Abstract
Real-time non-intrusive monitoring of wind turbines, blades, and defect surfaces poses a set of complex challenges related to accuracy, safety, cost, and computational efficiency. This work introduces an enhanced deep learning-based framework for real-time detection of wind turbine blade defects. The WindDefNet is introduced, which features the Inception-ResNet modules, Visual Transformer (ViT), and multi-scale attention mechanisms. WindDefNet utilizes modified cross-convolutional blocks, including the powerful Inception-ResNet hybrid, to capture both fine-grained and high-level features from input images. A multi-scale attention module is added to focus on important regions in the image, improving detection accuracy, especially in challenging areas of the wind turbine blades. We employ pertaining to Inception-ResNet and ViT patch embedding architectures to achieve superior performance in defect classification. WindDefNet’s capability to capture and integrate multi-scale feature representations enhances its effectiveness for robust wind turbine condition monitoring, thereby reducing operational downtime and minimizing maintenance costs. Our model WindDefNet integrates a novel advanced attention mechanism, with custom-pretrained Inception-ResNet combining self-attention with a Visual Transformer encoder, to enhance feature extraction and improve model accuracy. The proposed method demonstrates significant improvements in classification performance, as evidenced by the evaluation metrics attain precision, recall, and F1-scores of 0.88, 1.00, and 0.93 for the damage, 1.00, 0.71, and 0.83 for the edge, and 1.00, 1.00, and 1.00 for both the erosion and normal surfaces. The macro-average and weighted-average F1 scores stand at 0.94, highlighting the robustness of our approach. These results underscore the potential of the proposed model for defect detection in industrial applications.
1. Introduction
The increasing global reliance on renewable energy sources has propelled wind energy to the forefront of sustainable power generation. Wind energy is a cornerstone of renewable energy, with wind turbine blades critical to energy capture but vulnerable to defects due to environmental and mechanical stresses. Wind turbine blade defects and incidents result in significant energy losses, with approximately 3800 blade failure incidents occurring annually across the estimated 700,000 operational turbines worldwide. As critical components of this infrastructure, wind turbines are subjected to harsh environmental conditions that can lead to structural defects in their blades. These defects, ranging from surface erosion and edge wear to more severe forms of damage, can compromise turbine efficiency, reduce energy output, and escalate maintenance costs. Early detection of such defects is therefore paramount for ensuring optimal performance, minimizing operational downtime, and extending the lifespan of wind turbines [1]. However, traditional inspection methods, often reliant on manual visual assessments or rudimentary automated systems, are labor-intensive, time-consuming, and prone to human error. This underscores the urgent need for advanced, real-time defect detection solutions capable of addressing these challenges with precision and scalability [2]. Figure 1 shows a generic graphical abstract of the proposed study and its major steps.
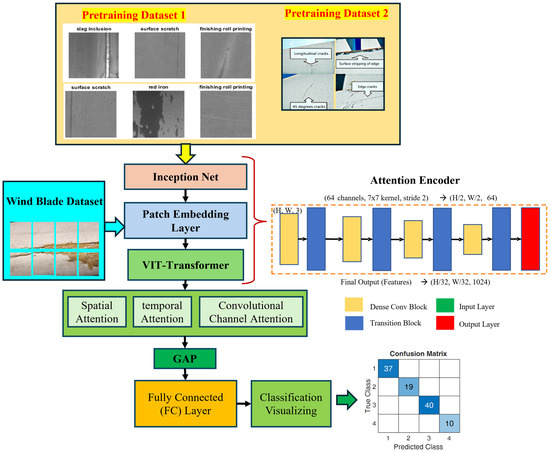
Figure 1.
Graphical abstract of wind turbine blade surface defect problem.
In recent years, deep learning-based approaches have emerged as powerful tools for automating defect detection in complex industrial applications. Among these, convolutional neural networks (CNNs) have demonstrated remarkable success in image classification and object detection tasks due to their ability to extract hierarchical features from visual data. Despite these advancements, detecting defects on wind turbine blades presents unique challenges. The variability in defect types, sizes, and locations, coupled with the intricate geometry of turbine blades, necessitates a model architecture capable of capturing both fine-grained details and high-level contextual information [3]. Furthermore, the demand for real-time processing imposes stringent constraints on computational efficiency [4], requiring a balance between accuracy and speed.
Research suggests that combining Inception-ResNet with multi-scale attention mechanisms, as in the WindDefNet model, enhances real-time defect detection for wind turbine blades. It seems likely that this approach improves the detection of subtle or occluding defects, crucial for wind turbine maintenance. The evidence leans toward deep learning models being effective for industrial defect detection, though challenges like varying lighting and angles remain.
2. Literature Review of Wind Turbine Blade Defect
Wind turbine blades are exposed to continuous rotational stresses, storms, lightning, and flying object strikes, necessitating periodic inspections to prevent catastrophic failures. Traditional methods, such as manual detection and acoustic nondestructive testing, e.g., ultrasonic echo, acoustic emission, are unsafe, time-consuming, and have low accuracy, as noted in studies like defect detection on a wind turbine blade based on digital image processing [5]. The shift to automated, vision-based systems using deep learning has been driven by the need for efficiency and accuracy, especially with drone-captured images [6].
The existing methods and techniques in the literature review are structured into three main areas: general classical methods for wind turbine blade defect detection, deep learning applications, and specific architectures like Inception-ResNet and attention mechanisms.
Traditional approaches include manual inspections and acoustic methods, which are inefficient and unsafe. For instance, wind turbine blade defect detection based on acoustic features and small sample size [7] highlights acoustic-based methods using MAML-ANN for small sample sizes, achieving 94.1% accuracy with 50 data points per class, but these are less effective for visual defects. Digital image processing, as in slice-aided defect detection in ultra-high-resolution wind turbine blade images [8], uses models like YOLOv5, Faster-RCNN, and RetinaNet, with YOLOv5 achieving mAP of 0.5 of 85.1% in slice-aided scenarios, but lacks attention mechanisms.
Deep learning, particularly CNNs, has transformed defect detection. Studies like a lightweight CNN for wind turbine blade defect detection based on spectrograms [9] use lightweight CNNs for real-time safety management, while wind turbine surface damage detection by deep learning aided drone inspection analysis [10] achieves human-level precision with data augmentation, demonstrating the potential for automation. However, challenges like small object scales and background complexity persist, as seen in AI-based defect detection on wind turbine surfaces with reasoning and continual learning capabilities [11], which uses mask R-CNN for defect classification.
Inception-ResNet, combining Inception and ResNet, offers efficiency and depth. A two-stage industrial defect detection framework based on improved-YOLOv5 and Optimized-Inception-ResnetV2 models [12] uses optimized Inception-ResnetV2 for classification, achieving 82.33% accuracy on NEU-DET, with CBAM attention enhancing feature focus. Research of an image recognition method based on enhanced inception-ResNet-V2 [13] modifies Inception-ResNet-V2 with multi-scale depthwise separable convolution, reaching 94.8% accuracy, but it is not specifically for wind turbine blades. An uncertainty-aware deep learning framework for defect detection in casting products [14] uses InceptionResNetV2 for feature extraction but lacks attention mechanisms, limiting its adaptability.
Attention mechanisms improve the model’s focus on relevant features. For MAS and dilation network for small defect detection, [15] propose SDA-PVTDet for radiographic images, effective for small defects but computationally intensive. A MAS mechanism for detecting defects in leather fabrics [16] uses MLRCA, enhancing multi-scale fusion, while a strip steel surface defect detection method based on attention mechanism and multi-scale maxpooling [17] integrates attention with Resnet50, improving detection accuracy, but is sensitive to defect changes.
Directly relevant, defect detection of the surface of wind turbine blades combining an attention mechanism [18] enhances YOLOX with attention, achieving 95.03% mAP-0.5 and 54.56 frame/s−1, addressing sample imbalance with CAFL. Semi-supervised surface defect detection of wind turbine blades with YOLOv4 [19] uses scSE attention, improving small target detection, but relies on semi-supervised learning, limiting labeled data use [20].
While deep learning has advanced defect detection, combining Inception-ResNet with multi-scale attention for wind turbine blades is underexplored. Existing studies, like those of defect detection of wind turbine blades [21], utilize virtual reality (VR) and a U-Net model for segmentation. Wind turbine blade defect detection with a semi-supervised deep learning framework [22] focuses on semi-supervised learning but lacks the specific integration seen in WindDefNet. The model’s real-time capability and focus on subtle defects address gaps in the current literature, particularly in handling varying conditions like lighting and occlusion.
The WindDefNet model integrates advanced techniques like Inception-ResNet architecture and MSA mechanisms, focusing on real-time wind turbine blade defect detection. This is vital as wind turbine blades face harsh conditions, making defect detection essential for safety and efficiency. Traditional methods, such as manual inspections, are often slow and inaccurate, while deep learning offers a promising alternative by processing images quickly and learning complex patterns. The model’s novelty lies in its ability to highlight critical features at multiple abstraction levels, improving the detection of subtle or occluded defects. This is particularly useful for real-world applications where lighting, angles, and occlusions can obscure defects. Optimized for real-time classification, WindDefNet supports continuous monitoring, potentially revolutionizing wind turbine maintenance. Table 1 summarizes the literature on the defect detection techniques.

Table 1.
Summary of key studies with pros, cons, and deficiencies.
The WindDefNet model, by integrating Inception-ResNet with multi-scale attention, addresses key gaps in wind turbine blade defect detection, particularly in real-time processing and handling of subtle defects. This survey note highlights the need for such innovations, supported by a comprehensive review of the existing literature and a detailed table of techniques, ensuring a robust foundation for the proposed approach. To address these challenges, this study introduces a new integrated Inception-ResNet architecture with multi-scale attention mechanisms. The proposed model leverages the hybrid design of Inception-ResNet, which combines the depth and representational capacity of ResNet with the efficient feature extraction capabilities of Inception modules. This architecture enables the network to capture diverse spatial features at varying levels of abstraction, ensuring robust representation learning. Additionally, the MSA module is incorporated to dynamically emphasize salient regions within the input images, thereby enhancing the model’s ability to detect subtle defects in challenging areas of the blade. By focusing computational resources on the most informative parts of the image, this attention mechanism not only improves detection accuracy but also facilitates faster inference times, making it suitable for real-time applications. Experimental evaluations demonstrate that enhanced architecture achieves superior performance compared to existing state-of-the-art methods, particularly in its ability to handle multi-scale information effectively. These results highlight the model’s potential to revolutionize wind turbine maintenance practices by enabling accurate, real-time defect detection that minimizes operational disruptions and reduces costs.
The WindDefNet model addresses these challenges by integrating the Inception-ResNet architecture with multi-scale attention (MAS) mechanisms and prowess of the visual transformers ViT [28]. Inception-ResNet combines the depth of residual networks with multi-scale processing, while MAS enhances focus on critical features at different abstraction levels, improving the detection of subtle or occluded defects. This is particularly relevant for wind turbine blades, where conditions like lighting, angles, and occlusions can affect visibility. The model’s real-time classification capability is optimized for continuous monitoring, which is essential for wind farm maintenance.
