
Robust Classification and Detection of Big Medical Data Using Advanced Parallel K-Means Clustering, YOLOv4, and Logistic Regression



Abstract
1. Introduction
- The successful application of advanced parallel k-means clustering as a pre-processing step for both the images and the data to improve the accuracy of image feature extraction and detection, as well as the accuracy of data classification.
- Both hardware and software improvements were employed to significantly accelerate the classification and detection processes. Hardware acceleration was achieved by utilizing the latest neural engine processor while the software optimization involved using parallel-processing mechanisms.
2. Data Classification
Logistic Regression Algorithm
- Initialize the weights to random values.
- Calculate the linear combination for each training example using the current weights.
- Calculate the predicted output variable for each training example using the logistic function.
- Calculate the error between the predicted output variable and the true output variable for each training example.
- Calculate the gradient of the likelihood function with respect to each weight.
- Update the weights using the gradient descent update rule.
- Repeat steps 2–6 until the error converges or a maximum number of iterations is reached.
3. Image Detection Technique
YOLOv4 Algorithm
- The probability of an object being present in that cell (denoted ).
- The x and y coordinates of the center of the bounding box, relative to the coordinates of the cell (denoted by and , respectively).
- The width and height of the bounding box relative to the size of the cell (denoted by and , respectively).
- The class probabilities for each object class (denoted by , ,…, , where n is the number of classes).
| Algorithm 1 YOLOv4 object detection algorithm |
| Require: Input image I Ensure: Bounding boxes B and class probabilities C
|
4. Medical Data Classification and Detection
4.1. Medical Data and Image Classification
- Deep Learning: Deep learning has revolutionized the field of medical data classification and image detection, due to its ability to handle large and complex datasets with improved accuracy and efficiency [31]. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are two widely used deep-learning techniques that have demonstrated exceptional performance in the medical field [32]. CNNs have been specifically designed to analyze visual imagery, making them a popular choice for medical image analysis. They consist of multiple layers that learn different features of an image, such as edges and textures, and then use these features to classify the image. The ability of CNNs to automatically extract relevant features from medical images has led to their use in a wide range of applications, such as mammogram analysis for breast cancer detection and brain tumor segmentation. Furthermore, RNNs have been designed to process sequential data and have been extensively used in various medical applications, such as medical signal processing, clinical event prediction, and ECG signal analysis [33]. They are able to analyze the temporal dependencies in sequential data by using a memory component that allows them to remember past inputs and use them to influence future predictions. RNNs have also been used in combination with CNNs to analyze both image and sequential data, such as in the case of electroencephalogram (EEG) signal analysis [34]. In addition to CNNs and RNNs, other deep-learning techniques, such as generative adversarial networks (GANs) and auto-encoders have also been explored in medical data classification and image detection [35]. GANs have been used to generate synthetic medical images, which were then used to augment existing datasets and improve the performance of image classifiers. Auto-encoders, in contrast, have been used for feature extraction and dimensionality reduction, which improved the efficiency of classification algorithms.
- Support Vector Machines (SVMs): SVMs are a type of supervised learning algorithm that has been widely used for classification tasks in many areas, including in medical data classification. SVMs have been particularly useful for classification tasks in which the number of features was much greater than the number of samples [36]. SVMs find the optimal hyperplane that separates the different classes in a dataset. For medical data classification, SVMs have been used for tasks such as disease diagnosis, the classification of different types of cancer, and the identification of abnormal medical images [37]. SVMs have shown high accuracy and robustness in these tasks due to their ability to handle non-linear data and their resistance to over-fitting.One example of SVMs being used in medical data classification was for the identification of breast cancer using mammograms [38]. SVMs had a high accuracy in distinguishing between benign and malignant tumors, which is critical for the early detection and treatment of breast cancer. SVMs have also been used for the classification of brain tumors and the identification of Alzheimer’s disease in medical imaging data.
- Random Forest: Random forest is a type of ensemble learning algorithm that combines multiple decision trees to improve its classification accuracy. The method is considered a supervised learning technique that operates by constructing several decision trees during training and then predicts the class label of an input data point by aggregating the predictions of all the decision trees [39]. Random forest has been effective in medical data classification due to its ability to handle high-dimensional data and its resistance to over-fitting. In medical applications, random forest has been used for various classification tasks, such as disease diagnosis, the prediction of treatment responses, and mortality risk assessments [40]. One advantage of random forest is its ability to handle missing data and noisy features. This is achieved by randomly selecting a subset of features at each node in the decision tree, which reduces the risk of over-fitting and improves the model’s generalization performance. Additionally, the method allows for the calculation of feature importance, which can help identify the most important variables that contribute to the classification task.
4.2. Medical Image Detection
- Convolutional Neural Networks (CNNs): In medical imaging, CNNs have been used for a variety of applications, such as the detection of breast cancer, lung cancer, and brain tumors [44]. For example, in breast cancer detection, CNNs have been used to analyze mammograms and detect subtle changes that could indicate the presence of cancer. In lung cancer detection, CNNs have been used to analyze CT scans and identify nodules that could be indicative of cancer. In brain tumor detection, CNNs have been used to analyze MRI scans and identify regions of abnormal tissue growth [45].One of the advantages of using CNNs for medical image detection is their ability to learn and extract features automatically, without the need for manual feature extraction [46]. This makes them particularly useful for analyzing large and complex medical images, where manual feature extraction can be time-consuming and prone to error. Another advantage of CNNs is their ability to learn from large amounts of data. With the increasing availability of medical imaging data, CNNs can be trained on large datasets to improve their accuracy and generalization performance [47]. Additionally, CNNs can be fine-tuned and adapted for specific medical image detection tasks, which can further improve their performance.
- Transfer Learning: In the context of medical image detection, transfer learning was an effective method for improving the accuracy and efficiency of image classification tasks [48]. Pre-trained models, such as those based on CNNs, can learn generic image features that can be transferred to new medical imaging datasets, even when the size of the new dataset is relatively small [49]. This can be particularly useful in healthcare, where obtaining large labeled datasets can be challenging and time-consuming. By using transfer learning, researchers and clinicians leveraged the knowledge and expertise gained from pre-trained models to improve the accuracy and efficiency of image detection in healthcare [50]. For example, a pre-trained model that was trained on a large dataset of chest X-rays was then fine-tuned for a smaller dataset of lung cancer images, resulting in improved accuracy and faster training times.
