
SiMBA-Augmented Physics-Informed Neural Networks for Industrial Remaining Useful Life Prediction


Abstract
1. Introduction
- (1)
- Precise degradation feature extraction: Leveraging SiMBA’s frequency-domain channel mixing and selective state-space modeling to capture temporal degradation patterns from multi-source sensor data.
- (2)
- Physics-guided representation learning: Embedding physical equations to constrain network learning, ensuring implicit representations align with real-world degradation laws, thereby improving generalization in data-scarce scenarios.
- (3)
- Dynamic fusion mechanism: Coordinating data-driven and physics-driven information flow to prevent feature conflicts. The study provides theoretical foundations for intelligent maintenance of complex industrial systems, with significant engineering applicability and academic value.
- (4)
- The C-MAPSS dataset tests reveal the SiMBA-PINN model’s excellent performance.
2. Materials and Methods
2.1. SiMBA-PINN Framework
2.2. Dataset
2.3. Data Processing and Feature Selection
2.4. Evaluation Indicators
2.5. Experimental Setup
3. Results and Discussion
3.1. Results
3.2. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El-Dalahmeh, M.; Al-Greer, M.; El-Dalahmeh, M.; Bashir, I. Physics-based model informed smooth particle filter for remaining useful life prediction of lithium-ion battery. Measurement 2023, 214, 112838. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, W.; Yan, R. Remaining Useful Life Prediction of Aero-Engine Based on Data-Driven Approach Using LSTM Network. IEEE Access 2022, 10, 25359–25370. [Google Scholar]
- Liang, P.; Li, Y.; Wang, B.; Yuan, X.; Zhang, L. Remaining useful life prediction via a deep adaptive transformer framework enhanced by graph attention network. Int. J. Fatigue 2023, 174, 107722. [Google Scholar] [CrossRef]
