
An Interpretable Approach with Explainable AI for Heart Stroke Prediction

 , , , and
, , , and
Abstract
1. Introduction
1.1. Problem Statement
1.2. AI Challenges in the Field of Heart Strokes
1.3. Research Drive
1.4. Objectives, Contribution, and the Structure of the Paper
- The proposed model introduces a meticulously designed, effective, and easily interpretable approach for heart stroke prediction, leveraging explainable AI techniques;
- Model quality and effectiveness can be enhanced by using several techniques in ML and DL. The proposed approach has incorporated techniques such as resampling, data leakage prevention, and feature selection, which are significant;
- To enhance the model’s reliability and balance accuracy and interpretability, we provided insight into the model’s internal workings. The model is, therefore, easier for healthcare professionals to understand and apply.
- The second section provides an overview of the most recent research in the topic;
- Our suggested methodology is broken down in Section 3, including explanations of datasets and methods;
- The performance of the model is presented in Section 4;
- In this report’s fifth and last section, we summarize the most important findings from our investigation and discuss new potential lines of inquiry for further study.
2. Literature Review
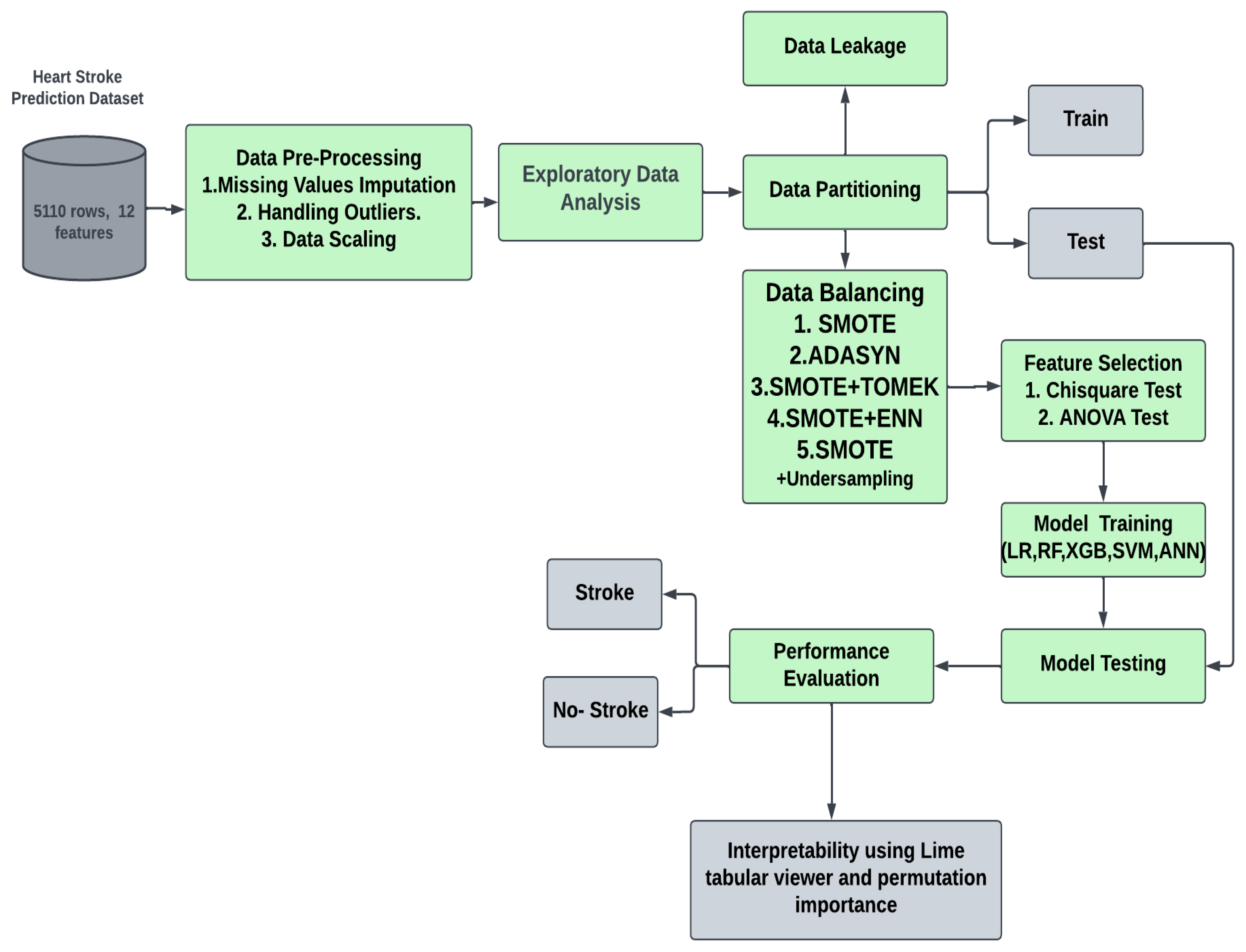
3. Proposed Methodology
3.1. Proposed Approach
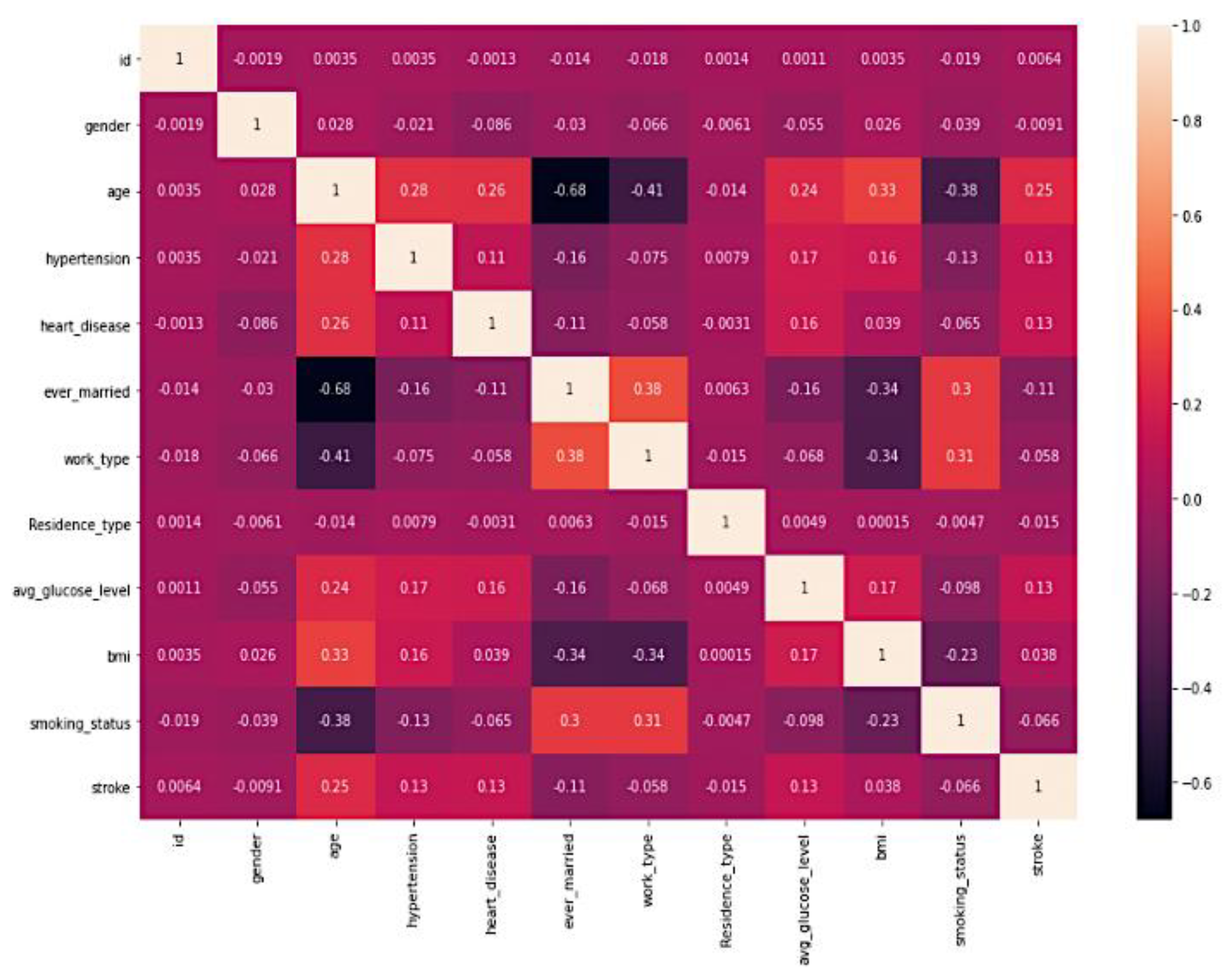
3.2. Feature Analysis
3.3. Data Insights