5. Related Works
6. Proposed Solution
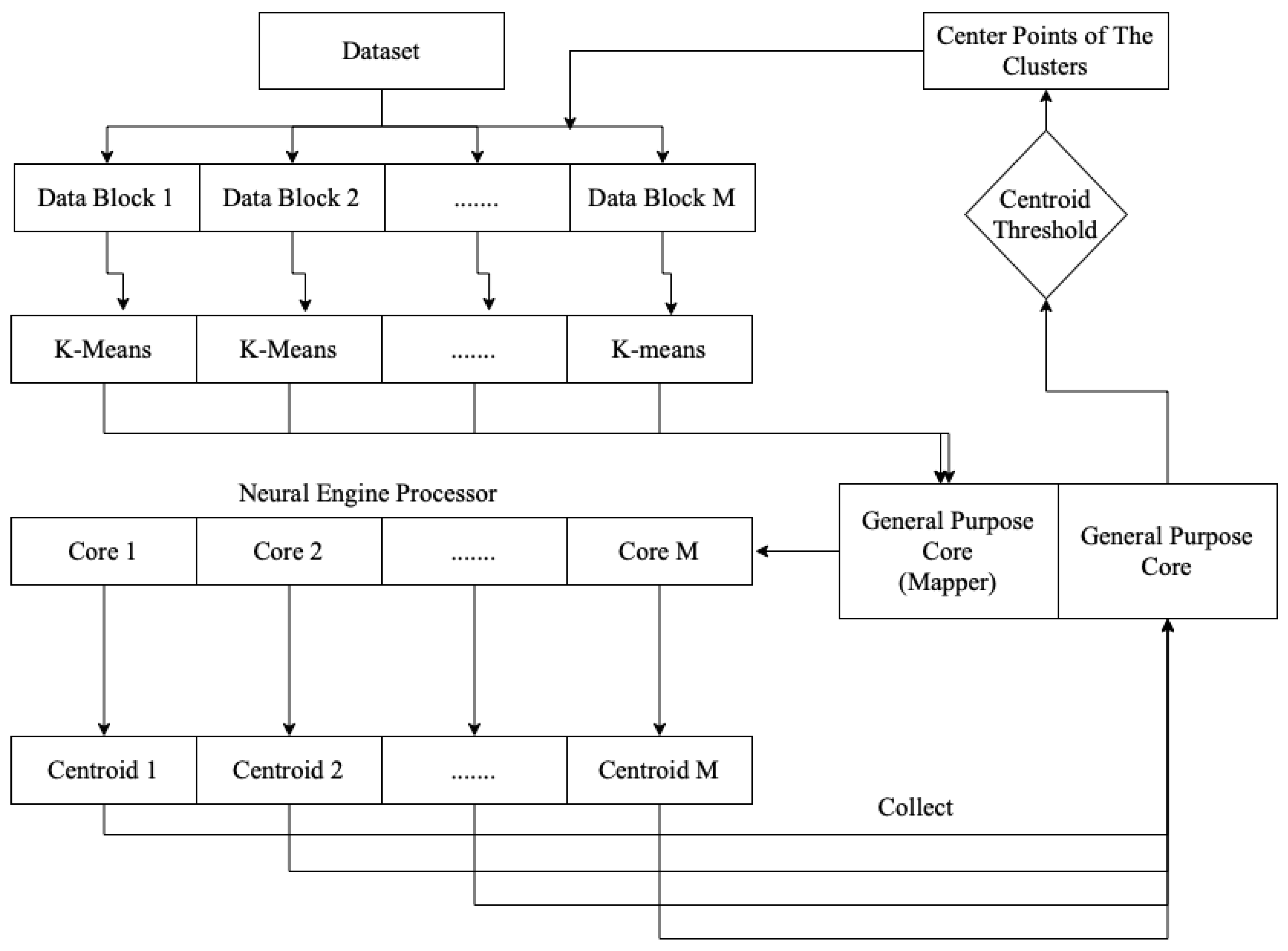
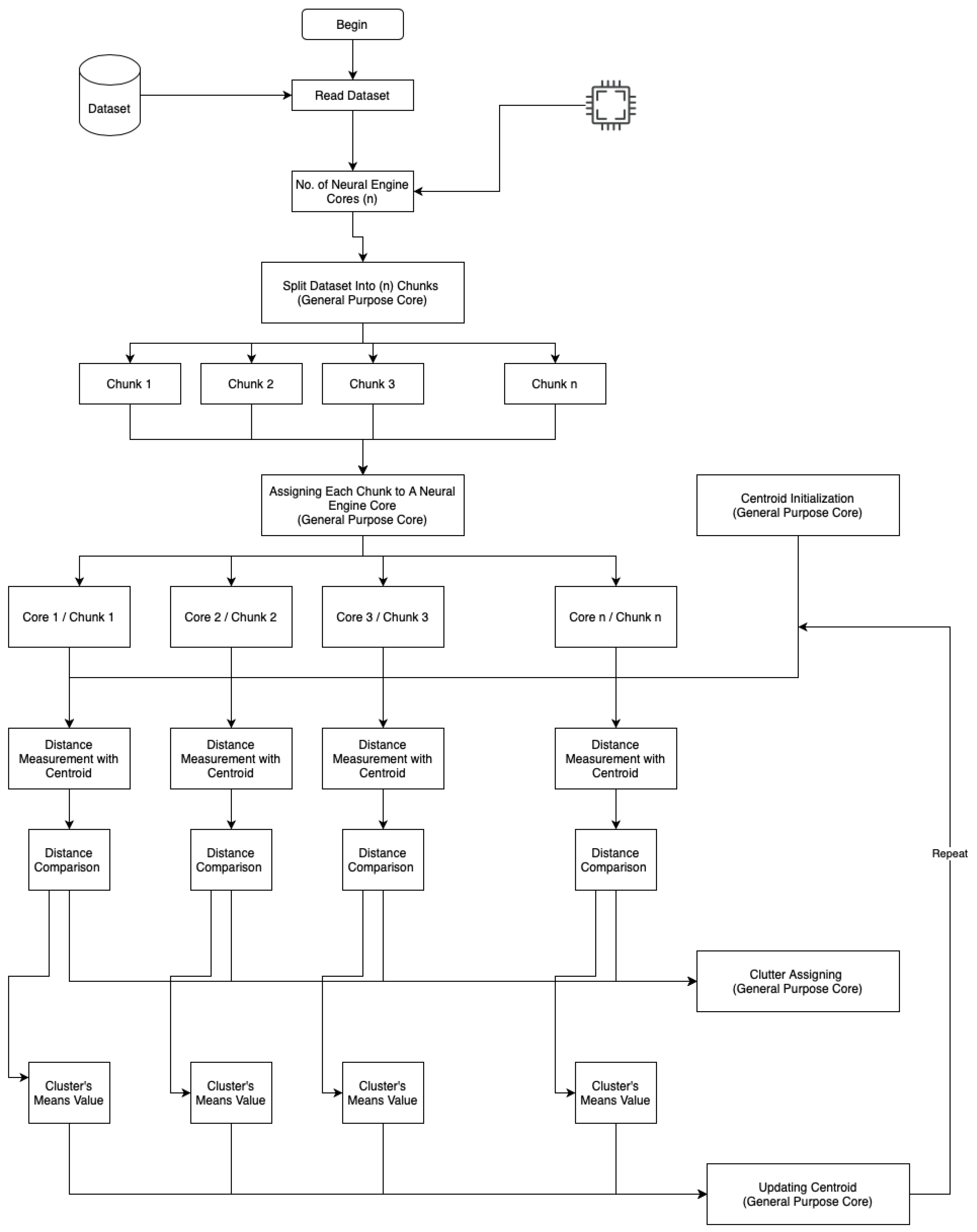
6.1. Advanced Parallel K-Means Clustering
6.2. Advanced Classification Solution
- Pre-processing: As with non-parallel logistic regression, it was important to pre-process the data before applying the model. This included tasks such as missing-value imputation, scaling, and feature selection.
- Splitting the data: The data had to be split into training and testing sets in order to evaluate the model’s performance on unfamiliar data.
- Choosing a parallelization method: We had to decide whether to use data parallelism, model parallelism, or a hybrid parallelism.
- Partitioning the data: Depending on the chosen parallelization method, the data had to be partitioned into smaller chunks and distributed across multiple processors or devices.
- Training the model: Each processor or device was responsible for training a separate logistic-regression model on its chunk of the data. The models were then combined to form the final model.
- Evaluating the model: The trained model was then evaluated on the testing data. This involved calculating evaluation metrics, such as accuracy, precision, and recall.
- Assessing the model’s predictions: Once the model had been trained and evaluated, it was used to make predictions according to new data. To achieve this, the model’s parameters were used to calculate the probability of an instance belonging to each class. The class with the highest probability was then predicted as the output.
| Algorithm 2 Parallel Logistic-Regression Classification |
|
Classification Pre-Processing
- Dimensionality reduction: K-means clustering was used to group similar data points together into clusters, which reduced the number of features in the dataset. By selecting the centroids of the clusters as the new features, we reduced the dimensionality of the data and removed the noise, which improved the performance of the logistic regression.
- Feature engineering: K-means clustering was used to create new features that captured the structure of the data. We added a new binary feature that indicated whether a data point belonged to a particular cluster or not. These new features enabled the logistic regression to capture complex relationships in the data that had not been apparent previously.