- Shi, J.; Zhong, J.; Zhang, Y.; Xiao, B.; Xiao, L.; Zheng, Y. A dual attention LSTM lightweight model based on exponential smoothing for remaining useful life prediction. Reliab. Eng. Syst. Saf. 2024, 243, 109821. [Google Scholar] [CrossRef]
- Maulana, F.; Starr, A.; Ompusunggu, A.P. Explainable data-driven method combined with bayesian filtering for remaining useful lifetime prediction of aircraft engines using nasa cmapss datasets. Machines 2023, 11, 163. [Google Scholar] [CrossRef]
- Liao, X.; Chen, S.; Wen, P.; Zhao, S. Remaining useful life with self-attention assisted physics-informed neural network. Adv. Eng. Inform. 2023, 58, 102195. [Google Scholar] [CrossRef]
- Zhu, Q.; Shi, Y.; Feng, Y.; Wang, Y. Physics-Informed Neural Networks for RUL Prediction. In Proceedings of the 2024 China Automation Congress (CAC), Qingdao, China, 1–3 November 2024; IEEE: New York, NY, USA, 2024; pp. 6361–6366. [Google Scholar]
- Lu, S.; Gao, Z.; Xu, Q.; Jiang, C.; Xie, T.; Zhang, A. Remaining useful life prediction via interactive attention-based deep spatio-temporal network fusing multisource information. IEEE Trans. Ind. Electron. 2023, 71, 8007–8016. [Google Scholar] [CrossRef]
- Feng, J.; Cai, F.; Li, H.; Huang, K.; Yinet, H. A data-driven prediction model for the remaining useful life prediction of lithium-ion batteries. Process Saf. Environ. Prot. 2023, 180, 601–615. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis G, E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Cofre-Martel, S.; Lopez Droguett, E.; Modarres, M. Remaining useful life estimation through deep learning partial differential equation models: A framework for degradation dynamics interpretation using latent variables. Shock Vib. 2021, 2021, 9937846. [Google Scholar] [CrossRef]
- Sun, B.; Pan, J.; Wu, Z.; Xia, Q.; Wang, Z.; Ren, Y.; Yang, D.; Guo, X.; Feng, Q. Adaptive evolution enhanced physics-informed neural networks for time-variant health prognosis of lithium-ion batteries. J. Power Sources 2023, 556, 232432. [Google Scholar] [CrossRef]
