1. Introduction
Neural networks are used to perform image processing tasks in computer vision. One such task is to extract useful information from digital images. These networks are used to perform object detection, classification, and segmentation tasks. From an engineering perspective, the goal of computer vision is to create autonomous systems that can perform tasks that humans do, and, in many cases, to do so faster and more efficiently.
Autonomous driving is a revolutionary technology that is likely to have a very significant impact on people’s daily lives in the future. Image segmentation systems provide autonomous cars with a view of the surrounding world and are critically important in achieving safe autonomous vehicle driving. According to a study conducted by the US National Highway Traffic Safety Administration, 94% of all traffic accidents are caused by human error [
1]. The realization of autonomous car driving aims to solve this serious problem regarding car accidents. Since autonomous systems are programmed to drive efficiently and safely, they reduce—and sometimes even eliminate—the need for human driving, thus eliminating the aforementioned human error [
2]. The automotive industry is a very promising area for the development of computer vision solutions in autonomous vehicles. The more accurate the image segmentation process and the less the time that it takes, the more accurately autonomous vehicles will understand their surroundings and the more likely they will be to make safer decisions. Providing autonomous vehicles with a view of the world around them using computer vision solutions can offer many benefits, such as increased road safety, lower costs, more comfortable travel, greater mobility, and smaller ecological footprints [
3].
With the rapid development of autonomous driving technology, an accurate visual understanding of the surroundings is crucial to ensure road safety and efficient autonomous vehicle navigation. The accurate detection and classification of objects such as pedestrians, vehicles, and traffic signs is essential because it directly impacts the safety and efficiency of autonomous driving systems. Image segmentation is one of the most important processes in digital image processing and has been widely used in the automotive industry and robotics in recent years. The field of computer vision, which is related to artificial intelligence, has seen great progress in the past decade, and today’s computer vision systems can recognize visual data more quickly than humans. In the field of computer vision, the semantic segmentation task remains one of the most challenging ones. The assignment of class labels to each pixel, and the classification task at the pixel level, is a key approach that enables vehicles to distinguish between different objects, roads, pathways, pedestrians, and the remaining environmental elements of the road.
As computer vision systems are widely applied in the automotive industry, the same methods can be equally applied to a broader spectrum of autonomous systems in the robotics or aerospace industries. For example, during the NASA Mars 2020 mission, to land the Perseverance rover, a computer vision system was used for hazard and obstacle detection, enabling it to land safely by autonomously selecting the safest landing position [
4]. Autonomous robots play an important role in various applications, where accurate perception and effective path planning are key requirements in achieving full autonomy. The perception component is dedicated to understanding the surrounding environment, enabling these robots to make informed decisions [
5]. To obtain different fully autonomous vehicles in the future, accurate perception systems are indispensable, ensuring the reliable monitoring and interpretation of complex, dynamic environments [
6]. Moreover, the use of semantic segmentation techniques can offer higher precision in detecting urban environments [
7]. Semantic data can help to reduce the dependence of a robot on raw sensor input and external signals such as GPS by providing useful environmental information for navigation [
8]. In fact, in this work, the demonstrated approach to segmenting road scene images from a driver’s perspective can also be used in other applications, such as delivery or taxi robots and various service robots, which need to accurately understand their surroundings when navigating urban environments and avoiding obstacles. Among the most notable applications is parcel delivery, with autonomous delivery robots emerging as key components in the solutions to different delivery challenges [
9].
Autonomous robotic platforms operate in complex urban environments and require precise understanding and reliable path planning, while having limited processing resources. Many computer vision models often require extensive computational power, and a Transformer-based system can offer a lightweight alternative, making it suitable for deployment across different autonomous robotic platforms. The ability of the autonomous robot to understand its working environment is the basis for the solution of more complicated problems [
10]. The results described in this work show that the proposed approach, which is effective in detecting objects at a close distance, can be particularly advantageous for use in autonomous self-driving robots. These robots generally operate at lower speeds compared to cars. While a car traveling at 60 km/h covers 100 m in just a few seconds, a robot may take up to 30 s to travel the same distance. Thus, for the robot, distant objects in the environment are not as critical as they are for an autonomous car.
Autonomous systems and their effectiveness are highly dependent on the ability to navigate a complex and unstructured environment [
11]. Recent advances have further improved robotic navigation by enabling real-time performance in critical tasks such as environment perception, obstacle detection, obstacle avoidance, path planning, and path tracking [
12]. Within path planning, obstacle avoidance is a crucial task in robotics, as autonomous robot operation requires that they reach their destinations without collision [
13]. Effective object detection strategies face static obstacles, such as infrastructure or parked vehicles, and dynamic obstacles, including pedestrians and moving vehicles, with each presenting unique challenges to safe navigation. To prevent a potential collision with pedestrians, an accurate detection system enables autonomous robots to intervene early, reducing the risk of accidents [
14]. Thus, an accurate computer vision system is essential to ensure the safe and efficient operation of autonomous robots, especially in dynamic urban environments. The main solutions currently focus on understanding the environment through visual information using various computer vision techniques, machine learning, and algorithms [
15]. The use of computer vision techniques enables robots to autonomously understand their surroundings, adapt their trajectories, and perform tasks such as maintenance or exploration without human intervention. In addition, for autonomous robots to navigate in urban environments, it is very important to navigate on designated paths, such as footpaths or sidewalks, and avoid areas such as grass to ensure both safety and social conformity. Robots deployed in public environments as autonomous delivery robots operate in spaces in which people live and work [
16]. For example, package delivery robots must be able to identify and follow safe and appropriate routes that allow them to navigate autonomously in a manner that is not only efficient but also socially acceptable to the people sharing the environment [
17]. Since robots increasingly share space with humans in everyday environments, ensuring safety is paramount [
18]. Computer vision applications help to improve the efficiency of transportation systems, increase their levels of intelligence, and improve traffic safety [
19]. Moreover, the integration of computer vision with robotics holds significant promise for environmental protection efforts by enabling more efficient resource management and reducing urban environmental impacts [
20]. In general, the development of robotic vision is more than just a scientific curiosity or a passing trend. It marks a significant step forward in what machines can do, and this is expected to strongly impact our daily lives [
21].