- Outlier detection: K-means clustering improved the identification and removal of outliers in the dataset. Outliers had a significant impact on the performance of the logistic regression, and removing them improved the accuracy of the model.
- Data normalization: K-means clustering was used to normalize the data by scaling it to a range from 0 to 1. Normalizing the data improved the performance of the logistic regression by reducing the impact of outliers and ensuring that all features were on a similar scale.
- Train individual models: The dataset was divided into subsets, and each subset was used to train a logistic-regression model on a separate processor or device.
- Obtain model weights: Once the individual models had been trained, each model was assigned a weight based on its performance on a validation set. The weights were determined using a variety of methods, such as the accuracy or the area under the receiver-operating characteristic curve (AUC-ROC).
- Combine the models: The predicted probabilities or coefficients from each individual model were multiplied by their corresponding weights, and the weighted sum was used as the final output. For example, if there were three individual models with weights of 0.3, 0.5, and 0.2, the predicted probabilities of each model were multiplied by 0.3, 0.5, and 0.2, respectively, and then summed to obtain their final predicted probabilities.
- Model selection: The performance of the final model was evaluated on a validation set, and the weights assigned to the individual models were adjusted to improve the performance of the final model. This process was repeated until the desired level of performance was achieved.
- Apply the final model: Once the final model was selected, it was implemented to make predictions on new data.
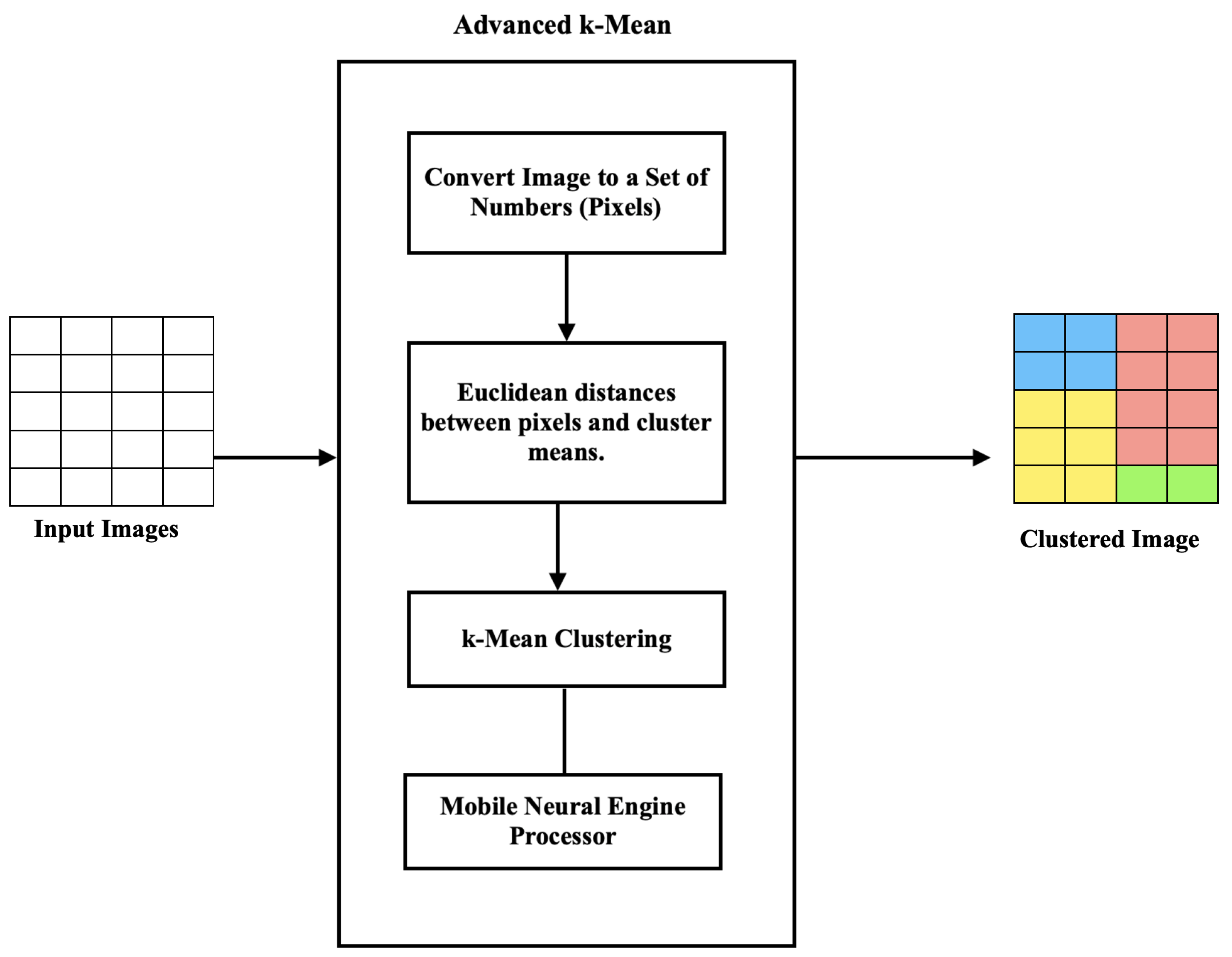
6.3. Advanced Image Detection
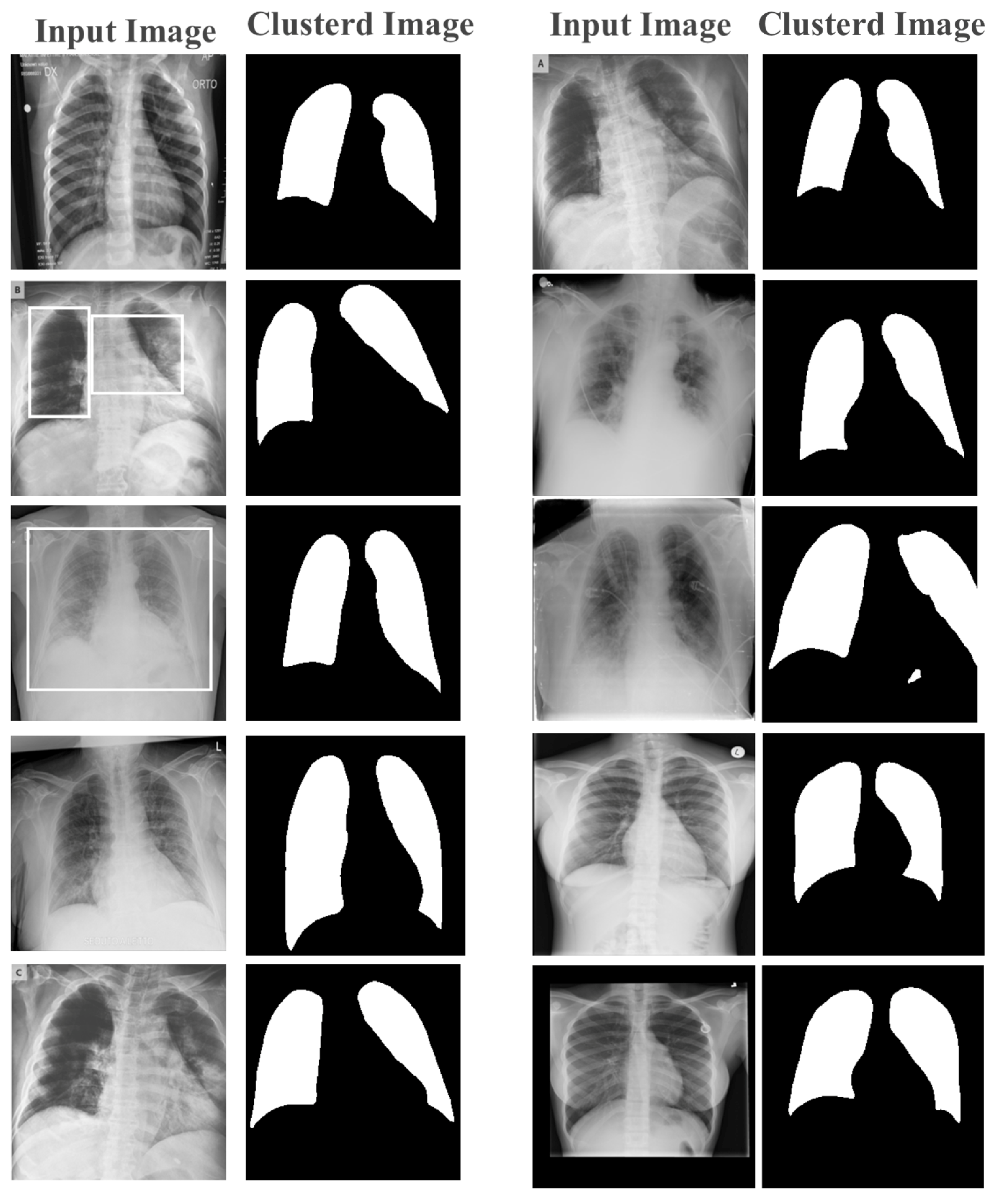
Stage 1: Image Clustering and Pre-Processing
| Algorithm 3 K-Means Image Clustering |
| Require: Image Dataset Input: Random Centroid Points Start: Clustering Pixels while do Select: Neural Engine Core Assign: Processing to Core Calculate: Mean Value Set: Pixel-to-Cluster end while Output: Clustered Pixels |
6.4. Stage 2: YOLOv4 Image Detection
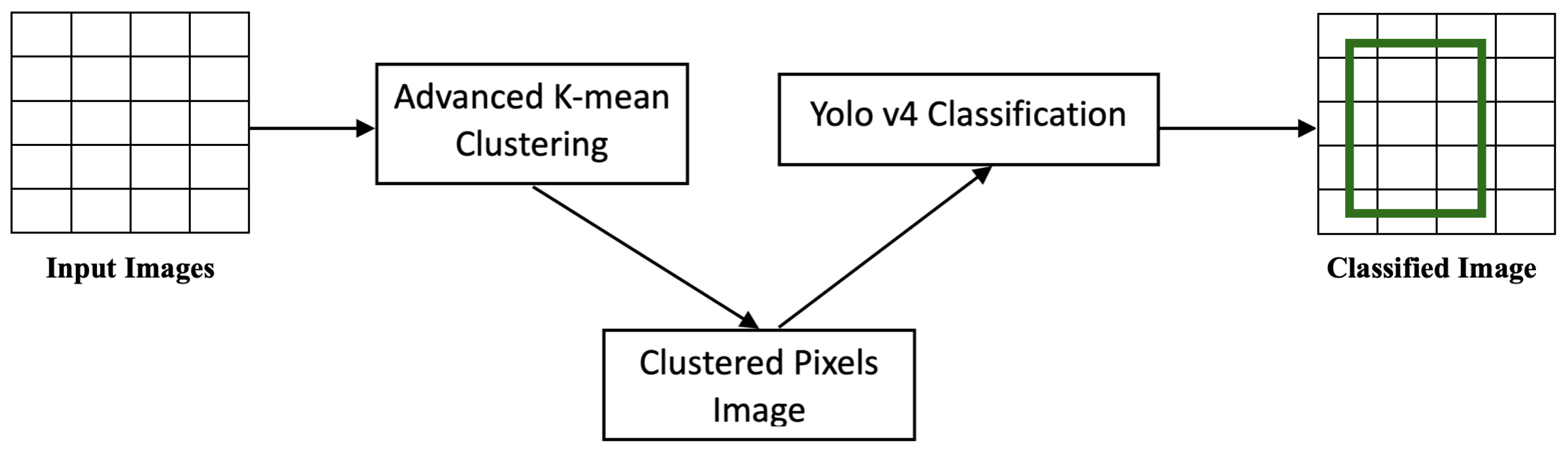
6.5. Stage 3: K-Means–YOLOv4 Clustering
| Algorithm 4 K-Means–YOLOv4 Classifier |
| Require: Image Dataset Input: Random Centroid Points Start: Clustering Pixels while do Select: Neural Engine Core Assign: Processing to Core Calculate: Mean Value Set: Pixel to Cluster end while Run: YOLO’s Backbone on Clustered Image if Image Contains (COVID) then Flag: Image as Affected else Flag: Image as non-Affected end if Output: Classified Image |
7. Performance Evaluation and Datasets
7.1. Performance Metrics
- Precision: This metric represented the fraction of genuine positives among the expected positives. As a result, true-positive (TP) and false-positive (FP) values were important.
- Recall: The ratio of true positives accurately categorized by the model was the recall. The recall was calculated using TP and FN values.
- Specificity: This was defined as the proportion of true negatives (those not caused by illness) correctly classified by the model. The TN and FP values were used to calculate specificity.
