1. Introduction
Rotating machinery plays a pivotal role in modern industrial systems, serving as critical equipment across various production environments, including bearing assemblies, fluid compression devices, power transmission mechanisms, and aerospace propulsion units [
1,
2]. Among these, rolling-element bearings and gear transmission systems are fundamental functional components of rotating machinery, whose operational integrity directly influences overall system reliability. Any malfunction can lead to unplanned downtime, resulting in significant production losses and potential safety hazards. In recent years, advancements in intelligent algorithms and signal processing techniques have spurred growing interest in vibration-based condition monitoring and fault diagnosis methods for bearings [
3,
4]. These diagnosis techniques extract fault information from a large amount of monitoring data and are suitable for application in complex environments where models are difficult to define precisely [
5].
Recently, the integration of signal processing and deep learning technologies has significantly advanced intelligent fault diagnosis of rolling bearings. Particularly, deep learning has shown exceptional performance in the field of pattern recognition, leading to its growing popularity in fault diagnosis technologies. These methods examine raw data by employing neural networks and can automate the extraction of important features, minimizing the demand for traditional data preprocessing and expertise. Convolutional Neural Networks (CNNs) have demonstrated their superiority in several fields, and their application in bearing fault diagnosis is rapidly expanding [
6,
7]. For example, Song et al. [
8] extracted high-dimensional and temporal features from raw vibration signals through CNNs to accurately identify fault characteristics and enhance diagnosis accuracy. Similarly, Ruan et al. [
9] leveraged fault cycles corresponding to various fault types and shaft rotation frequencies to establish the CNN input size and then used the signal length to define the kernel size of the CNN. In addition, the study by Jie et al. [
10] was the first to design a systematic degradation testing method for electric vehicle bearings considering circulating bearing currents. It provided a data acquisition and analysis platform for scenarios where electrical and mechanical loads are coupled, which are common in real industrial environments. This significantly improves the realism of the data and the applicability of diagnostic methods. Nevertheless, in complex data environments, especially under high noise levels, the distinctions across various types of bearing faults can be very subtle, posing a challenge to the discriminative ability of CNNs. The considerable level of similarity and variability in fault diagnosis presents certain difficulties in precisely identifying particular types of faults.
Attention mechanisms have been successfully incorporated into deep learning models, greatly enhancing the feature interpretability of models in various fields. Attention mechanisms enhance the accuracy of fault diagnosis by assigning weights to input data segments, enabling the model to focus on anomalies within vibration patterns [
11]. Furthermore, the model is able to recognize complex patterns and long-term dependencies in the data, given that these mechanisms produce outputs by concentrating on certain elements of the input sequence. Several deep learning architectures have been developed to tackle complex fault diagnosis challenges by utilizing these features. For example, Zhou et al. [
12] designed a CNN fault diagnosis method for rolling bearings based on a frequency attention mechanism, which effectively addressed the issue of poor diagnosis performance under the interference of strong noise. Cui et al. [
13] incorporated self-attention as the network’s backbone and used contrastive (comparative) learning on positive samples to extract key features from unlabeled fault data. Zhong et al. [
14] proposed a weighted domain adaptive network with residual denoising and multi-scale attention. This network integrates residual denoising and multi-scale attention modules to enhance domain adaptation performance even when significant domain interference exists. Li et al. [
15] introduced a hybrid attention mechanism to improve the neural network’s ability to extract effective feature information, addressing challenges related to small and imbalanced samples under noisy conditions. Despite the exciting research opportunities in fault diagnosis, the integration of attention with neural networks lacks unified guidelines for attention structure design, and most models have not yet established an explicit connection with fault processes [
16,
17].
Although current deep learning methods have shown significant advantages in bearing fault diagnosis, they still face major challenges in real industrial applications due to the lack or scarcity of fault data. In recent years, many studies have proposed innovative solutions to address this issue, such as physics-driven domain adaptation and zero-shot learning approaches. Sobie et al. [
18] proposed a simulation-driven machine learning method that uses bearing dynamic models to generate high-fidelity simulated fault data. This helps to overcome the shortage of real data and enables accurate fault classification. In addition, Matania et al. [
19] introduced a zero-fault-shot learning method, which combines physical simulation with a small amount of real data. By projecting fault signals into an invariant feature space, this approach allows for effective fault type identification even without real fault samples. These studies offer new perspectives for addressing data scarcity in bearing diagnosis and promote the practical application of fault diagnosis methods in real industrial settings.
In summary, although deep learning technologies have achieved significant achievements in the fault diagnosis of bearing, several key challenges remain in practical applications: (1) While deep neural networks, primarily CNNs, can automatically extract features from vibration data, these models often struggle to differentiate which features are important fault indicators and which are just environmental noise. (2) The occurrence of bearing faults is usually complex, and damage at multiple locations can lead to overlapping features, which makes it possible for models to mistakenly classify multiple faults as more common single faults. (3) The invisibility of the decision-making processes and internal mechanisms of deep neural networks typically makes them inappropriate for widespread application in industries that demand robust auditing.
In this paper, a new Masked and Cascaded Multi-Branch Attention Network (MCMBAN) is proposed. Initially, a Noise Mask Filter Block (NMFB) is constructed to efficiently filter and eliminate high-frequency noise from the signal by using the wide convolutional layer and the top k neighbor self-attention masking mechanism. Subsequently, a Multi-Branch Cascade Attention block (MBCAB) was designed to deeply analyze the correlation between multiple time-scale fault features using attention cascade layers. Finally, these two core blocks are combined to form an efficient and interpretable fault diagnosis model. Moreover, the feature interpretability of the model is further enhanced by applying a continuous wavelet transform to analyze the variation in signals within the model. The main outcomes of this research include the following:
(1) The proposed MCMBAN model utilizes NMFB to distinguish and filter out high-frequency noise features, while MBCAB helps the model to identify and differentiate the relationships among different fault information. (2) The designed framework based on MCMBAN demonstrates effectiveness in handling high levels of noise backgrounds and complex fault situations while also exhibiting superior adaptability and diagnosis performance. (3) Through time–frequency analysis, the fluctuations of non-periodic signals in the model are characterized, which enhances the feature interpretability of the model in fault diagnosis applications.