1.1. Evolution of Deep Learning Architectures
In 1989, the French scientist Yann LeCun created one of the first convolutional neural networks, which was called LeNet-5. This neural network was designed for a handwritten digit recognition task. The emergence of the LeNet-5 architecture paved the way for the continued success of convolutional neural networks in performing high-complexity computer vision tasks, and it encouraged researchers to explore the capabilities of convolutional neural networks in performing image segmentation tasks [
22]. Among the different deep learning models, convolutional neural networks have achieved excellent performance in different computer vision tasks, such as image classification, object detection, or digital image segmentation. Convolutional neural networks have become one of the most successful and widely used deep learning architectures in computer vision tasks over the past decade.
While, for many years, the convolutional neural network architecture was the state of the art in computer vision tasks, this situation changed in 2017, when the Transformer architecture was introduced. Recently, Vision Transformers have emerged as a competitive alternative to the long-standing convolutional neural network for computer vision tasks. The Transformer neural network was developed and introduced by the scientist Ashish Vaswani in 2017 [
23]. Today, these neural networks compete with state-of-the-art convolutional neural network architectures in terms of efficiency and accuracy.
During research, it was found that it is possible to create accurate computer vision models without using convolutional layers as the main components. One such idea is to use the Vision Transformer neural network architecture for feature extraction; it applies an attention-based mechanism to input images and can achieve competitive efficiency in performing the computer vision semantic segmentation task [
24]. The use of Transformer-based architectures over traditional convolutional neural networks as the main component for the feature extraction part is due to the Transformer architecture’s improved capacity for global context understanding. The use of self-attention mechanisms in the Transformer architecture allows the system to capture relationships between distant regions of the image. This approach enables the network to integrate information throughout the image. It is especially beneficial for semantic segmentation tasks that require full-scene understanding. Transformers process images as sequences of patches, which gives the opportunity to model both global and local interactions without being constrained by convolutional fixed-size kernels. Thus, the results can be more robust, particularly in situations where the boundaries of the object and contextual cues are crucial [
23].
Another important quality of the Transformer architecture is its robustness to variations. Attention mechanisms can dynamically focus on the most relevant parts of the image, making them more resilient to different changes, like rotation, scaling, or occlusion. This adaptability in complex road scenes is beneficial when noise or local variations hinder the performance. In addition, Transformer architectures show improved performance as the data volume increases, making them highly scalable to large datasets [
25].
1.2. Modern Approaches to Semantic Segmentation
Semantic segmentation is the core task and remains one of the most challenging in computer vision; it involves the classification of every pixel in a digital image into a corresponding class. It gives the complete context of the scene by incorporating the categories, locations, and shapes of all elements in the scene, including the background [
26]. However, it is more challenging and usually more time-consuming than object detection and requires more advanced techniques and more high-quality annotated training data [
27]. Over the years, modern approaches have been introduced to perform semantic segmentation tasks—from the early fully convolutional networks that introduced pixel-level predictions to advanced encoder–decoder architectures, which integrate multiscale feature fusion and context-aware processing [
23,
28]. Recently, the incorporation of attention mechanisms and Transformer-based models have offered new capabilities to capture long-range dependencies and global contextual information, pushing the performance to new heights. The progression of modern techniques is reshaping the state-of-the-art performance in the computer vision field.
Table 1 presents a systematic summary of these methods in the field of computer vision image segmentation, including their core architectures, benchmark datasets, and mIoU results.
Fully convolutional networks (FCNs) were among the first breakthroughs in the semantic segmentation task. By replacing the fully connected layers of traditional CNNs with convolutional layers, FCNs enabled end-to-end pixel-wise prediction, which allowed models to generate spatially dense outputs by upsampling the low-resolution feature maps from the convolutional layers. An evaluation of FCNs shows that this method can effectively segment images, establishing a solid baseline for subsequent models [
28].
Building on the FCN framework, encoder–decoder architectures such as U-Net have become a popular approach to segmentation tasks. U-Net uses a symmetric architecture in which an encoder gradually reduces the spatial dimensions while capturing semantic features, and a decoder progressively upsamples the features to produce a prediction at the pixel level. Skip connections are used between the corresponding encoder and decoder layers to help recover spatial details lost during downsampling. The demonstrated U-Net approach is particularly effective for tasks that require the precise detection of objects, such as the segmentation of the road scene [
29].
The DeepLabV3+ model uses a dilated convolution-based approach to better capture multiscale contextual information without decreasing the resolution. Using this type of approach increases the receptive fields of convolutional filters, without additional parameters or a reduction in the spatial resolution. Using spatial pyramid pooling and an encoder–decoder structure, the DeepLabV3+ model can fuse features from multiple scales, which is critical for the complex and varied environments encountered in road scenes [
30].
The adaptation of Transformer architectures is another trend. Although originally developed for natural language processing, they were later used in the domain of image segmentation. Models such as SETR or SegFormer use a self-attention mechanism to capture long-range dependencies and global contexts. The images in these models are partitioned into patches and then processed as token sequences, enabling the network to model relationships between distant regions. The global modeling capability is especially advantageous for complex scenes, such as urban road environments, where contextual signals are critical [
31,
32].
