1. Introduction
The main goal of digital dentistry is to replace cast impressions with 3D digital models for treatment planning and estimation of tooth movement. To this end, the 3D meshes must be segmented to identify the individual teeth and superimpose sequential scans on relatively stable oral anatomic structures. This process enables the accurate measurement of tooth movement during growth and orthodontic treatment. Considering the variability in tooth shapes, the development of a general robust geometric model is essential to define the parameters of teeth and segment them individually through machine learning methods. Several authors have attempted to reach this goal, but their methods had various limitations, including human intervention and/or pre-processing or post-processing of the data [
1,
2,
3,
4,
5].
Recent developments in deep learning have advanced the segmentation of 3D dental meshes. Krenmayr et al. [
1] proposed DilatedToothSegNet, enhancing segmentation accuracy through expanded receptive fields. Wang et al. [
2] introduced STSN-Net, which effectively segments and numbers teeth, even in crowded conditions. Estai et al. [
3] demonstrated successful automated detection and numbering of permanent teeth on panoramic images, supporting the growing role of AI in dental diagnostics.
Despite this progress, challenges remain with partial or low-quality scans. Jana et al. [
4] highlighted the limitations of current deep learning models in handling incomplete dental meshes. Raith et al. [
5] showed that artificial neural networks can classify 3D tooth features effectively, but remain sensitive to data quality. These findings suggest that, while AI tools hold significant promise, further refinement is needed for broader clinical use.
This study aimed to develop a fully automated tooth segmentation algorithm based on machine learning for evaluating dental movement following orthodontic treatment. To achieve this, a labeled dataset of 3D texture-colored models from real patients, along with their corresponding 2D projections, was created.
2. Methods
The planned strategy consisted of segmenting 3D textured scans, first by performing 2D semantic segmentation of 2D images using a robust Fully Convolutional Neural Network (F-CNN), then back projecting onto the original 3D scans. The motions of individual orthodontically displaced teeth would then be measured (via the Iterative Closest Point (ICP) method) after defining a stable coordinate frame on geometrically segmented palatal rugae, used as stable references to match the scans. The motion estimate would then be decomposed into unique three-dimensional translation and rotation about the unique axes of the coordinate frame.
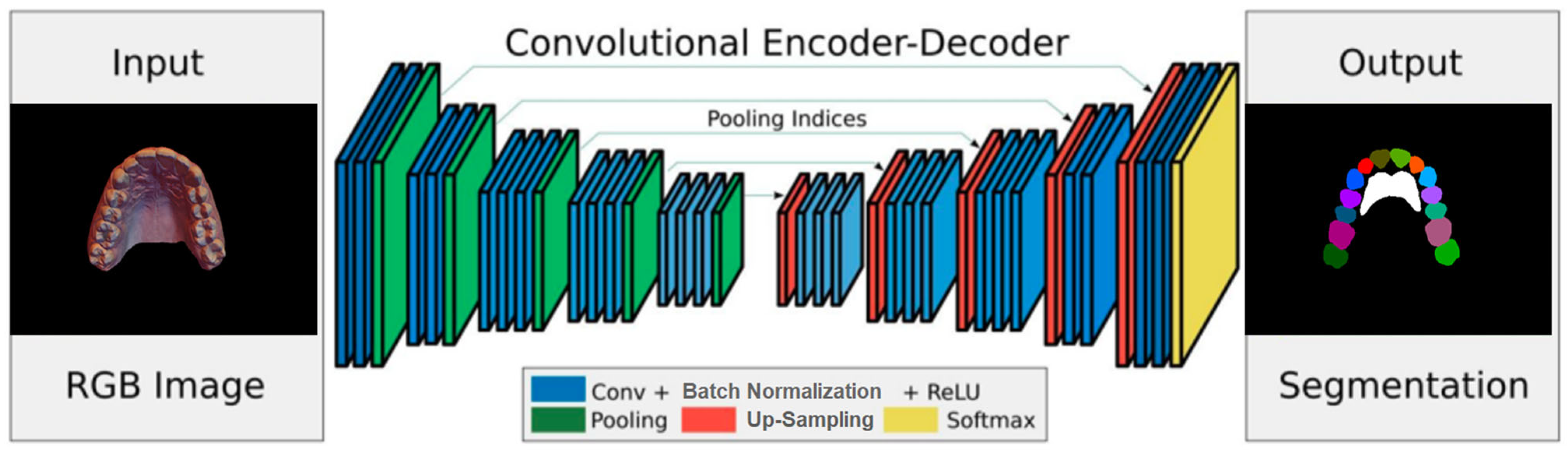
2.1. Deep Network Architecture
A deep network architecture was devised to perform semantic segmentation of 2D images using an Encoder–Decoder–Skip based on SegNet [
6,
7], which relies on a VGG-style encoder–decoder. Because the regions of teeth and rugae appear as continuous blobs in the 2D images, an attention layer was designed and introduced into the network to improve training accuracy.
The encoder network consists of 13 convolutional layers. For each layer, a convolution with a filter bank produced a set of feature maps. This step was followed by batch normalization and an element-wise ReLU; then, max-pooling was performed with a 2
× 2 window and stride of 2. For every encoder layer, there was a corresponding decoder layer, for a total of 13 layers, similar in structure to the encoder layers (
Figure 1). While the latter use max pooling, the decoder layers use up-sampling of the input feature map, followed by batch normalization. The up-sampling in the decoder uses transposed convolutions. The architecture employs additive skip connections from the encoder to the decoder layers. To improve the accuracy of semantic segmentation, two attention layers, (channel and spatial) were implemented, and their effects were evaluated. The channel attention aims to learn a one-dimensional weight and assign it to a corresponding channel by utilizing the relationship between each channel of the feature map. Spatial attention uses the relationships between different spatial positions to learn and assign a 2D spatial weight to a corresponding position. Adding the attention layers helps the model to learn more representative features.
Two different implementation augmentations were tested on the architecture. In the first, the feature map was fed into the channel and spatial attention layers before being fed into the final (Softmax) layer that generates the predictions [
8,
9,
10]. In the second application, the channel and spatial attention layers were applied at the transition between the encoding and decoding layers. The training prediction results are presented in
Section 2.2, below.
2.2. 3D Data Collection and Annotation
The material comprised 100 3D textured scans of the maxilla that were manually processed to remove disconnected components, and the back base was constructed. In each 3D mesh, the surface areas that represent the individual teeth, the rugae, and the gingiva were manually labeled. The meshes were then rotated, translated, and positioned in roughly the same configuration in 3D space. This step was followed by the 2D projection of the meshes onto a virtual camera image plane; 100 random 3D camera poses were used for each scan. The lighting conditions were also randomized to generate the 2D images.