The structure of this article is organized as follows:
Section 2 provides the comprehensive description of the composition of the MCMBAN model, including the detailed design of NMFB and MBCAB.
Section 3 validates the fault diagnosis results of the method and explores the feature interpretability.
Section 4 summarizes the experimental and research results.
2. Method Overview
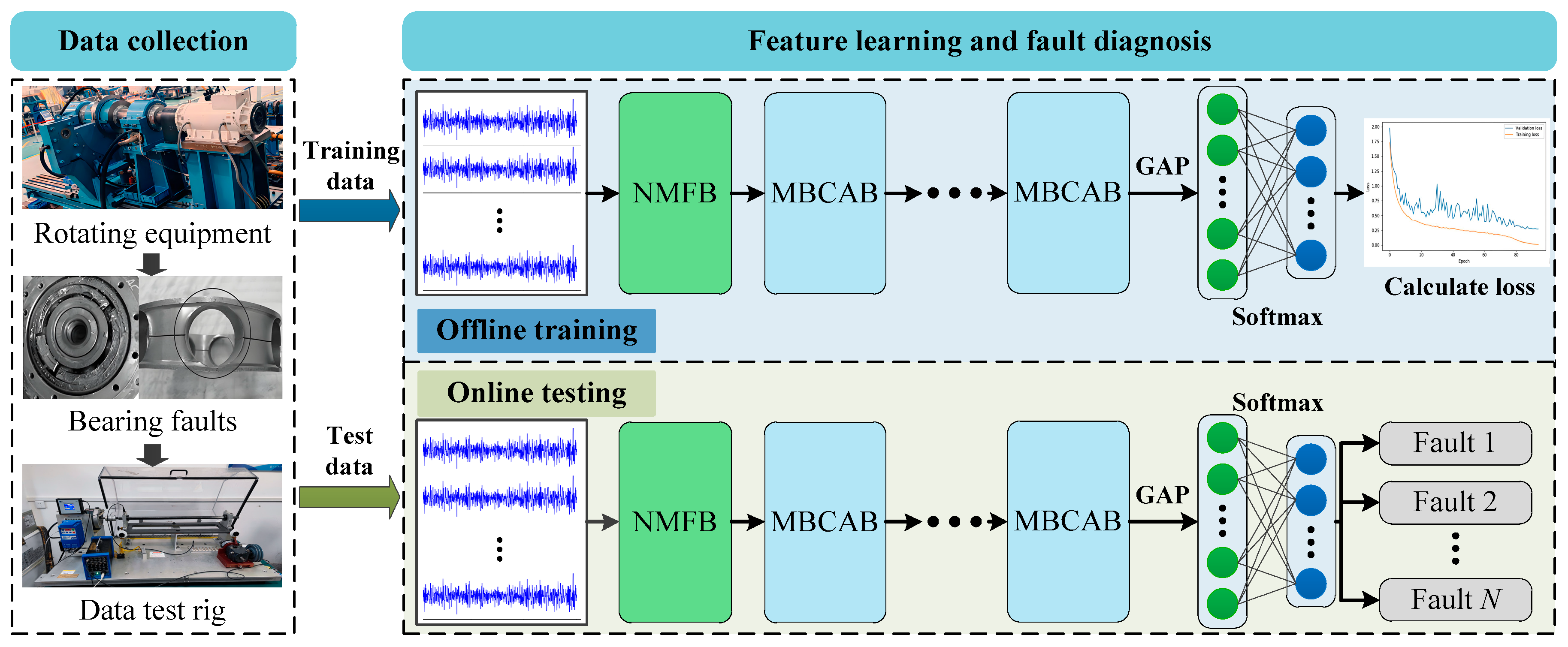
Rolling bearings in manufacturing processes often exhibit several types of failures, which can manifest similar features in vibration signals; thus, fault diagnosis systems are susceptible to misclassifying complex faults as common single fault types [
20]. In addition, the masking effect of high-frequency environmental noise can impair the ability of the diagnosis system to identify real fault signals [
21]. In order to tackle these difficulties, this paper proposes a novel Interpretable Multi-Branch Cascade Network (MCMBAN) for fault diagnosis in noisy environments. The structure of MCMBAN is illustrated in
Figure 1, where the system acquires the raw vibration data from the bearing acquisition equipment and feeds it into MCMBAN. MCMBAN consists of two key feature learning blocks: Noise Mask Filter Block (NMFB) and Multi-Branch Cascade Attention Block (MBCAB). NMFB effectively filters out high-frequency noise by using a wide convolution with a top k neighbor self-attention masking mechanism, while MBCAB explores the interrelationships between different fault types through inter-layer interactions. Ultimately, these features are compressed into one-dimensional features by means of a global average pooling (GAP) layer, as well as fault category mapping by means of a softmax function.