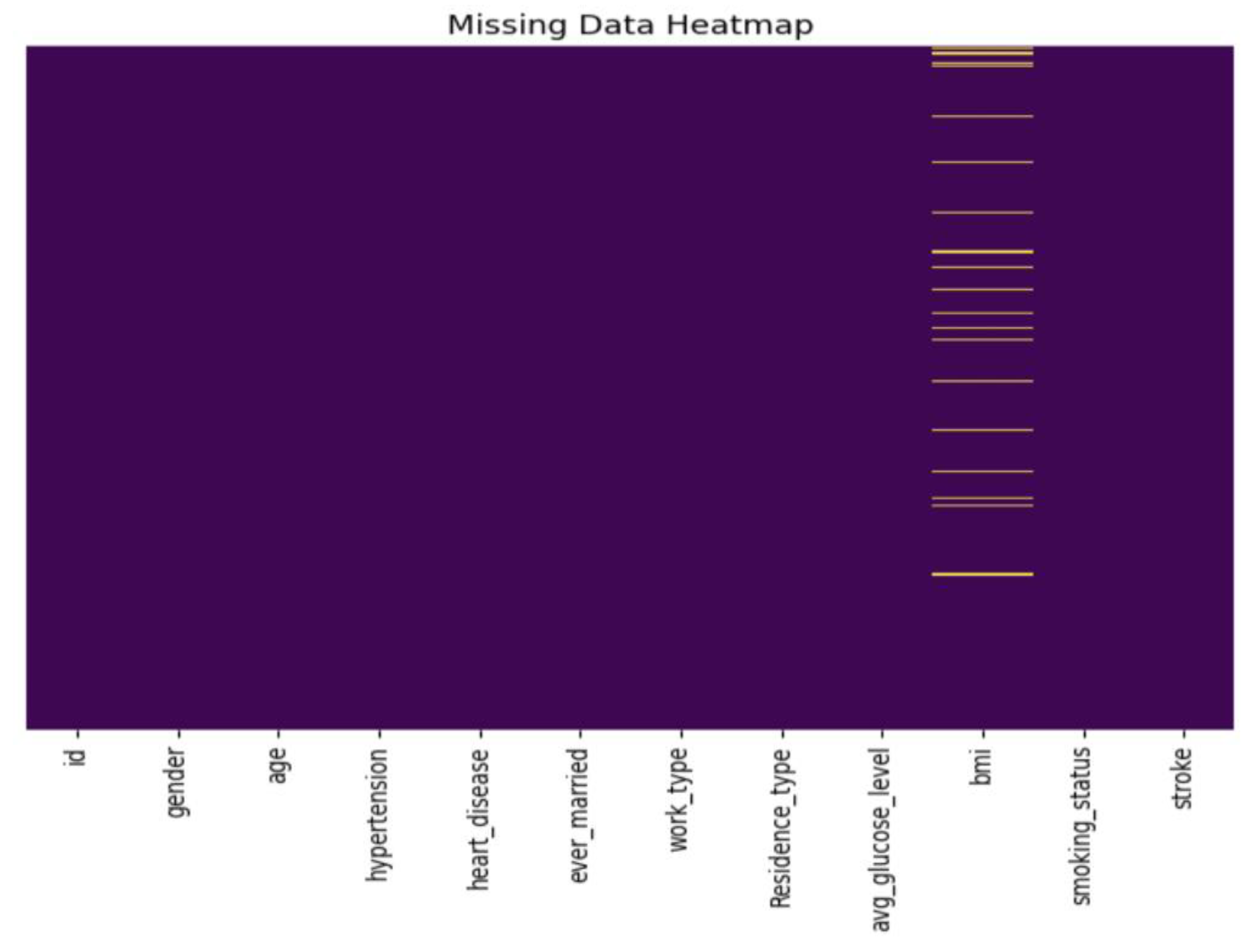
3.4. Data Pre-Processing
3.4.1. Missing Data Handling
- Detecting and addressing missing values;
- Eliminating the ‘id’ column;
- Handling outliers.
3.4.2. Handling Imbalanced Data
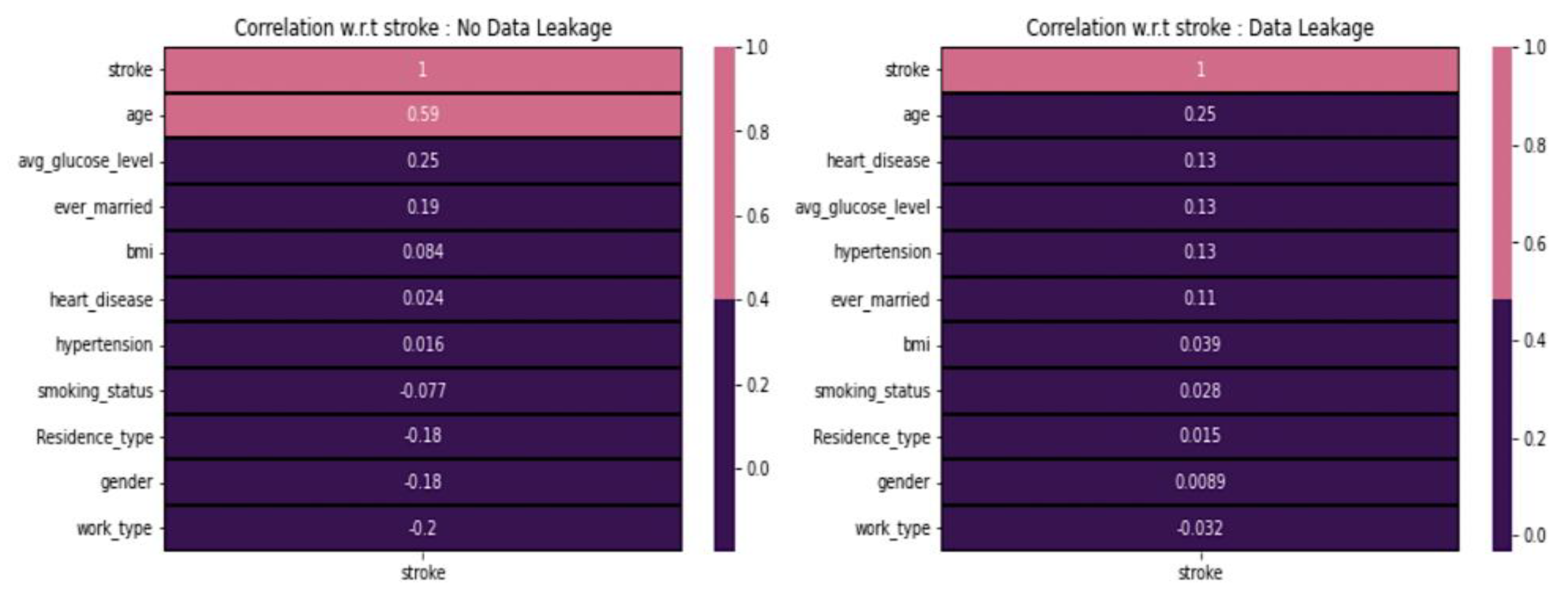
3.4.3. Data Leakage
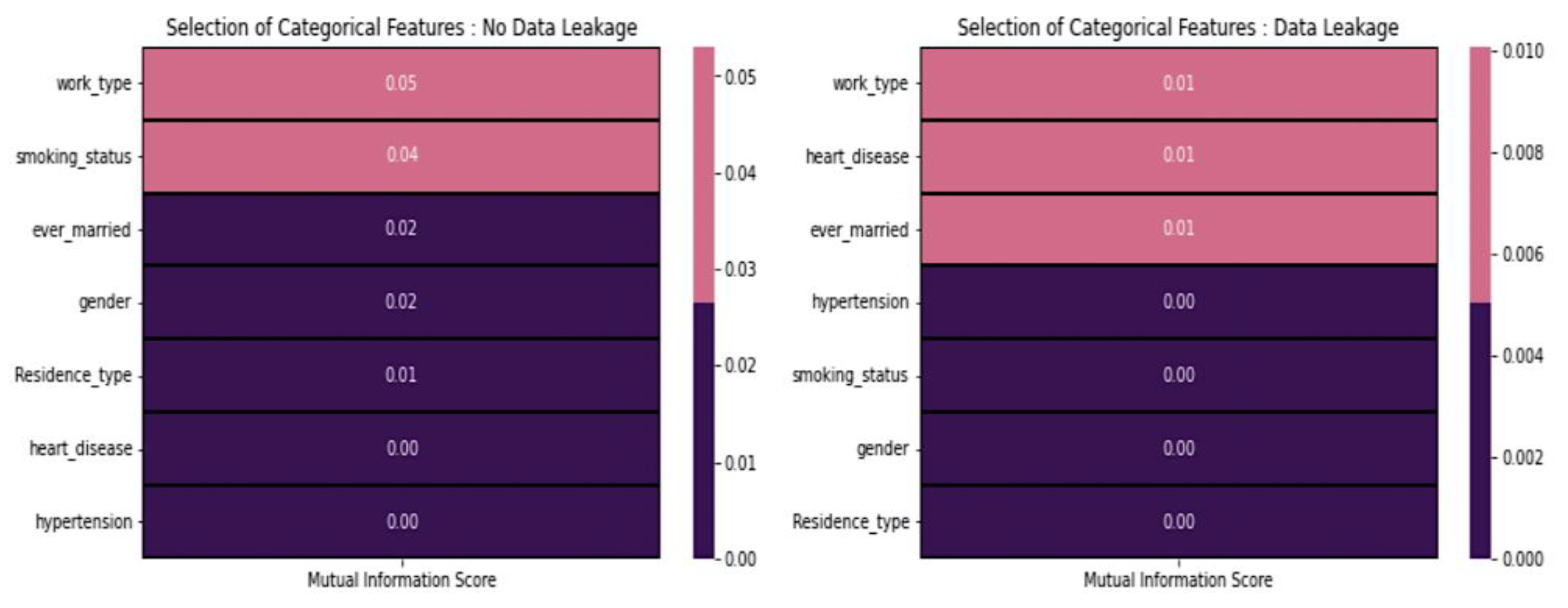
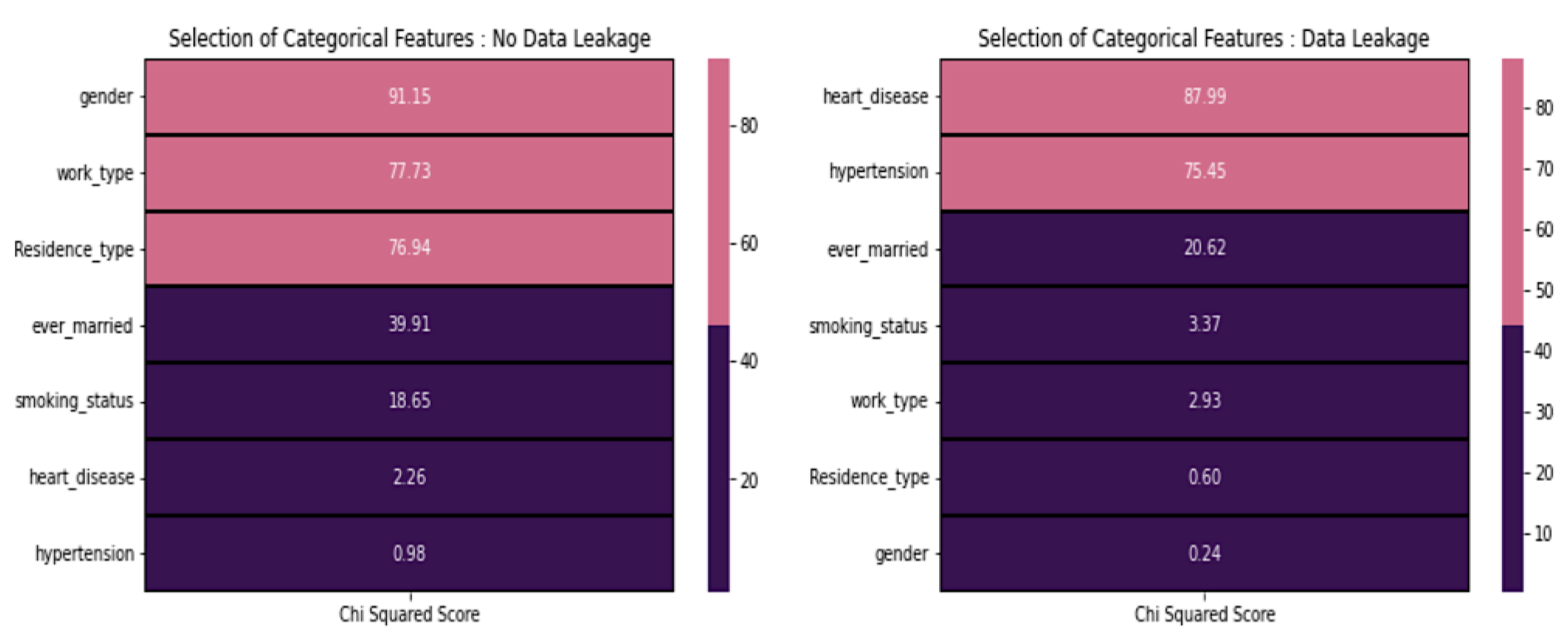
3.4.4. Feature Selection
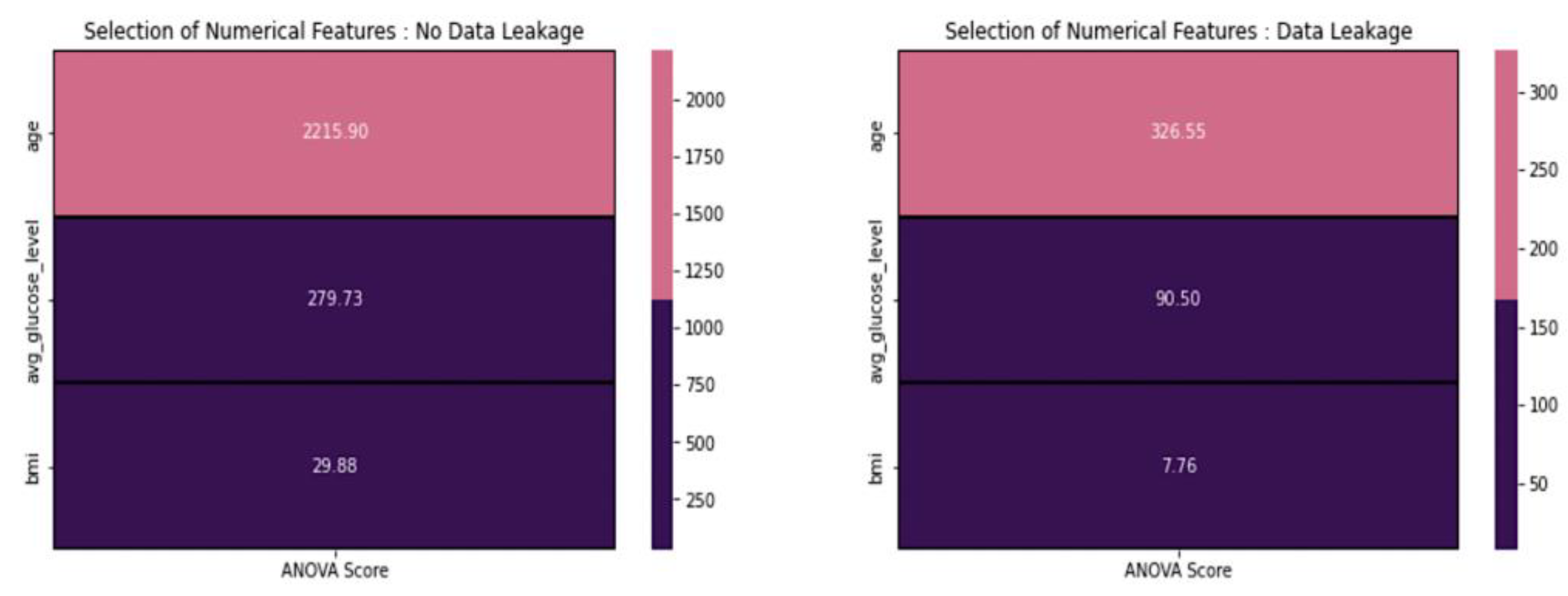
3.4.5. Feature Selection for Numerical Features
3.4.6. Data Scaling
- Normalization: features with non-normal (Gaussian) distributions can benefit from this method;
- Standardization: standardization is used for features that exhibit a normal distribution but have values that are significantly larger or smaller in range compared to other features.
