
Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine


Abstract
1. Introduction
2. Feature Extraction Using Shift Invariant K-SVD Algorithm
2.1. Shift Invariant K-SVD Algorithm
2.2. Shift Invariant Sparse Feature
3. Classification with Optimized SVM
3.1. Grid Search
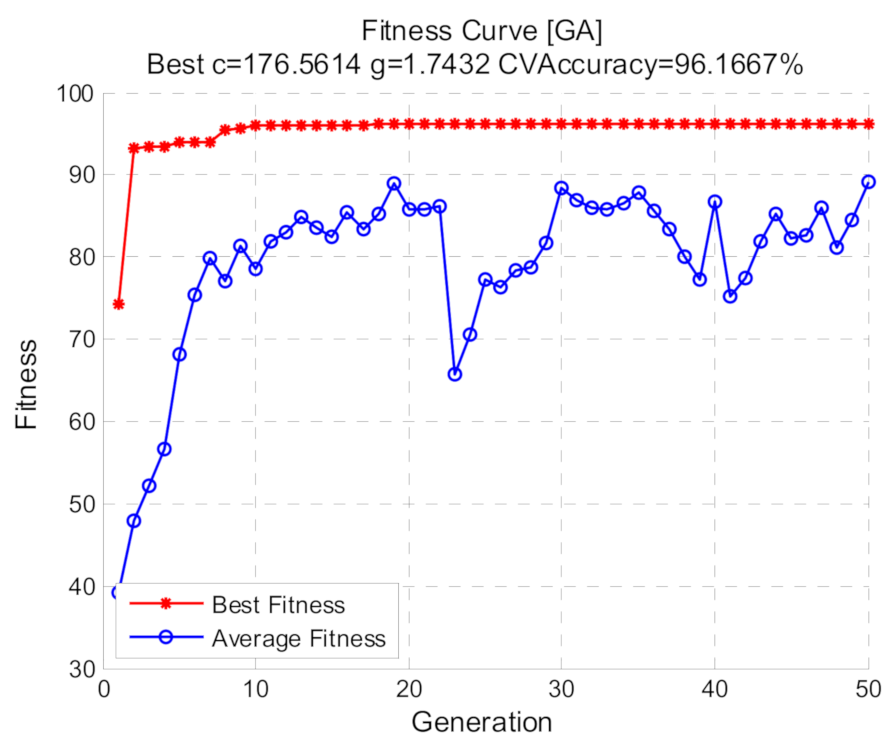
3.2. Genetic Algorithm
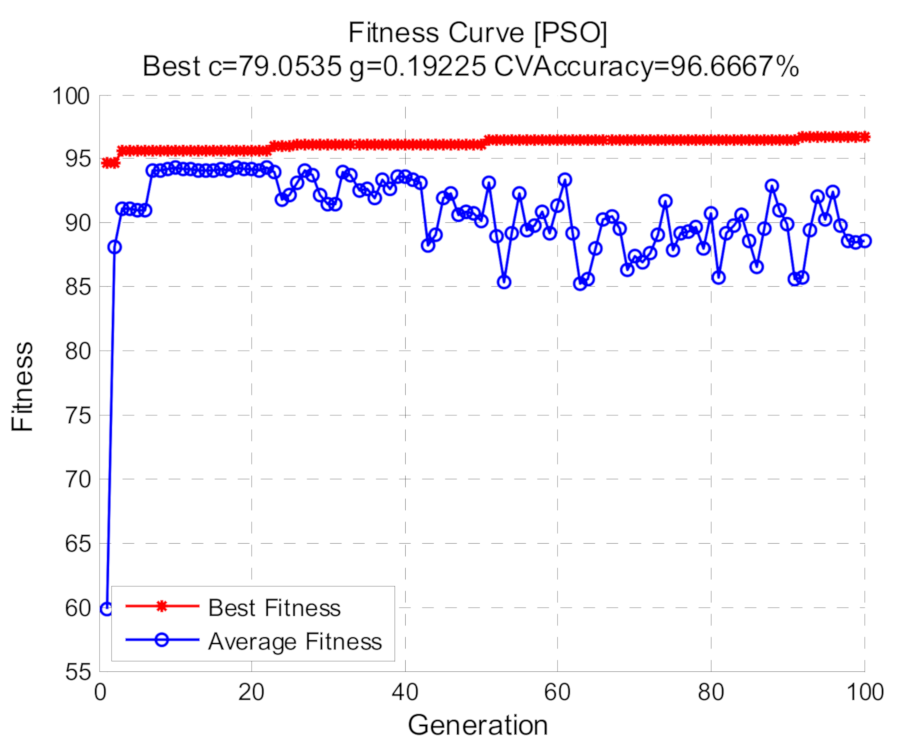
3.3. Particle Swarm Optimization
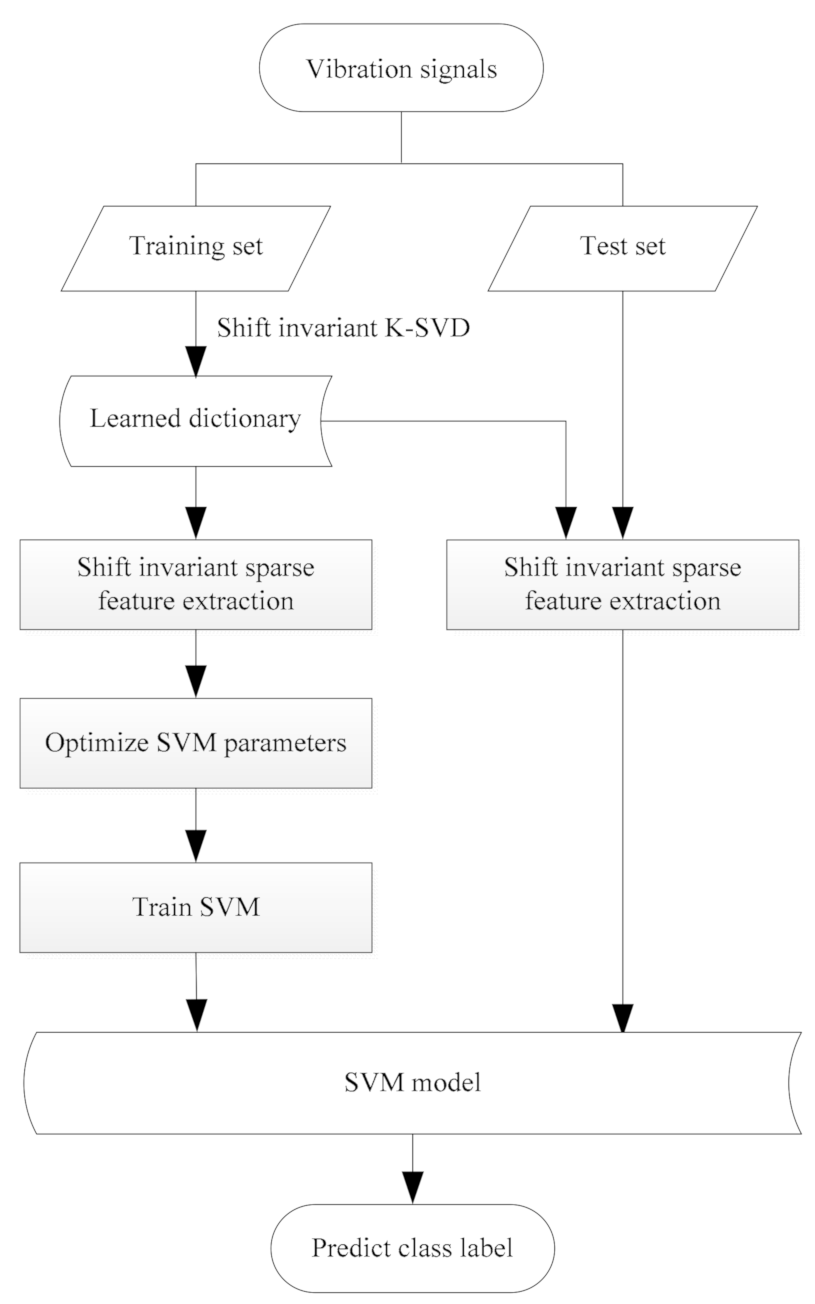
4. Bearing Fault Diagnosis Method Using Shift Invariant Sparse Feature and Optimized SVM
5. Experiment and Analysis
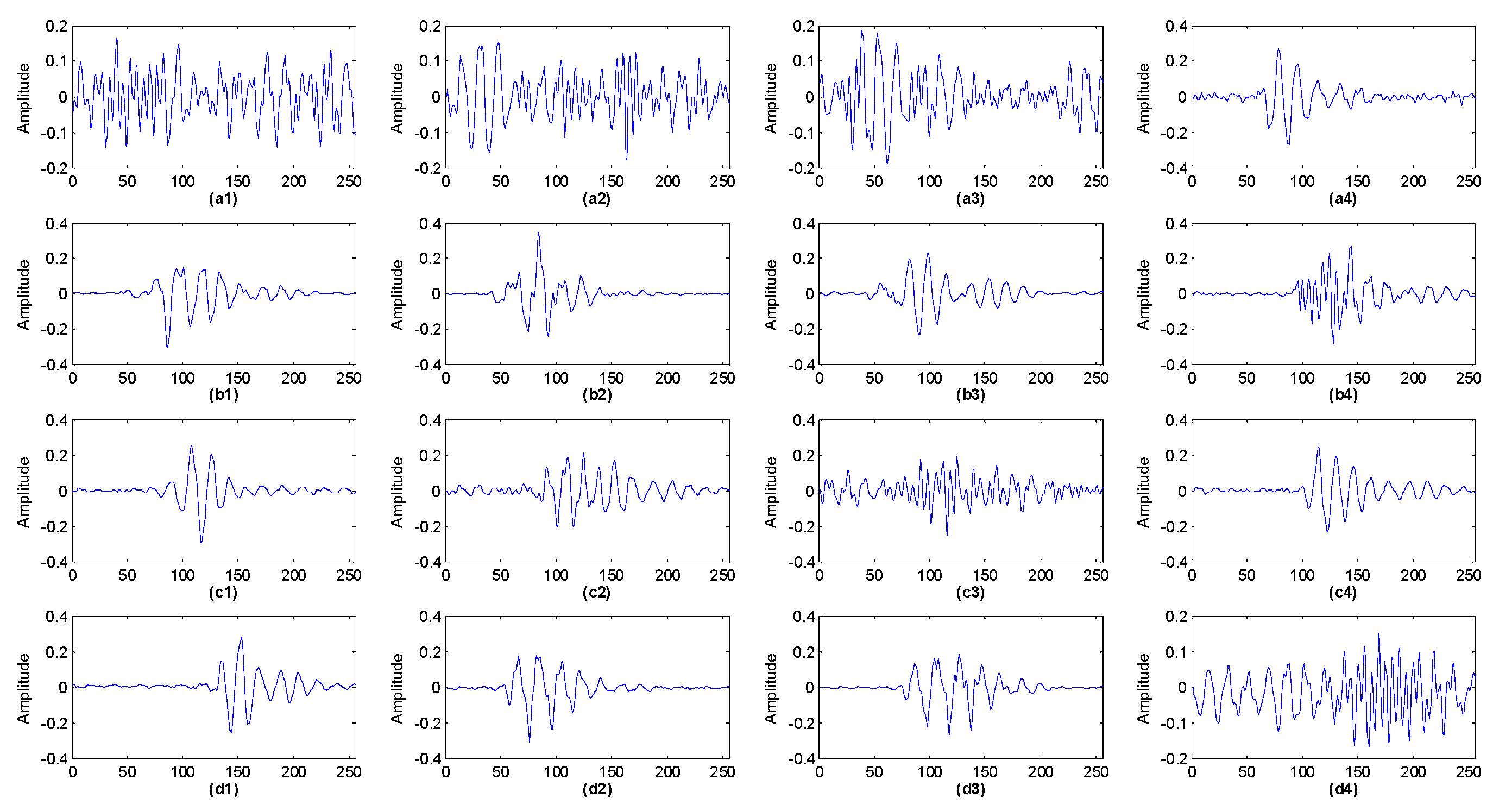
5.1. Description of the Experiment
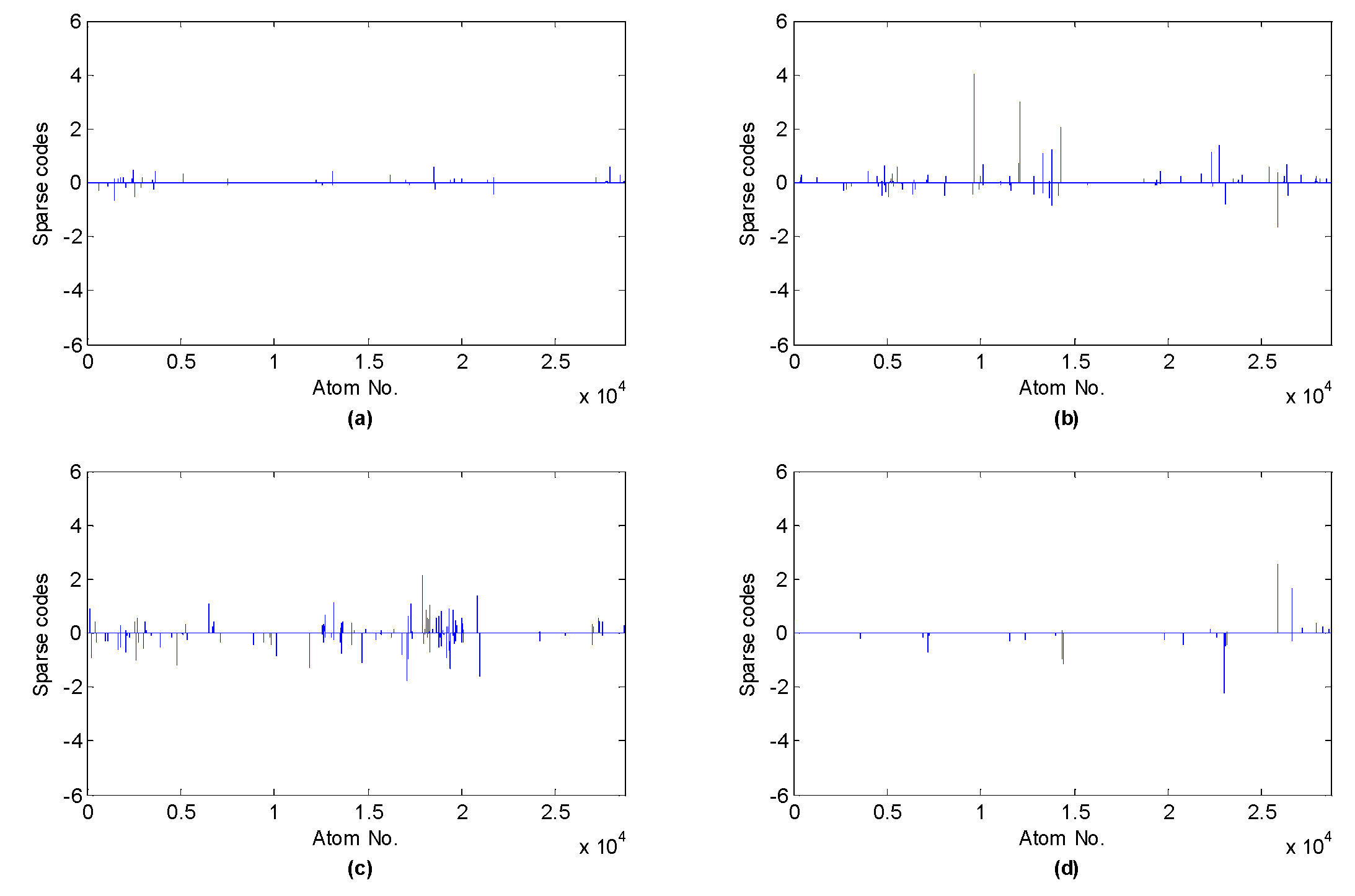
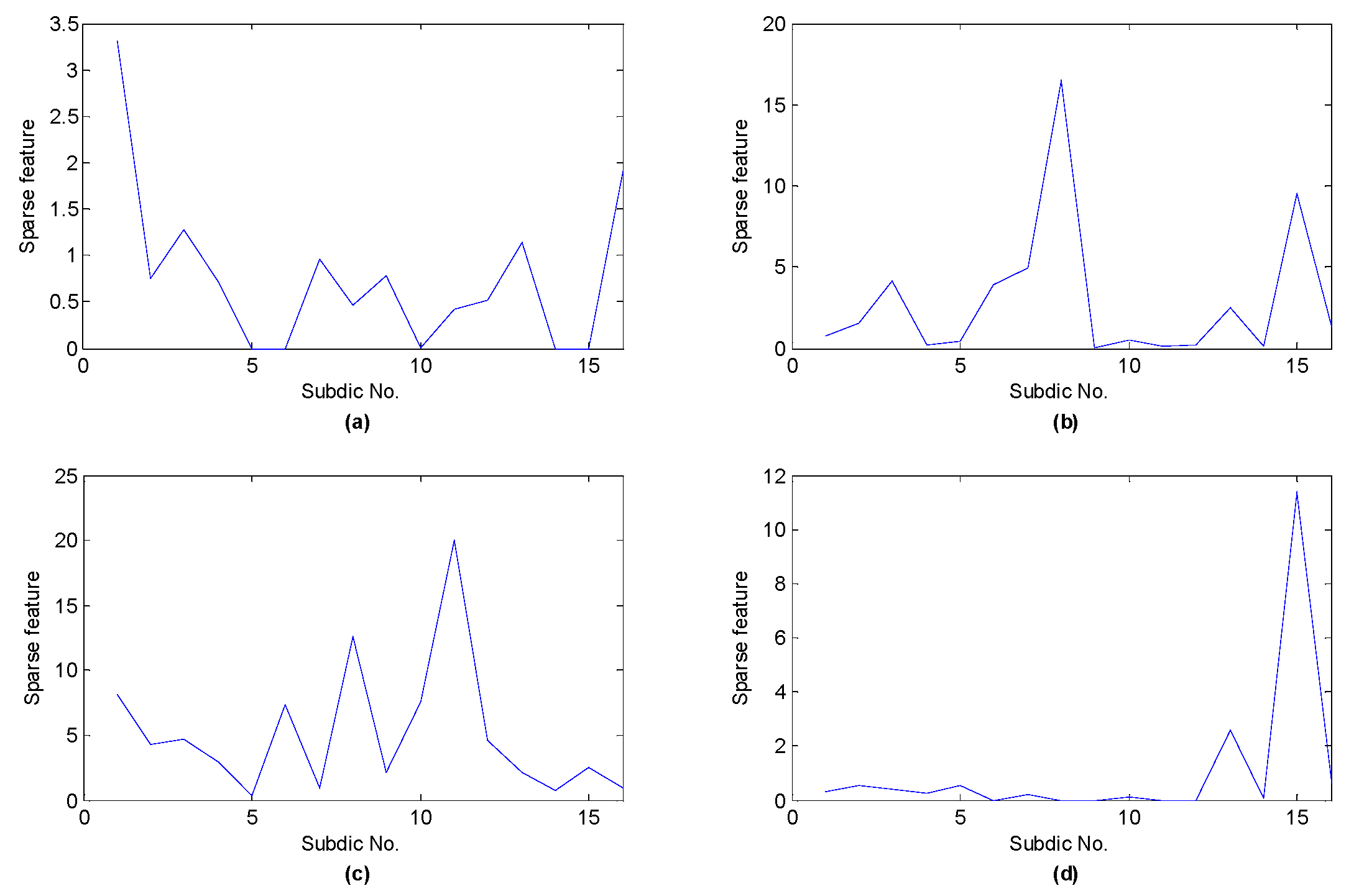
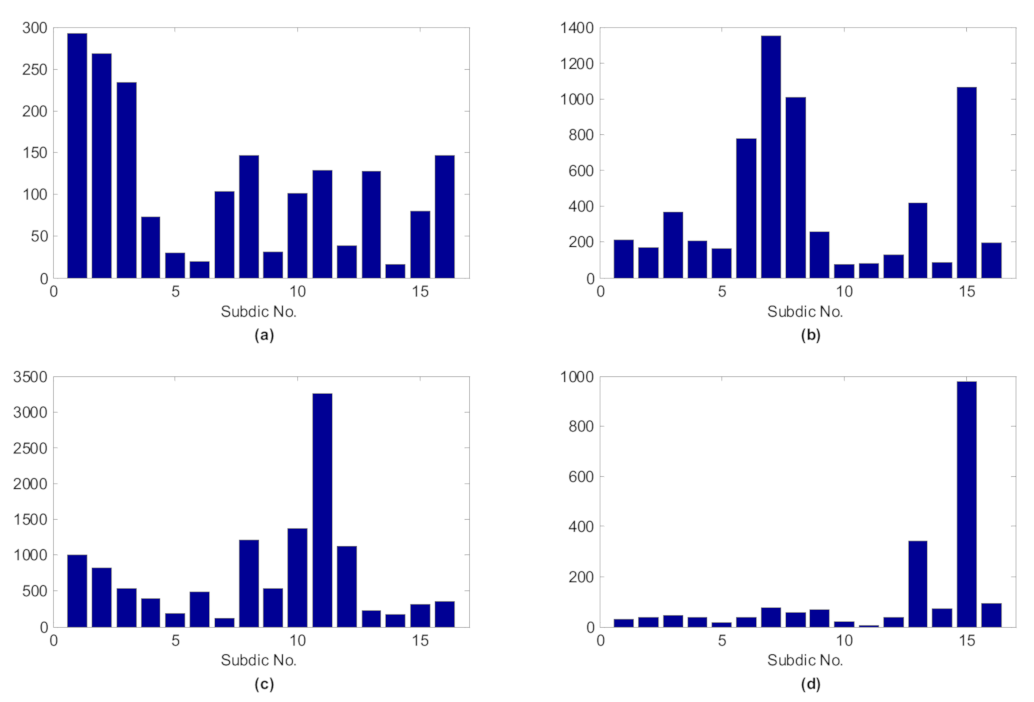
5.2. Feature Extraction with Shift Invariant Sparse Feature
5.3. Fault Diagnosis Using Shift Invariant Sparse Feature
5.3.1. Diagnosis Result with Standard SVM
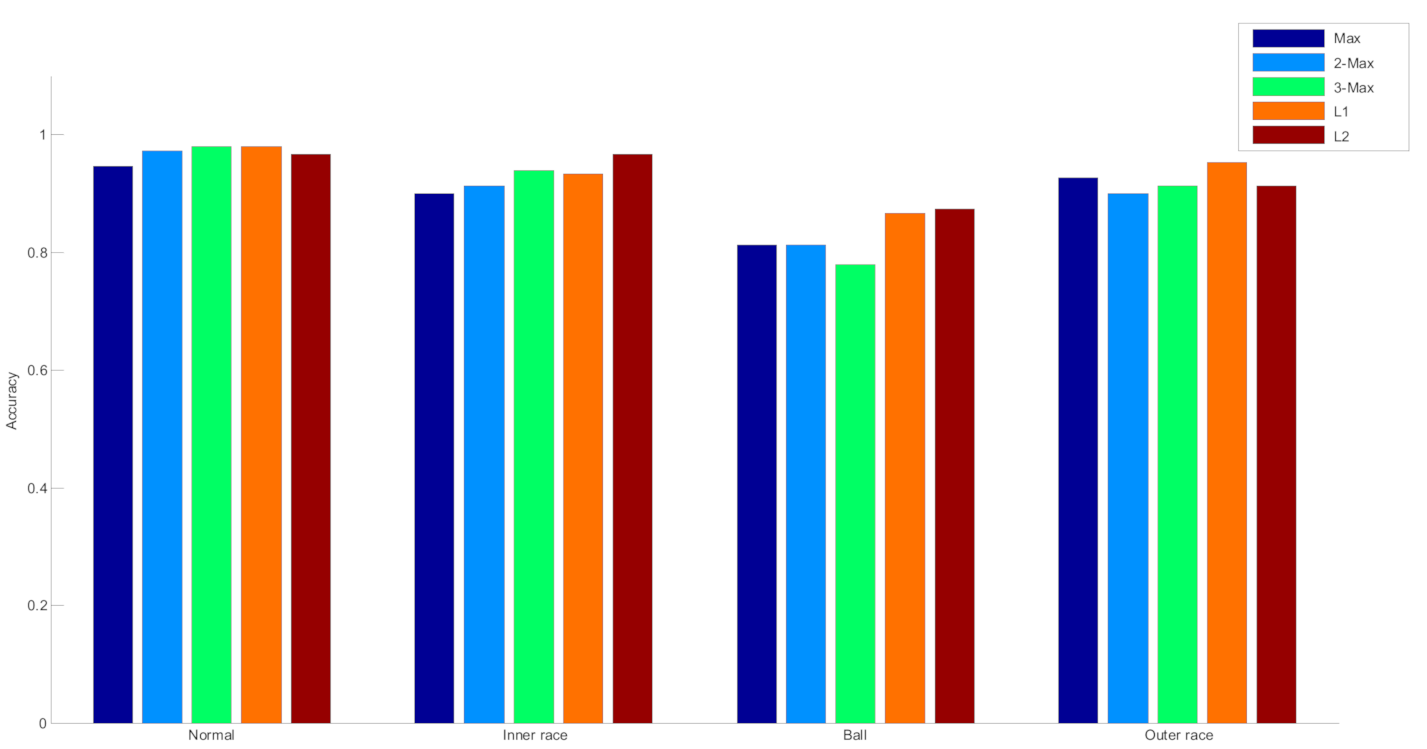
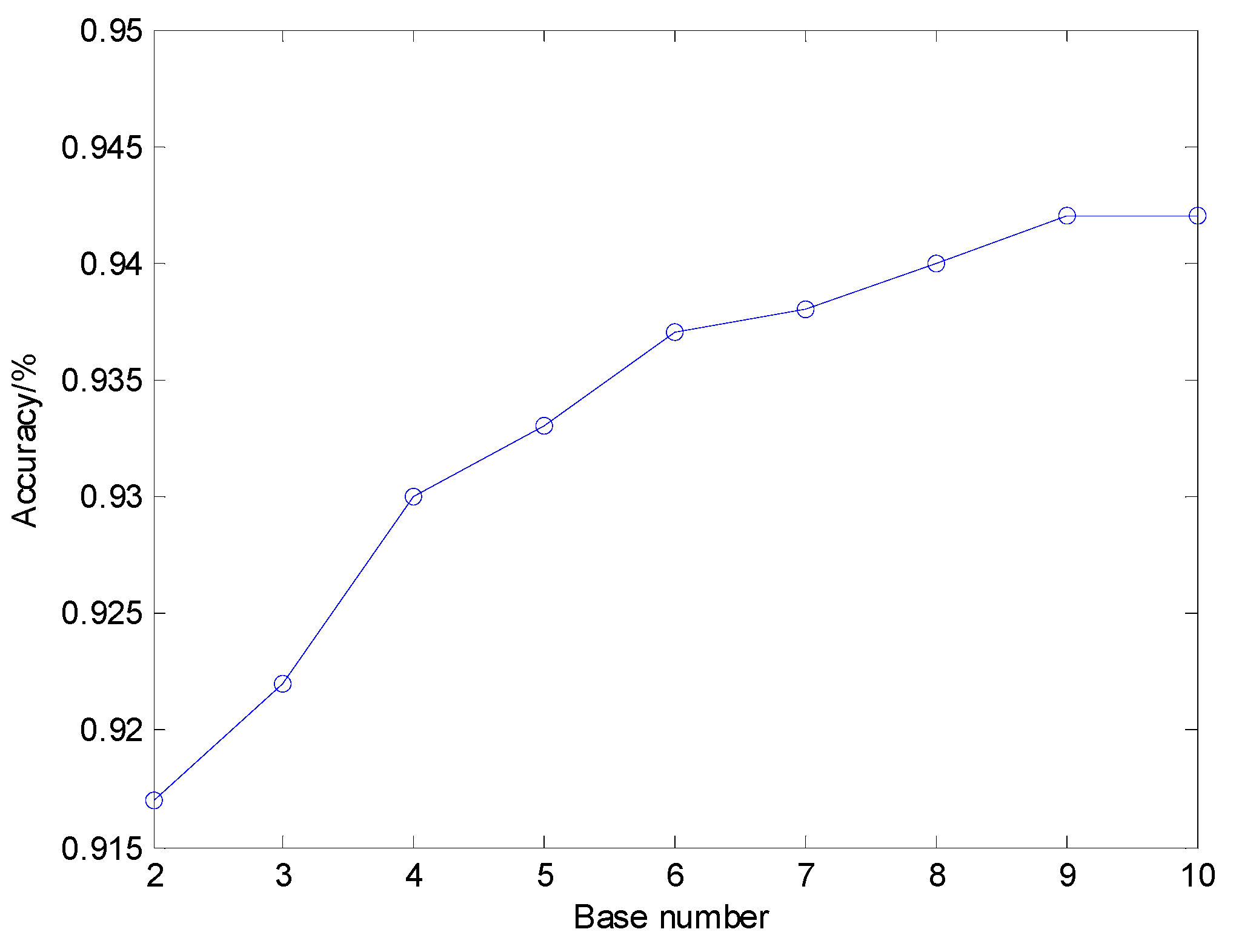
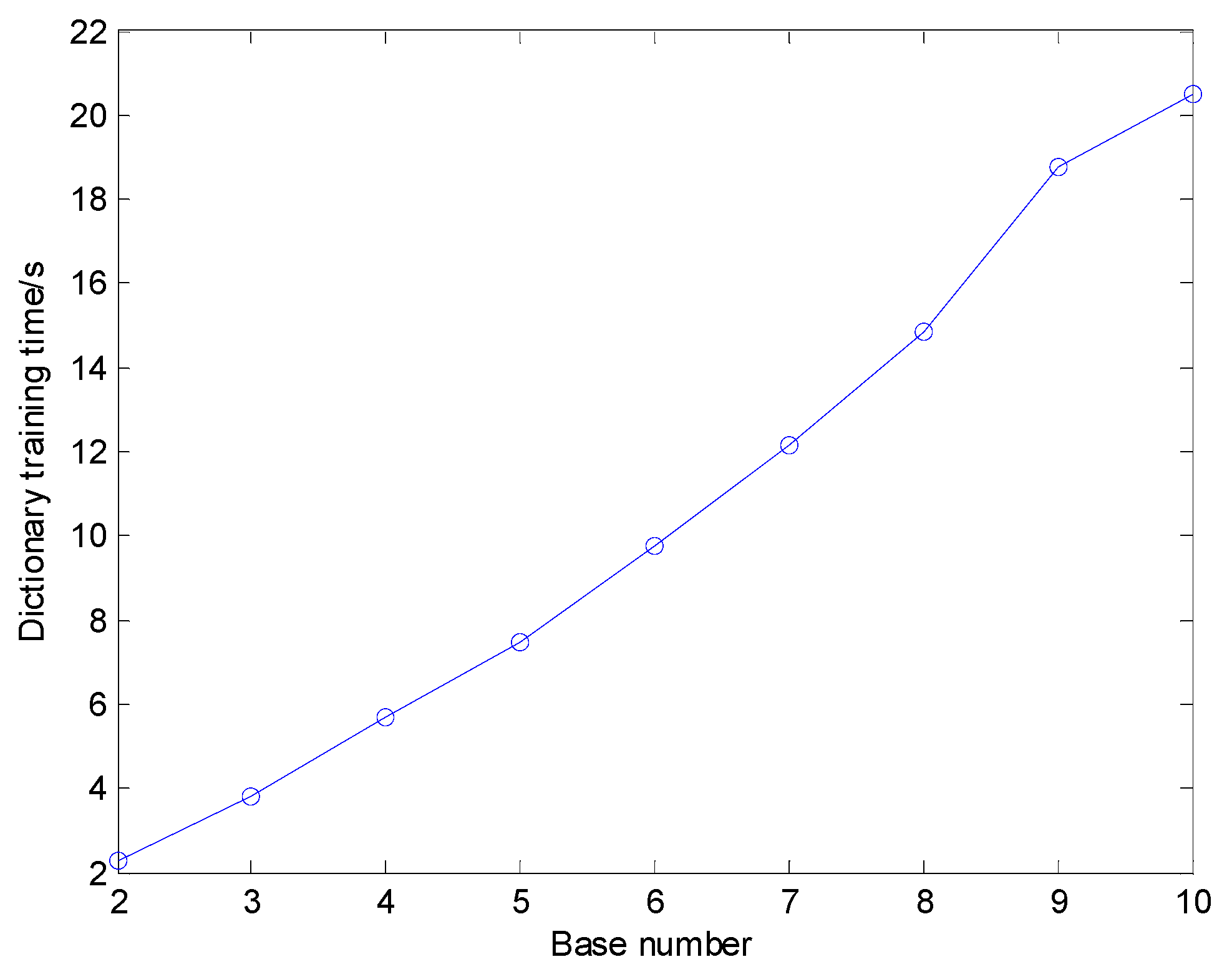
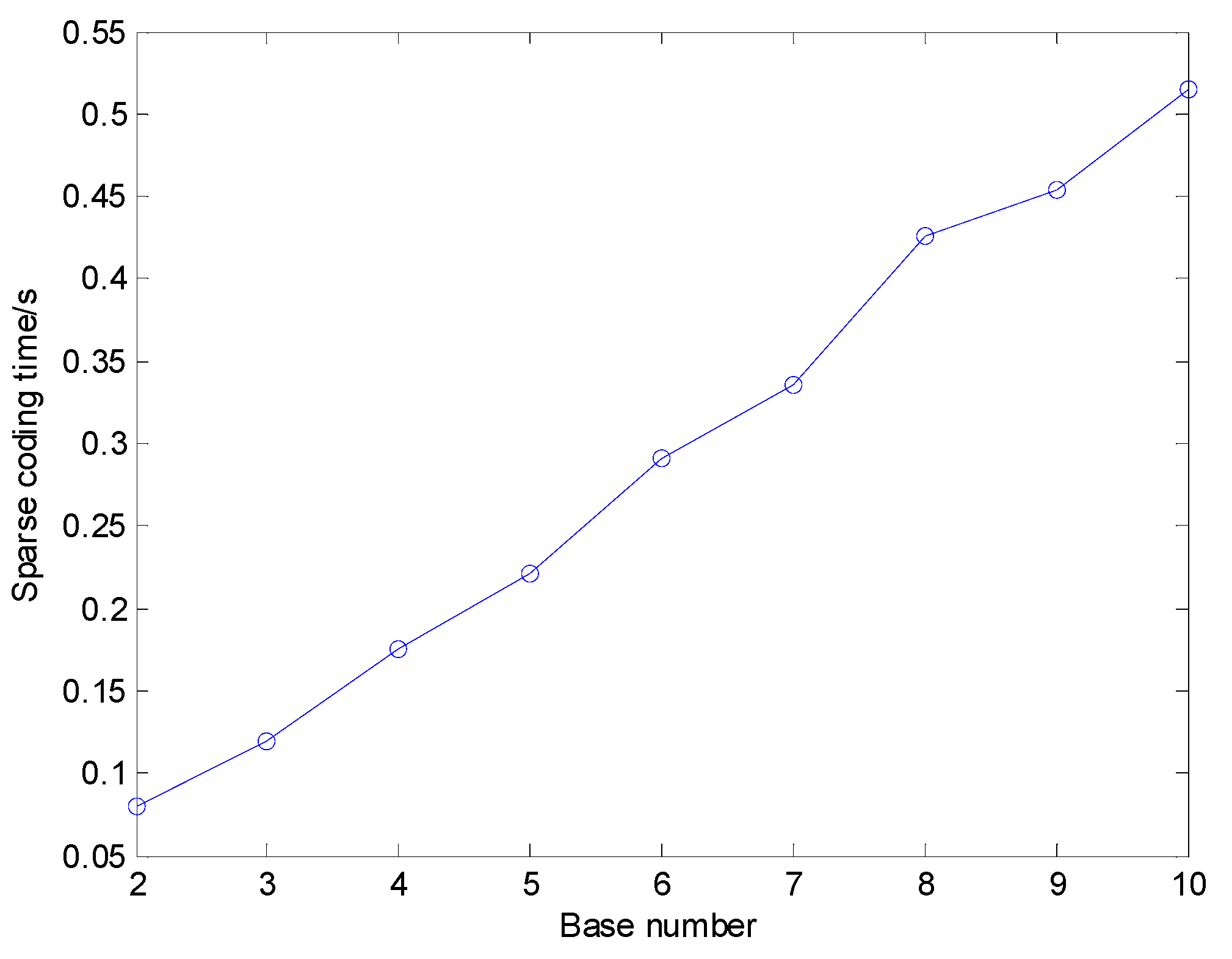
5.3.2. Influence of Parameter Set of Shift Invariant Sparse Feature
5.3.3. Diagnosis Results Using Optimized SVM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Notations
| c | penalization factor in SVM |
| c1 | acceleration coefficient that represents the local search ability |
| c2 | acceleration coefficient that represents the global search ability |