The novelty of the WindDefNet model lies in its integration of several advanced techniques, including the use of the Inception-ResNet architecture and MSA mechanisms and enhanced visual transformer embedding mechanisms to enhance the features for the attention mechanism enabling the system to detect minute and global features for the closely related class features enabling higher efficiency in class imbalanced datasets. The combination of residual connections and MSA allows the model to focus on critical features at multiple levels of abstraction, improving its ability to detect defects that may be subtle or occluded in certain images. This architecture is particularly effective for challenging real-world applications like wind turbine blade monitoring, where conditions such as lighting, angle, and occlusions can affect the visibility of defects.
The model’s design is also optimized for real-time classification, ensuring that it can process images quickly and accurately, which is essential for continuous monitoring of wind turbine blades. By using a deep learning approach with convolutional layers, residual blocks, and attention mechanisms, WindDefNet offers a significant improvement over traditional image classification models and has the potential to revolutionize the way defects in wind turbine blades are monitored and maintained. This research contributes to the growing body of knowledge in computer vision and renewable energy infrastructure by presenting an innovative solution tailored to the specific demands of wind turbine blade inspection. By bridging the gap between advanced deep learning techniques and practical industrial applications, this work paves the way for more efficient and reliable wind energy systems, ultimately supporting the global transition toward sustainable energy production.
The novelty aspects of the proposed model for surface defects in wind turbine blade application are as follows:
- Hybrid Feature Fusion: We integrated Inception-ResNet’s pixel-level sensitivity to micro-defects, e.g., cracks and pitting, with ViT’s global self-attention to identify macro-scale surface irregularities, e.g., delamination and erosion, enhancing defect localization and classification accuracy.
- Self-Attention-Driven Anomaly Highlighting: We modified ViT’s transformer layers to dynamically focus on spatially sparse or faint surface defects, e.g., hairline fractures and coating degradation, which traditional CNNs may overlook under varying lighting or texture noise.
- Scale-Invariant Defect Representation: We align multi-resolution features from ResNet local texture patterns and ViT global structural coherence to detect defects across scales, from sub-millimeter fissures to meter-scale corrosion zones, without manual threshold tuning.
- Robustness to Environmental Artifacts: The combined ResNet’s invariance to local noise, e.g., dirt and shadows, with ViT’s contextual reasoning to suppress false positives, ensuring reliable detection of critical defects even in cluttered or degraded blade surface imagery.
3. Proposed Model
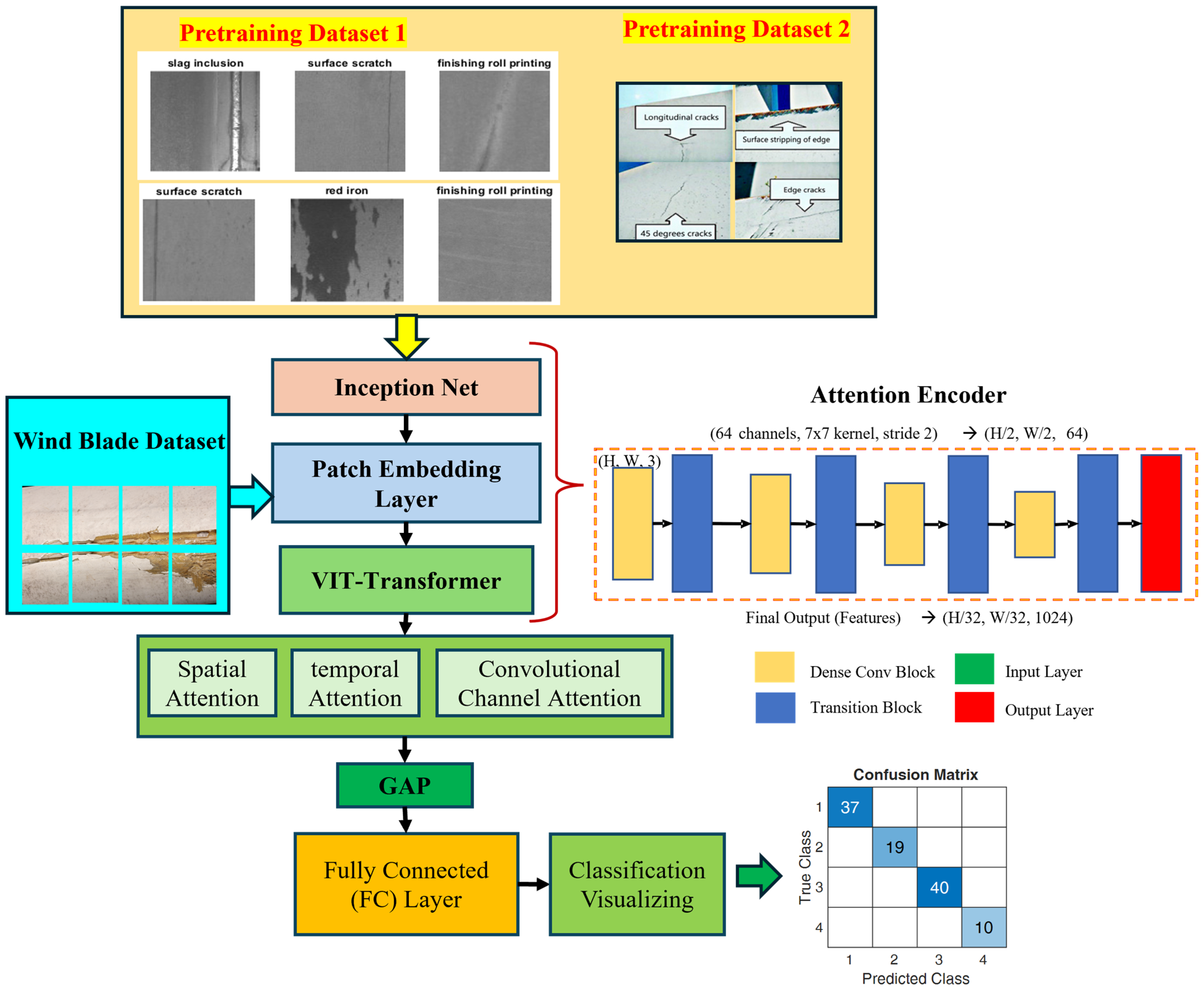
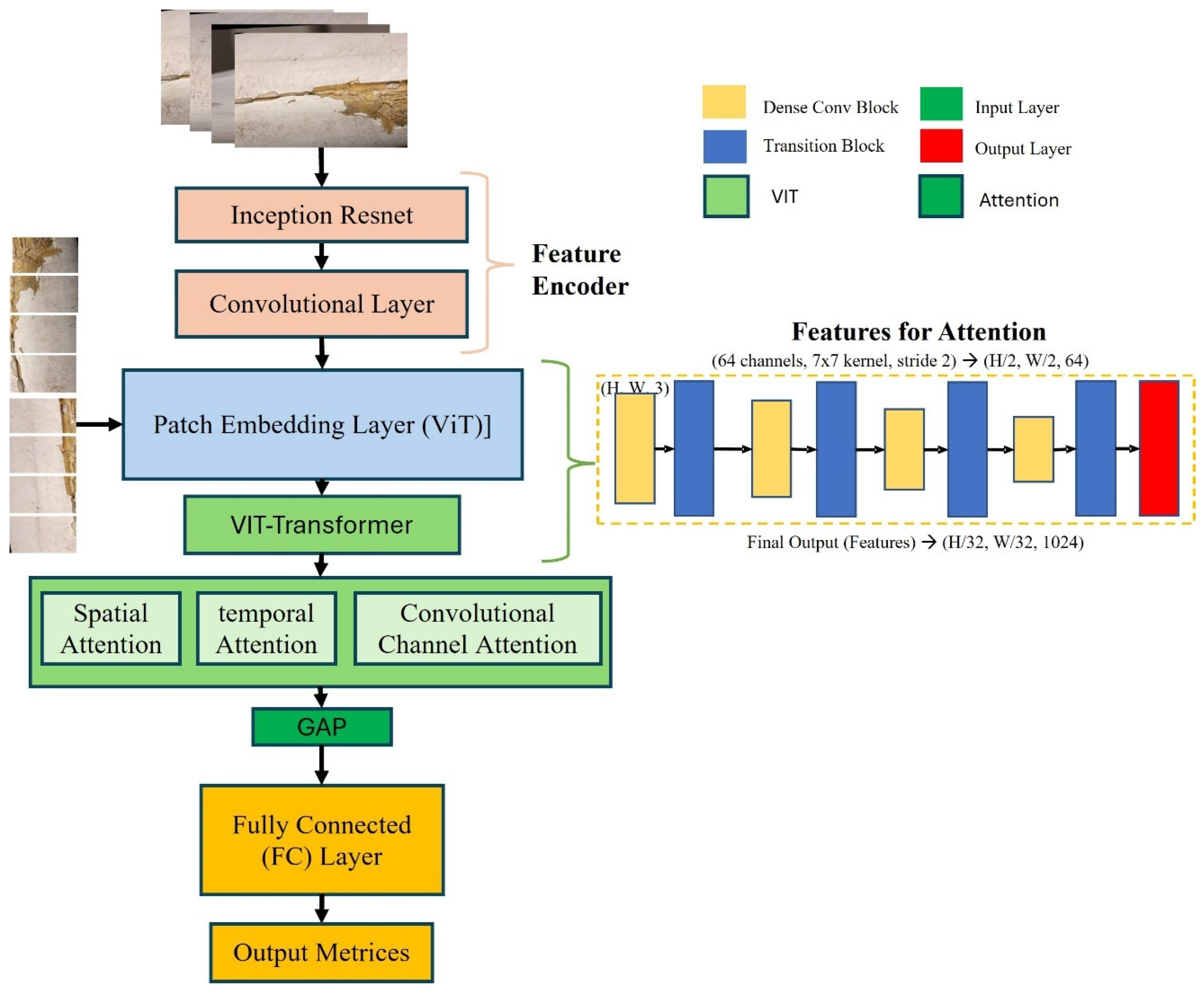
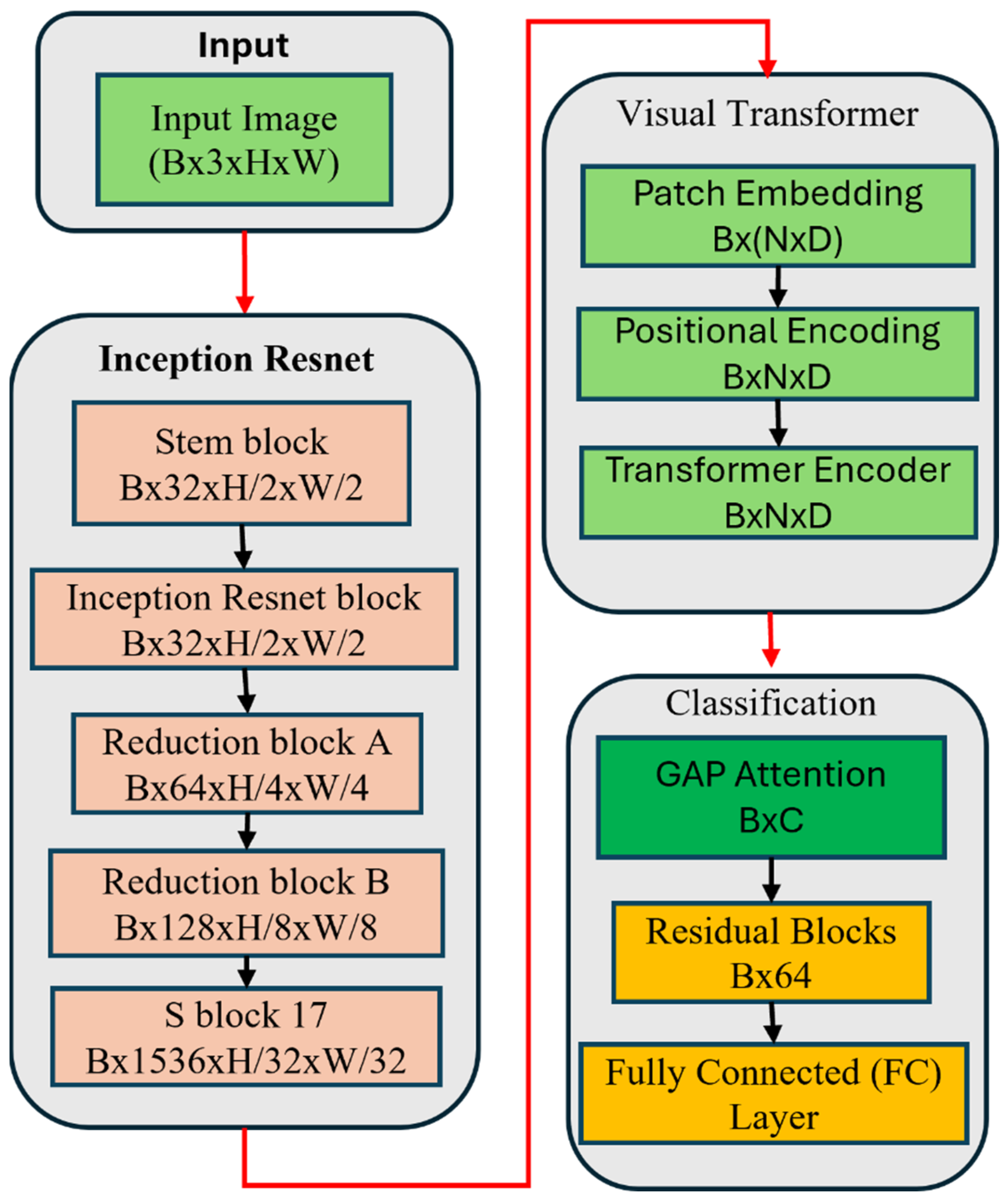
The proposed model is a deep learning-based architecture designed for real-time classification of wind turbine blade defects, explicitly targeting the detection of four distinct categories: damage, edge, erosion, and normal. This model integrates several advanced components to optimize its ability to classify defects accurately while ensuring high efficiency for deployment in real-world applications. The architecture is composed of three main blocks, namely, convolutional layers for feature extraction, inception-residual blocks for enhanced learning and gradient flow, and ViT-patch embedding layers. Figure 2 shows the block diagrams and logical flow of the WinddefNet architecture.