3.5. Model Building
3.5.1. Random Forest
3.5.2. XGBoost
3.5.3. Logistic Regression
- -
- is the cost function to be minimized;
- -
- is the number of training examples;
- -
- is the actual label of the training example;
- -
- is the predicted probability that belongs to the positive class.
3.5.4. Support Vector Machine
- -
- is the weight vector;
- -
- is the input feature vector;
- -
- is the bias term.
3.5.5. Artificial Neural Network
4. Experimental Results and Performance Analysis
4.1. Performance Parameters
- -
- True Positives (TP): the number of correctly predicted stroke cases;
- -
- True Negatives (TN): the number of correctly predicted non-stroke cases;
- -
- False Positives (FP): the number of incorrectly predicted stroke cases;
- -
- False Negatives (FN): the number of incorrectly predicted non-stroke cases.
- Accuracy (ACC): accuracy measures the proportion of all correct predictions, the corresponding formula is shown in Equation (8).
- Precision (PR): precision assesses the accuracy of positive predictions, the corresponding formula is shown in Equation (9).
- Recall (Sensitivity) (RE): recall, also known as sensitivity, evaluates the model’s ability to identify all positive instances, the corresponding formula is shown in Equation (10).
- Specificity (SP): specificity gauges the model’s capacity to correctly identify negative instances, the corresponding formula is shown in Equation (11).
- F1-Score (F1): The F1-score combines precision and recall into a single metric, the corresponding formula is shown in Equation (12).
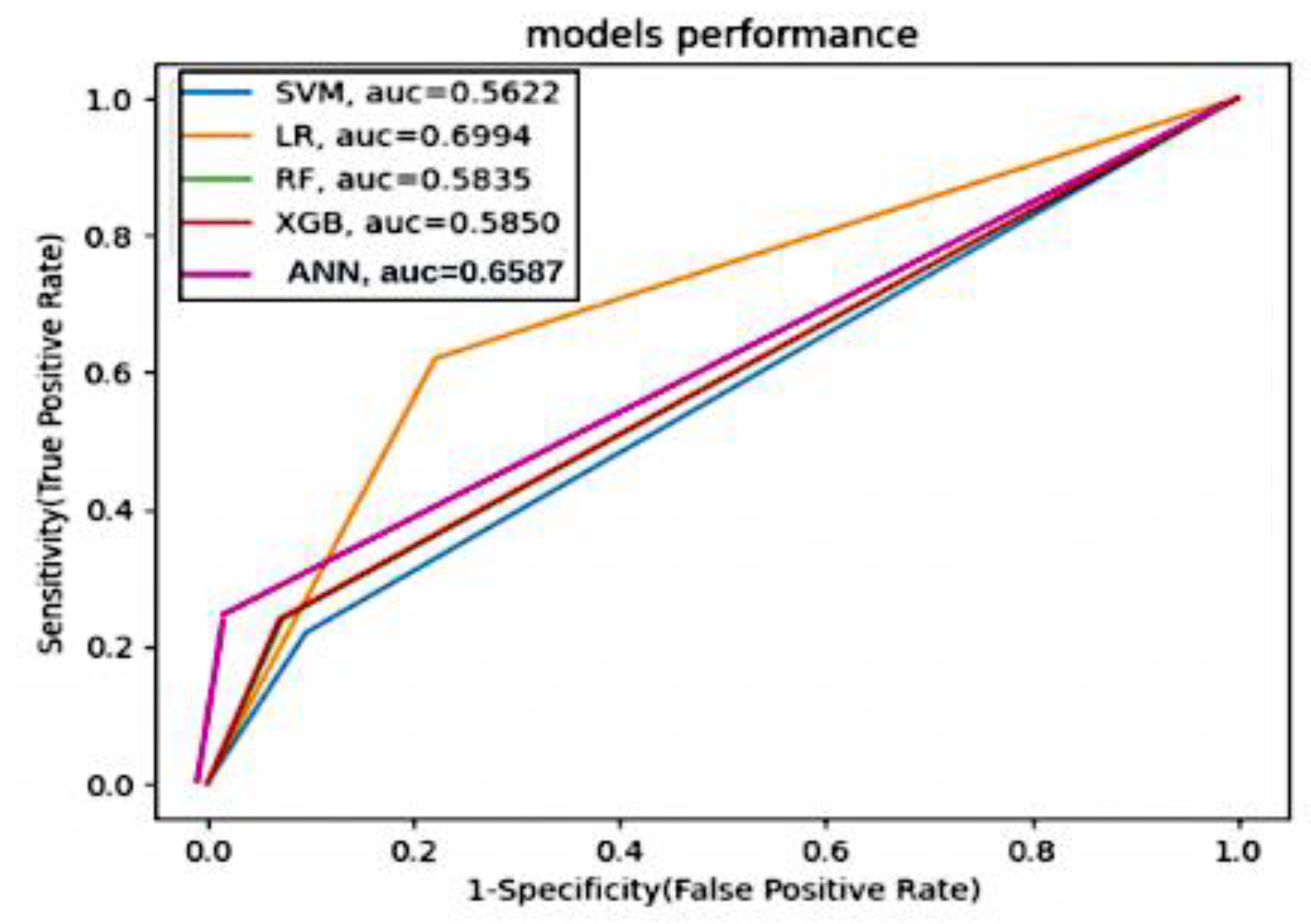
- ROC Curve and AUC-ROC: the ROC curve graphs the true positive rate (recall) against the false positive rate (1—specificity) at different decision thresholds. The AUC-ROC quantifies the area under the ROC curve, indicating the model’s discriminatory power. These formulas provide quantitative ways to assess the performance of stroke prediction models based on their predictions of true positives, true negatives, false positives, and false negatives. Each metric serves a specific purpose and can help evaluate the model’s effectiveness in different aspects of stroke prediction.