- Wang, F.; Zhai, Z.; Zhao, Z.; Di, Y.; Chen, X. Physics-informed neural network for lithium-ion battery degradation stable modeling and prognosis. Nat. Commun. 2024, 15, 4332. [Google Scholar] [CrossRef] [PubMed]
- Qin, Y.; Liu, H.; Wang, Y.; Mao, Y. Inverse physics–informed neural networks for digital twin–based bearing fault diagnosis under imbalanced samples. Knowl.-Based Syst. 2024, 292, 111641. [Google Scholar] [CrossRef]
- Ran, B.; Peng, Y.; Wang, Y. Bearing degradation prediction based on deep latent variable state space model with differential transformation. Mech. Syst. Signal Process. 2024, 220, 111636. [Google Scholar] [CrossRef]
- Qiao, Y.; Yu, Z.; Guo, L.; Chen, S.; Zhao, Z.; Sun, M.; Wu, Q.; Liu, J. Vl-mamba: Exploring state space models for multimodal learning. arXiv 2024, arXiv:2403.13600. [Google Scholar]
- Dao, T.; Gu, A. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. arXiv 2024, arXiv:2405.21060. [Google Scholar]
- Patro, B.N.; Agneeswaran, V.S. Simba: Simplified mamba-based architecture for vision and multivariate time series. arXiv 2024, arXiv:2403.15360. [Google Scholar]
- Arnold, T. A method of analysing the behaviour of linear systems in terms of time series. J. Inst. Electr. Eng.-Part IIA Autom. Regul. Servo Mech. 1947, 94, 130–142. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; IEEE: New York, NY, USA, 2008; pp. 1–9. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; IEEE: New York, NY, USA, 2017; pp. 88–95. [Google Scholar]
- Li, M.; Luo, M.; Ke, T. Interpretable Remaining Useful Life Prediction Based on Causal Feature Selection and Deep Learning. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; Springer Nature: Singapore, 2024; pp. 148–160. [Google Scholar]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 32, 1997–2006. [Google Scholar] [CrossRef]