2.2.1. Dataset Collection
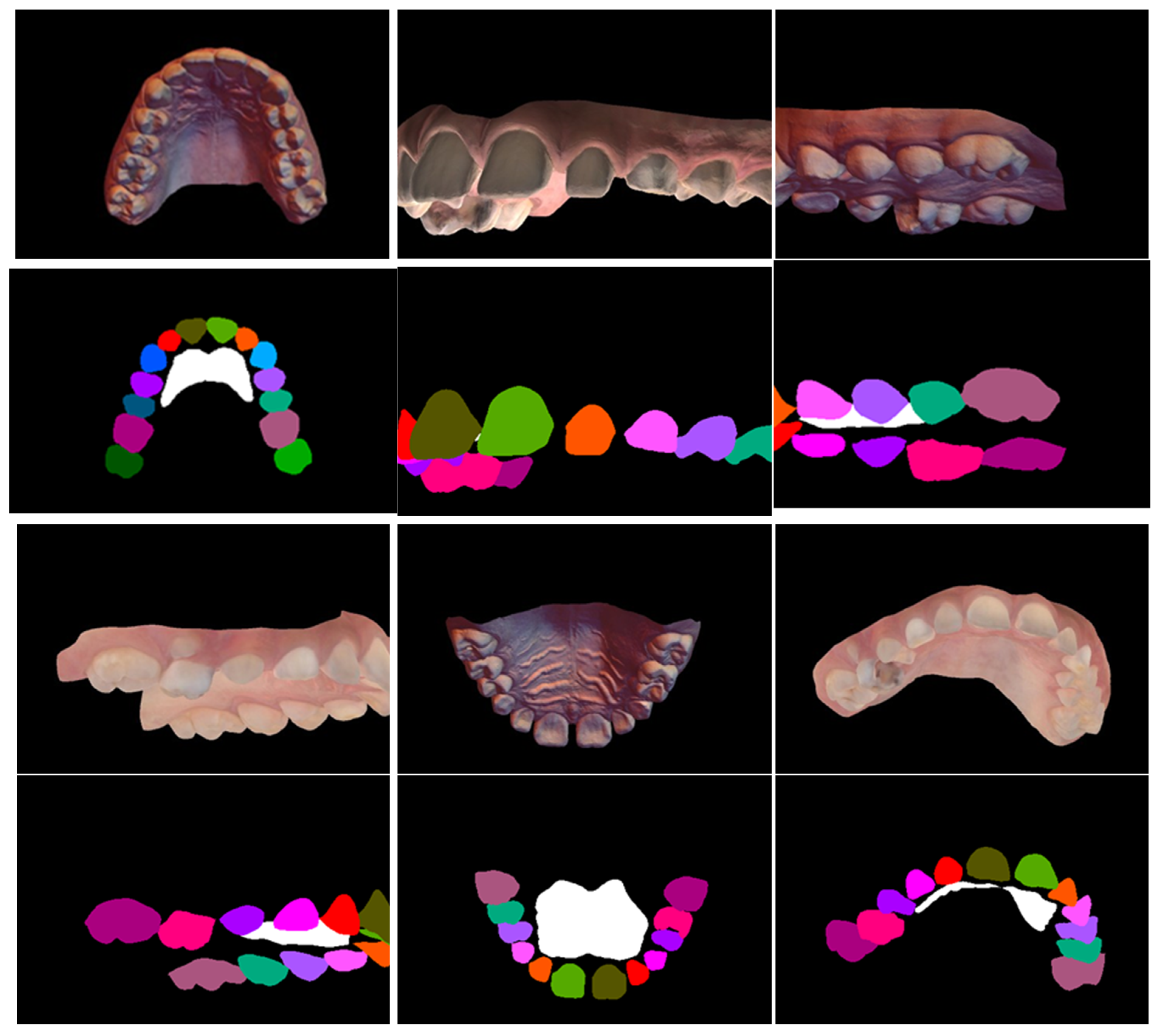
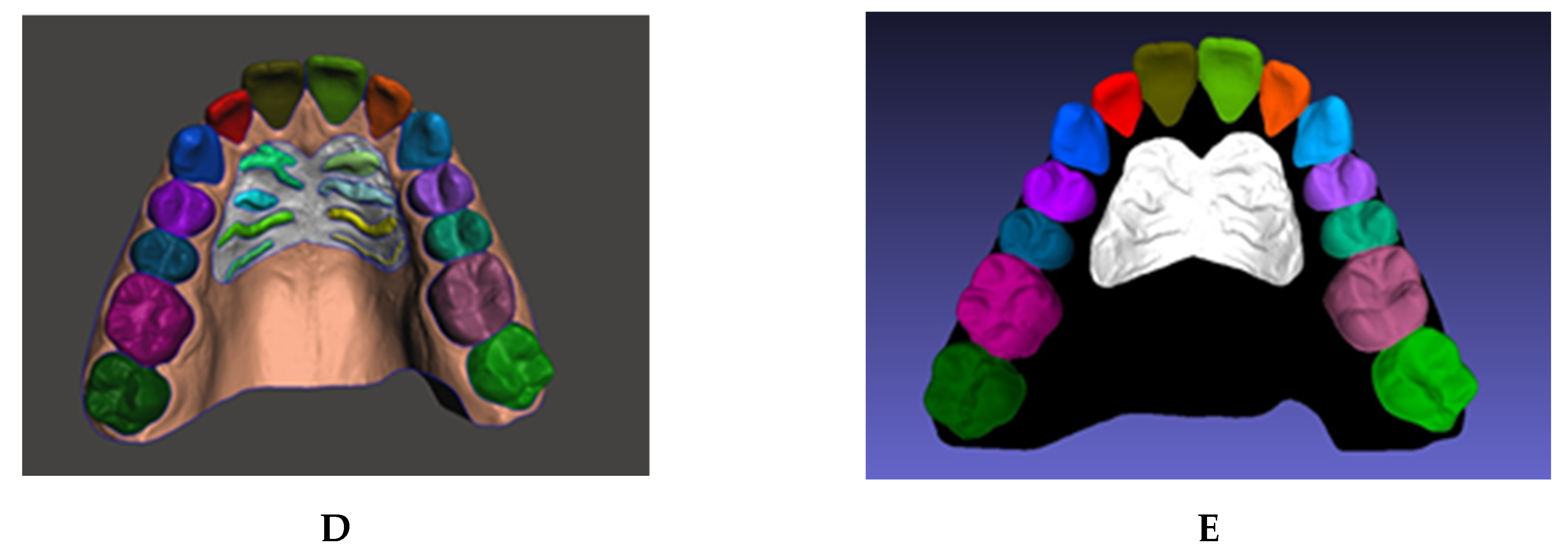
One hundred maxillary arch scans were randomly selected from patient records, regardless of age or gender. A dataset was generated, labeled, and augmented from the set of texture-colored 3D meshes of the maxilla (
Figure 2A). The 3D images were taken, using a 3D intraoral scanner (3Shape TRIOS Intraoral scanners—Copenhagen, Denmark) in the Department of Dentofacial Medicine at the American University of Beirut Medical Center, and saved as textured 3D meshes using the PLY file format.
2.2.2. 3D Mesh Shell Decomposition
The 3D meshes used for semantic segmentation were annotated by assigning a class to every vertex in the mesh and were manually segmented using Meshmixer [
11]. In this process, the user can select the vertices that represent an individual element and separate the selected shell into an independent component. Manual selection often results in rough edges because of limitations of human precision. Therefore, a built-in boundary smoothing tool was applied before finalizing the selected regions for separation, ensuring a more accurate and visually coherent segmentation. The procedure was performed on a total of 100 3D scans, generating independent components of the teeth and rugae patch (
Figure 2B–D).
2.2.3. 3D Mesh Shell Labeling
The vertices in each component were assigned to a class by color using a fill coloring tool in MeshLab version 2016.12 [
12,
13], such as coloring the right central incisor with RGB [85,85,0] (
Figure 2E). Accordingly, 28 unique labels were generated: 26 for teeth, 1 for rugae, and void. The gingiva and background were assigned a black color, denoting a void label.
2.2.4. 3D Mesh Label Statistics
To assess the variability of label size, the statistics of the label distribution throughout the dataset were computed. For every 3D scan, 100 projection images were produced. To ensure that the projections were not biased, the relative number of vertices for each label should relate to the corresponding number of pixels. Most of the low labels fell in the primary tooth and third molar categories, as the dataset had minimal representation of these labels.
The distribution of the number of pixels per label is the same as the distribution of the number of vertices per label. To verify this consistency, the number of pixels per individual label was divided by the number of vertices for that label, and the ratio was computed for all labels. The average ratio was 25 ± 4.4 SD, and the variation in the ratios was minimal because of the randomness of the projection viewpoints, as well as the size of the label.
2.3. Generating Labeled 2D Data
Using simulated camera projection, 2D images were generated from the labeled 3D meshes. For each 3D mesh, an algorithm was used to generate 100 labeled 2D images, which were used to train a 2D semantic segmentation convolution network.
2.3.1. Coordinate Frame Definition
When 3D scans are initially generated, their orientation is not calibrated to a fixed reference in space. Hence, a standardized coordinate frame was established to enable a robust and consistent alignment across all scans. This process ensures that all scans are spatially normalized, allowing for accurate relative comparisons.