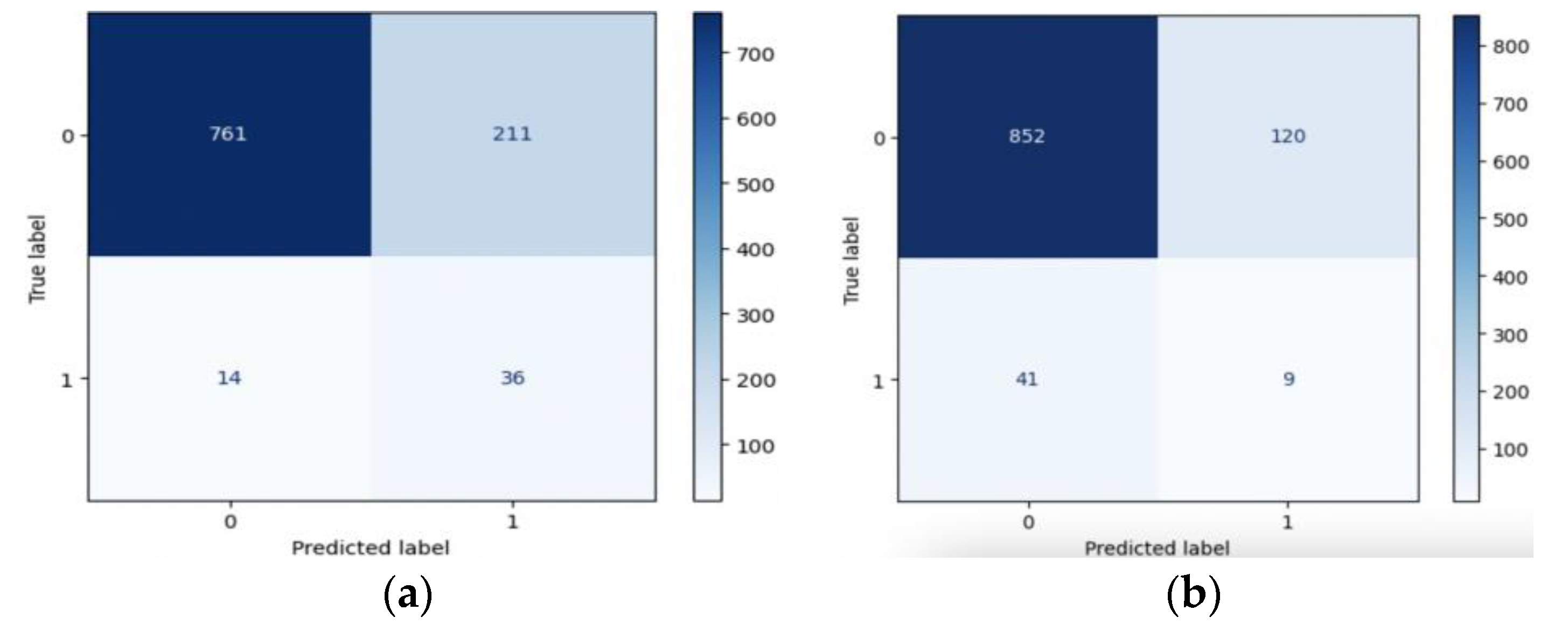
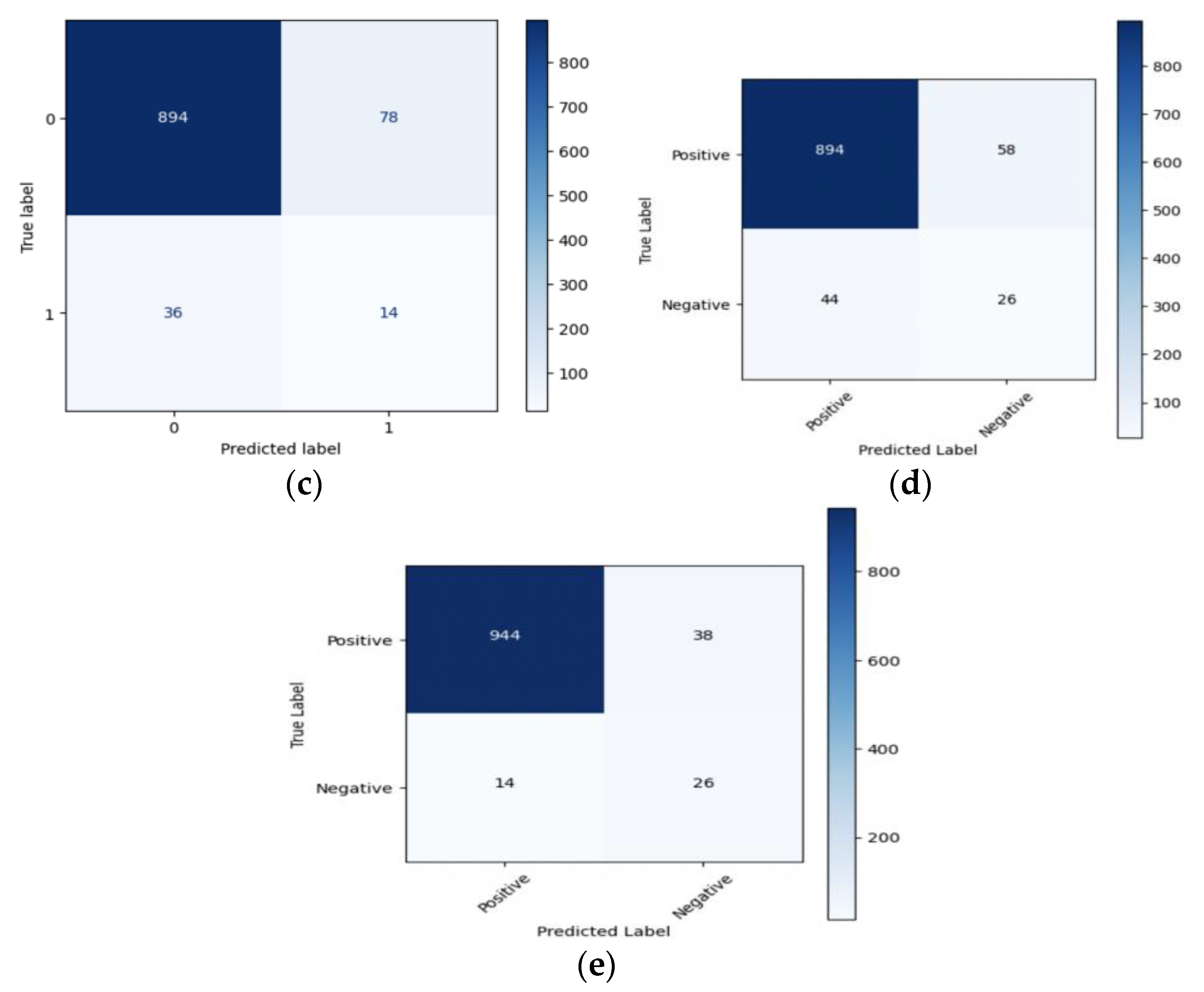
4.2. Performance Results
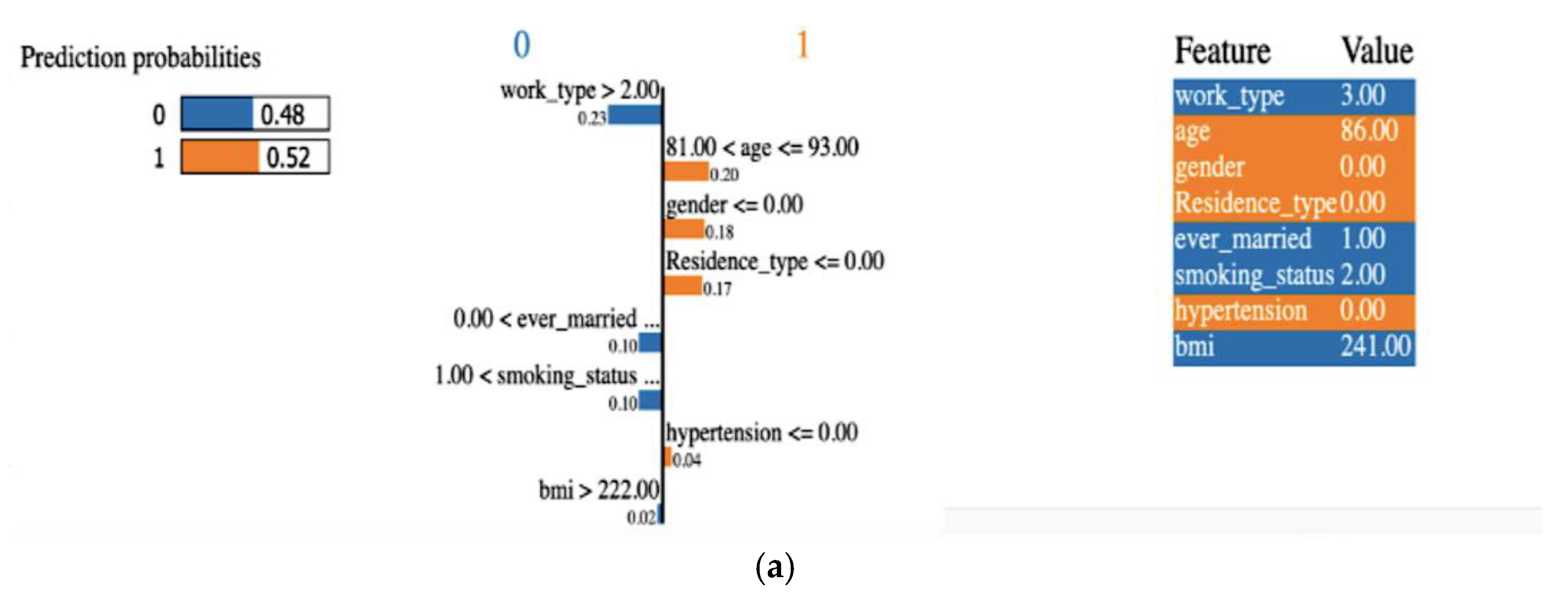
4.3. Model Interpretability
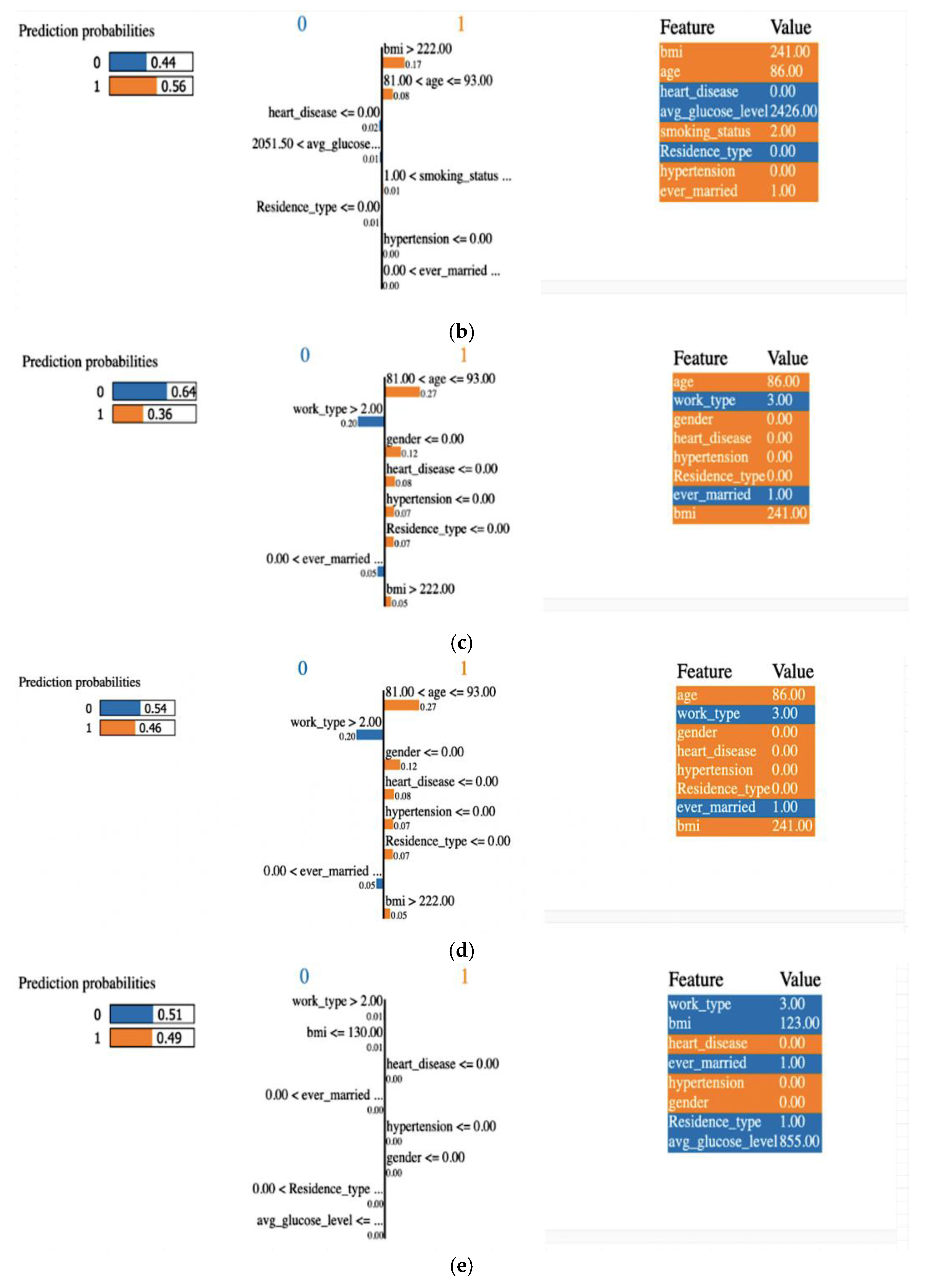
4.3.1. Explainability Using LIME (Local)
4.3.2. Permutation Importance
- Feature Selection: it helps identify the most relevant features in your dataset, allowing you to simplify and optimize your model;
- Model Evaluation: it provides insights into which features contribute the most to the model’s predictive power;
- Interpretability: permutation importance offers a way to explain model predictions by highlighting the importance of each feature.
- Prevention initiatives and treatment program development;
- Coordinating with EHRs;
- Medical professionals’ decision-support tool;
- Prevention through patient education;
- Remote monitoring and telemedicine;
- Working in tandem with program that promote public health;
- Constantly enhancing models and feedback system.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Burns, S.P.; Fleming, T.K.; Webb, S.S.; Kam, A.S.H.; Fielder, J.D.; Kim, G.J.; Hu, X.; Hill, M.T.; Kringle, E.A. Stroke recovery during the COVID-19 pandemic: A position paper on recommendations for rehabilitation. Arch. Phys. Med. Rehabil. 2022, 103, 1874–1882. [Google Scholar] [CrossRef] [PubMed]
- Coute, R.A.; Nathanson, B.H.; Kurz, M.C.; Mader, T.J.; Jackson, E.A. Disability-Adjusted Life-Years after Adult In-Hospital Cardiac Arrest in the United States. Am. J. Cardiol. 2023, 195, 3–8. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Chen, M.; Wang, Y.; Jiang, G.; Hou, N.; Wang, L.; Wen, K.; Li, W. Development of a predictive risk stratification tool to identify the population over age 45 at risk for new-onset stroke within 7 years. Front. Aging Neurosci. 2023, 15, 1101867. [Google Scholar] [CrossRef] [PubMed]
- Das, M.C.; Liza, F.T.; Pandit, P.P.; Tabassum, F.; Al Mamun, M.; Bhattacharjee, S.; Bin Kashem, S. A comparative study of machine learning approaches for heart stroke prediction. In Proceedings of the 2023 International Conference on Smart Applications, Communications and Networking (SmartNets), Istanbul, Turkey, 25–27 July 2023; IEEE: Piscataway, NJ, USA; pp. 1–6. [Google Scholar]
- Emon, M.U.; Keya, M.S.; Meghla, T.I.; Rahman, M.; Al Mamun, M.S.; Kaiser, M.S. Performance analysis of machine learning approaches in stroke prediction. In Proceedings of the 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 5–7 November 2020; IEEE: Piscataway, NJ, USA; pp. 1464–1469. [Google Scholar]
- Ramesh, G.; Aravindarajan, V.; Logeshwaran, J.; Kiruthiga, T.; Vignesh, S. Estimation analysis of paralysis effects for human nervous system by using Neuro fuzzy logic controller. NeuroQuantology 2022, 20, 3195–3206. [Google Scholar]
