In the literature, the ulcer detection methods using WCE images are divided into two categories which are based on features extraction: handcrafted-feature-based methods and deep-learning-based methods. As handcrafted feature approaches encode just a portion of the information in WCE photos, many researchers choose to employ deep learning methods to detect ulcers in WCE images. For ulcer identification and categorization, Alaskar et al. [
4] employed deep learning networks. To categorize WCE photos as ulcerous or non-ulcerous, they used two deep learning architectures: AlexNet and GoogLeNet. Using WCE video frames, they created experimental image datasets. In a separate study [
5], the researchers used 6-layer CNN to detect ulcers. To select the region of interest, statistical color features were extracted first, followed by thresholding. Following the thresholding phase, the found region of interest is fed into a 6-layer CNN model. The final stage involves generating entropy-based characteristics for the final layer, which are subsequently presented to the classifier for classification. An average accuracy rate of 96.4% was obtained after completing research on privately provided datasets. V and Prashanth [
6] also present a deep CNN for detecting ulcers at different ratios. They used 1000 to 10,000 WCE images of ulcers and non-ulcers in their research. The researchers also looked into different network depths and node configurations. The performance of the 3 × 3 convolution filter was reported to be satisfactory. In addition, they examined hyper-parameters such as drop schemes, activation functions, optimizer, number of layers, learning rate, pooling schemes, and epochs during their experiments.
Another paper [
7] describes a novel technique for classifying and detecting gastrointestinal illnesses. To improve the lesion contrast, the researchers applied HSV transformation, 3D-median filtering, and 3D-box filtering in the pre-processing step. Second, a binary image was constructed and used in the saturated channel after geometric characteristics were extracted. To extract aspects such as waves, form, and color, binary segmentation and HSV pictures were used. Subset feature selection was based on correlation coefficient and principal component analysis. For categorization, a support vector machine was utilized. WCE images were analyzed by Wang et al. [
8] to improve the CNN-based architecture and identify ulcers effectively. For ulcer detection, they looked at deep learning architectures, and then proposed a HANet architecture. ResNet-34 was the foundation for the fused hyper features employed in their final diagnostic judgement. They identified ulcers with a success rate of 92.05%.
Various researchers have used many different traditional machine learning techniques for predicting the different types of peptic ulcer. Grace Lai, Hung Wong et al. [
10] developed a peptic ulcer machine learning model which was built on a retrospective cohort of 22,854 patients (training cohort) diagnosed with peptic ulcer disease in 2007 and 2016. He used logistic regression and ridge regression and obtained a maximum accuracy of 82.6% and 83.3%. Sen Wang et al. [
8] proposed a Second Glance framework for ulcer detection and verified its efficiency and strength on a large scale WCE (Wireless Capsule Endoscopy) images dataset which consisted of 1504 independent WCE videos. The performance of his method/framework achieved the best ROC-AUC, which was 0.9235. Khan et al. [
11] presented a fully automated system for the diagnosis of gastric infection. The diagnosis of gastric infection was carried out by numerous types of features, extraction features, fusion features, and robust features selection. The main problem in the GI tract diseases was that there were many similarities in the pattern of the infected region. So, Khan introduced a modern CAD which contained handcrafted features, fusion features, and deep CNN features. Datasets used in this paper were from Kvasir, CVC-ClinicDB, Private, and ETIS- LaribPolypDB. The accuracy they achieved by using this dataset was 96.5%. Ouiem Bchir et al. [
12] compared the performance of different visual descriptors for the detection of ulcers using WCE (Wireless Capsule Endoscopy) frames. This comparison was intended to determine which visual descriptor represents better WCE frames and yields more accurate gastrointestinal ulcer detection. During the experiments, different visual descriptors were used along with SVM classifiers. The authors achieved maximum accuracy of 98.85% using an LBP descriptor along with SVM classifier. Jinn-Yi Yeh et al. [
13] employed a technique which utilized a WCE images dataset for the detection of bleeding and ulcers and used color features. They combined all the features of images in one matrix and also engaged texture information. This matrix of features was passed to different classifiers such as support vector machine, neural network NN), and decision trees. Different performance measures were incorporated for evaluation and achieved an accuracy of 92.86–93.64%, respectively. They try to resolve the problems of low contrast images and variation in the shape of the lesion. Authors in [
14] tried to resolve these problems by proposing a novel automated method for WCE images classification which involves color features and color coherence vector for determining the small intestine status and classifying it using the support vector machine. They implemented a novel method for the automated detection and classification of gastrointestinal infection. By employing the proposed automated method, the authors achieved a maximum accuracy of 98.3%. Rashid et al. [
15] projected a computer aided methodology for the accurate diagnoses of stomach diseases from WCE pictures. The presented system had four basic steps, i.e., before implementing active contour segmentation, color transformation was performed using HSI (hue, saturation, intensity) color transformation. Then, the saliency-based method is implemented in the YIQ color space. After that, image fusion was performed and the last step was using SVD, LBP, and GLCM, where the extracted features were fused. In the end, the classification was carried out using neural networks. The dataset contains 9000 ulcer, bleeding, and healthy samples.