- F1-Score: The F1-score measured the model’s accuracy by combining precision and recall. Doubling the ratio of the total accuracy and recall values defined the F1-scores.
- Performance (Speed): This was an important performance metric in image detection and data classification and clustering, particularly when dealing with large datasets and real-time applications. It measured the time required to process and analyze the data and produce the desired output. In image detection, speed is important for applications such as autonomous vehicles, surveillance systems, and medical imaging, where the detection and analysis of images must be performed in real-time. The speed metric is usually measured in frames-per-second (FPS), which represents the number of images that can be processed in one second. In data classification and clustering, speed is important for applications such as recommendation systems, fraud detection, and customer segmentation, where large amounts of data must be analyzed and classified in a timely manner. The speed metric is usually measured in terms of processing time or throughput, which represents the number of data points that can be processed per unit of time.
7.2. Dataset
- Radiography database for COVID-19 in [63]. The authors gathered chest X-ray images of COVID-19-positive individuals, along with healthy people and those with viral pneumonia, and made them accessible to the public on https://www.kaggle.com/ (accessed on 20 February 2023).
- Actualmed, Pau Agust Ballester, and Jose Antonio Heredia from Universitat Jaume I (UJI) created the Actualmed COVID-19 Chest X-ray Dataset for study (https://github.com/agchung/Figure1-COVID-chestxray-dataset/tree/master/image (accessed on 20 February 2023)).
Data Preparation
- Noise Removal: The advanced parallel k-means clustering algorithm utilized the mean imputation as the method for handling missing data. In this approach, missing values were replaced with the mean value of the corresponding feature across all samples. This method is simple and computationally efficient, and it has been shown to be effective in practice. However, the mean imputation may introduce bias in the clustering results if the missing data were not missing completely-at-random (MCAR). If the missing data were missing-at-random (MAR) or missing not-at-random (MNAR), more sophisticated methods such as regression imputation and multiple imputation could be required to avoid bias.
- Number of Clusters: Selecting the optimal number of clusters in the advanced parallel k-means clustering was crucial for achieving effective cluster analysis. This is particularly true in the medical field, where the identification of meaningful clusters can lead to more accurate diagnoses and treatments. However, the traditional methods of finding k-value, such as the Elbow method or the Silhouette method, are not always sufficient in the medical field, where the data are often complex and high-dimensional. In such cases, expert knowledge could be required to identify clinically relevant subgroups, which could then be used to determine the optimal number of clusters. In this paper, the k-value set to 2 in the clustering of numeric and text data and set to 5 for image clustering, as there were 5 main gray-scale stages of colors in the X-ray and MRI images.