The integration of convolutional neural networks with Transformer modules is a promising direction, combining the strengths of both architectures. Hybrid computer vision models often use convolutional layers for efficient local feature extraction and are combined with additional Transformer layers to capture global context details through self-attention mechanisms. The use of this approach can lead to improved segmentation performance, especially in scenarios where both detailed spatial information and a wider contextual understanding are necessary. One work incorporating the convolution technique into Vision Transformers shows that the combination of these two methodologies can yield competitive performance in segmentation tasks [
33].
The main purpose of this study is to develop a Transformer-based semantic segmentation approach, specifically designed for the road scene segmentation task, which takes advantage of the latest advances in Vision Transformers. This paper is organized as follows.
Section 2 describes our proposed semantic segmentation approach.
Section 3 presents the experimental results, and
Section 4 and
Section 5 conclude the document with a discussion and future directions.
2. Materials and Methods
In this section, we provide the details of the implementation, the structure of the model, and the configuration settings used to train and evaluate our Transformer-based road scene segmentation system. Moreover, we describe the components of other state-of-the-art computer vision models, the components of our approach, and how our approach is different, as well as presenting some advantages over the previously used implementations. In addition, we describe the dataset in more detail and explain how the data are divided into training, validation, and test set splits. In further sections, we also explain the internal structure of the encoder module, as well as the decoder part of the system with attention-based fusion mechanisms for the extraction and combination of multiscale features. Details of each component’s structure are provided in further subsections.
The current state-of-the-art computer vision approaches for road scene segmentation have demonstrated significant success by using different types of architectures and achieving competitive results. Methods that use Transformer-based architectures typically rely on standard feature fusion, and they often use simple projection layers to merge different features from different Transformer-based encoder resolutions. Computer vision models have also been introduced, such as RoadFormer, which uses a query-based decoder module to iteratively update query features for mask predictions [
34]. Although these approaches work well in many cases, they can struggle to maintain important fine-grained details when working with complex road scene environments.
Our decoder module processes the data with attention-based fusion mechanisms, providing competitive results in the road scene segmentation task in complex urban scenes compared to other lightweight computer vision models that have a similar number of parameters in the network. The mechanism in the decoder part uses specialized attention blocks to progressively fuse low-resolution decoder features with high-resolution features from the encoder part. This can effectively emphasize the most relevant spatial information at multiple scales. Using this approach, it is possible to ensure that the fine-grained features of the encoder can be integrated together with the high-level semantic features of the decoder, giving accurate and competitive segmentation results when compared with other introduced approaches. Moreover, instead of using traditional normalization techniques, the model uses group normalization, which normalizes over the feature channels instead of on the batch dimension. This can give better stability in the training process, particularly in scenarios where the batch size may be different or in cases of high-resolution feature fusion, where traditional methods such as BatchNorm may not be as effective.
It is also worth mentioning that, while many existing approaches rely on standard feature fusion techniques with different scales, this approach can provide better control over which features are fused via the use of attention blocks, which allow it to adapt more effectively to the different complexities of road scene segmentation. Using this approach gives competitive results in terms of segmentation accuracy, particularly in challenging road scene environments with fine details.
2.1. Dataset
All experiments were performed using the widely known Cityscapes dataset, which is used for the benchmarking of computer vision models in semantic segmentation tasks with different urban scene images. The dataset consists of 5000 high-quality, finely annotated, pixel-level, high-resolution images recorded in 50 different cities across Germany. Each pixel in every image in the dataset is annotated to one of 19 semantic categories, representing typical elements of the urban road scene, such as roads, cars, pedestrians, sidewalks, or traffic signs. These 5000 images are split as follows.
Training set, consisting of 2975 images: This subset of the data is used to learn the parameters of the model during the training process.
Validation set, consisting of 500 images: This part of the data is used during the training process to configure the model, adjust the hyperparameters, and monitor the performance of the model during the training phase.
Test set, consisting of 1525 images: The last part of the data is used for the final evaluation phase to evaluate the precision of the model in an unseen dataset.
In
Figure 1, we provide some examples from the Cityscapes dataset, demonstrating different environments and urban conditions. All details of the dataset used in the model training process and the final evaluation, including the annotated classes and examples of annotations, are publicly available at
https://www.cityscapes-dataset.com/ (accessed on 11 March 2025).
2.2. Implementation Details
Our Vision Transformer-based road scene segmentation model is implemented using the mmsegmentation framework codebase and uses an MiT as a backbone network, with attention-based fusion mechanisms in the decoder module. The system’s encoder module is pre-trained on the ImageNet-1k dataset for the extraction of robust visual features, while the system’s decoder module is randomly initialized to learn task-specific upsampling. To improve the model’s robustness and generalization, in the training process, data augmentation techniques were applied using the Cityscapes dataset. We used additional measures of random horizontal flipping, scaling, and cropping. The crop size of 768 × 768 pixels was chosen during the training phase. At inference time, a sliding-window strategy was used to generate full-size segmentation predictions.
The computer vision model was trained using the AdamW optimization algorithm with an initial learning rate of 0.00005. In addition, the polynomial decay learning rate schedule with the power parameter set to 1.0 was used, and the linear warm-up phase consisted of up to 1500 iterations at the start of the training process. Due to GPU resource constraints and the high-resolution input images, a batch size of 1 image was used in the training process. The training schedule was set for 160,000 iterations, and it was later extended to 200,000 iterations to explore the possibility of further model accuracy improvements. In the end, it was clear that no significant improvements would be achieved in the training cycle after 160,000 iterations. The best-performing model checkpoint was taken at 156,000 iterations. Model performance was primarily evaluated using the widely used mean intersection over union (mIoU) metric.