- Caso, V.; Martins, S.; Mikulik, R.; Middleton, S.; Groppa, S.; Pandian, J.D.; Thang, N.H.; Danays, T.; van der Merwe, J.; Fischer, T.; et al. Six years of the Angels Initiative: Aims, achievements, and future directions to improve stroke care worldwide. Int. J. Stroke 2023, 18, 898–907. [Google Scholar] [CrossRef] [PubMed]
- Ospel, J.M.; Kunz, W.G.; McDonough, R.V.; Goyal, M.; Uchida, K.; Sakai, N.; Yamagami, H.; Yoshimura, S.; RESCUE-Japan LIMIT Investigators. Cost-effectiveness of endovascular treatment for acute stroke with large infarct: A United States perspective. Radiology 2023, 309, e223320. [Google Scholar] [CrossRef] [PubMed]
- Singh, M.S.; Choudhary, P.; Thongam, K. A Comparative Analysis for Various Stroke Prediction Techniques. In Computer Vision and Image Processing; Springer: Singapore, 2020. [Google Scholar]
- Pradeepa, S.; Manjula, K.R.; Vimal, S.; Khan, M.S.; Chilamkurti, N.; Luhach, A.K. DRFS: Detecting Risk Factor of Stroke Disease from Social Media Using Machine Learning Techniques; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Bandi, V.; Bhattacharyya, D.; Midhunchakkravarthy, D. Prediction of Brain Stroke Severity Using Machine Learning. Int. Inf. Eng. Technol. Assoc. 2020, 34, 753. [Google Scholar] [CrossRef]
- Nwosu, C.S.; Dev, S.; Bhardwaj, P.; Veeravalli, B.; John, D. Predicting stroke from electronic health records. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Berlin, Germany, 23–27 July 2019; IEEE: Piscataway, NJ, USA. [Google Scholar]
- Alotaibi, F.S. Implementing Machine Learning Model to Predict Heart Failure Disease. Int. J. Adv. Comput. Sci. Appl. IJACSA 2019, 10, 261–268. [Google Scholar] [CrossRef]
- Ohoud Almadani, Riyad Alshammari: Prediction of Stroke using Data Mining Classification Techniques. Int. J. Adv. Comput. Sci. Appl. IJACSA 2018, 9, 457–460. [CrossRef]
- Kansadub, T.; Thammaboosadee, S.; Kiattisin, S.; Jalayondeja, C. Stroke risk prediction model based on demographic data. In Proceedings of the 8th Biomedical Engineering International Conference (BMEiCON), Shenyang, China, 14–16 October 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Khosla, A.; Cao, Y.; Lin, C.C.Y.; Chiu, H.K.; Hu, J.; Lee, H. An Integrated Machine Learning Approach to Stroke Prediction. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Shanthi, D.; Sahoo, G.; Saravanan, N. Designing an artificial neural network model for predicting thrombo-embolic stroke. Int. J. Biom. Bioinform. IJBB 2009, 3, 10–18. [Google Scholar]
- Sirisha, U.; Praveen, S.P.; Srinivasu, P.N.; Barsocchi, P.; Bhoi, A.K. Statistical analysis of design aspects of various YOLO-based deep learning models for object detection. Int. J. Comput. Intell. Syst. 2023, 16, 126. [Google Scholar] [CrossRef]
- Sirisha, U.; Chandana, B.S. Privacy preserving image encryption with optimal deep transfer learning based accident severity classification model. Sensors 2023, 23, 519. [Google Scholar] [CrossRef] [PubMed]
- Stroke Prediction Dataset. Available online: https://www.kaggle.com/fedesoriano/stroke-prediction-dataset (accessed on 2 January 2024).