7.3. Operating System Implementation
8. Results and Discussion
8.1. Operating System Performance
8.2. Data Classification Model
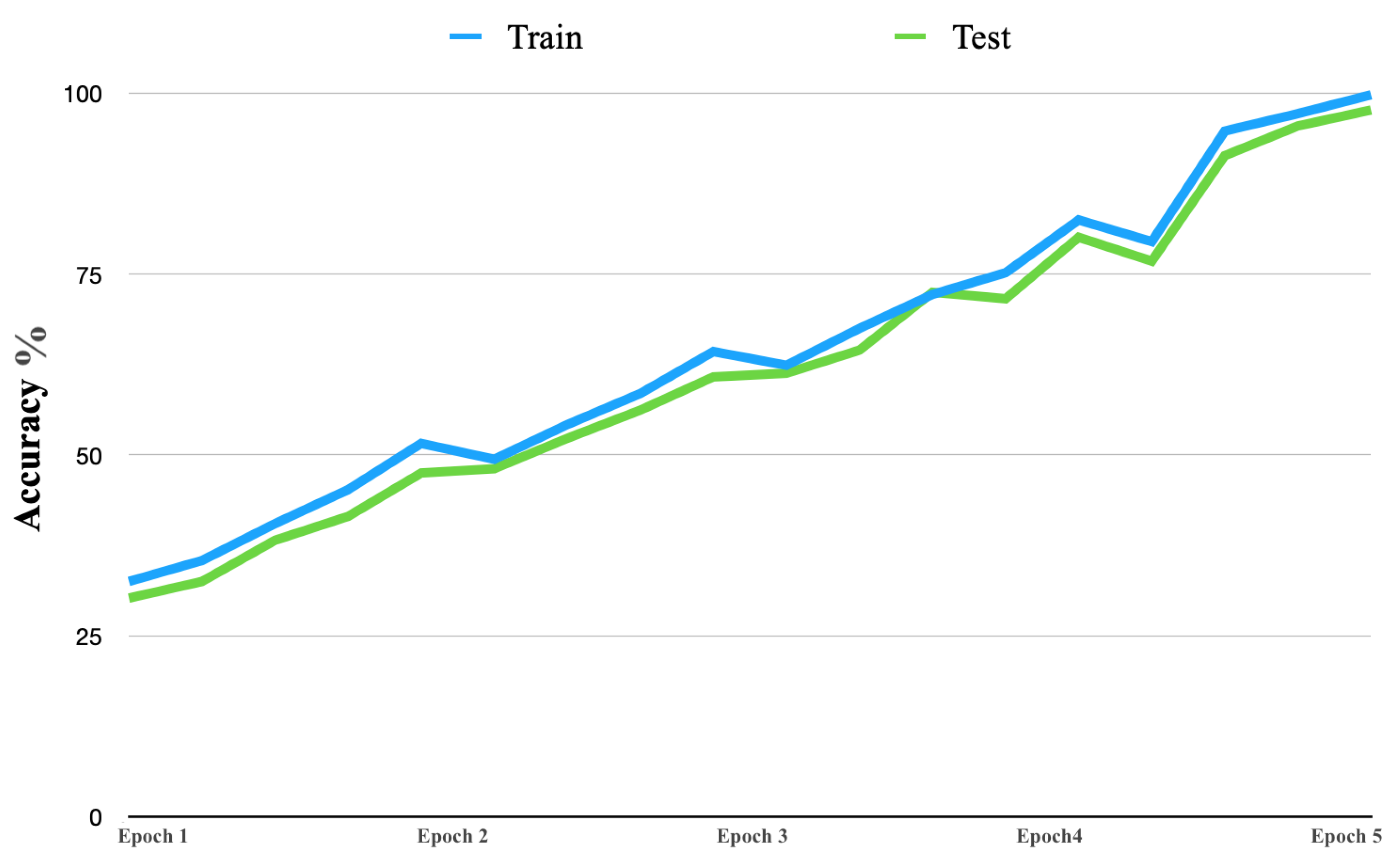
8.3. Training Proposed Model
8.4. Object Detection Speed
8.5. Object Detection Performance
9. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lawonn, K.; Smit, N.N.; Buhler, K.; Preim, B. A survey on multimodal medical data visualization. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2018; Volume 37, pp. 413–438. [Google Scholar]
- Seo, H.; Badiei Khuzani, M.; Vasudevan, V.; Huang, C.; Ren, H.; Xiao, R.; Jia, X.; Xing, L. Machine learning techniques for biomedical image segmentation: An overview of technical aspects and introduction to state-of-art applications. Med. Phys. 2020, 47, e148–e167. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Fadhel, M.; Al-Shamma, O.; Zhang, J.; Santamaria, J.; Duan, Y. Robust application of new deep learning tools: An experimental study in medical imaging. Multimed. Tools Appl. 2022, 1–29. [Google Scholar] [CrossRef]
- Boyapati, S.; Swarna, S.R.; Dutt, V.; Vyas, N. Big Data Approach for Medical Data Classification: A Review Study. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 3–5 December 2020; IEEE: New York, NY, USA, 2020; pp. 762–766. [Google Scholar]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef]
- Awad, F.H.; Hamad, M.M. Improved k-Means Clustering Algorithm for Big Data Based on Distributed SmartphoneNeural Engine Processor. Electronics 2022, 11, 883. [Google Scholar] [CrossRef]
- Patel, H.; Singh Rajput, D.; Thippa Reddy, G.; Iwendi, C.; Kashif Bashir, A.; Jo, O. A review on classification of imbalanced data for wireless sensor networks. J. Distrib. Sens. Netw. 2020, 16, 1550147720916404. [Google Scholar] [CrossRef]
- De Menezes, F.S.; Liska, G.R.; Cirillo, M.A.; Vivanco, M.J. Data classification with binary response through the Boosting algorithm and logistic regression. Expert Syst. Appl. 2017, 69, 62–73. [Google Scholar] [CrossRef]
- Karasoy, O.; Ballı, S. Spam SMS detection for Turkish language with deep text analysis and deep learning methods. Arab. J. Sci. Eng. 2022, 47, 9361–9377. [Google Scholar] [CrossRef]
- Theodoridis, S. Machine Learning: A Bayesian and Optimization Perspective; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Tigga, N.P.; Garg, S. Predicting type 2 diabetes using logistic regression. In Proceedings of the Fourth International Conference on Microelectronics, Computing and Communication Systems: MCCS 2019; Springer: Berlin/Heidelberg, Germany, 2021; pp. 491–500. [Google Scholar]
- Itoo, F.; Singh, S. Comparison and analysis of logistic regression, Naïve Bayes and KNN machine-learning algorithms for credit card fraud detection. Int. J. Inf. Technol. 2021, 13, 1503–1511. [Google Scholar] [CrossRef]
- Sen, S.; Kundu, D.; Das, K. Variable selection for categorical response: A comparative study. Comput. Stat. 2022, 1–18. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, Z.; Yang, Z.; Li, D. Application of logistic regression with fixed memory step gradient descent method in multi-class classification problem. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; IEEE: New York, NY, USA, 2019; pp. 516–521. [Google Scholar]
- De Caigny, A.; Coussement, K.; De Bock, K.W. A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. Eur. J. Oper. Res. 2018, 269, 760–772. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Galvez, R.L.; Bandala, A.A.; Dadios, E.P.; Vicerra, R.R.P.; Maningo, J.M.Z. Object detection using convolutional neural networks. In Proceedings of the 2018 IEEE Region 10 Conference (TENCON 2018), Jeju Island, Republic of Korea, 28–31 October 2018; IEEE: New York, NY, USA, 2018; pp. 2023–2027. [Google Scholar]
- Yu, J.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Li, S.; Gu, X.; Xu, X.; Xu, D.; Zhang, T.; Liu, Z.; Dong, Q. Detection of concealed cracks from ground penetrating radar images based on deep learning algorithm. Constr. Build. Mater. 2021, 273, 121949. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of YOLOv4 algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Haggui, O.; Bayd, H.; Magnier, B. Centroid human tracking via oriented detection in overhead fisheye sequences. Vis. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based YOLOV4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]
- Bao, W.; Xu, B.; Chen, Z. Monofenet: Monocular 3d object detection with feature enhancement networks. IEEE Trans. Image Process. 2019, 29, 2753–2765. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Implementing a real-time, AI-based, people detection and social distancing measuring system for COVID-19. J.-Real-Time Image Process. 2021, 18, 1937–1947. [Google Scholar] [CrossRef]
- Sun, J.; Ge, H.; Zhang, Z. AS-YOLO: An improved YOLOv4 based on attention mechanism and SqueezeNet for person detection. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; IEEE: New York, NY, USA, 2021; Volume 5, pp. 1451–1456. [Google Scholar]
- Singh, A.; Kalaichelvi, V.; DSouza, A.; Karthikeyan, R. GAN-Based Image Dehazing for Intelligent Weld Shape Classification and Tracing Using Deep Learning. Appl. Sci. 2022, 12, 6860. [Google Scholar] [CrossRef]
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face mask detection using YOLOv3 and faster R-CNN models: COVID-19 environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef] [PubMed]
- Nair, R.; Vishwakarma, S.; Soni, M.; Patel, T.; Joshi, S. Detection of COVID-19 cases through X-ray images using hybrid deep neural network. World J. Eng. 2021, 19, 33–39. [Google Scholar] [CrossRef]
- Yoshitsugu, K.; Nakamoto, Y. COVID-19 Diagnosis Using Chest X-ray Images via Classification and Object Detection. In Proceedings of the 2021 4th Artificial Intelligence and Cloud Computing Conference, Kyoto Japan, 17–19 December 2021; pp. 62–67. [Google Scholar]