2.3. Encoder
In the system, the encoder backbone network is implemented using the MiT architecture, with the configuration settings named “mit b1” [
32]. Using these configuration settings, the input image is processed through a patch embedding module that divides the image into smaller patches and projects them into a feature space. The first stage of the network uses an OverlapPatchEmbed module with a fixed patch size of 7 × 7 and a stride parameter of 4. The module is responsible for mapping each 7 × 7 image patch to a 64-dimensional embedding space and generating the initial feature map. The patch embedding can be written as
where
I is the input image. The output after this processing stage is then flattened and normalized. The subsequent stages of the encoder network use patch embedding modules with a set patch size of 3 × 3 and a stride parameter of 2. These network encoder stages progressively reduce the spatial resolution while increasing the number of channels. Using the “mit b1” configuration, the embedding dimensions are preset to [64, 128, 320, 512] for the four network stages. The encoder progressively extracts hierarchical features with increasing channel numbers:
Stage 1 (c1): 64 channels;
Stage 2 (c2): 128 channels;
Stage 3 (c3): 320 channels;
Stage 4 (c4): 512 channels.
Each of the stages is further processed by a sequence of Transformer blocks. Using the b1 network configuration, the depth of each block is [2, 2, 2, 2] for the four stages. In addition, with each Transformer block, the multi-head self-attention mechanism is used. The attention computation can be written as
where
Q is a query,
K is the key, and
V is the value received by linear projections of the input features. At each stage, the number of attention heads used is [1, 2, 5, 8], and the MLP within each block expands the dimensions of the feature by a factor of 4.
In each stage, spatial reduction ratios are also used with values [8, 4, 2, 1] to downsample the spatial dimensions during the self-attention processing step. In this way, we reduce the computational load while maintaining an essential global context.
After the processing step is performed through different Transformer blocks, each stage uses a final normalization layer, and the resulting feature maps are reshaped in the [B, C, H, W] format. The final outputs of all four stages are named c1, c2, c3, and c4. These outputs capture a rich hierarchy of features that combine fine spatial details from the early stages of the network with high-level semantic information from the deeper stages of the network. In a further step, all generated feature maps from each encoder network stage are passed to the decoder module for further processing.
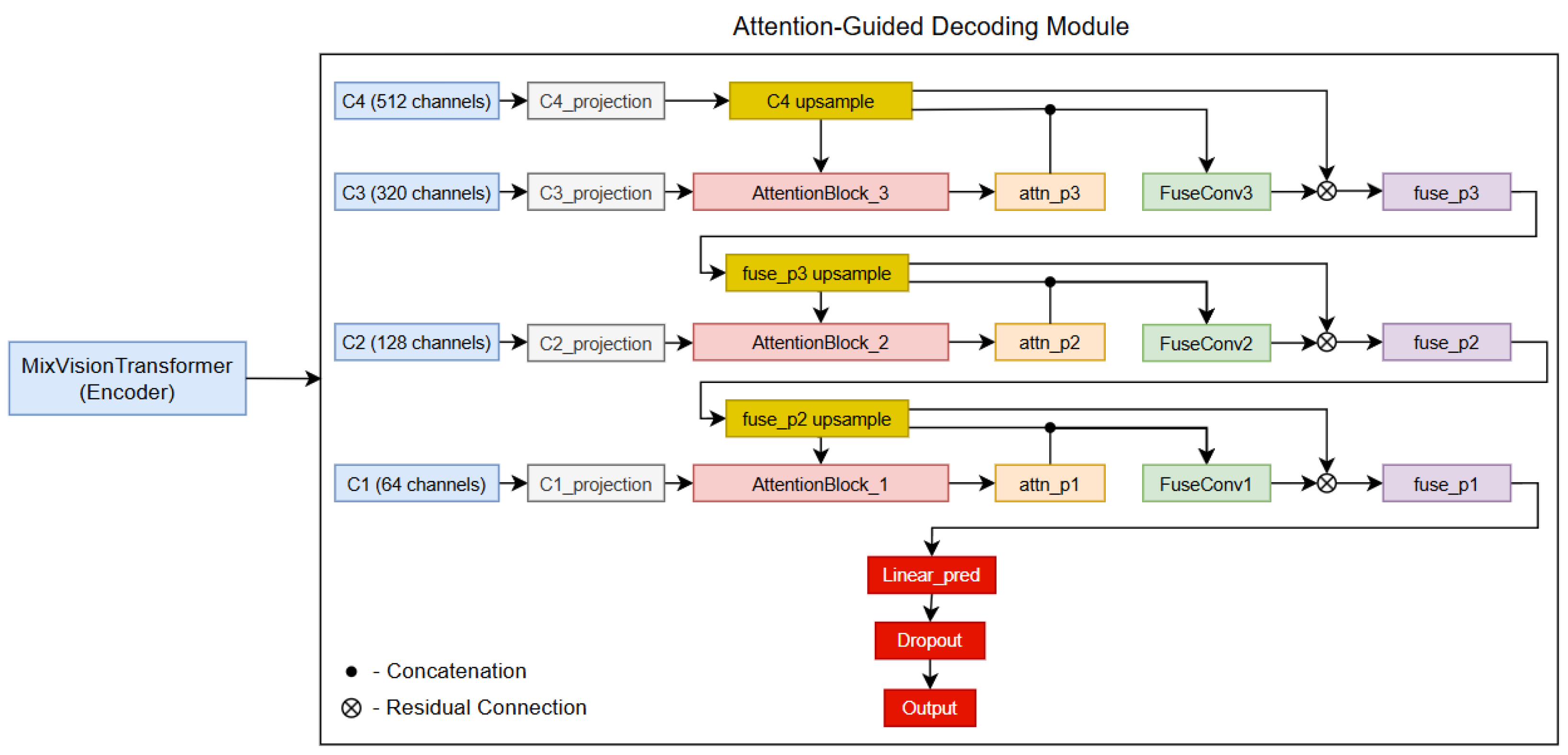
2.4. Decoder
The decoder module approach combines the features from the encoder using an attention-based mechanism. In this subsection, we propose an attention-guided decoding module that fuses multiscale Transformer features via hierarchical attention and residual convolutional fusion. The decoder design allows the rich semantic information from deeper layers to be combined with the fine spatial details of shallower layers; in this way, it can achieve good accuracy and spatial precision.