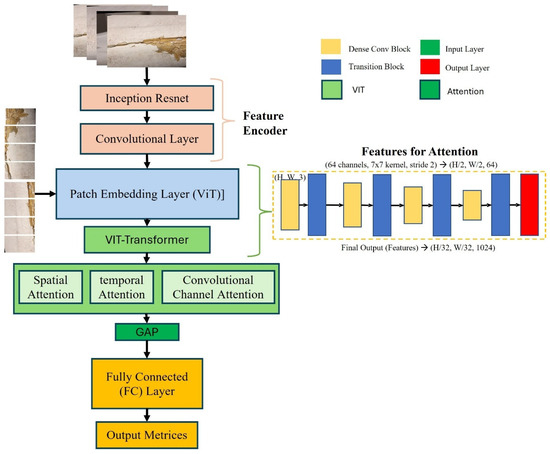
Figure 2.
Block diagram of WindDefNet architecture.
The model begins with an input image of size H × W × 3H, representing the height, width, and three channels (RGB) of the image. This input image is passed through the initial convolutional block for feature extraction. The model utilizes three convolutional blocks, each designed to extract spatial features from the image. The convolutional layers use a kernel size of 3 × 3 with padding to preserve the spatial dimensions of the image. These layers progressively learn higher-level features, starting from simple edges and textures to more complex patterns that are relevant for defect detection.
Conv1 is the first convolutional layer that takes in the RGB image and outputs 32 feature maps. This is followed by batch normalization (BN1) and a ReLU activation function to introduce non-linearity. Conv2 is the second convolutional layer increases the depth of the feature maps to 64, again followed by batch normalization (BN2) and ReLU activation. Conv3 is the third convolutional layer increases the feature map depth to 128, with batch normalization (BN3) and ReLU activation.
The output of each convolutional block is then downsampled using max pooling, which reduces the spatial dimensions by half, preserving the most important features for subsequent layers. The output of the last convolutional block (Conv3) is flattened to convert the multi-dimensional feature maps into a one-dimensional vector. This vector will serve as the input for the fully connected layers that follow. The flattened size is after three max pooling operations. This dimensionality depends on the height and width of the input image. After flattening, the vector is passed through a fully connected () layer that reduces the dimensionality to 64 units. This layer uses a ReLU activation function to learn complex patterns between the extracted features. The model incorporates three residual blocks, which help mitigate the vanishing gradient problem by adding skip connections. These residual connections allow the model to retain earlier learned features while introducing new ones. Each residual block consists of a fully connected layer followed by a ReLU activation and a skip connection, ensuring that the learned features are passed directly to the next layer. The first fully connected layer (FC1) takes the output of the residual blocks and processes it to reduce the dimensionality to 64 units. This is followed by another fully connected layer (FC2) that produces the final output, which is a 4-dimensional vector representing the probabilities of the four classes (damage, edge, erosion, normal). A softmax activation function can be applied at the output layer to convert the raw scores into probabilities. The final output layer produces a vector of size (B, 4) where B is the batch size. Each element of this vector corresponds to the predicted class for each input image [29].
3.1. Visual Transformer and GAP Attention Encoder
3.1.1. Visual Transformer (ViT) Module
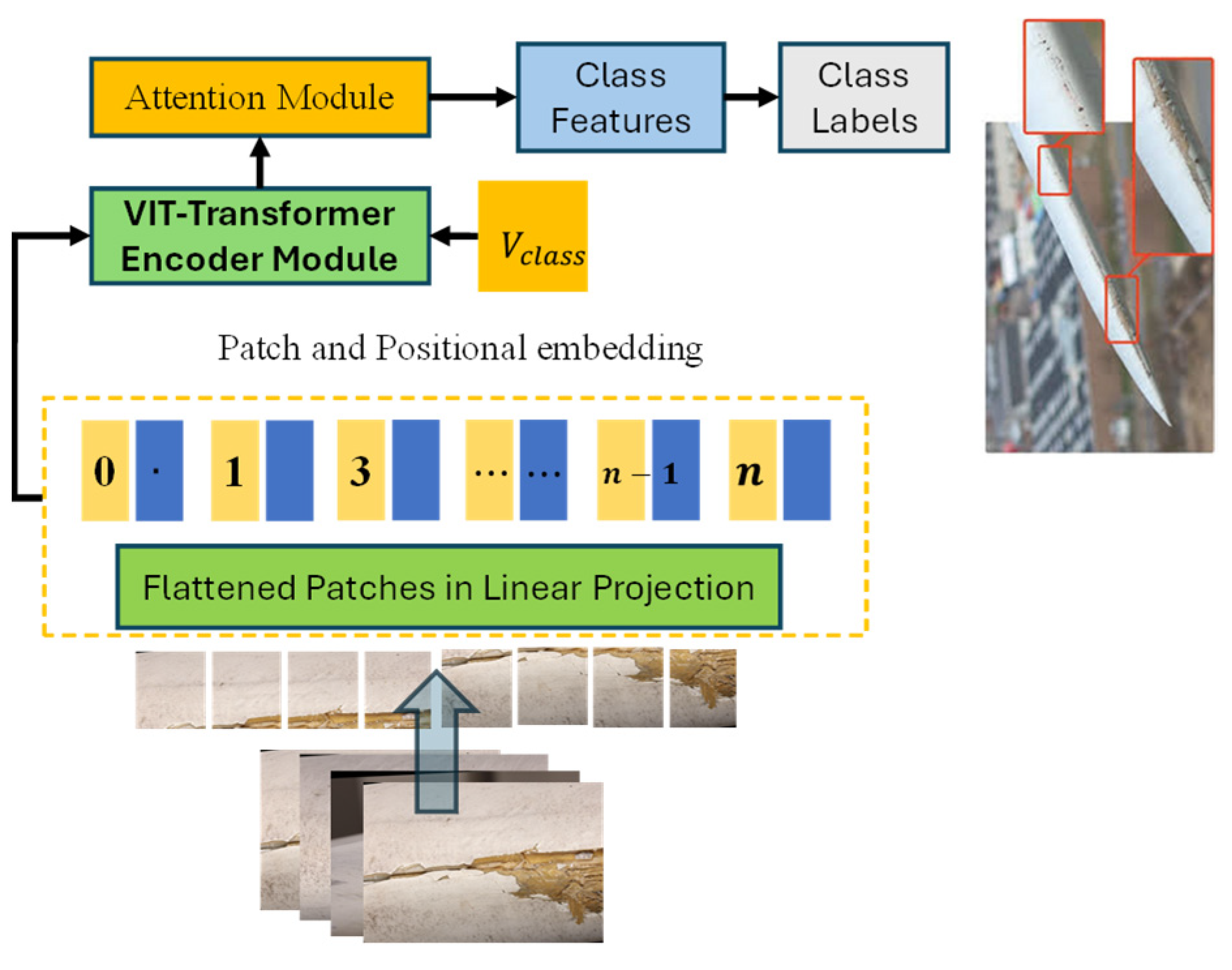
The visual transformer is a state-of-the-art model architecture designed to process image data by applying transformer-based self-attention mechanisms [30]. It treats images as sequences of patches, allowing the transformer model to capture long-range dependencies in the data, and its structure is explained in Figure 3.