2.1. Noise Mask Filter Block (NMFB)
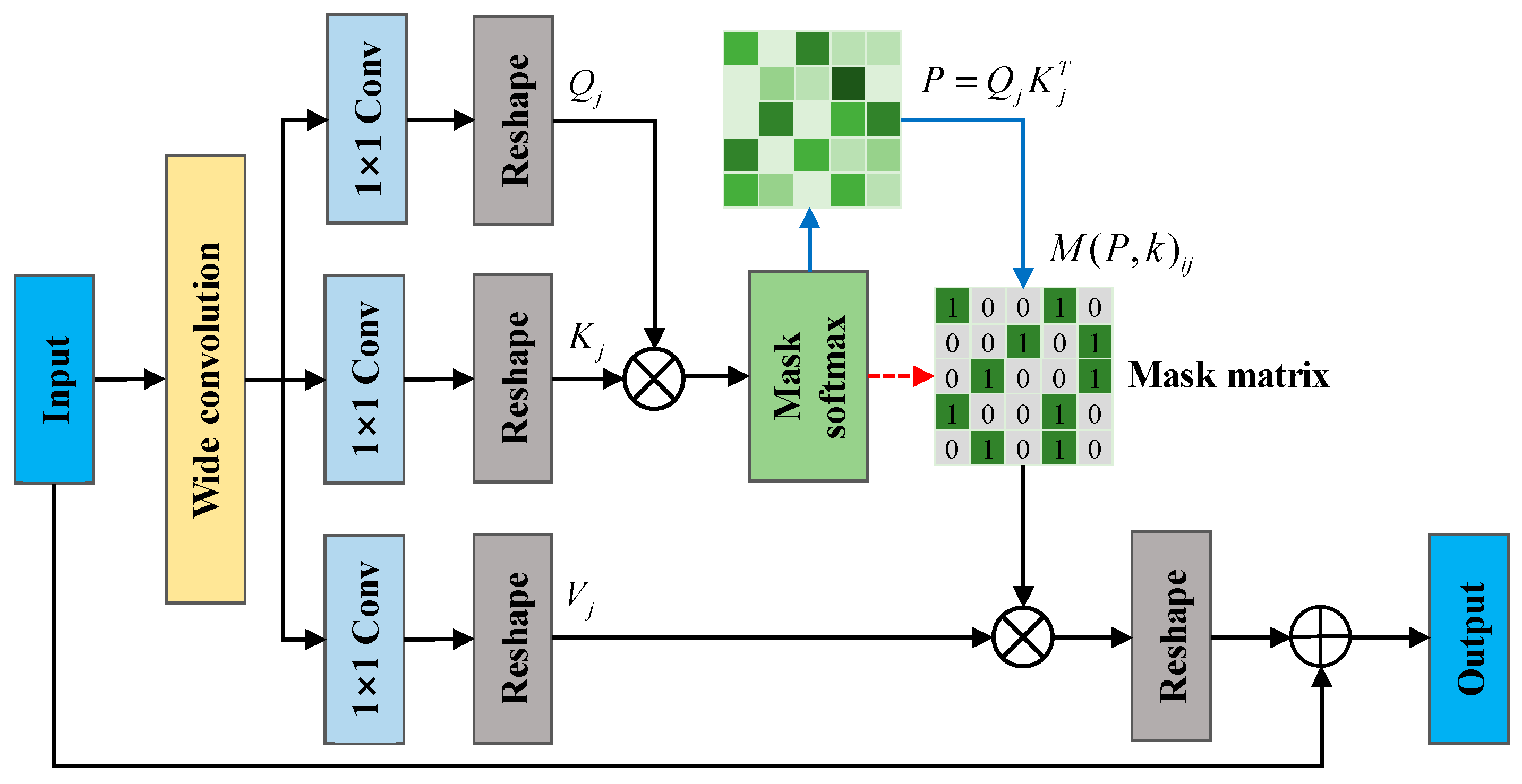
During the operation of bearings, internal friction and structural vibrations inevitably generate substantial background noise, which often masks the critical fault-related information embedded in the vibration signals. To effectively mitigate the influence of such noise, contemporary deep learning-based fault diagnosis methods commonly employ wide convolutional (Wide Convolution) structures with large convolutional kernels. By covering a broader temporal receptive field, large kernels exhibit stronger responsiveness to low-frequency components of the signals, thereby contributing to the suppression of high-frequency noise.
However, bearing faults are typically characterized by significant high-frequency features. Traditional wide convolution layers, while attenuating high-frequency noise, may simultaneously suppress these critical fault frequencies, leading to a degradation in diagnostic sensitivity. To address this challenge, this paper proposes a Noise Mask Filter Block (NMFB).
Figure 2 illustrates the structure of NMFB.
Within NMFB, the wide convolution operation is integrated with a self-attention mechanism to explore the internal correlations among the extracted features. Through the top k neighbor self-attention masking mechanism, the network can adaptively analyze the interdependencies and relative importance of different features, dynamically enhancing fault-relevant information while suppressing irrelevant or redundant noise components. This enables fine-grained optimization of the feature representations obtained by the wide convolution. Compared to conventional wide convolution approaches, NMFB achieves superior noise suppression while effectively preserving key high-frequency fault features, thereby significantly improving both diagnostic accuracy and robustness. In the following sections, we will provide a comprehensive explanation of the construction, underlying mechanisms, and application effectiveness of the proposed NMFB within the context of fault diagnosis tasks.
Step 1: Wide convolutional layers can suppress high-frequency anomalous information in features, so a wide convolutional layer is used to process the original signal, following the formula below:
where
is the wide convolutional layer operation,
is the input signal,
refers to the convolution kernel parameter,
represents the convolution output,
, and the number of channels is
.