Figure 2 shows the complete model architecture, including the encoder and the attention-guided decoding module.
Using the MiT as a backbone feature extraction network, the encoder part produces a set of feature maps at different resolutions, typically named c1, c2, c3, and c4, from the shallowest to the deepest network stage. Each feature map captures information at a different scale. Although deeper features contain more semantic information, shallow features preserve detailed spatial information, which is critical for accurate segmentation in complex road scenes.
The decoder first projects each of the feature maps to a common embedding space with a fixed number of channels. This process is achieved by using a 1 × 1 pixel convolutional layer, which is later followed by the normalization of the feature maps across channels to help improve the consistency of the feature representations. After this, the ReLU activation function is used to introduce non-linearity, allowing the network to learn more complex patterns. The mentioned process not only standardizes the channel dimensions across different scales but also improves the stability of the whole training process. Mathematically, this projection can be described as follows:
In addition, in the decoder part, we use an attention-based fusion mechanism. When using separate 1 × 1 convolutional and normalization layers for upsampled decoder features and corresponding encoder features, we generate an attention map that highlights the most relevant spatial regions. This selective weighting approach helps the decoder to focus on important details. As a result, the integration of rich semantic features with fine spatial details helps to achieve a more effective and accurate segmentation process in different road scenes. The attention block in the decoder part is the main component that serves to fuse features from different scales. In this decoder implementation, the fusion process is performed in a top-down approach. In the first stage, the deepest feature map p4 is first upsampled to match the spatial resolution of p3. After this, the attention block receives the upsampled p4 feature map (acting as a gating signal) and the p3 feature map from the encoder backbone. Later, the attention block projects both received inputs using a 1 × 1 convolutional layer followed by a normalization layer. Specifically, the projections can be formulated as follows:
where
g is the gating signal (upsampled p4) and × is the encoder feature (p3). The resulting outputs are then summed, activated by the ReLU function, and further processed by another 1 × 1 convolutional layer with the sigmoid activation function to produce an attention map:
The produced map selectively weights the p3 features, suppressing less relevant regions. The weighted encoder feature is concatenated with the upsampled p4, and a convolutional module refines this fusion. Additionally, a residual connection is added by introducing the upsampled p4.
In addition, the fused features from the previous stage are upsampled in the same way to match the resolution of p2 and fused with p2 using an analogous attention-guided procedure. The same process is repeated once again with the highest-resolution p1 feature map to produce the final fused representation.
In this decoder approach, there are combined residual connections at each fusion stage. These connections add the upsampled features back into the fused output, and, in this way, we ensure that essential spatial details are kept throughout the upsampling process. By using residual connections at each stage, we stabilize the training process by maintaining a smoother gradient flow. In addition, this allows the model to take advantage of the refined fused features and the original upsampled signals, thereby improving the overall robustness of the segmentation process.
After the progressive fusion step, a dropout layer is applied to the refined feature map for regularization. After this step, the final 1 × 1 convolutional layer is used to project the features to the preset number of segmentation classes, generating the final segmentation output. The final prediction can be written as
This decoder approach can be effective for road scene segmentation tasks due to its ability to preserve spatial precision by maintaining high-resolution feature maps and integrating fine-grained details using the attention mechanism, which ensures the accurate distinction of road boundaries and different objects. The attention mechanism used in the decoder module works as a gating function that merges context-rich deep features with detailed shallow features. In doing so, it emphasizes the spatial regions that are most relevant. In addition, the use of residual connections throughout the fusion process helps with training stability and convergence, even when the model incorporates multiple upsampling stages.
Overall, this decoder approach proves robust and efficient in fusing multiscale features, and, when combined with the MiT backbone for feature extraction, it can achieve competitive accuracy in the road scene semantic segmentation task.
3. Results
In this section, we present the experimental results for our Vision Transformer-based road scene segmentation system. First, the training process is described, followed by additional details regarding the performance metrics per class and the global metrics of the system. At the end of this section, we provide the visualization results for the road scene environment to demonstrate that the system is capable of detecting different objects on the road.
3.1. Training Process
As described in more detail in
Section 2.2, the model training schedule was preset to 160,000 iterations. Moreover, to examine whether additional training could lead to better accuracy metrics, the training process later was extended to 200,000 iterations. An analysis of the training log from the
mmsegmentation framework yielded the following observations.
Initial Training Phase: The training phase from the beginning showed a high decoder loss parameter of 2.43. During the full 160,000 iterations of training, the model loss parameter decreased as we approached 160,000 iterations. This behavior demonstrates that the computer vision model was continuously learning and improving until the end of the training cycle, while it achieved a loss parameter of approximately 0.11 in the final iterations.
Iteration 156,000 as the Final Checkpoint: At this point in the training cycle, the model demonstrated the highest precision metrics. From the training log review, the decoder loss parameter was recorded at 0.1161 and we achieved the highest accuracy values. This confirms that the highest performance was reached at this point, leading us to select this checkpoint as our final model.