| dk | the kth basis function |
| d | basis function |
| D | over-complete dictionary |
| F | shift invariant sparse feature |
| g | the width of RBF kernel in SVM using RBF kernel |
| gbest | the best particle that indicates the global best |
| j | class label |
| K | basis function number |
| L | class number of signals |
| M | the number of maximum absolute values |
| N | population size in PSO |
| p | the length of the long signal x |
| pbesti | the best value of the ith particle that indicates the local best |
| pi | the ith particle |
| q | the length of the basis function |
| r | residual signal |
| r1 | random number uniformly distributed in [0, 1] |
| r2 | random number uniformly distributed in [0, 1] |
| s | sparse coefficient corresponding to the long signal |
| Sk,τ | the sparse coefficient corresponding to the dictionary atom after basis function is translated to time τ and extended |
| t | iteration number |
| T | sparsity prior |
| Tτ | shift operator |
| the operator corresponding to , which can extract a segment with the same length q as the basis function from the long signal and the segment starts at time τ | |
| vi | velocity of the ith particle |
| wv | elastic coefficient for velocity update |
| wp | elastic coefficient for particle update |
| x | long signal |
| X | training set |
| the signal with no contribution from other basis functions | |
| σκ | the set of non-zero elements |
| ε | tolerance error |
References
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, H.; Yu, M.; Kwong, S.; Ho, Y.S. Sparse Representation-Based Video Quality Assessment for Synthesized 3D Videos. IEEE Trans. Image Process. 2020, 29, 509–524. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.Q.; Liu, S.J.; Li, Y.; Li, D.; Truong, T.K. Speech Denoising Based on Group Sparse Representation in the Case of Gaussian Noise. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018. [Google Scholar]
- Zhong, J.; Wang, D.; Guo, J.; Cabrera, D.; Li, C. Theoretical Investigations on Kurtosis and Entropy and Their Improvements for System Health Monitoring. IEEE Trans. Instrum. Meas. 2020, 1–10. [Google Scholar] [CrossRef]
- Yu, F.J.; Zhou, F.X. Classification of Machinery Vibration Signals Based on Group Sparse Representation. J. Vibroeng. 2016, 18, 1540–1554. [Google Scholar] [CrossRef]
- Peng, W.; Wang, D.; Shen, C.Q.; Liu, D.N. Sparse Signal Representations of Bearing Fault Signals for Exhibiting Bearing Fault Features. Shock Vib. 2016. [Google Scholar] [CrossRef]
- Fan, W.; Cai, G.G.; Zhu, Z.K.; Shen, C.Q.; Huang, W.G.; Shang, L. Sparse Representation of Transients in Wavelet Basis and its Application in Gearbox Fault Feature Extraction. Mech. Syst. Signal Process. 2015, 56–57, 230–245. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Engan, K.; Aase, S.O.; Husoy, J.H. Multi-Frame Compression: Theory and Design. Signal Process. 2000, 80, 2121–2140. [Google Scholar] [CrossRef]