Step 2: Queries (
Q), keys (
K), and values (
V) are generated by three 1 × 1 convolution operations and shape transformations, which will be used to calculate the correlation of features in
following the formula below:
where
,
, and
represent the convolutional weights of the
j-th head. Then, the similarity between
and
is computed to obtain the attention score. The formula is as follows:
where
represents the similarity matrix. Since noise typically manifests as globally low-correlated random fluctuations in signals, while fault features exhibit locally strong correlations, mask screening can help the model suppress low-correlation noise connections and focus on fault-sensitive features with strong correlations by retaining high-similarity feature connections. To this end, this paper filters out elements in the similarity matrix that fall below a threshold using a mask, retaining only the k neighbors most relevant to the current feature. For each row of the similarity matrix
, the values are sorted in descending order, and only the top k largest values are retained, with the rest set to zero. The formula is as follows:
Afterwards, the softmax function normalizes all similarity values into a probability distribution, so that the output of each position is a weighted sum of all position values following the formula below:
where
is the dimension of
, which is used to scale the dot product result.
denotes the attention weights, and
denotes the weight-calibrated feature of the
j-th head. Finally, the outputs of all heads are combined as follows:
where
denotes the weight of the output linear transformation, which is applied to combine the outputs of the multiple heads.
denotes the output of the top k neighbor self-attention masking mechanism, and the attention masking mechanism dynamically adjusts the contribution to enhance the representation of features relevant to faults while simultaneously suppressing noise.
In summary, by introducing the top k neighbor self-attention masking mechanism, NMFB can process information in parallel across multiple representation subspaces, which improves the model’s ability to distinguish between faulty and noisy features in the signal. The top k neighbor self-attention masking mechanism allows the model to capture different feature spaces information, thereby increasing its capacity to identify complex patterns. This is especially well-suited for applications such as bearing fault diagnosis, where absolute sensitivity and accuracy are crucial.
2.2. Multi-Branch Cascade Attention Block (MBCAB)
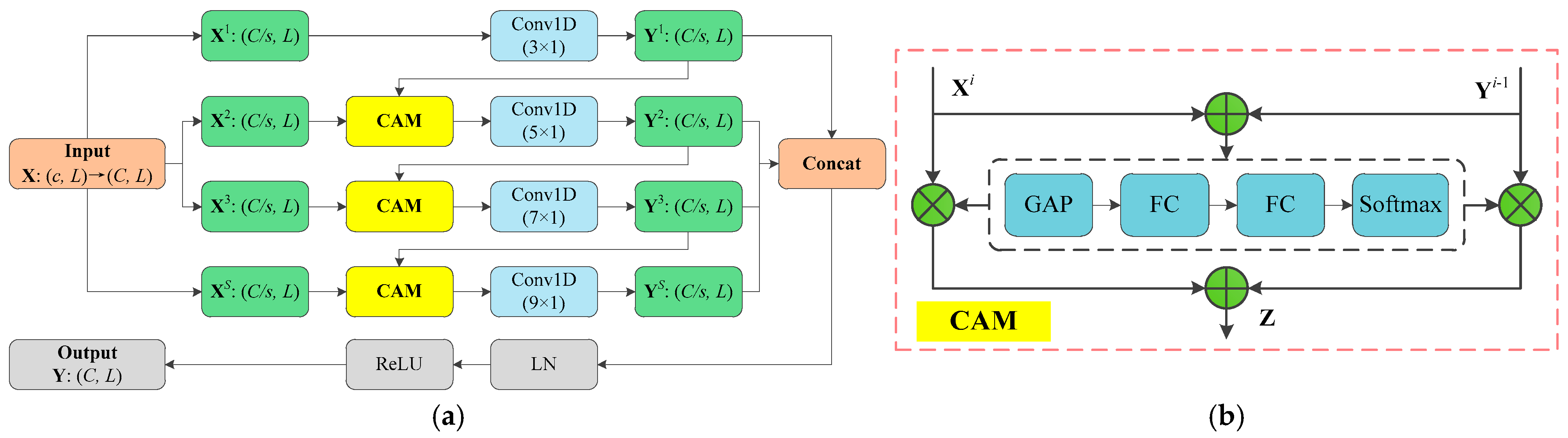
Bearing failures often generate distinctive periodic impulses in the vibration data, with significant correlations between these impulses. Through detailed analysis of these correlations, the degree of the type of fault can be effectively identified. Therefore, this article designs a Multi-Branch Cascade Attention Block (MBCAB), which helps the network to capture pulse correlation information in vibration signals.
Figure 3a illustrates the structure of MBCAB, which principally consists of cascaded attention mechanism (CAM) and multi-scale convolution layers. The details of MBCAB are introduced as follows.
Step 1: Multi-branch feature segmentation
Initially, a 1 × 1 convolutional layer is employed to adjust the number of channels in the input feature matrix to
. The adjusted features can be expressed as
. Subsequently,
is divided along the channel dimension into
branch features
, and each branch feature contains
channels, where
. This division aids the model in independently extracting information from different branch features, following the formula below:
where
is the
i-th feature subset’s channel features.
Step 2: Multi-branch feature extraction
A convolutional kernel of varying sizes is first applied to each branch feature
, gradually increasing from small to large, in order to capture features ranging from fine-grained to coarse-grained. Subsequently, the cascade attention structure is utilized to facilitate the interaction among several convolutional layers, allowing the output of the previous layer to influence the input of the next layer, thereby enhancing the correlation and continuity among features. The structure of CAM is shown in
Figure 3b. Assuming that
is the output features of the previous layer and
is the input features of the next layer, the cascade attention simultaneously processes
and
. First,
and
are fused by element-wise addition to obtain the fused feature
. Then, the feature
is processed through a GAP layer, the channel aggregation layer, and the softmax layer to obtain the weight features
and
of the two features. After that, the weight features are multiplied with
and
, respectively, to calibrate the output features of the previous layer and the input features of the next layer. Finally, the calibrated features are merged to produce the output features of the cascade attention layer. To summarize, the output features of each convolutional layer are combined with the input of the adjacent layers and processed through larger convolutional layers to achieve efficient interactions among the layers.