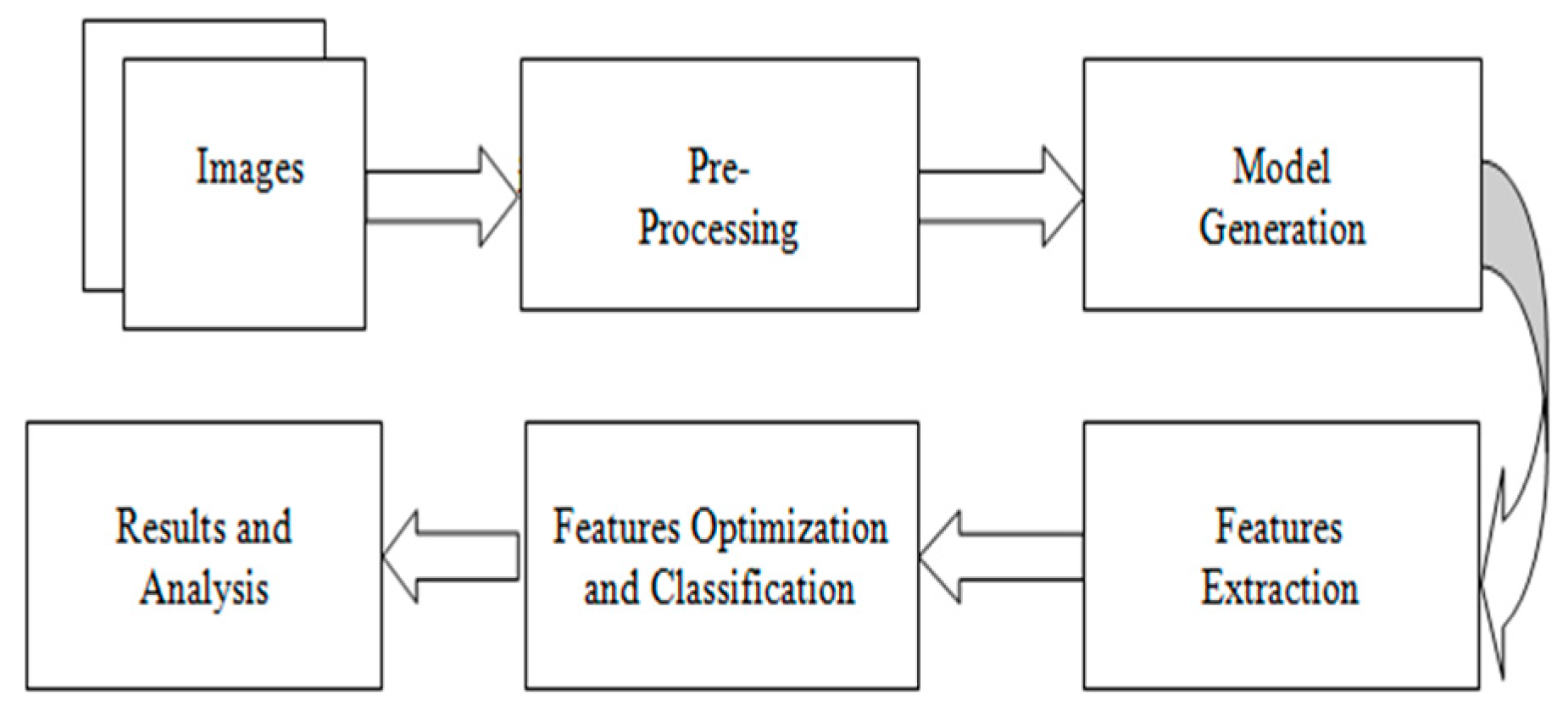
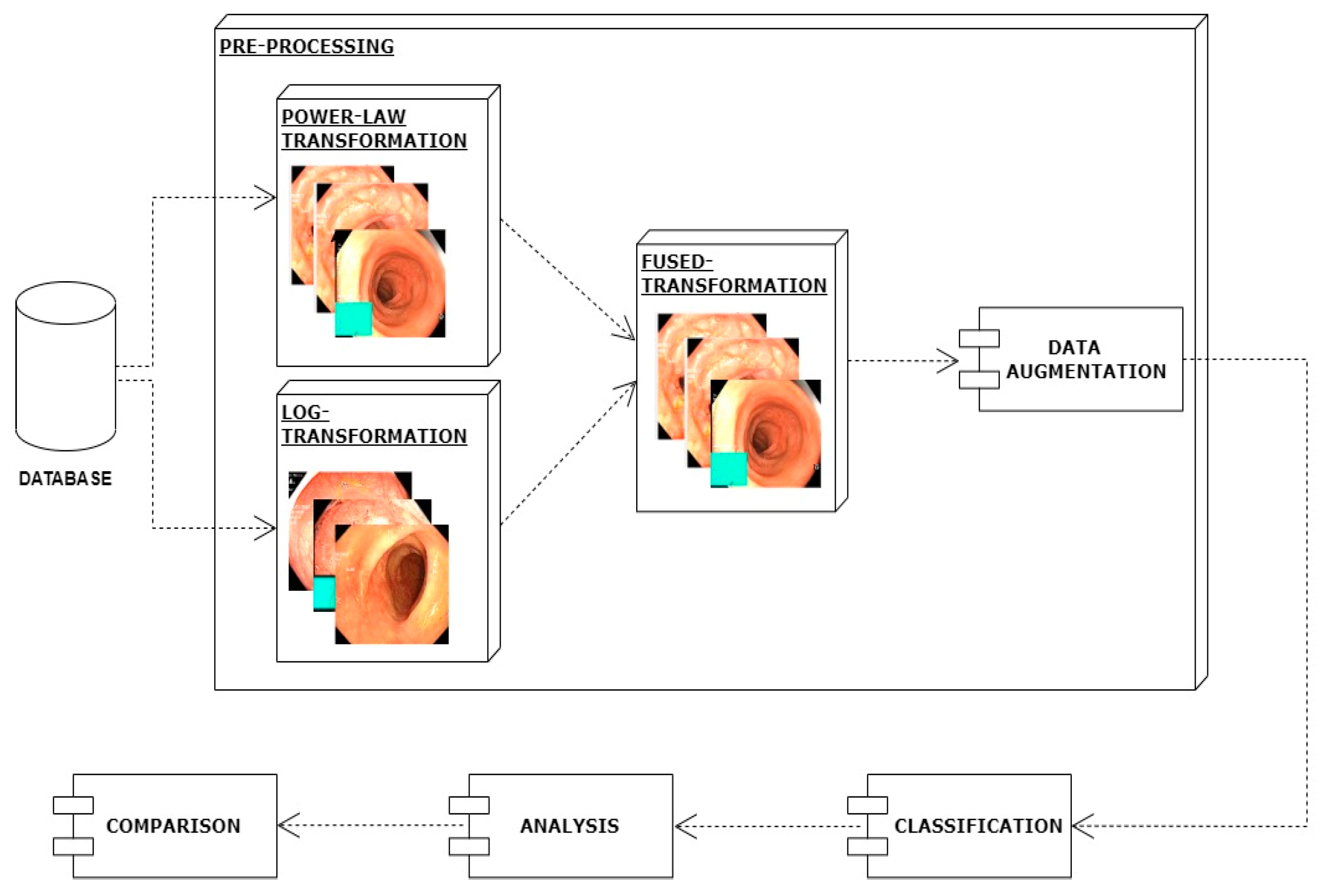
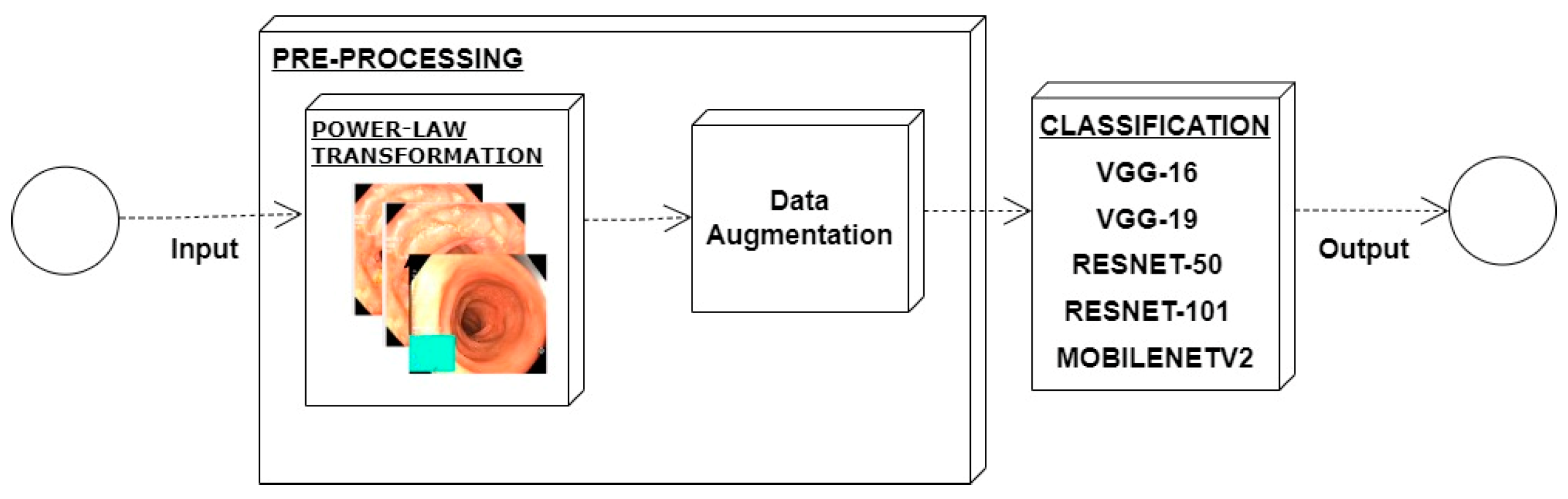