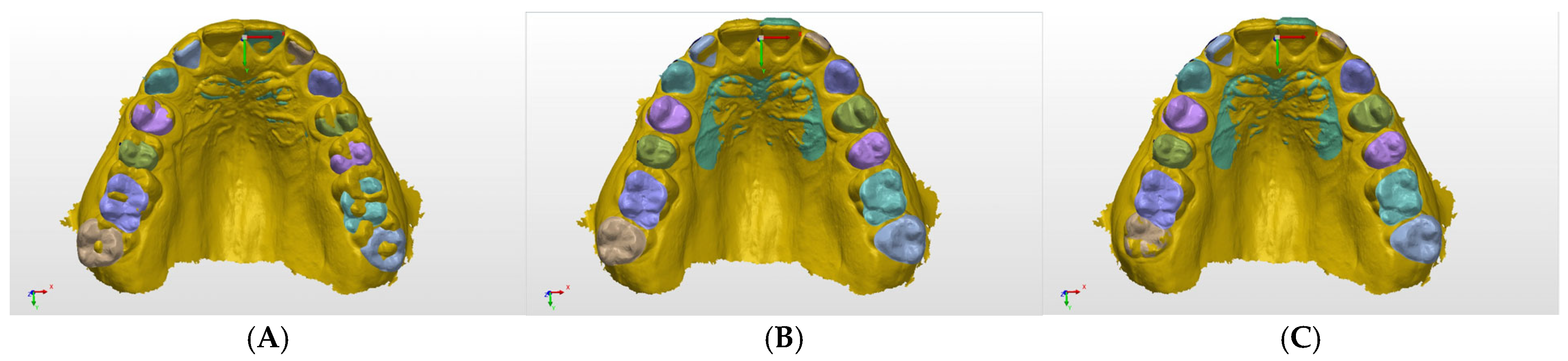
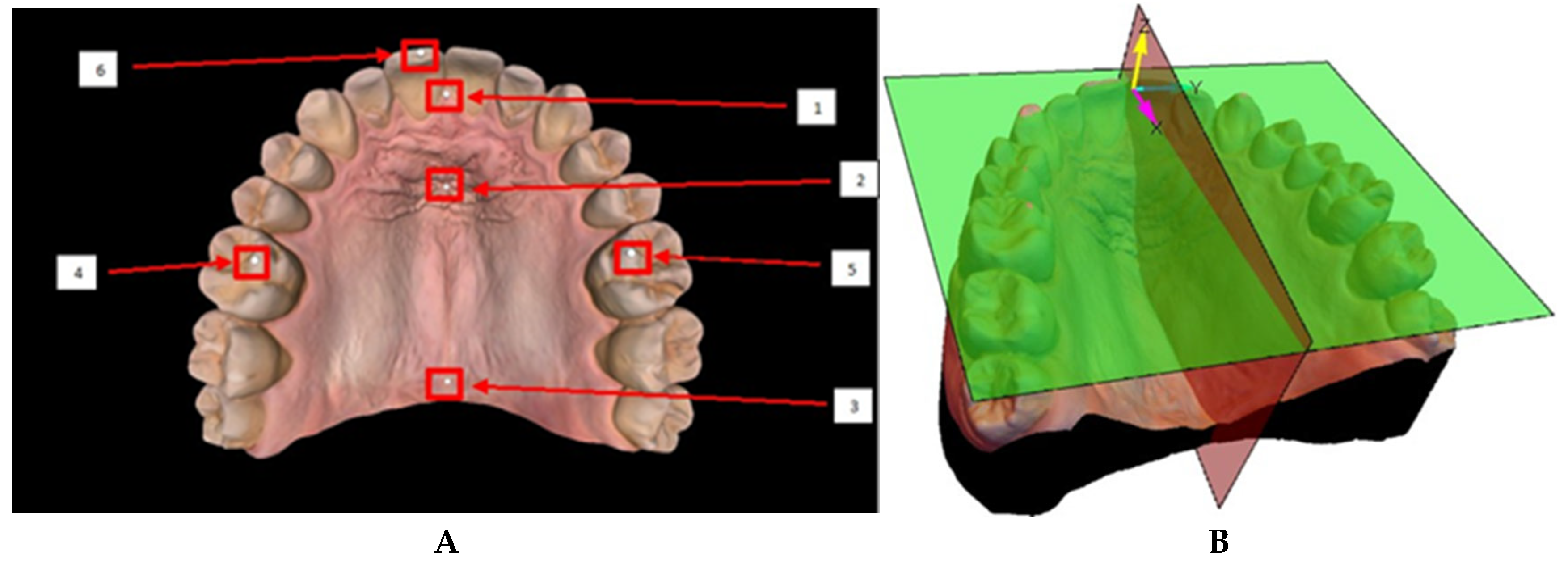
The coordinate frame was defined by manually placing 6 spheres on specific anatomical landmarks of the mesh (
Figure 3A). The spheres were positioned at the molar cusps, at the incisor edges, and along the median raphae in the rugae region. Two planes could be generated: the occlusal plane, determined by the centers of the three spheres located at the cusps of the molars and incisors, and the sagittal plane, defined by the alignment of the spheres located along the median raphae, through the middle of the rugae patch [
14]. A coordinate frame was defined with the
z-axis normal to the occlusal plane, and the
x-axis along the line of intersection of the occlusal and sagittal planes. The origin of the coordinate frame was defined as the normal projection of the center of the sphere located at the incisive papilla onto the occlusal plane. The
y-axis was drawn to complete a right-handed orthonormal frame, ensuring consistency across all scans (
Figure 3B).
2.3.2. 2D Dataset Generation
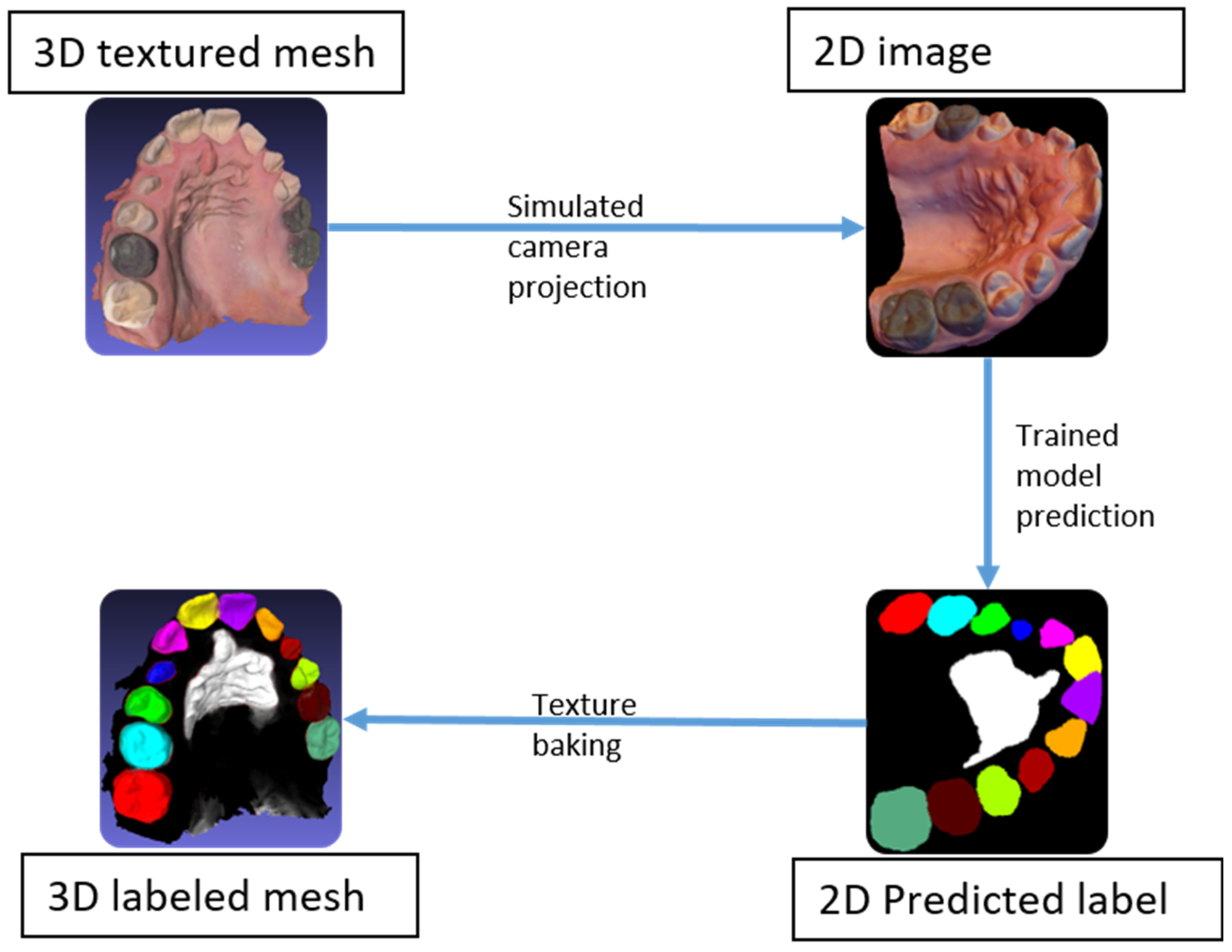
A simulated camera projection was used to transform the 3D textured meshes into 2D images, taken from various viewpoints. The 100 viewpoints were distributed randomly on a hemisphere with the camera’s optical axis pointing toward the 3D scan. The vertical axis of the camera was randomly rotated about its optical axis to randomize the rotation of the mesh within the 2D projections. The projections were applied to the textured 3D mesh and the associated 3D labeled mesh. Accordingly, for each 3D mesh, this method produced 100 pairs of 2D images, along with their associated labels. The flowchart depicting the process is shown in
Figure 4. This labeling method not only eliminated the time needed to hand label the 2D images, but also produced accurate and consistent labels for all classes.
2.3.3. Data Augmentation
The 2D image generation was augmented to account for scenes under various lighting conditions: glow with no lighting, natural ambient light at infinity, and close spot lights with varying intensity and direction. For the last of these, two positions were chosen for light location, but the light intensity was randomly generated at every iteration. The three lighting conditions varied in the way the software rendered the shadows on the 3D mesh, with the first eliminating the shadows completely, the second producing consistent parallel shadows, and the third generating variable shadows, depending on the spot light position with respect to the mesh.
Lighting was not used for the associated 3D labeled mesh; instead, the colors were assigned as glowing colors. Moreover, the anti-aliasing option of the shader was turned off, ascertaining the lack of color mixing at the boundary between two labels. Another augmentation was implemented that randomized the perspective projection of the camera model, thereby simulating the mesh projection at various perspective distortions. For each 3D mesh in the original 3D dataset, 100 2D images were created with their associated labels. Thus, the 2D dataset of images included 10,000 labeled images. A sample of the images, various data augmentations, and the associated image labels are shown in
Appendix A (
Figure A1).
2.4. Rasterization
The original 3D meshes were segmented through 2D semantic segmentation using back projection. Starting with a 3D textured mesh, a set of 2D images was generated by simulating a set of known camera positions to capture the entire 3D mesh, then segmented using the trained model. Subsequently, using the known camera positions, the image predictions were used to back project the label onto the 3D mesh. The predictions on the images, known as rasters, could be back projected (or baked) onto the mesh using the saved camera poses. Afterwards, all vertices were assigned a label according to their baked colors, before segmenting the mesh by color to achieve the 3D semantic segmentation of the entire mesh (
Figure 5).
2.5. Motion Estimation
After performing 3D segmentation on two meshes from the same patient, an algorithm was developed to measure the motion of all maxillary teeth. The first and second scans were the pre-treatment and post-treatment scans, respectively. The alignment of the scans on the defined coordinate frames provided rough initial positioning, insufficient for accurately estimating the motion of individual teeth. Aligning the pre- and post-treatment scans was further complicated because of the composition of the mesh, which includes the soft tissue (mucosa), which undergoes deformation, and the rigid teeth that had moved between scans. As a result, direct global alignment would lead to inaccurate captures of tooth motions. The rugae were reported as geometrically stable structures. Specifically, changes at the medial rugae points were less clinically significant than those at the lateral points [
15,
16]; thus, they were ideal references for alignment. Hence, the semantic segmentation included the rugae patch as a stable landmark upon which the pre- and post-treatment scans were aligned to measure the relative tooth movement.