The multi-branch feature extraction part of the MBCAB module introduces convolution kernels of multiple sizes, with the aim of extracting both local and global features of the fault signal across different time scales. MBCAB uses four convolution kernels of sizes 3 × 1, 5 × 1, 7 × 1, and 9 × 1 to extract fault signal features at different time scales. The 3 × 1 convolution kernel has the narrowest receptive field and is used to extract high-frequency transient features, helping the model identify minor faults, local perturbations, and anomalies. The 5 × 1 convolution kernel balances the local and periodic structure of the vibration signal, assisting the model in extracting periodic impact features for moderate damage. The 7 × 1 and 9 × 1 kernels cover larger receptive fields, capturing low-frequency long-period vibration features and the overall temporal trend of the signal, enabling the model to perceive the characteristics of long-period, strong-impact features in composite faults. Therefore, in the multi-branch convolution structure, four representative kernel sizes were selected based on the time-domain feature distribution differences of fault modes in the vibration signal. This approach not only covers a wide range of fault signal patterns, from subtle changes to long-period composite impacts, but also enables comprehensive modeling and complementary enhancement of temporal features through parallel processing across branches, significantly improving the model’s ability to extract complex vibration features. Subsequently, to avoid weak information interactions in multi-layer convolution networks, a Cascade Attention Mechanism (CAM) is employed to construct cross-layer information channels and weighted fusion of upper- and lower-layer features. This allows the multi-scale features extracted by different convolution layers to form a joint representation, where the feature information from the previous layer can dynamically modulate the feature extraction of the next layer. This enhances the model’s contextual awareness and cross-scale discriminative ability, leading to more precise fault identification in complex noise environments.
Step 3: Multi-branch feature fusion
Channel fusion is performed on all
to obtain synthesized output features
. For MBCAB, the relationship between input
and output
can be described as follows:
where
represents the convolution operation, and
denotes the weight of the convolutional layer. In summary, MBCAB not only improves the interaction between the features within the network but also significantly enhances the sensitivity of the model to fault signals.
2.3. Diagnosis Process of the MCMBAN Model
The fault detection process of MCMBAN includes two critical stages: offline training and online testing. Of these, in the offline training stage, historical vibration data are employed to construct and preliminarily train the MCMBAN model. This process encompasses the design of the overall network architecture; the definition of individual layers and functional modules; and the careful initialization of model parameters, including weights and biases. Following initialization, the model parameters are iteratively optimized using the training dataset. Concurrently, a validation set is leveraged to monitor the training process, prevent overfitting, and guide hyperparameter tuning. Upon completion of training, the model’s generalization performance is rigorously evaluated on an independent test set to ensure its robustness and effectiveness in fault classification tasks. In the online testing stage, the trained MCMBAN model is deployed for real-time fault detection. Online data streams collected during equipment operation are continuously fed into the model, enabling immediate and automatic diagnosis of fault conditions without manual intervention. The model, having undergone extensive offline training and validation, is expected to accurately recognize various fault patterns based on real-time input signals. To maintain the long-term reliability and adaptability of the diagnostic system, it is necessary to periodically update and fine-tune the MCMBAN model as new operational data become available. This model maintenance may involve retraining the network with newly collected datasets, adjusting certain parameters, or selectively fine-tuning specific layers, depending on the extent of distribution shift observed in the input data. Such continuous model updating ensures that the fault detection capability remains accurate and responsive under evolving operating conditions, thereby enhancing the practical applicability and sustainability of the proposed method.
2.4. Feature Interpretability of the MCMBAN Model
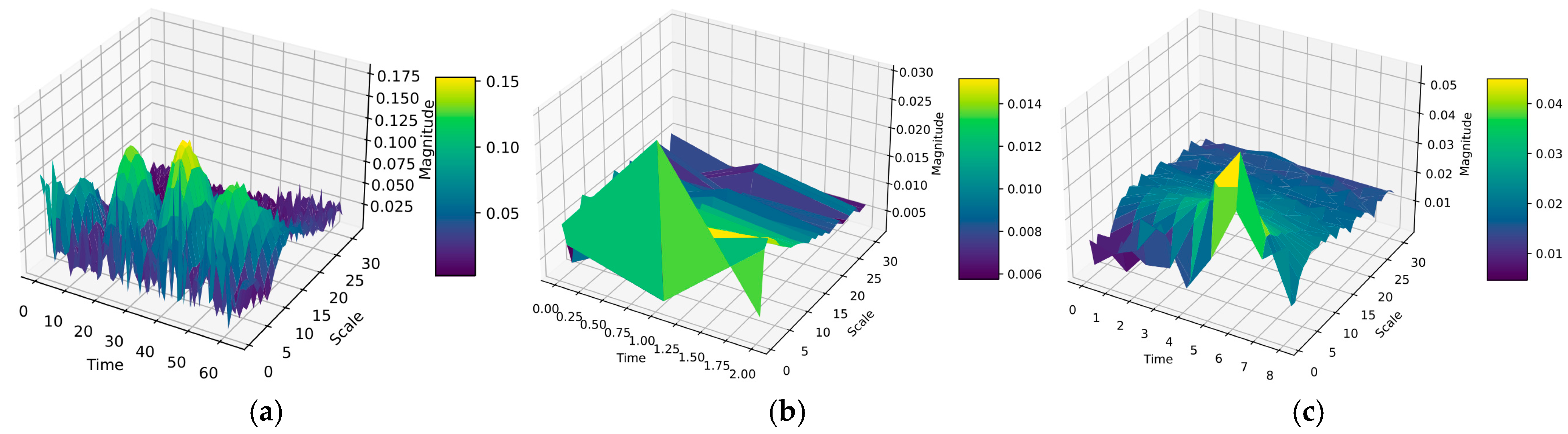
In deep learning models, understanding how each feature layer processes information of varying frequencies is crucial for optimizing the model. By visualizing the weights of convolutional layers, researchers can gain insights into how the model recognizes different fault patterns; this visualization helps to improve the interpretability of the model, which is highly valuable for the application of fault diagnosis technology. This paper employs the Short-Time Fourier Transform (STFT) to conduct a detailed analysis of the time–frequency properties of weights within each layer of the model. First, the weights of each convolutional kernel are averaged along the input channel dimension to obtain a one-dimensional weight sequence. Then, STFT is used to obtain the averaged one-dimensional weight sequence through a sliding window, where the STFT analysis calculates the amplitude and phase of each frequency component in each window, thereby transforming the one-dimensional weight sequence into a frequency domain representation. As the window slides along the time axis, STFT repeats this process at each position, gradually constructing a complete time–frequency matrix. Each column of this matrix represents the spectrum at a specific time point, and each row represents how a particular frequency changes over time. Finally, the results of this time–frequency analysis are visualized in the form of heatmaps, where different shades of color in the heatmap reflect the intensity of weight changes across different times and frequencies.