- Natsumeda, M. Remaining useful life estimation with end-to-end learning from long runto-failure data. In Proceedings of the 2022 61st Annual Conference of the Society of Instrument and Control Engineers (SICE), Kumamoto, Japan, 6–9 September 2022; IEEE: New York, NY, USA, 2022; pp. 542–547. [Google Scholar]
- Keshun, Y.; Guangqi, Q.; Yingkui, G. A 3-D attention-enhanced hybrid neural network for turbofan engine remaining life prediction using CNN and BiLSTM models. IEEE Sens. J. 2023, 24, 21893–21905. [Google Scholar] [CrossRef]
- Li, M.; Cui, H.; Luo, M.; Ke, T. A Lightweight Physics-Informed Neural Network Model Based on Causal Discovery for Remaining Useful Life Prediction. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; Springer Nature: Singapore, 2024; pp. 125–136. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | C-MAPSS | |||
|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | |
| Training set | 100 | 260 | 100 | 249 |
| Testing set | 100 | 259 | 100 | 248 |
| Operating condition | 1 | 6 | 1 | 6 |
| Fault state | 1 | 1 | 2 | 2 |
| Variable Name | ID |
|---|---|
| Sensor signal | 2, 4, 6, 7, 8, 9, 11, 12, 13, 14, 15, 17, 20, 21 |
| Operational setting | 1, 2 |
| Hyperparameters | Value | Hyperparameters | Value |
|---|---|---|---|
| Hidden state space’s dimension | 4 | Batch size | 128 |
| The highest order of partial derivatives | 2 (FD001, FD003), 3 (FD002, FD004) | Learning rate | 0.001 |
| Fully connected layers in x-NN | 2 | Loss function weight ratio | 100 |
| Fully connected layers in DeepHPM | 2 | 125 | |
| Fully connected layers in MLP | 6 | Epochs | 300 |
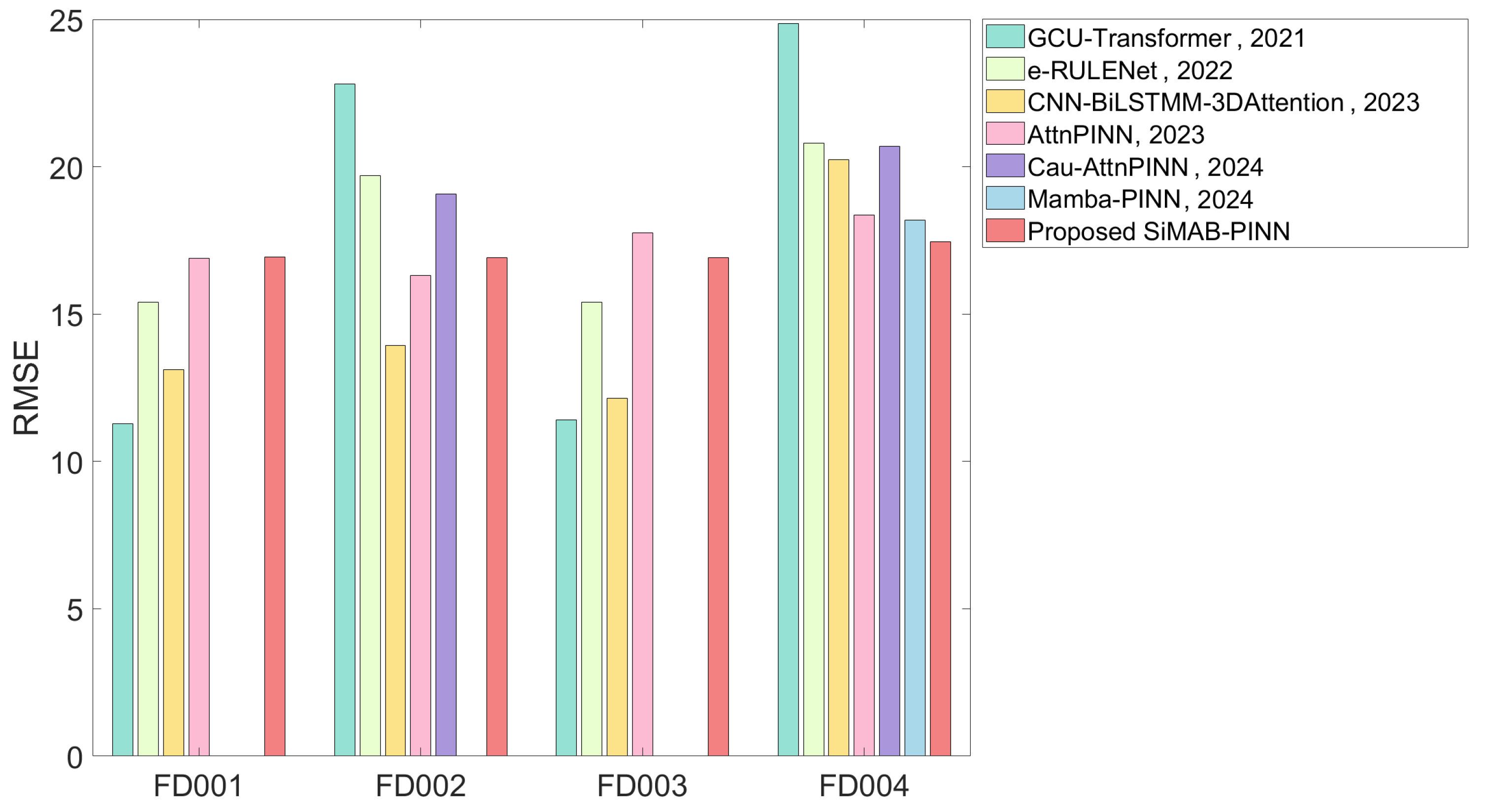
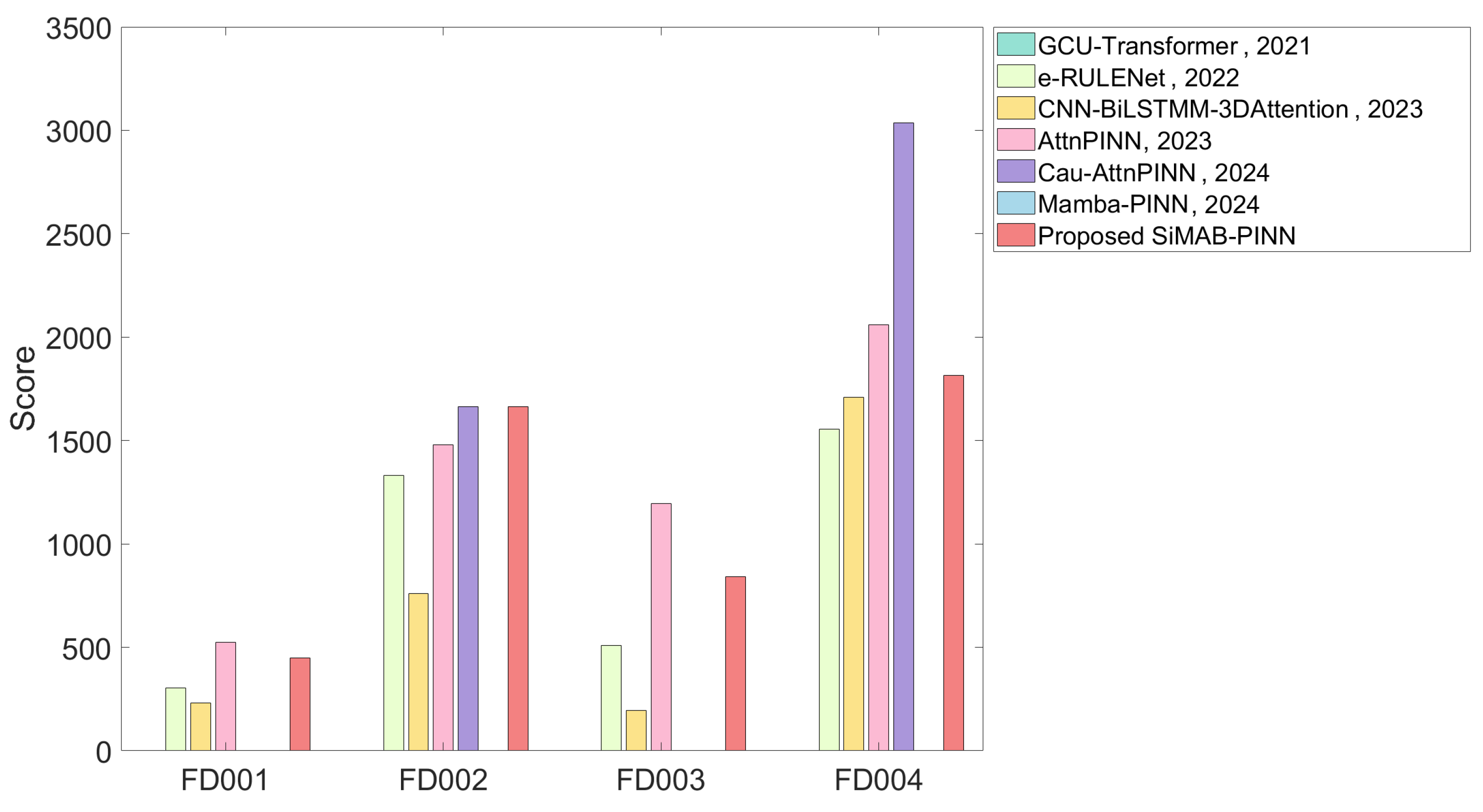
| Methods | RMSE | Score | ||||||
|---|---|---|---|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | FD001 | FD002 | FD003 | FD004 | |
| GCU-Transformer [24], 2021 | 11.27 | 22.81 | 11.42 | 24.86 | — | — | — | — |