The rugae patch of the post-treatment scan was first aligned to the pre-treatment scan using the Iterative Closest Point (ICP) algorithm. The metrology software Polyworks version 2017 (InnovMetric Software Inc., Quebec City, QC, Canada) [
17,
18] was used to perform the ICP algorithm and mesh transformations). The algorithm generates a transformation matrix that represents a 3D rigid body motion. Applying this transformation to the post-treatment scan transforms the entire scan and aligns it relative to the rugae patch (
Appendix A Figure A2A,B). Estimating the motion of the individual teeth entailed separately aligning every single tooth with its counterpart from the other mesh. After the first ICP implementation alignment of the scans, a second implementation was applied to each tooth individually (
Appendix A Figure A2C). The rigid body transformation output of the second implementation isolated the individual tooth movement. Accordingly, for each tooth, an associated transformation matrix that gauged the tooth motion was computed.
3. Method Evaluation and Results
The machine learning algorithms applied to the 2D projection and the final results of the 3D segmentation of the original meshes are presented in this section.
3.1. Training Evaluation
Semantic segmentation predictions are generally evaluated using average mean Intersection over Union (average mIoU), which is the mean of all the IoU values for all the classes in an image pair, ground truth and prediction. For a dataset comprising many image pairs, the average mIoU is the average of the mean IoUs for all image pairs. The IoU for a given class
c can be defined [
19,
20] as follows:
whereby
oi is for prediction pixels,
yi for target or label pixels,
is a logical and operation, and
is a logical or operation. This equation is summed over all of the pixels
i in the image.
Moreover, since the dataset exhibits class imbalance, that is, the various class sizes are not similar, the average mIoU represents a better metric through which to assess the network compared to the pixel accuracy because mIoU gives the same weight to under-represented classes as to all other classes. The class imbalance in the dataset exists because the background and the rugae labels cover relatively larger areas compared to the rest of the classes, namely the teeth. Hence, the high pixel accuracy does not imply superior segmentation ability [
21].
3.2. Attention Layer Evaluation
To gauge the effects of the two attention layers (channel and spatial), a reduced dataset of 2000 images (20 scans with 100 projections each) was used to lower the computation time and determine the attention layer implementation to use on the full dataset. The latter was split into 76.4% for training (1528 images), 7.0% for validation (139 images), and 16.6% for testing (333 images). The hyper parameters used for the architecture training were as follows: 150 epochs, a batch size of 1, a learning rate of 0.0001, and a decay of 0.995.
To assess the value of all three architectures (original and both attention implementations), the architectures were trained on the reduced dataset. The training results are shown in
Table 1, including prediction results conducted on unseen projections of unseen 3D scans. The best results were obtained when placing the attention layers at the end, with an average accuracy of 98% and an average mIoU of 79.01%, which was expected because the model was trained on 20 scans, a relatively small number for training (
Figure 6). Therefore, this implementation was used to refine label prediction [
8,
9,
10].
3.3. Final Network Evaluation
The dataset of 100 scans was split into 80% for training (80 scans with 8000 associated projection images), 10% for validation (10 scans, 1000 associated projection images) and 10% for testing (10 scans, 1000 associated projection images). The validation and test scans, and their associated projections, were disjointed from the 80 scans used for training. The 80/20 training–test split is a common practice in machine learning. This choice ensures that the model is trained on a larger portion of the data, allowing it to better capture feature variability and learn complex patterns. The increased training size also helps to reduce overfitting and improves generalization on the test set. The hyper parameters used for the architecture training were as follows: a batch size of 1, a learning rate of 0.0001, and a decay of 0.995.
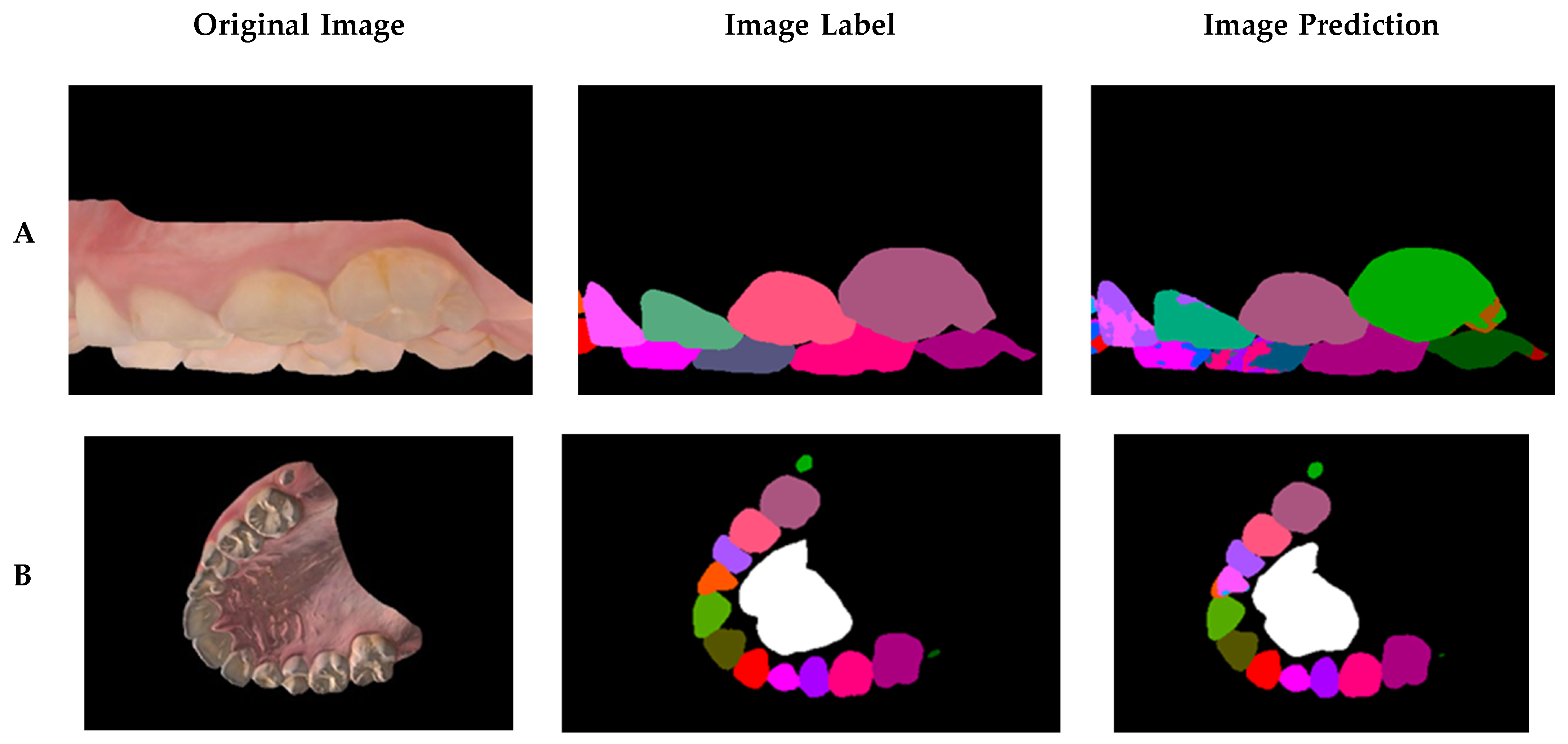
In a sample of the prediction results (
Figure 7), the worst, average, and best prediction outcomes are shown in the rows A, B, and C, respectively. The training results are shown in
Table 2, in which a precision metric is defined as the ratio of all of the correctly detected pixels with respect to the predicted pixels. Certain labels have low accuracy compared to others because they were not as common in the dataset, such as the labels of primary teeth and third molars. The final training had an average accuracy of 98.69%, an average precision of 98.71%, and an average mIoU score of 85.41%. To assess the network accuracy on the labels found in most scans, the adult teeth average mean IoU was introduced, similar in calculation to the average mean IoU score, but excluding third molars, primary teeth, rugae, and background. The average mean IoU score was 84.26%.