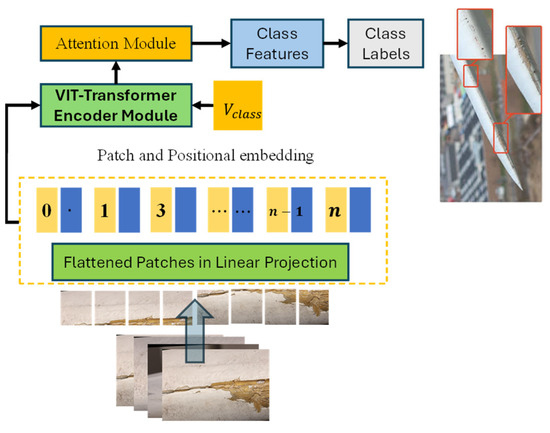
Figure 3.
Block architecture of ViT.
Input Patch Creation: Given an image X with dimensions , where H is the height, W is the width, and C is the number of channels, the image is divided into P × P patches. Each patch be denoted by Equation (1) as follows:
The output patches are flattened into vectors and embedded using a linear projection to create patch embeddings , with being the number of patches , and being the embedding dimension.
Positional Encoding: To preserve the spatial information of the patches, positional encodings are added to the patch embeddings in Equation (2) as follows:
where is the learned positional encoding. The self-attention mechanism computes attention scores for each patch based on its relationship with all other patches. The scaled dot-product attention is defined by Equation (3) as follows:
where Q, K, and V are the query, key, and value matrices, respectively, and is the dimensionality of the key vectors. In the case of the Visual Transformer, the input to the attention block is the patch embeddings E′. The query, key, and value matrices are computed by Equation (4) as follows:
where are learned weight matrices.
Transformer Encoder Block: The output of the self-attention mechanism is passed through a feedforward network (FFN) with ReLU activation by Equation (5) as follows:
The output is then normalized using layer normalization. The output of the transformer encoder is a sequence of patch embeddings, which are used for downstream tasks such as classification.
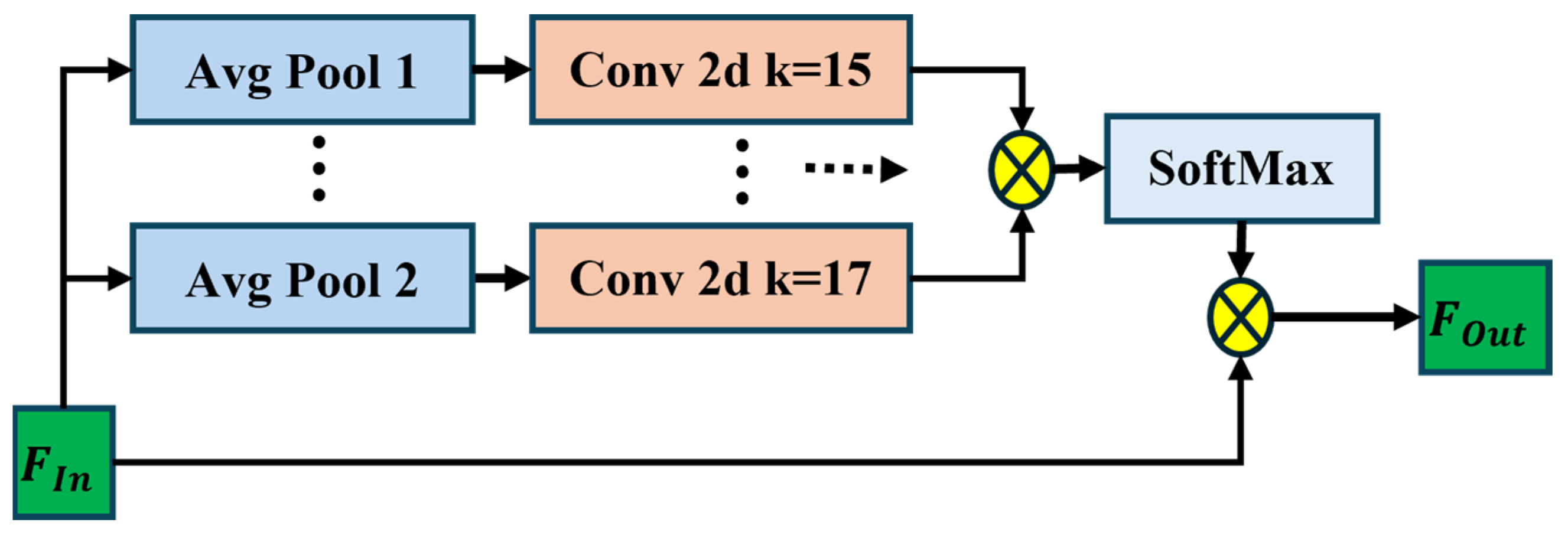
3.1.2. Global Average Pooling (GAP) Attention Encoder
The Global Average Pooling GAP Attention Encoder focuses on capturing global information through global pooling, allowing the model to focus on the most important features across the entire image. The GAP physical layout is given by Figure 4. Given the output from the previous layers, such as the Visual Transformer and Inception-ResNet, the global average pooling operation is applied across the spatial dimensions of the feature map by Equation (6):
where is the output of the GAP operation as a vector of size C, which is the number of channels. F represents either Fin or Fout, H is the height of the feature map, W is the width of the feature map, and represents the spatial coordinates. The equation performs element-wise averaging across all spatial dimensions while preserving the channel/patch dimension, effectively reducing spatial dimensions to 1 × 1 while maintaining feature representation. For Inception-ResNet output (Fin), the input shape is B × C × H × W and the output shape is B × C × 1 × 1, and C represents the number of channels. For the ViT encoder output (Fout), the input shape is B × N × D, the output shape is B × D × 1 × 1, N is the number of patches, and D is the embedding dimension. The GAP output is passed through an attention mechanism to focus on the most relevant features. Let the attention weights A be learned for each channel ccc, and let the feature vector be transformed by Equation (7) as follows:
where is the attended global feature vector. Q, K, and V are derived from the input feature map F, and σ represents the softmax activation function. The GAP operation is applied separately to each component. To incorporate the Visual Transformer and GAP Attention Encoder into the existing architecture, Figure 5 is the flow of the GAP, represented as a block diagram along with detailed equations and dimensionality of the blocks.
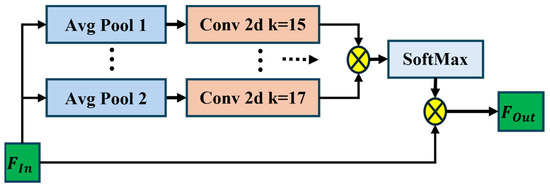
Figure 4.
Global average pooling physical layout.
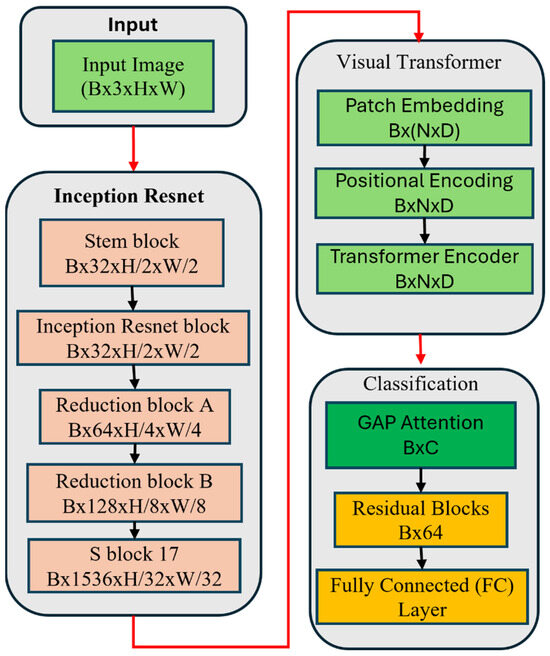
Figure 5.
The proposed WindDefNet dimensionality diagram.
Three residual blocks are applied sequentially. Each block involves a skip connection, and the output dimensions remain the same. Each residual block . With dimensionality after each residual block, the output remains with activations. The final output layer dimensionality is (B, 4), corresponding to the four classes of defects.
3.2. Mathematical Model of Convolutional Block
Convolution blocks act as a basic neural network architecture. Convolution blocks employ a more specialized strategy, using local connections with shared weights to scan input data in small regions, preserving spatial relationships and reducing the parameter count dramatically. The convolution blocks leverage spatial locality and weight sharing to capture meaningful patterns in structured data. In image processing tasks, CNN require far fewer parameters than their fully connected counterparts while maintaining remarkable effectiveness in extracting spatial features.
Convolutional Block (Conv1, Conv2, Conv3) are governed by Equation (8) as:
Batch normalization by Equation (9) as follows:
where and are the mean and variance, and are the scale and shift parameters. The residual block is governed by the Equation (10) as follows:
The fully connected layer is embedded for the feature preservation and forwarding for patch embedding as governed by Equation (11) as follows:
where the output size is 64 for the first fully connected layer and 4 for the final classification layer.