3. Experiments and Discussions
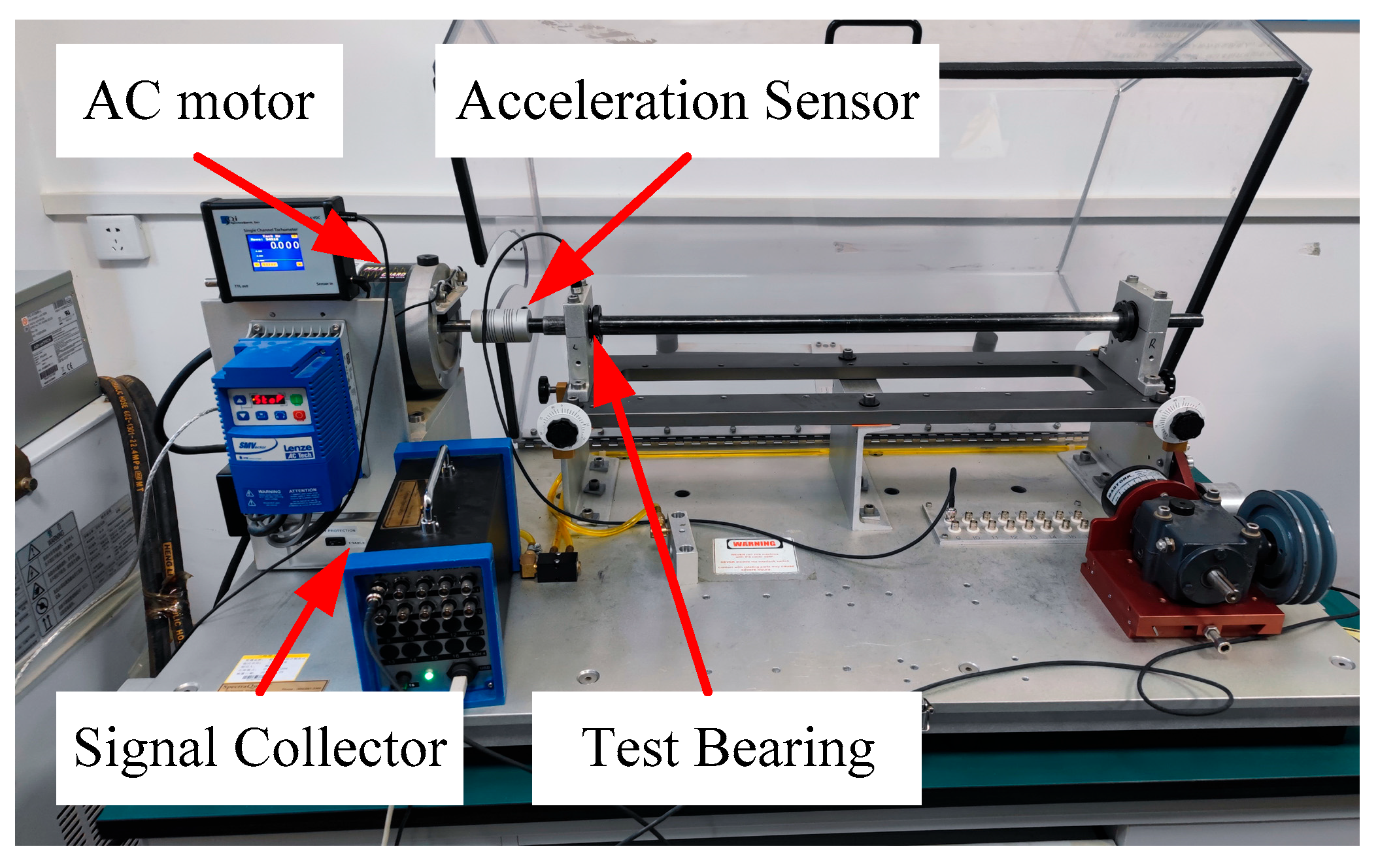
In this section, we provide an exhaustive description of the parameter configuration of the MCMBAN model. A series of fault diagnosis experiments are conducted on the bearing test platform of Case Western Reserve University (CWRU) as well as on our bearing test dataset
https://github.com/haoppppp/MCMBAN.git (accessed on 31 July 2025).