- Wang, T.; Feng, H.S.; Li, S.; Yang, Y. Medical Image Denoising Using Bilateral Filter and the KSVD Algorithm. In Proceedings of the 2019 3rd International Conference on Machine Vision and Information Technology (CMVIT 2019), Guangzhou, China, 22–24 February 2019; Volume 1229. [Google Scholar] [CrossRef]
- Liu, J.J.; Liu, W.Q.; Ma, S.W.; Wang, M.X.; Li, L.; Chen, G.H. Image-set Based Face Recognition Using K-SVD Dictionary Learning. Int. J. Mach. Learn. Cybern. 2019, 10, 1051–1064. [Google Scholar] [CrossRef]
- Li, S.T.; Ye, W.B.; Liang, H.W.; Pan, X.F.; Lou, X.; Zhao, X.J. K-SVD Based Denoising Algorithm for DoFP Polarization Image Sensors. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar] [CrossRef]
- Zhu, K.P.; Vogel-Heuser, B. Sparse Representation and its Applications in Micro-Milling Condition Monitoring: Noise Separation and Tool Condition Monitoring. Int. J. Adv. Manuf. Technol. 2014, 70, 185–199. [Google Scholar] [CrossRef]
- Zeng, M.; Zhang, W.M.; Chen, Z. Group-Based K-SVD Denoising for Bearing Fault Diagnosis. IEEE Sens. J. 2019, 19, 6335–6343. [Google Scholar] [CrossRef]
- Grosse, R.; Raina, R.; Kwong, H.; Ng, A.Y. Shift-Invariant Sparse Coding for Audio Classification. In Proceedings of the Proceedings of the Twenty-Third Conference on Uncertainty in AI, Vancouver, BC, Canada, 19–22 July 2007; pp. 149–158. [Google Scholar]