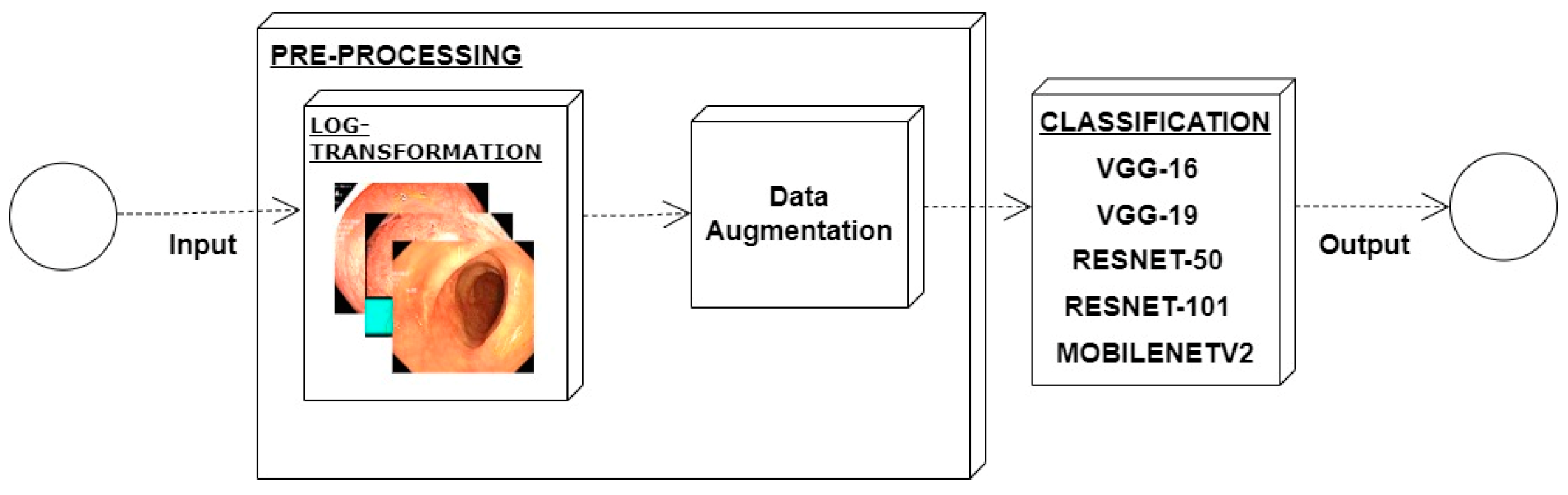
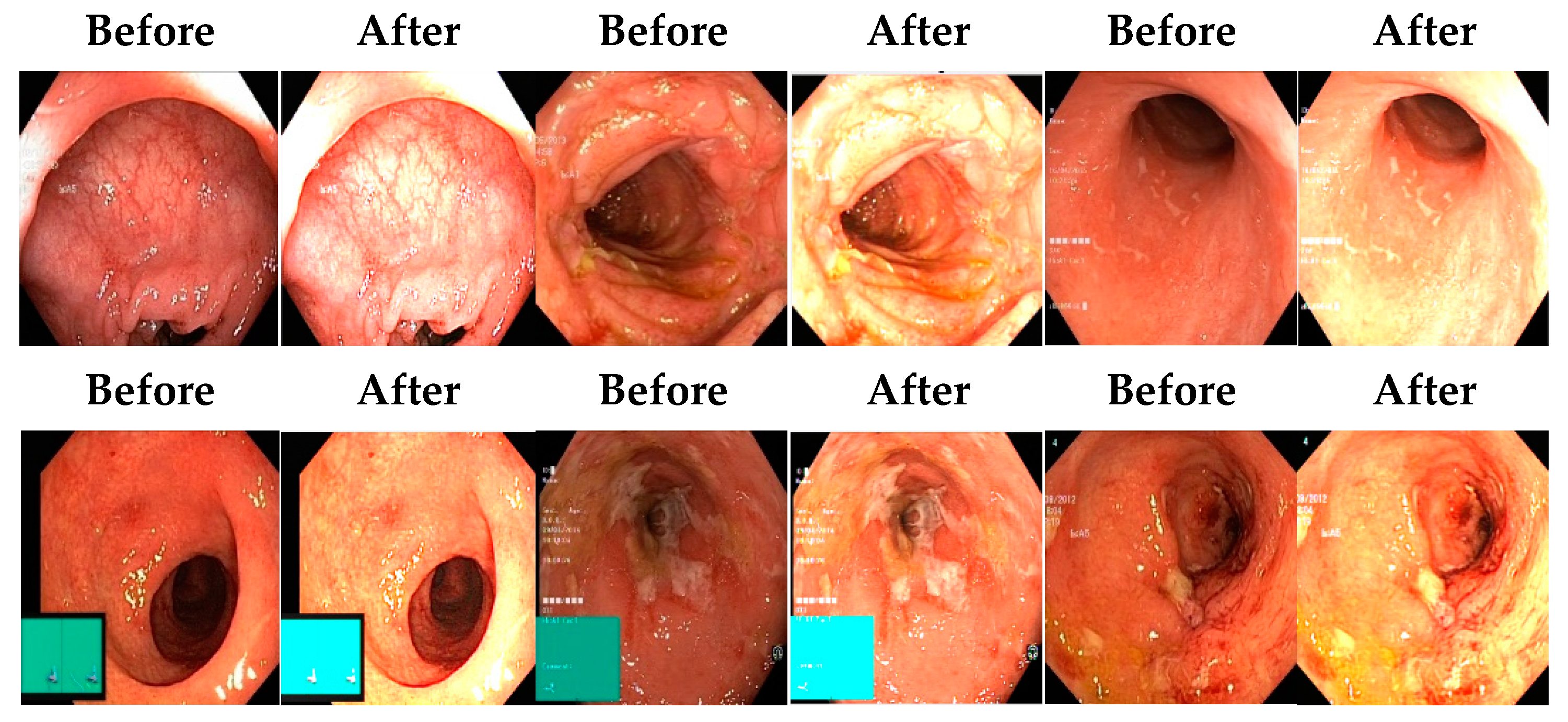
From the above discussion, it has been observed that the previous models lacked core steps of preprocessing, i.e., contrast enhancement, and illumination balance. Models presented in the literature have been found to utilize more features and there is also room for improvement in accuracy.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