3D Mesh Segmentation Evaluation
The rasterization and final 3D mesh color are depicted. After rasterizing all 10 3D meshes from the test set, the IoU metric was applied to the vertices of the 3D mesh. The results of the 3D mesh segmentation are shown in
Appendix A (
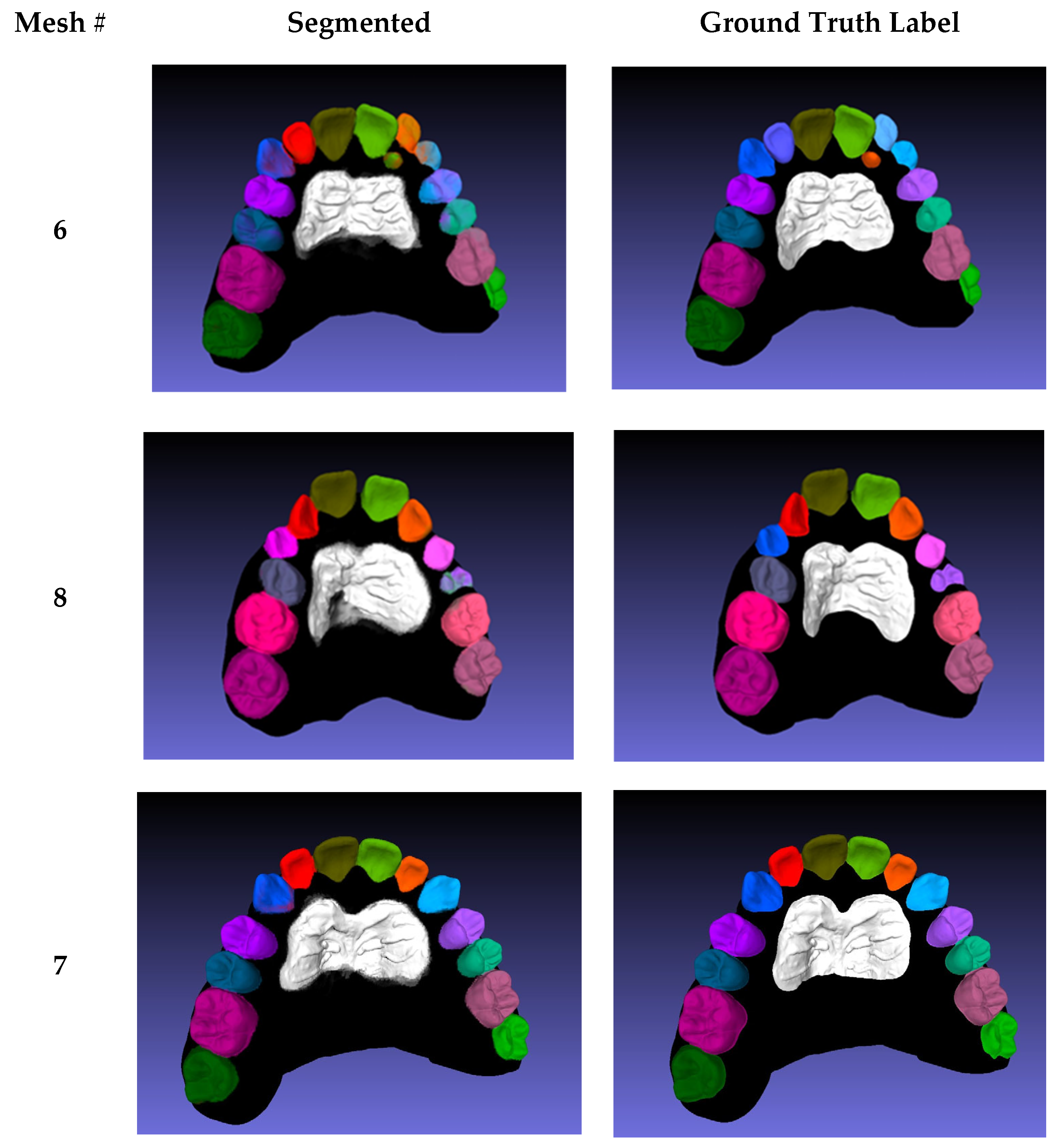
Table A1), where the mean IoU per scan is listed in the last row. The values are comparable to the 3D average mIoU; however, two meshes (6 and 8) exhibited lower segmentation scores.
In Mesh 6, the lateral incisors were falsely predicted as permanent rather than primary incisors, and the left lateral incisor was still erupting, which made it difficult to predict (
Appendix A Figure A3). The low number of erupting teeth in the dataset explains their low prediction accuracy. A similar outcome was observed for the erupting left first pre-molar in Mesh 8, in which the right canine was also falsely predicted as a primary canine because of the close resemblance between primary and permanent canines. Mesh 7 was the best mesh, segmented with an average IoU of 87.67%; the segmentation was very close to the ground truth in all classes. Disregarding rugae, third molars, and Meshes 6 and 8, the proposed method achieved an average IoU value of 84.5%. The rugae exhibited lower segmentation scores compared to teeth because of the variability of the ground truth labeling; labels were manually segmented and classified by several technicians. The projections for the 3D segmentation evaluations were conducted using MeshLab [
12,
13], whereas the projections used for training the network were performed with Mathematica version 11.0.1 [
22]. Given that each software used different shaders to generate 2D images from textures 3D meshes, the prediction results of the MeshLab projections were expected to be of lower accuracy.
3.4. Teeth Motion Evaluation
The motion of each individual tooth between pre- and post-treatment scans for the same patient was calculated. To validate the proposed method to compute the rigid motion of 3D meshes, an example was set up with known motion of the segmented parts. Then, the proposed ICP algorithm was applied to gauge whether the known motions were computed accurately. The result of the ICP algorithm is a 4 × 4 homogeneous transformation matrix, H, which represents a general 3D rigid body motion, and is composed of six individual transformations, three translations, Ti, and three rotations, Ri. The sequence of the six transformations is provided as follows:
The ICP algorithm provides numerical values for H, specifically for variables Rij, Tx, Ty, and Tz. To determine the corresponding transformation parameters, an analytical expression of the transformations is equated to the numerical values of H. Using inverse kinematics, the parameters are found as follows:
Note that the rotation around y-axis β has two solutions; however, considering the clinical context of orthodontic applications, a rotation exceeding 90 degrees is implausible for tooth movement. Therefore, the second larger angle solution is excluded to ensure relevant motion estimation.
For the verification example, a segmented pre-scan was used, whereby all of the teeth were transformed manually via a predefined rigid body transformation. These known transformations were labeled “Actual”, and the computed motions using the proposed algorithm were labeled “Experimental” (
Table A2 and
Table A3). The algorithm was able to identically reproduce the ground truth transformation for all 14 teeth, except for 3 minimal numerical translation errors. The ground truth rotation was computed accurately using the proposed algorithm.
To compute the movement of individual teeth after superimposition on the palatal rugae patch, each tooth pair in the two scans was aligned using transformation alignment, and the resulting transformation was estimated. After verifying that the algorithm accurately computed the rigid body motions of 3D meshes, it was applied to an actual scan pair. Since the real movement of the teeth is unknown, ground truth for the rigid body transformations was not present. The pair of pre-treatment and post-treatment scans for the same patient are shown in
Appendix A (
Figure A4). Computed rigid body motion for all of the teeth is also depicted in
Appendix A (
Table A4).
4. Discussion
The proposed automated method algorithm was successful in segmenting permanent teeth in 3D, with lesser accuracy on unerupted, primary, and wisdom teeth, and enabled the measurement of rotational and translational tooth movement after orthodontic treatment relative to the palatal rugae used as a stable reference.
This method offers advantages relative to prior studies. Zhao et al. [
23,
24,
25,
26] used minimum curvature in 3D scans of the maxillary jaw to initiate the segmentation process, but their method required user interaction at multiple stages to exclude the undesirable areas picked by the curvature-based algorithm. Other authors used artificial neural networks to classify teeth features from a 3D scan, manually labeling only cusps of the teeth, not segmenting the individual teeth [
5,
27].
Xu et al. [
28,
29,
30,
31] performed segmentation directly on a 3D model through classification of mesh faces on a two-level segmentation, the first of which separated the teeth from the gingiva, while the second segmented individual teeth. A label optimization was introduced after each prediction to correct wrongly predicted labels, but sticky teeth (adjacent pairs of teeth with the same label after optimization) were sometimes predicted falsely. In our method, the need for pre-processing and post-processing steps was removed. In addition, Xu et al. did not use a stable reference for motion estimation.
Cui et al. [
32,
33] performed 3D segmentation using 3D dental scans and cone beam computed tomography (CBCT) images, whereby edges were extracted using a deep network model as a pre-processing step. This method required pre-processing steps to facilitate the segmentation process of the 3D model and another imaging modality, the CBCT images. In addition to removing pre-processing steps, our method enabled the acquisition of textured meshes more frequently in multiple stages without the need for CBCT scans that must be limited due to exposure measures. Tian et al. [
34,
35,
36] involved performing 3D segmentation using three-level hierarchical deep learning. The method also required pre-processing and post-processing of the dental model to enhance the segmentation results achieved, as well as point cloud reconstruction, which could generate non-original mesh data.
One of the most practical methods to assess tooth movement during growth and orthodontic treatment has involved the use of the palatal rugae as a relatively stable reference for superimposition, allowing for multiple stages of assessment and foregoing the need for radiologic exposure. Such approaches have included the generation of a reference coordinate system through the manual transfer of palatal “plugs” across sequential maxillary arches, the labeling of points of reference on the rugae across the arches over time, and the best fit of palatal surfaces that did not necessarily accurately reproduce the stable rugae [
15]. These approaches carry potential errors in measurement of tooth movement, particularly rotation and translation. The proposed scheme provides more accurate assessment because of the closer representation of rugal anatomy. However, additional work is needed to use specific pairs of rugae that are more stable over time, as rugal anatomy may be altered by certain tooth movements [
15]. Recent evidence suggests that the third rugae are the most stable [
37].