Extended Training Experiment: To determine whether the computer vision model could achieve better accuracy, an extended training process of up to 200,000 iterations was carried out. After this, the results of the training log showed that additional training did not give accuracy improvements, indicating that further training beyond the 160,000 point is not effective.
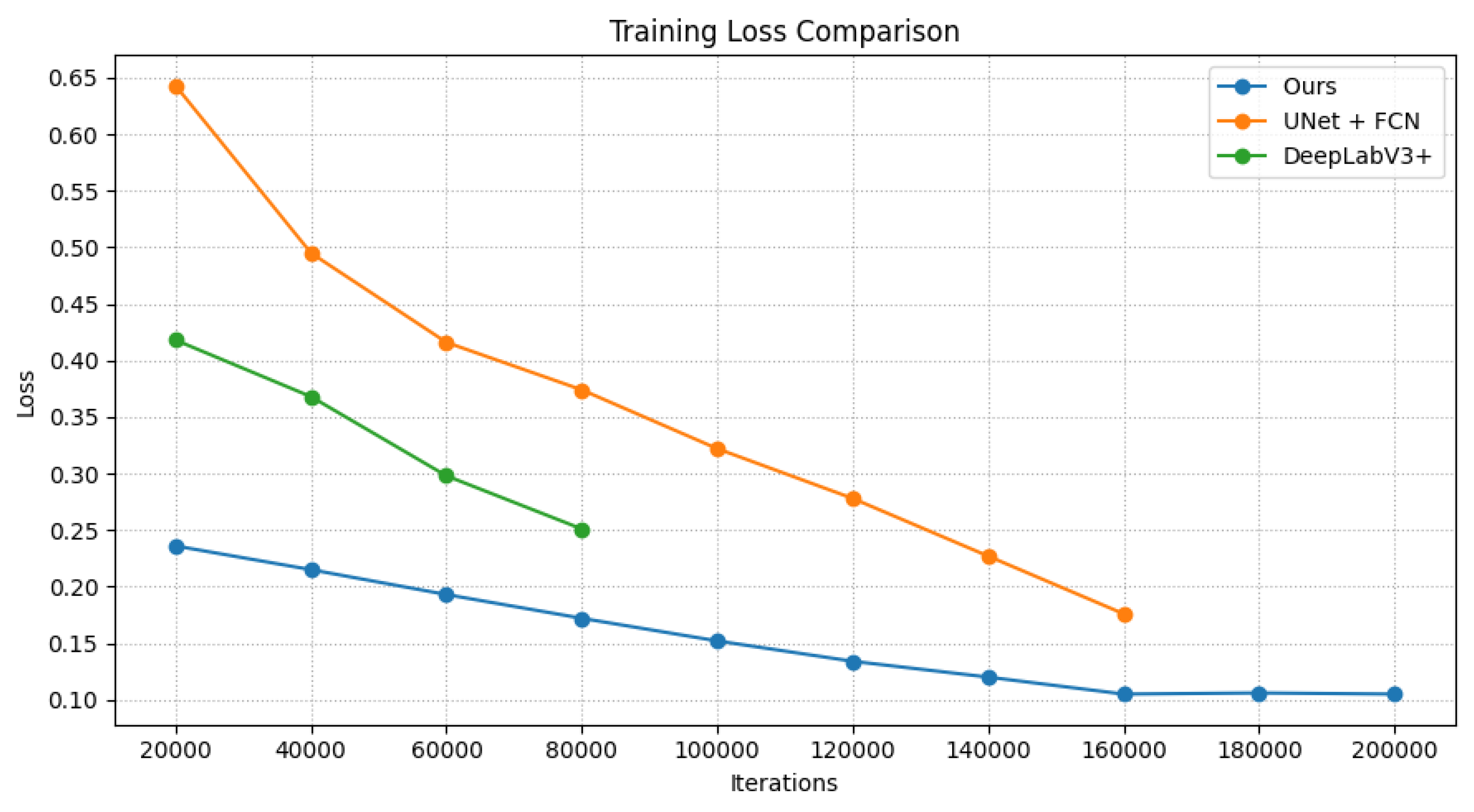
Figure 3 illustrates the training convergence curves of our proposed model compared to traditional segmentation architectures, specifically U-Net+FCN and DeepLabV3+. Our model demonstrates a consistent decrease in loss, reaching approximately 0.11 at 160,000 iterations. In contrast, U-Net, trained up to 160,000 iterations, and DeepLabV3+, trained up to 80,000 iterations, exhibit higher loss values at corresponding iteration points, indicating slower convergence and less efficient learning.
The results show the efficiency of our proposed training approach. Although we extended the training to 200,000 iterations, we saw no further improvement beyond 160,000 iterations, so further training would not have been cost-effective.
3.2. Per-Class Performance
Our computer vision model segments urban road scenes into 19 different classes according to the standard of the Cityscapes dataset. It uses the cross-entropy loss function for optimization. For better understanding, we divide the classes into two different groups based on the segmentation accuracy that they achieved, measured by the main intersection over the union value. The first group of classes consists of those with the highest mIoU, which is above ≥76%, while the second group of classes consists of those who reached the mean intersection over union far below the 76% line. It is worth mentioning that, despite being trained exclusively on the Cityscapes dataset, without using any additional datasets, the computer vision model is capable of achieving good accuracy in the semantic segmentation task while having less than 20 million parameters and is capable of detecting different classes, such as roads, cars, sidewalks, vegetation, or buildings.
In
Table 2, we show the first group of classes that yielded higher accuracy than 76%, ordered in descending order by the IoU metric for every class.