- Praveen, S.P.; Srinivasu, P.N.; Shafi, J.; Wozniak, M.; Ijaz, M.F. ResNet-32 and FastAI for diagnoses of ductal carcinoma from 2D tissue slides. Sci. Rep. 2022, 12, 20804. [Google Scholar] [CrossRef] [PubMed]
- Srinivasu, P.N.; Shafi, J.; Krishna, T.B.; Sujatha, C.N.; Praveen, S.P.; Ijaz, M.F. Using Recurrent Neural Networks for Predicting Type-2 Diabetes from Genomic and Tabular Data. Diagnostics 2022, 12, 3067. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Guo, Y.; Sheng, Q.; Shyr, Y. Advanced heat map and clustering analysis using heatmap3. BioMed Res. Int. 2014, 2014, 986048. [Google Scholar] [CrossRef] [PubMed]
- Jonathan, B.; Putra, P.H.; Ruldeviyani, Y. Observation imbalanced data text to predict users selling products on female daily with smote, tomek, and smote-tomek. In Proceedings of the 2020 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bali, Indonesia, 7–8 July 2020; IEEE: Piscataway, NJ, USA; pp. 81–85. [Google Scholar]
- Rana, C.; Chitre, N.; Poyekar, B.; Bide, P. Stroke prediction using Smote-Tomek and neural network. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; IEEE: Piscataway, NJ, USA; pp. 1–5. [Google Scholar]
- Goel, G.; Maguire, L.; Li, Y.; McLoone, S. Evaluation of sampling methods for learning from imbalanced data. In Proceedings of the Intelligent Computing Theories: 9th International Conference, ICIC 2013, Nanning, China, 28–31 July 2013; Proceedings 9. Springer: Berlin/Heidelberg, Germany; pp. 392–401. [Google Scholar]
- Ye, X.; Xu, W.; Ye, X.; Long, D.; Yin, Q.; Huang, B. Stroke Prediction Using the Trust Evaluation with Data Leakage Avoiding. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2023; Volume 2560, p. 12051. [Google Scholar]
- Pathan, M.S.; Nag, A.; Pathan, M.M.; Dev, S. Analyzing the impact of feature selection on the accuracy of heart disease prediction. Healthc. Anal. 2022, 2, 100060. [Google Scholar] [CrossRef]
- Awan, S.E.; Bennamoun, M.; Sohel, F.; Sanfilippo, F.M.; Chow, B.J.; Dwivedi, G. Feature selection and transformation by machine learning reduce variable numbers and improve prediction for heart failure readmission or death. PLoS ONE 2019, 14, e0218760. [Google Scholar] [CrossRef] [PubMed]
- Clifford, T.; Bruce, J.; Obafemi-Ajayi, T.; Matta, J. Comparative analysis of feature selection methods to identify biomarkers in a stroke-related dataset. In Proceedings of the 2019 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Siena, Italy, 9–11 July 2019; IEEE: Piscataway, NJ, USA; pp. 1–8. [Google Scholar]
- McHugh, M.L. The chi-square test of independence. Biochem. Medica 2013, 23, 143–149. [Google Scholar] [CrossRef] [PubMed]
- An, J.; Zhang, Y.; Joe, I. Specific-Input LIME Explanations for Tabular Data Based on Deep Learning Models. Appl. Sci. 2023, 13, 8782. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute-Name | Attribute-Type | Attribute-Description |
|---|---|---|
| Id | Unique Identifier | A unique identifier for each patient. |
| Gender | Categorical | Gender of the patient is categorized as “Male”, “Female”, or “Other”. |
| Age | Numeric | Age of the patient. |
| Hypertension | Binary (0, 1) | In this case, a value of 1 denotes the presence of hypertension, whereas a value of 0 denotes its absence. |
| Heart_Disease | Binary (0, 1) | In this case, a value of 1 denotes the presence of a heart disease, whereas a value of 0 denotes its absence. |
| Ever_Married | Categorical | Patient’s marital status is coded as “No” or “Yes”. |
| Work_Type | Categorical | We can filter results by occupation or job status using terms like “children”, “Govt_jov”, “Never_worked”, “Private”, or “Self-employed”. |
| Residence_Type | Categorical | Classification of the patient’s place of residence, either “Rural” or “Urban”. |
| Avg_Glucose_Level | Numeric | A measurement of the average blood sugar level for the patient. |
| Bmi | Numeric | The patient’s body mass index. |
| Smoking_Status | Categorical | Patient’s smoking history; possible values are “formerly smoked”, “never smoked”, “smokes”, and “Unknown”. |
| Stroke | Binary (0, 1) | Whether the patient had a stroke (1) or not (0) is indicated by this value. |
| Attribute Name | Age | Hypertension | Heart_Disease | Avg_Glucose_Level | Bmi | Stroke |