4.1. Medical Diagnostic Relevance
Accurate segmentation of maxillary teeth and palatal rugae in 3D scans has significant implications for medical diagnostics, particularly in orthodontics, forensic odontology, and craniofacial anomaly assessments. The precise identification of tooth position, movement, and morphology allows for the improved diagnosis of malocclusions, temporomandibular joint disorders (TMDs), and dental asymmetries [
38]. Furthermore, this method enhances orthodontic treatment planning by providing quantitative measurements of tooth displacement over time, allowing for personalized interventions and monitoring of treatment efficacy [
39]. In forensic sciences, the detailed segmentation of palatal rugae, considered unique to individuals, can serve as a reliable biometric marker for human identification [
40]. Additionally, the ability to assess morphological changes in dentition and surrounding structures can aid in the early detection of pathological conditions such as periodontitis and alveolar bone loss [
41]. By integrating deep learning-based segmentation with diagnostic applications, this approach holds promise for enhancing clinical decision making and reducing reliance on invasive imaging techniques, thereby improving patient outcomes in dental and orthodontic treatments [
42,
43].
4.2. Limitations and Future Considerations
The proposed method showed excellent performance in 3D semantic segmentation and motion analysis, with high accuracy and no need for additional processing steps. However, there are several opportunities to further strengthen and expand its clinical applicability. While our dataset of 100 scans provided a solid foundation for model development and testing, Future studies with larger and more diverse patient populations should aim to include a broader range of ages, malocclusion types, and dentition stages to better assess and confirm the generalizability of the method. The current approach also offers the potential for comparison with other segmentation techniques in the literature, which could further highlight its efficiency across different clinical scenarios. Additionally, applying the method to the early stages of treatment could reveal its value in detecting changes and improving treatment planning. This method holds strong potential as a tool for evaluating orthodontic treatment quality, and we encourage further validation in broader clinical contexts to fully realize its benefits.
5. Conclusions
A maxillary teeth dataset of textured 3D mesh consisted of 100 texture-colored and segmented scans that were used to generate a total of 10,000 labeled projections. A machine learning method with attention layers was used to semantically segment 2D projection images. The best network yielded an accuracy of 98.69% and average mIoU of 85.41. Using rasterization and texture baking, the 2D predictions were used to segment individual teeth and rugae in three-dimensional textured scans.
The proposed method did not require pre- or post- processing of the data to enhance the segmentation. Motion measurements were successfully performed using the palatal rugae area as stable reference points. The method provided rotation and translation measurements of teeth.
Author Contributions
Conceptualization, E.S. and J.G.G.; methodology, A.R.E.B., E.S., J.G.G., A.T.M. and K.G.Z.; software, A.R.E.B. and E.S.; validation, A.R.E.B., E.S., J.G.G., A.T.M. and K.G.Z.; formal analysis, A.R.E.B., E.S., J.G.G. and A.T.M.; investigation, A.R.E.B., E.S., J.G.G., A.T.M. and K.G.Z.; resources, J.G.G., A.T.M. and K.G.Z.; data curation, A.R.E.B.; writing—original draft preparation, A.R.E.B.; writing—review and editing, A.R.E.B., E.S., D.A., J.G.G. and A.T.M.; visualization, A.R.E.B., E.S., J.G.G. and A.T.M.; supervision, E.S., D.A. and J.G.G.; project administration, E.S. and J.G.G.; funding acquisition, J.G.G. and E.S. All authors have read and agreed to the published version of the manuscript.
Funding
Funding was provided by the American University of Beirut Collaborative Research Stimulus Grant: Project 23720/Award 103319 and the Healthcare Innovation and Technology Stimulus Grant: Project 26204/Award 104083.
Institutional Review Board Statement
The study was approved by American University of Beirut (Bio-2021-0153)—16 November 2021.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available upon request to interested researchers.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Baking results of 3D mesh segmentation.
Table A1.
Baking results of 3D mesh segmentation.
| | Test Meshes | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|
| | LABEL | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value | IoU Value |
|---|
| LEFT | central incisor | 89.91% | 88.11% | 84.50% | 91.88% | 88.65% | 87.20% | 93.62% | 91.57% | 80.98% | 88.80% |
| | lateral incisor | 89.48% | 84.17% | 85.82% | 63.04% | 74.17% | 1.61% | 85.61% | 86.10% | 82.77% | 80.49% |
| | canine | - | 85.10% | 87.90% | - | - | 27.18% | 90.52% | - | - | - |
| | first pre-molar | 85.83% | 89.08% | 81.47% | - | 65.40% | 27.26% | 86.08% | 8.25% | 85.21% | - |
| | second pre-molar | 78.89% | 87.93% | 78.45% | - | - | 70.03% | 87.84% | - | 88.86% | - |
| | first molar | 89.29% | 90.46% | 82.93% | 78.12% | 81.10% | 90.42% | 92.43% | 88.26% | 84.52% | 86.64% |
| | second molar | - | - | 79.07% | - | - | 82.02% | 89.67% | - | - | - |
| | third molar | - | - | 72.72% | - | - | - | - | - | - | - |
| RIGHT | central incisor | 87.32% | 90.78% | 83.17% | 91.55% | 90.25% | 86.56% | 89.34% | 87.69% | 85.22% | 83.47% |
| | lateral incisor | 84.75% | 85.42% | 80.95% | 84.57% | 85.38% | - | 89.16% | 88.81% | 77.48% | 85.36% |
| | canine | - | 79.60% | 79.66% | - | - | 39.97% | 76.22% | 0.00% | - | - |
| | first bicuspid | 89.50% | 88.54% | 77.68% | - | 85.49% | 85.41% | 88.34% | - | - | - |
| | second bicuspid | - | 90.26% | 76.06% | - | - | 82.06% | 86.06% | - | - | - |
| | first molar | 84.42% | 93.28% | 79.95% | 91.36% | 77.73% | 92.45% | 92.78% | 84.54% | 82.41% | 83.36% |
| | second molar | - | - | 76.05% | - | - | 84.99% | 83.80% | - | - | - |
| | third molar | - | - | 66.07% | - | - | - | - | - | - | - |
| | rugae | 77.57% | 80.12% | 66.02% | 85.59% | 80.18% | 79.54% | 83.53% | 80.26% | 77.06% | 84.27% |
| | PRIMARY TEETH | | | | | | | | | | |
| LEFT | central incisor | - | - | - | - | - | - | - | - | - | - |
| | lateral incisor | - | - | - | - | - | 0.00% | - | - | - | - |
| | canine | 79.33% | - | - | 14.20% | - | - | - | 77.93% | - | 90.47% |
| | first molar | - | - | - | 16.35% | - | - | - | - | - | 91.21% |
| | second molar | - | - | - | 14.77% | 45.56% | - | - | 89.72% | - | 85.19% |
| RIGHT | central incisor | - | - | - | - | - | - | - | - | - | - |
| | lateral incisor | - | - | - | - | - | 0.00% | - | - | - | - |
| | canine | 67.83% | - | - | 33.59% | 64.17% | - | - | - | 70.33% | 89.62% |
| | first molar | - | - | - | 41.21% | - | - | - | 65.60% | - | 86.27% |
| | second molar | 81.73% | - | - | 83.49% | 71.26% | - | - | 84.66% | 37.47% | 82.02% |
| | Mean IoU | 85.69% | 87.14% | 78.73% | 83.73% | 80.93% | 66.91% | 87.67% | 68.39% | 82.72% | 84.63% |
Table A2.
Translation motion results, comparing actual ground truth movement with respect to the movement achieved from the software.
Table A2.
Translation motion results, comparing actual ground truth movement with respect to the movement achieved from the software.
| Model | Translation in X-Axes (mm) | Translation in Y-Axes (mm) | Translation in Z-Axes (mm) |
|---|
| Tooth Number | Actual | Experimental | Actual | Experimental | Actual | Experimental |
|---|
| Tooth 1 | −2 | −2 | 0 | 0 | 0 | 0 |
| Tooth 2 | 0 | 0 | 1 | 1 | 0 | 0 |
| Tooth 3 | 2 | 2 | 0 | 0 | 0 | 0.07 |
| Tooth 4 | −2 | −2 | 0 | 0 | 0 | 0 |
| Tooth 5 | 1 | 1 | 2 | 2 | 0 | 0 |
| Tooth 6 | −1 | −1 | −1 | −1 | 0 | 0 |
| Tooth 7 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 8 | 0 | −0.00034 | −3 | −2.999 | 0 | 0 |
| Tooth 9 | 0 | 0 | −1 | −1 | 0 | 0 |
| Tooth 10 | 2 | 2 | −2 | −2 | 2 | 2 |
| Tooth 11 | 0 | 0 | −2 | −2 | 0 | 0 |
| Tooth 12 | 2 | 2 | 0 | 0 | 0 | 0 |
| Tooth 13 | 2 | 2 | 0 | 0 | 0 | 0 |
| Tooth 14 | 0 | 0 | 1 | 1 | 0 | 0 |
Table A3.
Rotation motion results, comparing actual ground truth movement with respect to the movement achieved from the software.
Table A3.
Rotation motion results, comparing actual ground truth movement with respect to the movement achieved from the software.
| Model | Rotation in X-Axes (Deg) | Rotation in Y-Axes (Deg) | Rotation in Z-Axes (Deg) |
|---|
| Tooth Number | Actual | Experimental | Actual | Experimental | Actual | Experimental |
|---|
| Tooth 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 3 | 0 | 0 | −2 | −2 | 0 | 0 |
| Tooth 4 | 3 | 3 | 0 | 0 | 0 | 0 |
| Tooth 5 | 0 | 0 | 0 | | 0 | 0 |
| Tooth 6 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 7 | 0 | 0 | 0 | 0 | 20 | 20 |
| Tooth 8 | 0 | 0 | 0 | 0 | −20 | −20 |
| Tooth 9 | 0 | 0 | 3 | 3 | 0 | 0 |
| Tooth 10 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 11 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 12 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 13 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tooth 14 | 0 | 0 | 0 | 0 | 0 | 0 |
Table A4.