The table above demonstrates that classes such as roads, cars, sky, vegetation, and buildings yield accuracy above 90%. Others, like buses, people, sidewalks, trucks, traffic signs, and bicycles, yield lower accuracy. Nonetheless, these are satisfactory results given the lightweight model approach, the quantity of data used, and the difficulty in distinguishing classes like traffic signs in different distance conditions. In the following,
Table 3 lists the classes with an mIoU below 76%, indicating that they are more challenging to accurately segment.
Table 3 indicates that classes such as motorcycles, trains, traffic lights, poles, terrain, fences, walls, and riders yield lower precision. These challenges may be due to the inherent complexity and variability of these objects in different road scenes. In the future, by using more data with greater diversity, it will be possible to obtain better accuracy results for these classes. Here, it was challenging to detect these classes accurately, because distinction is needed between concrete walls, buildings, or fences, and many state-of-the-art models lack accuracy for these classes. Overall, the computer vision model, with 17.2 million parameters, detects different objects and environmental elements, such as cars, roads, and sidewalks, with good accuracy, while its lower performance in certain classes highlights opportunities for future improvements.
3.3. Global Metrics
To evaluate the final performance of our computer vision model with the Cityscapes validation set, we collected different accuracy metrics. The following accuracy metrics were obtained after the final evaluation phase:
The above metrics demonstrate that the computer vision model, having 17.2 million parameters, is capable of reaching a global mean intersection over union of 76.41%. This metric reflects the average overlap between the predicted segments and the ground truth values across all classes, and it is widely used in evaluating the performance of computer vision models. The data provided above also show that the model achieved a mean accuracy (mAcc) value of 83.66%. This metric represents the average classification accuracy per pixel for each class. Lastly, the overall accuracy (aAcc) of 95.87% is reached. This metric shows the ratio of correctly classified pixels to the total number of pixels in the Cityscapes validation set.
3.4. Qualitative Analysis
In
Figure 4, we show an example image of a road scene, where the original image is presented on the left and the segmentation output produced by the system is shown on the right. From this side-by-side comparison, it is clearly shown that the model can perform semantic segmentation on road scene images, detecting different objects in the digital image with good accuracy. From this comparison, the following observations emerge.
Accurate detection of close objects: The model is capable of detecting near-field classes with good accuracy, including roads, cars, pathways, and buses, when these objects are at an approximately 50–100 m distance.
Challenges with distant objects: It is more challenging to detect distant objects like traffic signs, indicating potential areas for further improvement.
Overall performance: Under ideal weather conditions, the segmentation quality is good, and the model clearly defines boundaries for different objects, although minor inaccuracies can appear in more complex or distant regions.
The segmentation results provided above demonstrate that the computer vision model developed can effectively detect and segment close objects, ensuring the clear and detailed recognition of the main elements on the road. It should be mentioned that lower accuracy metrics were reached for more distant objects such as traffic signs, poles, or traffic lights. This is a possible area for improvement in the future, where the main focus could be on improving the ability of the computer vision model to detect fine details in more distant regions. This could be achieved by modifying the model architecture or by using additional datasets. In this way, it would be possible to further enhance the performance of the system in different real-world scenes on the road.
3.5. Model Robustness Analysis
To evaluate the robustness of our segmentation model, we also tested it on images of a different dataset (Mapillary Vistas) that were not used during training. The examples provided below include images captured in an urban city area, which highlight the model’s performance in a different environment, as well as another image taken on a highway to demonstrate the model’s ability to accurately segment unseen data across different scenarios.
In
Figure 5, we show the original image on the left and the corresponding segmented result on the right. This visual presentation demonstrates the ability of the model to detect major objects and the environment with good overall accuracy. It also indicates that there is room for improvement in the segmentation of small objects, such as traffic signs or traffic lights, and that the accuracy at larger distances could be improved. For example, in the highway image, where the distance is more than 100 meters, the model lacks the accuracy to differentiate cars from the road, but, with closer objects and environmental elements, the accuracy is good.
As demonstrated in
Table 4, the highest performance metrics are obtained for the main environment and object classes, such as roads, cars, buildings, and vegetation, which indicate good segmentation performance for these dominant regions. Meanwhile, classes such as people or traffic signs result in lower performance, which can be attributed to their smaller sizes and greater variability in their appearance.
3.6. Computational Performance Analysis
The computer vision model, with 17.2 million parameters, was evaluated on an NVIDIA GTX 1060 GPU, chosen specifically to represent the low-end sector of Cuda-capable devices (released in 2016). The test was performed using a single image with a batch size of 1, with different input resolutions. The computational performance metrics, such as the computational cost (GFLOPs), inference time (ms), and throughput (FPS) at different resolutions, are provided in
Table 5, illustrating the model’s resource requirements under the different conditions. As the resolution increases, both the computational cost (GFLOPs) and inference time increase, while the throughput (FPS) decreases. Specifically, at a 256 × 256 resolution, the model requires 9.1 GFLOPs and achieves 42.4 FPS with an inference time of 24 ms. With the highest resolution of 2048 × 1024, the computational cost reaches 419.4 GFLOPs, and the inference time increases to 769 ms. The data provided in the table demonstrate the trade-offs between the resolution, computation, and performance, which must be carefully considered when a different resolution is needed for resource-constrained applications.
In
Table 6, we present the computational performance of our segmentation model on the NVIDIA Jetson Orin Nano 8 GB embedded platform. The performance metrics are reported for three different input resolutions, capturing the inference speed (FPS) and GPU memory usage.