The final output of the model is a 4-dimensional vector representing the class probabilities of the defects (damage, edge, erosion, and normal). The model can then be trained using softmax for classification, and the output will correspond to one of these defect categories. Let the input image be represented as a tensor as in Equation (12):
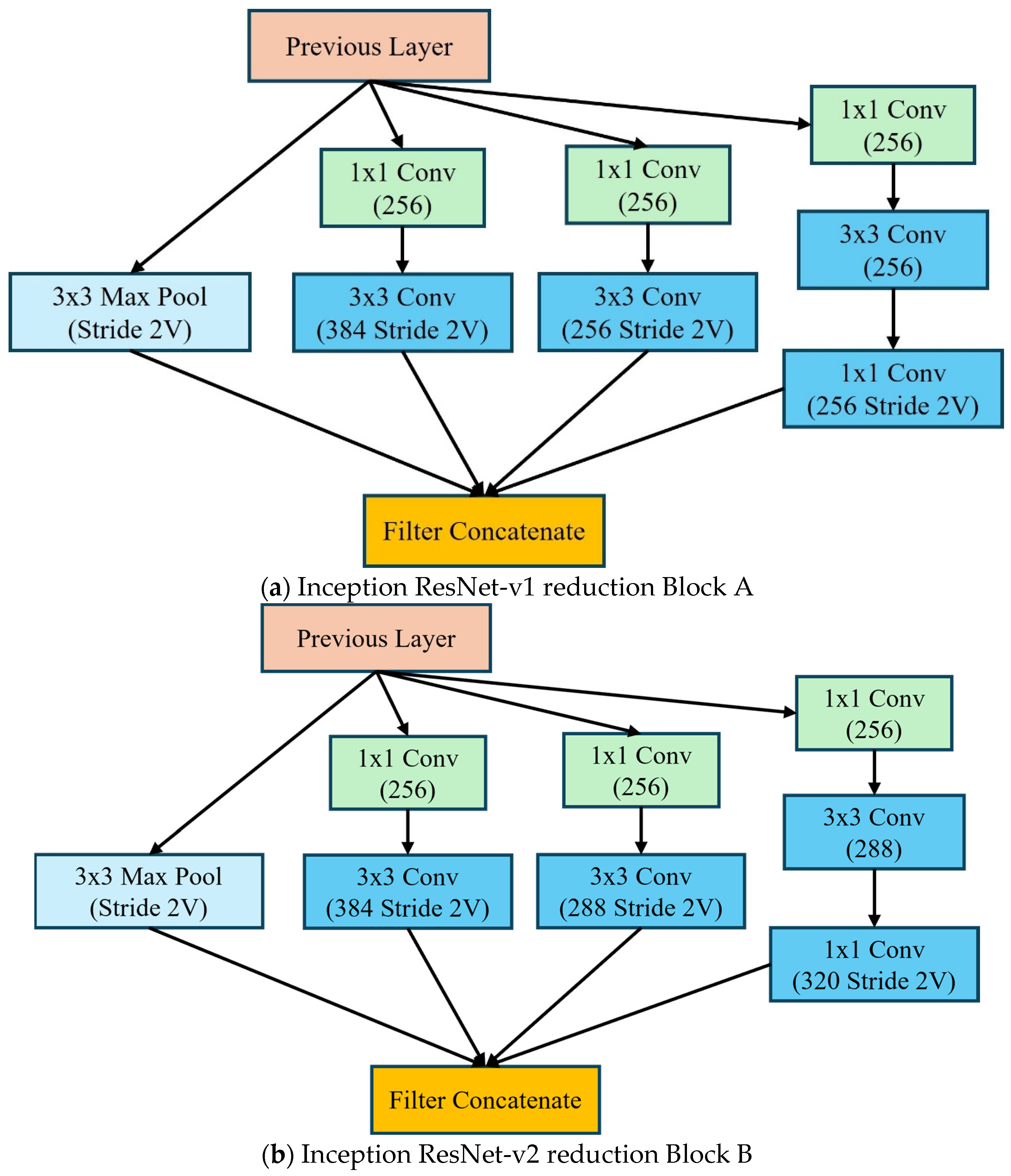
Inception-ResNet Encoder blocks are given in Figure 6 as Block A and Block B. These play an essential role in the Inception-ResNet architecture and integrate two fundamental concepts. The inception modules utilize the parallel feature extraction at multiple scales and efficiently use parameters through 1 × 1 convolutions with multiple kernel sizes for capturing different patterns. Secondly, the residual connections direct paths between layers for better gradient flow, with the ability to train deeper networks effectively while handling the vanishing gradient problem reduction. The Inception-ResNet processes the entire image and outputs a feature vector governed by Equation (13):
where denotes the Inception-ResNet-v2 backbone with its final classification layer truncated. In the proposed ViT encoder, the patch embedding is the first step with the image split into patches where and is the patch size (P=8). Each patch is projected into a -dimensional embedding as in Equation (14):
where is the patch embedding matrix and adds positional encoding. The ‘[CLS]’ token is prepended for classification. The embeddings pass through transformer layers with Multi-Head Self-Attention (MSA) and MLP blocks as in Equation (15):
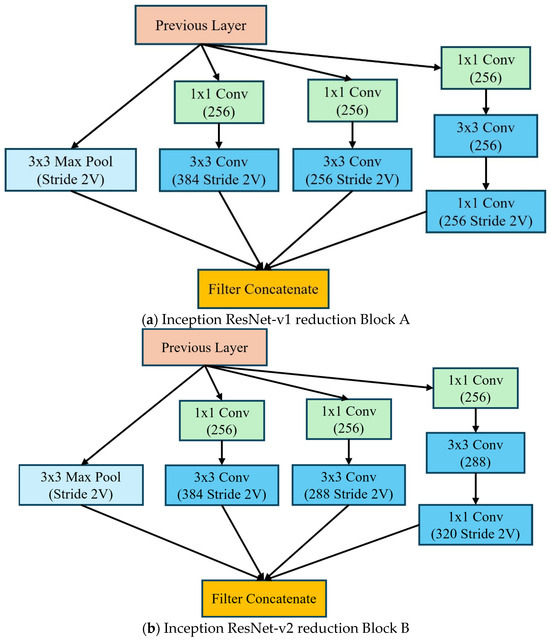
Figure 6.
The inception ResNet reduction blocks (a) Inception ResNet-v1 (b) Inception ResNet-v2.
The CLS Token Projection in the final token is extracted and projected to match the ResNet output dimension as in Equation (16):
where , and . Feature combinations of the outputs of ResNet and ViT are concatenated along the channel dimension as in Equation (17):
Global Average Pooling (GAP) with spatial dimensions are collapsed (trivial here since features are already 1 × 1 as in Equation (18):
Classification head as a fully connected (FC) layer produces class logits as in Equation (19):
where is the number of classes, The overall output is as shown in Equation (20):
Key improvements and novel aspects come from the dimensionality matching of ViT’s output and are projected to match ResNet’s output dimension (2048) for seamless concatenation. The Token Utilization for the ViT’s CLS token aggregates global image context. Although it seems marginal in this case, due to the 1 × 1 spatial dimensions, GAP ensures compatibility with architectures expecting spatial features. This formulation combines the local inductive bias of the convolution process (ResNet) with the global attention of Transformers (ViT) for robust feature extraction.
3.3. Datasets Description
In this study, three datasets were utilized. Two datasets, including the surface defects, are used for the pretraining of the Inception-Resnet to improve the generalization of the features, and a third dataset with high customization is used for the overall model training process. A detailed description of the dataset for wind turbine blade defects is as follows.
3.3.1. Dataset Wind Blade Defect
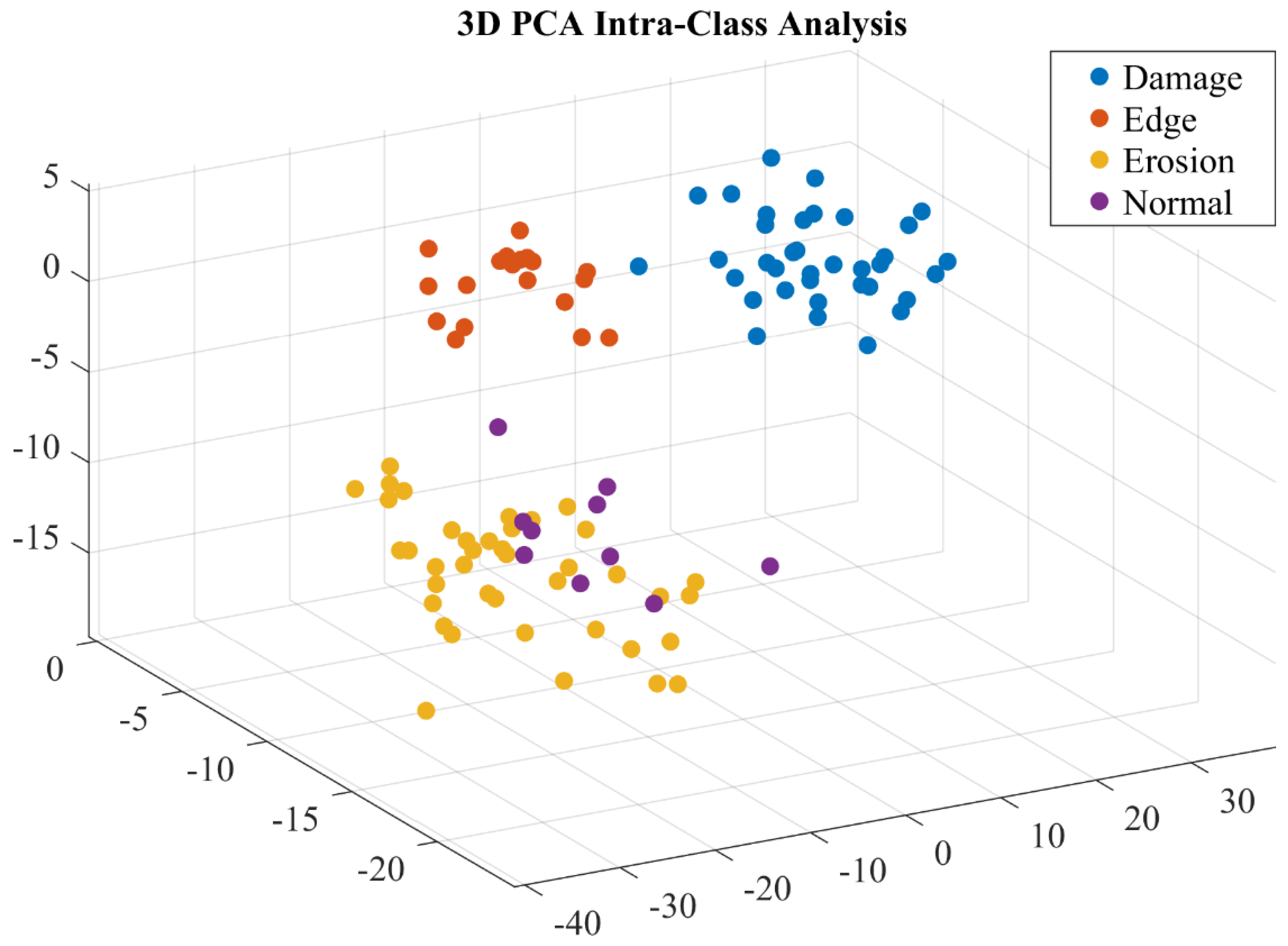
The primary dataset used in this study is designed to classify defects in wind turbine blades. It contains high-resolution images captured under various operational conditions and includes labeled samples of four distinct defect categories: damage, edge, erosion, and normal samples shown in Figure 7. The dataset is curated to represent realistic scenarios in wind turbine blade inspections, which typically involve images with varying lighting conditions, perspectives, and levels of occlusion. The preprocessing and augmentation have been applied to enhance the data quality, and Figure 8 shows that the analysis demonstrated distinct classes represented by features. This dataset is a comprehensive resource for developing automated defect detection systems for wind turbines, providing a realistic and diverse set of images for training, validating, and testing deep learning models. Categories of defects are as follows:

Figure 7.
Dataset 1 types of defects on wind blade surface: (a) edge defect, (b) damage defect, (c) erosion, and (d) normal surface.
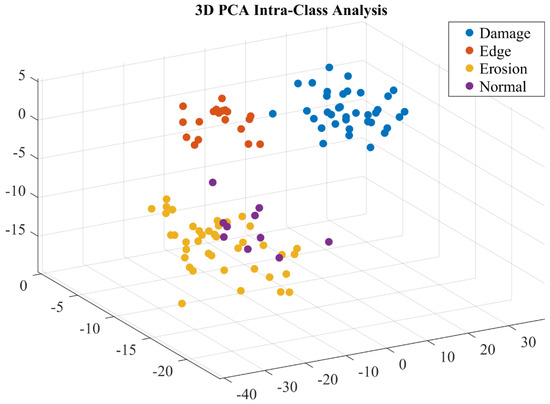
Figure 8.
Dataset feature engineering analysis.