- Arunkumar, N.; Mohammed, M.A.; Abd Ghani, M.K.; Ibrahim, D.A.; Abdulhay, E.; Ramirez-Gonzalez, G.; de Albuquerque, V.H.C. K-means clustering and neural network for object detecting and identifying abnormality of brain tumor. Soft Comput. 2019, 23, 9083–9096. [Google Scholar] [CrossRef]
- Razzak, M.I.; Naz, S.; Zaib, A. Deep learning for medical image processing: Overview, challenges and the future. In Classification in BioApps: Automation of Decision Making; Springer: Berlin/Heidelberg, Germany, 2018; pp. 323–350. [Google Scholar]
- Alzubaidi, L.; Fadhel, M.; Al-Shamma, O.; Zhang, J.; Duan, Y. Deep learning models for classification of red blood cells in microscopy images to aid in sickle cell anemia diagnosis. Electronics 2020, 9, 427. [Google Scholar] [CrossRef]
- Khalifa, Y.; Mandic, D.; Sejdić, E. A review of Hidden Markov models and Recurrent Neural Networks for event detection and localization in biomedical signals. Inf. Fusion 2021, 69, 52–72. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. The COVID-19 epidemic analysis and diagnosis using deep learning: A systematic literature review and future directions. Comput. Biol. Med. 2022, 141, 105141. [Google Scholar] [CrossRef] [PubMed]
- Battineni, G.; Chintalapudi, N.; Amenta, F. Machine learning in medicine: Performance calculation of dementia prediction by support vector machines (SVM). Inform. Med. Unlocked 2019, 16, 100200. [Google Scholar] [CrossRef]
- Houssein, E.H.; Emam, M.M.; Ali, A.A.; Suganthan, P.N. Deep and machine learning techniques for medical imaging-based breast cancer: A comprehensive review. Expert Syst. Appl. 2021, 167, 114161. [Google Scholar] [CrossRef]
- Kaur, P.; Singh, G.; Kaur, P. Intellectual detection and validation of automated mammogram breast cancer images by multi-class SVM using deep learning classification. Inform. Med. Unlocked 2019, 16, 100151. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Shakhovska, N.; Yakovyna, V.; Chopyak, V. A new hybrid ensemble machine-learning model for severity risk assessment and post-COVID prediction system. Math. Biosci. Eng. 2022, 19, 6102–6123. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.J.; Nakarmi, U.; Kin, C.Y.S.; Sandino, C.M.; Cheng, J.Y.; Syed, A.B.; Wei, P.; Pauly, J.M.; Vasanawala, S.S. Diagnostic image quality assessment and classification in medical imaging: Opportunities and challenges. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: New York, NY, USA, 2020; pp. 337–340. [Google Scholar]
- Sarvamangala, D.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2022, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Alshamma, O.; Awad, F.; Alzubaidi, L.; Fadhel, M.; Arkah, Z.; Farhan, L. Employment of multi-classifier and multi-domain features for PCG recognition. In Proceedings of the 2019 12th International Conference On Developments In ESystems Engineering (DeSE), Kazan, Russia, 7–10 October 2019; pp. 321–325. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Al-Shamma, O.; Fadhel, M.; Arkah, Z.; Awad, F. A deep convolutional neural network model for multi-class fruits classification. In Proceedings of the Intelligent Systems Design And Applications: 19th International Conference On Intelligent Systems Design And Applications (ISDA 2019), Auburn, WA, USA, 3–5 December 2019; pp. 90–99. [Google Scholar]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical image analysis using convolutional neural networks: A review. J. Med. Syst. 2018, 42, 226. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.; Oleiwi, S.; Al-Shamma, O.; Zhang, J. DFU QUTNet: Diabetic foot ulcer classification using novel deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 15655–15677. [Google Scholar] [CrossRef]
- Kora, P.; Ooi, C.P.; Faust, O.; Raghavendra, U.; Gudigar, A.; Chan, W.Y.; Meenakshi, K.; Swaraja, K.; Plawiak, P.; Acharya, U.R. Transfer learning techniques for medical image analysis: A review. Biocybern. Biomed. Eng. 2022, 42, 79–107. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Al-Shamma, O.; Fadhel, M.; Farhan, L.; Zhang, J.; Duan, Y. Optimizing the performance of breast cancer classification by employing the same domain transfer learning from hybrid deep convolutional neural network model. Electronics 2020, 9, 445. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; Gao, L.; Shen, W. Improving computer-aided cervical cells classification using transfer learning based snapshot ensemble. Appl. Sci. 2020, 10, 7292. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Rabani, S.T.; Khan, Q.R.; Rouf, N.; Mohi Ud Din, M. Machine learning based approaches for detecting COVID-19 using clinical text data. Int. J. Inf. Technol. 2020, 12, 731–739. [Google Scholar] [CrossRef]
- Deepa, N.; Prabadevi, B.; Maddikunta, P.K.; Gadekallu, T.R.; Baker, T.; Khan, M.A.; Tariq, U. An AI-based intelligent system for healthcare analysis using Ridge-Adaline Stochastic Gradient Descent Classifier. J. Supercomput. 2021, 77, 1998–2017. [Google Scholar] [CrossRef]
- Wu, J.; Hicks, C. Breast cancer type classification using machine learning. J. Pers. Med. 2021, 11, 61. [Google Scholar] [CrossRef] [PubMed]
- Krishnamoorthi, R.; Joshi, S.; Almarzouki, H.Z.; Shukla, P.K.; Rizwan, A.; Kalpana, C.; Tiwari, B. A novel diabetes healthcare disease prediction framework using machine learning techniques. J. Healthc. Eng. 2022, 2022, 1684017. [Google Scholar] [CrossRef] [PubMed]
- Shakouri, S.; Bakhshali, M.A.; Layegh, P.; Kiani, B.; Masoumi, F.; Ataei Nakhaei, S.; Mostafavi, S.M. COVID19-CT-dataset: An open-access chest CT image repository of 1000+ patients with confirmed COVID-19 diagnosis. BMC Res. Notes 2021, 14, 178. [Google Scholar] [CrossRef] [PubMed]
- Gaur, L.; Bhatia, U.; Jhanjhi, N.; Muhammad, G.; Masud, M. Medical image-based detection of COVID-19 using deep convolution neural networks. Multimed. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Mijwil, M.M.; Al-Zubaidi, E.A. Medical Image Classification for Coronavirus Disease (COVID-19) Using Convolutional Neural Networks. Iraqi J. Sci. 2021, 62, 2740–2747. [Google Scholar]