The results provided in
Table 6 demonstrate that, at the lowest resolution, the computer vision model can achieve an inference speed of 52.89 FPS while consuming 54 MiB of GPU memory. When using a higher resolution, the inference speed decreases to 32.23 FPS at an input size of 320 × 320. At a 512 × 512 resolution, the GPU memory consumption increases to 112 MiB, and 15.56 FPS is still acceptable for many autonomous applications. However, for applications that require higher input resolutions or faster inference speeds at larger scales, a more powerful embedded device with greater computational resources may be more appropriate than the Jetson Nano embedded platform.
4. Discussion
The experimental results obtained with the computer vision road scene segmentation system demonstrate good accuracy and effectiveness when the model uses a Transformer-based MiT backbone as an encoder for feature extraction and attention-based mechanisms in the decoder module. During the training log analysis, the results revealed that, during the whole training cycle, the mode’s loss parameter steadily decreased; shortly before reaching the final iterations, it demonstrated the best accuracy performance at 156,000 iterations. Furthermore, the training process confirmed that setting the training schedule at 160,000 iterations was cost-efficient and effective, because an additional experiment extending the training process was not effective. In addition, the per-class performance metrics show that the main elements of the road scene, such as the road, cars, and buildings, are segmented with good accuracy, indicating the model’s strong ability to detect and distinguish different objects and environmental elements on the road.
Creating a model that maintains a lightweight design with a low parameter count while achieving competitive accuracy is a challenging task. It is always necessary to have a balance between accuracy and lightweight model design, because, while a more complex model can achieve better accuracy metrics, it also has a significantly larger number of parameters and is consequently not as lightweight. This balance is critical, as increasing model complexity often improves the performance, but it can compromise the efficiency and suitability of the model for deployment in memory-limited environments.
According to the global evaluation metrics of the developed model, the results validate the good performance of the system and its capacity to detect and differentiate objects in digital road scene images, achieving a mean IoU of 76.41% with 17.2 million parameters in the network. Despite its compact size, the computer vision system is capable of maintaining competitive segmentation performance, making it suitable for use in memory-limited resource environments. The visual examples provided in
Figure 6 show that the model is successful in segmenting near-field objects within 50–100 m, and classes like roads, cars, and pathways are detected with good accuracy. However, it is worth mentioning that more distant objects, such as poles, traffic lights, and traffic signs, as well as fences, yield lower precision. Thus, these classes could represent an avenue for future system enhancement by incorporating additional training data or modifying the internal system architecture to capture small-scale objects or environmental elements in distant regions. In
Figure 6, we provide qualitative results, with the original RGB image on the left, the ground truth masks in the middle, and the segmentation results on the right.
Regarding other open-source computer vision approaches, models such as DSNet [
35], HRNetV2 + OCR [
36], DeepLabv3 + [
36], CSFNet-1 [
37], and EEEA-Net-C2 [
38] have demonstrated good accuracy results on the Cityscapes dataset while maintaining a relatively low parameter count. The demonstrated approach has 17.2 million parameters and achieves a 76.41% mIoU. This approach also demonstrates that, by using a Transformer-based encoder for feature extraction and an attention-based mechanism to fuse multiscale features, it is possible to achieve competitive accuracy with other models while maintaining a lightweight design and good overall performance. The developed approach also extends the knowledge provided by existing studies, showing that Transformer-based architectures can effectively segment complex urban scenes with models that have a low parameter count and are capable of achieving good accuracy in road scene semantic segmentation tasks.
Table 7 shows details of several semantic segmentation models evaluated on the Cityscapes validation set, including their input resolutions, parameter counts, GFLOPs, and mIoU values, as reported in the literature.
The computer vision models in
Table 7 are sorted by the number of parameters in the network. From the data provided in the table, we can see that our approach offers a balance between segmentation accuracy, model size, and computational efficiency. The proposed model has 17.2 million parameters and requires 37.9 GFLOPs at an input resolution of 512 × 512. Models like EEEA-Net-C2 and CSFNet-1 represent lightweight architectures, achieving mIoU accuracy metrics of 76.8% and 74.8%, respectively. In comparison, CSFNet-1 has a slightly lower parameter count but a larger computational cost. DSNet gives good accuracy results and computational efficiency, but it has more than twice as many parameters in the network. Moreover, models like DeepLabV3+ and HRNetV 2 + OCR offer better accuracy but at the cost of having much larger architectures. This comparison highlights that the proposed approach offers a compelling trade-off by delivering good segmentation performance in a lightweight architecture.
In
Table 8, we compare the intersection over union (IoU) per class of our lightweight segmentation model against those of two much larger architectures: HRNet-W48 (65.9 M) and DeepLabV3-R101 (84.7 M). Despite having roughly one-quarter to one-fifth of the number of parameters, our approach achieves only marginally lower IoU scores across many semantic categories. The side-by-side comparison makes it clear that, although larger architectures can reach slightly higher accuracy scores, our Transformer-based design with an attention-guided decoding module offers a compelling trade-off, maintaining competitive performance while drastically reducing the model complexity.
In addition to the overall quantitative comparison,
Table 8 shows that our Transformer-based encoder with an attention-guided decoding module matches the larger HRNet-W48 and DeepLabV3-R101 architectures almost exactly in large and homogeneous classes such as roads, cars, buildings, and vegetation, with IoU differences of less than 1.2 percentage points. The results show that the global context modeling of the MiT backbone effectively captures broad, texture-rich regions. However, all three architectures, including the larger baselines, have the greatest difficulty in accurately segmenting slender or distant objects, such as poles, fences, and walls.
In summary, the demonstrated approach confirms that a computer vision system based on the Transformer neural network architecture with an attention-guided decoding module can effectively capture contextual information for the road scene segmentation task. While the model performs well with near-field objects, future work could direct more attention to areas with more distant, small-scale objects, because many models lack accuracy in this regard, and it remains a challenging task.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}