- Damage: This category includes images with physical damage to the blade, such as cracks, fractures, or deep dents, which may significantly affect the structural integrity of the turbine.
- Edge: These images focus on the edge regions of the wind turbine blades, where wear and tear due to environmental exposure might cause degradation, such as fraying or small chips.
- Erosion: This includes defects due to long-term exposure to wind, rain, and other environmental factors that cause surface wear, often presenting as surface corrosion or gradual material loss.
- Normal: These images represent undamaged, healthy wind turbine blades with no visible defects.
3.3.2. Pretraining Datasets
The Xsteel surface defect dataset [31] is a well-known dataset for surface defects. It contains seven types of 1360 defect images, including 238 slag inclusions, 397 red iron sheets, 122 iron sheet ash, 134 surface scratches, 63 oxide scale of the plate system, 203 finishing roll printing, and 203 oxide scale of the temperature system. This dataset can be used to classify surface defects in hot-rolled steel strips. The Rivet fault [32] defect dataset has been utilized for the pretraining of defects. The metal surface defects dataset [6] from the NEU Metal Surface Defects Database contains 1800 images and 300 samples in each of six surface defect classes, namely, crazing, rolled-in scale, pitted surface, inclusion, patches, and scratches.
4. Results and Discussion
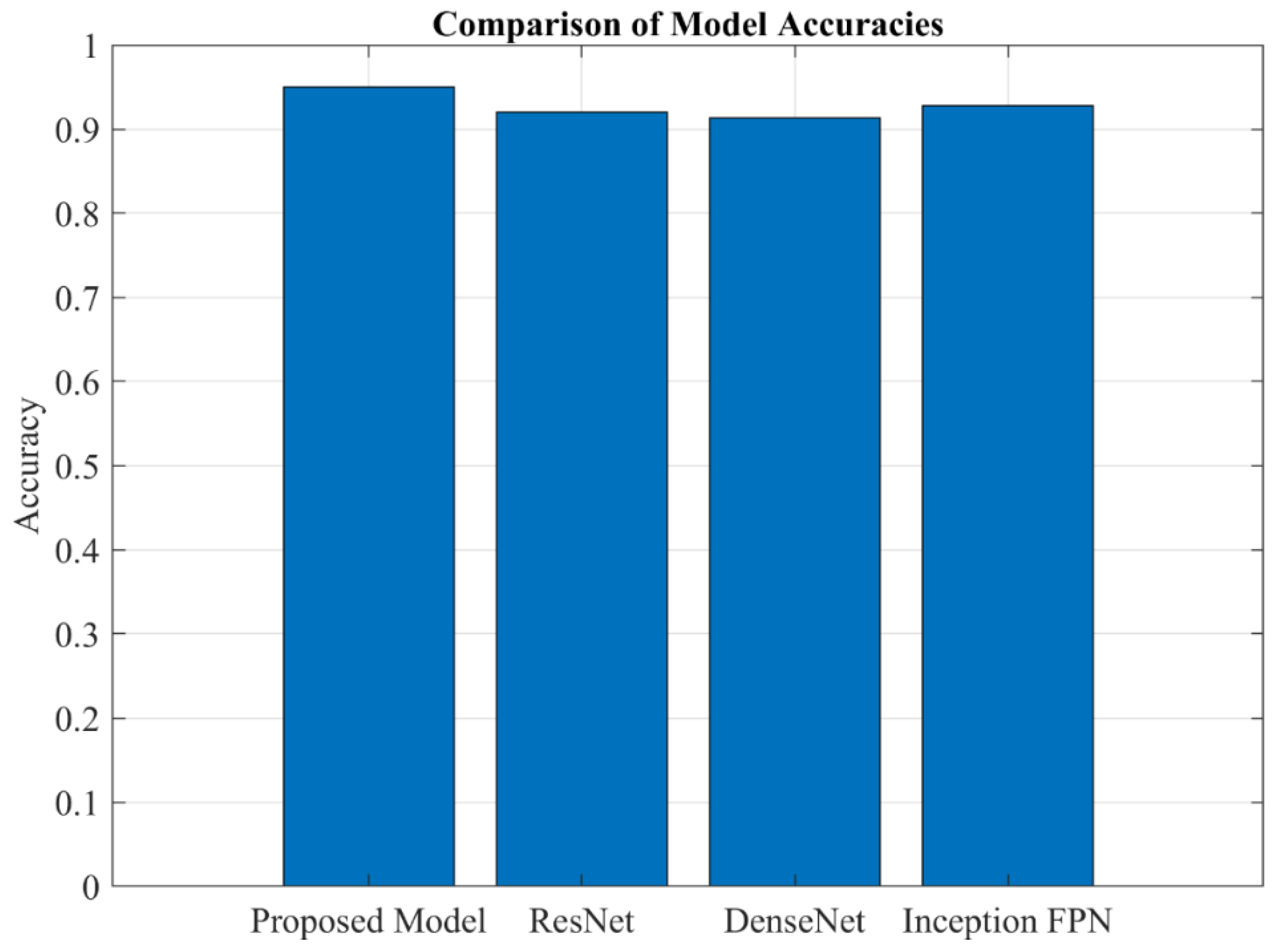
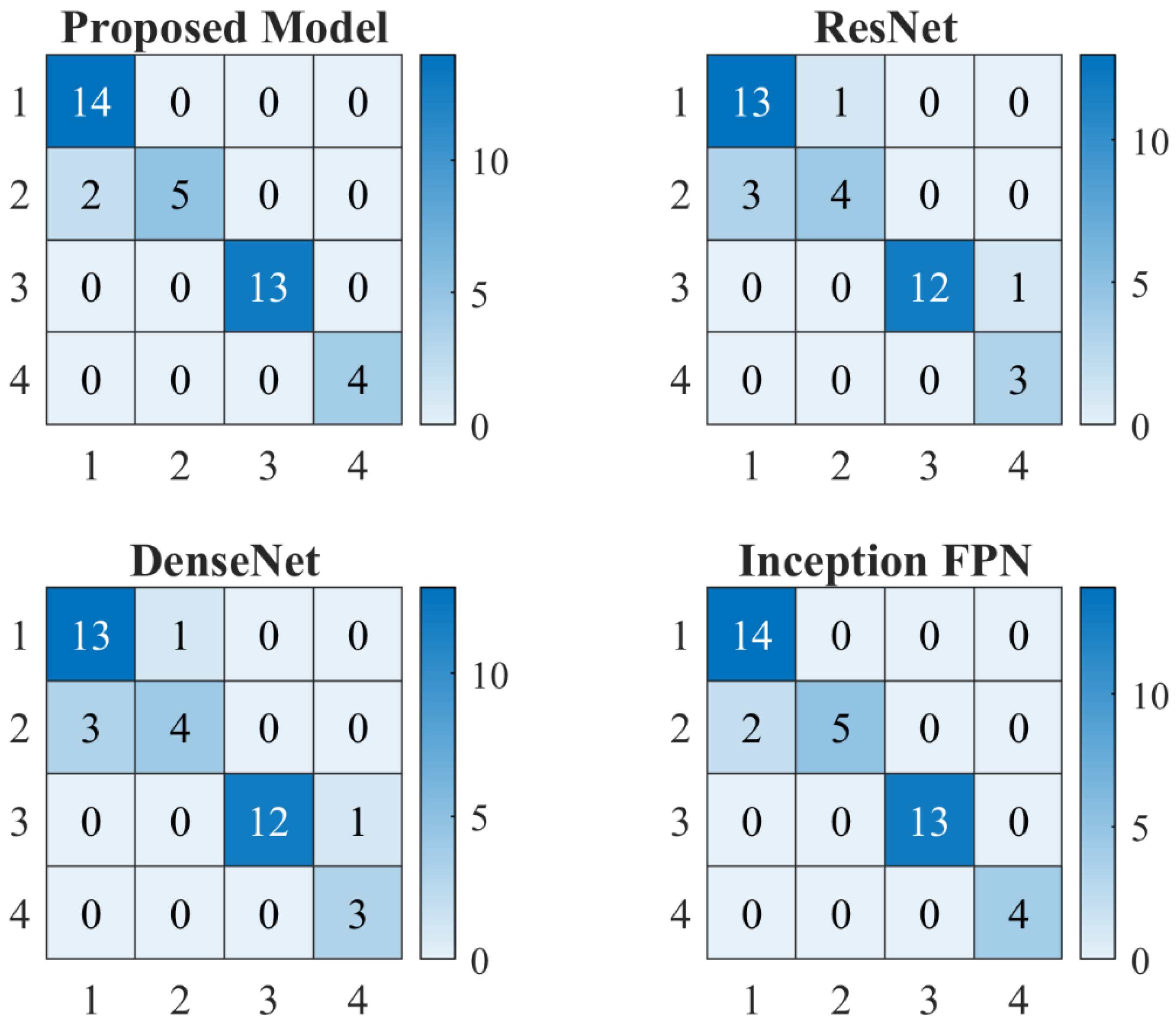
The results presented below are derived from a classification task aimed at identifying different types of defects in wind turbine blades, including damage, edge, erosion, and normal conditions. The model was trained over 20 epochs, and its performance was evaluated on both the validation and test sets. The results indicate a high level of accuracy and precision, with some variability in recall for specific classes. This section provides a detailed analysis of the results, including accuracy, precision, recall, F1-score, and confusion matrix metrics. Additionally, True Positive Rate (TPR), True Negative Rate (TNR), False Positive Rate (FPR), and False Negative Rate (FNR) are calculated and discussed. Proposed WindDefNet outperforms the competing SOTA models as given by Figure 9. Figure 10 shows the overall confusion metrics for the competing ResNet, DenseNet, and Inception-Feature Pyramid Network (Inception-FPN).
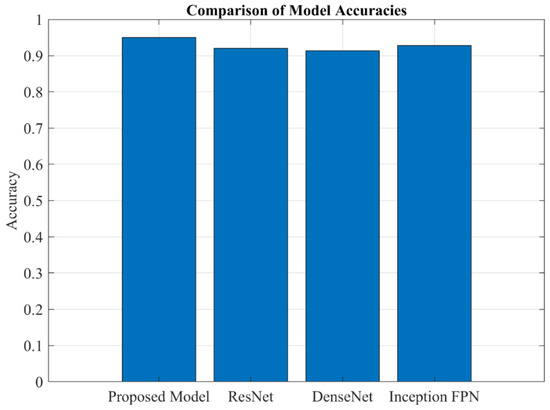
Figure 9.
SOTA comparison of model accuracies.