- Islam, M.R.; Nahiduzzaman, M. Complex features extraction with deep-learning model for the detection of COVID19 from CT scan images using ensemble based machine learning approach. Expert Syst. Appl. 2022, 195, 116554. [Google Scholar] [CrossRef]
- Abirami, R.N.; Vincent, P.; Rajinikanth, V.; Kadry, S. COVID-19 Classification Using Medical Image Synthesis by Generative Adversarial Networks. Int. J. Uncertain. Fuzziness-Knowl.-Based Syst. 2022, 30, 385–401. [Google Scholar] [CrossRef]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Acharya, U.R. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al Emadi, N.; et al. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Lu, W. Improved K-means clustering algorithm for big data mining under Hadoop parallel framework. J. Grid Comput. 2020, 18, 239–250. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Q.; Hu, Y.; Sun-Woo, K.; Zhang, X.; Zhu, H.; Li, S. Novel binary logistic-regression model based on feature transformation of XGBoost for type 2 Diabetes Mellitus prediction in healthcare systems. Future Gener. Comput. Syst. 2022, 129, 1–12. [Google Scholar] [CrossRef]
- Dubey, P.K.; Naryani, U.; Malik, M. Logistic Regression Based Myocardial Infarction Disease Prediction. In Intelligent System Algorithms and Applications in Science and Technology; Apple Academic Press: Palm Bay, FL, USA, 2022; pp. 39–51. [Google Scholar]
- Mansour, N.A.; Saleh, A.I.; Badawy, M.; Ali, H.A. Accurate detection of COVID-19 patients based on Feature Correlated Naive Bayes (FCNB) classification strategy. J. Ambient Intell. Humaniz. Comput. 2022, 13, 41–73. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.N.; Gaskins, J.T. Shared Bayesian variable shrinkage in multinomial logistic regression. Comput. Stat. Data Anal. 2023, 177, 107568. [Google Scholar] [CrossRef]
- Botlagunta, M.; Botlagunta, M.D.; Myneni, M.B.; Lakshmi, D.; Nayyar, A.; Gullapalli, J.S.; Shah, M.A. Classification and diagnostic prediction of breast cancer metastasis on clinical data using machine-learning algorithms. Sci. Rep. 2023, 13, 485. [Google Scholar] [CrossRef]
- Karacı, A. VGGCOV19-NET: Automatic detection of COVID-19 cases from X-ray images using modified VGG19 CNN architecture and YOLOv4 algorithm. Neural Comput. Appl. 2022, 34, 8253–8274. [Google Scholar] [CrossRef]
- Al-Antari, M.A.; Hua, C.H.; Bang, J.; Lee, S. Fast deep learning computer-aided diagnosis of COVID-19 based on digital chest x-ray images. Appl. Intell. 2021, 51, 2890–2907. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Duan, Y.; Al-Dujaili, A.; Ibraheem, I.K.; Alkenani, A.H.; Santamaría, J.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J. Deepening into the suitability of using pre-trained models of ImageNet against a lightweight convolutional neural network in medical imaging: An experimental study. PeerJ Comput. Sci. 2021, 7, e715. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Hasan, R.I.; Awad, F.H.; Fadhel, M.A.; Alshamma, O.; Zhang, J. Multi-class breast cancer classification by a novel two-branch deep convolutional neural network architecture. In Proceedings of the 2019 12th International Conference on Developments in eSystems Engineering (DeSE), Kazan, Russia, 7–10 October 2019; IEEE: New York, NY, USA, 2019; pp. 268–273. [Google Scholar]
- Zhu, Z.; Xingming, Z.; Tao, G.; Dan, T.; Li, J.; Chen, X.; Li, Y.; Zhou, Z.; Zhang, X.; Zhou, J.; et al. Classification of COVID-19 by compressed chest CT image through deep learning on a large patients cohort. Interdiscip. Sci. Comput. Life Sci. 2021, 13, 73–82. [Google Scholar] [CrossRef]
- Kumar, K.A.; Prasad, A.; Metan, J. A Hybrid Deep CNN-Cov-19-Res-Net Transfer Learning Architype for an Enhanced Brain Tumor Detection and Classification Scheme in Medical Image Processing; Elsevier: Amsterdam, The Netherlands, 2022; Volume 76, p. 103631. [Google Scholar]
- Sahlol, A.T.; Yousri, D.; Ewees, A.A.; Al-Qaness, M.A.; Damasevicius, R.; Elaziz, M.A. COVID-19 image classification using deep features and fractional-order marine predators algorithm. Sci. Rep. 2020, 10, 15364. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dataset Size |
|---|---|
| COVID-19 Dataset | 54 MB |
| COVID-19 | 362 MB |
| COVID-19 Open Research Dataset Challenge | 20 GB |
| Dataset | Dataset Size | No. of Images/Slices | No. of Classes |
|---|---|---|---|
| Large COVID-19 CT-scan-slice dataset | 2 GB | 7593 | 9 |
| COVIDx CT | 65 GB | 194,922 | 10 |
| CT Low-Dose Reconstruction | 20 GB | 16,926 | 6 |
| Dataset | Number of Records |
|---|---|
| Google Play Store | 11,000,000 |
| KDD99 [64] | 9,000,000 |
| Dataset | Windows OS | iOS | Android OS |
|---|---|---|---|
| Google Play Store | 90 min | 46.1 | 56.4 |
| Education Sector | 24.3 ms | 2.4 | 6.3 |
| Algorithm | Performance (m.) |
|---|---|
| Logistic Regression | 23.1 |
| Naive Bayes | 31.4 |
| Dataset | Algorithm | Speed (m.) |
|---|---|---|
| 1 | Logistic Regression | 12.2 |
| Naive Bayes | 8.5 | |
| K-Means–Logistic Regression | 9.7 | |
| 2 | Logistic Regression | 63.2 |
| Naive Bayes | 83.1 | |
| K-Means–Logistic Regression | 45.1 | |
| 3 | Logistic Regression | 2754 |
| Naive Bayes | 3571 | |
| K-Means–Logistic Regression | 1693 |
| Dataset | Algorithm | Accuracy (%) |
|---|---|---|
| 1 | Logistic Regression | 93.4 |
| Naive Bayes | 92.1 | |
| K-Means–Logistic Regression | 95.3 | |
| 2 | Logistic Regression | 94.2 |
| Naive Bayes | 93.5 | |
| K-Means–Logistic Regression | 97.2 | |
| 3 | Logistic Regression | 93.1 |
| Naive Bayes | 91.3 | |
| K-Means–Logistic Regression | 97.6 |
| Algorithm | Performance (m.) |
|---|---|
| Logistic Regression [66] | 34.1 |
| Novel Binary Logistic Regression [65] | 28.3 |