- Wohlberg, B. Efficient Algorithms for Convolutional Sparse Representations. IEEE Trans. Image Process. 2016, 25, 301–315. [Google Scholar] [CrossRef]
- Mailhé, B.; Lesage, S.; Bimbot, F.; Vandergheynst, P. Shift-Invariant Dictionary Learning for Sparse Representations: Extending K-SVD. In Proceedings of the 16th European Signal Processing Conference (EUSIPCO’08), Lausanne, Switzerland, 25 August 2008; pp. 1–5. [Google Scholar]
- Liu, H.N.; Liu, C.L.; Huang, Y.X. Adaptive Feature Extraction Using Sparse Coding for Machinery Fault Diagnosis. Mech. Syst. Signal Process. 2011, 25, 558–574. [Google Scholar] [CrossRef]
- Feng, Z.P.; Liang, M. Complex Signal Analysis for Planetary Gearbox Fault Diagnosis via Shift Invariant Dictionary Learning. Measurement 2016, 90, 382–395. [Google Scholar] [CrossRef]
- Tang, H.F.; Chen, J.; Dong, G.M. Sparse Representation Based Latent Components Analysis for Machinery Weak Fault Detection. Mech. Syst. Signal Process. 2014, 46, 373–388. [Google Scholar] [CrossRef]
- Yang, B.Y.; Liu, R.N.; Chen, X.F. Fault Diagnosis for a Wind Turbine Generator Bearing via Sparse Representation and Shift-Invariant K-SVD. IEEE Trans. Ind. Inform. 2017, 13, 1321–1331. [Google Scholar] [CrossRef]
- Ding, J.M. Fault Detection of a Wheelset Bearing in a High-Speed Train Using the Shock-Response Convolutional Sparse-Coding Technique. Measurement 2018, 117, 108–124. [Google Scholar] [CrossRef]
