T. Why don’t patients take their medicine? Reasons and solutions in psychiatry. Adv. Psychiatr. Treat. 2007, 13, 336–346. [Google Scholar] [CrossRef]
- Polley, E.C.; Van Der Laan, M.J. Super learner in prediction. Collect. Biostat. Res. Arch. 2010. Available online: https://biostats.bepress.com/ucbbiostat/paper266/ (accessed on 1 December 2020).
- Polley, E.; LeDell, E.; Kennedy, C.; Lendle, S.; van der Laan, M. Package ‘SuperLearner’. CRAN 2019. Available online: https://cran.r-project.org/web/packages/SuperLearner/SuperLearner.pdf (accessed on 1 December 2020).
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Danaei, G.; Rodríguez, L.A.G.; Cantero, O.F.; Logan, R.; Hernán, M.A. Observational data for comparative effectiveness research: An emulation of randomised trials of statins and primary prevention of coronary heart disease. Stat. Methods Med. Res. 2013, 22, 70–96. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernán, M.A.; Robins, J.M. Using big data to emulate a target trial when a randomized trial is not available. Am. J. Epidemiol. 2016, 183, 758–764. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
| Algorithm Description | R Functions in SuperLearner |
|---|---|
| Bayesian GLM | SL.bayesglm |
| Generalized additive model | SL.gam |
| Generalized linear model | SL.glm |
| Ridge | SL.glmnet (alpha = 0) |
| Elastic net | SL.glmnet (alpha = 0.25) |
| SL.glmnet (alpha = 0.5) | |
| SL.glmnet (alpha = 0.75) | |
| LASSO | SL.glmnet (alpha = 1) |
| Support vector machine | SL.ksvm |
| k-nearest neighbors | SL.kernelKnn |
| Linear discriminant analysis | SL.lda |
| Neural network | SL.nnet |
| Polynomial spline regression | SL.polymars |
| Random forest | SL.ranger |
| Extreme gradient boosting | SL.xgboost (max_depth = 1, shrinkage = 0.01) |
| SL.xgboost (max_depth = 1, shrinkage = 0.1) | |
| SL.xgboost (max_depth = 2, shrinkage = 0.01) | |
| SL.xgboost (max_depth = 2, shrinkage = 0.1) | |
| SL.xgboost (max_depth = 4, shrinkage = 0.01) | |
| SL.xgboost (max_depth = 4, shrinkage = 0.1) |
| Failure Rate, Overall (%) | Treatment Change (%) | Psychiatric Hospitalization (%) | Emergency Room Visits (%) | Self-Harm (%) | |
|---|---|---|---|---|---|
| First treatment episodes (n; column %) | |||||
| Overall (572,204, 100%) | 26.6 | 25.1 | 2.3 | 0.8 | 1.1 |
| Amitriptyline (2131; 0.4%) | 21.5 | 21.1 | 0.6 | 0.5 | 0.7 |
| Bupropion (19,286; 3.4%) | 27.7 | 26.6 | 2.0 | 0.6 | 0.8 |
| Citalopram (50,724; 8.9%) | 27.9 | 26.4 | 2.1 | 1.0 | 1.2 |
| Doxepin (1727; 0.3%) | 22.5 | 22.2 | 0.8 | 0.3 | 0.5 |
| Duloxetine (15,671; 2.7%) | 28.3 | 27.3 | 1.9 | 0.6 | 1.0 |
| Escitalopram (56,338; 9.8%) | 25.7 | 24.2 | 2.2 | 0.7 | 1.1 |
| Fluoxetine (128,062; 22.4%) | 22.8 | 21.2 | 2.2 | 0.9 | 1.1 |
| Fluvoxamine (15,644; 2.7%) | 30.9 | 29.5 | 2.3 | 1.0 | 1.2 |
| Imipramine (4696; 0.8%) | 19.9 | 19.4 | 1.5 | 0.7 | 0.5 |
| Milnacipran (2938; 0.5%) | 34.6 | 32.9 | 3.4 | 1.2 | 1.3 |