| Correlated Naive Bayes [67] | 37.4 |
| K-Means–Logistic Regression | 21.1 |
| Algorithm | Accuracy (%) |
|---|---|
| Logistic Regression [66] | 88 |
| Novel Binary Logistic Regression [65] | 98 |
| Correlated Naive Bayes [67] | 97 |
| Shared Bayesian Variable Shrinkage [68] | 93 |
| Classification of Breast Cancer Metastasis Using Machine-Learning Algorithms [69] | 92 |
| K-Means–Logistic Regression | 99.8 |
| Algorithm | Speed (ms.) |
|---|---|
| SPP-net | 1500 |
| R-CNN | 900 |
| Fast R-CNN | 750 |
| Faster R-CNN | 600 |
| R-FCN | 550 |
| Mask R-CNN | 400 |
| YOLOv3 | 250 |
| YOLOv4 | 150 |
| Advanced Parallel K-means–YOLOv4 (APK-YOLO) | 90 |
| Algorithm | CPU (ms.) | GPU (ms.) | Neural Engine (ms.) |
|---|---|---|---|
| YOLOv4 | 350 | 280 | 150 |
| APK-YOLOv4 | 220 | 120 | 90 |
| Algorithm | Speed (ms.) |
|---|---|
| VGGCOV19-NET [70] | 620 |
| CAD-based YOLOv4 [71] | 530 |
| APK-YOLOv4 | 90 |
| Fold | Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|---|
| 1 | VGGCOV 19-NET [70] | 78.20 | 78.80 | 78.30 | 78.22 |
| CAD-based YOLOv4 [71] | 75.90 | 75.6 | 75.8 | 75.4 | |
| APK-YOLOv4 | 82.2 | 82.6 | 82.7 | 82.7 | |
| 2 | VGGCOV 19-NET [70] | 91.10 | 91.10 | 91.10 | 91.11 |
| CAD-based YOLOv4 [71] | 89.5 | 89.4 | 89.5 | 89.5 | |
| APK-YOLOv4 | 93.4 | 93.4 | 93.3 | 93.4 | |
| 3 | VGGCOV 19-NET [70] | 84.40 | 84.80 | 84.50 | 84.44 |
| CAD-based YOLOv4 [71] | 90.2 | 90.1 | 90.2 | 90.1 | |
| APK-YOLOv4 | 94.2 | 94.23 | 94.2 | 94.3 | |
| 4 | VGGCOV 19-NET [70] | 95.10 | 95.20 | 95.10 | 95.11 |
| CAD-based YOLOv4 [71] | 94.5 | 94.2 | 94.4 | 94.4 | |
| APK-YOLOv4 | 96.7 | 96.4 | 96.5 | 96.5 | |
| 5 | VGGCOV 19-NET [70] | 95.60 | 95.70 | 95.60 | 95.56 |
| CAD-based YOLOv4 [71] | 94.2 | 94.1 | 94.2 | 94.2 | |
| APK-YOLOv4 | 97.2 | 97.6 | 97.4 | 97.5 |
| Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| VGGCOV 19-NET [70] | 92.80 | 99.15 | 95.87 | 87.89 |
| CAD-based YOLOv4 [71] | 91.5 | 95.7 | 85.7 | 90.67 |
| APK-YOLOv4 | 93.8 | 99.7 | 97.44 | 96.21 |
| Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| VGGCOV 19-NET [70] | 90.20 | 86.40 | 88.26 | 85.80 |
| CAD-based YOLOv4 [71] | 89.1 | 82.3 | 80.4 | 89.7 |
| APK-YOLOv4 | 92.9 | 95.4 | 92.6 | 91.82 |
| Fold | Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|---|
| 1 | Compressed Chest CT Image through Deep Learning [74] | 79.10 | 79.30 | 79.10 | 79.87 |
| APK-YOLOv4 | 83.5 | 83.4 | 83.4 | 83.3 | |
| 2 | Compressed Chest CT Image through Deep Learning [74] | 93.10 | 92.80 | 92.60 | 92.8 |
| APK-YOLOv4 | 94.1 | 94.3 | 94.7 | 94.6 | |
| 3 | Compressed Chest CT Image through Deep Learning [74] | 89.10 | 89.70 | 89.60 | 89.8 |
| APK-YOLOv4 | 93.8 | 94.1 | 93.9 | 93.8 | |
| 4 | Compressed Chest CT Image through Deep Learning [74] | 96.20 | 96.30 | 96.18 | 96.20 |
| APK-YOLOv4 | 97.1 | 97.5 | 97.4 | 97.2 | |
| 5 | Compressed Chest CT Image through Deep Learning [74] | 98.78 | 98.75 | 98.80 | 98.7 |
| APK-YOLOv4 | 99.4 | 99.7 | 99.3 | 99.2 |
| Fold | Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|---|
| 1 | hybrid deep CNN-Cov-19-Res-Net [75] | 78.50 | 78.70 | 78.40 | 78.12 |
| APK-YOLOv4 | 82.4 | 82.3 | 82.4 | 82.3 | |
| 2 | hybrid deep CNN-Cov-19-Res-Net [75] | 91.30 | 91.20 | 91.60 | 91.3 |
| APK-YOLOv4 | 93.5 | 93.4 | 93.2 | 93.3 | |
| 3 | hybrid deep CNN-Cov-19-Res-Net [75] | 90.10 | 90.2 | 90.3 | 90.1 |
| APK-YOLOv4 | 94.5 | 94.5 | 94.3 | 94.3 | |
| 4 | hybrid deep CNN-Cov-19-Res-Net [75] | 95.30 | 95.20 | 95.10 | 95.40 |
| APK-YOLOv4 | 96.3 | 96.5 | 96.3 | 96.2 | |
| 5 | hybrid deep CNN-Cov-19-Res-Net [75] | 97.18 | 97.15 | 97.30 | 97.2 |
| APK-YOLOv4 | 98.1 | 98.2 | 98.1 | 98.1 |
| Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| Deep Features and Fractional-Order Marine Predators [76] | 98.2 | 98.5 | 99.6 | 98.7 |
| APK-YOLOv4 | 98.8 | 99.1 | 99.8 | 99.1 |
| Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|
| Deep Features and Fractional-Order Marine Predators [76] | 97.7 | 98.1 | 99 | 98.2 |
| APK-YOLOv4 | 98.5 | 99.3 | 98.1 | 99.6 |
| Fold | Algorithm | Recall | Precision | F1 | Accuracy |
|---|---|---|---|---|---|
| 1 | VGGCOV 19-NET [70] | 77.30 | 77.20 | 77.10 | 77.34 |
| CAD-based YOLOv4 [71] | 78.80 | 78.9 | 78.5 | 78.4 | |
| APK-YOLOv4 | 85.1 | 84.1 | 85.3 | 85.7 | |
| 2 | VGGCOV 19-NET [70] | 90.30 | 90.40 | 90.60 | 90.4 |
| CAD-based YOLOv4 [71] | 90.6 | 91.2 | 91.6 | 91.8 | |
| APK-YOLOv4 | 94.3 | 95.1 | 95.2 | 95.1 | |
| 3 | VGGCOV 19-NET [70] | 88.60 | 88.85 | 87.40 | 87.74 |
| CAD-based YOLOv4 [71] | 91.3 | 91.1 | 91.5 | 91.4 | |
| APK-YOLOv4 | 96.52 | 96.27 | 97.1 | 96.8 | |
| 4 | VGGCOV 19-NET [70] | 95.30 | 95.24 | 95.34 | 95.61 |
| CAD-based YOLOv4 [71] | 94.7 | 94.25 | 94.7 | 94.8 | |
| APK-YOLOv4 | 97.7 | 98.5 | 97.8 | 97.9 | |
| 5 | VGGCOV 19-NET [70] | 96.60 | 96.30 | 95.9 | 95.76 |
| CAD-based YOLOv4 [71] | 95.2 | 95.13 | 95.22 | 95.12 | |
| APK-YOLOv4 | 98.8 | 98.4 | 98.7 | 98.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awad, F.H.; Hamad, M.M.; Alzubaidi, L. Robust Classification and Detection of Big Medical Data Using Advanced Parallel K-Means Clustering, YOLOv4, and Logistic Regression. Life 2023, 13, 691. https://doi.org/10.3390/life13030691
Awad FH, Hamad MM, Alzubaidi L. Robust Classification and Detection of Big Medical Data Using Advanced Parallel K-Means Clustering, YOLOv4, and Logistic Regression. Life. 2023; 13(3):691. https://doi.org/10.3390/life13030691
Chicago/Turabian StyleAwad, Fouad H., Murtadha M. Hamad, and Laith Alzubaidi. 2023. "Robust Classification and Detection of Big Medical Data Using Advanced Parallel K-Means Clustering, YOLOv4, and Logistic Regression" Life 13, no. 3: 691. https://doi.org/10.3390/life13030691
APA StyleAwad, F. H., Hamad, M. M., & Alzubaidi, L. (2023). Robust Classification and Detection of Big Medical Data Using Advanced Parallel K-Means Clustering, YOLOv4, and Logistic Regression. Life, 13(3), 691. https://doi.org/10.3390/life13030691