- Li, Q.C.; Ding, X.X.; Huang, W.B.; He, Q.B.; Shao, Y.M. Transient Feature Self-Enhancement via Shift-Invariant Manifold Sparse Learning for Rolling Bearing Health Diagnosis. Measurement 2019, 148. [Google Scholar] [CrossRef]
- Ding, C.C.; Zhao, M.; Lin, J. Sparse Feature Extraction Based on Periodical Convolutional Sparse Representation for Fault Detection of Rotating Machinery. Meas. Sci. Technol. 2021, 32. [Google Scholar] [CrossRef]
- He, L.; Yi, C.; Lin, J.H.; Tan, A.C.C. Fault Detection and Behavior Analysis of Wheelset Bearing Using Adaptive Convolutional Sparse Coding Technique Combined with Bandwidth Optimization. Shock Vib. 2020, 2020. [Google Scholar] [CrossRef]
- Zhou, H.T.; Chen, J.; Dong, G.M.; Wang, R. Detection and Diagnosis of Bearing Faults Using Shift-Invariant Dictionary Learning and Hidden Markov Model. Mech. Syst. Signal Process. 2016, 72–73, 65–79. [Google Scholar] [CrossRef]
- Zhu, K.H.; Chen, L.; Hu, X. Rolling Element Bearing Fault Diagnosis Based on Multi-Scale Global Fuzzy Entropy, Multiple Class Feature Selection and Support Vector Machine. Trans. Inst. Meas. Control 2019, 41, 4013–4022. [Google Scholar] [CrossRef]
- Zhao, H.S.; Gao, Y.F.; Liu, H.H.; Li, L. Fault Diagnosis of Wind Turbine Bearing Based on Stochastic Subspace Identification and Multi-Kernel Support Vector Machine. J. Mod. Power Syst. Clean Energy 2019, 7, 350–356. [Google Scholar] [CrossRef]