3.1. Multi-Branch Cascade Attention Block (MBCAB)
Table 1 summarizes the detailed hyperparameter settings of the proposed MCMBAN model. The network architecture begins with a Noise Mask Filter Block (NMFB), which utilizes a 32 × 1 convolutional kernel with a stride of 4 and outputs 16 feature channels. This layer serves to initially capture coarse-grained features and suppress high-frequency noise through a wide receptive field. Following NMFB, a series of three Multi-Branch Convolution Blocks (MBCABs) are applied. Each MBCAB incorporates four parallel convolutional branches with kernel sizes of 3 × 1, 5 × 1, 7 × 1, and 9 × 1, designed to extract rich multi-scale features from the input. The first MBCAB outputs 32 channels, while the subsequent two each output 64 channels, enabling progressively deeper feature extraction. Between each MBCAB, a 2 × 1 max pooling layer with a stride of 2 is inserted to perform temporal downsampling, reducing the feature length by half at each stage while preserving critical information. After the final MBCAB, another pooling operation is applied before global aggregation. At the classification stage, a GAP layer is used to reduce each channel to a single value, with model outputs as the final class probabilities. Notably, the GAP and Softmax layers do not involve kernel or stride settings and are therefore denoted with dashes (“–”) in the table. These parameter choices are based on extensive empirical validation and are optimized to balance model capacity, noise robustness, and diagnostic precision.
3.2. Comparison Methods
By comparing MCMBAN with existing advanced techniques such as MCAMDN [
22], RESCNN [
23], MSDARN [
24], MBSDCN [
25], MA1DCNN [
26], and GTFE-Net [
27], its performance is evaluated, and the parameter details of comparison methods are shown in
Table 2.
MCAMDN proposes a multi-scale selectable branch network structure, where each branch network contains convolution kernels with different sizes. The core idea is to use the attention mechanism to dynamically select effective branches and determine the contribution of each branch. However, the branches in MCAMDN operate independently and in parallel, lacking information interaction, whereas MCMBAN achieves cross-layer feature fusion through cascade attention.
RESCNN adopts a residual network architecture to alleviate the vanishing gradient problem by using residual connections. It also uses wide convolution layers to suppress high-frequency noise and enhance low-frequency feature extraction. However, its network structure is single-scaled and single-pathed, making it difficult to model multi-frequency features, pulse frequencies, etc. MCMBAN, on the other hand, covers the full frequency range of fault features through multi-branch multi-scale kernels.
MSDARN combines multi-scale convolution with a dynamic attention mechanism, using residual connections to fuse features from different scales and introducing adaptive weights to adjust inter-channel correlations. However, MSDARN fuses multi-scale features serially within a single branch, emphasizing the dynamism of scale feature fusion. In contrast, MCMBAN independently extracts features through parallel branches and then uses cascade attention for cross-layer interaction, emphasizing the diversity and interaction of scale features.
MBSDCN enhances channel expression through multi-branch input and a channel reconstruction attention mechanism, dividing input features into multiple branches. Each branch uses a fixed-size convolution kernel, and dynamic convolutions generate kernel weights. However, the fusion process primarily focuses on channels, lacking inter-layer structural interaction and independent denoising modules.
MA1DCNN embeds a multi-head attention mechanism into a 1D convolutional network, where each head independently computes feature correlations. The outputs from multiple heads are concatenated to enhance the model’s attention to fault impulse signals. However, MA1DCNN is a single-branch structure, and the attention mechanism only operates on the local layer. In contrast, MCMBAN is composed of a denoising module and feature cascading, with more efficient inter-layer collaboration.
GTFE-Net designs a frequency-domain filtering-based denoising method based on the periodicity and self-similarity characteristics of vibration signals. Additionally, it constructs a three-branch network structure to process the original vibration signal, denoised signal, and frequency spectrum signal. Compared to MCMBAN, GTFE-Net’s structure relies on external preprocessing modules, making its overall architecture more complex, and the feature fusion process is relatively static.
3.3. Experimental Environment and Noise Environment
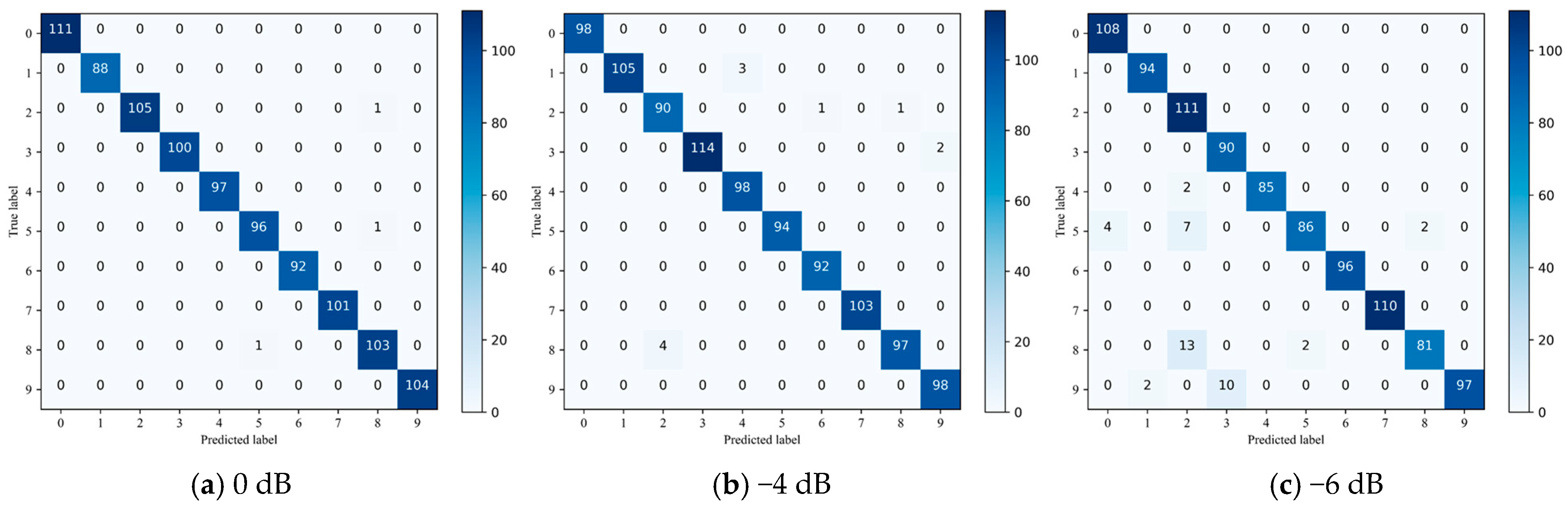
In this study, all experiments are conducted using the TensorFlow 2.5 framework, with programming carried out in Python 3.7. The hardware required for the experiments included an RTX 3050 graphics card, an AMD 5600H processor, and 16GB RAM. The equipment was sourced from Lenovo, based in Hefei, China. We set 50 training cycles, 32 samples per batch. The learning rate is 0.001. The optimizer is the Adam optimizer, which reduces the fluctuations in training losses, and experimental results are evaluated by calculating the average accuracy over five iterations.