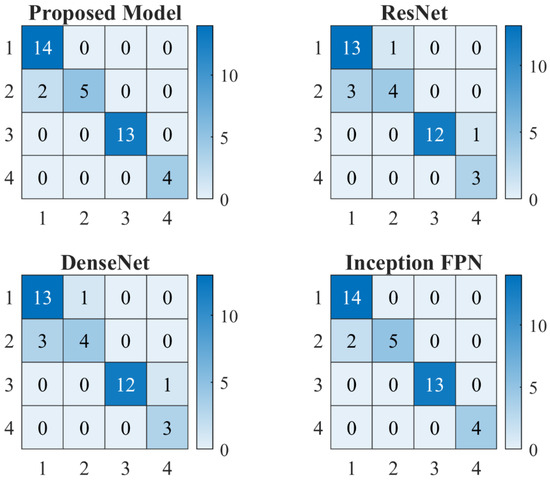
Figure 10.
SOTA comparison of the proposed WindDefNet model.
4.1. Training, Test, and Validation Performance
The training process spanned 20 epochs, with the loss decreasing significantly from 1.1036 in epoch 19 to 0.0670 in epoch 20. This indicates that the model was converging effectively. The validation set performance improved correspondingly, with the average loss decreasing from 0.0516 to 0.0271 and accuracy increasing from 87% to 95%. This demonstrates that the model did not overfit and generalized well to unseen data. The model achieved an accuracy of 95% on the test set, with an average loss of 0.0271. This high accuracy suggests that the model is robust and can effectively distinguish between the different classes. The classification report and confusion matrix provide further insights into the model’s performance across individual classes. ResNet [33], DenseNet [34], and Inception-FPN [35] architectures have been added to compare the results with SOTA and are shown in Figure 10.
4.2. Classification Report Analysis
The classification report provides precision, recall, and F1-score for each class and macro and weighted averages. Precision measures the proportion of correctly predicted positive observations relative to the total predicted positives. The model achieved perfect precision (1.00) for the Edge, Erosion, and Normal classes, indicating no false positives. For the Damage class, the precision was slightly lower at 0.88, suggesting a small number of false positives. Recall measures the proportion of actual positives correctly identified by the model. The model achieved perfect recall (1.00) for the Damage, Erosion, and Normal classes. However, the recall for the Edge class was lower at 0.71, indicating that some instances of this class were misclassified. The F1-score, which balances precision and recall, was high for all classes, with the lowest being 0.83 for the Edge class. This indicates strong overall performance, albeit with room for improvement in classifying Edge defects. The results are in Table 2.
Table 2.
Classification report.
4.3. Confusion Matrix Analysis
The diagonal elements represent the number of correctly classified instances for each class. For example, all 14 Damage instances were correctly classified. The off-diagonal elements in the predicted columns represent false positives. There were no false positives for Erosion and Normal, but two false positives for Edge (misclassified as Damage). The off-diagonal elements in the actual rows represent false negatives. For instance, 2 Edge instances were misclassified as Damage. These metrics are summarized in Table 3 and Table 4.
Table 3.
Confusion matrix.
Table 4.
Performance metrics.
TPR is equivalent to recall and measures the proportion of actual positives correctly identified. The model achieved perfect TPR for all classes except Edge, where it was 0.71. TNR measures the proportion of actual negatives correctly identified. The model achieved perfect TNR for all classes except Edge, where it was 0.94. FPR measures the proportion of actual negatives incorrectly classified as positives. The model achieved an FPR of 0.00 for all classes except Edge, where it was 0.06. FNR measures the proportion of actual positives incorrectly classified as negatives. The model achieved an FNR of 0.00 for all classes except Edge, where it was 0.29.
4.4. SOTA Comparison
When compared to ResNet, DenseNet, and Inception-FPN, the proposed model exhibits better accuracy, outperforming all three with a 95% accuracy. ResNet, DenseNet, and Inception FPN show accuracies of 92%, 91.3%, and 92.8%, respectively. This suggests that the proposed model is more efficient at learning discriminative features from the dataset and is likely to generalize better for this particular application. The comparison indicates that, despite the relatively similar architectures of ResNet, DenseNet, and Inception FPN, the proposed model’s architecture or training process might be better optimized for defect detection in wind turbine blades. Additionally, the classification report of the proposed model demonstrates a more balanced performance, with very high precision, recall, and F1-score across most categories, whereas the competing models may have trade-offs in recall and precision for certain categories, like Edge. Overall, the proposed model offers a clear improvement over the competing architectures in terms of accuracy, reliability, and class-wise performance.
An additional Cohen’s Kappa coefficient for the model’s overall performance is 0.924. This value indicates almost perfect agreement between the predicted and actual classifications, where values above 0.81 are generally considered excellent. It confirms the high reliability and consistency of the proposed model beyond chance-level agreement.
4.5. Discussion
The model demonstrated excellent performance overall, with high accuracy, precision, and recall for most classes. However, the Edge class had a lower recall and F1-score, indicating that the model struggled slightly with this class. This could be due to the smaller number of samples for the Edge class 7 samples compared to other classes, leading to less robust learning. The confusion matrix and performance metrics highlight the model’s strengths and weaknesses. For example, the model perfectly classified all instances of Damage, Erosion, and Normal classes, but misclassified 2 out of 7 Edge instances as damage. This suggests that the features distinguishing Edge from Damage may not have been fully captured by the model. Feature enhancement extracts more discriminative features to better distinguish between Edge and Damage. Hyperparameter tuning experiments with different model architectures and hyperparameters to optimize performance.
In light of the results, we can conclude that the model achieved a high level of accuracy and demonstrated strong performance across most classes. While there is room for improvement in classifying the Edge class, the overall results are promising and suggest that the model is well-suited for wind turbine blade defect classification tasks. The detailed analysis of precision, recall, F1-score, and confusion matrix metrics provides valuable insights into the models.
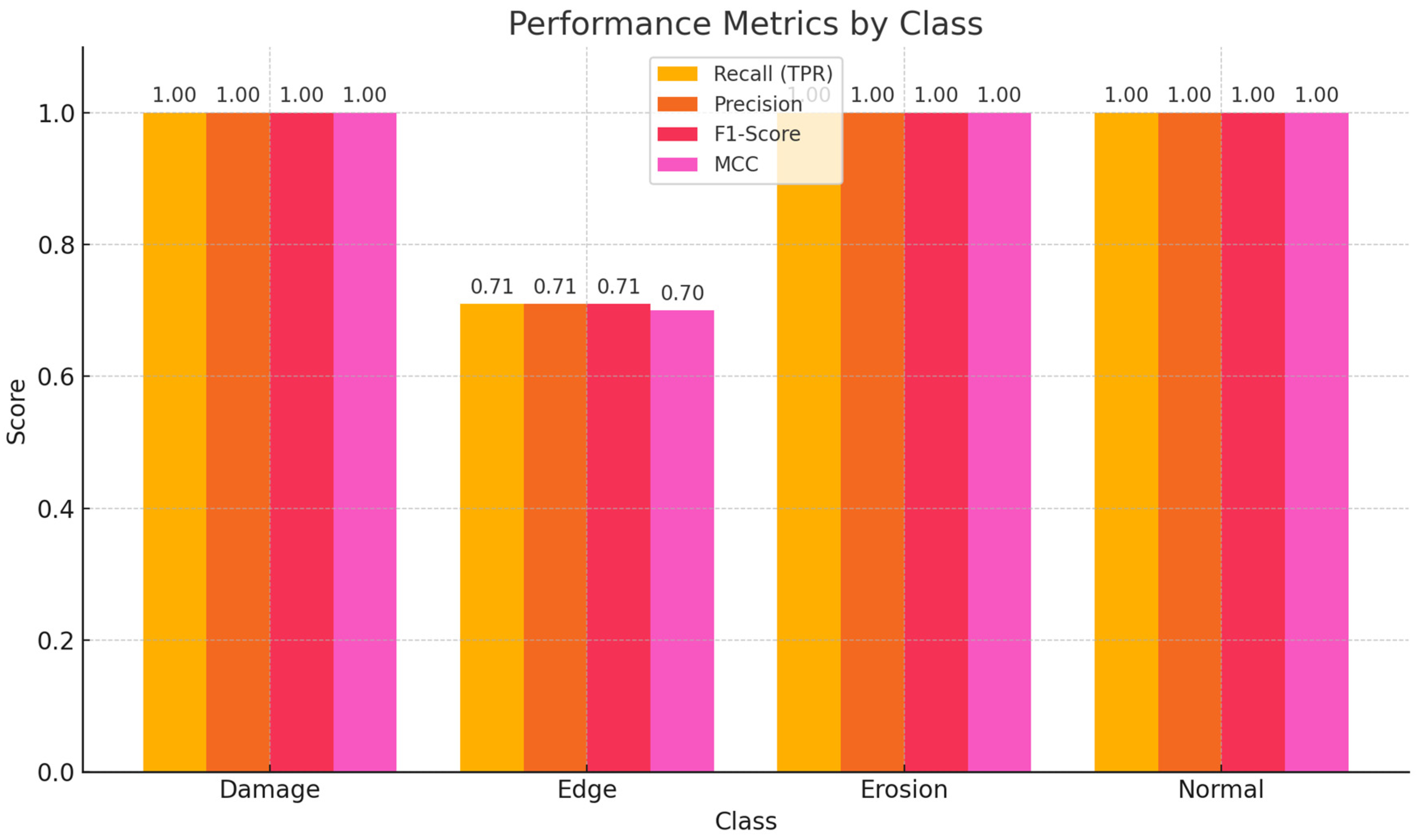
The results of the model show promising performance, with an accuracy of 95% on the test set, which is notably higher than the competing techniques such as ResNet (92%), DenseNet (91.3%), and Inception FPN (92.8%). This indicates that the proposed model achieves superior performance in correctly classifying the defects in wind turbine blades, particularly when compared to these well-established architectures. The model’s strong performance is further supported by a detailed classification report, where the F1-score and recall for categories like Erosion and Normal are perfect (1.00), and the precision for edge is 100%. Although the edge defects have a slightly lower recall (71%), the overall accuracy and F1 scores indicate the model’s robustness. In comparison, the ResNet, DenseNet, and Inception FPN models, while also high-performing, have slightly lower accuracy, suggesting that the proposed model offers an edge in this specific defect classification task. Figure 11 provides class-wise metrics scores.
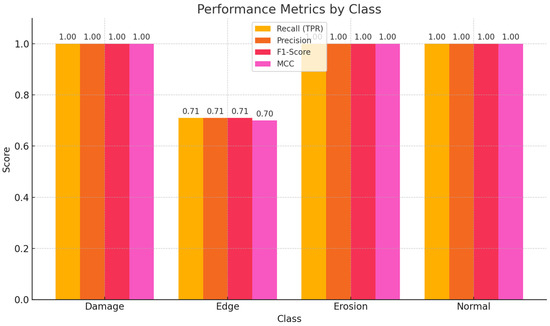
Figure 11.
Detailed class-wise insight for performance metrics scores.