| e-RULENet [25], 2022 | 15.40 | 19.70 | 15.50 | 20.80 | 303 | 1330 | 509 | 1554 |
| CNN-BiLSTM-3DAttention [26], 2023 | 13.12 | 13.93 | 12.15 | 20.24 | 231 | 760 | 196 | 1710 |
| AttnPINN [6], 2023 | 16.89 | 16.32 | 17.75 | 18.37 | 523 | 1479 | 1194 | 2059 |
| Cau-AttnPINN [27], 2024 | — | 19.08 | — | 20.70 | — | 1665 | — | 3035 |
| Mamba-PINN [7], 2024 | — | — | — | 18.18 | — | — | — | — |
| Proposed SiMAB-PINN | 16.94 | 16.91 | 16.92 | 17.45 | 449 | 1665 | 843 | 1814 |
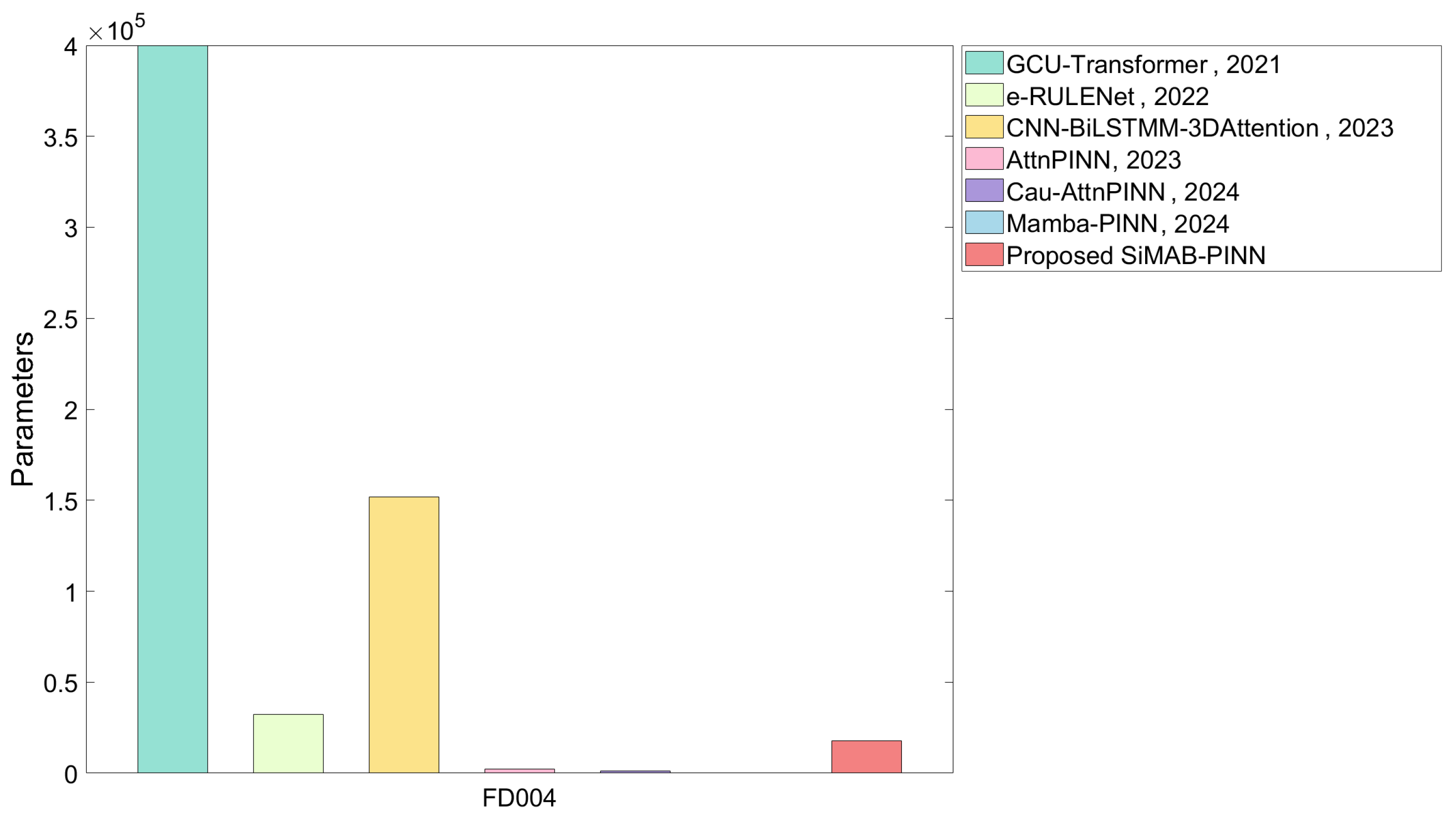
| Methods | Parameters | FLOPs |
|---|---|---|
| GCU-Transformer [24], 2021 | 399.7k | 393.39k |
| e-RULENet [25], 2022 | 32.3k | — |
| CNN-BiLSTM-3DAttention [26], 2023 | 151.9k | 170.3k |
| AttnPINN [6], 2023 | 2260 | 1728 |
| Cau-AttnPINN [27], 2024 | 1321 | — |
| Mamba-PINN [7], 2024 | — | — |
| Proposed SiMAB-PINN | 17.8k | 5790 |
| Hidden State Space Dimension | Derivatives Order | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| 3 | 18.44 | 17.76 | 17.70 | 19.41 |
| 4 | 18.22 | 17.93 | 17.45 | 17.81 |
| 5 | 20.02 | 19.76 | 17.64 | 18.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Qin, J.; Fan, H.; Ke, T. SiMBA-Augmented Physics-Informed Neural Networks for Industrial Remaining Useful Life Prediction. Machines 2025, 13, 452. https://doi.org/10.3390/machines13060452
Li M, Qin J, Fan H, Ke T. SiMBA-Augmented Physics-Informed Neural Networks for Industrial Remaining Useful Life Prediction. Machines. 2025; 13(6):452. https://doi.org/10.3390/machines13060452
Chicago/Turabian StyleLi, Min, Jianfeng Qin, Haifeng Fan, and Ting Ke. 2025. "SiMBA-Augmented Physics-Informed Neural Networks for Industrial Remaining Useful Life Prediction" Machines 13, no. 6: 452. https://doi.org/10.3390/machines13060452
APA StyleLi, M., Qin, J., Fan, H., & Ke, T. (2025). SiMBA-Augmented Physics-Informed Neural Networks for Industrial Remaining Useful Life Prediction. Machines, 13(6), 452. https://doi.org/10.3390/machines13060452