Tooth motion results between pre-treatment and post-treatment scans.
Table A4.
Tooth motion results between pre-treatment and post-treatment scans.
| Model | Trans in X (mm) | Trans in Y (mm) | Trans in Z (mm) | Rot in X (Deg) | Rot in Y (Deg) | Rot in Z (Deg) |
|---|
| Tooth Number | Value | Value | Value | Value | Value | Value |
|---|
| Tooth 1 | 4.066 | −0.366 | 6.514 | −3.036 | −5.325 | 2.494 |
| Tooth 2 | −0.122 | −2.948 | 4.505 | −8.474 | 80.83 | 1.5 |
| Tooth 3 | 0.698 | −0.588 | −1.006 | 5.734 | 1.756 | 0.337 |
| Tooth 4 | 0.490 | −0.016 | 2.312 | −1.09 | −3.18 | 0.379 |
| Tooth 5 | −0.079 | 0.241 | −0.143 | −0.13 | 3.6 | 1.25 |
| Tooth 6 | 0.461 | 0.270 | 0.460 | 1.37 | −1.1 | 0.277 |
| Tooth 7 | 0.192 | 0.689 | 0.127 | 2.68 | −0.21 | 0.675 |
| Tooth 8 | 0.068 | 0.916 | 0.035 | 3.55 | 0.75 | −0.070 |
| Tooth 9 | −0.107 | 0.381 | 0.111 | 2.4 | 0.489 | 0.43 |
| Tooth 10 | 0.306 | −0.062 | 0.099 | 0.792 | −2 | 0.796 |
| Tooth 11 | −0.946 | 0.914 | 2.110 | −0.77 | 2.758 | −2.76 |
| Tooth 12 | −1.027 | 0.223 | −0.954 | 4 | −3 | −2.5 |
| Tooth 13 | −1.500 | −0.901 | 2.235 | −5.1 | −6.769 | −3 |
| Tooth 14 | −4.035 | 0.035 | 5.653 | −3.18 | 2.9 | −3.7 |
Figure A1.
3D scan samples showing different camera proximities and their associated image labels.
Figure A1.
3D scan samples showing different camera proximities and their associated image labels.
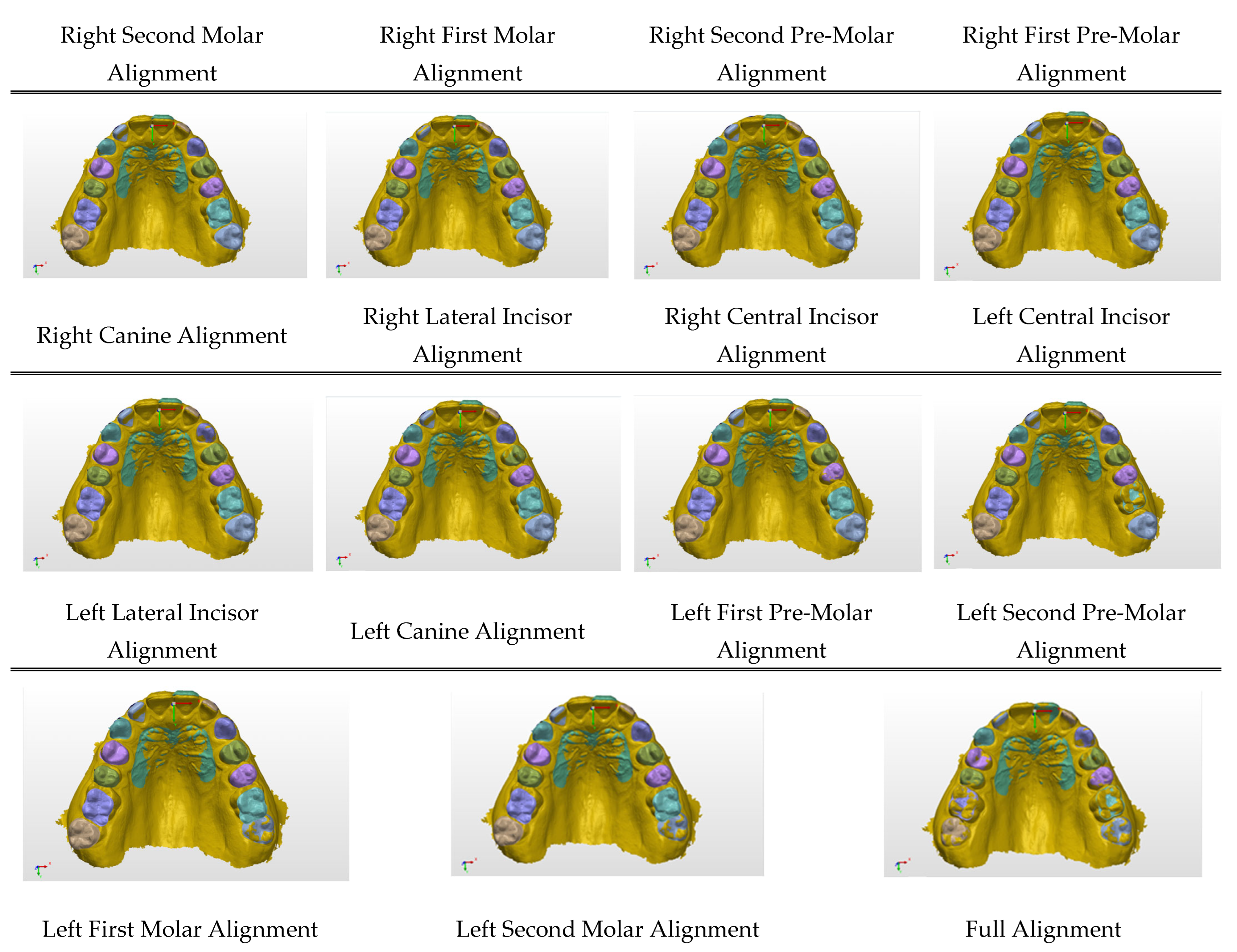
Figure A2.
(A) Imported scans; (B) alignment on palatal rugae; and (C) motion measurement process applied on right second molar alignment as an example.
Figure A2.
(A) Imported scans; (B) alignment on palatal rugae; and (C) motion measurement process applied on right second molar alignment as an example.
Figure A3.
The first column depicts the segmented scans, and the second column shows the ground truth labeled meshes. The first row depicts Mesh 6, the second row depicts Mesh 8, and the final row depicts Mesh 7 (best mesh segmented).
Figure A3.
The first column depicts the segmented scans, and the second column shows the ground truth labeled meshes. The first row depicts Mesh 6, the second row depicts Mesh 8, and the final row depicts Mesh 7 (best mesh segmented).
Figure A4.
A diagram showing the process of alignment being conducted on pre-treatment and post-treatment scans of a real patient. Scans are imported and aligned on the reference rugae, followed by individual alignment of every tooth with respect to the rugae; aligned reference for measurement purposes.
Figure A4.
A diagram showing the process of alignment being conducted on pre-treatment and post-treatment scans of a real patient. Scans are imported and aligned on the reference rugae, followed by individual alignment of every tooth with respect to the rugae; aligned reference for measurement purposes.