| Mirtazapine (41,442; 7.2%) | 29.8 | 27.9 | 3.0 | 0.9 | 1.4 |
| Moclobemide (14,684; 2.6%) | 25.1 | 24.2 | 1.3 | 0.6 | 0.7 |
| Paroxetine (72,822; 12.7%) | 29.0 | 27.5 | 2.5 | 0.9 | 1.1 |
| Sertraline (102,517; 17.9%) | 25.9 | 24.6 | 2.0 | 0.7 | 1.1 |
| Trazodone (3510; 0.6%) | 23.7 | 22.7 | 3.1 | 1.3 | 0.9 |
| Venlafaxine (40,012; 7.0%) | 30.7 | 29.1 | 2.9 | 0.8 | 1.3 |
| Next-step treatment episodes (n, column %) | |||||
| Overall (591,424; 100%) | 54.2 | 52.7 | 5.1 | 2.0 | 2.4 |
| Switching to (538,050; 91.0%) | 54.1 | 52.7 | 4.7 | 1.9 | 2.3 |
| Amitriptyline (2926; 0.5%) | 62.4 | 61.7 | 3.6 | 2.1 | 3.8 |
| Bupropion (28,526; 4.8%) | 58.5 | 57.4 | 4.4 | 1.3 | 1.8 |
| Citalopram (44,037; 7.4%) | 54.5 | 53.3 | 3.5 | 2.0 | 2.1 |
| Doxepin (2692; 0.5%) | 64.5 | 63.6 | 5.5 | 2.5 | 2.9 |
| Duloxetine (24,485; 4.1%) | 56.6 | 55.1 | 5.9 | 1.6 | 2.4 |
| Escitalopram (60,965; 10.3%) | 48.5 | 47.2 | 3.7 | 1.5 | 2.0 |
| Fluoxetine (78,423; 13.3%) | 49.6 | 48.0 | 4.5 | 2.1 | 2.4 |
| Fluvoxamine (17,068; 2.9%) | 59.3 | 57.9 | 5.5 | 2.1 | 2.5 |
| Imipramine (4050; 0.7%) | 63.1 | 62.0 | 5.0 | 2.1 | 2.1 |
| Milnacipran (4963; 0.8%) | 64.5 | 62.6 | 7.2 | 2.9 | 2.3 |
| Mirtazapine (60,339; 10.2%) | 60.5 | 58.7 | 6.3 | 2.2 | 3.0 |
| Moclobemide (10,331; 1.7%) | 52.0 | 51.1 | 3.7 | 1.4 | 1.5 |
| Paroxetine (62,149; 10.5%) | 54.0 | 52.6 | 4.6 | 1.9 | 2.2 |
| Sertraline (77,362; 13.1%) | 49.5 | 48.4 | 3.4 | 1.5 | 1.8 |
| Trazodone (6030; 1.0%) | 71.0 | 68.7 | 10.4 | 5.4 | 3.3 |
| Venlafaxine (53,704; 9.1%) | 56.8 | 55.1 | 5.7 | 1.9 | 2.6 |
| Combinations with (n, column %) Overall (16,846; 2.8%) | 55.6 | 53.3 | 8.7 | 2.5 | 3.2 |
| Amitriptyline (478; 0.1%) | 57.3 | 56.1 | 9.2 | 2.7 | 4.6 |
| Bupropion (3475; 0.6%) | 50.3 | 48.1 | 7.5 | 1.6 | 2.2 |
| Citalopram (440; 0.1%) | 58.0 | 56.1 | 7.3 | 4.1 | 5.5 |
| Doxepin (421; 0.1%) | 68.9 | 65.8 | 12.8 | 5.0 | 3.8 |
| Duloxetine (873; 0.1%) | 54.2 | 51.1 | 9.0 | 1.9 | 3.4 |
| Escitalopram (1117; 0.2%) | 54.1 | 51.9 | 8.6 | 1.7 | 3.2 |
| Fluoxetine (1552; 0.3%) | 54.1 | 52.1 | 7.8 | 2.8 | 3.5 |
| Fluvoxamine (255; 0.0%) | 65.1 | 61.6 | 8.6 | 3.9 | 5.1 |
| Imipramine (599; 0.1%) | 62.1 | 59.9 | 6.5 | 1.3 | 2.8 |
| Milnacipran (174; 0.0%) | 65.5 | 64.4 | 8.6 | 3.4 | 3.4 |
| Mirtazapine (2577; 0.4%) | 55.6 | 53.3 | 9.0 | 2.4 | 2.8 |
| Moclobemide (168; 0.0%) | 60.1 | 58.9 | 7.1 | 2.4 | 3.0 |
| Paroxetine (964; 0.2%) | 53.2 | 51.0 | 9.4 | 2.5 | 2.9 |
| Sertraline (1037; 0.2%) | 51.0 | 49.3 | 6.2 | 2.2 | 2.8 |
| Trazodone (1148; 0.2%) | 62.7 | 59.5 | 13.5 | 5.3 | 4.0 |
| Venlafaxine (1568; 0.3%) | 59.8 | 56.8 | 9.8 | 2.3 | 4.3 |
| Augmentations (36,528; 6.2%) | 55.7 | 52.4 | 10.2 | 2.8 | 3.6 |
| Amisulpride (1644; 0.3%) | 59.2 | 56.8 | 10.5 | 1.8 | 2.4 |
| Aripiprazole (3499; 0.6%) | 55.4 | 52.7 | 9.4 | 2.0 | 2.7 |
| Olanzapine (2215; 0.4%) | 64.0 | 61.0 | 13.1 | 2.6 | 3.7 |
| Quetiapine (15,119; 2.6%) | 54.3 | 50.8 | 9.8 | 2.9 | 3.9 |