- Lu, D.; Qiao, W. Fault Diagnosis for Drivetrain Gearboxes Using PSO-Optimized Multiclass SVM Classifier. In Proceedings of the 2014 IEEE PES General Meeting | Conference & Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar]
- Wang, C.; Jia, L.M.; Li, X.F. Fault Diagnosis Method for the Train Axle Box Bearing Based on KPCA and GA-SVM. Appl. Mech. Mater. 2014, 441, 376–379. [Google Scholar] [CrossRef]
- Long, J.; Mou, J.; Zhang, L.; Zhang, S.; Li, C. Attitude Data-Based Deep Hybrid Learning Architecture for Intelligent Fault Diagnosis of Multi-Joint Industrial Robots. J. Manuf. Syst. 2020. [Google Scholar] [CrossRef]
- Malik, H.; Pandya, Y.; Parashar, A.; Sharma, R. Feature Extraction Using EMD and Classifier Through Artificial Neural Networks for Gearbox Fault Diagnosis. Appl. Artif. Intell. Tech. Eng. 2019, 697, 309–317. [Google Scholar] [CrossRef]
- Wu, Q.E.; Guo, Y.H.; Chen, H.; Qiang, X.L.; Wang, W. Establishment of a Deep Learning Network Based on Feature Extraction and its Application in Gearbox Fault Diagnosis. Artif. Intell. Rev. 2019, 52, 125–149. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin, Germany, 1995. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Houck, C.R.; Joines, J.A.; Kay, M.G. A Genetic Algorithm for Function Optimization: A MATLAB implementation. NCSU 1998, 22. [Google Scholar]
- Long, J.Y.; Sun, Z.Z.; Panos, M.P.; Hong, Y.; Zhang, S.H.; Li, C. A Hybrid Multi-Objective Genetic Local Search Algorithm for the Prize-Collecting Vehicle Routing Problem. Inform. Sci. 2019, 478, 40–61. [Google Scholar] [CrossRef]