In actual industrial environments, the vibration signals collected are inevitably subjected to environmental noise interference. Environmental noise is commonly characterized as random, has a low bandwidth, and often has a non-stationary nature, with certain features resembling high-frequency interference. This paper discusses methods for filtering out such noise in complex environments. The signal-to-noise ratio (SNR) of the vibration signal is commonly used to quantify noise resistance. In this experiment, the noise interference is modeled as Gaussian white noise, and the SNR is calculated as follows:
where
is the original signal,
is the noise-corrupted signal, and
is the square of the
. In the process of adding noise, the power
of each sample signal
is first calculated:
where
represents the signal length. The target SNR values are set as 0 dB, −4 dB, and −6 dB, where a lower SNR corresponds to higher noise intensity. Based on the SNR values, the noise power
is calculated as follows:
Subsequently, the noise standard deviation is calculated, and the noise is assumed to follow a Gaussian distribution .
Finally, the noise is added to the original signal to obtain the noisy signal
as follows:
In summary, during the experiment, to simulate real-world conditions, noise is injected into the signals, and the noise levels are controlled to assess the model’s performance under various noise conditions. The goal is to ensure that the model maintains its robustness in the presence of noise and demonstrates practical applicability in real-world scenarios.
To ensure a fair comparison, all competing models were retrained under the same noise settings and consistent data splits. Specifically:
Noise settings: All models were trained and tested under identical noise conditions. This ensured that the comparison was not affected by variations in noise environments.
Data splits: A uniform data splitting strategy was applied. The training, validation, and testing sets remained the same across all models to guarantee consistency during evaluation.
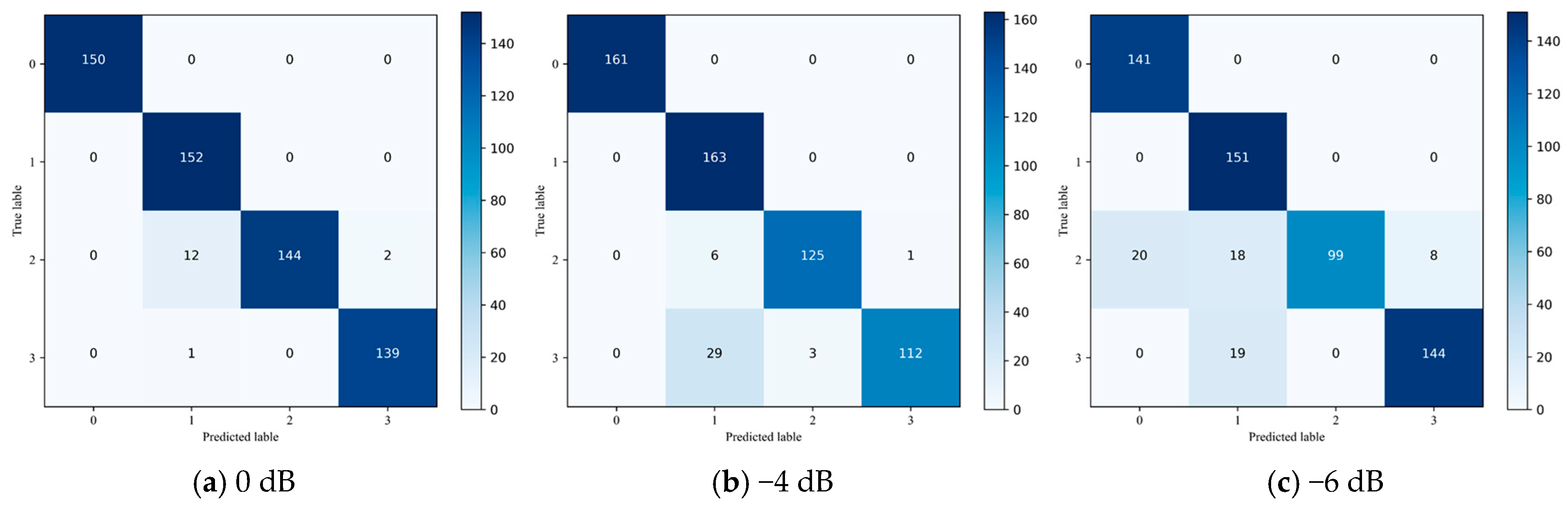
The criteria for evaluating fault diagnosis (FD) results include four key metrics: accuracy, precision, recall, and F1 score. The calculation of these metrics is based on the following four types of samples: true positives (TP), true negatives (TN), false negatives (FN), and false positives (FP).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}