| Risperidone (2894; 0.5%) | 55.6 | 52.3 | 11.0 | 3.1 | 2.4 |
| Zotepine (1274; 0.2%) | 67.1 | 62.9 | 14.4 | 3.3 | 5.8 |
| Lamotrigine (1442; 0.2%) | 57.4 | 54.4 | 9.8 | 2.1 | 3.5 |
| Lithium (1839; 0.3%) | 58.9 | 56.6 | 8.9 | 2.0 | 3.4 |
| Valproic acid (6602; 1.1%) | 52.1 | 48.2 | 9.7 | 3.5 | 4.1 |
| Intention-to-Treat Analysis | As-Treated Analysis | |||
|---|---|---|---|---|
| Incidence of treatment failure (no./person-year) | Hazard ratio (95% Confidence intervals) Treatment vs. controls | Incidence of treatment failure (no./person-year) | Hazard ratio (95% Confidence intervals) Treatment vs. controls | |
| Initial treatment episodes | ||||
| Treatment selected by model recommendation | 0.27 (5314/20,032) | 0.39 (3811/9784) | ||
| Treatment as usual | 0.34 (38,289/114,250) | 0.84 (0.82, 0.86) | 0.47 (28,102/60,161) | 0.88 (0.85, 0.91) |
| Treatment selected randomly by prescription proportion | 0.32 (4812/14,879) | 0.86 (0.82, 0.89) | 0.45 (3470/7664) | 0.87 (0.83, 0.91) |
| Treatment selected randomly by recommendation proportion | 0.29 (4757/16,363) | 0.92 (0.89, 0.96) | 0.43 (3455/8098) | 0.87 (0.83, 0.91) |
| Next-step treatment episodes | ||||
| Treatment selected by model recommendation | 0.70 (8460/12,110) | 0.89 (6389/7177) | ||
| Treatment as usual | 0.94 (80,478/85,742) | 0.82 (0.80, 0.83) | 1.26 (63,195/50,335) | 0.82 (0.80, 0.85) |
| Treatment selected randomly by prescription proportion | 0.91 (9528/10,519) | 0.85 (0.83, 0.88) | 1.22 (7482/6154) | 0.85 (0.82, 0.88) |
| Treatment selected randomly by recommendation proportion | 0.85 (7199/8472) | 0.87 (0.84, 0.90) | 1.12 (5560/4975) | 0.82 (0.80, 0.84) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.-S.; Yang, A.C.; Chang, S.-S.; Chang, C.-M.; Liu, Y.-H.; Liao, S.-C.; Tsai, H.-J. Validation of Machine Learning-Based Individualized Treatment for Depressive Disorder Using Target Trial Emulation. J. Pers. Med. 2021, 11, 1316. https://doi.org/10.3390/jpm11121316
Wu C-S, Yang AC, Chang S-S, Chang C-M, Liu Y-H, Liao S-C, Tsai H-J. Validation of Machine Learning-Based Individualized Treatment for Depressive Disorder Using Target Trial Emulation. Journal of Personalized Medicine. 2021; 11(12):1316. https://doi.org/10.3390/jpm11121316
Chicago/Turabian StyleWu, Chi-Shin, Albert C. Yang, Shu-Sen Chang, Chia-Ming Chang, Yi-Hung Liu, Shih-Cheng Liao, and Hui-Ju Tsai. 2021. "Validation of Machine Learning-Based Individualized Treatment for Depressive Disorder Using Target Trial Emulation" Journal of Personalized Medicine 11, no. 12: 1316. https://doi.org/10.3390/jpm11121316
APA StyleWu, C.-S., Yang, A. C., Chang, S.-S., Chang, C.-M., Liu, Y.-H., Liao, S.-C., & Tsai, H.-J. (2021). Validation of Machine Learning-Based Individualized Treatment for Depressive Disorder Using Target Trial Emulation. Journal of Personalized Medicine, 11(12), 1316. https://doi.org/10.3390/jpm11121316