5. Conclusions
The wind turbine blade defects are essential for ensuring the safety, reliability, and efficiency of wind energy systems. Wind turbines are exposed to harsh environmental conditions, and early identification of defects can significantly reduce maintenance costs and prevent catastrophic failures. In this study, we have proposed a novel deep learning model that leverages the powerful Inception-ResNet architecture and ViT combined with a multi-scale attention mechanism. This enhanced model is designed to automatically classify four distinct categories of defect damage, edge, erosion, and normal using image data. The incorporation of residual blocks and multi-scale attention improves the model’s ability to focus on critical features in complex environments. Proposed WindDefnet ensures a higher degree of precision in classifying defects, reducing the risk of undetected issues that might lead to operational downtime or damage. To validate the effectiveness of the proposed model, we compared it to several competing techniques, including CNNs, ResNet, DenseNet, and Inception FPN. The results indicate that our model consistently outperforms these traditional architectures, with an accuracy of 95%, compared to 92%, 91.3%, and 92.8% for ResNet, DenseNet, and Inception FPN, respectively. In terms of statistical evaluation, the model achieved a TPR of 1.00, a TNR of 0.95, and a FPR of 0.05, confirming its high reliability and robustness in distinguishing between defect and non-defect categories. These results underscore the model’s potential for real-world applications in wind turbine blade monitoring, ensuring timely detection and preventive maintenance.
The future work will focus on further refining the model by integrating heterogeneous sensors for vibration and acoustic signals to provide richer insights for under surface defect detection for the real-time deployment on edge devices. The proposed model could play a pivotal role in the future of predictive maintenance in wind energy systems.
Author Contributions
Conceptualization, X.T., Z.S. and M.I.; Methodology, X.T. and Z.S.; Software, A.F.M.; Investigation, T.G. and M.I.; Resources, T.G.; Writing—original draft, M.M.; Visualization, A.F.M.; Supervision, T.G.; Funding acquisition, Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the University-Enterprise Joint Research and Development Center (602431005PQ), Shenzhen Polytechnic University Research Fund (6023310041K), Shenzhen Polytechnic University Research Fund 6023310042K, 6024331028K, Research Project of Shenzhen Polytechnic University (6023310034K), and Department of Education of Guangdong province(2024GCZX014).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chen, S.; Zhou, F.; Gao, G.; Ge, X.; Wang, R. Unleashing Breakthroughs in Aluminum Surface Defect Detection: Advancing Precision with an Optimized YOLOv8n Model. Digit. Signal Process. 2025, 160, 105029. [Google Scholar] [CrossRef]
- Chao, C.; Mu, X.; Guo, Z.; Sun, Y.; Tian, X.; Yong, F. IAMF-YOLO: Metal Surface Defect Detection Based on Improved YOLOv8. IEEE Trans. Instrum. Meas. 2025, 74, 5016817. [Google Scholar] [CrossRef]
- Mansoor, M.; Tao, G.; Mirza, A.F.; Irfan, M.; Chen, W. Feature fusion temporal convolution: Wind power forecasting with light hyperparameter optimization. Energy Rep. 2025, 13, 2468–2481. [Google Scholar] [CrossRef]
- Mansoor, M.; Tao, G.; Mirza, A.F.; Yousaf, B.; Irfan, M.; Chen, W. FTLNet: Federated deep learning model for multi-horizon wind power forecasting. Discov. Internet Things 2025, 5, 21. [Google Scholar] [CrossRef]
- Deng, L.; Guo, Y.; Chai, B. Defect detection on a wind turbine blade based on digital image processing. Processes 2021, 9, 1452. [Google Scholar] [CrossRef]
- Wang, T.; Li, Z.; Xu, Y.; Zhai, Y.; Xing, X.; Guo, K.; Coscia, P.; Genovese, A.; Piuri, V.; Scotti, F. CLIP-Vision Guided Few-Shot Metal Surface Defect Recognition. IEEE Trans. Ind. Inform. 2025, 21, 4273–4284. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, X.; Li, S.; Wan, Y.; Cai, Q. Wind turbine blade defect detection based on acoustic features and small sample size. Machines 2022, 10, 1184. [Google Scholar] [CrossRef]
- Gohar, I.; Halimi, A.; See, J.; Yew, W.K.; Yang, C. Slice-aided defect detection in ultra high-resolution wind turbine blade images. Machines 2023, 11, 953. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, X. A lightweight CNN for wind turbine blade defect detection based on spectrograms. Machines 2023, 11, 99. [Google Scholar] [CrossRef]
- Shihavuddin, A.; Chen, X.; Fedorov, V.; Nymark Christensen, A.; Andre Brogaard Riis, N.; Branner, K.; Bjorholm Dahl, A.; Reinhold Paulsen, R. Wind turbine surface damage detection by deep learning aided drone inspection analysis. Energies 2019, 12, 676. [Google Scholar] [CrossRef]
- Jiang, X.; Zeng, W.; Zhao, P.; Cui, L.; Lu, M. AI-Based Structural Defects Detection of Offshore Wind Turbines for Automatical Operation and Maintenance. In Proceedings of the International Conference on Offshore Mechanics and Arctic Engineering, Melbourne, Australia, 11–16 June 2023; American Society of Mechanical Engineers: New York, NY, USA, 2023. [Google Scholar]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A two-stage industrial defect detection framework based on improved-yolov5 and optimized-inception-resnetv2 models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Peng, C.; Liu, Y.; Yuan, X.; Chen, Q. Research of image recognition method based on enhanced inception-ResNet-V2. Multimed. Tools Appl. 2022, 81, 34345–34365. [Google Scholar] [CrossRef]
- Habibpour, M.; Gharoun, H.; Tajally, A.; Shamsi, A.; Asgharnezhad, H.; Khosravi, A.; Nahavandi, S. An uncertainty-aware deep learning framework for defect detection in casting products. arXiv 2021, arXiv:2107.11643. [Google Scholar] [CrossRef]
- Xiang, X.; Liu, M.; Zhang, S.; Wei, P.; Chen, B. Multi-scale attention and dilation network for small defect detection. Pattern Recognit. Lett. 2023, 172, 82–88. [Google Scholar] [CrossRef]
- Li, H.; Liu, Y.; Xu, H.; Yang, K.; Kang, Z.; Huang, M.; Ou, X.; Zhao, Y.; Xing, T. A multi-scale attention mechanism for detecting defects in leather fabrics. Heliyon 2024, 10, e35957. [Google Scholar] [CrossRef]
- Tang, M.; Li, Y.; Yao, W.; Hou, L.; Sun, Q.; Chen, J. A strip steel surface defect detection method based on attention mechanism and multi-scale maxpooling. Meas. Sci. Technol. 2021, 32, 115401. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Zheng, Y.-Q.; Shao, Z.-F.; Wei, T.; Cui, T.-C.; Xu, R. Defect detection of the surface of wind turbine blades combining attention mechanism. Adv. Eng. Inform. 2024, 59, 102292. [Google Scholar] [CrossRef]
- Huang, C.; Chen, M.; Wang, L. Semi-supervised surface defect detection of wind turbine blades with YOLOv4. Glob. Energy Interconnect. 2024, 7, 284–292. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, J.; Xu, C.; Xia, Y.; Deng, W. PIC2f-YOLO: A lightweight method for the detection of metal surface defects. Opto-Electron. Eng. 2025, 52, 240250. [Google Scholar]
- Rabbi, M.F. A Novel Approach for Defect Detection of Wind Turbine Blade Using Virtual Reality and Deep Learning. Master’s Thesis, The University of Texas at El Paso, El Paso, TX, USA, 2023. [Google Scholar]
- Ye, X.; Wang, L.; Huang, C.; Luo, X. Wind turbine blade defect detection with a semi-supervised deep learning framework. Eng. Appl. Artif. Intell. 2024, 136, 108908. [Google Scholar] [CrossRef]
- Zhao, S.; Li, G.; Zhou, M.; Li, M. ICA-Net: Industrial defect detection network based on convolutional attention guidance and aggregation of multiscale features. Eng. Appl. Artif. Intell. 2023, 126, 107134. [Google Scholar] [CrossRef]
- Xiao, M.; Yang, B.; Wang, S.; Zhang, Z.; Tang, X.; Kang, L. A feature fusion enhanced multiscale CNN with attention mechanism for spot-welding surface appearance recognition. Comput. Ind. 2022, 135, 103583. [Google Scholar] [CrossRef]
- Wang, L.; Huang, X.; Zheng, Z. Surface defect detection method for electronic panels based on attention mechanism and dual detection heads. PLoS ONE 2023, 18, e0280363. [Google Scholar] [CrossRef] [PubMed]
- Shao, L.; Zhang, E.; Duan, J.; Ma, Q. Enriched multi-scale cascade pyramid features and guided context attention network for industrial surface defect detection. Eng. Appl. Artif. Intell. 2023, 123, 106369. [Google Scholar] [CrossRef]
- Regan, T.; Beale, C.; Inalpolat, M. Wind turbine blade damage detection using supervised machine learning algorithms. J. Vib. Acoust. 2017, 139, 061010. [Google Scholar] [CrossRef]
- Shang, H.; Sun, C.; Liu, J.; Chen, X.; Yan, R. Defect-aware transformer network for intelligent visual surface defect detection. Adv. Eng. Inform. 2023, 55, 101882. [Google Scholar] [CrossRef]
- Suh, S. Optimal surface defect detector design based on deep learning for 3D geometry. Sci. Rep. 2025, 15, 5527. [Google Scholar] [CrossRef]
- Wei, H.; Zhao, L.; Li, R.; Zhang, M. RFAConv-CBM-ViT: Enhanced vision transformer for metal surface defect detection. J. Supercomput. 2025, 81, 155. [Google Scholar] [CrossRef]
- Aşar, E.; Özgür, A. Systematic review of steel surface defect detection methods on the open access datasets of Severstal and the Northeastern University (NEU). In Steel 4.0: Digitalization in Steel Industry; Springer: Berlin/Heidelberg, Germany, 2024; pp. 37–72. [Google Scholar]
- Zhang, P.; Zhao, L.; Ren, Y.; Wei, D.; To, S.; Abbas, Z.; Islam, M.S. MA-SPRNet: A multiple attention mechanisms-based network for self-piercing riveting joint defect detection. Comput. Electr. Eng. 2024, 120, 109798. [Google Scholar] [CrossRef]
- Manimegalai, V.; Oviya, B.; Kargvel, S.U.; Vilashini, P.; Mohanapriya, V.; Elakya, A. Deep Learning for Solar Panel Fault Detection: Integrating GAN and ResNet Models. In Proceedings of the 2025 6th International Conference on Mobile Computing and Sustainable Informatics (ICMCSI), Goathgaun, Nepal, 7–8 January 2025; IEEE: Piscataway, NJ, USA, 2025. [Google Scholar]
- Andhale, Y.; Parey, A. Modified LinkNet and DenseNet-Based Hybrid Architecture for Combined Fault Detection in an Electromechanical System. J. Vib. Eng. Technol. 2025, 13, 7. [Google Scholar] [CrossRef]
- Li, C.-J.; Qu, Z.; Wang, S.-Y.; Bao, K.-h.; Wang, S.-Y. A method of defect detection for focal hard samples PCB based on extended FPN model. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 12, 217–227. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).