|---|---|---|---|---|---|---|
| Count | 5110 | 5110 | 5110 | 5110 | 4909 | 5110 |
| 25% | 25 | 0 | 0 | 77.245 | 23.5 | 0 |
| 50% | 45 | 0 | 0 | 91.885 | 28.1 | 0 |
| 75% | 61 | 0 | 0 | 114.09 | 33.1 | 0 |
| MAX | 82 | 1 | 1 | 271.74 | 97.6 | 1 |
| MIN | 0.08 | 0 | 0 | 55.12 | 10.3 | 0 |
| Mean | 43.226614 | 0.097456 | 0.054012 | 106.147677 | 28.893237 | 0.048728 |
| STD | 22.612647 | 0.296607 | 0.226063 | 45.28356 | 7.854067 | 0.21532 |
| SMOTE Techniques | Numbers in Class 0 (No Stroke) | Numbers in Class 1 (Stroke) |
|---|---|---|
| Before SMOTE | 3771 | 156 |
| SMOTE | 3771 | 3771 |
| ADASYN | 3790 | 3771 |
| SMOTE + TOMEK | 3763 | 3763 |
| SMOTE + ENN | 2452 | 2033 |
| SMOTE + Undersampling | 2827 | 1131 |
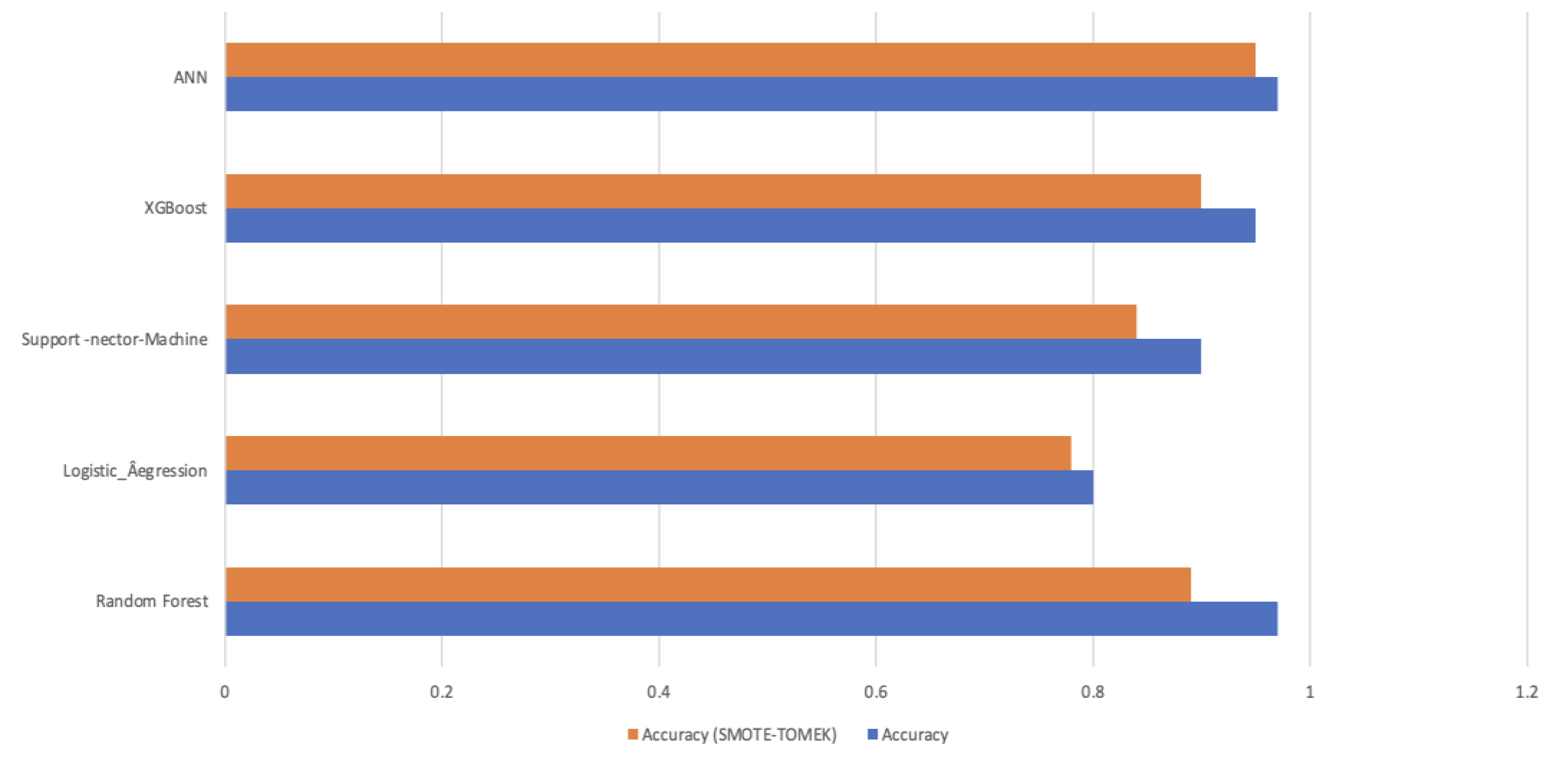
| Model | Accuracy | Accuracy (SMOTE-TOMEK) |
|---|---|---|
| Random Forest | 0.97 | 0.89 |
| Logistic_Regression | 0.80 | 0.78 |
| SVM | 0.90 | 0.84 |
| XGBoost | 0.95 | 0.90 |
| ANN(Proposed) | 0.97 | 0.95 |
| Model | ACC | PR | RE | F1 | Resample Technique Used |
|---|---|---|---|---|---|
| Random Forest | 0.87 | 0.141414 | 0.264151 | 0.184211 | Smote |
| Random Forest | 0.89 | 0.128205 | 0.188679 | 0.152672 | Adasyn |
| Random Forest | 0.89 | 0.126761 | 0.169811 | 0.145161 | Smote_Tomek |
| Random Forest | 0.84 | 0.130435 | 0.339623 | 0.188482 | Smote_Enn |
| Random Forest | 0.90 | 0.152542 | 0.169811 | 0.160714 | Undersampling |
| LR | 0.77 | 0.128492 | 0.433962 | 0.198276 | Smote |
| LR | 0.78 | 0.133333 | 0.452830 | 0.206009 | Adasyn |
| LR | 0.78 | 0.135294 | 0.433962 | 0.206278 | Smote_Tomek |
| LR | 0.77 | 0.135593 | 0.603774 | 0.221453 | Smote_Enn |
| LR | 0.75 | 0.158537 | 0.490566 | 0.239631 | Undersampling |
| SVM | 0.83 | 0.140351 | 0.301887 | 0.191617 | Smote |
| SVM | 0.84 | 0.087719 | 0.188679 | 0.119760 | Adasyn |
| SVM | 0.84 | 0.109677 | 0.320755 | 0.163462 | Smote_Tomek |
| SVM | 0.79 | 0.140097 | 0.547170 | 0.223077 | Smote_Enn |
| SVM | 0.84 | 0.177966 | 0.396226 | 0.245614 | Undersampling |
| XGB | 0.89 | 0.127671 | 0.168911 | 0.145161 | Smote |
| XGB | 0.84 | 0.077819 | 0.184679 | 0.117760 | Adasyn |
| XGB | 0.90 | 0.155342 | 0.168911 | 0.107714 | Smote_Tomek |
| XGB | 0.89 | 0.127761 | 0.168911 | 0.146461 | Smote_Enn |
| XGB | 0.84 | 0.124535 | 0.339723 | 0.178482 | Undersampling |
| ANN | 0.94 | 1.000000 | 0.218868 | 0.137037 | Smote |
| ANN | 0.96 | 1.000000 | 0.18868 | 0.037037 | Smote |
| ANN | 0.95 | 1.000000 | 0.18868 | 0.037037 | Smote_Tomek |
| ANN | 0.93 | 0.210526 | 0.075472 | 0.111111 | Smote_Enn |
| ANN | 0.95 | 0.000000 | 0.000000 | 0.000000 | Undersampling |
| Algorithm | Parameter | Values |
|---|---|---|
| Random Forest | n_estimators | 200 |
| max_depth | 20 | |
| min_samples_split | 5 | |
| min_samples_leaf | 2 | |
| max_features | ‘sqrt’ | |
| bootstrap | True | |
| Logistic Regression | C | 1 |
| penalty | ‘l2’ | |
| max_iter | 200 | |
| SVM | C | 1 |
| kernel | ‘rbf’ | |
| gamma | ‘auto’ | |
| degree | 4 | |
| XGBoost | n_estimators | 200 |
| max_depth | 5 | |
| learning_rate | 0.1 | |
| subsample | 0.9 | |
| min_child_weight | 2 | |
| Artificial Neural Network | hidden_layer_sizes | (100) |
| activation | ‘relu’ | |
| alpha | 0.001 | |
| learning_rate_init | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Srinivasu, P.N.; Sirisha, U.; Sandeep, K.; Praveen, S.P.; Maguluri, L.P.; Bikku, T. An Interpretable Approach with Explainable AI for Heart Stroke Prediction. Diagnostics 2024, 14, 128. https://doi.org/10.3390/diagnostics14020128
Srinivasu PN, Sirisha U, Sandeep K, Praveen SP, Maguluri LP, Bikku T. An Interpretable Approach with Explainable AI for Heart Stroke Prediction. Diagnostics. 2024; 14(2):128. https://doi.org/10.3390/diagnostics14020128
Chicago/Turabian StyleSrinivasu, Parvathaneni Naga, Uddagiri Sirisha, Kotte Sandeep, S. Phani Praveen, Lakshmana Phaneendra Maguluri, and Thulasi Bikku. 2024. "An Interpretable Approach with Explainable AI for Heart Stroke Prediction" Diagnostics 14, no. 2: 128. https://doi.org/10.3390/diagnostics14020128
APA StyleSrinivasu, P. N., Sirisha, U., Sandeep, K., Praveen, S. P., Maguluri, L. P., & Bikku, T. (2024). An Interpretable Approach with Explainable AI for Heart Stroke Prediction. Diagnostics, 14(2), 128. https://doi.org/10.3390/diagnostics14020128