References
- Krenmayr, L.; von Schwerin, R.; Schaudt, D.; Riedel, P.; Hafner, A. DilatedToothSegNet: Tooth Segmentation Network on 3D Dental Meshes Through Increasing Receptive Vision. J. Imaging Inform. Med. 2024, 37, 1846–1862. [Google Scholar] [CrossRef]
- Wang, S.; Liang, S.; Chang, Q.; Zhang, L.; Gong, B.; Bai, Y.; Zuo, F.; Wang, Y.; Xie, X.; Gu, Y. STSN-Net: Simultaneous Tooth Segmentation and Numbering Method in Crowded Environments with Deep Learning. Diagnostics 2024, 14, 497. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Estai, M.; Tennant, M.; Gebauer, D.; Brostek, A.; Vignarajan, J.; Mehdizadeh, M.; Saha, S. Deep learning for automated detection and numbering of permanent teeth on panoramic images. Dentomaxillofac. Radiol. 2022, 51, 20210296. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Jana, A.; Maiti, A.; Metaxas, D.N. A Critical Analysis of the Limitation of Deep Learning based 3D Dental Mesh Segmentation Methods in Segmenting Partial Scans. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney, Australia, 24–27 July 2023. [Google Scholar] [CrossRef]
- Raith, S.; Vogel, E.P.; Anees, N.; Keul, C.; Güth, J.F.; Edelhoff, D.; Fischer, H. Artificial Neural Networks as a powerful numerical tool to classify specific features of a tooth based on 3D scan data. Comput. Biol. Med. 2017, 80, 65–76. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Özçelik, S.T.A.; Üzen, H.; Şengür, A.; Fırat, H.; Türkoğlu, M.; Çelebi, A.; Gül, S.; Sobahi, N.M. Enhanced Panoramic Radiograph-Based Tooth Segmentation and Identification Using an Attention Gate-Based Encoder-Decoder Network. Diagnostics 2024, 14, 2719. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Liu, C.; Wang, W.; Sun, R.; Wang, T.; Shen, X.; Sun, T. A dual-decoder banded convolutional attention network for bone segmentation in ultrasound images. Med. Phys. 2025, 52, 1556–1572. [Google Scholar] [CrossRef]
- Zhang, W.; Chen, S.; Ma, Y.; Liu, Y.; Cao, X. ETUNet: Exploring efficient transformer enhanced UNet for 3D brain tumor segmentation. Comput. Biol. Med. 2024, 171, 108005. [Google Scholar] [CrossRef] [PubMed]
- Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation. Diagnostics 2021, 11, 501. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Armijos Yunga, A.D.; Juela Corte, N.A.; Pesantez Ocampo, F.V.; Bravo Calderón, M.E. Comparative study of reliability in three software Meshmixer, 3D Slicer, and Nemocast of the intercanine and intermolar spaces of digital models. World J. Adv. Res. Rev. 2023, 17, 1040–1045. [Google Scholar] [CrossRef]
- Cignoni, P.; Callieri, M.; Corsini, M.; Dellepiane, M.; Ganovelli, F.; Ranzuglia, G. MeshLab: An open-source mesh processing tool. In Proceedings of the Eurographics Italian Chapter Conference, Salerno, Italy, 2–4 July 2008; pp. 129–136. [Google Scholar] [CrossRef]
- Pan, F.; Liu, J.; Cen, Y.; Chen, Y.; Cai, R.; Zhao, Z.; Liao, W.; Wang, J. Accuracy of RGB-D camera-based and stereophotogrammetric facial scanners: A comparative study. J. Dent. 2022, 127, 104302. [Google Scholar] [CrossRef] [PubMed]
- Ashmore, J.L.; Kurland, B.F.; King, G.J.; Wheeler, T.T.; Ghafari, J.; Ramsay, D.S. A 3-dimensional analysis of molar movement during headgear treatment. Am. J. Orthod. Dentofac. Orthop. 2002, 121, 18–29; discussion 29–30. [Google Scholar] [CrossRef] [PubMed]
- Saadeh, M.; Macari, A.; Haddad, R.; Ghafari, J. Instability of palatal rugae following rapid maxillary expansion. Eur. J. Orthod. 2017, 39, 474–481. [Google Scholar] [CrossRef]
- Farronato, M.; Begnoni, G.; Boodt, L.; Thevissen, P.; Willems, G.; Cadenas de Llano-Pérula, M. Are palatal rugae reliable markers for 3D superimposition and forensic human identification after palatal expansion? A systematic review. Forensic Sci. Int. 2023, 351, 111814. [Google Scholar] [CrossRef] [PubMed]
- InnovMetric Software Inc. PolyWorks: The Smart 3D Metrology Digital Ecosystem. 2025. Available online: https://www.innovmetric.com/products/products-overview (accessed on 5 June 2024).
- Yilmaz, B.; Alshahrani, F.A.; Kale, E.; Johnston, W.M. Effect of feldspathic porcelain layering on the marginal fit of zirconia and titanium complete-arch fixed implant-supported frameworks. J. Prosthet. Dent. 2018, 120, 71–78. [Google Scholar] [CrossRef] [PubMed]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef]
- Villarini, B.; Asaturyan, H.; Kurugol, S.; Afacan, O.; Bell, J.D.; Thomas, E.L. 3D Deep Learning for Anatomical Structure Segmentation in Multiple Imaging Modalities. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 166–171. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Tiu, E. Metrics to Evaluate Your Semantic Segmentation Model. Medium. Available online: https://medium.com/towards-data-science/metrics-to-evaluate-your-semantic-segmentation-model-6bcb99639aa2 (accessed on 10 March 2024).
- Wolfram Research, Inc. Mathematica, Version 14.2; Wolfram Research, Inc.: Champaign, IL, USA, 2024. [Google Scholar]
- Zhao, M.; Ma, L.; Tan, W.; Nie, D. Interactive tooth segmentation of dental models. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 654–657. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, H. Interactive Tooth Separation from Dental Model Using Segmentation Field. PLoS ONE 2016, 11, e0161159. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Mai, H.N.; Han, J.S.; Kim, H.S.; Park, Y.S.; Park, J.M.; Lee, D.H. Reliability of automatic finish line detection for tooth preparation in dental computer-aided software. J. Prosthodont. Res. 2023, 67, 138–143. [Google Scholar] [CrossRef] [PubMed]
- Xia, Z.; Gan, Y.; Chang, L.; Xiong, J.; Zhao, Q. Individual tooth segmentation from CT images scanned with contacts of maxillary and mandible teeth. Comput. Methods Programs Biomed. 2017, 138, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Huang, J.; Salehi, H.S.; Zhu, H.; Lian, L.; Lai, X.; Wei, K. Hierarchical CNN-based occlusal surface morphology analysis for classifying posterior tooth type using augmented images from 3D dental surface models. Comput. Methods Programs Biomed. 2021, 208, 106295. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Liu, C.; Zheng, Y. 3D Tooth Segmentation and Labeling Using Deep Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2336–2348. [Google Scholar] [CrossRef]
- Kearney, V.; Chan, J.W.; Wang, T.; Perry, A.; Yom, S.S.; Solberg, T.D. Attention-enabled 3D boosted convolutional neural networks for semantic CT segmentation using deep supervision. Phys. Med. Biol. 2019, 64, 135001. [Google Scholar] [CrossRef] [PubMed]
- Chung, M.; Lee, M.; Hong, J.; Park, S.; Lee, J.; Lee, J.; Yang, I.H.; Lee, J.; Shin, Y.G. Pose-aware instance segmentation framework from cone beam CT images for tooth segmentation. Comput. Biol. Med. 2020, 120, 103720. [Google Scholar] [CrossRef] [PubMed]
- Pei, Y.; Ai, X.; Zha, H.; Xu, T.; Ma, G. 3D exemplar-based random walks for tooth segmentation from cone-beam computed tomography images. Med. Phys. 2016, 43, 5040. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Li, C.; Wang, W. Toothnet: Automatic tooth instance segmentation and identification from cone beam CT images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6361–6370. [Google Scholar]
- Ayidh Alqahtani, K.; Jacobs, R.; Smolders, A.; Van Gerven, A.; Willems, H.; Shujaat, S.; Shaheen, E. Deep convolutional neural network-based automated segmentation and classification of teeth with orthodontic brackets on cone-beam computed-tomographic images: A validation study. Eur. J. Orthod. 2023, 45, 169–174. [Google Scholar] [CrossRef] [PubMed]
- Tian, S.; Dai, N.; Zhang, B.; Yuan, F.; Yu, Q.; Cheng, X. Automatic classification and segmentation of teeth on 3d dental model using hierarchical deep learning networks. IEEE Access 2019, 7, 84817–84828. [Google Scholar] [CrossRef]
- Fan, W.; Zhang, J.; Wang, N.; Li, J.; Hu, L. The Application of Deep Learning on CBCT in Dentistry. Diagnostics 2023, 13, 2056. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Shaheen, E.; Leite, A.; Alqahtani, K.A.; Smolders, A.; Van Gerven, A.; Willems, H.; Jacobs, R. A novel deep learning system for multi-class tooth segmentation and classification on cone beam computed tomography. A validation study. J. Dent. 2021, 115, 103865. [Google Scholar] [CrossRef] [PubMed]
- Aybout, J. Palatal Rugae in 3D Superimposition Technique. Master’s Thesis, Department of Dentofacial Medicine, Faculty of Medicine, American University of Beirut, Beirut, Lebanon, 2023. [Google Scholar]
- Proffit, W.R.; Fields, H.W.; Larson, B.E.; Sarver, D.M. Contemporary Orthodontics, 6th ed.; Elsevier: New Delhi, India, 2019. [Google Scholar]
- Nan, L.; Tang, M.; Liang, B.; Mo, S.; Kang, N.; Song, S.; Zhang, X.; Zeng, X. Automated Sagittal Skeletal Classification of Children Based on Deep Learning. Diagnostics 2023, 13, 1719. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Mustafa, A.G.; Allouh, M.Z.; Alshehab, R.M. Morphological changes in palatal rugae patterns following orthodontic treatment. J. Forensic Leg Med. 2015, 31, 19–22. [Google Scholar] [CrossRef] [PubMed]
- Mengel, R.; Candir, M.; Shiratori, K.; Flores-de-Jacoby, L. Digital volume tomography in the diagnosis of periodontal defects: An in vitro study on native pig and human mandibles. J. Periodontol. 2005, 76, 665–673. [Google Scholar] [CrossRef] [PubMed]
- Hendrickx, J.; Gracea, R.S.; Vanheers, M.; Winderickx, N.; Preda, F.; Shujaat, S.; Jacobs, R. Can artificial intelligence-driven cephalometric analysis replace manual tracing? A systematic review and meta-analysis. Eur. J. Orthod. 2024, 46, cjae029. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- El Bsat, A.R.; Shammas, E.; Asmar, D.; Sakr, G.E.; Zeno, K.G.; Macari, A.T.; Ghafari, J.G. Semantic Segmentation of Maxillary Teeth and Palatal Rugae in Two-Dimensional Images. Diagnostics 2022, 12, 2176. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}