- Krstulovic, S.; Gribonval, R. MPTK: Matching Pursuit Made Tractable. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006; pp. 496–499. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Max | 2-Max | 3-Max | L1 | L2 |
|---|---|---|---|---|
| 89.7 | 90.0 | 90.3 | 93.3 | 93.0 |
| Default | Grid Search | GA | PSO | |
|---|---|---|---|---|
| Normal | 97.3 | 98.7 | 98.0 | 98.0 |
| IRF | 94.7 | 96.7 | 97.3 | 96.7 |
| REF | 88.7 | 92.0 | 90.7 | 93.3 |
| ORF | 91.3 | 96.7 | 96.7 | 97.3 |
| Average | 93.0 | 96.0 | 95.7 | 96.3 |
| Time/s | 0.1976 | 57.3465 | 81.7135 | 112.4451 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, H.; Wu, N.; Chen, X.; Wang, Y. Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine. Machines 2021, 9, 98. https://doi.org/10.3390/machines9050098
Yuan H, Wu N, Chen X, Wang Y. Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine. Machines. 2021; 9(5):98. https://doi.org/10.3390/machines9050098
Chicago/Turabian StyleYuan, Haodong, Nailong Wu, Xinyuan Chen, and Yueying Wang. 2021. "Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine" Machines 9, no. 5: 98. https://doi.org/10.3390/machines9050098
APA StyleYuan, H., Wu, N., Chen, X., & Wang, Y. (2021). Fault Diagnosis of Rolling Bearing Based on Shift Invariant Sparse Feature and Optimized Support Vector Machine. Machines, 9(5), 98. https://doi.org/10.3390/machines9050098